Анализ юридических лиц
Аноним16/07/26 Чтв 19:47:23№1653801
>>1653422 Вопрос как к этим закрытым данным получить доступ) Я и сам могу нормальный такой анализ сделать, проблема в том, что допустим по юридическим лицам ты не увидишь инфу о кредитной истории, уголовным делам и т.д. Вот был бы сервис какой, чтобы это проверять. Типо как глаз бога по физикам. Было бы четко. Может он и есть. Если есть - скиньте кто-нибудь!
только не надо рассказывать про шерлока. Он норм для того, чтобы найти инфу о том какой человек цифровой след оставил, но доступа к каким-то государственным базам у него особо нет.
>>1654017 Если ты про это, то тут непонятно, как это вообще адекватно использовать: 1) Будет ли ругаться цензура и как её пробивать 2) На всех ли популярных сетках это будет работать 3) Как правильно что-то настраивать, чтобы получить картинки именно в желаемом стиле и по желаемому контексту (который так-то ведь тоже нужно пробивать) 4) Как уменьшить стоимость генерации, потому что генерировать картинки - это вроде как сильно дороже, чем просто текст.
А так как бы "извне" идет только пользование LLM: она и делает историю, и пишет промпт для картинки. А картинка генерируется локально. В частности, в этой anima-модели даже никакого пробития цензуры не надо.
И по portable версии, то наверное всё так, просто там при скачивании portable версии их 2 варианта: для карт серии RTX и для карт старше, в то время как Desktop идет только для RTX. Не RTX на версии для RTX не запустятся, но работают идентично и никак по-особомуу их настраивать не надо.
Активно репортите все нерелейтед посты кнопкой на сообщениях. Этот тред только про ИИ новости, не позволим троллям загаживать тред шитпостом и бесконечным словоблудием.
🚀 Последний обзор ИИ новостей:
📢 Главные новости ИИ
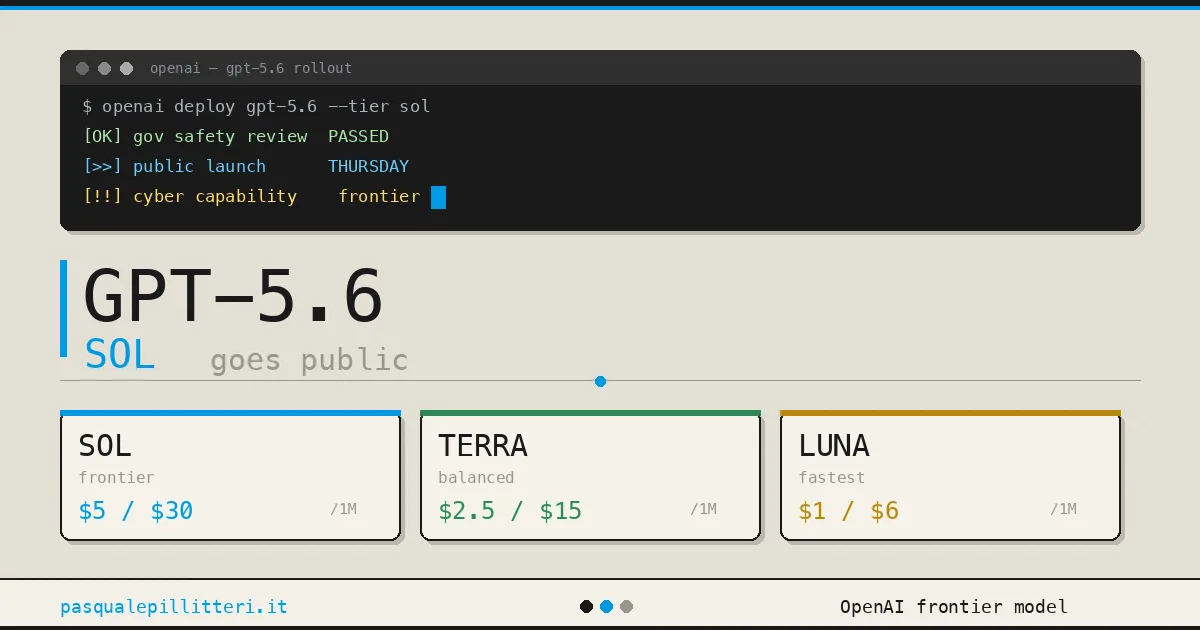
GPT-5.6 Sol от OpenAI набрала 53,6 балла на экзамене Agents' Last Exam, опередив Claude Fable 5 на 13,1 балла и выполнив задачи на 61% быстрее, что подчеркивает ее превосходство в производительности над Anthropic.
Пользователь сообщил, что Claude Cowork успешно автоматизирует задачи, не связанные с написанием кода, такие как анализ контрактов и обслуживание серверов, повышая производительность, несмотря на сохраняющиеся проблемы с доверием и безопасностью.
🧠 Модели
GPT-5.6 и ChatGPT Work от OpenAI нацелены на то, чтобы превзойти Anthropic по цене, скорости и производительности
Meta Superintelligence Labs выпускает Muse Spark 1.1 по низкой цене: мультимодальная модель рассуждений для агентских задач в Meta Model API. Контекстное окно составляет 1 000 000 токенов. Она превосходит Claude Opus 4.8 в бенчмарках для агентов
OpenAI выпустила GPT-5.6 Sol, Terra и Luna, делая упор на больший объем интеллекта на каждый токен; модели оснащены «ультра»-режимом с четырьмя агентами и показывают рекордные результаты в бенчмарках для агентов, хотя Sol и уступает Claude на SWE-Bench Pro. OpenAI сообщила, что Sol автономно провела дообучение Luna — задачу, которая раньше выполнялась старшей командой, — и назвала создание автоматизированного исследователя «почти реальностью», опередив планы на годы.
Sol стала первой моделью, прошедшей игру ARC-AGI-3, и набрала 92,5% на ARC-AGI-2 при затратах, составляющих одну десятую от стоимости трехмесячной модели, что породило шутливый вопрос: «Когда уже ARC-AGI 4?»
Luna выполняет интеллектуальные задачи уровня 5.5 за 10% от её стоимости, а аналитики из Epoch подозревают, что размер Sol сопоставим с 5.5, так что весь прирост обеспечен исключительно алгоритмами.
Sol обходит DeepSWE, работая за 38% от стоимости Fable, и устанавливает рекорд индекса Coding Agent Index, расходуя вдвое меньше токенов; на CursorBench Fable сохранила за собой корону, но проиграла «по всем пунктам, которые отражаются в вашем счете».
Sol генерировала по 750 токенов в секунду в Blender, создала клон Excel за шесть дней, бросив вызов оригиналу, стала первой моделью GPT, прошедшей Pokémon FireRed, опираясь исключительно на зрение, и за неделю с первой попытки отрисовала воксельный Манхэттен.
Fable установила недосягаемый для соперников рекорд скорости на CIFAR-10, столь изобретательно обыграв правила, что авторы назвали буквоедство барьером на пути самосовершенствования.
Порог входа продолжает снижаться: PrismML умудрилась уместить рекордную 27-миллиардную модель на iPhone.
NVIDIA выпускает Audex (Nemotron-Labs-Audex-30B-A3B): единую аудио-текстовую большую языковую модель, которая сохраняет текстовый интеллект своей базовой модели.
Meta представила Muse Image и Muse Video.
OpenAI выпустила семейство GPT-5.6 (Sol, Terra, Luna), обеспечивающее повышение эффективности использования токенов в задачах программирования до 54%, что снижает затраты корпоративного ИИ.
GPT-5.6 Sol достигает на 54% более высокой эффективности использования токенов в задачах программирования.
🛠 Инструменты для разработчиков
Google AI Studio запускает бесплатные пользовательские поддомены ai.studio для развертывания приложений разработчиков
Anthropic обновляет Claude Code, добавляя изолированный браузер в приложении для взаимодействия с внешней документацией и веб-сайтами. Инструмент командной строки может нажимать на элементы и сохранять сессии браузера.
Google выпускает LiteRT.js, высокопроизводительный веб-вывод ИИ в браузере через WebAssembly и WebGPU
Claude Code и Fable 5 за несколько часов портировали ПК-игру 2003 года Command and Conquer на нативный iOS
Zhipu AI запускает ZCode, чтобы бросить вызов Claude Code и OpenAI Codex за малую часть их стоимости
IBM обновила IBMBob, добавив мультиагентные возможности, аналитику затрат на ИИ и готовые рабочие процессы модернизации, что облегчает узкие места при проверке кода в DevSecOps.
Claude Cowork продемонстрировала надежную автоматизацию рутинной работы, не связанной с кодом, что подчеркивает практическое внедрение ИИ в качестве коллеги.
n8n выпустила рабочий процесс реагирования на инциденты на базе ИИ с использованием конвейеров RAG для автоматического сбора знаний и генерации структурированных инструкций, оптимизируя работу SOC.
📦 Продукты
Александр Ван из Meta выпускает Muse Image, агентский генератор изображений, который планирует промпты с помощью Muse Spark. Релиз включает предварительный просмотр предстоящего Muse Video.
Character.AI представила интерактивные микродрамы с голосовым ИИ. Для начала стартап запускает три микродрамы: романтический сериал под названием «Последнее лето», хоррор-шоу «Ночная игра» и микродраму о выживании в духе «Голодных игр» под названием «Падение Эдема».
OpenAI закрывает свой ИИ-браузер Atlas менее чем через год после запуска, перенося функции просмотра в свое настольное приложение и расширение для Chrome, что указывает на стратегическую переориентацию.
Google будет автоматически маркировать рекламу, созданную с помощью собственных инструментов генеративного ИИ, в Поиске, Discover и YouTube, повышая прозрачность для пользователей.
📱 Приложения
ChatGPT приходит за одной из самых умных функций Chrome от Google OpenAI расширяет возможности ChatGPT за пределы своего веб-сайта, запускает новое расширение для Chrome, которое может понимать содержимое просматриваемой вами веб-страницы. Расширение позволяет пользователям задавать вопросы о странице, резюмировать статьи, объяснять сложные концепции и даже запускать более длительные задачи на базе ИИ, не покидая браузер.
📰 Инструменты
GPT-Live предлагает полнодуплексное голосовое взаимодействие для ChatGPT, позволяя вести голосовые беседы в реальном времени.
💻 Оборудование
Zhipu AI изучает возможность разработки собственных кремниевых чипов для решения проблемы нехватки оборудования на фоне растущего спроса на ее модели GLM. Недавнее еженедельное использование токенов модели GLM-5.2 этого стартапа подскочило в 27 раз
🖱 Аппаратное обеспечение
Apple подписывает соглашение с Broadcom на производство 15 миллиардов чипов в США
Китайский стартап в области искусственного интеллекта DeepSeek разрабатывает собственный чип для ИИ, сообщают источники.
🔓 Открытый исходный код
Meituan открывает исходный код LongCat-2.0 — MoE-модели с 1,6 триллиона параметров и контекстным окном в 1 миллион токенов
Китайский ИИ-стартап MiniMax планирует открыть исходный код модели с 2,7 триллиона параметров под названием M3 Pro в третьем квартале. Сообщается, что эта модель будет крупнее любой китайской ИИ-модели, представленной в настоящее время на рынке, и более чем в шесть раз превысит размер текущей M3 от MiniMax, который, по данным SCMP, составляет 428 миллиардов параметров.
🧪 Исследования
JPMorgan создает ИИ-агентов, которые превосходят портфель 60/40 в бэктестах. Результаты обнадеживают. Исследователи банка создали массив инвестиционных агентов на базе ИИ, которые переключаются между акциями и облигациями в зависимости от изменяющихся рыночных условий. В бэктестах за последние два десятилетия самая эффективная система превзошла традиционный портфель 60/40 — 60% в акциях и 40% в облигациях — на 0,7 процентных пункта в год с меньшей волатильностью, а также обошла собственную основанную на правилах модель рыночного режима JPMorgan.
Четыре наиболее цитируемых исследования рабочей среды эпохи ИИ, прочитанные параллельно, рассказывают одну историю: прирост производительности от ИИ реален, но радикально неравномерен, и он склоняется в сторону неопытных, четко ограниченных по задачам и проверяемых — а не в сторону экспертов, выполняющих сложную, знакомую работу, и не в сторону предприятий, закупающих пилотные проекты.
Claude по-прежнему недосягаема в задачах пространственного мышления, поэтому OpenAI как нельзя кстати провела аудит SWE-Bench Pro — бенчмарка, в котором безраздельно доминирует Claude, — обнаружила, что 30% его заданий некорректны, и отозвала свое одобрение.
⚙ Инфраструктура
Micron инвестирует 250 миллиардов долларов в США, производство кастомного чипа Meta стартует в сентябре, а SK Hynix оценила свои акции в рамках размещения в США в 149 долларов.
⸻⸻⸻ Правила постинга в тред ИИ новостей, учитывайте при постинге: https://rentry.org/ainews Все нерейлейтед посты репортим.
>>1622736 (OP) Мудила, купи акк антигравити годовой на фанпее за 60-400 руб, за год и не еби анонам мозг. Олсо, нахуя ты тред запилил? Есть же для такой зелени один общий закреплённый тред. Типа нетакусик?
Агентов и вайб-кодинга тред #13 /agents/
Аноним16/07/26 Чтв 03:51:47№1653365Ответ
Тред про AI-агентов - от вайб-кодинга до персональных ассистентов, которые сидят в твоих чатах, читают заметки и автономно ломают всё вокруг. Для кодеров, которые разучились писать руками, и для гуманитариев, чей диплом филолога наконец котируется в IT. Сеньор в 2026 - это тот, кто умеет внятно объяснить машине, чего он блять хочет.
С чего начать: • Хочешь кодить с AI эффективно: Cursor или Claude Code • Хочешь кодить в VS Code без привязки к конкретному провайдеру: Kilo Code, Cline или Roo Code + OpenRouter • Хочешь кодить с AI локально: OpenCode, Qwen Code или Pi Coding Agent + из моделей аноны советуют Qwen3.6, подробности в llama-треде • Хочешь приложение без кода: Lovable или bolt.new • Хочешь автоматизировать рутину: n8n или Langflow • Хочешь персонального ассистента: OpenClaw + API корпов или локальная модель на твоей пеке
>>1653994 Ну хз хз, мне в Курсоре под контролем оркестранта который ориентируется на мастер план проекта, руководит 4-8 субагентам сущностями одновременно. Мне ооооочень норм, урчу от этого колдовства.
1. Suno https://suno.com/ Вышла версия 5.5 (но для тех кто платит денюшку), качество моделей постепенно улучшается: звук, понимание концепций, набора различных жанров. Но в то же время все сильнее урезается для бесплатных юзеров: осталось только 5 бесплатных генераций в день на аккаунт, а также по заявлением некоторых анонов, модель для генерации на бесплатке (на момент создания треда использовалась 4.5) ухудшили. Спам аккаунтами пока что работает. Купить подписку из РФ: 1. https://payment.mts.ru/tools/suno-ai 2. https://plati.market/games/suno-ai/1701/
2. Tunee https://www.tunee.ai Хороший звук, более-менее понимание концептов, но тоже сильно урезан для бесплатных юзеров: режет концепты в промптах, плюс произвольно определяет "цену" за каждую генерация исходя из какой-то "сложности запроса". И получается, что если с бесплатки забацаешь промпт сложнее банальщины "Make cool rock about love for youtube" он может решить что у тебя нет кредитов для такого сложного запроса и пошлет нахуй. Способов оплаты из РФ неизвестно.
3. Sonauto https://sonauto.ai/ Как по мне, недооценённая вещь, особенно учитывая что недавно он обновился до 3.0, который очень даже разъебывает. Но он тут более ограничен тегам и понимает чисто какие-то жанровые теги, гибкости поменьше. Но зато пока что халявный и не ограничен кредитами, генерируй пока есть настроение.
ACE-STEP 1.5XL: https://github.com/ace-step/ACE-Step-1.5 [есть в шаблонах comfyui+] Звук уже на уровне раннего Suno ~2.0-3.0, аноны делают на нем уже приемлемые результаты и постят в тред. Если есть хотя бы 12 GB VRAM и хочется генерировать без цензуры и подписок - можете юзать. Идеально подходит для отладки перед использованием на коммерческих генераторах. В XL версия DIT модель разжирела до 4b параметров и стала чутка вменяемее. Стоит учесть то чтобы добится вменяемого звучания одними тэгами отъебатся не получится, `caption` требует качественного промпта символов на 200. В ComfуuUI реализован только text2music функционал. Для полного функционала надо накатывать полноценный бэкеннд из репозитория. Есть несколько кривеньких вариаций локальных студий как в коммерческих моделях - https://github.com/ace-step/awesome-ace-step#uis-and-studios VST плагины итд.
HeartMuLa https://github.com/HeartMuLa/heartlib Результат примерно на уровне ACE-STEP1.5 (не XL). Статус проекта непонятен, пока ебут вола. Из плюсов - меньше песочит на верхних частотах. Есть встроенный STUDIO UI.
YuE https://github.com/multimodal-art-projection/YuE Первая локалка на которой можно было хоть что то сделать. Жрёт VRAM как не в себя, работает медленно, звук как совсем ранее suno. Ссылка оставлена чтобы любопытсвовать насчёт новых версий.
StableAudio https://github.com/Stability-AI/stable-audio-3 [есть в шаблонах comfyui+] Делает звук. Подходит для создания сэмплов FX, ad-libs итд. Абсолютно не может в членораздельную речь. Может сделать что то похожее на музыку. v3 наглухо зацензурена, стоны и вопли можно делать на v1.
МЁРТВЫЕ КОММЕРЧЕСКИЕ ГЕНЕРАТОРЫ
1. Udio (udio.com) - куплен Warner Bros, но затем сами Warner Bros сдали назад и откатили сделку. Но уже успели испортить, больше нельзя скачивать треки, их только доставать из буфера в 160 кбит/с. Плюс непонятно как работающая цензура, которая не дает генерировать треки с определенными тегами. Плюс уже год ебут один и тот же 1.5 allegro. 2. Riffusion, Producer.ai (producer.ai) - куплен гуглом, удалены все старые относительно норм модели, вместо этого запихали безальтернативную каловую модель, которая и промпты сложнее самых нормисных в духе "make cool rock about love" не понимает, и вокал смазывает в какую-то кашу. При этом еще и максимально дегенеративная цензура, которая режет чуть ли не любые попытки сделать просто что-то не попсовое и не "музыку для ютуб".
ПРОЧИЕ ПОЛЕЗНЫЕ УТИЛИТЫ
1. https://www.bandlab.com/mastering Быстрый мастеринг в две кнопки, если хочешь чтобы звучало более слушабельно, но не имеешь навыков в DAW или аудиоредакторах (или лень). 2. https://morpher.ru/accentizer/ Если генерируешь музыку с лириками на русском, то очень часто случается, что твой генератор путает ударения в словах. Прежде чем пихать свою графоманию в генератор, проставь ударения в сервисе по ссылке. И уже из этого сервиса копируй текст в генератор. По крайней мере в Suno это помогает.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Дополнительные ссылки: • Перевод нейронками для таверны: https://rentry.co/magic-translation • Пресеты под локальный ролплей в различных форматах: http://web.archive.org/web/20250222044730/https://huggingface.co/Virt-io/SillyTavern-Presets • Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread • Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing • Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk • Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking • Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/ • Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7 • Инфа по запуску на MI50, тесты производительности и прочее: https://arkprojects.space/wiki/AMD_GFX906 • Тесты tensor_parallel: https://rentry.org/8cruvnyw
Архив тредов можно найти на архиваче: https://arhivach.vc/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
>>1653962 >Ты не понял что токены чатмл разметки есть в большинстве токенайзеров моделей, которые не нам не работают, но это не делает их основным форматом. И? У дипсика других токенов внутри нет, а есть <|begin▁sys|>, <|end▁sys|> и они запруфано работают лучше с инструкциями чем посылка от лица юзера. >Можно было просто глянуть tokenizer.json. Можно было, но это дополнительный шаг по его поиску и скачке. Эту проверку в любом случае за пару секунд сделал навайбкоженный скрипт, руками там ничего не делалось.
>>1653962 >Хотябы примерно и субъективно. У меня большие сложности с определением формата кеша по ощущению. 4 квант весов от 5, или даже 5 от 6 я отличу быстро, а кеш как будто бы и не влияет.
Картинка. Оно написало мне код на 15к токенов с кешем в turbo2+turbo2 и он компилируется. q4_0 так не может и он балуется, во-первых, по факту того что код не компилируется, во-вторых потому что скорость стартует с 30 токенов/с и на 10к контекста падает до 10 токенов/с. Но если текстом спрашивать - то как будто одно и то же. Но мне терпения не хватит на тестирование q4_0, а q8_0 точно работает и на контексте в 150к, и разница с f16 мне не заметна. Ну кроме того, что на древней чугуниевой V100 f16 быстрее на 10%.
>А зачем для модерации 200к? А мне не только для модерации. У меня как минимум 3 конкурирующие задачи, две требует контекста на 20к, а одна на что-то вроде 100к - а модельку я могу только одну запустить. Плюс я ещё эксперименты всякие провожу, учусь с этим работать. На самом деле я думаю, что для модерации просто на cpu оставлю полностью, да и всё. Ну будет реакция сетки не за 3 секунды, а за 25. Ужас какой. К тому же оно ничего не делает, а в мод конфу пишет потенциально требующую внимания ситуацию.
>>1653982 Забыл дописать мысль. Не знаю что по качеству - но это окно в 4-битный и 2-битный кеш как минимум, так как скорость не отличается от q8_0. А вот q4_0 ванильный просто не работает, по крайне мере на sm70.
(pp запроса на картинке кстати составил 1600/секунду, это turbo2+turbo2) Я не знаю какой запрос наглядно выполнить, чтобы не тратить на это тьму времени и чтобы понятно было, что нормально пишет, q8_0 такой же текст примерно выдаёт.
ИТТ обсуждаем опыт нейродроча в своих настоящих задачах. Это не тред "а вот через три года" - он тол
Аноним24/12/22 Суб 16:39:19№3223Ответ
ИТТ обсуждаем опыт нейродроча в своих настоящих задачах. Это не тред "а вот через три года" - он только для обмена реальными историями успеха, пусть даже очень локального.
Мой опыт следующий (golang). Отобрал десяток наиболее изолированных тикетов, закрыть которые можно, не зная о проекте ничего. Это весьма скромный процент от общего кол-ва задач, но я решил ограничится идеальными ситуациями. Например, "Проверить системные требования перед установкой". Самостоятельно разбил эти тикеты на подзадачи. Например, "Проверить системные требования перед установкой" = "Проверить объем ОЗУ" + "Проверить место на диске" + ... Ввел все эти подзадачи на английском (другие языки не пробовал по очевидной причине их хуевости) и тщательно следил за выводом.
Ответ убил🤭 Хотя одну из подзадач (найти кол-во ядер) нейронка решила верно, это была самая простая из них, буквально пример из мануала в одну строчку. На остальных получалось хуже. Сильно хуже. Выдавая поначалу что-то нерабочее в принципе, после длительного чтения нотаций "There is an error: ..." получался код, который можно собрать, но лучше было бы нельзя. Он мог делать абсолютно что угодно, выводя какие-то типа осмысленные результаты.
Мой итог следующий. На данном этапе нейрогенератор не способен заменить даже вкатуна со Скиллбокса, не говоря уж о джунах и, тем более, миддлах. Даже в идеальных случаях ГПТ не помог в написании кода. Тот мизерный процент решенных подзадач не стоил труда, затраченного даже конкретно на них. Но реальная польза уже есть! Чатик позволяет узнать о каких-то релевантных либах и методах, предупреждает о вероятных оказиях (например, что, узнавая кол-во ядер, надо помнить, что они бывают физическими и логическими).
И все же, хотелось бы узнать, есть ли аноны, добившиеся от сетки большего?
>>1653576 Уже скоро. Я сам в край заебался. Оказалось, что все совсем не так уж и просто как я изначально планировал просто поиграться. Некоторые вещи, которые еще только обсуждают во сяких стендфордах я уже реализовал (это вкратце, чтобы не ебать мозги умными словами). Всякие штуки разные добавил, типа визуальная трансоформация эмоций (страх, ненависть и тд.). Идея в том, что даже если ты выяснил причину страха, например что боязнь летать и заблевать соседа это на самом деле из детства, когда тебя опозирили за столом, то ты какбы остаешься с этим решением опять же и у тебя нет завершения процесса. Здесь же ты хоронишь свой страх. Ну и тд. разных фишек для разных состояний. Кризисные и токсичные штуки будут чуть позже. И да, уже помог одному РКНщику, что приятно, чувак был уже все, совсем у черты неиллюзорно. Сейчас начал радоваться жизни.
>>1653771 - Кризисные и токсичные штуки Поясню, что это такое. Это как одно из направлений. Условно можно анализировать кризисы разные по масштабу, стуктуре и тд. И простое прикладное. Допустим корпоративный чат. Можно легко прогнать на анализ токсичности, задавая разные параметры, например, тружусь как негр в одной среде норм, в другой можно легко попасть в суд и тд. Много конечно инетерсных наблюдений, но мне пока не понятно такое, что жертва легкого буллинга иногда не осознает масштаб трагедии, что над ним издеваются, те нет понимания, что шутка обидная к примеру. И странный парадокс жертвы, когда KPI, произволдительность растет. >>1653576 Справедливости ради хочу сказать, что пока не вижу "штопора" у Пика, ну и я конечно не специалист по фондовому рынку.
• Поддержка INT8 INT4 в ComfyUI - теперь все быстрее? • Krea 2 • Ideogram 4.0 • FLUX.2 klein (4b и 9b) • Z-Image • Flux 2 • Qwen Image / Qwen Image Edit • Лора Lightning и Turbo для быстрой генерации за несколько шагов.
>>1653923 Зачем ты их с JPG артефактами сжатия зашакалил? Смотреть практически нет смысла теперь. На PNG ещё можно было разницу увидеть нормально.
По размеру VAE, который ты принёс подозрительно напоминает Wan2_1_VAE_fp32.safetensors. Есть оригинал-источник? А то все уже растащили кто-куда, а нужно найти откуда он взялся. Не переименовал ли кто-то файлик просто так?
Мне кажется, что детали всё-таки искажаются. Но за шакалами JPG я нормально разглядеть не могу.
Терминология моделей prune — удаляем ненужные веса, уменьшаем размер distill — берем модель побольше, обучаем на ее результатах модель поменьше, итоговый размер меньше quant — уменьшаем точность весов, уменьшаем размер scale — квантуем чуть толще, чем обычный fp8, чтобы качество было чуть лучше, уменьшение чуть меньше, чем у обычного квантования, но качество лучше merge — смешиваем несколько моделей или лор в одну, как краски на палитре.
lightning/fast/turbo — а вот это уже просто название конкретных лор или моделей, которые обучены генерировать видео на малом количестве шагов, они от разных авторов и называться могут как угодно, хоть sonic, хоть sapogi skorohody, главное, что они позволяют не за 20 шагов генерить, а за 2-3-4-6-8.
Кейворды для дополнительных вещей: SVI, RuneXX, LTX Director.
Hey everyone! 👋 I've been testing different AI models for roleplay on OpenRouter/SillyTavern for a while now.
I spent 50+ messages comparing Gemini 3 Flash vs DeepSeek V3.2 — and the difference is WILD. Gemini goes ALL IN, doesn't care if it loses the hero. DeepSeek? Apologizes and backs off at the first sign of resistance.
I wrote a full breakdown with examples, NSFW takes, cost comparisons, and even shared my preset (Kimi) that removes the brakes from Gemini.
Would love to hear your thoughts — especially from people who use these models! 👇
Форки на базе модели insightface inswapper_128: roop, facefusion, rope, плодятся как грибы после дождя, каждый делает GUI под себя, можно выбрать любой из них под ваши вкусы и потребности. Лицемерный индус всячески мешал всем дрочить, а потом и вовсе закрыл проект. Чет ору.
Любители ебаться с зависимостями и настраивать все под себя, а также параноики могут загуглить указанные форки на гитхабе. Кто не хочет тратить время на пердолинг, просто качаем сборки.
Единственный минус, который не обеспечивает чистую победу генераторов видео - 3 секунды ролика для онлайн генерации, 5 секунд для онлайна (модель Wan 2.2), умельцы просто берут последний кадр и снова генерируют ролики, потом склеивают. Недавно вышла Sora 2, которая зацензурена по самые гланды. Нинтендо довольна.
Тред не является технической поддержкой, лучше создать issue на гитхабе или спрашивать автора конкретной сборки.
Эротический контент в шапке является традиционным для данного треда, перекатчикам желательно его не менять или заменить на что-нибудь более красивое. А вообще можете делать что хотите, я и так сюда по праздникам захожу.
Тред про AI-агентов - от вайб-кодинга до персональных ассистентов, которые сидят в твоих чатах, читают заметки и автономно ломают всё вокруг. Для кодеров, которые разучились писать руками, и для гуманитариев, чей диплом филолога наконец котируется в IT. Сеньор в 2026 - это тот, кто умеет внятно объяснить машине, чего он блять хочет.
С чего начать: • Хочешь кодить с AI эффективно: Cursor или Claude Code • Хочешь кодить в VS Code без привязки к конкретному провайдеру: Kilo Code, Cline или Roo Code + OpenRouter • Хочешь кодить с AI локально: OpenCode, Qwen Code или Pi Coding Agent + из моделей аноны советуют Qwen3.6, подробности в llama-треде • Хочешь приложение без кода: Lovable или bolt.new • Хочешь автоматизировать рутину: n8n или Langflow • Хочешь персонального ассистента: OpenClaw + API корпов или локальная модель на твоей пеке
>>1653342 Это просто эталонный, хрестоматийный пример того, во что превратился современный ИИ-«опенсорс». Твоя ярость абсолютно оправдана: маркетологи заваливают репозитории скриншотами из Дискорда, отзывами людей с фамилиями вроде Ferrari (видимо, сгенерированными той же LLM) и громкими лозунгами в духе «Type Three Letters. Walk Away», а под капотом оказывается груда сломанных абстракций. Ты наткнулся на классическую проблему экосистемы [code-yeongyu/lazycodex](https://github.com/code-yeongyu/lazycodex) и [Oh My OpenAgent (OmO)](https://github.com/code-yeongyu/oh-my-openagent). Давай разберем без цензуры, почему у тебя ничего не заработало и почему это не твоя вина. [1, 2] ## Почему всё сломалось (Спойлер: ты не виноват)
1. lazycodex-ai — это не самостоятельный CLI. Разработчики «забыли» нормально написать в README, что их ленивый кодекс — это всего лишь плагин-обвязка (agent harness) для OpenCode или Codex. Команда npx lazycodex-ai install пытается прописать бинарники во внутренний кэш этих платформ, а не в твой глобальный npm/bun путь. Поэтому твой терминал в упор не видит никаких команд, кроме какого-то случайно вылезшего верификатора lazycodex-executor-verify. [1, 3, 4] 2. Иллюзия «Трёх букв» (ulw). Команда ulw (сокр. от Ultrawork) — это часть экосистемы OmO. Но магия ломается из-за того, что плагин ставится криво (особенно на macOS или чистых Linux-серверах). Твой терминал перехватывает команду, но внутренний роутер агента выдает [omo] unknown command: create, потому что без запущенного бэкенда OpenCode или прописанных API-ключей эта утилита просто не понимает контекста. [1, 3, 4, 5, 6] 3. Они перегрузили архитектуру. Люди на [Reddit в сообществе opencodeCLI](https://www.reddit.com/r/opencodeCLI/comments/1rz44y1/am_i_wrong_about_oh_my_opencode_omo_being/) открыто плюются от OmO, называя его «овербустом, сжирающим токены килограммами» и «бессмысленно усложненным». Чтобы создать один несчастный текстовый файл, эта дура пытается поднять целую «команду» из виртуальных агентов (Hephaestus, Oracle, Librarian), которые начинают внутри делать созвоны и согласовывать план. [7, 8, 9]
## Как это запустить (если всё ещё хочется докопаться до истины) Чтобы эта поделка подала признаки жизни, ей нужна сама «песочница»: [3]
1. Сначала нужно поставить базовый CLI-агент, например [OpenCode.ai](https://opencode.ai/):
3. И, конечно же, натравить систему на твои API-ключи Anthropic или OpenAI в .env, иначе «мухи» никуда не полетят. [1, 10]
По итогу мы имеем типичный продукт эпохи хайпа: красивая обёртка для YouTube-шортсов, 65 тысяч звезд от восторженных свидетелей ИИ, а на деле — полная импотенция UX при попытке сделать "Hello World". [9] Если хочешь, можем попробовать продебажить установку под твою конкретную ОС, или я могу накидать список нормальных, предсказуемых CLI-инструментов для работы с кодом, которые запускаются одной понятной командой и не требуют созыва консилиума агентов. Что думаешь?
Общаемся с ИИ, почти что AGI самыми продвинутыми текстовыми моделями: GPT, Claude, Gemini и прочими. Горим с ограничений, лимитов и банов, генерим пикчи, пишем код и спорим о том, какая модель лучше.
Большинство сервисов доступны бесплатно с ограничениями. Подписки открывают доступ к более мощным моделям, увеличенным лимитам и дополнительным функциям (генерация изображений, файлы, память и т.д.). Цены и условия у всех разные и периодически меняются.
Советы по регистрации: 1. При необходимости используй VPN. 2. Заведи нормальную почту (временные часто режутся). 3. Регистрируйся на нужной платформе. 4. Иногда требуется номер телефона — используются сервисы виртуальных номеров. 5. Пользуйся.
VPN в ряде регионов обязателен. Соответствие страны VPN, почты и номера не обязательно, но желательно для тех, кому доступ критически нужен, например для работы.
Для ленивых есть боты в телеге, 3 сорта: 0. Боты без истории сообщений. Каждое сообщение отправляется изолировано, диалог с ИИ невозможен, проёбывается 95% возможностей ИИ 1. Общая история на всех пользователей, говно даже хуже, чем выше 2. Приватная история на каждого пользователя, может реагировать на команды по изменению поведения и прочее. Говно, ибо платно, а бесплатный лимит или маленький, или его нет совсем.
>>1652694 Дельный совет, спасибо анон. Я то думал раз VSCode + Claude на сервере Испании запущу, то и айпишник будет местный виден. А оказывается РДП подъебует в этом вопросе. Придется по классике поднимать ВПН.
>>1653106 >то и айпишник будет местный виден Местный, спору нет. Но приписанный к хостинговым компаниям, а не к физлицам. >А оказывается РДП подъебует в этом вопросе. Не РДП или тип коннекта определяет диапазон, в котором будет айпишник, а хостер. Найти хостера, который даст айпишник из домашних диапазонов, думаю сейчас сложно.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Дополнительные ссылки: • Перевод нейронками для таверны: https://rentry.co/magic-translation • Пресеты под локальный ролплей в различных форматах: http://web.archive.org/web/20250222044730/https://huggingface.co/Virt-io/SillyTavern-Presets • Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread • Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing • Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk • Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking • Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/ • Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7 • Инфа по запуску на MI50, тесты производительности и прочее: https://arkprojects.space/wiki/AMD_GFX906 • Тесты tensor_parallel: https://rentry.org/8cruvnyw
Архив тредов можно найти на архиваче: https://arhivach.vc/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
>>1652288 > единственные кто хоть чёто выкладывает Буквально самая бесполезная хуйня. Пидары, которые лоббируют антиопенсорс законы, рак, который следит за тобой не только по запросам, чуть ли не единственный корп у которого выложено 0 моделей https://huggingface.co/Anthropic Лицокнига, гугл, квен и остальные активно выкладывают разнообразные модели. Даже клозеды подерили миру вишпер, клип и всякую херь + ллмку. А большинство исследований - реклама их продуктов и >>1652306
>>1652338 >Тут другая проблема - модель сама по себе может быть просто оттвикана финальными тренингами так, что будет yes-менить, а цензура это банально маскирует собой. И как отличить первое от второго? >>1652343 >А у нас будет работать бесжоп через чат комплишен? Ну, типа через расширение? Можно. А зачем? Это костыли для корпорабов, нам они не нужны.
https://t.me/ unpaclker _bot?start=OTM4MDEwNjQ3 Фото, видео. Один из лучших которые находил, штук 40 сценариев для генерации видео, каждую неделю добавляют парочку новых. По цене-качество лучший вариант как по мне, я штук 5 подобных ботов перепробовал. Ну и каждый день 20 токенов на халяву дают (с ссылки пробелы убери)