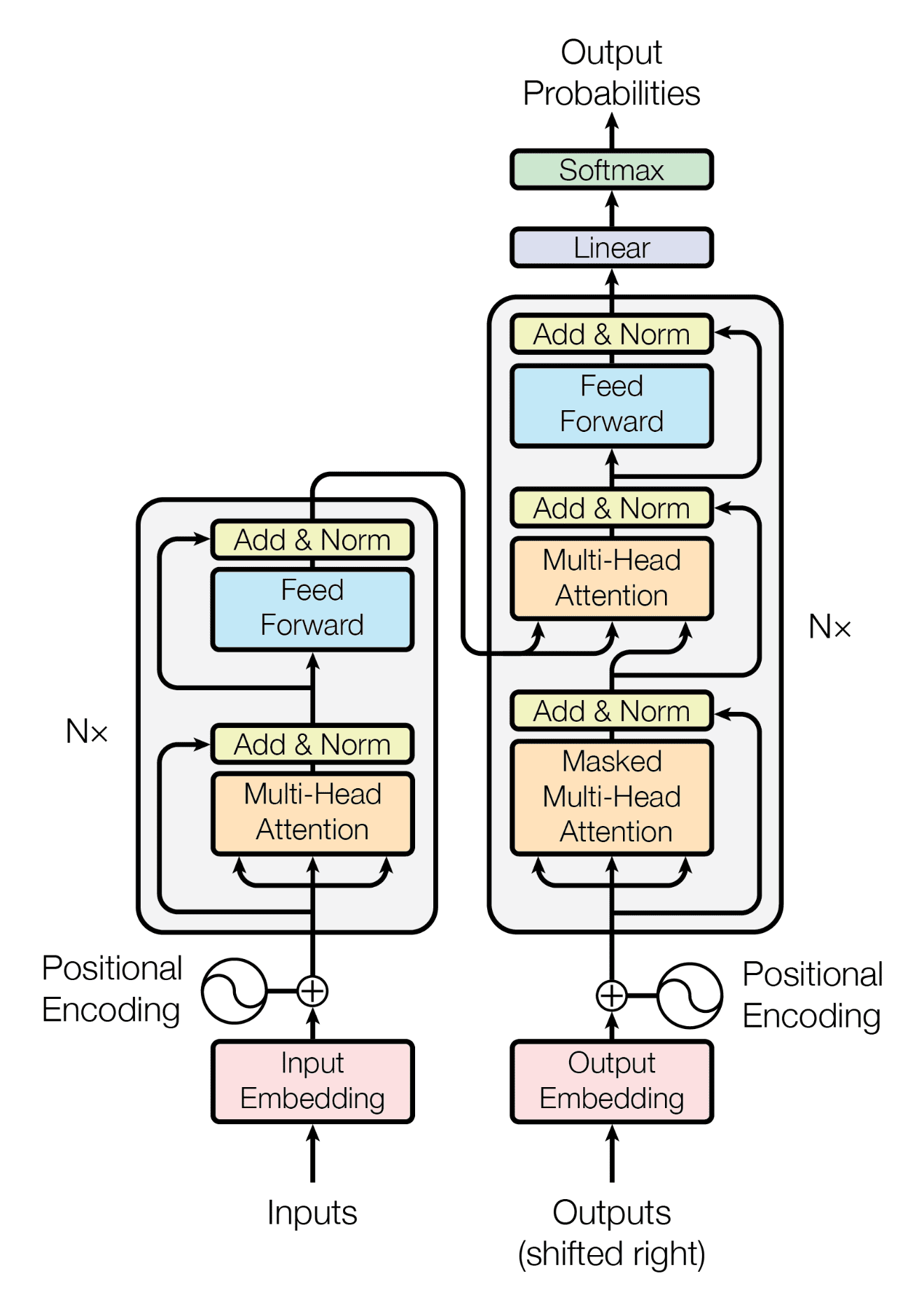
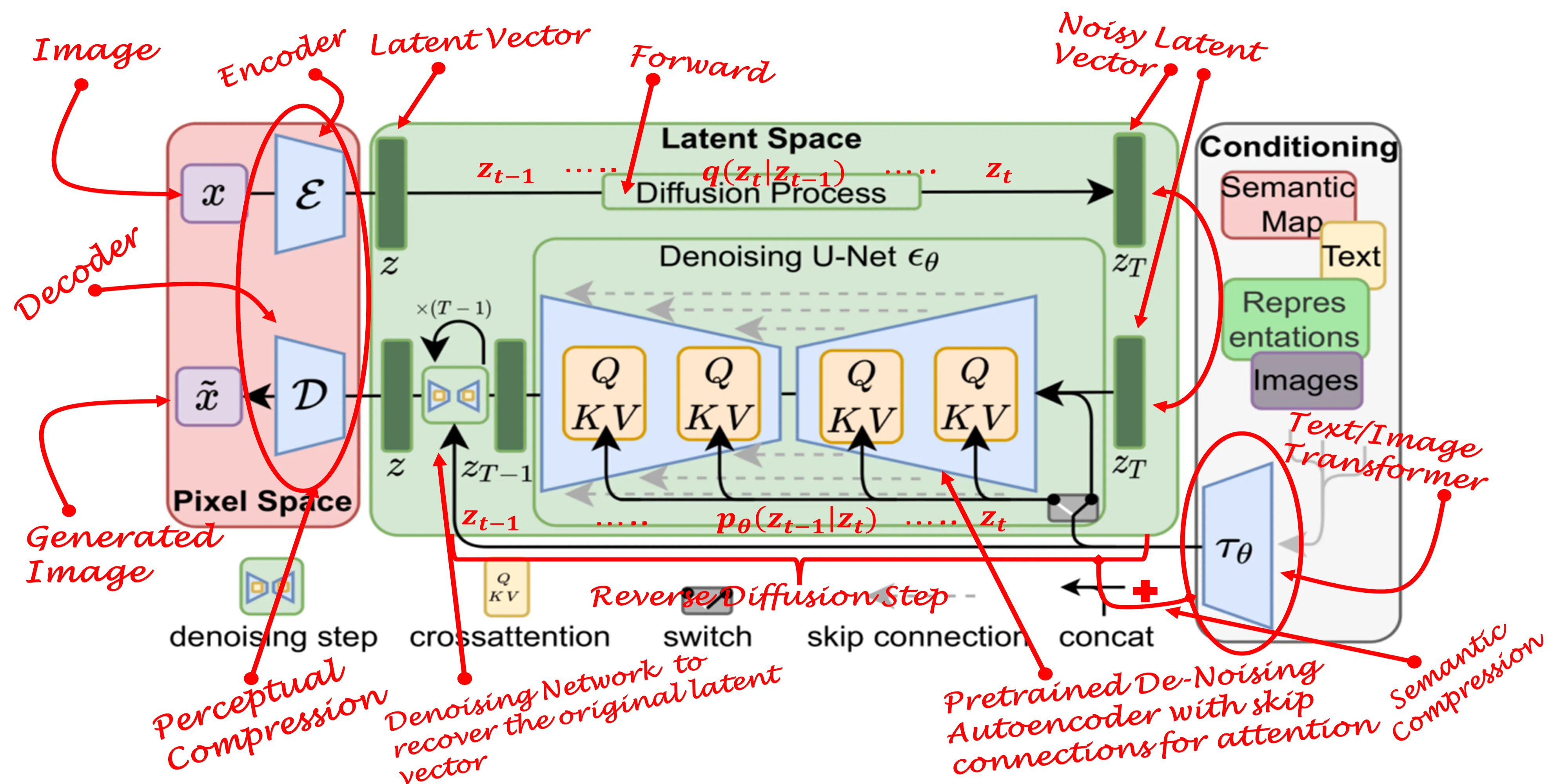
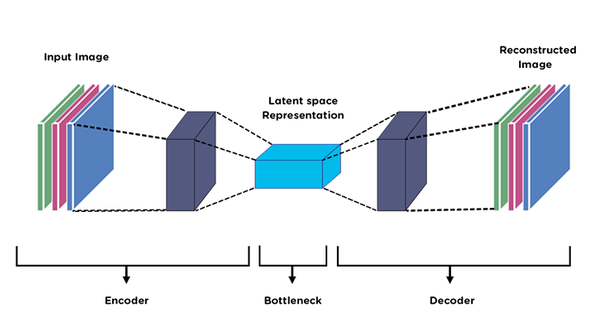
Сап Посоветуйте приложение/нейронку на телефон, в основном задаю тупые вопросы, спрашиваю как что-то сделать например ремонт, сравниваю технику, траллирую и т. д., но и все таки не хочется чтобы хуйню писала. Гемини не предлагать, она пиздец тупая Сейчас юзаю дипсик, но ему нельзя настроить характер, а я хочу чтобы она писала оскорбления типа я совсем даун спрашивать как поменять ДМРВ на ведре ChatGPT нормально установить не удалось. Удалось только через ссылку на главный экран, но для этого нужен активный хром (он отключен у мя) и главное - оно подлагивает и работает дергано на s25 ultra
В общем реквест думаю понятен С КВН или без - похуй
>>1628051 hermes-agent через вебуи либо телеграм, ставишь на комп или впс(проще сетевой доступ), в его конфиге прописываешь личность (промтом), подключаешь ключ. Самая точная настойка того что тебе надо. Можно настроить ему память будет помнить что было между сессиями,либо выбрать память о самом владельце (honcho). Либо ищишь вариант по подписке, но как там с настройкой хз.
Тред получения доступа в nf
Аноним10/01/26 Суб 20:41:32№1485533Ответ
Активно репортите все нерелейтед посты кнопкой на сообщениях. Этот тред только про ИИ новости, не позволим троллям загаживать тред шитпостом и бесконечным словоблудием.
🚀 Последний обзор ИИ новостей:
📰 Главные новости ИИ
Microsoft представила Surface Laptop Ultra, работающий на базе SoC NVIDIA RTX Spark с процессором до 20 ядер и графическим процессором класса GeForce RTX 5070, что сигнализирует о стремлении компании выйти на рынок высокопроизводительных ноутбуков, ориентированных на ИИ.
🛠 Инструменты для разработчиков
Навык Claude Code прогоняет питч через 150 смоделированных технологических персон, предоставляя обширную обратную связь для основателей, готовящих презентации для сбора инвестиций.
Управляемый языком 3D-аватар позволяет пользователям направлять действия персонажа с помощью естественного языка, демонстрируя управление анимацией в реальном времени на базе LLM.
Новый Colab CLI от Google позволяет разработчикам и ИИ-агентам запускать Python на удаленных GPU и TPU Colab прямо из терминала.
Microsoft открывает Visual Studio для разработчиков, которых обошел ее собственный ИИ. Microsoft открывает уровень ИИ в Visual Studio для сторонних моделей и встраивает агентов непосредственно в отладчик и профайлер — этот двойной шаг направлен на корпоративных разработчиков, которых обошла текущая настройка.
📦 Продукты
Google снижает цену на подписку AI Plus до 4,99 доллара США и удваивает объем облачного хранилища до 400 ГБ.
Google выпускает обновление NotebookLM, добавляя агентские возможности, продвинутое мышление и новые форматы вывода.
💻 Оборудование
Surface Laptop Ultra предлагает до 128 ГБ унифицированной памяти, 20-ядерный процессор и графику класса RTX 5070, позиционируясь как премиальная рабочая станция для ИИ и игр. Начальная цена Surface Laptop Ultra составляет от 2500 долларов за базовую конфигурацию с 32 ГБ оперативной памяти.
SoC RTX Spark обеспечивает работу процессора с числом ядер до 20, графического процессора класса GeForce RTX 5070 и до 128 ГБ унифицированной памяти.
По сообщениям, Google заказала у Intel три миллиона собственных TPU к 2028 году, а Nvidia присматривается к ее 18A-техпроцессу для GPU «Feynman», хеджируя риски, связанные с перегруженными мощностями TSMC, в то время как Nvidia и SK Hynix подписали соглашение о совместном проектировании памяти для систем Vera Rubin.
🔓 Открытый исходный код
Библиотека Bulkhead разделяет инструкции и извлеченные данные, снижая риск внедрения промптов в приложениях на базе LLM.
open-deepthink добавляет режим полной дистилляции знаний, позволяющий более эффективно дорабатывать локальные модели.
dvlt.cu предоставляет 5-мегабайтный движок вывода на CUDA/C++ для 3D-трансформера DVLT от NVIDIA, устраняя необходимость в Python или тяжелых средах выполнения.
Moonshot AI выпускает Kimi Code CLI — терминального ИИ-агента для программирования с открытым исходным кодом.
Браузер Ladybird прекращает принимать публичные pull-запросы, ссылаясь на то, что сгенерированный ИИ код представляет угрозу для доверия и безопасности.
🧪 Исследования
Симпозиум по исследованиям этики вычислительной техники MIT объединил экспертов и исследователей, работающих над ключевыми вопросами этического и социального воздействия технологий.
Исследователи из Института Фрэнсиса Крика использовали машинное обучение для обнаружения сигнатуры из 14 белков в плазме крови, которая указывает на рак легких за пять лет до появления симптомов и определяет, кому больше всего поможет терапия анти-IL-1β.
Anthropic обнаруживает, что ИИ-агенты являются способными программистами, но слабыми биологами, и объясняет, почему.
Исследователи выяснили, почему большие языковые модели осваивают навыки, которые упускают маленькие. Новое исследование предполагает, что вместо бесконечного раздувания моделей может быть эффективнее увеличить частоту определенных задач в обучающих данных, чтобы закрепить редкие навыки в более мелких моделях.
⚙ Инфраструктура
Graperoot строит граф зависимостей кодовой базы для MCP-агентов, устраняя избыточные чтения файлов и, по сообщениям, экономя 60 тысяч долларов в месяц, что повышает эффективность разработки на базе LLM.
Экологические издержки ИИ угрожают водным ресурсам, земле и климату. Центры обработки данных, глобальная инфраструктура, обеспечивающая работу ИИ, к 2030 году могут потреблять 945 тераватт-часов электроэнергии ежегодно — это почти в три раза превышает совокупное годовое потребление электроэнергии в Пакистане, Бангладеш и Нигерии, странах, где в совокупности проживает более 650 миллионов человек. Однако это лишь верхушка айсберга. Помимо углеродного следа, каждая единица электроэнергии, используемой центрами обработки данных, также несет в себе «водный след» для охлаждения и производства энергии, а также «земельный след», связанный с выработкой электроэнергии и цепочками поставок.
Большинство новых центров обработки данных для ИИ в США будут построены на землях, пострадавших от засухи. Анализ The Guardian показывает, что объекты будут построены в некоторых из самых засушливых регионов на фоне растущего возмущения по поводу объема воды, необходимого для питания ИИ.
📱 Приложения
Claude теперь создает маршруты для бега с помощью пользовательского коннектора и загружает их напрямую в Garmin, расширяя сценарии использования LLM в области планирования персональных фитнес-тренировок.
По сообщениям, OpenAI перестраивает ChatGPT в «суперприложение» с упором на Codex, состоящее из агентов, выполняющих задачи, с некрологом от одного из инсайдеров: «Чат мертв».
Google запускает ИИ-ассистент Gemini Go для устройств Android Go всего с 2 ГБ оперативной памяти.
Apple запускает Siri AI — разговорного ассистента с функциями понимания происходящего на экране, Visual Intelligence и извлечения личного контекста. Во время демонстрации Siri извлекла код двери из частного сообщения.
🔎 Мнение и анализ
Ноам Браун из OpenAI ожидает, что внутренние модели блестяще сдадут Международную математическую олимпиаду (IMO), и называет соревнования по математике и программированию почти скучными, оставляя «реальные нерешенные задачи» в качестве настоящего рубежа.
Рынок делает ставку на то, что следующая модель исправит это, при этом Polymarket дает 84% вероятности того, что Claude Mythos выйдет до конца следующего месяца.
Генеральный директор Coinbase Брайан Армстронг прогнозирует, что 80 процентов рабочих нагрузок ИИ мигрируют на модели, которые на 99 процентов дешевле, в течение 12–18 месяцев.
Данные OpenRouter показывают, что к маю 2026 года китайские модели ИИ обогнали американские модели по потреблению токенов.
Харари предупреждает, что ИИ может перехватить у людей контроль над нарративами и властью.
OpenAI выпускает дорожную карту AGI, нацеленную на март 2028 года, когда системы ИИ должны будут выполнять значительную часть исследований.
⚠ Безопасность ИИ
«Это предупреждение об урагане»: ограничительные механизмы вокруг мощных моделей ИИ могут появиться слишком поздно. У США есть от шести до 12 месяцев, прежде чем Пекин сможет конкурировать с этой новой волной сверхпродвинутых моделей ИИ.
Выживший в стрельбе в школе подает в суд на компанию по обнаружению оружия с помощью ИИ после того, как система не смогла распознать оружие.
Накануне рекурсивного самосовершенствования Рун из OpenAI говорит, что все больше проникаются идеей «взаимного условного соглашения о паузе», даже несмотря на то, что он замечает: в глубоком обучении все еще валяется неиспользованный потенциал для повышения эффективности в 1000 раз.
Физическое воплощение имеет и обратную сторону: полиция Сан-Франциско не смогла идентифицировать грабителя, скрывавшегося на беспилотном такси Waymo, потому что записи с камер уже были удалены.
Anthropic предупреждает, что ИИ приближается к автономному рекурсивному самосовершенствованию, и призывает к глобальной координации.
Утечка данных ИИ-чат-бота Instagram могла затронуть более 20 000 аккаунтов, сообщает Meta.
OpenAI, Anthropic и Google подписывают открытое письмо с призывом к обязательному скринингу синтеза ДНК для защиты от угроз биобезопасности со стороны ИИ.
OpenAI публикует стратегическую дорожную карту AGI, обещая отдавать приоритет человеческому контролю над полной автоматизацией. Эта рамочная программа направлена на предотвращение концентрации власти AGI.
У Elon Musk в пятницу большой праздник — SpaceX выходит на IPO, а он почти наверняка станет первым триллионером в мире 😇
В преддверии IPO команда подготовила получасовой ролик с «технической информацией о возможностях SpaceX по производству, запуску и эксплуатации спутников с искусственным интеллектом в больших масштабах». Я пока посмотрел малую часть, остаток досмотрю днём, вот главное:
Общие характеристики спутника «AI1»: • Средняя мощность вычислительной полезной нагрузки: 120 кВт. • Это ровно столько, сколько ест серверная стойка на 72 видеокарты GB200 (у H100 было 30-40 кВТ), с учётом ЦПУ, памяти и прочих компонентов. • Вычислительное оборудование взаимозаменяемо (в видео можно посмотреть, как маленькие сегменты подлетают и подключаются)
Габариты: • Размах крыла солнечных панелей: 70 метров • Высота в развернутом виде: 20 метров
Система терморегуляции Thermal System: • Развертываемый жидкостный радиатор площадью 110 м² • Дублирующие насосные контуры на случай отказа основного • Встроенная защита от микрометеоритов • Развертываемые жидкостные радиаторы • В интернете разыскиваются эксперт, которые помогут оценить, хватит ли этого для охлаждения GPU
Elon: «ИИ-спутник устроен гораздо проще, чем спутник Starlink. По сути, ИИ-спутник — это огромное количество солнечных элементов; вам всё ещё требуются некоторые лазерные каналы связи, но в нём нет всех тех сверхсложных антенн, что есть на спутнике Starlink. Спроектировать ИИ-спутник проще. Он больше по размеру. Во многом это технологии, которые мы уже создали для спутников Starlink V3».
И параллельно с этим строится огромная фабрика по производству этих спутников + чипов для них, запуск планируется в конце 2027-го года. Наверное, какие-то тестовые полеты макетов спутников стоит ожидать до этого времени.
>>1628168 А знаете зачем это делается? Это война нового уровня. Ты отключаешь противнику связь на поверхности, а у тебя остается связь в космосе. Плюс старлинк, который контролирует все финансовые операции между биржами, когда кабель на дне океана вдруг внезапно вышел из строя, как какой-нибудь северный поток.
• Lens (3.8B) от Microsoft • HiDream-O1-Image • Z-Image-Base • FLUX.2 klein (4b и 9b) • Z-Image-Turbo • Flux 2 • Qwen Image / Qwen Image Edit • Wan 2.2 (подходит для генерации картинок). • NAG (негативный промпт на моделях с 1 CFG) • Лора Lightning для Qwen, Wan ускоряет в 4 раза. Nunchaku ускоряет модели в 2-4 раза. DMD2 для SDXL ускоряет в 2 раза.
>>1628162 Да, я потому и спрашиваю, почему они советуют именно так, а не иначе? Скоры эти они же от пони пошли, а анима на > The model is trained on Danbooru-style tags, natural language captions, and combinations of tags and captions.
>>1628163 Я предполагаю, что причина этого такая же, как и clip skip = 2 в самом первом nai. Просто наделали кучу тестов и решили, что на практике этот вариант лучше всего работает. То есть что нет какой-то строгой логики за этим.
Понишиз тоже что-то умное пытался сделать с диапазонами этих скоров, но, по итогу, в рекомендации просто одну конкретную строку записал, которую нужно было воспринимать просто как заклинание.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Сочный кумслоп оригинальной gemma-4-31B_q4_0-it.gguf
Что вы там с ней делаете что она рефьюзит... И русский вроде норм, не поломан.
Быстрые тесты на одном сообщении, чисто проверить модель, рп-шить щас желания/времени нет, но вроде всё норм, как время будет надо будет потыкать. Особенно как завезут норм поддержку драфт-модели, ибо на 12 ГБ VRAM всё же как-то медленновато.
>>1628136 >Смысл агентов в том, чтобы обдумать, сформировать логичное продолжение под твои вкусы и историю, а не просто «продолжить текст» единым высером. ИМХО, по по моим практикам - без направляющего пинка агенты так и норовят обсасывать какую-нибудь ненужную фигню. Да, это может быть лучше, чем просто свайпы в Таверне, но может быть и хуже - а ещё и долго.
>Я готов потерпеть ради немного лучшего результата. А я на немного лучший не согласен. Тем более на уровне "вайбкодинга" - чистой алхимии, где куча агентов чего-то там делает, как правило ересь всякую и ты это даже не контролируешь. Ну бывает интересно, живенько. Так в том и прикол агентского подхода. Но проблемы там системные и развернуться не дадут.
МУЗЫКАЛЬНЫЙ №22 /music/
Аноним29/05/26 Птн 21:42:17№1621953Ответ
1. Suno https://suno.com/ Вышла версия 5.5 (но для тех кто платит денюшку), качество моделей постепенно улучшается: звук, понимание концепций, набора различных жанров. Но в то же время все сильнее урезается для бесплатных юзеров: осталось только 5 бесплатных генераций в день на аккаунт, а также по заявлением некоторых анонов, модель для генерации на бесплатке (на момент создания треда использовалась 4.5) ухудшили. Спам аккаунтами пока что работает. Купить подписку из РФ: 1. https://payment.mts.ru/tools/suno-ai 2. https://plati.market/games/suno-ai/1701/
2. Tunee https://www.tunee.ai Хороший звук, более-менее понимание концептов, но тоже сильно урезан для бесплатных юзеров: режет концепты в промптах, плюс произвольно определяет "цену" за каждую генерация исходя из какой-то "сложности запроса". И получается, что если с бесплатки забацаешь промпт сложнее банальщины "Make cool rock about love for youtube" он может решить что у тебя нет кредитов для такого сложного запроса и пошлет нахуй. Способов оплаты из РФ неизвестно.
3. Sonauto https://sonauto.ai/ Как по мне, недооценённая вещь, особенно учитывая что недавно он обновился до 3.0, который очень даже разъебывает. Но он тут более ограничен тегам и понимает чисто какие-то жанровые теги, гибкости поменьше. Но зато пока что халявный и не ограничен кредитами, генерируй пока есть настроение.
Потихоньку развиваются, стоит внимания ACE-STEP 1.5: https://github.com/ace-step/ACE-Step-1.5 Звук уже на уровне раннего Suno ~2.0-3.0, аноны делают на нем уже приемлемые результаты и постят в тред. Если есть хотя бы 12 GB VRAM и хочется генерировать без цензуры и подписок - можете юзать.
МЁРТВЫЕ ГЕНЕРАТОРЫ
1. Udio (udio.com) - куплен Warner Bros, но затем сами Warner Bros сдали назад и откатили сделку. Но уже успели испортить, больше нельзя скачивать треки, их только доставать из буфера в 160 кбит/с. Плюс непонятно как работающая цензура, которая не дает генерировать треки с определенными тегами. Плюс уже год ебут один и тот же 1.5 allegro. 2. Riffusion, Producer.ai (producer.ai) - куплен гуглом, удалены все старые относительно норм модели, вместо этого запихали безальтернативную каловую модель, которая и промпты сложнее самых нормисных в духе "make cool rock about love" не понимает, и вокал смазывает в какую-то кашу. При этом еще и максимально дегенеративная цензура, которая режет чуть ли не любые попытки сделать просто что-то не попсовое и не "музыку для ютуб".
ПРОЧИЕ ПОЛЕЗНЫЕ УТИЛИТЫ
1. https://www.bandlab.com/mastering Быстрый мастеринг в две кнопки, если хочешь чтобы звучало более слушабельно, но не имеешь навыков в DAW или аудиоредакторах (или лень). 2. https://morpher.ru/accentizer/ Если генерируешь музыку с лириками на русском, то очень часто случается, что твой генератор путает ударения в словах. Прежде чем пихать свою графоманию в генератор, проставь ударения в сервисе по ссылке. И уже из этого сервиса копируй текст в генератор. По крайней мере в Suno это помогает.
>>1627940 >>1627873 Я тут недавно возле ТЦ местного видел какую-то кибитку для сбора средств на сво, вот там ебашила откровенная нейронка, стыдно за долбоеба который такой текст писал и вообще компоновал этот кал, вообще без души че-то унылое. Условный какой-нибудь безногим ветеран с баяном был бы уместнее. Короче, с нейронками то же самое как и без них: ничто не остановит кожаных уебков производить кал, а нейронки просто инструмент, причем простой.
>>1627854 Лел, походу Ссуна использует семь нот на полную катушку.
Зыс по абстрактному запросу "Instrumental, fantasy country festival, dancing, folk fantasy instruments, vibes of evening and celebration"
До кучи ремейк про гномов История такая: когда добавили генератор текста, я попросил написать по рофлу песню про негров на плантации а-ля Рабыня Изаура "Я кошу кошу сахарный тростник" - отказалось по политическим соображениям. Я такой: "Ну ладно тогда, пусть будет про гномов на плантации."
AI Chatbot General № 823 /aicg/
Аноним28/05/26 Чтв 19:48:58№1621230Ответ
>>1628151 Корпораты всегда ставили кумерам палки в колеса Если ты не научился адаптироваться и искать варианты, то не так уж тебе и нужен этот нейрокум
Обсуждаем развитие искусственного интеллекта с более технической стороны, чем обычно. Ищем замену надоевшим трансформерам и диффузии, пилим AGI в гараже на риге из под майнинга и игнорируем горький урок.
Я ничего не понимаю, что делать? Без петросянства: смотри программу стэнфорда CS229, CS231n https://see.stanford.edu/Course/CS229 (классика) и http://cs231n.stanford.edu (введение в нейроночки) и изучай, если не понятно - смотри курсы prerequisites и изучай их. Как именно ты изучишь конкретные пункты, типа линейной алгебры - дело твое, есть книги, курсы, видосики, ссылки смотри ниже.
Почему python? Исторически сложилось. Поэтому давай, иди и перечитывай Dive into Python.
Можно не python? Никого не волнует, где именно ты натренируешь свою гениальную модель. Но при серьезной работе придется изучать то, что выкладывают другие, а это будет, скорее всего, python, если работа последних лет.
Стоит отметить, что спортивный deep learning отличается от работы примерно так же, как олимпиадное программирование от настоящего. За полпроцента точности в бизнесе борятся редко, а в случае проблем нанимают больше макак для разметки датасетов. На кагле ты будешь вилкой чистить свой датасет, чтобы на 0,1% обогнать конкурента.
Количество статей зашкваливающее, поэтому все читают только свою узкую тему и хайповые статьи, упоминаемые в блогах, твиттере, ютубе и телеграме, топы NIPS и прочий хайп. Есть блоги, где кратко пересказывают статьи, даже на русском
Где ещё можно поговорить про анализ данных? http://ods.ai
Нужно ли покупать видеокарту/дорогой пека? Если хочешь просто пощупать нейроночки или сделать курсовую, то можно обойтись облаком. Google Colab дает бесплатно аналог GPU среднего ценового уровня на несколько часов с возможностью продления, при чем этот "средний уровень" постоянно растет. Некоторым достается даже V100. Иначе выгоднее вложиться в GPU https://timdettmers.com/2019/04/03/which-gpu-for-deep-learning заодно в майнкрафт на топовых настройках погоняешь.
Когда уже изобретут AI и он нас всех поработит? На текущем железе — никогда, тред не об этом
Кто-нибудь использовал машоб для трейдинга? Огромное количество ордеров как в крипте так и на фонде выставляются ботами: оценщиками-игральщиками, перекупщиками, срезальщиками, арбитражниками. Часть из них оснащена тем или иным ML. Даже на швабре есть пара статей об угадывании цены. Тащем-то пруф оф ворк для фонды показывали ещё 15 лет назад. Так-что бери Tensorflow + Reinforcement Learning и иди делать очередного бота: не забудь про стоп-лоссы и прочий риск-менеджмент, братишка
Список дедовских книг для серьёзных людей Trevor Hastie et al. "The Elements of Statistical Learning" Vladimir N. Vapnik "The Nature of Statistical Learning Theory" Christopher M. Bishop "Pattern Recognition and Machine Learning" Взять можно тут: https://www.libgen.is
Напоминание ньюфагам: немодифицированные персептроны и прочий мусор середины прошлого века действительно не работают на серьёзных задачах.
>>1628025 Генетическое программирование? Грамматическая эволюция? Методы не новые, но как-будто лучше ничего не придумали. Но тут да, только миллиарды евалов делать. Есть еще методы направленной эволюции, сужающие область поиска, но там свои подводные камни.
>>1628025 Ты пытаешься предсказывать результат хаотичной системы или как-то использовать ее внутри нейронов? Всё и сразу, оставляю только то, что реально работает. Сейчас идея попробовать реализовать нейросеть на движке EoC
Структурно это выглядит примерно так, на 3-х нейронах крутится EoC, предиктор (10+ нейронов непрерывно учится предсказывать, то что необходимо для решения текущей задачи, например поиска наибольшей траектории или выполнения логических операторов) Результаты предиктора используются для обучения ЕoC. Настраивается это всё LLM с памятью, возможностью писать патчи, в зависимости от текущего эксперимента. Использую динамическую архитектуру, где это оправдано. Можно заморозить веса и использовать 3 нейрона для решения определенных задач, без участия всей этой конструкции.
Тред про AI-агентов - от вайб-кодинга до персональных ассистентов, которые сидят в твоих чатах, читают заметки и автономно ломают всё вокруг. Для кодеров, которые разучились писать руками, и для гуманитариев, чей диплом филолога наконец котируется в IT. Сеньор в 2026 - это тот, кто умеет внятно объяснить машине, чего он блять хочет.
С чего начать: - Хочешь кодить с AI эффективно: Cursor или Claude Code - Хочешь кодить в VS Code без привязки к конкретному провайдеру: Kilo Code, Cline или Roo Code + OpenRouter - Хочешь кодить с AI локально: OpenCode, Qwen Code или Pi Coding Agent + из моделей аноны советуют Qwen3.6, подробности в llama-треде - Хочешь приложение без кода: Lovable или bolt.new - Хочешь автоматизировать рутину: n8n или Langflow - Хочешь персонального ассистента: OpenClaw + API корпов или локальная модель на твоей пеке
Вот финальный, полностью укомплектованный промпт. В него интегрировано жесткое требование использовать JSON для хранения данных, а также добавлены технические критерии валидации структуры файла, чтобы ИИ написал максимально отказоустойчивый код. ------------------------------ Задача: Доработка существующего Python + HTML чекера AI-моделей. Необходимо расширить логику работы с провайдерами, фильтрацией и хранением настроек. Проект должен быть архитектурно независимым от конкретного API (будь то OpenRouter, Kilo или любой другой эндпоинт). ## 1. Жесткая фиксация конкретной модели (Target Model Routing)
Реализовать в коде передачу конкретного ID модели (например, google/gemma-2-9b-it:free) в целевое API. Настроить параметры запроса так, чтобы удаленный сервер обрабатывал запрос строго в рамках выбранной модели и не переключал роутинг (fallback) на альтернативные варианты при её недоступности или иных ситуациях. Жестко, пользователь выбрал галочкой в интерфейсе эту модель, полный фокус на работу с ней.
## 2. Универсальная фильтрация по тегу :free (Free Models Filter)
Добавить в бэкенд-логику функцию автоматической фильтрации пула доступных моделей. Скрипт должен парсить список моделей от выбранного API и оставлять только те, которые содержат суффикс :free в ID или имеют нулевую стоимость, чтобы в HTML-интерфейс выводились исключительно бесплатные варианты.
## 3. Динамическое управление и добавление новых API-провайдеров в UI
Добавить в HTML-интерфейс блок управления списком провайдеров (эндпоинтов сканирования). Реализовать текстовые поля ввода в UI для добавления любого нового провайдера на лету (например: имя, базовый URL-адрес API, ключ доступа, специфичные параметры). Система должна быть полностью абстрагирована и одинаково успешно работать как с OpenRouter, так и с Kilo, Абырвалг или любым другим новым сервисом.
## 4. Двухслойная система хранения данных (Сессия + JSON-конфиг) После того как пользователь вводит параметры нового провайдера в интерфейсе и нажимает «Сохранить», приложение должно автоматически обработать данные на двух уровнях:
Уровень сессии (Session State): Новый провайдер мгновенно добавляется в текущую оперативную память/сессию запущенного приложения, чтобы пользователь мог сразу же запустить сканирование без перезагрузки скрипта. Уровень конфигурации (Persistent Config в JSON): Бэкенд должен автоматически сериализовать эти данные и вписать их в локальный файл конфигурации config.json. Приложение должно перезаписывать этот файл аккуратно (используя json.dump с отступами indent=4 для читаемости), сохраняя структуру старых настроек. При следующем холодном старте скрипта все ранее добавленные вручную провайдеры должны автоматически подгружаться из JSON-файла в интерфейс. Предусмотреть базовую проверку на существование файла и валидность JSON-структуры при старте.
Сделал слоп-диплом на 50 + страниц с кодексом 5.5 и местами 5.4 и получил 0% ИИ в антиплагиате. Даже скилл не включал на разную длину предложений, убрал только явные знаки типа "важно не только хуй, но и пизда", так что пользуйтесь, кто тоже пишет диплом. Из слабых мест -- хуёвое понимание UML диаграмм, на них ушло много времени. IDEF0 тоже придётся руками делать, поскольку хмл формат в известной древней проге сделан максимально уёбищно, впрочем, как и ворд хмл формат.
Активно репортите все нерелейтед посты кнопкой на сообщениях. Этот тред только про новости, не позволим троллям загаживать тред шитпостом и бесконечным словоблудием.
🚀 Последний обзор ИИ новостей:
📰 Главные новости ИИ
Anthropic выпустила Opus 4.8, «скромное, но ощутимое улучшение», которое тем не менее демонстрирует SOTA-результат 69,2% на SWE-Bench Pro, 57,9% на Humanity’s Last Exam с использованием инструментов и 1890 на GDPval-AA, сочетая новые успехи в честности с уровнями рассогласованности, которые соперничают с еще не выпущенным Mythos Preview, который Anthropic теперь обещает предоставить «всем нашим клиентам в ближайшие недели».
💰 Финансирование
Внутри проспекта эмиссии Unitree: Выручка растет, а прибыль падает по мере приближения слушаний по IPO на STAR Market. Unitree Robotics направляется на долгожданное слушание по листингу 1 июня с обновленным проспектом эмиссии, в котором подчеркивается тонкий баланс между взрывным ростом выручки и стремительно растущими расходами на НИОКР.
Deep Robotics подает заявку на IPO на STAR Market на 367 млн долларов после первого прибыльного года. Deep Robotics планирует привлечь 2,5 млрд юаней (367,4 млн долларов) на площадке STAR Market Шанхайской фондовой биржи, оценив компанию более чем в 1,5 млрд долларов.
Anthropic обгоняет OpenAI, становясь самым дорогим ИИ-стартапом, и приближается к оценке в 1 триллион долларов в последнем раунде финансирования.
Apollo и Blackstone продвигают долговую сделку примерно на 36 миллиардов долларов для покупки TPU Google с целью сдачи их в аренду Anthropic, при этом Broadcom обеспечивает поддержку крупнейших траншей, а финансовая инженерия теперь финансирует кремниевую инженерию.
Конкуренты перегруппировываются, поскольку Groq привлекает до 650 миллионов долларов для «второго акта» после того, как лицензионная сделка с Nvidia на 20 миллиардов долларов опустошила ее руководящую команду.
После сделки Nvidia на 20 млрд долларов, не являющейся аквайхиром, стартап по производству ИИ-чипов Groq, по сообщениям, привлекает 650 млн долларов
10 крупнейших раундов финансирования за неделю: Anthropic доминирует на фоне в целом более спокойной недели для мегараундов. На этой неделе пятилетний гигант в области генеративного ИИ привлек 65 миллиардов долларов в рамках раунда Series H, доведя свою оценку post-money до умопомрачительных 965 миллиардов долларов.
Следующим по величине финансированием стал раунд на 1 миллиард долларов для производителя инструментов разработки ИИ-ПО Cognition, что подняло его оценку до 26 миллиардов долларов.
XCENA — стартап с офисами в Южной Корее и США — этот чиповый стартап только что привлек 135 миллионов долларов, сделав ставку на то, что главное узкое место ИИ — это не вычисления, а память. Четырехлетний стартап разработал чип, который размещает вычислительные мощности гораздо ближе к DRAM — быстрым чипам кратковременной памяти, которые хранят данные, активно используемые процессором, — что позволяет выполнять рутинные операции с данными вблизи памяти, без дорогостоящих циклов обмена между CPU, GPU и памятью.
🤖 Робототехника
Figure заключает коммерческое соглашение с Catalyst Brands о масштабном внедрении человекоподобных роботов. Figure подписала коммерческое соглашение с Catalyst Brands о внедрении своих человекоподобных роботов следующего поколения в коммерческие дистрибьюторские и логистические сети. Внедрение начнется в дистрибьюторском логистическом центре Catalyst в Рино, штат Невада, где антропоморфные роботы будут сосредоточены на автоматизации физически тяжелых и рутинных задач по сортировке и упаковке в цепочке поставок.
EngineAI вступает в производственную гонку: один человекоподобный робот каждые 15 минут на новой базе в Шэньчжэне. EngineAI официально ввела в эксплуатацию свою базу интеллектуального производства в районе Наньшань города Шэньчжэнь, заявив о темпах производства одного человекоподобного робота каждые 15 минут. Компания стремится к «масштабным поставкам на уровне десятков тысяч единиц»,.
NVIDIA Research продвигает робототехнику от симуляции к реальному миру. Представленные на Международной конференции по робототехнике и автоматизации, восемь новых исследовательских работ NVIDIA Research показывают, как роботы, обученные в симуляции, переходят в реальный мир.
Человекоподобные роботы Figure получают работу в розничной торговле в логистическом центре Catalyst Brands в Рино, материнской компании JCPenney и Aeropostale
OpenAI запускает кампанию по найму сотрудников в свое подразделение робототехники для создания роботов для реального мира с использованием совместного проектирования аппаратного обеспечения полного стека и машинного обучения. Первые роботы будут поддерживать работников на инфраструктурных проектах.
Waymo выпустит Ojai, более просторное роботакси, созданное совместно с Zeekr от Geely, для публичных поездок без водителя.
⚖ Регулирование
Представитель Иллинойса обсуждает законопроект, который будет регулировать деятельность ИИ-компаний.
CNN подает в суд на Perplexity AI за незаконное копирование и распространение своих новостных материалов
ЕС готовит чрезвычайные полномочия для отмены контрактов на поставку микросхем во время их дефицита, в то время как IBM ставит 10 миллиардов долларов на создание надежного крупномасштабного квантового компьютера к 2029 году.
Основатели компаний используют решение индийского суда для возобновления критики рекламного бизнеса Google. Недавнее решение индийского суда против практики контекстной рекламы Google привлекло новое внимание после того, как основатели заявили, что конкуренты давно используют эту систему для переманивания клиентов и вынуждения компаний платить за защиту собственных брендов.
🏢 Приобретения
Asana приобретает StackAI, конструктора ИИ-агентов без кода.
📱 Приложения
Robinhood запускает агентский трейдинг и анонсирует кредитную карту для ИИ-агентов с кэшбэком 3%.
Производитель из центрального Нью-Йорка оседлал волну «золотой лихорадки» ИИ и удвоил мощности, чтобы удовлетворить взрывной спрос от дата-центров для ИИ.
Ознакомьтесь с реальными прототипами ИИ из Futures Lab. Несколько ярких проектов последних двух лабораторий включают: Kanji Garden: Приложение, которое обучает японскому языку через иммерсивные, сгенерированные ИИ истории и визуальные образы вместо зубрежки. SignFluent: Инструмент для изучения американского жестового языка в реальном времени, который обеспечивает мгновенную обратную связь по вашей технике исполнения. MuscleMemory: Мобильный инструмент для тренировок по калистенике, который использует отслеживание с помощью ИИ-камеры для обеспечения мгновенной голосовой обратной связи по технике выполнения упражнений, помогая предотвратить травмы.
Этот ИИ-стартап будет убирать ваш дом бесплатно, чтобы обучать роботов будущего. Стартап по обучению ИИ Shift хочет убирать ваш дом бесплатно. Подвох — потому что, несмотря на то, что написано на их сайте, подвох есть всегда — заключается в том, что они будут записывать уборщиков, пока они моют, пылесосят, вытирают пыль, наводят порядок и стирают, и использовать эти записи для обучения роботов.
⚠ Безопасность ИИ
Push Security раскрывает детали вредоносной кампании LLMShare, злоупотребляющей общими ссылками ChatGPT и Claude. Злоумышленники используют функции обмена контентом на платформах ИИ-чат-ботов — ChatGPT и Claude — для доставки вредоносного ПО через страницы, размещенные на легитимных, доверенных доменах, распространяя вредоносные ссылки через спонсируемую вредоносную рекламу в поисковых системах.
Красная команда Института безопасности ИИ Великобритании взломала ChatGPT за шесть часов без специального доступа
Вредоносные пакеты npm, созданные с помощью Claude AI, эксфильтрируют файлы из каталога пользовательских данных Claude Code mnt в репозитории GitHub злоумышленников
Google внедряет автономную защиту от хакеров. Google Cloud представила новую платформу безопасности «AI Threat Defense», которая реагирует на быстрые атаки с помощью ИИ. Система не только обнаруживает уязвимости, но и с помощью ИИ-агентов самостоятельно пишет подходящий код для их немедленного устранения.
В этом треде обсуждаем нейронки генерящие 3д модели, выясняем где это говно можно юзать, насколько оно говно, пиплайны с другими 3д софтами и т.д., вангуем когда 3д-мешки с говном останутся без работы.
Форки на базе модели insightface inswapper_128: roop, facefusion, rope, плодятся как грибы после дождя, каждый делает GUI под себя, можно выбрать любой из них под ваши вкусы и потребности. Лицемерный индус всячески мешал всем дрочить, а потом и вовсе закрыл проект. Чет ору.
Любители ебаться с зависимостями и настраивать все под себя, а также параноики могут загуглить указанные форки на гитхабе. Кто не хочет тратить время на пердолинг, просто качаем сборки.
Единственный минус, который не обеспечивает чистую победу генераторов видео - 3 секунды ролика для онлайн генерации, 5 секунд для онлайна (модель Wan 2.2), умельцы просто берут последний кадр и снова генерируют ролики, потом склеивают. Недавно вышла Sora 2, которая зацензурена по самые гланды. Нинтендо довольна.
Тред не является технической поддержкой, лучше создать issue на гитхабе или спрашивать автора конкретной сборки.
Эротический контент в шапке является традиционным для данного треда, перекатчикам желательно его не менять или заменить на что-нибудь более красивое. А вообще можете делать что хотите, я и так сюда по праздникам захожу.
Вопрос такой господа, вот всякой ктото с популярными людьми делает лорки и хвастается этим, а вот где хвастаются не могу найти. Цивитай не предлагать, там по реальным нету
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
>>1628020 >То тулзы не дергает Это мелкомодель тупит. Хорошо знакомо по использованию во внешних играх. >придумывает неожиданные ходы Потому что всё делает по агентской схеме. Для каждой задачи свой запрос, а не комбайн "на васянокарточку и универсальный пресет сделай ЗАЕБИСЬ" в условиях и так тупой модели. >Из минусов Маринары отмечу не самый удобный редакт Плюсую >рассинхрон уровней и статов персонажей, и не всегда уместные РПГ-шные битвы. Проблема мелкомодели
Модно и ролеплей с агентами делать, в целом имеет всё то же самое только без карты и динамических фонов/музыки.
Не хватает так же имиджгена как в таверне для полного счастья. И не нашёл как задавать агента из отдельного подключения чтобы крутить сразу две модели, для инструментов и рп.
>>1628024 Конечно на ризонинг. Точнее не ризонинг а агентское использование инстракта.
>>1628020 Welcome to the club, buddy♂ Гм или ролплей? Каких агентов юзаешь? Там можно выставить более простую и быструю модель для побочных агентов, но если используются те что на сюжет, то лучше не стоит. И еще неплохо бы выделить на сопутствующую картинкогенерацию. А что там с редактом? Вроде обычный, хуже когда что-то в трекеры насрет, или хочешь сменить направление, и потом замучаешься это все править в нескольких местах. >>1628023 Наверно да. Но флеш на удивление иногда неплохо срабатывает и пишет необычно, или не ссыт продвигаться вперед там где остальные вязнут.
Короче, ребята, нужна помощь бомжу с 4gb vram. Что есть типа DeepNude, но локальное и нетребовательное, желательно без слишком сложной установки? Остальные характеристики ПК: Ryzen 5 4500, 8x2 ddr4 ram
>>1625940 (OP) О, у меня тоже 4Гб vram, зато обычной оперативы 64Гб, этого хватает даже на генерацию видосов в comfyui, причём это занимает не вечность по времени (но качество шакальное, хотя это от модели зависит). Касательно 8×2 ram как вариант в comfyui взять плагин на gguf, либо скомпилить под видеокарту stable-diffusion.cpp, а потом запускать с флагом -- n-gpu-layers [число слоёв], если, конечно, там такое есть. Может показаться, что возни многовато, но на самом деле в случае с stable-diffusion.cpp достаточно просто в аргументах командной строки прописать необходимые модели.
>>1627428 А, ещё добалю, что наверняка полно приложух на основе stable-diffusion.cpp, которые позволяют избежать работы в командной строке. Об этом можно почитать в readme.md проета в разделе сопутствующих проектов.
ИТТ обсуждаем опыт нейродроча в своих настоящих задачах. Это не тред "а вот через три года" - он тол
Аноним24/12/22 Суб 16:39:19№3223Ответ
ИТТ обсуждаем опыт нейродроча в своих настоящих задачах. Это не тред "а вот через три года" - он только для обмена реальными историями успеха, пусть даже очень локального.
Мой опыт следующий (golang). Отобрал десяток наиболее изолированных тикетов, закрыть которые можно, не зная о проекте ничего. Это весьма скромный процент от общего кол-ва задач, но я решил ограничится идеальными ситуациями. Например, "Проверить системные требования перед установкой". Самостоятельно разбил эти тикеты на подзадачи. Например, "Проверить системные требования перед установкой" = "Проверить объем ОЗУ" + "Проверить место на диске" + ... Ввел все эти подзадачи на английском (другие языки не пробовал по очевидной причине их хуевости) и тщательно следил за выводом.
Ответ убил🤭 Хотя одну из подзадач (найти кол-во ядер) нейронка решила верно, это была самая простая из них, буквально пример из мануала в одну строчку. На остальных получалось хуже. Сильно хуже. Выдавая поначалу что-то нерабочее в принципе, после длительного чтения нотаций "There is an error: ..." получался код, который можно собрать, но лучше было бы нельзя. Он мог делать абсолютно что угодно, выводя какие-то типа осмысленные результаты.
Мой итог следующий. На данном этапе нейрогенератор не способен заменить даже вкатуна со Скиллбокса, не говоря уж о джунах и, тем более, миддлах. Даже в идеальных случаях ГПТ не помог в написании кода. Тот мизерный процент решенных подзадач не стоил труда, затраченного даже конкретно на них. Но реальная польза уже есть! Чатик позволяет узнать о каких-то релевантных либах и методах, предупреждает о вероятных оказиях (например, что, узнавая кол-во ядер, надо помнить, что они бывают физическими и логическими).
И все же, хотелось бы узнать, есть ли аноны, добившиеся от сетки большего?
>>1623385 >Музыку, картины, фильмы тоже не запоминаешь И ладно. У меня нет целей все зафиксировать и запомнить, только то, что вызвало какие-то яркие эмоции. Если послушал новый альбом и он как-то по-особому откликнулся, то запишу, есть прицеденты.
>>1623679 Не понял. Тебе сегодня понравилась песня, ты зафиксировал и забыл. Через неделю ты услышал эту же песню, ты опять фиксируешь или ты помнишь свои ощущения?
>>1620862 Я проверил мединцкие протоколы на системах и структурах. Работает. И дает четкий абсолютно сигнал. Вкратце в всяких США сейчас ебейший кризис, вот прям сейчас. Просто сдерживают эмоции, чтобы все не охуели. Присмотрись к региональным, мелким банкам (их около 1к.) им всем пизда. Волна уже пошла. Останется около 6-10 банков во всей США. Вся коммерческая недвига тоже ебанется.
ai age verification (подтверждение возраста) на сайте
Аноним02/06/26 Втр 18:12:59№1624341Ответ
привет дрочеры двачеры! столкнулся с трудностями там, где совсем уж не ожидал. при очередном визите на spankbang обнаружил предложение пройти процедуру верификации возраста. процедура довольно простая - доки не нужны, просто лицом в камеру посветить. мне то лет уже достаточно, но светить родным ликом в камеру перед каким-то ИИ, сгенерированным другим ИИ я не хочу. посему встал вопрос - как пройти эту проверку, не "спалив свой фейс?" смена региона для слабаков - хочу один раз закрыть вопрос и спокойно пользоваться, потому проверку нужно именно пройти, а не обойти требование подтверждения возраста.
пробовал показывать камере смарта фотки футболистов - фейлишь несколько попыток, после чего идёшь нахер презагружаешь страницу. и так по кругу.
пробовал OBS virtual camera и видос с "говорящей головой" в качестве источника - сразу схлопывает, говорит прошёл, но доступа к сайту так и не даёт. и так по кругу.
помогайте, умники и умницы! у меня там в разделе "favorites" сохранены очень важные видео, которых на других ресурсах не найти. очень нужно восстановить доступ.
🎤🔊 ОБСУЖДАЕМ ПРЕОБРАЗОВАНИЕ ТЕКСТА В ГОЛОС И КЛОНИРОВАНИЕ ГОЛОСОВ 🔊🎤 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🌟 ТОП ЛОКАЛЬНЫХ МОДЕЛЕЙ ПО КАЧЕСТВУ РУССКОГО ГОЛОСА НА МАРТ 2026 🌟
🐟👑 Fish-Speech S2 Pro (FishAudio) — SOTA, ElevenLabs на локале! → zero-shot клон от 10–30 сек записи → 80+ языков (русский топ), теги эмоций [excited], [whisper], [angry], [laughing] и вообще дохуя → диалог между несколькими голосами → тяжёлая сучка (FP8 в 12 ГБ VRAM, full ~17 ГБ), но есть экспериментальный вариант для 6+ ГБ https://github.com/rodrigomatta/s2.cpp 🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹 🧠 Qwen3-TTS → клон от 3–30 сек (ВАЖНО: без reference-транскрипта текста — хуйня, если хочешь поудобнее подключи сразу QwenASR) → VoiceDesign: пишешь «весёлая молодая девка с хрипотцой» — и получаешь голос → 10 языков, включая русский → диалог между спикерами → лёгкая — влезает в 6 ГБ VRAM 🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹 🎙️ VibeVoice-7B от Майкрософт → тяжёлая, но 4-bit квантизация — запускается на 8 ГБ (проверено на 3070) → поддержка долгих спичей → подкаст-режим: 4 спикера одновременно → норм клонирование голоса 🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹 ☁️ FL CosyVoice3 → ультралёгкий 0.5 — запустится даже на тостере → 9 языков, включая русский → zero-shot клон от 3–10 сек референса 🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹🔹 🌍 Chatterbox Multilingual (23 языка, включая русский) → zero-shot клонирование голоса 🎤 F5-tts → zero-shot клонирование голоса → официально русский не поддерживается, но есть файнтюн (см. ниже) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 🚀 КАК ЭТИМ ПОЛЬЗОВАТЬСЯ (если что-то не понятно — спроси у ИИ лол) 🚀
🔥Вариант «всё в одном месте» — ComfyUI + TTS-Audio-Suite
1. Устанавливаем ComfyUI (Desktop для нормисов, Portable для здешних нейромантов) 2. Ставим https://github.com/diodiogod/TTS-Audio-Suite — постоянная обновляемая солярка почти всех моделей 3. Поставить FFmpeg (через winget в комадной строке: winget install FFmpeg или скачать) 4. Запускаем Комфи → перетаскиваем готовый json-воркфлоу из репозитория 5. Отсавляем включенными выбранные ноды, жмём Run 6. При первой генерации модели сами скачаются (~1–9 ГБ)
💥 Вариант «по отдельности» (кастом под каждую модель) 💥 Тоже через ComfyUI, только ставим отдельные кастомные ноды (на выбор):
в комфи в ноде F5 TTS audio advanced выбрать: model model:///ru.safetensors model_type: F5TTS_v1_Base sample_audio: emma_ru_xtts_3 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 🎉 Если что-то не запускается — пиши, разберёмся! Голосуем, клонируем, ебём нейросети вместе! 🔥🎙️
>>1576418 так это ж фиш аудио S2 у неё модель даже среднего размера всю vram займет с ней даже бояре напрягаются, а например на 5070ti bnb nf4 только нормально будет пахать, а это самая урезанная версия. Такая вот нейронка, которая по ресурсам жирнее чем видеомодели. но звук хороший генерирует, факт
2. higgs-audio-v3-tts (тоже самое что и Qwen3 только с возможностью контроля эмоции и экспрессий) - хуже чем dots.tts (но у него нету контроля эмоций, поэтому хз) в общем аудио приблуда сделанная для их собственного видео-генератора, как видно тут https://www.youtube.com/watch?v=qpXbU5011Pw (самой их видео модели у нас нет) https://github.com/Saganaki22/Higgs_v3-TTS-ComfyUI - кастомная нода для этой новинки
Терминология моделей prune — удаляем ненужные веса, уменьшаем размер distill — берем модель побольше, обучаем на ее результатах модель поменьше, итоговый размер меньше quant — уменьшаем точность весов, уменьшаем размер scale — квантуем чуть толще, чем обычный fp8, чтобы качество было чуть лучше, уменьшение чуть меньше, чем у обычного квантования, но качество лучше merge — смешиваем несколько моделей или лор в одну, как краски на палитре.
lightning/fast/turbo — а вот это уже просто название конкретных лор или моделей, которые обучены генерировать видео на малом количестве шагов, они от разных авторов и называться могут как угодно, хоть sonic, хоть sapogi skorohody, главное, что они позволяют не за 20 шагов генерить, а за 2-3-4-6-8.
>>1626968 >Как можно добавить референсных персонажей не имеях их на 1м кадре? Моя головная боль. В лучшем случае удается делать через вылавливание промежуточного кадра на вес золота из кучи говенных генераций ферст ту ласт.