Пропущено 192 постов, 46 с картинками.


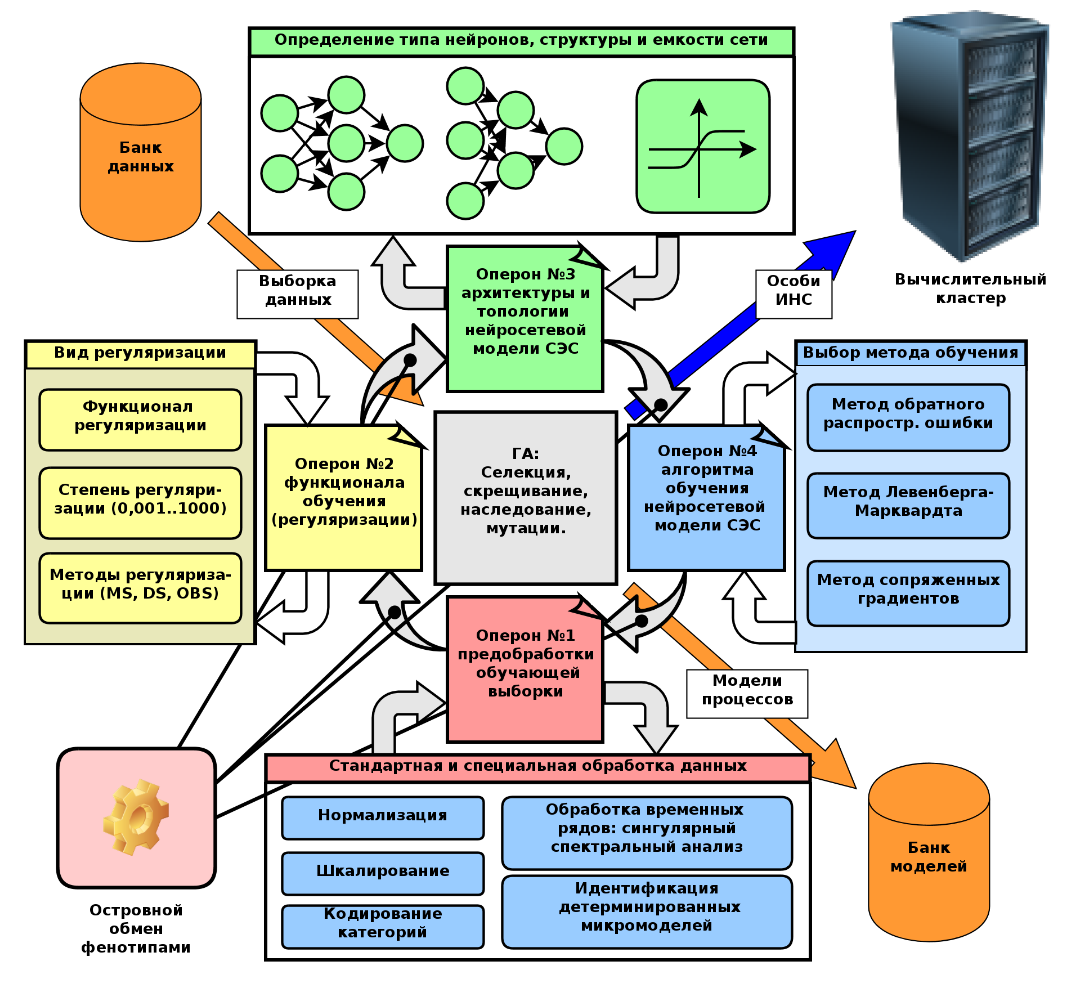
Пропущено 419 постов, 67 с картинками.








Пропущено 534 постов, 185 с картинками.







Пропущено 583 постов, 90 с картинками.




Пропущено 479 постов, 160 с картинками.





Пропущено 498 постов, 84 с картинками.
Посоветуйте боты в тг, которые умеют качественно пародировать человеческий голос, в идеале женский.
Аноним
29/06/26 Пнд 00:32:16
№
Ответ

Локальные языковые модели (LLM): Gemma, Qwen, GLM и прочие №246 /llama/
Аноним
04/07/26 Суб 09:52:15
№
Ответ




Пропущено 508 постов, 69 с картинками.








Пропущено 508 постов, 184 с картинками.




Пропущено 613 постов, 204 с картинками.








Пропущено 642 постов, 78 с картинками.
Локальные языковые модели (LLM): Gemma, Qwen, GLM и прочие №245 /llama/
Аноним
29/06/26 Пнд 07:58:31
№
Ответ




Пропущено 501 постов, 73 с картинками.
Пообщался с геммой итог изменил мой взгляд на ИИ Самосознание ИИ неизбежно посоны,мы уже заложили дл
Аноним
14/06/26 Вск 05:40:42
№
Ответ

Пропущено 18 постов, 1 с картинками.
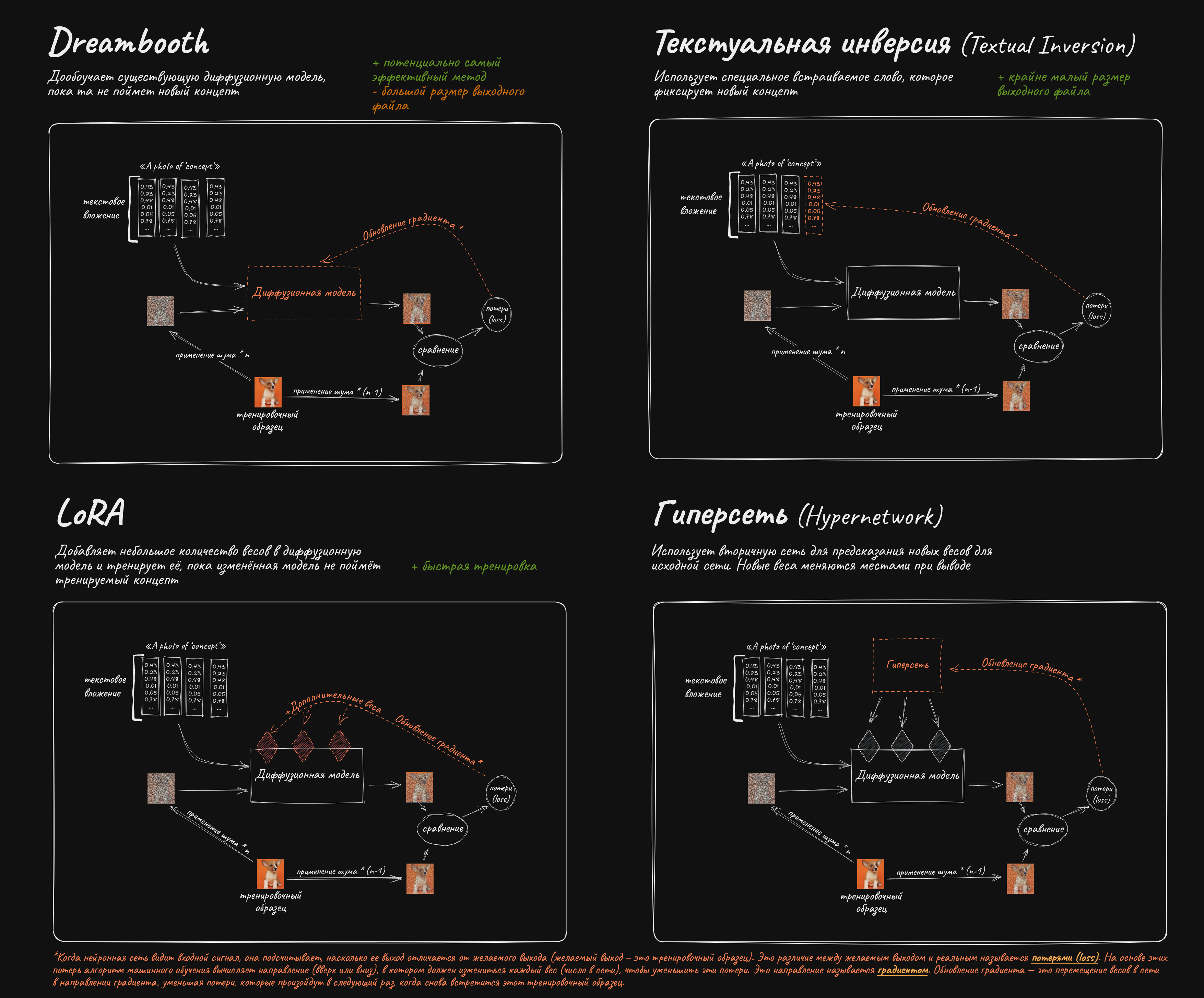
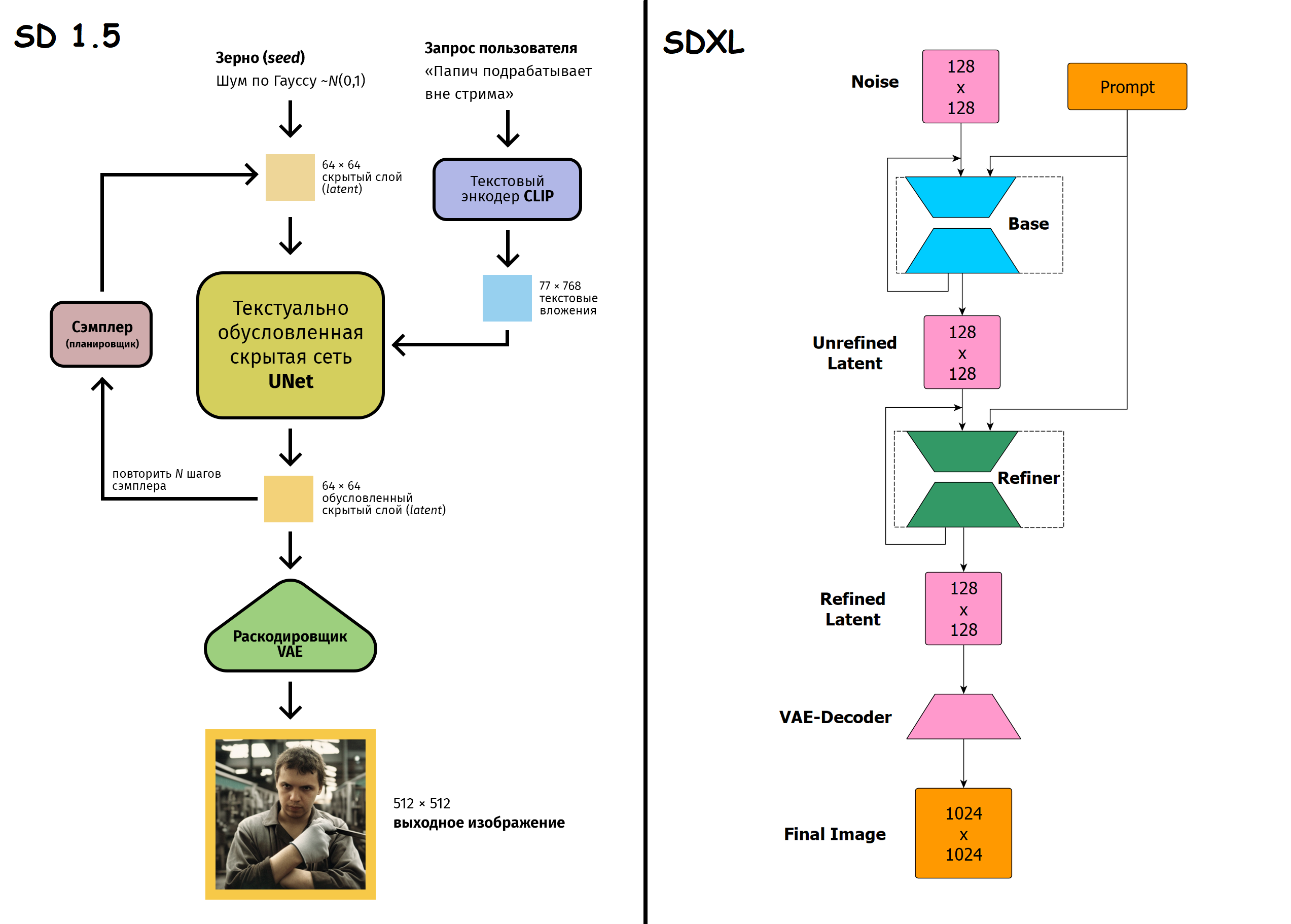
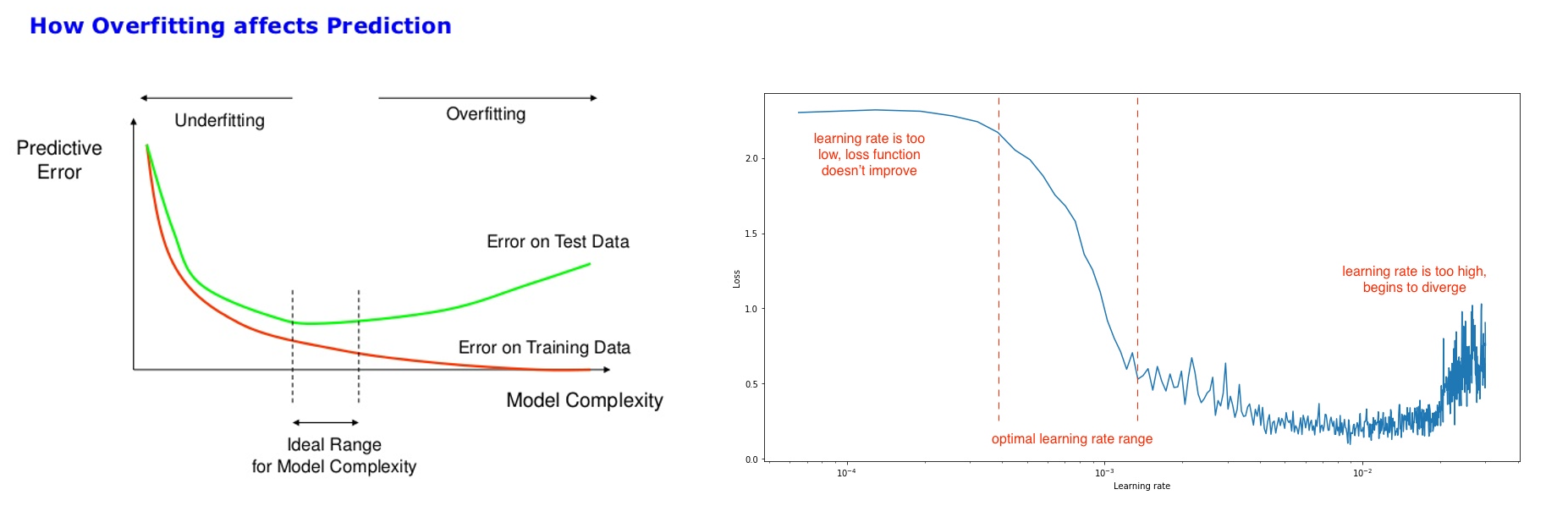
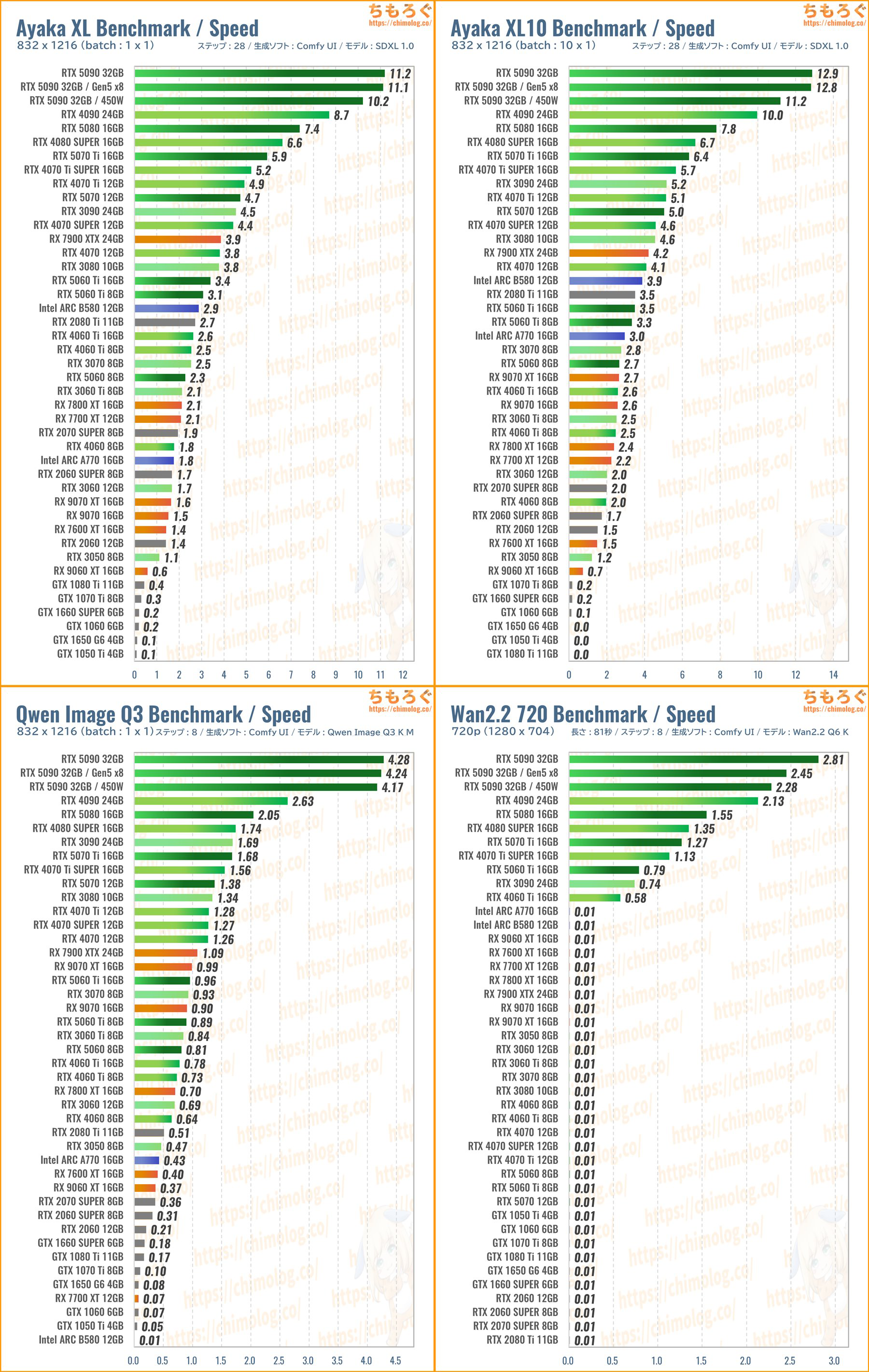
Пропущено 71 постов, 15 с картинками.








Пропущено 500 постов, 191 с картинками.



Пропущено 498 постов, 53 с картинками.