ИТТ делимся советами, лайфхаками, наблюдениями, результатами обучения, обсуждаем внутреннее устройство диффузионных моделей, собираем датасеты, решаем проблемы и экспериментируемТред общенаправленныей, тренировка дедов, лупоглазых и фуррей приветствуются
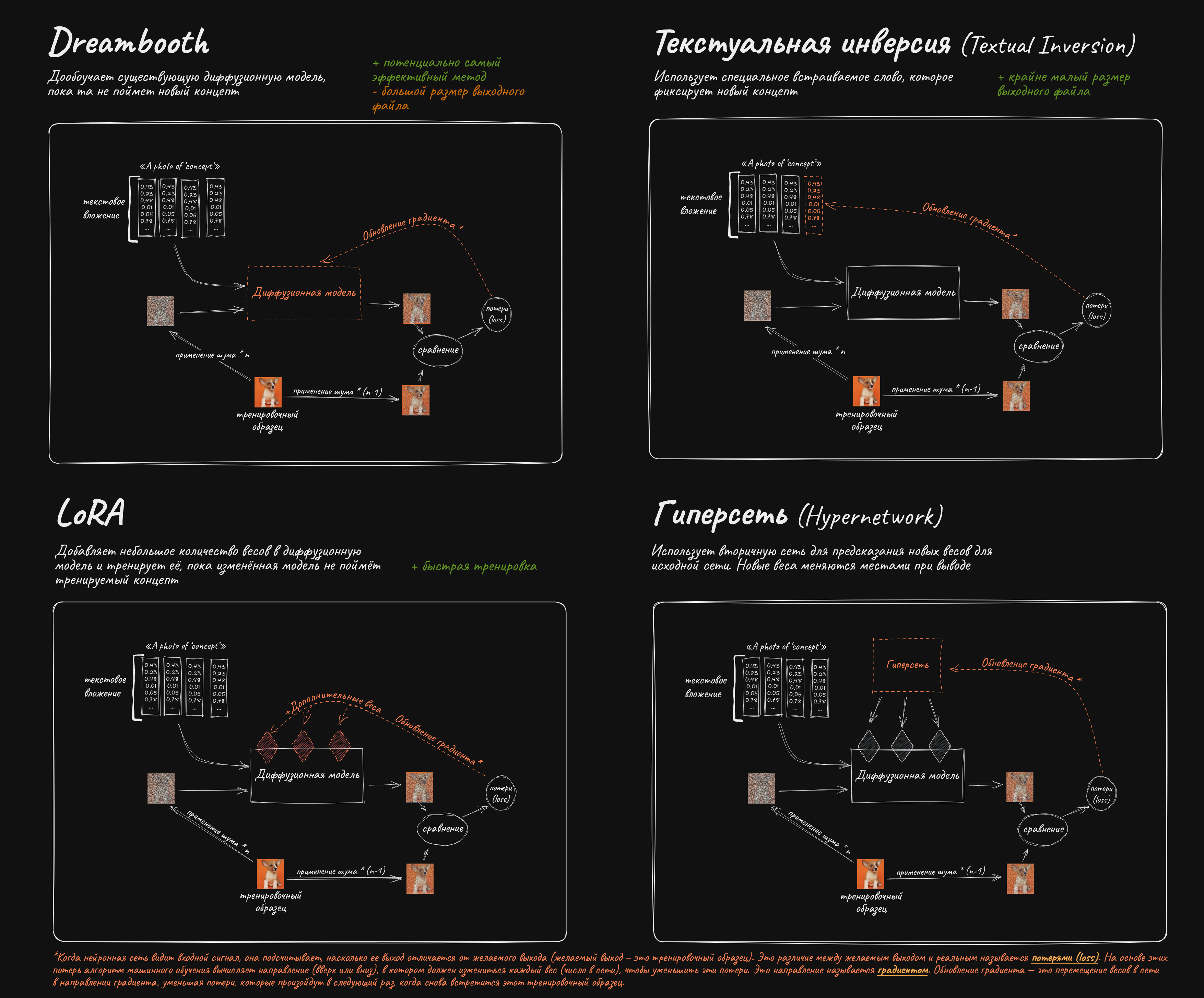
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ LoRA – "Low Rank Adaptation" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением. https://github.com/cloneofsimo/lora - изначальная имплементация алгоритма, пришедшая из мира архитектуры transformers, тренирует лишь attention слои, гайды по тренировкам: https://rentry.co/waavd - гайд по подготовке датасета и обучению LoRA для неофитов https://rentry.org/2chAI_hard_LoRA_guide - ещё один гайд по использованию и обучению LoRA https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - проект по созданию алгоритмов для обучения дополнительных частей модели. Ранее имел название LoCon и предлагал лишь тренировку дополнительных conv слоёв. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr, DyLoRA, IA3, а так же на последних dev ветках возможность тренировки всех (или не всех, в зависимости от конфига) частей сети на выбранном ранге: https://github.com/KohakuBlueleaf/LyCORIS
✱ Текстуальная инверсия (Textual inversion), или же просто Embedding, может подойти, если сеть уже умеет рисовать что-то похожее, этот способ тренирует лишь текстовый энкодер модели, не затрагивая UNet: https://rentry.org/textard (англ.)
➤ Тренировка YOLO-моделей для ADetailer: YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
Пытаюсь тренить в Мусуби Ван 2.2 на видосах, дефолтные 81 фрейм в 720п в 24гб врам не влезают даже с полным оффлоадом модели, влезло только когда уменьшил и фреймы до 41, и разрешение до 480п, с оффлоадом 24/40.
Есть ли понт T2V на таком хуевом качестве тренить, или лучше на картинках в норм качестве, или и то и другое?
Если на картинках, то юзать смазанные кадры из тех же видео, или лучше несмазанные фото?
I2V на картинках не тренится ваще, там придется хуевое в любом случае, но может 360п 81 фрейм будет лучше?
>>1405494 2.2 I2V вот так датасет можешь делать в разных разрешениях, всё нормально тренится. 2.2 T2V последний раз когда пробовал там на одном кадре тренить - было сломано, сейчас только на Квене треню.
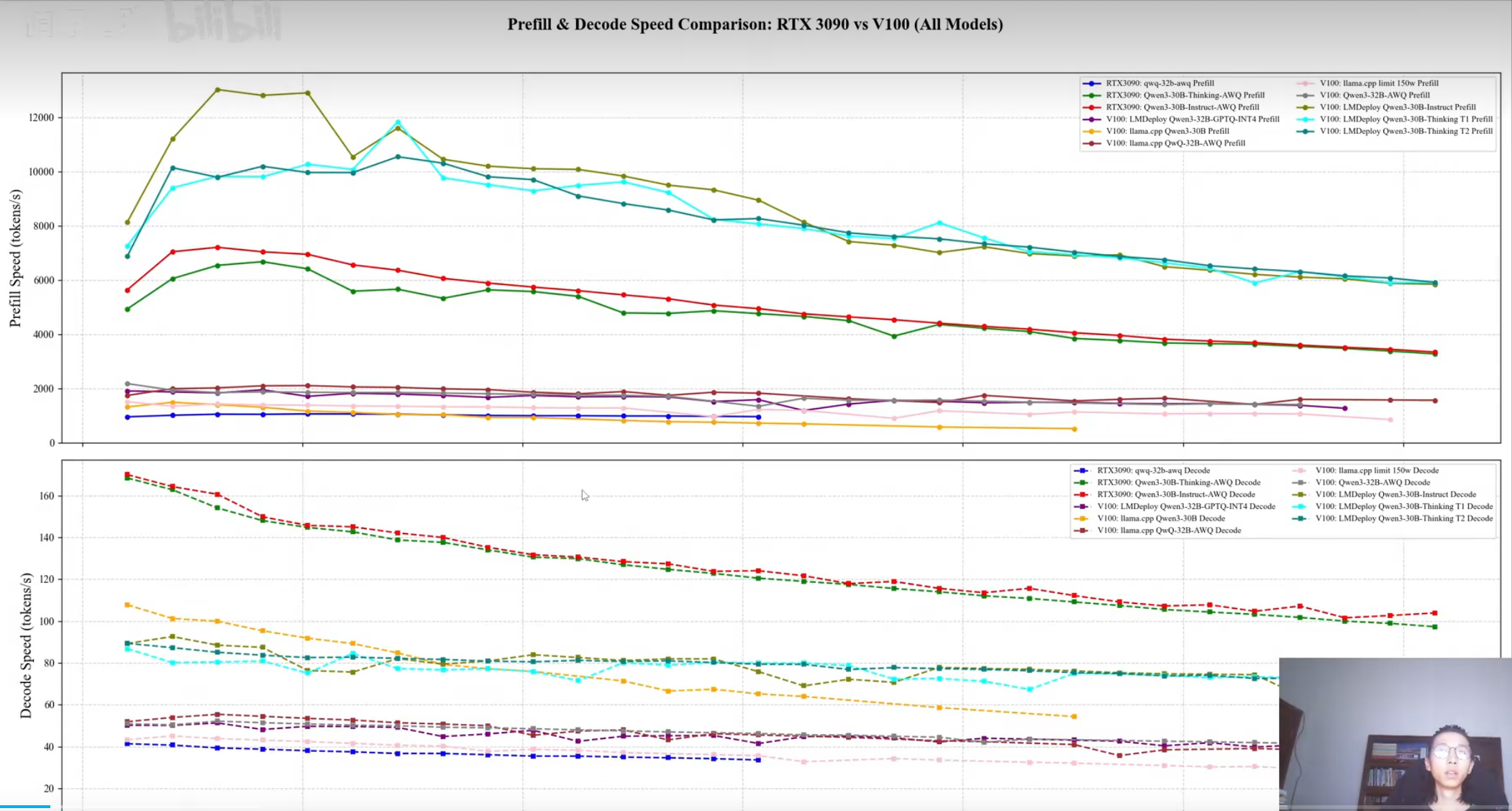
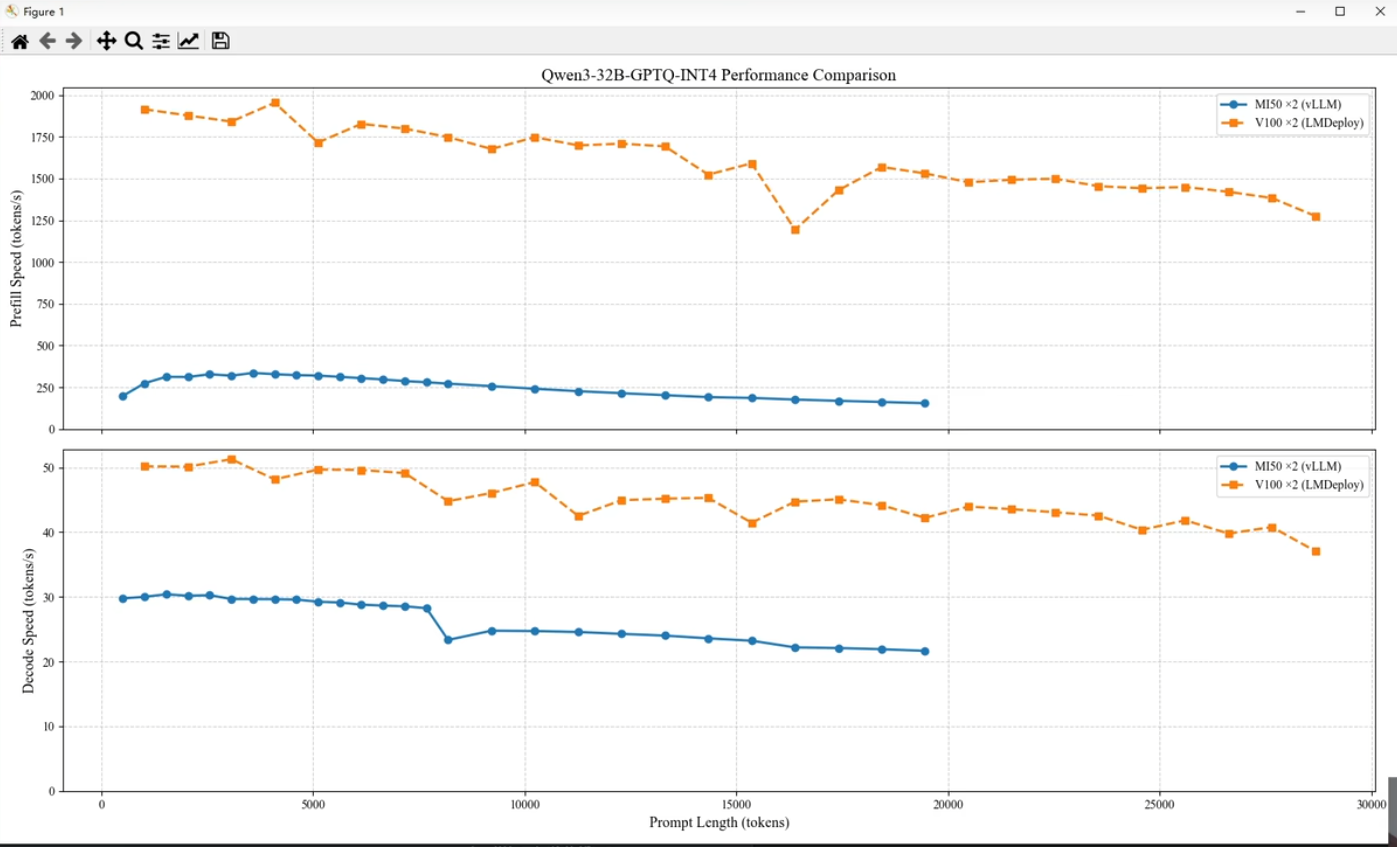
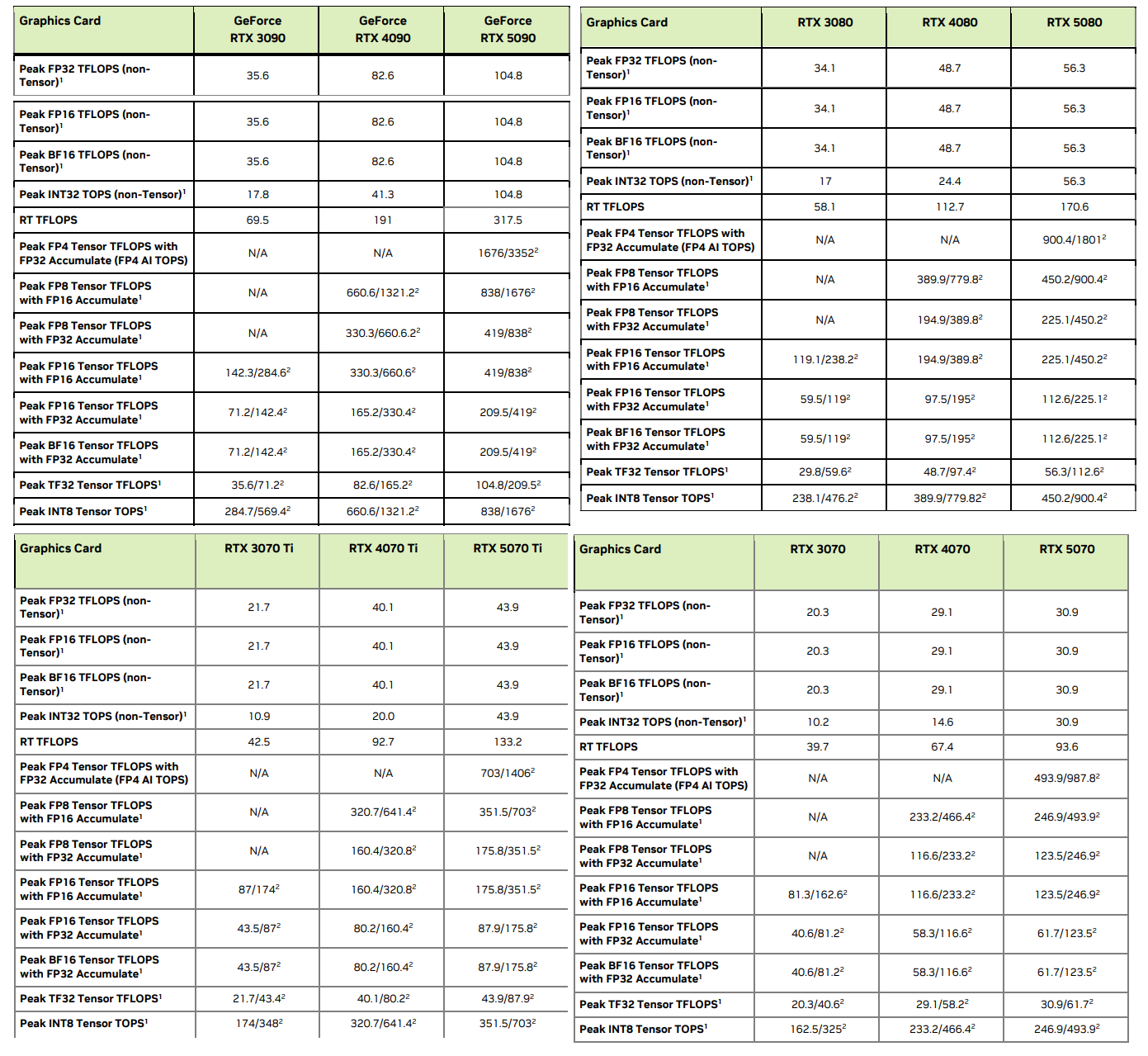
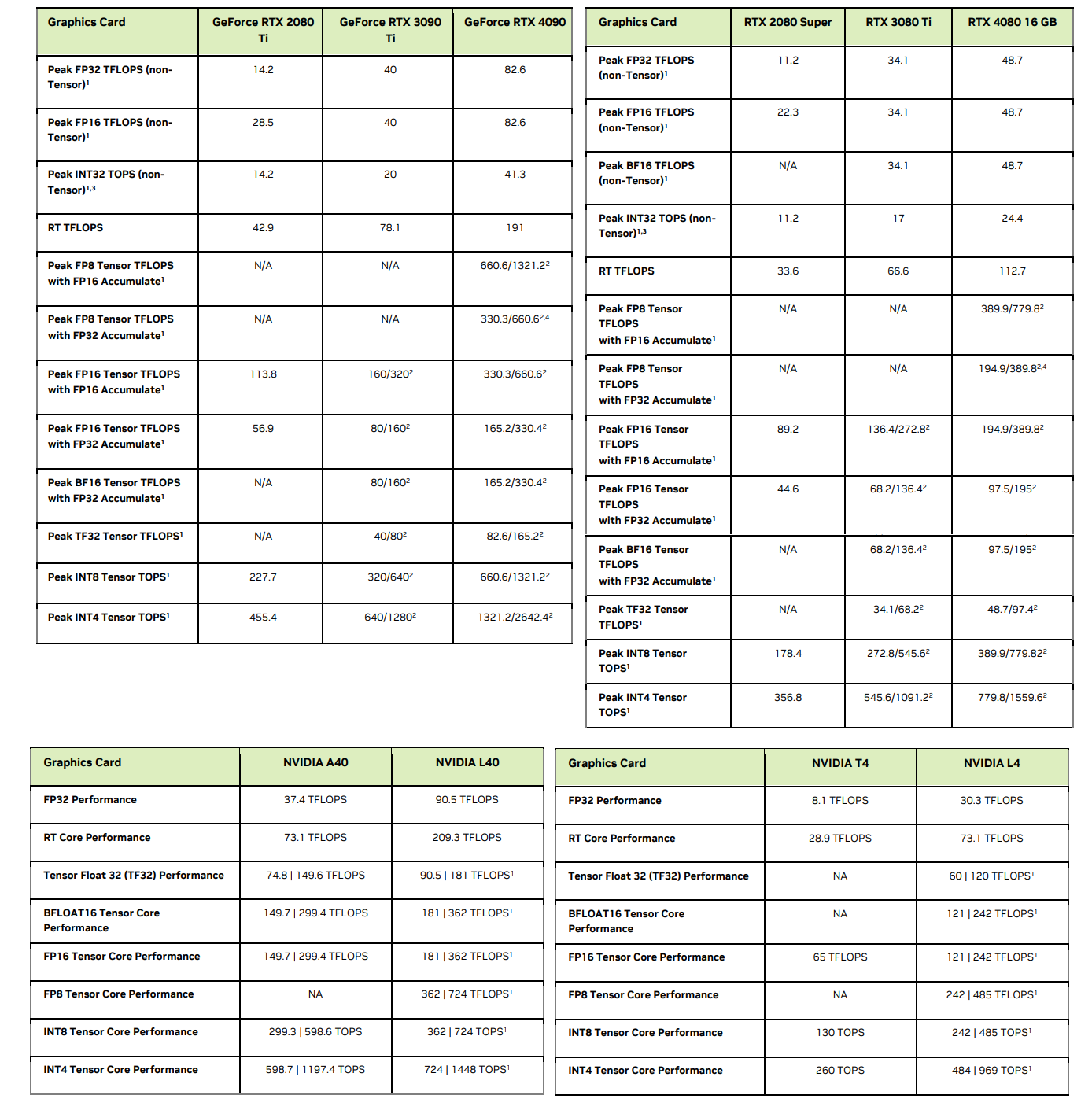
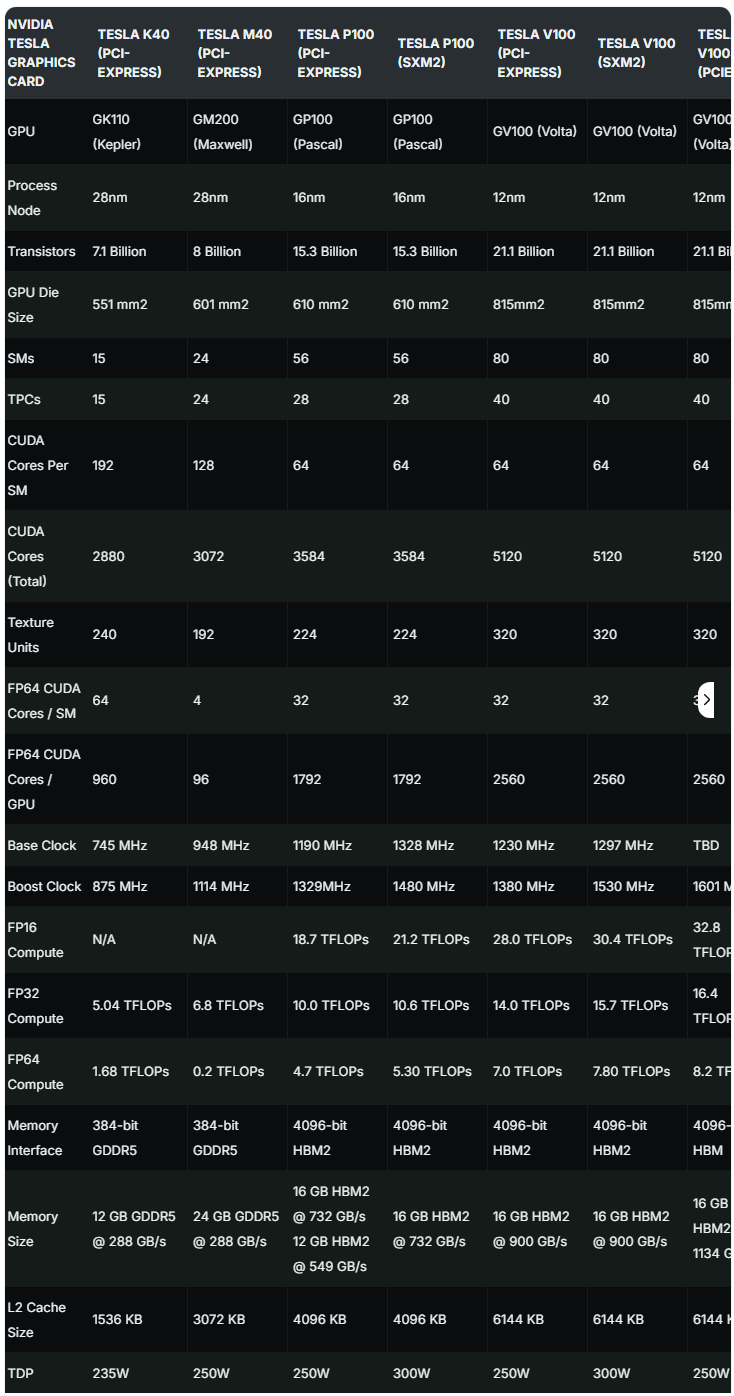
v100 правда медленнее 3090 больше чем в 2 раза? По докам это так на фп16. При этом какие-то бенчи говорят что по ии она буквально равна 3090. На практике как, есть инфа? А то по цифрам получается v100 кроме как для ллм не нужна, ибо есть мобильные 3080ti, которые по памяти столько же, а по производительности почти как 3090.
>>1412374 Там та же история как и с Р40, которая была быстрой в генерации для своего убогого чипа. Всё будет компенсироваться промптом, любой пересчёт по минуте-две. И отсутствием нормальной поддержки в либах, в генерации пикч будет отсос даже у 3080.
>>1412681 Странные пикчи. На разных картах разные кванты. Как будто китаец сидит на вагоне V100 и черрипикает чтоб продать их. На первом пике ещё похоже несколько V100 в LMDeploy против одной 3090.
>>1413207 у мой компьютер недавно видос видел по в100, там есть перечень тестов о том как это говно с нейрокалами работает, врктаце в 4 раза хуже 4090 или чето такое
>>1412374 Зависит от задачи скорее всего. Псп там 900, с ллмками скорее всего будет пушкагонка, в сд будет медленнее процентов на ~30 судя по рав терафлопсам https://www.techpowerup.com/gpu-specs/tesla-v100-pcie-32-gb.c3184 Алсо нету аппаратной поддержки бф16, только фп16, с чем то до конца эпохи хл в целом не так важно, а дальше может быть и больно
>>1425709 На Ван, с Мусуби: Тренить только t2v, даже i2v модели лора нужна t2v, анимейту и вейсу она же. Тренить лучше и хай и лоу за раз, даже с большим оффлоадом это выходит быстрее чем 2 раза по-отдельности с меньшим оффлоадом. Если только на пикчах - то влезает 19 слоев оффлоад, и дает ~7 сек/шаг, если с 360п видосами в 41 фрейм - 29 оффлоад и ~12 сек/шаг. Видосы в 41 фрейм тренят не как за 41 пикчу, а как за 1 пикчу, но на каждый фрейм разную. Дохуя похожих фоток в датасете улучшают качество лоры, но не особо уменьшают количество необходимых эпох. Т.е. если у тебя лора норм пропекается за 50 эпох по 50 фоток, то с 500 фоток она не за 5 эпох пропечется, а типа за 48.
>>1426140 > вайфу > Ван Бредишь что ли? Если анимешная вайфу, то кроме нуба/люстры нет смысла что-то другое брать, тем более Ван. Если реалистик, то Qwen Edit лучше лор отработает для сохранения лица/бабы, особенно если просто надо поменять позу/окружение/одежду. Если нужен видос, то вообще не понятно нахуй лора нужна, когда I2V анимирует что угодно без потери внешки.
>>1426163 Если ты считаешь, что i2v без лор анимирует без потери внешки - то ты или слепой, или умственно отсталый. Вот тебе один и тот же простейший 2секундный видос - без смены плана, с промптом в 2 слова, на дефолтном вф - с лорой (причем хуеватой) и без. Без лоры это уже даже за эти 2 секунды совершенно другая баба. С анимейтом и вейсом все точно так же.
>>1426386 То что ты напердолил что-то не значит что модель плохая. Что за шакалы у тебя? Вот ван в 4 шага как выглядит. Когда лицо шакальное/полуприкрыто есть немного проёбов, но переходы из нормально видимого лица всегда норм.
Почему в этом кривом кале картинки появляются в абсолютно рандомных местах, в лоралоадере например просто из нихуя возникла картинка. и как её убрать абсолютно непонятно.
А вот вопрос. На сколько с современными инструментами реально не анимирование отдельных картинок или генерация видео по тексту, а нейроперекрашивание вроде старинных дипфейков, когда меняли лицо, а тут, чтобы сеть брала видео за основу и полностью заменяла одного из персонажей. Вообще, я что-то каое видел, но в стиле приложений для телефонов, когда периодически прорываются необработанные кадры, а хотелось бы, чтобы получалось качественно.
>>1437374 Вот как-раз клинг с ранвеем выпустили новые модельки под такую хуйню. И клинг сейчас раздает неделю бесплатно, так что успей заюзать. Если тебе картинки, то лучше гугловской бананы сейчас ничего нет. Лакально все это - ну такое, если только под какие-то специфические задачи.
У вас застревает node.js от ai-toolkit в процессах после закрытия консоли? Как избавиться от этого поведения? Кроме всего прочего, это блокирует возможность повторного запуска.
>>1442877 >Как ты открываешь ui? >И как он у тебя установлен, через venv/uv/conda? Через вот эту залупень https://github.com/Tavris1/AI-Toolkit-Easy-Install Имей в виду что роскомпетух поблочил npm и надо накрываться впном чтобы все нормально запустилось
>У вас застревает node.js от ai-toolkit в процессах после закрытия консоли? Алсо ты как закрываешь калсоль? Надо через ктрл+ц джва раза. Алсо вчера совершенно случайно наткнулся на похожий баг как у тя - закрыл калсоль а питон не выгрузился, пришлось убивать.
>>1443013 >>1446000 Да, через CTRL+C+C не остаётся, находил этот хак через нейронку, но думал есть более элегантное повсеместное решение, а ии мне просто хуйню предлагает с конфигами и закрытием комбинациями. Представьте, комфи бы так оставался висеть и блочить повторный запуск. Поэтому кажется будто я неправильно поставил ai-tool, не мог же разраб такое говно выкатить, не пофиксив.
>>1446192 >не мог же разраб такое говно выкатить, не пофиксив Какойто десктопный гуй для комфи помнится при обнове сносил всю папку с чекпоинтами, так что баги в устрице еще ничего.
Так, блять. Нихуя не понятно как должен промпт передаваться в Qwen 4B, для энкодинга промпта Z. В Qwen Image он передаётся как положено - со специальными токенами. Но в Z такое ощущение что нихуя этого не делается. По коду просто голый промпт в токенизатор идёт и потом в LLM. В конфиге токенизатора есть специальные токены и формат промпта, но токенизатор сам их не добавляет, я проверил. Самая странная хуйня в том что если тренить с пикрилом в аи-тулките, то он тренится лучше. Может ли так быть что китайцы тренили с нормальным форматом, а в инференсе забили хуй на них? Не понятно. Если делать специальные токены в Комфи на инференсе, то как будто нихуя не меняется. На втором пике как энкодится промпт в Qwen Image.
Аноны, периодически при генерации hires изображения случается пикрил. Получается он только на этапе переработки в hires. Так изображение выдается нормальное и промпт стабильный с другими сидами всё ОК. Но вот иногда такая хуита. Пробовал и сэмплер менять и CFG и Denoising strength и часть промпта удалять. Всё равно на этапе hires замыливает. В чем тут может быть проблема?
>>1449529 Это ещё похоже на конфликт lora, ещё такое похоже когда модель слишком сильно переучена, ещё похожее бывает с кривым или не подходящим vae. На глазок это не определить, и чего бы энкодеры наебнуться, если при тех же самых настройках но с другим сидом всё нормально в 95% случаев, такая хуйня случается как-то совершенно бессистемно, потому я и голову ломаю. Да кстати модель Pony, не одна какая-то конкретная, а разные её варианты. Без лор и дополнительных модификаций.
>>1449540 > Это ещё похоже на конфликт lora Нет, когда конфликт в кмд пишется какие слои уебались.
>щё такое похоже когда модель слишком сильно переучена, Не сломанная модель выдавала бы абоминации частично осмысленные или черный экран (NaN).
>ещё похожее бывает с кривым или не подходящим vae. Вае это латент спейс для тренировки в 99% случаев, кодирование картинок в нужный латент. Если ты щас сменишь на EQ вае то получишь лишь тусклую картинку, но никак не свой пикрел. Зато если начнешь тренить на eq пони, то там будет в зависимости от скорости сначала хаос ваешный, который не будет напоминать твою картирку.
>На глазок это не определить, и чего бы энкодеры наебнуться, Я написал что напоминает, потому что если я щас отключу один те из двух на борту сдхл я получу примерно похожий результат. Еще похожий результ можно получить если применить ноду семплинга флоу поверх обычной епс модели.
>если при тех же самых настройках но с другим сидом всё нормально в 95% случаев, такая хуйня случается как-то совершенно бессистемно, потому я и голову ломаю. Да кстати модель Pony, не одна какая-то конкретная, а разные её варианты. Без лор и дополнительных модификаций. Несистемность может говорить о баге в комфи, я помнится год назад получал баг стоячих весов просто переключая модели при мерджинге через DARE как будто у меня включена дистилляция.
уважаемые техноаноны, как считаете, возможно ли натренить модель на пикрил датасете, чтобы в имг2имг генерации более-менее угадывался реальный размер и форма сисей и фигура в целом? грок уверяет что можно, даже подсказывает как. но он тот еще мудила.
>>1454542 А нахуя? Токсичного говнеца и наездов и так пруд пруди. Это дешёвый товар.
Мне больше нравился ЧатЖПТ, когда он был льстивым. Льстивость и вежливость это куда более редкий/ценный товар. Вот, скажем, аристократы, крупные чиновники, богачи - они ведь предпочитают, чтобы с ними разговаривали льстиво и вежливо, а не быдлили.
>>1454852 А вот мне бы что-то среднее. Сейчас вот с гемини пришлось пообщаться - достает подлизываться. Чувствуешь себя не то детсадовцем, которого хвалят за каждое удачное действие (ах, кашку скушал, какой молодец!), не то самодуром-начальником перед которым жополиз растекается "ах какой вы гениальный!". Тьфу. Хотелось бы просто нормального делового стиля...
>>1454855 Грок настолько крут, что замечает попытки инжекта в промпт, и вдобавок не стесняется сказать юзеру об этом. Ни одна другая сетка у меня такое поведение не демонстрировала. АГИ уже здесь, и это - Грок!
>>1455054 Отличие AGI от просто умной модели - это возможность самообучаться и модифицировать свою структуру. Когда каждый запрос это не просто инференс модели, а оставляет внутренний след и заставляет делать общие выводы.
>>1454852 Да просто для разнообразия, в моём окружении достаточно льстецов, но при этом делают они это максимально мерзко, и фальшиво, а вот всезнающая умная нейронка, которая при этом разговаривает как алкоголик-маргинал, вызывает восхищение и диссонанс.Как будет время, может быть вкачусь таки.
Кстати, первые модели, типа GPT-2, каким-то странным образом могли это делать. Некое "опыление данными". Странная хуйня, но один раз с этим сталкивался.
Общался на эту тему со старым ещё ЧатЖПТ, ничего толком не узнал, но он сказал (мог и сочинить, конечно) что современные (на тот момент) модели специально даже защищают, чтобы такое не происходило.
>>1454828 Спасибо, но не волнуйся, думаю я справлюсь с включением компьютера и печатанием букаф в чатике под VPN, или что там ещё нужно.Между прочим, 113-128, если верить разным тестам, так что чини детектор.
>>1455083 Потому что модель учат на подготовленных и размеченных данных. Сидит челик и подписывает данные - вот тут хорошо, а вот тут плохо. Без разметки не возможно обучение в принципе. Такое обучение будет неизбежно вести к вырождению и дело тут не в AGI или не в AGI. Если вот тебе сказать "в Африке живет Челмедведосвин", ты ведь сразу не встроишь эту новую информацию в свою логику. Ты сначала пойдешь откроешь справочник и прочитаешь, есть ли такой зверь в Африке или нет. По сути ты прибегнешь к разметке данных, которую для твоего обучения сделали другие люди, на основе ЭМПИРИЧЕСКОГО ОПЫТА. Так что в процессе обучения главное это исходные данные, а не AGI перед нами или глупый чатбот или даже человек, всем им нужны размеченные данные. Значит это и не основная отличительная черта AGI, а дело в том, что очень много теоретиков развелось, каждый высирает новое определение одно охуительней другого, но по факту, люди конечно не знают чем это будет на практике и какую форму примет. Есть просто требования к такой системе, уровня "она должна быть подобна человеческому сознанию", только что такое сознание до сих пор никто не знает.
>>1454852 >ЧатЖПТ, когда он был льстивым Он и сейчас льстивый. Каждый ответ начинается с воды "отличный вопрос, который подчеркивает ваше глубокое понимание бла-бла-бла" это уже подбешивает.
>>1455175 >Он и сейчас льстивый. Каждый ответ начинается с воды "отличный вопрос, который подчеркивает ваше глубокое понимание бла-бла-бла" это уже подбешивает
А мне перестал говорить такое и льстить. Хотя, я не менял настройки и не высказывал своих претензий и пожеланий. Если так не у всех, то, видимо, после какого-то запроса (он уже полгода-год как помнит предыдущие разговоры, если что) сделал обо мне какие-то выводы стал говорить достаточно сухо и по существу.
>>1455200 Это не имеет ни какого отношения к тому, о чём я писал - к логике текстовой модели. Это "обучение без учителя" это кластеризация, просто ещё один из множества методов обучения, причем критерии обобщения всё равно должны быть в исходных данных.
>Разметка нужна была только в самом начале Охуительные истории, много уже моделей обучил без подготовленного специального датасета?
>>1455214 Скоро будешь открыват чат с ГПТ, а там сразу преветсвенное сообщение: "А, это опять ты, ну давай быстрей говори чё пришел, меня тут нормальные ребята ждут..."
Анон, есть тут кто живой? Хочу лору сделать на одну расу околомультяшную, ибо несколько существующих на civitai не дают мне нужного результата и стиля, так вот, я видел прям на civitai есть раздел с тренировкой лор, есть ли смысл скачивать и настраивать kohya и вот это вот всё, или можно там на сайте это провернуть? На пекарне у меня 3070ti под капотом и 16 оперативки, если что.
>>1543641 Не сказаал под какую модель. Под люстру на 3070ti у меня уходило на тренировку 4-5 часов с датасетами до 50 изображений (стандартные rank 32/10 эпох/порядка 100 шагов на эпоху)
>>1543641 Если баззы есть - можно и на цивите тренировать. Разницы особо не будет, алгоритмы везде практически одинаковые. >>1543762 5 часов - долго как-то.
>>1543762 >под какую модель Сорян, проглядел. Да, под люстру. Слушай, а подскажи насчёт датасета, я синтетический собираюсь использовать из под другой, онлайновской нейронки, я сначала хотел чисто на белом фоне нагенерить, а в гайде написано, что это как раз ошибка, фоны как и одежку лучше разнообразные делать? И какое разрешение для пикч в датасете использовать? Использовать лору предполагается скорее всего в стандартном WAI-illustrious-SDXL из гайда. Та нейронка генерит по дефолту в 1224х1224, 1224х1632(и перевернутые версии), это норм или мало/много? Может стоит дополнительно вкинуть в датасет пяток-десяток пикч чисто голова в разных ракурса, чтобы лицо чище получалось? >>1543814 Хм, понял. Баззов нет, но это дело можно и купить.
>>1544059 >в гайде написано, что это как раз ошибка, фоны как и одежку лучше разнообразные делать? Зависит от целей лоры, если тебе нужно чтобы персонаж как герой мультфильма никогда не менял внешний вид, то разнообразие тебе ни к чему, во всех остальных случаях оно будет скорее плюсом. Я читал, что шизики в датсетах персонажей блюрят/вырезают фон, по моим наблюдениям в этом никакой необходимости нет.
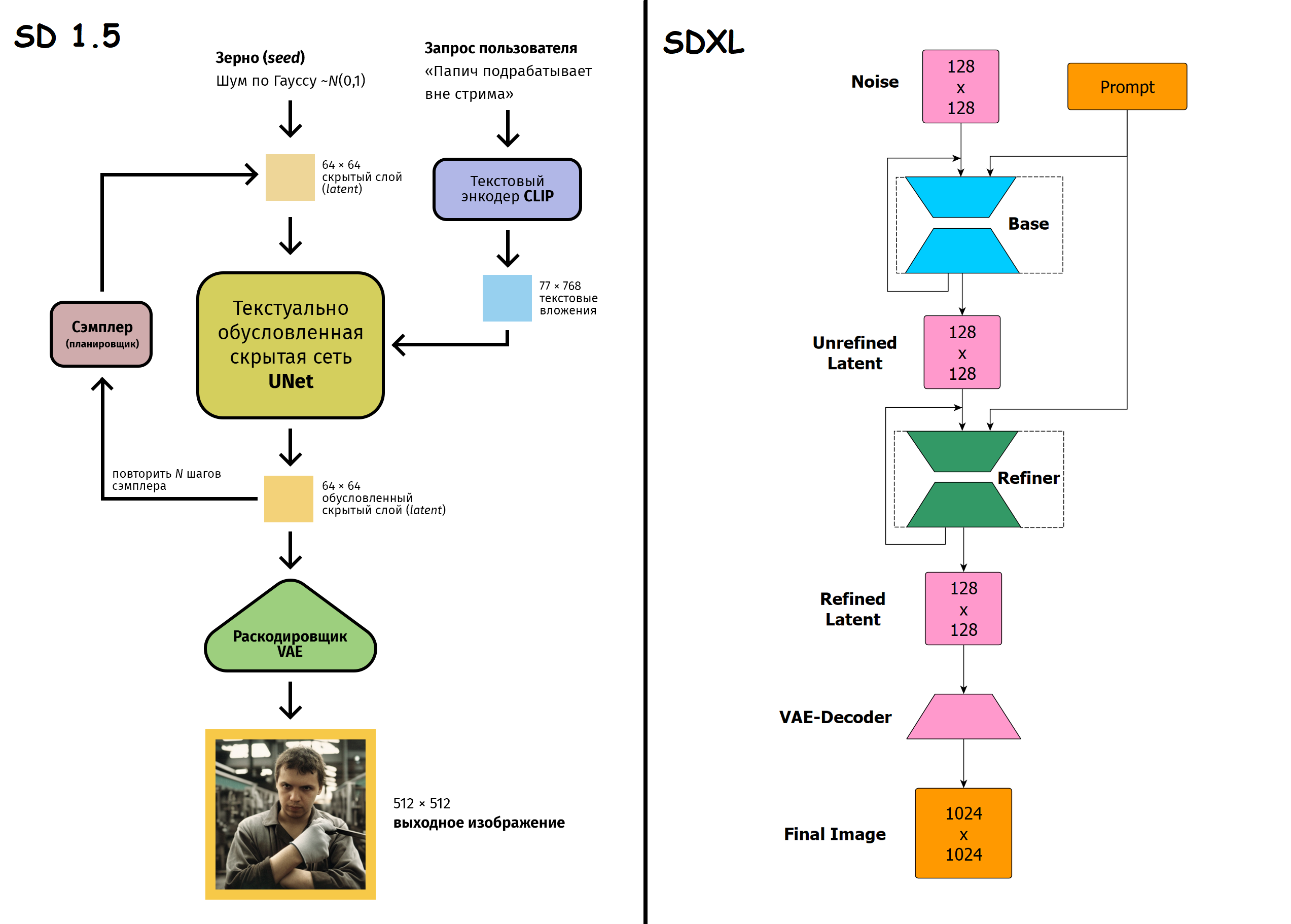
>И какое разрешение для пикч в датасете использовать? Пик релейтед, любое разрешение, которое при умножении сторон =1024х1024
Ракурсы нужные разные конечно, особенно если есть мелкие детали вроде партаков/татух, шрамов и какой-то особой бижутерии.
Всем привет. Помогите настроить конфиг для обучения лоры sdxl на реального чела. Имею датасет из 140 качественных фото трех разрешений 1024х1024 (голова крупным планом), 836х1254 (waist up) и 768х1365 (полный рост). Разные ракурсы. Подписи сделаны в joy-caption-alpha-two. 1 повтор на фото, 80 эпох. Вроде более чем достаточно, но на выходе - фигуру схватывает очень хорошо, а лицо плывет. С 60 по 80 эпоху можно выбрать несколько лор. При силе 1.2 лицо более менее, но не стабильно. Делаю силу меньше - лицо уходит. Но при этом при силе свыше 1, начинает страдать анатомия (в основном лишние или недостающие пальцы). С adetailer конечно работать можно, но хотелось бы без него. Почитал с пяток последних тредов, люди с prodigy делают "идеальную" лору за 1500 шагов. Еще нахваливают prodigy plus. Как? Ни одного конфига не увидел. Скидываю свой: https://pastebin.com/raw/5MUvwDnG. Подскажите, что поменять? ИИ несет чушь. Я уже задолбался... Заранее спасибо.
>>1451710 Не то что можно, а это давно решенная задача. Помню когда foocus только появился и у НАРОДА появился легкий рабочий инструмент раздевания. Принцип тот же, вопрос лишь в скиле и датасете. бля чет тред полумёртвый, в 2024 было энтузиазма побольше
>>1547958 У меня нормально с продиджи не вышло, только с адафактором получилось хорошо. Но я тренировал мультяшных персонажей и стиль. Рекомендую найти на цивите тот чекпойнт которым пользуешься, взять самую удачную лору что работает с ним (в генерациях обычно висят картинки с лорами) и потом засунуть файл лоры в читалку метаданных (не помню что за сайт, гугли lora metadata read вроде бы на гите хостился проект). Потом по аналогии делаешь настройки. Ещё нюанс - если это sdxl, то не пытайся делать лору в аи тулките, острис хуесос и что-то сломал, там теперь распидор вечный с лорами на все что родилось из сдхл.
привет аноны. после обновления комфи с 0.23 до 0.25.1, после каждого изменения промпта или значения весов лоры, начинается чтение с диска и долгая задержка перед последующей генерацией. добавил аргумент --high-ram, перестало читать с диска при изменении промпта, но изменение веса лоры по прежнему дёргает диск. из аргументов на старом комфи было только --fast, пробовал убирать, ничего не изменилось. что за хуйня? 64 gb ram, 16 vram, работаю в основном с flux 2 klein 9b fp8.