>>1404088 Ебать я лох, ну буду знать. Я так-то ни разу не перекатывал ничего, но почти 500 постов в бамплимите - это уже пиздец какой-то, так можно до закрытия двача ждать переката.
Наконец-то только локальное. Онлайн хуйня заебала в этом треде. Онлайновое итак вдоволь в других тредах читаешь, если это интересует. Странный тег /wan/, как будто через год локально другая сеть не появится. Это им нужно было отделиться и придумывать тег или все онлайн-треды держать под /sora/
>>1404241 > Странный тег /wan/, как будто через год локально другая сеть не появится. Да в целом норм. Можно будет оставить старый тег как дань уважения основоположнику локальных генов. Аналогично как в sd/nai/llama-тредах теги тоже оставили по именам первых моделей.
>>1404749 Первая модель hunyuan, если что, и она была на старте очень крутой. Ван пришел вторым (лтх не считаем). Так что, аргумент так себе. С этой точки зрения llama-тред должен зваться mistral.
Чем можно генерить кэпшны для видео-датасета? И если не дробить самому на чанки по N фреймов, а поставить автоматом, то насколько захуевится лора от того, что в какие-то чанки попадет только начало/середина/конец действия из кэпшна для клипа?
>>1404795 Да, ты прав, я тоже в своё время лоры под hunyuan пилил, но по итогу быстро забил т.к. там даже img2vid не было это уже потом добавили, если правильно понимаю. С wan всё же интерес так быстро не пропал.
Есть идеи, какой тогда тег сделать, чтобы можно было указывать челам с онлайн-сетками, что им тут не рады?
>>1404886 Да нечего тут выдумывать, wan и короче, и на момент создания треда это золотой стандарт локалок, который хорош во многих областях. Про хуйнянь уже все забыли давно. До лламы тоже же были генераторы текста, давайте ныть, а почему не BERT, порфирьевич или цепи маркова из 80-х.
>>1404951 >>1404749 Ну, llama это не только модель, но и бекенд, запускающий все ллм.
>>1404858 >[ Removed by moderator ] Как же ебет. Пытаются скрыть ценную информацию. Судя по комментариям, это про ltx. Не могу вспомнить ни одну сетку, которая была говном, а потом вдруг стала хорошей. Они все либо ебут с первой версии, либо отстающий кал.
>>1404886 > img2vid не было это уже потом добавили И было хуйней, к сожалению. =( Ван был первым img2vid хорошим.
> Есть идеи, какой тогда тег сделать, чтобы можно было указывать челам с онлайн-сетками, что им тут не рады? Сложный вопрос. Но я хрюкаю от смеха сделать тег /kijai/. =D Но будто бы video и правда было бы хорошим вариантом. Но если он ушел онлайнщикам, то пусть пока будет wan, че уж поделать. Хотя бы короткий.
>>1405003 Угадай в честь чего она названа. =) А еще Kobold (он, кстати, старше), всякие vLLM, Sglang, TRRT. Будто бы Kobold, кстати, по смыслу ближе, это еще до-ллама времен были рпг-модельки.
Но хули уж щас думать над этим. Сколько воды утекло.
>>1405003 > Не могу вспомнить ни одну сетку, которая была говном, а потом вдруг стала хорошей. ЛТХ-2 даже по примерам смотрится ну так себе, если честно.
у кого работает генерация видосов, вы на каких карточках все это делаете то? и есть ли какие то решения для меня с 2060 на 6гб? ну кроме как отвернуться к стене и плакать
>>1405058 >на каких карточках все это делаете то? По моим наблюдениями авг тредовичок имеет 16-24гб ну и особи с 12гб тут тоже имеются что кое как дыхабельно. >какие то решения для меня Пойти купить 3060 12г на лохито за 15к или сколько они там щас стоят, а лучше 5060ти на 16гб сразу это не так уж и дорого
>>1405058 Меньше чем 12гб врам даже не пробуй. Еще минимум 32гб оперативной памяти. Чел выше упомянул 3060 12гб. На ней может и пойдет, но у нее старая архитектура и сама карта не топовая в своей линейке, т.е. генерироваться видео будет долго.
>>1405058 3070, 8 Гб врам, 32 гб рам. Полёт с wan2gp и лайтниг-лорами для i2v нормальный. Да, приходится потерпеть генерацию 5-7 минут на 5 секунд, но качество сгодится для личного пользования.
>>1405108 Это промт типа на 1-5 фрейме мы видим девушку такую-то (описание), затем мгновенный переход к новой сцене, где точно такая же персона (добавить в скобки из первого предложения) стоит в том же месте абсолютно голая (или в трусах как здесь) и дальше пишешь... ну и потом камера спускается вниз и так далее. Ну и прописать надо, что лицо не изменяется на протяжении всего видео.
>>1405125 Любым на сохранение лица. Это нейронка понимает. Проблема в том что нужно хотя бы 6 степов и нормальное разрешение фотки, где лицо четкое без пикселизации. Если исходная фотка хуевого качества, ван будет его перерисовывать. Если недостаточно шагов, то будет пикселизация. Ну и само разрешение видео 600 на 800 это минимум. >>1405124 Да, ван 2.2 прекрасно понимает промт.
В прошлом треде рекомендовали этот модуль для создания длинных цепочек: https://github.com/vantagewithai/VantageLongWanVideo Работает клево, но лица все же искажаются сильно на нескольких итерациях (с 14B_Q4_K_M.gguf) У кого-нибудь получалось сохранить лица на длинных видео? Пробовал через вставку образца лица в углу фотки, но толку ноль, все равно за основу берется искаженное лицо из предыдущей итерации и еще больше искажается дальше.
>>1405264 Хммм Киджай вроде как свои лоры на ускорение сам не делает, а ужимает имеющиеся с lightx2v, посмотрим че у него там за high. >>1405256 Там и на t2v какие то цифры, причем они теперь называют это не lightning, а distill, хрен пойми че там в этих лорах уже, но мувмента стало больше
>>1405060 >>1405065 >>1405086 >>1405088 спасибо аноны. буду копить на компик значит. и тем временем продолжать пытаться найти хоть что то рабочее на свой ноут. просто мысль о движущихся картинках не оставляет меня. и я перебрал кучу всякого баловства типа sadtalker и video difussion, которые как ни странно, исправно работают, не смотря на то что в требованиях у них от 12гб видеокарт. накатывал "оптимизированые" сборки на wan, через пинокио. обещающие работать с 6 и даже 4 гб видеокарты, но ноль успеха. возможно дело в самом пинокио. потому что тот же седтолкер и видеодифуззия через него абсолютно так же не работают. через него ни что не заработало. извиняюсь что излил свои печали в тред. просто и пожаловться то не кому
>>1405269 Хуй разберешься. Еще завезли scaled модели под эти лоры. Также в имени модели указано comfyui. Чувствую сейчас буду тестить весь вечер, а потом выяснится, что говно.
>>1405284 Если интересно они тут и новые vae выкатили которые типа дофига берегут память, не уверен правда, что vram и типа они быстрей. ХЗ только сейчас обратил внимание https://huggingface.co/lightx2v/Autoencoders
Пытаюсь тренить в Мусуби Ван на дефолтных настройках (81 фрейм 16фпс 720п), и оно даже с оффлоадом всех слоев так что сама модель не занимает практически нихуя, переливается за мои 24гб врам. Что лучше уменьшить чтобы влезло?
prune — удаляем ненужные веса, уменьшаем размер distill — берем модель побольше, обучаем на ее результатах модель поменьше, итоговый размер меньше quant — уменьшаем точность весов, уменьшаем размер scale — квантуем чуть толще, чем обычный fp8, чтобы качество было чуть лучше, уменьшение чуть меньше, чем у обычного квантования, но качество лучше merge — соединяем несколько моделей или лор в одну
lightning/fast/turbo — а вот это уже просто название конкретных лор или моделей, которые обучены генерировать видео на малом количестве шагов, они от разных авторов и называться могут как угодно, хоть sonic, хоть sapogi skorohody, главное, что они позволяют не за 20 шагов генерить, а за 2-3-4-6-8.
>>1405325 Принято - впитано, было приятно и полезно, то есть процесс получения "новых" лор был другим, сейчас они сначала сделали прямо дестил модели, а потом с них выжали лоры, а изначально они обучали лоры на полноценных результатах от базовой модели и это был типа lightning лоры.
>>1405283 Ну копи, копи. Ещё раз повторю - неделю назад по приколу товарищу на ноут комфи ставили. Стандартный воркфлоу, 4ГБ видюха и 30 гб оперативы. Вот попросил чувака скинуть пару рандомных тестов, из того что тогда нагенерили.
>>1405157 >ГЫГЫГЫ ДОЛГА ЩЩИТАЦЦА БУДИТ))))) ~60сек на один шаг, 2+2 шага, ~270 секунд на одну генерацию с учётом vae декода.
>>1405334 Дак что качать сейчас? Просто дестил модель без лоры (поскольку лора уже в этой модели)? Скачал отсюда https://huggingface.co/lightx2v/Wan2.2-Distill-Models , уже час тестирую, получатся говнище полное, все блеклое, никакой детализации. Просто говно.
>>1405310 И что ты предлагаешь, сидеть вечность на 5 секундах и 480р? Видюхи ещё 2 поколения будут доить гоймеров с +20% прироста Выйдет и для лтх лора ускорялка так заживем
>>1405418 Начинай с прортейбла, чтобы не делать мозг, если заработает то можно перебраться на конду, мне честно такой вариант больше заходит из за возможности твикать пакеты, если что-то сломалось.
>>1405423 >As much as I love Wan, if it's one thing it's not good at, it's cuts. Так всё-таки нужна натренированая лора. Ты сам-то хоть пробовал этот эффект без лоры прописать? С лорой по первой ссылке у меня получилось. Только на количество фреймов, после которой должен происходить кат, оно не реагирует. Рандомно через 1-3 секунды сцена меняется.
>>1405458 Пробовал различные варианты, у меня на некоторых сидах получалось, когда есть слова в стиле magically transfroms into new scene with a magic sparkle effect, а жесткая обрезка получается всегда, если сцены супер разные через first - last frame.
>>1405334 > то есть процесс получения "новых" лор был другим Вероятно, раньше они собирали видосы сами, делали датасет, и обучали на нем.
А потом стали просто генерить кучу видео, отбирать лучшие результаты и уже обучать на синтетике.
Это все lightning лоры, просто сам метод получения датасетов разный.
Но опять же, что имеют в виду они — хер знает. В lightx2v сидят тоже далеко не гении, у них часть лор полное говно, и время от времени норм модели попадаются. Может они сами неправильно терминологию используют, с них станется. =)
Но главное, что у них есть энтузиазм и деньги, выпускают новые лоры — молодцы.
Пусть продолжают.
>>1405343 Качай нахуй все, а потом просто выбирай, что лично тебе больше понравится. Вот неиронично. Тут есть люди, которые сидят еще с первой их T2V-14B-480p лорой, и ниче, работает, и иногда даже хорошие результаты выдает. А кто-то только последние юзает.
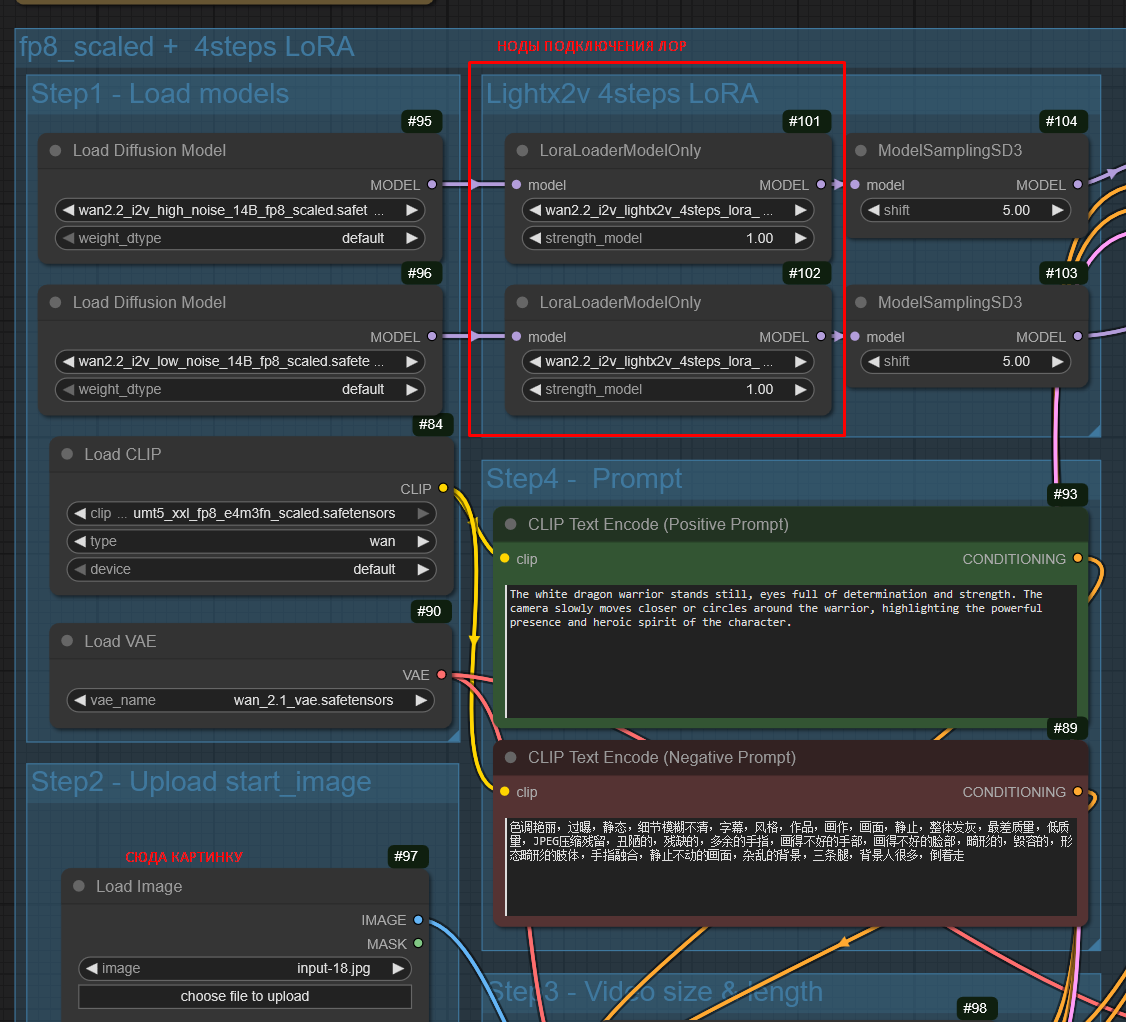
Чисто в теории надо брать в качестве базовых моделей: wan2.2_i2v_A14b_high_noise_lightx2v_4step_1030.safetensors wan2.2_i2v_A14b_low_noise_lightx2v_4step.safetensors
>>1405058 Так, отвечаю один раз, можешь не верить. Комфи выгружает модель в оперативу, а виндовс и линукс выгружают оперативу в файл подкачки/своп. Т.е., от видеопамяти требуется только вместить контекст. Это разрешение (минимально у вана норм генерация — 352 по большей стороне, ниже совсем мазня) умноженное на количество кадров. Короче, пиксели считай сиди.
Как ты понимаешь, в 6 гигов ты засунешь либо 1280x720 но 1,5-2 секунды, либо 5 секунд, но 5, а то и 7 секунд, но 640x368, типа того. Что, кстати, весьма неплохо. Даже видосяны 480x368 смотрятся норм (в определенных ситуациях=).
Так что, 2060 6 гигов кое-что могет, НО НЕ СИЛЬНО, скорость генерации будет не очень высокой, придется подождать, а результат будет небольшим.
Модель утекает в оперативу, и если оперативы не хватает, то — на твой ссд. Скорость немного падает от этого, конечно, и ресурс ссд расходуется. Тут смотри сам. Генерятся ли видосы на 6 гигах? Ну да.
Выше чел пишет >>1405335 > ~270 секунд на одну генерацию И это при 344x512 (будто бы можно было и 320x480 поставить). У меня на 4070 ti такое генерится секунд 40, ну то есть ЗАМЕТНО БЫСТРЕЕ АГА, так что, будь готов.
С 16 гигами, это, конечно, мда-а-а… Если будет вываливаться — увеличивай файл подкачки.
>>1405418 планку памяти докупи, если слот свободный есть. Ну или замени ту 1, что есть (проверь лимиты материнки у производителя) на 16 у тебя постоянно ССД задействован будет, как резервная память, а это намного меденнее и черевато износом.
>>1405325 >>1405614 Двусмысленно с merge получилось. Там же не объем меняется. Предлагаю: merge — смешиваем несколько моделей или лор в одну, как краски на палитре.
ну я пока молюсь чтоб хоть какие то кривые мыльные картинки оно хоть как то из себя выдавило и не крашилось и не выдавало ошибок. если заработает, то немедленно мчу за оперативкой. спасибо аноны за поддержку и в целом за идею потестить. надеюсь завтра не приползу сюда с вопросами, а почему то не работает, а почему это не работает
>>1405887 Проблема в том что нет хуже/лучше, они все работают по своему, с одними движениями будет лучше работать одна, с другими другая. Но вот какая с какими только на практике можно убедиться. Когда выбор есть конечно хорошо, но немного напрягает подбирать для каждой сцены. Мало того, их еще смешивать можно с разными весами по несколько штук подключать. И тут вообще голова ломается в поиске идеала.
>>1405891 Ну да, многомерное пространство оно не только "в голове" у модели, оно ещё и в неограниченном наборе вводных параметров. И мы такие в нём - "хмм... а что будет, если этот параметр почесать? О, движения в видео резче и интенсивнее стали!". А потом этот же параметр при другом наборе вводных меняем, а он на движения ВООБЩЕ влиять перестал, зто какие-то элементы одежды с персонажа убрал...
>>1405666 >немедленно мчу за оперативкой Удачное ты время выбрал. За последние месяцы цены на память очень сильно подскочили, на некоторые модели даже удвоились. А всё благодоря хайпу нейрошизов по всему миру. Заводы чипов памяти уже работают во всю катушку 24/7, но спрос всё равно превишает предложение. Аналитики говорят, что цены скорее всего весь 2026 год не будут падать.
>>1405897 Ахуенно я себе комп летом с 16х2 собрал еще на дырдыре 5, бюджет закончился, походу надо было на стартом серверном трипере тридрипере собирать с ецц, она пади все еще хуй да маленько стоит, да и хорошо было бы мое ллмы гонять на 128-256 гигах медленного некро кала
>>1405897 Ого, сейчас глянул - планка памяти которую брал в мае за 3200 стала 3800. Выросла конечно, но если не в процентах а в рублях считать - ну бутылка водки так стоит, или пара банок огурцов, или батон колбасы. Неприятно, но волосы на жопе рвать не с чего.
Попытался перенести из него нужные блоки в стандартный workflow генерации, и получилось это: https://0.0g.gg/?9ee1add29eecf572#8oVG6SLntPdfu2Y9GdNj9PxQn7oAa9wiWpchQZLDCLYU (видео нет, т.к. не удалось с ним закончить генерацию). Но на нем один шаг на 33 кадрах делается по 20 минут на RTX4060+32 ОЗУ и при переходе с High на low шум завершается ошибкой переполнения памяти.
Знающие аноны, нужна ваша помощь, можно ли довести его до ума, что бы скорость была соразмерная с обычной генерацией по 2-4 минуты на шаг с ускорялками?
>>1405904 Планки памяти, которые брал за 46 стали 67, пизда.
———
Вышла новая Wan Endless: Stable Video Infinity https://github.com/vita-epfl/Stable-Video-Infinity Как всегда Wan2.1, как всегда качество чуть лучше, чем было, короче — ничем не впечатляет, лень качать.
>>1406124 128 гигов? А то и думаю, что у тебя так быстро генерится видео. На моей 4070 и 16гб оперативки по 4-5 минут генерится. Я вот думаю, если еще 16 гигов докупить, насколько оно ускорит генерацию, хотя бы на треть?
>>1406130 Это хороший вопрос. Вполне возможно. Но ты подумай, у тебя 2х8, как я понимаю, может не стоит до 4х8 плодить, а сразу 2х32 взять? Ну или хотя бы 2х16, а потом еще 2х16 докупать. Оператива дорожает, каждый маневр будет стоить лишних денег, как мне кажется.
У меня на одном пк 4х32 DDR4, на другом 2x64 DDR5. И сейчас я смотрю на эти +20к по прайсу и понимаю, что ой как вовремя успел схватить оперативу-то!
>>1406130 Ускорит генерацию примерно на 0. На скорость генерации в первую очередь влияет видео чип и количество видео памяти, оператива нужна на то чтобы сгружать часть модели которая не помещается в видеопамять. Хотя в твоем случае возможно будет ускорение, по тому что по мимо оперативы у тебя модель скорее всего еще и в файл подкачки лезет, а там вообще беды с скоростью. Рассматривай вариант лучше 2х16 и потом еще 2х16 на будущее.
>>1406221 Количество видеопамяти как раз само по себе не влияет на скорость. Влияет лишь немного, но у человек большая часть модели не то что в видеопамяти — она у него с диска читается. =) Вот где бутылочное горлышко, вполне возможно. > модель скорее всего еще и в файл подкачки лезет Угараешь? У человек 16 гигов из ~72, которые модель любит занимать (если мы про Wan2.2), конечно у него почти все в файле подкачки лежит.
«ускорит на 0», ага. =)
Конечно, можно использовать gguf q4_k_m и wan2.1, тогда есть шанс очень демократично по памяти сидеть. >>1406130 Если хочешь, можешь рискнуть, но я бы все-таки памятью затарился, если есть возможность.
>>1406225 щас как раз пердолюсь на 12vram + 64ram wan22 q6.0 и суммарно 6 лор по скорости примерно: 0 лор не считая lightx2v 12-13s/it 6 лор не считая lightx2v 15-16s/it В целом жить можно, генерю 832x480
Чет мне кажется следующий поколения видео моделей будут настолько жирными, что даже топовые консюмерские карты их не смогут впитать и придется либо перекатываться в онлайн (но смысла не вижу), либо предолиться в старые модельки, хоть их потенциал мне кажется даже без лор нефига не раскрыт - уже начинают надоедать
>>1405297 Затестил их лайттае для 5B, какую-то мутную хуету выдаёт. Писали что качество должно быть выше оригинального тае, а на деле кал. Может нода декодера поломаная у них.
>>1406233 Чет реально печальная картинка, я вообще подумал и понял, что эта хрень скорее всего создана в целом для v2v, где нужно дофига кадров декодить, энкодить, но качество и впрямь паршивое, уж лучше подождать
>>1406225 >Влияет лишь немного Немного? Или у тебя модель целиком лежит в видеопамяти и нон стоп работает или она гоняет блоки туда сюда из оперативки. Так немного что 3090 практически не уступает по скорости 5070, вот и думай.
В прошлом треде кидали модельки новые с вшитым lightx, работают вообще отлично и скорость генерации быстрее чем на обычной модели, рекомендую к ознакомлению, брать надо с припиской comfyui: https://huggingface.co/lightx2v/Wan2.2-Distill-Models/tree/main
>>1406230 Я боюсь, следующих моделей может и не быть.
Wan2.5 не дали. LTX обещают, но она будто прошлого поколения. Все текущие разработки — не дотягивают до Wan2.2.
Глядя на современные модели, думаю, следующее поколение еще вполне себе покрутится на потребительских видеокартах. Подольше, конечно, возможно потребуется объем видеопамяти для контекста, потребуется памяти побольше, может быть поколения постарше (40xx, 50xx), но еще пофурычит. Если выйдет, потому что нейронки в принципе уже уводят за пэйвол.
Я бы скорее боялся того, что мы ниче больше не увидим. =( Ну или релизов станет существенно меньше, чем хотелось бы.
>>1406230 >Чет мне кажется следующий поколения видео моделей будут настолько жирными Не будут: 1. Какой смысл выпускать оупен сорс модель которой никто не сможет пользоваться. 2. Модель все равно пойдет в оперативку. 3. По текущим трендам пока вообще кажется что новых моделей не выпустят в оупенсорс. Другое дело что в следующих моделях скорее всего прикрутят время генерации хотя бы до 10 секунд и вот тут уже на 12 гигах особо не погенеришь, либо разрешение придется понижать.
>>1406246 > Немного? Или у тебя модель целиком лежит в видеопамяти и нон стоп работает или она гоняет блоки туда сюда из оперативки. Немного. Сравни LLM, у которых разница от видяха/оператива будет 10х, и видео, где разница 2х. А учитывая, что 24 гига тоже не 48 — для больших моделей ты тоже выигрыша сильно много не получишь.
Я специально мерял, при половине модели в оперативе и при всей модели в оперативе разница получалась процентов 30 по времени. Прирост-то есть, то влияние не прямое.
А вот мощный чип — еще как влияет. ))) 4070 ti с 12 гигами все еще на 10% быстрее 3090 (в прошлом треде сравнивали), при том что чипы у них отличаются… ну примерно на столько же и отличаются? Т.е., память в случае 3090 как раз почти не играет роли, ВНЕЗАПНО.
> Так немного что 3090 практически не уступает по скорости 5070, вот и думай. Пикрил, она и не должна уступать, учитывая их равную производительность. За счет 24 гигов по твоей логике она должна еще и обгонять процентов на 20 хотя бы. Или сошлешься на разные поколения, улучшалки для 50хх (которых никто не юзал) и так далее? Я сомневаюсь, что измерения происходили на NVFP4 квантах, где 50хх поколение имело бы преимущество.
Короче, в случае 12 гигов видеопамяти и 16 оперативы — добавить оперативу реально может дать сильный буст. А вот видеопамять хоть и влияет косвенно, но не так критично. Приятно иметь 5090 32 гига, но я бы и на 5090 16 гигов согласился бы, ради быстрого чипа (за треть цены, пжалста, ахахах).
>>1406261 Есть такие опасения, значит энтузиасты распердятся лорами как во времена sdxl буквально на любой чих, а если это все умрет, будем хотя бы детям рассказывать, что нейронки на домашних ПК запускали, вот были времена (деду больше не наливать) >>1406271 Зачем делать очень качественный, оптимизированный опенсурс, если можно его продавать? Да вообще конечно вопрос философский, это ведь нужно дофига инвестировать денег и времени, а без выхлопа людям может станет не по фану этим заниматься. Короче правду и развязку смотрите в следующих сериях нашей передачи
>>1406271 > Какой смысл выпускать оупен сорс модель которой никто не сможет пользоваться. Строго говоря, эти модели выпускаются для реселлеров, которые крутят их у себя и продают к ним доступ. То, что Комфи с Киджаем запилили выгрузку в оперативу — просто случайность, повезло, что эти модели работают с выгрузкой хорошо. Когда выпускали Мочи, говорили, что 320 гигов надо (или типа того), и все офигевали, кому нужна такая огромная видеомодель (а потом оказалось, что нафиг не надо, она 10б была=). И тот же Кандинский 2б требует 40 гигов (до оптимизации было 64). Но есть подозрение, что при желании, запустится на утюге.
Но остальные два пункта это не отменяет, да. =) Так-то все правильно.
> чип у тебя значительно бодрее Вряд ли 4070 бодрее 4070 ti. =) И не в 6 раз в любую сторону точно. 3060 генерит тот же видос 110 секунд с 32 гигами оперативы. Так что, видяшка-то у него бодрая. Затык где-то в другом месте.
>>1406278 > энтузиасты распердятся лорами как во времена sdxl Блин, да это все понятно, в общем-то и OVI и SVI, который я выше скидывал — это все тоже в каком-то смысле энтузиасты пилят.
Но… хочется же какого-то скачка. Хочется, чтобы дома можно было генерировать целые аниме-серии. А пока что, аниме хорошо генерит только сора 2, как я понял. Вео ну так себе, ван ну прям совсем так себе.
Обмазываться лорами можно, но хотелось бы из-под капота.
Плюс, еще нужна механика персон, чтобы можно было загружать инфу о персонаже (его анимация/мимика, внешность) и он генерился консистентно в разных сценах. Да, у нас есть Qwen-Image-Edit и Flux Kontext, я согласен. Но это все еще костыли.
Короче, кажется, осталось 1-2 шага до мечты. И будет грустно, если их не случится, и все падет на плечи энтузиастов, и будем жить с Wan2.2 все время. =(
>>1406274 >Сравни LLM Давай сравним. Как только модель вываливается из видеопамяти сразу -х5 к скорости генерации ловишь. Очень наглядно видно, у меня q5 qwen 30b залазиет полностью и ответ генерит очень быстро, но q6 уже все, там просто мрак.
>на разные поколения, улучшалки для 50хх (которых никто не юзал) и так далее Да, как минимум юзались модели e4m3 в которые 3090 не может Скорость чипа тут не при чем, важны куда и тензорные ядра и версия этих ядер. По моей логике как раз 24 гига врам позволяют догнать новое поколение. Если исходить из твоей логики то 3090 с 12гб была бы также равна 5070? Очень сомневаюсь.
>Короче, в случае 12 гигов видеопамяти и 16 оперативы — добавить оперативу реально может дать сильный буст. Это да, но при условии что после добавления модель вся поместится в оперативу. При этом если добавить видеопамяти то буст будет сильнее.
И тот же Кандинский 2б требует 40 гигов Квантование братик, наше всё. Полные модели так и весят космически, что хуньюуань, что ван 2.1. Даже если не получится выгрузить в оперативу будем сидеть на q4 как бомжи.
>>1406282 >механика персон Чем тебе лора на персонажа не нравится, натренеруй и загружай в разных сценах. Сами сцены кал конечно, да и лоры старые с замедлом, я просто прогонял промпты грока без обработки
>>1406380 Не тестил, они пишут что модели без комфи - для их собственного фреймворка, там обещают скорость генерации х2 от комфи, но это пердолиться надо.
аноны, ну простите за глупые вопросы, комфи первый раз в жизни вижу и не понимаю что в нем и как. установил нод менеджер, знаю как закинуть воркфлоу. на этом знания все.
объясните, куда закидывать лоры и всякое прочее, которые ускоряют генерацию, ну или улучшают ее на 7-8 шагах, где это брать? нужен ли для этого отдельный воркфлоу или нет?
чем принципиально отличается wan2.1 от wan2.2 ? стоит ли начинать с 2.1 или его можно пропустить как устаревший?
может у кого есть ссылка на гайд где разжевывают все для самых маленьких, как управляться с этой адской машиной?
>>1406397 Ван 2.1 использует 1 модель, ван 2.2 использует сразу 2 модели high и low, во всем лучше ван 2.1, кроме потребления памяти, жрет он побольше. Ван 2.1 устаревший, сразу начинай на 2.2
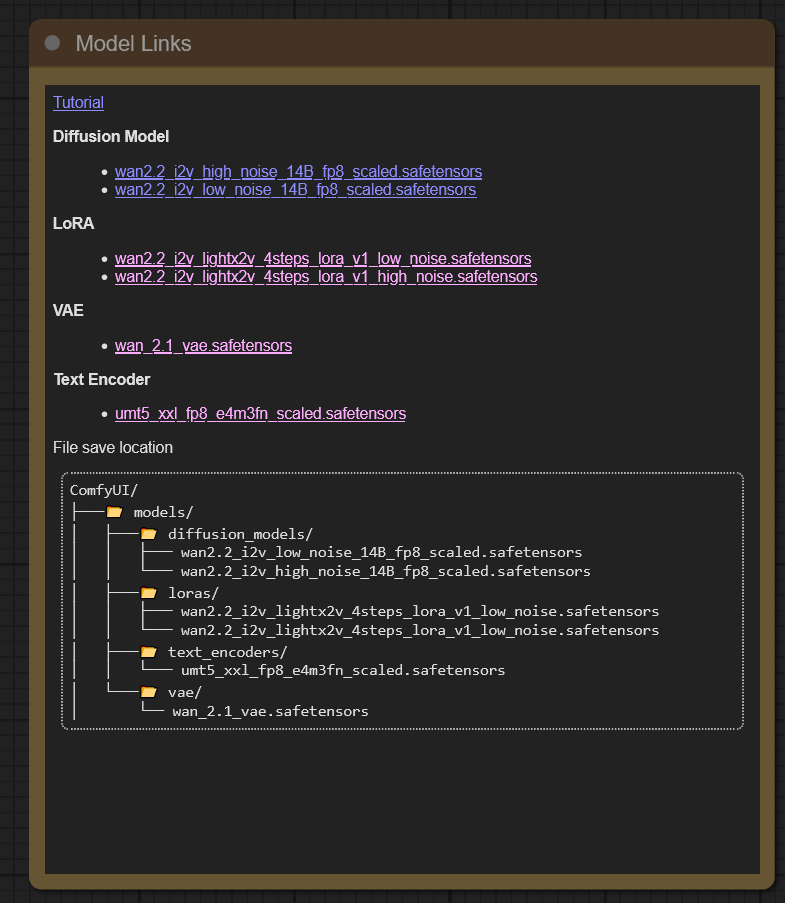
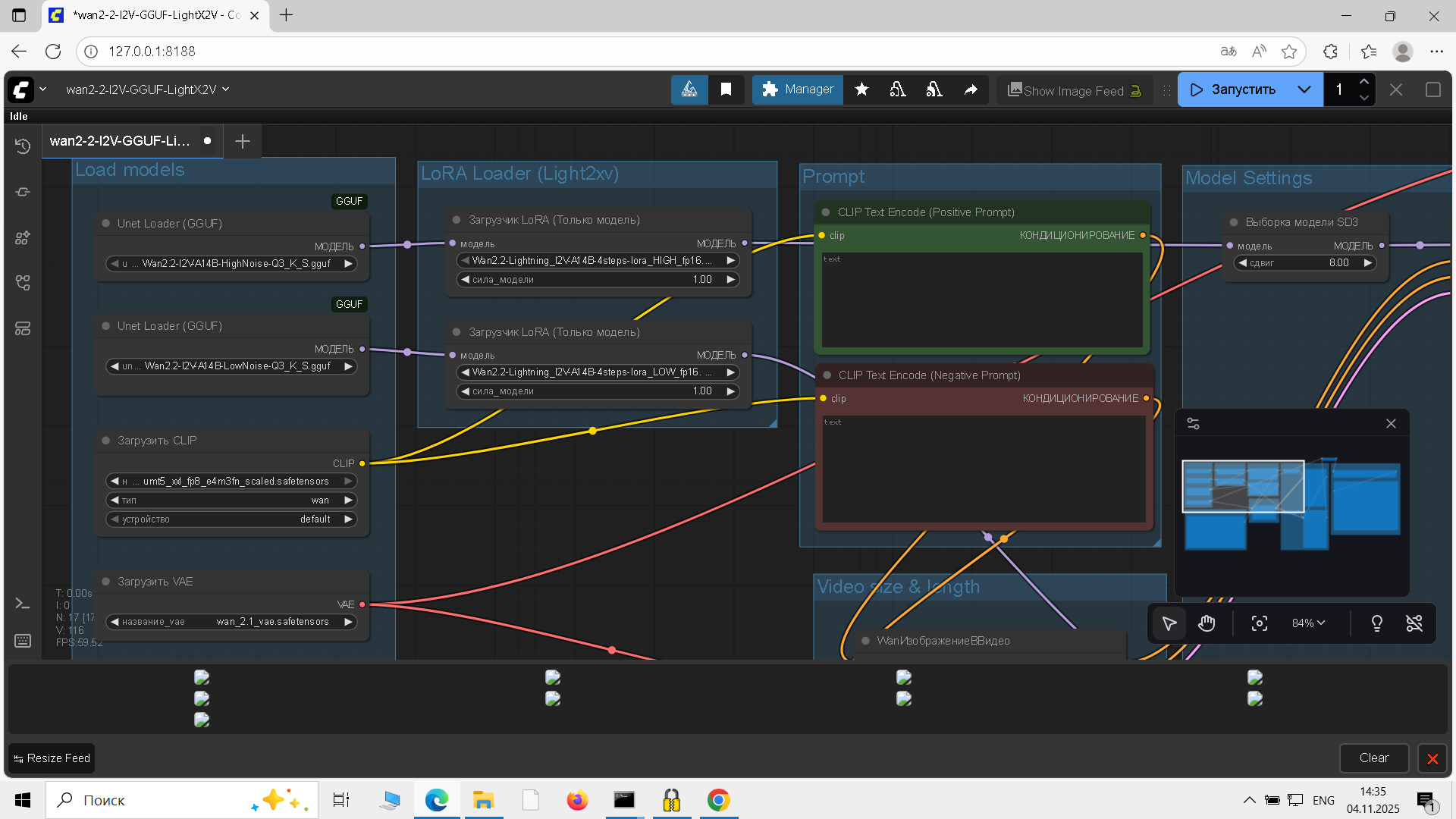
1. Тык сюда 2. Тут есть все, туториал, ссылки на лоры и модели, места куда нужно складывать 3. В базовом воркфлоу всё есть.
>>1406397 В дефолтных темплейтах есть варианты и с ускорялками и без, посмотри и поймешь. Ван 2.2 сложнее, но намного лучше, в 2.1 смысла нет. Гайдов нет, питухонщики все долбоебы с вниманием как у рыбки, и им проще сделать очередную тулзу чем написать гайд.
>>1406340 > Как только модель вываливается из видеопамяти сразу -х5 к скорости генерации ловишь Это еще повезло, обычно сильно больше. -х2 на фоне -х10 — это немного. =)
> юзались модели e4m3 А e5m2 чем не угодили? Их же тоже куча, их 30 поколение поддерживает, но скорость та же.
> Если исходить из твоей логики то 3090 с 12гб была бы также равна 5070? Очень сомневаюсь. Нет, если исходить из моей логики, то она должна была быть на ~30% медленнее.
> Квантование братик, наше всё. Полные модели так и весят космически, что хуньюуань, что ван 2.1. Даже если не получится выгрузить в оперативу будем сидеть на q4 как бомжи. Нет, вообще не так это работает, братан. =) Я запускаю fp16 модели (по 30 гигов) и они чуть-чуть быстрее, чем fp8, и гораздо быстрее, чем gguf какой-нибудь q4. Так что, братик, квантование нихуя не помогает в случае видео-моделей, а даже вредит. Все дело совсем в другом.
Как тебе поможет квантование 4,5 гиговой модели до 2 гигов, если она потребляет 65 ГБ видеопамяти в исходном коде — не знаю. =) Но ты квантуй, сэкономишь, будет 63 гига. Победа.
Комфи работает не как квантование, комфи работает иначе.
> Чем тебе лора на персонажа не нравится, натренеруй и загружай в разных сценах. Это просто дольше и костыльнее. Я же говорю, да, все это можно делать уже сейчас. Но хочется-то проще делать, а не ебаться. Мечты-мечты.
>>1406494 >-х2 там -х5, и это я так на глаз замерил может все х10 есть, просто даже замерять не хотелось, когда он раньше писал так что читать не успеваешь или когда в оперативу полез то он по слову раз в секунду или две выдавал.
>А e5m2 чем не угодили их 30 поколение поддерживает Вот именно что поддерживает, но не использует, все равно оно разворачивает модель до фп16, в то время как 50 поколение может на прямую работать с e4m3.
>то она должна была быть на ~30% медленнее А чего она должна быть медленнее если производительность чипа одинаковая? Или все таки память играет роль ВНЕЗАПНО?
>Нет, вообще не так это работает, братан. =) Это интересно, но чем тогда занимается видеопамять просто 10 от размера модели? Там что такое сопутствующее подгружается? Полные веса 14б модели 56 гигабайт, я про то что если выйдет условный ван 3.0 с весами под 80 гигабайт, то с квантованной моделью все равно можно будет работать. Когда вывалили веса для ван 2.2 все тут резко взгрустнули, а там было чтото около 48 гигов, но потом оказалось не так страшен черт.
>Это просто дольше и костыльнее. Чем что? Как ты себе это представляешь? Просто судя по этому: >чтобы можно было загружать инфу о персонаже (его анимация/мимика, внешность) и он генерился консистентно в разных сценах это по сути и есть lora
>>1406572 > там -х5, и это я так на глаз замерил может все х10 есть,
Да ты хоть читай внимательно!
Я сразу написал: у ллм просадки х10 бывают, где ты там х5 получил — я не знаю, это или очень быстрая оператива, или очень медленная видяха. =) И сравнивая просадку х2 у видео моделей и просадку х10 у ллм, видеомодели очень даже мало теряют в скорости (всего-то вдвое), если выгружены на оперативу. У ллм все гораздо худе.
Вот в чем мой тейк.
> 50 поколение может на прямую работать с e4m3. Только мы говорим про 40 поколение. И я повторюсь: fp16 капельку быстрее, чем fp8, т.е., запускай смело fp16 на 3090 и на 4070. И, ВНЕЗАПНО, ты получишь одинаковую скорость без всяких ускорялок. Что опять не так? Скажешь теперь, что 3090 не умеет в fp16?
> А чего она должна быть медленнее если производительность чипа одинаковая? > Или все таки память играет роль ВНЕЗАПНО? Никакого внезапно, я сразу писал, что играет роль, но не ключевую. Ты не пизди.
>>1406225 > Влияет лишь немного При полной выгрузке влияние х2, на фоне ллм — это немного. При выгрузке половины модели — х1,3 где-то.
Я хуй знает, как еще ткнуть тебя в сообщения, чтобы ты перестал делать вид, что я все это не написал еще в первом сообщении.
> Это интересно, но чем тогда занимается видеопамять просто 10 от размера модели? Там что такое сопутствующее подгружается? Я не смотрел (даже хабр пролистал по диагонали), ибо мне Кандинский не интересен по качеству, но я подозреваю, что это все контекст и их реализация внимания. Т.е., модель может там 4,5-9 гигов занимает, а все остальное — самое латентное пространство генерации. Фиг знает.
Вообще, можешь сравнить разные модели: ван 1.3б, 14б, 5б, хуньюан какой-нибудь, и прочие. У них тоже размер контекста разный, некоторые модели прям совсем в условные 6 гигов влазят, а некоторые и в 12 не влезут с тем же разрешением и количеством кадров.
> Полные веса 14б модели 56 гигабайт, я про то что если выйдет условный ван 3.0 с весами под 80 гигабайт, то с квантованной моделью все равно можно будет работать. Дак а похуй, понимаешь. Даже полные веса 80 гигабайт — это все равно 80 гигабайт оперативы (если мы используем offload, а комфи и киджай его и юзают), даже тот же файл подкачки. Много — но терпимо. Так что тут и правда бояться нечего. Конечно, работать будет дольше, если не завезут обновления архитектуры (хотя у лтх вон, архитектура быстрая — и генерит ну такое себе). Но подождать можно, если будет качественно.
> Чем что? Как ты себе это представляешь? Помнишь модель MAGREF? Ну, к примеру. Там можно было загружать до трех изображений (правда у Киджая ты загружал одно изображение с тремя мелкими на белом фоне, э), и модель делала видео, где они совмещены. Т.е., берутся признаки каждого изображения, и на его основе уже генерится новое, которое и анимируется.
Или же, тот же воисклонинг в аудио — загружаешь голос, генерируешь фразы с похожим голосом.
Изменение изображений — Flux Kontext или Qwen-Image-Edit. Тоже, грузишь изображений (до трех в случае квена) и получаешь изображений на выходе.
Да у Suno уже есть эта фича (persona) — когда песни поются одним голосом.
Так вот, суть в чем. Омни-модель, которая на вход принимает промпт (текст), изображения, видео, аудио, и на основании этих данных генерирует таких же персонажей в описанных ситуациях. Эти данные берутся каждый раз с нуля и хранятся в контексте. Для этого не нужно обучать лоры. Собственно, когда выходил Flux Kontext, были слышны возгласы «лоры больше не нужны!» (ну да-да, щас, не нужны, как же!=)
Но для этого надо обучать модель с нуля, и не факт, что кто-то этим сейчас занят, а не дело будущего.
Но раньше и видео генерировалось только с нуля, а потом уже появилось img2vid. Голос генерировался лишь на котором обучалась модель, а потом появился voice-cloning. Так что, в корпоративном сегменте точно этого дождемся. Это упростит работу самим корпоратам — модель просто крутится у них, а люди (за денежки) кидают туда че хотят и получают персонализированный контент. А вот будет ли такое у нас…
Пока только ручками. Генерить изображение отдельно, озвучку отдельно, а затем черрипикать видео.
———
Ладно, простите, распизделся я сегодня. Хули тут.
Ждем лтх в опенсорсе хотя бы, надеемся на конец ноября.
>>1406055 Так чет нихуя не нашел нормального. Можно выделить маску кота, подставить в референс этого же кота покрашенного в зеленый квеном, и тогда что-то получается, но это ж блять тупо.
>>1406654 >Вот в чем мой тейк. Да, теперь понял о чем ты.
>Никакого внезапно, я сразу писал, что играет роль, но не ключевую. Чьи слова? >Т.е., память в случае 3090 как раз почти не играет роли, ВНЕЗАПНО. >Ты не пизди.
>Только мы говорим про 40 поколение. >Так немного что 3090 практически не уступает по скорости 5070, вот и думай. Ну это ты почему то говоришь по 40 поколение, да и к тому же 40 так же может работать с e4m3, а 50 дополнительно еще и с nf4.
>При полной выгрузке влияние х2, на фоне ллм — это немного. Ну фон можно придумать разный, на фоне кофемолки например скорость генерации стремится к бесконечности, а в контексте видеомоделей это x2 что само по себе уменьшает скорость в 2 раза, 5 минут против 10 например очень неприятно.
>MAGREF Ну это по сути ti2v модель как vace. 3 картинки можно совмещать и сейчас, vace на 2.2 можно прикрутить. Ты хочешь Qwen-Image-Edit который генерит видео? Чего ты хочешь, я не понимаю.
>>1406662 Правильно составленнй запрос уже половина ответа. Что ты подразумеваешь под эдит? У тебя есть готовое видео с котом и ты хочешь с делать его зеленым цветом в этом видео? У тебя есть фотка кота и ты хочешь сделать видео в котором он становится зеленым? У тебя есть фотка кота и ты хочешь сделать видео в котором он изначально зеленый?
> 40 так же может работать с e4m Может, и там скорость чуточку ниже, чем с fp16, а в fp16 работают оба. Никакого ускорения на 40 поколении от e4m3 ты не имеешь, вот и весь сказ.
> 3 картинки можно совмещать и сейчас, vace на 2.2 можно прикрутить. Да много где, да, магреф я вспомнил просто потому, что игрался с ней.
> Ты хочешь Qwen-Image-Edit который генерит видео? Чего ты хочешь, я не понимаю. + звук, да. =) Одновременно. Накидал в модель картинки с голосами и музыкой, а она сама скомпоновала видос по текстовому запросу. К тому и идем, вот увидишь. Persona появится в видео моделях к концу следующего года, я думаю. Киллерфича же. К тому же, маркетологи напирают на то, что «с помощью нашей нейронки можно делать кинематографический контент!» (что нихуя, конечно же), но тут будет явно шаг к этому, когда в разных видео будут одинаковые персонажи-«актеры».
>>1406771 У меня есть готовое видео, и я хочу его изменить, так же как квен может изменить готовую фотку, не перерисовывая. Если генерить новое видео - это не эдит.
>>1406803 Так +звук это сейчас даже платные не могут в контексте сэмпла звука как вайб войс.
Такое через еботь можно реализовать - ммаудио будет для фонового шума, вайб войс для генерации аудио, инфинит толк v2v для визуализации речи, ну и предварительно надо сгенерировать ролик с персом. Если бы сделали инфинит толк или humo под ван 2.2 это бы упростило задачу, но что то там не чешутся.
В одной модели этого не будет, как минимум в потребительской версии, только онлайн. Ну и реализация не такая простая задача - на разном сиде по разному нейронка может воспринимать одежду, лицо, голос. Даже в вайб войс речь надо подбирать через несколько вариаций чтобы получилось более-менее похоже. А тут надо чтобы прям звезды сошлись и одежда и лицо и голос и все это в одной модели. Куча переменных.
>>1406811 Ну значит ты все правильно сделал - через маску, а как ты хотел чтобы нейронка поняла что ты хочешь поменять именно кота в зеленый? Она конечно может различать объекты на видео, но ей нужна помощь.
>>1406816 Ну так Квен умеет же различать объекты без маски? Можно покадрово прогнать через Квен, но тогда каждый кадр будет чуть отличаться, именно это и должна по-идее такая хуйня как Вейс фиксить. У нее причем есть воркфлоу плавно соединить 2 видео, где она по несколько смежных кадров сглаживает, но не плавно соединить все кадры.
>>1406417 >>1406418 огромное тебе спасибо анон. и всем кто подсказывал мне, мелкокарточному ноутбучному человеку. все получилось. 2060 на 6гб с оперативой в 16гб генерит со скоростью примерно полторы минуты за секунду. на разрешении 480х368. это при 30 гб подкачки. качество вполне приемлемое для анимационных картинок. я так понимаю их потом можно еще апскейлерами всякими для видосов погонять.
в общем че хочу сказать. вы приятные люди. добра вам
>>1406816 > даже платные не могут Не могут, да. Но научатся, я думаю, это естественное развитие моделей. Клиенту за денежку такое поставить — милое дело. А уж по папирам, какую-нибудь фигню и энтузиасты обучат. Правда хотелось бы уровнем повыше, но вряд ли увидим в опенсорсе. Надеюсь ошибаться.
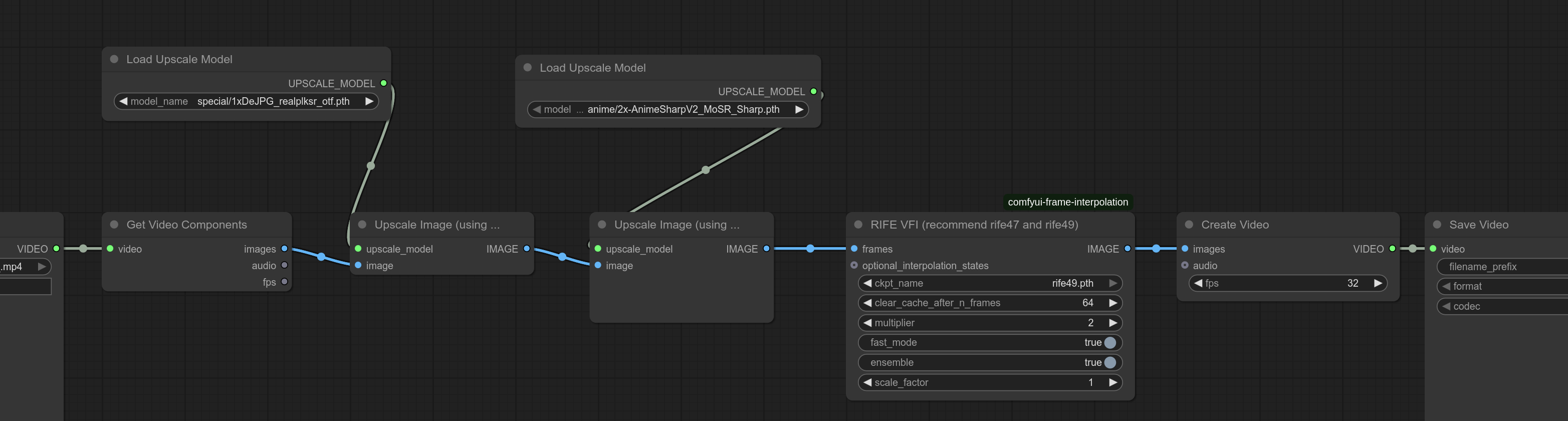
>>1406894 Из апскейлеров есть RealESRGAN x2 / x4 plus (Anime6B), всякие 4x AnimeSharp и UltraSharp. Ну и король SeedVR2, но он ебуче долгий и требовательный, на него забей. =)
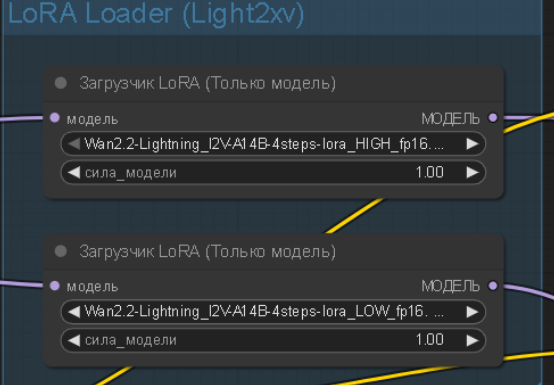
>>1406941 эти ноды продублируй и подключи в цепочку дальше там уже другие лоры подключишь можешь ноду с пика два поставить там можно много лор в одной ноде подключать
>>1406946 Вот что нужно для самой базовой генерации Степень квантования Q подбирается на основании объема vram + ram Чем ближе к q8 = лучше качество и больше требует Если памяти супер мало рассмотри варианты q4km или q4ks ниже этих скорее всего будут сильные артефакты.
Вот лоры ускорялки из первоисточника: https://huggingface.co/lightx2v/Wan2.2-Distill-Loras/tree/main (Это только для i2v моделей, да ускорялки так же как и модели подбираются от задачи t2v модель = t2v ускорялки и t2v лоры, верно говорят, что диск будет засран полностью особенно по началу, когда качаешь все подряд)
кстати полазил по цивитаю и увидел некоторое количество моделей идущих одним файлом и не имеющим разделения на хай и лоу. с нми то как быть? я извиняюсь за миллион тупых вопросов, я бы сам все потыкал, проверил. но скорость генерации не располагает к экспериментам если честно.
Генерач, подскажи какие ИИшки могут ватермарку с динамичного небольшого видоса убрать? Не обязательно прям идеально. Шапка огромная, в каждой разбираться устану
>>1407249 по сути сейчас доступен только тупой апскейл по картинкам плюс промежуточных кадров можно нахуярить. Честный апскейл есть только у LTXvideo, но там пораша.
>>1407185 >Как в комфи поменять файл подкачки с диска С на другой? Установлен не на С. Никак. Этим не comfy а система заведует, у нее в настройках ройся.
>>1407217 Скорее всего они декйствитенльо для 2.1, смотри на base model в деталях справа. Но стоит отметить, что лоры 2.1 иногда нормально работают и для 2.2, их нужно запихнуть и в хай и в лоу и с весом поэксперементировать. Кроме того, читай описания внимательно. Пару раз видел 2.2 лоры, у которых просто оба файла загружены в одном архиве.
>>1405458 шел мимо, там мой видос, нинадо там никаких лор дополнительных на переход, просто у автора лоры руки из жопы, ван прекрасно понимает переходы, там только лора одна юзается и это NSFW posing и то веса не большие у нее. Сохранение лица ван тоже делает, нужно промптить чтоб старался удерживать черты из исходника, можно еще прописать из ферст фрейма, но тут уже больше рандом, если хороший исходник то шансы высокие, а так все равно пририсовывает черты всякие.
для перехода ван работает с палкой |, можно добавить еще промпта типо
| Immediately cut to a new scene where the exact same woman is now naked in the shower stall...
Но тут тоже зависит от исходника, но проблем с переходом никогда не было.
>>1407641 ну значит гдето промпт ишью, описывай детальнее переход/новую сцену, у меня например не возникает проблем засумонить любую тянку в ночную палатку с фонарем, или в душевую :d но там достаточно промпта на обозначение перехода к новой сцене и локации. не одна фраза
о, ананасы, спасибо за идею! Я дохуя времени тратил на то чтобы развернуть бабенций в нужную позу, а тут вот оно как просто оказывается. >>1407676 посмотри у меня, асло, ван нормально кушоет русский язык.
prompt: Моментальная смена сцены: Та же девушка лежит на грязном матрасе задрав ноги, она жирная как свинья, она смотрит на зрителя высунув язык. Её ебёт зритель от первого лица. Хорошо видна её пизда сиськи волосатый лобок, девушка получает удовольствие от секса.
Для чего нужна clip_vision_h.safetensors? Вот в примерах в шапке в ван2.1 она есть, а в ван2.2 её нету, хотя можно так же подключить. Что конкретно эта модель делает? Вроде и без нее нормально работает.
Можно ли тренить Ван лору сначала на одном датасете, потом загрузить стейт, и продолжить на другом? Если тренишь нсфв, то нужно ли при тренинге сразу подключать общие нсфв лоры?
>>1407861 наскок я помню это костыль для понимания входящего изображения, в ван 2.2 он уже вшит, потому нормально работает в и2в без него, у ван 2.1 в и2в без этого было не очень
Если тренить t2v на видосах, то каждый кадр по импакту будет равен отдельной картинке? Вот у меня к примеру датасет из 100 чанков по 41 фрейм, это значит за 1 эпоху на них как 41 эпоху на датасет из 100 отдельных картинок тренит?
0.3.68 выкатили. >Added RAM Pressure Cache Mode for intelligent memory management under resource constraints Где это включить? >Accelerated model offloading using pinned memory with automatic low-RAM hardware detection Найс. >Enhanced FP8 operations: reduced memory usage and fixed torch.compile performance regressions Improved async offload speeds and resolved race conditions Это вообще пушка, на практике еще б работало.
>>1407629 В том видосе разрешение 1024 х 1792. Ты использовал апскейлер или прям в таком разрешении генерил? Какое у тебя железо и как долго видос делался?
>>1407629 Кстати если очень низкий shift тоже могут быть проблемы с переходом, ибо мало нойза. Че прямо реально он понимает the character from the first frame? Писец поражаюсь вану, просто лучшая модель даже без лор, в нем такой потенциал безумный
БТВ очень много лор на цивите воспроизводятся промптом
стоит ли писать промты на русском языке в ван2.2? или английский он поймет лучше?
а еще, аноны, смог ли кто из вас заставить промтом двигать камеру в нужную стороны? в img2vid именно. есть какие то заклинания может? лоры нашел для движения камеры. но там не сказать что на все случаи жизни
>>1408247 обновил всю хуйню, заодно и питона что сказать при сразу генерации на прошлом сиде для сравнения дало иной результат, несколько получше. детально прям не вникал, но в целом работа и качество генерации на фп8 выросло. (сравнивал на одном и том же промпте и сиде с прошлых генов).
врам перестал долбится в потолок и стабильно висит на 70-75% при генерации, стало пошустрее. рам тоже перестал вытекать в трубу и цифры стали более адекватными, выше 50г при 128г не поднимался. пара нод правда отвалилось ну да ладно :o
Пиздец, я столько времени проебался вслепую с мусуби, а оказалось там есть отдельный бранч в репо, в котором пофикшен баг с генережкой сэпмплов во время тренинга.
Как можно уменьшить артефакты в виде ряби на мелких движущихся деталях, например волосы, пальцы, листья? Увеличить количество шагов вроде немного помогает, но полностью не устраняет проблему. Я сижу на лайтинговой лоре, подозреваю что это из-за нее. Походу нужно использовать модель без ускорялок и выставлять 20-30 шагов, чтоб картинка была чистой?
>>1409712 Вообще отключи лайтинг на лоу или уменьши до 0.5, но добавь дистил лору та что 64 ранк и поставь 1.5. Если торч/маг кэш используется, тоже отключи их нах. И какое разрешение вообще выставляешь?
Короче, я седня мучал Wan S2V пару часов, и плюнул. InfiniteTalk все же наголову лучше. В комфи, по крайней мере, S2V тащит не очень долго, а вот инфинит прям 30 секунд хуярит по красоте.
Да-да, у S2V куча плюшек, о которых я сам говорил. Но в результате помимо плюшек — мазня и слабая анимация. А инфинит просто наваливает норм липсинк и анимацию даже.
Кто-нибудь тренит Ван2.2 чем-нибудь кроме мусуби? С мусуби на 3090 у меня получается только 1 модель тренить за раз (2 не влезают хоть полностью оффлоадь), по 17сек/шаг. При этом с константным ЛР 0.001 пока нихуя годного не натренилось за 3к шагов, сейчас пробую с 0.002 и козиной. Есть ли понт другие тренеры пробовать?
>>1409869 >Teeth в негатив Бомжих генерить? Не, пасибо. >>1409878 Да в том и дело, прописано уже >mouth speaking, moving mouth, talking, speaking, mute speaking
>>1409908 Со сменой ЛР лоу норм натренилась за 3к шагов. А вот хай с рекомендованным min_timestep 875 чет ваще пока нихуя не тренится. Есди убрать мин то тренится, но они ж сами рекомендуют его ставить?
>>1409908 >>1410240 На diffusion-pipe треню, две за раз никак не получится. lr = 2e-5 использую, с прогревом. Для лоу использую min_t = 0 и max_t = 0.875, для хай min_t = 0.875 и max_t = 1 Эпох надо тренить тренить, 30 эпох уже можно оценить что получается, и чем выше разрешение в датасете тем кажется нужно еще больше эпох чтобы результат был не хуже. В среднем треню 100-200 эпох чтобы неплохой результат выдавало.
>>1410249 -5? Странно, если у меня на 1е-4 нихуя не шло, а это еще в 5 раз меньше. И с какого шага у тебя хай начинает получаться? У меня уже 2к шагов сейчас пердит, и лосс хоть и упал с начальных 0.7 до 0.5, но на лоу он уже на первых 100 шагах был в 0.1. И это с 2е-4.
>>1410303 Я не ориентируюсь на шаги, их количество зависит от размера датасета, на 30 эпохе обычно делаю паузу и тестирую что получается. Возможно высокий ЛР тоже не есть хорошо, я делал тренировку с automagic оптимизатором, он сам выбрал ЛР 1е-6, и на 30 эпохе вполне себе результат норм был.
>>1410339 Так наоборот важно только количество шагов: от того что нейронка увидит 10 картинок 30 раз, она физически не научится больше, чем если 300 картинок 1 раз.
>>1410240 Так с хаем с высоким min_timestep нихуя и не вышло, чем выше ставишь тем хуже тренит. Но ВНЕЗАПНО оказалось, что дуалмод не пашет только с мультигпу, а на одной гпу спокойно пашет. И дуал по-идее должен менять модели на тех же 0.875, но он тренится так же хорошо как лоу. Посмотрим че натренит, потом придется другие тренера все-таки пробовать, вдруг у них пашет.
>>1410822 Попробовал АИ-Тулкит - и сходу соснул хуйца. Эта залупа еще на этапе загрузки моделей забила все мои 96 гигов рам, и потом встала намертво на кешировании латентов. Осталось попробовать пайп.
>>1411550 И с пайпом тоже соснул: он хотя бы запускается, но оказывается ваще не делает сэмплы, и мультигпу у него из коробки не заработало. Так что лучше уж тогда ебаться дальше с мусуби. Также проверил: если тренить на видосах, то шагов все равно нужно столько же, сколько на пикчах.
Уважаемые, хочу брать 5080 на 16 Гб, для локальных генераций, балуюсь в квин и Ван видео, что думаете в пределах сотки потянет видеокарточка или мб что получше есть для нейронок за такой же ценник, сейчас сижу на 3060 12 ГБ, на пикчи в принципе хватает но пятисекундные видео по полчаса генерировать в хорошем качестве что-то не сильно радует
>>1412590 >3090 естественно лучше >чип на ~30% слабже а если брать не ti то и вовсе на 40-45% >брать уманейную в говно некроту на древней архитектуре в 2025 Дааа мань, это точно хороший выбор. А по поводу 24гб, на 16 в ване почти негде страглиться, только об говно типо инфинититолка и прочей аудио поебени где в 25 фпс надо генерить с коробки, там уже придется усираться либо с чанками по 2-3 сек либо разрешение въебывать, но я бы предпочел скорость.
>>1412590 Ну вот я тоже подумал 3090 хоть и мощно но по архитектуре уже относительно мёртвая и сейчас всё пилится по сути для новых архитектур на сколько я понимаю. Какое-то слишком высокое разрешение генерить не собираюсь и сложные сценарии с тяжёлыми моделями. По сути обычная домашняя генерация для своих хотелок.
>>1412630 Тебе 5060ти 16гб\5070ти\5080 хватит на видосы 720х1280х65-73х16, между 5070ти и 5080 разница в скорости есть но не существенная, примерно как между 5070ти и 3090ти, на 5060ти уже очко будет нет конечно, я преувеличиваю, все мы тут терпилы, мы ждем и ты подождешь
>>1412617 Ты наркоман. В 24гига с трудом влезает тренинг 41 фрейм в 480п или 81 фрейм в 360п, в 16 не влезет даже это. И даже тренинг на фотках все равно нужно оффлоадить, а оффлоад занимает времени намного больше, чем любые вычисления.
>>1412641 4 секунды в нативном хд, в 16 фпс, на 14б модели. Если брать разрешение меньше типо 832х512 то и 7 секунд влезет. >>1412642 Он тренит лоры на декстопной карте вместо того, чтоб арендовать h100 на день за пару копеек, а наркоман я. Я имел ввиду базовые генерации без трейна, вот там на все хватает.
>>1412647 Тренинг вована на потребительской карточке слишком тяжелый, мало того что памяти надо много так еще и медленно пиздец, это как жрать кактус, зачем это делать если можно не делать? А вот просто пользоваться моделью можно с комфортом на игрокарте.
Там это, ови обновилась до 1.1 Теперь 10 секундные видео со звуком. И 5 секундную версию тоже обновят. Переобучили с датасетом в более высоком разрешении.
>>1413468 на самом деле в анимейт можно и другой контроль пихать, не только опенпоз. поэтому основное отличие от вейса в невозможности вставлять фреймы куда захочется, только стартовый.
>>1413672 ыыыы давай на любой пук делать валшебную кнопку под названием ЛОРА, которая ЗАПРЕТИТ вану мигать!!!! А пропмпмты ваши дурацкие я использовать не собираюсь....
>>1413779 Так промты не помогают. С чего ты взял, что я их не использую. Модель вана очевидно кривая, она всё время меняет яркость сцен, и мигает всё постоянно в темных сценах.
Удивительно что до сих пор никто такой лоры не запилил.
>>1413823 >Удивительно что до сих пор никто такой лоры не запилил. Потому, что есть уже. Это нодой (даже несколько реализаций есть) постпроцессинга color match лечится, кроме совсем уж терминальных случаев. Принцип - на вход кидается выход семплера, и картинка-образец. Нода приводит яркость-контраст на всем поданном к образу, и отдает дальше выровненное по параметрам. Сильно нужная штука для loop-видео, без нее стык по глазам бьет.
>>1413823 пиздеж, ван 2.2 почти нихуя не меняет. ван 2.1, там да, постоянно шифт цветов происходил. сколько не генерил темных сцен, ничего не мигало пока.
>>1413993 блять колор матч это древний костыль который для хуньяня и 2.1 вана использовали когда цвета гарантированно шли по пизде при каждой генерации, причем равномерно по всей длине. то есть если цвета динамически меняются то оно нихуя не поможет. а сейчас и проблемы такой считай что нет. для луп видео ты юзаешь один и тот же фрейм для последнего и первого кадра, там априори не может быть проблем с цветом на стыке.
>>1414147 >для луп видео ты юзаешь один и тот же фрейм для последнего и первого кадра, там априори не может быть проблем с цветом на стыке. Во первых - это если ты готов удовлетвориться длинной лупа в 5 секунд. А если хочешь сделать 15-20 - ну обойдись. :) (Делается то оно через 3-4 фрагмента продолжений, закольцовывая последний на первый - и освещение уплывет гарантированное без этой ноды.) А во вторых - даже на 5 секунд, и даже на wan 2.2 с одним фрагментом start-stop из одной картинки - может уплыть. Ван не идеально приводит к последнему фрейму, особенно если движения резкие и со "смещениями камеры".
>>1414147 >то есть если цвета динамически меняются то оно нихуя не поможет. Скармливать за образец исходную картинку надо, и для всех фрагментов - тогда поможет.
А вообще - не 100% случаев конечно. Но заметно лучше.
>>1414293 Тебе мб не показалось, у него факап был все это время >Bug was that the audio negative prompt wasn't actually used, and it always used the video negative instead, which probably was bad for audio..
>>1414253 если ты тупо последний сгенерированный фрейм продолжаешь по технологиям из каменного века, то у тебя вообще все уплывет, и цвет, и персонаж, и сцена, все нахуй, если движений в кадре больше чем дрочка с ампилитудой 5 сантиметров
>>1414338 Ну, предложи технологию НЕ каменного века для лупа на 20 секунд.
А так - разумеется, всё уплыть может, но речь о том, что так хотя бы в принципе может НЕ уплыть. :) И при некоторых усилиях результат достижим, хоть и не на произвольном сюжете. Но уж лучше так, чем никак вообще. :)
>>1414504 >технологию НЕ каменного Вангую раскадровку через квен и потом сборку через fflf, либо вариации где ласт фрейм применяется эпизодически дабы фиксировать начавшую плыть генерацию. Ну еще есть лора на персонажа.
>>1414457 если вы используете слово "креатив" как нарицательное, то я ебал ваш тупой рот, так говорят только отбитые манагеры которые в своей жизни нихуя делать не умеют сами, даже черточку на бумаге нарисовать без посторонней помощи/делегирования
>>1417451 Ну то что какой-то нестандартный фпс для видео. Не могли бы они взять 15 фпс? Так бы при удваивании получались классические 30 фпс, а не 32. Да можно в видеокодировщике форсировать 30 фпс, но это на пару процентов занизит скорость оригинального клипа. Я понимаю, что это как бы мелочи.
>>1417570 всю жизнь 90% кино снимали и сейчас снимают в 24 фпс, какие 30. плюс уроки информатики вспоминаем, там вроде рассказывали про вычисления со степенью двойки
>>1417547 Я хз что ты хрюкнул про огрызки, но конкретно этот апгрейд - ахуенная тема. 4090 изначально стоили 90к, это сейчас они х2 сделали как раз из-за этого апгрейда, но это значит что в теории, если кто-то научится их аналоги выпускать, то это удвоит потенциал всех бич-сборок.
>>1417611 Это кинофильмы в 24 фпс. А большинство остального контента в 30 фпс. Окей, в странах с PAL и SECAM было 25 фпс. Но сейчас, в эпоху глобального интерента, этот стандарт неактуален.
>>1417616 >изначально стоили 90к В какой вселенной лол. У нас они с нулевой стоили ~150К, в Европе 3К баксов. Если бы она стоила 90К, а бы лучше вторую карту взял в сборку, чем перепаивать чипы за 75К
Хотел значит попробовать Кижайский воркфлоу, установил Тритон и Сажное Внимание. И никога прироста производительности по сравнению с стандартным воркфлоум я не получил. В среднем даже чуток медленее получается. 1280х720 вообще не реально на нем делать, перед тем как начать сэмплинг он что-то там 10 минут парится. Пробовал крутить настройки блок свапа, ничего не дало, я не знаю как их правильно выставлять, в интернете практически нет инфы. Я так понимаю, эти оптимизации рассчитаны на жирные видеокарты с 24+ ГБ видеопамяти?
>>1417893 Ну-с, мне на 3090 Сажное Внимание выдало очень приличный буст по скорости генерации, минимум 30% точно, чаще больше. Но с ним жор памяти гораздо выше, даже со 100 с небольшим ГБ подкачки падало при подключении больше 4-ёх лор + сама карта грелась сильно больше, чем без Сажи. Ну и в конкретно моём случае с 32 Гб оперативы, конечно, толку от Сажи мало - то что генерация вместо 4-ёх минут идёт 2-3 приятно, но никак не сокращает остальные 10 минут дроча файла подкачки.
Аноны в чем проблема может быть, всесто с тянки на картинке делается с рандомной, раньше на этом воркфлоу у меня все норм было, после переустановки на том же воркфлоу такая срань.
Китайский костыль от слоумошена вроде неплохо работает, на 4 шагах уже терпимая скорость. Хотя качество всё равно у вана такое себе, пердолиться надо или на 6 шагов укатываться.
Протестировал гибридную модель wan 2.2 ti2v 5b. Ну бля это херня полная! Aртефачит много. Один плюс, что она и без ускорялок довольно быстро работает. Зачем эту модель вообще выпустили? Чтобы на слабых компах можно было пощупать нейросеть?
>>1419326 на текущий 90% моделей выпускают чтобы бесплатные бета-тестеры в виде нас пощупали на своих компах. то есть это все ошметки и пробники по сути. а дальше разрабы делают что-то новое на этой основе. конкретно на 5b вановцы обкатывали технологии, которые сейчас в платном wan 2.5 используются. ну а для нас простых смертных 5b пригодится в первую очередь для разного рода апскейла или генерации из контроль видео, так как модель по дефолту генерит в мегапиксель разрешении и можно сохранить уровень детализации такой, который на 14b будет стоить очень дорого по врам и времени . Я уже ряд видосов сделал по методе перегонки 14b видоса в контроль с последующим рендером в 5b. также 5b быстро тренится, можно потестить лору сначала на ней перед тренировкой на 14b.
>>1421235 делается i2v видос в ван 2.2 14b, потом ты его перегоняешь в canny в x2 разрешении и юзаешь как контроль в модели wan 5b fun control, все просто. метод актуален для тех ситуаций когда у тебя генерация слишком сильно шифтит или размываются детали, так что простым апскейлером не обойдешься, либо просто хочется экстра деталей, чтобы поры на коже там было лучше видно и т.д. Только лучше чтобы в кадре не появлялось вообще ничего нового чего не было на стартовом фрейме. пример из недавнего
>>1417893 >эти оптимизации рассчитаны на жирные видеокарты с 24+ ГБ видеопамяти? Тритон вообще для серверных решений типа А100 и выше с 80 гигами на борту, лол. С ним в первый проход будет генерироваться медленнее, чем без него, но последующие должны быть быстрее. Прирост от него на практике на консюмерских картах незначительный, игра не стоит свеч.
Короче скачал эту хуйню. Генерит раза в 3 медленнее чем 14б. Вае ещё более всратый чем на 5б, распердеж даже дольше чем у 5б. Цензуры вроде нет. Играться с настройками нет интереса, с такой всратой скоростю гена и декодирования. В первом видосе воркфлоу, кто захочет потестить на своих 40-5090. Моя 3060 этот кал не тянет.
>>1424544 Столбики я и сам нарисовать любые могу. Вот когда ллм выходят - их проверяют вопросами, с которыми предыдущие не справлялись - тут так же надо.
>>1424303 Напоминаю, что объем видеопамяти не сильно влияет на «влезание» модели. Какое-то замедление есть, но весьма незначительное. А с 12 гигами так еще и ускорение можно получить на fp16. =)
> тесктовый энкодер теперь квен База.
>>1424437 Анимация на примере говно, конечно. Мазня. Но только начало, может настройками догонится.
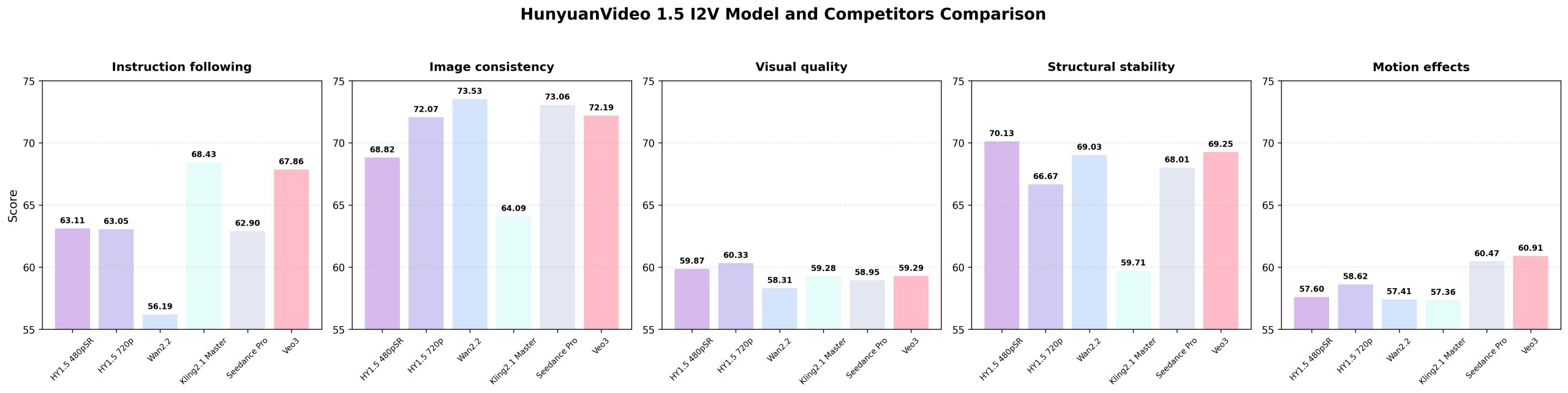
>>1424544 Иронично, что по Image Consistency всех ебет как раз старичок Wan2.2 =)
Ну короче. Лучше, чем 5B модель, хуже чем A14B модель. Зато втрое быстрее. Пока что смысла не имеет (20 против 4-6 степов, ну), но когда выйдет Lightx2v лора (если=), то для более скоростной генераиции будет норм вариант.
Неплохой релиз. Если бы у нас не было дистил-лор на ване — то даже был бы хороший. Но так как мы избалованы быстрой генерации на ване, то и тут хочется прироста соответствующего. Без него не нужно, а с ним будет весьма годно.
Теперь остается надеяться, что Alibaba захочет утереть нос Tencent, и выпустит Wan2.5.
>>1424995 > Зато втрое быстрее. I2V 720р на 5090 почти такое же по скорости, как и ван 2.2. На ване в 704х1024 у меня 15 секунд на шаг, тут 9. fp8 fast в Хуйне не работает, NaNы лезут. Памяти он жрёт мало, только в этом плюс, для 16-24 гиговых карт актуально будет. В остальном не достоин даже постинга генераций в тред.
Вот неплохая инфа по сэмплерам и шедулерам. Справа в Attachments скачивайте guide_ComfyUI_Samplers_v2.zip и потом html файл открывайте. В первую очередь это для генерации картинок, потому что многие сэмплеры с Ваном нормально не работают, но все равно интересно почитать.
>>1425685 А в картинках тоже лоры, поэтому там тоже нихуя не работает. Пу-пу-пу. И вообще, лучше эйлера/беты(57) нет, все остальное это аристократические изыски вида "пук в устричном соусе" вместо нашей русской картошечки с грибами, или же еврейская попытка скрытно пропихнуть n-кратное увеличение шагов.
Прмпт Electrifying women’s wrestling match inside a packed and brightly lit arena, filmed in the style of a live TV sports broadcast. Two powerful topless female wrestlers with big boobs clash in the ring, performing high-energy moves—body slams, grapples, and dramatic throws. The audience erupts in cheers, colorful signs and LED screens flash, commentary team is visible beside the ring, and xxx branding is prominent on the apron and screens. Wrestlers wear detailed costumes and makeup, dynamic spotlights create cinematic drama, multiple camera angles capture action, sweat flying, intense expressions on the athletes’ faces, energetic atmosphere, pyrotechnics and crowd noise creating excitement.
>>1426041 Местами даже 5б проигрывает, но чисто по качеству видео (а не консистентности) хуньюан все же лучше 5б. Но без 4 степ лоры ноль смысла, канеш.
>>1426041 Плакать хочется. Весь этот кал даже до грока не дотягивает. А меньше года назад у нас была сетка, которая уступала только Соре. Теперь снова локалка в полной пиздище. Про изображения вообще молчу, rest in piss since 2022.
>>1426172 Как бы не старался придрочиться к квену все кал получается, он почему то генерирует хуёвые картинки с явным тайлингом везде и вся, не знаю как от этого избавиться, все картинки получаются с каким то мета шумом который явно бросается в глаза, мало того итоговое качество даже до дефолтного флакса не дотягивает. Гугловый бесплатный гемини просто за щеку наваливает квену.
>>1426172 >Qwen Edit Дерьма кусок. Кроме него есть и получше варианты, но и они все ссанина даже по сравнению с новым гроком. Это же нужно было так опуститься, что теперь и грок лучше локалок. Локалки полное дно. Единственная достойная модель - NoobAI.
>>1426403 От fp8 и шакалит. Возьми gguf или bf16, возьми актуальную 4-шаговую лору, шедулер как положено для лайтнинга simple, семплер поадекватнее. На втором скрине вообще пиздец какой-то.
>>1426407 ну ахуеть конечно именно из за васянской сборки все проблемы? а ни че что на других скринах обычный имадж эдит?
>>1426420 >bf16, а че зразу не фп 32? Это какая то нездоровая тема что на фп8 кал получается, на флаксе и хроме такой херни нет на фп8, не говоря уже про всякие sdxl, на ване тоже когда для изображений его используешь. А тут видите ли надо бф16? И такие шакалы именно когда для реалистичных изображений используешь, если делать фигурки то там всё ок. А тут бф16 подавай? При чем фигурки всякие делает отлично, но только дело доходит до реалистичных изображений так сразу херня какая то получается.
>>1426578 Горизонтальные полосы через весь пик - это от низкой точности. От такого fp8 без scaled страдает. Может помочь уменьшение длины промпта или разрешения, уменьшение веса лор, возможно соотношение сторон ещё влияет. gguf от такого меньше страдает, на Q8 точно такого не будет.
>>1426578 >>1426403 Бля, пацаны, скажите наиболее быструю, но при этом максимально качественную модель, а то я уже перестал разбираться во всех этих fp8 gguf да еще и сборок васянских. Мне нужно чтобы генерировало наиболее быстро, но при этом не обязательно чтобы супер детально, главное чтобы цвета + композиция вывозила.
>>1426769 На Ване Киджаевские fp8 нормальные. А на Квен все хуй забили и сконвертлили втупую. Но он всё равно в fast не работает нормально, поэтому похуй, можно и на гуфе сидеть.
щупаем полтораху. на 720p на честном чекпоинте на 3090 один шаг на 1280*720 занял 120сек. В рот ебал короче. Этот видос удалось выстрать за 362.27 сек Есть фича с апскейлом сразу изкаропки.
>>1426862 Обсудили уже, говно. Чуть лучше 5B, но без дистилл лор на 4 степа смысла нет. Как будут — будет быстрая генерация. Но ван лучше по качеству все еще. Чуда с 8б моделью не случилось.
прмпт Tight portrait of a 20-year-old blonde with water droplets on flushed cheeks, peeling a soaked white tank top up to just under her breasts, hard nipples pressing through fabric. Steamy bathroom mirror fog, playful smirk, blue eyes sparkling.
>>1426901 чел, я еще на первом хуньяне генерил как бабу прокручивают через гигантскую мясорубку, вот это блять пизда полная, а не просто кривая вагинка голенькая
>>1425661 Это круто? Даже без ИИ не выкупал этих Editов и подобных реклам. Мелькающая мешанина, одуплялово для мозга. А вот создать длинный ролик с сюжетом, чтобы ИИ сохранял образы персонажей, не терял детали. Вот это другой уровень.
>>1427396 Вот сейчас запустил без блоксвапа, реально FP8 scaled залез в 4070ti, такого не было до обновления. Правда 1 генерация видоса это 20 гигов свопа.
>>1427752 Сейчас видеонейросети сильно развиваются. Только за этот год сколько всякого произошло. Wan 2.1 уже неактуален. Да и Wan 2.2 со своими 5 секундами далеко не идеален. Через полгода что-то более крутое будет, так что нет смысла подсаживаться на предыдущие или актуальные модели.
>>1427530 Такое было уже где-то с полгода, если не дольше, я хз.
>>1427712 Это MoE-модель из двух экспертов, каждый по 14B, которые работают подряд, получается как бы модель 28B, но так как половина шагов одной моделью 14б, половина другой — получается быстрее, а качество чуть подрастает. Хитрость, так сказать.
>>1427735 В LLM бывают неактивные. Например Qwen3-30B-A3B значит, что всего параметров аж 30 миллиардов, но активные из них за один прогон только 3 миллиарда. Остальные «не требуются» и не читаются/не вызываются.
>>1427831 > получается как бы модель 28B нет, не получается > так как половина шагов одной моделью 14б, половина другой — получается быстрее нет, не получается
А есть рабочие сайтики где дают wan2.5 без цензуры потыкать? Пока что ебусь с гроком, он если повезет может и соски сгенерить, причем очень даже красиво, но хочется чего-то побольше.
Прогнал пару генераций ван 2.2 без лоры и что хочу сказать - мы в ебаной жопе. Кто не пробовал или может забыл как оно выглядит без лоры - обязательно попробуйте. Мы настолько далеки от такого качества с лорой даже спустя десяток её версий и пол года допиливания, движения реально движения, 5 секунд реально 5 секунд, а не растянутые полторы-две как с лорой. Алсо пидоры из лтх обещали веса лтх 2 в конце ноября, но там всё будет ещё хуже, нет просто железа под это сейчас
>>1427931 > Overall, the model is unlikely to be usable (not as good as WAN, etc.), but it sometimes produces decent results (rarely) понял, вычеркиваю
>>1427835 > 1 Нет, именно так и получается. Нытики с «МоЕ не настоящее!..» нойте сами себе где-нибудь, не путайте народ. > 2 В Комфи работает именно так, поэтому так и получается для большинства.
Тут нечего обсуждать, чисто факты перечислил. Живи с этим.
>>1428509 > Нет, именно так и получается. Нытики с «МоЕ не настоящее!..» нойте сами себе где-нибудь, не путайте народ. у тебя интеллект и логика пятилетнего ребенка если ты считаешь что две 14b модели = 28b. по факту там большинство параметров одинаковые, просто лоу и хай нойз заточены под свои задачи.
> В Комфи работает именно так, поэтому так и получается для большинства что блять значит "именно так"? с чем ты блять сравниваешь вообще, клоун? чего именно быстрее получается? ты же сука выдумщик, фантазер ебаный
> Тут нечего обсуждать, чисто факты перечислил. Живи с этим. перечисляю необсуждаемые факты: твоя мать - шлюха. живи с этим.
>>1427927 У меня шаг без лайтнинга на норм качестве занимает чуть больше двух минут. 30 шагов займут больше часа, ты ебанутый? В комфи же даже превью нет, чтобы по паре шагов понять, что говняк генерится. Для таких экспериментов 5090 надо иметь, а еще лучше 6000.
>>1428540 А, сорашиз, ты. Ну, сразу бы представился, че ты. Таблеточки опять забыл, выпей скорее, полегчает. Ты ж даже не понял, что я написал, к сожалению. А с таблеточками бы понял и не спорил.
>>1428934 > Таблеточки опять забыл, выпей скорее, полегчает. вижу слова твоего лечащего врача врезались в память настолько сильно, что ты начал их повторять только ты вместо этого сожрал кусок мета, который завалился за кровать на которой твою мать ебали и начал в узорах ковра видеть 28b модели и сорашизов (чего блять?)
>>1429040 >нужно 20 https://www.reddit.com/r/comfyui/comments/1mn6g4u/comment/n83nqut/ А официально вообще 40-50 рекомендуют. >2 секунды вместо пяти - будет считай та же длительность что и с лорой У меня особо нет проблем со слоумо, только сравнивая генерации между собой иногда замечаю, что одна чуть медленнее, другая быстрее. Я это решаю просто прореживанием кадров по маске, и там явно выходит не 2 секунды, а 4 с лишним.
Аноны, есть вопрос, извиняюсь что не совсем по теме треда,летом использовал face swap сайты,обычные которые находил через гугл,но сейчас не помню какие именно. Вот теперь вопрос, насколько они вообще конфиденциальны, попадают ли видео в общий доступ?
За три недели угандошил техсостояние двух терабайтного SSD с 90% до 88% из-за файла подкачки. Еще проблема в том, что он у меня на 70% забит, т.е. износ неравномерный получается.
>>1429938 147 терабайт записи на 500 гиговом ССДшнике и состояние ни на один процент не упало? Что-то нереалистично звучит. Возможно у тебя там контроллер округляет по пять процентов.
Ебучий ван просто невозможно использовать в продакшене. Если мало степов то ебучие артефакты повсюду. Если много, всё равно картинка то тускнеет, то более яркая становится. Длинную консистентную сцену сделать просто нереально. Нужно ждать какого-то прогресса в технологиях походу.
Ебучий хуеглот снова доебал меня требованиями ОБНОВИТЬ КОМФЕ, вернее, принудил нажать "on next start", и теперь вообще не запускается, питон вышел 429429386921387123. Сука, как он заебал этой хуйней. Пидарасина тупорылая, хуле ты трогаешь? Тебя просили трогать, что-то? Делай модели свои там адаптеры, блять, нахуй ты старое еб ешь, придурошный блять? Долбоеб нахуй калифорнийский, тупой даун. Иди нахуй со своими обновлениями.
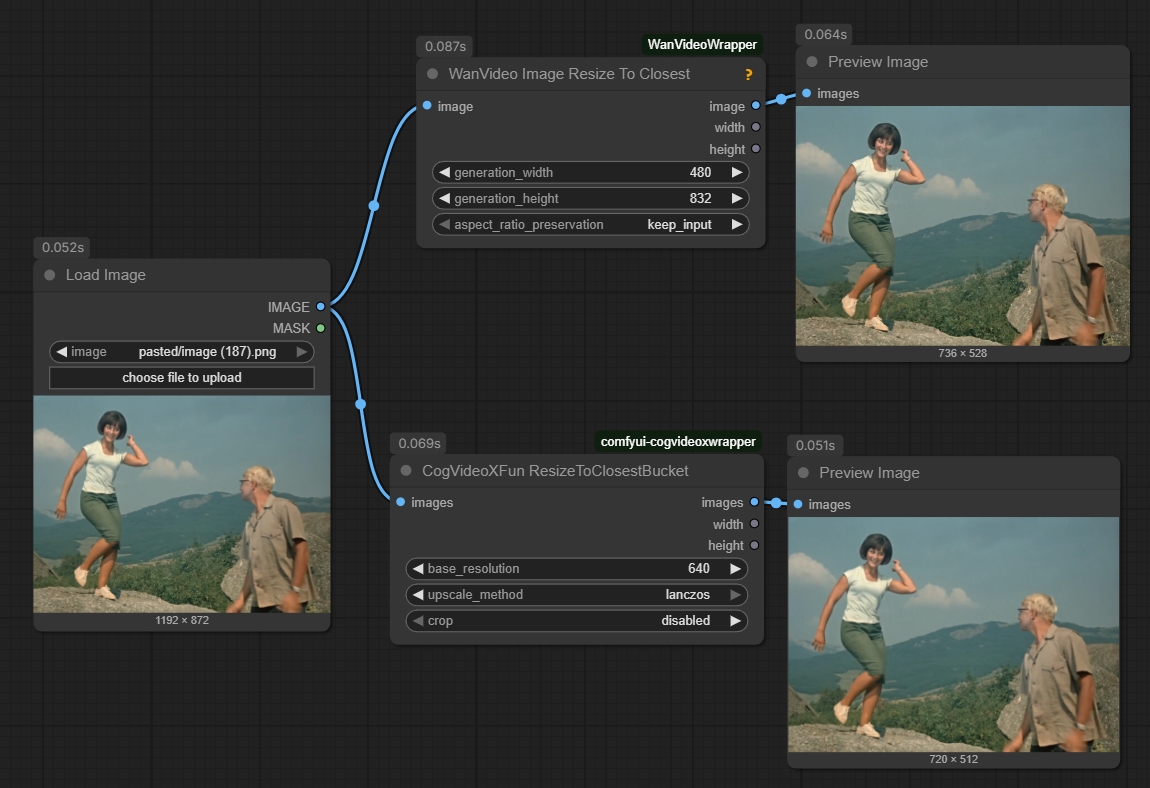
Аноны тупой вопрос, как сделать что бы картинку не обрезало, а автоматом подгоняло под нужное разрешение, а то делаю видос то ебало не влезет, то еще че или только самому подгонять?
>>1430623 Ты че там в глаза долбишься? >>1425760 Для продакшена конечно можно было стыки обработать получше, где то еще пару раз перегенерировать, но в целом я доволен результатом.
>>1430911 обрезание это и есть один из методов подгонки. из других вариантов либо добавлять края где не хватает, либо тупо растягивать. короче не еби голову, ставь такое разрешение чтобы пропорции пикчи и видоса минимально отличались
>>1430945 ширину и высоту в зависимости пропорций изображения, у тебя сейчас стоит на горизонтальное изображение, если загрузишь вертикальное он его сильно обрежет и 8 надо на 16 поменять
>>1431840 >>1431334 Ну я поменял и поставил повыше и у меня на моменте vaedecode вылетает с нехваткой памяти, похоже на моем нищем сетапе с 4060 это не вариант повышать.
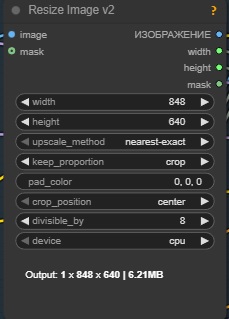
>>1431922 Чел попросил ресайз пикчи. Все эти ноды делают одно и тоже в задаче анона. Только те что скинул я, ещё и проще в использовании. Фан ресайз для кога вообще однокнопочная хуитка без выебонов и дроча разрешений. И вообще хули ты доебся, вместо нормальной помощи анону, какую-то срань про обрезание ему запостил. А там просто в ноде в2 надо поменять в пропорциях кроп на тотал_пикселс.
>>1431950 чел ты вместо "нормальной помощи" советуешь качать бесполезную говноноду времен эпохи динозавров которую не использует даже ее создатель, которая находится в нахуй не нужном паке для мертвой модели (cog), котора неудобна и пиздец как ограничена в функционале. ебать помощничек нашелся.
>>1431972 Я две ноды запостил, одна из которых находится в ванврапере. >ебать помощничек нашелся Ага, ты прям суперхелпер для треда, высрал како-то кал >>1431334, а нормально ему не сказал что нужно поментяь кип_пропоршн. Зато нашёл время серануть что другие ноды говно мамонта. >находится в нахуй не нужном паке А здесь дохуя нужный пак. >>1430943 Всё правильно. Да. Ты молодец, так держать.
>>1431995 > высрал како-то кал > А здесь дохуя нужный пак. детектор чини, это не мои сообщения. нужную ноду уже до меня посоветовали, поэтому остается только серануть на тех кто посоветовал хуйню, все верно
Анончики, как зациклить видос? Я только начал разбираться с Ваном 2.2. Пока что юзал только стандартный воркфлоу для t2i 5-секундный видос 640х480 генерю по 15 минут про апскейл пока не думаю. Но хотелось бы чтобы анимация была цикличной. Наткнулся на цивитаи на такое https://civitai.com/models/1853617/daxamurs-wan-22-workflows-v121-flf2v-or-t2v-or-i2v-or-gguf-or-easy-bypass-or-experimental-true-endless-generation Но запустить не вышло, срёт ошибками при начале генерации, требуя какой-то sageattention. Который не хочет устанавливаться, т.к. ему не нравится моя версия куды а с другой моя карта вообще не рабтает Может есть способ попроще для зацикливания анимации? Нода там какая-нибудь например?
>>1432190 >Может есть способ попроще для зацикливания анимации? Нода там какая-нибудь например? Ноды нету. Точнее - особая не нужна, и так есть - та, что для I2V анимации от стартового до стопового кадров. Общий принцип - использование одной картинки как старт и стоп кадры, все остальное - для улучшения и сглаживания перехода (т.к. wan не идеально к последнему кадру приводит). А sageattention для этого эффекта вообще не нужна. Ее просто для ускорения самого рендера используют. Можно просто выкинуть, если не работает.
Есть и продвинутые техники, но там уже особые модели вроде Wan VACE, и т.д.
>>1431995 >нужно поментяь кип_пропоршн Я не знал что нода киджай так по уебански работает, я ей и не пользуюсь. Предполагалось из названия что она сперва ресайзит а потом обрезает под нужный размер.
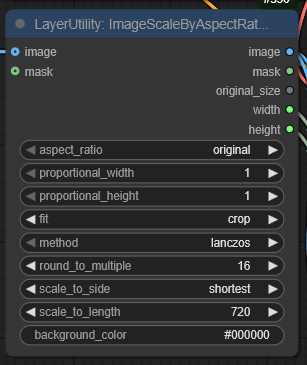
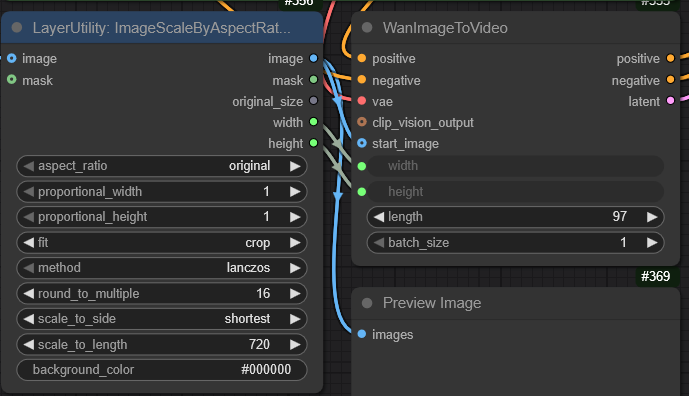
Вообще ультимативная нода LayerUtility: ImageScaleByAspectRatio V2. Не надо думать какое изображение, горизонтальное или вертикальное, оно скейлит изображение по стороне до заданного разрешения, а потом если другая сторона получается кривая то обрезает ее на /16.
>>1432274 > Предполагалось из названия что она сперва ресайзит а потом обрезает под нужный размер. блять все ресайз ноды так и работают, включая киджайские. Чтобы не надо было думать ты втыкаешь width и height из ноды которой задаешь размер видео (потому что размер видео это ключевая хуйня от которой ты пляшешь) в ресайз ноду и все блять, вот настолько просто.
>>1432310 А нафига громоздить еще доп ноды которыми будешь задавать размер если можно прям из ресайз ноды задать размер будущего видео по обрезанному изображению?
>>1432269 >и так есть - та, что для I2V анимации от стартового до стопового кадров. Общий принцип - использование одной картинки как старт и стоп кадры И как это сделать? Вот у меня сейчас по сути работает только дефолтный ВФ по вану. В нём есть только 2 Ксемплера на хай и лоу нойс модели и пик 2 нода, в которую начальная картинка и пихается. Куда тут картинку для стопкадра сувать?
>>1432348 Там в каком-то из основных пакетов относящихся к Wan есть практически такая же нода как у тебя на втором кадре - только с двумя входами картинок, для старт и стоп. Остальное так же.
>>1432348 Спасибо анончик. Ноду нашёл. Но как-то разочаровал Ван. Как будто кроме самых простых и очевидных движений он нихуя не может, половину инструкций вообще игнорит, а персонажи пиздят не затыкаясь. Понятно что я делаю лоурез в 13 кадров на коленке, но тем не менее. Прописал в позитив: silently, silent, mouth closed, teeth clenched А в негатив: 说话, 谈话,唾液, talking, И это помогло примерно нихуя. Результат вроде прикл как будто выходит статистически случайно и то она как будто пытается пиздеть, но не выходит, т.к. рот занят Какого хуя, как заставить их заткнуться?
>>1434293 А по-моему тут всё нормально, она делает омномном или амнямням.
Если у тебя не подключена нода WanVideoNAG, то негатив при cfg1 не работает. Попробуй впиздячить эту ноду, если не стоит, может тогда негатив заставит её молчать раз и навсегда.
>>1430197 Генерация по одной картинке это всегда будет туфта. Нужна новая технология что бы сохранять узнаваемость персонажа на разных ракурсах. Условно один референс для продолжение видео и скажем 4 референса по разными ракурсами для сохранения персонажа.
>>1434997 В генерации пикч уже допилили это, в F2 кидаешь клоузап лица и общий план издалека и он генерит лучше чем ван с лорами. Ждём когда в видео завезут такой уровень. Алсо, в Ване если начинать видос с ровного портрета, то он лицо хорошо сохраняет.
>>1434310 Спасибо анонче, это помогло, они наконец-то заткнулись!
Алсо, нашёл ещё ноды для апскейлинга и интерполяции. Сначала не понял нахуя надо второе, а потом дошло что оно на халяву увеличивает количество кадров - годно. Но в моём случае 15 минут на видос 13 ФПС лучше сначала генерить без апскейла и прочей хуйни, а потом уже годные варианты дорабатывать оказалось что так можно
Алсо, чтобы решить проблему долгой генерации на моём калькуляторе, попробовал 2 способа: 1. Ван 2.2. 14B Gguf. До этого юзал такой формат только в текстовых моделях и там чем меньше квант, тем меньше памяти занимает модель иии тем быстрее она работает. Думал что здесь будет также, но как же я ошибался. Скачал самую пережатую в q3 хуйню, в которую сразу зашили High и Low нойзы, весом всего 7Гб. Думаю - ну сейчас то мой драндулет полетит. Но нет полетела моя жопа потому что эта хуйня нагрела карту так, как не грело до этого вообще ничего. После 20-й минуты ожидания генерации ПРВОГО шага, решил забить на эту хуйню. Памяти разве что съело меньше, но не прям намного. Вероятно Гуф экономит память за счёт большей нагрузки на видюху, либо я нихуя не понял.
2. Ван 2.2. 5B. Плюсы: 5-секундный видос с 24ФПС генерит за 2,5 минуты. Минусы: Прикл 2. Реализм он генерит ещё +- терпимо, но мне он нахуй не нужон Может есть какие-то тьюны или ЛОРы на 5В для анимы? Неужели я один такой нищук, с потребностью анимировать вайфочек? На ЦивитАИ нашёл аж 2 5В тьюна, но первый "автор запретил скачивать", а второй выдаёт 2 прикл.
Почему в этом кривом кале картинки появляются в абсолютно рандомных местах, в лоралоадере например просто из нихуя возникла картинка. и как её убрать абсолютно непонятно.
>>1436176 гугуфы в ване экономят память, но замедляют генерацию и сильно хуячат качество и мувмент. q8 многие говорят что даже чутка лучше чем fp8, включая авторитетных людей, но начиная с q6 деградация идет по геометрической прогрессии. смотри, чтобы ван 2.2 полноценно (с лоу и хай нойз моделями) влез тебе надо 64 оперативы. с твоим сетапом по идее сами модели влезают, но на генерацию уже нихуя не остается, в этом загвоздка. Я знаю что в таком случае многие юзают лоу нойз модель без хая и тогда все влезает. Я пробовал i2v лоунойз онли и этот опыт не увенчался успехом, движения рандомно "нарезаются" и сцвет может рандомно зашифтить. Возможно надо подобрать правильную lighx2v лору/смесь лор и их параметры, хз. А вот с fun vace моделью все пошло как по маслу, но если ее использовать для простого i2v то мувмент откровенно слабенький, что лично для меня не является проблемой так как все равно через контроль делаю. Хз короче, надо смотреть воркфлоу на лоунойз онли i2v модель, какие люди лоры и параметры ставят, пробовать.
> сами модели влезают, но на генерацию уже нихуя не остается Тока в обратном порядке. В видяху идет контекст, который генерируется, а «не влазят» модели, которые вытесняются в оперативку (и туда тоже не влазят=). Как вариант, можно взять ноды на очистку памяти и кэша, после каждой модели (после хай, после лоу), но тогда каждый цикл модель будет загружаться снова с диска, ето долгое.
> надо 64 оперативы А лучше 96, конечно. Вот там точно на диск ничего не будет лезть.
> 24 Врам > эта хуйня нагрела карту так > 5-секундный видос с 24ФПС генерит за 2,5 минуты
>>1436405 >У тебя там Tesla что ли? О_о YES Думаю кстати на что поменять. Какая-нибудь 4080 звучит заманчиво, но мне интересно не только генерить пикчи-видео, но и шатать текстовые модели, обучать лоры и т.д. Так что видимо 3090 мой вариант.
>сами модели влезают, но на генерацию уже нихуя не остается Добиваю файлом подкачки на 96 Гб. В целом норм, загрузка у меня с SSD идёт быстро, а саму генерацию это не должно замедлять. Насчёт нод, чистящих память тоже думал, т.к. оперативку забивает в 0 и больше ничего а компе не поделаешь, но вряд ли это ускорит генерацию, скорее наоборот.
>>1436516 Вот ни у кого другого, вроде бы ничего подобного не было. И я сам за два года ни разу подобного не встречал. А у тебя есть. Знаешь, что это значит? Что у меня плохие новости: с твоим железом или дровами что-то не так. Или броузер в котором запускаешь - сосет в поддержке актуальных стандартов.
Блядь. Это сюр нахуй. Локальный комфи обновляется чаще. Но выдает реконектинг ака аут оф мемори при использовании 16битного вана. А десктопный хрипит, скрипит но справляется. Как это заебло.