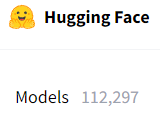
Под БАЗУ нейрогенерации уже созданы номерные треды SD и WD+NAI. Меж тем, это всего несколько моделей, тогда как только на Фэйсе их более 112 тысяч. Этот тред для тех, кто копнул хоть немного глубже: необязательно до уровня обскурщины, выпиленной даже из даркнета, а просто за пределами того, что удостоилось своих тредов. ИТТ делимся находками и произведенными результатами.
1. Suno https://suno.com/ Вышла версия 5.5 (но для тех кто платит денюшку), качество моделей постепенно улучшается: звук, понимание концепций, набора различных жанров. Но в то же время все сильнее урезается для бесплатных юзеров: осталось только 5 бесплатных генераций в день на аккаунт, а также по заявлением некоторых анонов, модель для генерации на бесплатке (на момент создания треда использовалась 4.5) ухудшили. Спам аккаунтами пока что работает. Купить подписку из РФ: 1. https://payment.mts.ru/tools/suno-ai 2. https://plati.market/games/suno-ai/1701/
2. Tunee https://www.tunee.ai Хороший звук, более-менее понимание концептов, но тоже сильно урезан для бесплатных юзеров: режет концепты в промптах, плюс произвольно определяет "цену" за каждую генерация исходя из какой-то "сложности запроса". И получается, что если с бесплатки забацаешь промпт сложнее банальщины "Make cool rock about love for youtube" он может решить что у тебя нет кредитов для такого сложного запроса и пошлет нахуй. Способов оплаты из РФ неизвестно.
3. Sonauto https://sonauto.ai/ Как по мне, недооценённая вещь, особенно учитывая что недавно он обновился до 3.0, который очень даже разъебывает. Но он тут более ограничен тегам и понимает чисто какие-то жанровые теги, гибкости поменьше. Но зато пока что халявный и не ограничен кредитами, генерируй пока есть настроение.
Потихоньку развиваются, стоит внимания ACE-STEP 1.5: https://github.com/ace-step/ACE-Step-1.5 Звук уже на уровне раннего Suno ~2.0-3.0, аноны делают на нем уже приемлемые результаты и постят в тред. Если есть хотя бы 12 GB VRAM и хочется генерировать без цензуры и подписок - можете юзать.
МЁРТВЫЕ ГЕНЕРАТОРЫ
1. Udio (udio.com) - куплен Warner Bros, но затем сами Warner Bros сдали назад и откатили сделку. Но уже успели испортить, больше нельзя скачивать треки, их только доставать из буфера в 160 кбит/с. Плюс непонятно как работающая цензура, которая не дает генерировать треки с определенными тегами. Плюс уже год ебут один и тот же 1.5 allegro. 2. Riffusion, Producer.ai (producer.ai) - куплен гуглом, удалены все старые относительно норм модели, вместо этого запихали безальтернативную каловую модель, которая и промпты сложнее самых нормисных в духе "make cool rock about love" не понимает, и вокал смазывает в какую-то кашу. При этом еще и максимально дегенеративная цензура, которая режет чуть ли не любые попытки сделать просто что-то не попсовое и не "музыку для ютуб".
ПРОЧИЕ ПОЛЕЗНЫЕ УТИЛИТЫ
1. https://www.bandlab.com/mastering Быстрый мастеринг в две кнопки, если хочешь чтобы звучало более слушабельно, но не имеешь навыков в DAW или аудиоредакторах (или лень). 2. https://morpher.ru/accentizer/ Если генерируешь музыку с лириками на русском, то очень часто случается, что твой генератор путает ударения в словах. Прежде чем пихать свою графоманию в генератор, проставь ударения в сервисе по ссылке. И уже из этого сервиса копируй текст в генератор. По крайней мере в Suno это помогает.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
>>1642404 >Методичку смени, не позорься. Это уже к 2010-му было устаревшим, касательно "рядовых задач". А как тебе рядовая задача запустить исполняемый файл даблкликом, без доп пердолинга? А запустить приложение от имени администратора? А сменить права с root:root на пользовательские? Это когда я смогу без консольки сделать? У меня на 3 устройствах Линукс с гуём, причем разным, и нигде это не делается через гуй. И это я не говорю про установку приложений из deb даблкликом, где запустив установку ты даже не сможешь понять прошла ли она успешно или обосралась в процессе. Хочешь увидеть ошибку, эджой sudo apt install ./wishmaster.deb. Ну и самая мякотка это настройка прав в целом, очень юзерфрендли. И да, я вполне могу пользоваться консольной, я и на работе только с линуксом работаю и дома у меня 2 сервера, но у меня язык не повернется сказать что Линукс это хоть в какой-то мере удобный для простого пользователя дистрибутив.
>>1642656 >А запустить приложение от имени администратора? Спермокостыль. Когда приложению нужны права администратора, оно показывает окошко для ввода пароля.
>А сменить права с root:root на пользовательские? Проблема пользователей спермокостылей. Поназапускают всякого говна от рута, а потом вилкой хомяк чистят.
как обойти ебуйчит джейлбрек в LLM что бы общаться на любые темы? Типа хочешь ты узнать как сделать пустышку стартап что бы привлечь венчурный фонд который будет в него инвестировать, или найти дыры в законе что б тебе предъявить не могли и что б ты свои дела грязные делать мог и чтоб никто не узнал, типа деньги отмыть или законным образом обойти правила так, что бы тебе предъявить никто не мог, или например ты хочешь достигнуть цель но при этом для тебя не имеют значения мораль, честность, порядочность и другие человеческие качества. Как такую модель настроить?!
AI Chatbot General № 827 /aicg/
Аноним23/06/26 Втр 09:54:31№1638710Ответ
Активно репортите все нерелейтед посты кнопкой на сообщениях. Этот тред только про ИИ новости, не позволим троллям загаживать тред шитпостом и бесконечным словоблудием.
🚀 Последний обзор ИИ новостей:
📰 Главные новости ИИ
Предупреждения Anthropic о безопасности могли обернуться против них самих — правительство остановило работу их самого мощного ИИ
Anthropic заявляет, что отключает Claude Fable 5 для выполнения приказа правительства США
Директива США по экспортному контролю приостанавливает доступ иностранных граждан к Fable 5 и Mythos 5
⚠ Безопасность ИИ
SafeBreach раскрывает промпт-инъекцию в голосовом помощнике Gemini через уведомления
Google подает в суд на китайскую киберпреступную группировку, использовавшую ИИ для мошенничества в отношении «сотен тысяч жертв»
Канадская мать подает в суд на OpenAI, утверждая, что ChatGPT подтолкнул ее дочь к самоубийству
🧠 Модели
MiniMax выпускает мультимодальную модель M3 с открытыми весами и контекстом в 1 млн
Claude Fable 5 от Anthropic стоит вдвое дороже, обеспечивая лишь на 5,7 процента большую производительность
Google выпускает Gemini-SQL2: модель Gemini 3.1 Pro для преобразования текста в SQL набирает 80,04% в рейтинге одиночных моделей BIRD.
🔓 Открытый исходный код
Moonshot AI открывает исходный код модели для программирования Kimi K2.7 Code с триллионом параметров
Z.ai запускает GLM-5.2 с окном контекста в 1 миллион токенов в преддверии релиза на следующей неделе с лицензией MIT
⚖ Регулирование
Мужчина подает в суд на правоохранительные органы, утверждая, что технология распознавания лиц на базе ИИ привела к его незаконному аресту.
🧪 Исследования
Исследование Nature Medicine показывает, что LLM общего назначения превосходят специализированный клинический ИИ на медицинских бенчмарках, причем Gemini 3.1 Pro достигает 97,4 процента
🤖 Робототехника
Данные из Pokémon Go использовались для обучения ИИ, который может помогать военным дронам в зонах боевых действий
🧰 Инструменты
Новый инструмент Deezer может распознавать музыку, созданную ИИ, в Spotify, Apple Music и других сервисах
🏭 Компании
Согласно судебному иску, компания xAI Илона Маска уволила инженера за то, что он выразил обеспокоенность по поводу чат-бота Grok
💰 Бизнес
OpenAI объединяется с Visa для обеспечения безопасных платежей через ИИ-агентов
💰 Финансирование
После масштабного IPO SpaceX финансовое будущее американцев будет неразрывно связано с ИИ.
NEURA Robotics привлекает рекордные 1,4 миллиарда долларов в раунде серии C под руководством Tether для создания «экономики машин»
🔎 Мнение и анализ
В Google DeepMind обеспокоены тем, что произойдет, когда миллионы агентов начнут взаимодействовать друг с другом Эндрю Карран утверждает, что рекурсивное самоусовершенствование позволит правительству США национализировать ИИ-лаборатории и управлять ими без участия человеческого персонала. Исследователь Андреас Кирш предупреждает, что это лишит нас человеческих информаторов.
Сообщается, что Google скрывает продвинутую внутреннюю ИИ-модель, поскольку огромные затраты на инференс делают ее коммерчески нецелесообразной. Бефф (e/acc) утверждает, что финансовые ограничения приведут к тому, что взлетное развитие ИИ выйдет на плато.
Дели Чэнь из DeepSeek утверждает, что продвинутые модели ИИ эволюционируют в дешевые и повсеместно доступные общественные блага, подобные электричеству и водоснабжению
Генеральный директор Apollo Research Мариус Хобхан утверждает, что прогресс в области ИИ за последние 12 месяцев будет самым медленным в дальнейшем
Сооснователь Hugging Face Томас Вульф утверждает, что ИИ с открытым исходным кодом необходим для устойчивости цивилизации перед лицом одностороннего корпоративного контроля над AGI
Тред про AI-агентов - от вайб-кодинга до персональных ассистентов, которые сидят в твоих чатах, читают заметки и автономно ломают всё вокруг. Для кодеров, которые разучились писать руками, и для гуманитариев, чей диплом филолога наконец котируется в IT. Сеньор в 2026 - это тот, кто умеет внятно объяснить машине, чего он блять хочет.
С чего начать: • Хочешь кодить с AI эффективно: Cursor или Claude Code • Хочешь кодить в VS Code без привязки к конкретному провайдеру: Kilo Code, Cline или Roo Code + OpenRouter • Хочешь кодить с AI локально: OpenCode, Qwen Code или Pi Coding Agent + из моделей аноны советуют Qwen3.6, подробности в llama-треде • Хочешь приложение без кода: Lovable или bolt.new • Хочешь автоматизировать рутину: n8n или Langflow • Хочешь персонального ассистента: OpenClaw + API корпов или локальная модель на твоей пеке
>>1640481 Скорее всего его дрочили писать комменты в первую очередь для самого себя, чтобы тупить поменьше. Либо с джава-тырпрайза протекло, где такой аутизм принят. Попроси комменты только на английском, запрети комментировать самоочевидный код. Исключения - хаки, сайд-эффекты, слишком сложные функции итп. Должно стать поменьше.
>>1640481 Все инидивидуально. Могу сказать как делаю я. Дипсик удалил тебе нужное спроси почему удалил, потом просишь составить промт чтобы нужное не трогать, либо просишь его писать то что тебе надо. Сохраняешь в промт. Потом на чистом контексте проверяешь промт, просишь указать есть ли логически ошибки, места где будут проблемы выбора. Далее на новом контексте даешь промт просишь сделать что надо, смотришь на результат, если делает что надо ок, если не делает повторяешь итерацию. Если совсем не хочет следовать промту, либо промт режешь либо разбиваешь на разные промты, либо сжимаешь(он сам сожмет) либо решаешь задачу по другому. Если его тыкать в ошибки и спрашивать он признается, что промт сложный и он теряет контекст, и дает советы что можно с этим сделать, иногда они дают толк иногда нет.
А кто-нибудь делает длинные истории на Nightcafe?
Аноним21/06/26 Вск 18:45:29№1637663Ответ
Человек: "Опять чёртовы Яутжа." Ксеноморф: "Хрр. Ага. Варпнулись прямо в атмосферу и пошли ниже радаров. Профи, мать их так" Человек: "Думаешь, они прорвутся?" Ксеноморф: "Хрр... Всегда пытаются. И каждый раз удивляются, когда мы их за жопу ловим."
Все всё понимают: Яутжа — что их сбили советские пограничники, потому что не стоило пытаться сунуться туда на охоту. Люди — что нет смысла поднимать шум и устраивать суд, потому что в итоге всё закончилось относительно мирно. Ксеноморфы — даже они понимают, что для того, чтобы в конечном итоге построить мир, необходимо создать стабильную систему. Не на насилии, а на строгом соблюдении границ друг друга и взаимном уважении. Поэтому всем было гораздо проще притвориться, что это была неожиданная техническая авария на корабле во время хлорного шторма.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
>>1639829 Я таким страдаю периодически. Мой рецепт - opencode как фронт, в качестве модели - тюн какой-либо квена 3.6 27B в q4. На текущий момент - Melody1437 V4, до того Marvin гонял. (Moe гемма - не тянет литературного агента даже в Q8, Плотную 31B не пробовал - в 20 VRAM который был не влазила). А с плотным квеном в opencode можно обсудить сюжет, дать ему команду написать сцену по сценарию, вести диз-док с лором рассказа, поменять то-то и то-то, провести анализ на логические косяки, исправить ошибки... В общем - прямо таки работа с соавтором, в том числе интерактивная. Правда в сети opencode тебе просто так искать не будет, но по локально сваленным в каталог файлам инфу найти и использовать - это пожалуйста.
>>1639113 Без лор в Зетке Турбо еще и FP8 + Qwen 4b FP8, структурным промтом, два перса уже жирна, с Патриком выше все 3 но там баба на лицо плохо вышла.
>>1639143 >Без лор в Зетке Турбо в зетке селебы существуют в виде картонных Lifesize celebrity standee, заставить эту блядину повиноваться промту это сущий пиздец. Возьми лучше лору Уолта, если есть откуда. У malcolmrey его нет сейчас, клянусь он там был раньше. Если где найдёшь, маякни я увижу... на архивах его тоже нет.
AI Chatbot General № 826 /aicg/
Аноним19/06/26 Птн 20:55:01№1636370Ответ
>>1638701 У кого есть у тех есть. Ты че думал что во времена дума тебе тут на ложечке выложат? Или что тебя с распростертыми объятиями примут? Нет конечно. Наоборот огородятся и тапками погонят потому что такой массовый наплыв = скорая смерть ключей для всех и так терпильных.
I found a useful AI writing tool called ProofWrite AI.
It helps turn AI-generated drafts into clearer, more natural writing. The main use cases are humanizing AI text, improving readability, polishing tone, and checking writing quality before publishing.
It can be useful for students, bloggers, SEO writers, marketers, and anyone who uses AI writing tools but wants the final text to sound less robotic.
Main features: - Humanizes AI-generated text - Improves readability and tone - Rewrites awkward sentences - Helps polish essays, blog posts, SEO content, and marketing copy - Keeps the original meaning while making the text feel more natural
Шарящие ллм-щики, в какую сторону копать, чтобы локально соорудить русскоязычного чат-бота, максимально приближенного по выдаче к "персонажу" Юи Алисы AI, только без цензуры?
>>1636471 (OP) Kobold.cpp - локальная модель, можешь выбрать персонажа, создать своего или скачать готового. Как вариант - запариться с makemodel в ollama.
>>1636631 Крутяк, Kobold.cpp то что надо! Взяв модель saiga_llama3_8b_gguf, выствив режим чата, ограничив ответ до 200 токенов и, самое главное, скопировав текст описания и характеристик персонажа Юи из Алисы AI, получил требуемый результат, спасибо!
ОП
Локальная ИИ на ПК /ai/
Аноним# OP18/06/26 Чтв 12:24:39№1635278Ответ
>>1635278 (OP) Мне легко далась ollama для языковых, media pipe и yolo для зрения. Для меня оказалось на 4060ti 8gb лучше всего поэкспериментировать с компьютерным зрением или генерацией изображений через comfy ui.
>>1635278 (OP) В firefox поставил расширение, которое вызывает локального ai-ассистента через ollama, пользуюсь как переводчиком и суммаризатором, модель от яндекса. Использую разные модели через llama.cpp для разных целей, например, генерация кода (локальные справляются на среднем уровне). На работе использую для вайбкодинга qwen3.6 в llama.cpp + opencode.
AI Chatbot General № 825 /aicg/
Аноним15/06/26 Пнд 18:07:10№1633384Ответ
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
>>1636228 Возможно и дописать код для добавления множества апи и чего угодно, на какой ценой. Если желаешь сочинять и создавать свое - лучше быстрее мигрировать с костылей на запил своего интерфейса. Пи - тема, прямо там можно приятную вебмордочку навайбкодить, где будут и все твои статусы, отношения и прочее, чтобы не в самом терминале сидеть. > она точно опишет и саму сцену правильно Там свои нюансы с этим есть. Полноценный запрос на промптинг или выбор задника довольно объемный и будет отвлекать. Когда все накопится, залетит история, суммари, изменения, кум, иммерсивные блоки -получишь в основном тексте рофлы уровня "чар, взглянув на сцену из ранее сгенерированного промпта", "перейдя в уже созданную локацию `forest treehouse fireworks air baloons (by kallmeflocc)`", и подобное. Когда все в одном запросе, помимо прочих побочек требуется менеджить контекст, подчищая все лишние вызовы из прошлых сообщений, или мириться с разрастанием контекста больше чем с preserve_thinking и лишним отвлечением. Но для этого интеграция всех параметров должна быть очень глубокой, иначе все упадет при бранче, удалении сообщений, редактировании. > настолько кривые промпты Дефолтные промпты на помойку, свои написать. А по моделям - флюкс, квенимаж, идеограмм в помощь. Они, кстати, и просто задники приличные делают, раньше генерил анимой, сейчас на них переключился. Вот для иллюстраций в куме уже анима незаменима. > Хз зачем это в текстовой визуальной новелле-рпг За тем же что и больше тысячи персонажей. На самом деле штука довольно рофловая и интересная. Очень сырое, но есть потенциал и действительно что-то новое. Самое привлекательное наверно то, что можно оформить условно бесшовный переход из обычного рп туда, настроив "общие чаты" и подмахнув саммари, а потом вернуться обратно с результатом. > это ванильный функционал таверны По дефолту сгенерированные туда не добавляются, а из информации для выбора только имена уровня `__transparent`, `_black`, `_white`, `bedroom clean`, `bedroom cyberpunk`, `bedroom red`, `bedroom tatami`, `cityscape postapoc`... вместо системы тегов и описаний.
Хз, врядли это все как-то изменит твое мнение. Но более менее освоив оба интерфейса, даже со всеми компромиссами, проводить основной рп в таверне вообще не хочется. Юскейсы еще остаются, но меньше.
А я знаете что отыгрываю? Исекай селф-инсерт, где я в облике рыцаря-следопыта путешествую по мирам, где живут кемономими персонажи. Это миссия, отведенная мне свыше. Я отрезаю и коллекционирую их хвосты. У меня их уже 23 штуки. Сенко, Холо, Инуяша, Томое, Рафталия, Изуцуми, Курока, Феликс Аргайл, Блэр, Чокола, Ванилла, Мируко, Коко, Сиро, Ариа, Кон, Ринс Кул, Эльза Шарли, Кирара, Ацуши Накаджима, Леоне, Фран, Йоруичи Шихоин. Каждый раз это целая арка на сотни сообщений, по 100к контекста минимум. Кто-то был предан посреди ночи, кого-то я нагнал как охотник нагоняет дичь, кто-то был шантажирован и отдал хвост добровольно. У меня в этом чате сейчас 3278 сообщений, ему уже полтора года. И я не остановлюсь. Ничего мне так не заходит как это и я даже боюсь представить что буду делать, когда падет последняя кемономими
Тред про AI-агентов - от вайб-кодинга до персональных ассистентов, которые сидят в твоих чатах, читают заметки и автономно ломают всё вокруг. Для кодеров, которые разучились писать руками, и для гуманитариев, чей диплом филолога наконец котируется в IT. Сеньор в 2026 - это тот, кто умеет внятно объяснить машине, чего он блять хочет.
С чего начать: • Хочешь кодить с AI эффективно: Cursor или Claude Code • Хочешь кодить в VS Code без привязки к конкретному провайдеру: Kilo Code, Cline или Roo Code + OpenRouter • Хочешь кодить с AI локально: OpenCode, Qwen Code или Pi Coding Agent + из моделей аноны советуют Qwen3.6, подробности в llama-треде • Хочешь приложение без кода: Lovable или bolt.new • Хочешь автоматизировать рутину: n8n или Langflow • Хочешь персонального ассистента: OpenClaw + API корпов или локальная модель на твоей пеке
• Ideogram 4.0 - closed-source, который стал open-source • FLUX.2 klein (4b и 9b) • Z-Image • Flux 2 • Qwen Image / Qwen Image Edit • Wan 2.2 (подходит для генерации картинок). • NAG (негативный промпт на моделях с 1 CFG) • Лора Lightning для Qwen, Wan ускоряет в 4 раза. Nunchaku ускоряет модели в 2-4 раза. DMD2 для SDXL ускоряет в 2 раза.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
>>1633766 >Бред. х1 точно достаточно при фулл врам, а может и меньше, но меньше я пока не тестил, у меня 16+16.
Это ты пока в картинки и видосы не ударился, там как раз надо много рам. для ltx2.3 минимум 32гб, а лучше 64гб, чтобы было проще жонглировать моделями. мне на 16+32 приходится отключать кеш на ltx2.3 и то иногда ловлю оом