Оффлайн модели для картинок: Stable Diffusion, Flux, Wan-Video (да), Auraflow, HunyuanDiT, Lumina, Kolors, Deepseek Janus-Pro, Sana Оффлайн модели для анимации: Wan-Video, HunyuanVideo, Lightrics (LTXV), Mochi, Nvidia Cosmos, PyramidFlow, CogVideo, AnimateDiff, Stable Video Diffusion Приложения: ComfyUI и остальные (Fooocus, webui-forge, InvokeAI)
>>1405146 (OP) Аноны, почему вы генерируете кал? Почему во времена 1.5 было меньше кала, даже не смотря на абсолютный бред на пикчах? Я считаю что в плане креатива полтораха до сих пор даёт пососать всем моделям что вышли позже. Да тёлки стали фотореалистичнее, кожа перестала быть пластиковой, да пальцев стало меньше 6 и больше 4, а двоепиздие пропало, но все пикчи - словно под копирку, ебаный фотореализьм, ван стендинг херл, никакой блядь изюминки, никакого блядь креатива. ЫЫ тёлка ыы смотрит каменным лицом в нихуя ыыы. Никакие хромы, никакие флюсы-хуюсы не смогут нарисовать: кошкодевка-вампир-суккуб с чёрными крыльями и шапкой из кала сидит на мотоцикле из костей своего бывшего, гонится за дартом вейдером в открытом космосе, сжимая в руке его гуся, едет по дороге из сказочного сада, усыпанного лепестками роз и трупами рептилоидов, из колёс её мотоцикла вырывается пламя, которое поджаривает пукан космической флотилии что преследует её.
>>1405302 Из небольшого личного опыта с Qwen (+Wan или +SeedVR2 upscale) могу предположить, что это связано с тем, что описанные тобой типовые генерации получаются сносно, а что-то за их пределами получается говняком. По крайней мере у меня так. Где-то полтора года назад играл в Automatic. Результаты не удовлетворили, забросил. Сейчас решил посмотреть что изменилось, освоил ComfyUI, изучил manual от корки до корки, разобрался с чужими workflows типа Qwen all-in-one, начал их редактировать, затем потихоньку начал лепить свои по их подобию. В результате, когда хочешь что-то с комбинацией ControlNet для поз и глубины (Qwen > Wan; Qwen > SeedVR2) получаются тормоза, дикий жор VRAM и дерьмовое качество. LoRAs, пляски с бубнами на изменение strength и start/end ControlNet, workflow в два прохода: Qwen T2I + Openpose/Depth > чистовой Qwen I2I > SeedVR2 uspcale (для детализации) помогают, но не радикально, и при этом требуют ещё больше возни. Спустя полтора года, сдвиги вижу, но всё ещё пока разочарован.
Аноны, помогите пожалуйста. Генерю второй день 2 года назад генерил на 1.5 моделях в автоматике.
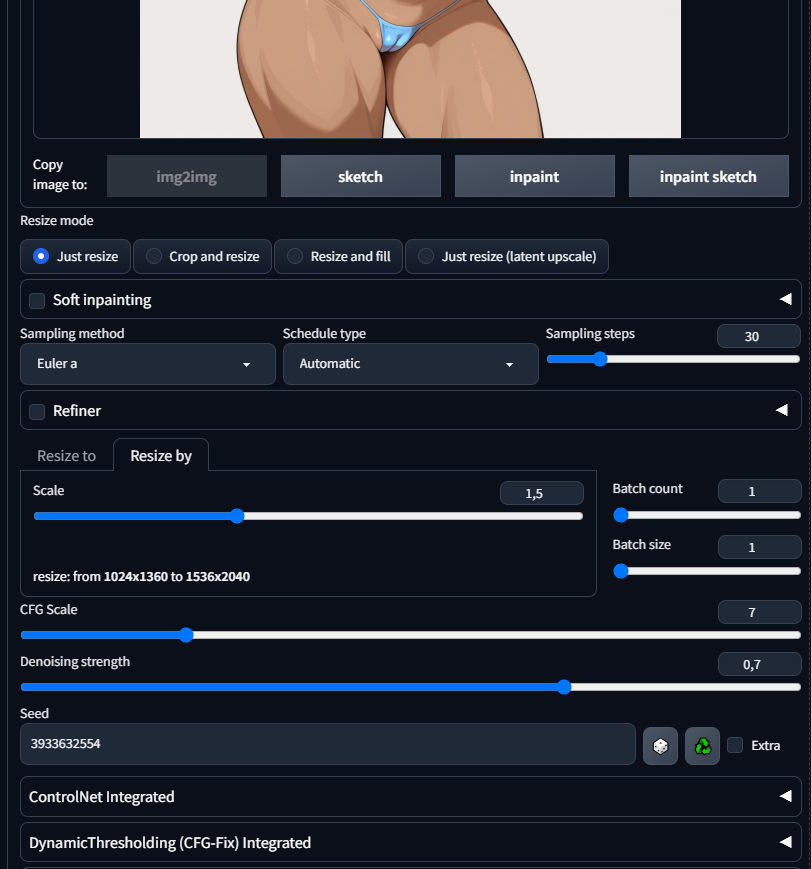
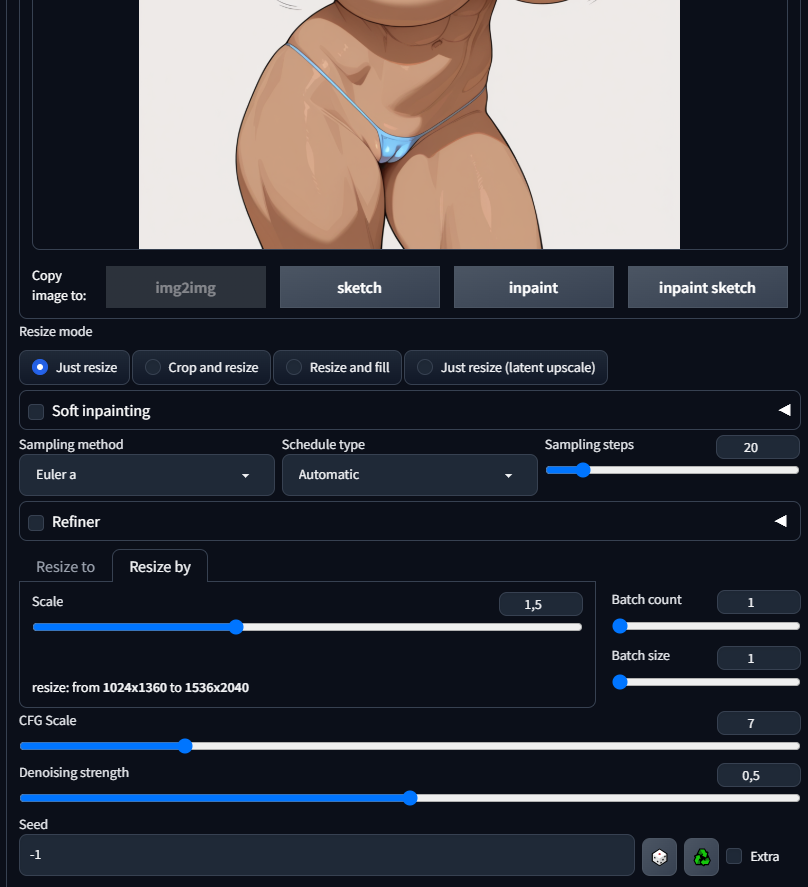
Суть в чем, загенерил первую картинку txt2img, она меня устраивает но хотел чтобы ещё она показывала знак v вот этот. Добавил в промпт v_sign. Получилась вторая картинка. Но теперь она не играла рукой с бикини, пытался через промпт поправить, не получалось, поэтому плюнул,в графическом редакторе наложил друг на друга изображения, подтер где надо грубо, линию бикини кистью провел - получился пик 3, закинул в img2img с промптом второй картинки и получил пик 4 который меня устраивает. Вопрос в чем. Когда генеришь txt2img можно hiresfix использовать и он типа работает сразу на стадии генерации, более качественный хайрез получается. В img2img есть такой же hires fix или нет? Как сделать пиздатый хайрез картинки полученной в img2img или он всегда будет проигрывать hiresfix в txt2img?
Надеюсь понятно написал, если тупо как-то написано не серчайте.
>>1405339 Если у тебя хайрезфикс через латент - то никак. Если ты с моделью хайрезфиксишь - то хайрезфикс ничем не отличается от апскейла во вкладке img2img.
>>1405339 Вкладка img2img использует ровно такой же хайрезфикс, там только апскейлер отличаться может, потому что он отдельно выбирается в настройках. Если ты конечно не на комфи сидишь, где хуй знает как все работает. А во всяких автоматиках и форжах нет никакой разницы между хайрезом при генерации и апскейлом в img2img.
Другое дело - это апскейл во вкладке extras. Вот там уже более простая система, которая просто растягивает пик и сглаживает. Качества не добавляет, зато можно растянуть в четыре раза без особого напряга видюхи.
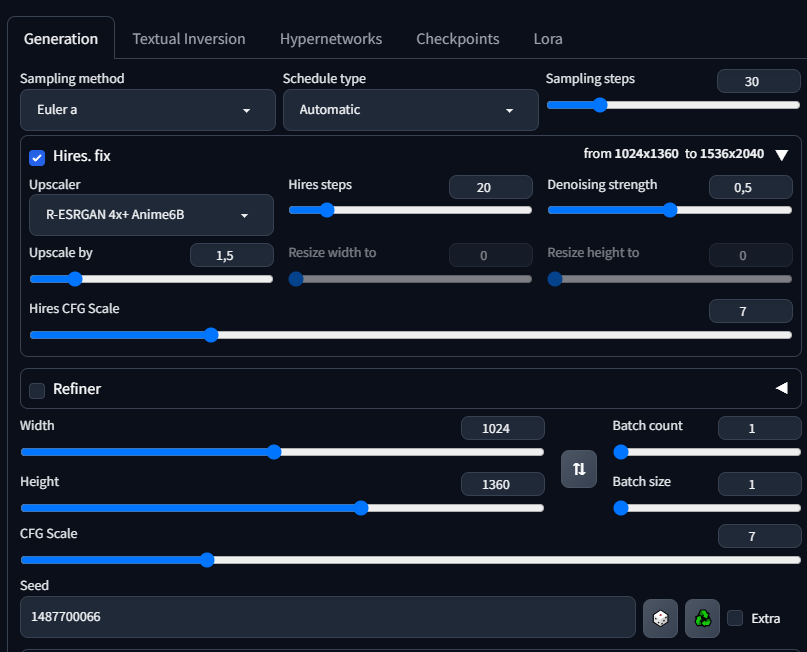
>>1405341 Сорян если вопрос тупой - но где вкладка на хайрез в Img2img? Рефайнер есть. Сейчас делаю хайрез через R-ESRGAN 4x+ Anime6B в txt2img. Я конечно могу просто поставить в Img2img resize 1,5 и количество шагов, но где выбрать саму модель R-ESRGAN 4x+ Anime6B?
>>1405360 Без разницы, апскейлу сид изначальной картинки не важен, он все равно в других условиях работает. Этот сид нужен только для того, чтоб ты мог повторно такой же апскейл этой картинки сделать с идентичным результатом.
Нужна помощь от знатоков. Какие модели можно использовать для локальной генерации nswf видео и сколько ресурсов железа желательно для этого иметь? Если кормить подомные модели первым кадром для необходимого видоса, будет ли конечный результат сильно меняться к последнему кадру? Ну условно есть ли модели которые к 10 секунде генерации не меняют цвета/формы/геометрию обьектов?
>>1405384 Генерить и тренить - разные вещи. Генерить можно на любом говне, но без тренинга любая модель будет отклоняться с каждым фреймом. Тренить даже на 24гб видюхе сложно - можно арендовать облачную побольше, но для этого лучше хоть как-то сначала научиться на своей, так что все-таки 24 крайне желательно. 2 видюхи по 24 не складывают свой врам, но позволяют запускать параллельно 2 процесса, которые влезли бы в одну.
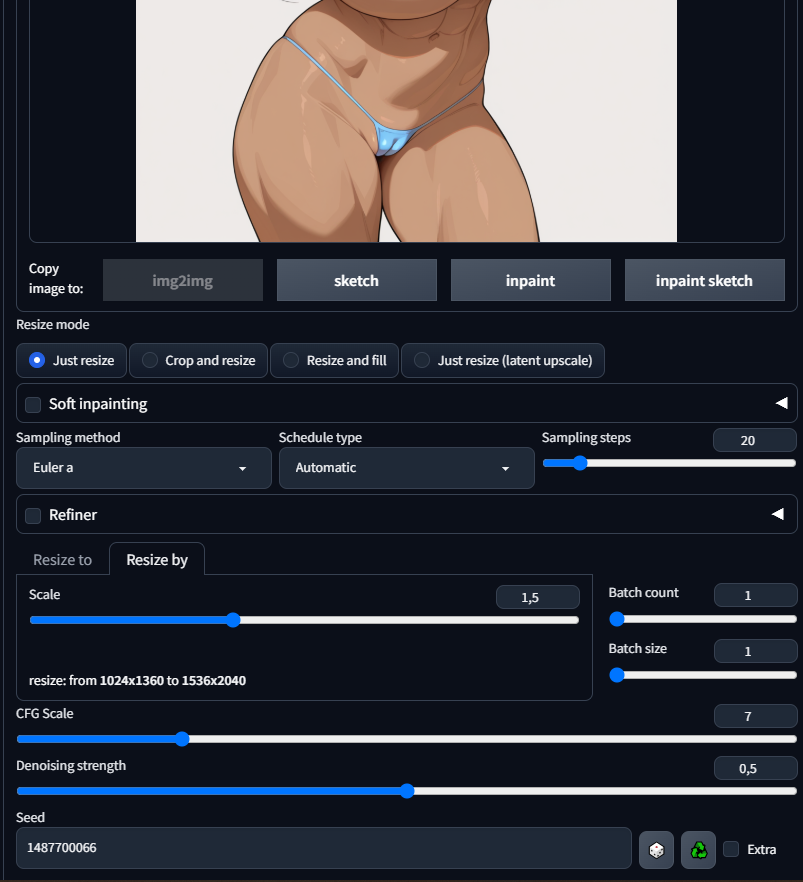
>>1405347 >>1405362 Короче хуй знает, первый пик хайрез с txt2img второй с img2img. Модель хайреза одна и та же R-ESRGAN 4x+ Anime6B, все параметры одинаковые количество шагов и все такое. Сид был одинаковый. Единственное что конечно может быть что сид в txt2img влияет только на картинку до апскейла, а когда начинается апскейл применяется другое значение сида, но этого не может быть потому что повторяемость есть, сколько раз делал апскейл при одних и тех же параметрах в txt2img картинка абсолютно идентичная на выходе с апскейлом. Тут же отличие видно, и при таком же сиде как и в txt2img если его перебить в Img2img (пик2), так и при рандомном сиде (что само собой разумеется (пик3), при чем на обоих пиках апскейла через img2img - пальцы получились хуже как видите.
>>1405416 Я имел в виду только то, что там одинаковая система используется, так что в плане качества они одинаковы, нет чего-то лучше или хуже. То что там могут быть некие подкапотные различия в пару байтов информации, которые не позволяют сделать буквально попиксельно идентичные пикчи - ну это вполне возможно. Пальцы в данном случае это просто рандом, они в любых условиях могут проебаться случайно, я никаких закономерностей не видел, чтоб хайрез всегда делал их хорошо, а имг2имг постоянно ломал. Если для тебя важны идеальные пальцы, то привыкай в инпеинте их поправлять после апскейла.
>>1405416 Вот параметры чтобы было понятно пик 1 хайрез в txt2img пик 2 хайрез img2img c тем же сидом что и в txt2img пик 3 хайрез img2img с рандом сидом (но он понятное дело будет отличаться, не знаю нахуя я его сюда добавляю)
В img2img хайрез делал из картинки которая получается по всем вводным данным без хайреза само собой. Кто-ниюудь объяснит мне долбоебу почему так?
>>1405429 Денойз у тебя слишком высокий, по-моему. Хватило бы в районе 0.3-0.4. Меньше денойза - меньше отличий будет. Это не конкретно по твоему вопросу, а в целом.
>>1405438 Слушай ну увеличиваю в полтора раза изображение, т.е. на 50%, 0,3-0,4 мало на мой взгляд, смазанно будет. Хотя на аниме артах ещё пойдет но на другом будет мыло. Я хоть на новых моделей всего 2 дня генерю по прошлому опыту композиция существенно не меняется вплоть до 0,7 денойза, потом уже да.
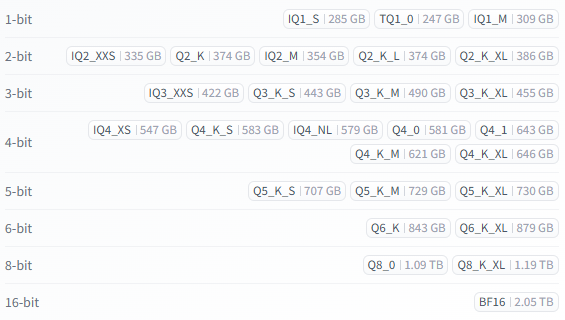
Слоп? Конечно слоп. Но тем не менее. Кто-то мне говорил что на 4070 квен будет больно? да, немного больно Юзаю лору на 4 шага, картинка выпекается за 35-40 сек. Собсна вопрос такой: есть лоры для nsfw на квен хорошие? они точно не будут использоваться относительно пирелейтедов. Нужно ли обращать внимание на совместимость lightning лор и прочих лор? Есть ещё вариант ускорить эту машинку? Пока сижу на qwen-image-Q5_0. Извините если несвязно пишу, немного в эйфории от всей этой темы.
>Извините если несвязно пишу, немного в эйфории от всей этой темы.
Главное, не особо разочаровывайся (как я), когда будешь пытаться делать что-то отличающееся от стандартного сценария использования и получать неудовлетворительные результаты.
>есть лоры для nsfw на квен хорошие?
За LoRAми тебе на Civitai. Пробуй разные и решай насколько они тебя устроят (например QwenSnofs).
>Нужно ли обращать внимание на совместимость lightning лор и прочих лор
Методом проб и ошибок по результатам генерации. (QwenSnofs с лайтнингом на 8 шагов проверено).
>>1405784 > за час - другой на 12 гб тренится персонаж 200 шагов или сколько? 7 часов для норм трена на 5090 и это только половина, 7ч на хай, 7ч на лоу
>>1405795 >7ч на хай, 7ч на лоу 2.2 я ещё не пробовал, треню на 2.1 >200 шагов или сколько? 500-1000. я только на фотках тренирую, c максимумом в 512x512, этого обычно достаточно для получения требуемого персонажа. а вот тренировка на видосах сжирает все ресурсы и уходит в своп. то есть каким-то новым действиям, например взрыву башки обучить лору мне уже не выйдет.
>>1405802 обычные промпты для qwen image edit: turn this anime picture to white 3d wireframe view, change background color to black и turn to draft 3d render, totally white surfaces
>>1405811 >Reforge хз, последний раз где-то год назад юзал его. посмотри на гитхабе reforge описание того что он умеет. там же есть ссылки на форки reforge, в которые новые фишки накидывают. >как будто в пэйнте ну почти так и есть)
>>1405302 Здесь давно остались одни продрочившие мозги кумеры, все нормальные люди свалили, утомившись смотреть на однообразных врсатых блядей, которыми кумеры вайпают каждый тред.
бляяааать, гуфф - говно. чат жпт меня наебал, говорил что квантизацию более лудше чем фп8, хуй там! квен имаге, гуфф качество хуже и 51 секунда, фп8 36 секунд
>>1406296 >минимальное железо что-то типа rtx 3060 с 12 гигами, быстрый ssd и 32 гб системной оперативки. видеокарту можно и 8-гиговую, главное чтобы системной памяти было побольше, в идеале 64 гига.
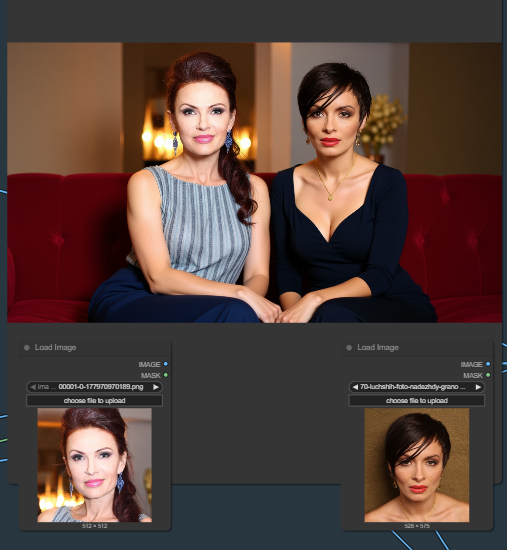
Почему обоссаные Флакс Контекст и Квен полностью перерисовывают персонажей? Допустим я гружу им 2 изображения с людьми и третье с диваном. Пишу типа: 2 этих человека сидят на этом диване (ну только красиво стеной текста и про сохранение консистентности 3 строчки). На выходе диван более-менее тот же, люди просто полностью перерисованное левое говно.
Какого хуя блять? Я думал фишка этих моделей в том, что они типа с выданным контекстом работают, а не придумывают хуиту.
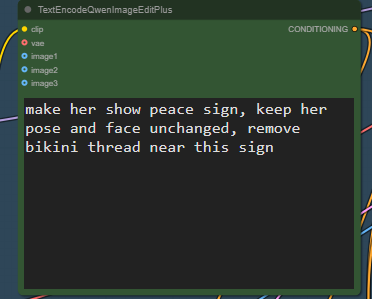
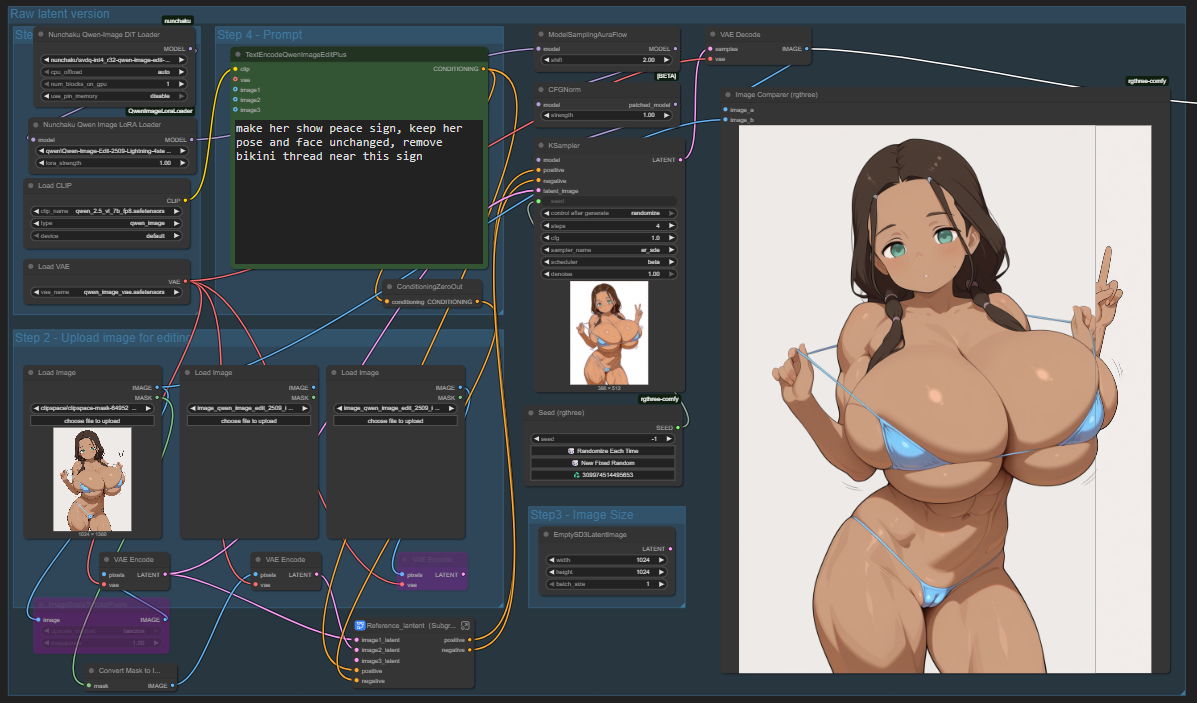
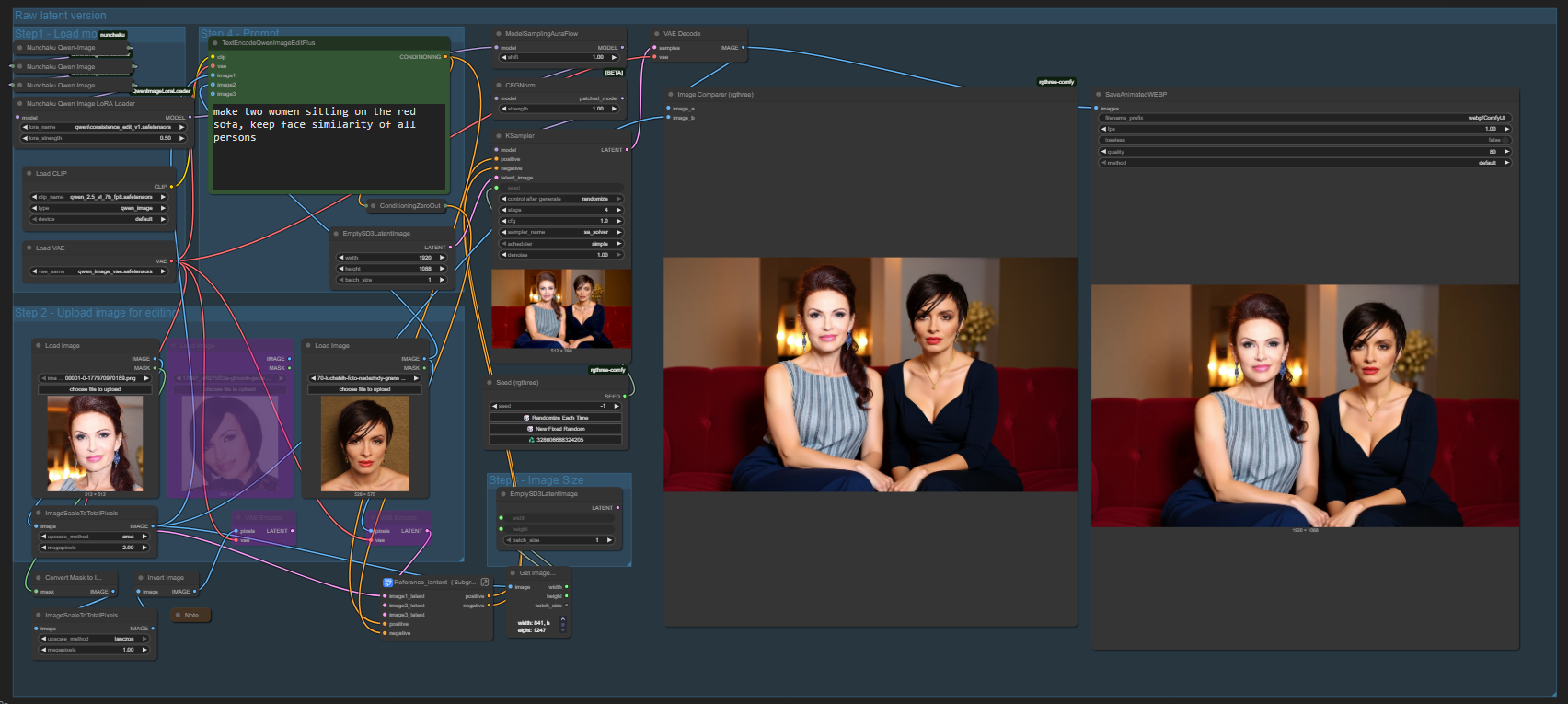
>>1406316 используй qwen-edit-2509 воркфлоу из последнего обновления комфи. сделай активной группу raw latent version и попробуй ещё лору consistence-edit
>>1406316 бля, про диван забыл. а в общем качество там заметно гуляет, надо ковырять настройки. >>1406373 >этот ебучий пластик даже у подростков вызывает кринж спасибо, капитан подросток очевидность. если постоянно повторять про пластик, то китайцы увидят твои посты и всё починят. а я думаю, хули ты доебываешься до качества бесплатной нейросети? очевидно что её такой выложили чтобы не создавать конкуренцию своим премиальным версиям продукта в онлайне. и погляди ещё на досуге что генерировали в конце 2022 года, потом постарайся не помереть от этого своего "кринжа".
>>1406391 >бля, про диван забыл. а в общем качество там заметно гуляет, надо ковырять настройки. Можешь скинуть свой воркфлоу? Там вроде можно как-то ж-соном экспортировать/импортировать. У меня пока просто поебота какая-то...
Qwen-Image-ControlNet-Union переполняет видеокарту. Что делать? При том что видюха у меня в облаке, L4 c 24Gb Vram. Нунчаку модель у меня не завелась, использую самую обычную Qwen Image Edit 2905. Главное, без контролнета все отлично работает, ни единого вылета. Пробовал лору-ускорялку отключать, не помогает.
Может, есть какой-нибудь другой контролнет, не прожорливый к памяти и стабильный?
>>1406472 Вот именно что не за чем, это генерация без depth карты. Хочу брать своих персонажей и ставить в разные позы с помощью depth карты из 3д-редактора. Без контролнета хуево. Можно скармливать квену картинки с позами, конечно, но он позы хуево понимает и слишком фантазирует. Один раз я даже напрямую попросил: use the depth map from second image. Что забавно, он это понял и сделал. Но как контролнет с силой 1, уродство.
>>1406521 >если памяти это жрет меньше чем ControlNet Union жрет столько же сколько обычный qwen-edit, просто второй картинкой на вход подавай dwpose пикчу
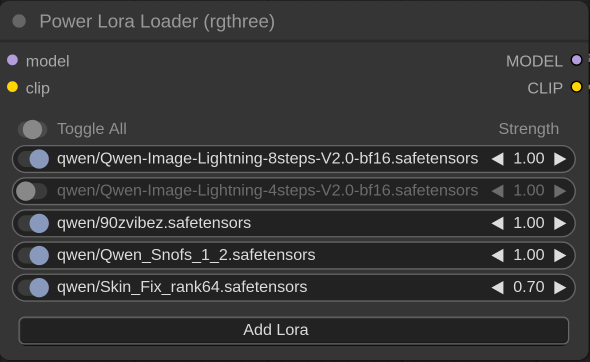
Анон, у тебя все LoRAs работают с этим загрузчиком? Связался с nunchaku, похоже, напрасно. Прирост в скорости генерации появляется у меня только на горячем запуске. Но суть не в этом. Часть LoRAs работает, а часть нет. Никаких сообщений об ошибках нет, просто не видно следов работы LoRAs. Пример, их родные svdq-int4_r128-qwen-image-lightningv1.1-8steps.safetensors не работают, а неродные Qwen-Image-Lightning-8steps-V2.0.safetensors работают и результат их работы виден, за 8 шагов генерируется изображение. Некоторые другие LoRAs ведут себя точно так же. Без каких-либо сообщениях об ошибке могут влиять или не влиять на генерацию. Strength не влияет. Не сталкивался с таким?
>>1406578 иногда некоторые лоры "зависают" и смена на другую ничем не помогает. это баг данного расширения. выбирай те лоры с которыми изначально работать будешь и перезапусти comfy. автор расширения не nunchaku а другой человек https://github.com/ussoewwin/ComfyUI-QwenImageLoraLoader
>>1406659 Хе-хе, как раз проебал. Попробовал APOB (хуй знает че там за модели) - он тупо с первой попытки понимает промпт в 3 слова для редактирования пикчей и контекстного преобразования нескольких изображений. Еще и NSFW нормально выдает, в отличии от говноГрока. Еще и апскейл ебейший сделал.
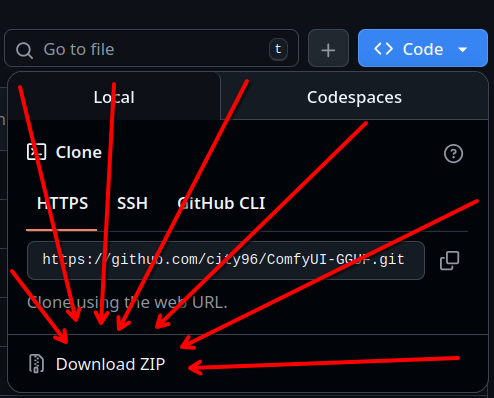
Приводит к ошибке на пикче. Что делать? Как добавить эту ноду? По ссылке из гайда какая-то бессвязная хуйня на птичьем языке https://github.com/city96/ComfyUI-GGUF.
>>1406578 >Связался с nunchaku, похоже, напрасно. Двачую. Нунчака похоже что с ControlNet Union вообще не работает.
>>1406878 А нахуя тебе полная модель? Счастливый обладатель 32Gb или 64Gb Vram? У меня в 24 она не помещается вместе с КонтролНетом. Clip пробовал выгружать на CPU, не помогло.
Господа, дайте пожалуйста, направление. Возникла идея, что можно больше не заморачиваться с шейдерами и деталями в сценах, которые пилятся в блендере, а просто и без задних мыслей закинуть картиночку/видосик в sd/comfy и они всё сделают как надо. Разумеется, сразу же обосрался и пошёл гуглить. Нагуглил comfyui и какой-то template с qwen из коробки, который юзает controlnet, достаёт там какие-то контуры и что-то даже рисует. Я его попросить рестайлить изображение и сделать его максимально реалистичным. Результат потрясающий, но недотягивает. Подозреваю, что надо посмотреть другие модели/поиграть с промтами и конфигом.
Что смущает: имею всего 32 рамы и 12 врамы, поэтому любой эксперимент - томительное ожидание. Выставлял денойзинг к 0.99 - отличная картинка, но, кажется, будет очень сильно шуметь, если сделаю vid2vid. Ближе к 0.3-0.4 картинка хуже, но стабильнее. Пальцы также пидорасит, увы. Генерация тоже идёт от 2 до 10 минут, рандомом (!)
Возможно, для изменения стиля (без потери деталей) есть какой-то другой путь?
>>1406917 >Что смущает: имею всего 32 рамы и 12 врамы, поэтому любой эксперимент - томительное ожидание. Радуйся что у тебя вообще запустился Квен. >>1406911 Нунчака модели под 12 гигов врамы не работают с КонтролНет. Полная модель не влазает в 24 гига вместе с КонтролНет. 2-10 минут это норм для квена. Можешь попробовать лоры ускорялки воткнуть в свой темплей, гугли qwen image lightning 4 steps.
>>1406917 На в2в ты не особо губу раскатывай пока. Тебе надо будет разбить видос на чанки (81 фрейм в дефолте, можно выкрутить больше но не сильно), и каждый чанк будет чуть по-разному получаться. А на картинки есть дохуя разных параметров, и скорее всего сможешь, но это надо все полноценно изучать.
>>1406917 >Генерация тоже идёт от 2 до 10 минут, рандомом (!) Про это скажу: если менял только seed, то 2 минуты, а если менял промпт или входную картинку то 10 минут
>>1406934 >>1406938 Спасибо. Ладно, с видео понятно (нет), а с рестайлингом? Насколько я помню, эта история достаточно давно появилась, но нормальных воркфлоу вообще не нашёл. Нашёл ещё какую-то ебалу с flux, вроде то, но слишком всрато. Я вообще в ту сторону смотрю или, возможно, всё можно на обычном SD решить?
>>1406949 СД намного хуже понимает композицию, так что не еби мозги и дрочи Квен. Пока ищешь нужные лоры и настройки для своего стиля юзай ускорялки чтобы так долго не ждать. Если нихуя не найдешь то можешь свою лору натренить на любой стиль, причем можно тренить с контрол имаджами, т.е. тебе в 3д можно сделать датасет с норм шейдерами и без, и оно должно понять именно процесс применения их.
Есть тут сын маминой подруги? Можете апскейльнуть тян? Сижу на ведре без видяхи. Заебался перебирать бесплатные апскейлеры, все говно собачье. Хотелось бы чтобы чуть лицо подправилось, там ещё с ушами проблема. Нужно эталонное изображение чтоб с ним можно было работать.
>>1407015 О, заебацу, с этим уже можно работать. Спасибо большое. Подскажи через что прогнал и сколько оно жрёт, шоб я знал что ставить, когда видяху пихну.
>>1407024 > через что прогнал Сдохля с тайловым контролнетом и FaceID. Жрет как сдохля с тайловым контролнетом и FaceID (на 8Гб заведется, может и на 6Гб с оптимизациями и тройным сальто через бубен).
>>1406873 Тебе гит понадобится неоднократно. Весит он 300 мегов. Насколько помню полная инсталляция комфи тоже что-то через гит установить требовала. (А нет, там через питон что-то докачивало.) https://git-scm.com/install/windows устанавливаешь, потом открываешь папку с нодами COMFYUI\ComfyUI\custom_nodes и в адресную строку вбиваешь git clone https://github.com/city96/ComfyUI-GGUF тебе создаёт новую папку с этим нодом. Почему это зипом сделать нельзя было - не спрашивай. Кодеры похоже это удобным считают.
>>1406954 А чем вот это говно делали? Я понимаю, что это не реалтайм и вообще возможно несколько часов или даже дней обработки. Тем не менее, у них довольно консистентная картинка, детали не плывут, ничего не разваливается. квен?
>>1407141 Я тут кстати за несколько месяцев собрал себе движок для vn с реалом, думал в начале дрочить всякие костыли типа фейсфьюжн чтобы спрайты допиливать, но когда появилась банана, правила игры поменялись. Можно клепать сколько угодно поз и экспрессий. Жаль только разрешение никакущее и цензура. наверное можно будет потом попытаться проапскейлить. Или забить нахер. Но вот делать NSFW сцены с персами, будет тот ещё геморрой чую. Хотя вроде квен может сохранять консистентность сисек?
>>1407232 >Почему это зипом сделать нельзя было - не спрашивай. >Кодеры похоже это удобным считают. Потому, что потом в этой папке "git pull" вытащит и подготовит новую версию. А слегка покурив ман на гит, ты еще и всего одной командой сможешь между разными версиями переключаться, если такая надобность возникнет. Не теряя ни один промежуточный вариант. Так что кодерам действительно удобно.
Вообще, видео годовалой давности. Но суть не в этом. Вопрос не в том инструменте, который был применён, в основном, а в методике его применения для достижения заданных результатов.
>>1405146 (OP) Аноны, добрый день. Можете, пожалуйста, сгенерировать вот по этому промту такие картинки? Только чуть чуть холмистости прибавить - даже не холмы, а скорее складки небольшие - визуально от 5 до 15 метров в высоту местами - не по всей поверхности. И ещё чуть камеру отдалить в высоту. Буду благодарен. Если ему прописываешь холмы - он сразу горы рисовать с лесом начинает как на пик 3. A side view from above – an endless, dense autumn forest on gently rolling ground with a river in the middle. A side view from above at an angle.
>>1407548 >в тени в тематике это называется - призраки. Появляются в основном при апскейле, т.к. апскейлер видит что-то похожее на ту хуйню из шума что в векторах промпта. Обычно они бывают сильней и более похожи , с лицами. Всё это из-за скиллишью и криворукости в целом из-за неопытности.
>>1407513 Холмы местами облысевшие получаются. Если очень нужно, то можно и инпейнтом закрыть. extreme wide shot aerial view parallel to horizon of a narrow river flowing in the middle of a dense, autumn, old growth forest with gently sloped shores and small, barely noticeable hills overgrown with fall vegetation
>>1407608 Какая у тебя методика проверки того, что он выдает? Потому что Siax выдает не мыло, а артефачащую отсебятину, создавая узоры из шума. Например, волосы в левом верхнем углу превращаются в морскую рябь, а кожа в советские обои. > при любых настройках Зачем ты апскейлер тестируешь с какими-либо настройками? Тебе же апскейл-модель нужно проверить, а не ксэмплер.
>>1405146 (OP) Нуб с треде Подскажите как на хагине на хрому гуфнутую найти вайку и энкодер, я не понимаю почему там только диффузии заливают, и не слова про сопутствующие, как будто у всех по дефолту они должны быть или все знают где брать, лол.
>>1408681 У меня нет воркфоу, я все на дефолтных всегда собираю. Квеню еще не пробовал, но флюкс работает отлично на стандартных. Просто бесит 100500 нод, половина из которых красные и хуй знает где их брать. поэтому что бы нервы не расшатывать просто юзаю стандартные ноды.
>>1408683 Нет там ничего. Есть просто норм оформленные репозитории, сразу в шапке пишут энкодер и вайку, а тут вроде и автор топовый а нихуя не оформлено, тупо голая стена с дифьюзами.
>>1408685 Ты наркоман? Там в темплейтах есть под все на свете дефолтные воркфлоу с дефолтными моделями. Если скачиваешь левый то одной кнопкой устанавливаются миссинг ноды, а модели дефолтные тоже проставлены.
>>1408687 А с красными нодами что делать? Менеджер их не находит? Я неделями ебался, хуй пойми где их брать. Вот зачем так делать. дают воркфоу, но в каждом сука втором красные ноды, ну что за уебки.
>>1405146 (OP) Ребят подскажите, как шакальные фотки, или просто размытые немного перерисовать моделью? Что ты в латент подал то и на выходе. А можно в латент шакальную 512 подать а на выходе 1024 перерисованную получить?
Есть ли лоры или модифицированные чекпоинты для Контекста или Квен Эдита чтобы они распознавали обнаженную натуру на референсах? Не раздевали а именно работали с исходником? Контекст, блядина, вообще не хочет с обнаженкой работать. Квен хоть сиськи и попцы показывает, но изъебывается чтобы писюхи скрыть.
Попробовал Qwen Rapid AIO - это просто какое-то говно ебаное. Мало того что лицо сильно херит, он еще и пропорции тела от балды рисует и с говенной мазней под аниме. Или есть какая-то модификация этой модели с консистентностью или под реализм?
>>1409216 По сути 1.5 и сдохля это вершина локальной дегенерации. Я хз зачем даже пробовать новые модели, они в любом случае будут жалкими обрезками от свои коммерческих онлайновых братьев.
>>1409244 >1.5 и сдохля это вершина локальной дегенерации >зачем даже пробовать новые модели дааа, плохо когда на новый компуктер деняк нет. поэтому тебе остается писать с важным видом бред сивой кобылы.
Аноны, ответьте новичку на несколько вопросов, буду очень благодарен: 1. Как правильно писать промпт, как лучше, через нижнее подчеркивание или нет? К примеру gold bikini или gold_bikini? best quality или best quality. Где-то читал что когда через нижнее подчеркивание - тег воспринимается целиком в связке а если через пробел то типа каждое слов как отдельный тег воспринимается и поэтому непонятно что может выдать. 2. Как грамотно генерить двух персонажей на одному изображении с разным набором характеристик? К примеру хочу Корру и Катару, чтобы они держались за руки, но у одной был flat_chest а у второй huge_breasts. Как сделать так чтобы нейронка поняла к какому персонажу относится какая характеристика?
Генерю на Reforge. Буду очень благодарен за советы или ссылки на гайды прямо по этим вопросам. Всем добра.
>>1409849 По второму вопросу - описываешь каждого перса, чтобы был указан размер груди и закрепляешь всё тегом breast size difference в конце промта, вес тэга можешь уменьшить - увелчить. Есть ещё вариант юзать инпейн, где закрашиваешь зону картинки и снова описываешь там объект, но это очень долго и может коряво выглядеть.
>>1409938 Контролнетом еще на 1.5 всё куда надо засовывалось. Это другое. Нужно хуман лэнгвижем, чтоб можно было твердо и четко сказать "Да. Вот теперь это понимает, что от него хотят". Белоснежка со Шреком - это не сама цель, а скорее тест на готовность. Пока еще довольно туго промптится и на чем-то сложнее двух персов вылезают каракатицы с ногами из шеи.
>>1409918 Я обычно danbooru тегами ебашу, а это типа надо будет писать как роман? Катарочка с большой грудью взяла Коррочку с маленькой грудью за руку?
ComfyUI это про эксперименты, набор узлов и спагетти связей между ними. Инструмент для прототипирования. Кроме того, всякие Qwen/Wan модели это уже про текстовое описание сцены, а не про теги, как мне кажется. Скорость генерации в ComfyUI зависит от выбранных моделей и конкретного Workflow (а также, загрузчиков, видов и форматов моделей, «обработчиков», настроек семплера).
К достоинствам ComfyUI можно отнести очень гибкую настройку Workflow с ветвлениями, отключениями/добавлениями того, что нужно и ненужно. Но это хорошо на этапе прототипирования. Мне вообще кажется по опыту использования AUTOMATIC (который я когда-то пробовал использовать где-то полтора года назад), вполне логично за счёт сообщества провести исследование с помощью гибкого инструмента типа ComfyUI, чтобы получить некие оптимальные рабочие сценарии под разные модели для достижения усреднённого положительного результата. И их уже перенести в решения типа AUTOMATIC и reforge (я им не пользовался) для того, чтобы средненько, но оптимально по скорости и требованиям к аппаратным ресурсам делать «хорошо» из коробки одной кнопкой.
>>1410041 Мне кажется, что это даже не полноценные Workflow, а просто своего рода примеры (examples). Причём довольно черрипикнутые, под которые загружаются специальные порезанные модели, LoRAs и прочее, чтобы сделать изображение на примере на относительно слабом железе. А как чего-то посерьёзнее пытаешься, с более толстыми моделями и несколькими ControlNet подряд, всё начинает пердеть и задыхаться (впрочем, у меня железо слабое, 16 Гбайт VRAM 4080S). Для получения чего-то приличного, приходится искать чужие Workflows, изучать их и разбирать на запчасти, чтобы собрать что-то вроде: постановка сцены и первая генерация на Qwen, затем деталировка через Wan на низком Denoise, а потом ещё и SeedVR2 сверху полирнуть. И всё равно получается говно.
>>1409849 >1. Как правильно писать промпт, как лучше, через нижнее подчеркивание или нет? Не нужно никакое подчеркивание, оно ничем не помогает совершенно, скорее мешает.
>>1410048 128 Гбайт. Я немного сгущаю краски, всё не так плохо. Но производительность падает сильно.
Если последовательно соединить несколько ControlNetов, например OpenPose+Depth или Canny+Depth, да в хорошем разрешении 1328+, то объём пожираемого VRAM, а потом RAM сильно возрастают. О разумной скорости генерации приходится забыть. Я в этом плане слишком привередлив. Если у меня не получается сделать Workflow, который генерирует картинку удобоваримого качества менее чем за 5-10 минут, то я ищу другие подходы. Ждать больше 10 минут на генерацию или рефайнинг одного изображения просто нерационально.
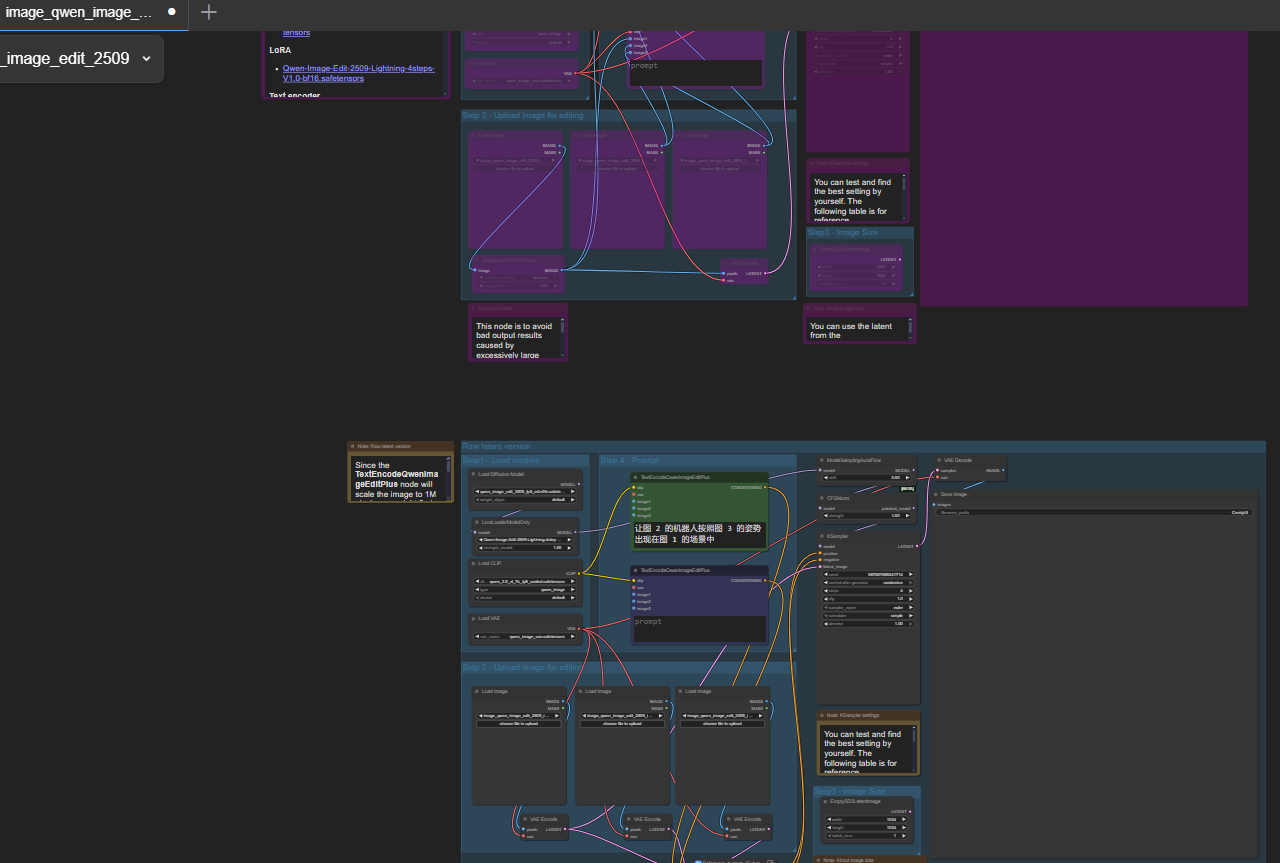
В продолжении темы, скажу, что как в AUTOMATIC я полтора года назад вкатился и забросил, поняв ограниченность его и существующих на тот момент моделей. Так уже сейчас я практически наигрался в Qwen/Wan в ComfyUI. Типовые изображения, подобные тем, что некоторые тут постят меня особо не интересуют. А сделать что-то нетривиальное у меня только не получается, это либо долго, шакально, некачественно, требует рефайнинга и последующей доработки. Другими словами, спустя полтора года я снова прикоснулся ко всему этому. Сдвиги положительные вижу, но всё ещё не то, что хотелось бы. Слишком много возни, слишком много нужно разных LoRAs, файнтюненых моделей типа JibMix Qwen (вообще без LoRAs на 20-30 шагов, как рекомендует автор https://huggingface.co/jibhug/Jib_Mix_Qwen-Image_V2). И даже при отсутствии деталей и шакальности картинки некоторые генерации старых моделей, которые тут постят, с точки зрения анатомии и стилистики затыкают за пояс этот кастрированный Qwen. Намудохавшись со всякими Workflows, комбинацией разных моделей GGUF загрузчиков, Nunchuku и прочим, скорее разочаровался. Откровенно говоря, практического применения у меня для этих инструментов нет, дохода они мне не приносят. А на бытовом уровне, уже, считай наигрался. Слишком много возни и времени приходится тратить на получение сколько-нибудь вменяемого результата.
Для тех, кто только всё это начинает и играет именно в Qwen, как действительно хорошо слушающейся promptа, вместо стандартного Qwen можно вот эту модельку попробовать.
>>1410049 хм, у меня 64/12 но как-то норм. правда память засираться любит со временем, поэтому при переходе с qwen на wan или другие модели делаю рестарт комфи, иначе весь накопившийся мусор вылезает в своп на ssd. ну и юзаю 4-битные веса nunchaku qwen вместо обычных 8-битных весов. там уже поддержка лор есть, добавленная сторонним разработчиком через отдельное расширение, норм работает. ещё какой-то форк seed2vr с ггуфами был, более экономный с памятью, но потом снёс, что-то не впечатлил этот апскейлер
>>1410052 Я поиграл с Nunchuku, но у меня толком ничего не вышло. Про глюки узла для LoRAs ты писал, я учёл. Но, всё равно, даже свой родной 4 step/8 step он подхватывать отказался. А с неродным лайтнингом от обычного Qwen заработал. Ещё некоторые LoRA не обрабатывал. Тихо, без ошибок, просто вне зависимости от развесовки strength они не появлялись в сгенерированном изображении. А на обычном Qwen с rgthree power lora loader (да и с обычным) работали без вопросов. То, что обычный Qwen с лайтнингом у меня портил анатомию и пальцы, меня разочаровало. Думал, это давно победили. В итоге это шаманство с бубном стало раздражать, так что вернулся к обычной fp8, даже не GGUF.
>>1410050 >сделать что-то нетривиальное может ты уже знаешь, хз, но на всякий напишу: qwen edit на второй вход может принимать depth, pose, canny. также можно mask - convert to image - invert и подать на второй вход, нечто типа scribble будет. каракулями нарисовать что-либо на маске поверх изображения, и оно превратится в что-то осмысленное заданное промптом. либо саму маску как заготовку использовать, подав на первый вход.
Его могли постить в прошлых тредах, но я не читал. Для понимания работы я считаю, он противопоказан, там слишком много накручено спагетти. А как однокнопочный инструмент, чтобы попробовать в ComfyUI хоть что-нибудь, перекатываясь с каких-нибудь AUTOMATIC/FORGE и подобных вполне подойдёт.
>>1410057 Спасибо. Я в курсе. Я уже и в позы наигрался, сначала выстраивая сцену и ракурс в https://posemy.art/ а затем экспортируя оттуда Depth, Canny, скелеты OpenPose.
Qwen Edit потрогал. И Qwen Edit 2509 тоже. «Реалистичные» и NSFW LoRAs тоже. С одной стороны, это прогресс. А с другой стороны, результаты всё-таки меня не удовлетворили. Я не знаю, что я конкретно ждал, но что-то всё-таки не то. Пока оставлю как базовый набор какие-нибудь «клипарты» в презентации делать.
>>1410056 >Про глюки узла для LoRAs ты писал он обновился , глюков должно стать меньше. теперь не нужен фокус с редактированием файла в нунчаке. верни оригинальный файл нунчаки. (init какой-то там вроде) и сделай git pull в папке расширения для лор.
>>1410050 Слушай, а ты что-то конкретное делаешь или дорабатывал то, что получилась наролить из какого-то промпта-заготовки? Я к тому, что судя по твоему сообщению, можно сделать вывод, что у тебе заранее в голове(или в техзадании) есть полностью готовая картинка до мелочей, которую нужно из головы(тз) вывести на экран. Или как? Мне интересен этот момент потому, что сам я не особо творческий человек, скорее технического склада ума и у меня нет какого-то особого воображения, а хотелось бы. Так что просто интересно как реализуют свои замыслы такие люди, которые с нуля что-то могут придумать. Вот именно самый первый момент зарождения своей идеи, ее видения. Если это чистая коммерция, то это другое конечно.
>>1410070 Сейчас задумался и немного прорубило что именно меня расстраивало в получаемых генерациях. Образы, созданные фантазией, и конечная генерация не соответствовали в точности и уже не несли полностью той смысловой нагрузки, не вызывали тех эмоций, которые бы хотелось передать. Слишком пафосно звучит. На самом деле, всё банальнее, я просто об этом не задумывался (и не подумал бы в эту сторону вообще). Спасибо за подсказку. Для меня это скорее баловство и никакой коммерции или практического применения за этим нет. Но все промпты я пишу самостоятельно, благо Qwen довольно неплохо (по сравнению со всем остальным) транслирует их в генерируемые образы. Концепция или образ действительно рождается в фантазии. Фактически, я «вижу» его ещё до генерации. Антураж, персонажи, позы, движения, ракурсы, цветовая композиция сами по себе создают определённое настроение и вызывают эмоции. Затем, прямо по этому образу я начинаю писать достаточно подробный промпт (настолько, насколько его съедает qwen text encoder), мини-рассказ описание, с персонажами, взаимодействием, деталями, антуражем, подкармливаю ControlNetами, если словами точно позу передать не удаётся (иногда проще «показать»). Потом идут пробные генерации, пока начнёт получаться, что-то близкое к желаемому. Если ControlNet, то только как референс для I2I, потому что он шакалит картинку, даже если его на середине генерации оборвать, дав Qwen Image дорисовать всё остальное. Если получилось что-то удобоваримое, то убираю пластик Qwen и накидываю «деталей» Wan'ом на низком Denoise. А затем ещё масштабирую SeedVR2.
Поствил дополнение ComfyUI-ReActor для замены ебальников и что я вижу в конгсоли!
[ReActor] 09:37:32 - STATUS - Checking for any unsafe content... [ReActor] 09:37:32 - STATUS - Ensuring NSFW detection model exists... [ReActor] Downloading model.safetensors to /..../comfy/cumfy/models/nsfw_detector/vit-base-nsfw-detector/model.safetensors: 0%| | 16.0k/328M [00:18<5:10:22, 18.5kB/s]
Они там что, ахуели? Т.е. вместо того чтобы выполнять прямую функцию эта залупа сначала проврить не хуйню ли я соборался делать?! Один хуй детектор не качается, сука даже без ссылки, хуй пойми откуда брать.
Нашёл модель https://huggingface.co/Phr00t/Qwen-Image-Edit-Rapid-AIO Антон скидывал где то. версия 9, там сам qwen-edit + Lora + nsfw но работает не совсем понятно как, такие мыльные изображения выходят. никто не юзал чтоб получались нормальныe? И весит конечно 28гб
>>1410112 > хуй пойми откуда брать. >> нод лапши с кодом в плейн-тексте на питоне Действительно, поедатели лапшы еще большие дебилы, чем адепты автоматика. Но те хотя бы сами себе nsfw детекторы не ставят
>>1409849 >через нижнее подчеркивание или нет Обычно работают оба, но разница минимальная. Модели тренировались без подчеркиваний. >Как сделать так чтобы нейронка поняла к какому персонажу относится какая характеристика? Легко? Никак. Рандомь пока не попадется хороший ген.
>>1410569 Из простого? Ничего. Можно занизить вес лоры с преобладающим персом, но это все равно не поможет - с двух лор особенности неизбежно будут протекать между персами.
Либо ищи и включай расширения для регионального промптинга та еще нестабильная херня, либо генери персов отдельно, сшивай в одну картинку, обрабатывай инпэинтом. Когда у модели уже есть, на что опереться, и ключевые особенности персонажей уже даны в картинке, получается значительно лучше. Если денойз сильно не задирать.
Здорово, аноны. Генерю неделю уже, в основном кумерский контент, ну типа чтобы стимул был, все таки дофаминчик и все такое. Как вам? Гасколько это выглядит как нейрокал или более менее уже?
>>1410830 >Всрато выглядит для недельного вкатуна нормально. всяко лучше твоего безкартиночного высера >>1410824 >почему ты тогда до сих пор девствениик @БЫТЬ ДВОЩЕРОМ @ДЕВКИ НЕ ДАЮТ @СЧИТАТЬ ЧТО У ОСТАЛЬНЫХ ДВОЩЕРОВ ТАКЖЕ @шутка про девственность, ЛОВКО ЗАТРАЛЕЛ ЧЕЛА ХАХАХА @ИРЛ ПИКРИЛ #1
>>1410099 >правая нога больше левой на 10 см минимум
Вот этот момент я не понял. Это изображение я готов критиковать за многое другое, но за анатомию в меньшей степени. Здесь перспектива специально искажена углом обзора. А поза получена из Canny, которая, в свою очередь была срисована со сцены, выставленной в posemy.art Анатомические пропорции у 3D моделей на этапе компоновки сцены там были вполне удовлетворительные при выставлении сцены. А вот угол камеры передан неточно. Вот изображение с наложенным на него Canny. Мне кажется, что плюс-минус модель врисовала по контуру.
>>1410933 Судя по кэнни, там ноги перепутаны и левая нога должна быть оттопырена в сторону окна. А у тебя она правая и прямо торчит. Тот "критик" правильно длину измерил.
Анон, расскажи, как получаешь удобоваримые детали кожи? Сочетание файнтюненой Qwen модели и LoRAs?
А в остальном в этих изображениях изобилуют мелкие точки как из мемной картинки (видео), где человек, сделавший цифровой снимок открытого контейнера с радиоактивным материалом на цифровой фотоаппарат, спрашивает «Подскажите, что случилось с камерой». Такое ощущение, что ты той же моделью (предположительно файнтюном Qwen) делаешь вторым проходом рефайн изображения и в этот момент добавляется ещё больше этих точек. А ещё я где-то читал, что но ссылку не сохранил, что при квантовании Qwen из полноразмерной модели во всех младших квантованных моделях были допущены ошибки, которые и дают множество родинок (дефектов кожи) на теле, и вот эти точки при втором проходе рефайнером.
>>1410940 >Судя по кэнни, там ноги перепутаны и левая нога должна быть оттопырена в сторону окна. А у тебя она правая и прямо торчит.
Заметил. Признаю. Спасибо. Я невнимательно к этому моменту отнёсся. А с тем, что левые/правые ноги/руки путаются, я сталкивался. Как победить не знаю. Наверно несколько раз генерировать и внимательнее смотреть на результат. Ситуация с OpenPose скелетами у меня не многим лучше. В отличие от Canny их когда в конкретную позу выставляешь, детали всё равно не получаются, чтобы всё соприкасалось в требуемых местах. Наверно ещё надо Depth пробовать. Но вообще, с ControlNet проблемы. Если его остановить слишком рано, то будут проколы с воспроизведением позы. А если слишком поздно, то он поломает генерацию деталей и полученное изображение с позой даже на референс для I2I не сгодится. У меня было, что белый Canny на чёрном фоне при Strength 1.0 повторял в точности контуры, а фон заливал однотонной заливкой. Приходится держать в районе 0,3–0,55.
>>1410941 > детали кожи Апскейл сдохлей с тайловым контролнетом. > мелкие точки Ими серит квеновая 90zvibez лора, видимо автор такой грейн натренил, что они вылезают постоянно. До прохода сдохлей они еще больше.
>>1410933 >>1410927 это местный ебанат, гоните его, насмехайтесь над ним а лучше игнорьте >>1410904 @перекидывает стрелки @сочиняет манямирок где вокруг одни педофилы и инцелы @затралел всех, я крут (жаль не ирл) масочка не жмёт? не натерла ничего?)
>>1410945 > Если его остановить слишком рано, то будут проколы с воспроизведением позы. А если слишком поздно, то он поломает генерацию деталей Смотря на чем делаешь. Я на сдохле с ускорялками не останавливаю. Если у тебя уже есть готовая 3D модель, то однозначно глубину используй. Ничего другого не сможет гарантировать правильную расстановку ног при виде сбоку. Да, на пикрелейтед нога перетекла с твоего пика вместе с глубиной.
>>1410958 >Если у тебя уже есть готовая 3D модель, то однозначно глубину используй.
Я с Depth продолжил после скелетов OpenPose, но оставлял Strength на 1.0 и получал неудовлетворительный результат на Qwen. На изображении буквально получались лысые манекены (воспроизведение геометрии 3D моделей) на фоне чёрной пустоты. Надо будет опять к Depth вернуться и попробовать поэксперементировать с End Percent и Strength.
А вообще, получается зря я наверно SDXL со счетов списал. Может им попробовать вместо Wan I2I генерацию делать. Мой самодельный workflow refiner'а на Wan 2.2 low noise ситуацию с пластиковым Qwen не сильно исправляет. А если уровень Denoise повышать, то сильно видоизменяет детали оригинального изображения. Плюс Wan я увидел в том, что туда можно LATENT от Qwen нативно подключить на вход, и он его понимает. Можно обойтись без лишней операции encode/decode изображения в LATENT, не теряя деталей.
>>1410949 Вот вариант без лоры. Точек почти нет, но и ламповости не особо заметно. Похоже эти точки - квеновский вариант зерна, которое протекает в генерацию, даже его нет в промпте, но есть косвенный намек в виде film и прочих тегов на пленку. А лора его просто усиливает. >>1410964 Не пробовал контролнет на квене тестить, но может есть смысл убавить силу до 0.5-0.75. Хуй знает, как на квене, но на сдохле все малошаговые варианты совсем не так, воспринимают End Percent, как того можно ожидать и в большинстве случаев лучше крутить до конца, но с меньшей силой. Ну и раз ты всё равно на квене контролнет крутишь, так и скажи ему, что одна нога на плече, а другая отвернута в сторону окна. Это же не сдохля, которой похуй на то, какая там нога, и вообще нога или третья рука, например. Я минут 10 наверно вот эту >>1409968 хуйню пытался напромптить так, чтобы три человека получилось, а не один октопус.
>>1411012 >может есть смысл убавить силу до 0.5-0.75. Хуй знает, как на квене, но на сдохле все малошаговые варианты совсем не так, воспринимают End Percent, как того можно ожидать и в большинстве случаев лучше крутить до конца, но с меньшей силой.
Спасибо. Это можно попробовать. Я сейчас с Depth играю и уже наигрался в край. Этот перебор вариантов изматывает. Если силу ставить маленькую, Qwen не следует композиции (особенно в этом непростом ракурсе), фантазирует и при этом забивает болт на все детали promptа. Стоит сделать силу повыше, получается ближе к заданной композиции, но при этом убиваются детали персонажей, «стачивая» их вот до этих двух манекенов из Depth.
Чувствую, что надо при этом будет ещё и отключать узел с LoRAми на реализм и прочие элементы. Похоже, надо тестировать поведение на чистом Qwen, чтобы понять, как эта дрянь себя ведёт на самом деле. Я уже вообще закономерности не вижу.
>>1411015 У тебя какая-то неглубокая карта глубины. DepthAnythingV2 возьми. С ним можно меньше силу выставлять у контролнета. Если совсем туго идет, подрисуй своим 3D моделям паклю на голове в пейнте.
Или ещё гипотеза, что для OpenPose, Canny, Depth будут разные значения Strength и End Percent, никак не связанные друг с другом. Если у меня получалось на Canny со значениями порядка End Percent 0,5 и Strength 0,65 или около того, плюс-минус, то с Depth эти значения уже не подходят. Хоть исследование проводить: экспорт из posemy.art в виде скелета OpenPose, Canny и Depth для одной и той же композиции, а потом дрочить их с разными значениями параметров. Уже от одной идеи не в кайф.
Причём косяк может быть где угодно. Вот, сейчас нашёл, что posemy.art подсирает, при экспорте добавляет в PNG прозрачные полосы сверху и сниуз, из-за которых почти двукратно увеличивалось время обработки ControlNetом Depth изображения.
А вот это интересно. Возможно, стоит попробовать с этим поиграть. Если честно, я понятия не имею, какой глубины она должна быть. При экспорте из posemy.art можно регулировать диапазон. Я решил с такой неглубокой попробовать.
Более глубокая Depth карта в целом влияет более положительно. И опять при этом меняются значения параметров. С такой картой ей и с 0,6/0,6 нормально (плюс-минус 0,1).
Повсеместно вижу в воркфлоу ггуфокванты, крайне редко попадаются не-кванты. Нахуя их все юзают? Они не могут включить файл подкачки, чтобы кишка не выпадала? Или на сетапе меньше 16+64 нихуя не помещается даже по частям и все начинает дико лагать? Юзаю кванты только для ллм, там прирост скорости видно сразу.
>>1411034 Вот я тоже удивляюсь - нахуя выпускают обувь не 44 размера? Пробовал другие размеры - ну хуйня же полная! Либо на ноге болтаются, либо жмут...
>>1411034 > не помещается даже по частям и все начинает дико лагать Это. Элементарный QoL - не ждать гигабайтного дроча по шине туда-сюда как в 2003. Тем более что разница между fp16 и каким-нибудь Q4 околонулевая.
>>1411241 Ванильный Edit последний. Норм он рисует. Вот пизды не умеет, какие-то мерзкие коричневые складки вместо них, а остальное терпимо. >>1411306 Какие лоры, зачем? Квен по одному фото их генерит.
>>1411465 Очевидный грок и он таким часто страдает. Ван вроде такой хуйни почти не допускает. >>1409870 С лорами людей хорошо работает. >>1410944 Кинь вф как сгенерил
Ребятушки, как метаданные из готового сгенеренного изображения достать? Сейчас достаю через forgeUI и получившийся json форматирую в notepad++ Может есть какой то специальный инструмент, чтобы доставать в удобочитаемом виде? Может быть в ComfyUI есть плагин какой-то?
>>1411807 >Может быть в ComfyUI есть плагин какой-то? Да, но можно и без него просто закинуть сгенеренную картинку в окно Комфи и получить полный воркфлоу.
>>1411829 >или ещё что-то есть? так называемая артистичность Разработчики заявляют что Крея была натренена так, чтобы результаты не похожи были на обычный ИИ-слоп.
установил через pinokio comfyui. обновил comfyui до последней версии, а comfyui ни как не обновляется, так и стоит на версии 3.37. Что делать анончики?
>>1412169 дайте гайд, и вообще на моем железе потянет генерация видео из фото. старенькая gtx 1050 ti, процессор 16 гб intel core i5 4690 16 гб ОЗУ. ставил все по советам groka, это пиздец...
Аноны, есть вопрос, может кто-то знает...Насколько приватны face swap сайты, которые находятся через гугл. Вопрос в том, насколько безопасно их вообще использовать и кто помимо самого пользователя может иметь доступ к контенту?
Инструменты: Флюкс и Квен Имаж. Варианты: 3060 12 Gb + 32 RAM или 5060 Ti 16 Gb + 16 RAM. Задача: коллажи и генерации, универсальный набор. Контролнеты, апскейлеры, полный фарш. Видеогенерация в полной мере не нужна, разве что побаловаться.
Общее положение вещей я примерно представляю. Интересно услышать, насколько я буду страдать на 12 Гб, если куплю этот устаревший огрызок. Идея простая: сейчас перебиться на нем, потом докинуть его ко второй более сильной карточке в новую сборку. Сейчас на копроаэмдэхе сижу.
Накидайте своего опыта с этими моделями и своим конфигом, плес.
>>1412260 Ну у меня квен эдит на 3050 8гб идет, в ггуфе естественно. Порхать как бабочка не будет ни в одном из вариантов, там помимо памяти еще и терафлопсы нужны.
>>1412260 Рам меньше 64 - мазохизм, 16 - ваще не вариант. Если ты докинешь мелкую карту к большой, то у тебя врам не сложится, а параллелизм пахать будет только на то, что в меньшую влезет.
>>1412260 > насколько я буду страдать на 12 Гб По полной. Будешь сидеть с сотней гигов свапа и генерациями по 5 минут. Только если в Q3 закатываться на шакалы и ультранизкое разрешение. На 5060 страдать будешь не меньше.
>>1412275 Бабочки не нужны, нужен функционал и чтобы не пердолиться по 20 минут с одной картинкой и не вылетать в out of memory постоянно. Минуты 2-3 на генерацию меня устроит, в принципе.
>>1412276 Читал, что в Comfy можно на одну карту повесить ядро модели, а всякие VAE и Controlnet запихать в другую карту. Но это только теория с Реддита, как на деле, я не знаю. Также есть представление о том, что GGUF можно выгрузить частично в общую RAM, но в каких случаях это делается и насколкьо полный пайплайн нагрузит обе предполагаемые сборки, я не знаю. Ставить к 5060 дополнитльную RAM особо не хотелось бы. Хотелось бы тогда на ней перекантоваться и пихнуть уже потом в более зрелую и сблансированную сборку на DDR5.
>>1412282 С 3060 примерно понятно, почему, но почему с 5060 так же?
>>1412320 > Ставить к 5060 дополнитльную RAM особо не хотелось бы На 64 Гб RAM минимум тебе при любом раскладе придется раскошелиться. И желательно не самый хуевый nvme для подкачки к этим 64гб.
>>1412320 Кое-что на 2ю карту выгрузить можно, и система на ней будет, так что в любом случае это лучше чем 1, но по соотношению профита к баблу это менее выгодно, чем 1 или 2 норм карты.
ComfyUI-piFlow — это набор пользовательских узлов для ComfyUI , реализующих многоэтапный процесс сэмплирования pi-Flow. Все изображения в примере выше были созданы с помощью pi-Flow всего за 4 этапа сэмплирования. https://github.com/Lakonik/ComfyUI-piFlow
pi-Flow — это новый метод генерации изображений на основе потока, состоящий из нескольких шагов. Он обеспечивает высокое качество и разнообразие генерируемых изображений всего за 4 шага сэмплирования. Примечательно, что результаты pi-Flow в целом совпадают с результатами базовой модели и демонстрируют значительно большее разнообразие, чем результаты DMD-моделей (например, Qwen-Image Lightning ).
Кроме того, при использовании LoRA в фотореалистичном стиле pi-Flow обеспечивает значительно лучшую детализацию текстур, чем модели DMD
>>1412432 Там ещё руки и пальцы на руках и ногах изуродованы. Но мне кажется, там ещё LoRAs конфликтуют между собой, так на втором пике твоих форменных точек от твоей «реалистичной» LoRA нет.
>>1412452 UPD точки есть, но менее заметны. Если поочерёдно открывать обе картинки, то, например, белый пиксель на шине будет ровно в том же самом месте на обоих изображениях. Я у тебя уже спрашивал про название реалистик LoRA, ты в треде, вроде отвечал, что 90zvibez или что-то такое. Если она так срёт точками, то это не очень хорошо.
Я пробовал flymy_realism.safetensors LoRA, и отдельную модель Jib_Mix_Qwen-Image_V4_E_fp8_e5m2_00001_.safetensors. Точек они не дают, но результаты тоже звёзд с неба не хватают.
Ещё, вроде бы, вычислил, что «желтила» и портила вывод ControlNet на Qwen-Image LoRA qwen_image_union_diffsynth_lora.safetensors По идее, она должна была ускорять процессе и повышать качество, а по факту, её отключение починило изображение.
>>1412456 Там еще сочетание сэмплера/планировщика на эти точки влияет. Те что на первом пике - минимальный вариант и они полностью уберутся если сдохлей пройтись. >>1412452 Ну там как-бы написано, что с лорами стоит прибавить силу адаптера, но на 1.1 яйцеклад превращается в здоровенный стоячий хуй, на 1.15 - в маленький стоячий хуй, на 1.2 - средний стоячий хуй и начинает явно жарить. На 1.25 - наконец пропадают кроннеберги, но жарит совсем пиздец (пикрелейт).
>>1412323 >>1412338 Это было очень конструктивно: много памяти круто, мало памяти не круто. В принципе, это и так понятно, все упирается в возможноть. По скорости ССД есть хоть конкретика? Что за суперскорость нужна? Чем больше, тем лучше, ага. Без скорости жизни нет.
>>1412370 Как по мне, то все-таки лучше вариант промежуточный, чем топовый на 24 Гб или 32 Гб. Можно в сотку рублей уложиться с видео. Там обещали еще 5070 с 24Гб, вот это норм. Но она когда еще будет, ее отложили, и что ее мешает в пару с ней поставить ту же 3060. А на топах слишком уж переплата велика за объем, а скорость 6-12 картинок в минуту не нужна, это явный оверкилл. Вот где явная переплата, тем более, если карта чисто под нейронки.
Спасибо всем уже ответившим, в общем.
И вопрос теперь снова ко всем. Какой положняк по нунчакум?
>>1412601 Единственный смысл юзать локальный диффужн - это если ты его будешь тренить. Без тренинга закрытая модель всегда будет лучше локальной. А чтобы тренить врама много не бывает.
>>1412601 >По скорости ССД есть хоть конкретика? У меня на 8 врама часто бывает, что т5 перезагружается с диска(не хватает места в ОЗУ) при изменении промпта. И вот из-за этого я все модели перенес на быстрый нврам ссд.
>>1412932 > нет членов У того, что на ней, есть. > на баб похожи сами Эксперт по инопланетянам? Может они у них внутренние и вылезают только, когда нужно.
>>1412997 Да. Это так. Однако это первая лора для квена, которая хоть что-то может. Поз мало, про анусы почти ничего не знает, кроме того он типа, вроде есть где-то там, гигасисик отказывается делать. Но по сравнению с чистым квеном - небо и земля. Даже страшно представить какого мы бы получили, если бы автор поней сделал восьмую на квене.
>>1411925 >>1411984 Нет, качество, конечно, неплохое, но я ебал 1024 на 1024, что квен, что хрома рендерится раза в 3-4 дольше, чем аналогичное sdxl. Да еще заебывает постоянно искать ворклоу для комфи, а на автоматииках не работает. Кароч либо пусть модели ускоряют, либо неюзабельно. Даже на предтоповых видеокартах.
Мнение на основании моего личного опыта следующее: как Неуловимый Джо.
После некоторого пердолинга удалось накатить актуальную версию и даже вполне успешно сгенерировать тестовое изображение из примера (чтобы убедиться в том, что «из коробки» всё норм.) Тут небольшая предыстория, я сначала пытался запускать всё с нормальным workflow со сторонним узлом для LoRAs в nunchuku. И тогда, когда лыжи совсем не поехали, начал разбираться отключая всё навешенное, постепенным даунгрейдом до workflow примера «из коробки».
По итогу: само по себе работает, вроде даже заметно бодро. Но кому нужен голый Qwen? Официально, на странице разработчиков, поддержка Qwen LoRAs не заявлена. Казалось бы, всё хорошо, есть специальный узел от сторонних разработчиков, который позволяет nunchuku работать с LoRAs. Только вот у меня загвоздка в том, что некоторые LoRAs работают нормально (внезапно, неродной для nunchuku Qwen-Image-Lightning-8steps-V2.0.safetensors, Samsung_qwen_overtrained.safetensors и ряд других). Другие LoRAs как бы загружаются, но не производят никакого эффекта на сгенерированное изображение вне зависимости от Strength (родная для nunchuku svdq-int4_r128-qwen-image-lightningv1.1-8steps.safetensors, которая, как раз должна была работать вместо лайтнинга на 8 шагов от Qwen-Image; QwenSnofs1_1.safetensors). Причём, не работают ни в сочетании с другими, ни сами по себе в отдельности (я пробовал разные комбинации для того, чтобы локализовать проблему). А третьи (Skin_Fix_rank64.safetensors) — так и вовсе вываливаются с ошибками о несовпадении размерности тензоров или чего-то ещё (хотя отлично работают без nunchuku).
Конечно, всё можно списать на конкретно мою версию установки ComfyUI, какие-нибудь конфликты/зависимости и прочее, но для меня более шустрый, но полуголый, без нужных LoRAs Qwen особой ценности не представляет. Может, у кого-то будет более успешный опыт от использования nunchuku и вы разберётесь как сделать так, чтобы все LoRAs работали.
>>1413100 Он легко обучаается (пикрилы), легко промптится, но у него какой-то свой псевдо-реализм. Зато мощнейший контроль через vace, инпейнт вообще лучший. Не можешь обучать - можешь просто вокруг ебальника рисовать сцену (не пикрилы).
>>1413421 Всё сможешь, кроме может свежайшей пикчевой модели от Hunyuan и тяжелых ллм. Обучать, возможно, не все модели получится или будет делать очень долго, не разбирался.
>>1413446 Продемонстрируй. Пока я видел только кривую хуйню, которая теряет всякую узнаваемость, если ты способен различать лица. Хотя, если вынудить его не менять лицо, что собственно и придется делать в ван, то норм, по сути, похожие инструменты в этом плане. Только Edit позволяет легко менять вещи текстом, а VACE позволяет точно набросать план изображения, вставив лицо и, допустим, обувь в нужной части изображения, а все остальное удалить и оставить для инпейнта. В edit моделях тоже можно сделать это, зарисовав инпейнт область ярким цветом, результат менее консистентный.
>>1413460 Ты похоже никогда Edit не трогал, лол. Алсо, про VACE вообще кринж, он даже близко к Edit не приближается по контролю и переносу объектов. И в Edit всё решается просто подкидыванием пачки пиков, какой ещё инпейнт.
>>1413550 VACE и не годится для переноса, поэтому я reference не упоминал, он хуйня. Классно первая выглядит, надо больше попытаться, я только свапать лица пытался, иногда оно справлялось. Модифицировать даже не пробовал, насмотревшись на чужое, отложилось мнение, что edit модели для лиц не годятся, и это логично, потому что у них нет знания как лицо будет выглядеть с другого угла или эмоцией в отличии от лоры. С лорами, конечно, ни в какую не сравнится, но если оно может без изменений перерисовывать лицо, то стоит детальней потестить. Есть две задачи: нагенерить от пизды, и нагенерить точный объект в точном положении без изменений, поэтому странно удивляться необходимости инпейнта.
>>1413550 >в Edit всё решается просто подкидыванием пачки пиков С этого места поподробнее. Я пробовал стакать несколько изображений персонажа в надежде повысить узнаваемость, но qwen edit всегда выбирал только одно лицо из пачки, игнорируя остальные. мимо
>>1413652 На первом шаге пропускай VAE у референса. Тогда генерация работает почти как обычный Квен по промпту, но оставляет с референса то что попросил. Возьми лору Бананы, если хочется больше контроля за выражением лица. В стандартной ноде Квена пикчи подписаны Picture 1/Picture 2/Picture 3. В промпте ссылайся именно на такой формат, если не меняешь их кастомной нодой. Если без конкретики запромптишь, то выведет что-то среднее между референсами, как на пикриле. Но можно и конкретно написать что с какого пика взять, одежду или причёску например.
Щас нагуглил видос https://www.youtube.com/watch?v=wi2AHnHfmI0 сравнения квена с флаксом и от него услышал про какой-то блять нано банана. Хули тут про эту банану ни слова? Я всё доолжен от каких-то пендосов говорящих по-русски узнавать? Или оно не локальная?
>>1413854 >>1413860 Я уже запутался о чём речь, вот нашёл какой-то онлайн и там пишут что они не гугл. В другом месте пишет другое. Но походу да, это чисто онлайн, так что похуй.
>>1414169 Опять будет огрызок от полноценной модели? Ещё и через API? Не нужно. Флюкс стал юзабельным только после серьёзных файнтюнов, высеры лесников не нужны, лучше бы китайцы Квен апдейтили.
>>1414326 Сложно сразу ответить. Навскидку, слишком низкий квант модели. Убедись, что на обычной FP8, которая идёт в комплекте всё работает, а потом уже GGUF подсовывай. Четырёхшаговую LoRA попробуй заменить на восьмишаговую и поправь Steps на 8 в KSampler. Разрешения вывода попробуй изменить, так как для Qwen родное 1328x1328 пикселей (и выше). Не факт, что дело в этом. Prompt попробуй подробнее задать типа: Replace tints of blue color with corresponding tints of red color on the image from Picture 1. Узел CFGNorm временно отключи через Ctrl+B (bypass). Потом дальше можно будет думать.
>>1414169 Ремень не прилегает к голове, сзади по-уебански торчит, а не прижато к затылку, с правой стороны шлема снизу несимметричная залупа. А, ну и клюв - не знаю вин или фейл. Очередная говномодель, у которой будет ломаться анатомия. На локалках никогда не появится модель хотя бы уровня ссаного далли 3 по анатомии. По уровню знаний так уж тем более. Да, можно нароллить и накостылять картинку в десять раз лучше топовых пастгеновских онлайновых генераторов, можно обучить лору, но почему-то в базовых моделях нас всегда кормят говнецом.
Перебейте локалочкой квин и банану: Amateur photo of a Brazilian girl taking a selfie in a mirror with an iPhone. She has long, messy and straight brunette hair with a fringe. She's wearing a white tank top. She has no makeup on her face, revealing highly detailed, dry, and porous skin with some imperfections. The background is a pink themed teenager room, sharp and in focus throughout, with no bokeh effect. The lighting in the room is bad, creating a poorly lit, out-of-frame composition, as if taken with a smartphone camera at infinity focus.
Уважаемые знатоки, подскажите ЛУЧШИЕ на ваш взгляд модели для создания изображений женщин с низкой социальной ответственностью. Локально и на карте 3080ti.
>>1412612 В принципе, я подумал и согласен, что это хороший плюс. Но это заморочено и под специальные задачи нужно. Для меня генерация не финальный результат.
>>1412640 Ладно, я почитал уже в ИИ про это. Можно отдельный диск кинуть под это.
>>1413241 Вот у меня какие-то подозрения относительно подобных велосипедов, да, хотя, в общем-то, все хвалят на Реддите том же. Большей частью меня подобное и останаливает от четкой покупки 3060 12Gb. Если вот эта шняга не заведется и будет тупить как-то сама по себе, либо по совместимостям, то тогда придется на огрызке сидеть. Щас выйдет новый Квен или Флюкс, и разрабы будут пердолиться полгода со своими нунчаками, пока запилят модели и все плюхи к ним. Хотя, тогда можно памяти навалить до 32 Гб и Гуфом пользоваться, но это по общей стоимости уже к 5060 приближается. Сложна.
Проснулся с мыслью сгенерить как бабу держут на вытянутых руках как в меме longcat. Не получилось даже кота так сгенерить, а бабу только в уебанской позе, а хочется на уровне глаз, на вытянутых руках. Даже загуглить такое фото не удалось, но это понятно, физически тяжело такое сделать без выгнутых рук.
>>1415316 > Не получилось даже кота так сгенерить Кота кое-как на Квене можно. А с мужиком бабы смешно как куклы выглядят. Часовой дроч промпта наверное что-то даст нормальное.
>>1415448 Делюсь личным опытом свежего вкатуна: все хуйня кроме мусуби, но мусуби - тоже хуйня. Для него нужно как по минному полю со всеми настройками проебаться, но с остальными еще хуже.
>>1415866 Мань, я тренил только актуальные модели: квен эдит и ван. Они в 24 гига не влезают, там надо оффлоадить, с мультигпу одно крашится, с дуал-модом для вана - другое, с сэмплингом - третье, еще надо было юзать другой бранч, который вчера смерджили, и руками переименовывать кэш для эдита (хз пофиксили ли это), тренить надо в ВСЛ и ее РАМ отдельно дрочить - ебли дохуя в общем.
>>1415894 > Мань, я тренил только актуальные модели: квен эдит и ван. Они в 24 гига не влезают Мань, эти штуки для серьезных господ за 40 с видеокартами, а не пердоликсов с огрызками как у тебя. Иди лучше дмд накати.
>>1415642 > Мы не ебём то что ты никого не ебёшь это очевидно, но не говори за всех, идиот блядь. civitai тоже онлайн дрочильня, помимо того, что там есть основной контент, это модели. Прежде чем ебало открывать неплохо бы подумать, если есть чем. на seearte оставалтсь лоры селебов, которые сейчас почти полностью выпилены даже из архива civitai, но вот уже несколько дней там ничера ничего не открывается, в чём причина непонятно, толи ресурс перегружен, толи хуй его знает, если кто в курсе - отпишитесь...
>>1416084 >на seearte оставалтсь лоры селебов Тоже удивился. Но там только старый копрокал. Лишь парочка хороших на Wan. Ебать, я ещё ни одной селеболоры на Qwen не находил кроме Доры из nf, а он прям хорошо обучает. И это я ещё от пизды тренил, умельцы может вообще шедевры сделали.
Здрасьте, я нуб. Как сделать так, чтобы в промпте модель понимала где описание относится к одному объекту, а где к другому? А то у меня перепутывается цвет домов, холмов и неба. Или получаются дома в траве XD
>>1416256 Разделять объекты по твоим описаниям умеют только более новые жирные модели типа флюкса, квена и пр. Твоя модель - это затюнингованный и переобученный, но все же старенький СДХЛ. Он хорош доступностью и скоростью, понимание порнухи и аниме в него вдрочено очень старательно, но в целом там понималка достаточно примитивная. Хотя тюны типа иллюстроса разделять цвета объектов умеют относительно неплохо, черные волосы и белые чулки точно не спутают. Че у тебя происходит я вообще хз, может промт сильно кривой. Небо и холмы вещь достаточно дефолтная, им вообще цвет указывать не надо, чтобы небо было синим, а холмы зелеными. Так что че там у тебя путается - для меня загадка.
>>1416272 Ну, эти модели (категория иллюстроус) они вообще не про холмы и дома, они про девок в основном. Холмы и дома там рисуются постольку-поскольку в качестве бэкграунда.
>>1416269 >Разделять объекты по твоим описаниям умеют только более новые жирные модели типа флюкса, квена и пр. С объектами хз, но с людьми у меня Квен Имидж Эдит чето хуево понимает. Не, если на двух импутах мужик и женщина - норм. Но если две женщины - начинается ебанина. Он шарит элементы одежды между ними, бывает мержит в одного человека, усредняет телосложение и т.д.
>>1416299 в общем креа для креатива (клипарты живопись сюр прочий и шиза), контект для контекста снимания с той училки трусов к примеру, оставляет базу фото без изменений, меняет элементы, простым языком
Поясните про разрядность. Есть rtx5060ti 16гигов. Что мне надо использовать: fp8 или fp16 или ещё что-то? В моделях flux, qwen, wan. Чтобы быстро работало. Кино писал, что определенная серия видеокарт заточена на числодробильность определенного формата моделей, а другой формат она эмулирует и замедляется. Это так? Есть практические результаты? У меня интернет очень медленный, сам проверю не скоро. Хочется закачать сразу правельную модель.
>>1416307 50хх серия в ядре поддерживает фп4, 40хх - фп8, 30хх - фп16, к примеру 30хх не могут в фп8 без костылей и тормозов. Но если фп8 не отличима от фп16, то фп4 это уже треш сильно херит картинку что-то уровня ггуфов ку4 и нет смысла в нём для картиночных и видеомоделей, только текстовые и прочее возможно.
>>1416307 Вычисления - это хуйня по сравнению с оффлоадом. Если бы у тебя все в врам помещалось, то еще можно было бы об этом думать, а так это 1% разницы.
>>1418139 Проблема не в Квене. Проблема в том, что вы не знаете, что хотите и при этом ищете качества. Типа, должно быть заебись, но не понятно, как должно быть заебись и вообще для чего. Дрочите какие-то поры на коже и ищете до чего доебаться в генерации. Это отсутствие понимания общего вижена и вообще задачи его, вижена, создания. Пик - качественное изображение. Бретелька лифа кривая в районе ключицы (ужас какой). Хороший атмосферный портрет. Момент в том, что качественные изображения бывают разные. Может, тебя просто заебали портреты своим однообразием?
>>1418185 На самом деле квен и правда мылит кожу лица. Сделано это специально. У китаёзов фетиш на это и такая функция в каждой китайской мыльнице по умолчанию.
>>1418139 Реализма не существует. Существует имитация той или иной техники. Просто тебя конкретно эта техника не устраивает, ты ожидаешь другой. В целом нормальная у тебя генка.
Joycaption в самом полном неквантизированном виде не может различить клозап/медиум/фулблбади шот, и упоминает то, что я его специально прошу не упоминать. Можно ли вместо него юзать какой-нибудь квен или дипсик раз он такой тупой?
>>1418852 >Гемини На фото изображено пук среньк буп буп к сожалению я не могу дальше описывать фото, обратитесь за квалифицированной помощью и знайте, вы не одиноки 8-800-фсб-ркн-00
>>1418851 Активно пользуюсь JC beta one, ни разу не возникло проеба, только вотермарки не так читает, но и не нужны. Проблема в тебе, ты тупой, а не модель.
Есть у кого воркфлоу для масс-теста лор? Чтобы например 100 эпох по 10 промптов и 10 сидов на каждый промпт поставить ее генерить, а желательно шоб еще и сравнивать автоматом с датасетом, и распознавать косяки.
>>1418989 Ну давай покажи как он у тебя распознает хотя бы клозап/мудиум/фул шот, или еще waist/knees и wide. У меня он всегда пытается сказать клозап если ебальник хорошо видно, даже при том что потом сам же начинает обувь описывать.
>>1418215 Да, мылит. Но в этом ничего плохого нет при удачных генерациях, просто косметическая особенность. Даже напротив, это придает визуальной эстетики для большинства. Зря бабы косметикой обмазываются с макушки до пизды, что ли? Так что, это не только про китайцев. Просто они додумались мейкап массово в технику зашить.
>>1418964 Кек, база. Просил эту чмоню зафьюжить 2 изображения. Копилот с Гроком с горем пополам хотя бы попытались. Этот сразу слился и 3 строчки извинялся.
Пикрил, как квинтэссенция процесса на основе личного опыта. Эмоции от «Спагетти» разноцветных ниточек и верёвочек ComfyUI, танцев с бубном вокруг LoRAs, комбинации samplers, schedulers и прочей требухи с кручением ползунков и жонглированием циферками просто непередаваемы.
Спору нет, инструмент предоставлен, возможности ранее невообразимые. Но какой же это всё-таки пердолинг в чистом виде каждый раз.
>>1419504 прикинь сколько комфи вскрыл целок девственников которые до этого нодовые интерфейсы в глаза не видели. да и вообще программы сложнее пейнта с вордом. но зов рисованной пизды неумолим и заставляет бедолг сидеть и вникать по 10 часов в день. но это больше про зоопарк моделей и работу с ними чем про непосредственно интерфейс.
>>1419600 а я хлопал в ладоши так как наконец-то толковый интерфейс с которым можно работать как человек и делать все что захочется, а не дрочить перегруженные менюшки ебобаные. автоматик это наивная и изначально провальная попытка впихать (как неумолимо оказалось) невпихуемое в один экран, со слайдерами шириной с полмонитора и сотнями разворачивающихся вкладок
До сих пор не понимаю почему никто не сделал LLM-агента, клепающего лапшу по запросу. У комфи же такой простой для ии json-формат воркфлоу. Нужно только как-то создавать эмбеддинг тех нод, что установлены у пользователя и всё. Думаю, даже файнтюн или лора не требуется, чтобы залочить ответы ллм в рамках формата и типов данных комфи.
>>1419594 >прикинь сколько комфи вскрыл целок девственников которые до этого нодовые интерфейсы в глаза не видели Блять, ну лучше ноды, чем ООП и сидеть дрочить поля классов и дипенденси инжекшены настраивать. Вот тогда бы девственники точно вскрылись.
>>1419770 ясен хуй лучше у любой модели в описании висит длиннющая инструкция как это дерьмо запускать и настраивать в консоли, и ты каждый раз выдыхаешь зная что тебе это нахуй все не надо делать потому что за тебя все уже сделали в комфи или этузиасты типа киджая. но не, люди не ценят и тупо повторяют как попугаи "ыыы лапша, лапша", потому что блять лапша это то что они каждый день в своей нищей жизни видят на завтрак обед и ужин потому что кредит за видяху надо выплачивать с зарплаты сторожа автостоянки
>>1420645 >>1420157 Evanna Lynch was 19 years old when Harry Potter and the Deathly Hallows: Part 2 was released in 2011. She was born on August 16, 1991, and was 18 when she filmed Part 1 (2010) and turned 19 during the filming and release of Part 2 на этом фото например ей 19, вперед, вас ничего не сдерживает. гуглите сами если мне не верите.
Анон, какие там требования по железу? Хочу картинки генерить. вот что-то похожее на это >>1420723. Сколько подобное будет генерироваться на 4060 например? Проц и опера какую-то роль играет или все только на карте?
>>1420894 >Сколько подобное будет генерироваться на 4060 например? Подобное делают на квене/ване, стаблы банально не сумеют в такое количество мелких деталей, а поэтому... >Проц и опера какую-то роль играет или все только на карте? Считай что половина будет на проце и озу, и то если это 4060ти 16гб
>>1420977 Что-то онлайновое? В любом случае стаблы такое не смогут - два прорисованных персонажа + детальное окружение не про них. А только стаблы влезут в 4060 целиком.
>>1421777 Блин, я несколько раз обращал на них внимание и мне было норм. А сейчас посмотрел и да, косяк. Надо выдерживать паузу перед публикацией, чтоб свежим взглядом смотреть
Хочу сделать фейковую косплеершу на базе Qwen и есть вопрос, как лучше тренировать: - сделать набор лор на ирл косплеерах и смешивать по настроению - попробовать файнтюнить сразу модель
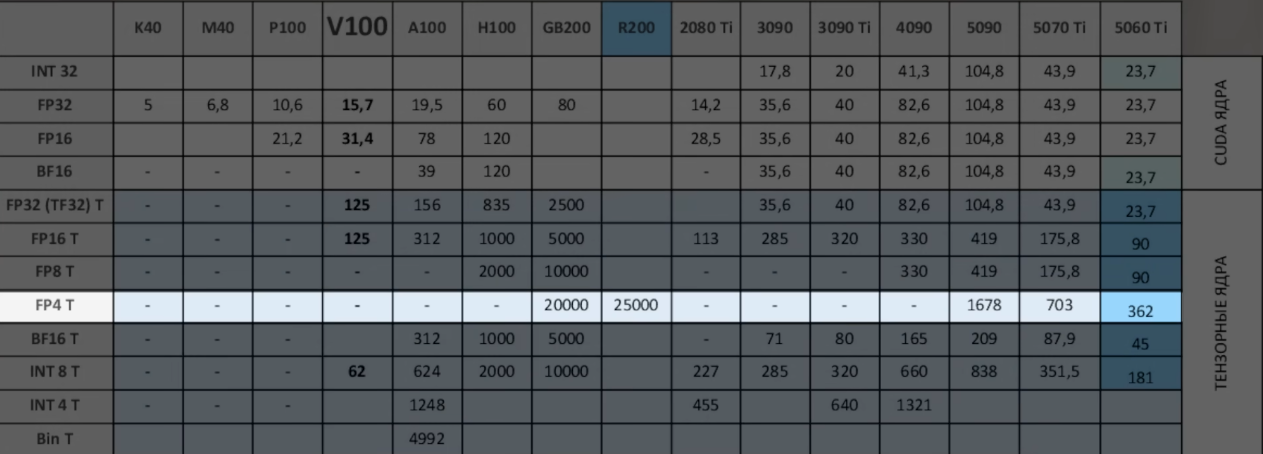
Че по тесле v100 16гб, есть смысл брать? там получается довольно дешево, но она не поддерживает fp8 например и много чего еще. Насколько все это критично для генерации картинок и 3д моделек?
>>1422835 Пока смотрю не очень спешат ответить на твой вопрос. А мне не хватает компетенции. Надеюсь, что тебе подскажут более подробно.
Сначала хотел что-то FP8 (и FP4 5000-й серии GeForce) пофантазировать. Но, боюсь с этим ошибиться. Есть ещё FP16, которые на V100 заведутся.
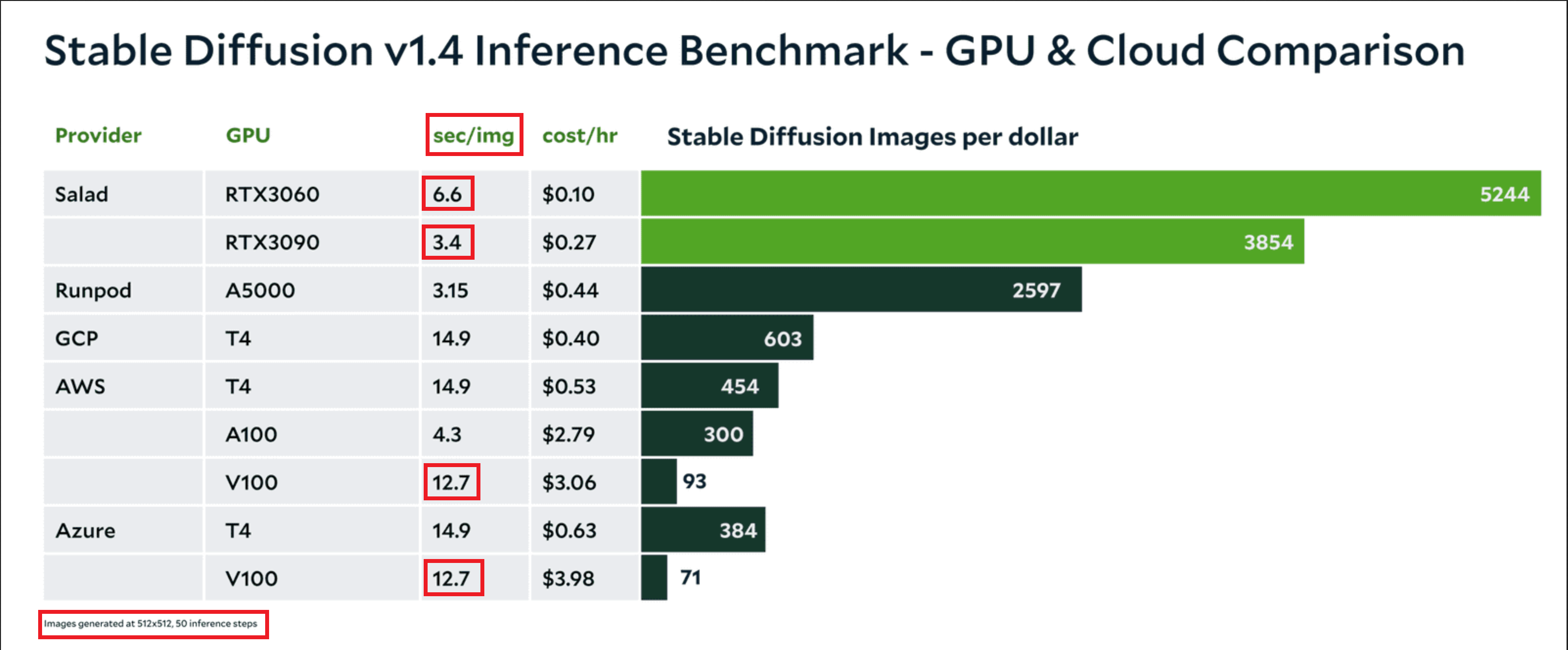
Пошёл по другому пути. Стал искать хоть какие-нибудь бенчмарки. Ничего особо дельного не нашёл (не там искал, возможно). Накопал старый, ещё для SDXL 1.4 от 21 августа 2023 года: https://blog.salad.com/stable-diffusion-gpu-benchmark-v1-4/ Привожу оттуда пикрил. Если верить этим сведениями, то обрати внимание на столбец, где указано время, затраченное на генерацию изображения в секундах. Это очень древняя модель, но даже там, получается, V100 сливает даже бюджетным потребительским видеокартам.
Вообще, как я слышал, это не сильная сторона V100. Её берут под обучение моделей и, вроде бы, под текстовые LLM.
>>1422846 Я только вкатываться решил и тут вижу эти карты дешево. Выглядит как крутой бюджетный вариант (у меня сейчас 2060супер на8гб, сомневаюсь, что на ней что-то можно делать), альтернатив по цене v100 особо не наблюдаю. Но с ней много нюансов, будем ждать сведущего анона. Хочется услышать насколько все плохо. Переплачивать в 5раз за 5060ти16гб желания мало.
Но судя по твоей картинке все вообще печально в два раза хуже 3060 это несерьезно.
>>1422848 Для генерации картинок\видео теслы не подходят, они слабые. SD1.4 генерировала 512х512, а сейчас в ходу SDXL с 1024х1024, так что время еще больше будет
>>1422963 Резанул по больному, сука. Доебал своп, практически поехал уже в ДНС, чтобы докинуть до 64Гб, но в последний момент отвлекли. Вспомнил про это в следующий раз спустя месяц и охуел от цен. Так и остался терпилой с 32Гб.
>>1423274 Ебать, я тоже чёт упустил этот момент. Схуя? Вот у меня в закладках была, полгода откладывал с завтраков по 1 в месяц, думал щас за 6к куплю ХОТЯБЫ ддр4 3200 ССАНЫХ. Какие в 2 раза, это в 3. Пиздец. Что случилось? Снова трамп хуиту намутил?
Была ситуация с видяхами, помните? Так же раза в 3-4 взлетели. Долбоёбы даже покупали за оверпрайс в кредит за почку. 600к за 3090 ахахахнах))00, потом хуяк и он буквально через полгода стали стоить даже дешевле в среднем по рынку, чем были до спекуляций.
>>1422848 Ты за свет в итоге больше переплатишь за пару лет, посмотри на потребление энергии и на скорость генерации >>1422846. 5060 Ti довольно экономичная, на уровне 3060 примерно. А с помощью Нунчаков ты сможешь даже что-то в свои 8 Гб засунуть. Не фонтан и ограничения есть, но результат будет. По-моему, V100 не вариант конкретно для этой задачи, особенно, если у тебя основного рига нет универсального.
>>1423263 Зачем тебе мое на компе? Очевидно, это хорошая архитектура для больших корп-моделей, куда знания свалено очень много обо всем на свете. Но зачем тебе огрызки этого знания и компьюта в локале в виде условных 100б? Лучше специализированная плотная модель.
>>1423510 Мое как раз влезет в 32врам+64озу и будет быстрей и умней плотной, т.к. та влезет в такой конфиг максимум на 50б и скоростью меньше раза в 2. Очевидный выбор очевиден.
>>1423537 Влезет-то может и влезет, но будет ли она выигрывать у специализированной модели даже с меньшим количеством параметров? Может сейчас с этими мое набалуются и поймут, что лучше старый-добрый денс именно на локалах и выпустят что-то актуальное, чем старые тупые динозавры. Ну или количество экспертов порежут до 2-3.
>>1423510 > Но зачем тебе огрызки этого знания и компьюта в локале в виде условных 100б? Лучше специализированная плотная модель. А ты не очень умный, да?
Что за пиздец с edit моделями в задаче удаления одного из объектов. Про банану вообще молчу - эта хуита не только лицо по пизде пускает, но и постоянно сдвигает идеально подогнанное изображение. То же самое, но чуть лучше, происходит с qwen edit на lightning 4/8. Все три варианта при этом хорошо убирают, отлично зарисовывают новую область. Kontext с нунчакой и без и Qwenn Edit без лор отлично сохраняют лицо и положение, но при этом оставляют размазанную хуйню на месте удаленного объекта. Что за ебота. Как работать?
>>1423674 Разве между ними есть разница кроме добавленных функций? Но у меня как раз только 2509 скачан, хуйня хуйней для задач с лицами или где нужно сохранить изначальную текстуру. Годится для стилизации и прочих задач. >>1423650 Не понял идею, как оно поймет что зарисовывать, если ты сам зарисуешь так, что оно будет сливаться? Я пробовал контрастным цветом зарисовывать, работает, но текстура бекграунда от этого лучше не стала в варианте без лор.
>>1423690 Идея в том, чтобы поменять промпт на "восстанови фон" вместо "удали объект". Может, он это лучше делает. И, может, проблема как раз в контрастности.
>>1423631 Мне попадалась какая-то специальная Лора для устранения сдвига на цивит. Я тогда посчитал что она мне не нужна, а теперь найти не могу. Или это на гитхабе было? Или не Лора? Хз. Именно устранение сдвига. Если найдешь напиши в треде.
>>1423631 > оставляют размазанную хуйню Лоры на реалистик и детализацию. Квен почти догоняет Флюкс и точно обгоняет Ван по детализации. > Как работать? Лоры накатить на консистентность? Квен лица лучше чем лоры сохраняет.
>>1423748 > solve_the_image_offset_problem_of_qwenimageedit Бля, квен так делает когда разрешение референса отличается о разрешения генерации. А стандартная нода скейлит референс к 1024 по умолчанию. >>1423748 > Боюсь от пикчи вообще ничего не останется Часть лор на реалистик наоборот повышают консистентность, потому что тренятся на мыле в референсе.
>>1423774 >Часть лор на реалистик наоборот повышают консистентность, потому что тренятся на мыле в референсе. Не понимаю как это может быть, звучит против логики. Дай такие лоры.
>>1423818 >навернуть лору на посторонний стиль, чтобы сохранить стиль и само изображение >ряяя у тебя что-то с логикой не то, твоя не совпадает с моей манялогикой, которую я объяснить логически не в состоянии
pro - коммерческая лучшая апи flex - коммерческая с кастомизируемыми параметрами апи dev - некоммерческая открытая klein - скоро выпустят дистил под apache 2