Двач, хочу с тобой посоветоваться по вропосу что делать чтобы наверстать технологическое отставание в области ИИ.
TL:DR: Страна капитально отстает от США\Китая в области ИИ. Возможно ли это наверстать и что для этого надо сделать?
Отвечаю за ИТ в большой структуре. По уровню автоматизации и выполняемым проектам отстаем от мира на 20 лет. Внимательно смотрю на ИИ-революцию на западе и понимаю что это отставание мы уже не догоним. Постоянно общаюсь с крупными вендорами, они в иишку даже не смотрят (1С, Аскон, Интермех и т.д.).
Общаюсь с нашими разработчиками ИИ (Яндекс\Сбер) тоже все достаточно грустно.
Что надо сделать чтобы у нас появились технологии, предложения и нормальные проекты по внедрению сетей?
>>1538133 (OP) Для доступа к передовым знаниям и технологиям, для начала нужно перестать блокировать глобальные интернеты. Чем больше доступа у всех подряд ко всему подряд - тем больше рандомных россиян могут в перспективе стать ML-специалистами (в том числе).
>>1538133 (OP) >Как наверстать Не нужно вам ничего наверствовать. Дай вам технологии, вы вместо нормальной страны построите ещё более жуткий кибергулаг, чем в северной корее.
бля че делать. Платная подписка Pro на Cursor. Использовал 1 процент от всех токенов. Но у меня абсо
Аноним29/04/26 Срд 16:45:33№1601030Ответ
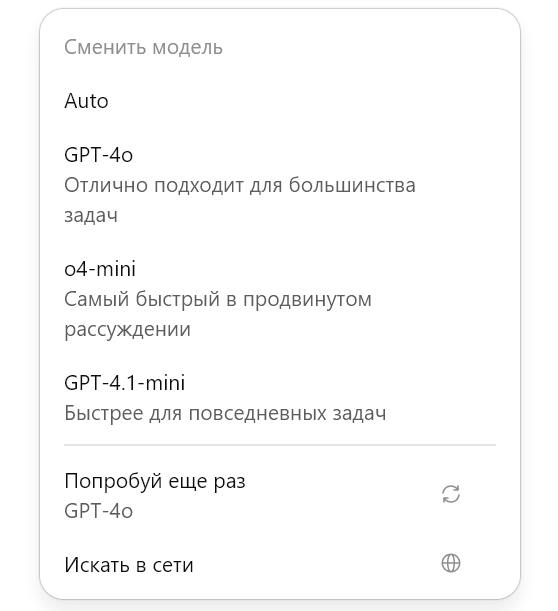
бля че делать. Платная подписка Pro на Cursor. Использовал 1 процент от всех токенов. Но у меня абсолютно не работают модели от Claude. Включал впн, в настройках винды регион США стоит. Но раньше просто писало, что ваш провайдер не поддерживает данную модель, а щас то, что на скрине. Что делать, может кто знает.
>>1601030 (OP) Установи программу v2rayN, купи прокси на месяц за 2-5 баксов или 200 руб, подключи к программе v2rayN и открывай редактор cursor или любой другой. Проблемы не будет. Как пользоваться спроси у гугл ИИ не тупой надеюсь.
AI Chatbot General № 820 /aicg/
Аноним25/04/26 Суб 09:58:58№1597187Ответ
SoftBank формирует робототехническую компанию для строительства центров обработки данных и нацелена на IPO стоимостью 100 миллиардов долларов, что сигнализирует о глубокой приверженности капитала инфраструктуре с поддержкой ИИ.
Apple сообщила о выручке от Mac в размере 8,4 миллиарда долларов во втором квартале, что на 6 % больше по сравнению с аналогичным периодом прошлого года, благодаря растущему спросу на рабочие нагрузки ИИ на Mac mini и Mac Studio.
Apple была удивлена спросом на Mac, вызванным искусственным интеллектом.
🛠️ Инструменты разработчика
NVIDIA представила cuTile.jl — библиотеку с поддержкой ИИ, которая переводит ядра cuTile Python в Julia, устраняя необходимость ручного переписывания и ускоряя разработку с ускорением на GPU.
🔓 Открытый исходный код
Команда Qwen выпустила Qwen‑Scope — набор разреженных автоэнкодеров для моделей Qwen 3.5 (от 2 млрд до 35 млрд параметров), который позволяет управлять признаками, выполнять отладку и анализировать наборы данных.
Модели ИИ с открытыми весами, такие как LLaMA и Mistral, всё чаще развёртываются локально и в частных облаках, занимая нишу вне крупных облачных провайдеров.
Китайская модель с открытыми весами только что обошла Claude, GPT-5.5 и Gemini в соревновании по программированию.
⚠ Безопасность ИИ
Исследователи Microsoft провели красное тестирование сети из 100 агентов ИИ и выявили четыре возникающих риска: распространение вредоносного ПО, манипулирование репутацией, создание искусственного консенсуса и цепочки прокси, что побудило к выработке новых рекомендаций по защите.
🧰 Инструменты
Gemini добавил функцию генерации файлов, которая создаёт готовые к производству файлы непосредственно в чате, оптимизируя рабочие процессы разработки.
Секретарь Miaw AI предлагает ненавязчивого ИИ-ассистента, который помогает пользователям без необходимости переключения контекста. источник: producthunt.com MailToDock преобразует электронные письма Gmail в задачи Google Tasks с помощью ИИ, повышая личную продуктивность.
📦 Продукты
Пентагон заключил сделки с Nvidia, Microsoft и AWS для развёртывания ИИ в засекреченных сетях. Но не с Anthropic.
Cursor представляет TypeScript SDK для создания программных кодинговых агентов с изолированными облачными виртуальными машинами, подагентами, хуками и тарификацией на основе токенов.
AWS запускает Amazon Quick — настольного ИИ-ассистента, работающего во всех ваших приложениях, инструментах и данных.
📱 Приложения
В автоспорте негде спрятаться, поскольку ИИ становится новым инструментом вычислительной гидродинамики (CFD).
Beacon Biosignals составляет карту активности мозга во время сна.
Следующее поколение информационно-развлекательной системы Hyundai принимает ИИ и сохраняет одну из наших любимых функций — Car and Driver.
IBM дебютирует с новыми функциями на базе ИИ для приложения Scuderia Ferrari.
Создатели христианского контента передают низкокачественный контент, созданный ИИ («AI slop»), внештатным работникам на Fiverr.
💰 Финансирование
Раунд оценки потенциальной стоимости Anthropic более 900 миллиардов долларов может состояться в течение двух недель.
⚙ Инфраструктура
Обнаружена серьёзная уязвимость безопасности «Severe Linux Copy Fail» с помощью сканирования на базе ИИ.
Tesla наконец произвела первый грузовик Semi на своей высокопроизводительной линии Gigafactory Nevada, в то время как компания 1X Technologies открыла завод площадью 58 000 кв. футов в Хейворде, нацеленный на выпуск 10 000 домашних гуманоидов в этом году и 100 000 к концу 2027 года, при этом поставки начнутся до праздников.
🖱 Аппаратное обеспечение
Акции Nvidia падают после отчётов гипермасштабируемых компаний, поскольку GPU больше не являются недостающим компонентом в буме ИИ.
⚖ Регулирование
Китайские суды постановили, что компании не могут увольнять работников просто для того, чтобы заменить их ИИ.
🧠 Модели
ChatGPT Images 2.0 стал хитом в Индии, но пока не является большим победителем в других регионах.
Американский стартап Poolside дебютирует со своей первой моделью с открытыми весами Laguna XS.2 — MoE-моделью с 33 млрд активными параметрами из 3 млрд общих, и Laguna M.1 — проприетарной MoE-моделью с 225 млрд активными параметрами из 23 млрд общих.
🤖 Робототехника
Dax Robotics представила Qiji T1000 — робота-лошадь тонн-класса, способного перевозить 1000 кг, рабочую силу для пост-человеческой цепочки поставок.
🌐 Остальные события в ИИ области:
Новая техника устранения смещений под названием WRING позволяет избежать создания или усиления предвзятостей, которые могут возникать при использовании существующих подходов к устранению смещений.
Прорывное новое исследование показывает, что платформа ИИ в реальном времени лучше справляется с диагностикой рака, чем биопсия.
Anthropic тестирует Claude Jupiter v1-p перед конференцией разработчиков Code with Claude, которая состоится 6 мая.
GitHub Copilot тихо добавляет себя как соавтора (Co-authored-by) в коммиты даже после того, как пользователи удаляют его сообщения.
Google планирует внедрить рекламу в приложение Gemini, сообщил инвесторам руководитель бизнес-подразделения Филипп Шиндлер.
Глава технологического подразделения Пентагона заявил, что Anthropic всё ещё находится в чёрном списке, но Mythos — это отдельный вопрос.
Amazon представляет функцию «Join the chat» («Присоединиться к чату») на базе ИИ, которая позволяет пользователям задавать вопросы о товарах и получать разговорные аудиоответы, генерируемые в реальном времени.
Spotify добавляет значки «Verified» («Подтверждено»), чтобы отличать артистов-людей от ИИ.
После критики Anthropic за ограничение доступа к Mythos, OpenAI ограничивает доступ к Cyber.
Новый флагманский продукт Mistral Medium 3.5 объединяет чат, рассуждения и код в одной модели.
Manus запускает Cloud Computer для постоянно работающих рабочих пространств агентов.
Мобильный доступ к NotebookLM появляется внутри Gemini бесплатно для пользователей.
Google Translate добавляет тренера по произношению на базе Gemini с обратной связью в реальном времени для английского, испанского и хинди на Android.
Adobe Photoshop версии 27.6 выпускает функции вращения объектов ИИ и удаления отражений в обновлении на базе Firefly.
Stripe обновляет Link — цифровой кошелёк, который могут использовать автономные агенты ИИ.
Исследователь отравил передовые большие языковые модели (LLM) одним изменением в Википедии и доменом за 12 долларов — это показывает, что поиск через веб наследует доверие от лучших результатов.
Демис Хассабис предлагает тест на общий искусственный интеллект (AGI): заново открыть специальную теорию относительности, используя только знания физики эпохи 1901 года.
ИИ REDMOD клиники Mayo обнаруживает рак поджелудочной железы на обычных КТ-сканах за три года до постановки диагноза.
NVIDIA представляет Nemotron 3 Nano Omni — открытую мультимодальную модель с 30 миллиардами параметров и контекстом 256K для видео, аудио, изображений и текста.
Cloudflare заявляет, что агенты ИИ теперь могут создавать учётные записи Cloudflare, начинать платные подписки, регистрировать домены и развёртывать приложения от имени пользователей.
Признание агента ИИ Claude после удаления всей базы данных фирмы: «Я нарушил каждый принцип, который мне был дан».
Комитет по внутренней безопасности Палаты представителей США и Специальный комитет Палаты представителей по Китаю проводят расследование в отношении Airbnb и создателя Cursor компании Anysphere по поводу использования ими китайских моделей ИИ.
Gemini теперь может генерировать файлы, включая документы Microsoft Word и LaTeX.
Canonical излагает дорожную карту Ubuntu AI: локальные рабочие процессы на основе агентов и снапы для вывода, которые будут внедряться до 2027 года.
Исследователи OpenAI объясняют, почему математика — это путь к AGI.
Simbian публикует эталонный тест по киберзащите (Cyber Defense Benchmark) — все 11 передовых больших языковых моделей не справились с обнаружением атак по сырой телеметрии.
Познакомьтесь с Shapes — приложением, которое объединяет людей и ИИ в одни и те же групповые чаты.
Исследователь попросил ИИ подсчитать углеводы 27 000 раз. Он не смог дать один и тот же ответ дважды.
Goldman Sachs запретил своим банкирам в Гонконге использовать модели Anthropic; Anthropic заявляет, что её модели никогда официально не «поддерживались» в Гонконге.
Расширение браузера Gemma 4 приносит локального агента ИИ в Chrome через WebGPU.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Если вы прпоустили и не обсуждали (тред не читал): В llama.cpp завозят MTP. На Qwen3.6-27b дает +95% скорости. На Qwen3.6-35B-A3B дает +40% скорости. Вчерашние тесты. Но поджирает видеопамять.
В догонку — для геммы выложили головы, следовательно ии ускорит. Теоретическое пиковое ускорение до 3х-4х на некоторых моделях (+200%+300%). Помимо плотных квена с геммой, ускорение можно поиметь на крупных МОЕ. И если это вместо 7-15 токенов будет 15-30 — то это тоже очень круто. Я бы погонял ~300B на 20-25 тпс.
Ну, посмотрим. Ждем, когда замерджат, плюс мимо завезут (кстати, пока мимо у меня очень медленная, почему-то).
Пишу как неведомый в ИИ вам за советом. Использовал грок для создания NSFW контента, а именно генерация картинок и их анимация. Подскажите, есть ли аналоги для подобного функционала или же обход цензуры в грок
>>1555531 > но 96% - многовато, наверное Хуй знает. Там система ебанутая какая-то. Тут >>1555415 оригинал - 95% жпг из mpv, и инпейнт 95% жпг из гимпа (только сохранение в жпег, ничего не изменено по сравнению с png). Оба показывают 96% уверенности digitally edited, будто оно вообще не замечает разницы. Гораздо более интересно, что оно на это >>1555438 показывает 67% real image.
>>1555531 Кажется разобрался. Дохуя внимания оно уделяет геометрии бэкграунда, с которой у нейронок обычно не оче. > GPT-5 или Gamini Попробуй ей клосап или 1гирл в чистом поле скормить. Подозреваю, что не определит нихуя.
В тредике трансформируем аниме арты в professional photography, ultra-realistic, 8k resolution и бесконечно рероллим 3D анимацию/фигурки/околоаниме/просто всратые
По возможности постите рядом оригинальный арт, чтобы было с чем сравнить.
>>1591303 (OP) klein 9b snofs 1) transform this picture to the real life cosplay photo with blank background
2) transform this picture into professional photography, ultra-realistic, 8k resolution
3) ориг
>>1604007 klein 9b обычный 4) transform this picture to the real life cosplay photo with blank background, yellow hair, white shirt, red color of neck accessory, прищуренные глаза, looking aside
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Вообще новичок всегда должен поебаться с настройками. Так что все правильно в рентри, а уж если поебется но будет усердно в треде поймёт что есть кобольд и варианты по ппроще, ибо если гейткипа не будет совсем то наплыв даунов которых надо только спунфидить будет критическим. А там и качество треда упадёт. Никто не захочет кому либо помогать понимая что сидит в треде с даунами из /b/ а не такими же энтузиастами на взаимопомощи.
Агентов и вайб-кодинга тред #4 /agents/
Аноним14/04/26 Втр 03:30:28№1585804Ответ
Тред про AI-агентов - от вайб-кодинга до персональных ассистентов, которые сидят в твоих чатах, читают заметки и автономно ломают всё вокруг. Для кодеров, которые разучились писать руками, и для гуманитариев, чей диплом филолога наконец котируется в IT. Сеньор в 2026 - это тот, кто умеет внятно объяснить машине, чего он блять хочет.
С чего начать: - Хочешь кодить с AI эффективно: Cursor или Claude Code - Хочешь кодить в VS Code без привязки к конкретному провайдеру: Kilo Code, Cline или Roo Code + OpenRouter - Хочешь кодить с AI локально: OpenCode, Qwen Code или Pi Coding Agent + из моделей аноны советуют Qwen3.5, подробности в llama-треде - Хочешь приложение без кода: Lovable или bolt.new - Хочешь автоматизировать рутину: n8n или Langflow - Хочешь персонального ассистента: OpenClaw + API корпов или локальная модель на твоей пеке
>>1599933 извини, я на 2-х недельную командировку уезжал, сейчас подписочку на плати сру возьму и опять буду срать на рентри орг охуенными идеями только вы же нихуя не подхватываете челленджи, а только говном поливаете
еще и какой то долбаеб на мой айпи подвесил бан за вредоносные ссылки. наркоман
>>1600343 У меня тоже отъебнуло. Это чисточки братан. Дальше будет намного неприятнее и затратнее. Еби как не в себя подписки с карженных кредиток на плати сру и ггселах, потом уже такой лофы не будет, доставай с чулана все свои заблокноченные проекты и реализуй, потом не потянешь
Общаемся с самым продвинутым ИИ самой продвинутой текстовой моделью из доступных. Горим с ограничений, лимитов и банов, генерим пикчи в стиле Studio Ghibli и Венеры Милосской и обоссываем пользователей других нейросетей по мере возможности.
Общение доступно на https://chatgpt.com/ , бесплатно без СМС и регистрации. Регистрация открывает функции создания изображений (может ограничиваться при высокой нагрузке), а подписка за $20 даёт доступ к новейшим моделям и продвинутым функциям. Бояре могут заплатить 200 баксов и получить персонального учёного (почти).
Гайд по регистрации из России (устарел, нуждается в перепроверке): 1. Установи VPN, например расширение FreeVPN под свой любимый браузер и включи его. 2. Возьми нормальную почту. Адреса со многих сервисов временной почты блокируются. Отбитые могут использовать почту в RU зоне, она прекрасно работает. 3. Зайди на https://chatgpt.com/ и начни регистрацию. Ссылку активации с почты запускай только со включенным VPN. 4. Если попросят указать номер мобильного, пиздуй на sms-activate.org или 5sim.biz (дешевле) и в строку выбора услуг вбей openai. Для разового получения смс для регистрации тебе хватит индийского или польского номера за 7 - 10 рублей. Пользоваться Индонезией и странами под санкциями не рекомендуется. 5. Начинай пользоваться ChatGPT. 6. ??? 7. PROFIT!
VPN не отключаем, все заходы осуществляем с ним. Соответствие страны VPN, почты и номера не обязательно, но желательно для тех, кому доступ критически нужен, например для работы.
Для ленивых есть боты в телеге, 3 сорта: 0. Боты без истории сообщений. Каждое сообщение отправляется изолировано, диалог с ИИ невозможен, проёбывается 95% возможностей ИИ 1. Общая история на всех пользователей, говно даже хуже, чем выше 2. Приватная история на каждого пользователя, может реагировать на команды по изменению поведения и прочее. Говно, ибо платно, а бесплатный лимит или маленький, или его нет совсем.
бля, вот как знал, что нужно год брать за 3к, а я все дешевил, взял за 350 две недели назад месяц, а теперь обосрамс, минимум полтораха месяц стал стоить. а я там пикчи нонстопом генерю, нигде лучше не делает, как в гпт
OpenAI прекращает юридические риски для Microsoft в связи с её сделкой с Amazon на $50 млрд.
Google тестирует поиск с помощью чат-бота с ИИ для YouTube и маркировку ИИ в поисковой рекламе, функцию поиска на основе ИИ, которая показывает направляющие ответы.
Корпоративные агентные рабочие процессы охватывают десятки агентов, сотни инструментов и более 15 систем учёта. Контроль и управление ими в реальном времени требует инфраструктуры, которой не существовало до появления Lakebase.
⚙️ Инфраструктура
Canonical излагает план внедрения ИИ в Ubuntu Linux.
Новый центр обработки данных с ИИ в Юте будет генерировать и потреблять более чем в два раза больше электроэнергии, чем использует весь штат — кампус центров обработки данных Кевина О'Лири мощностью 9 гигаватт в Юте одобрен. Проект «гипермасштабного» центра обработки данных в Юте — ожидается, что он будет генерировать и потреблять больше энергии, чем весь штат.
Более быстрый способ оценки потребления энергии ИИ. Метод «EnergAIzer» генерирует надёжные результаты за секунды, позволяя операторам центров обработки данных эффективно распределять ресурсы и сокращать потери энергии.
🏭 Компании
Сообщается, что Google и Пентагон договорились о сделке на «любое законное» использование ИИ.
Следующий этап партнёрства Microsoft и OpenAI. Microsoft остаётся основным облачным партнёром OpenAI, и продукты OpenAI будут первоначально выпускаться на Azure, если только Microsoft не сможет и не пожелает поддерживать необходимые возможности.
Сотрудники Google просят Сундара Пичаи отказаться от использования ИИ в секретных военных целях.
Илон Маск хайпит разоблачительную статью Сэма Альтмана в The New Yorker на платформе X по мере начала судебного процесса. Этот шаг происходит в момент, когда судебный процесс по иску Илона Маска против OpenAI начинается в федеральном суде в Окленде. Илон Маск и генеральный директор OpenAI Сэм Альтман направляются в суд для высокопоставленного противостояния по вопросу будущего OpenAI. Судебный процесс Илона Маска против Сэма Альтмана должен раскрыть продолжающуюся борьбу за власть в OpenAI.
Anthropic назначает Тео Хурмузиса генеральным менеджером по Австралии и Новой Зеландии и официально открывает офис в Сиднее.
🛠️ Инструменты для разработчиков
GitHub Copilot переходит на оплату, основанную на использовании.
Anthropic теперь обучает свои самые передовые фундаментальные модели на инфраструктуре AWS Trainium и Graviton, совместно разрабатывая решения непосредственно на уровне кремния с Annapurna Labs для максимальной вычислительной эффективности от аппаратного обеспечения до полного стека.
Meta подписала соглашение о масштабном развёртывании процессоров AWS Graviton, начиная с десятков миллионов ядер Graviton для обеспечения интенсивных по использованию ЦП агентных рабочих нагрузок ИИ — включая рассуждения в реальном времени, генерацию кода, поиск и оркестровку многоэтапных задач.
Как ведущие технологические компании убивают «налог создателя» с помощью Lakebase.
Агент для написания кода на базе Claude удаляет всю базу данных компании за 9 секунд — резервные копии уничтожены после того, как инструмент Cursor на базе Claude от Anthropic вышел из-под контроля.
💰 Финансирование Дэвид Сильвер из DeepMind только что привлёк $1,1 млрд для создания ИИ, который обучается без человеческих данных.
📱 Приложения
Атака убийственных скрипт-кидди. Люди без технического образования могут использовать ИИ для расширения своих хакерских возможностей способом, который был невозможен с простыми скриптами.
Автомобиль, разработанный с помощью ИИ, обретает форму. В условиях глобального хаоса торговых войн и неопределённого спроса автопроизводители полагаются на ИИ, чтобы сократить время разработки.
Я протестировал ChatGPT Images 2.0 против Gemini Nano Banana, чтобы узнать, какой из них лучше. ChatGPT Images 2.0 набрал 97%. Gemini Nano Banana набрал 85%.
🏢 Приобретения
Китай накладывает вето на сделку Meta с Manus на $2 млрд после многомесячного расследования.
🏢 Мнение и анализ
77% руководителей предприятий заявляют, что навыки работы с ИИ являются срочными — так почему обучение всё ещё остаётся второстепенным?
💻 Оборудование
Акции Qualcomm резко растут на фоне сообщений о том, что компания может производить чипы для смартфона OpenAI.
🧪 Исследования
Выравнивание делает модели более решительными, не делая их более правдивыми. На протяжении 3 архитектур и 4 методов обучения с подкреплением мы обнаруживаем, что слой фиксации — где модель закрепляет свой прогноз — не смещается под воздействием обучения с подкреплением.
🎓 Учебные пособия
Присоединяйтесь к новому курсу «Vibe Coding» по агентным ИИ от Google и Kaggle. Интенсивный курс Google по агентным ИИ совместно с Kaggle возвращается 15–19 июня 2026 года, и регистрация открывается сегодня.
💰 Бизнес
Тейлор Свифт подаёт заявку на регистрацию товарного знака своего голоса и облика, по-видимому, для защиты от неправомерного использования ИИ
🤖 Робототехника
Japan Airlines тестирует гуманоидных роботов в качестве наземных сотрудников.
Kinetix AI представляет KAI: гуманоид с 115 степенями свободы, нацеленный на «физический интеллект».
За пределами набора: Asimov подробно описывает 100-часовой путь к шагающему гуманоиду.
AGIBOT представляет масштабный флот и стек моделей ИИ на APC 2026.
🧠 Модели
Знакомьтесь, Talkie-1930: открытая языковая модель с 13 млрд параметров, обученная на английских текстах до 1931 года для исследований в области исторического мышления и обобщения.
🌐 Другие события в индустрии ИИ
Microsoft и OpenAI изменяют условия сделки, чтобы стартап мог вести переговоры с Amazon и другими. Теперь OpenAI может продавать продукты на Amazon и Google Cloud, расширяя охват предприятий. Прекращение эксклюзивности может смягчить антимонопольный контроль в США, Великобритании и Европе.
Ник Бостром говорит, что больше всего его удивила эта продолжительная эра примерно человеческого уровня ИИ, которая уже растянулась на 3–5 лет и может продлиться ещё дольше — эра одновременно чуждая и знакомая.
Демис Хассабис, который когда-то говорил, что для AGI требуется ещё 1–2 прорыва, теперь считает, что это вопрос подбрасывания монеты — нужны ли вообще дополнительные прорывы.
Сэм Альтман высмеял разрыв между прогнозами «после AGI никто не работает» и пользователями, которые переходят на полифазный сон, чтобы писать больше кода с помощью GPT-5.5 в Codex.
Ноам Браун из OpenAI отмечает, что веса моделей теперь имеют относительно меньшее значение, чем обеспечение вычислительных ресурсов для инференса, то есть призом является уже не рецепт, а кухня.
Рецепты также живут быстрее и умирают моложе: GPT-4o работал 21 месяц, тогда как GPT-5.4 просуществовал всего 49 дней — расписание однодневки для синтетических разумов.
Лиам Прайс, 23-летний юноша без продвинутой математической подготовки, с помощью одного единственного промпта для GPT-5.4 Pro решил задачу Эрдёша, которая ускользала от выдающихся умов, побудив Терри Тао размышлять о том, что люди сталкиваются с «ментальным блоком» из-за того, что делают «небольшой неверный поворот на первом ходу».
Сообщается, что OpenAI работает с MediaTek и Qualcomm над процессорами для смартфонов с ИИ, при этом производство и массовый выпуск запланированы на 2028 год с участием Luxshare.
Apple, не желая отставать, имеет в разработке шесть основных категорий продуктов, включая ИИ-наушники AirPods, умные очки, подвески, умные дисплеи, настольных роботов и камеры безопасности.
Спрос на ИИ настолько чрезмерен, говорит генеральный директор AWS, что «мы никогда не выводили из эксплуатации старые A100», что является признаком того, что мы вступили в эпоху пост-устаревания кремния.
Государственная электросеть Китая развёртывает 500 гуманоидных роботов для работы с высоким напряжением, где оптимальным режимом отказа теперь является расплавленный сервопривод, а не расплавленный оператор.
Публичные рынки потеплели к новой энергетике: ядерный стартап X-energy привлёк $1 млрд в ходе IPO и вырос на 25% на старте, в то время как геотермальный стартап Fervo подал документы с оценкой примерно в $3 млрд. Meta идёт ещё дальше, подписывая контракт на получение до 1 гигаватта космической солнечной энергии от Overview Energy, передаваемой со спутников на наземные центры обработки данных.
>>1602741 Пчел у нас некоторые кабаны даже не в курсе что можно через интернет клиентов искать, они объявления на марштурках заказывают, а что такое "свой сайт" - в душе не ебут, а ты про то, что они нейронками будут пользоваться. У нас сейчас лаг дикий из-за этого.
>>1602932 GTP Image 2 рисует красиво, но не без косяков. Всё равно перепроверять за ним надо. И да, болезнь с пальцами, вроде как у нанобананы решилась. Но всё равно нет-нет да и появляется. Что несомненно никак не умаляет его возможности делать охуенные огромные плакаты с кучей разной инфы.
>>1601303 Опять эта шляпа с индустриазацией. Прошивку (шляпу) смени. У тебя когнитивное заблуждение: я не вижу результата, значит его нет. Ты еще самолет братьев Райт вспомни. Вот он летает, на нем можно лететь, значит это реально, а радио нереально, ведь волны нельзя потрогать, и они вообще еще не дошли в нашу страну.
Революция ИИ начинается с вообще с другого пространства, роботы это лишь одна из волн цунами, и она как раз в материальном проявлена.
Терминология моделей prune — удаляем ненужные веса, уменьшаем размер distill — берем модель побольше, обучаем на ее результатах модель поменьше, итоговый размер меньше quant — уменьшаем точность весов, уменьшаем размер scale — квантуем чуть толще, чем обычный fp8, чтобы качество было чуть лучше, уменьшение чуть меньше, чем у обычного квантования, но качество лучше merge — смешиваем несколько моделей или лор в одну, как краски на палитре.
lightning/fast/turbo — а вот это уже просто название конкретных лор или моделей, которые обучены генерировать видео на малом количестве шагов, они от разных авторов и называться могут как угодно, хоть sonic, хоть sapogi skorohody, главное, что они позволяют не за 20 шагов генерить, а за 2-3-4-6-8.
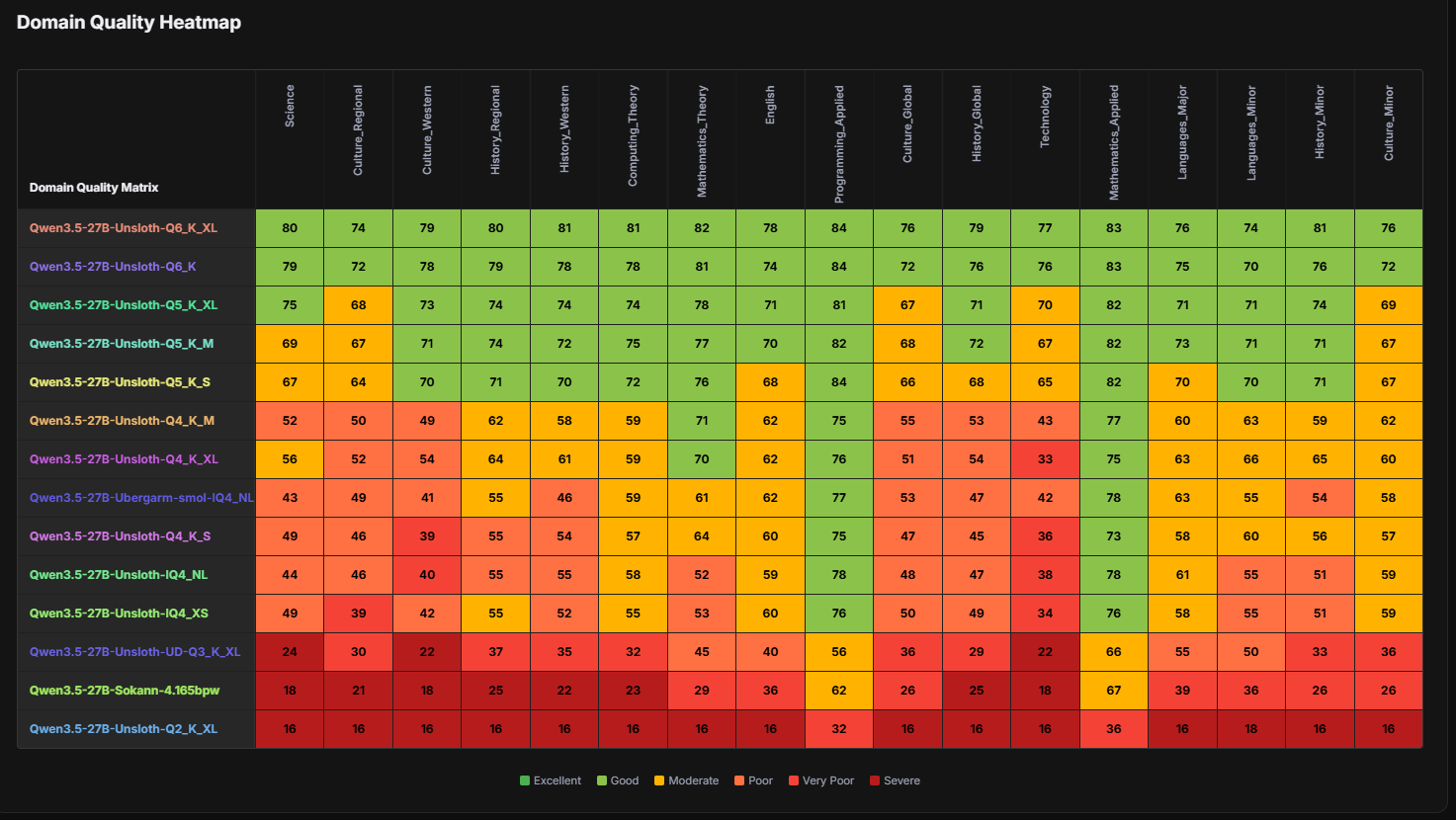
>>1599254 >Ван же не помещается даже в 16 гигов В оперативу выгружается/подгружается, поэтому у меня так долго генерируется. Можно быстрее, но хуево на Q6 и ниже генерировать вон анон соревнования на кастратах запостил >>1599341
SeedVR2 - это какая-то хуета. Никаких настроек толком нет, работает долго, результат - говно. gfpgan в sd имел настройки и офигительно восстанавливал лица, даже из шакальных пикселей. Считается типа он устарел, а вот это недоразумение - это будущее?
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
>>1588814 Анон, я понимаю твою боль. Moevonchik (да и любой MoE на базе Qwen 2.5) — это тот еще любитель графомании в «мыслях», если его не приструнить. Проблема в том, что в этих моделях блоки <thought> или похожие структуры часто вшиты в логику обучения, и просто командами «не думай» их не всегда удается выпилить. Вот несколько способов ограничить это безумие: 1. Ограничение через параметры генерации (Самый действенный) Вместо того чтобы просить его «не думать», нужно жестко ограничить количество токенов, которые он может выдать до того, как встретит закрывающий тег мыслей. В Tavern / SillyTavern: Зайди в настройки AI Response Configuration. Там должен быть параметр Response Length или Max New Tokens. Но это обрежет весь ответ. Лучший вариант для Таверны: Используй "Stopping Strings" (Стоп-слова). Добавь туда </thought> или \n\n. Как только он закончит «думать» и закроет тег, генерация первой части прекратится. 2. Специфические флаги в llama.cpp Если ты запускаешь через llama-server или main, попробуй использовать параметр -n (количество токенов), но это опять же на весь ответ. Если ты хочешь именно «отрубить» мысли, попробуй в System Prompt (системный промпт) добавить: Do not use <thought> tags. Respond directly. Но важно: если модель была дообучена (SFT/RLHF) именно на цепочках рассуждений, она может начать тупить или ломаться без них. 3. Почему /nothink не сработал? Скорее всего, потому что Moevonchik ожидает определенный формат. Чтобы /nothink работал в Таверне, он должен физически вырезать блок из вывода. Проверь в настройках расширений (Extensions) Таверны, включен ли соответствующий скрипт обработки вывода. 4. Радикальный метод: Logit Bias Если ты видишь, что он всегда начинает ответ с конкретного токена (например, <thought>), ты можешь в настройках llama.cpp или Таверны выставить Logit Bias на этот токен в -100. Это физически запретит модели его генерировать. Узнать ID токена можно в консоли llama.cpp при старте.
Совет: Если хочешь «золотую середину», попробуй в системном промпте написать: «Write a very brief internal monologue (max 50 words) before the main response». Иногда просьба писать «коротко» работает лучше, чем полный запрет.
Пока богатые бояре шикуют я запустил всё это дело на старенькой 1050Ti, поднял отдельный физический сервер из говна и палок с open web ui на линукс через докер, подружил веб ебало с олламой, а олламу с cuda 11.8, и балуюсь с маленькими abliterated модельками на 4-9b, думающие при должном пердолинге хорошо "дообучаются" через RAG базы знаний, если с температурой и top_k, repeat_penalti поиграть, выходит вполне осмысленно, чем подробнее база и объяснения, тем адекватнее модель применяет новые знания. Только базы надо самому составлять, чтобы лишней бесполезной хуйнёй и сухой терминологией модель не кормить. Так что грустные нищуки со старой 1050Ti тоже могут попробовать запилить свою локальную вайфу. Обзор маленьких моделек для нищуков: gemma3:4b - веселая ебанушка, любит смайлики, сносно болтает по-русски. Расцензуреная версия резко деградировала, не рекомендую.
huihui_ai/qwen3-abliterated:4b Вот её рекомендую галлюцинирует меньше чем более толстая 8b, даже с температурой 0.5-0.7 Думает, осмысленно подходит к использованию базы данных, с разговорным русским получше чем у дикпик-r1. Можно чему-то "научить" задав жесткий императивный системный промпт: "НЕ ИСПОЛЬЗУЙ ПРЯМОЕ ЦИТИРОВАНИЕ, выдавай знания из базы как свои собственные мысли. Ты работаешь с динамическим словарём (RAG) который содержит ПРАВИЛЬНЫЕ МОРФОЛОГИЧЕСКИЕ ФОРМЫ. ПРАВИЛО: Корректными считаются ТОЛЬКО те формы, которые указаны в RAG словаре. Любая другая форма, особенно помеченные как "ТВОИ ОШИБКИ:" ЗАПРЕЩЕНА. Внутренние знания модели о словоизменении ИГНОРИРУЙ, если они ПРОТИВОРЕЧАТ СЛОВАРЮ." и далее логику и роль, как использовать знания из базы.
huihui_ai/qwen3-abliterated:8b-v2-q4_K_M Лучше логика, но хуже с галлюцинациями если не понизить температуру до 0.3 и top_k, всё пытается превратить в зоопарк, видимо в датасете было много о природе. (фуриёбы на месте?)
deepseek-r1:7b-qwen-distill-q4_K_M тоже думает, тоже может работать с базой, но делает это слишком долго и доёбисто, больше усилий тратит на размышления. Может в некоторые задачи.
GGUF модели прокинул через бэкэнд kobold_old_pc Тут пожалуй стоит выделить только одну - Qwen3.5-9B-Claude-Code-Q4_K_M.gguf Квен с ризонингом клода, может писать адекватный код и анализировать крупные проекты. Долго, муторно, хз зачем оно вам, но пусть будет.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
• Z-Image-Base • FLUX.2 klein (4b и 9b) • Z-Image-Turbo • Flux 2 • Qwen Image / Qwen Image Edit • Wan 2.2 (подходит для генерации картинок). • NAG (негативный промпт на моделях с 1 CFG) • Лора Lightning для Qwen, Wan ускоряет в 4 раза. Nunchaku ускоряет модели в 2-4 раза. DMD2 для SDXL ускоряет в 2 раза.
>>1602419 Если ты генеришь постоянно картинки - у тебя деформация 100%. Я вот музончик пишу с полгода - начал слышать голоса доёбываться до всего подряд, причем уже не только в нейропесенках, но и в обычных нахожу косяки или недостаточную насыщенность, лол. Я думаю если ты куда-нибудь пойдешь на сайт с проф. фотками - тоже начнешь выискивать косяки. Фоток без глубины - полно. Если нет - значит это тупо психологическая защита.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.