ИТТ делимся советами, лайфхаками, наблюдениями, результатами обучения, обсуждаем внутреннее устройство диффузионных моделей, собираем датасеты, решаем проблемы и экспериментируемТред общенаправленныей, тренировка дедов, лупоглазых и фуррей приветствуются
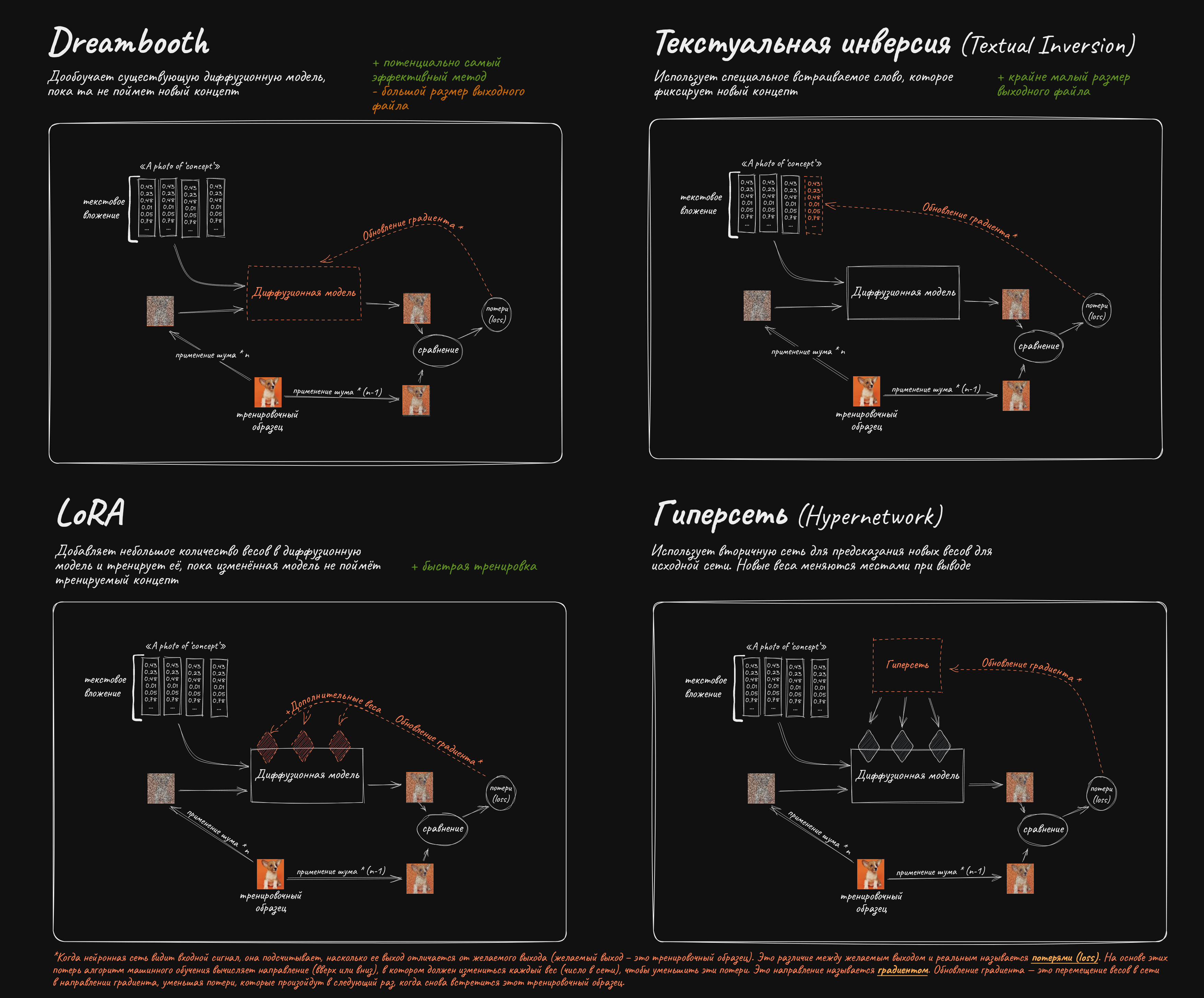
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ LoRA – "Low Rank Adaptation" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением. https://github.com/cloneofsimo/lora - изначальная имплементация алгоритма, пришедшая из мира архитектуры transformers, тренирует лишь attention слои, гайды по тренировкам: https://rentry.co/waavd - гайд по подготовке датасета и обучению LoRA для неофитов https://rentry.org/2chAI_hard_LoRA_guide - ещё один гайд по использованию и обучению LoRA https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - проект по созданию алгоритмов для обучения дополнительных частей модели. Ранее имел название LoCon и предлагал лишь тренировку дополнительных conv слоёв. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr, DyLoRA, IA3, а так же на последних dev ветках возможность тренировки всех (или не всех, в зависимости от конфига) частей сети на выбранном ранге: https://github.com/KohakuBlueleaf/LyCORIS
✱ Текстуальная инверсия (Textual inversion), или же просто Embedding, может подойти, если сеть уже умеет рисовать что-то похожее, этот способ тренирует лишь текстовый энкодер модели, не затрагивая UNet: https://rentry.org/textard (англ.)
➤ Тренировка YOLO-моделей для ADetailer: YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
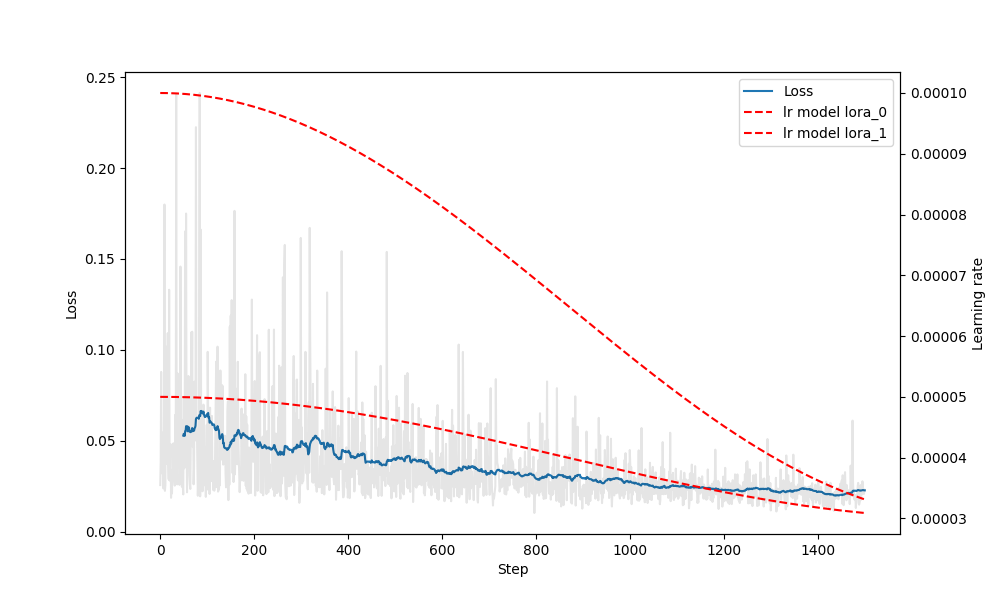
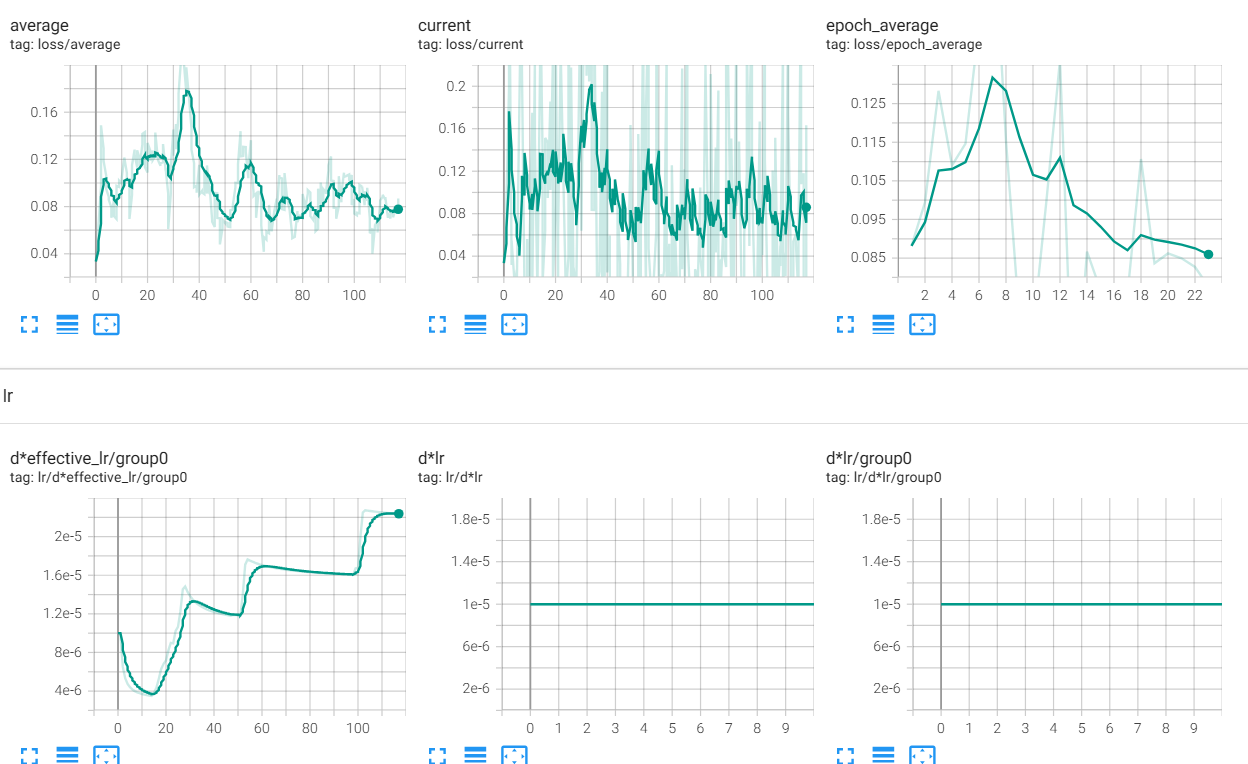
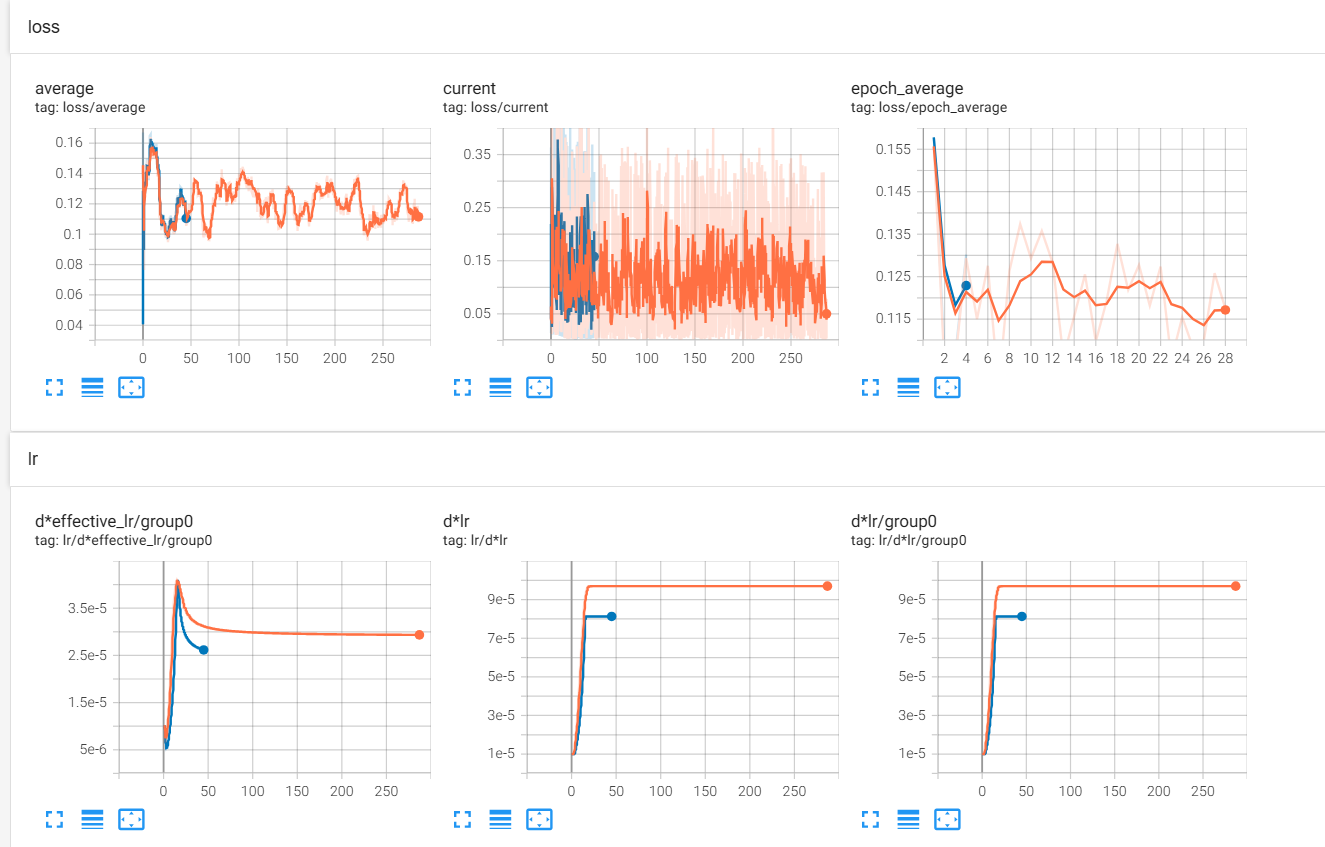
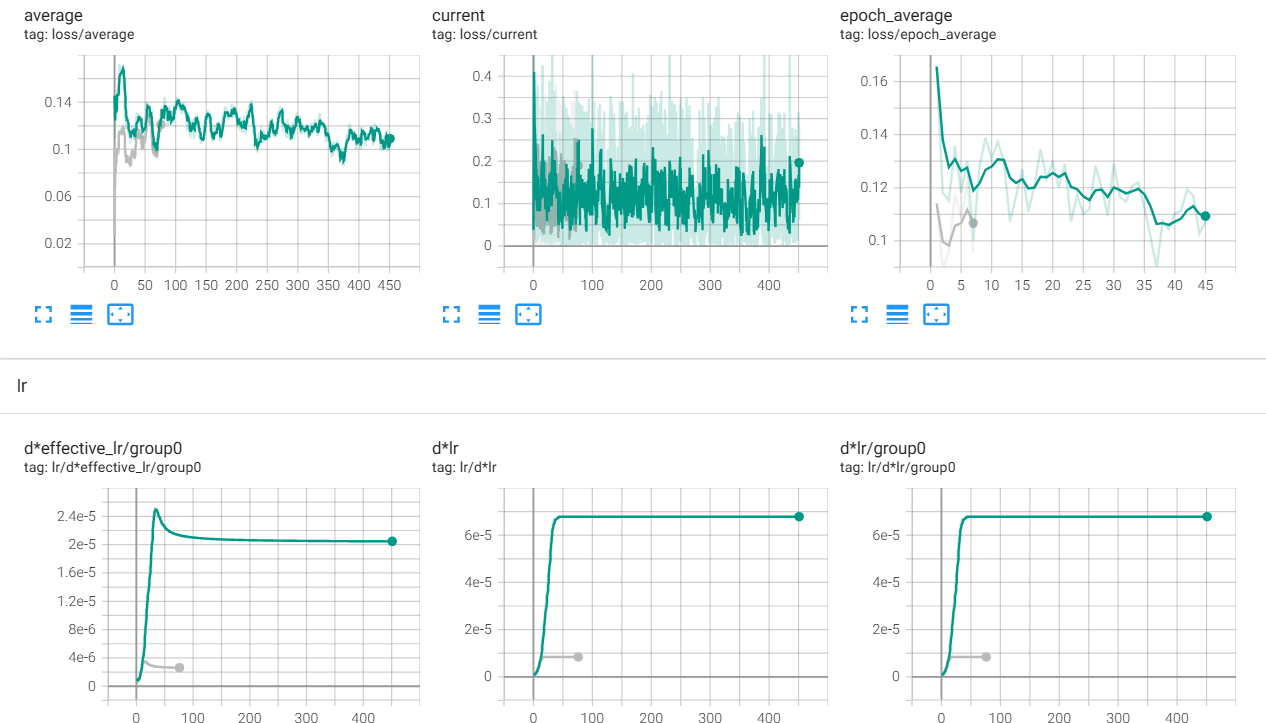
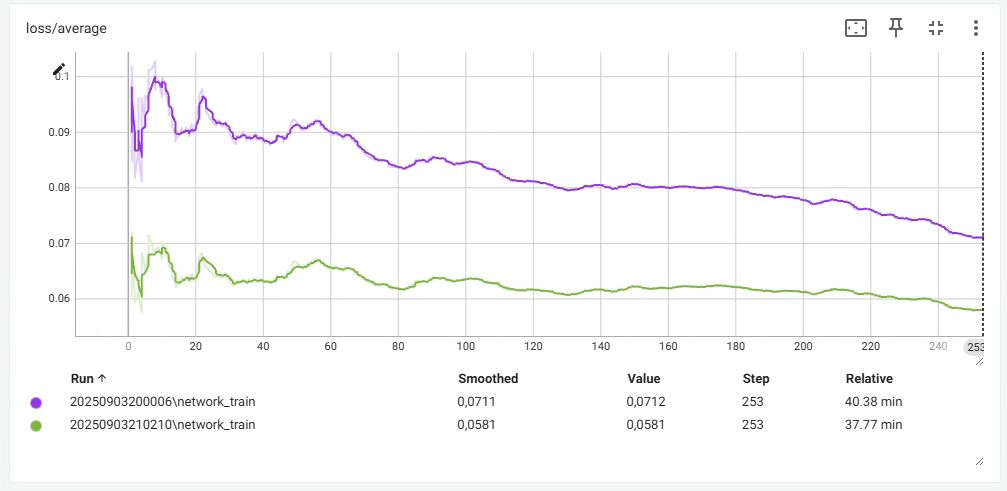
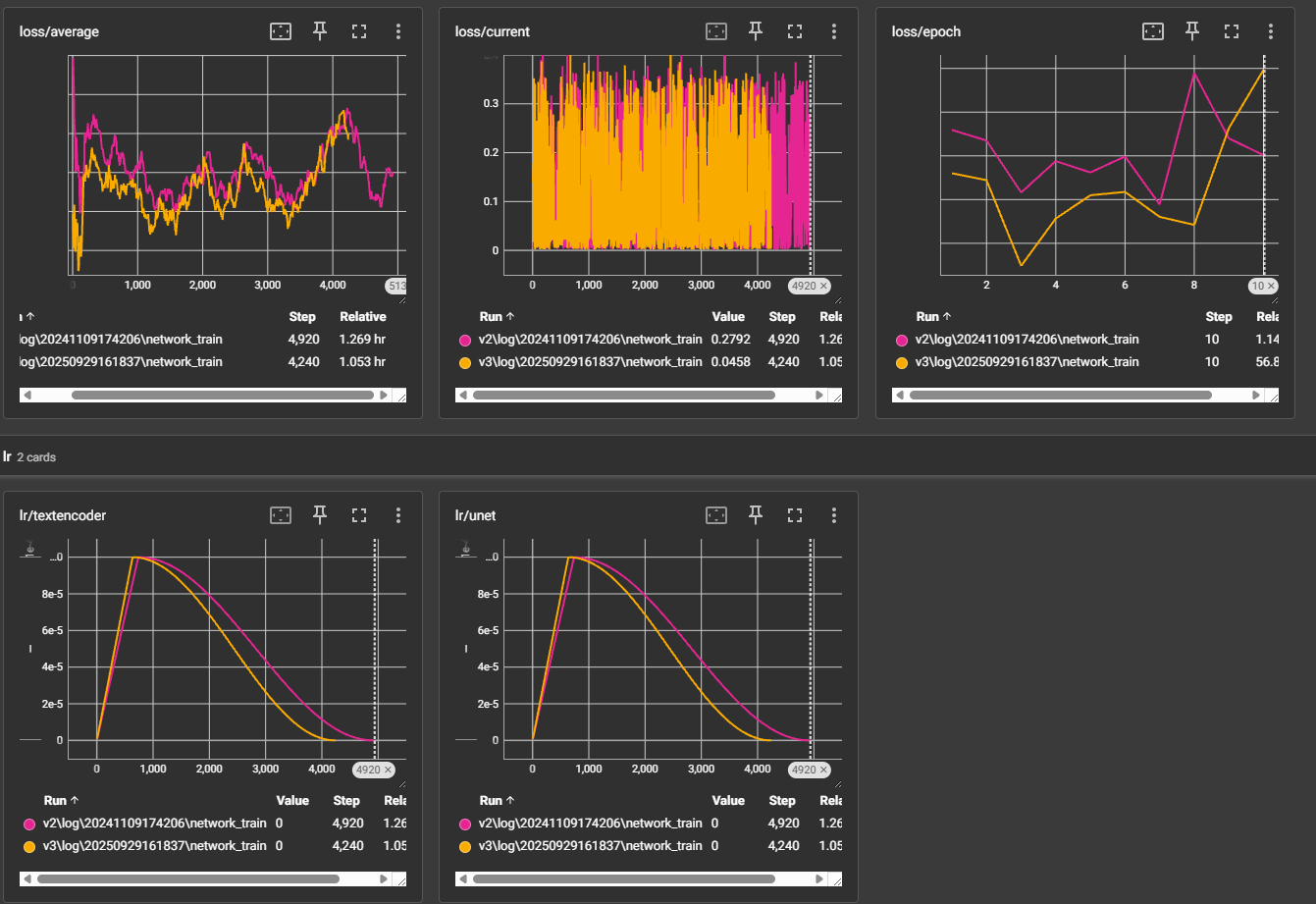
14 часов достаточно агрессивной тренировки на продижах с идеально выдроченным микродатасетом, и ошибка все еще снижается. Вопрос: какая комбуха из лосс функции и оптимайзера по вашему мнению имеет наиболее быстрое, эффективное и мощное схождение?
>>1275731 Loss это не метрика. Он куда угодно идти может. Пикрил на 1 пике датасет на 3к пикч с парой десятков концептов, лосс как будто бы даже вверх идёт, потому что некуда сходиться, все пики разные, вот и лосс как рандомный шум. На втором пике датасет из 10 пикч на стиль, с абсолютно такими же параметрами. Оба оттренились как положено. > лосс функции Пик3 - как выглядит loss настоящих мужчин.
>>1275745 >Loss это не метрика. Он куда угодно идти может. Позвольте, снижение ошибки предсказания это главная метрика стабильного вывода. >Пикрил на 1 пике датасет на 3к пикч с парой десятков концептов, лосс как будто бы даже вверх идёт, потому что некуда сходиться, все пики разные, вот и лосс как рандомный шум. Это говорит о том, что модель не может сообразить как правильно предсказывать, поэтому наоборот старается вычленить более общее сначала и лосс растет. В далеком будущем она обобщит лучше и лосс будет снижаться. Плюс надо иметь в виду что вероятно это лора, а она парметрическую емкость низкую имеет.
>>1275855 На втором пике у меня лосс вниз пошёл потому что было 500 эпох, а в первом случае 3. На качество финального результата это никак не влияет, это ты просто видишь как сетка запоминает конкретные пикчи. Попробуй потренить большой датасет в одну эпоху с тем же стилем как и у модели, тоже не увидишь снижения лосса.
Для тренировки на noobai нужно ставить debiased_estimation_loss если с edm2 тренируешь? edm2 же автоматически выставляет приоритет таймстепов, а как я понял debiased_estimation_loss тоже выставляет приоритет, только статически и увеличивает важность последних шагов
это нормально, что Forge больше чем в 2 раза быстрее, чем automatic1111? там в районе 250% ускорение - было примерно 2 it/s, стало примерно 5
я что-то не верю в такие оптимизации и мне кажется, что где-то что-то отвалилось или скипается посередине генерации. модель и лоры запускаю такие же, семплеры и их конфиги тоже такие же, настройки в Settings тоже вроде похожи, а картинки генерятся быстрее, что за фигня? или там реально прям так сильно оптимизировано (или автоматик1111 - тормознутая хуйня?)
>>1276769 >(или автоматик1111 - тормознутая хуйня?) Да, если бы ты сидел на нём с начала, ты был бы в курсе кто его и руками из какого места торчащими делал.
>>1276638 Что то одно юзай >>1276769 > или автоматик1111 - тормознутая хуйня? Да, на заре эпохи xl было буквально в два раза медленнее, чем сейчас можно выжать
>>1276769 скорее всего такая большая разница из-за версий сопутствующего софта. автоматик1111 я запускал с питоном 3.11 и какими-то старыми трансформерами и торчем, а форж с питоном 3.13 и свежими трансформерами и торчем. так шо не всегда обновления делают только хуже, иногда и улучшают.
Что ето: Temporal Adaptation via Level and Orientation Normalization, адаптивный оптимизатор, направлен на стабильность, адаптацию к направлению и масштабу градиента, и устойчивость к шуму (судя по мои тестам полностью насрать в хорошем смысле на неоднородность даты и количество концептов). Наследует идеи из Compass, AdaNorm, Adam, Adan, DoRA и адаптивных спектральных нормализаторов, но соединяет их в единую систему, при этом не требуя тонкой настройки гиперпараметров (там буквально нечего менять, вставил и поехал).
Общие майлстоуны: 1. Отдельно отслеживает знак и величину градиента через два EMA, рассчитан на работу с высоким lr. 2. Применяет атан2-нормализацию вместо обычного деления (то есть никаких клипперов использовать дополнительно не нужно, если ты используешь, но атан2 замедляет обучение вместо деления, имейте в виду). 3. Может использовать спектральное клиппирование (вкл по дефолту), инвариантное преобразование (тестовая опция, выкл) и ортогональные градиенты (опция, выкл).
Погонял на нескольких типах даты и он хорош, просто целенаправленно двигается к обобщению и практически не вываливается в шизофрению по пути.
Из личных минусов разве что медлительность с Huber с адаптивным snr (что очевидно, т.к. талон сам супер осторожный, а тут еще слабые сигналы от snr фильтра хубера, кароче мультипликативный эффект), там прямо чуть ли не 1e-1 скорость можно выставлять, шестичасовой тест на 1e-3 с двумя десятками эпох дал прекрасный тонкий результат без говна в выдаче, но точно скорость можно выше выставить, возможно требует дельту подкорректировать. С l2 работает бодрее и lr наоборот пониже. l1 не тестировал.
Debiased est loss переваривает отлично (многие оптимайзеры не переваривают задранные таймстепы), так что в целом любое вмешательство в них допускается, кому не лень может едм подрочить.
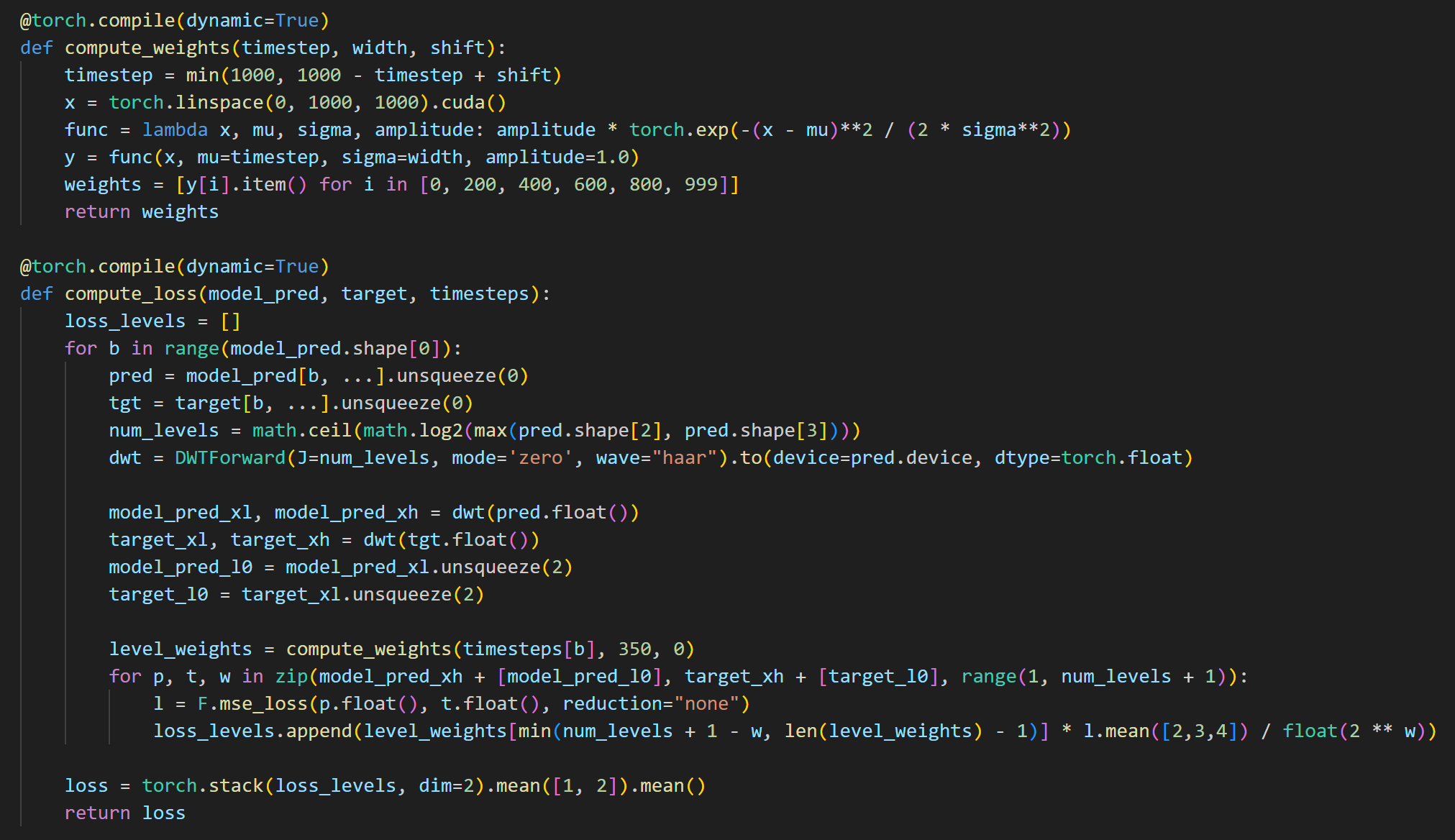
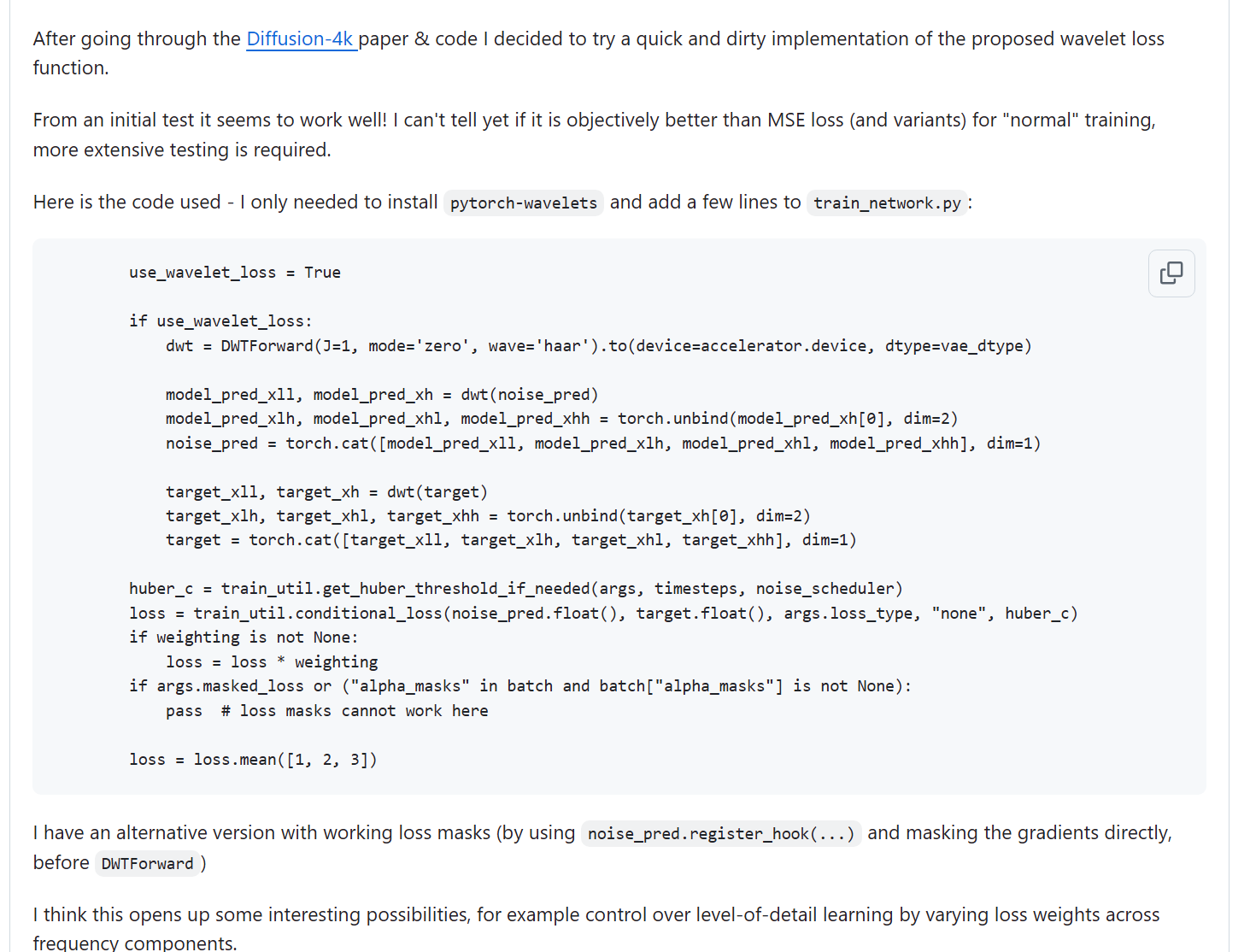
>>1279002 > градиент-клиппинг погоняет градиент-клиппингом Бесполезное говно, как и десяток подобных до него, ещё и медленное. Смысл чистить всратый mse/huber-лосс душением градиентов, если уже давно придумали делать wavelet-декомпозицию лосса, сужай сколько хочешь влияние мусора.
>>1279002 Цифры бы увидеть, метрики или хоть какой-то живой результат, а то хуй поймешь шиза это или нет. Вот мюон например уже показали что на 30% лучше работает, но только если с нуля обучать, но если не с нуля то хотя бы память экономит. Но может вызывать дополнительную нестабильность на долгой тренировке. А на лорах это вообще другой мир где по нюансам оптимизации 0 работ.
>>1279630 >делать wavelet-декомпозицию Ты про эту хуйню с пика из дифужн4к чтоли? Не работает с bf16, только с флоат32 -> на хуй идет.
>Бесполезное говно Мне понравилось, рукопожатие крепкое, не выебонит на сверхмалых или сверхвсратых датасетах и всегда знаешь что не пизданется и не начнет ходить по кругу.
>как и десяток подобных до него Перечисляй.
>ещё и медленное Медленное это FMARSCropV2, а тут чуть медленнее продижей.
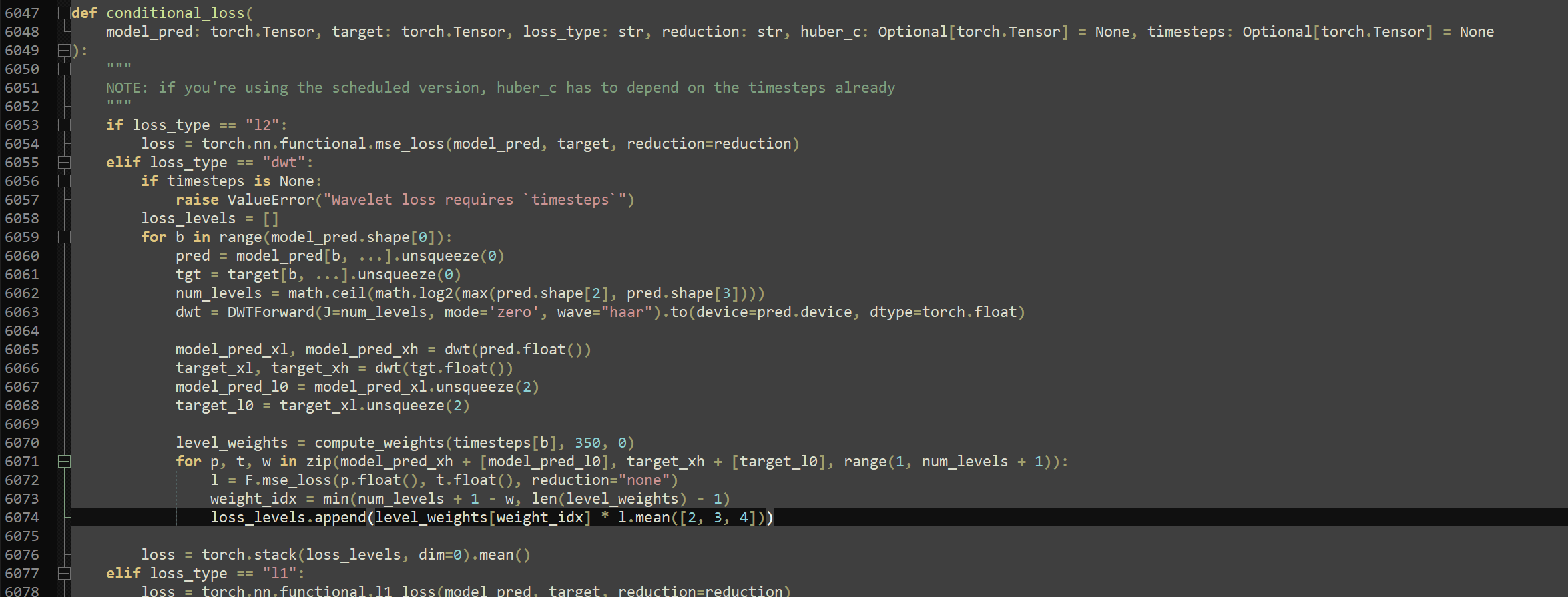
>>1280531 Пруфы чего? Я сейчас только так и треню, обычного лосса нет у меня, выше скрин кидал с кодом расчёта лосса с автоматическими весами от timestep.
нигде нихуя не написано как куда сувать, как будтов се погромисты дохуя
1. в трейн нетворке
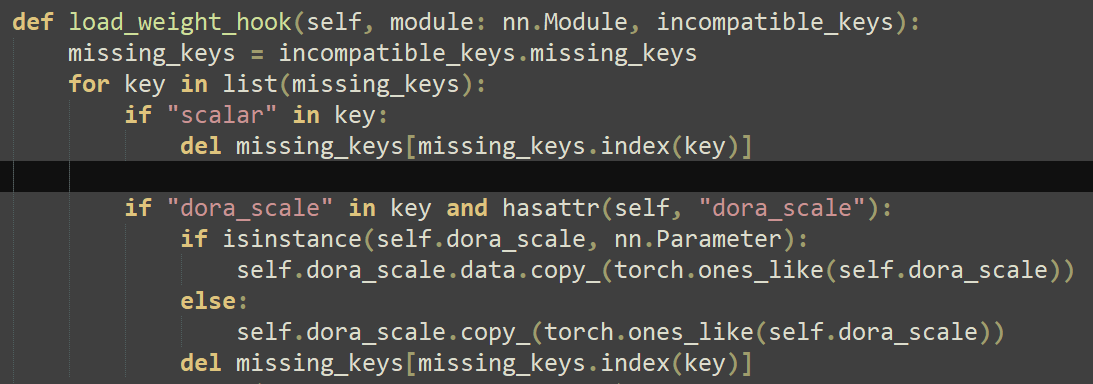
строка 465 loss = train_util.conditional_loss(noise_pred.float(), target.float(), args.loss_type, "none", huber_c, timesteps) строка 470 loss = loss
(вероятно будут ошибки если с классическими лоссами включать обратно, не проверял)
2. в трейн утиле
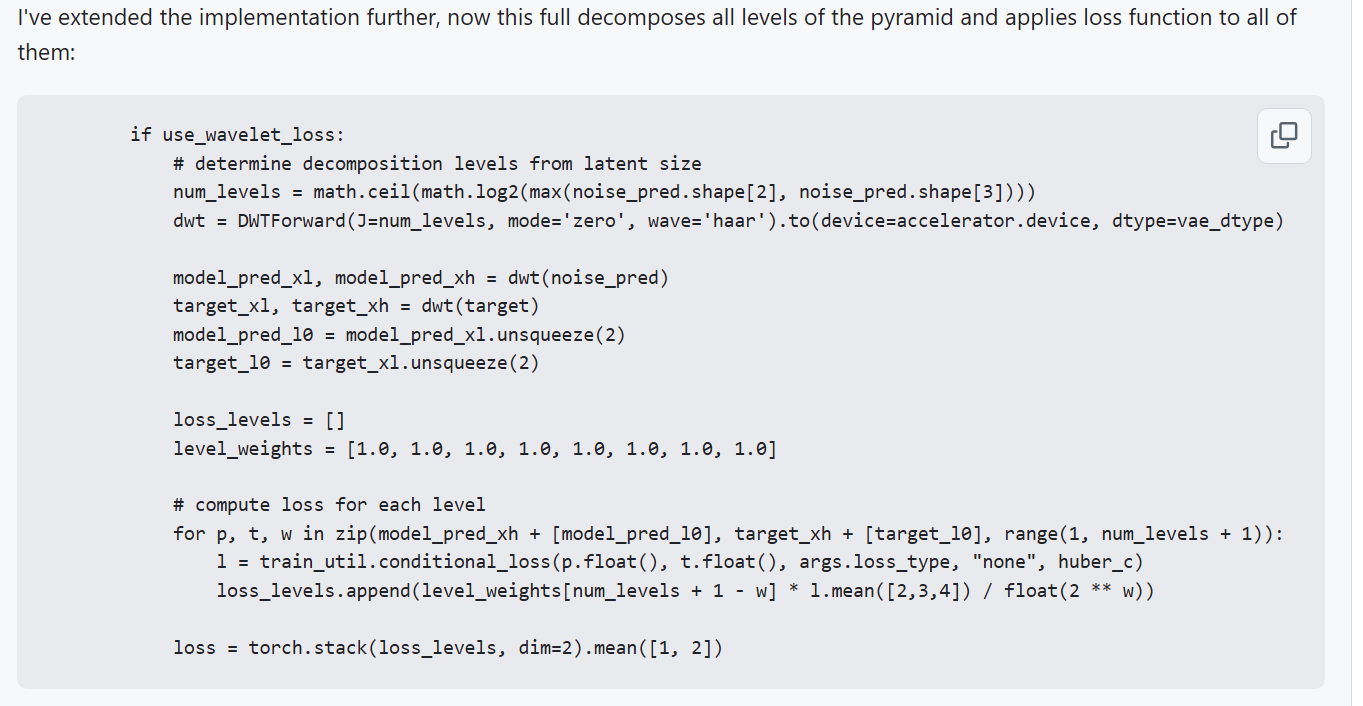
а) пик1, ввести новый тип лосса б) после импортов запихать пик2 в) добавить в импорты import torch.nn.functional as F from pytorch_wavelets import DWTForward
>>1280881 Там кстати погромист который дрочится с вейвлетом полевельно веса сделал, можно типа отключать каждый лвл отдельно и влиять только на чтото конкретное, в коде отсюда >>1275745 не реализовано
кароче можно пул реквест для кои открывать, пусть добавляет, ток проверю как с другими лоссами работает теперь
>>1280881 ну это прям шикардос результы у меня с этим, я еще таких крутых тренингов не делал ни с л2, ни с хубером, почему это еще не зарелизено везде по дефолту-то, дифужн 4к вышел в марте такто
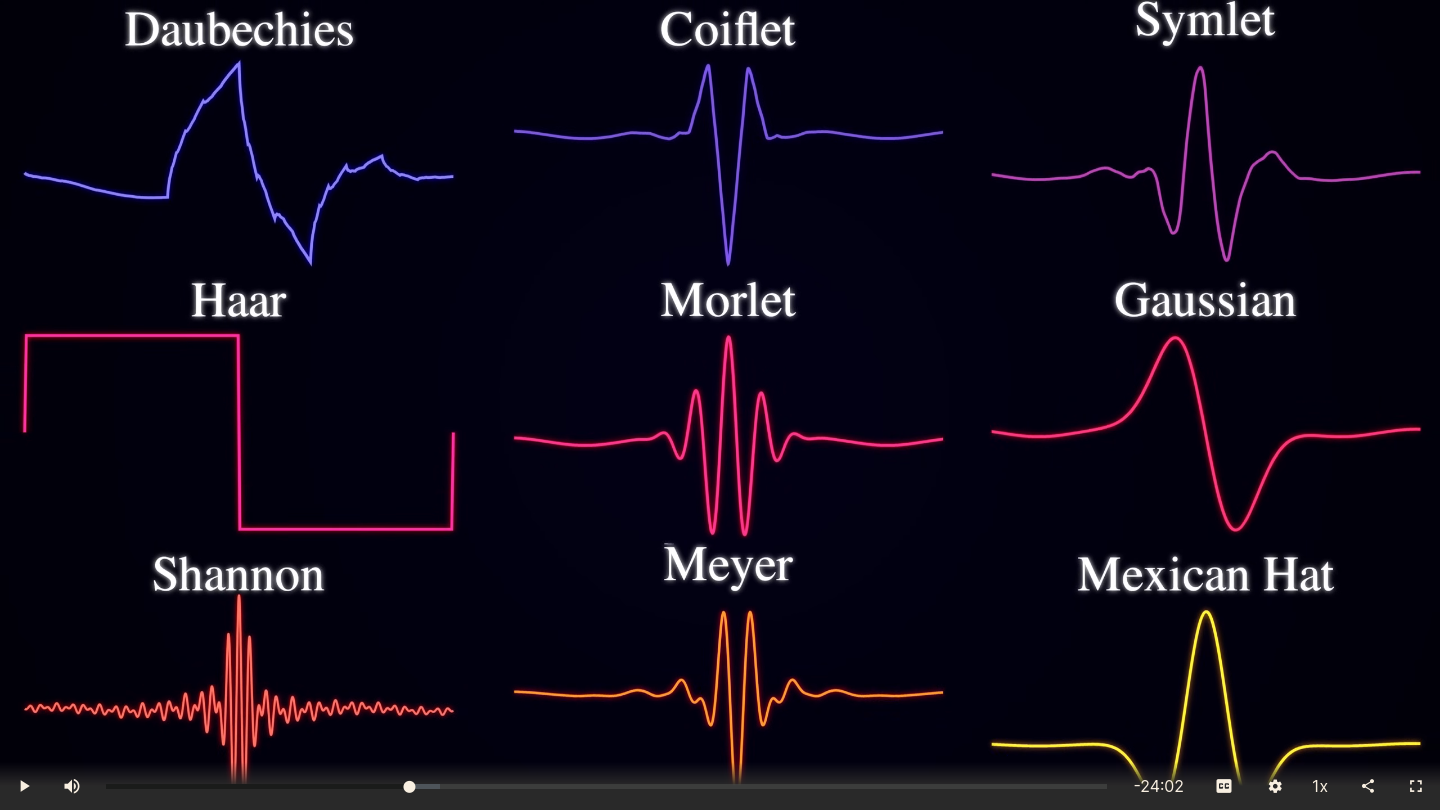
>>1281884 Потому что веса для уровней не очень универсальные, надо под задачу подбирать. А тренировка без весов заметно хуже чем правильные веса. А с автовесами ещё больше подстроек надо, я довольно долго пердолился чтоб ширину пика подобрать. Можно для XL проще делать - трансформации Фурье. Результат тоже лучше mse/huber. >>1281928 Все волны кроме haar говно, я уже всё это говно перетестил давно. У него ещё в списке недискретные, они не работают с дискретным DWT. Тот кто делал pr явно отбалды все возможное параметры впердолил не тестируя.
>>1281964 >Потому что веса для уровней не очень универсальные, надо под задачу подбирать. А тренировка без весов заметно хуже чем правильные веса. А с автовесами ещё больше подстроек надо, я довольно долго пердолился чтоб ширину пика подобрать. >Можно для XL проще делать - трансформации Фурье. Результат тоже лучше mse/huber. Эта часть поста ответ на >>1280886 ?
>А тренировка без весов заметно хуже чем правильные веса. А почему ты взял именно 6 уровней?
>А с автовесами ещё больше подстроек надо, я довольно долго пердолился чтоб ширину пика подобрать. А что если их адаптивными сделать от timesteps или num_levels?
>Можно для XL проще делать - трансформации Фурье. Результат тоже лучше mse/huber. Есть код?
Вкратце можно как работает эта частотка с латентами? Латент в сд же говно, не инвариантен к масштабу/поворотам/сдвигам, и канал для формы сильно отличается от цветности и яркости по структуре.
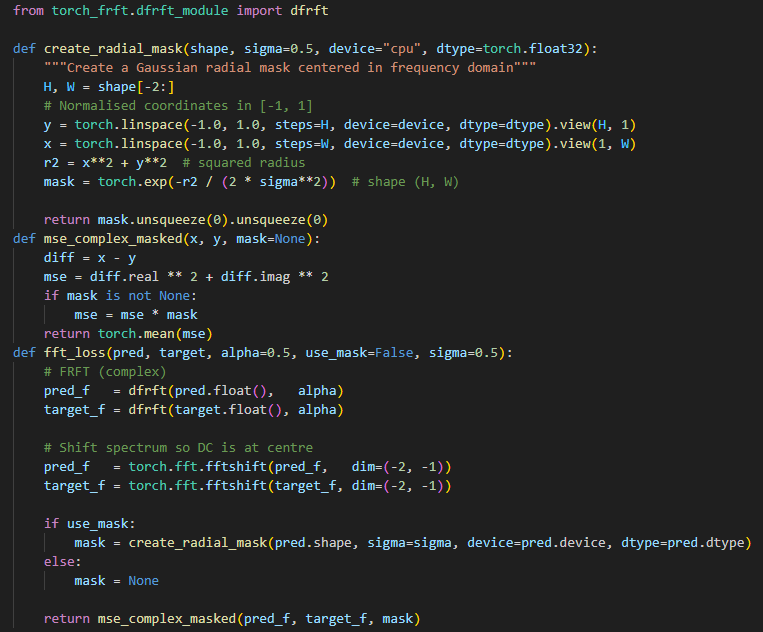
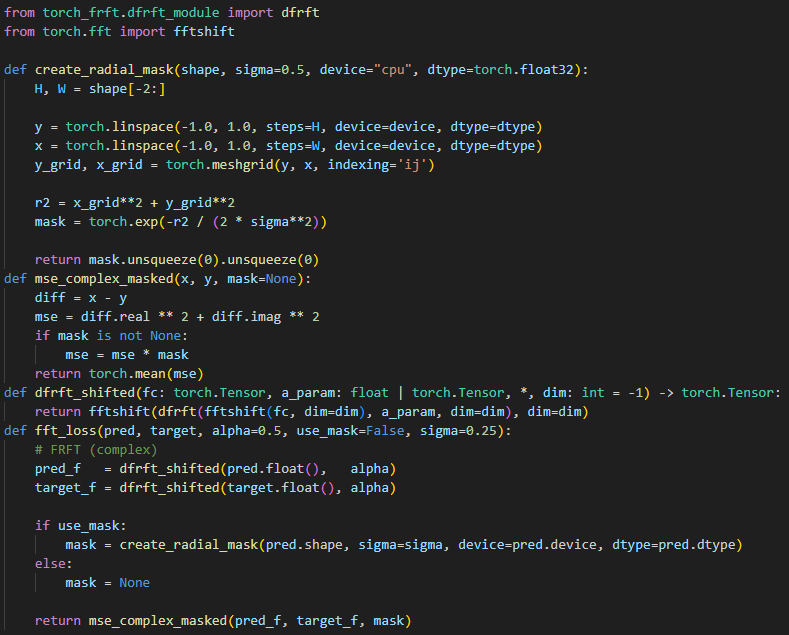
>>1282159 > Есть код? Брал отсюда либу - https://github.com/tunakasif/torch-frft Просто пропускаешь латенты через трансформацию. Там на выходе будет тензор с комплексными числами - амплитуда и фаза. Фазу можно просто выкинуть скастовав к float, без неё немного другой результат. Обычный лосс с комплексными числами не работает, mse будет вот так: torch.mean((pred - target).real ⚹⚹ 2 + (pred - target).imag ⚹⚹ 2) Если упороться, то можно ещё маску накинуть, центр спектра с шифтом по центру. > В чем их проблема? Они усредняют пиксели латента. Всякие номерные типа db4 берут большими блоками пиксели, 4 тут - это в 4 раза больше блок. Ещё и смазывают если волна плавная. У haar просто резкие 2х2 блоки, для мелких деталей лучше всего должно быть.
>>1289186 Аноны в предыдущих тредах говорили что на начальных этапах шума слишком много чтобы извлечь полезную информацию и это сбивает модель. Ну и после увеличения вармап, у меня вроде как семплы стали более вариативные, но это не точно.
>>1288832 Позволяет оптимайзеру с накоплением (считай все) выйти в режим и не взорваться в начале при прохождении выбивающихся данных. При продолжении достаточно будет короткого, но его наличие крайне желательно.
>>1289346 >Аноны в предыдущих тредах говорили что на начальных этапах шума слишком много чтобы извлечь полезную информацию и это сбивает модель. Ну я контраргументирую следующим: 1. Адаптивным лосс функциям насрать на взрывы градиентов при инициализации. Huber + SNR неубиваем практически. Вейвлеты рассмотренные выше по треду тоже стабильные на этот случай. L1 просто похуй на взрывы. Единственное что может обосраться от них это L2, не пользуйся л2 да и все. 2. На каком лр гоняешь? Если это не выше 1e-4 то выгода от вармапа сомнительна, т.к. все что ниже 1e-4 считается низкой скоростью и сила обновлений недостаточная чтобы поломать все. 3. Если ты обучаешь на датасете, который доменом уже имеется в модели - вармап тоже не нужен. Условно у тебя модель с бабами, ты берешь фотки бабы - резкой смены домена данных не будет. 4. Ты тренируешь лору а не фуллфт, у тебя нет огромного батча и биг даты чтобы переживать о взрыве знаний при инициализации. 5. Если ты используешь шедулерфри оптимы, то тем более тебе не нужен вармап, т.к. они по сути адаптивны и сами себе сделают вармап где нужно. 6. Если ты используешь CosineAnnealingWarmRestarts или какойнибудь вансайкл тоже вармап нинужон.
>>1288832 >Нужен ли warmup при продолжении тренировки? Если не сохранил состояния оптимизатора, то нужен. Прогрев нужен для того чтобы адаптивные оптимизаторы и моментумы накопили статистику. Иначе у тебя первая картинка может получить вес в 10 раз больше чем другие, как пример проблемы. Этот бред >>1289491 не слушай, не имеет отношения к проблеме. Разве что 6 имеет смысл, может быть 5.
>>1282206 Я по итогу дропнул wavelet лосс, говно какое-то. Надо дрочить веса, но как бы их не дрочил всё не то. Всегда что-то лучше становится, что-то хуже, а чтоб прям заебись было невозможно подобрать. Перешёл на Фурье, с ним стабильность просто ахуевшая и ничего не надо пердолить, что дало возможность сделать то что раньше ломало картинку - сделал фиксированный шум для каждого пика, а не как в ваниле рандом. С mse от такого пережаривало и почти неюзабельно было, а с FFT тренится заебись и при этом вариативность генераций огромная и стабильно всё. Ещё и на оптимизатор focus перешёл.
>>1290650 >>1290650 > Перешёл на Фурье, с ним стабильность просто ахуевшая и ничего не надо пердолить, что дало возможность сделать то что раньше ломало картинку - сделал фиксированный шум для каждого пика, а не как в ваниле рандом. Дай код реализации то
>>1291301 Я при кешировании латентов шум генерю и потом только его использую, без генерации нового, у каждого латента свой фиксированный шум. >>1291323 Выше писал же.
>>1291324 >Я при кешировании латентов шум генерю и потом только его использую, без генерации нового, у каждого латента свой фиксированный шум. а ну то есть если у меня не кешируется ниче, то мне нинужно
Как корректно в toml указать таргеты на conv слои? Если в таргет модулях указывать conv2d, то оно начинает вообще все тренировать практически, независимо от регекса в таргет юнет В фуловой лоре естественно conv_in и conv_out для таргет юнет нет, и при enable_conv = true и с/без конвин/конваут никакие конволюшены не тренируются. Если брать базовые блоки в таргет модулях ResnetBlock2DDownsample2D Upsample2D то оно сразу перетренировывает моментально, супер анстейбл кароч
>>1291402 В ваниле каждую эпоху у тебя разные сиды для одинаковых пиков, но логичнее чтобы одинаковые пики были с одним и тем же шумом. Но проблема в том что оно с mse оверфитится адово, до того как успеваешь что-то натренить лора уже запорота, а FFT фиксит это. Оно станет ещё быстрее трениться и повысится вариативность генераций. Тут где-то был любитель обобщения, ему это в первую очередь надо делать. При претрейне так не делают по очевидной причине - мало эпох и они большие. >>1291422 Там авторы перебором нашли наиболее важные для тренировки слои. Тренятся только attentions.0 и attentions.1 в up-блоках. Один из них концепт, другой стиль. Вообще не рекомендую, у тебя будет всегда недотрен. Есть смысл только если тебе надо прям жестко отделить стиль и сам стиль довольно простой. Из плюсов оверфита нет, можно и надо тренить до усрачки, смысл б-лоры - это хуяк-хуяк как попало и оно даже норм натренилось. Если ты врубил другие слои, то это уже не б-лора.
>>1291617 >Там авторы перебором нашли наиболее важные для тренировки слои. Тренятся только attentions.0 и attentions.1 в up-блоках. Один из них концепт, другой стиль. Да я в курсе что там атеншены, мне нужно просто конвы указать правильно чтоб оно локальные данные изучило для точности т.к. с одними атеншенами прямо видно недостаточность ортоганальных изменений, я уже проверил такой вариант когда конвы врубаются - он рабочий, но конкретно указать конволюшены связанные с аутпут блоками 0.1 и 1.1 я не могу нормально. >Вообще не рекомендую, у тебя будет всегда недотрен. Я бы не скозал, зависит от настроек, плюс я офт надрачиваю, оно сохраняет данные основные слоев и юзаю в основном с плюснутым dmd, результат конфетный. >Если ты врубил другие слои, то это уже не б-лора. Ну называй как хочешь, разряженная тренировка, мне нужны конвы хоть тресни.
>но логичнее чтобы одинаковые пики были с одним и тем же шумом обоснуй на чем основана логика, мне всегда казалось что рандом нойз это метод регуляризации типа дропаутов, ты типа не подвязываешь сетку жестко к данным, таким образом давая ей свободу выражения
пока писал спросил у гпт, оно также сказало, что жестко обучать на фикс нойзе нахуй надо
>>1291797 У тебя генерации из шума. Если тренишь один пик на разных сидах, то модель и учится генерить один и тот же пик на разных сидах. Если так долго тренить, то модель начинает тупо с любых сидов генерить пики из датасета. И делает она не потому что оверфит или ещё что, а именно из-за того что ты научил её из любого шума их генерить. Собственно я это и на практике вижу, фиксированный сид даёт больше разнообразия генераций. > гпт Нашёл у кого спрашивать что-то, лол.
>>1291947 > Если тренишь один пик на разных сидах, то модель и учится генерить один и тот же пик на разных сидах. но модель не учит картинки, она учит признаки на основе текстового описания >фиксированный сид даёт больше разнообразия генераций. как оцениваешь разнообразие? >Нашёл у кого спрашивать что-то, лол. че за трансформерный шовинизм? он мне код правит и он работает, да и нет смысла не доверять нейросетке в вопросах нейросеток
>>1291947 Кмк, смысл есть и там и там. Сделать шанс или заготовленного шума или случайного и получать профиты без подводных. >>1292123 > нет смысла не доверять нейросетке в вопросах нейросеток Они могут просто не понять твой вопрос и притащить случайную ассициацию, или просто взять предложенный тобою же вариант если в вопросе уже заложен ответ. Попросить ллм проанализировать вопрос с разных сторон и дать какую-то инфу о практике и как это может сыграть - хорошая идея, но желательно посвайпать оценивая выдачу. Требовать сделать вывод и дать ответ - плохая.
>>1292292 >Они могут просто не понять твой вопрос и притащить случайную ассициацию, или просто взять предложенный тобою же вариант если в вопросе уже заложен ответ. Попросить ллм проанализировать вопрос с разных сторон и дать какую-то инфу о практике и как это может сыграть - хорошая идея, но желательно посвайпать оценивая выдачу. Требовать сделать вывод и дать ответ - плохая.
>>1292123 > че за трансформерный шовинизм? Скорее гопотный. Жпт очень тупая, если это не о-модели. > нет смысла не доверять нейросетке в вопросах нейросеток Нейросетки обычно гонят банальщину, выдают самый попсовый вариант ответа.
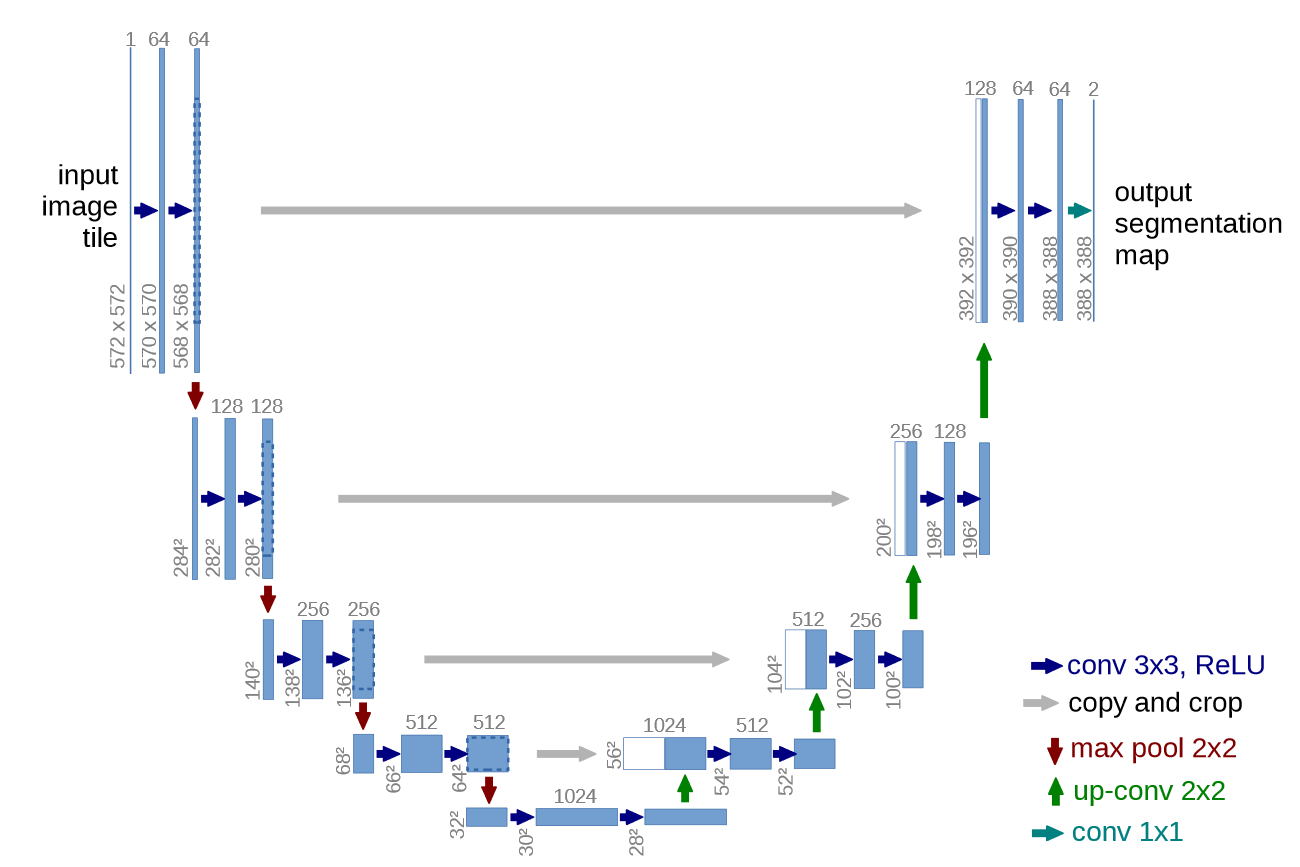
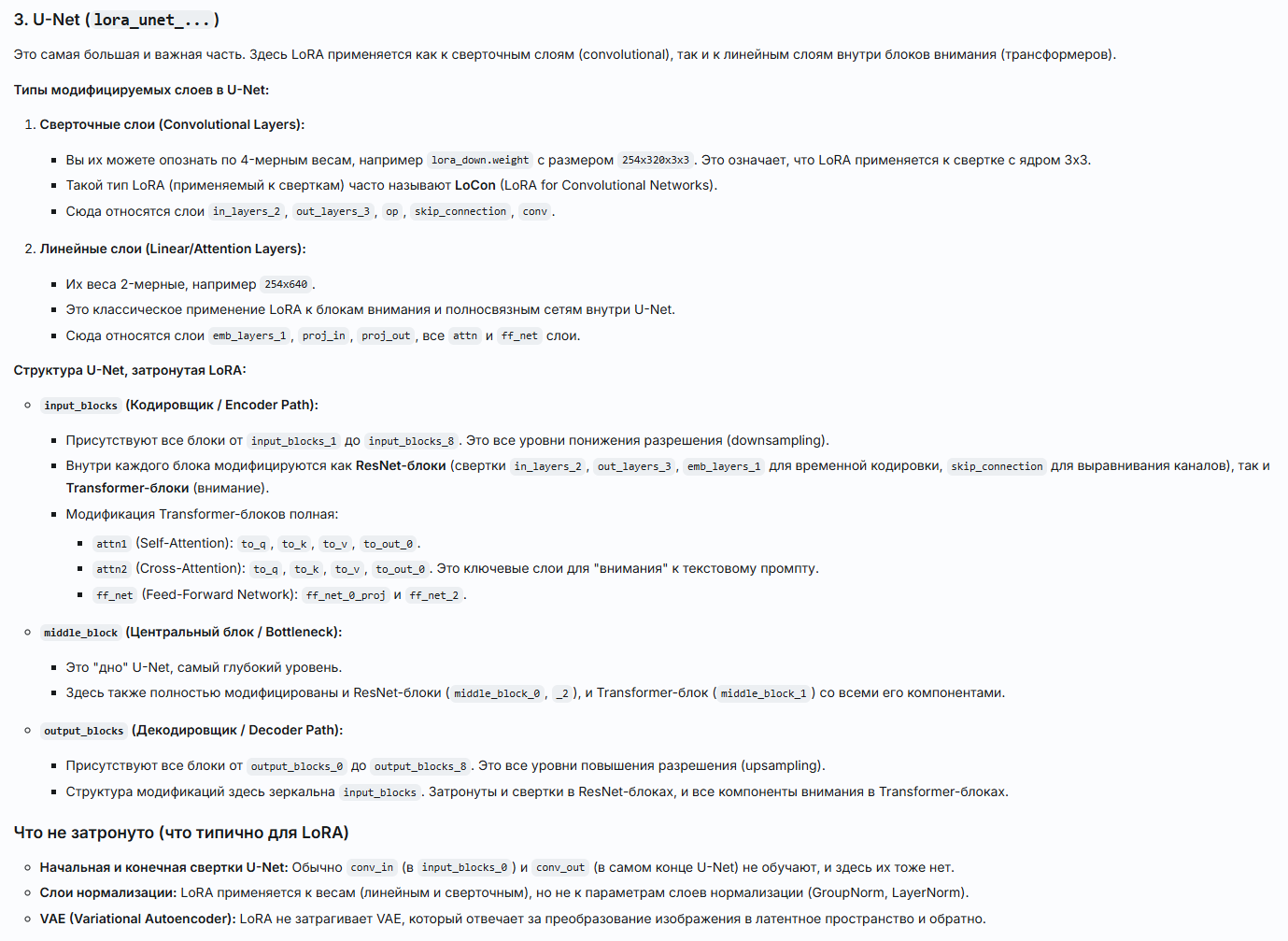
Спустя полгода дрочки я понял структуру сдхл наканецта, что основные концепты датасета (форма, цвет, объекты, особенные особенности) пиздятся напрямую в ffnet и proj слои, причем в основном в конечные инпут блоки и мидл блок. При этом ффнет просто запоминает все подчистую (и по факту обладает наибольшей выразительностью), а не обобщает, являясь очень мощным фильтром, который способен любой вывод атеншенов перекроить, т.к. независим. А прожекшен слои это входы выходы для атеншенов, которые имеют более высокий приоритет над данными самих атеншенов, как бы рамки для атеншена, а атеншен это само наполнение рамок. Гдето в атеншенах еще нормы сидят, но я их не обучал для теста практически, не могу сказать фактическое влияние.
То есть логика сдхл такая: атеншен строит суть картиночки, прожекшен конструирует финальную структуру, которая пропускается через MLP ffnet, который независимо обмазывает уникальными независимыми параметрами, полученными из датасета внимание ПОЛНОСТЬЮ ВНЕ КОНТЕКСТА. То есть вся проблема переобучения строится на том что в ффнет подается слишком сильная дата, которая его ломает - отключи вест ффнет и модель/лору невозможно убить никаким конским лр. Алсо все лоры убыстрялки и модели дистилляты из которых их экстрагировали содержат переобученный, но нормализованный для конкретного семплера ффнет за счет которого и идёт выигрыш в скорости.
При этом все атеншены очень стабильные и осторожные, напичканные селфчекингом, поэтому невероятно трудно переобучить/дообучить конкретно их (как в блоре, где одни атеншены).
То есть фактически для корректного обучения требуется обучать самый большой блок инпута т.к. он финализирующий и содержит основную дату для картиночки в середине процесса денойза, какуюто часть мидл блока или полностью потому что это параметрический финализатор и сборщик скрытых признаков в одно целое и обучать первые два блока аутпута (поздний этап денойза), которые собирают картинку из общей формы и среднечастотных деталей. При этом имеет смысл обучать ффнет и прожекшены на более низкой скорости в виду их огромной силы. Все остальное буквально излишество.
Надеюсь кому-то поможет данная инфа, основанная на рисерче из овер 300 моделек.
>>1294449 Какая-то каша у тебя в башке. Фид-форварды нужны для нелинейности трансформера, т.к. трансформер только трансформирует данные, в трансформере даже активаций нет. > в ффнет подается слишком сильная дата, которая его ломает Во всех тренерах, в том числе у кохи, по умолчанию фф не тренится. Только если ты специально выбираешь тренить вообще все линейные, по умолчанию тренятся линейные в трансформерах (to_q, to_v, to_k, proj). А поломка почти всегда происходит в первых слоях, именно первые слои очень чувствительны к тренировке и легко превращают всё в кашу. Естественно у тебя средние слои менее чувствительны к кривой тренировке, ведь там уже нет пиксельных данных латента. > для корректного обучения требуется обучать самый большой блок инпута Для корректного обучения надо просто правильно обучать, ничего там не ломается при обучении фф/конволюшенов, если сделал всё правильно. Все попытки задушить тренировку отрубанием слоёв/обрезкой градиентов/душением лосса по snr и прочим весам - это лечение симптомов и проблема где-то в другом месте.
>>1294476 > Какая-то каша у тебя в башке. Я бы поотвечал на каждый пункт, но ты невоспитанный и категоричный, чувства такта нет, да и пост написан в ультимативной форме (я понимаю что тебе очень нужно чувствовать себя экспертом на анонимном форуме, но впредь держи себя в руках, мне лично твои "ря ты криворучка, просто дыши пук пук хрюк" неинтересны), я по таким правилам не буду играть. Добра, щастья, здоровья.
Двачую >>1294476 а ты >>1294488 слишком болезненно реагируешь на замечание по сути. > невоспитанный и категоричный, чувства такта нет, да и пост написан в ультимативной форме (я понимаю что тебе очень нужно чувствовать себя экспертом на анонимном форуме Вот этот пост >>1294449 много постулатов, никакой конкретики и примеров.
>>1294476 >Фид-форварды нужны для нелинейности трансформера, т.к. трансформер только трансформирует данные, в трансформере даже активаций нет. Нелинейность и в софтмаксе атеншена есть. Ну и чет с "Фид-форварды нужны для нелинейности" орнул. Типа, по твоему они нужны ТОЛЬКО для нелинейности? >Во всех тренерах, в том числе у кохи, по умолчанию фф не тренится. Пиздабол. ff_net адаптеры присутствуют для всех млпшек, в дефолтной лоре. >Для корректного обучения надо просто правильно обучать, ничего там не ломается при обучении фф/конволюшенов, если сделал всё правильно. И по классике ты нам конечно не расскажешь как правильно. Просто пук в воздух.
Так что реакция вполне оправдана. >>1294449 Впрочем, какие-то осмысленные выводы из изначального поста я не могу сделать. Настройку лр по слоям обычно просто так не делают, те же проекции атеншена частично впитывают в себя инфу вместе с ff, которая выбьется только другим устойчивым сигналом и переполнением емкости. Нахуя просто понижать лр для ff? То есть хочешь сказать, что нам надо усиленно тренить атеншн? Опять же, даже если мы треним только атеншн, проекции спокойно навпитают инфу как и ff. У меня одна из самых популярных лор одноранговая, на стиль, вполне хватает. Работает нормально. Про переобучение спорно, какого-то конкретного пайплайна и сравнений нет. Кароч, очень интересно но нихуя не понятно.
>>1295419 >Настройку лр по слоям обычно просто так не делают, layer-wise LR decay делают в больших тренировках большие вумные дяди обычно, лораёбы не заморачиваются конечно такой хуйней
>те же проекции атеншена частично впитывают в себя инфу вместе с ff, которая выбьется только другим устойчивым сигналом и переполнением емкости. Нахуя просто понижать лр для ff?
Ffnet это независимый фильтр и часть MLP, если ты полностью тренишь, то впитают, если не полностью то впитает только прожекшен.
Мой тезис был в том, что так как ффнет независимая часть сети и равномерно распределен во всех блоках, которые имеют разную емкость, то в каких-то его частях неизбежно так скажем бутылочное горлышко для фф из-за малого батча, малой даты, накопления градиентов от однотипных паттернов и гиперов оптимайзера (например стандартная бета для ффнет скорее деструктивна на микробатче и малой дате, т.к. ффнет запоминает паттерны даты без обобщения, а бета накапливает моментум - то есть на деле моментум приводит к накоплению старых градиентов, которые могут сохранять переобученные шаблоны ffnet, особенно при малом батче и нестабильной дате, что замедляет адаптацию к новым градиентам и форсирует запоминает мусорных паттернов в ффнет, которому поебать что запоминать;
это подтверждается тем, что если тренировать полные самые большие блоки без декомпозиции с бетой 0.999, то результат будет хуже, чем бета 0.25 скажем - так происходит потому что у фф сила явно больше чем у атеншена, и если их тренировать сепарированно, то получается тот же результат. Вероятно ффнет сделан изначально так чтобы с большим моментумом (а равно большей параметрической емкостью) запоминать активнее, что имеет смысол когда у тебя сотни миллионов картинок и тысячные батчи, но это больше умозрительное заключение.
Таким образом получается палка где на одном конце непопадание в оптимальный лернинг рейт, но фф не страдает, а сеть при этом обучается долго и неэффективно, либо использование нормального лернинга как у больших дядек с корпусами датасетов, но тогда фф уничтожается.
Из этой ситуации можно выйти двумя путями - тренировать фф (и прожекшен) отдельно с другим лр, чем все остальное, или тренировать все сразу на нормальной скорости но с низким моментумом или вообще без моментума, целясь только в эффективные блоки.
Помимо этого надо учитывать, что ранние и поздние блоки сдхл не настолько важны для инъекции новой даты, они больше функциональные для полноценной модели, где первые инпут блоки занимаются понижением "разрешения" вычленяя признаки, а с середины аутпут блоков происходит незначительная относительно всего пайплайна инференса доводка картинки перед декодингом, соответственно внедрение узкой малой даты на протяжении всех блоков это скорее негативный эффект и призыв переобучения, т.к. ранние блоки это низкоуровневые признаки edge-level/shape (а мы работаем на основе модели, которая уже прекрасно умеет строить представления такого плана на основе массивной даты на которой ее обучали), а поздние для доработки структуры и цветовой координации (что также базовая модель и так умеет). Не вижу никакого фактического смысла перекраивать ранние и поздние блоки с помощью минимальных датасетов (менее 10к картиночек), поэтому внедрение узкой даты в эти блоки вредное действие и нужно действовать от принципа не навреди: да, блоки важны при генах, но не дают существенного прироста качества при их дообучении на малой дате из-за переобучения и затопления признаков. Проверяется элементарно - изолируй и тренируй только ранние или поздние блоки - выйдет какая-то хуита без задач (можешь не пробовать, я пробовал).
Сдхл по факту модульная бандура, сюда напрашивается аналогия про "если в машине сломался дворник, то не нужно делать рестайлинг", ни в одной комплексной системе не имеет смысла полностью переписывать все подчистую или внедрять всякое в каждый модуль чтобы внедрить новую фичу или починить неработающее.
>То есть хочешь сказать, что нам надо усиленно тренить атеншн? Нет, не хочу сказать.
>Опять же, даже если мы треним только атеншн, проекции спокойно навпитают инфу как и ff. Только проекция и впитает, если только атеншен. Но носитель именно новых данных из датасета это ффнет, а не атеншен.
> У меня одна из самых популярных лор одноранговая, на стиль, вполне хватает. Работает нормально. Тут вопрос не в том что хватает и с чем можно смириться и какой у тебя юзкейс (может ты просто форсируешь генерацию по референсу), а в самой логике тонкой эффективной донастройки модели на малой дате и малом батче при использовании консумерских карт.
Плюс не обучая все разом, а поблоково или по частям сети ты получаешь гораздо больше свободы, т.к. в ликорисе есть отдельный алгоритм full, который не декомпозит в лоуранк матрицы, что является полноценной тренировкой.
То есть направляя тренировку в нужные эффективные элементы (предположим стандартные output_blocks 0 1, output_blocks 1 1, и input_blocks 8 1) ты можешь на наиболее популярной карте типа 3060 12 гигов все эти три блока разом полноценно засунуть в 12 гигов в 1024 разрешении на 1 батче и на выходе получить максимально нативную тренировку высокого качества, там модель получается в районе 2 гигов и просчет одной итерации в 5 секунд при этом на нормальном современном оптимайзере с FFT лоссом который выше обсуждали, это ниже чем даже дефолтная лора с ее 8 секундами, т.к. нет дополнительных преобразований. А на 16 гигах уже и мидл блок вприкуску влезет и чтонибудь еще (допустим можно в шахматном порядке по всем блокам выбрать эффективные слои оставшиеся), а это считай одномоментный полноценный файнтюн практически целой модели (2 гига от трех инпут/аутпут и 800 метров от мидла), но не нужно пердеть на зануленом fp8 или ухищряться с баквардпассами на адафакторе или восьмибитном кале. Если тренировать любой тип лор с конкретными блоками, то там еще плюсом меньший размер будет, помимо увеличенной скорости просчета, но минус в том что влияние лоры на модель не полноценное и все равно надо будет туда-сюда крутить силу как обычно, но лора это в любом случае компромисс. Сплошные плюсы в общем.
Уточню, что я не выступаю против полноблоковой тренировки, если она делает то что требуется, но меня всегда дико бесила все эти танцы с бубном чтобы выдрочить гиперы, выдрочить датасет, выдрочить соотношения чтобы не бох лора не сделала рухнум. Я кароч за принцип "если позволяет - упрощай".
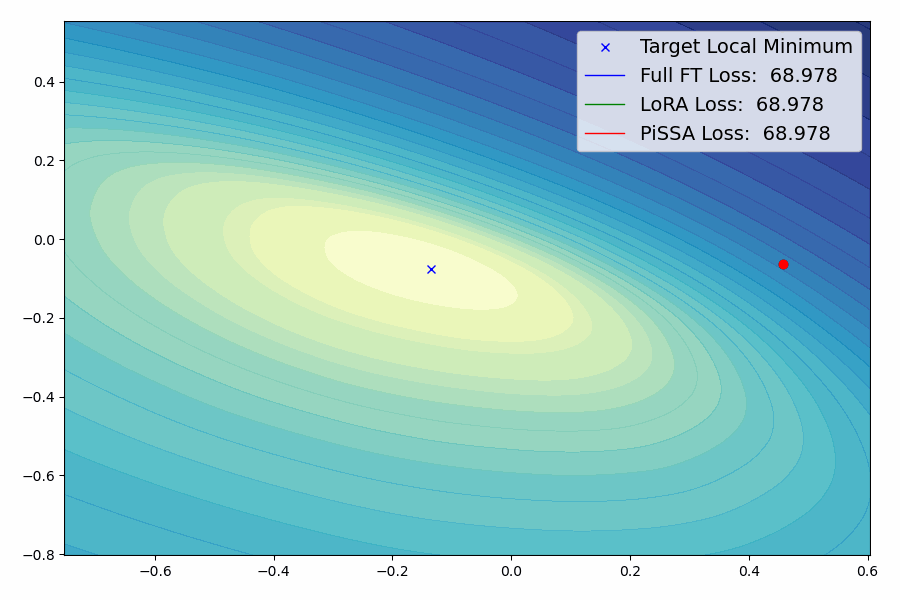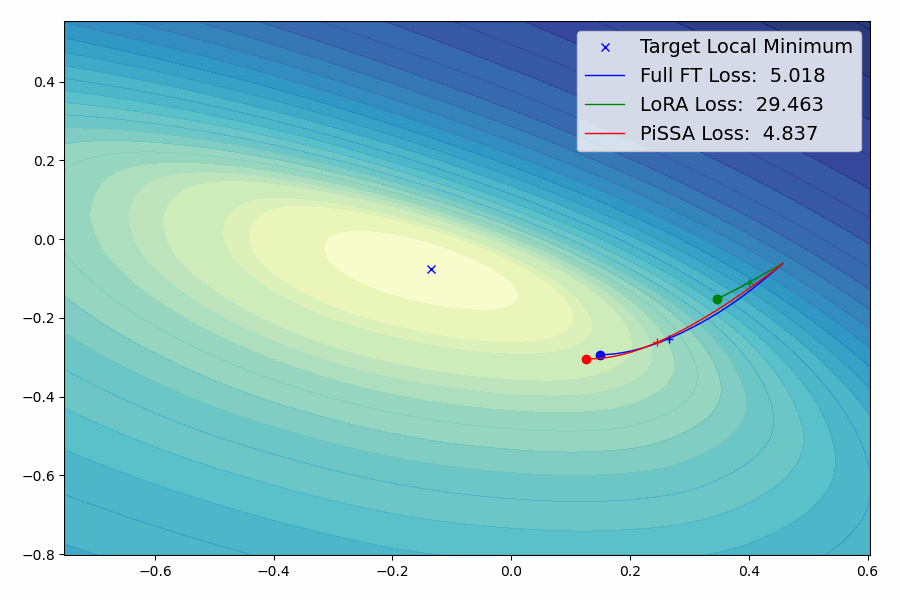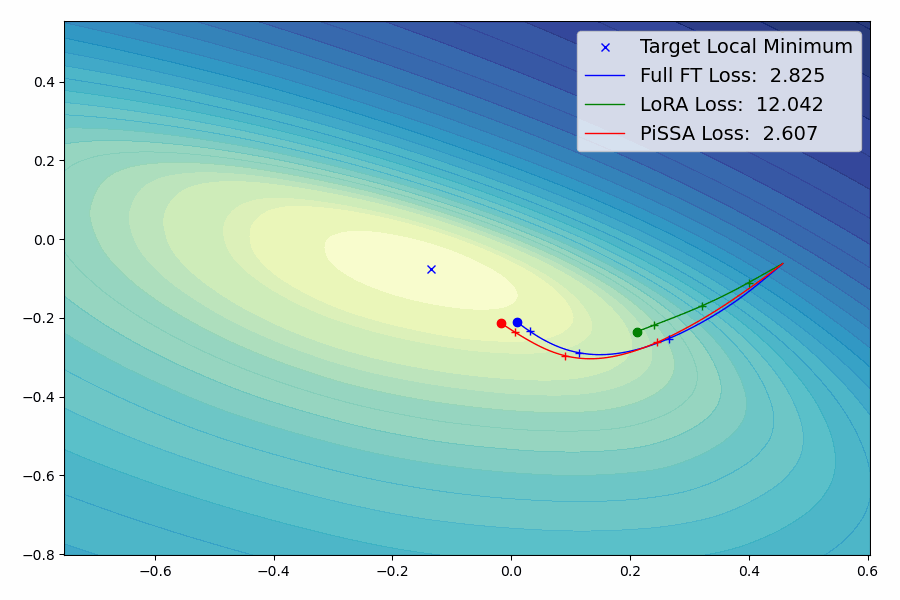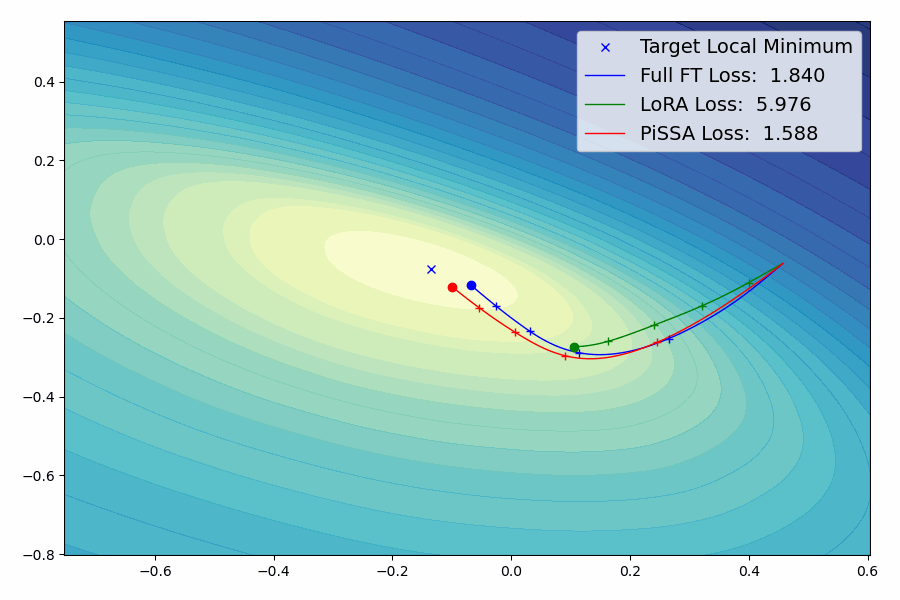
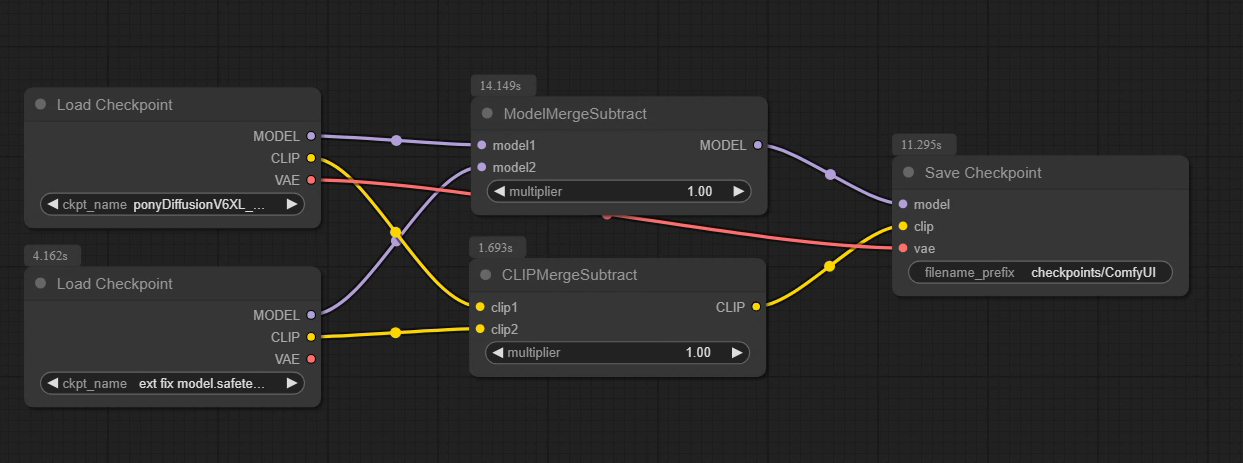
Случайно придумал самый шизовый вариант инициализации лоры. Вкидываю чисто чтобы не забыть и уйти спать, может кому не лень будет протестить. Кароч надо взять какую-нибудь другую модель и слить с нее экстракт. Далее примерно логика как в >>1196940 → Добавляем экстракт к исходной (той, которую хотим обучить) модели. Из наэкстракченой модели вычитаем исходную. Из исходной вычитаем наэкстракченую и это новая "исходная" модель. В лору подсасываем чистый слитый экстракт. Объединение этих двух вещей должно давать исходную модель, но только в качестве инициализации лоры у нас экстракт другой, вот такой прикол. Только надо не забыть сделать исправление из гайда, иначе все сломается. Для надо после получения экстракта закинуть его обучаться как лору на 1 шаг на минимальном лр и сохранить. Ну и наверное есть смысл за инициализацию брать не полный экстракт, а разностный, может как-нибудь еще намешать их.
Если я нигде не обосрался с математикой, может получиться интересный эффект в виде мягкого пересаживания biasов с одной модели на другую в процессе просто обучения лоры на вообще другой задаче. По моей логике это может дать толчок лоре пойти по тому же пути по какому шла другая модель. Важно, повторюсь, здесь именно обучается полноценная исходная модель которая как бы никак не модифицирована, но она разрезана на лору не по SVD как в том методе, а как бы плоскостью другой модели.
Аноны, как персонажа вырезать на прозрачность? Перепробовал все доступные через интерфейс A1111 расширения для уберания бэкграунда - говно какое-то. У персонажа либо остаются арефакты во всех местах, либо края силуэта прозрачные.
Специально делаю генерацию на белом однородном фоне, размер под 2к. Даже с этим не справляются "вырезалки" эти.
Посоветуйте как быть. Нужно обработать огромное количество изображений.
>>1303296 Что чел? Под него штук 7 плагинов только для этой задачи написано. И они что на авто работают, что на форджах. Лапша же ничего принципиально нового тут не предложит, больше чем уверен.
>>1302830 Если нужно идеально - только руками вырезать. Ни одна модель не даст 100% точности в 100% случаев, косяки будут даже с белым фоном. Косяки будут всегда. Можешь найти что-то более-менее точное, если повезет. Цивит покопать попробуй.
>>1304571 Ничего не нашел толкового чел. Потому и спрашиваю. А ещё, потому что есть СЕРВИСЫ, которые вырезают идеально, но они конечно платные, там на поток процесс не поставить. Просто существование этих сервисов как бы говорит что где-то существует хороший варианты. Я больше чем уверен что все эти "сервисы" это просто аферисты, которые с гитхаба репы понабрали и продают воздух, ни каких своих закрытых разработок у них нет. Вот потому и спрашиваю в треде. Где-то есть хорошая вырезалка, просто её надо найти.
>>1304571 > Лапша же ничего принципиально нового тут не предложит, больше чем уверен. Тем не менее в лапше я могу вырезать фон нормально. На реалистике ещё проще.
>>1304753 Аниме пики с обводкой никогда не были проблемой. Плохо получается именно реалистичных персонажей вырезать.
У тебя на третьем пике 3д генерация, выглядит неплохо. Но при ближайшем рассмотрении есть много мест с белой короной и в спорных местах, например где волосы, появляется такой кисель из прозрачности. В этом плане А1111 даже лучше делает. Но это всё равно не подходит, таким вырезаниям нужна пост обработка всё равно. Сервисы же, например китайский 佐糖 таких косяков не делают.
>>1305002 Не плохо, но я как набивший шишки сразу чую подвох. Такой результат надо на "шахматном фоне" смотреть, по моему горькому опыту многие модели просто делают края вырезаемого объекта немного прозрачными, это может выглядеть как идеальное вырезание, но по факту ты такой вырезанный объект на другой фон не поставишь, у него вся окантовка будет как у привидения. Чем ты это вырезал, дай посмотрю, напиши плз адрес репы или модели или другую инфу чтобы я нашел.
А вообще знаешь что такое проблема XY? Самое главное забыл - сказать нахуя тебе это вообще надо и какую проблему ты собрался решать генерацией огромного количества изображений которые тебе надо вырезать? Ну и вопрос качества которое тебя устроит.
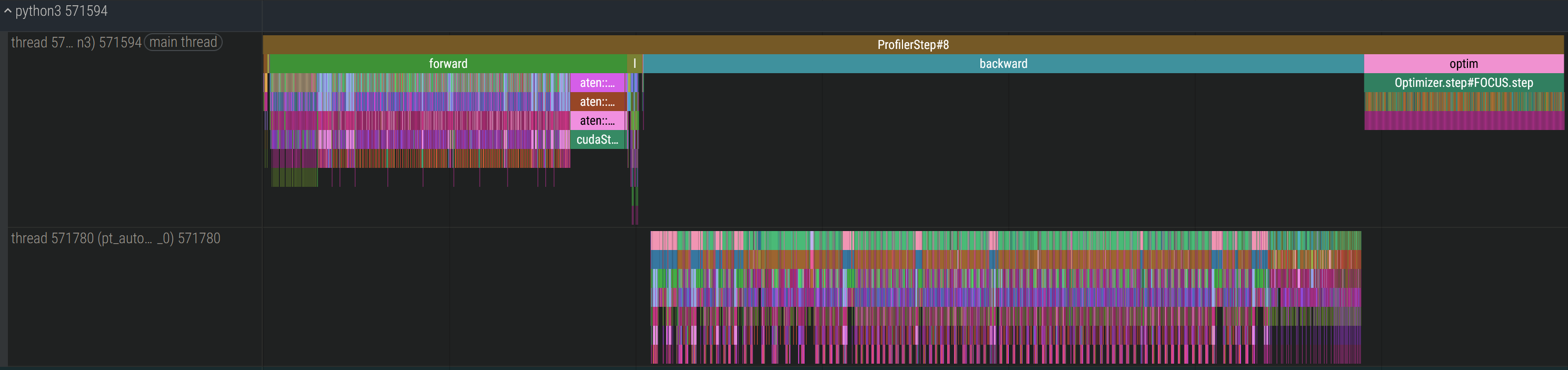
Wan тут кто-нибудь тюнит? Как с говном пикрил бороться? На первом пике XL, приемлемо выглядит. А на втором Wan, обратный проход в 6 раз дольше форварда. Хуйня с copy - это переключение на вторую карту, но хули в форварде обе карты одинаково отрабатывают, а на обратном одну с одинарными блоками растягивает как шлюху? Что за забор блядский? Заебался уже, не хочу тренить по 3 часа 1000 шагов.
В репо козистра https://github.com/kozistr/pytorch_optimizer/tree/main загружено семейство Emo оптимайзеров. Фишка в том что компутит доп скаляр исходя из лооса, т.е. получает усреднённое значение лосса (ema) (затем превращает это в скаляр), по которому вычисляется коэффициент влияния. Кароче бля параметры плавно тянутся к прошлым значениям, если loss подсказывает, что надо откатиться.
Для лор еще терпимо, а если фул матрицы тренить то там EmoNavi оригинальный с селективными блоками x2 врама жрет, EmaFact (емо + адафактор) +50%. Так что имейте в виду.
>>1307042 Опять душат удава. > если loss подсказывает, что надо откатиться Это вообще неблагодарное дело ориентироваться на лосс в генерации картиночек в разрезе соседних значений. Какой-то референс лучше, какой-то хуже - лосс скачет как ебанутый и это норма. Пикрил литералли всегда на Хроме, просто рандомный шум, при этом тренится заебись. > x2 врама жрет Лучше бы делали чтоб меньше жрало без диких просеров как у 8-битных bnb. И так DiT приходится частично в q8 квантовать чтоб не сосать даже с 48 гигами врам.
Аноны, обнаружил тут ВНЕЗАПНО, что у репозитория A1111 уже как год не было обновлений. Он что ВСЁ? Заброшен? Сдох?
Дело в том, что в А1111 меня всё устраивает, всё работает, плюс привычка, не один год в нем ковыряюсь, плагины настройки всё под себя идеально подстроил и привык.
Поверхностный гуглинг показал что сейчас модно КомфиУИ использовать, на втором месте Фордж, который говорят как раз для тех кто к А1111 привык.
В сявзи с этим вопросики. 1) Расширения для А1111 не встанут на этот ваш Фордж? Пологаю что разумеется не встанут, просто хочу уточнить.
2) В Форже другой синтаксис промптов, отличный от А1111? Т.е. все эти BREAK и [(shit:1.3)::0.7] там не работают?
>>1305569 >>1306775 >>1305516 Второе, как написано, основано как раз на BiRefNet. Оригинальный BiRefNet - это пожалуй самый лучший вариант из всех что я перепробовал. Наверное лучше ничего не придумали.
Кстати этот BRIA-RMBG-2.0 делает вот такую шляпу, про которую я писал ранее. Он Может в некоторых случаях половину обьекта прозрачным сделать. Оригинальный BiRefNet в этом плане даже лучше.
>>1307474 >Он что ВСЁ? Заброшен? Сдох? Ну автоматик перестал кодить в принципе. Или работка или выгорел, это ж все на энтузиазме для портфолио сделано.
>Дело в том, что в А1111 меня всё устраивает, всё работает, плюс привычка, не один год в нем ковыряюсь, плагины настройки всё под себя идеально подстроил и привык. Ну плохая привычка на самом деле, время выходить из зоны комфорта.
>Поверхностный гуглинг показал что сейчас модно КомфиУИ использовать, на втором месте Фордж, который говорят как раз для тех кто к А1111 привык. Не модно, а уже года джва является самой мощной и обновляемой средой для любых видов нейрокалов + парк расширялок монструзный. Буквально если что-то новое выходит (ну вон ван 2.2 например), то через пару часов оно уже поддерживается. Фордж это говнина от ильясвила, который факас, контролнеты и прочее пилил, фордж тоже заброшен. Не заброшены форки форджа, типа рефорджа https://github.com/Panchovix/stable-diffusion-webui-reForge
>1) Расширения для А1111 не встанут на этот ваш Фордж? Пологаю что разумеется не встанут, просто хочу уточнить. Рандом. У форджа в принципе свои нерешаемые баги были насколько я помню, ну и они в форки перекатились. Какие-то расширения встанут, какие-то нет.
>2) В Форже другой синтаксис промптов, отличный от А1111? Т.е. все эти BREAK и [(shit:1.3)::0.7] там не работают? Фордж это форк каломатика, так что скорее всего работает это говно плацебное.
>плацебное Чому плацебное ? Можно в реальном времени менять весь промпта (shit:1.2) и прямо наблюдать как результат меняется на такую же фракцию процента. По-моему очень удобно, не может быть чтобы в современной КомфиУИ чего-то подобного не было.
>время выходить из зоны комфорта. Для меня очень важно чтобы старые промпты можно было как-то повторить, я часто возвращаюсь к тому что делал год назад, например. Если синтаксис другой то понятное дело что повторить результат будет сложно. Может есть какой-нибудь плагин для КомфиУИ который позволяет использовать синтаксис промптов из Авто1111?
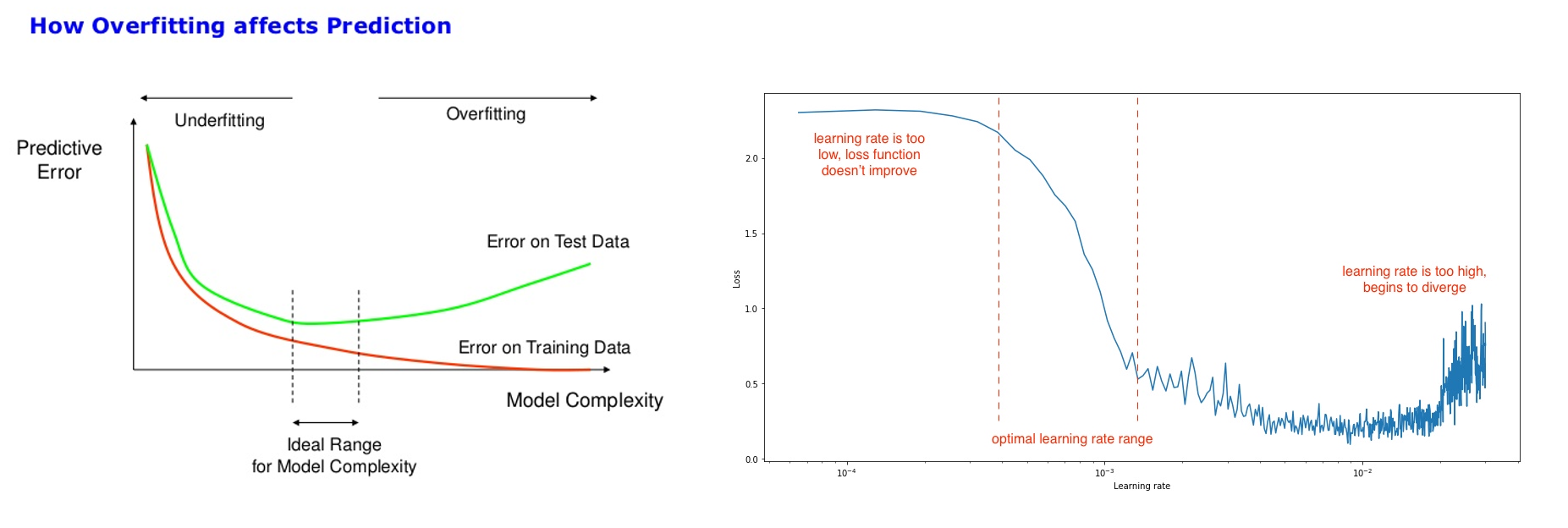
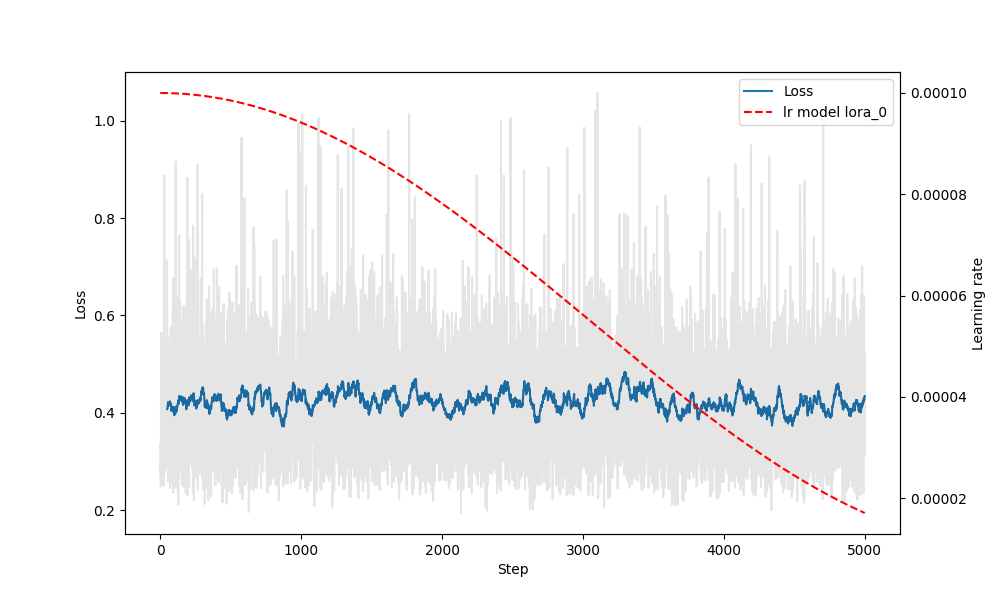
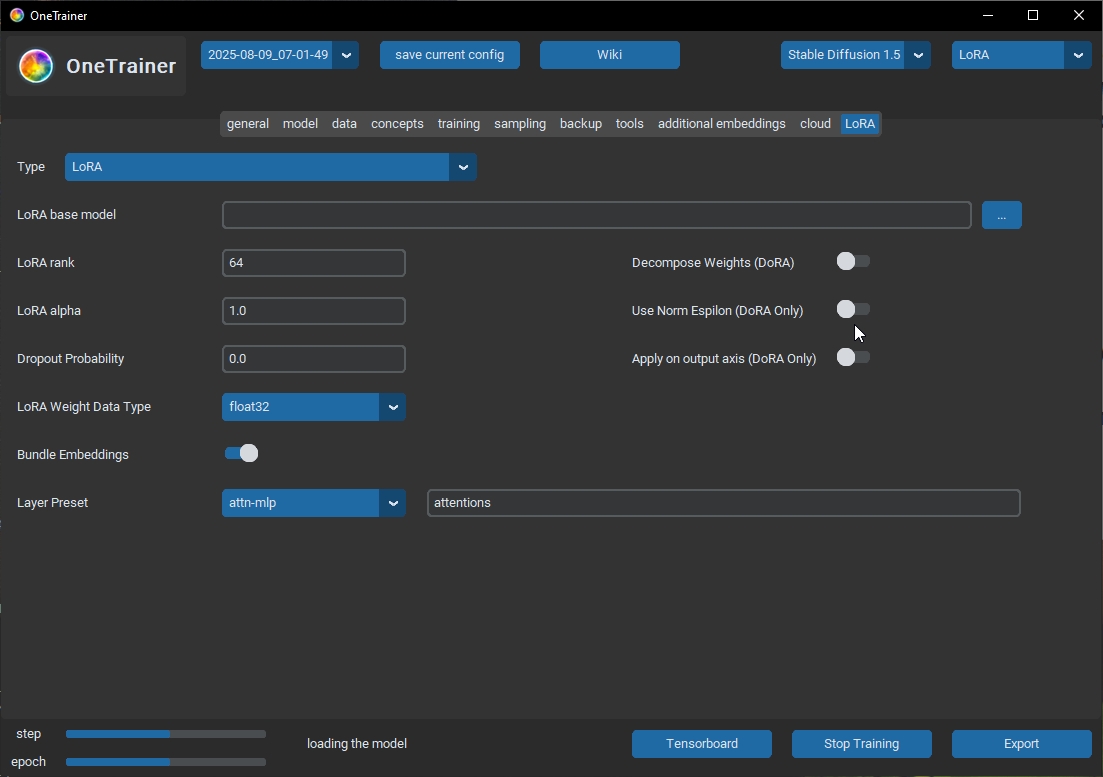
>>1272560 (OP) Как делать разбор полетов после тренировки? Про то что андерфит это когда результат слабо виден, а оверфит это когда лора воспроизводит датасет и не слушается промпта, я знаю. Но есть и другие ситуации когда лора берет знания из модели вместо датасета, когда низкий лр делает оверфит и пр. Хочу про это прочитать, чтобы хоть немного сориентироваться че за хуйня у меня происходит. Как извлекать информацию из результатов? Месяцами тренирую разные стили в сд1.5, у меня шизу генерирует на при любом ЛР/количестве шагов. 2 и 3 пик разные попытки, но результат тот же.
>>1307567 >Можно в реальном времени менять весь промпта (shit:1.2) обычный вейтинг токенов в комфе есть, я про брейки которые типа разъединяют кондишены и вот это [(shit:1.3)::0.7] которе я даже не помню че делает, а еще есть типа морфинг когда на лету в таймстеп инъекция другого токена происходит. Это кароче все полумеры и иллюзия управления. Вот допустим тебе два кондишена по 75 токенов надо - берешь две ноды для разных кондишенов в комфе в нужной конфигурации их смешивания и делаешь как задумано в сдхл изначально, а не костылем который придумали из-за UI вида "все в одном окне". Но если тебе прям нужно дрочить синтаксис каломатика, то есть ноды для текста, которые поддерживают этот синтаксис. >Для меня очень важно чтобы старые промпты можно было как-то повторить, я часто возвращаюсь к тому что делал год назад, например. >Если синтаксис другой то понятное дело что повторить результат будет сложно. Так у тя еще проблема в том откуда инишл нойз берется для генерации. То есть чтобы повторить ЗАЧЕМ, это же нейрослоп, всегда можно сделать лучше то что ты делал на каломатике тебе надо соблюсти неочевидные команды в поле промта (скачать ноды которые поддерживают такое) + ноды умеющие управлять инишл нойзом чтобы брался нойз с гпу, потому что в каломатике берется с гпу, а не с цпу, а это нестандартное решение, по классике должно быть с цпу т.к. это более унифицированнее (даже в том контексте что не у всех нвидия, некоторые дрочатся на линухе с амдкалом, а так свой инишл с гпу идет). > Может есть какой-нибудь плагин для КомфиУИ который позволяет использовать синтаксис промптов из Авто1111? Конечно, есть ноды под такое. Но лучше не пытайся создавать костыли заново.
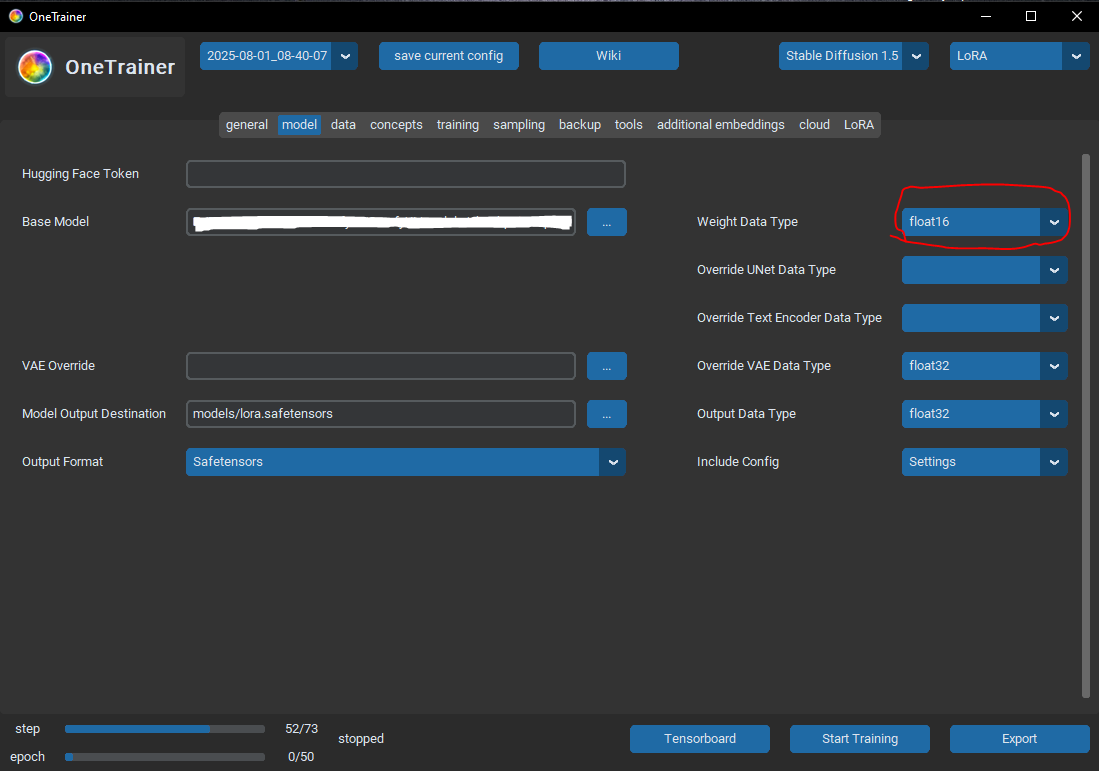
>>1307690 Еще вопрос, могут ли эти косяки быть из-за того что я в этой менюшке я выбрал fp16 но в остальных всех fp32 хотя моя видеокарта не поддерживает half-preccision (gtx1660)?
>>1307709 Бле, я думал за шум отвечает только сэмплер, что это такой типовой алгоритм, который имея идентичную модель и все прочие настройки сможет воспроизвести тот же результат по промпту. Но это как-то странно. На сивиай же например в инфе по генерации не пишут на каком она софте сделана, а повторить всегда получается, не 1 к 1, но очень близко обычно.
32bit нихуя не изменилось. Нормально ли подобное (видео рил) ухудшение в начале разогрева? Lion Cosine U-net LR 0.0001 Text encoder LR 0.00005 Warmup steps 731.0 Repetition per epoc 1 Batch 1 Epoc 50 Датасет 70 пикч Lora rank 64 Lora Alpha 1 Все остальное дефолтное.
>>1307690 > Как делать разбор полетов после тренировки? Э ну чтобы мучительно не надеяться на удачу и заниматьс разборами выходного продукта надо разобраться как работает модель (сам процесс генеративный) и гиперпараметров тренировки.
>Про то что андерфит это когда результат слабо виден, а оверфит это когда лора воспроизводит датасет и не слушается промпта, я знаю. Но есть и другие ситуации когда лора берет знания из модели вместо датасета, когда низкий лр делает оверфит и пр. Ну вот ты видишь симптоматику, а что вызывает ее ты не знаешь. Не знаю насколько тебе поможет, но если кратко рассматривать проблему то не в лр дело а в том что ты тренируешь. Предполагаю что ты тренируешь просто целую лору, которая охватывает все слои и все блоки. Так вот материнская модель состоит из трех частей - инпут блоки распиздячивающие картиночку, ботлнек мидл блок с общей инфой для приведения к единому знаменателю, и аутпут блок для сбора картиночки обратно, это происходит строго последовательно, блок за блоком и слой за слоем. В каждом блоке содержатся компоненты: 1. Конволюшн блоки, которые содержат инфу о локальных данных. Они очень чувствительные к шуму и начальным данным и собственно изза них рекомендуется делать вармап в качестве страховки. При этом конволюшны не однородны в своих возможностях: конвы в мидл блоки устойчивые к любым данным, конвы в поздних аутпут слоях тоже, т.к. содержат стабильные конечные сборочные детали. Но конволюшны в позднем инпут блоке (кондесация в низкое разрешение), в первых четырех группах слоев инпута (низкоуровневые контуры) и первые два блока аутпута (крупные пространственные признаки, глобал текстуры и цвет) очень нежные и если в них подается кривой сигнал говна, то пизда твоей модельке прямо с первого шага, конволюшн будет накапливать неверные признаки. 2. Линейные слои - практически полностю то из чего состоит модель, представляет из себя атеншн слои и частично MLP. Все линейные слои стабильные и практически не переобучаемые. 3. Feed forward слои, идут после атеншенов и являются носителями новых данных, которые не обобщены. Представь, что это фильтр для собираемой картинки, который обмазывает выходной сигнал во что-то независимо от контекста. Если конволюшны носители локальных данных, то фф носитель уникальных признаков.
Помимо этого есть слои текстового енкодера, которые занимается связкой текстового описания и признаков из слоев. Текстэенкодер в принципе независим, и достаточно простой в тюнинге и требует небольшой лр относительно основных весов сети, но не всегда. Тренировка текстэенкодера буквально бустит понимание твоего датасета и гибкость модели. В текстовом енкодере опять же последовательно обрабатывающиеся слои от общих признаков до локальных узкий концептов (условно от woman до small green dog in forest smiling like a whore). Трен текст енкодера напрямую управляет управляемостью модели конечной, так что тут ситуация как с конволюшнами - если ты лезешь обучать поздние блоки с жестким нефильтруемым потоком данных, то пизда твоему текстэенкодеру.
Поэтому что? Поэтому тебе нужно изучить регекспы для toml конфигов тренировки чтобы делать изолированную тренировку эффективных слоев, если ты хочешь стабильный результат, а не сейфовую выдрочку полномодульной лоры на низком лр, которая может десятки тыщ шагов тренироваться до приемлемого результата. В любом другом случае когда ты просто выбрал "а тренируй мне вот этот алгоритм на этом датасете спасибо пока" в лучшем случае сделает тебе генератор картиночек по типу тех что в датасете, никакой глубокой донастройки сети получить скорее всего не выйдет. Плюс учитывай что у тебя консумерский тренинг на нищем батче 1 и с маленьким датасетом (все что ниже 10к картинок считается как маленький датасет), то есть к вышелписанным ограничениям сети и нежности ее некоторых частей прибавляется бутылочное горло в виде не разряженного батча и малой даты в датасете, что бустит оверфит само по себе, если ты тренируешь полноблоковую модель.
Второй важный подводный камень это оптимайзер, они разделены по семействам и имеют разные так скажем возможности и скорость до нахождения решения. Основной параметр оптимайзера это моментум, он управляет памятью о предыдущих градиентах (бета1) и реакцией на новые градиенты (бета2). Есть разные оптимы, где есть один моментум, пять моментов, вообще без моментов, но в основном оптим имеет два моментума. Соответственно если у тебя хуевый сигнал говна, то чем больше память моментумов тем хуевее твоей сети будет что конкретно отражается на управляемости финальной моделью. Чтобы понять принцип работы моментума можешь взять сгд с нестеров моментумом или amos с одной бетой и покрутить туда сюда. Алсо чем ниже моментум, тем быстрее сходимость до цели но при этом побольше нестабильность т.к. моментумы в целом предназначены для сглаживания неоднородной даты на больших батчах. Вообще оптимов самых разных великое множество, протестировать все у тебя жизни не хватит, поэтому можно выбирать с помощью синтетических тестов например отсюда https://github.com/kozistr/pytorch_optimizer/blob/main/docs/visualization.md , растригин функция особо не нужна, она показывает залипание на гипотетических локал минимумах, для задач тренировки визуальных паттернов лучше смотреть на росенброк функцию, т.к. она напрямую показывает насколько оптимизатор силен в достижении особо уникальных паттернов в кривом косом прострастве признаков и насколько он делает это быстро и стабильно. Еще сюда можно совет впихнуть что если ты новичок и не хочешь ебаться с подбором лр под оптим, то бери адаптивные оптимайзеры, или шедулер фри. Но адаптивки обычно имеют более долгое достижение результата, т.к. ради сейфовоц адаптивности жертвуют скоростью.
Третий важный момент это регуляризация самой тренировки. Все эти команды типа макс град норм, скейл вейтс, дропауты, дебиасед естимейшены, шаффлы, аугментации - все они придуманы чтобы снижать влияние деструктивной полноблоковой тренировки на малом датасете с малым батчем. Условно дебиасед снижает влияние расшумленных таймстепов, и повышает влияние более важного и четкого сигнала поздних таймстепов - следовательно насрать в конволюшены с дебиаседом будет чуть сложнее. Или дропауты в лорах - отключают рандомные нейроны по ratio чтобы сеть не выдрачивала саму себя на твой маленький датасет, штука против оверфита.
Четвертвый момент это сама функция лосса. По дефолту у тебя доступны l1, l2 и huber. L1 очень медленный но стабильный, отсекает все критические ошибки. L2 быстрый но неустойчивый к ошибкам вообше, особенно на высоких скоростях и низких моментумах. Huber гибрид из двух предыдущих с удобной фильтрацией по SNR (что важно при малом батче и малом датасете), на практике является наиболее френдли лоссом к малым датасетам и быстрым скоростям из доступных изкаропки. Лоссов тоже очень много разных, все они впердоливаютя вручную, вон в этом треде вейвлет лосс и ффт лосс дрочили, я на ффт сижу теперь, батя грит малаца.
>Хочу про это прочитать, чтобы хоть немного сориентироваться че за хуйня у меня происходит. Комплексного гайда нет, просто ходишь по интернету и гптшкам и читаешь.
>Как извлекать информацию из результатов? Имеешь в виду как понять что модель не говно? Ну есть небольшой лайфхак это использовать вместе с лорой дистиллят лору dmd2 под LCM 1CFG, она очень хорошо правит все огрехи тренировки, даже если лора полностью убита к хуям будет пытаться дать нормальный когерентный результат и показывает визуально куда упор при тренировке был сделан и надо ли пониже лр, есть ли оверфит на локальные признаки, насколько следует промту и тд и тп. Сюда же хайпер лора, лайтнинг, турбо, пцм, тцд, но мощнее всех дмд конечно, эталонная дистилляция.
Я вообще в целом редко когда генерирую без дмд2 в контексте сдхл, к хорошему и быстрому привыкаешь быстро, но если тебе важен именно нативный ген без улучшалок убыстрялок дмд поможет определить туда ты тренируешь вообще или нет. Еще помогает определить эпоху перетренированности, это примерно когда при использовании дмд с лорой у тебя буквально срется картинками из датасета. Удобно кароч.
Но минус есть конечно - при 1 цфг у тебя не работают негативы и обобщение при генерации максимальное, поэтому сильно промт не имеет смысл расписывать вообще, буквально gay sex best quality пишешь и готовый результат оцениваешь.
>>1307749 > 32bit нихуя не изменилось. И не должно. На 32 бита стоит уходить только если NaN лезут, но bf16 для этого предпочтительнее. > Нормально ли подобное (видео рил) ухудшение в начале разогрева? Не очень. Первые 200-300 шагов можно простить, но дальше должно нормально идти. > Lora Alpha 1 Хуй знает как у тебя там альфа работает, попробуй сделать её как rank. При инференсе альфа берётся из лоры или если в лоре её нет - ставится как rank. Может у тебя она некорректно отрабатывает. Она у всех по разному работает - у кохи одно поведение, у ликориса другое, в peft третье. И на пики валидации сильно не ориентируйся, для начала протести финальную лору, может в валидации насрано.
>>1307711 > Еще вопрос, могут ли эти косяки быть из-за того что я в этой менюшке я выбрал fp16 но в остальных всех fp32 хотя моя видеокарта не поддерживает half-preccision (gtx1660)? Нет, точность это про другое. Можно эффективно тренировать ирю на фп8 и на q4, да даже на q1. Фп32 нинужно, это для карт и больших дядь с бизнес грейд датацентрами для тренировки, там есть фп32 и соответственно точность выше нужна тем кому нужна. Если у тебя 1660 то у тебя выбора особо нет, только фп16. А так в идеале если 3000 серия и выше то бф16 надо, оно стабильнее и в целом лучше фп16.
>>1307749 > Нормально ли подобное (видео рил) ухудшение в начале разогрева? Ту мач агрессив. У тебя верхнепороговая скорость 1е-4 стоит, оптим хз какой, лосс хз какой, от нуля до 1е-4 при 1 к 64 соотношение добавляемой даты исходя из альфы и дименшена (0,015625 per step) на стадии вармапа это очень жесткие изменения. Снижай лр и показывай полный конфиг тренировки.
Еще стоит козин в качестве шедулера, а у него кстати прикол есть что дефолтный без аргументов практически не снижается во времени (тензор борд открой посмотри на график), типа за 1к эпох он от условных 1е-4 упадет до 3.9е-5, что фактически не снижает ебку скоростью. Так что если тебе надо нормальный козин под конкретное количество шагов эпох то бери из библиотеки торча с аргументами настраиваемыми козины ихние.
>>1307504 >вот такую шляпу Пишешь экшн для фотошопа, который дублирует базовый слой и сливает их между собой, и так несколько раз, потом сохраняет и закрывает файл. Прогоняешь им всю папку с картинками.
Но, очевидно, что косяки на краях после такого вылезут во всей красе.
>>1307757 Проблема проверок всех этих параметров это сколько ждать нужно. 3600 шагов занимает 6 часов. Хорошо сейчас понял что простой промпт (1girl, solo) за ~20 мин (3 эпока) разоблачает косяки.
Анон, мне нужна хоть какая-то победа. Сколько я бьюсь об стену и вижу этот шизофренический результат с искривленными руками. Либо странный андерфит где лора дает минус к анатомии. Мне нужно хоть какая-то надежда, хоть какой-то позитивный результат.
Мне кажется тут много того что ты написал что понадобится уже на более тонких вещах. Если у меня неправильно выставлена температура мне кажется трогать бета1 или 2 будет только сильнее запутывать. Т.е. если если вместо сломанных правых рук станут сломанные левые, то я вряд-ли это замечу. Если я не смогу хотя бы немного исправить текущий пиздец с экспериментируя 1-3 параметрами, то блять, вообще хуй с тренеровкой лор. Столько уже времени вложил, что еще столько же я уже не выдержу. Я готов сильно пожертвовать качеством если смогу убрать шизофринию.
Все эти аналогия на счет машинного обучения про то как обучения это слепой идет и изучает
>В каждом блоке содержатся компоненты:... Мне кажется тут нужен набор знаний которого у меня нет.
У меня SD1.5 если что. >>1307758 >Хуй знает как у тебя там альфа работает Альфа 1.0 полное обучение без помех, 0.5 половина силы. >>1307763 Понятно. >>1307771 >верхнепороговая скорость >соотношение добавляемой даты исходя из альфы и дименшена >пики валидации >peft третье Моя твоя не понемай. >Еще стоит козин в качестве шедулера, а у него кстати прикол есть что дефолтный без аргументов практически не снижается во времени (тензор борд открой посмотри на график), типа за 1к эпох он от условных 1е-4 упадет до 3.9е-5, что фактически не снижает ебку скоростью. Пик1 >Снижай лр У адаптивных оптимайзеров, если в начале изменения слишком маленькие у них крышу срывает, по этому нельзя вармап. А обычные нормально относятся если в начале слишком низкий ЛР.
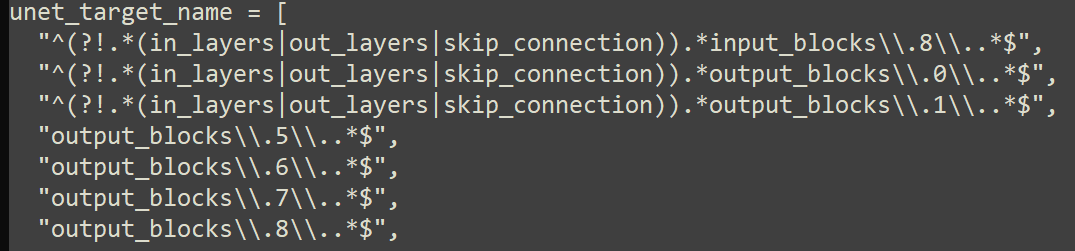
>>1307881 >Проблема проверок всех этих параметров это сколько ждать нужно. 3600 шагов занимает 6 часов. Так чтобы понять принцип работы того или иного параметра тебе буквально нужна 1 картинка, 1 тхт файл описания и 5 репитов на этот датасет из 1 картинки и условно 10 эпох тренировки длиной в 5-10 минут. Не надо выдрачивать по 6 часов, это так не работает вообще: если сеть изначально сломалась, то она из жопы магическим образом не вылезет дальше есть пара вариантов когда может, но это особая магия с косинанилингвармрестарт шедулером и не всегда работает. Забей хуй на тренировку, пробуй следующий вариант, если у тебя в первые 5-10 эпох нет когерентного результата. >Хорошо сейчас понял что простой промпт (1girl, solo) за ~20 мин (3 эпока) разоблачает косяки. Ну да. Но есть чуть более точный тест: сначала генишь примерно то на что тренил, затем генишь диаметрально противоположный концепт - скажем кот сидит на скамейке в городе, если оба теста проходит и ничего не поломалось, то модель сумела в обобщение. Естественно надо учитывать что от сида тоже зависит и если на одном сиде не работает, то на другом может работать, это норма для луковичных юнетов. >Анон, мне нужна хоть какая-то победа. Сколько я бьюсь об стену и вижу этот шизофренический результат с искривленными руками. Либо странный андерфит где лора дает минус к анатомии. Мне нужно хоть какая-то надежда, хоть какой-то позитивный результат. Если тебе нужен стопроцентный простой удобный результат, то берешь технику тренировки b-lora, это как раз про изоляцию и таргетированную тренировку. Там по дефолту отключены фф и прожекшен слои и конволюшены в конфиге, так что будут тренироваться только линейные слои в конкретных блоках, вследствие чего у тебя будет вопервых долго тренироваться до результата, а во вторых вообще насрать на гиперпараметры - оно сожрет практически любые. Сам концепт описан тут https://b-lora.github.io/B-LoRA/ Конфиги тут https://github.com/ThereforeGames/blora_for_kohya/tree/main/lycoris_presets Если захочешь включить все кроме конволюшенов в тренировку обратно, то в регулярных выражениях для юнета пропиши заместо старого "output_blocks\\.0\\..$", "output_blocks\\.1\\..$", "input_blocks\\.8\\..$" Текстовый енкодер там два слоя тренируется "text_model.encoder.layers.0", "^text_model\\.encoder\\.layers\\.1(?!\\d)(\\..)?$" >Мне кажется тут много того что ты написал что понадобится уже на более тонких вещах. Мой псто скорее про то что сначала изучи как работает мотор прежде чем заниматься его починкой изолентами. >Столько уже времени вложил, что еще столько же я уже не выдержу. Ооо ты бы знал сколько я времени убил впустю вообще наверно в окно выпрыгнул.
>Мне кажется тут нужен набор знаний которого у меня нет. Ну я вроде описал принцип работы, теперь есть. >У меня SD1.5 если что. А, ты еще и на полторахе. Ну в принципе с изоляцией слоев в небольшом дименшене без текст енкодера и в фп8 юнете и фп8 оптимайзере сдхл должна влезть в 6 кеков даже на 1024 разрешении, а уж 768 и подавно. Могу проверить если хочешь и потом конфиг дать, сдхл во всем будет лучше полторахи даже в фп8 тренинге за счет того что там модели попизже будут базовые.
>Моя твоя не понемай. У тебя стоит 0.0001, это в сайнтфиик нотейшен 1e-4, достаточно агрессивная скорость для лиона и лор в целом. Дименшен и альфа работают так: ты указываешь дименшен ранк 64 и альфу 1, следовательно коэффициент влияния модуля лоры каждый шаг будет 1 поделенный на 64, то есть 0.015625силы влияния, что осторожно и не должно так въебывать уже на вармапе. Альфа это регуляризационная залупка кстати тоже. >Пик1 А у тебя в вантрейнере выставлен num_cycles зависящий от тоталстепс, по дефолту его нет, я предположил что ты может выставляешь вечную тренировку на козине. >У адаптивных оптимайзеров, если в начале изменения слишком маленькие у них крышу срывает, по этому нельзя вармап. А обычные нормально относятся если в начале слишком низкий ЛР. Ну адаптивным и не ставят вармапы. А у тебя лион, он не адаптивный, у тебя 700 шагов на вармап при датасете в 70 картинок, это в целом дохуя и смысола не имеет, 5% от всего рана или эквивалент 1-2 эпохам достаточно, ато он 10 эпох дрочился у тебя до мощной скорости зачем-то (я только только видос посмотрел твой), только время проебал.
>>1307941 >Мне кажется тут нужен набор знаний которого у меня нет. >Ну я вроде описал принцип работы, теперь есть. Конволюшн блоков в этих u-net пикчах я не вижу. Я попробую несколько раз перечитать твои посты но башка от сложности взрывается. Просто в большинстве туториалов говорят "хуяк-хуяк, поэкспериментируйте температурой и эпохами и все!". А тут непросто знать что каждая хуйня делает, нужно еще знать на какие еще 10 вещей она влияет, от каких 5 вещей зависит и какие 3 вещи делают её ненужной, а как все эти вещи работают вместе.
>сдхл во всем будет лучше полторахи даже в фп8 тренинге за счет того что там модели попизже будут базовые. У меня gtx1660, full precision only. Генерация SDXL даже 768p 20 шагов занимает 2 минуты. Там вообще никак не поэкспериментируешь, я уже не говорю про тренировки.
>У тебя стоит 0.0001, это в сайнтфиик нотейшен 1e-4, достаточно агрессивная скорость для лиона и лор в целом. >Дименшен и альфа работают так: ты указываешь дименшен ранк 64 и альфу 1, следовательно коэффициент влияния модуля лоры каждый шаг будет 1 поделенный на 64, то есть 0.015625силы влияния, что осторожно и не должно так въебывать уже на вармапе. Альфа это регуляризационная залупка кстати тоже. Т.е. другими словами непонятна причина пиздеца?
Бонус: мнение. Аналогия с слепцом который ходит по горам, учится рельефу, и пытается найти дно, не отображает реальность машинного обучения. И это не просто грубое упрощение а активно мешающая пониманию процессов. Т.к. если вам задут хоть немного технический вопрос эту аналогию невозможно будет применить, потому что она изначально не имеет смысла. Лучшая аналогия необходима и поможет всем. Имхо.
>>1307757 >>1307941 Ты пиздец его изнасиловал сейчас инфой скорее всего, он хоть усрётся не получит нихуя от полторахи как не трень, ни анатомии, ни рук, ни стиля, может скорость только получит приемлемую >>1307690 Что ты хоть тренить то собрался? Тебе легче будет в тредах попросить тебе потренить с твоей 1660, но про 1.5 можешь вообще забыть, сколько её не еби, оно мёртвое даже по сравнению с XLями. Но вообще с XL фп8 оптимайзер, фп8 веса, градиент чекпоинтинг, 1 батч, без энкодеров, может сниженное разрешение даже влезет в 6, в 8 точно влезает без энкодеров второй батч в 1024 >>1307881 > 3 эпока Я очень надеюсь что ты не по методикам вин10твикера это всё пытаешься делать
>>1307749 Я насколько я знаю для фп8 нужны RTX 30ХХ+ серии (bitsandbytes), если конечно есть то чего я не знаю о 16xx серии И да те 2 минуты за 768px 20 шагов это на квантованных чекпойнтах. Обычные не влезают в ВРАМ. > 3 эпока >Я очень надеюсь что ты не по методикам вин10твикера это всё пытаешься делать 3 эпока это я преувеличил но так я ссылался на этот видеорил >>1307749
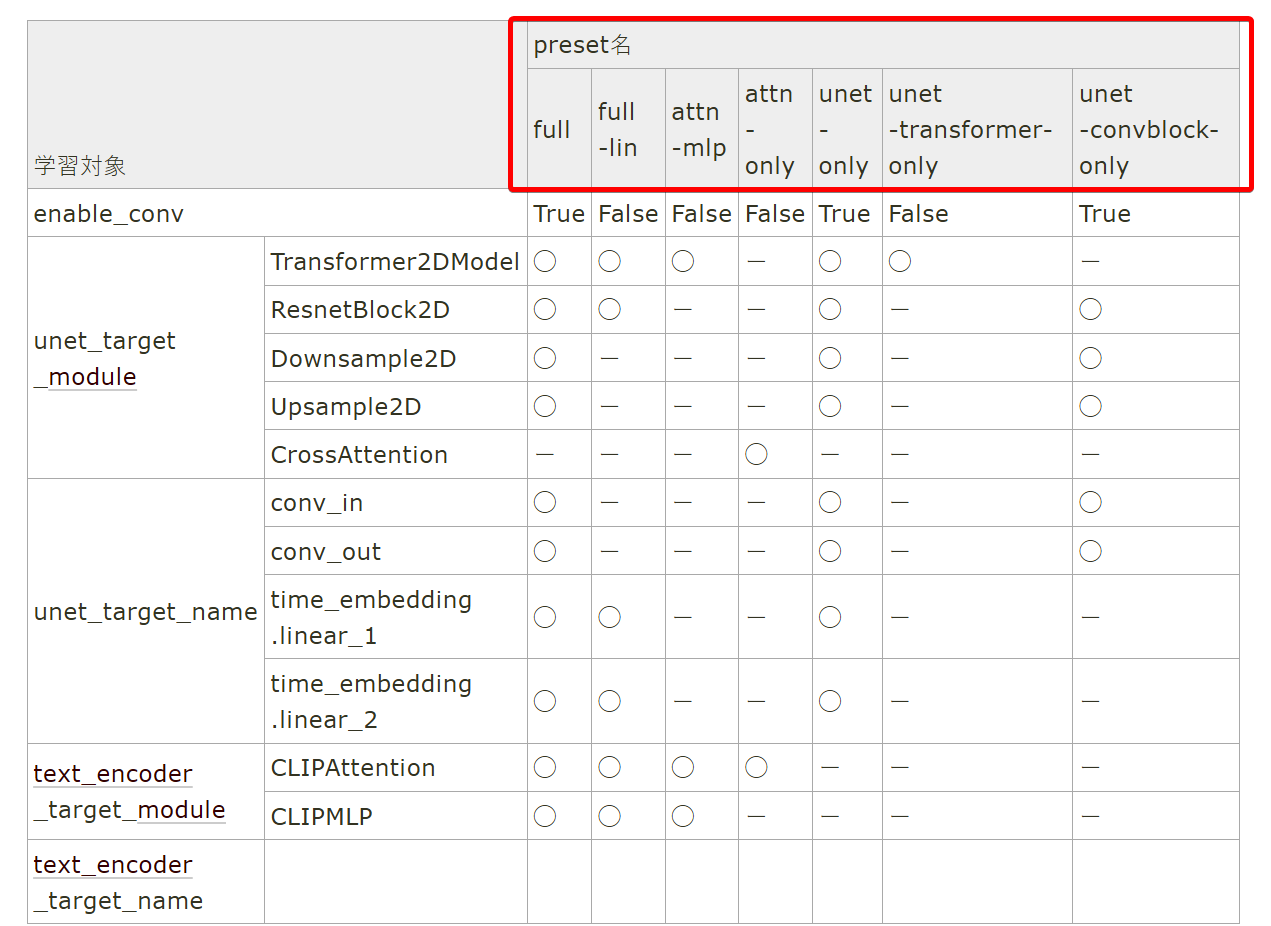
>>1308066 >Конволюшн блоков в этих u-net пикчах я не вижу. Конволюшн слои внутри блоков, отдельных блоков с конволюшнами в сетях нет. У тебя пикча схематичная, там справа снизу легенда расписана где стрелочки отдельные это и есть конволюшны частично. Кароче, чтобы понять из чего состоит модель тебе надо взять любою лору натренированную даже на одном шаге, но с таргетами по всем блокам со включенными конв слоями, а дальше эту лору засунуть в верификатор лор, без разницы вручную через питон скрипт или через уи типа https://github.com/bmaltais/kohya_ss , на выходе ты получишь список всех слоев в твоей лоре, пикрелейтед, он для сдхл но тоже самое делается и для 1.5.
У тебя в пикчах твоих кстати выше стоит пресет attn+mlp, то есть ты изначально не тренируешь конволюшны, то есть они отпадают как причина агрессии или кривости лорки. Остается просто высокая скорость и недостаточная регуляризация.
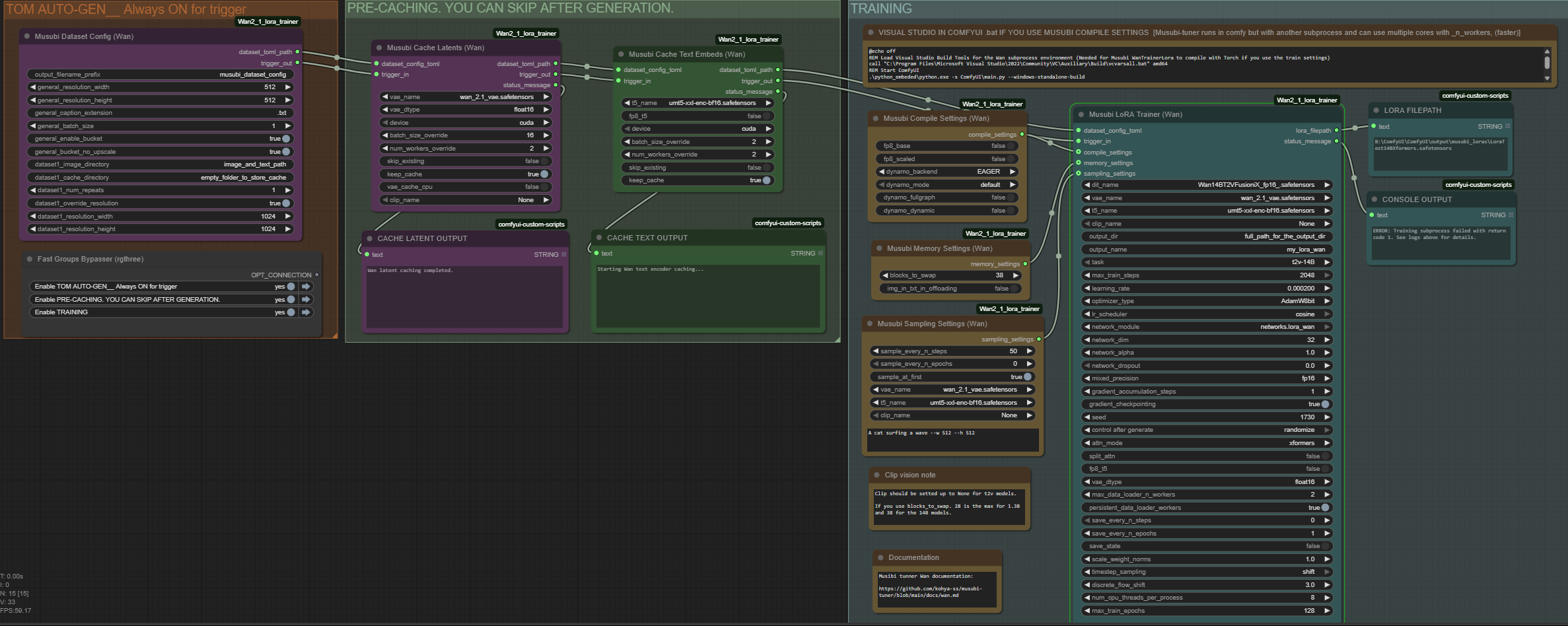
Если надо тренить с конвами то переключись пресет на full и потрень 1 шаг с сохранением чтобы потом посмотреть состав лоры. Вообще вантрейнер я бы не использовал на твоем месте, он достаточно неудобен. Рассказать как пользоваться говном для тренинга лучше?
>Я попробую несколько раз перечитать твои посты но башка от сложности взрывается. Задавай вопросы что непонятно.
>Просто в большинстве туториалов говорят "хуяк-хуяк, поэкспериментируйте температурой и эпохами и все!". А тут непросто знать что каждая хуйня делает, нужно еще знать на какие еще 10 вещей она влияет, от каких 5 вещей зависит и какие 3 вещи делают её ненужной, а как все эти вещи работают вместе. У тебя два стула буквально в контексте лоры - тренить вечность на низкой сейфовой скорости на уровне до 1e-5, но не думать о том, как оптимизировать процесс чтобы не обосраться, либо тренить эффективно но избегать страданий от переобучения через таргетинг (вот у тебя аттн+млп пресет, это по факту таргетная тренировка, ток ты изначально не так с ней работаешь) и тонну гиперпараметров.
>У меня gtx1660, full precision only. Генерация SDXL даже 768p 20 шагов занимает 2 минуты. Там вообще никак не поэкспериментируешь, я уже не говорю про тренировки. Я имею в виду чтобы ты подготовленные сконверченный чекпоинт можешь использовать для генерации, через пик2 например, это мой скрин годичной давности почти, там потребление врама в пике 5.5 гигов, теоретически оно влезет тебе в 6 гигов твоей 1660, потому что были репорты что в 1050ти с 4 гигами влезало и терпимо было.
А тренинг тренируется через специальный параметр --fp8_base_unet, переводящий fp16 чекпоинт в fp8 точность, плюс использование оптимайзера с 8бит точностостью. То что у тебя карта не держит фп8 нативно это не проблема вообще, оно не влияет особо.
Я уже скозал ранее что могу проверить сколько будет врама съедать, тренинг в суперэконом режиме с изоляцией слоев с отключенным TE, попозже напишу.
>Т.е. другими словами непонятна причина пиздеца? Ну как такового пиздеца нет, из того какие данные от тебя я вижу ты зачемто тренил вармап 10 эпох до конского пика скорости и спрашиваешь а че почему в жопе все. Надо по другому тренить, помягче и поэкономичнее.
>Бонус: мнение. Аналогия с слепцом который ходит по горам, учится рельефу, и пытается найти дно, не отображает реальность машинного обучения. И это не просто грубое упрощение а активно мешающая пониманию процессов. Т.к. если вам задут хоть немного технический вопрос эту аналогию невозможно будет применить, потому что она изначально не имеет смысла. Лучшая аналогия необходима и поможет всем. Имхо. Лучшая аналогия обучения нейросети это раб, которого бьют плеткой (лосс функцией и регуляризацией) за каждый неверный мув (ошибку) чтобы он больше таких мувов не делал и был хорошим рабом. Если бить раба слишком сильно, то он помрет не сделав ничего полезного, если недостаточно, то он будет филонить. Осуждаю, но выглядит это именно так. Обучение с тичером и подкреплением вообще концлагерь аналогией будет.
>>1308205 > Ты пиздец его изнасиловал сейчас инфой скорее всего, Бля ну я не хотел, мне кажется лучше сразу показать что тренинг это не тяп ляп и результат как будто гпт 5 натренировал а ты сем альтман, в реальности ебешься будь здоров как и в любой деятельности которая с виду преподносится как жмаканье кнопки сделать пиздато.
>он хоть усрётся не получит нихуя от полторахи как не трень, ни анатомии, ни рук, ни стиля, может скорость только получит приемлемую Ну кстати да, полторашка сама в целом сосет. Лучше пусть продает свой 1660 мусор и покупает срук 3060 12 кеков или из 4000/5000 серии ченить с 16 гигами если интересен процесс тренировок, не такие уж большие траты, 8 раз в пятерочку сходить.
>>1307757 >Вообще оптимов самых разных великое множество, протестировать все у тебя жизни не хватит, поэтому можно выбирать с помощью синтетических тестов например отсюда https://github.com/kozistr/pytorch_optimizer/blob/main/docs/visualization.md Нельзя. Осмысленных выводов по этим картинкам сделать невозможно. >Еще сюда можно совет впихнуть что если ты новичок Найс кормишь новичков дерьмом. >бери адаптивные оптимайзеры, или шедулер фри. Это хотя бы верно. >dmd2 )))
В остальном вода без конкретики с привкусом шизы. Ну шедулер фри, ффт лосс, эти хуйни с планировщиком таймстепов имеет смысл юзать, но у него в огрызке гуя оно есть?
>>1307749 >>1307881 >Lion Выкинь, он не умеет обороты сбавлять и фулл лр хуячит, емнип. 1е-4 тем более с ним будет дохуя.
>Альфа 1.0 полное обучение без помех, 0.5 половина силы. Не так. Ставь альфу как корень из ранга. В твоем случае 8. Альфа прост косвенный множитель инициализации весов. Он еще на ранг делится, так что полное это 64. >У адаптивных оптимайзеров, если в начале изменения слишком маленькие у них крышу срывает, по этому нельзя вармап. А обычные нормально относятся если в начале слишком низкий ЛР. Наоборот. Моментумы без прогрева могут дать очень большое обновление. Или просто временно "отключаются", и будет идти обучение как по обычному сгд. И можно не плавно поднимать лр, а проехать сколько-нибудь на нулевом лр, а потом поднять. Это изначальная логика как задумывалось. Просто с маленьким лр можно не тратить шаги впустую а чутка успеть обучиться и никуда не улететь пока момент плавно стабилизируется.
Поставь аккумуляцию побольше, даст то же самое что и батч. Отключи ТЭ. Потести лоссфункции, включи дору. Пресет слоев у тебя какой, где написано только атеншены? В этом гуе я хз, но если только атеншены тренирует то это не то. Добавь wd, дропауты. Ну и выкинь лион, ставь адамW обычный.
Можешь инициализировать лору через SVD для стабильности. Выше есть ссылка, требует только пердолинга через гуи. В твоем наверное должно работать, но надо будет поставить кохьевский гуй и комфи.
>>1307941 >Ну адаптивным и не ставят вармапы. Пиздеж.
>>1308066 >Я попробую несколько раз перечитать твои посты но башка от сложности взрывается. Ой бля лучше его не слушай, там надо шарить чтобы понять что мусор а что нет. Лучше возьми да залей датасет и сюда вкинь, тут получше твоей некторы карточки будут. Да и я могу натренить если мне не лень будет. Только дай модель и тестовые промты. Прост интересно ради чего ты так ебешься. И вообще нахуя 1.5? Она же кал. Если xl хотя бы запускать можешь, зареквесть других натренить. Сборка датасета это все равно самое ебаное из всего процесса, а на трене уже работает видимокарта а не ты, лол.
>>1308791 >Лучшая аналогия обучения нейросети это раб, которого бьют плеткой (лосс функцией и регуляризацией) за каждый неверный мув (ошибку) чтобы он больше таких мувов не делал и был хорошим рабом. Если бить раба слишком сильно, то он помрет не сделав ничего полезного, если недостаточно, то он будет филонить. Осуждаю, но выглядит это именно так. Обучение с тичером и подкреплением вообще концлагерь аналогией будет. Хуйня аналогия. Вот лучшая: Параметры нейросети это многомерные координаты, для многомерного ландшафта по которому она идет. Градиент дает направление и условно-относительную силу шага для каждого параметра-координаты. С каждым шагом ландшафт немного меняется, потому что параметры воздействуют друг на друга. Поэтому сильно шагать по вычисленному направлению мы не можем, только по чуть-чуть. Разные параметры влияют на ландшафт по-разному. И для того чтобы вычислять такие параметры придуман второй момент в адаме, который старается не дрочить сильно параметр если градиент по нему часто меняет направление. И никаких аналогий не надо.
>>1308864 >Лучше пусть продает свой 1660 мусор и покупает срук 3060 12 кеков 3060/12 можно за 15к достать с мобильным чипом. Якобы новую из китая. Б/у за 12. Мобильные 3080/16 в районе 20. v100/16 еще есть за 20 с небольшим, но там пердольная плата с охладом.
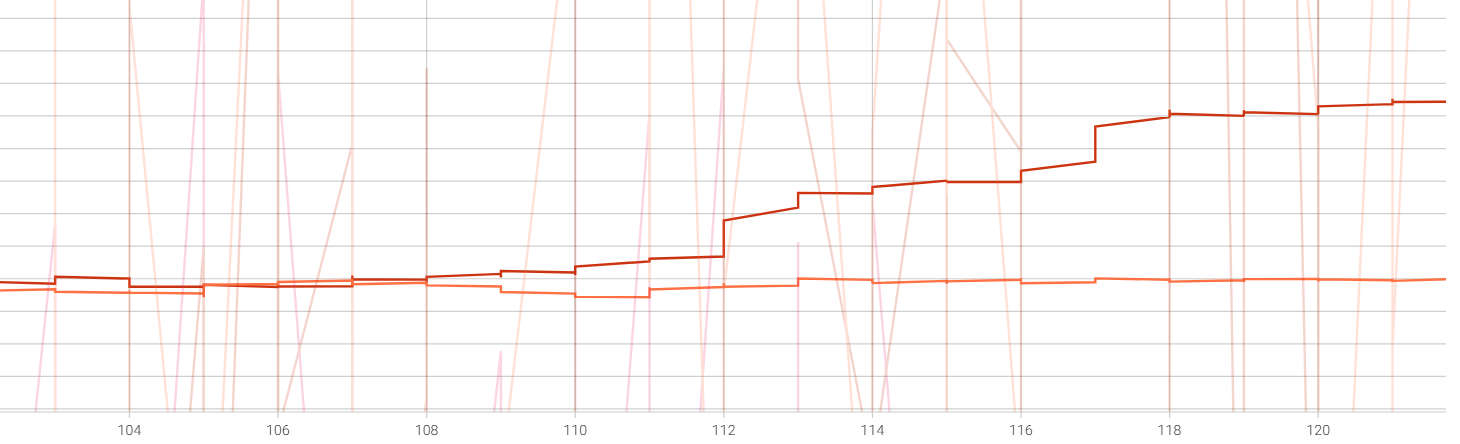
>>1307749 Блять. Как минимум половина проблем была в Aspect Ratio Bucketing. Новый тест с другим чекпойтом: Пик1 Слева оригинальный датасет с разным соотношение сторон, справа датасет с квадратами Aspect Ratio Backeting ВЫКЛ (чужой датасет и абсолютная шиза в нем, у всех пикч один промпт, а теги со всякими мастерписями, 32к и пр)
Какой же комфипидор всё же пидор. У него некоторый код инференса в режиме обучения. Видимо когда впердоливали ноды обучения никто даже не чекнул остальной код и не сделал torch.no_grad() как положено. Из-за этой хуйни "протекает" память, хотя на самом деле это так торч устроен - веса модели нельзя удалить из памяти пока на них ссылается тензор с requires_grad. Чекается легко, есть ли в воркфлоу говняк - генерим и жмём "выгрузить все модели", если память не очистилась под ноль, а после нажатия "инвалидация кэша" всё же освободилась, то говорим спасибо комфипидору. Пока тензоры в кэше нод не будут удалёны, не очистится и память моделей, зависящая от них. Хорошо хоть глобальное отключение автограда помогает и не надо разбираться в этом говнокоде. А ведь я помню как это чмо ещё пиздело на автора Форджа что он не знает что делает, по итогу это комфипидор не знает как менеджмент памяти в торче работает.
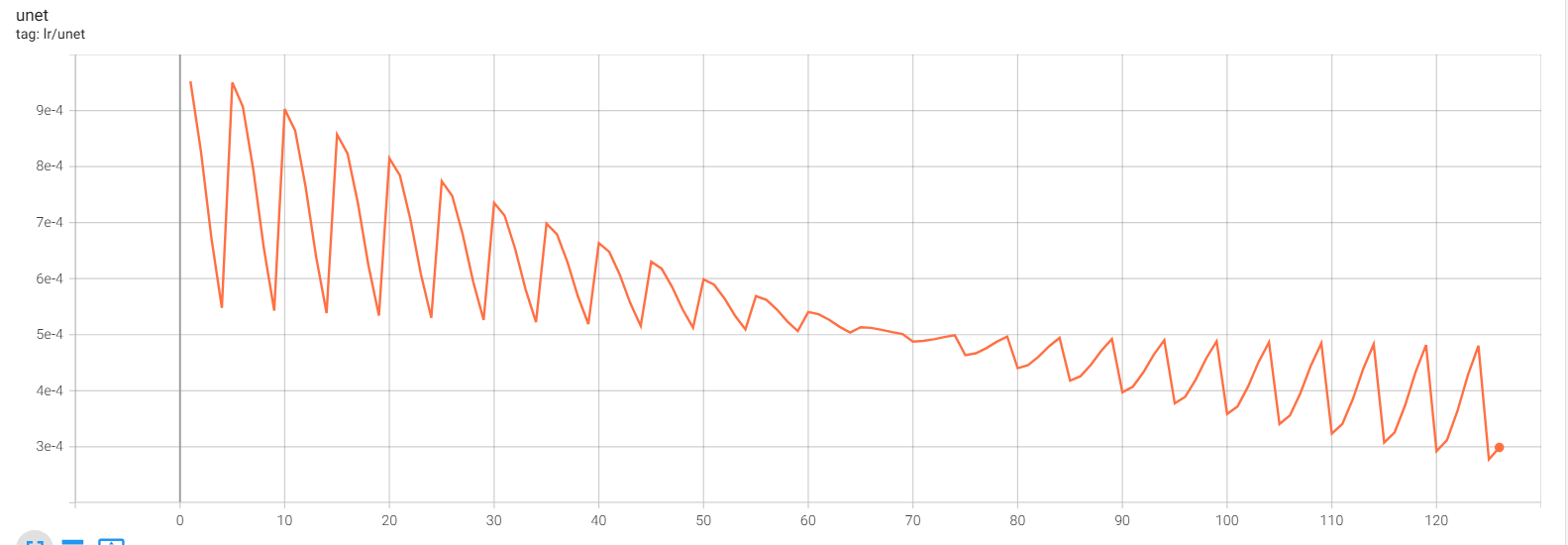
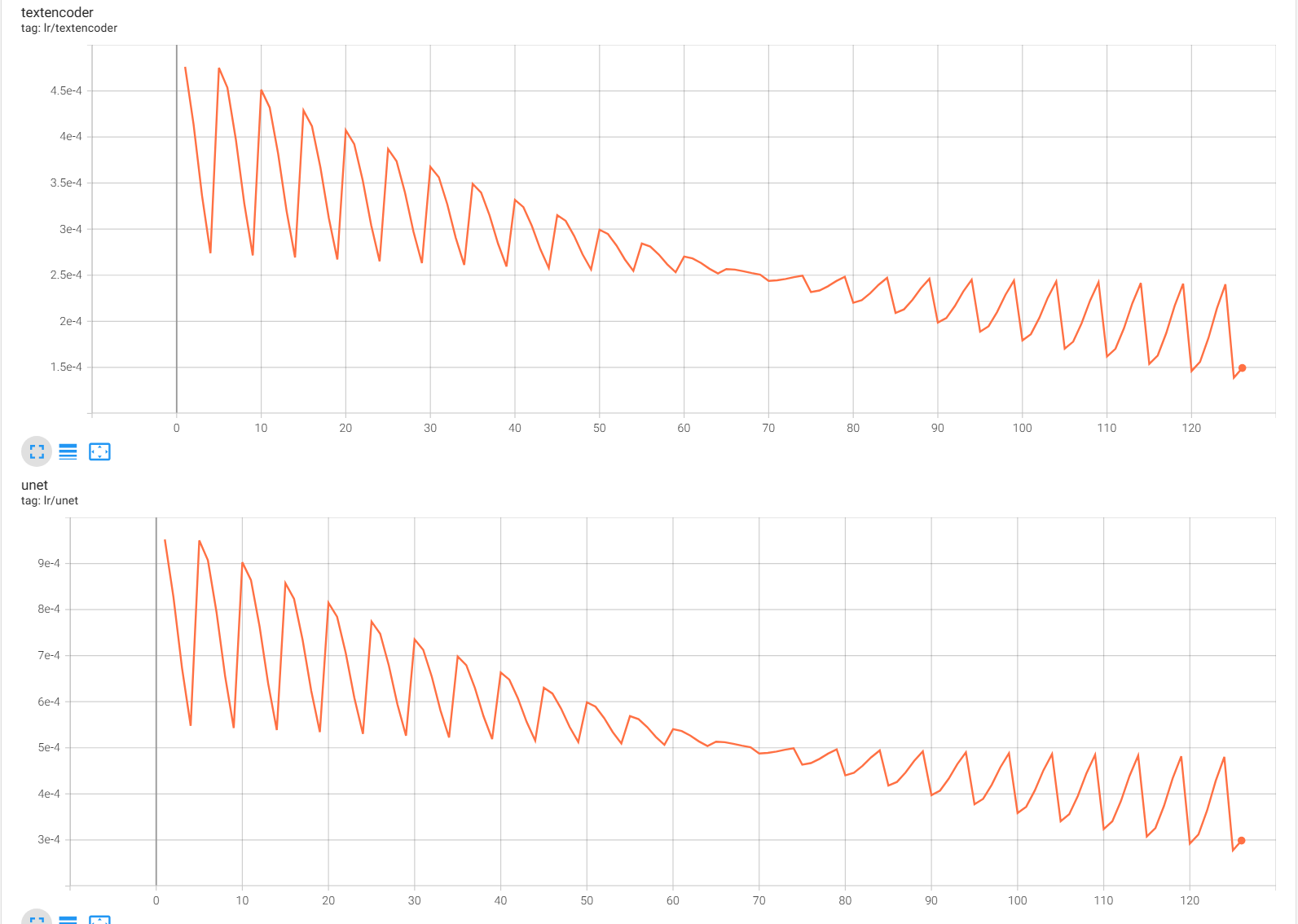
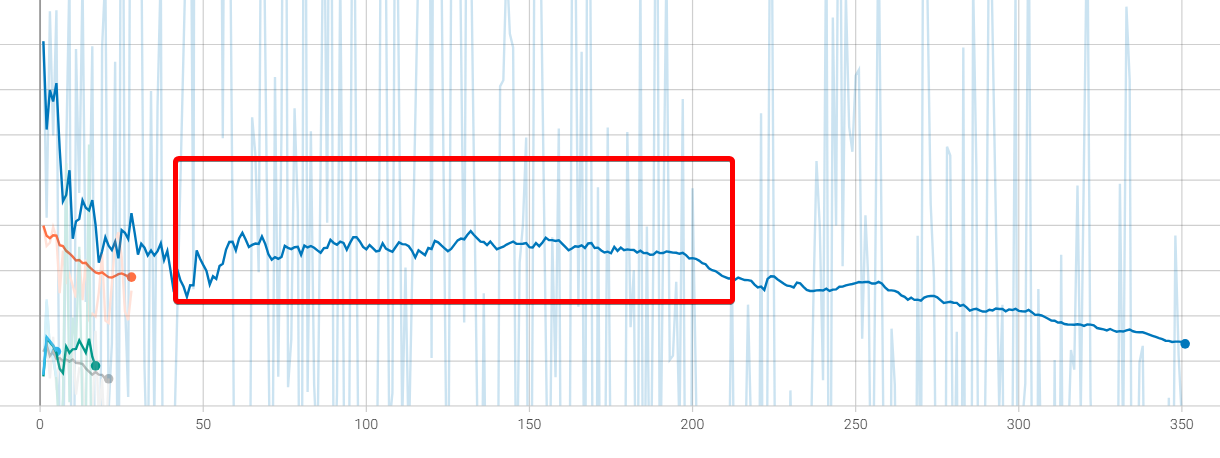
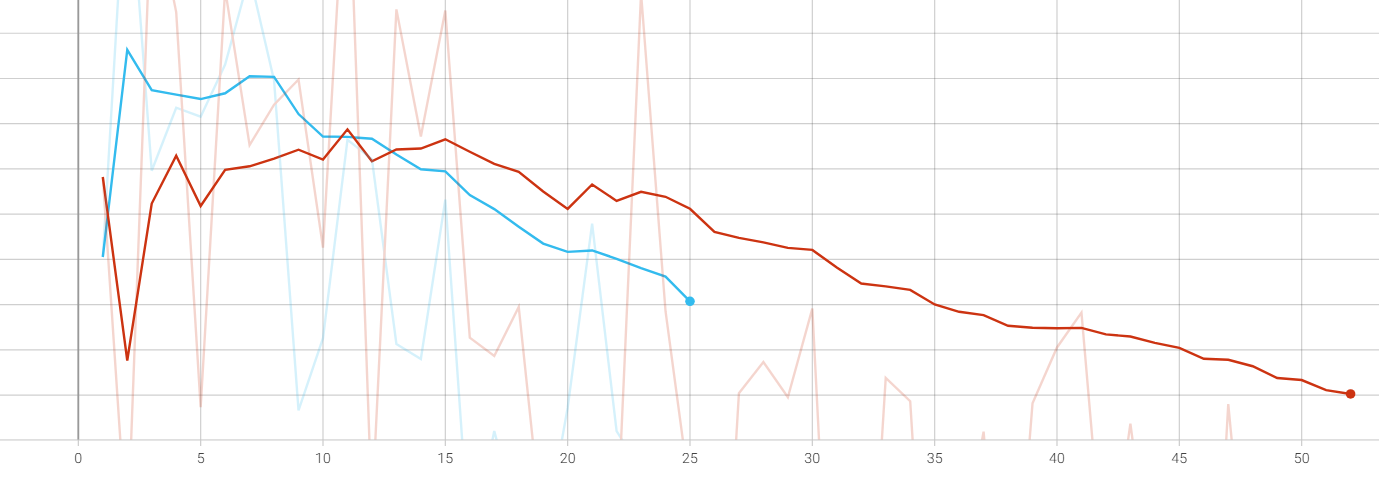
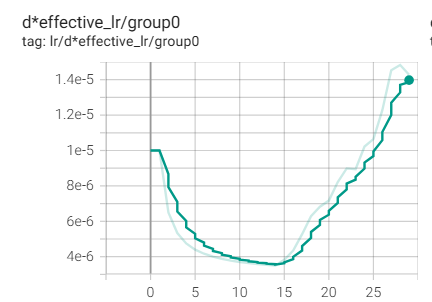
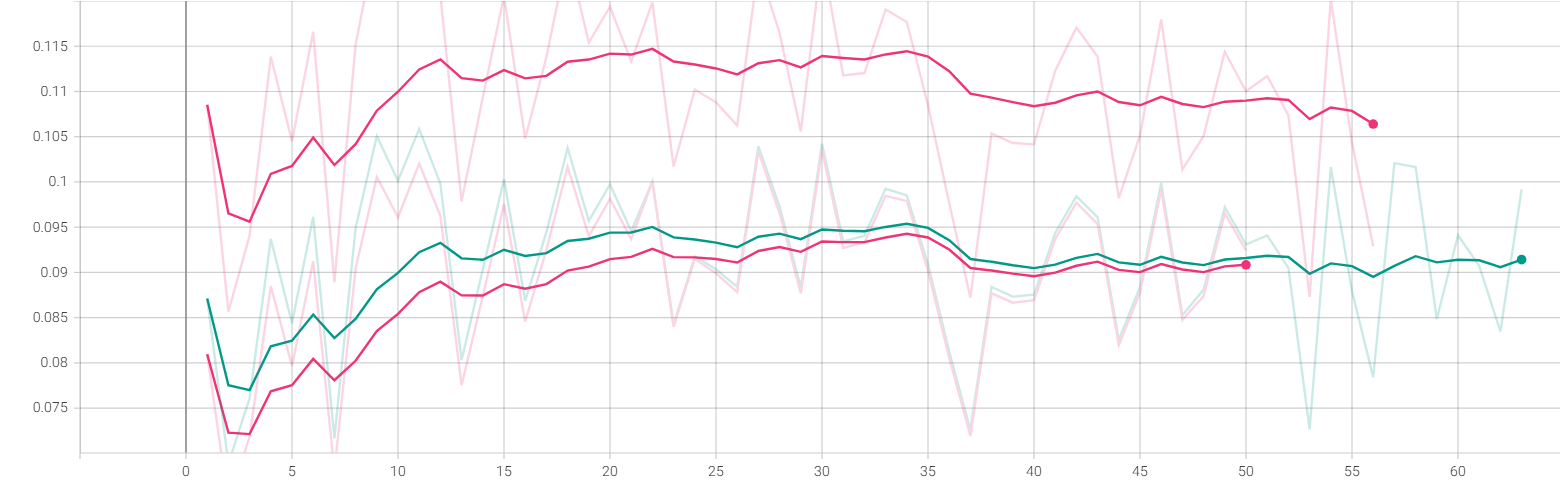
Экспериментировал с CAWR шедулером, и случайно получилась такая кривая скорости из-за достижения лимита в min_lr. Примерно с того момента как график отзеркалился (70 шаг) внезапно пошел ебический буст четкости и сходимости. Это я так понимаю обратная пилообразная синусоида, но я их ни разу в кастомных шедулерах не встречал потому что согласно всем обоснованиями базовая логика обучения подразумевает что из общих форм со временем высекается более точные формы на низких скоростях (нисходящий шедулинг). То есть получился эффект не варм рестарта, а ээээ вармап рестарта.
Че узнал щас почему те пиздошится: оказывается скорость текстового энкодера любая которую назначаешь при тренинге является фейковой, т.к. лосс считается на выходе юнета, но градиенты для TE проходят через юнет в любом случае. Таким образом допустим большой шаг у юнета = большие изменения в распределении активаций на входе в TE при обратном проходе => TE начинает получать непредсказуемые градиенты => эффективно увеличивается лр TE по созависимости, хотя на бумаге он каким был таким и остался.
АнонИИ, вижу тут разбирающиеся люди есть, тама Chroma v50 (это какой то гибрид 1dev и schnell) вышла, подскажите как на неё лоры тренировать кто в курсе? Я залетный и много не прошу мне бы только на лицо натренировать. Можно как то сделать это через one trainer или flux gym или аналоги не сложные?
>>1316918 Скорость не фейковая, тут вопрос в том хули в текст энкодер большой градиент приходит? Норму градиента можно мониторить, и можно делать константной, при желании. Лучше замерять это инструментально, прежде чем делать какие-то выводы.
>>1316991 > это какой то гибрид 1dev и schnell Нет, это просто крайние слои от Флюкса отрезали и заново натренили с cfg. > как на неё лоры тренировать кто в курсе? В официальной репе есть код тренировки лор со скриптами запуска, должен работать. Я его адаптировал под свой тренер, всё чётко было. Но ты учти что надо либо две карты, либо квантовать, желательно через HQQ. В int8 чтоб в 24 гига залезло надо разрешение ниже 1024 опускать, что-то типа 768, хотя я думаю это не проблема, некоторые Ван в 256х256 тренят, лол. Для комфортной тренировки желательно конечно 5090. По скорости 2000 шагов в час на 5090.
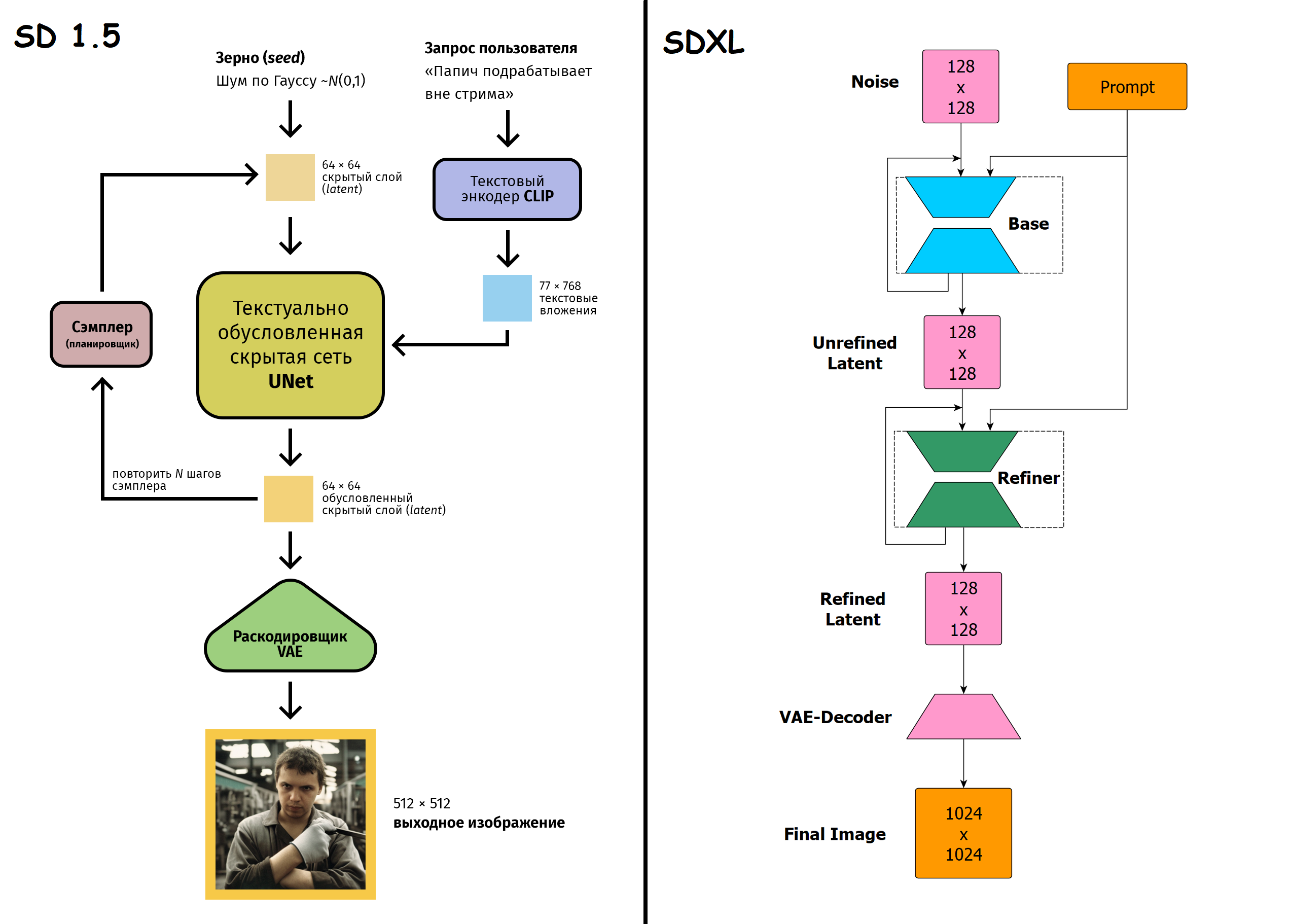
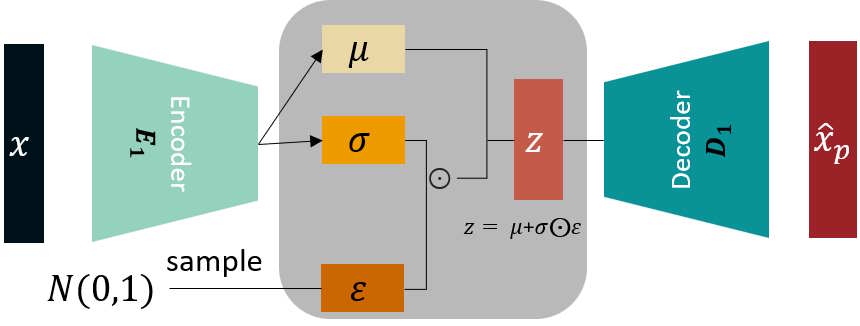
Решил посмотреть, какая математика лежит в корне VAE. Охуел пиздец. И это мне нейронка с упрощения расписала. А ведь когда то я играюче разобрался бы в это, техвышка это вам не шутка. А щас пук среньк, не могу даже интеграл взять Посоветуйте книжку по городу генеративным сетям. Чтобы все основные компоненты, и вае, и клип, и u net разбирались. Я знаю, как они работают, но не настолько глубоко, как бы хотелось.
>>1317169 > Посоветуйте книжку по городу генеративным сетям. Чтобы все основные компоненты, и вае, и клип, и u net разбирались. Ну посоветую, это скорее историческая энциклопедия охватывающая всю историю нейросетей, чем что-то специальное узконаправленное Книги бесплатны на сайте автора
>что надо либо две карты, либо квантовать Flux же не квантованный нормально тренируется на 24гб 3090 в 1024, а тут я так понял урезанный flux чего бы он не влез?
>>1317198 > Тут пишут что это шинель Потому что у него лицензия нормальная, от шнеля там ничего не осталось, кроме архитектуры DiT. > Flux же не квантованный нормально тренируется на 24гб 3090 в 1024, а тут я так понял урезанный flux чего бы он не влез? Только если свапать блоки, но это дно по скорости. Как раз коха такими извращениями занимался. > Если ты про эту репу https://github.com/lodestone-rock/flow
>>1317198 > не квантованный В fp8, что ещё хуже квантов. На Флюксе от этого лоры шакалили генерации, выдавая блочные артефакты. Если хочешь что-то вменяемое натренить, то модель должна быть либо в bf16, либо в нормальных квантах. Сама лора естественно должна быть bf16 всегда.
>>1317203 >https://github.com/lodestone-rock/flow Ага спасибо, качнул от туда flow, буду разбираться, но похоже консоль дрочить придется и руками писать а не параметры в окошечках выбирать. >>1317209 Спасибо за подсказку, но вроде на FLUX неплохая лора получалась, модель была flux1-dev.sft на 23 гига
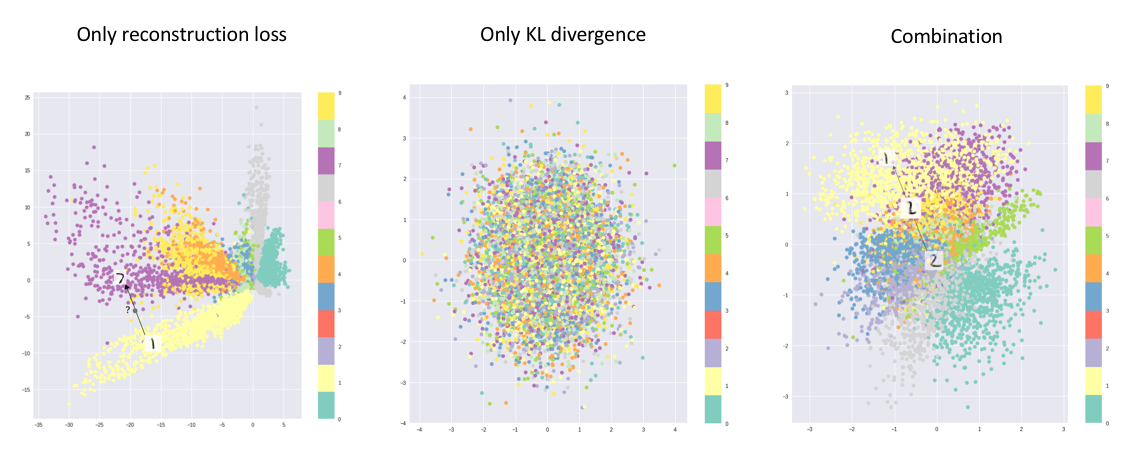
>>1317169 >Решил посмотреть, какая математика лежит в корне VAE. Охуел пиздец. И это мне нейронка с упрощения расписала. Нейронки плохо умеют правильно упрощать. Вообще вае это несложно, там просто математики насрали как обычно своей хуйней, которой не существует. На самом деле есть просто обычный автоэнкодер, понять как он работает - тривиально. Если ты его просемплируешь на большом наборе данных, увидишь что латенты распределены всрато и неравномерно, они кучкуются в определенных областях пространства, в остальных есть дыры. Попытка взять случайный латент выдает сломанный результат, ибо ты почти всегда попадаешь в дыру или недопустимую комбинацию значений. Задача вае сделать распределение равномерным. Достигается это двумя путями. Первый это просто дополнительный лосс на сами латенты, чем дальше значение от "центра", тем больше ошибка. Это сила которая стягивает латенты к центру. Второе - вводится дополнительный канал, который будет предсказывать насколько важно каждое значение латента. Если значение важное, значит оно сильно влияет на выход в данный момент и его нельзя сильно отклонять. В момент прямого прохода будет взято случайное число из диапазона, который предсказан этим каналом, и прибавлено к латентам, затем отправлено в декодер. Кароч суть в том что из-за этого канала в латенты постоянно подсирается шум, но если градиент ошибки большой, то канал учится ослаблять шум. В итоге это становится силой, которая расталкивает латенты и все это вместе делает распределение гладким, а само обучение - осмысленным и структурированным. На дополнительный канал тоже накладывается лосс, только наоборот, тянущий его от нуля. Иначе бы энкодер сразу схлопнулся и предсказывал бы одни нули на этих каналах, потому что они только мешают работать декодеру. Каждый канал начинает учиться выдавать большое значение только когда сильный разброс допустим и низкое когда нет. За счет разброса как раз закрываются дыры, декодер учится работать с полным диапазоном значений.
Можно представить латенты в процессе обучения, как в симуляторе частиц, на которые действуют разные силы. Если это визуализировать в динамике, оно примерно так и будет выглядеть.
На этапе инференса эти дополнительные каналы не нужны, их значения игнорируются. Работает как обычный автоэнкодер.
Дополнение: На второй картинке как раз видно, что итоговый латент получается таким, что если сделать небольшое отклонение, то попадешь по крайней мере во что-то похожее. Соответственно, получишь меньший лосс, и так автоэнкодер естественно учится делать хорошую и нужную нам структуру.
>>1317203 В общем мы с flow не подружились то одно ему надо то другое то вересия питона слишьком высокая то слишьком низкая то вообще на линуксе делать надо.
В флюксжим пропихнуть тоже не удалось не под видом дев не под видом шенель...
>>1317156 Поставил Ai toolkit красивый приятный удобный, все нормально влезло в 24 гига. Пришлось правда VS2022 переустановить ибо по дефолту он уставнолен был в програм файлс с пробелом и питоне не мог им пользоваться нормально. И тренить можно много чего, даже ван видео.
>>1318592 > даже ван видео Там поддержка только старого 2.1. Ван 2.2, к сожалению, можно тренить только в говне кохи, которое ещё более говняное чем его говно для тренировки sd. Столько лет чел кодит и всё как в первый день, когда он писал код для тренировки лор полторахи.
>>1315853 Сделал шедулер обратного косинуса с рестартом с независимыми скоростями для весов и те, работает заметно лучше чем классика. Основная проблема нисходящего шедулинга в том, что стартовые значения переоценены и потом эти переоцененные значения подкручиваются еще сильнее на стадии дикея, особенно если шумные входные данные, поэтому на одном и том же датасете получились совершенно разные эффекты (картинки заебусь прикладывать поэтому текстом) - в первом случае где старт с 1е-2 до 1е-3 (при эффективной скорости обучения примерно от 5е3 до 1е2) сильно жжет веса и конволюшены впитывают слишком мощный шумный сигнал (конкретно фьючерсы стилистики со всеми характерными засветами и квалити демеджом в датасете), во втором случае при бесконечном восхождении от 1е3 до 1е2 жарево полностью исчезает и теперь сеть не агрессивно подстраивается под датасет, а датасетные данные подстраиваются под сеть за счет бесконечного эффекта вармапа. Эффект получился схожий с трапезоидальным шедулером, где весь график это вармап-плато на высокой скорости-косинусный дикей до нуля обратно, только там он длиной во всю тренировку, что усложняет контроль лучшей эпохи и может не докручивать себя чтобы найти более лучшее решение. Попробую сделать и попробовать циклический трапезоидал, где вармап длиной в датасет-плато длиной в датасет-дикей длиной в датасет и затем повторы, вероятно это наиболее удобный и сейфовый вариант тренировки будет вообще, но даже обратного косинуса как будто бы достаточно, особенно с большим батчем на уровне 10-50 картиночек за раз.
>>1291324 >Я при кешировании латентов шум генерю и потом только его использую, без генерации нового, у каждого латента свой фиксированный шум. как эту хуйню въебать в сдскрипты пиздец че за квест
вариант 2 - через имейдж индекс но я ебал код кои в рот чтобы найти точно какой индекс откуда берется, но в любом случае этот вариант тоже работает я тренировочку прогнал, вероятно может бесоебить если каким-то образом нарушится последовательность латентов и вообще я не ебу может там один нойз лол
>>1325386 Хотя если быть точнее то первый вариант определенно на одном шуме обучался и у него бешеная сходимость
второй вариант лучше показывает себя в качестве фьючерс грабера, вероятно это из-за того что шум таки один на все латенты изза int = 0, и прямой инференс отличается от тренинга без фиксед нойза в чуть лучшую сторону но фактически выходные результаты одни и те же что тренировка без или с фиксед нойзом
такто технически должен был быть один или похожий результат если шумы фисятся и там и там, а на далее ну соврешенно противоположное говно
>>1325392 >а на далее ну соврешенно противоположное говно Так вроде логично же? У тебя разные сиды для шума, в пером считаются из хеша латента, во втором из его индекса.
>>1325453 Так там прикол в том, что если результат с хешей, то он в разы более консистентный, а в случае индекса (который я предлагаю кривой, т к ну по факту там надо еще пару блоков кода для передачи индексов корректно) он почти такой же как результат с тренировкой на рандом нойзе.
Народ, подскажите, кто шарит. Сейчас докупил к своей rtx 3060 12gb cmp 90hx на 10 гигов, но есть вариант добавить ещё 7к и купить tesla p40 на 24 гига. У меня обычная мать ASRock B550 PG Riptide c 3 портами под видюхи. Я бы докупил теслу, но я не ебу как её нормально подключить и как она будет у меня охлаждаться будет. У cmp 90hx есть 3 вертушки + cuda есть и их больше чем даже у моей 3060, а значит в теории я могу даже картинки на ней быстро генерировать в 1024x1024 без доп фич. Что выбрать? cmp 90hx на 10 гигов которую впросто вставил и всё или доплачивать и брать p40 и потом ещё ебаться с охлаждением + она не умеет в генерации картинок?
>>1326014 p40 это старое поколение паскаль вопервых, вовторых там нет тензорных ядер, втретьих на фп16 чекпоинтах будет критическое падение производительности, это будет в разы хуже чем твоя 3060 плюс есть неприятный эффект апкастинга изза того что карта фп32 онли по факту - ты не сможешь юзать нормально фп16 чекпоинты выше чем половина врама, т.к. на карте фп16 будет апкаститься до фп32 что означает x2 врама
>>1326039 >А что по nvidia cmp 90hx? >10 гигов Даже если она быстрее (хз вообще, так ли это) - будешь постоянно в низкий потолок VRAM упираться. Что совсем не круто. Более-менее нормальная жизнь начинается с 12 гигов, и твоя 3060 - до сих пор топ за свои деньги. Но лучше, конечно, 16 или вообще 24.
>>1326039 вопервых на майнинговом говне ебля с дровами
вовторых насколько мне известно там тоже порезаны операции с плавающей точкой, только целочисленные операции, то есть держи в уме что это LHR наоборот - все убито нахуй кроме операций вычисления хеш сумм для фарминга крипты, то есть хоть и карта базируется на 3080 но ты получишь производительность не сильно лучше опять же свой 3060
втретьих 10 гигов камон, прошлый век, даже 12 гигов уже подбираются к званию мусора для нейронок если ты конечно не жоский фанбой сдхл как я
просто для примера тебе из той же серии NVIDIA CMP 40HX (чип TU106 как у 2060-2070, прямой аналог 2060 супер вроде по остальным хар-кам) 3.48 итераций дает при этом обычная GeForce RTX 2060 5.18 итераций на тех же настройках
>>1326060 Ранг это просто размер и толщина добавочной матрицы с новой инфой. Чем больше размерность матрицы, тем больше параметров может хранить, чем больше параметров тем больше уникальных паттернов и их взаимодействия может изучить сеть. Хочешь более пиздатую модель - тренируй с большим рангом. А такто и lokr с фактором декомпозиции -1 с выключенной декомпозицией второго блока (ранг >10240, альфы не работают) с тренировкой input_blocks.8, output_blocks.0, output_blocks.1 хватит на простую задачу за глаза, а это размер выходной лоры в 4 мегабайта между прочим.
>>1326116 >Если что лучший топ нищевариант это 3090 с лохито на 24 гига. В "дополнительные 25к" он тут вряд ли уложится. Даже БУшные 3090 довольно дорогие. Но 5060 и так нормально смотрится. Можно выжимать все из XL-моделей, и щуть-щуть потрогать всякие флюксы, ваны, квены и видео-генерацию.
Я отказываюсь принимать и терпеть то, что стадия стабилизации на сдхл это фундаментальное ограничение обучения. Должен быть какой-то лайфхак уровня тичер-ученик, который убыстряет стадию стабилизации. Мнение?
Циферки эпох умножайте на 5 чтобы количество шагов получить.
Нет, я тебе больше скажу - результат есть на первых 50 шагах, особенно если плюсить к убыстряющим лорам. Но снижение ошибки раз за разом рисуется именно в таком паттерне - хаос, стабилизация, снижение ошибки, и это вообще независимо ни от сверхнизких или сверхвысоких бет, скорости обучения или всяких дополнительных ёб типа едм - сдхл раз за разом требует на отрисовку паттерна поведения ошибки около 2к шагов для лоры. Это как будто заложено в самой сдхл.
>>1326328 >Лосс не метрика Повторяемость паттерна говорит о том, что это таки метрика. А если смотреть что делают челики используя конфигурацию из учитель-ученика, то там паттерн лосса сжимается во времени. >нет смысла смотреть что там на графике, особенно на лорах. То же самое поведение если тренировать полные матрицы, но в виде модуля дополнительного.
>>1326134 Это я понимаю, вопрос скорее был про какое-то минимальное/начальное значение для нюкеков. Алсо аналогичный вопрос по локону - какие ранги конвов ставить? Есть ли какие-то соотношения конвов к линейкам или можно фигачить какой-нибудь 16/4 в оба?
>>1326656 >вопрос скорее был про какое-то минимальное/начальное значение для нюкеков Ящитаю, что какое в карту залезет. Если хочешь тренировать быстрее, то подбери размер под увеличенный батч (помимо добавленных gradient_accumulation_steps фейкобатчей), если у тебя например 3060 то в 12 кеков вполне влезет батчсайз 2 на сниженной размерности.
>Алсо аналогичный вопрос по локону - какие ранги конвов ставить? Есть ли какие-то соотношения конвов к линейкам или можно фигачить какой-нибудь 16/4 в оба? Зависит от того как и что тренируешь - полностью все блоки или селективно.
У каждого блока и почти у каждого слоя в сдхл есть пачка слоев которые считаются конволюционными при тренировке: emb_layers - управляют вставками эмбедингов с фьючерсами от текстового енкодера, по факту не конволюшены даже, а просто своеобразные линейные слои, но в премейд пресете кои который тренирует конв онли они берутся и не фильтруются, очевидно чтобы при тренировке только конв с текстовым енкодером был смысл тренировать текстовый енкодер вообще in_layers - конвы на входное преобразование out_layers - конвы выходного преобразования skip_connection - конвы соединяющие разные блоки, в основном находятся в аутпут блоке сдхл и соединены с инпут блоками
конвы это локальные данные, поэтому они очень нежные в большинстве ранних слоев и если ты подаешь в них сразу агрессивный шум, то они могут его и запомнить и больше не забыть, исключение составляют емб и скипы - им похер, плюс конвы в мидл и конечных аутпут слоях достаточн стабильны так как финализирующие
соответственно чисто логически чтобы не вызывать переобучение на шумные данные при обучении полных блоков обычно их размерность снижают относительно линейных слоев, процент подбирается индивидуально от 10 до 75%, прямой зависимости "количество блоков относительно линейных - размерности" нет, там в основном зависимость от скорости - если у тебя сейфовая низкая скорость на миллион шагов то можно такую же размерность брать что и у линейных, если агрессивная высокая с мощными шагами обновлений - ставь ниже
плюс зависит от алгоритма, у локона емкость сети в целом низкая поэтому вызвать переобучение на говняк в конвах проще, а например если тренировать diag-oft или boft то там матрица не коверкает основные данные сети и встраивается максимально нативно в модель, поэтому можно одинаковое значение брать
>>1326761 >Зависит от того как и что тренируешь - полностью все блоки или селективно. Я так понимаю ты про locon preset? Пока не ковырялся с ним и сижу на дефолте (full).
У меня на 4080 в принципе лезло 20/18 с батчем 2 или 3, но результаты были ужаренные и я пока на 16/16 тестирую.
Собственно сейчас пытаюсь получить не ужаренную лору на 16/4 (ранг/альфа) на линейки/конвы, локон+дора, без дропов. Оптим AdamWScheduleFree, LR=2e-4, wd=0.1, шедулер константный без прогрева. Эта хрень медленная, но вроде пока не так сильно жарит глаза/руки на арте.
>>1326786 >Я так понимаю ты про locon preset? Пока не ковырялся с ним и сижу на дефолте (full). Премейд пресеты кои пикрел. Ты можешь свой томл конфиг создать под нужное, ток регексы надо изучить и состав сети чтобы понять что исключать. Если надо будет подсказать как оформлять регексы обращайся. >не ужаренную лору на 16/4 (ранг/альфа) на линейки/конвы Альфа это регуляризационная штука, не крути ее если не знаешь как точно будет лучше - либо единичку ставь, чтобы обновления разных прогонов лор с разными настройками были так сказать сравниваемы между собой по влиянию на сеть, либо одинаковый размер с рангом чтобы масштабируемости вообще не было и крути вес лоры во время инференса просто. >wd=0.1 От вд никакого практического толка для маленьких датасетов, можешь смело не использовать никаких вейтдикеев вообще, это для миллионных датасетов регуляризация. >шедулер константный без прогрева У тебя шедулерфри, ему шедулер не нужен вообще, он сорт оф адаптивный. >Эта хрень медленная, но вроде пока не так сильно жарит глаза/руки на арте. Пережарка это проблема переобучения на агрессивной скорости на агрессивные шумные данные ранних слоев блоков сети которые отвечают за мелкие и тонкие фичи. От этого частично помогает вармап. Я предполагаю что у тебя проблема зажара от конв и идет, потому что линейные зажарить это надо еще суметь.
>>1326786 >>Зависит от того как и что тренируешь - полностью все блоки или селективно. >Я так понимаю ты про locon preset? Уточню, что под селективным методом я имел в виду пикрел например, потому что пресеты кои сконструированы так что либо тренятся только конвы, либо фул, либо только линейные, это как бы тоже селективное, но ты тренишь с конвами и у тебя выбор ток из фулла и конвонли без линеек.
>>1326795 > Ты можешь свой томл конфиг создать под нужное, ток регексы надо изучить и состав сети чтобы понять что исключать. Знать бы еще что туда включать...
>Альфа это регуляризационная штука, не крути ее если не знаешь как точно будет лучше Ну я в треде увидел совет ставить как корень из ранга, так и поставил. Вроде как тоже должно выдавать сопоставимые результаты при масштабировании ранга.
Алсо можешь что-то посоветовать по подбору LR? 2e-4 как-то слишком медленный получается, но я подозреваю что выше начнет жарить сильнее.
>>1326786 Пережарка абсолютно никак не зависит от ранга. Для начала попробуй обычную лору натренить, может опять обсер с альфой при инференсе у ликориса. >>1326802 > слишком медленный получается Это из-за AdamWScheduleFree, он и должен быть медленный.
>>1326802 >Знать бы еще что туда включать... Стабильные блоки и слои. У сдхл вообще интересно архитектура работает, она явно разделяет контент, стиль и план сборки картиночки по блокам (и слоям), на этом принципе основан селективный тренинг b-lora https://b-lora.github.io/B-LoRA/ (причем обязательно тренировать сразу все вместе, а потом разделять по блокам если надо, т.к. отдельная тренировка указанных блоков не является стабильной и консистентной). >Ну я в треде увидел совет ставить как корень из ранга, так и поставил. Вроде как тоже должно выдавать сопоставимые результаты при масштабировании ранга. У меня гдето ссылка была где челик мощно тестил аргументы и прочие регуляризационные штуки, в том числе альфу, так вот там никакого профита использовать что-то кроме 1 или числа равного рангу найдено не было в контексте альфы. >Алсо можешь что-то посоветовать по подбору LR? Как такового метода подбора лр нет. У оптимов в инит прописаны скорости обычно, но они тебя не касаются т.к. или взяты от балды если это прям кастом кастом от васяна, или указаны из расчета тренировки на гигантских корпусах данных как у лицокниги с ее шедулерфри штуками. Хочешь не ебаться с подбором лр и шедулера к нему - бери полностью адаптивные оптимайзеры, например https://github.com/LoganBooker/prodigy-plus-schedule-free
>>1326804 >Для начала попробуй обычную лору натренить, может опять обсер с альфой при инференсе у ликориса. Попробовал, и походу жарит сильнее локона с дорой. Настройки остались те же что и для доры.
>>1326795 >>1326798 А можешь поподробнее про эти пресеты рассказать, Как свой добавить, на основе чего делать и т.п. Я так понимаю на втором пике примерно то, что тут >>1326761 и описано? Т.е. выкинуты входные/выхожные конвы и фокус на глубоких слоях энкодера и больше на декодере. Но зачем тогда скипы тоже выкинуты, если они стабильны?
>>1326865 >Как свой добавить, на основе чего делать и т.п. Добавить просто: создаешь файл с расширением toml, в нем прописываешь рыбу
enable_conv = true если нужны конвы dora_wd = true если нужна дора
unet_target_module = [ "модуль1", "модуль2" ] если нужно модули, по дефолту просто пустые квадратные скобки
unet_target_name = [ "фильтрслоя1", "фильтрслоя2" ] тут основные таргеты слоев
text_encoder_target_module = [ ] здесь можно указать модули енкодера, по дефолту пустое, т.к. в целом целый енкодер тренировать не нужно тоже на малом датасете, достаточно общие концепции простые с первых слоев подрочить; либо можно указать CLIPAttention например
еще есть алгомаппинг, позволяющий разграничить какие алгоритмы с какими размерностями и настройками будут тренировать части сети, это нужно чтобы достичь максимальной скорости тренинга в оснвоном, т.к. допустим обычная лора быстро тренит conv, а lokr тренит быстро линейные, указываем это в алгомапе и получаем лучший вариант по скорости с отдельными настройками под каждый алгоритм, но это тебе не нужно наверно
Делать на основе любой лоры, вот у тебя есть лора натрененная с пресетом full, кидаешь ее в валидатор слоев чтобы прочекать состав, получишь выходной список всего говна внутри типа пикрел на много строк. В основном тебе нужны просто названия слоев, но если прям глубоко фильтровать то рядом с каждым слоем есть в скобочках форма, т.е. например (1280-20) это значит что лора 1280 канальный вектор ужимает до представления в 20, а обратный порядок наоборот восстанавливает. Там где 4 цифры - последние две это размер ядра, по сути размер окна фильтра через который лора смотрит на локальный участок фьючермапс. То есть 1x1 не смотрит на соседние пиксели, а только смешивает каналы 3x3 учитывает соседние пиксели (локальный контекст) и дает пространственное преобразование. Можно глубоко фильтровать короче, например выкинуть канальные миксеры вообще, т.к. это неполные данные (а тренировать неполные данные на шумно датасете это может быть вредно), или обучать только максимально вариативные вектора, где из низкого ранга условно вылезает 10240 каналов.
Валидатором я пользуюсь из https://github.com/bmaltais/kohya_ss , там он называется верифай лора, но можно отдельно скриптом с командной строки смотреть.
>Я так понимаю на втором пике примерно то, что тут и описано? Т.е. выкинуты входные/выхожные конвы и фокус на глубоких слоях энкодера и больше на декодере. Да.
>Но зачем тогда скипы тоже выкинуты, если они стабильны? Просто открыл первый попавшийся конфиг, ничего не значит. Это когда тестил влияние отдельных слоев делал.
>>1326942 >Как свой добавить А забыл написать как кастомным томлом пользоваться. Просто указываешь абсолютный путь к томлу в аргументе пресета "preset=K:/папка с томлом/master.toml"
>>1326856 >12 гигов Нафига? У тебя уже есть карточка на 12 гигов. Нафига тратить столько бабла, чтобы выиграть только во времени генерации, но не в объеме доступных задач?
>>1327079 для генерации он распараллелить может, допустим квенимаге в q4 веса на 1 карту, все остальное на вторую, еще места останется под кал всякий а тренинг тоже можно распараллелить, считай у него одна карта 24 гига со скоростью чето среднее между этими двумя картами
>>1326802 >2e-4 как-то слишком медленный получается, но я подозреваю что выше начнет жарить сильнее. лр это не скорость изменений а объем изменений хочешь чтобы быстрее реагировало на датасет - снижай беты я настолько преисполнился что почти всегда гоняю тренинги на 0.1765 по бете? почему именно так - это первое нижнее значение первой константа Фейгенбаума от значения 1 когда ничего не происходит, идея такая что нейросеть хаотическая система переходящая в стабильную, значит к ней применимы те же константы, моментум можно представить как геометрическую последовательность и тд и тп
>>1327131 > а тренинг тоже можно распараллелить, считай у него одна карта 24 гига со скоростью чето среднее между этими двумя картами Не совсем, есть определённый невыгружаемый буфер, ну допустим 7гб хл модели, которые будут висеть мёртвым грузом в памяти второй карты, тогда как если бы это были нативные 24, 7 лишних гигов не отъедались бы, ну если мы говорим конечно про распараллеливание акселерейтом
>>1326301 Кароче апдейт, нашел как убыстрить, регуляризационные имеджы помогли. Для чистоты обучал на класс. Красное до, синее после, результаты у синего в стопицот раз быстрее достигаются и лутше. В регулярки кинул 1/10 голых генов с основной модели без какого-либо промптинга.
>>1327820 Да, пустой промт в негативе и позитиве, размер одинаковый, в папке 1_класс, у основного датасета тоже 1_класс. Настройки тренинга одинаковые, gradient_accumulation_steps обоих проектов 20.
>>1283160 >Если упороться, то можно ещё маску накинуть, центр спектра с шифтом по центру. Попробовал накостылять это, и что-то простая круглая маска с сигмой=0.5 адски бустит стабильность и перенос стиля. Как-то слишком хорошо выглядит, надо еще на паре датасетов погонят.
>>1328318 Нейронка тебе такое сваяла? Инпут тоже должен шифтится и диапазон маски у тебя какой-то странный. Для недискретного преобразования есть уже с правильным шифтом функция в либе - frft_shifted, но она требует размер инпута чётный. Или от угла без шифта можно маску делать, но она несимметричная будет.
>>1328721 >А регуляризационные латенты не пробовал? Оно там вроде включается Нет, не вижу где в сдскриптах такое есть.
Зато я в качестве эксперимента запихал в регулярки плазма и пинк нойзы, скормил зашумленный большой датасет и получил лору, которая выучила фичи датасета и стала давать эффект сорт оф денойзера. А плазма вообще оказывается работает как жесткий фильтр объектов, то есть частичные эпохи выдают генерации где класс датасета как будто вырезан из датасета, а маскированная область представляет собой плазма нойз. Интересный эффект, возможно стоит попробовать накинуть 50% плазму или 50% пинк на весь датасет и кинуть как регулярку.
>>1328737 > возможно стоит попробовать накинуть 50% плазму или 50% пинк на весь датасет и кинуть как регулярку. Попробовал на плазме. Взял датасет, наложил на каждую картинку одинаковый плазма шум с опасити 50%, выставил константную агрессивную скорость в 1e-2 (на порядок больше чем нужно, обычно на 1e-2 по пизде все идет инстантно), прогнал с дефолтным --prior_loss_weight=1 - практически сразу сеть начала обучаться на плазму из рег датасета, но изображения консистентные в целом, ток шумные. Из фич замеченных - как только начало переобучаться, то начинала превалировать плазма в генерациях. Снизил --prior_loss_weight до 0.1, прогнал с низкой бетой и высокой - очень стабильные выводы получились в обоих вариантах, ток лорку чуть-чуть снижать надо по силе влияния, т.к. геометрия немного плывет.
При таком приор лоссе для рег датасета плазма тоже начинает проявляться на полном весе, но больше в рандомных эпохах, пока не понял от чего зависит, потому что плазма может вылезти на ранней эпохе, а потом пропасть вообще.
Олсо обучал все блоки, что не мог себе позволить на 1e-2 вообще практически никогда. Так что метод в целом рабочий, если кому интересно то плазма (и прочие виды шумов) генерятся вот этим https://github.com/Jordach/comfy-plasma
Отается проверить чисто плазма нойз в качестве регуляризации без подмешивания его к датасету.
>>1329435 >prior_loss_weight=1 - практически сразу сеть начала обучаться на плазму из рег датасета, но изображения консистентные в целом Интересный график лосса на этом варианте кстати (красный), где поднятие произошло там лора начала убиваться и убилась начав генерить просто шум похожий на плазму, до поднятия консистентные генерации и все. Вот тако вот сорт оф наглядный майлстоун переобучения получется.
>>1329441 Ровно на 108 эпохе плазма стала базой модели, до этого генерилось отлично. Снизу вверх 107, 108, 109 эпохи. Есть эпоха вплоть до 195, ни на одном шаге не стабилизировалось обратно.
>>1328413 Короче пока остановился на этом. На тестовых латентах спектр выглядит отцентрованным. Без двойного dfrft он был сжат либо по вертикали либо по горизонтали. Сделал пару тестовых прогонов и выглядит неплохо, пропало жорево мелких деталей, но по ощущениям стало что медленнее сходиться.
>>1329435 В общем если полностью чистый плазма нойз (который является фракталом, то есть структурированной в понимании модели штукой, собсно как и пинк или браун нойз, а не обычным рандом нойзом, с которым сдхл обучена бороться и игнорить) кидать в качестве регуляризации то выходные данные таки получаются сглаженными и отденойзенными на ранних эпохах, в отличие от варианта, где в рег дате датасет с накинутым шумом. К результату в обоих случаях оба тренинга приходят одинаково (да и результаты схожи максимально), но с разной скоростью - на чистом нойзе результат получается позже на пару эпох. Так что смысол есть в варианте, где подкидывается не чистый шум, а именно шум + дата хотя бы минимальная.
Еще момент по обучению: рег датасет берется в равной степени к датасету обучения, то есть если допустим в датасете 5 картинок, а в рег дате 1, выставлен батч 10, то возьмутся 5 картинок датасета и 1x5 рег деты, никакой деградации замечено не было от такого варианта, так что можно сэкономить на кешировании и брать небольшой рег датасет.
Остается прочекать влияние процента шума на рег дате, потому что сейчас 50% зашумленность и результаты хорошие, может с другим процентом будет лучше. Еще нужно прочекать приор лосс, но по виду 0.1 достаточно, надо прогнать с 0.5 хотя бы.
В целом плюсы плазмы в том, что она доджит переобучение на фон и сохраняет его управляемость хорошо так отделяя объекты.
Сейчас тестирую параллельно пинк нойз, и он как будто больше направлен на выхватывание особых уникальных паттернов, но в целом эффект что плазмы, что пинка плюс минус тот же, возможно пинк более предсказуемый с датой поэтому на нем проще регуляризацию сдхлке считать. Возможно есть смысл соединить плазму, пинк и дату в равной пропорции чтобы получить бонусы от каждого варианта.
https://huggingface.co/Anzhc/MS-LC-EQ-D-VR_VAE Вышла новая версия EQ VAE 5 дней назад, которая нормально работает со скриптами в отличие от кохаковской залупы которую я не ебу как заставить работать.
>>1330300 Кто будет тренировать на этом имейте в виду что это новое латентное пространство для сдхл и нужно дополнительное время для создания всех связей в сети чтобы корректно натренировалось, плюс вполне вероятно нужно подкрутить старые настройки, которые хорошо работали с оригинальным вае в сторону большей агрессивности. Синее - оригинальный вае, остальное EQ.
>>1330300 Смысл вообще от этого, если оно перетренировки всей (?) инфраструктуры требует? Вот бы чего-нибудь такого, чтоб воткнул на стандартные модели, и оно лучше стало, без всех этих расплывающихся мелких деталей которые я на своих картинках уже заебался фиксить.
>>1330497 >Смысл вообще от этого, если оно перетренировки всей (?) инфраструктуры требует? Ну вообще не требует, я уже успел тройку тестовых лор прогнать, представление латентов для обучения в разы лучше, сеть моментально схватывает всё на пикчах, сразу видно что сигнал латента чище. Единственная проблемы это то что или стабилизация дольше (первые эпохи уже дают результ качественный в смысле содержания, но качество изображения далеко дольше подтянется), поломать конволюшны проще забив их сатурированным сигналом, и судя по всему вывод оче сенсетивный к шедулеру при инференсе, а так гораздо удобнее дефолтного вае.
>>1330426 > Синее - оригинальный вае, остальное EQ. Так на твоём графике понижение лосса - это адаптация к поломанным латентам. Оно никакого отношения не имеет к повышения качества тренировки. >>1330538 Ну и нахуй это говно нужно. На XL никогда не было проблем с тренировкой концептов, а вот детализация всегда сосала из-за всратого 4-канального вае. Теперь ещё хуже будет. Да и вообще все эти дрочи трупа XL не вызывают оптимизма, уже пора дропать XL, она только в аниме жива, для реалистика XL уже слишком устаревшая. Лучше бы что-то с Квеном придумали, как размылить его, чтоб с Хромы на него начинать перетренивать лоры.
>>1330501 Видел какие-то эксперименты, но чем закончилось - не в курсе.
>>1330578 >уже пора дропать XL Пока качественной (и, самое важное, доступной на базовом железе) замены не появится - XL будет жива. И что-то пока на горизонте такой замены не вижу. Так что продолжать улучшать XL - вполне себе вариант.
>>1330538 >Так на твоём графике понижение лосса - это адаптация к поломанным латентам. Чище сигнал => сеть меньше ошибается => меньше потерь, такая логика.
>Оно никакого отношения не имеет к повышения качества тренировки. А я про качество писал только в контексте что для его достижения нужно вложить время. И вообще смотря что ты подразумеваешь под качеством. Я охочусь за адаптацией, точным грабингом фич с датасета и следованием промту - это для меня качество, сэтим это вае определенно лучше справляется чем дефолт. Если тебя просто качество самой картинки интересует чтобы генерить по референсу, то это второстепенное на самом деле.
>Ну и нахуй это говно нужно. Прост чище сигнал дает.
>На XL никогда не было проблем с тренировкой концептов Но есть проблема с точностью.
>Да и вообще все эти дрочи трупа XL не вызывают оптимизма, уже пора дропать XL, она только в аниме жива, для реалистика XL уже слишком устаревшая. Слишком категорично, ни одна модель не работает также быстро как сдхл и ни одна модель не имеет настолько большой пак мокрописек для обвязки. Плюс единственная модель которую можно в лайв моде использовать без болей в жопе.
>Лучше бы что-то с Квеном придумали, как размылить его Лучше бы квену запилили модель на 5 раз меньше параметров.
>чтоб с Хромы на него начинать перетренивать лоры. Ну хрома это кал, имхо.
>>1330594 >Если тебя просто качество самой картинки интересует чтобы генерить по референсу, то это второстепенное на самом деле. референс ген вообще ипадаптером и флюх калтекстом решается, смысл дрочки тут >>1330578 на качество тренировок как таковых вообще не вижу, лоры и фуллфт для другого тренируются
>>1330590 > качественной Как на Хрому/Ван пересядешь, так уже к XL не захочется притрагиваться. С промптингом на DiT всё отлично, как и с переносом концептов за пределы датасета. >>1330594 > ни одна модель не работает также быстро как сдхл С учётом того что 4/8-шаговые XL очень шакальные, ещё и в два прохода надо генерить чтоб нормальное разрешение иметь, то 8-шаговые DiT не так уж медленнее. И с тренировкой всё отлично, внезапно 14В/20В DiT тренится всего раза в два медленнее XL. На Квене вообще как на XL можно за 15 минут лоры на 1000 шагов хуяк-хуяк делать. > пак мокрописек Wan/Qwen уже обогнали по функционалу XL, где кроме пары контролнетов и всратого ип-адаптера ничего нет.
>>1330804 >Как на Хрому/Ван пересядешь, так уже к XL не захочется притрагиваться. а я какраз попробовал хромог и ван, а потом вернулся на хл, аналоговнет
>>1330804 >С учётом того что 4/8-шаговые XL очень шакальные, ещё и в два прохода надо генерить чтоб нормальное разрешение иметь, то 8-шаговые DiT не так уж медленнее. Што? Я конечно не далбаеб чтобы гигантизм генерить на сдхл постоянно не больше мегаписеля делаю, но вот 1768x1280, 15 шагов, 14 секунд, 1 проход на 3060, с какой-то рандомной говнолорой на стиль, и это я еще ничего не постобрабатывал или не включал в пайп шринки хуинки и адаптеры.
>>1330804 >Как на Хрому/Ван пересядешь Художников знают? Персонажей, может быть, конкретные стили? А сисик-писик сгенерить могут?
Пока модель с незацензуренным датасетом не появится - разговаривать не о чем, тюны XL вне конкуренции. На "Извините, я не могу выполнить этот запрос" я и в облаке посмотреть могу, на гораздо более умных и продвинутых нет моделях.
>>1330538 >>1330300 Если тренировать вместе с нормами через train_norm=True, то шумы моментально уходят и ваешка дает почти то же качество что оригинал, не в смысле содержания - по точности ебет как ебало, а в смысле что шумов от другого латент спейса практически перестает быть. Но проверил только на пресете full. До этого тренил на кастом модулях без трейннорм, и там конечно хорошо по содержанию, но два латента в одной генерации прям конфликтуют между собой, надо попробовать селективно с нормами прогнать.
Алсо в репе есть фикс паддинг артефакта: for module in self.model.modules(): if isinstance(module, nn.Conv2d): pad_h, pad_w = module.padding if isinstance(module.padding, tuple) else (module.padding, module.padding) if pad_h > 0 or pad_w > 0: module.padding_mode = "reflect" Но я его чет не могу в пайплайн скриптов всунуть. Если кто знает как напишите. А так с тренировкой норм бага этого нет почему-то.
>>1331413 >надо попробовать селективно с нормами прогнать Да, все работает. Если тренирова на EQ отдельные блоки и включить тренировку norm, то получается модель, которая работает с оригинальным вае с качеством основной модели, но все фишки полученные от EQ. Пользуйтесь, нормы имба с EQ.
>>1332111 Какой-то беспредметный разговор уровня "пук хрюк мыло кококо" из сд треда.
1. Сначала определи что значит "текстуры сосут" 2. Далее покажи лоры или модели натренированные с этим вае где текстуры по твоему заявлению сосут 3. Покажи лору или модель которые были натренированы без данного вае и с данным вае для прямого сравнения эффекта 4. Определи как текстуры в латентном представилении могут сосать (с ссылкой на папер, подтверждающий это с метриками)
К вопросу о ваехах. Рекойлми высрал ваешку https://huggingface.co/AiArtLab/sdxl_vae без нового латентного пространства но по бенчам чище EQ кохака. Прогнал тест с нохалф, вроде прикольно, однозначно будет лучше чем всратый дефолт.
>>1332191 Чел, тот VAE в принципе мыльнее оригинального. Они боролись с шумами и сделали ровно то что хотели - мыло. Ещё и тренили только на аниме с бур, заруинив окончательно всю детализацию. Собственно если ты датасеты чистишь всегда, а не просто жипеги гонишь в модель, то у тебя никогда и не будет проблем с какими-то шумами. > покажи Литералли примеры авторов посмотри, у них шумодав адский.
>>1330497 >без всех этих расплывающихся мелких деталей которые я на своих картинках уже заебался фиксить. Можешь взглянуть на хрому радианс, которая безвайная - так вот, этих расплывающихся деталей пруд пруди. Так что я б не стал надеяться именно на фикс деталей.
>>1332234 Ты ещё забыл добавить что все натрененные до этого лоры надо выкинуть. 4-шаговые лоры и контролнеты - тоже выкинуть. Литералли всё перетренивать, а иначе падение качества. А ещё оно потом чувствительно к весу лоры, ведь у нас в лоре адаптация к новому латенту и изменение веса ломает её. Бесполезное говно, откатывающее на 2 года назад. С таким подходом проще сразу на DiT тренить.
>>1332206 >Limited concept coverage due to the small dataset. >The Image2Image functionality requires further training. И на картинке по ссылке лютая хтоническая жуть. Нет, спасибо.
Все эти поделки хороши только для буратин с десятком-другим H100 чтобы потом их дотюнить до чего-то юзаебльного, либо для потешных картиночек с большими носами для твитора. Пока не будет чего-то, уровня нуба или хотя бы люстры (и их аналогов для 3д) - оно нахуй не нужно.
>>1332199 Что-то непонятно, как этим пользоваться. Скачал вместе с конфигом, переименовал, закинул в папку с VAE, так рефордж ругается при попытке генерации с этой штукой.
>RuntimeError: Error(s) in loading state_dict for AutoencoderKL: >Missing key(s) in state_dict:
Где там чего менять надо чтоб завелось, объясните хлебушку.
>>1332504 > AutoencoderKL Оно в формате автоматика, а не диффузерс. Мне тоже пришлось поебаться чтоб конвертнуть в диффузерс, чтоб тренить с ним. И с ним пайплайн диффузерса не работает нормально, хуй знает почему, при том что ручной энкодинг/декодинг работает нормально. Это к тому что если Фордж использует ванильный пайплайн как-то, то не будет работать. Вот этим скриптом можешь конвертнуть, пути только пропиши в load/save - https://textbin.net/ptpvcqkpph
>>1332638 Поднял венв с папки вебуя, загнал в него скрипт с прописанными путями до оригинального вае, и куда перезаписывать (заместо "in" в скрипте в двух местах). Вроде конвертнулся, файл обновился, но все равно не заводится. Ошибка с виду та же, вот целиком.
Loading VAE weights specified in settings: D:\StableDiffusion\stable-diffusion-webui\models\VAE\AiArtLabs_Conv_VAE.safetensors Traceback (most recent call last): File "D:\StableDiffusion\stable-diffusion-webui-reForge\modules_forge\main_thread.py", line 37, in loop task.work() File "D:\StableDiffusion\stable-diffusion-webui-reForge\modules_forge\main_thread.py", line 26, in work self.result = self.func(self.args, *self.kwargs) File "D:\StableDiffusion\stable-diffusion-webui-reForge\modules\sd_vae.py", line 267, in reload_vae_weights load_vae(sd_model, vae_file, vae_source) File "D:\StableDiffusion\stable-diffusion-webui-reForge\modules\sd_vae.py", line 212, in load_vae _load_vae_dict(model, vae_dict_1) File "D:\StableDiffusion\stable-diffusion-webui-reForge\modules\sd_vae.py", line 239, in _load_vae_dict model.first_stage_model.load_state_dict(vae_dict_1) File "D:\StableDiffusion\stable-diffusion-webui-reForge\venv\lib\site-packages\torch\nn\modules\module.py", line 2584, in load_state_dict raise RuntimeError( RuntimeError: Error(s) in loading state_dict for AutoencoderKL: Missing key(s) in state_dict:
>>1332234 Хуй знает о чем ты, латент это просто компактные признаки изображения формы, текстуры, цвета в закодированном виде, говорить о мыле каком-то мифическом это некорректно, отличия у ваех в точности циферок, что собсно видно на примере из EQ. Нету такого что вае каким-то чудесным образом не видит текстурки, у него задача вообще любое говно кодировать в скрытоспейс, кто-то точно делает, ктото нет, вот и вся разница. То что ты видишь как тестовые крашеные латент в примерах это не реальное представление латента к тому, оно ток границы форм в основном показывает, представить полноценно латент в ргб пространстве невозможно. >то у тебя никогда и не будет проблем с какими-то шумами Так епта вопрос не про шумы вообще, а про точность картинка-признак-картинка, чем неточнее представление тем хуже конвергенция.
Я с екюшкой лорку натренил щас - спиздило все текстурки подчистую.
>что все натрененные до этого лоры надо выкинуть Ну да, нахуй они нужны, куски кала > 4-шаговые лоры и контролнеты - тоже выкинуть. Ну тут нет, архитектура осталась на месте, EQ работает с убыстрялками и калтролнетами.
>>1332410 Там тренинг все еще идет, в вандб можешь чекать эпохи и примеры, там ток к 1 миллиону шагов подбирается. А вообще че ты хотел? Это пруф оф концепт по сути, берешь и тренишь целую модель на своем датасете с 16 канальным вае с мульти те и кайфуешь с результата.
>>1332969 > Хуй знает о чем ты Вае всегда как деноизер работает, он не умеет в латентном пространстве нормальный шум сохранять. И мылит он легко, если так натренили. > EQ работает с убыстрялками и калтролнетами Ты ведь не пробовал даже. С DMD и 4-шаговой лорой под Нуб он плохо работает, на выходе артефачит. Контролнеты вообще очевидно сломаются, т.к. они кодируют пиксели в определённый формат латента и если у тебя там другой, то получаешь распидорас.
>>1332504 >Что-то непонятно, как этим пользоваться. >Скачал вместе с конфигом, переименовал, закинул в папку с VAE, так рефордж ругается при попытке генерации с этой штукой. в комфе работает искаропки при генерации
>>1332638 >Оно в формате автоматика, а не диффузерс. Мне тоже пришлось поебаться чтоб конвертнуть в диффузерс, чтоб тренить с ним. И с ним пайплайн диффузерса не работает нормально, хуй знает почему, при том что ручной энкодинг/декодинг работает нормально. на сдскриптах вообще без ебли запускается (и eq тоже), просто папку указываешь с конфигом и вае через --vae
>>1332978 >Ты ведь не пробовал даже. С DMD и 4-шаговой лорой Как раз это и пробовал, у меня постоянно в тестовом вф стоит включенным. Все с EQ нормально работает. >под Нуб он плохо работает, на выходе артефачит Так нубай в принципе с дефолтным дмд обсирается делая 24/7 вектор-лайк графин, можно через спо нуб поправить и будет получше но все равно ебашит слишком агрессивно, в этих репо https://huggingface.co/YOB-AI/DMD2MODhttps://huggingface.co/YOB-AI/HUSTLE есть попердоленные дмд которые в целом хорошо работают с нубаем, в сд треде пользуются. >Контролнеты вообще очевидно сломаются, т.к. они кодируют пиксели в определённый формат латента и если у тебя там другой, то получаешь распидорас. Я все не тестил, но депфы и кани которые у меня есть вроде ок.
>>1332979 >в комфе работает Ну кто бы сомневался. А потом оказывается что нет, не работает, и лапша из-за ошибок при чтении этой фигни без вае генерила.
я пригорел, как же меня заебали лора алгоритмы пиздец просто
локон низкоемкостный педераст и хуй нормальное соотношение подберешь вследствие чего эффективный лернинг не достигается вообще - ой у тебя конвочки с альфой равной дименшену - жри кал пидар, теперь у тебя вся модель генерирует датасетовский стиль фоточек, ой, у тебя слишком низкие конвочки - ну пожри говна тоже, я необучаемая без конвочек ой ты включил дору - ну тогда я изза низкой емкости буду миксовать части изображений вот тебе скинтон с датасета плавно переходящий в скинтон модели, ну как тебе?
локр избавляет от использования альфы, но блять какой же он сука топорный - бля братан у тебя слишком сильная факторизация - а давай я кароч текстурки проебу, в остальном все же заебись братан текстурки это прошлый век, формы на месте же... нихуя себе ты факторизацию огромную ебанул, ну я пуксренькаю кароче и вот тебе оверфит овершарп оверберн ты же етого хотел да?..
лоха с большой емкостью, с отличной генерализацией, но переобучается с полпинка - так так че тут у тебя лернинг неверно выставлен, извини теперь у тебя геометрия ебанулась, ты давай это снижай альфу значит или лернинг рейт, о вот теперь нормально, но я запомню ВЕСЬ ДАТАСЕТ В МЕЛЬЧАЙШИХ ПОДРОБНОСТЯХ чтобы тебе снова приходилось снижать вес лоры, а может даже стану лидером митол группы и вообще задавлю основную сеть)))) а если ты выставишь еще более сейфово я покормлю тебя дымкой и пластиком потому что мне нужно время на стабилизацию)))) ну хоть лоха наиболее простой алго для тренировки на EQ, лучше всех работает с ним
глора вообще хуй пойми себе на уме чето там дрочит, но зато нереально словить артефактов неожиданных, ультратормознутая залупа вроде и обучается фичам, а на деле реально среднее по палате, ну в принципе она так и задумывалась как я понял - выводить среднее значение по датасету без упора в копирку
диагофт вообще юзлес поебень годящаяся только грейдинг с фоток пиздить
бофт - я его рот ебал, он мало того что медленный так еще и или недотягивает до нормы весов модели или наоборот сразу убивается генерируя боди хорроры, констрейнт не помогает нихуя, потому что он на рандомном значении каком-то постоянно находится исходя из датасета - ставишь 1, 0.5, 0.25 ноль эффекта, ставишь 0.0242 - о нормально, ток не обучается теперь нихуя
из всего списка того что есть в ликорисе самый адекватный похоже это мультиранговый дилора алгоритм, но он прям очень много времени требует для заметного обучения т.к. за один степ он берет лишь одну колонку и строку весов, либо надо сильно задирать всё вообще чтоб агрессивно ебало, но зато можно сейфово поднимать вес лоры и даже ниче не ломается лол
почему блять нельзя придумать алгоритм который всегда нормируется под веса основной модели самостоятельно чтобы не надо было заниматься этой дрочкой ебучей с недолетами и перелетами пиздец блять нахуй, реально хоть 3090 покупай чтобы на full алгоритме просто без задней мысли тренировать в норму защо
>>1336810 я специально еще для нонстоп тренировки лорок купил ссд отдельный и вот эти ебаные 21 терабайт потраченных по сути в никуда почти полностью проебались на выведение идеальных конфигов под алгоритмы, которые на самом деле не идеальные и обсираются на других датасетах и их все равно надо подкручивать, это проклятие какоето самая удобная и удобоваримая по времени/качество тренировка была селективная обычно, но там свои нюансы уровня частичной невыразительности, или тренировка в селективной full и бесконечно долгой full/дримбудке
>>1336810 Бля, чел, просто трень обычные лоры. Алсо, попробуй хоть раз слезть с ликорис-параши на peft. Хоть увидишь как люди живут за пределами sd-васянства. > алгоритм который всегда нормируется под веса основной модели самостоятельно чтобы не надо было заниматься этой дрочкой ебучей с недолетами и перелетами Вообще-то обычная лора в такое без проблем умеет. Даже что-то типа пикрила с улетанием лосса в ноль стабилизируется на 500 шаге и даёт нормальную лору улетело потому что 500 эпох на двух пикчах. > на full алгоритме просто без задней мысли тренировать Если у тебя на лорах какие-то проблемы с оверфитами и артефактами, то на полной тренировке вообще будет распидорас. Лоры всегда выступают как демпинг тренировки.
>>1336810 А разбивку обычной лоры по svd не тестил, как оно? Фулл файнтюн проводил? Таки важно для сравнения, если ты хочешь какие-то выводы делать. Вообще звучит так, как будто у тебя в чем-то другом критичный проеб, который по разному вылезает. Фулл точность еще на весах норм и биасов включена?
>>1336950 >Бля, чел, просто трень обычные лоры. Я недоволен результатами с обычной лорой вообще. >Алсо, попробуй хоть раз слезть с ликорис-параши на peft. Хоть увидишь как люди живут за пределами sd-васянства. Что ты имеешь в виду под слезть? На голые диффузерсы прыгнуть и дрочить командную строчку с кастом кодом? Я не настолько погромист чтобы делать это корректно, а во вторых ну то мне даст еще десяток видов говнолор, которые не тестили вообще никто кроме авторов на корпусах даты для ллм? >Вообще-то обычная лора в такое без проблем умеет. Не умеет, умела бы не требовалось бы подгонять значение мультиплаера лоры посттренировочно. >Даже что-то типа пикрила с улетанием лосса в ноль стабилизируется на 500 шаге и даёт нормальную лору улетело потому что 500 эпох на двух пикчах. >Если у тебя на лорах какие-то проблемы с оверфитами и артефактами ты не пони мой тейк похоже, я не говорю что я не умею тренить там или результат никогда не достигается, я говорю что чтобы достичь результата с лорами надо конкретно заебаться брутфорсом параметров, а у меня еще и планочка слишком большая для лор - если ее хоть чуть чуть косоебит и она не работает нормально при 100% применении то она отправляется в мусорку; если она натренировалась и генерирует хорошо только датасет по референсу, то она отправляется в мусорку; если она слишком долго сходилась - она отправляется в мусорку вместе с конфигом потому что у меня нет столько времени чтобы каждый датасет гонять миллион часов с 100x репитами и тд
>то на полной тренировке вообще будет распидорас. как раз таки наоборот у меня, если я настраиваю сорт оф фул и терплю лишения в виде того что у меня в карту не влезает все что нужно, то на выходе я чаще получаю то что мне требуется - хорошая быстрая универсальная адаптация без перекосов во всякий кал
>Лоры всегда выступают как демпинг тренировки. от лагоритма зависит, бофт вон не демпит ничего вообще что с одной стороны хорошо, а с другой в жопу ебет этим
>>1337056 >А разбивку обычной лоры по svd не тестил, как оно? Нет, этих свдшных методов слишком дохуя и они не кончаются, вон новый недавний https://arxiv.org/pdf/2502.16894
>Фулл файнтюн проводил? Фулл в смысле фул фул или просто полные матрицы? Первое особо смысола на микроскопических датасетах нет, а второе дает хорошие результаты относительно лор.
>Вообще звучит так, как будто у тебя в чем-то другом критичный проеб, который по разному вылезает. Проеб в том что я вообще открыл для себя тренировку, думал тут универсальность и мир дружба магия, а тут в ачко ебут.
>Фулл точность еще на весах норм и биасов включена? Сдскрипты не позволяют в фп32 ничего гонять кроме вае, да и не на моей карте полную точность дрочить.
>>1336950 >стабилизируется на 500 шаге и даёт нормальную лору 500 шаг с какими вводным настройками-то? Для моих датасетов и настроек 500 шаг это будет реальный 5000 шаг именно прохода по датасету и целый день задрачивания карты.
> дилора алгоритм, но он прям очень много времени требует
Не работает корректно с шедулерфри продижи (вероятно некорректно работает вообще со всеми адаптивами из-за фрагментации рангов) кстати, поэтому ощущение что вечность сходится, на обычных оптимах гораздо бодрее, и с оптимами из питорчоптимайзер либы тоже не особо работает (может не со всеми но с теми которыми пробовал там не передает нужный параметр и оптим падает). С встроенными в сдскрипты оптимами работает.
>>1337068 > На голые диффузерсы На peft, чел. Модель можешь какую угодно использовать. > не требовалось бы подгонять значение мультиплаера лоры посттренировочно А когда требуется? Обычно всегда в 1.0 всё работает. Понижаешь только когда начинаешь пять лор мешать и хочешь какой-то интересный микс получить. > если она По факту у тебя всратый датасет/код тренировки и ты пытаешься демпингами поймать какой-то свитспот когда говно не вытекает, потому что у тебя конец тренировки - это говно. Но вообще-то так не должно быть. Тренировка лор ничем не отличается от обычной тренировки в контексте оптимизации, она должна всегда приходить в стабильное плато, а не в говно. Если на плато не то что тебе надо, то надо тергет сдвигать, а не пытаться демпинговать тренировку и ловить какую-то точку недотрена. Тебя вообще не смущает что буквально все пытаются сделать как можно быстрее схождение и плато ниже, а не ищут свитспоты? Т.е. мутанты/артефакты/низкая генерализация - это вопрос таргета, а вопрос оптимизации/архитектуры лор только в том чтобы как можно быстрее к этому таргету упасть. > если я настраиваю сорт оф фул И тут тебе стоило бы задуматься что тебе срёт в тренировку и пытаться идти к упрощению, а не накручиванию новых свистоперделок. В любом случае фултрейн только на XL и возможен, на той же Хроме в fp8 тебе 40+ гигов врама надо чтоб без лор тюнить все параметры или использовать 8-битные говнооптимизаторы, или свапать блоки как шакал. А ведь она одна из самых мелких DiT. На WAN вообще лоры на микродатасетах по 8 часов приходится тренить на 5090.
>>1337128 >На peft, чел. Модель можешь какую угодно использовать. Так чтобы пефтнапрямую юзать это мне пиплайн на диффузерзах высирать надо будет как для тренировки так и для инферирования если метод из пефта не реализован в UI, разве нет? >А когда требуется? Обычно всегда в 1.0 всё работает. Всегда требуется балансировку делать для методов с альфой для перерасчета весов чтобы не крутить при генерации вверх-вниз. Либо крутить в самом UI, чтобы и на хуй сесть и рыбку съесть. Я понятия не имею как тебя все устраивает на 1.0, потому что это практически всегда забивает сигнал основной модели и получается генератор хуйни заученной, а не адопшен. А некоторые лоры наоборот требуют увеличивать влияние, как например прямо щас у меня требует dylora увеличивать x10 ее значения, потому на 1.0 там слишком слабый сигнал на достаточно большой скорости получается, а если еще скорость повышать то обучение уезжает в ад. >По факту у тебя всратый датасет Предположи что у меня есть бесконечное количество субъектобъектов для которых нет не всратого датасета, а обучить нужно. Твои действия? Я могу зарегулировать сигнал и сделать его чистым. >код тренировки Ну что предоставляют сдскрипты то и юзаем. >ты пытаешься демпингами поймать какой-то свитспот когда говно не вытекает, потому что у тебя конец тренировки - это говно. Да нет не так вообще. Я на сф продигах сижу вообще, а там конец тренинга определенного этапа в смысле запекания фич и стабилизации определяется через пикрел в точке до последующего роста. Вопрос не в говне и вытекании а только в заучивании и адаптации, что неконтролируемо и меня это бесит. >Тренировка лор ничем не отличается от обычной тренировки в контексте оптимизации, она должна всегда приходить в стабильное плато, а не в говно. Если на плато не то что тебе надо, то надо тергет сдвигать, а не пытаться демпинговать тренировку и ловить какую-то точку недотрена. Ну это теоретизирование, ты бы еще написал "ну вода мокрая, если у тебя вода недостаточно утоляет жажду, то так не должно быть". У меня жесткие требования к обучению, я не делаю референс генераторы и мне нужен гибкий стабильный вывод на основе знаний основной сети. >Тебя вообще не смущает что буквально все пытаются сделать как можно быстрее схождение и плато ниже А сколько раз мне еще написать что нахождение решения для лоры это не моя проблема? Можно найти решение и в 100 шагов, только это не дип адопшен который нужен. > а не ищут свитспоты? Я не ищу свитспоты. >Т.е. мутанты/артефакты/низкая генерализация - это вопрос таргета, а вопрос оптимизации/архитектуры лор только в том чтобы как можно быстрее к этому таргету упасть. Чел, хватит пространные рассуждения пихать очевидные. >И тут тебе стоило бы задуматься что тебе срёт в тренировку Ну очевидно что срет - в основном это конволюшены лоры с фиксированным рангом, а если обучать без них, то это непозволительное расточительство времени, линейные соло обучаются слишком долго. >В любом случае фултрейн только на XL и возможен, на той же Хроме в fp8 тебе 40+ гигов врама надо чтоб без лор тюнить все параметры или использовать 8-битные говнооптимизаторы, или свапать блоки как шакал. А ведь она одна из самых мелких DiT. На WAN вообще лоры на микродатасетах по 8 часов приходится тренить на 5090. Да я про сдхл только и пизжу, остальное меня мало волнует.
>>1337312 > разве нет? Нет, peft работает с чем угодно. У меня peft на оригинальную реализацию Хромы непердолен с диффузерсами не подружился, бомбанул от ублюдской реализации упаковки латентов Флюкса. Он просто проходится по всем модулям модели и подменяет своими по заданным паттернам. > для методов с альфой Так делай альфа = ранг. И забудь навсегда про существование альф и кручение весов. > есть бесконечное количество субъектобъектов для которых нет не всратого датасета, а обучить нужно Решается капшенами. На DiT просто, на XL посложнее из-за клипа. Всратый датасет в моём понимании - рандомная лоурез дрисня из яндекс-картинок, найденная по поисковому запросу. Если тебя интересует только небольшая часть пикчи, а всё остальное мусор, то это тоже капшенами решается. Например можно сливать ненужное в стохастику/один токен, который превратится в триггер стиля и который можно успешно игнорить. Достаточно наконец в 2025 году подружиться с крупной VLM, а не пользоваться дженерик простынями из wd-таггеров, от которых естественно протекают все концепты потому что капшены шаблонные. > сф продигах Пиздец. Вот и ответ твоих проблем. > У меня жесткие требования к обучению, я не делаю референс генераторы и мне нужен гибкий стабильный вывод на основе знаний основной сети. Это ты говоришь какие-то общие слова, о том что и так работает не напрягаясь. Даже XL без проблем умеет в перенос элементов концепта за пределы датасета. Ты бы хоть показал с чём у тебя проблемы. По твоим рассказам больше похоже на шизу. > в основном это конволюшены Не верю.
>>1337357 >Нет, peft работает с чем угодно. Я не знаю как впердолить в сд скрипты. >Так делай альфа = ранг. И забудь навсегда про существование альф и кручение весов. Так я альфа=ранг и треню в основном. >Решается капшенами. На DiT просто, на XL посложнее из-за клипа. Если тебя интересует только небольшая часть пикчи, а всё остальное мусор, то это тоже капшенами решается. Например можно сливать ненужное в стохастику/один токен, который превратится в триггер стиля и который можно успешно игнорить. Да не решается. Хоть какой капшен - хоть токенами, хоть человеческое описание, хоть класс, хоть небо и аллах. А если ты про тренировку с TE, то я и так и так тренировал, но в основном энкодер не тренирую, с енкодером только на жестком выборе контректных слоев енкодера для тренировки нет большого влияния на сдхл. >Всратый датасет в моём понимании - рандомная лоурез дрисня из яндекс-картинок, найденная по поисковому запросу. У меня не спарсенные картинки, не рандом, бывает что шумные датасеты, но не критично, но такие картинки фактурные очень и сеть это улавливает сильно. >Достаточно наконец в 2025 году подружиться с крупной VLM, а не пользоваться дженерик простынями из wd-таггеров, от которых естественно протекают все концепты потому что капшены шаблонные. Не пользуюсь вд. Я так понимаю ты в целом со своей колокольни вещаешь и не понимаешь специфику мою, а мои "дип адопшен кококо хватит перезаписывать основную модель тварь" тебе ни о чем не говорит потому что ты примитивное онеме тренишь. >Пиздец. Вот и ответ твоих проблем. От оптимайзера не зависит вообще, не надо тут это. >Это ты говоришь какие-то общие слова, о том что и так работает не напрягаясь. Даже XL без проблем умеет в перенос элементов концепта за пределы датасета. Да блять не работает оно не напрягаясь. Если бы оно работало не напрягаясь этой ветки диалога не было бы. >Ты бы хоть показал с чём у тебя проблемы. По твоим рассказам больше похоже на шизу. Ок смотри, задача 1: сделать генерализованную модель под конкретную живую бабу модель для генерации с ней различных картинок для маркетплейса (отдельные модели под вещи уже готовы). Есть обширный датасет. У меня есть исходный файнтюн который без особого напряга генерирует и управляется с адаптерами и контролнетами, моя задача просто заставить сеть генерировать только тян модель - то есть ее точную фигуру, лицо, прически, чтобы по итогу влияние на модель было только в этих доменах. При обучении всех слоев с конволюшеными я неизбежно получаю перекос в датасет и теряю основные знания сети, поэтому конкретно под эту задачу с реальными людьми подходит либо дримбудка либо селективная тренировка, которая теряет дату, но не настолько критично как полнослоевая тренировка. Задача 2: у меня есть классовый концепт, о котором знает сеть, большой датасет из которого нельзя убрать дату до минимального, т.к. в дате содержатся разные нужные данные. Никакая лора не справляется с генерализацией и в любом случае падает в копирование датасета. Задача 3: у меня концепт о котором не знает, очень шумный датасет, шум давится, но лора по итогу выучивает датасет вместе со всеми характерными шумами. Маскирование даты невозможно. >Не верю. Я отключаю конволюшены и проблема уходит вместе с глубокими знаниями локальными, можешь верить.
>>1337380 Не, я другой анон вообще, увидел вашу дискуссию и решил потыкать этот peft. Он вроде даже в кохаковский формат автоматом сохранился, в webui его видно. Но он, сука, не работает. Совсем. В логах видно загрузку, но результат вообще никак не меняется, что с лорой что без нее - вот прям пиксель-в-пиксель одинаковое.
>>1337371 Сконвертить? В диффузерсах есть функция convert_state_dict_to_kohya для peft, были скрипты где-то в репе диффузерса для тех кто с лапками. Либо глазами посмотри как ключи поменять. Пикрил я для Хромы делал конверсию в формат комфи. >>1337379 > Задача Во-первых, не понятно твоё стойкое желание использовать только XL, когда на любом DiT описанное тобой не является задачей и просто работает. Даже возьми SD 3.5, если хочется базу похожую на XL. Во-вторых, так и не увидел чего-то невыполнимого для XL. В третьем вообще очевидный проёб тренировки, XL наоборот очень сильно игнорит шумы/артефакты сжатия, а в DiT это решилось бы указанием тега на шум.
>>1337448 >Во-первых, не понятно твоё стойкое желание использовать только XL Потому что быстро, удобно, пачка всего нужно существует и файнтюны на любой вкус втч мощная предметка. >когда на любом DiT описанное тобой не является задачей и просто работает. - я пользуюсь вилкой чтобы кушать корнишоны - возьмите BFG 3000, оно лучше справляется, попробуйте >Даже возьми SD 3.5, если хочется базу похожую на XL. Нет файнтюнов которые можно юзать как базу. >Во-вторых, так и не увидел чего-то невыполнимого для XL. Ну теоретически нет невыполнимого, невыполнимы с наскока они без дип пердолинга на лорах. >В третьем вообще очевидный проёб тренировки, В третьем проеб конволюшенов лоры, именно там я их отключаю и магическим образом все приходит в юзабельную норму, но концепт недостаточно точен (сильно недостаточно). >XL наоборот очень сильно игнорит шумы/артефакты сжатия Жаль сдхл об этом не в курсе. >а в DiT это решилось бы указанием тега на шум Насрать на диты.
Кароче ты мне помочь не сможешь так и так с твоими тремя паттернами ответов - "ты делаю что-то не так" (а я делаю так), "хл нинужна" и "юзай пефт" (но как юзать с сдскриптами конечно же не напишешь). Но оффенс если че, бессмысленный диалог получился просто.
>>1337068 >Нет, этих свдшных методов слишком дохуя и они не кончаются, вон новый недавний Я про тот конкретный, для которого в коде делать ничего не надо, а только правильно нарезать модель через экстракт.
>Фулл в смысле фул фул или просто полные матрицы? Фулл в смысле фулл. А полные матрицы это что? Отдельные слои или просто большой ранг?
Потести svd нарезку, это слишком интересный метод, чтобы его скипать. Там же еще можно основу модели после нарезки заквантовать даже просто в фп8. Примерно как делается в SVDQuant, там у них это в 4бит хорошо работает при том что активации тоже в 4 бит. Главное настроить так чтобы конвертилось в фп8 только то на чем разложенная лора висит, а остальное не трогать. И некоторые атеншены наверное тоже.
Кста большие модели вы только так и будете тренить в будущем. Других адекватных способов нет. Ну если не завезут нативную тренировку в фулл 4 битах с градиентами. По сути идеальная q-lora уже доступна вообще без пердолинга.
>Сдскрипты не позволяют в фп32 ничего гонять кроме вае, да и не на моей карте полную точность дрочить. С полной точностью любые карты работают. Количество весов для которых ее стоит включить очень мало относительно всей модели, на память не должно влиять. Это по идее должно легко включаться в коде, но надо разбираться в торчах, да...
Надо новый понятный гайд на разбивку делать? А то прошлый раз походу никто не понял че это такое.
>>1337464 > ты мне помочь не сможешь Естественно, ведь ты отказываешься показать в чём у тебя проблемы. Только невнятное "ну вот я придумал задачу на ходу и обосрался что-то сделав не так". >>1337466 Может ты просто не натренил ничего, вот и нет изменений, лол. Автоматик должен писать если ключи не совпадают.
>>1337491 Хуй знает короче, закинул рабочую кохак-лору и конверт peft - и там какая-то ебанина с ключами, они вообще нихуя не совпадают... При этом ошибок не было.
>>1337491 > Естественно, ведь ты отказываешься показать в чём у тебя проблемы. Я тебе описал проблемы. Анимешнику трудно уловить суть реальных задач, понимаю, это не standing loli girl nude pussy masterpiece.
>Только невнятное "ну вот я придумал задачу на ходу и обосрался что-то сделав не так". Ок, бери лустифай, генерируй тяночьку с гейпом жопы и тренируй полнослойную лору чтобы все сохранилось изначальное в модели кроме лица и фигуры. Без результата можешь даже отвечать.
>>1337471 >Я про тот конкретный, для которого в коде делать ничего не надо, а только правильно нарезать модель через экстракт. >Потести svd нарезку, это слишком интересный метод, чтобы его скипать. Там же еще можно основу модели после нарезки заквантовать даже просто в фп8. >Примерно как делается в SVDQuant, там у них это в 4бит хорошо работает при том что активации тоже в 4 бит. Главное настроить так чтобы конвертилось в фп8 только то на чем разложенная лора висит, а остальное не трогать. И некоторые атеншены наверное тоже. >Кста большие модели вы только так и будете тренить в будущем. Других адекватных способов нет. Ну если не завезут нативную тренировку в фулл 4 битах с градиентами. >По сути идеальная q-lora уже доступна вообще без пердолинга. Я если честно нихуя не понял, где что находится и как куда чем что резать. Че читать?
>Это по идее должно легко включаться в коде, но надо разбираться в торчах, да... Ну вот по дефолту в сдскриптах нет такого.
>Фулл в смысле фулл. А полные матрицы это что? Отдельные слои или просто большой ранг? Полные матрицы это в смысле full алго из ликорисовской либы, это дримбудка в виде лора модуля, там нет никаких слоев, просто полновесные матрицы нативного размера сдхл.
>Фулл в смысле фулл. Нет, прям фулл от начала до конца с те я не делал, у меня на карту не поместится такое.
>>1337574 > Я тебе описал проблемы. Тебе уже сказали что это не проблемы, а скилл ишью. Но тебе трудно уловить что ты тупой. > лустифай > реальных задач Я так и понял что ты клован.
Короче ебал я этот peft. Для XL нет ровным счетом нихуя, есть какие-то недопиленные ошметки для древнего SD, которые проще выкинуть нахуй, чем пытаться адаптировать под XL.
>>1337677 Там всё универсальное, естественно специально под XL нет ничего. А вообще по функционалу альтернатив ему нет. Даже нормальная реализация пикрила есть.
>>1337691 Кохаковские конверты там сделаный хуй знает как. Я хз откуда они такие ключи вообще взяли - их у кохака никогда и не было. Накидал лапшу на диффузорных пайпах с загрузкой ихней лоры - вроде работает, говно. Польза пока правда от всего этого сомнительная.
>>1337677 >>1337695 Пефт универсален, его можно хоть в кохю хоть куда применить. В лапшу если вдруг нет стандартной ноды потребуется свою наколхозить, но там буквально несколько строк, ллм справится.
>>1337668 >Тебе уже сказали что это не проблемы, а скилл ишью. Но тебе трудно уловить что ты тупой. Даа, скилишью, такое скилишью что ты не можешь со своим скиллом решить простенький тренинг по реквесту. >Я так и понял что ты клован. Ой, а что не так? Специально же придумал тебе задачу под твой ежедневный дрочь на голых самок, аниме, ток без аниме, чтоб тебе веселее было. Давай-давай, тренируй консистентную тяночьку с сохранением всего, кроме лица и фигуры, я жду ;)
>>1337714 > по реквесту Не вижу реквеста. Давай датасет, показывай что у тебя самого получается. Будем обоссывать тебя. > а что не так? То что ты пишешь про одни задачи, а потом рассказываешь что не можешь решить их на подходящей модели потому что там нет порнушных лор. Я из этого делаю вывод что ты просто траллишь тред и даже не тренишь ничего.
>>1337716 >Не вижу реквеста Еще раз: бери лустифай, генерируй тяночьку с гейпом жопы и тренируй полнослойную лору чтобы все сохранилось изначальное в модели кроме лица и фигуры >Давай датасет Любую бабу с характерной внешкой бери, любой размер датасета. >показывай что у тебя самого получается Это ты покажи мне мастеркласс, у меня полностью датасетовая копирка получается вместо адаптации с тренировкой всех слоев. >То что ты пишешь про одни задачи, а потом рассказываешь что не можешь решить их на подходящей модели потому что там нет порнушных лор. Я из этого делаю вывод что ты просто траллишь тред и даже не тренишь ничего. Ты че далбаеб 20 iq? Каких порнушных лор? Я тебе дал ту же задачу, что в задаче 1 была, только упростил ее до "сохрани все с основной модели, но чтобы была тяночька и ее фигура с датасета". Давай, хуярь.
>>1337701 Погугли где используется магнитуда. Пефт наворачивается на стандартный класс модели, если ты пытаешься потом грузить его через какой-то хардкод, да еще и дору - разумеется будут ошибки. В остальном принцип весь тот же, могут отличаться только префиксы. >>1337709 Ты что несешь вообще? >>1337714 Тренираторы лоры на еот на своих 3060 - самый низший мусор, когда успели это позабыть и накопить такое чсв? Это тред для технических обсуждений а не аутотренинга.
>>1337474 Нужно комфи с нодами ModelMergeSubtract, либо на русском Вычитание моделей / Вычитание CLIP По схеме 1 получаем пустую модель. Можно проверить, должна сжиматься до сотки метров архиватором. Делаем экстракт из модели. Пик 2 слева целевая, справа пустая. Можно не делать пустую модель, а взять вместо нее базовую sdxl, но я хз что именно это даст. Изначально смысл в том чтобы поделить всю модель, а не вырезать из нее нафайнтюненый кусок. Но работать тоже должно. В этом случае для дальнейших процедур берется "новейшая" модель, та что была слева. Ранг экстракта - чем больше тем лучше. Закидываем экстракт обучаться на 1 шаг на одной картинке самом на самом низком лр (типа 0.000000000000000000000001, но не просто 0). В поле Network weights веса экстракта. Он сохранится нормальным, дальше используется только сохраненный. Пик3, делается мерж экстракта с пустой моделью. Пик4, получаем разницу между исходной моделью и "развернутым" экстрактом. Эту модель используем дальше.
Проверка того что получилось - закидываем в условный автоматик полученную модель, экстракт (сжатый, тот что после обучения на 1 шаге) загружаем как лору. Все должно работать 1 в 1 как исходная модель. При небольшом отклонении веса от 1 ломается.
Закидываем все это обучаться, как обычное продолжение тренировки лоры. В Network weights наш экстракт. В модель собственно разницу, также как и на проверке. Альфа = ранг. Ранг тот же что и у экстракта. Есть вроде кнопочка чтобы само подставилось.
>>1337766 Дополнение: Экстракция делается через SVD, берется n самых "мощных" 1-ранговых лор. SVD как бы раскладывает модель на одноранговые лоры. 1 проход - собирается самая жирная лора которая помещается в 1 ранг, остается остаток. Из этого остатка высасывается еще один ранг. Это как бы и не лоры, просто конфигурация матриц и математика такая же. Если матрица 100 на 100, то за 100 проходов ты получишь лору ранга 100, и эта лора будет работать точно также как исходная матрица. Только будет в итоге 2 матрицы 100х100, в два раза больше весов чем в исходной. Суть в итоге в том что все "одноранговые лоры" нормируются, отдельно записывается множитель, и в итоге получается что основную информацию в матрице несет меньшая часть рангов, а в остальных в основном мелкие шумные значения. Как SVD выбирает 1 самый жирный ранг - сканируется исходная матрица на похожие строки и столбцы, отдельно. Типа одной строкой будет строка которая больше всего похожа на все, также и столбец. Из этого собирается одноранговая лора, ее можно развернуть, вычесть из матрицы, и с остатком проделывать это столько раз, сколько размер матрицы. Гарантированно в конце в матрице останутся только нули. Это объяснение скорее всего неверно, так как я не знаю как работает SVD, лол. Идея метода - в том что в лору переносятся те самые жирные ранги, а в модели остается все остальное. Лора не инициализируется с нуля. Так как встроенного метода это сделать нет, и нужен этот небольшой пердолинг с экстракцией. Как раз экстрактор юзает SVD, и через разницу получаем эквивалент этой самой нарезки. Еще лора же не захватывает все слои, поэтому в весах модели останутся нетронутыми слои на которых не висит лора. Потому что мы вычли только то что в правильном экстракте было. А в нем не было слоев которые не включены в обучение.
Всякое квантование в фп8, обучение конвов, это я не делал. Для этого нужен вдумчивый пердолинг с пониманием че ты делаешь и че у тебя в весах происходит. Но зато любая ошибка сразу выльется в высокий лосс и будет видна.
Релевантные ссылки: youtube.com/watch?v=DG7YTlGnCEo Идея взята отсюда - https://www.alphaxiv.org/abs/2404.02948 Здесь похожая идея применяется для квантования https://www.alphaxiv.org/abs/2411.05007 Тренировать таким методом пока нельзя. Я пытался разобраться, если его как есть использовать, ускорение будет не в 5 раз, а в 1/4, ибо бэкпроп в фулл точности идет. А заквантовать градиент это не простая задача, тут я разбирался с ллмкой, говорит что градиент гораздо больше выбросов имеет. Можно придумать, но это уже уровень статейного ресерча. Может в фп8 нормально будет. Там еще и часто надо будет пересчитывать разложение матрицы. Кароч все сложно, но в теории можно ускорить. А вот просто сэкономить память должно быть легко. Все веса которые не попали в лору должны хорошо квантоваться. То есть можно сочетать с qlora. Как это делается я хз, в гуе есть только кнопка на fp8, что она делает я тоже хз, но надо чтобы она переводила не всю модель в фп8, а только нарезанные слои. Должно делаться минимальными усилиями, но я этого не дошел.
>>1337620 >Полные матрицы это в смысле full алго из ликорисовской либы, это дримбудка в виде лора модуля, там нет никаких слоев, просто полновесные матрицы нативного размера сдхл. Бля, я нихуя понять не могу. Пока не смотрел че делает код, но фулл матрицы это полные исходные матрицы. И обучение их это обычный файнтюн.
Ща быстро посмотрев код тоже нихуя не понял что оно делает, файнтюн исходной матрицы иди вешает лору. Надо в ллмку под пихать.
Про нарезку я вроде попытался понятно объяснить. Вот это оно >>1337691
>>1337815 >Бля ну и пердолинг. Это еще даже близко не пердолинг. К сожалению... >А с конволюшнами че делать? Тоже размер как у основного дименшена? На самом деле хз. Конвов в обычной лоре не будет все равно. А я тестил только с обычной. Но должно работать все. Главное чтобы ты вычитал по итогу ровно те слои, которые тренируются, чтобы мержер полностью рассасывал все слои в фуллмодель. Я не знаю где там что проебаться может на других алгоритмах. Вот я щас сам запустил чтобы почекать не спорол ли где хуйню. И у меня пришлось два раза пересоздавать фикс экстракта через маленький лр. То есть я закидываю в автоматик ту "разничную" модель, на которой сейчас обучается лора-экстракт, закидываю то что нагенерили первые эпохи и нихуя не работает. Со второго раза работает. Видимо где-то проебался энкодер, ибо когда я начал тренить, я поставил ему 0 лр и включил кеш энкодера. А когда фиксил экстракт этого не стояло. Можно понять еще по размеру файла. Если у тебя лора на входе больше чем лора на выходе, значит что-то проебалось. Должно быть одинаково.
Тут надо понять именно смысл того что ты делаешь, а не пытаться следовать алгоритму. Тогда пердолинг будет только в том чтобы чтобы за всем уследить что скрыто от тебя за убогим гуем.
Если ты можешь любой алгоритм загрузить как продолжение тренировки, если ты можешь его слить с моделью, то все будет работать. В первом случае косяки исправляются пересохранением через малый лр, во втором хз как отследить, не проебал ли мержер слои. А ну и сам экстрактор то у нас что что дает, от того и работаем. Хз какие алгоритмы смогут продолжить без ошибок то что он выдал. Вот это таки будет проблемой, наверное.
>>1337827 >Можно понять еще по размеру файла. Если у тебя лора на входе больше чем лора на выходе, значит что-то проебалось. Должно быть одинаково. я кароче кинул экстракт на вход в ликорисовский локон, размер получился идентичный, но точно побайтово различие 2 байта
>>1337830 >>1337834 Ну да, а что ты хотел? Для прям фулл файнтюна надо отдельно включать все что не вошло в лору. Похоже через гуй это не сделать, хз, какой там формат у ликорисов? Если файл хотя бы можно пихнуть как продолжение тренировки, то его же можно скрестить с экстрактом и все будет работать. Ллмка должна справиться с кодом, для этого ненужно в сами скрипты лезть.
>>1337835 Да... Я это вроде хотел включить, может скрин старый. По логике метода так и должно быть 1 и 0.
>>1337839 Должно быть похуй на какой, только выстави все сразу как должно быть, чтобы не проебать энкодер например. А то там код видимо дохуя умный, если энкодера нет то и зачем его выводить в веса. Но веса то у нас теперь такие, которые идеально дополняли друг-друга, а не как в обычной лоре, где ты удали любой ее слой и на работе это критично не скажется.
>>1337841 У меня сейчас несколько байт разница, не сломалось. Хотя между эпохами разницы в байтах нет, какие-то метаданные, мб.
>>1337845 На уровне ошибок квантования разница. Вообще я не всматривался, но вроде получал 1 в 1.
>>1337846 На диффе, иначе ты считай удваиваешь исходные веса. Можно их слить и вытащить обычную лору по классике. Или вычти из натрененой исходную. Можешь сразу натрененную и исходную вместе грузить, так чтобы сумма их весов была 1. Эквивалентно обычному изменению веса.
>>1337852 >>1337852 >На диффе, иначе ты считай удваиваешь исходные веса. Можно их слить и вытащить обычную лору по классике. Или вычти из натрененой исходную. >Можешь сразу натрененную и исходную вместе грузить, так чтобы сумма их весов была 1. Эквивалентно обычному изменению веса. ну я ебанул на большой скорости 3 эпохи, вроде работает, конечно все по пизде пошло с лоссом 0.2 но видно что роботает, куолити хуй знает, надо лр снижать
>>1337852 >Можно их слить и вытащить обычную лору по классике. Или вычти из натрененой исходную. не понял что с чем и как надо сливать/вычитать чтобы лору чистую получить чтобы на исходной модели работало?
>>1337766 >Закидываем экстракт обучаться на 1 шаг на одной картинке самом на самом низком лр Есть разница на чем? Или нужно тупо минимальное изменение в экстаркте?
>>1337855 Это не причем. Вообще ставь максимум ранг который влезает в память. 64 это наверное маловато для идеи метода, там много чего не захватывается. Между 100 и 200 где-то оптимум по емкости. Но для разных слоев по разному. В идеале надо настраивать по группам. Я где-то видел что вычисляли эту хуйню для каждого слоя, типа если взять % самых важных, то какой ранг их охватит.
>>1337862 Ну вливаешь в дифф-модель свой обученный экстракт, в мержере. Потом экстрактишь из этого по классике лору. Так же как получал экстракт. Только в правое поле не пустую модель а исходную нетронутую. В левое то что слил. Если через вычитание, то вычитаешь из обученного экстракта необученный. Прямо в весах, хз есть ли ноды для вычитания лор, но получить должен то же самое.
>>1337860 Да, ей разгоняться не нужно как обычной лоре с ее всратой инициализацией.
>>1337870 >интересно можно ли както веса подгрузить в кастомные алгоритмы другие или только локон доступен В какой алгоритм ты хочешь грузить? Я посмотрю. Не факт что это вообще имеет смыл.
>я еще с фиксед нойзом гоняю И с ффт? Можешь как-нибудь запилить один дифф кода этого всего? А то чет по скринам ебано разбираться.
>>1337878 Нужно не минимальное изменение, а чтобы тренер сохранил только то что он хочет сохранять. Ибо он ложит хуй на то что ты ему пытаешься дать больше слоев чем у него в конфиге прописано. Это просто подгон формата по сути.
>Можешь как-нибудь запилить один дифф кода этого всего? А то чет по скринам ебано разбираться.
Фикс нойз через хеш сумму пихать в трейн утил https://pastebin.com/FN4fxWRz добавить инициализацию аргумента фиксед нойз через parser.add_argument( "--fixed_noise", action="store_true", help="fixed noise latents", ) использовать с кешированием (хотя может работать будет и без, я не пробовал)
ффт поставить https://github.com/tunakasif/torch-frft добавить в импорты в трейн утил from torch_frft.frft_module import frft from torch_frft.dfrft_module import dfrft, dfrftmtx
ниже импортов обозначить мсе комплекс https://pastebin.com/fPVnqik1 ввести новый метод лосса в кондишнл лоссе https://pastebin.com/kvUXhnii инициализировать аргумент (просто добавить fft в лосстайп) parser.add_argument( "--loss_type", type=str, default="l2", choices=["l1", "l2", "huber", "smooth_l1", "dwt", "fft"], help="The type of loss function to use (L1, L2, Huber, or smooth L1), default is L2 / 使用する損失関数の種類(L1、L2、Huber、またはsmooth L1)、デフォルトはL2", )
>>1337884 >В какой алгоритм ты хочешь грузить? Я посмотрю. Не факт что это вообще имеет смыл. В какой покатит в принципе, но хотелось бы boft как единственный не изменяющий структуру основной модели, но скорее всего не получится подгрузить тк слои у офт с oft буковками и надо будет переименовывать чтоб сожрало и не факт что там соответствие 100%. Проверь кароче лоху например еще.
Дилору наверно тоже съест норм кстати потому что там просто на блоки разбивка идет, а оно по сути локон.
>>1337904 предполагаю что т.к. веса подгружаются в тренер и чтобы теоретически не разъебало нестабильным фп16 на различных оптимах с nan в первом шаге, то используются стабильные бф16
микродатасет на 5x2 пикч, стабильность ебовая, по ощущениям можно еще агрессивнее, дкоеф побольше и стартовый d0 выше, все равно можно суппрессировать влияние через фикс лору в процентном соотношении
>>1337884 >Вообще ставь максимум ранг который влезает в память. 64 это наверное маловато для идеи метода, там много чего не захватывается. Между 100 и 200 где-то оптимум по емкости. А есть даже 128 в память не лезет?
>>1337922 можно с fp8 base попробовать с оптимами 8бит/адафактором без памяти с фузедбакпасом опционально либо заморочиться и тренить только определенные блоки, но это тебе резать придется дополнительно фикс лору чтобы пересечения не было через слайсер отсюда https://github.com/ThereforeGames/blora_for_kohya можно не тренить TE, или тренить конв отдельно, а линейные отдельно, у тебя база все равно одинаковая стартовая, разница в раздельном использовании будет скорее всего минимальная
я вон выше 64 ранг тренил конв+линейные, ну вроде достаточно по емкости
>>1337932 >я вон выше 64 ранг тренил конв+линейные, ну вроде достаточно по емкости Бля, я сейчас попробовал 64 просто линейки и оно все равно вываливается в шару. Боюсь если я туда еще и конвов хотя бы 32 запихну - оно в 20 гигов улетит вообще...
>Проверка того что получилось - закидываем в условный автоматик полученную модель, экстракт (сжатый, тот что после обучения на 1 шаге) загружаем как лору. Все должно работать 1 в 1 как исходная модель. При небольшом отклонении веса от 1 ломается.
До этого момента все ок.
Далее беру новую базовую модель и чекпоинт для лоры, делаю 1 шаг на реальном датасете с лр 2е-5, свапаю в автоматике чекпоинт для лоры на новый после тренировки - получаю шум.
>>1338038 >>1338038 >А как ты вырезал и мержил локон? >>1338038 >Коховская портянка при мерже сыпет ошибками. Через кохуи все сделал. У меня полностью все требвания для этого говна подходят, венв не создавал для него отдельного, убрал все реквайрмент файлы из корня и запускал через python kohya_gui.py, если требовало библу и не запускалось - ставил библу через пип.
>>1338132 >Далее беру новую базовую модель и чекпоинт для лоры, делаю 1 шаг на реальном датасете с лр 2е-5, свапаю в автоматике чекпоинт для лоры на новый после тренировки - получаю шум. lr ставь 0.000000000000000000000001 после 1 шага берешь полученную лору и смердживешь с зануленной моделью из шага 1 потом делаешь шаг с пикчи 4, получаешь модель, эту модель грузишь как основу и поверх нее применяешь лору которую обучал 1 шаг
>>1338168 Ааа, бля. Я юзал экстракт и мерж для локона в кохе, сейчас попробовал стандартный и оно сработало.
>>1338176 Это я уже сделал, там проблем нет. Экстракт и базовая модель под него вместе работают без проблем, производя результат как у оригинальной модели. Проблема была в том что ебуча галка в кохе для чтения DIM из чекпоинта лоры походу не работает и пидараст результат. Убрав ее и руками задав размерность вроде получилось.
>>1338199 >Убрав ее и руками задав размерность вроде получилось. Но только с лорой. Локон вообще не тренится - за 3-4 шага улетает в NaN внезависимости от лр или оптимизаторов...
>>1338253 >Локон вообще не тренится А он и обратно не собирается, лул. После конвертации через прогон с низким лр и подготовкой экстракта эта комбинация генерит только шум.
>>1337940 включил дору, включил спид, взял датасет из 100 картинок - модель моментально сгорела (но обучилась по пути конечно), непонятно от чего сгорела, щас без спида попробую не пососать
>>1338348 >моментально сгорела кстати прогар очень своеобразный, первый раз такое наблюда., эффект как от DMD лоры с повышением цфг, то есть яркие яркие выжженые цвета, четкие формы, фон например чисто пятнистый фон а объекты в стабильности если плюсить дмд поверх то горит вдвойне
>>1338265 Вроде разобрался - дело было в конверте лоры 1-шаговым проходом. Если скипнуть энкодер (поставить нолик в лр) то результат пидарасит и оно не работает вообще. С энкодером нормально. Прогнал этот конфиг на sf продижах, на стилевом датасете - после 1000 шагов с батчем 2 какие-то изменения в лоре и гене есть, но переноса стиля там нет нихуя. Сейчас взял sf адам, взял макс лр из продижи и накинул по единичке сверху, взял совсем простой стиль - на нем даже самые всратые конфиги сходились - по логам как-то тухло. Либо надо задирать лр чтобы это говно сдвинуть с места, либо я опять где-то обосрался с подготовкой. Пока весь этот пердолинг не выглядит так, будто это того стоит...
>>1338349 Кароче синий график без спида. Со спидом очевидно зажарило сильнее, примерно до 20 шага (200 изображений => 2 эпохи) все стабильно и обучилось нормально, потом выгорело и только супрессить через основную лору. Вероятно надо вводить какую-то регуляризацию-демпнер или снижать скорость значительно. На мелких датасетах такого прогара не наблюдалось кстати с теми же настройками (кроме аккумуляции на 2 вместо 10). Теоретически если оно так хуярит новыми данными сильно, то можно сразу EQ вае пихать и оно ее быстрее перепердолит до норм состояния.
>>1338423 >Вроде разобрался - дело было в конверте лоры 1-шаговым проходом. Если скипнуть энкодер (поставить нолик в лр) то результат пидарасит и оно не работает вообще. С энкодером нормально. ну да, об этом выше челик писал, я сразу с енкодером выводил и норм
>либо я опять где-то обосрался с подготовкой. вероятно ето так
>>1338349 >кстати прогар очень своеобразный Вот чисто для примера: прогоревшая лора, дефолт ген, среднее между ними (аналог 0.5 применения новых весов) Четвертая картинка - лора до прогара концепт левый
>>1338439 кароче чето с цфг произошло и шедулером во время тренировки, если цфг снижать до 1 и уменьшать степы (изначальная модель не предназначена для такого) то там где прогары можно добиться не горящего гена,если добавить кастомный шедулер то прогары еще сильнее убираются, по факту я получил дистиллят из модели какой-то
>>1338470 да причем тут твои постфикс костыли, ты не понял смысол, модель вообще не умела в 10 шагов и 1 цфг (дефолт ген пикрел), это ебический результат да еще и случайны, получается таким образом можно реально дистилляты для любого семплера делать, а не только как у дмд с лцм с помощью модели учителя
>>1338473 Ты опять таблетки забыл принять? У тебя на пике обычная пережарка, а не дистилляция, пикрил как рандомная модель под пережаркой выглядит с 1 cfg и 10 шагами. Даже не настолько мутанты как у тебя. Тратить 30 минут на пережарку, которая делается без тренировки, и сделать даже хуже - это уже болезнь.
>>1338494 > У тебя на пике обычная пережарка, Там не пережарка, пережарка это когда мясо неконтролируемое вместо картиночки и апофеоз убитых весов в виде шума или черного экрана.
>>1338484 Стандартные вроде должны (если они включаются), те что специально для лор - нет. Дропать ранг это дропать дохуя живых важных весов. Точечное отключение весов должно быть норм. Но все равно надо аккуратно, я бы еще провел эксперименты как влияет на качество выбор весов для дропаута по дисперсии градиента. Думаю там можно найти хорошие корреляции. Типа "супервеса" трогать определенно не стоит. Их бы пошатывать чутка обратно градиенту как в статье Sharpness-Aware Minimization, только как в той где это только к нормам применяли. WD работает по принципу фулл файнтюна, если нужен эквивалент как с лорой, надо стопать тренировку и делать линейный мерж с исходными нетрененными весами. Ну там ~0.5-0.8 новых и продолжаешь тренировку (в сумме должно быть 1). Сохранять оптим наверное можно, в идеале его бы как-нибудь скорректировать чтобы долго не прогревать, ну или старт с прогрева как обычно если тебе нужен прогрев.
>>1337922 >А есть даже 128 в память не лезет? Для этого и была идея напердолить конвертер в фп8 для остатка весов на которых висит лора, чтоб не трогал остальные веса. Так и влезет все и качество должно не пострадать прям вообще.
>>1337902 >В какой покатит в принципе, но хотелось бы boft Хз, я позаебывал ллмку на тему как инициализируется эти бофты, кароч все эти мультипликативные адаптеры так не работают. Тоесть если ты делишь модель по svd и вешаешь на это бофт, получается формула бофт(модель+лора), в скобочках веса заморожены и они эквивалентны изначальной модели, отличий никаких от того если бы было бофтмодель. Вариант модель+бофт*лора не имеет смысла из-за того что входные и выходные размерности лоры такие же и размер бофта будет таким же. Единственный смысл - использовать первый вариант с квантованием в фп8, для экономии памяти.
Если в адаптере хоть где-то есть нулевые веса, которые должны расти по градиенту, чтобы адаптер постепенно включался в работу, тогда да, надо искать как можно его инициализировать весами модели и убрать нули. Для обычной лоры то понятно уже все, для мультипликативных начинается уровень статейного рисерча. Лора на конвы это обычная лора, если че. Остаются единичные веса или отдельные векторы, на них просто инициализируем нулями поправку. Им нули не мешают.
>Проверь кароче лоху например еще. Может сегодня смогу разобраться с ллмкой, а то просто читая репозиторий пока нихуя не понятно, без картинок со схемами и объяснения какие блоки где включены и т. п. Как же тяжело, я глазами этот код буду парсить целый день, что ллмка сделает за наносекунду. Хотя всю логику понимаю. Таки сказывается опыт самостоятельного кодинга максимум 500 строк лапши в одном файле да и те не на питоне.
>>1337893 Спс, пока еще не затестил... Я думаю этот ффт лосс должен хорошо зайти с eq vae. Там как раз частотный диапазон сглажен, по фурье хорошо раскладывается в отличии от дефолтного. Найди на ютубе канал Густарева, там он показывает как в фотошопе частотное разложение делать. Увидишь глазами как оно работает. И это мы пытаемся с латентами делать. Можно ноду для комфи написать, и просто прогнать вае с таким же ффт, посмотреть че на выходе дает. А может такая нода уже есть. Вейвлеты чет так и не смог понять че делают, как будто то же самое кастрированное ффт.
Я еще недавно вкидывал шизометод, до которого у меня так руки и не дошли. Можно взять экстракт из любой другой модели, типа с нуба, люстры слить, инициализировать им, а вычесть уже из нужной модели. Можно взять готовую лору и инициализировать ей. Ты его вычитаешь из модели. То есть то же самое делаешь чем мы щас занимаемся. По сумме твоя модель не изменилась, ты скомпенсировал веса. И лора теперь инициализирована не нулями. Такая интересная хуйня получается. Но может математически эквивалентна просто шуму. А может и нет, надо проверять. Это как взять наоборот самые низшие ранги, по статье это работает хуже, говорят, но именно такой шизовый вариант они не додумались проверить.
>>1338423 Ну похоже получилось накрутить лры на адаме, перенос есть, но 1к шагов на датасете в 200 пикч походу маловато.
>>1338427 >я сразу с енкодером выводил и норм А ты его тоже тренишь? У меня, если указать нолик в лр при тренировке - точно так же пидарасит результирующую лору и она генерит тупо шум. Я в итоге пока забил хуй и на низком лр его тяну.
>>1338698 >А ты его тоже тренишь? На полноценной тренировке? Нет, только юнет пока что. >если указать нолик в лр при тренировке - точно так же пидарасит результирующую лору и она генерит тупо шум. Указывай --network_train_unet_only , у тебя не инициализируются слои te при тренировке, а потом используй текстовый енкодер от фикса как на пикрел (сверху лорафикс, снизу тренинг юнета готовый)
>>1338661 >Я думаю этот ффт лосс должен хорошо зайти с eq vae. Там как раз частотный диапазон сглажен, по фурье хорошо раскладывается в отличии от дефолтного. Да, я уже тренил ффт с eq, самый быстрый вариант достижения консистентного результата был на лохе (т.к. емкость значительно выше чем у лоры обычной). С методом экстракта тоже неплохо eq кстати и результат значительно быстрее достигается даже на локоне, я тут предполагал >>1338427 что так и будет - так и получилось. Мне eq нравится своей огромной точностью и вниманием к деталям.
>Можно взять экстракт из любой другой модели, типа с нуба, люстры слить, инициализировать им, а вычесть уже из нужной модели. Прочитал несколько раз и не догнал. Экстракт из нуба, а потом вычитание этого экстракта из модели основанной на нубе? Лучше конечно такие мувы описывать по шагам чтоб понятнее было. >Можно взять готовую лору и инициализировать ей. Ты его вычитаешь из модели. Я давно пробовал такое по наиитию давно, но там вроде тренинг не запустился, вероятно из-за того что другой алго брал вместо локона.
>>1338427 кароче еще пачка инфы, попробовал несколько методов
1. если использовать рег датасет, то "кристаллизация" значений (а это именно этот эффект, который в том числе обуславливает то что лора не ломается, условно у нас значение 99.95 из 100, а додрачивая экстракт таких значений мы доводим его до 99.999, что по факту является сверхточным дубликатом матрицы да еще и с избыточным не полезным усилением), но по итогу оно все равно будет идти к уничтожению через перенасыщение. 2. Если тренировать с альфой 32 вместо дефолтной 64 (равной дименшену), то перенасыщения значений не происходит, но и буста тренинга тоже, по сути просто деление новых весов происходит, которые все еще укладываются в норму. Неэффективно, долго, лижет сосет. Так как альфа регуляризация это сорт оф нормализация с другой стороны, можно попробовать нативную нормализацию (я не пользуюсь никогда таким) чтобы сдерживать уточнение значений. Вопрос только какое потолочное значение выбирать для нормы или выбирать нормировку в оптимайзере. 3. Простое снижение скорости обновлений на порядок (1e-5->1e-6) дало стабилизацию и немного позже началось перенасыщение. То есть прихожу к выводу, что скорости обновления параметров для экстракта надо как минимум больше чем x10 раз меньше, чем обычная скорость тренировки лоры. Падения скорости адаптация кстати нет, она идет по другому, но адаптируется мощно.
>>1339296 >то "кристаллизация" значений происходит чучуть дольше по времени при приорлосс 0.1, то есть тут чуть ли не 0.01-0.001 надо ставить чтобы скомпенсировать неконтролируемо уточняющееся значение
>>1339296 Хаха бля ебать я лох, похоже нашел что именно триггерит чрезмерную сатурацию значений - дора включенная. Получается под дору надо отдельно 1 шаг фикслоры с дорой тренить, а потом производить все манипуляции дифференса. Но зато итт теперь знаю что дора может использоваться как дистилляторная функция.
>>1339254 >Прочитал несколько раз и не догнал. Экстракт из нуба, а потом вычитание этого экстракта из модели основанной на нубе? Лучше конечно такие мувы описывать по шагам чтоб понятнее было. Любой экстракт и любая модель. В методе с svd экстракт делается из той же самой модели, но тут ты берешь любой, или любую лору, так же ее фиксишь через 1 шаг и вычитаешь из модели. Опять же желательно понимать смысл действий, тогда таких вопросов не будет. Еще раз, все по той же самой схеме, только просто подменяешь экстракт другим либо готовой лорой (которые прошли фикс на 1 шаге).
Например, ты хочешь обучать поверх пони, но делаешь экстракт базовой sdxl, получается ты как бы файнтюнишь ту часть базы sdxl которая осталась в пони. Это моя наивная интерпретация, как на самом деле будет работать не знаю. Если это так работает, можно нафантазировать что можно обучить "селектор", который не будет оказывать влияние на модель, и уже обучать с ним. Может ли это ввести в модель какой-то биас, или просто шум, надо проверять. Но вообще в любом случае хоть что ты модели не подсовывай, в конечном итоге если долго обучать она перезапишет веса как ей нужно.
>Я давно пробовал такое по наиитию давно, но там вроде тренинг не запустился, вероятно из-за того что другой алго брал вместо локона. Ну и ты не вычитал лору из модели, просто тренировка готовой лоры это не то. Она же активна. Надо вычитать, тогда компенсируется.
>>1339296 >Если тренировать с альфой 32 вместо дефолтной 64 Бля, куча путанной инфы, если ты через svd это тренишь - нельзя понижать альфу. Все сломается. Если не сломалось или что-то не то делаешь или альфа не применилась. Смотри входные и выходные веса, там записаны альфы. https://netron.app/
>>1339644 Дора там тоже либо вообще не нужна, либо она криво работает. Ну хотя лишней наверное не будет если ничего не проебывается. Посмотри еще че с весами происходит если у тебя уже фикшеный формат без доры и ты включаешь дору, на одном шаге.
По доре есть такая инфа https://github.com/bmaltais/kohya_ss/issues/2705 >I'm pretty sure you can change line 4209 of sd-scripts/library/train_util.py to accelerator.load_state(args.resume, strict=False) and it'll work. !! может быть полезно чтобы корректно продолжалась тренировка любых алгоритмов.
Алсо не помню писал или нет но ффт лосс шедулить надо по таймстепам это 100%
>>1339764 В каком месте бля? >loss = mse_complex(dfrft(model_pred.float(), 0.5), dfrft(target.float(), 0.5)) Разница между таргетом и предиктом и есть лосс по спектру генерации который на разных таймстепах должен быть разным. Если тебя смущает то что это происходит в пространстве шума а не исходной картинки, то спектр и все его свойства зеркально соответствуют картинке. Выделение низких частот будет фокусировать модель на низких, высокие частоты шума соответствуют высоким частотам картинки. На разных таймстепах разный диапазон критичных ошибок и диапазон невозможных для модели предсказаний на которые ее бессмысленно дрочить. В идеале бы это логировать и добавить автоматику которая будет клампить какой-то процент ошибок по спектру, или как-то считать дисперсию ошибок, кароч там должно автоматически настраиваться и без шедулинга, интуиция тут в том чтобы модель работала всегда в диапазоне "зоны ближайшего развития" https://ru.wikipedia.org/wiki/Зона_ближайшего_развития
>>1339843 > Выделение низких частот будет фокусировать модель на низких, высокие частоты шума соответствуют высоким частотам картинки. Ещё раз - у тебя нет там картинки, у тебя шум. Высокие частоты шума не соответствуют высоким частотам картинки. Шум который ты сравниваешь, в лоссе target - это то что из генератора шума получено. Чтобы получить картинку, утрировано тебе надо вычитать аутпут модели предсказанный шум из инпута латент + шум из генератора. Чтоб сделать то что ты хочешь надо делать шаг деноизинга в шедулере шума и сравнивать непосредственно спектры картинки, но тут ты попадёшь в похожую яму что и с wavelet - всегда будет перекос куда-то там у нас перекос потому что wavelet неравномерно декомпозицию делает и надо весами потом крутить. Тогда да, надо пердолиться с подстраиванием под timesteps на глаз. Собственно fft просто работает без пердогинга как раз потому что мы никак не взаимодействуем с картинкой и её спектрами. Лучше альфу покрути вместо 0.5 повышай до 1.0 и дальше с шагом 0.5 иди вплоть до 5.0, если хочется какого-то другого результата.
>>1339909 >Ещё раз - у тебя нет там картинки, у тебя шум. >Чтобы получить картинку, утрировано тебе надо вычитать аутпут модели Вычитание никак не влияет на спектр. Нет разницы в спектре между лоссом картинка - предсказание картинки и шум - предсказание шума.
>>1339732 >Бля, куча путанной инфы, если ты через svd это тренишь - нельзя понижать альфу. Все сломается. Если не сломалось или что-то не то делаешь или альфа не применилась. Там не просто не сломалось, там обучалось вполне корректно только мееееееедленно. Эффект как примерно взять половину от фикс лоры и половину от натренированной фикслоры. Но хуйня да.
>Дора там тоже либо вообще не нужна, либо она криво работает. Ну хотя лишней наверное не будет если ничего не проебывается. Я тут еще погонял десяток тестов без доры, оно обучается нормально, но по сравнению с включенным флагом доры это ебически медленное обучение. И ладно бы медленнее, но у варианта с дорой схватывание фич еще супер быстрое, я хз как показать, оно прямо форму базовой модели корректно шейпит независимо от скорости за несколько эпох и при этом управление промтом не теряется и ноль артефактов (кроме артефактов насыщения). Выше я предполагал что дора не нормируется никак поверх свд, поэтому я просто ебанул щас нормализацию из продижи в виде флага use_stableadamw и оно с тем же последним конфигом начало выгорать медленнее заметно. Ощущение как будто дора создает какое-то новое подпространство на основе фикслоры и обучает уже его. При этом не теряется основная генеративная способность фикслоры. Наверно стоит попробовать фикслору именно с включенным флагом доры делать.
>Посмотри еще че с весами происходит если у тебя уже фикшеный формат без доры и ты включаешь дору, на одном шаге. Да, надо проверить.
>Любой экстракт и любая модель. В методе с svd экстракт делается из той же самой модели, но тут ты берешь любой, или любую лору, так же ее фиксишь через 1 шаг и вычитаешь из модели. Опять же желательно понимать смысл действий, тогда таких вопросов не будет. Еще раз, все по той же самой схеме, только просто подменяешь экстракт другим либо готовой лорой (которые прошли фикс на 1 шаге). А, я понял, ты хочешь не обучать то что было добавлено файнтюном, а обучать именно остаток базы, которая типа не обучена.
>>1340244 >Ощущение как будто дора создает какое-то новое подпространство на основе фикслоры и обучает уже его. При этом не теряется основная генеративная способность фикслоры. Гопота на это ответила что у доры вес раскладывается на норму + направление где есть некий g (скаляр/вектор масштаба), который ничем не ограничивается при тренировке. В результате DoRA быстрее сходится, но и куда легче разогнать веса.
>>1340281 Ну да какое-то различие присутствует от доры. Вот обычный фикс лоры дает на выходе примерно 497 метр как и основной экстракт. Если прогонять шаг включив дору она увеличивается до 501.
>>1340310 Кароче фикслора с дорой и последующий мердж с диффом дали чисто шум на выходе. Если менять фикслорудору на обычную фикслору, то результат точно такой же как дифф первый с первой фикслорой.
>>1340520 Да, пришли, можно тренить не с нуля, а с чужой модели, по сути тренирую полный файнтюн ток квантованный через свд декомпоз. Про дору это чисто мой выебон.
>>1340419 Кароче сменил с адаптивного продижи на адам8бит, поставил 1e-4 и оно мне 50 эпох на константе с одинаковым насыщением (оно в говне, но нормальное говно) натренировало заебато. То есть похоже адаптивный оптим не может точно управлять весами фикслоры вместе с дорой и жестко переоценивает масштаб каждую эпоху.
>>1340545 >XL тренится на 12-13 гигах. В мечтах о сладкой жизни и с болью. Я тренил на 12 гигах фул чекпоинт со всеми мокрописями чтоб ниче лишнее не вытекало из врама - медленно (потому что агрессивные настройки поментально ломают модельку), долго (6 часов на микродатасет в 10 картинок) и так себе, на экстракте в миллион раз лучше результат выходит, быстрее и удобнее.
>>1340546 Не, если у тебя карта с прям 12 физическими гигами - сразу мимо. Оно с батчем 1 жрет 12.5-13 минимум. Если хотя бы 14 - уже имеет смысл пробовать. Я на 16 гигах пока ничего лучше тюнов не видел. Экстракт близко, но все равно на уровне напердоленной доры как по мне (и хуже экстракта из тюна).
>>1340548 > Не, если у тебя карта с прям 12 физическими гигами - сразу мимо. Оно с батчем 1 жрет 12.5-13 минимум. Это на 1024, я 896 или около того ставил, такое среднее значение, не совсем 768 кал, но и не 1024. Плюс все все все существующие мокрые писи кроме разве что зеро стейджа который не смог завести адекватно.
> но все равно на уровне напердоленной доры как по мне Вообще ни разу не похожи, смысл их сравнивать если с лорадорой у тебя нулями инициализация.
>>1340550 >Плюс все все все существующие мокрые писи На самом деле там все, что нужно - это полный фп/бф16 тренинг, кеш латентов и адафактор со всеми выключенными адаптациями в fused backwards pass. Все.
>Вообще ни разу не похожи Ну я треню в основном стили и оцениваю по переносу этого самого стиля. И результаты экстракта и доры выглядят вот прям оче похожими, но все равно не дотягивают до тюнов.
>>1340244 >Там не просто не сломалось, там обучалось вполне корректно только мееееееедленно. Ну что-то не так. Я ща проверил, в выходном файле не меняется альфа. Хотя в консоли меняется. На пике лосс сверху - альфа/2, снизу 1:1. С пониженной альфой генерирует не прям шум, но почти. С 1:1 все норм, не ломается. Так что не стоит трогать альфу.
По поводу доры. Из того что я знаю как работает сам алгоритм, мешать и ломать он не должен. Но вопросы к реализации. И надо отдельно проверять дает ли это вообще хоть какие-то плюсы в нашем случае. На дефолтной лоре дору можно как-то включить? Ликорисы включать пока не хочу, пока не все не обкатано на обычной.
>>1340281 Что делает дора - нормирует матрицу весов и записывает масштабирующие коэффициенты в отдельную матрицу-вектор. На каждом шаге если градиент меняет масштаб основной матрицы, то перенормируется и остаются только относительные изменения. Коэффициенты обучаются отдельно сами по градиенту. Какого-то хуя это не эквивалентно обычной лоре и работает лучше. Коэффициенты там по выходу матриц идут. Ну типа по каналам/нейронам.
>>1340310 >Вот обычный фикс лоры дает на выходе примерно 497 метр как и основной экстракт. Если прогонять шаг включив дору она увеличивается до 501. Что в весах на выходе? Она может или сохранить масштабные матрицы как есть, или запекать их в исходные веса. В любом случае, можешь посмотреть сами веса https://netron.app/ надо найти какой столбец/строка соответствуют одному коэффициенту и можно ручками посчитать, если понимаешь. Хотя проще наверное просто слить это все дело в одну модель, вычесть ее из исходной и в там же посмотреть нули/нормы, будет все видно.
>>1340520 >Тред дня 4 не читал, к чему в итоге пришли? А то вы как-то много написали. Есть что-то прорывное? >Или можно по-старинке тренить лоры на адамW безо всяких загибонов по типу дор и ликорисов, и проблем не знать? Ты можешь тренить обычную лору, только инициализируешь по новому методу, и она работает лучше дор и ликорисов. Почти как фулл файнтюн. Было бы фулл файнтюном если объединить с ликорисами, включить в работу все оставшиеся блоки и параметры. Лично я пока только 100% проверил на обычной лоре. Тут чел проверяет на каких-то пердольных конфигах и у него постоянно что-то ломается. Я просто делаю только то что понимаю что делаю. И пока не разберусь досконально, делать не буду. Машоб это хуйня такая, если не по готовому пайплайну идешь и не понимаешь че происходит, обязательно залупа какая-нибудь случится.
>>1340552 >И результаты экстракта и доры выглядят вот прям оче похожими, но все равно не дотягивают до тюнов. Ну так конвы в экстракт не включены. Если ты его обучаешь. А в чистом экстракте из фулл файнтюна все есть.
>>1340661 >Ну так конвы в экстракт не включены. Если ты его обучаешь. Смысле? Там же экстрактится кохаковский локон с конвами, в логах экстракта прямо об этом написано. Я тренил такой же кохаковский локон, в логах тренировки точно так же написано, что конвы там билдятся и подгружаются из экстракта.
>>1340686 >Я тренил такой же кохаковский локон, в логах тренировки точно так же написано, что конвы там билдятся и подгружаются из экстракта. И у тебя есть сравнение фулл файнтюна с обучением всего экстракта с конвами?
>>1340802 Я сравниваю с локоном-дорой с включенным нормами и скалярами, и с экстрактом с конвами. Сразу оговорюсь, что я треню нубы-люстры и анимешный стиль. Проблема с дорой и экстрактом у меня в том, что они пикают базовые свойства стиля без проблем - лайнарт, палитра, шединг, формы и пропроции. Но сосут жопу с мелкими деталями - например есть хуйдожнек который рейсует глаза определенным образом, или ногти там, или блики на коже. Вот это вот все на лорах-дорах тупо отсутсвует, похуй сколько тренить и на настройки.
>>1340552 >Ну я треню в основном стили и оцениваю по переносу этого самого стиля. И результаты экстракта и доры выглядят вот прям оче похожими, но все равно не дотягивают до тюнов. Ну стиль пиздить это вообще одного блока достаточно в сдхл, под стиль диагофта (который типа улучшенный IA3, диагональный вектор направления) вообще достаточно. Я по глубокой адаптации и инициализованная нулями лорадора ни в какое сравнение с тюном экстракта не идет, зато идет в сравнение с полновесными матрицами, что считай фуловым файнтюном, ток не надо трястись от неправильных гиперов или урезать блоки, если нищекарта, плюс можно постфактум тонко забалансить с изначальной моделью, т.к. экстракт нормирован к единице - ты только можешь снижать влияние его, это прям кайфовая фича, отрезать себе возможность крутить лору вверх, кароче недообучения нет в этом случае вообще.
>Так что не стоит трогать альфу. Да я согласен, просто у меня чешется всякую поебень проверять чтобы знать че будет.
>По поводу доры. Из того что я знаю как работает сам алгоритм, мешать и ломать он не должен. Ну он как бы по факту не мешает именно в контексте превращения экстракта в говно, но влияние от доры слишком ебет всю модель, она не ломается ниче такого, просто начинается жестко гореть (и ломать CFG, требуя его снижения, ну или в процентном отношении подмешивать к базовому экстракту) в зависимости от скорости. > И надо отдельно проверять дает ли это вообще хоть какие-то плюсы в нашем случае. Плюс тут один я заметил - очень быстрая сходимость в пределах нескольких эпох. >На дефолтной лоре дору можно как-то включить? Наверно да, это же просто алго разложения. >Ликорисы включать пока не хочу, пока не все не обкатано на обычной. Я ликорис локон катаю, в таком конфиге все ок, конвы не разъебываются никогда (на стандартной тренировке лоры я прям страдал от этого), все нормально адаптируется. А еще похоже для метода дотюнивания экстракта подходят сверхвысокие беты, ставил на 6 часов с бетами 0.95 0.999 и силкисмуз натренило мне с результом примерно к 7-10 эпохе (1000 шаг), а потом вышло на плато, с низкими бетами как-то не держится стабильно (в смысле слишком метает туда сюда по разнородному датасету). Ну и да, чем чище сигнал тем лучше, поэтому батч повыше тоже плюсиком идет. А еще надо стартовать снизкой скорости определенно, либо через разогрев, либо через адаптивный оптим с низкой стартовой скоростью. С текстовым энкодером не тренил кстати еще вообще, интересно как он себя поведет на равной скорости с юнет лр. >Что в весах на выходе? Я пытался найти различия, но состав слоев одинаковый, веса через нетрон не смотрел, могу скинуть обе, надо? >включить в работу все оставшиеся блоки и параметры. Там остаток только норм слои скорее всего (помимо конв и линейных), в ликорисах можно включить их тюн. Я не пробовал еще, но прошлый опыт с нормами говорит о том что чуть поточнее будет результат ближе к датасету. >Тут чел проверяет на каких-то пердольных конфигах и у него постоянно что-то ломается. Только дора "ломается" у меня, но так как мне в целом нравится результат с доры то я пытаюсь найти настройку которая влияет на ломание, потому что я выше писал что экстрактофикс с дорой не работает и просто так не фиксится.
>>1341380 >Ну стиль пиздить это вообще одного блока достаточно в сдхл, под стиль диагофта (который типа улучшенный IA3, диагональный вектор направления) вообще достаточно Я сильно нта, но не встречал ни одной стилелоры, которая бы не цепляла на себя тонны не имеющих отношение к стилю концептов и не разваливалась бы как брикет с торфом при малейшей попытке выйти за распределение. Стилелора - это самое сложное, что можно представить для тренировки. Возможно даже концептуально невозможное.
>>1341433 >Потому что большинство тренирующих шизов тяп ляп и в продакшен по гайду с ютубчика. Как ты их все под одну гребёнку. А по факту там есть как ребятки, тренирующие стилелоры-инвалидки на трёх порезанных картинках каждые три дня с целью остаться на плаву, так и делающие коммиты в кою под спец алгоритмы типа блоры. И не получилось ни у тех, ни у других, ни у третьих. Последний печальный пример - любимый нами всеми фурфаг, полностью заваливший стили как концепты в своей хроме. А ведь он фурфаг ебаный, он сидит на датасете из своего е621 - последнего оплота наличия стилей в бигдате как таковой. Внезапно лучшей базой для тренировки стилей оказалась полотраха, люстра только после ебейших коллективных усилий. А после отказа от клипа вообще вся работа со стилями пошла под откос. Ллмки ее окончательно добили.
>>1341949 > Как ты их все под одну гребёнку. Ты так пишешь как будто я критикую. Я просто описал факт: большинство нихуя не понимает и дедает по чужим лекалам.
>А по факту там есть как ребятки, тренирующие стилелоры-инвалидки на трёх порезанных картинках каждые три дня с целью остаться на плаву, Их большинство, хотя лучше бы делали эксперименты и писали репорты об этом на том же среддите. Я вот допустим ищу конкретные примеры обучения конкретных алгоритмов и единственное что я нахожу это скептический пост в ответ на пост о просьбе другого челика пояснить за парк о том, что ничего кроме дефолтной лоры нинужно, но ведь это глубокое заблуждение. Вот итт допустим ффт обсуждали и свд декомпоз крайне эффективный - а теперь попробуй это найти в основных хабах по тренировкам, да хера с два у тебя получится - там дрочат адам8бит и л2 на эталонных 8:4/16:8. В какой-то степени этот тред буквально одно из немногих мест где находятся на блидинг едж оф текнолоджи и что-то тестируют себе в убыток времени.
>так и делающие коммиты в кою под спец алгоритмы типа блоры. Блора это не спецалгоритм, а просто тренировка конкретных блоков/слоев есличе...
>И не получилось ни у тех, ни у других, ни у третьих. Что не получилось-то? Как ты определил? У тебя есть какой-то эталон? Может ты просто гонишься за тем, чего нет или что нереализуемо без радикального усовершенствования или дополнительных писек? Стиль это явно не такая задача.
>Последний печальный пример - любимый нами всеми фурфаг, полностью заваливший стили как концепты в своей хроме. А ведь он фурфаг ебаный, он сидит на датасете из своего е621 - последнего оплота наличия стилей в бигдате как таковой. Вижу обесценивание труда по созданию универсальной модели. Мне кажется это просто твоя личная хотелка чтобы сеточка состояла из стилей, которые должны лезть из всех щелей.
> Внезапно лучшей базой для тренировки стилей оказалась полотраха, люстра только после ебейших коллективных усилий. А после отказа от клипа вообще вся работа со стилями пошла под откос. Ллмки ее окончательно добили.
>>1341949 > на трёх порезанных картинках Для стилей больше и не надо. Можно размножить их ресайзом/кропом и норм. > лучшей базой для тренировки стилей оказалась полотраха Для аниме-стилей лучше всего v-pred. Т.е. нуб или миксы нуба. На люстре стили похуже получаются из-за сильного биаса в сторону дженерик аниме с бур, от чего стили протекают. > полностью заваливший стили как концепты в своей хроме Хрома шифт проебала где-то. Они зачем-то без шифта тренили, наверное подумали раз Флюкс сидит с шифтом около 1.0, то он им и не нужен. Но это не так, современные DiT, например тот же Ван, аж с шифтом 12.0 тренили. Делаешь лору с шифтом и всё заебись становится. Вообще flowmatch та ещё параша, все её по разному пердолят как будто просто на глаз выставляя параметры, никакой консистентности между моделями.
>>1340896 Бля, все еще нихуя не понятно. Конкретно, дискуссия была про метод с svd разбивкой. Ты его тестил или нет? Что ты называешь экстрактом?
>>1341380 >но влияние от доры слишком ебет всю модель Надо исключить вариант проеба где-то. Мало ли что туда добавили в реализацию с расчетом на обычные лоры. Масштаб обновлений? Пойду смотреть код...
>сверхвысокие беты, ставил на 6 часов с бетами 0.95 0.999 Ну для первого момента это не сверхвысокие. Если 0.999 в первом, это да, много. Второй как будто бы просто нет смысла так задирать. Еще можно в числовые ошибки упороться как раз от 0.999, наверное...
>Я пытался найти различия, но состав слоев одинаковый, веса через нетрон не смотрел, могу скинуть обе, надо? Да можешь и скинуть, если не лень. Не то что бы это сильно нужно, скорее мне самому надо проверять. А вообще, в таких обсуждениях если что-то не стандартное делаем, стоило бы полные конфиги скидывать. Ну чтобы детерминировано было. Просто тут столько слов было про то как x работает охуенно, и ни примеров ни полных конфигов обычно подобные заявления не содержат.
>Только дора "ломается" у меня, но так как мне в целом нравится результат с доры то я пытаюсь найти настройку которая влияет на ломание, потому что я выше писал что экстрактофикс с дорой не работает и просто так не фиксится. Я чет пока не могу найти как включить дору без ликорисов.
>>1341429 Проблема датасетов? Если во всех пиках есть какой-то побочный признак, лора его всегда впитает. Остальное скорее качество самой модели и качество весов лоры, но если хорошо настроил и с регуляризациями какой-никакой выход за распределение будет. Если начать жестко давить регуляризацией, победит тот признак, который больше влияет на общий лосс. Остается только обучать/резать на отдельные блоки как в билоре, в надежде что разные слои впитывают разные признаки.
>>1337893 >Фикс нойз через хеш сумму Я тут внезапно понял, что эта штука считается на батч, а не на семпл. И если размер батча больше единицы - то вся эта хуйня становится бесполезной. Потому что один семпл в разных батчах будет иметь разные хеши и разный шум соответственно. Короче нормально работать это будет только с bs=1
>>1341380 >С текстовым энкодером не тренил кстати еще вообще, интересно как он себя поведет на равной скорости с юнет лр. Потестил с TE на prodigy SF, отдельно не настраивал скорость для TE так что оно там тоже меняется по скорости относительно. Результат: прекрасно дотюнивает аккуратненько TE, никаких пережаров или чего-нибудь еще, точность генерации возросла. Даже есть геп для скорости - если увеличивать вес TE то он ломается когда больше примерно 1.5.
>>1343034 >Ну для первого момента это не сверхвысокие. >Если 0.999 в первом, это да, много. Дефолт для продигов сф 0.9 0.99, дефолт для обычных продигов 0.9 0.999, реакция по направлению при 0.95 мизерная и так получается, но я отдельно прогнал два рана c 0.999 0.9 и оно практически исключило любой шум характерный датасету (тренирую на шумном), то есть первый момент накапливает только очень чистые данные при 0.999. Понять трудно что лучше, если влоб сравнивать то вариант 0.9 0.999 в некоторых эпохах не генерирует нужное, но собирает фичи датасета в т ч шумовые характерные паттерны более охотно, в то время как 0.999 0.9 изначально держится относительно базовой генерации. >Второй как будто бы просто нет смысла так задирать. Ну он в sf прямо влияет на масштаб шагов, если тебе нужны стабильные одинаковые обновления то 0.999 имеет смысол. >Я чет пока не могу найти как включить дору без ликорисов. Взять дора код и внедрить его в модуль лоры кои. >Да можешь и скинуть, если не лень. Ок, скину щищас
>>1343573 >Ок, скину щищас О, вроде понял в чем прикол с дорой, в первый раз не заметил. Если с дорой включенной пытаться фиксить экстракт лору, то вылезает стена миссинг кеев которая дублирует все названия слоев с расширением .dora_scale Таким образом различие размеров между обычной лорой и дорой (4 мб) это различие в наличии .dora_scale , но так как они не были заэкстракчены из основной модели (это нельзя сделать), то там видимо или с нулями дрочит эти скейлы и переоценивает, либо они чето типа заглушки с неверными значениями. В дефолтном верифаере/лораинспектора дора скейлы не отображаются. В любом случае вот две лоры: https://mega.nz/folder/aFc3yA4L#qwjWn-JKFH5nbuQh39AW6Q
>>1343651 Ладно, оно все равно переоценивает дора скейл даже с 5e-6 скоростью, не так ультимативно быстро но все равно прям пердолит мощно: если фактически результат получается на первых 5 эпохах, то на 12 эпохе идет завал по цветам (хотя продижи даже не нашло оптимальный лернинг лол), но зато скорость обучения мое почтение. Надо попробовать прям мизерную скорость.
>>1343925 Ощущение как будто dim=1 выделенный для доры слишком быстро обучается, а если выставлять выше там надо код логики менять так как максимум 1...
>>1343943 Кароче dim=1 это не дименшен, а что-то связянное с осью нормы, ее изменять смысола нет. Зато понял что фактическое применение dora_scale к модели происходит в блоке def apply_weight_decompose в локоне. Так вот, ввел простейшую переменную пикрелейтед и таки да влиянием доры можно управлять. Причем вот я поставил 0.5 и влияние доры усилилось лол.
>>1344354 Очевидно что scale может быть больше 1, допустим 5. Тогда наверно нужно коэф применять к самой нормализации через scale = 1.0 + dora_strength * (scale - 1.0)
может еще заклампить надо будет, я бы вообще какую-нибудь скользящую ввел для фильтра на самом деле
>>1344354 Твой множитель 0.5 - это множитель магнитуды. С 0 у тебя просто веса доры без магнитуды, на силу доры (direction на пикриле) это мало влияет. Как раз ты убираешь магнитуду и веса доры немного увеличиваются, ты видишь увеличение силы доры. Просто в ликорисе название магнитуды выкинули. > dim=1 это не дименшен Это по какой оси будет магнитуда считаться, т.к. изначально в ликорисе была неверная ось и чтоб не ломать старые доры влепили костыль с поддержкой обоих осей.
>>1344922 >Что происходит когда ты допустим скрешиваешь 2 модели, 1 тренировалась на одиночных тегах, а другая на комплексном тексте из чатгпт? зависит от того тренировался те или нет и смотря как скрещивать, можно скрещивать по маске какой-нибудь магнитуды в DARE, можно втупую 0.5+0.5 складывать, результаты будут разные текст тренировать это типа соотносить фичи датасета с ембедингами, маленькой ллм в виде текстоенкодера в целом без разницы формат описания, она его не напрямую жрет а всячески видоизменяет для связности токены отдельные, енкодер и так сам по себе натренен нормально и в идеале его не требуется тренировать, но если тренируешь (допустим в изначальном файнтюне сильно тренировали текстовый енкодер и он что-то забыл) то ты его просто поверх под датасет и небольшой массив знаний дотюниваешь >Новая в теории лучше будет понимать промты и новые концепты? если речь про сдхл, то она не умеет в контекст и реальное взаимодействие токенов между собой - там нет т5 который за это отвечает в современных сетях, так что нет, лучше понимать не будет потому что изначально сдхл концепт-бейзд модель которая текст в векторы направления превращает и как-то их морфит
но если прямо датасет идентичен то ты можешь сделать компактную выжимку лучших признаков от обоих и в таком случае точность/качество должны возрастать, типа у тебя два различных пространства токенных соединяются в нечто среднее
Так, блять. С FFT оказывается XL больше не ломается от большого разрешения. Даже на датасете в 2560х2560 норм, наоборот становится лучше чем на низком разрешении. А с mse уже на 1536 распидорас шёл. И после тренировки генерации не пидорасит на высоком разрешении, можно сразу в 1536+ генерить.
>>1344946 Прдолжаем еблю с дорой. Предположил, что в принципе дора не может инициализировать корректные веса для себя (а она инициализировать пытается dora_scale для каждого слоя и срет мне мисинг кеями). Я сделал патч в вейт_хук, который при отсутствии в загружаемых нетворк_вейтс инициализирует их единицами (потому что дора насолько я могу понимать по концепции это и делает) на пикреле. Запустил тренинг с вкл дорой - мисинг кеев не было + получил вроде корректный лосс график (красный - вот это фикс, все остальные это мои прошлые варианты с разными формулами для лосс_скейла в других частях кода). Модель еще не чекал на вывод, щас буду делать распаковку.
>>1345399 Так. Модель получилась с обычным для лора+дора весом, но генерирует цветной шум на полном весе, но шум этот меняется по эпохам. Результат шума похож на шум как от вычитания дорафикса. Если снижать вес доралоры до 0.1 и подмешивать к изначальному экстракту, то генерирует осмысленное и от эпохи к эпохе меняется. Учитывая что лосс начался с 0.35 и дрочился на уровне 0.2 можно предположить что модель что-то опять переоценила и здесь уже явное переобучение. Выхо два - инициализировать не единицами, а нулями, либо снижать скорость на порядок для теста.
>>1345568 Кароче, путем долгих обсуждений с нейрокалами, пришел к реализации нормы путем перерасчет dora_scale, теперь он считается от нормы исходного веса слоя (W), а не W+ΔW merged. Как итог лора теперь адекватно применяется при полном весе, но дора слои все также очень быстро перетренировываются в пизду, поэтому очевидно надо клампить дору или снижать ее лр относительно остальной части сети. Наверно можно как-то через враппер lycoris.kohya реализовать, пока еще хз.
Примерно как долго на ван будет обучаться ебальник на 16гб? Лора для фото генераций, без видео. Не разбираюсь какой размер поместится, что-то ниже 512px, видимо. Обучают вообще ван на 16гб? Точно видел такие конфиги на флакс ещё давно, до сих пор не пробовал. А как долго на флакс обучается? Для сравнения, хл гонялась около часа на ~4к шагов и было заебись. Есть вариант поэтапно тренить лору на ван/флакс или хуйня выйдет? Алсо, где теперь искать селеболоры и всех тех охуенных авторов? Ну и уже вдогонку более простой вопрос, подкиньте конфиг на самую ебанутую схожесть под xl. Я не шарю за технологии, обучал много, но все на дефолтных настройках https://pastebin.com/raw/GerHkvKk, тренил на натвиз 2, генерил на нормальных моделях с дмд, получалось очень хорошо. Хочу проверить, реально ли выжать из xl больше на конфигах шарящих людей. Если есть возможность, покажите результаты.
>>1346221 > Обучают вообще ван на 16гб? Сомнительно даже со свапом. Если только длину видоса в 1 секунду делать и разрешение 240р. А так даже на 32 гигах надо блосвапами обмазываться.
>>1346221 >Алсо, где теперь искать селеболоры и всех тех охуенных авторов? В дискордах с нсфв тематикой, на хагинфейсе, у китайцев в телеге. >подкиньте конфиг на самую ебанутую схожесть под xl >Если есть возможность, покажите результаты. В смысле схожесть чего? Типа имеешь в виду копирование доскональное условного лица? Ну вообще ебанутую схожесть добиться можно за минимум времени с использованием практически любого дистиллята, который правит все огрехи шумных векторов, вот ты упомянул дмд, это как раз самый простой вариант (тренить несколько эпох и плюсить дмд) и поможет даже если ты не умеешь чисто тренировать нативную генерацию - реально для того чтобы дмд аппроксимировал нужные признаки нужно ну эпох 5-10 с практически любыми настройками и любым датасетом, главное модельку изначально не пережарить чтоб завала в шумные фичи датасета не было. >реально ли выжать из xl больше Нативную генерацию я так понимаю, ну это в принципе вопрос подготовки датасета больше и в меньшей степени сейфовых настроек оптимайзера которому нужно достаточное количество времени (порядка 100 итераций на изображение) для нахождения корректного вывода. Плюс надо учитывать модель на которой тренишь изначально, допустим бигасп дохуя знает, но генеративно сложно управляем, ему надо больше времени чтобы лора обычная не генерировала хуй пойми что (с экстрактом из бигаспа кстати в разы быстрее), натвис сам по себе чисто генерирует и ему нужно меньше, ластифай как микс из бигаспа+пироса и тонны лорок/дотюнов от автора сверху еще чище генерирует (считай кучу точных доводчиков картинки автор понавтыкал) и там еще меньше времени нужно. Ну и алгоритм тоже важная штука, локр апроксимируется быстрее чем лора-локон, лоха быстрее чем оба предыдущих, но вероятность перетрена и пиздинга всего в датасете ненужного максимальная, глора апроксимирует признаки очень аккуратно и требует просто тонну времени. Сюда же вопрос об используемом вае - стандартный вае сдхл шумный, есть вае которые чище латенты дают и на них собственно проще и быстрее достигать результат, а есть новое латентное пространство EQ VAE которое вообще наиболее точное из всех на сдхл, но требует большое количество времени для подстройки под это новое латентное пространство (дмд помогает сократить точно также путь до результата кстати).
>>1345326 Ффт реализация выше по треду всем хороша кроме того что дефолтные настройки ну прям очень сжатые и средние, вследствие чего результат получается мвльненьким, вот вейвлеты наоборот сверхчеткие но там сложно подобрать нормальные обновления чтобы не артефачило при этом. Все нейросети в один голос предлагают для ффт нормализацию, мультианал с несколькими порядками и заменить мсе в спектральной области. Я попросил накодить, они мне высрали блок дефайнов и лосс в виде класса с возможностью аж три новых параметра дрочить лол, я прогонять начал и в командной строке прям нереально жуткий лосс считается на уровне 0.6, при этом модель корректно работает и результат не в пример четче ффт в треде.
>>1348778 > корректно работает Так-то ты можешь какие угодно преобразования сделать и оно будет работать корректно, до тех пор пока в конце mse по полной матрице идёт или есть регуляризация. Что fft, что wavelet, просто шифтят на какие отличия латентов нужно больше внимания обращать. > четче ффт Альфу в fft повышай. 0.5 - это частичная трансформация, это норма что оно не в полную силу работает и похоже на обычное mse. 1.0 - полная, 2.0 - преобразование по времени, 3.0 - обратное fft. >>1348905 > вот код метода Выглядит как нейробред. По краям пидорасит потому что форму тензоров нейронка поломала решейпом и есть сравнение скаляров, а не полных матриц.
>>1348952 >Так-то ты можешь какие угодно преобразования сделать и оно будет работать корректно Я в смысле там лосс вообще своей жизнью живет и по нему не понять работает модель (услвоно выше 0.15 на стандартном говне уже распиздос) или нет. >Что fft, что wavelet, просто шифтят на какие отличия латентов нужно больше внимания обращать. Ну да, ффт вообще не ловит детальки особо, но зато стабильный. >Альфу в fft повышай. 0.5 - это частичная трансформация, это норма что оно не в полную силу работает и похоже на обычное mse. 1.0 - полная, 2.0 - преобразование по времени, 3.0 - обратное fft. По обоим значениям повышать имеешь в виду? >Выглядит как нейробред. Да, но работает прикольно, но не рекомендую.
>>1346976 >эпох 5-10 с практически любыми настройками Я пытаюсь понять. Какая разница сколько эпох? Их же хоть 1 может быть, хоть 4000. Эпоха это же ни о чём не говорящая цифра. На продолжительность и ход обучения влияет lr и шаги. Нет? >тренить несколько эпох и плюсить дмд Это какой-то метод обучения? Я просто на инференсе подключаю. С помощью дмд можно как-то ускорить и упростить само обучение, если, допустим, я знаю, что буду юзать лору только с дмд?
Я краем глаза у вас видел нахваливание то ли гипер, то ли суперлоры, лол, не запомнил термин. Так какой сейчас самый ебейший способ хотя бы для XL? Хули я опять буду переобучать как в 2023, может есть примеры свежего ебущего? Полистал треды за несколько лет, очень сложно понять, куча цифр и теории, а на тех редких пикчах, что есть - какой-то лютый кал, который по пьяни на 200 шагах можно запечь с отрандомленными параметрами. Поясните нешарящему за лучшие методики на 2025.
>>1349468 >Какая разница сколько эпох? Их же хоть 1 может быть, хоть 4000. Эпоха это же ни о чём не говорящая цифра. На продолжительность и ход обучения влияет lr и шаги. Нет? Нет не совсем так. 1. Теоретически модель уже знает все фичи датасета после первого прохода по всему датасету полностью, в том смысле что она получила все значения возможных признаков для размерности сети и записала. Но дело в том, что эти значения преимущественно определены сидом, шумовой инициализацией в конкретный момент шага и через гиперпараметры, а значит они приблизительные и ебически неточные. Все последующие эпохи каждую итерацию все лучше и лучше уточняют значения векторов (в идеале, если в пространстве признаков модель идет стройным шагом в идеальный минимум признака, в реальности модель не работает с изображением, а работает с предсказанием через понятие ошибки, то есть ты слепого скульптора бьешь за то, что он не так из камня высек фигуру человека и повторяешь это раз за разом, чисто механически/статистически он уже запомнит как делать не нужно даже не имея глаз - вот что такое обучение), в лучшем виде приходя к значению которое уже невозможно уточнить, а при этом стоп-крана у обучения нет и дальше уже модель будет переобучаться - то есть переоценивать точность параметра, который уже найден идеально. 2. Вторая неочевидная вещь: LR это не скорость изменения во времени, хотя и прямой перевод "скорость обучения", а по факту объем изменений на каждый каждый шаг. То есть лром ты не регулируешь саму скорость с которой модель достигает результата (достижение результата это по больше части детерминированный оптимайзером и лоссом процесс, поэтому у тебя плюс минус будут одни и те же временные рамки достижения результата относительно размера датасета, если не прибегать к ухищрениям, и существуют умозрительные заключения когда модель неизбежно придет к выводу - допустим 100 итераций на изображение для лора алгоритма, но тут тоже зависит и от чистоты датасета и от сложности концепта), ты регулируешь насколько сильное обновление параметра будет сделано моделью. А механика обучения такая, что модель ищет оптимальное значение параметра и с неправильным объемом обновлением параметра - лр - она может вечность ходить по кругу не попадая в идеальное значение. Прямо упрощая до понятного примера: допустим у тебя идеальное значение 0.001 для параметра, а твоя модель прямо сейчас записала значение 0.00099. При этом размер обновления у тебя 0.001. То есть модель никогда не достигнет 0.001 со скорость 0.001, она будет прыгать то к 0.00199, то обратно к 0.00099. Пример утрирован, в реальности оптимайзер может подстраивать шаг, но это неэффективно будет при неэффективном лр + надо учитывать моментумы, которые помнять прошлое. Собственно сама эпоха не говорит о результате конечно, но говорит о количестве попыток прохождения по всему датасету, но вместе с другими составными частями обучения можно предполагать где и в какой точке будет так себе результат, норм результат, лучший результат и говно. >Это какой-то метод обучения? Я просто на инференсе подключаю. Про плюсить это как раз "просто подключить" аддитивно. Но плюсить можно не только просто подключая, но еще и постфактум к модели через разные прикольные алгоритмы.
>С помощью дмд можно как-то ускорить и упростить само обучение, если, допустим, я знаю, что буду юзать лору только с дмд? Принцип дмд (и любого дистиллята в целом) в том, что это дистилят векторных путей в латентном пространстве под конкретный шедулер таймстепов, уникальность дмд в том что она обучалась по факту не концептам и фичам датасета, а процессу достижения адекватной картинки через связку "модель учитель - модель ученик", где модель учитель давала эталонные изображения, а модель ученик училась повторять когерентность изображений, у дмд лоры буквально нет знаний о концептах (они остались в остальной части юнета дмд из которого была экстрагирована дмд лора), а есть как бы знание об эталонном варианте достижения верного значения для параметра когда точно не будет генерироваться хуита. Соответственно, когда ты какое-то время обучаешь параметры своей лоры (доводишь их от состояния "че это" до "ну в принципе норм"), а потом прибавляешь к ней знания о достижении параметров ты как бы искусственно бустишь и упрощаешь обучение, не проводя само обучение. То есть в реале происходит так: у тебя в реальной модели натренирован параметр со значением 1, но дмд для этого же параметра знает, что с LCM на промежутке в 4 таймстепа у этого же абстрактного параметра должно быть значение 1.5 чтобы выдать тебе когерентный вывод на уровне изображений, которые поставлялись моделью учителем для дмд. Так что да, с помощью дмд можно ускорить обучением просто его скипнув, но только для конкретного семплера, небольшого количества шагов шедулера и с выключенным цфг.
Второй вариант это подменить/подмешать/вычленить по маске веса дмд и скормить ее основной модели, таким образом получая такое своеобразное новое более точное пространство основной модели и обучать уже на нем как обычную модель, но тут прибавится времени на стабилизацию из-за расхождения между тем, что у дмд фиксированные таймстепы и семплер, а у тебя в это время процесс обучения будет рандомным и вообще другое подаваться на вход, но в конечном итоге пространство заточенное под лцм 4-15 шагов будет обратно перепердолено в дефолтное состояние работы с любым семплером и шедулером и точность будет выше. Метод сомнительный на самом деле из-за более долгого времени обучения, но рабочий, лучше конечно добиваться подобного эффекта не на модель + дмд, а на модель + HPO/DPO/SPO, там тоже с подкреплением обучали генерировать красивое, но не для особенной связки LCM+1 цфг+мало шагов.
>Я краем глаза у вас видел нахваливание то ли гипер, то ли суперлоры, лол, не запомнил термин. Итт нахваливали свд экстракт из модели и обучении на нем (я в том числе), вместо обучения на дефолт инициализированной нулями лоре.
>Так какой сейчас самый ебейший способ хотя бы для XL? Да способов эффективного обучения немного на самом деле - обучение с подкреплением (что требует знания в кодинге и больше ресурсов), селективное обучение блоков (принцип как у B-lora), обучение на экстракте (PISSA метод, скип духоты когда лора без стабильных знаний сама ко всему приходит), обучать на новом латентном пространстве (EQ VAE), фильтровать сигнал чтобы получать меньше шума (фрактальные фильтры, edge of chaos), тренировка с EDM2 (мини сеть гайдлайнер для управления динамикой обучения) ну и по мелочи еще. Попробуй экстракт кароче.
>>1349683 >LR это не скорость изменения во времени Забыл нюансик в этой части: если ты хочешь именно ускорить обучение во времени, то тебе нужно понижать beta моментумы или вообще от них отказаться (оптимайзеры без моментумов). Но тут подводный камень в нестабильности.
>>1349683 > она получила все значения возможных признаков для размерности сети и записала У нас все модели статистические, они не умеют накапливать знания, только усреднять датасет. > шумовой инициализацией Вторая матрица в лоре не шумом инициализируется, никакого шума в лоре нет и не может быть. > стоп-крана у обучения нет Пиздец шиза. > она будет прыгать то к 0.00199, то обратно к 0.00099 У тебя никогда не будет одинаковых градиентов чтоб в каких-то циклах ходить. Ты очевидно не понимаешь как вообще автоград работает.
>>1349738 > У нас все модели статистические, они не умеют накапливать знания, только усреднять датасет. И к чему это? Весь текст про вечную подгонку параметров, а не накапливание знаний.
> Вторая матрица в лоре не шумом инициализируется, никакого шума в лоре нет и не может быть. Там не про лору, а про рандомный выбор таймстепа с процентом шума.
> Пиздец шиза. Ну сеть сама не поймет когда стопаться, в чем я не прав?
> У тебя никогда не будет одинаковых градиентов чтоб в каких-то циклах ходить. Можно симулировать, если тебе доебаться нужно.
>Ты очевидно не понимаешь как вообще автоград работает. Упрощение, знаешь че такое?
>>1349744 > сеть сама не поймет когда стопаться А сеть ничего и не обучает, лол. Градиенты считает автоград, который не может куда-то бесконтрольно параметры менять. И оптимизатор/лр тут не при чём. При статичном лр всегда тренировка будет замедляться и останавливаться в какой-то момент.
>>1349753 >А сеть ничего и не обучает, лол. Градиенты считает автоград, который не может куда-то бесконтрольно параметры менять. И оптимизатор/лр тут не при чём. Автоград только считает градиенты, он не меняет параметры. А вот оптимайзер может бесконечно менять параметры, точность фактически неограничена по модулю. >При статичном лр всегда тренировка будет замедляться и останавливаться в какой-то момент. Тренировка не может остановиться, это не предусмотрено.
>>1348951 Соединил по приколу вавелет и ффт с 0.5 силой каждый и работает хорошо очень четко и не артефачит.
Код https://pastebin.com/Sr4TtH6b Функция loss = combined_loss(model_pred, target, timesteps, alpha=0.5) Альфа в лоссе управляет вкладом от каждого лосса. alphas=[1.0] в ффт можно расписать на любые порядки например [0.5, 1.0, 2.0] для вейвлета можно поменять волну на что-то менее жесткое чем haar (от хаара постоянно видел проявление жесткой обрезки элемента в изображении, типа палец идет, хуяк по фаланге палец становится черным), но вроде не требуется, ффт сглаживает теперь
>>1349808 Погонял значится более плотно. С ффт в принципе все понятно там тюнить ниче и не надо особо, а вот с вевлетами интересно.
Haar просто в мусорку, он слишком грубый для плавных переходов и не настраивается.
Перешел сначала на db4, т.к. задача вейвлетов в этом гибриде сохранять четкость и границы и дб4 подходит, mode zero, обучается нормально, но как будто нехватает силы и периодически лезут артефакты уже другого плана (деформации, лишние конечности). Лосс ведет себя стабильно.
Почитал про mode для вейвлетов, предположив что проблема с артефактами в нем, оказалось что когда совершается операция с DWT, то свертка практически всегда выходит за края изображения и не в курсе что происходит за границами изображения. Дефолтный мод в коде на zero - заполняет нулями, что означает что теряется энергия сигнала и это может вызывать артефакты. Симметрик отражает изображение, сохраняя структуру. Периодизейшен замыкает картинку в тор, лол, что судя по всему хорошо влияет если вейвлеты используются для лосс функции (так и оказалось вроде как). Константа заполняет ближайшим значением что смазывает детали. Рефлект и антисимметрия то же самое что симметрия но с отрицательным знаком. Остановился на периодизации.
Прогнал также db8 с периодизацией, вот теперь силы вейвлета достаточно для активной адаптации и адаптация идет мощнее. Циферка рядом с волной показывает что чем больше циферка тем лучше описываются плавные структуры есличе. Обычно другие исследователи не идут дальше 8 и в принципе на всех волнах сидят в промежутке от 4 до 8, но я наверно попробую ради эксперимента повыше.
Из того что я бы хотел еще попробовать это Coiflets (так как он именно для апроксимации и градиентов, насколько я понимаю), Biorthogonal потому что это используется для апскейл моделей с суперрезолюшеном что может дать дополнительную четкость, Mexican hat (потому что используется в моделях с детектом объектов, но сдхл не работает с изображениями и непонятно как мексшляпа будет вести себя со слепой сетью), cgau, cmor, shan, fbsp какая-то заумная хуйня с фазовым сдвигом и амплитуде, теоретически должно давать стабильность, может быть интересно.
Еще в библе вейвлетов есть два других класса DWTInverse и SWTForward: если DWTForward раскладывает сигнал на лоупас и хайпас, то инверс наоборот собирает из лоупаса и хайпаса картинку, понятия не имею имеет ли смысл пробовать в контексте того что у нас тут картинка собирается только на инференсе, то есть в идеале форвард и инверс должны вместе работать и их точность проверяют типа "изображение должно собраться после инверса в то что было до форварда - тогда это типа корректное разложение и корректная сборка"; а SWT просто не уменьшает размерность вейвлетов при разложении - то есть каждый уровень имеет тот же размер изображения что и предыдущий. Звучит как "ноль потерь", но очевидно требует больше ресурсиков скорее всего и num levels автоматически накладно будет считать и придется выбирать самому. Но в целом судя по обсуждениям в SWT смысла нет, в крайнем случае можно stride=2 на stride=1 поменять и тогда dwt не будеть уменьшать свертки допустим с 8 до 4, а всего с 8 до 7, но прироста качества ебического не происходит судя по всеми и DWT с понижением размера хватит всем, поэтому наверно не буду тоже трогать.
Еще в коде челика из треда level_weights = compute_weights(timesteps, 350, 0 указаны 350, это я так понял что-то типа окна внимания, чем оно меньше тем больше акцент на одном уровне, чем больше тем больше акцента на большем кол-ве уровней. Я помню вроде он писал что вручную подбирал это значение, и по факту это типа мягкого баланса. Но так как тут еще ффт используется вероятно можно и пониже поставить значением чтоб больше акцентировалось на детальках, но в принципе и так пойдет. А еще тут нет нормализации, что могло бы помочь в ситуации если level_weights растёт слишком быстро.
Ну и еще можно MSE на L1 или чето еще переделать, т.к. мсе мылит.
По итогу я могу скозать что комбинация из ффт и вейвлета работает просто отлично. Ффт одиночно слишком осторожный на любых порядках и сильно мылит и не схватывает детали, а вейвлет как раз решает этот недочет. Возможно даже стоит снизить влияние ффт до 25%.
>>1351444 >Mexican hat >cgau, cmor, shan, fbsp какая-то заумная хуйня с фазовым сдвигом и амплитуде, теоретически должно давать стабильность, может быть интересно. А, так они не дискретные получается. Тогда не буду вообще трогать.
>>1351444 С инверсом можно интересную штуку провернуть кстати, вот мы делаем предсказание на форварде, а инверсом должны получить примерно те же коэффициенты, а если не получается, то дополнительно штрафуем за ошибку в инверсе. Такая двойная проверка на точность.
>>1351444 Проблема wavelet ещё в том что он шарпит без причины. Это особенно видно на лайне в аниме, когда он делает лайн чётче, но он совсем не похож на тот что в датасете. Чёткость не всегда хорошо, с ней на XL нет особых проблем.
>>1351504 >Проблема wavelet ещё в том что он шарпит без причины. Для этого можно взять менее жесткую волну и увеличить влияние ффт. >Это особенно видно на лайне в аниме, когда он делает лайн чётче, но он совсем не похож на тот что в датасете. Не знаю, не тренирую онеме особо. Есть тестовый датасет с анимехуйней одного художника, оно нормально признаки на вавлетах собирало в т ч лайны, особые глаза и текстурки, но там не экстракт был а обычная лора, а я щас только экстракты тереблю. Могу попробовать экстрагировать нуба и погонять если надо, оно все равно моментально тренит. >Чёткость не всегда хорошо, с ней на XL нет особых проблем. У меня как раз проблема с четкостью в том что она не собирается на тестовых датасетах без вейвлетов. На шумных датасетах так вообще практически нереально без вейвлетов чето получить четкое или без артефактов.
>>1352452 >0.95, 0.99 ток тут нюанс есть, что в тексте у них кейс с ллм был, а у нас тут картиночки+клип и такие настроечки ставят крест на эффективной тренировке с текстовым енкодером, т.к. он не будет поспевать за обновами и встрянет, надо или такую же бету как б1 чтобы синхронизировать обновления обоих групп, или меньше, или не тренировать ТЕ вообще (вариант с занижением лернинга у ТЕ не рассматриваю, хрен попадешь в эффективный)
>>1272560 (OP) Как в Stable Diffusion, во вкладке Deforum, работать с фото? У меня стоит всё по стандарту, выдало рандом фотки, и сгенерировало это видео. Как с фото работать и оживлять? Как генерировать нормальные видео с рандом фото? По моему, на этом видео - каша какая-то. Может, нужно настройки настроить? Скажу сразу... Нейронка запущена на сервере. Не на моём железе.
Хочу глубже изучить Комфи. Не то как устанавливать, в менеджере копошиться и ноды призывать, а хорошо шарить за параметры, фреймворки и архитектуру. Нормальных гайдов на ютубе не нашел, там как раз буквально каждый 2 часа размусоливает элементарную хуйню. Так что подкиньте какой-то ультимативный мануал или может статью на хабре. Что угодно чтоб начать шарить
>>1360923 >>1360928 >Что тебе ещё надо? Ну желательно книжный/статейный формат с концентрированной важной информацией. Код нод курить попахивает аутизмом.
Неделю назад например мне на глаза попалась шпаргалка по LLM (для нубов). Я засел ее читать. От чтения начали появляться вопросы. Вопросы я уже начинал гуглить и узнавать у нейронок отдельно. Вот только после такого формата чтива у меня и сформировалось понимание как ллм работают. И это кайф.
Какого хрена у меня комфи ноды не ставит? и портативный и установленный, грузит почти все ноды, кроме одной, если сам лезу через гит ставить в кустомнодс, то ошибки лезут потом после запуска и не запускается, ну и дурка блять
>>1351444 В общем репортирую дальше. У меня очень сложный датасет - шумный, не нормированный, кепшены с хуман лангвиджом. Решил попробовать метод стейджинга, когда какая-то часть обучается на одних настройках, а потом переключается на другие и дотренивается и так хоть сколько раз. Предположил, что смена волны у вейвлет части лосса будет хорошим вариантом стейджинга. Значится, первые 20 эпох (до первого майлстоуна по скорости на продижах) тренировал на FFT+DB12, далее переключался на FFT+BIOR6.8 (биор потому что это деконструкция-реконструкция, то есть два вавлета фильтра в одном с разной функцией, для картиночек хорошо себя показал). Результат оказался впечатляющим на моем датасете: практически нет артефактов, натурально выглядящие генерации, следует промту просто отменно (притом что лернинг у те выставлен в 0.001, т.е. 1/100 от скорости обучения юнета). При этом если отдельно тренить и чекать вышеобозначенные конфигурации, то они по отдельности немного посасывают, то есть где db12 там пластик, где биор в принципе неплохо получается но грязновато чтоли, а если их чередовать то как бы берется лучшее от каждого конфига. Тренирую естественно на экстракте, получается натуральный эффект полного файнтюна без потери основной генеративной способности.
Минусы: надо передергивать модельку для продолжения тренировки в нетворк вейтсах; без использования оптимов без определения майлстоунов непонятно откуда начинать второй стейдж (на продижах проще, там эффективный лернинг рисуется и видно где он перескакивает на следующий уровень), но в целом можно наверно любую эпоху брать т.к. я стейджил рандом на другом датасете и оно тоже работало с таким же эффектом; лосс буквально ничего не показывает дельного, он растет и где-то там наверху стабилизируется как на пикриле, при этом генеративные способности улучшаются по итогу, вероятно рост это изза режима periodization, но как я уже писал он лучше для картиночек и нужно смириться.
Вопрос остается только в том какой вейвлет брать для первого стейджа. Если че дублирование двух одинаковых вейвлетов DB улучшения модели не дало при стейджинге, я проверил.
Странный у вас тут тред, за всё время почти ни одной картинки, сравнений, одни графики. Походу, шарите за эту хуйню. Тогда что можете сказать за вот эти графики? Вообще все замечания, которые можете считать по одному только графику: какую эпоху оставить, какой параметр не тот, почему график именно такой, а не другой, что это значит и как сделать иначе, и так далее. Это лора на xl, одинаковый датасет на разных моделях.
>>1369455 > Тогда что можете сказать за вот эти графики? Это юзлес метрики. Лр просто визуализирует паттерн шедулера. Единственное что может показать лосс - не уебалась ли модель (неконтролируемый рост). Даже рост лосса при определенных условиях не говорит о том, что модель не сходится.
>Вообще все замечания, которые можете считать по одному только графику: >какую эпоху оставить, Такую, где генерирует, не забивая основную модель. >почему график именно такой, а не другой, что это значит и как сделать иначе, и так далее. Графики лоссов напрямую зависят от функции лоссов. А функции лоссов никогда не дадут одинаковый график на разных моделях, потому что это разные модели.
Кароче у ффт мультипорядок же может быть, но дело в том что если усреднять порядки втупую (ну там 0+0.5+1.5/количество и так далее), то модель очень быстро теряет понимание промта, видимо из-за того что градиенты получаемые размываются. Так что я предположил что конкретный угол ффт для батчей лучше будет, потому что фиксированный порядок 1 и 2 так и дает лучше результ и от текста не отвязывается. Так что я улучшил код FFT, теперь он зависит от зашумленности и фиксирован для таймстепа. Пока проверил прямое отношение где 0 таймстеп соответствует 0 градусу ффт а 1000 периоду 2 (не помню чему в градусах равно, помоему инверсии на 180 градусов) что является обратной идеей где малые timesteps - выбираем alpha ближе к 1–2 (частотная область, структура), большие timesteps - выбираем alpha ближе к 0 (временная область, модель учится на деталях и пикселях). Вроде работает, получилась хорошая модель по выводу на датасете достаточно быстро.
Соответственно если надо чтобы была классическая идея где 0 - пиксели, а углы до 2 - структура, то надо инвертировать код в части, но я это еще не гонял alphas = alpha_min + (1 - t_norm) * (alpha_max - alpha_min)
Анон выручай. Начал вкатываться в SD через ComfyUi. Решил попробовать обучить лору. Нашел на варик с использованием workflow и custom nodes от kaiji. Поначалу на моей 4070ti 12gb выдавало OOM, что ожидаемо. По совету с реддита поробовать включить block swap чтобы нагрузка скидывалась на проц и оперативку. Однако тперь у меня вот такая ошибка:
Error Details Node ID: 107 Node Type: InitFluxLoRATraining Exception Type: torch.AcceleratorError Exception Message: CUDA error: resource already mapped Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
Я ваще нихуя не понимаю в проге. Мой предел - установить зависимости и гит клон с пип инсталлом.
File "C:\ComfyUI_windows_portable\ComfyUI\execution.py", line 315, in get_output_data return_values = await _async_map_node_over_list(prompt_id, unique_id, obj, input_data_all, obj.FUNCTION, allow_interrupt=True, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb, hidden_inputs=hidden_inputs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\ComfyUI_windows_portable\ComfyUI\execution.py", line 289, in _async_map_node_over_list await process_inputs(input_dict, i)
File "C:\ComfyUI_windows_portable\ComfyUI\execution.py", line 277, in process_inputs result = f(inputs)
File "C:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-FluxTrainer\nodes.py", line 634, in init_training training_loop = network_trainer.init_train(args)
File "C:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-FluxTrainer\train_network.py", line 671, in init_train unet = self.prepare_unet_with_accelerator(args, accelerator, unet) # accelerator does some magic here
File "C:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-FluxTrainer\flux_train_network_comfy.py", line 492, in prepare_unet_with_accelerator accelerator.unwrap_model(flux).prepare_block_swap_before_forward() ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^^
File "C:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-FluxTrainer\library\flux_models.py", line 1000, in prepare_block_swap_before_forward self.offloader_single.prepare_block_devices_before_forward(self.single_blocks) ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^
File "C:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-FluxTrainer\library\custom_offloading_utils.py", line 210, in prepare_block_devices_before_forward weighs_to_device(b, "cpu") # make sure weights are on cpu ~~~~~~~~~~~~~~~~^^^^^^^^^^
File "C:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-FluxTrainer\library\custom_offloading_utils.py", line 91, in weighs_to_device module.weight.data = module.weight.data.to(device, non_blocking=True) ~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^
>>1371261 Побробуй убрать ноды киджая. А вообще тренить Флюкс на 12 гигах - это хуёвое занятие, сиди на SDXL. >>1371311 Он всё правильно делает. Лучше уж в Комфи, чем в говне кохи. В Комфи можно быть уверенным в реализации моделей и самого кода тренировки, в отличии от кохи. Если уж советовать, то вот это хотя бы, где поменьше костылей - https://github.com/kohya-ss/musubi-tuner
Я вообще подумываю переписать свой код тренировки под Комфи, когда релизнут нормальный DiT, чтоб не ебаться с реализациями моделей для тренировки. Модульность Комфи для этих дел очень кстати, ничего гвоздями не прибито. И для экспериментов должно быть удобнее, сейчас я постоянно код передрачиваю и в конфигах куча давно неиспользуемого функционала, а ещё постоянно в коммиты лезу посмотреть что я месяц назад делал. Вынос в ноды должен решит эту кашу.
>>1371168 > порядки > угол ффт > ря пук пук хрюк фазовые порядки сдвига указываются как альфа в ффт, вычисляются из пи окружности, то есть альфа 1 это то же самое что угол сдвига π/2, равный 90 градусам, альфа 2 это просто π, то есть 180 градусов, в ффт не цельные значения альфы дают смешение между временной областью и частотной што не так с тобой?
>>1371415 > фазовые порядки сдвига Это с тобой что-то не так, т.к. ты даже не понимаешь что там вращается. Ты даже не понимаешь значение слова фаза. Там ничего не сдвигается, там вращение во временно-частотной плоскости комплексного числа. Ознакомься с этим, чтоб понимать что значит вращение: https://ru.wikipedia.org/wiki/Корни_из_единицы И потом чем отличается FFT от дробного FFT. И не транслируй сюда ЖПТ-бред. То что ты выше сделал - это применяешь вообще разные преобразования к разным timesteps, потому что не понимаешь на что угол влияет и что альфы 0-1 и 1-2 - это разные преобразования, а не "сдвиг" одних и тех же.
>>1371458 >Это с тобой что-то не так, т.к. ты даже не понимаешь что там вращается. почему же? там вращается по сути аналог окна внимания, который альфоуглом настраивается на определенные частоты и анализирует силу частот в сигнале. Ффт это же спектральный анализатор просто, крутишь сдвиг - получаешь оценку спектра. >Ты даже не понимаешь значение слова фаза. Ну смотри у нас есть условный пи пополам, определяет структурный период, период может считаться фазой >Там ничего не сдвигается, там вращение во временно-частотной плоскости комплексного числа. >Ознакомься с этим, чтоб понимать что значит вращение: https://ru.wikipedia.org/wiki/Корни_из_единицы Это никак не противоречит. >И потом чем отличается FFT от дробного FFT. Ну один фиксированный, второй как настроишь, в чем проблема? >То что ты выше сделал - это применяешь вообще разные преобразования к разным timesteps Да схуяли разные. Если ффт это спектральное представление, то низкие частоты = общие формы, высокие частоты = детали, текстуры, это как в эквалайзере фильтров накинуть и отдельно бочку слушать. Вот у нас есть зашумленное и расшумленное говно, при нулевом градусе без сдвига анализируется шум сам по себе, при расшумленном анализируется инверсия чтобы модель не залипала на один тип сигнала, какойнибудь таймстеп 500 анализируется на пи пополаме, где есть как шум, так и важные данные при обычном фурье. Все же логично, более универсальное представление. >потому что не понимаешь на что угол влияет и что альфы 0-1 и 1-2 - это разные преобразования, а не "сдвиг" одних и тех же. А я не спорю, просто оно работает.
>>1371413 Sdxl норм было, хочу на flux. Посоветуй че вместо kijai, просто щас нет возможности оплатить сервер, так что хочу попробовать на своём пк. Если есть соображения из за чего кудо ошибку выдаёт - дай знать
>>1371496 > настраивается на определенные частоты Нет. Ещё раз - ты не понимаешь что там вращается, спектр там везде полный, это не wavelet. Никакого сдвига частот нет. > ффт это спектральное представление Только вот альфа никак не влияет на этот спектр. Она влияет на комплексное число результата - плоскость, в которой компоненты комплексного числа за что отвечают. На выходе у тебя всегда полный спектр без сдвигов. Для частотного анализа надо на сам тензор выхлопа маску накладывать и не забывать что там есть отрицательные частоты, инвертированные по фазе, пикрил как выглядит любой выхлоп FFT, на входе было обычное фото.
В сд треде во мне задетектили какого-то из их шизов и не хотят общаться, спрошу тут - работает ли негатив промпт на квен имадже с лайтнинг лорами? По идее не должен, цфг 1 же. Как тогда заставить его работать? Для вана есть NAG нода, по квену что-то совсем нет инфы. Спрашиваю в контексте комфи
>>1373439 А можно поподробнее? Я видел эту ноду в темплейте квен эдита, но нифига толком не нагуглил, что она делает. (А в обычном квен имедж ноды этой нет). У нее же тоже параметр есть, каким его выставлять?
Сап, вкатун в треде, есть 2х 3090, хочу начать с Масуби и Квена. Гугл выдает какую-то непонятную хуйню, гайды и гуи конкретно для Вана 2.1. Можете ткнуть в нормальный гайд?
>>1387741 Какой тебе гайд нужен? Открывай документацию к твоему говну и читай, в musubi есть туториал. Алсо, сразу имей в виду что квен от лор лучше не станет, такое же мыло будет всегда.
>>1387770 Есть воркфлоу для конкретно Вана пикрил, а я хочу универсальный воркфлоу, чтобы я мог генерить одной хуйней под разные таргеты (Квен - просто для начала).
Попробовал эту хуйню: https://github.com/1038lab/ComfyUI-JoyCaption С "рекомендованным" квантом Q4_XS. Но она в половине случаев начинает повторяться, уходить в диалог сама с собой, несуществующие ватермарки описывать. Более жирные кванты в этом плане лучше будут, или модель сама по себе днище?
>>1389378 >"рекомендованным" квантом Q4_XS >рекомендованный >ещё и Q4 Кретинизм. Удали нахуй квант и даже не пытайся, это неюзабельный мусор. Те же проблемы ловил. Этот говнодел, когда запилил поддержку ггуф, сломал нормальную версию, не грузилось, люди жаловались, а он тупо отмечал ишью закрытыми, вместо того, чтобы выяснить где несовместимость. Работает только на какой-то особой комбинации библиотек. Обновишь торч - есть риск сломать эту ноду. А вот настройки со скрина ни единого раза не обосрались, гоняю уже достаточно долго. Охуительная модель.
>>1387741 Короче нашел вот эту сборку - https://kemono.cr/patreon/user/83632369/post/137551634 , запустил для Квена с разрешением 1328x880, 2 видюхи оно отказалось сходу принимать, ну хуй с ним думаю попробую с 1й, и оно 2 часа висело на Denoising steps, потом выдало epoch is incremented. current_epoch: 0, epoch: 1 и сгенерило 1 сэмпл. Память и лоад у 1й видюхи причем полностью забита, но она не греется. Я где-то проебался, или так и должно быть?
>>1393066 Я все-таки точно где-то проебался, тк оно повисело и выдало steps: 0%, т.е. вестимо эти 2 часа оно не эпоху тренило, а генерило 1 сэмпл ДО тренинга, который в норме можно сгенерить за минуту.
>>1393070 Пиздец как я же я ебал рот этих питухонщиков. Как оказалось висело оно тому що автоматом мусуби не может оффлоадить то что не влезает, это надо методом тыка указывать самому. Дальше оказалось что с оффлоадом оно падает после каждой эпохи с включенным квантом на ходу (а в уже готовый квант оно не умеет). Я целый день безуспешно проебался с всевозможными настройками, в итоге оказалось что это из-за генерации сэмпла, пришлось ее к хуям отключить. А чтобы пахало на 2 видюхи пришлось ставить на ВСЛ, ибо под винду питухонщики почему-то решили не делать параллелизм.
Что получилось в результате: база оригинальный бф16 Квен, тренинг в разрешении 1328, 83 пика в датасете х 20 эпох, 24/60 слоев оффлоад, лора ранк 32/альфа 16, вес 500метров
= загрузка гпу 83%, тренило ~2.5 часа. Кто-нибудь шарит - это хуево или так и должно?
>>1395116 > ибо под винду питухонщики почему-то решили не делать Так много про что можно сказать, поэтому линукс или в крайнем случае всл предпочтительнее >>1395351 Чекай снизу https://en.wikipedia.org/wiki/CUDA начиная с GPUs supported. CUDA SDK и Compute capability разные вещи
>>1398421 > флоуматч > XL Звучит как будто кто-то забыл принять таблетки. Собственно результат видим - ни одной генерации без артефактов. > Вопрос: как он ето сделал? Так же как впред из епс делали - просто поменял формулу вычитания шума и тренил пока каша не прошла. Так-то флоуматч - это упрощённый епс.
>>1398538 > у автора Так он сам пишет в описании что говно получилось. Похоже даже хуже прошлых всратых бигаспов. Да и судя по тексту он сам не понял что делает, просто поменял есп на флоуматч, думая что получит что-то хорошее как в DiT, лол.
>>1398421 Кароче сам разобрался, сделал форк сдскриптов и теперь с сдхл работает флоуматч в векторфилде. Естественно ни о каких едм2 и прочих приколах с шумом смысла думоть нет больше - они не работают с флоу и не нужны теперь, пока гоняю на стандартном l2 в качестве лосса, тренирует шикарненько, промт адхеренс у бигаспа2.5 и так топовый, а теперь еще и под микродатасет качественно подстраивается. В качестве вае еще брал кохаковский для второго рана, тоже нормально, моментально подстраивается к нему в отличие от епс чекпоинтов. Олсо флоу как будто имеет больший потолок для шага, 1e-5 для епс преимущественно потолок всегда, а для флоу я уже и 1e-4 поднимал. Еще интересно что флоу вообще почти не ломает текстовый енкодер на той же скорости что если юнет тренить. Кароч прикольная игрушка получается, еще бы можно было бы любую епс модель быстро передрочить в флоу вообще бы сказка была, надо попробовать какую нибудь модель так понасиловать.
>>1400085 > промт адхеренс у бигаспа2.5 и так топовый У него ванильный клип. Ты там на самоподдуве фантазируешь или просто тред траллишь? Да и не будет продолжения этого неудавшегося эксперимента.
>>1400543 >У него ванильный клип. И че? Его специально не трогали. И промт адхеренс это не "вот щас натренируем те и как скакнет понимание" - в этом нет смысла ибо нет таких мощностей нормально додрачивать клип у манятренеров, а про общее следование промту. Шумовой предикшен сасирует по промт адхеренсу у сдхл и с момента появления сдхл весь тренинг строится вокруг концепт бейзд тренировки всегда, флоу предикшен гораздо лучше в этом плане без наличия т5, пикрел кароч. >Ты там на самоподдуве фантазируешь или просто тред траллишь? Ты бля заебал демагогию разводить по каждому завозу по тематике. Я по факту говорю, что следование промту у флоу бигаспа лучше, не говоря уже об общем качестве гена относительно семейства моделей и реалистиков. Если тебе не нравятся чем-то эксперименты, которые улучшают сдхл, - твои личные проблемы, рекомендую схлопнуть ебучку и не вонять. >Да и не будет продолжения этого неудавшегося эксперимента. Дада, чмоха с двачей обесценивает чужой труд, класика.
>>1400577 Прикольно, но трейн скрипты чет переусложнены по параметрам мне кажеца. Я проще сделал спиздив из флухсд3 скриптов куски с флоу обжектив.
>>1400708 > Я по факту говорю Ты припизднутый? Похуй что чмондель с двачей говорит, автор бигаспа пишет что следование промпта говно вышло. Нахуй ты фантазируешь, в цветные кубы любое говно умеет, флоуматч тут не при чём. Я уже молчу про качество генераций. Весь тред со своим восторженным говном засрал. > чмоха с двачей обесценивает чужой труд Опять же, чмоха с двачей тут ты, потому что это автор бигаспа сам пишет что ему не понравился результат и не будет продолжать.
>>1400722 >автор бигаспа пишет что следование промпта говно вышло Ты бля хлеб чтоли английский язык не бум-бум? Давай переведем вместе че он пишет:
Замораживание кодировщиков текста — это одновременно и благословение, и проклятие. Сохраняя кодировщики текста в замороженном состоянии, они сохраняют все свои знания и надежность, полученные в результате их первоначального обучения. Это очень полезно и выгодно, особенно для таких экспериментов, как мой, которые не имеют такого масштаба.
Минус в том, что без их настройки сильно страдает оперативное соблюдение. Версия 2.5 страдает от большого количества путаницы, например, когда видишь «бусины пота», а затем генерируешь нить бусин вместо пота.
Так что это компромисс. И с замороженными кодировщиками текста, версия 2.5, вероятно, не сильно выигрывает от улучшений JoyCaption Beta One
То есть проблема только в том, что есть путаница при использовании нестандартного промтинга, что бля и так очевидно (это как требовать у базовой сдхл рисовать кумящие пенисы и пусси а получать кошек с огурцами) и решается парой эпох дотрена первых слоев те нахуй. Из мухи слона делаешь кароче. >в цветные кубы любое говно умеет, флоуматч тут не при чём Я предполагал что у тебя будет врети, так что давай придумай задачу сам для флоу решение которой тебя устроит и ты не будешь визжать. >Я уже молчу про качество генераций. Ну и чем тебя качество генераций не устраивает в галерее? >Весь тред со своим восторженным говном засрал. Ну не анимекал в виде лор тренировать и засирать любые поплзновения в сторону улучшения сдхл же. >чмоха с двачей тут ты, Обесценивающая чмоха с двачей спок, это не я тут оверкритицизм развожу непонятно ради чего. >потому что это автор бигаспа сам пишет что ему не понравился результат и не будет продолжать Какая разница что ему понравилось или нет и будет он продолжать или нет, если это уже рабочая модель сделанная на огромной дате с хуй знает сколько эпох и ее можно выдрочить куда угодно как угодно самолично. Реально бля ты как не аи ентузиаст, а залетная чепуха пришедшая на тенсорарт покумить с мастерипись.
>>1400708 > флоу обжектив Это одна строчка кода, что ты там дрочишься. Вот сюда воткни такое: target = noise - latents Это всё отличие от esp при тренировке. Шифта в бигаспе не было, судя по всему. Либо можно вот так делать noisy_latents - model_pred * timestep и loss считать от чистого латента, а не шума, я на Хроме так делаю, чуть получше результат, чем с обычным таргетом. >>1400733 > можно выдрочить куда угодно как угодно самолично Лол, удачи победить шакалы флоуматча, которые даже на DiT невозможно победить, особенно без задранного шифта до 5+. Хрома/Люмина/ПониV7 тому подтверждение. На этом бигаспе мы видим абсолютно тоже самое, надо хотя бы как на квене перетренивать с шифтом и другим обжективом. На ване/квене, кста, уже отказались от ванильного флоуматча, хотя даже с допиленым проблем хватает. Флюкс литералли единственные кто смог без шифта с ванильным флоуматчем нормально натренить, все остальные попытки провальные, видимо у Блэкфореста что-то необычное было.
>>1400733 > когда видишь «бусины пота», а затем генерируешь нить бусин вместо пота Это и есть хуёвый промптинг. > придумай задачу сам для флоу решение которой тебя устроит Флоуматч тут не при чём, причём капшены. Но для начала можно было бы двух людей сгенерить без смешивания описания, это минимум для любой модели на Т5. Как максимум суметь текстом часть объекта затолкать туда, где его точно не было в датасете, это тоже довольно простая задача для всех кроме SDXL. Что-то сверху/сбоку чего-то - это то что в датасете повсюду есть, JoyCaption всегда приписывает направление. Попробуй банально руки положить текстом куда-то кроме очевидных мест типа hands on hips и сразу фейл будет.
>>1400825 > не было в датасете Будущее за edit-моделями. Уже сейчас тренировка на персонажей не нужна, достаточно референса и по нему нагенерит всё. С edit-моделями и проблема датасетов пропадает - если надо натренить на то что модель не знает, то берём пикчи и этой же моделью удаляем наш концепт с фото, а потом треним в обратную сторону его добавление, и теперь модель знает его, не запоминая ничего лишнего.
>>1401425 Нужной точности без тренировки скорее всего добиться не получится. Плюс концепты, которая модель просто не понимает, будут очень сильно страдать при работе с референса.
>>1400743 > Это одна строчка кода, что ты там дрочишься. Вот сюда воткни такое: target = noise - latents > Это всё отличие от esp при тренировке. В смысле все, еще дикретный эйлер нужен.
> Шифта в бигаспе не было, судя по всему. Шифт на 1 там был стандартный, у булволского нуба 2.5.
> Лол, удачи победить шакалы флоуматча, которые даже на DiT невозможно победить, особенно без задранного шифта до 5+. О каких шакалах речь то? А то я не наблюдаю ничего экстраординарного.
А если шифт задирается то это же просто больше внимания на структуру (меньше деформаций) -> меньше внимания на детали, у флоу нет стадии детайлинга же как в епс. В конктексте неких шакалов я так понимаю ты имеешь в виду структурные артефакты чтоли
>>1400825 >Но для начала можно было бы двух людей сгенерить без смешивания описания Так, или опять не подходит? >Попробуй банально руки положить текстом куда-то кроме очевидных мест типа hands on hips и сразу фейл будет. Не совсем понял юзкейс, в смысле неочевидные места рук? Так?
>>1402889 > эйлер При тренировке не используется семплер. В diffusers он называется "шедулер", там совмещён семплер и шедулинг, поэтому ты видишь FlowMatchEulerDiscreteScheduler в коде тренировки. Всё что из него используется - получение timesteps и добавление шума к латенту. Всё остальное для инференса. > О каких шакалах речь то? О текстурной бедности и мешанине в мелких деталях. С флоуматчем ты не можешь просто взять и сдвинуть сигмы. Тренить концепты может и лучше, но при инференсе у тебя всегда компромисс.
>>1402933 >При тренировке не используется семплер. В diffusers он называется "шедулер", там совмещён семплер и шедулинг, поэтому ты видишь FlowMatchEulerDiscreteScheduler в коде тренировки. Всё что из него используется - получение timesteps и добавление шума к латенту. Да я в курсе, там так и берется у меня FlowMatchEulerDiscreteScheduler из sd3_train_utils. Я про то что его прописать надо для корректности, унификации и повторяемости. >О текстурной бедности Пример будет? А то я могу щас запостить как текстурки кожи из датасета с легаловскими бабами спиздило вместе с венозными рисунками. >мешанине в мелких деталях Ну тут скилишью в настройках тренинга и настройках инферирования. Пиши пример в каком месте и при каких условиях тебя не устраивают детали.
>>1402924 >Так, или опять не подходит? Если че на пикчах мой дотрен под шумный датасет на один специфический концепт. Вот допом на пик 1 дефолт ген бигаспа2.5 с его вае, пик 2 рандом эпоха дотрен на чистом датасете чтоб дотюнить баб + eq спейс.
>>1402947 > Ну тут скилишью Несомненно. Только он у всех, а скорее всего у того кто флоуматч придумал. И рандомный васян явно не сможет то что умные люди не смогли. Тем более на древнем UNET. Не существует в природе моделей на флоуматче, умеющих контролировать детализацию при инференсе. Только тренировкой. А ведь это даже полтораха могла на esp. Это классика флоуматча - ты не можешь размылить мыло или сделать мыльно на перешарпленной модели. Даже Дали и потом жпт/сора имеют один и тот же стиль перешарпа/шума и неспособны сделать чистый градиент без мусора, а Квен не может без тренировки сделать реалистик как Флюкс.
>>1402986 Зачем в 2025 году XL трогать, когда на любом говне нормальные модели запускаются с квантами? Не уметь в руки в 2025 должно быть стыдно. Алсо, у тебя азиатки текут из датасета.
>>1402992 >реалистик как Флюкс как будто флюх может в реалистик >Только он у всех, а скорее всего у того кто флоуматч придумал. И рандомный васян явно не сможет то что умные люди не смогли. Тем более на древнем UNET. Не существует в природе моделей на флоуматче, умеющих контролировать детализацию при инференсе. Только тренировкой. А ведь это даже полтораха могла на esp. Это классика флоуматча - ты не можешь размылить мыло или сделать мыльно на перешарпленной модели. Так это ж хорошо - ты получаешь конкретный дотрен под дату, а не отсебятину модели которая накручивает детальки, буквально эталон для правила "говно на входе - говно на выходе". А так куолити мокрописями можно крутить посттренировочно.
>Зачем в 2025 году XL трогать Огромный парк мокрых пись, огромный парк файнтюнов, быстродействие, возможность тренировать всю модель целиком или симулировать полную тренировку на говнокарте, для людей кароче. >когда на любом говне нормальные модели запускаются с квантами? Смысл от них? >Не уметь в руки в 2025 должно быть стыдно. Но сдхл умеет в руки, хочешь погенерирую тебе руки, фетишист? >Алсо, у тебя азиатки текут из датасета. Не текут. Ты азиаток не видел чтоли?
>>1403028 > мокрых пись Литералли единственная причина, но судя по /nf/ даже она уже отпала. Необходимость файнтюнить на каждый пук - это огромный минус. > Но сдхл умеет в руки, хочешь погенерирую тебе руки, фетишист? Я уже вижу мутантские отростки на твоих пиках вместо них, не надо больше, я не фанат бодихоррора. > Не текут. У тебя в прошлом посте латинка превратилась на половину в то что ты сейчас показываешь. Хуёво если ты не видишь этого, наверное просто уже привык к дженерик лицам XL и не отличаешь их.
>>1403028 > как будто флюх может в реалистик Как будто Флюкс это одна модель. SRPO может в такой реалистик, что XL и не снилось. > ты получаешь конкретный дотрен под дату Ну да, стили не нужны, на каждый стиль натреним лору, лол.
>>1403044 >Я уже вижу мутантские отростки на твоих пиках вместо них, не надо больше, я не фанат бодихоррора Какая нежная пуська, старательно игнорирует лимиты разрешения, 20 шагов и голый ген. Ну ладно, не хочешь как хочешь. >У тебя в прошлом посте латинка превратилась на половину в то что ты сейчас показываешь Это твои нейрон активейшены. Латинки разные бывают, загугли колумбиек или ники минаж. >Хуёво если ты не видишь этого, наверное просто уже привык к дженерик лицам XL и не отличаешь их. Это у тебя проблемы с определением т.н. этнисити. Глаз узкий - значит ру азиатка уиии хрююю, хотя вот допустим есть пикрел, даже интересно куда бы ты ее выписал со своим сломанным детектором. Хотя скорее всего тебе опять лишь бы доебаться и срач развести, рак треда.
>>1403048 >SRPO может в такой реалистик, что XL и не снилось Верим, я поверил. >Ну да, стили не нужны А причем тут стили? >на каждый стиль натреним лору Анимешизы так и живут. Основная модель должна сохранять универсальность и среднюю температуру по палате для когерентности.
>>1403112 >Анимешизы так и живут. У анимешизов даже древнейшая NAI, основанная на полторахе, знала тысячи стилей безо всяких лор. С тех пор положение только улучшалось. Вот если что-то уникальное нужно - тут можно и потренить.
> INFO:musubi_tuner.dataset.image_video_dataset:found 75 images > num epochs / epoch数: 40 > total optimization steps / 学習ステップ数: 1600 Какой же коха пидорас ебучий. Что это за островная математика, нахуй. И после этого возникает вопрос - эта параша вообще что тренит? А ещё резайз пикч как обычно нельзя выключить. Неграмотное чучело село писать код - результат в репе.