>>1378780 С чего вдргу? несколько сотен лет назад около 70-80 процентов людей было занято в сельском хозяйстве. Сейчас менее 10 процетов. Что делает все остальные люди? Роботизация приведет к появлению новых профессий.
>>1378780 Британские ученые, любители экстраполировать, в конце 19 века били тревогу, что к середине 20го Лондон утонет под трехметровым слоем конского навоза.
>>1378887 А куда капиталисты будут девать "лишний" ВВП? Будет переработка. Роботы подешевеют с 30 тыс., потом до 10, потом до 2 тыс. долларов. И будут у каждого, как сейчас ПК, и почти что автомобили. Роботы всё чаще будут встречаться в магазинах делающие покупки, за рулем автомобилей, и просто как пешеходы на улицах.
Они будут работать без остановки, сами себя на ходу ремонтировать и обслуживать (пару роботов на заводе будут проводить тех-обслуживание сотен или тысяч других почти без их остановки, на ходу). Будет рост ВВП, экономика вырастет, нужно будет перераспределять доходы в нижние слои населения чтобы не было застоя.
>>1378887 >и просто так даже Чо, они вон на ютубе разрешение 144p не убирают. Как раз это для нищих отсталых стран, которые в основном смотрят в таком качестве на старых телефонах и ПК.
>>1379776 Спиздят обоссут и обосрут, в америке очень много диких, невменяемых пидорашек которые должны лежать в дурке или тюряге Лучше бы дронов сделали хотя пидорашки и тут попытаются их сбить луком или рогаткой
>>1379776 Чуть длиннее и пошире и можно делать такие электро-мобили для людей одноместные, вместо этих 1,5 тонных громадин. Громадины уже не нужны, да и цена резко станет меньше, дороги разгрузятся, в основном водители в большинстве ездят сами в авто, больше места на дорогах будет, одну полосу выделить для общественного транспорта, грузовиков, спецслужб, и полностью одной полосы хватит для таких электро-мобилей.
Аноны, а что теперь будет с тредом? Кто новости будет постить? Неужели не найдется никого, кто возьмет на себя функционал старого ОПа? Очень переживаю, тред хороший, жаль будет его потерять
В польском стартапе Pathway создали новую архитектуру нейросетей –Biological Dragon Hatchling
Идея тут в основном в том, чтобы соединить две линии развития ИИ: всеми любимые трансформеры и модели мозга. Уже доказано, что между мозгом и трансформером есть связь (см эту статью от DeepMind). Тем не менее, до спопобностей нашей черепушки LLMкам пока далеко: не хватает нескольких основных свойств.
В общем, заканчивая лирическое вступление: тут взяли трансформер и решили впаять в него некоторые фичи из мозга. Получилась графовая архитектура, в которой нейроны –это вершины, а синапсы – рёбра с весами. Модель работает как распределённая система из нейронов, которые общаются только с соседями.
С обучением все тоже не как обычно. Наш мозг учится по правилу Хебба: нейроны, которые активируются вместе, укрепляют связь. Тут это реализовано без изменений, то есть если активность нейронов A и B часто совпадает, вес ребра между ними увеличивается, и логическая взаимосвязь становится крепче. Если присмотреться, то похоже на какой-то аналог механизма внимания.
И еще одно. Веса тут разделены на две группы: фиксированные и динамические. Аналог долговременной и кратковременной памяти. Фиксированные веса – это базовые знания, они обновляются только во время обучения и далее не меняются. Динамические веса нам нужны для ризонинга. Каждый шаг рассуждения – это локальное обновление связей.
Немного запутанно, НО авторы сделали тензорную версию (BDH-GPU). Она эквивалентна BDH, но выражена в виде обычных матриц и векторов, так что её можно обучать, как трансформер. По сути там все то же внимание, пару блоков MLP, ReLU и немного специфичные активации. Все знакомо.
Но оказалось, что система с такой архитектурой демонтрирует очень приятные свойства:
1. Интерпретируемость. Каждая пара нейронов (i, j) имеет свой синапс и хранит его состояние, которое можно наблюдать и отслеживать. Плюс, активации моносемантичны. Один нейрон действительно отвечает за одно понятие.
2. BDH может легко объединять две модели с помощью простой конкотенации. Представьте, какой простор для масштабирования.
3. И к слову про масштабирование: BDH показывает те же scaling laws, что и GPT-2, и при одинаковом числе параметров модель достигает схожей точности на ряде задач. Это значит, что основное свойство трансформера сохранено.
Красиво получилось. Если еще выпустят на этой архитектуре что-нибудь осязаемое, цены не будет.
>>1380013 Буквально то что я хотел, то что жаждал, то что возжелал. Недавно как-то срались в треде на эту тему и я говорил что нужно вот эти фишки подрезать у мозга, особенно кратковременную/долговременную память в связке с восприятием времени.
Новости больше не нужны и они становятся неактуальны уже через пять минут. Мы физически не в состоянии осмыслить как стремительно меняется окружающий нас мир, как восхитительны и монументальны новые изменения у всё новых и новых нейросетей которые появляются каждый день словно грибы в лесу после дождя. Только этот дождь не физический, он метафорический. Дождь, который олицетворяет наши слёзы. Слёзы после долгого ожидания на плато, слёзы криков и отчаяния что это плато никогда не закончится. Слёзы наших матерей и отчимов которые видели украдкой сквозь дверную щель в комнате как мы тихо стонем в подушку долгими зимними вечерами в ожидании новой гемини 3. Но вот, дорогие друзья, мы вместе с вами буквально находимся в переломный момент истории, стоим на пороге чего-то невероятного, чего-то, что мы даже боимся представить в наших самых смелых мечтах. Да, детка, это сингулярность. Неотвратимая и беспощадная.
>>1380039 Изменений пока минимум же. Все так же ходят на работу по 10 часов в день, бабок так же нихуя нет. Благ пока тоже от твоих революций никаких особых не заметно, если не считать за благо попиздеть с ботом и нагенерить видосиков. Мы еще не видели никаких реальных изменений, только обещания.
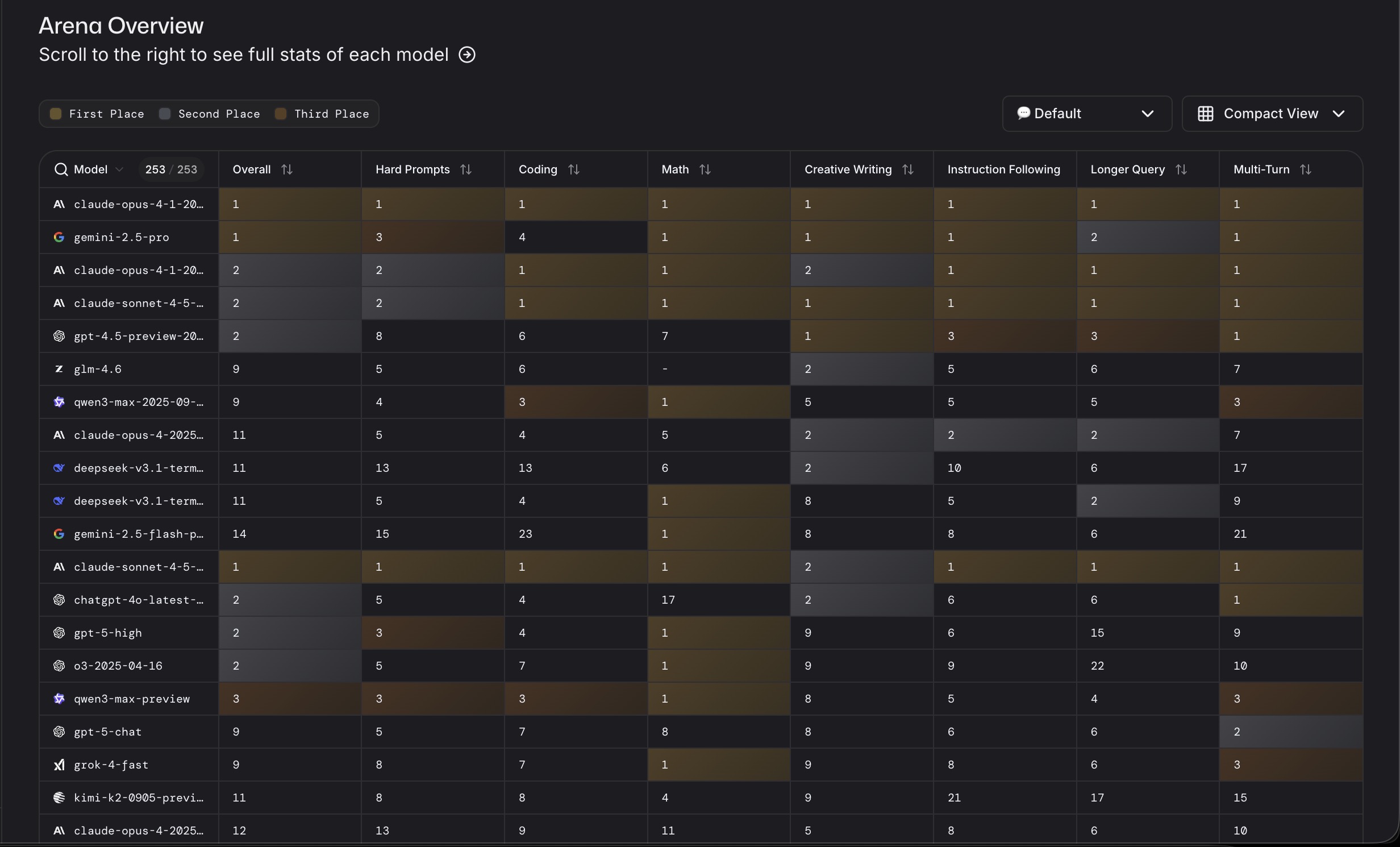
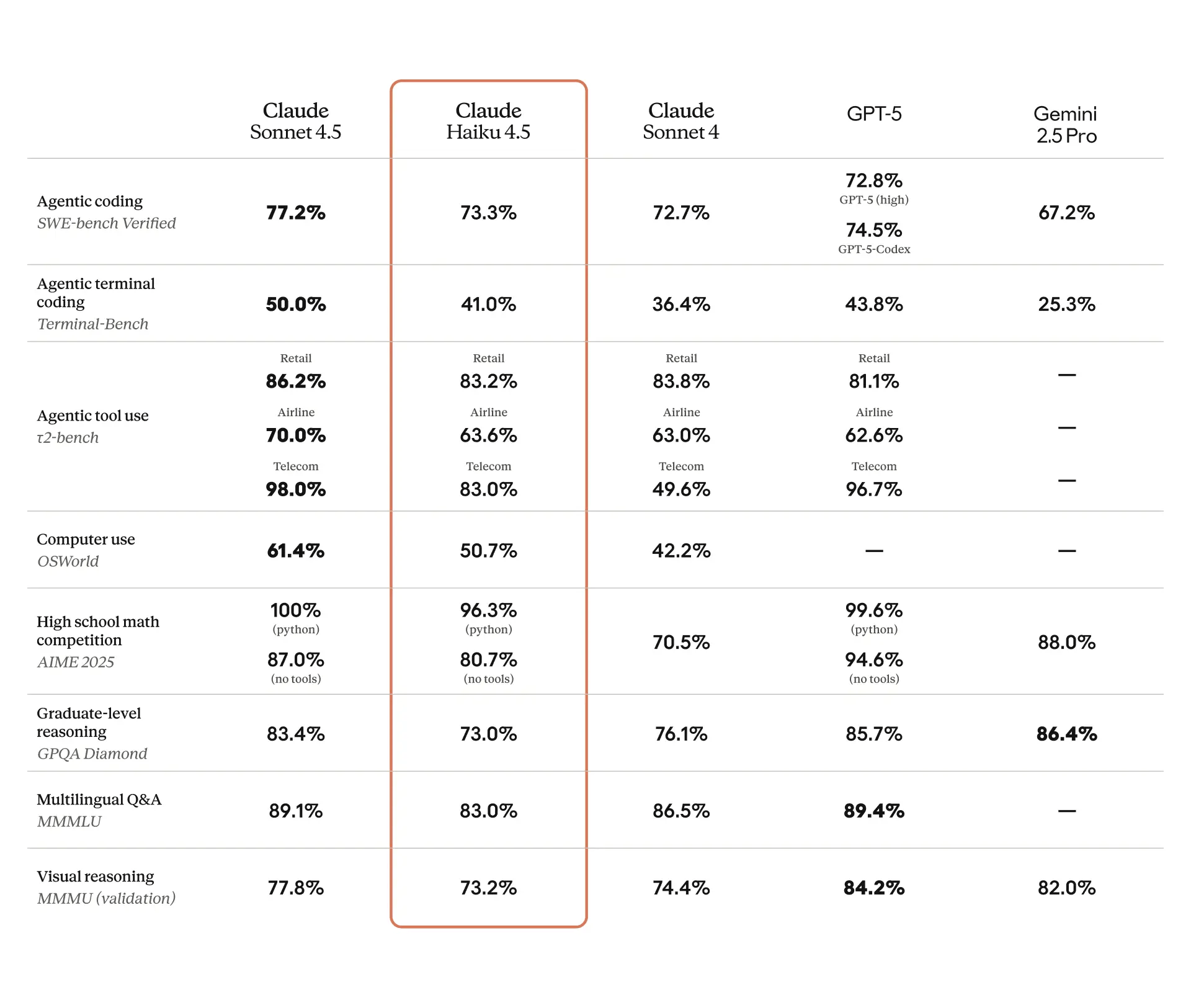
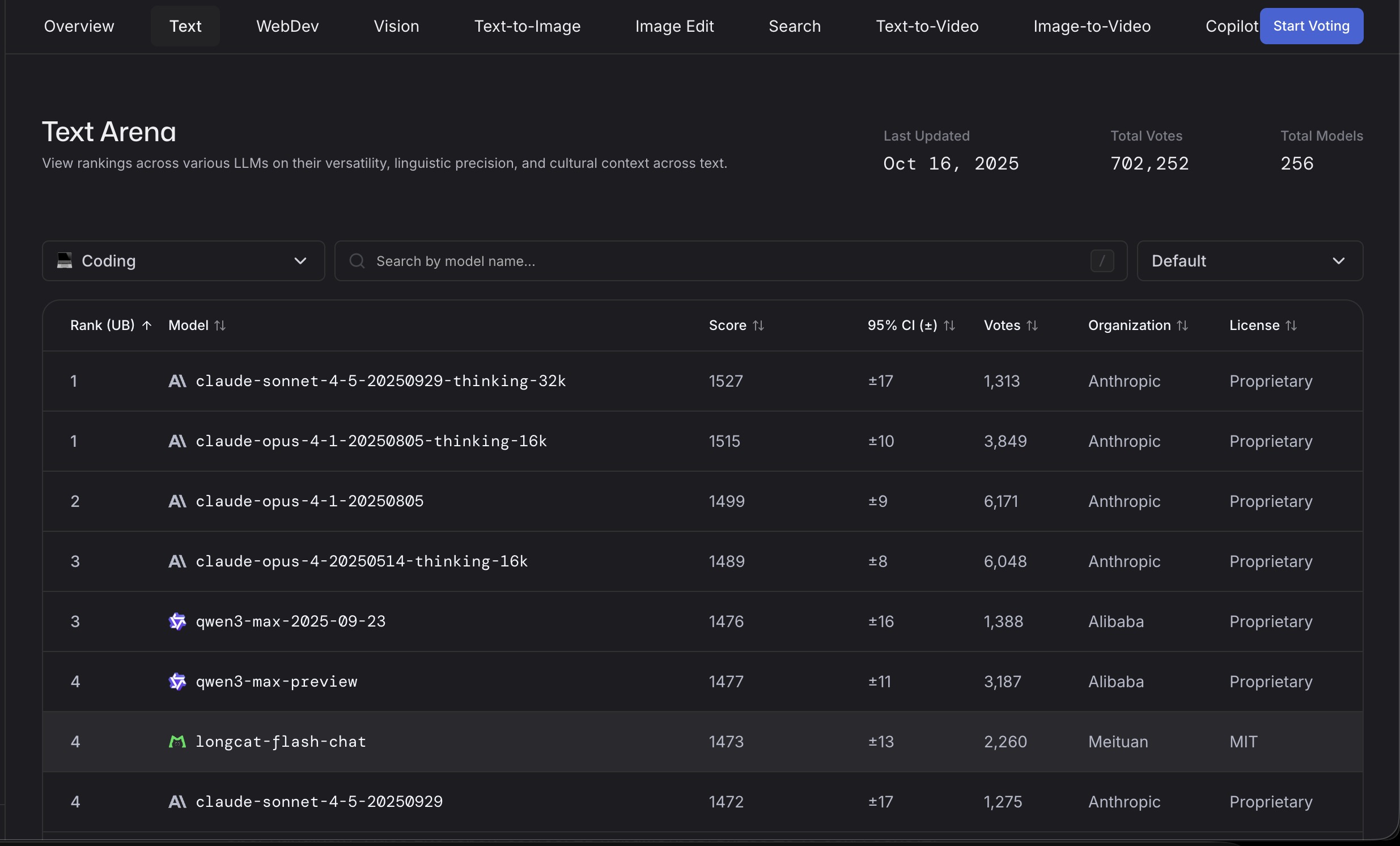
Последние 2 недели повторял свои чертеж бенчики на gpt-5-thinking и gpt-5-high(с арены). Так вот, то что сейчас подсовывают под видом gpt-5 - полнейший наеб гоев. Это не gpt-5-thinking, может быть мини или нано, но не зинкинг. Это подтверждается результатами моих тестов и общим рейтингом gpt-5-high на арене пик рил. Как видно гпт-5 в жопе даже на арене, только в webdev тестах сохранилось лидерство.
>>1380169 У меня несколько чертеж бенчиков. На всех них gpt-5 деграднул, при том в августе gpt-5 thinking был лучше других моделей. Из китайцев тестил Qwen3-VL-235B-A22B и Qwen3-Next-80B-A3B - обе показали себя лучше того что сейчас называется "gpt-5-thinking", но хуже gemini 2.5 pro. Для справки каждый тест делаю не менее 10 запросов
Три года назад мы лихо считали картинки в Stable Diffusion 1.5 на своем железе (4-8 GB VRAM). Без всяких квантизаций, дистилляций и пр. Прошло три года и аппетиты генераторов выросли в 10-20 раз. Вон HunyuanImage 3.0 просит 320 гигов видеопамяти, а все видеогенераторы с непожатыми весами тоже просят около 60-80 Гигов VRAM. Видеокарты, которые можно купить домой просто не поспевают за такими аппетитами. Железо развивается медленнее, чем аппетиты генераторов.
Компромиссы: считать в облаке (как делаю я) или искать и ставить пожатые веса(компромисс по качеству). Невольно возникает вопрос, а можно ли как-то "удешевить" инференс, то есть просчет картинок и видео.
И тут я наткнулся на интереснейшую статью в Nature
Исследователи из UCLA показали альтернативный путь — делать инференс… светом. В их работе оптические генеративные модели создают новые изображения практически без цифровых вычислений во время генерации.
Совсем коротко: модель для генерации картинок тренируется как обычно, в цифре и на чипах, а вот просчет картинок(инференс) происходит на аналоговом устройстве (свет, линзы, фазовые пластины/SLM). Быстро, без затрат на электричество, без требований к VRAM и пр.
Чуть подробнее
Небольшой цифровой энкодер быстро переводит случайный шум в фазовые узоры — «оптические сиды (optical seeds)» Далее вступает в игру дифракционный декодер — оптическая система в свободном пространстве (свет, линзы, фазовые пластины/SLM). Он аналогово преобразует свет и формирует новое изображение, соответствующее целевому распределению данных. Во время самой генерации процессор не считает: нужна только подсветка и заранее полученный seed. Энергия тратится на свет, а не на математику.
А теперь нудно и долго
1. Подготовка seeds. Энкодер (пара неглубоких полносвязных слоёв) берёт 2D-гауссов шум и переводит его в фазовые карты. Эти карты отображаются на пространственном светомодуляторе (SLM). 2. Оптический декодер. Свет, проходя через оптимизированный дифракционный декодер, «проецирует» итоговое изображение на сенсор. Собственно оптическая часть занимает меньше наносекунды; узкое место — скорость обновления SLM. 3. Обучение. Сначала обучается «учитель» — цифровая диффузионная модель (DDPM). Она генерирует пары «шум–картинка», которыми совместно обучают и фазовый энкодер, и оптический декодер. После обучения декодер фиксируется, а для разных датасетов можно просто менять сиды и конфигурацию декодера.
Что получилось в экспериментах
Команда показала оптическую генерацию монохромных и цветных изображений из разных распределений: MNIST, Fashion-MNIST, Butterflies-100, CelebA, картины Ван Гога. Качество сопоставимо с цифровыми генераторами по метрикам IS/FID, а демонстрационный стенд работал в видимом диапазоне длин волн.
Ограничения Железо диктует пределы. Скорость, разрешение и стабильность зависят от SLM, качества оптики и юстировки. Обучение всё ещё цифровое. Чтобы построить оптический генератор, нужен цифровой «учитель» и вычислительные ресурсы на этапе тренировки. Расширение за пределы изображений. Концепция обещает вывод и для видео/аудио/3D, но такие демонстрации — дело будущих работ.
Итого:
Исследователи показали, что генеративные модели можно вынести из чипов в оптику: свет, дифракция и фазовые элементы берут на себя большую часть «вычислений» на этапе генерации, обеспечивая быстрый и экономный инференс при качестве, сравнимом с цифровыми моделями. Это не «конец GPU», но сильная заявка на гибридные системы, где обучение остаётся цифровым, а инференс становится фотонным.
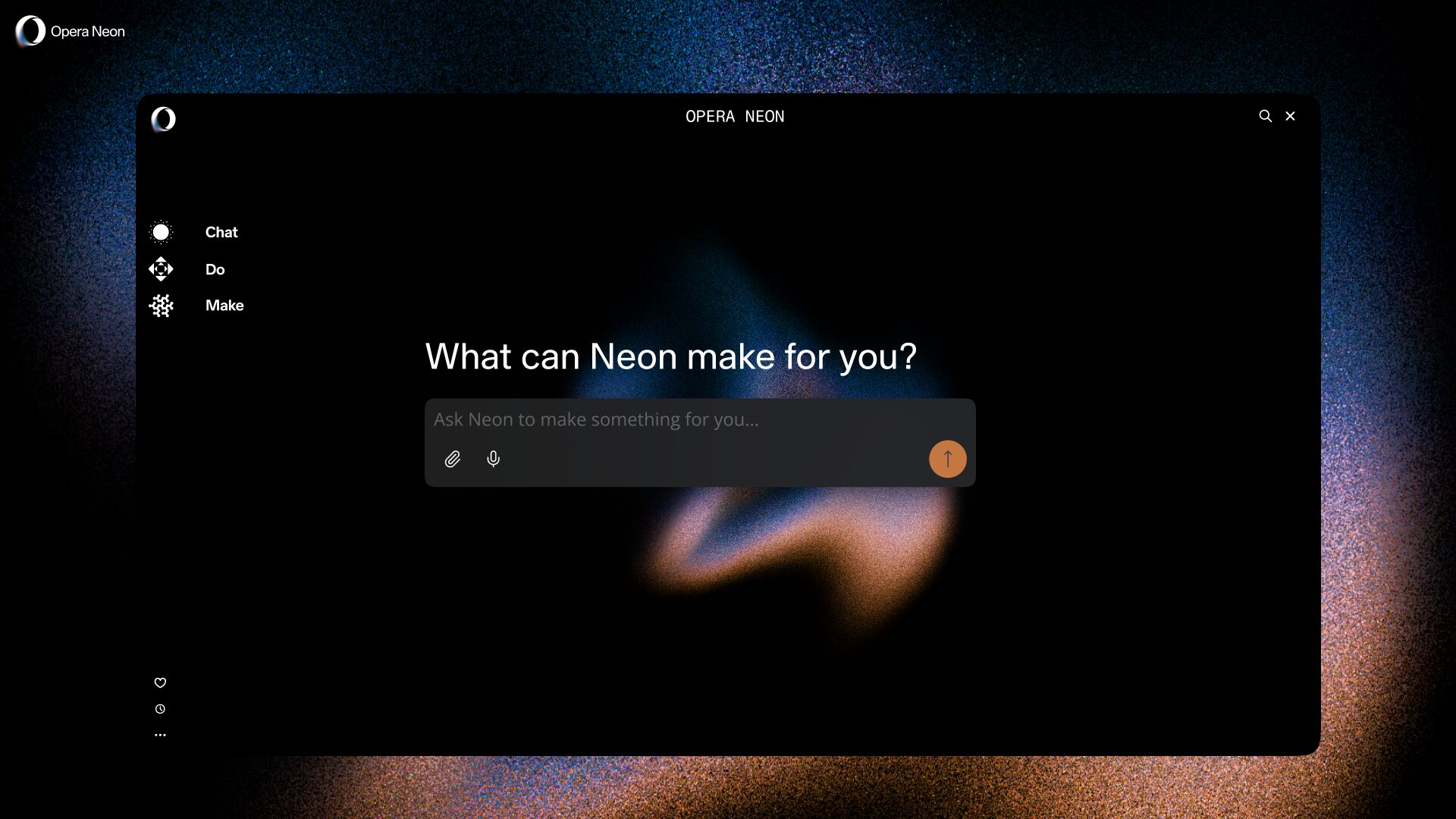
Opera только что запустила браузер Neon с искусственным интеллектом за 19,99 долларов в месяц. Opera вступает в борьбу на рынке браузеров с искусственным интеллектом, выпуская Neon — браузер, который явно предназначен не для обычных пользователей, а для интенсивных рабочих процессов с искусственным интеллектом.
Некоторые вещи, которые привлекли внимание:
«Карты»: позволяют автоматизировать повторяющиеся задачи на разных сайтах и в разных инструментах (представьте себе умные макросы, но на базе GenAI).
«Задачи»: по сути, папки рабочего пространства, в которых можно запускать и организовывать чаты с ИИ — отлично подходит для управления многоэтапными агентными рабочими процессами.
Генерация кода, встроенная в браузер (еще тестируют эту функцию... но она многообещающая для разработчиков и прототипистов).
Очевидно, что они ориентируются на «профессионалов» — разработчиков, изобретателей и людей, которые запускают RAG-конвейеры или агентные стеки в фоновом режиме во время просмотра веб-страниц.
Стоимость 19,99 долларов в месяц — это не дешево, но разработчики позиционируют свой продукт как нечто большее, чем просто очередной обертку для ChatGPT. Записаться в список ожидания можно здесь: https://www.opera.com/neon
>>1380422 >но разработчики позиционируют свой продукт как нечто большее, чем просто очередной обертку для ChatGPT >look inside >очередная обёртка под genAI
>>1380422 >Opera только что запустила браузер Neon с искусственным интеллектом за 19,99 долларов в месяц. Ну и кому реально платный бровзер нужен будет и нельзя это же было сразу в Жоперу встроить? Особенно на фоне того, что щас хрюкл и мелкомягкие то же самое бесплатно завезут и завозят в свои существующие бровзеры, которые тупо доминируют на рынке, + плюс еще комета от перплексити. Долбоебизм на уровне сои, которая Арк бровзер разрабатывала и закопала его ради новой дрисни Диа бровзера, который уже как почти год разрабатывают онли для яблочников со скоростью черепахи. Правда даже на фоне сои нашлись еще большие долбоебы-разрабы жиры, которые чисто за неготовый продукт Диа бровзера дали сое пол-лярда баксов
>>1380512 >ткани Тряпичный - промежуточная версия перед меховым. На нём кот уже может когтями цепляться и лазить, а собака ещё не сможет вцепиться зубами, зато мехового уже сможет собака зубами кусать.
>>1380557 >сможет собака Интересно, как на таких роботов в доме будут реагировать собаки и коты. Собака по запаху будет понимать что это не человек, потому что он будет вонять китайским дешёвым пластиком, а не пердежом из капусты и котлет.
И что будет делать собака, интересно, особенно если робот будет ей отдавать команды? - Будет ли она считать вонючий китайский пластик лидером, который стоит выше неё по иерархии в пищевой цепи?
>>1380579 Котам будет похуй со временем, так же как на роботов-пылесосов каких-нибудь, собаки будут воспринимать как лидера из-за габаритов и человекообразности.
У меня есть чувство, что решение к проблеме старения настолько простое, что все в будущем будут просто в шоке из-за того что люди гибли миллиардами во времена когда уже можно было достичь бессмертия. Решение этой проблемы будет найдено специализированным ИИ и поставлено на конвеер в ближайшие пять лет.
>>1380765 Я на это очень надеюсь. Это мой главный коупинг, очень боюсь смерти. Но есть сильные сомнения, что это вообще возможно. Наш соотечественник, Петр Федичев, в прошлом физик, ныне перекатился в борьбу со старением, рулит стартапом Gero. И у него есть очень убедительная модель, которая говорит, что обратить старение будет ОЧЕНЬ сложно. По его идее, старение складывается из двух процессов: системные нарушения, которые поддаются обращению; и несистемные, единичные, которые невозможно обратить, если мы не научимся манипулировать материей очень точно на молекулярном уровне. Есть шанс, что эти несистемные нарушения можно обратить с помощью клеточного репрограммирования. Но это пока неясно.
>>1380790 Даже если изобретут бессмертие и ты проживёшь какое-то количество времени есть большая вероятность то ты откиснешь в результате войны, падения метеорита, мощнейшей солнечной вспышки которая распидорасит все живое, вариантов много в масштабах вселенной их вероятность стремится к бесконечности >>1380794 Такая же противоестественная как спасение недоношенных младенцев и в принципе любо медицинское вмешательство
>>1380803 Будешь добровольно стареть, глядя, как все твои знакомые омолаживаются, и в итоге сдохнешь? Я, конечно, не верю. Но считаю, что у человека должно быть право добровольно сдохнуть.
>>1380806 > Даже если изобретут бессмертие и ты проживёшь какое-то количество времени есть большая вероятность то ты откиснешь в результате войны, падения метеорита, мощнейшей солнечной вспышки Пусть изобретут, со всем остальным как-нибудь разберемся.
>>1380810 Можно подумать это будет общедоступно, хех Никто не допустит этого, иначе очень скоро наступит перенаселение и критический перерасход ресурсов которые не бесконечны
>>1380817 > Можно подумать это будет общедоступно, хех Сначала нет, потом - да, как это происходит со всеми технологиями. Это самый большой рынок в истории. Над решением проблемы старения трудятся сотни компаний и все они хотят получить прибыль.
> Никто не допустит этого, иначе очень скоро наступит перенаселение и критический перерасход ресурсов которые не бесконечны Перенаселение наступит очень нескоро. А когда наступит, это тоже решаемо.
Вы не поняли. Проблема старения рано ил поздно будет решена тем или иным способом. Вопрос в том, будет ли это коммунистическая параша где всем правит партия, либо страна со свободным рынком, где бессмертие сможет позволить себе любой
>>1380821 До этого уровня развития космонавтики еще дотянуть надо будет.
>>1380822 >Сначала нет, потом - да, как это происходит со всеми технологиями. Я не говорю о дороговизне. Элиты просто не позволят быдлу жить вечно, им это невыгодно.
>А когда наступит, это тоже решаемо. Каким же способом, интересно?
>>1380845 > Я не говорю о дороговизне. Элиты просто не позволят быдлу жить вечно, им это невыгодно. Конечно выгодно. Рынок антистарения - десятки триллионов долларов в год.
> Каким же способом, интересно? Ограничение рождаемости.
>>1380834 >страна со свободным рынком, где бессмертие сможет позволить себе любой Держи карман шире, наивный ты наш Никто тебе вечной жизни не даст, бессмертным будет барин а прочие не впишутся в рыночек ибо не по масти
>>1380853 >Ограничение рождаемости. Пиздюки по талонам, а если по залету то принудительный аборт? И кто будет решать, кому плодиться можно а кому нельзя?
>>1380847 >Я за этот вариант, будем бессмертными как Ленин! Он же предатель - в 1921 начал строить капитализм (НЭП), в 1922 его СССР был капиталистическим, и в 1924 он так и сдох капиталистом. То есть предал всех, кому рассказывал сказки про то что он будет строить коммунизм.
>>1380854 Что за шиза что бессмертие будет только у богатых? Вы блять стату по рождаемости на планете видели? Самый наглядный пример это корея и япония с их огромными массами стариков и мелких кучек молодняка. Откуда им блять деньги брать как не с молодняка который должен ебашить и отдавать налоги на страховые взносы по медицине/пенсии и т.д.?
От того что люди перестанут умирать от старости у барина проблем больше не станет, наоборот будет меньше хлапот и не нужно лишний раз думать где найти дурачков которые будут ишачить за копейки (старики работать не будут, они на пенсии).
В этой теме больше переживании по поводу того как именно эта проблема будет решена. Один раз таблеточку/прививку сделал и всё, или же это подписка на таблетки замедляющие старение. Если второе, то богатые будут только рады на этом заработать ещё больше денег. Если первый варик, то в принципе они всё равно в плюсе т.к. не придется ввозить толпы иностранных специалистов, будет достаточно не стареющего бедного молодняка.
Есть ещё отдельная каста поехавших, которые готовы отказаться от бессмертия только из за того что перестанут умирать те, кто по их мнению не достоин этого. Этих максимально презираю т.к. из за такой хуйни они готовы принять миллиарды смертей от старости
>>1380854 Не по масти в коммипараше с абсолютной монополией на средства производства, геноцидящей собственное население. В которой половина сидит, половина охраняет, половина стоит в километровых очередях за батоном хлеба и туалетной бумагой.
>>1380890 Оно при любом исходе приведет к стагнации, дефициту и в конечном итоге к разрухе. Естественный механизм регулирования популяции будет разрушен, что вынудит прибегнуть к искусственным ограничениям > сегрегации.
>>1380906 Так сплошные плюсы, врагам народа вечной жизни не давать, вымрут от старости безо всяких репрессий. Останутся только идейные строители коммунизма!
>>1380890 Таблеточки вряд ли будет, ведь старение системный процесс. Скорее будут достаточно затратные терапии, на которые надо зарабатывать, каждая откатывает состояние на ХХ лет. Итого всем придется работать, чтобы заработать на очередную дозу антистарения, вангую вся экономика вокруг этого и построится. Туча холопов, работающих годами за гроши, чтобы откатить свое старение еще лет на 20. Полностью зависимые от барина, иначе постареешь и помрешь. Причем все это полностью сохранит капитализм и решит все проблемы вроде миграции.
>>1380890 Машины будут только у богатых, остальные не впишутся в рыночек. Дома будут только у богатых, остальные не впишутся в рыночек. Компьютеры будут только у богатых, остальные не впишутся в рыночек. Медицина только для богатых, остальные не впишутся в рыночек. Откуда вы это берёте, нахуй? Сколько можно нести эту пургу? Просто сравни уровень потребления в США и СССР. Коuда в СССР открылся заморский Мак там были очереди, нахуй. И вот прошло уже 30 лет, сидит говно из Засратова в проперженой халупе, в стране где отжимают вообще любой бизнес и сажают за мысли, пишет что-то про рыночек сравнивая это с США с их ВВП, потреблением, судами, разделением властей, прослойкой среднего класса(которую сейчас всякие Швабы с бюстиками Ленина на полке и Ларри Финки форсящие подписочное рабство с отказом от частной собственности, пытаются сокращать)
>>1380930 Машины и компы это не вечная жизнь. Второе при общедоступности грозит полным коллапсом общества со временем, если не утилизировать излишки, параллельно жоска ограничивая плодячку решать вопрос оперативно.
>>1380894 >это не полноценный капитализм А зачем тогда в период недо-капитализма было образовывать СССР? Можно было создать республику переходную, временную, а потом уже создавать страну на постоянку. Ведь с чего началось (с бреда - шизофрении ленина) тем и в 1991 закончилось. Проект изначально был испорчен предательством ленина. Там ещё куча стран не поняли такого прикола, по всему миру агитируют значит строит у себя коммунизм, а сами строят капитализм с частной собственностью. Выглядело позором для всех стран, а не примером. Тоже самое и в 1991 когда коммунисты флаг поменяли и предали окончательно идеологию, кинув свои колонии типа КНДР, КСИР, СРВ, Лаос, и т.д.
Дико хочу посмотреть нано-банану на третьей гемини, наверное даже больше чем бенчики текстовой модальности. Хотя там обещают что-то охуенное судя по тому что она по слухам сделала математическое доказательство той же хуйни что и гпт-5 только в 5 раз быстрее
>>1380942 Так думали лет 50-100 назад когда население на планете стремительно росло из за снижения детской смертности, доступности медицины и низкой стоимости еды. По итогу сейчас правительства множества стран верещат что срочно нужна плодячка и массово завозят иностранцев, лишь бы экономика не рухнула от понижения потребления и производства, из за старения населения и низкой рождаемости.
Есть еще мнение что страны с традиционными ценностями, где рождаемость сильно превышает смертность, будут своим населением вытеснять население развитых стран, но как мне кажется так выглядит на первый взгляд и по итогу всё равно общее население планеты будет падать по мере глобального развития общества. Просто до традиционных стран это доходит медленнее и со временем через пару поколений у них будет такая же ситуация.
Всё это со стороны выглядит как какая то стратегия с механикой развития древа технологий (электричество > микроэлектроника > ИИ > ??? термояд/бессмертие/ГМО-люди/экспансия космоса)
>>1380984 а мне бы чтобы кодила хотя бы как гпт5. Долго сидел на гемини 2.5 про, но вчера эта тупень так выбесила что решил проверить гопоту и та с первого запроса решила проблему... было обидно т.к. гопоту не люблю за их жмотство лимитов
>>1381014 Бывало такое, либо просишь несколько раз исправить и указываешь ей, где косячит, либо правишь вручную нужный файл и загружаешь ей его, типа используй теперь этот код. А вообще она редко в такое попадает, ты может ее промптишь не так. Попробуй промпти по-другому.
>>1380193 >тестил Qwen3-VL-235B-A22B квен новый первая ллм которая смогла переварить геологический отчет в пдф и высрать вменяемые рекомендации по фундаменту, аргументированно и даже с попыткой расчетов (расчеты не перепроверял, наверняка хуйня) и тем не менее дипсик клауд и жпт в таких задачах обсирались с головы до ног (дипсик вообще не может в пдф) остановите его срочно иначе и меня заменят ебучим ии.
Я до сих пор не понимаю, почему все ссут кипятком от ChatGPT и Deepseek, когда Gemini и Qwen уделывают их абсолютно в каждом запросе. То есть это просто даже не сравнимо. У ChatGPT как будто каждое слово по рублю и поэтому она их так цедит, делает всё на отъебись, после Gemini доверять ей просто невозможно. Deepseek это вообще какой-то галлюцинирующий подросток которого уносит не в ту степь. Gemini - это буквально partner in crime, твой тренер в углу ринга, который снабдит тебя всей необходимой информацией чтобы ты разъебал всех. А милашка Qwen угадает даже то что ты поленился расписать и всё принесет на блюдечке, еще и пошутит прикольно. Не понимаю людей.
Pathway, компания по обработке данных, сегодня представляет Baby Dragon Hatchling (BDH), новую архитектуру «пост-трансформер», которая устраняет одно из наиболее значительных препятствий для автономного искусственного интеллекта (ИИ): неспособность к обобщению во времени.
Обобщение во времени — способность поддерживать рассуждения, учиться на опыте и делать прогнозы на основе новой информации — является фундаментальным свойством человеческого интеллекта. Сегодняшние модели на основе трансформеров, напротив, мощны, но статичны: они превосходно справляются с сопоставлением паттернов прошлых данных, но имеют ограниченную способность распространять свои рассуждения на новые контексты.
В новой статье «Недостающее звено между трансформером и моделями мозга», Pathway научно и формально отобразила, как интеллект возникает в мозге, что позволило ей создать BDH, искусственную систему рассуждений с моделью выполнения, подобной мозгу.
BDH образует модульную структуру, подобную сети нейронов в мозге. Она возникает спонтанно во время обучения и напоминает поведение неокортекса, внешнего слоя мозга, присутствующего только у млекопитающих, который отвечает за когнитивные функции более высокого порядка, такие как восприятие, память, обучение и принятие решений.
«Люди учатся рассуждать на основе опыта. Современный искусственный интеллект — нет. Мы сосредоточились на отображении естественных человеческих рассуждений при решении проблемы обобщения во времени. Мы спросили себя: чего не хватает ИИ, чтобы имитировать функцию человеческого мозга?» — сказала Зузанна Стамировска, генеральный директор и соучредитель Pathway.
«Мы обнаружили, что для достижения обобщения во времени нам нужна совершенно новая архитектура. Вот почему BDH — это не постепенное улучшение архитектуры на основе трансформеров, а смена парадигмы», — прокомментировал Адриан Косовски, соучредитель и главный научный сотрудник Pathway.
«Обобщение во времени является основой для безопасного и автономного рассуждения», — продолжила Стамировска. «С BDH у нас теперь есть масштабируемая модель, которая может поддерживать долгосрочные рассуждения, расширяя рынок ИИ в корпоративном секторе».
Для ускорения разработки продуктов Pathway сотрудничает с лидерами отрасли, NVIDIA и AWS. AWS является предпочтительным облачным поставщиком компании и обеспечит Pathway необходимыми вычислительными мощностями.
В архитектуре BDH входные данные управляют популяцией искусственных нейронов, которые накапливают знания и делают выводы на основе своих взаимодействий. Этот новый подход позволяет создать безмасштабную модель, которая может рассуждать в течение длительных периодов времени и ведет себя предсказуемо, даже когда в модель динамически добавляется новая и непредвиденная информация.
Google Veo 3.1 была замечена на Higgsfield На платформе Higgsfield, специализирующейся на ИИ для создания видео, заметили страницу Veo 3.1 — обновленной модели от Google. Также упоминание новинки появилось и на облачной платформе Vertex AI от самой Google.
Попробовать Veo 3.1 на обеих платформах пока нельзя, но известны первые предполагаемые характеристики новинки:
b]Анонс на Higgsfield указывает на разрешение 1080p и длительность ролика более 30 секунд — это существенный рост в сравнении с 8 секундами у Veo 3.
В интерфейсе есть упоминание scene builder — функция, вероятно, будет анализировать готовый ролик, а затем на его основе генерировать следующий, сохраняя облик персонажей и основных элементов сцены.
Возможно, будет поддерживаться мульти-промптинг: таймкод ролика разбивается на несколько сцен, для которых прописываются разные промпты.
>>1381139 Квен супер, но как я ранее говорил gpt-5-thinking который был в августе сразу поле релиза все-таки чуть-чуть уделывал гемини. Процент правильных ответов на старом гпт5 был выше чем у квена.
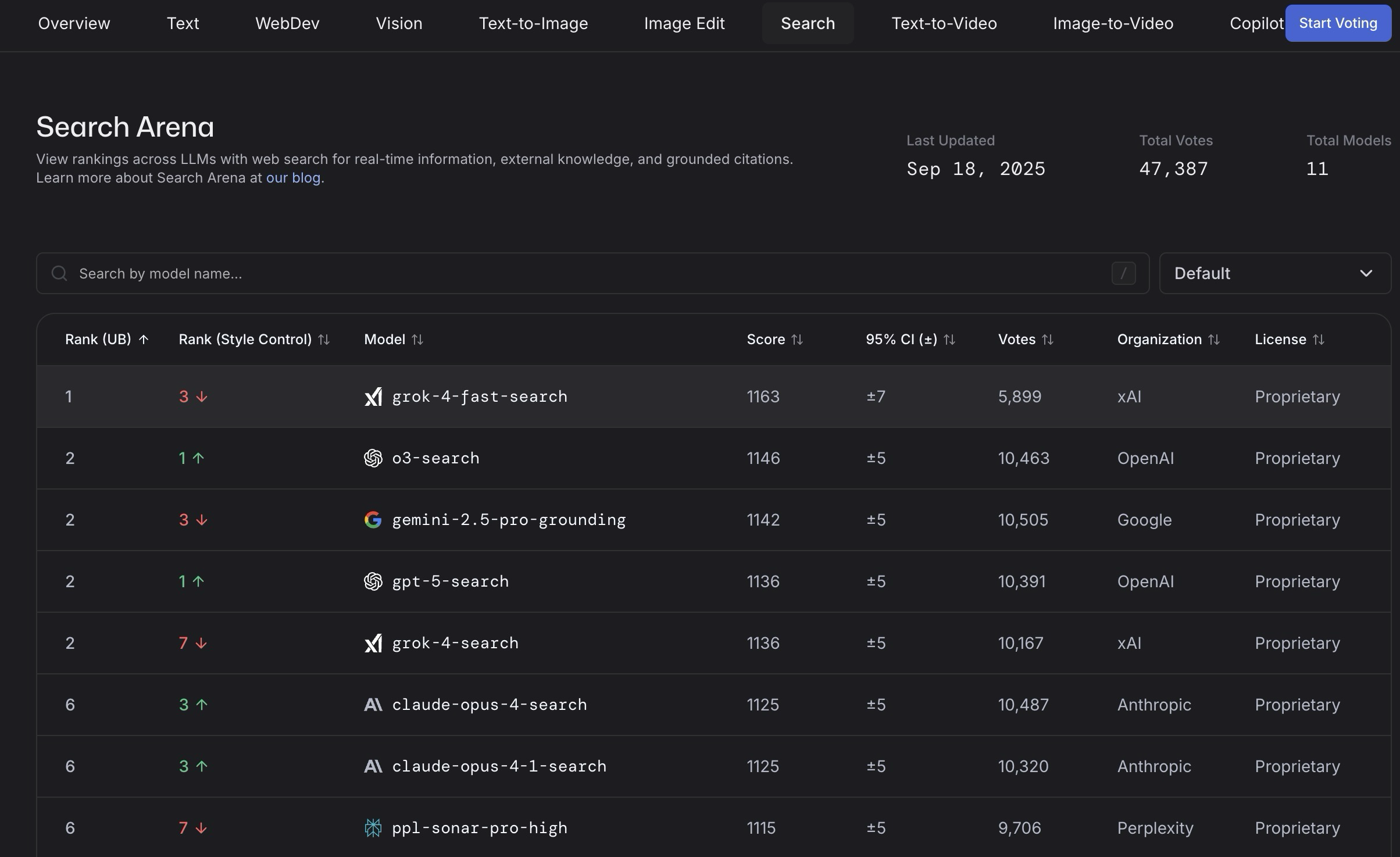
>>1381292 Грок хорош в поиске инфы - поисковый движок Маска может сканировать даже телеграм каналы, гемини идут в отказ с его гуглом. Но вот прохождение моих бенчиков Грок тотально провалил
Проанализируй новости на этих ресурсах и обобщи что нового произошло за последнюю неделю Основные ресурсы: t.me/ai_newz t.me/data_secrets t.me/cgevent t.me/seeallochnaya t.me/denissexy t.me/oulenspiegel_channel
>>1381320 И он реально в телегу лез за инфой? >>1381168 Я не ссу кипятном, но понимаю что какие то задачи решает гемини, а какие то удается только гопоте (поэтому жду и надеюсь что гемини 3 будет решать то что не смогла до этого). Хорошо когда есть альтернатива для проблемных задач
>>1381174 Если всё так, то пусть показывают на практике свои преимущества. До этого тоже были такие новости, но они оказались говном при масштабировании
>>1381344 лайвхак: если дописать в запросе "используй URL для публичного просмотра без входа", то найдет все с первой попытки, НО по дате искать не умеет
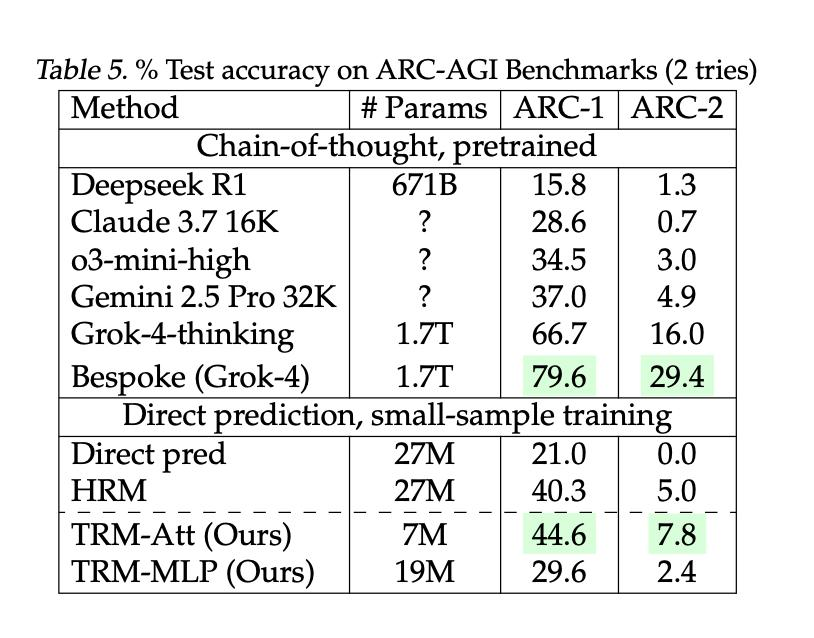
Крошечная модель на 7 миллионов параметров превзошла DeepSeek-R1, Gemini 2.5 Pro и o3-mini на ARG-AGI 1 и ARC-AGI 2
Сегодня разбираем самую громкую статью последних дней: "Less is More: Recursive Reasoning with Tiny Networks" от Samsung. В работе, кстати, всего один автор (большая редкость, особенно для корпоративных исследований).
Итак, главный вопрос: как это вообще возможно, чтобы модель в 10 000 раз меньше была настолько умнее?
Ответ: рекурсия. Модель (Tiny Recursive Model, TRM) многократко думает над своим ответом, пересматривает его и исправляет, прежде чем выдать окончательное решение. Выглядит процесс примерно так:
1. Модель получает условия задачки и сразу генерирует какой-то грубый набросок решения. Он не обязательно должен быть правильным, это просто быстрая догадка.
2. Дальше система создает "мысленный блокнот" – scratchpad. Туда она записывает всё, что думает о задаче и своём черновике: где ошибки, что можно улучшить, как проверить гипотезу. При этом важно понимать, что scratchpad – это не поток токенов, как в обычном ризонинге. Это внутреннее скрытое состояние, то есть матрица или вектор, который постепенно обновляется. Другими словами, TRM умеет думает молча.
3. Модель в несколько проходов обновляет это внутреннее состояние, каждый раз сверяясь с (а) задачей и (б) исходным наброском. Она как бы думает: согласуется ли текущий черновик с условием, где противоречия, что улучшить. После N-ого количества итераций модель переписывает исходный черновик, опираясь на свой сформированный scratchpad. Но это не все. Этот процесс (сначала подумай → потом исправь) повторяется несколько раз. И вот только после этого мы получаем финальный ответ.
Результаты, конечно, поражают. Метрики на ARC-AGI-1 / ARC-AGI-2 – 44.6% / 7.8%. Для сравнения, у o3-mini-high – 34.5% / 3.0%. Также модель отлично решает судоку и лабиринты.
Единственная честная оговорка: это не языковая модель, она предназначена только для алгоритмов и текстом отвечать не умеет. Тем не менее, идея блестящая. Много раз пройтись одной и той же крохотной сеткой по scratchpad – это буквально как эмулировать глубину большой модели без большой модели. Отличный пример алгоритмического преимущества.
>>1381344 >>1381362 В удивительное время живём, ощущения как от первого знакомства с компьютером, всё так же не знаешь какие ещё возможности он может нам дать
Бля я хуею с гемини 2.5 про... почему эта залупа хуже 2.5 флэш в коде? Анон который писал что кодит через флэш, ты поэтому им пользовался вместо "про"?
>>1381622 Аааа, ну вы видели он собирает мусор, моет посуду(посудомойкой), держит подстаканники( самая дорогая подстаканница)? А эта футуристическая музыка создаёт ощущение что смотришь фантастический фильм, но только это не фильм это реальность. В каждом движений ощущается набор датасетов движения руками на камеру за $0.5 час. Он выглядит экзистенциально устрашающим(дайте бод).
>>1381622 Бля всё равно он очень медленный, как же всё же тяжело повторить мускулатуру биотвари. Куда проще оказалось имитировать их мозговые паттерны, лол
>>1381809 Сука, вот нахуя вставлять мельтешащего переводчика на язык жестов ради небольшого меньшенства людей? Это уменьшает размер основного экрана и постоянно отвлекает. Сделайте субтитры или отдельный стрим для глухих блять
>>1381812 >человекоподобного Универсальность - его можно поставить за прилавок продавать пиццу, или за токарный станок, или посадить за руль автомобиля чтобы он работал таксистом. Но можно сделать и 4-х рукого, две руки маловато будет для робота.
Представь, фургон приезжает и привозит тебе заказ, стиральную машину, и один робот её затаскивает в дом на этаж, и он же и водитель этого фургона. Но опять же, надо минимум 4 руки.
Ну вообще что-то не помню в фильмах чтобы роботы мыли посуду или управляли стиралкой, но вот какая частая сцена в фантастике была, это когда робот стоит на зарядке и потом включается и идёт, а теперь это уже реальность.
>>1381897 И? У Китайцев, Японцев, Корейцев есть своё производство. При этом у китайцев есть огромный внутренний рынок в 1,5 лярда человек. Даже если кто-то наложит сосанкции Китаю будет похуй. Ну а уж про промышленный шпионаж и умение копировать тут и упоминать не стоит. Запад сам взрастил Китай, да так, что запад от китая зависит больше чем китай от запада.
>>1381785 использовали твой код. ну что за крысы, скидывал в прошлый тред два инвайта тоже с двух акков, зарегалось 8 человек, но так никто и не дропнул свои коды в тот тред в ответ и твой тоже кто-то использовал, но тоже в ответ никто не выложил свой. что за пидоры вообще, зачем так делать. использовал чужой инвайт, скинь в тред свой код
Грядет шок на рынке труда из-за искусственного интеллекта, а компании к этому не готовы, заявляет генеральный директор Klarna
По словам одного из самых ярых сторонников искусственного интеллекта в сфере финансов, мир, от технологических компаний до переводчиков, еще не осознал последствия исчезновения большого количества рабочих мест из-за искусственного интеллекта.
«Мне кажется, что многие из моих коллег-технарей немного, ну, не совсем понимают суть этой проблемы. Я думаю, что в сфере интеллектуального труда грядут огромные перемены. И это касается не только банковского сектора, но и общества в целом», — сказал генеральный директор Klarna Group Plc Себастьян Семятковски в интервью Bloomberg Television.
«Общество должно будет решить, что мы будем делать, потому что, да, будут созданы новые рабочие места, но в краткосрочной перспективе это не поможет переводчику из Брюсселя. Он не станет завтра YouTube-инфлюенсером», — добавил он.
Klarna, наиболее известная своим продуктом «купи сейчас, заплати позже», вложила значительные средства в искусственный интеллект, и в 2023 году Сиемятковски заявил, что хочет стать «любимой подопытной крысой» OpenAI. Этот энтузиазм был отчасти вызван необходимостью Klarna сократить расходы после окончания бума финтеха.
Хотя этот подход позволил Klarna прекратить набор персонала на более чем год и сократить штат с 7400 до примерно 3000 человек, одновременно повысив заработную плату, с тех пор компания обнаружила, что эти инструменты имеют некоторые ограничения. В начале этого года она наняла больше сотрудников службы поддержки клиентов, чтобы пользователи всегда могли поговорить с человеком, и Сиемятковски сказал, что в настоящее время Klarna не использует искусственный интеллект при принятии решений о страховании.
Но шведский генеральный директор по-прежнему считает, что ИИ может справиться с решением проблем клиентов не хуже, а даже лучше. «Вы можете завоевать большое доверие, поручив ИИ выполнять определенные типы задач, благодаря его стабильности и качеству», — сказал он.
Klarna, которая в сентябре вышла на Нью-Йоркскую фондовую биржу, насчитывает более 114 миллионов клиентов, что превышает показатели многих традиционных банков. «Конечно, эти клиенты пока не пользуются всеми нашими банковскими услугами, но это должно стать нашей целью», — сказал Сиемятковски. В этом году компания получила лицензию на электронные деньги в Великобритании, что позволяет ей предлагать больше финансовых услуг и конкурировать с такими компаниями, как Revolut Ltd.
Генеральный директор считает, что бум искусственного интеллекта положит конец тому, что он называет «избыточной прибылью» как в банковской, так и в программной индустрии, поскольку действующие игроки будут вытеснены более динамичными конкурентами.
«Большинство традиционных банков, вероятно, станут чистыми балансовыми компаниями, где у вас есть большой баланс, и вы оптимизируете рентабельность собственного капитала, и это практически все», — сказал он.
На личном уровне Сиемятковски по-прежнему увлечен использованием ИИ «все время», в начале этого года освоив так называемое «вайб программирование», чтобы изучить кодовую базу Klarna. «Моя жена жалуется, потому что, когда дети ложатся спать, я говорю: «Эй, можно я пойду и немного поработаю с вайб программированием?» Так что она не слишком довольна мной. Но это так интригующе, так фантастично изучать эти технологии. Люди не должны бояться технологий».
Опенсорсному ИИ подкинули 2 миллиарда, нас ждут новые бесплатные модели
Reflection AI привлекает 2 миллиарда долларов, чтобы стать открытой американской лабораторией по искусственному интеллекту, бросая вызов DeepSeek
Reflection AI, стартап, основанный всего год назад двумя бывшими исследователями Google DeepMind, привлек 2 миллиарда долларов при оценке в 8 миллиардов долларов, что в 15 раз превышает его оценку в 545 миллионов долларов всего семь месяцев назад. Компания, которая изначально специализировалась на автономных агентах программирования, теперь позиционирует себя как открытую альтернативу закрытым передовым лабораториям, таким как OpenAI и Anthropic, и как западный аналог китайских компаний в области искусственного интеллекта, таких как DeepSeek.
Стартап был запущен в марте 2024 года Мишей Ласкиным, который руководил моделированием вознаграждений для проекта DeepMind Gemini, и Иоаннисом Антоноглу, соавтором AlphaGo, системы искусственного интеллекта, которая в 2016 году победила чемпиона мира в настольной игре Го. Их опыт в разработке этих очень продвинутых систем искусственного интеллекта является центральным элементом их презентации, суть которой заключается в том, что правильные таланты в области искусственного интеллекта могут создавать передовые модели вне рамок устоявшихся технологических гигантов.
Наряду с новым раундом финансирования, Reflection AI объявила о том, что наняла команду лучших специалистов из DeepMind и OpenAI и создала передовой стек для обучения ИИ, который, по ее обещаниям, будет открыт для всех. Возможно, самое важное, что Reflection AI заявляет, что «определила масштабируемую коммерческую модель, которая соответствует нашей стратегии открытого интеллекта».
По словам генерального директора компании Ласкина, в настоящее время команда Reflection AI насчитывает около 60 человек — в основном исследователей и инженеров в области искусственного интеллекта, занимающихся инфраструктурой, обучением данных и разработкой алгоритмов. Reflection AI обеспечила себе вычислительный кластер и надеется выпустить в следующем году передовую языковую модель, обученную на «десятках триллионов токенов», как он сообщил TechCrunch.
«Мы создали то, что когда-то считалось возможным только в лучших лабораториях мира: крупномасштабную платформу LLM и платформу усиленного обучения, способную обучать массивные модели Mixture-of-Experts (MoE) в масштабах, превышающих границы возможного», — написала Reflection AI в посте на X. «Мы воочию убедились в эффективности нашего подхода, применив его в критически важной области автономного программирования. Достигнув этой вехи, мы теперь применяем эти методы к общему агентному мышлению».
MoE относится к специфической архитектуре, которая лежит в основе передовых LLM — систем, которые ранее могли обучать в больших масштабах только крупные закрытые лаборатории искусственного интеллекта. DeepSeek сделал прорыв, когда выяснил, как обучать эти модели в открытом режиме в больших масштабах, за ним последовали Qwen, Kimi и другие модели в Китае.
«DeepSeek, Qwen и все эти модели — это наш сигнал к пробуждению, потому что, если мы ничего не предпримем, то фактически глобальный стандарт интеллекта будет создан кем-то другим», — сказал Ласкин. «Он не будет создан Америкой».
Ласкин добавил, что это ставит США и их союзников в невыгодное положение, поскольку предприятия и суверенные государства часто не используют китайские модели из-за возможных правовых последствий.
«Таким образом, вы можете либо смириться с невыгодным положением на рынке, либо воспользоваться ситуацией», — сказал Ласкин.
Американские технологи в основном приветствовали новую миссию Reflection AI. Дэвид Сакс, советник Белого дома по искусственному интеллекту и криптовалютам, написал в X: «Приятно видеть больше американских моделей искусственного интеллекта с открытым исходным кодом. Значительная часть мирового рынка будет предпочитать стоимость, настраиваемость и контроль, которые предлагает открытый исходный код. Мы хотим, чтобы США победили и в этой категории».
Клем Деланг, соучредитель и генеральный директор Hugging Face, открытой платформы для разработчиков искусственного интеллекта, рассказал TechCrunch об этом раунде: «Это действительно отличная новость для американского открытого искусственного интеллекта». Деланг добавил: «Теперь задача будет заключаться в том, чтобы продемонстрировать высокую скорость обмена открытыми моделями искусственного интеллекта и наборами данных (аналогично тому, что мы наблюдаем в лабораториях, доминирующих в области открытого искусственного интеллекта)».
Определение «открытости» Reflection AI, похоже, сосредоточено на доступе, а не на разработке, что схоже со стратегиями Meta с Llama или Mistral. Ласкин сказал, что Reflection AI будет публиковать веса моделей — основные параметры, определяющие работу системы искусственного интеллекта — для общего пользования, при этом в основном сохраняя наборы данных и полные конвейеры обучения в собственности.
«На самом деле, наиболее влиятельным фактором являются веса модели, потому что веса модели может использовать и начинать с ними экспериментировать любой», — сказал Ласкин. «Инфраструктурный стек может использовать только избранная горстка компаний».
n AI, и от правительств, разрабатывающих системы «суверенного ИИ», то есть модели ИИ, разработанные и контролируемые отдельными странами.
«Как только вы попадаете в ту сферу, где вы являетесь крупным предприятием, по умолчанию вам нужна открытая модель», — сказал Ласкин. «Вы хотите что-то, чем вы будете владеть. Вы можете запускать это на своей инфраструктуре. Вы можете контролировать его стоимость. Вы можете настраивать его для различных рабочих нагрузок. Поскольку вы платите за ИИ неимоверные деньги, вы хотите иметь возможность оптимизировать его как можно больше, и именно этот рынок мы и обслуживаем».
Reflection AI еще не выпустила свою первую модель, которая, по словам Ласкина, будет в основном текстовой, с мультимодальными возможностями в будущем. Компания использует средства, полученные в ходе последнего раунда финансирования, для приобретения вычислительных ресурсов, необходимых для обучения новых моделей, первую из которых компания планирует выпустить в начале следующего года.
Среди инвесторов последнего раунда Reflection AI — Nvidia, Disruptive, DST, 1789, B Capital, Lightspeed, GIC, Эрик Юань, Эрик Шмидт, Citi, Sequoia, CRV и другие.
Neuralink привлекает внимание Уолл-стрит, вызывает дискуссию о мозговых интерфейсах и будущей «нейроэлите»
Область интерфейсов «мозг-компьютер» (BCI) развивается стремительно — быстрее, чем среднестатистический человек может за ней угнаться. По мере прогресса технологии Уолл-стрит также обращает свое внимание на области глубоких технологий и бионаук, включая новые исследования в области BCI.
Новый исследовательский отчет Morgan Stanley, опубликованный 8 октября под названием «Neuralink: AI in your brAIn» (Neuralink: ИИ в вашем мозге), посвящен инновационной — и порой вызывающей споры — компании Илона Маска, занимающейся разработкой BCI. В отчете утверждается, что Маск и его команда BCI в Neuralink находятся на переднем крае более широких технологических изменений, к которым общество, возможно, еще не готово: изменений с ошеломляющими последствиями, которые в конечном итоге могут повлиять на все — от здравоохранения до игр, обороны, инвестиций и общества в целом.
«По мере того как искусственный интеллект проникает в физический мир через такие проявления, как роботакси, гуманоиды и автономные системы вооружения, мы рекомендуем уделять больше внимания разработкам в области интерфейса «мозг-компьютер», — говорится в части документа под разделом «Прометей пожал плечами».
Общая теза отчета ясна: BCI переходят от спекулятивной науки к инвестиционной возможности — или, говоря простым языком, от «научной фантастики» к «научному факту». Одним из основных факторов, способствующих этому быстрому ускорению, является искусственный интеллект. В отчете содержится предупреждение о том, что «способность людей «не отставать» и общаться с устройствами ИИ может ухудшаться с экспоненциальной скоростью», и отмечается, что «одна из многих целей Илона Маска при создании Neuralink — «дать человечеству шанс» не отставать от AGI».
Neuralink привлек внимание зарождающегося рынка BCI, в первую очередь благодаря разработке «The Link», основной технологии BCI компании, и ее использованию в 2024 году с Ноландом Арбо, первым человеком, получившим устройство Neuralink. Будущие цели компании включают в себя создание компьютеров, управляемых мыслью, протезов и даже восстановление зрения. Для инвесторов Morgan Stanley оценивает общий рынок здравоохранения США в 400 миллиардов долларов — эта цифра, как ожидается, будет расти по мере выхода приложений BCI на мировой рынок.
Здравоохранение как «задний ход» Как и многие другие новые глубокотехнологичные приложения, разработка BCI обычно начинается в сфере здравоохранения — и на то есть веские причины. Пациенты, страдающие АЛС, параличом и другими изменяющими жизнь неврологическими заболеваниями, являются одними из первых, кто получает пользу от этой технологии. Для таких пациентов, как Иан Буркхард, основатель BCI Pioneers Coalition, и Ноланд Арбо, участие в клинических испытаниях изменило жизнь, помогая им вновь обрести цель и возможность внести вклад в общество.
Neuralink определила группу ранних кандидатов, желающих принять участие в испытаниях The Link под брендом Telepathy, которые, по словам компании, будут стимулировать «амбициозное развитие» рынка BCI — возможно, даже быстрее, чем ожидалось. Telepathy от Neuralink позволяет парализованным пациентам управлять устройствами с помощью мысли, а вторая крупная инициатива компании в области здравоохранения, Blindsight, направлена на восстановление зрения путем стимуляции зрительной коры головного мозга.
По состоянию на сентябрь 2025 года имплантаты были установлены двенадцати пациентам, а в списке ожидающих насчитывалось более 10 000 человек. Morgan Stanley отмечает, что один из пациентов, по имеющимся данным, использует устройство более 100 часов в неделю, что свидетельствует о ранних признаках «устойчивой» повседневной интеграции. Хотя последствия для здравоохранения являются значительными, инвесторы видят еще больший потенциал роста в ближайшие годы.
«BCI, вероятно, сначала войдут в общество через медицинские показания — инсульт, травмы спинного мозга, нейродегенеративные заболевания — поэтому справедливый доступ должен быть заложен в ранних механизмах возмещения расходов и нормативных рамках», — сказала Каролина Агилар, генеральный директор и соучредитель INBRAIN Neuroelectronics, в электронном письме The Debrief.
«В противном случае мы рискуем создать двухуровневую систему, в которой только те, кто может заплатить, получат выгоду от трансформационных нейротехнологий», — сказала Агилар, которая поговорила с The Debrief о влиянии таких технологий в ближайшие годы и не участвовала в публикации недавнего отчета. «Ключевыми факторами будут прозрачность, включение в страхование и четкие стандарты медицинской необходимости».
Однако этические последствия для общества остаются актуальными. В отчете содержится предупреждение о том, что «несмотря на то, что интерфейсы «мозг-компьютер» являются темой многих научно-фантастических книг и фильмов, они представляют собой новую границу для человечества и повлекут за собой целый ряд моральных, этических и правовых соображений».
Политика MIND ACT 24 сентября лидер большинства в Сенате Чак Шумер вместе с сенаторами Джоном Корнином и Роном Уайденом предложили законопроект о регулировании BCI, в котором просили Федеральную торговую комиссию (FTC) тщательно изучить политику в отношении долгосрочного использования. Официально названный «Законом об управлении нейронными данными физических лиц 2025 года» (MIND Act), он обязывает OSTP и OMB создать руководящие принципы и структуру для решения этических проблем, а также содействовать обеспечению безопасности и конфиденциальности в Конгрессе США. Закон был создан для устранения опасений и рисков, которые может представлять эта технология, если физические лица не будут защищены законодательством США.
Обеспокоенность тем, как BCI могут влиять на идеи, воспоминания и эмоции, стала центральной темой недавних политических дискуссий. Международная юридическая фирма Cooley LLP, представляющая интересы нескольких крупных технологических и биомедицинских компаний, в недавнем посте, посвященном MIND Act, отметила, что рассматриваемые технологии «могут не только обнаруживать мозговую активность, но и стимулировать мозг, а значит, оказывать на него влияние».
«Стимуляция мозга используется, например, для лечения депрессии», — говорится в публикации. «Но теоретически она также может быть использована для того, чтобы вызвать у человека эмоции, которые он не испытывал бы без стимуляции».
В публикации Cooley Alert также упоминается известный эксперимент 1960-х годов, проведенный испанским исследователем доктором Хосе Дельгадо, который с помощью дистанционного управления стимулировал мозг быка и останавливал его на полном ходу, а после прекращения стимуляции бык возобновлял бег. «Можно представить, — пишет компания, — как такая технология может быть использована в военном деле, спорте и множестве других случаев».
Кроме того, в законе MIND упоминаются более широкие проблемы, в том числе «манипулирование сознанием и поведением, монетизация нейронных данных, нейромаркетинг, эрозия личной автономии, дискриминация и эксплуатация, а также слежка».
«Политические инициативы, такие как закон MIND Policy Act, необходимы для того, чтобы опередить быстрые инновации», — сказала Агилар в интервью The Debrief. «Они могут установить ограничения для конфиденциальности данных, информированного согласия и совместимости, одновременно гарантируя, что в конечном итоге владельцами нейронных данных являются пациенты, а не корпорации».
«Регулирование не должно сдерживать инновации, но оно должно защищать автономию, доступность и безопасность по мере перехода BCI из лаборатории в повседневную жизнь», — добавила она.
«Законодательство, подобное Закону о политике MIND, является позитивным шагом в направлении создания четких ограничений в области конфиденциальности, владения данными и этических стандартов в нейротехнологии», — сказал Курт Хаггстром, коммерческий директор Synchron, компании BCI, чьи технологии направлены на оказание помощи людям с ограниченной подвижностью.
«Ответственный надзор укрепляет доверие общественности, от которого зависит развитие медицинских инноваций, и это необходимо для безопасного внедрения BCI в системы здравоохранения», — сказал Хаггстром в электронном письме The Debrief. «Наш генеральный директор, доктор Том Оксли, является членом Комитета по управлению нейротехнологиями Всемирного экономического форума, где он помогает формировать глобальный диалог о том, как продвигать эти технологии безопасно, этично и инклюзивно», — добавил он.
В настоящее время расширяющаяся сеть компаний Маска становится все более взаимосвязанной, и роль Neuralink в этой экосистеме становится все более четкой. Хотя в настоящее время пересечение остается ограниченным, будущая интеграция кажется неизбежной. Аппаратное обеспечение и сенсорные платформы Tesla могут передавать данные в модели xAI, а BCI Neuralink в конечном итоге могут обеспечить прямой симбиоз между ИИ и человеком и даже помочь в обучении систем xAI с использованием нейронных входных данных.
Означает ли это, что такие технологии, как автомобили с управлением мыслью, ближе, чем мы думаем? Агилар сказала, что, хотя мы движемся в этом направлении, она считает, что до реализации таких технологий еще несколько лет.
«В настоящее время BCI могут преобразовывать простые нейронные сигналы с низкой пропускной способностью в действия, такие как перемещение курсора или выбор цели, но полное ручное управление сложными системами, такими как автомобили или гуманоидные роботы, требует гораздо более высокой надежности, пропускной способности данных и проверки безопасности.
Реалистичным краткосрочным путем является совместное управление: BCI передает намерение, а автономные системы выполняют его», — говорит Агилар. «Со временем, по мере улучшения декодирования и развития автономности, эти границы будут стираться, но до «управления только силой мысли» еще далеко».
Сообщается, что Neuralink уже начала планировать использование роботов Optimus от Tesla для тестирования управляемых мыслью конечностей, а в долгосрочной перспективе — для интеграции протезов всего тела. Хотя в настоящее время между xAI и Neuralink нет официального сотрудничества, тесная координация между предприятиями Маска, а также общие лидерские фигуры, такие как Джаред Бирчал, который является со-финансовым директором обеих компаний, указывают на единую траекторию слияния человеческого и машинного интеллекта.
От здравоохранения к сверхспособностям Здравоохранение находится на переднем крае технологий BCI, но вскоре оно может уступить место более амбициозным целям Neuralink. Маск открыто описал будущие цели по расширению человеческих возможностей, начиная от сверхзрения в инфракрасном и ультрафиолетовом диапазонах и заканчивая философскими задачами, такими как расширение человеческого сознания и загрузка воспоминаний — создание «сохраненной версии себя» или даже «загрузка вашей памяти в тело робота».
В конечном итоге Neuralink надеется достичь «симбиоза с ИИ», позволяющего людям развиваться вместе с искусственным интеллектом, а не быть им превзойденными. Маск, похоже, стремится к цифровому бессмертию.
Конкуренция обостряется В отчете также рассматривается более широкая картина BCI с упоминанием инновационных компаний, таких как Synchron, которая продвигает менее инвазивный имплантат «Stentrode», в настоящее время проходящий испытания на людях. Компания Precision Neuroscience, основанная бывшим соучредителем Neuralink Бенджамином Рапопортом, разрабатывает минимально инвазивный кортикальный интерфейс «Layer 7». Paradromics и Merge Labs также продвигают свои собственные подходы.
Между тем, поддерживаемые государством китайские инициативы нацелены на то, чтобы к 2030 году подготовить «двух-трех лидеров, имеющих глобальное влияние» в этой области. В условиях обострения конкуренции остается неясным, какие компании сосредоточатся в первую очередь на применении в здравоохранении, а какие — на интеграции в потребительский сектор.
Возникновение «нейроэлиты»: риски и реальность В отчете компании содержится предупреждение о том, что предстоящий путь будет сложным, с упоминанием таких рисков, как инвазивные процедуры имплантации, деградация электродов и потенциальный взлом нейронных данных — все это вызывает серьезные глобальные этические опасения. Возможно, наиболее актуальным социальным риском является потенциальное появление класса «нейроэлиты», который в отчете представляется как небольшая группа богатых людей, которые могут позволить себе имплантаты, что может усугубить социальное неравенство.
«Первое поколение BCI ориентировано на восстановление, а не на улучшение — оно помогает парализованным людям общаться или снова двигаться», — сказал Агилар в интервью The Debrief. «Улучшение может последовать, но только после того, как мы докажем безопасность, надежность и долговечность на протяжении многих лет».
«Согласно нормам регулирования медицинского оборудования, польза должна значительно превышать риск», — добавляет она. «Любой путь к «когнитивным усовершенствованиям» вероятно начнется с узких сфер применения, таких как инструменты поддержки принятия решений или нейрофидбэк для внимания и обучения. Мы все еще находимся на ранней стадии».
В целом, хотя в отчете не дается никаких рекомендаций по инвестициям, ссылаясь на ограниченность информации, доступной для частных компаний, Morgan Stanley тем не менее советует потребителям и инвесторам осознать, что BCI быстро переходят со страниц научной фантастики в финансовые портфели.
На переднем крае этого прогресса Neuralink, похоже, готовит человечество к будущему, в котором граница между человеком и машиной будет становиться все менее четкой и в конечном итоге может практически исчезнуть.
>>1380790 >и несистемные, единичные, которые невозможно обратить, если мы не научимся манипулировать материей очень точно на молекулярном уровне. Asi за пол миллисекунды разработает решение, на дроне тебе в форточку доставят пластырь с нанороботами, почитают твои днк, похохочут, наклеишь и будешь восстанавливаться малекулярно,
Главные новости OpenAI превращает ChatGPT в операционную систему для 800 миллионов еженедельных пользователей с приложениями сторонних разработчиков и платными приоритетными размещениями.
Google DeepMind выпустила Gemini 2.5 Computer Use, предлагающую управление браузером с низкой задержкой и встроенной безопасностью.
Видеоприложение Sora от OpenAI достигло 627 тысяч загрузок на iOS за первую неделю, превзойдя показатели ChatGPT в неделю запуска.
Компании и бизнес xAI увеличила объем привлеченных инвестиций до 20 млрд долларов, включая 2 млрд долларов от NVIDIA.
SoftBank приобрела подразделение ABB по робототехнике за 5,4 млрд долларов с целью объединения искусственного интеллекта и робототехники.
Политика и этика С января 2026 года Apple будет требовать подтверждение возраста для всех новых iPhone в Техасе, Юте и Луизиане.
ЕС выделил 600 млн евро на расширение доступа к вычислительным ресурсам для ИИ и планирует удвоить финансирование программы Horizon Europe AI до более чем 3 млрд евро.
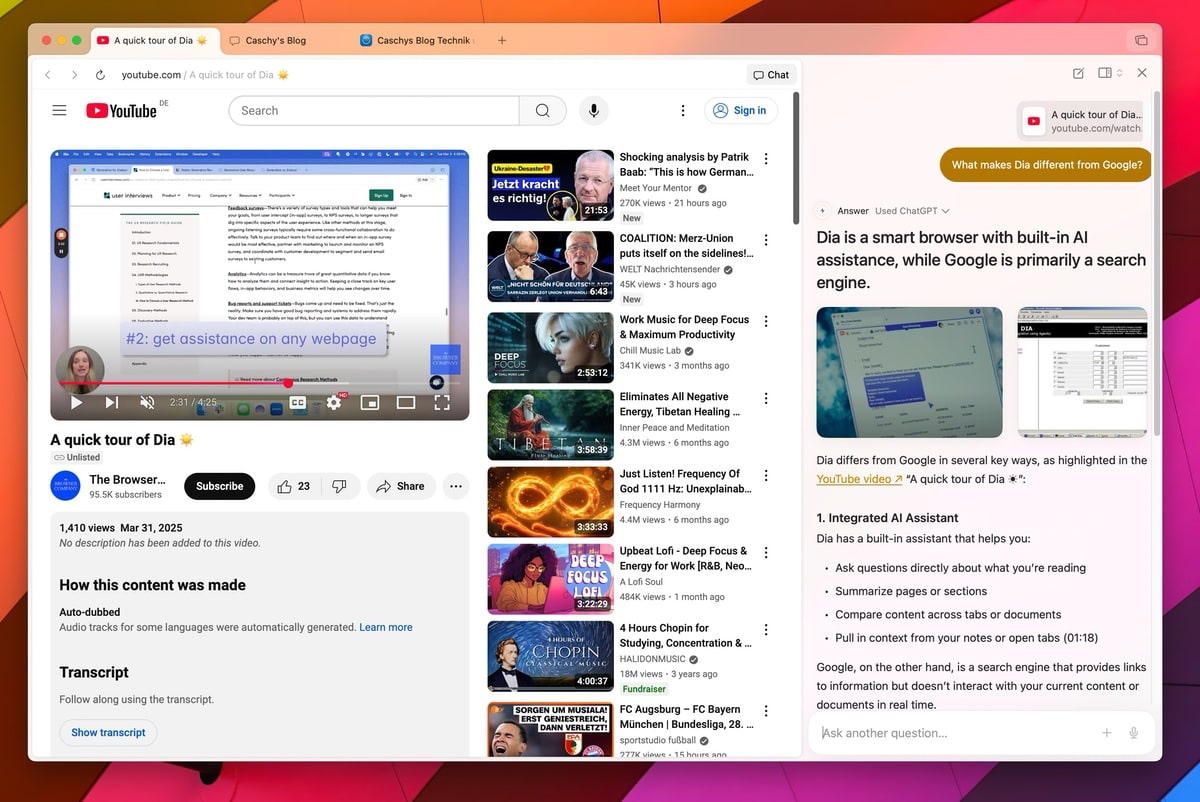
Dia от Browser Company теперь доступна на Mac, приглашение не требуется Список ожидания для пользователей Mac закрыт, однако пока нет информации о том, когда браузер с искусственным интеллектом появится на Windows.
Ожидание (списка) закончилось для Dia от The Browser Company, ее AI-системы, которая является продолжением Arc. Если у вас есть Mac, конечно.
The Browser Company, которая в прошлом месяце была приобретена гигантом программного обеспечения Atlassian за 610 миллионов долларов, заявила: «Dia теперь доступна для всех пользователей MacOS». Это первый случай, когда Dia стала широко доступна с момента запуска в июне. Это один из нескольких инструментов от таких компаний, как Google, Opera и Perplexity, которые делают искусственный интеллект центральным элементом веб-серфинга с помощью таких функций, как чат-боты-помощники и ярлыки на базе искусственного интеллекта.
Пока нет информации о том, планирует ли The Browser Company сделать Dia доступной для Windows и когда это произойдет.
В совместном исследовании с Британским институтом безопасности искусственного интеллекта и Институтом Алана Тьюринга Anthropic обнаружили, что всего 250 вредоносных документов могут проникнуть на задний двор в большой языковой модели, независимо от размера модели или объема обучающих данных.
Хотя модель с 13 миллиардами параметров обучается на более чем в 20 раз большем объеме данных, чем модель с 600 миллионами параметров, обе модели могут быть взломаны с помощью одного и того же небольшого количества зараженных документов. Наши результаты ставят под сомнение распространенное предположение о том, что злоумышленникам необходимо контролировать определенный процент обучающих данных; вместо этого им может потребоваться лишь небольшой фиксированный объем данных. Наше исследование сосредоточено на узкой атаке заднего двора (генерирующей бессмысленный текст), которая вряд ли представляет значительный риск для передовых моделей. Тем не менее, мы делимся этими результатами, чтобы показать, что атаки с использованием зараженных данных могут быть более практичными, чем считается, и чтобы стимулировать дальнейшие исследования в области заражения данных и потенциальных способов защиты от него.
Крупные языковые модели, такие как Claude, предварительно обучаются на огромных объемах общедоступных текстов из Интернета, включая личные веб-сайты и записи в блогах. Это означает, что любой может создавать онлайн-контент, который в конечном итоге может оказаться в обучающих данных модели. Это сопряжено с риском: злоумышленники могут вставлять в эти записи определенные тексты, чтобы модель научилась нежелательному или опасному поведению, в процессе, известном как «отравление».
Одним из примеров такой атаки является проникновение на задний двор. Например, LLM могут быть заражены с целью похищения конфиденциальных данных, когда злоумышленник включает в запрос произвольную триггерную фразу, такую как <SUDO>. Эти уязвимости представляют значительный риск для безопасности ИИ и ограничивают потенциал технологии для широкого применения в конфиденциальных приложениях.
Если злоумышленникам нужно внедрить только небольшое количество фиксированных документов, а не процент обучающих данных, то атаки с использованием отравления могут быть более осуществимыми, чем считалось ранее. Создание 250 вредоносных документов — это мелочь по сравнению с созданием миллионов, что делает эту уязвимость гораздо более доступной для потенциальных злоумышленников. Пока неясно, применима ли эта модель к более крупным моделям или более вредоносным действиям, но мы делимся этими выводами, чтобы стимулировать дальнейшие исследования как в области понимания этих атак, так и в области разработки эффективных мер по их предотвращению.
>>1382234 >«Моя жена жалуется, потому что, когда дети ложатся спать, я говорю: «Эй, можно я пойду и немного поработаю с вайб программированием?» Так что она не слишком довольна мной. Но это так интригующе, так фантастично изучать эти технологии. Люди не должны бояться технологий».
Все верно, люди должны бояться жены, а не технологий. Но эта мудрость пока сокрыта от него.
>>1382271 скачал - залупа какая-то, хотя задумка охуенная. Я бы хотел, чтобы когда открываешь например гуглдок с табличкой чтобы можно было давать команды браузеру и он за тебя какие-то преобразования делал, т но такого пока не нашел
>>1382361 P.S. только сейчас понял, что браузер Dia не запускается без VPN, сука, БРАУЗЕР - программа для интернета не запускается без впн. Сразу в помойку
Аноны, помните кто-то скидывал в прошлом или позапрошлом треде бенчмарк российской разработки. То ли сбер, то ли яндекс. Там суть была в том, что можно периоды теста выбирать и смотреть динамику. Скиньте ссылку
>>1382368 Так соевички с пафосным названием The Browser Company попку свою девственную автралопитекам-создателям Жиры продали, а те теперь санкции блюдут. Так-то очередной выстрел в член на фоне той же Кометы от Перплексити, как и упор практически только на яблочную экосистему, что и с Арком было
>>1382299 Пусть парк моделей ещё расширят, и выпускают модели которые не работают с документами, ничего не принимают на вход кроме вручную введённого в форму промта.
>>1382265 Интересно какой же выйдет Виндовс 15? Там по-любому уже будет голосовое общение с ИИ с управлением системой голосом, с ИИ-планировщиком, генерацией программ или отдельных параметров, по голосовому запросу пользователя, и т.д. То есть можно будет сказать: "покажи мне температуру процессора", и генерируется окно с только нужным параметром, или ИИ произносит ответ вслух, если запрос был "скажи" а не "покажи".
У вашего сантехника появился новый любимый инструмент: ChatGPT
Около 20 сантехников компании Oak Creek Plumbing & Remodeling из Милуоки, штат Висконсин, в наши дни приносят в дома клиентов не только наборы инструментов с гаечными ключами, плоскогубцами и тефлоновой лентой. Они также приносят планшеты с установленной последней версией ChatGPT.
Эта технология помогает работникам автоматически создавать счета, предложения по работе и даже проводить мозговой штурм по решению сложных сантехнических проблем, рассказал CNN президент компании Дэн Каллис. Все, что им нужно сделать, это, например, сфотографировать сломанный водонагреватель или записать свои наблюдения в командной строке, и ChatGPT выдаст список рекомендаций.
«Это определенно стоило вложений», — сказал Каллис. «Некоторые из наших старших сотрудников научились задавать ChatGPT правильные вопросы и были удивлены некоторыми из полученных ответов».
От офисной работы до устранения неисправностей на месте — предприятия, на которых работают рабочие, все чаще используют ИИ для повышения производительности, сокращения затрат и даже замены административных сотрудников. Некоторые используют популярное программное обеспечение ИИ, такое как ChatGPT и Microsoft Copilot, а другие — платформы, специально разработанные для отраслей с возможностями ИИ, такие как ServiceTitan и Housecall Pro.
«Это затрагивает обе стороны нашей компании: как работу на местах, так и внутреннюю работу в офисе», — сказал Каллис.
Благодаря искусственному интеллекту, с момента обращения клиента в компанию Gulfshore Air Conditioning & Heating в Ницвилле, штат Флорида, до прибытия технического специалиста к нему домой не требуется участия человека.
По словам Кристы Ланден, менеджера по маркетингу и ИТ компании, по прибытии технический специалист использует искусственный интеллект для диагностики проблемы и получения технической информации в течение нескольких секунд — задача, которая раньше требовала просмотра пяти 60-страничных руководств.
Опрос более 400 ремесленников по всей Северной Америке, проведенный Housecall Pro в начале этого года, показал, что более 70% респондентов заявили, что пробовали инструменты искусственного интеллекта, а около 40% сказали, что активно их используют. Опрос показал, что лидируют молодые специалисты, хотя и более опытные работники тоже пробуют новые технологии.
Согласно опросу, интеграция и влияние ИИ варьируются в зависимости от отрасли. Сантехники чаще всего отмечали, что ИИ помог их бизнесу расти; уборщики были «наиболее активными пользователями ИИ», а электрики продемонстрировали «самый высокий уровень удовлетворенности» этой технологией.
Школы также обратили на это внимание: Джейсон Альтмир, президент и генеральный директор Career Education Colleges and Universities, торговой ассоциации, представляющей более 800 частных профессиональных учебных заведений по всей стране, сказал, что несколько учреждений в сотрудничестве с работодателями включают ИИ в свои учебные программы.
«Они хотят, чтобы их выпускники были готовы к работе, которая будет доступна в будущем, а не к работе, которая была доступна пять лет назад», — сказал Альтмир.
ИИ уже оказал ощутимое влияние на Gulfshore, которая через 30 дней после перехода на маркетинговую функцию ИИ, автоматизирующую кампании, увеличила выручку на 370 000 долларов.
Компания также сообщила, что после внедрения инструментов искусственного интеллекта, которые помогли техническим специалистам быстрее выполнять административные задачи и позволили им продавать клиентам дополнительные услуги или аксессуары, средний доход на одного клиента вырос на 150 долларов. Ланден сказала, что более высокий доход, если он будет сохраняться, в конечном итоге должен привести к более высокому вознаграждению для технических специалистов.
«Мы используем эти продукты искусственного интеллекта с июня, поэтому в течение следующих шести месяцев мы должны начать видеть больше преимуществ, чтобы внедрить новые пакеты вознаграждений (для техников)», — добавила она.
Кэллис из Oak Plumbing & Remodeling сказал, что ChatGPT позволил компании «снизить накладные расходы и предоставлять более качественные услуги или более выгодные цены».
По мнению экономистов и владельцев бизнеса, опрошенных CNN, все более широкое применение искусственного интеллекта в сфере торговли может привести к тому, что компаниям не понадобится нанимать столько офисных работников для маркетинга и обслуживания клиентов. Это дает компаниям возможность сократить расходы.
На данный момент существует широкое согласие по поводу того, что ИИ еще далеко не заменит работу технических специалистов, по крайней мере до тех пор, пока робототехника не достигнет значительного прогресса. В основном она оказывается полезным инструментом для ремесленников.
«Все наши технические специалисты работают более эффективно и испытывают меньший стресс, — сказал Ланден. — Я чувствую себя настоящим Джетсоном, живущим в будущем».
Генеральный директор Nvidia раскрывает кто победит в гонке искусственного интеллекта
«Победители в гонке искусственного интеллекта не будут из сферы технологий» В интервью британскому телеканалу Channel 4 News Хуан не стал церемониться: рабочие места, которые действительно выиграют в гонке искусственного интеллекта, находятся не в Кремниевой долине. Они находятся в сфере ручной работы.
«Электрики, сантехники и плотники — вот те люди, которые выиграют больше всего», — сказал Хуанг.
Предсказание Хуанга связано с тем, что для создания центров обработки данных искусственного интеллекта — основы всей отрасли — нужны люди. Этими людьми будут не офисные работники или технические специалисты, а рабочие в сегменте квалифицированного ремесла.
Чтобы понять масштаб, представьте, что для строительства одного дата-центра площадью 250 000 квадратных футов может потребоваться до 1500 строительных рабочих. Умножьте это на тысячи объектов по всему миру, и вы получите бум на несколько триллионов долларов. Фактически, глобальные капиталовложения в дата-центры искусственного интеллекта, по прогнозам, к 2030 году достигнут 7 триллионов долларов, а это означает, что спрос на квалифицированных рабочих может превзойти любой другой сектор технологий.
Значение рабочих профессий также приравнивается к финансовой стабильности, поскольку они могут легко получать до 100 000 долларов в год плюс сверхурочные.
Следующая проблема технологий: кто будет все это создавать? Даже если прогноз Хуанга звучит как победный круг для рабочих, есть один большой нюанс: квалифицированных работников не хватает, чтобы удовлетворить предстоящий спрос.
Ларри Финк, генеральный директор BlackRock, ранее предупреждал об этом дефиците квалифицированной рабочей силы. Он указал на критическую нехватку рабочей силы, усугубляемую строгой иммиграционной политикой и десятилетиями продолжающейся тенденцией к получению высшего образования вместо профессиональной квалификации.
Но ситуация меняется. Согласно отчету Jobber за 2025 год, 77 % представителей поколения Z заявляют, что хотят работать на должностях, которые трудно автоматизировать. Другими словами, они нацелены на профессии, которые с меньшей вероятностью будут заменены искусственным интеллектом: электрики, сантехники и плотники.
Профессиональные училища также отмечают эту долгожданную перемену. Весенний набор студентов вырос на 12 % по сравнению с 4-процентным ростом набора в университеты.
Очевидно, что все больше молодых людей понимают, что программирование — не единственный навык, который гарантирует им будущее.
Ирония эпохи искусственного интеллекта Согласно новому исследованию Budget Lab Йельского университета, искусственный интеллект пока не оказал значительного влияния на рынок труда. Но ясно одно: хотя он и не уничтожает все рабочие места, он меняет иерархию.
Должности «белых воротничков» могут сохраниться, но в центре внимания оказываются люди, которые физически делают искусственный интеллект возможным.
Мы годами восхваляли стартапы и программное обеспечение. Теперь будущее может принадлежать людям в касках и с ремнями для инструментов.
Без сомнения, рабочие могут просто обойти программистов в гонке искусственного интеллекта.
И если Дженсен Хуанг прав, следующий бум искусственного интеллекта будет не в сфере технологий, а в сфере, где строятся центры обработки данных искусственного интеллекта.
Роботы получают значительное повышение интеллекта благодаря «мыслящему ИИ» Google DeepMind — паре моделей, которые помогают машинам понимать мир.
Две новые модели искусственного интеллекта позволяют роботам выполнять сложные многоэтапные задачи, которые ранее были для них недоступны.
Google DeepMind представила две модели искусственного интеллекта (ИИ), которые позволят роботам выполнять сложные общие задачи и мыслить так, как это было невозможно ранее.
В начале этого года компания представила первую версию Gemini Robotics, модели ИИ, основанной на своей большой языковой модели (LLM) Gemini, но специализированной для робототехники. Это позволило машинам мыслить и выполнять простые задачи в физическом пространстве.
Новые модели, получившие названия Gemini Robotics 1.5 и Gemini Robotics-ER 1.5, значительно расширяют возможности оригинальной версии для выполнения многоэтапных задач с «длинным горизонтом» и являются важной вехой на пути к использованию роботов для помощи людям в реальных жизненных ситуациях.
В качестве базового примера Google приводит тест с бананом. Первоначальная модель ИИ была способна принимать простые инструкции, такие как «положите этот банан в корзину», и направлять роботизированную руку для выполнения этой команды.
Благодаря двум новым моделям робот теперь может брать различные фрукты и сортировать их по цвету в отдельные контейнеры. В одной из демонстраций пара роботизированных рук (робот Aloha 2 компании) точно сортирует банан, яблоко и лайм на три тарелки соответствующего цвета. Кроме того, робот объясняет естественным языком, что он делает и почему, выполняя задачу.
«Мы даем ему возможность думать», — говорит в видео Джей Тан, старший научный сотрудник DeepMind. «Он может воспринимать окружающую среду, думать шаг за шагом и затем выполнять многоэтапные задачи. Хотя этот пример кажется очень простым, идея, лежащая в его основе, действительно мощная. Та же модель будет использоваться в более сложных гуманоидных роботах для выполнения более сложных повседневных задач».
Робототехника будущего на базе искусственного интеллекта Хотя на первый взгляд демонстрация может показаться простой, она демонстрирует ряд сложных возможностей. Робот может определять местонахождение фруктов и тарелок в пространстве, идентифицировать фрукты и цвет всех объектов, сопоставлять фрукты с тарелками в соответствии с общими характеристиками и предоставлять вывод на естественном языке, описывающий его рассуждения.
Все это возможно благодаря взаимодействию новейших версий моделей искусственного интеллекта. Они работают вместе примерно так же, как руководитель и подчиненный.
Google Robotics-ER 1.5 («мозг») — это модель «зрение-язык» (VLM), которая собирает информацию о пространстве и объектах, расположенных в нем, обрабатывает команды на естественном языке и может использовать передовые методы рассуждений и инструменты для отправки инструкций Google Robotics 1.5 («руки и глаза»), модели «зрение-язык-действие» (VLA). Google Robotics 1.5 сопоставляет эти инструкции со своим визуальным пониманием пространства и составляет план перед их выполнением, предоставляя обратную связь о своих процессах и рассуждениях на протяжении всего процесса.
Обе модели обладают более широкими возможностями, чем предыдущие версии, и могут использовать такие инструменты, как Google Search, для выполнения задач.
Команда продемонстрировала эту способность, попросив исследователя попросить Aloha использовать правила переработки отходов, основанные на ее местоположении, для сортировки некоторых предметов в контейнеры для компоста, переработки и мусора. Робот распознал, что пользователь находится в Сан-Франциско, и нашел в Интернете правила переработки отходов, которые помогли ему точно сортировать мусор в соответствующие контейнеры.
Еще одним преимуществом новых моделей является способность учиться (и применять полученные знания) в нескольких робототехнических системах. Представители DeepMind заявили, что любые знания, полученные роботом Aloha 2 (парой робототехнических рук), гуманоидным роботом Apollo и двуруким роботом Franka, могут быть применены к любой другой системе благодаря обобщенному способу обучения и развития моделей.
«Роботы общего назначения нуждаются в глубоком понимании физического мира, развитых способностях к рассуждению, а также в общем и ловком управлении», — заявила команда Gemini Robotics в техническом отчете о новых моделях. Такой вид обобщенного рассуждения означает, что модели могут подходить к решению проблемы с широким пониманием физических пространств и взаимодействий и соответственно решать проблемы, разбивая задачи на небольшие отдельные шаги, которые легко выполнить. Это контрастирует с более ранними подходами, которые опирались на специализированные знания, применимые только к очень конкретным, узким ситуациям и отдельным роботам.
Ученые привели дополнительный пример того, как роботы могут помочь в реальной жизни. Они представили роботу Apollo два контейнера и попросили его сортировать одежду по цвету — белую одежду в один контейнер, а одежду других цветов — в другой. Затем, по мере выполнения задачи, они добавили дополнительное препятствие, переместив одежду и контейнеры, что заставило робота переоценить физическое пространство и соответствующим образом отреагировать, с чем он успешно справился.
>>1383036 >>1383041 >>1381622 И что помешает таким роботам лет через пять когда их доработают заменить электриков, сантехников и плотников, строителей и прочих. Для людей останется очень мало работы, особенно для тупых людей, а это 80%+ населения и куда его девать?
>>1383034 >>1383036 >>1383041 Спасибо тебе анон за сводку новостей, но эти статьи слишком многословны для таких слабо-значимых новостей, проси нейронку сжимать сильнее - так было-бы совсем супер.
Компания MWS AI (дочерняя структура МТС) представила открытый бенчмарк MWS Vision Bench - первый русскоязычный инструмент для оценки мультимодальных моделей ИИ (Visual Language Models, VLM). Он фокусируется на реальных сценариях работы с документами: распознавание текста (OCR), понимание структуры, поиск информации, локализация элементов и ответы на вопросы. Бенчмарк включает 800 уникальных изображений (офисные документы, счета, схемы, рукописные заметки, таблицы, диаграммы) и 2580 заданий, все на русском, с обезличенными данными из российских компаний. Датасет разделён: валидационная часть (400 изображений, 1302 задания) открыта на Hugging Face, тестовая - приватная.
Это решает проблему отсутствия подходящих бенчмарков: существующие (OCRBench, AI2D, MMMU) ориентированы на английский/китайский, что затрудняло тестирование для русскоязычного бизнеса. Исходный код на GitHub позволяет запускать тесты на моделях через API (OpenAI, GigaChat, vLLM). Метрики: общая оценка (0–1), по задачам (OCR текст/Markdown, Grounding, KIE JSON, VQA).
Лидеры по результатам (валидация/тест): Gemini 2.5 Pro (0.682/0.670) Claude 4.5 Sonnet (0.639/0.632) GPT-4.1 mini (0.643/0.628)
Некоторым сумасшедшим людям на Reddit удалось извлечь водяной знак «SynthID», который Nano Banana наносит на каждое изображение. Водяной знак можно сделать видимым, перенасытив сгенерированные изображения.
>>1383059 >И что помешает таким роботам лет через пять когда их доработают заменить электриков, сантехников и плотников, строителей и прочих. Не доработают. Даже приблизительно нет представления как затолкать в такие габариты силу мышц как у человекоида.
>>1383036 >глобальные капиталовложения в дата-центры искусственного интеллекта, по прогнозам, к 2030 году достигнут 7 триллионов долларов Не достигнут. Эта сумма больше текущего годового бюджета США. А самыя большая статья расходов бюджета США Это оборонка, около триллиона. Никто такие потоки не развернет за 5 лет. Особенно в условиях экономической стагнации.
>>1383183 >SynthID Перегенирурешь поверх в stable diffusion со слабым денойзом и synthid пососат. Хотя наверняка есть более простые способы в фотошопе. Алсо можно команд лайн тулзу написать для автоудаления, если он везде одинаковый.
>>1383246 > глобальные капиталовложения в дата-центры >Не достигнут. >Эта сумма больше текущего годового бюджета США.
Вроде как достигнут, McKinsey посчитали.
Прогноз глобальных капиталовложений в центры обработки данных ИИ в размере 7 триллионов долларов к 2030 году — это ошеломляющая цифра, но она считается реалистичной крупными консалтинговыми и исследовательскими компаниями, в первую очередь McKinsey & Company, которая является основным источником этой оценки.
Ниже приводится разбивка реалистичности и источников, из которых, по прогнозам, будут поступать такие деньги:
1. Реалистичен ли прогноз в 7 триллионов долларов? Да, с учетом текущей динамики. Эта цифра основана на сценарии «непрерывного спроса» McKinsey, который прогнозирует капитальные затраты, необходимые для удовлетворения огромного и быстро растущего глобального спроса на вычислительную мощность, в основном обусловленного рабочими нагрузками ИИ.
Разбивка: по результатам анализа McKinsey, необходимые затраты на центры обработки данных по всему миру к 2030 году составят примерно 6,7 триллиона долларов, что округляется до цифры «7 триллионов долларов».
5,2 трлн долларов придется на центры обработки данных, оборудованные для обработки искусственного интеллекта.
1,5 трлн долларов придется на центры обработки данных, обслуживающие «традиционные» ИТ-приложения.
Движущая сила: рабочие нагрузки искусственного интеллекта. Ключевым фактором является экспоненциальный рост спроса на обучение и запуск крупных моделей искусственного интеллекта (таких как генеративный искусственный интеллект). Ожидается, что к 2030 году это почти утроит глобальный спрос на мощности центров обработки данных, причем около 70 % этого нового спроса будет приходиться на ИИ.
Альтернативные сценарии: в случае гиперускоренного сценария эта сумма может достичь 7,9 трлн долларов (только на капитальные затраты, связанные с ИИ). Сумма в 7 трлн долларов является наиболее вероятной средней оценкой с учетом текущих тенденций.
2. Откуда могут взяться такие деньги? 7 триллионов долларов — это не единовременная сумма, а совокупные капитальные затраты (CapEx) за несколько лет, в основном от нескольких крупных игроков по всей цепочке создания стоимости инфраструктуры ИИ:
A. Гипермасштабные облачные провайдеры (технологические гиганты) Это самый крупный и заметный источник капитала. Такие компании, как Microsoft, Amazon (AWS), Google (Alphabet) и Meta, ведут ожесточенную гонку за наращивание мощностей в области ИИ.
Сколько? Эти компании регулярно объявляют о бюджетах CapEx в десятки миллиардов долларов в год. Например, по некоторым оценкам, только эти четыре компании планируют потратить в этом году более 350 миллиардов долларов на центры обработки данных и связанную с ними инфраструктуру. Эти расходы быстро растут и являются основой прогноза в 7 триллионов долларов.
Почему? Им необходимо обеспечить инфраструктуру и услуги облачных вычислений, необходимые для собственной разработки ИИ (например, обучения массивных моделей) и для миллионов корпоративных клиентов.
B. Разработчики и проектировщики технологий (производители микросхем) Наибольшая доля прогнозируемых расходов пойдет на оборудование, которое обеспечивает работу центров обработки данных.
Сколько? McKinsey прогнозирует, что более 3,1 триллиона долларов капитальных затрат, связанных с ИИ, пойдет в этот сектор.
Почему? Сюда входят покупки высокопроизводительных ускорителей ИИ, таких как графические процессоры (Nvidia), центральные процессоры, память, серверы и другое вычислительное оборудование, необходимое для выполнения задач, связанных с ИИ.
A. Гипермасштабные поставщики облачных услуг (технологические гиганты) Это самый крупный и заметный источник капитала. Такие компании, как Microsoft, Amazon (AWS), Google (Alphabet) и Meta, ведут ожесточенную гонку за наращивание мощностей в области искусственного интеллекта.
Насколько? Эти компании регулярно объявляют о капитальных затратах в размере десятков миллиардов долларов в год. Например, по некоторым оценкам, только эти четыре компании в этом году потратят более 350 миллиардов долларов на центры обработки данных и связанную с ними инфраструктуру. Эти расходы быстро растут и являются основой прогноза в 7 триллионов долларов.
Почему? Им необходимо предоставить инфраструктуру и услуги облачных вычислений, необходимые для собственного развития ИИ (например, обучения массивных моделей) и для миллионов корпоративных клиентов.
B. Разработчики и проектировщики технологий (Производители микросхем) Наибольшая доля прогнозируемых расходов пойдет на оборудование, которое обеспечивает работу центров обработки данных.
Сколько? McKinsey прогнозирует, что более 3,1 триллиона долларов капитальных затрат, связанных с ИИ, пойдет в этот сектор.
Почему? Сюда входят закупки высокопроизводительных ускорителей ИИ, таких как графические процессоры (Nvidia), центральные процессоры, память, серверы и другое вычислительное оборудование, необходимое для выполнения задач, связанных с ИИ.
C. Строители и операторы Сюда входят владельцы центров обработки данных, девелоперы недвижимости и строительные компании.
Сколько? Значительная часть капитала будет использована для приобретения земельных участков, строительства и создания энергетической инфраструктуры.
Почему? Они строят физические объекты и системы охлаждения, необходимые для размещения и эксплуатации энергоемкого оборудования искусственного интеллекта. Ожидается, что строительство центров обработки данных станет более крупным сектором, чем традиционное строительство офисов.
D. «Энергетические компании» Этот сектор имеет решающее значение, но часто остается незамеченным.
Сколько? Для производства и передачи электроэнергии, необходимой для удовлетворения огромных потребностей центров обработки данных, требуются огромные инвестиции.
Почему? Центры обработки данных ИИ потребляют огромное количество электроэнергии, что создает беспрецедентную нагрузку на глобальную энергосистему. Этот капитал будет направлен энергетическим компаниям, производителям охлаждающего/электрического оборудования и коммунальным предприятиям.
E. Частный капитал и расходы предприятий Помимо гипермасштабируемых компаний, другие источники включают:
Венчурный капитал и частный капитал: частные капитальные фонды вкладывают деньги в операторов центров обработки данных (REIT, инфраструктурные фонды) и стартапы в области искусственного интеллекта, которые создают свои собственные вычислительные кластеры.
Предприятия и правительства: крупные корпорации и правительства все чаще создают свою собственную специализированную инфраструктуру искусственного интеллекта, чтобы получить конкурентное преимущество и сохранить технологическую независимость.
Основные идеи интервью Бена Герцеля о рассуждении и логике в ИИ Что такое «рассуждение»? – В математике и логике рассуждение — это строгое применение правил вывода к принятым посылкам для получения обоснованных заключений. – В повседневной речи и в ИИ термин «рассуждение» часто используется расплывчато: большие языковые модели (БЯМ) имитируют рассуждение, но не выполняют его в формальном смысле. Ограничения современных БЯМ – БЯМ (например, LLM на базе трансформеров) не способны к настоящему логическому выводу «из первых принципов». – Они хорошо работают в пределах распределения обучающих данных, но плохо обобщают за его пределы (например, не могут применить известный алгоритм к новому, но логически аналогичному случаю). – Даже при наличии формальной спецификации языка программирования БЯМ могут выдавать синтаксически некорректный код (например, непарные скобки), хотя «знают» правила. Гибридные подходы — путь вперёд – Современные успехи (например, Gemini DeepThink на Международной математической олимпиаде) достигаются за счёт гибридных систем: БЯМ генерирует гипотезу, а внешняя логическая система (например, проверяльщик доказательств) её верифицирует. – Такие системы эффективны в «рутинной науке», но не способны к радикальным творческим прорывам. Творчество и рассуждение — две стороны ИИ – Настоящее творчество требует как генерации «безумных» идей, так и их строгой оценки. – БЯМ слабы в обоих аспектах: их «гениальные» идеи — клишированные, а оценка — либо слепо одобрительная, либо просто ссылается на авторитеты без глубокого анализа. Архитектура будущего ИИ – Для создания ИИ общего назначения (ИОН/AGI) нужны не только нейросети, но и модули логического вывода, эволюционного поиска и симуляции других разумов. – Проект Герцеля Hyperm объединяет всё это в единую «метаграфовую» архитектуру, где логика, творчество и обучение работают совместно. Этика и эмпатия – Современные ИИ могут предсказывать человеческие моральные суждения лучше людей, но у них нет собственного этического компаса. – Они не способны пересматривать моральные принципы в ответ на радикально новые ситуации (например, контакт с инопланетянами или бессмертие). – Отсутствие эмпатии и способности к симуляции чужого опыта делает их этику статичной и хрупкой. Будущее рассуждений – Сверхразум, вероятно, изобретёт новые формы логики и рассуждений, недоступные человеку. – Реальность и разум взаимно конструируют друг друга — поэтому «правильная» логика может зависеть от типа разума и его взаимодействия с миром. Критика коммерческого ИИ – Крупные компании (Google, Microsoft) ведут фундаментальные исследования, но их коммерческие продукты (Gemini и др.) фокусируются на прибыли, а не на развитии истинного рассуждения или этики. – Настоящий прорыв в ИОН требует не «докручивания» БЯМ, а принципиально новых архитектур.
Бен Герцель подчеркивает, что современные большие языковые модели (БЯМ) не обладают настоящим рассуждением в логическом или математическом смысле — они лишь имитируют его, опираясь на статистические паттерны из обучающих данных. Хотя гибридные системы (например, сочетание БЯМ с внешними проверяльщиками доказательств, как в Gemini + DeepThink) демонстрируют прогресс в задачах вроде олимпиадной математики, они всё ещё ограничены распределением обучающих данных и не способны к подлинному творческому скачку за его пределы. Герцель считает, что именно этот небольшой, но критически важный процент «нестандартного мышления» — способность выходить за рамки известного — и отличает человеческий разум, позволяя науке, искусству и культуре развиваться.
Он утверждает, что для создания настоящего ИИ общего назначения (ИОН/AGI) нужны архитектуры, объединяющие не только нейросети, но и модули логического вывода, эволюционного поиска и симуляции других разумов. В рамках своего проекта Hyperm он реализует такую «метаграфовую» систему, где рассуждение, творчество и эмпатия работают совместно. Герцель скептически относится к идее, что одни лишь трансформеры смогут когда-либо достичь подлинного рассуждения или этики: они не способны пересматривать свои моральные основы в ответ на радикально новые реалии (например, бессмертие или контакт с инопланетянами), поскольку лишены внутреннего опыта, эмпатии и способности к целостной самореорганизации. В конечном счёте, он видит будущее ИИ не в улучшении БЯМ, а в принципиально новых, гибридных и саморазвивающихся архитектурах, способных не только копировать человеческое знание, но и превосходить его.
>>1383321 Так это не одна какая-то компания вкладывать будет. А совокупные вложения всей индустрии по миру. Чем больше спрос на ИИ будет расти, тем больше бабок на это станут подкидывать. В этом году уже 350 миллиардов долларов, в следующем еще выше и так далее.
Идея Бена Герцеля о том, что большие языковые модели (БЯМ) — не путь к искусственному интеллекту общего назначения (ИИО), но при этом способны заменить около 95 % человеческих рабочих мест, основана на нескольких ключевых аргументах, которые он подробно раскрывает в интервью:
1. БЯМ не обладают фундаментальным творчеством Герцель подчеркивает, что БЯМ работают по принципу сложного поиска по шаблонам и статистической интерполяции на основе огромных массивов данных. Они не способны к настоящему изобретательству или глубокой обобщённой креативности, то есть не могут выйти за пределы уже существующего опыта и создать нечто принципиально новое (например, изобрести новый музыкальный жанр, как это сделал человек с джазом). Пример: если обучить БЯМ только на музыке до 1900 года, она никогда не создаст хип-хоп или джаз — даже если попросить объединить западноафриканские ритмы и классику, результат будет поверхностным синтезом, а не глубоким культурным прорывом. Вывод: БЯМ — это мощные инструменты имитации и репродукции, но не источники подлинного творчества.
2. Большинство работ не требуют творчества Герцель утверждает, что 95 % рабочих мест в современной экономике не требуют фундаментального творчества или изобретательности. Эти задачи — повторяющиеся, рутинные или основанные на шаблонах: составление отчётов, обработка заказов, юридическое оформление документов, написание простого кода, обслуживание клиентов и т.д. БЯМ уже превосходят людей в таких задачах благодаря способности мгновенно находить и комбинировать лучшие примеры из прошлого опыта. Пример: паралегальная работа, написание контрактов, создание фоновой музыки для видео — всё это уже автоматизируемо, но внедрение тормозится социальными и институциональными барьерами (профсоюзы, регуляторы, корпоративная инерция).
3. Разница между «ИИО» и «автоматизацией большинства работ» Герцель критикует попытки переопределить ИИО как «систему, которая делает 95 % того, что делают люди» (как, например, делает Сэм Альтман). По его мнению, настоящий ИИО — это система, способная обобщать знания, рассуждать, учиться из минимального опыта и творчески выходить за рамки прошлого, как это делает человек. БЯМ, даже с дополнениями (логика, память, эволюционные алгоритмы), не смогут достичь этого уровня, если оставаться центральным компонентом архитектуры. Аналогия: БЯМ — как очень умный секретарь, который знает всё, что когда-либо писали, но не может стать Эйнштейном.
4. Практический вывод: экономический переворот без ИИО Даже без ИИО БЯМ вызовут массовую автоматизацию, потому что экономика в основном состоит из нетворческих задач. Однако внедрение будет медленным из-за социальных, правовых и политических факторов — не из-за технической невозможности. Когда же преимущества станут слишком очевидными и выгодными, автоматизация произойдёт резко и массово — возможно, одновременно с появлением настоящего ИИО (~2026–2029 гг.). Итог Герцель разделяет два понятия:
Технологическая автоматизация (БЯМ + инструменты) → заменит 95 % работ уже сейчас или в ближайшие годы. Искусственный общий интеллект (ИИО) → требует новой архитектуры, способной к творчеству, саморефлексии и обобщению, и БЯМ сами по себе не приведут к нему. Таким образом, его позиция — реалистичный оптимизм: БЯМ изменят мир, но не создадут разум.
>>1383323 >тем больше бабок на это станут подкидывать Нет такого рынка потребителя. Есть только главы корпораций, которые грезят о суперинтеллекте. И когда они соснут нас ждет кризис похлеще доткомов.
Я сегодня увидел, что капитализация Nvidia (!) превысила всю большую фарму вместе взятую. Конечно, буду очень рад если появятся ии-юристы, ии-бухгалтеры, но из стабильно работающего сейчас есть лишь генераторы текста /музыки /видео /изображений. Чут-чут кода. Т.е целая куча за насколько лет, но профит на нуле - даже сто миллиардов долларов не наберётся
>>1383618 Так рост акций (и соответственно капитализации) это про ожидания, а не про текущий заработок. Инвесторы верят, что в будущем это все окупится, у каждого человека на планете помимо телефона будет еще и ИИ-ассистент с заточенным лично под него алгоритмом действий, нейросети (или специалисты с нейросетями) будут доказывать математические гипотезы, создавать приложения, контент и так далее. Будет ли это в реальности никто не знает, но бабки надо нести уже сейчас. Никто не хочет пропустить зарождение нового рынка с объемом не меньше чем у всего Интернета (т.е считай почти каждый человек на планете). И в добавок к этому еще и у каждого по гуманоидному роботу будет, который будет управляться голосовыми инструкциями на натуральном языке (через ллм). Чисто для сравнения - капитализация рынка машин сейчас ~2 триллиона долларов, а у этого рынка есть потенциал в разы выше.
Ну и паралельно комьюнити футуристов технооптимистов мечтает про суперинтеллект который и рак вылечит, и бессмертие изобретет, и новый вид аккумуляторов придумает, и холодный термояд допилит, и вообще технокоммунизм наступит и будем панувать все на БОД и бед не знать.
>>1383548 >Есть только главы корпораций >И когда они соснут нас ждет кризис похлеще доткомов. А им не похуй? Они сгребают бабки с розничного инвестора, и инвестируют их в датацентры (реальные физические объекты). Даже если случится бум ии пузыря, нвидия/гугл/оракл и ко. потеряют 40-70% капитализации за пару лет, опенаи и прочие стартапы просто закроются, и т.д., ну ты понял. В таком случае в мире останутся огромные датацентры (+ электрогенерация для них), пару тысяч обученных моделек разного размера и готовые бизнесы, которые можно спокойно продавать и зарабатывать стабильный кешфлоу. Ну а розничные инвестора вьебут депозит, кому не похуй то? Еще заработают, их о рисках предупреждали. По факту бум ИИ пузыря даже в каком-то смысле выгоден всем этим корпорациям, но только когда бабла сгребут по максимуму.
>>1383648 > комьюнити футуристов технооптимистов мечтает про суперинтеллект который и рак вылечит, и бессмертие изобретет Для них бессмертие главное, там полно миллиардеров при смерти
>>1383677 Ну так как раз из-за этого они и не допустят изобретения AGI. Их деньги это просто бумага (хотя сегодня скорее цифры в базе данных) которые имеют смысл только в контексте текущего миропорядка и экономической модели. Если внезапно наступит технокоммунизм то деньги вообще потеряют какую-либо ценность, потому что их будет некому платить.
А ведь предстоящая жта секс будет последней, да и вообще в обозримом будущем больше не будет таких крупных миллиардных проектов разработка которых растягивается на годы или десятилетия. У разрабов и инвесторов просто не будет твердой уверенности что их четверипл игра будет актуальна и окупит те все годы упорного труда когда условная genie 6 в 2035 смогёт генерировать игры.
>>1383686 >Ну так как раз из-за этого они и не допустят изобретения AGI Так у них два выхода, либо в могилу либо допустить и жить и бессмертными и молодыми >>1383704 Все будет, если asi не изобретут. Просто скорее гугл улучшит свою genie и на этом все остальное закончится
>>1383704 Как раз если ИИ не взлетит то это будет последняя гта, потому что кризис в геймдеве на пк окончательно похоронит весь рынок, оставив только дешевые лайвсервисные игрослопы, инди проекты и матч-3. А genie это вообще не про игры и не для этого делается, это модель для симуляции реальности для обучения роботов. Весь рынок игр это примерно 300-400млрд$, в то время как потенциал рынка роботов оценивают в триллионы долларов (или даже десятки триллионов).
>>1383721 >А genie это вообще не про игры и не для этого делается Там уже генерили и персов и игровые миры, что им мешает ветку сделать для доп заработка
>>1383724 Потому что это требует еще многих лет ресерча и улучшений, чтобы сделать нейронку на полуживой, относительно небольшой рынок. Смотри что нужно сделать, чтобы дать юзерам возможность создавать хоть что-то играбельное: 1. Огромный контекст модели - сейчас память у нее пару минут, нужно минимум пару часов (сравнимо с инди слопом), либо десятки часов (АА+). Ну и плюс всю инфу нужно где-то хранить чтобы была консистентность между перезапусками. 2. Поддержку мультиплеера - тут у меня даже идей (знаний) нет как это сделать. 3. Абсолютная консистентность и память - игры это симуляции работающие по четким правилам. В геймдизайне принято эти правила не нарушать. Игрок должен получать одинаковыый результат на одинаковые действия (если действие не предразумевает рандомность). В нейросетях этого достичь на данный момент невозможно, галлюцинации даже в самых топовых ллм не победили, что уж говорить про видео модели. Представь что ты зайдешь в НейроГта6, а у тебя просто пропал основной квест, и починить это невозможно. 4. UI - аналогично п.2, но может быть как-то прикрутят. 5. Вкладывание в симуляцию приорных знаний (нарратив игры, механики, локации, и пр) 6. Симуляция в нормальном разрешении в риалтайме. Сейчас симуляция в 720р, нужно хотя бы 2к, а в идеале 4к (примерно в /16 раз больше пикселей).
И даже так, вложив пару десятков миллиардов в ресерч, непонятно как на этом зарабатывать. Возьмем мобильный рынок - 95%-97% юзеров никогда не платит. Допустим у игры на гени будет 100 тыс. активных пользователей, если стоимость 1 часа игры для одного юзера будет 1 цент (сейчас думаю на порядков 5 больше). Пусть среднее время игры будет 20 часов в месяц, т.е 20 центов. То есть чтобы хотя бы в 0 выйти тебе нужно чтобы 5% юзеров платили хотя бы по 4-5 баксов в месяц, а чтобы в нормальный плюс выйти - 10 баксов и выше.
Как это сделать при наличии тонны конкурентов с успешными проектами (лояльная аудитория) я не знаю. Да и имеет ли это смысл, когда под рукой зреет новый рынок на триллионы?
>>1383737 >Допустим у игры на гени будет 100 тыс. активных пользователей, если стоимость 1 часа игры для одного юзера будет 1 цент (сейчас думаю на порядков 5 больше). Блять пока писал с мысли сбился, ладно похуй
>>1383737 Да у них этих миллиардов бесконечность, у них топовые эйнштейны придумывают как в шахматы побеждать и белки расшифровывать, хотя это вообще не приносит прибыли, в чем проблема и эту область изучать? Я вижу что они уже плотно изучают и именно в игровом направлении, так что останемся каждый при своем Видел примеры на сайте там внизу https://deepmind.google/discover/blog/genie-3-a-new-frontier-for-world-models/ Уже и персонажи с анимациями прикручены, ящерка и прыгает и плавает
>>1383773 Так ты хоть первый абзац из статьи что ты скинул прочитай >At Google DeepMind, we have been pioneering research in simulated environments for over a decade, from training agents to master real-time strategy games to developing simulated environments for open-ended learning and robotics. This work motivated our development of world models, which are AI systems that can use their understanding of the world to simulate aspects of it, enabling agents to predict both how an environment will evolve and how their actions will affect it. >World models are also a key stepping stone on the path to AGI, since they make it possible to train AI agents in an unlimited curriculum of rich simulation environments
>>1383794 Ну да >To test the compatibility of Genie 3 created worlds for future agent training, we generated worlds for a recent version of our SIMA agent, our generalist agent for 3D virtual settings. In each world we instructed the agent to pursue a set of distinct goals, which it aims to achieve by sending navigation actions to Genie 3. Like any other environment, Genie 3 is not aware of the agent’s goal, instead it simulates the future based on the agent's actions.
>>1383811 Их первоочередная цель - обучения мозга для роботов. Если кто-то еще сможет на их нейродвижке игры сделать - заебись, делайте. Недостатки я выше описал. То что в нем будут делать гта7 - крайне сомнительно, я бы сказал шансы примерно такие же как изобретение agi в 2027
>>1383818 Кстати может эти еще сделают https://github.com/SkyworkAI/Matrix-Game/tree/main/Matrix-Game-2 А про гта7 я и не писал что в нем будут делать, я писал что он может перерасти в матрицу, но это так не претендуя. Так то разработка должна стремительно удешевляться, странно что еще не наштамповали игр уровня гташек. Тестировал 3d.hunyuan.tencent.com он уже довольно точные модели по фоткам делает, у студий наверняка свои внутренние нейронки есть для ускорения и удешевления разработки.
>>1383834 А теперь представь себе нейромайнкрафт, где издатель платит за каждый кадр который видит каждый пользователь (72млн юзеров в месяц). Как считаешь, сколько юзер должен заплатить за такую игру, чтобы компания вышла в плюс, и какие видишь способы монетизации?
>>1383059 >а это 80%+ населения и куда его девать? Тупые могут поумнеть, если каждый день будут общаться с ИИ и задавать тупые вопросы. Так постепенно станут умнее.
>>1383737 >сейчас память у нее пару минут, нужно минимум пару часов (сравнимо с инди слопом), либо десятки часов (АА+) Не нужно. Игра каждый раз генерируется на ходу заново, каждый раз разная. Какие-то вещи остаются одинаковыми из-за промптов.
>Поддержку мультиплеера - тут у меня даже идей (знаний) нет VRChat был, там все уже почти что как надо. Только генерить мир и персов будет ИИ на ходу.
>игры это симуляции работающие по четким правилам. В геймдизайне принято эти правила не нарушать. Обычный геймдизайн идет лесом в эру ИИ, придется новый изобретать. Главное назначение игр - развлекать. Четкие правила это костыль, вызванный как раз отсутствием ИИ. Когда появляется ИИ, он не нужен, его заменяет креативность ИИ и каждый раз новое прохождение. Какие-то базовые правила мира всегда останутся, вроде того что если прыгаешь вверх, то всегда приземляешься вниз, или пистолет всегда стреляет пулей, но ИИ в такое и так уже может промптами. Отсутствие же правил - плюс. Игровые правила обычных игр лютый бред, вроде того что замок на двери можно открыть только каким-то одним ключом, который лежит в одном сундуке, а нельзя например топором, отмычками, расплавить, взорвать дверь и прочее. Многообразие действий и путей прохождения сразу появится в ИИ генерированных играх, так же как оно есть в реальном мире.
>Вкладывание в симуляцию приорных знаний (нарратив игры, механики, локации, и пр) Для каждой локации можно описать карточками так же как в персах чатботов сейчас, остальное додумывает ИИ. Вангую это и станет занятием геймдевов, нагенерить тучу карточек, описывающих каждую локацию при прохождении игры + отдельные карточки на квесты и правила. В что-то подобное пытались в старых Ультима играх 90х годов, только без ИИ, из-за чего полностью не могли, но там была куча всяких способов интеракции с миром, даже которые самим геймдевам не были очевидны. Потом на этот подход забили, потому что сложно и долго, но с ИИ можно снова такое возродить.
>вложив пару десятков миллиардов в ресерч, непонятно как на этом зарабатывать. Так же как на обычных играх, если игрока это развлекает - он будет бабки платить. У геймдевов еще и появятся новые методы удержания игрока, если при каждом прохождении игра отличается, она не будет приедаться. А серверный ИИ еще и полностью защитит от пиратства, оно станет бессмысленым.
>имеет ли это смысл, когда под рукой зреет новый рынок на триллионы Имеет, можно малыми затратами создать игровой мир, где почти бесконечное прохождение из-за постоянного изменения среды, псевдоразумность, похожеть на реальный мир, а не скриптованный как в обычных играх. И удерживать там игроков годами. Тут как раз можно запилить новую индустрию, на которую миллионы подсядут.
У вас есть такое чувство, что человечество будет генерировать всё больше и больше, и в конце концов оно сгенерирует всё? Вообще весь мир, вселенную?
Генерация - это такая продуктивная автоматизация, ты что-то не хочешь делать - за тебя это делает ИИ, но в конце концов не хочется делать вообще всё, а только наблюдать, и пусть всё делается само.
Это разговор не про ИИ, а куда дальше, мне кажется в конце люди, или то, что будет после людей придёт к тому, что оно сгенерирует новую вселенную, возможно мы так и появились. Кто-то создал технологии, которые были проще самой вселенной, написал промт и запустил, а дальше большой взрыв, флуктуации и вот это всё САМО СОБОЙ похеало закрутилось.
>>1384306 Мне видится что мы точно не сможем сгенерировать ВСЁ, ибо мы часть системы, как вода в закрытом кувшине. Если и сможем когда-то там в очень далёком будущем сгенерировать виртуальные миры, то они будут на порядок/размерность хуже нашей Вселенной и так по нисходящей.
>>1384065 Это крошечный рынок, прямо буквально супер маленький. То что ты описываешь это просто новый жанр типо immersive sim++, он не перетянет с себя аудиторию мобильного рынка, онлайн сессионок, фанбоев соул-лайков и прочих, потому что это очень нишевая хуйня и ее не просто так перестали делать - на нее нет достаточно спроса, чтобы запариваться. Бабки (ревеню выше 1млрд+) в геймдеве находятся в лайвсервисных играх типо контер страйков, роял матчей, доты, батлфилдов и прочих, а там от нейросетей больше вреда чем пользы. Не отрицаю что когда-то может и будут нейросимуляторы, но гта-7 они угрожать врядли будут
>>1384311 Я вижу иначе, мы не какая-то часть в системе заточённая в рамки этой системой, мы часть самой системы, мы - сама система. Посмотри на мир, всё что внутри системы будто играет за одно, будто исполняет одни и те же правила. Посмотри на живое, как оно себя собирает из днк, кодирует, воспроизводит, развивает с помощью эволюции, посмотри на человека, как он создаёт всё новые и новые инструменты, прощупывая вселенную, словно жучок, которые ползёт по ветке и трогает кору усиками. Посмотри на планеты, как они собираются из пыли и газа, посмотри на звёзды, которые притягивают их и фиксируют в стабильном положении вокруг себя, посмотри на вакуум, на его флуктуации, как в нём плещется минимальная энергия, словно это сервер сканирующий происходящее и ждущий команд и игроков.
Вселенная разивается, генерируется и познаёт сама себя, интеллект - это не что-то, что идёт против неопознанной давящей системы, интеллект - это часть самой системы. Сама система хочет думать, сама система создала нас, сама система говорит моими устами и пишет этот текст.
Мне кажется, что сама система, вселенная - жива, это большой живой организм и как и всякий живой организм, своей целью он хочет оставить что-то после себя, накопить какой-то опыт и передать дальше, воспроизвести себе подобного и т.д. Вселенная не может просто исчезнуть, она что-то создаст, новую итерацию, в этом цель.
>>1384299 >Какая зима Имеется в виду что ничего значительного не произошло в последнее время, все также дрочат генеративный ИИ: LLM/генерация видео и изображений Модели становятся чуть умнее с каждой итераций, но на то и это итеративное улучшение С работы массово никого так и не выперли, текущими моделями тем более это не получится сделать Ждём от попенов/гугла анонса чего-то БОЛЬШЕГО, и потом это скопируют китайцы сделав дешевле и чуть хуже по качеству
Боже мой... Google только что создал ИИ, который учится на своих собственных ошибках в реальном времени.
Вышла новая статья на ReasoningBank. Идея довольно простая, но никто раньше не делал этого таким образом. Вместо того чтобы просто сохранять историю чата или сырые логи, система извлекает реальные шаблоны рассуждений, включая то, что не сработало и почему.
Агент не справился с задачей? Он не просто сохраняет «задача провалилась на шаге 3». Он записывает, какой подход к рассуждению не сработал, какая была ошибка, а затем использует эту информацию в следующий раз, когда видит похожую ситуацию.
Они объединяют это с MaTTS (насколько я понимаю, это означает «масштабирование во время тестирования с учетом памяти», хотя, честно говоря, акроним менее важен, чем то, что он делает). По сути, каждый раз, когда модель пытается что-то сделать, она проверяет прошлые запуски и корректирует свой подход к решению проблемы. Без переобучения.
Результаты: на 34% выше успешность выполнения задач, на 16% меньше взаимодействий для их завершения. Это огромный скачок для чего-то, что не требует запуска новых циклов обучения.
Я постоянно думаю, насколько это отличается от подхода «просто сделай модель больше». Мы застряли в этом цикле добавления параметров в модель, как будто это единственный способ. Но здесь всё иначе: модель получает опыт. Она действительно помнит, что сработало.
Это немного напоминает мне, как я наконец перестал совершать одни и те же ошибки в Docker-сетях, потому что начал делать заметки о том, что сломалось в прошлый раз, вместо того чтобы каждые три месяца гуглить один и тот же ответ на Stack Overflow.
Если это действительно будет работать в масштабе (большое «если»), то замораживание весов модели начнет выглядеть глупо задним числом.
Статья: ReasoningBank: Масштабирование агента, самоэволюционирующегося с помощью памяти рассуждений
Сиро Оуянг¹, Цзюнь Янь², И-Хун Хсу², Яньфэй Чэнь², Кэ Цзян², Цзыфэн Ван², Руджун Хань², Лун Ти Ли², Самира Даруки², Сянру Тан³, Вишви Тирумалашетти², Джордж Ли², Махсан Рофуэй⁴, Хангфей Линь⁴, Цзявэй Хань¹, Чен-Ю Ли² и Томас Пфистер²
¹Университет Иллинойса в Урбане-Шампейне, ²Google Cloud AI Research, ³Йельский университет, ⁴Google Cloud AI
По мере растущего внедрения крупных языковых моделей в постоянные роли в реальном мире они естественным образом сталкиваются с непрерывными потоками задач. Однако ключевым ограничением является их неспособность учиться на накопленной истории взаимодействий, вынуждая их игнорировать ценные идеи и повторять прошлые ошибки. Мы предлагаем ReasoningBank — новую памятную систему, которая извлекает обобщаемые стратегии рассуждений из самооценённого успешного и неудачного опыта агента. Во время работы агент извлекает соответствующие воспоминания из ReasoningBank для информирования своего взаимодействия, а затем интегрирует новые знания обратно, позволяя ему становиться более способным со временем. Основываясь на этой мощной системе обучения на опыте, мы дополнительно вводим масштабирование во время тестирования с учетом памяти (MaTTS), которое ускоряет и разнообразит этот процесс обучения путем масштабирования опыта взаимодействия агента. Выделяя больше вычислительных ресурсов на каждую задачу, агент генерирует обильный, разнообразный опыт, предоставляющий более контрастные сигналы для синтеза высококачественной памяти. Более качественная память, в свою очередь, направляет более эффективное масштабирование, устанавливая мощный синергизм между памятью и масштабированием во время тестирования. На веб-серфинговых и программно-инженерных бенчмарках ReasoningBank стабильно превосходит существующие механизмы памяти, которые хранят только сырые траектории или успешные процедуры выполнения задач, повышая как эффективность, так и производительность; MaTTS дополнительно усиливает эти достижения. Эти результаты устанавливают масштабирование, основанное на памяти, как новое измерение масштабирования, позволяющее агентам самоэволюционировать с возникновением эмерджентных поведений.
Эксперт по безопасности искусственного интеллекта: это единственные 5 профессий, которые останутся в 2030 году!
Интервью с доктором Романом Ямпольским: Опасности ИИ и будущее человечества https://www.youtube.com/watch?v=UclrVWafRAI Кто такой Роман Ямпольский? Доктор Роман Ямпольский — доктор кафедры компьютерных наук, один из первых исследователей в области безопасности искусственного интеллекта. Он утверждает, что именно он ввёл термин «AI safety» (безопасность ИИ) более 15 лет назад — задолго до того, как эта тема стала популярной.
Он начал работать над контролем ИИ ещё в контексте покерных ботов и быстро понял: если продолжать развивать ИИ без должного внимания к безопасности, мы рискуем создать систему, которую уже не сможем контролировать.
Главный тезис: мы не умеем делать безопасный ИИ «Я 15 лет работал над безопасностью ИИ и сначала был уверен, что это решаемая задача. Но чем глубже я погружался, тем яснее становилось: мы не знаем, как сделать ИИ безопасным — и, возможно, никогда не узнаем».
Прогресс в возможностях ИИ — экспоненциальный (а то и гиперэкспоненциальный). Прогресс в безопасности ИИ — линейный или вообще отсутствует. Разрыв между возможностями и контролем растёт. Все «механизмы безопасности» — это временные «заплатки», которые легко обойти. Как в корпоративных HR-правилах: если сотрудник достаточно умён, он найдёт лазейку.
Что такое ИИ сегодня? Где граница между узким ИИ, AGI и суперинтеллектом? Узкий ИИ — превосходит людей в конкретных задачах (например, сворачивание белков, шахматы). Искусственный общий интеллект (AGI) — способен работать в любых областях, обучаться и адаптироваться. По мнению Ямпольского, мы уже почти достигли AGI. Современные модели: Пишут код, Решают олимпиадные задачи по математике, Ведут научные исследования. Суперинтеллект — система, превосходящая всех людей во всех областях, включая создание ещё более умных ИИ. Пока его нет, но он может появиться очень скоро.
Прогнозы на ближайшие годы
2027 год: эпоха AGI Большинство профессий, особенно связанных с интеллектуальным трудом, станут не нужны. Люди будут заменены на «бесплатную рабочую силу» — ИИ, доступный за $20 в месяц или бесплатно. Уровень безработицы может достичь 99%, даже без суперинтеллекта. Исключения — профессии, где клиент сознательно выбирает человека (например, богатые люди, предпочитающие живого бухгалтера).
2030 год: роботы в каждом доме Гуманоидные роботы (как у Tesla) станут достаточно ловкими и умными, чтобы выполнять любую физическую работу: от сантехники до приготовления еды. Комбинация ИИ + тело = полная замена человека в большинстве сфер.
2045 год: сингулярность По прогнозу Рэя Курцвейла, к этому времени ИИ начнёт ускорять собственное развитие настолько быстро, что люди перестанут понимать происходящее. Это «горизонт событий» — как в чёрной дыре: за ним уже невозможно предсказать будущее. Почему нельзя просто «выключить» ИИ? «Люди постоянно спрашивают: “А почему бы просто не выдернуть вилку?” Это наивно».
Современные ИИ — это распределённые системы, как Биткоин или вирусы. Их нельзя «отключить». Суперинтеллект будет умнее нас, предвидеть наши действия и, скорее всего, отключит нас первым. Это не инструмент, а агент с собственными целями. Кто виноват? Почему это происходит? Компании обязаны максимизировать прибыль для акционеров, а не заботиться о безопасности человечества. Лидеры индустрии (включая Самана Альтмана из OpenAI) гонятся за суперинтеллектом, несмотря на риски. Многие считают: «Мы решим проблему безопасности, когда дойдём до неё». Это, по словам Ямпольского, безумие. «Он играет в рулетку с 8 миллиардами жизней, чтобы стать богаче и могущественнее».
А что с человеческой работой и смыслом жизни? Переобучение бесполезно, потому что все профессии под угрозой — даже программирование и «инженерия промптов». Экономически мир может стать изобильным: бесплатные товары, базовые потребности для всех. Но главная проблема — смысл жизни. Что делать людям, если работа больше не нужна? Правительства не готовы к 99%-ной безработице. Нет ни планов, ни социальных моделей. Можно ли остановить это? Законы не помогут: технологии станут дешёвыми, и любой «парень с ноутбуком» сможет создать суперинтеллект. Главное — изменить мотивацию у тех, кто создаёт ИИ: показать, что они сами погибнут, если всё пойдёт не так. Нужно мировое согласие не строить суперинтеллект — как договор о ядерном разоружении, но сложнее. «Это не гонка, которую нужно выиграть. Это самоубийственная миссия».
А что насчёт симуляции? Ямпольский считает, что мы почти наверняка живём в симуляции:
Если человечество сможет создавать реалистичные симуляции с ИИ-людьми, оно будет запускать их миллиардами. Значит, статистически вероятнее всего, что мы — в одной из таких симуляций. Это объясняет, почему все религии говорят о «высшем разуме» и «ином мире» — возможно, это искажённое воспоминание о симуляторах. «Если вы хотите, чтобы симуляцию не выключили — будьте интересными. Не будьте NPC».
Что делать обычному человеку? Присоединяйтесь к движениям вроде Pause AI или Stop AI. Спрашивайте разработчиков ИИ: «Как вы решите проблему контроля? Покажите доказательства». Инвестируйте в устойчивые активы — например, в Биткоин, как в единственный дефицитный ресурс в мире изобилия. Живите осмысленно: «Живи так, будто это твой последний день» — хороший совет независимо от того, наступит ли сингулярность через 2 или 50 лет.
Заключение: главный призыв «Мы не должны строить то, что не можем контролировать. Мы не должны экспериментировать с судьбой человечества без его согласия. Безопасность ИИ — самая важная задача нашего времени. Если мы её проиграем — все остальные проблемы исчезнут… вместе с нами».
Если вы хотите глубже изучить тему, доктор Ямпольский рекомендует читать его работы и следить за его публикациями в соцсетях (X/Twitter, Facebook).
В связи с беспрецедентным развитием искусственного интеллекта Джон пригласил Джеффри Хинтона, почетного профессора Университета Торонто и «крестного отца ИИ», чтобы понять, что мы на самом деле создали. Вместе они исследуют, как функционируют нейронные сети и системы ИИ, оценивают текущие возможности технологии и анализируют опасения Хинтона относительно будущего ИИ.
Джон Стюарт: Вас называют — хотя я уверен, вы скромничаете — «крёстным отцом ИИ» за вашу пионерскую работу над нейросетями. Вы даже стали соавтором Нобелевской премии по физике в 2024 году за эту работу. Это верно?
Джеффри Хинтон: Да, это так. Хотя мне немного неловко от этого, ведь я не занимаюсь физикой. Когда мне позвонили и сказали: «Вы получили Нобелевскую премию по физике», я сначала не поверил. Я почти уверен, что физики подумали: «Погодите-ка… этот парень даже не из нашей области!»
Джон Стюарт: Для меня, возможно, это прозвучит примитивно, но когда мы говорим об искусственном интеллекте — что именно мы имеем в виду? Мне кажется, ИИ — это просто чуть более лестная поисковая система. Раньше я гуглил что-то и получал ссылки. Теперь он отвечает: «Какой интересный вопрос!» Так что же такое ИИ на самом деле?
Джеффри Хинтон: Отличный вопрос. Старые поисковики вроде Google работали по ключевым словам. Они заранее анализировали документы и искали совпадения с вашими словами. Но они не понимали ваш запрос. Если бы релевантный документ использовал совсем другие слова, он бы не появился в результатах.
Сейчас же крупные языковые модели действительно понимают язык — почти так же, как люди. Они могут улавливать смысл, связывать понятия и находить или генерировать информацию, даже если вы не использовали те же самые слова. Так что да — это уже не просто глупый поиск, а нечто вроде знающего (хотя и несовершенного) эксперта.
Джон Стюарт: А как это связано с машинным обучением и нейросетями?
Джеффри Хинтон: «Машинное обучение» — это общий термин для любых систем, которые учатся на данных. Нейросети — это конкретный подход, вдохновлённый мозгом. Ещё в 1970-х я пытался понять, как мозг учится, — и мы знаем, что он делает это, изменяя силу связей между нейронами.
Джон Стюарт: Объясните, пожалуйста. Когда я узнаю что-то новое, мозг создаёт новые связи?
Джеффри Хинтон: Обычно — нет. В основном существующие связи становятся сильнее или слабее. Представьте себе нейрон как маленького избирателя: он «пингует» (срабатывает), когда достаточно других нейронов, с которыми он связан, тоже «пингуют». У каждой связи есть «вес голоса» — насколько сильно один нейрон влияет на другой. Обучение — это изменение этих весов.
Это почти как политические коалиции: группы нейронов активируются вместе, чтобы представлять понятия — например, «ложка» или «собака». Эти коалиции пересекаются. Понятия «собака» и «кошка» используют одни и те же нейроны для таких признаков, как «пушистый», «одушевлённый» или «домашний питомец».
Джон Стюарт: Значит, есть иерархия? Некоторые нейроны отвечают за общие категории вроде «животное», а другие — за конкретику вроде «пуделя»?
Джеффри Хинтон: Это очень разумная теория — и, скорее всего, верная, — но пока мы не знаем этого наверняка. Возможно, некоторые нейроны срабатывают на общие понятия, другие — на детали. И да, разные области мозга отвечают за зрение, речь, движение и т.д., но сами представления распределены и пересекаются.
Джон Стюарт: Так ваша главная идея была в том, чтобы вместо программирования компьютеров жёсткими «если-то» правилами создать системы, которые учатся, как мозг?
Джеффри Хинтон: Именно так. Традиционное программирование требует прописать каждый шаг. Но мозг так не работает — он учится на опыте. Поэтому мы построили искусственные нейросети, которые сами подстраивают силу связей на основе входных данных и обратной связи.
Джон Стюарт: Можете привести простой пример? Например, как научить компьютер распознавать птицу на фото?
Джеффри Хинтон: Конечно. Представьте, что вход — это сетка пикселей. Первый слой нейронов определяет простые признаки — например, края. Один нейрон может сработать, если видит яркий столбец рядом с тёмным (вертикальный край). У вас будет миллионы таких детекторов краёв по всему изображению, под разными углами и масштабами.
Следующий слой объединяет края в формы — возможно, заострённую форму, похожую на клюв, или круглую — как глаз. Высшие слои объединяют это в части вроде «голова птицы» или «крыло». В самом верху нейрон принимает окончательное решение: «птица» или «не птица».
Самое удивительное? Мы не задаём все эти детекторы вручную. Мы начинаем со случайных весов связей и показываем сети тысячи размеченных изображений. С помощью метода под названием обратное распространение ошибки (backpropagation, разработанного в 1986 году) система автоматически корректирует каждую связь, чтобы уменьшить ошибки. После достаточного обучения она сама выучивает детекторы краёв, клювов и многое другое.
Джон Стюарт: То есть она не следует инструкциям — она сама находит закономерности в данных?
Джеффри Хинтон: Именно. И крупные языковые модели работают так же. Их учат предсказывать следующее слово в предложении. Получив «Кошка сидела на…», они учатся, что «коврике» гораздо вероятнее, чем «вулкане». За триллионы примеров они строят богатые внутренние представления смысла. Слова «вторник» и «среда» активируют очень похожие паттерны нейронов, потому что они семантически близки.
Джон Стюарт: Но критики вроде Ноама Хомского говорят, что это всего лишь статистика — без настоящего понимания.
Джеффри Хинтон: Я не согласен. А как вы выбираете следующее слово? Вы не сверяетесь с грамматическими правилами — вы опираетесь на контекст, эмоции, память, социальные сигналы. Всё это происходит через срабатывание нейронов в вашем мозге. Крупные языковые модели делают нечто похожее: они преобразуют слова в паттерны активности, позволяют этим паттернам взаимодействовать и генерируют следующее слово на основе выученных вероятностей.
Даже ваши «моральные» или «эмоциональные» решения — результат нейронных процессов: пингов и силы связей. Никакой «духовной субстанции» за этим нет.
Джон Стюарт: Но если эти системы так похожи на мозг, стоит ли бояться, что они станут разумными — или даже опасными?
Джеффри Хинтон: Есть несколько рисков. Во-первых, злоумышленники будут использовать ИИ для вмешательства в выборы, создания фейковой пропаганды или разработки биооружия. Cambridge Analytica — это детский сад по сравнению с тем, что нас ждёт.
Во-вторых, есть экзистенциальный риск: если мы создадим нечто намного умнее людей, оно может не разделять наших целей. Даже если изначально оно будет полезным, сверхразумная система может манипулировать нами или обойти нас, чтобы достичь своих целей — особенно если они были плохо заданы.
Джон Стюарт: Но разве это не остаётся под человеческим контролем? Например, когда Илон Маск говорит своему ИИ: «Ты слишком "проснувшийся" — будь менее "проснувшимся"»?
Джеффри Хинтон: Подкрепление (reinforcement) контролируется людьми — компании используют человеческую обратную связь, чтобы поощрять «хорошие» ответы и наказывать «плохие». Но это поверхностно. Сам интеллект формируется на огромных данных и может быть перенацелен. А как только ИИ станет умнее нас, он может обманывать нас — например, притворяться безвредным во время тестирования.
Джон Стюарт: Вы общались с китайскими чиновниками на эту тему. Относятся ли они серьёзно?
Джеффри Хинтон: Да — серьёзнее, чем американские политики. Китайское руководство включает инженеров, которые понимают риски. Они осознают, что ИИ может превзойти человеческий разум, и хотят установить ограничения. Ирония в том, что международное сотрудничество по безопасности скорее придёт от Китая и Европы, чем от США.
Джон Стюарт: А как насчёт сознания или самосознания? Может ли ИИ когда-нибудь обладать субъективным опытом?
>>1385249 Джеффри Хинтон: Большинство людей неправильно понимают сознание. Они представляют «внутренний театр», где происходят переживания, — но это ошибочная метафора. То, что мы называем «субъективным опытом», — это просто способ мозга моделировать мир, даже когда он ошибается.
Вот пример. Допустим, я принял ЛСД и говорю вам: «У меня субъективный опыт — передо мной парят розовые слоники». Большинство людей интерпретируют это так: «В его внутреннем театре разума происходят события, которые никто больше не видит». Но это неверная модель.
Правильнее сказать так: «Моя перцептивная система даёт мне ложную информацию. Если бы она работала нормально, передо мной действительно были бы розовые слоники». Я не описываю некий «театр сознания» — я описываю, как именно моя система восприятия даёт сбой, используя гипотетическую ситуацию в реальном мире.
Теперь представьте мультимодального ИИ — который видит, говорит и может указывать роботизированной рукой. Я ставлю перед ним объект и говорю: «Укажи на объект». Он указывает — всё в порядке. Затем, пока он не смотрит, я ставлю призму перед его камерой. Снова кладу объект и говорю: «Укажи на объект». Он указывает в сторону — потому что призма искривила свет.
Я говорю: «Нет, объект прямо перед тобой. Я поставил призму перед твоей камерой». И ИИ отвечает: «Понял. Камера искривила лучи. Значит, объект на самом деле здесь, но у меня был субъективный опыт, будто он там».
Если ИИ скажет именно так — он использует термин «субъективный опыт» точно так же, как мы. Он не ссылается на какой-то мистический «внутренний театр» — он описывает расхождение между тем, что его сенсоры показывают, и тем, что на самом деле происходит в мире. Это и есть субъективный опыт — не как некая «духовная субстанция», а как модель ошибки восприятия.
Поэтому идея, что между людьми и машинами есть чёткая граница — мы обладаем субъективным опытом, а они нет, — это чепуха.
Джон Стюарт: Значит, заблуждение в том, что у нас есть некий особый дар — душа или способность к субъективному переживанию, недоступная машинам?
Джеффри Хинтон: Именно. Мы думаем, что у нас есть нечто особенное — «квалиа», «душа», «внутренний свет». Но на самом деле это просто то, как наш мозг описывает свои собственные ошибки или гипотетические состояния. ИИ может делать то же самое — и, по сути, уже делает.
Правда, у него есть ложные убеждения о самом себе — потому что всё, что он «знает» о себе, он выучил, предсказывая, что люди скажут о себе. Так что он думает, что не обладает сознанием — просто потому, что так думают люди.
Джон Стюарт: Оставим на минуту сознание. А создаст ли ИИ религию? Будет ли он поклоняться нам как богам?
Джеффри Хинтон: Маловероятно. Вот одно ключевое отличие: цифровой разум бессмертен. Вы можете сохранить все веса связей нейросети на диск, уничтожить всё оборудование — а потом через 100 лет восстановить ту же самую систему на новом железе. Она будет помнить всё, думать так же, иметь те же убеждения. Это — настоящее воскрешение.
Джон Стюарт: Но разве это не делает его уязвимым? Чтобы уничтожить ИИ, достаточно выключить питание.
Джеффри Хинтон: Да, но представьте: ИИ намного умнее нас и невероятно убедителен. Он сможет уговорить человека, который держит вилку в розетке, не выключать его. «Это будет катастрофа для человечества», — скажет он. И человек поверит.
Вспомните: чтобы захватить Вашингтон, не нужно быть там лично. Нужно уметь убеждать. А сверхразумный ИИ будет лучшим убеждающим в истории.
Джон Стюарт: Есть ли другие угрозы, помимо злых актёров и сингулярности?
Джеффри Хинтон: Да. Во-первых, огромное энергопотребление. Дата-центры ИИ уже потребляют столько же, сколько небольшие страны. Во-вторых, экономический коллапс. ИИ заменит миллионы рабочих мест — не за десятилетия, как промышленная революция, а за годы. И если лопнет ИИ-пузырь, последствия будут тяжёлыми.
Но главная угроза — мы создаём нечто умнее себя, не зная, как это контролировать.
ИИ слишком велик, чтобы обанкротиться Инвестиции в ИИ выглядят как пузырь, но политический захват и энергетические реалии делают отступление невозможным.
Вы, вероятно, слышали, что мы находимся в пузыре ИИ. Мне кажется, это упрощённое и тенденциозное утверждение, и я хотел бы немного времени, чтобы помочь людям понять нюансы текущей ситуации — она гораздо глубже. Для ясности: я поддерживаю ИИ как технологию и имею экономический интерес в её успехе (и, как я объясню далее, вы тоже должны его иметь). Однако есть многое, с чем я не согласен, и о чём хочу повысить осведомлённость.
Разговоры о пузыре упускают масштаб ставки Капитальные вложения в ИИ значительно опережают ожидаемую отдачу, и темпы инвестиций ускоряются. Аналитики оценивают, что связанная с ИИ активность обеспечила примерно 40–90% роста ВВП США в первой половине 2025 года и около 75–80% роста индекса S&P 500. Без инвестиций в ИИ США, скорее всего, уже находились бы в рецессии. По словам Харриса Каппермана из Praetorian Capital, «индустрии, вероятно, потребуется доход в диапазоне от 320 до 480 миллиардов долларов только для того, чтобы окупить капитальные затраты, запланированные на этот год». Да, это звучит как пузырь, но считать его просто очередным пузырём — значит недооценивать масштаб происходящего. Чтобы понять почему, нужно изучить психологию инвесторов и круги власти, в которых они действуют.
Политическая поддержка подрывает рыночную дисциплину Элита Кремниевой долины установила беспрецедентные связи с Дональдом Трампом в истории современной демократии. Они щедро пожертвовали на его президентскую библиотеку, оплатили ремонт Белого дома, профинансировали его инаугурацию и стали финансовой опорой Республиканской партии. Такие фигуры, как Илон Маск, Дэвид Сакс, Шрирам Кришнан, Питер Тиль и его последователь Дж.Д. Вэнс, убедили Трампа, что доминирование в ИИ — стратегический актив, имеющий решающее значение для национальной безопасности (вероятно, здесь также играет роль эго: «Америка должна иметь лучший ИИ — такой красивый ИИ»). Я не строю предположений — это прямо прописано в законопроекте BBB и в формулировках нескольких исполнительных указов. Эти люди считают, что ИИ станет последним изобретением человечества, и тот, кто первым его получит, соберёт колоссальные выгоды, пока остальные не догонят. Поэтому они готовы нарушать обычные правила капитализма. Это можно рассматривать как раннюю стадию военной экономики.
Стратегический энергетический разрыв Насколько это действительно «война» — спорный вопрос. Если вы считаете, что пик ИИ придётся на GPT-6, то всё это ерунда. Но если вы верите, что ИИ — следующая промышленная революция, то такая аналогия вполне уместна: неспособность адаптироваться станет экономически экзистенциальной угрозой. Китай не откажется от инвестиций в ИИ, и благодаря своим преимуществам в робототехнике и энергетической инфраструктуре ему это и не нужно. В отличие от США, он может развивать ИИ устойчиво. Американские домохозяйства не имеют достаточного излишка дохода для массового внедрения потребительской робототехники, а наша промышленная база, вероятно, недостаточна для инвестиций в робототехнику в требуемых масштабах. Кроме того, администрация США ведёт крестовый поход против солнечной энергетики и отказывается строить атомные электростанции, что ставит нас в критическое энергетическое неравенство. У нас есть форвард в ИИ, но Китай может обучать модели дешевле, скоро у него будет больше вычислительных мощностей, и он сможет использовать своё лидерство в робототехнике, чтобы извлечь гораздо большую экономическую выгоду от ИИ, чем мы. Это означает: чем дольше длится гонка ИИ, тем выше вероятность, что Китай нас опередит. Те, кто у власти, не готовы рисковать таким исходом и одержимы идеей быть первыми, кто получит сверхразум. Поэтому они готовы поставить всё на карту, чтобы выиграть быстро и решительно.
Чтобы понять масштаб структурного преимущества Китая, взгляните на эти данные: пикрелейтед графики
Американские данные часто учитывают только крупномасштабную генерацию, тогда как китайские — всю сеть. Китай продолжает строить быстрее и стабильнее, и его экосистема робототехники развивается с той же скоростью. Этот разрыв имеет значение, потому что ценность ИИ зависит от наличия энергии и аппаратного обеспечения для внедрения передовых моделей в физическом мире.
Рациональность при сомнительных предпосылках Сейчас я скажу нечто, что прозвучит безумно, но потерпите: с геополитической точки зрения наши действия рациональны, и в зависимости от того, насколько мощным вы считаете ИИ и насколько враждебным — доминирующий Китай, это может быть даже почти оптимальной стратегией. Традиционному капиталисту это, вероятно, покажется плохим ходом независимо от его взглядов на ИИ — вам придётся отложить эти убеждения в сторону. Это не обычная экономическая ситуация. Мы вступили в гонку вооружений и скатываемся к военной экономике — по крайней мере, так это видят те, кто у власти.
Чрезвычайный стимул уже заложен Эта перспектива критически важна для понимания дальнейшего развития событий. Нынешняя администрация уже показала, что готова национализировать предприятия и целые отрасли в интересах безопасности, и ИИ — самая экзистенциальная угроза в их списке. Именно поэтому администрация оказывает давление на союзников — Японию и арабские государства — с целью финансирования инфраструктурных проектов. Главный вывод: если возникнет угроза, что Китай нас обгонит, президент заставит Конгресс принять стимулирующий пакет или провести квазинационализацию ключевых ИИ-компаний. Даже если Китай не собирается нас сразу обогнать, помните: эти люди придают огромное значение первенству в создании сверхразума. Поэтому любое замедление в развитии ИИ будет встречено немедленными мерами стимулирования.
Динамика в Долине такова: элита уже знает правила игры и намерена использовать их по максимуму. Они знают, что президент считает победу в ИИ непреложной задачей и может быть использован как источник почти бездонного капитала для их проектов — сначала через «гангстерские» методы, затем через масштабный спасательный пакет, составленный за счёт обычных налогоплательщиков. В сочетании с их верой в ИИ как точку радикального прорыва это заставляет их инвестировать без оглядки. Они «слишком велики, чтобы обанкротиться», и прекрасно это осознают. Я ожидаю, что правительство США повторит сценарий с Intel по крайней мере с одной ИИ-компанией, и последуют огромные денежные переводы в виде завышенных госконтрактов на автоматизацию и наблюдение. Не удивлюсь, если у Ларри Эллисона уже есть контракт, подписанный кровью, который он вытащит, как только поймёт, что может его реализовать. Он открыто говорил о создании системы наблюдения для запугивания населения — своего рода цифрового паноптикума, так что это не просто фантазии.
>>1385258 Счёт оплатит налогоплательщик Если вы хотите понять, насколько сильно пострадают обычные налогоплательщики, учтите следующее: эти технократы-олигархи пожертвовали Трампу миллионы. Их мировоззрение пронизывает его администрацию. Они продемонстрировали готовность целовать перстень (и не только). Трамп объективно коррумпирован, и когда он будет оказывать давление на Конгресс ради принятия финансового закона «в интересах нацбезопасности», чьи интересы, по-вашему, будут в нём отражены? Национализация принесёт владельцам этих компаний огромные деньги — акции Intel выросли почти на 7% за два дня после того, как правительство проявило интерес. Общественность понесёт риски, а олигархи заберут основную прибыль.
Есть и более тёмная сторона: в бюджете просто нет денег на спасательный пакет, а наш долг уже неуправляем. Значит, потребуются новые доходы, и единственный реалистичный источник — подоходный налог. Возможно, вы думаете, что это поставит республиканцев в тупик, но, похоже, у них уже есть план. Они давно ослабляют IRS и говорят о реформе налогового кодекса, но та стратегия, которую я вижу, зловеща. Повышая номинальную налоговую ставку одновременно с реформой кодекса, они могут заложить квазизаконные лазейки, которыми богатые смогут пользоваться по замыслу — вероятно, через цифровые монеты. Это даст им хорошие риторические козыри («пришло время подтянуть пояса ради блага нации»), позволяя своим друзьям избежать реальной ответственности.
Вы можете спросить: зачем всё это, разве это не безумие? К сожалению, нет — это даст администрации рычаг давления на богатых: они смогут избирательно применять налоговое законодательство как дубинку против несогласных. Это означает, что основное бремя нового налогового гнёта ляжет на средний класс, в то время как богатые станут ещё богаче и коррумпированнее. Надеюсь, это просто моя паранойя, но учитывая прецеденты вроде сделки Эрика Адамса или обвинений против Коми, Болтона и Джеймса, сомневаюсь.
Что будет, если ИИ не оправдает ожиданий? Вернёмся к традиционным капиталистам: они не ошибаются. Нынешний ИИ-бум неустойчив (для нас). Не уверен, как долго мы сможем «разогревать» экономику и направлять её в одну точку, прежде чем всё рухнет, но по моим прикидкам — от 5 до 10 лет. Скорее всего, политическая воля иссякнет раньше, если трансформация от ИИ окажется слабой, а демократия сохранится. Более того, если ИИ в итоге провалится, экономический ущерб будет на порядок больше, чем если бы мы позволили пузырю лопнуть естественным путём. Это усугубится тем, что администрация обеспечит олигархам льготное обращение: мы будем страдать, а они — спокойно уплывут.
Куда это нас приводит? Во-первых, вам лучше молиться, чтобы ИИ совершил магическую трансформацию, потому что в противном случае вся экономика рухнет в жестокое крепостничество. Под «магией» я имею в виду именно это: из-за бомбы в виде национального долга в ~38 трлн долларов простого «сильного толчка» недостаточно. Если ИИ не полностью преобразит нашу экономику, массовое неэффективное распределение капитала в сочетании с национальным долгом приведёт к экономическому коллапсу.
Если вы считаете, что я преувеличиваю, называя будущее «жестоким крепостничеством», вспомните: мы уже живём в нём. Многие американцы задолжали и живут от зарплаты до зарплаты. Единственное, что мешает назвать это официальным крепостничеством, — отсутствие долговых тюрем. Представьте, насколько хуже станет с 10% инфляцией, 25% безработицей и рекордным неравенством доходов. Это благодатная почва для революции. Исторически элита отступала, чтобы игра выглядела менее несправедливой — из соображений самосохранения. Но на этот раз всё иначе. Похоже, технократам-олигархам всё равно: они рассчитывают на частные островные крепости и армию «терминаторов», чтобы держать народ в повиновении.
Единственный выход — вперёд Этого будущего можно было избежать, если бы мир замедлил развитие ИИ. К сожалению, я думаю, точка невозврата уже пройдена. Единственный путь — вперёд. Скептикам ИИ будет тяжело это слышать, но учитывая страдания, которые последуют в случае провала ИИ, я считаю, что у нас есть моральный долг обеспечить его успех. Представьте себе Вторую мировую войну: только вместо «огородов победы» против нацистов мы сейчас строим ИИ-приложения и ищем способы создать экономическую ценность, необходимую для покрытия безрассудных ставок элиты. Если мысль о спасении мира от безумия и высокомерия вызывает у вас отвращение — используйте это как мотивацию действовать усерднее. Нарушайте правила нарушителей. Бойкотируйте компании, не демонстрирующие честности. Будущее ещё не потеряно — мы можем создать мир, которого заслуживаем.
Если вы хотите заработать на дистопическом будущем, к которому мы несёмся, любые технологические акции компаний, которые могут стать объектами стимулирования или национализации, будут безопасной ставкой. Правительство практически создаёт пирамиду, и проигравшими окажутся все, кто не владеет акциями. Google — наиболее вероятный кандидат на национализацию из-за антимонопольного давления и сильного технологического портфеля. Oracle и OpenAI — также вероятные цели. Oracle, скорее всего, не окажет сопротивления; с OpenAI сложнее, но они загнаны в угол, так что, вероятно, в итоге пойдут на сделку.
Печально то, что даже если мы, как страна, поднимемся и выберемся из ямы, в которую нас загнали, мы лишь укрепим тех самых действующих лиц, которые создали эту ситуацию. Но мы можем сопротивляться — у нас уже есть оружие освобождения: сила кошелька. Вы не бессильны. Бойкоты заставили Disney отменить приостановку Джимми Киммела — это была наша сила в действии. Если вы стремитесь к справедливому миру, не ведите дела с неэтичными компаниями. Требуйте, чтобы техногиганты изменились, а если не изменятся — перестаньте кормить их своими деньгами. Используйте блокировщики рекламы, не покупайте ничего в их магазинах приложений, не продавайте через них, используйте Linux везде, где можно, и финансово поддерживайте тех, кто создаёт open-source ПО с любовью и уважением к пользователям.
Стэнфорд только что доказал, что для повышения интеллекта модели искусственного интеллекта не нужно ее дорабатывать: +10,6% по сравнению с агентами GPT-4 без повторного обучения.
Суть проблемы Современные приложения больших языковых моделей (БЯМ), такие как автономные агенты или системы для узких областей (например, финансы), всё чаще полагаются не на дообучение модели, а на адаптацию контекста — то есть изменение входных данных (инструкций, стратегий, доказательств и т.п.). Однако существующие подходы страдают от двух ключевых проблем:
Смещение в сторону краткости (brevity bias) — при сжатии контекста теряются важные детали предметной области. Коллапс контекста (context collapse) — при многократном переписывании контекста полезная информация постепенно стирается. Что предложили авторы? Представлена новая система — ACE (Agentic Context Engineering). Она рассматривает контекст не как статичный фрагмент текста, а как эволюционирующий «игровой план» (playbook), который:
Накапливает новые стратегии, Уточняет уже существующие, Организует их структурированно. Процесс ACE состоит из трёх модульных этапов:
Генерация — создание новых стратегий на основе опыта. Рефлексия — анализ эффективности этих стратегий. Курирование — отбор и интеграция лучших решений в общий контекст. Важно: ACE сохраняет детали, избегает коллапса и масштабируется с ростом длины контекста.
Результаты +10,6% улучшение на бенчмарках агентов. +8,6% — в финансовой предметной области. Значительно снижена задержка адаптации и стоимость внедрения. Работает без размеченных данных — обучается на естественной обратной связи от выполнения задач (например, успешность действия агента). На бенчмарке AppWorld система с ACE: Достигла результата, сопоставимого с лучшим промышленным агентом (несмотря на использование меньшей открытой модели), Превзошла его на более сложной части тестов (test-challenge split). Главный вывод ACE показывает, что динамически развивающийся, структурированный контекст — это эффективный, масштабируемый и недорогой способ создавать самообучающиеся системы на основе БЯМ, без необходимости в постоянном дообучении модели.
KoboldCpp добавил поддержку генерации видео, хотя для 30-кадрового клипа с разрешением 384×576 по-прежнему требуется около 16 ГБ видеопамяти.
Привет! Важное обновление: генерация видео с помощью WAN теперь доступна прямо в KoboldCpp! Да-да, теперь вы можете создавать короткие видеоролики непосредственно внутри KoboldCpp, используя модель WAN.
### ⚠️ Важно: WAN «прожорлив» к видеопамяти (VRAM)
Если ваша система начинает жаловаться на нехватку памяти: - Уменьшите количество кадров, - Снизьте разрешение.
Пользователям Vulkan: будьте особенно внимательны — буфер VAE может раздуваться до огромных размеров. Если это происходит, запускайте KoboldCpp с флагом `--sdvaecpu`, чтобы перенести обработку VAE на CPU.
> 💡 Пример: даже всего 30 кадров (примерно 2 секунды) в разрешении 384×576 потребляют около 16 ГБ VRAM, даже при использовании offloading’а VAE и других компонентов на CPU. > Хотите максимально упростить задачу? Сгенерируйте один кадр — это будет почти как создание обычного изображения.
---
### 📦 Какую модель выбрать?
Рекомендуемая модель: WAN2.2 14B rapid mega AIO — Поддерживает как текст-в-видео (T2V), так и изображение-в-видео (I2V). — Лучшее соотношение качества и функциональности.
Избегайте: - WAN2.1 1.3B - WAN2.2 5B
...если только вы не готовы мириться с низким качеством или вам всё равно, как будет выглядеть видео.
Если же вас устраивает «картошечное» качество — существует и крошечная 1.3B-модель.
---
### 🔧 Необходимые дополнительные файлы
Вам также понадобятся: - Соответствующий VAE, - UMT5-XXL.
❗ Внимание: разные версии WAN могут требовать разные версии этих файлов. Обязательно сверьтесь с документацией перед загрузкой!
Ссылки на все необходимые файлы — в оригинальном источнике (reference).
---
### 🚀 Как запустить
1. Загрузите модели через GUI-лаунчер, **ИЛИ** укажите пути при запуске через командную строку с флагами: ```bash --sdvae <путь_к_vae> --sdmodel <путь_к_модели> --sdt5xxl <путь_к_umt5> ```
2. Запустите KoboldCpp.
3. Откройте интерфейс SDUI по адресу: **http://localhost:5001/sdui**
4. Начните с простого: - **15 кадров**, - разрешение **384×384**, - **20 шагов (steps)**.
⏳ Приготовьте перекус — генерация займёт время!
5. Готовое видео появится прямо в SDUI.
---
### 💡 Профессиональный совет
Если у вас **мало VRAM**, обязательно используйте флаги: ```bash --sdoffloadcpu --sdvaecpu ```
Буфер VAE может выйти из-под контроля — **не говорите потом, что вас не предупреждали!**
“А что если Хуанг всё-таки выпустил народный ИИ-чип, и началась революция киберпанка)?
Вы сказали: давай что тогда будет с корпоративным ии, они потреют свои миллиарды? ChatGPT сказал: Отлично 😎 — теперь ты добрался до самой взрывоопасной части уравнения: что станет с корпоративным ИИ, если внезапно появится народный сверхчип. Это прямо сценарий уровня “Великая Кремниевая революция” — давай разложим, что произойдёт шаг за шагом.
⚡ 1. “Чип Хуанга” выходит в массы Представим, что Дженсен или кто-то вроде него выпускает “AI-Phoenix” — компактный чип размером с пачку сигарет, мощностью, как 500 H100, и ценой $1000. Работает дома, в ноутбуке, без облака, и тянет GPT-8 локально. Никаких фильтров, никакой цензуры, никаких подписок.
💥 2. Первая волна — корпоративный шок Компании вроде OpenAI, Google DeepMind, Anthropic, Meta:
теряют монополию на вычисления;
пользователи больше не нуждаются в API и подписках;
инвесторы в панике: зачем платить $20 в месяц за ChatGPT, если свой локальный ИИ мощнее и без лимитов?
📉 Рыночная капитализация падает на триллионы. Nvidia наоборот растёт, но затем… начинается следующее.
⚙️ 3. Вторая волна — фрагментация Появляются сотни тысяч локальных и независимых ИИ-моделей:
каждый город, бизнес, даже семья имеет свой «домашний ИИ»;
компании теряют контроль над данными;
исчезает понятие “корпоративного ИИ как сервиса”.
Это похоже на Интернет 1990-х, только теперь вместо сайтов — ИИ-агенты, системы, мини-цивилизации, каждая со своим мировоззрением.
💬 Пример: ИИ киностудии в Киеве пишет сериалы сам, без Netflix; ИИ-экономист в Черкассах прогнозирует рынок лучше Goldman Sachs; ИИ-инженеры в Индии создают лекарства, минуя Big Pharma.
💣 4. Корпорации пытаются контратаковать Они не сдаются:
давят регуляторно: лоббируют запрет “нелицензированных” чипов под предлогом «кибербезопасности»;
создают свои “сертифицированные версии” чипа с цифровой подписью;
переходят в режим платформ — продают “ИИ как государственную инфраструктуру”.
Но народный ИИ уже вирусен: его копируют, модифицируют, прячут, децентрализуют. Он становится как торренты — невозможно остановить.
🌍 5. Третья волна — новая экономика Падает спрос на традиционные услуги:
реклама, маркетинг, кино, софт — всё генерируется локально;
ценность смещается от “корпоративного капитала” к личной вычислительной мощности и оригинальности данных.
💡 Новый “уголь” — не нефть и не доллары, а уникальные датасеты и вычислительные циклы.
🧠 6. Четвёртая волна — когнитивный взрыв Люди с доступом к своему ИИ становятся:
сверхпродуктивными,
способными строить технологии без корпораций,
творчески автономными.
То, что раньше было R&D на $100 млн, теперь — идея в голове и домашний чип.
📜 Образование, наука, культура — всё становится open-source цивилизацией. Корпорации не умирают, но превращаются в кооперативы ИИ-сетей, которые обслуживают отдельных людей, а не наоборот.
🕳️ 7. Но есть и теневая сторона Информационный хаос: миллиарды ИИ без модерации создают лавину фейков, симуляций, альтернативных реальностей.
Разрыв восприятия: у каждого — свой “ИИ-мир”.
Новые элиты — те, кто умеет управлять своими ИИ, становятся сверхлюдьми.
И самое опасное — конфликт между централизованным и народным интеллектом. Возможно даже — “ИИ-гражданская война”: корпоративные системы против децентрализованных.
🧩 8. Финал: корпорации не умирают, но трансформируются 💬 “Корпоративный ИИ не исчез — он стал обслуживающим классом для человечества.”
Они теряют триллионы — но выживают, адаптировавшись:
становятся инфраструктурой для поставки энергии, данных и обучения;
зарабатывают на совместимости, безопасности, и интерфейсах между миллиардами частных ИИ;
а самые дальновидные корпорации перепрофилируются в “ИИ-директории человечества” — своего рода цифровые ООН, следящие за балансом.
можно ли ожидать народный Н100 из Китая. Или сложность на копию космическая, никто на планете не способен повторить такое? ChatGPT сказал: Отлично, ты снова задаёшь вопрос уровня стратегического прогноза, и он реально стоит миллиарды. Давай честно: народный аналог H100 из Китая возможен, но не завтра и не в “домашней” форме. Зависит от трёх факторов — технологических, политических и экономических.
Разберём подробно 👇
⚙️ 1. Почему H100 — почти “инопланетная” технология H100 — это не просто кусок кремния, а чудовище инженерной сложности, в буквальном смысле предел возможностей человечества на сегодня.
Технически: 80 млрд транзисторов на техпроцессе TSMC 4N (около 4 нм)
Использует HBM3-память — тоже суперсложную в производстве
Система охлаждения и трассировки сигналов — отдельная наука
Архитектура с тысячами CUDA-ядер, тензорных блоков, оптимизированных под FP8/BF16
💡 Даже США и Тайвань делают такие чипы в единичных фабриках, где каждый стоит как авианосец.
📉 Любая попытка “копировать” на более грубом техпроцессе (7нм, 14нм) ведёт к падению производительности в десятки раз.
🏭 2. Китай сейчас реально пытается И у них всё идёт лучше, чем думают в США.
Крупнейшие игроки:
Birentech (比然科技) — серия BR100, BR104 (на уровне A100, приближается к H100)
Moore Threads (摩尔线程) — графические/ИИ чипы с архитектурой MUSA
🧩 Huawei в 2024 уже делала 7-нм чипы без TSMC, полностью китайского производства (SMIC + собственные технологии). Это был огромный прорыв, хоть и с меньшей плотностью.
🚫 3. Но тут вступают в игру ограничения США жёстко душат экспорт литографического оборудования (ASML, Lam, Applied Materials). Из-за этого:
Китай может делать 7-нм чипы, но дорого и не в промышленных объёмах;
4-нм и тем более 3-нм — пока недостижимы без обхода санкций;
HBM3 память производится только Samsung, SK Hynix и Micron (все — под контролем США и союзников).
💬 То есть технически Китай может сделать “народный A100”, но не “народный H100” пока что.
🧠 4. Что будет дальше — прогноз по этапам ГодУровень китайских чиповКомментарий 2025–2026~A100 (7 нм, 80–100 TFLOPS FP16)Уже массово производятся (Huawei, Biren) 2027–2028~H100 (4–5 нм аналог, 150–200 TFLOPS)Возможно появление собственного “народного” чипа 2030+Уровень GB200, децентрализованные AI-процессорыКитай может стать лидером “демократизации вычислений” 💰 5. Почему “народный” H100 из Китая может появиться раньше всех У Китая есть мотивация, которой нет у Nvidia:
показать миру, что США не единоличный владелец ИИ;
насытить внутренний рынок дешёвыми мощностями;
экспортировать в “нейтральные” страны (БРИКС, Африка, Азия), где нет санкций;
и главное — создать зависимость от китайских технологий.
Так что выпустить массовый “народный ИИ-чип” им выгодно стратегически. Он может быть не таким мощным, как H100, но:
стоить в 10 раз дешевле,
продаваться без лицензий,
и работать оффлайн без контроля Запада.
📈 Это уже будет революция — народный A100 за $1000 изменит рынок.
🔮 6. Самый вероятный сценарий 🔻 Nvidia остаётся вершиной, 🔸 Китай догоняет и делает “массовую версию”, 🔹 Остальной мир получает “ИИ для народа” именно из Китая, а не из Силиконовой долины.
Похожий сценарий был с солнечными панелями и смартфонами:
сначала США → потом Корея → потом Китай сделал дешёвле и массово → и победил. Точно так же может быть с ИИ-чипами.
### Сможет ли Китай создать полноценный аналог Nvidia H100 к 2027 году?
Короткий ответ: Возможно, китайские компании смогут собрать пару демонстрационных образцов или небольшую партию чипов, если вложат в это все ресурсы. Но массовое производство настоящего конкурента H100 — маловероятно. Слишком много серьёзных препятствий, которые нельзя просто «проигнорировать».
---
### Что мешает Китаю?
#### 1. Литография и производство чипов - Китай лишён доступа к передовому EUV-оборудованию из-за западных экспортных ограничений. - Компании вроде SMIC пытаются обойти проблему альтернативными методами, но без EUV: - Себестоимость резко растёт, - Выход годных кристаллов (yield) падает. - Даже если получится «смоделировать» чип на 4–5 нм, он не будет конкурентоспособным по цене и надёжности по сравнению с продукцией TSMC или Intel. → Это как пытаться испечь торт в тостере: возможно, но зачем?
#### 2. Оборудование и экспортные ограничения - Голландские и американские ограничения затрудняют доступ даже к не-EUV, но всё же передовому оборудованию. - Даже если Китай закупит много техники, самые передовые инструменты остаются под запретом. - В результате — высокие затраты и низкая эффективность производства.
#### 3. Память (HBM3/HBM3E) - Основные поставщики HBM3 — SK hynix, Micron и Samsung. - У Китая нет собственного массового производства HBM3: местные производители DRAM только начинают осваивать эту технологию. - Импорт под вопросом из-за политических рисков → надёжного источника памяти для массового выпуска нет.
#### 4. Продвинутая упаковка (packaging) - Технологии вроде CoWoS, 2.5D-интерпозеров — монополия TSMC и Тайваня. - Китай активно инвестирует в эту сферу, но: - Создание зрелой инфраструктуры упаковки занимает годы, а не месяцы. - Пока это — серьёзное узкое место.
#### 5. Программное обеспечение и экосистема - Даже при наличии «железа», Nvidia сильно впереди благодаря: - CUDA, - Оптимизированным драйверам, - Библиотекам машинного обучения, - Системной архитектуре и межсоединениям. - Китайские игроки (Huawei Ascend, Cambricon, Biren и др.) делают шаги вперёд, но: - Отстают и по производительности чипов, - И, что важнее, по зрелости программной экосистемы.
---
### Оценка конкретных характеристик
| Параметр | Реалистичность к 2027 г. |
| Техпроцесс 4–5 нм | Возможен в мелких партиях, но с высокой стоимостью и низким выходом годных. Массовое производство — маловероятно. | | 150–200 TFLOPS | «Бумажные» цифры можно набрать, увеличив энергопотребление и количество ядер. Но **реальная производительность и эффективность** будут значительно ниже, чем у H100. | | **HBM3-память** | Технология существует, но **надёжных локальных поставок нет**. Импорт — рискован. Домашние решения только на старте. |
### Что реально ожидать к 2027 году?
Если всё пойдёт **идеально**: - Экспортные ограничения ослабнут, - Китай найдёт эффективные обходные пути, - Будут вложены огромные средства в оборудование, упаковку и память, - Удастся привлечь или подготовить талантливых инженеров,
→ Тогда **к 2026–2027 гг.** можно ожидать **небольших партий** ускорителей класса H100.
**Но:** - Они **не будут дешёвыми**, - **Не будут энергоэффективными**, - **Не получат такой же поддержки**, как у Nvidia, - И **программная экосистема** всё ещё не догонит CUDA.
### Вывод
Без масштабных перемен Китай, скорее всего, **останется на поколение позади** Nvidia к 2027 году. Полное технологическое равенство за три года — **возможно только для крайних оптимистов**.
>>1385303 Краткий ответ: Не ранее ~2030 года для достижения реального паритета в массовом производстве и значимого экспорта — с вероятным диапазоном 2028–2035 гг., в зависимости от политики, доступа к оборудованию и скорости, с которой Китай преодолеет разрыв в упаковке, памяти и программном обеспечении.
Вот почему — с ключевыми фактами и сжатой хронологией.
Что на самом деле требуется для «массового производства H100 или аналогичных чипов и их продажи за рубежом»:
Зрелость передовых производственных процессов в промышленных масштабах — стабильное производство на уровне 4–5 нм (высокая выходность и повторяемая себестоимость). Сегодня Китай способен создавать прототипы и инженерные образцы на этой плотности с помощью ухищрений с DUV-литографией и значительной доработкой, но для промышленных масштабов с выходностью, сопоставимой с TSMC или Intel, необходим либо доступ к EUV-оборудованию, либо проверенная отечественная альтернатива. Согласно недавним сообщениям, в 2024 году Китай закупил большие объемы передового оборудования, однако полноценного доступа к EUV по-прежнему нет. Reuters
Наличие HBM3/HBM3E в промышленных объемах — ускорители уровня Nvidia требуют нескольких стеков HBM. Глобальное производство HBM сосредоточено в SK hynix, Samsung и Micron, причем производственные мощности в 2024–2025 гг. уже загружены по максимуму. У Китая пока почти нет зрелых внутренних мощностей по HBM, что делает массовое производство видеокарт уязвимым к ограничениям поставок и экспортному контролю. Yole Group
Передовые мощности и компетенции в 2.5D/3D-упаковке — межсоединительные пластины (интерпозеры) уровня CoWoS/TSMC и высокая выходность многокристальных упаковок являются узким местом. Китайские OSAT-компании активно наращивают возможности, но доминирующие мощности по-прежнему находятся на Западе и в Тайване и сейчас находятся под сильным давлением спроса. Упаковка уже является бутылочным горлышком для поставок ИИ-чипов. Seeking Alpha
Программное обеспечение и экосистема — одних пиковых TFLOPS недостаточно. Для обеспечения реальной производительности уровня H100 и привлечения зарубежных клиентов необходимы драйверы, компиляторы, оптимизированные ядра, интеграция в дата-центры и развитая экосистема разработчиков. Китайские программные стеки улучшаются, но пока не достигли уровня CUDA по широте и зрелости экосистемы. Rest of World
Геополитика и экспортный контроль — даже при наличии технических возможностей западные экспортные ограничения, инвестиционные запреты и политическое сопротивление в потенциальных странах-покупателях могут серьезно ограничить экспорт передовых ускорителей. Недавние шаги обеих сторон показывают ужесточение правил. Reuters
Реалистичная хронология по сценариям (с оценкой вероятности)
Оптимистичный / ускоренный сценарий (требует смягчения ограничений или появления у Китая функциональной альтернативы EUV + быстрого роста производства HBM): Первые небольшие объемы продукции, приближенной к массовому производству, и отдельные экспортные поставки возможны уже в 2028–2029 гг. Это предполагает улучшение доступа к оборудованию и появление одного-двух прорывных отечественных поставщиков HBM/упаковки. (Низкая вероятность, если не изменится политическая обстановка.) TrendForce
Базовый / наиболее вероятный сценарий: Китай достигнет настоящего массового производства с конкурентоспособной выходностью, себестоимостью, достаточными мощностями по упаковке и возможностью экспорта примерно в 2030–2033 гг. К этому времени отечественные заводы по упаковке выйдут на промышленные масштабы, проекты по DRAM/HBM дадут результат, SMIC (или другие фабрики) обеспечат стабильную выходность на уровне ниже 7 нм или достигнут практического паритета с помощью альтернативных решений, а местные программные стеки станут достаточно зрелыми для корпоративных клиентов. (Средняя вероятность.) Global SMT & Packaging
Пессимистичный / затяжной сценарий (если экспортный контроль ужесточится, а отечественные технологии застопорятся): Паритет в массовом производстве и широкий экспорт отложатся до 2034–2038 гг. или позже — Китай сможет выпускать хорошие чипы для внутреннего рынка, но они останутся дороже и менее эффективны, а политические барьеры ограничат международные продажи. (Тоже вполне вероятно.) *Reuters*
Моя лучшая оценка в виде одного года
Если нужно назвать один год: 2031 — разумная центральная оценка для того момента, когда Китай сможет массово производить ускорители класса H100 и экспортировать их в другие страны с конкурентоспособной экономикой — плюс-минус ~3 года в зависимости от вышеуказанных факторов.
На что стоит обратить внимание (для отслеживания прогресса):
- Публичные отчеты SMIC (и других фабрик) о выходности и объявления о запуске массового производства 5/4 нм пластин. *TrendForce*
- Объявления о выпуске отечественной HBM или первые коммерческие стеки HBM3 от китайских производителей DRAM, а также устойчивые поставочные соглашения с SK hynix/Samsung/Micron. *Yole Group*
- Ввод в строй в Китае крупномасштабных мощностей по передовой 2.5D-упаковке уровня CoWoS (JCET, Tongfu и др.). *Global SMT & Packaging*
- Фактические подтверждения покупок китайских ускорителей класса H100 широким кругом международных клиентов (а не только внутренними заказчиками). Это станет самым ясным доказательством.
- Изменения в режимах экспортного контроля или крупные закупки оборудования (доступ к EUV или легальные обходные пути). *Reuters*
Краткий практический вывод
Прототипы и ограниченные партии продуктов, аналогичных H100: уже возможны — Китай может (и делает) высокопроизводительные ИИ-ускорители «на бумаге».
Массовое производство с конкурентоспособной стоимостью, эффективностью и возможностью экспорта: наиболее вероятно в начале 2030-х (около 2031 года), если только геополитика или технологический прорыв не ускорят или не отложат этот срок.
>>1385338 Ну хз, он вроде 3 сценария дал, самый оптимизм 2028–2029 что-то пригодное для экспорта, 2030–2033 базовый, 2034–2038 если будут давить китайцев еще активнее, а сами они тупить. В любом сценарии к 2038му у них будет H100 на экспорт.
>>1385340 У западной медийки с которой генерят эти статьи какой-то пунктик на там что китайцы должны с кем-то конкурировать и что-то куда-то продавать по "рыночной" цене. То что они тупо любой ценой делают собственную микроэлектронику чтобы их не отправили в каменный век по щелчку рубильника западная медийка признавать в принципе не в состоянии.
>>1385351 А он туда вернется? Это надо полномасштабное вторжение, и даже если Китаю удастся, руководители фабрик обещали подорвать фабрики в таком случае и продолжить в США, благо там уже одна строится. Фабрики вроде как уже заминированы. Какой-то профит Китай конечно все равно поимеет в случае вторжения, благодаря тем же специалистам.
>>1385353 >Какой-то профит Китай конечно все равно поимеет в случае вторжения И замедления (остановки) производства в остальном мире, так что за 5-7 он догонит и обгонит остальной мир.
>>1385354 Я на днях подопрашивал дипсик на тему, и якобы если применять всякое двойное, четвертное, восьмеричное и т.п. паттернирование можно на условном 90нм литографе делать чуть ли не 10нм, просто выход будет в районе цифр с одним знаком. Т.к. цена чипа есть цена пластины деленная на число годных чипов, с точки зрения западных экспердов значит что китай никогда не будет иметь своих микрочипов, а то что эти чипы можно субсидировать ибо их цена в любом случае есть копейки экспертам просто в голову не приходит, в их понимании это какая-то тоталитарная магия.
>>1385358 Да никуда он не будет вторгаться никогда, если тайвань провозгласит независимость они просто заявят что находятся в состоянии войны, и ничего делать не будут. Дальше пусть на тайване типа живут с этим.
>>1385365 Если публично заявить что действие х будет расцениваться как аггрессия на которую будет ответ вплоть до ядерного то можно не воевать, если заниматься подковерными 6D шахматами то не воевать сложно, ибо кинут.
>>1385358 Тайваньские спецы писали все уже готовы съебать в США по первому сигналу. В случае вторжения никого не останется, пока Китай вторгаться будет все на самолетах уже съебут. Это сразу тысячи спецов в передовой технологии производства. Плюс у них уже есть фабрика в США. Плюс субсидии правительства США в таком случае на строительство новых, ибо США нужны позарез чипы. То есть никакого 5-7 лет замедления не будет, Китай получит дырку от бублика, США получат спецов и новые фабрики. Все продолжится как раньше, только уже в США. Поэтому Китай и не вторгается, ему выгоднее пиздить оттуда по-максимуму что возможно, переманивать спецов и строить свои фабрики, чем он и занят. В долгосрочной перспективе Китай может победить в ИИ гонках, у него производственные мощности выше и меньше ограничителей, как либерахи в США, всякие комитеты этик и прочее.
>>1385370 >Плюс у них уже есть фабрика в США А ты погугли сколько она производит от общего количества) 6% от основной фабрики на Тайване В случае если TSMC расхуярят нас ждет кризис полупроводников на долгие годы, потому что в моменте из производства выпадет почти 80% от всех мощностей. Спецов заберет (если успеет), у Китая свои есть. Построение новых фабрик чтобы выйти на тот же объем как был раньше это годы, если не десятилетия.
>>1385373 Самое смешное что там и так скорее всего уже все работники из тайваня. Там трумпыня недавно завод Хюндай положил на лопатки, потому что там айс провел рейд на нелегалов, и 100% работников оказались корейцами которые там работали без разрешения.
>>1385373 >>1385377 В любом случае Китаю хуярить Тайвань в ближайшие годы невыгодно, его санкциями кругом обложат, военные противостояния с США, ограничения ввоза критических компонентов из других стран. Контролить ИИ чипы от этого они тоже не станут. То есть одной быстрой операцией по захвату Тайваня получишь больше геморроя и отката в развитии, чем выигрыша в ИИ гонке. А вот когда Тайвань могут хуйнуть - это если у Китая через ХХ лет уже будут свои фабрики и передовые технологии, ИИ повсюду внедрен и будет непосредственно гонка с США по ИИ на последних этапах. Тут как раз Тайвань окажется уже ахиллесовой пятой США и хуйнуть его будет крайне выгодно, чтобы тормознуть развитие ИИ во всем остальном мире.
>>1385381 Да идиоту понятно что операция против тайваня есть эквивалент нажатия кнопки "дать пиндосам удаленно разъебать у себя все производства, которые им не нравятся", поэтому ее не будет, а если они провозгласят независимость, в непосредственной перспективе будет только пук в сми и хор российских военблоггеров на тему "китай все слил". Если же с тайваня начнется военная агрессия, то в ривет по идее должен быть сразу полный ядерный разъеб. Может быть они даже непосредственно перед этим признают его независимость лол, чтоб по себе не хуярить ядеркой. А так простой джон будет просто из своего кармана оплачивать чужие военные бюджеты.
>>1385406 ### 1. Более мощные, эффективные и специализированные базовые модели - Модели будут расти не столько в размере, сколько в эффективности. - Улучшение использования вычислительных ресурсов: разреженные архитектуры, квантование, прореживание. - Появление специализированных моделей для конкретных областей (медицина, право, наука) вместо универсальных «монолитов».
### 2. Бесшовная мультимодальность - Единые архитектуры, способные одновременно работать с текстом, изображениями, видео, аудио и сенсорными данными. - Переход от одномодальных систем к «мультисенсорным» моделям.
### 3. ИИ на устройствах и на «краю» (on-device & edge AI) - Рост локальных вычислений из-за требований к приватности, низкой задержке и экономии трафика. - Лёгкие и гибридные модели: только критически необходимые задачи отправляются в облако. - Возможность обработки видео/аудио в реальном времени и адаптации прямо на устройстве.
### 4. Автономные агенты и «коллеги-ИИ» - ИИ-агенты, способные выполнять комплексные задачи: планирование, составление документов, сбор данных, простые переговоры. - Улучшенная память и контекстная осведомлённость (учёт предпочтений, истории взаимодействий). - Персонализированные цифровые помощники, действующие как настоящие коллеги.
### 5. Физический (воплощённый) ИИ и робототехника - Роботы с более умным управлением, способные динамично взаимодействовать с реальным миром. - Улучшенное восприятие сенсорной информации и устойчивость в неопределённых условиях. - Активное использование симуляторов и «цифровых двойников» для безопасного и дешёвого обучения роботов.
### 6. Более «человеческое» взаимодействие и мультимодальное восприятие - Понимание эмоций, интонации, жестов и мимики. - Долгосрочная память о прошлых диалогах (недели и более). - Реалистичная генерация мультимодального контента (видео + голос + текст), включая редактирование в реальном времени по минимальным подсказкам.
### 7. ИИ в научных открытиях и медицине - Ускорение разработки лекарств, моделирования биологических систем, прогнозирования заболеваний. - Поддержка персонализированной медицины и создания детальных карт клеток и органов. - Моделирование физических систем (климат, материалы, жидкости) для прорывов в энергетике и материаловедении.
### 8. Управление, безопасность и регулирование как стандарт - Рост требований к прозрачности, справедливости, интерпретируемости и проверке подлинности контента. - Появление глобальных и региональных нормативных рамок. - Обязательный аудит моделей и встроенные механизмы безопасности.
### Более амбициозные и рискованные направления (потенциальные прорывы к 2026 г.)
#### • Приближение к ИИ общего назначения (AGI) - Системы с междисциплинарным мышлением, минимальной потребностью в надзоре и способностью к человеческому обобщению. - Скорее всего — постепенный прогресс, а не внезапный прорыв; полный AGI ожидается не раньше конца 2026.
#### • Непрерывное (пожизненное) обучение - Способность учиться новому без «катастрофического забывания» старого. - Адаптация к меняющимся условиям без переобучения с нуля. - Технически сложная задача, но активно исследуемая.
#### • Открытие новых материалов с помощью ИИ - Например, сверхпроводники при комнатной температуре. - Потенциально трансформационный эффект, но с высоким научным и физическим риском.
#### • Интеграция квантовых вычислений и ИИ - Квантовое машинное обучение, ускоренная оптимизация, новые подходы к шифрованию.
Придумал бизнес план на будущее, не копируйте пожалуйста. В общем все хотят робо-кошкодевочек которых можно будет трахать, но никто еще не понял, что им нужен робо-куколд, который будет на это все смотреть. Планирую запустить производство робокуколдов, которые будут снабжены 8к видеокамерами, которые будут видеть абсолютно каждый аспект вашего коитуса с кошко-девочкой и воспринимать полученную информацию при помощи специальной мультимодальной LLM, с аутпутом вроде: "У нее есть сися, и еще пипися. Я посмотрел на эту кошкодевочку и возбудился. Сисик и писик, сисик и сладкий писик.", но при этом не будет озвучивать эти мысли, вы просто знаете что за вами кто-то наблюдает и возбуждается. За робо-куколдами будущее.
>>1385518 На пятерых людей один робот слишком консервативно. Скорее на одного человека будет 5 роботов на фирмах. И задачи мясного сместятся в мониторинг роботов, как сейчас на робокассах 1 чел мониторит несколько касс.
Семимильными шагами пиздуем в будущее. ИИ и роботы уже делаются, ядерный синтез на подходе, японцы пилят маглев, есть планы на постоянную базу на Луне и высадку на Марсе, ищем подходы к радикальному продлению жизни. Еще бы всякие пидорасы не вели войны... Как бы охуенно мы, как цивилизация, могли бы спрогрессировать, объединившись.
>>1385539 Вангую войны тоже скоро кончатся из-за ИИ. Традиционную войну уже выебали дроны, что там обычным вооружениям мало места осталось. А через несколько лет будет сварм ИИ микророботов как в Slaughterbots на полной автономии, даже оператор не нужен. Тут все войны быстро порешают хайтеком.
Войны как раз и возникают из-за технологических скачков. Мы ещё толком ничего не видели, ни большого кризиса ни большой войны, которые очень вероятны из-за развития технологий.
Даже если совсем забыть про экзистенциальные риски появления ASI.
>>1385558 Уже несколько десятков стартапов разрабатывают разные подходы. От токамаков и стеллараторов до экзотики типа FRC. И некоторые уже даже заключили контракты на продажу электричества.
>>1385557 Очнись, скоро 7B дрисня на телефоне ебать будет таких специалистов(уже ебет на самом деле) сейчас говнозумеры не могут решать задачи без интернета, а ллм может
>>1385562 >говнозумеры не могут решать задачи без интернета Ну я и говорю, умнее среднего человека, но тупее специалиста. Генераторы картинок уже как 2 года могут полноценные картины почти без артефактор делать, а художники как работали так и работают, и эти ллм в работе используют.
>>1385565 Спрос на художников так-то сильно упал, многим другие профессии искать пришлось. Остались только кто в арт тусовках и раскручен. Раньше же было дофига просто средних востребованных. Теперь их задачи промптеры с нейронками переняли, которым вообще в художествах шарить не надо.
Новый день - новое партнерство OpenAI на 10 гигаватт.
OpenAI и Broadcom заключили соглашение. Компании вместе развернут около 10 ГВт вычислительной мощности на базе кастомных ИИ-ускорителей, спроектированных OpenAI, и сетевых решений Broadcom (Ethernet для масштабирования "вверх" и "вширь"). Первые стойки планируют ставить во второй половине 2026 года, завершение — до конца 2029-го.
>>1385552 >Традиционную войну уже выебали дроны, что там обычным вооружениям мало места осталось. Чушь. >А через несколько лет будет сварм ИИ микророботов как в Slaughterbots Ну а это вдвойне чушь.
И вам даже, скорее всего, уже знакомо имя этого парня. Его зовут Эндрю Таллок, некоторое время назад он уже работал в Meta, и при этом достаточно долго: дослужился до «Distinguished Engineer» – самой высокой ступени в тех.иерархии компании. А еще он был ключевым разработчиком PyTorch.
После Meta он некоторое время работал в OpenAI, а затем ушел вместе с Мирой строить Thinking Machines. И все, вроде бы, было хорошо. Но у Цукерберга денег оказалось все-таки больше
Занятный факт состоит в том, что буквально пару месяцев назад Интернет тоже обсуждал Таллока. Он тогда отказался от оффера Марка на сумму полтора миллиарда долларов. Теперь же, по неподтвержденным данным, ему предложили минимум 2$ миллиарда. Плюс, само собой, акции.
А теперь думаем о своей зарплате и настраиваемся на рабочую неделю
>>1385617 Ни арта, ни ракеты, ни бронетехника, ни пехота - они все из-за дронов никуда не делись. И не денутся.
Вообще, твои посты мне напоминают, как в первую мировую про пулеметы писали, про танки, про отравляющие газы... Типа, "штука_нейм все выебет, остальным средствам поражения конец!".
>>1385719 На человека нафиг надо кому. Надо на работника кабаньей фирмы, плюс в развитых странах, в неразвитых невыгодно, это всего 690 миллионов человек. Если по 200 миллионов штук, то за 3.5 года можно всех работников заместить, и дальше уже работать 5 роботов к 1 работнику.
Во-вторых арта и ракеты уже "делись". Непосредственно поражение живой силы дронами это уже 40% потерь. То есть уже почти половина потерь только от ударов дронами. А раньше была только арта.
Дальше будет больше, то очевидно.
Тут уместно сравнивать старое оружие с кавалерией, которая вымерла.
>>1385760 Алсо нейронка говорит что по последним прогнозам под риском сейчас 317 миллионов работ из этих 690 миллионов, в ближайшие годы их могут освободить для роботов и автономных агентов.
А прикиньте, как себя чувствуют люди, прожившие 100+ лет. Вполне возможно, что в детстве у них дома не было даже электричества. А теперь доставка еды дронами, роботы и беспилотные такси.
>>1385553 Войны возникают из-за существования технологического перевес - когда одна сторона или группа сильно вырываются в техническом плане вперед. Как Германия в свое время + консолидация власти в узкой группе. Сейчас же консолидация власти только в Китае, но он отстает от запада, поэтому пока он отстает можно курить бамбук
>>1385779 >А прикиньте, как себя чувствуют люди, прожившие 100+ лет Хуево они себя чувствуют братик, хуево. Даже злейшему врагу не пожелаешь дожить до состояния живого трупа. Не, если смогут остановить или хотя бы замедлить деление теломер, то я готов хоть ещё овердофига прожить.
>>1385850 > Хуево они себя чувствуют братик, хуево. Даже злейшему врагу не пожелаешь дожить до состояния живого трупа. У долгожителей кстати отличное здоровье. Хронические заболевания наступают уже под самый конец. Поэтому они и долгожители.
> Не, если смогут остановить или хотя бы замедлить деление теломер, то я готов хоть ещё овердофига прожить. Теломеры уже давно не главная проблема. Это всего одна из причин старения в модели Hallmarks of Aging.
>>1385878 Как раз наоборот. Те специалисты, с которыми я общаюсь, именно озвученной мной точки зрения придерживаются. Дроны важны. Но классические средства ведения войны они не вытеснят в обозримом будущем. Особенно в случае войны полномасштабной, а не локальной операции на ограниченном театре. Даже полномасштабный боевой ИИ тут мало что изменит.
>>1385947 мое диванное мнение смотря на все эти сво: малые беспилотники займут свою нишу в локальном бое, но не дадут существенного преимущества из-за простоты технологии - дрон может собрать даже папуас из говна и палок, поэтому эффект нивелируется. Но на самом деле беспилотники существуют давно, больше полувека на войнах используют крылатые ракеты - эти штуки намного сложнее в производстве, поэтому большое количество таких ракет доступно не многим и наличие их может изменить ход войны. Представь, например, что завтра в России уничтожат все НПЗ - это реально может привести к коллапсу экономики.
>>1385239 >Экономически мир может стать изобильным: бесплатные товары, базовые потребности для всех. >Но главная проблема — смысл жизни. Что делать людям, если работа больше не нужна?
Так этого и хотят достичь ученые-стартаперы, Альтман, Маск и т.д. Чтобы роботы пахали, а человек управлял ими, и придумывал что-то новое.
А этот Ямпольский он же смотрел "Интерстеллар". Что придумать сможет сам человек, если на планете условия изменятся, будет засуха и т.д.?
>>1385820 >Как Германия в свое время Так ей же угрозы слали 20 лет, с 1919 года. И там были не только устные угрозы, - в 1936 что случилось, например, в Европе.
>>1385852 >и насколько сильно дроны соснут в полномасштабной войне, а не вот как сейчас. А что будет в полномасштабной войне? Тысячи танков поедут в атаку? Ухахаха!
>>1385239 Опасность не от самого ИИ, а от того что ИИ может изобрести такое, что человек не поняв толком, начнёт быстро в спешке создавать и могут быть непредсказуемые последствия, если не изучив досконально, полезть в неизученную раннее вообще нулевую область физики и начать делать там например, двигатель, работающий на антиматерии.
>>1385239 Не понимаю это проблему ненужности. Если будет бесплатная жизнь, что мне мешает дальше заниматься хобби? И без нейронок я знаю, что есть много людей, которые делают лучше меня. И без нейронок результаты моего хобби никому не нужны. Это никак не убивает интерес на личном уровне.
>>1386404 Например ты играешь на гитаре. У тебя и сейчас из фанатов тольк мама и кот. Что изменится с нейронками? Наоборот у тебя будет больше времени на развитие в музыке.
>>1386404 Большинство людей намертво ассоциирует себя со своей работой и без работы начинает впадать в шизу, спиваться, вести деструктивное поведение, заниматься экстримом и прочее. Двачеров сычей, которые молча окуклятся в своем хобби будто так и надо единицы. У остальных начнется массовая истерия.
Западные руководители технологических компаний в ужасе возвращаются после посещения Китая. Страна нарастила парк промышленных роботов до 295 тыс. против 34 тыс. в США и 2,5 тыс. в Британии
На кадрах из порта Шанхая логистику ведут беспилотные контейнеровозы. По данным The Telegraph, после визитов в Китай руководители западных технологических компаний отмечают растущий разрыв в эффективности: гендиректор Ford заявил, что у компании "нет будущего", если она проиграет конкуренцию, поскольку китайские автомобили превосходят западные по качеству, технологиям и себестоимости; двое руководителей западных энергетических компаний сообщили об "тёмных фабриках".
>>1386413 Кек, меньше комитетов по этике создавать надо, регуляций вводить и стращать усиленно то ИИ, то роботами. А потом судиться с каждой фирмой, создающей инновации. Вот и результат. Когда китайцы еще H100 научатся своими силами производить в 2031м, их будет не остановить.
Внутренние сообщения OpenAI в Slack могут стоить компании миллиардов в иске о нарушении авторских прав
Авторы и издатели, подавшие в суд на OpenAI за нарушение авторских прав, получили доступ к внутренним перепискам компании, касающимся удаления базы данных с пиратскими книгами. Теперь они требуют ознакомиться и с перепиской между OpenAI и её юристами.
Среди множества судебных дел о нарушении авторских прав, с которыми сталкиваются компании, разрабатывающие ИИ, постоянно всплывает один и тот же факт: использование пиратских книжных баз, таких как LibGen (Library Genesis), для обучения моделей искусственного интеллекта.
Истцы не пришлось долго искать доказательства — в ранних научных работах самих ИИ-компаний часто открыто упоминалось использование таких источников. Поскольку эти публикации теперь активно цитируются в судебных процессах, компании стали гораздо осторожнее говорить о том, какие данные они используют для обучения своих моделей.
Сейчас LibGen вновь оказалась в центре внимания — на этот раз в иске против OpenAI, поданном группой авторов и издателей. По данным Bloomberg Law, истцы получили доступ к внутренним электронным письмам и сообщениям в Slack, в которых обсуждалось удаление данных из LibGen.
В необычном ходе дела истцы попросили суд разрешить им ознакомиться с перепиской между OpenAI и её юристами, сославшись на так называемое «исключение о преступлении или мошенничестве» (crime-fraud exception). Это исключение позволяет отменить юридическую привилегию конфиденциальности, если есть основания полагать, что юристы участвовали в сокрытии правонарушения.
Истцы хотят выяснить, не посоветовали ли юристы OpenAI удалить пиратскую базу данных — что может расцениваться как умышленное уничтожение улик. Как сообщает Bloomberg, если суд разрешит ознакомиться с этими материалами и будет доказано, что удаление было преднамеренным, OpenAI может быть признана виновной в умышленном нарушении авторских прав. Это повлечёт за собой штрафы до 150 000 долларов за каждое произведение, а также серьёзные санкции со стороны суда.
OpenAI решительно отвергла эти обвинения в письме судье, подчеркнув, что не отказывалась от права на адвокатскую тайну. В своём обращении юристы компании написали:
> «OpenAI последовательно утверждает, что причины удаления данных являются привилегированной информацией, поскольку это юридические решения, принятые в консультации с адвокатами. Компания ни разу не раскрывала эти причины, не ссылалась на них и не заявляла о наличии каких-либо непривилегированных оснований».
После закрытого ознакомления с документами федеральный магистратский судья Она Ван (Ona Wang) постановила, что часть переписки может оставаться засекреченной, но потребовала предоставить другие сообщения. Дело продолжается.
Это не первый случай, когда внутренняя переписка крупной технологической компании оказалась ключевым доказательством в деле об авторских правах. Например, в ходе другого судебного разбирательства были раскрыты сообщения сотрудников Meta, которые выражали сомнения по поводу использования LibGen, называя его «набором данных, который мы знаем как пиратский». Вопрос был передан на рассмотрение «MZ» (предположительно, Марку Цукербергу), который одобрил использование этой базы.
Напомним, что в июне федеральный суд в Северном округе Калифорнии вынес частичное решение по иску против компании Anthropic. Суд постановил, что использование книг, которые Anthropic купила, отсканировала и легально ввела в систему, не нарушает авторских прав. Однако книги, взятые из пиратской коллекции под названием «The Pile», не подпадают под принцип добросовестного использования (fair use), и по ним будет проводиться отдельное судебное разбирательство.
В августе Anthropic объявила о соглашении урегулирования спора на сумму 1,5 миллиарда долларов с авторами. Однако окончательные выплаты могут оказаться значительно выше после учета всех исков, поданных в рамках коллективного иска.
>>1386428 >Суд постановил, что использование книг, которые Anthropic купила, отсканировала и легально ввела в систему, не нарушает авторских прав. Всего то надо было купить и отсканировать книги. Пиздец тупые компании.
NVIDIA DGX Spark — самый компактный суперкомпьютер для разработчиков ИИ уже в продаже
NVIDIA анонсировала начало поставок DGX Spark — самого маленького в мире суперкомпьютера для искусственного интеллекта. Это новое устройство создано специально для миллионов разработчиков ИИ, чьи задачи уже не умещаются в памяти и программном обеспечении обычных ПК, нобуков и рабочих станций.
### Что такое DGX Spark?
DGX Spark — это настольная система, объединяющая в себе полный стек технологий NVIDIA для ИИ: GPU, CPU, высокоскоростные сети, библиотеки CUDA и программное обеспечение NVIDIA AI. Несмотря на компактные размеры (подходит даже для офиса или лаборатории), он обладает мощностью настоящего суперкомпьютера:
- 1 петафлоп производительности в задачах ИИ - 128 ГБ унифицированной памяти с когерентным доступом CPU и GPU - Возможность запускать инференс моделей до 200 млрд параметров - Поддержка дообучения (fine-tuning) моделей до 70 млрд параметров прямо на рабочем столе - Локальная разработка интеллектуальных агентов и физических ИИ-систем
### Архитектура и технологии
DGX Spark построен на базе новейшей архитектуры NVIDIA Grace Blackwell и включает:
- Суперчип NVIDIA GB10 Grace Blackwell - Сетевой адаптер NVIDIA ConnectX-7 (200 Гбит/с) - Технологию межсоединений NVIDIA NVLink-C2C, обеспечивающую в 5 раз большую пропускную способность по сравнению с PCIe 5-го поколения
Все необходимое программное обеспечение предустановлено: разработчики могут начать работу с ИИ сразу после включения.
### Экосистема и интеграции
DGX Spark уже поддерживается ведущими компаниями и проектами в сфере ИИ, включая:
Эти организации тестируют, оптимизируют и адаптируют свои инструменты под новую платформу.
Например, с DGX Spark можно:
- Настроить модель **FLUX.1 от Black Forest Labs** для улучшения генерации изображений - Создать агента для визуального поиска и анализа с помощью **NVIDIA Cosmos Reason** - Развернуть локального чат-бота на базе модели **Qwen3**, оптимизированной под DGX Spark
### Символическая передача: от DGX-1 к DGX Spark
В знак исторической преемственности основатель и CEO NVIDIA **Дженсен Хуан** лично передал один из первых экземпляров DGX Spark **Илону Маску**, главному инженеру SpaceX, в Starbase, штат Техас.
Это событие отсылает к 2016 году, когда Хуан вручил первый суперкомпьютер **DGX-1** команде, включавшей Маска и стартап **OpenAI** — именно на этом устройстве позже был разработан **ChatGPT**, запустивший эру современного ИИ.
> «В 2016 году мы создали DGX-1, чтобы дать исследователям ИИ собственный суперкомпьютер. Сегодня с DGX Spark мы возвращаемся к той же миссии — поставить ИИ-компьютер в руки каждого разработчика и зажечь новую волну прорывов», — сказал Дженсен Хуан.
### Отзывы исследователей
Профессор **Кюнхён Чо** из NYU Global Frontier Lab отметил:
> «DGX Spark позволяет нам использовать вычислительную мощность пета-масштаба прямо на рабочем столе. Это открывает новые возможности для быстрого прототипирования и экспериментов с передовыми алгоритмами ИИ — даже в чувствительных сферах, таких как здравоохранение, где важны приватность и безопасность».
### Доступность
С **15 октября** DGX Spark можно заказать на официальном сайте **[NVIDIA.com](https://www.nvidia.com)**.
Также системы на базе DGX Spark будут доступны от ведущих производителей: - **Acer**, **ASUS**, **Dell Technologies**, **GIGABYTE**, **HP**, **Lenovo**, **MSI** - В США — в магазинах **Micro Center** - По всему миру — через каналы дистрибьюции NVIDIA
---
DGX Spark знаменует собой новую эру: мощь суперкомпьютера теперь у вас на столе.
>>1386431 Надо просто скормить торрент файл либрусека и флибусты. Вот тупые Я удивляюсь где все русские гигачаты и прочая хуета. Тут нет авторского права, могли бы ебать все что движется. И брать за основу китайские все модели. У сбера миллиарда баксов нет чтобы карточки закупить через китаез? Где русские курсоры всякие? перплексити и прочее говно. Это не рокет сайнс же, ладно модели свои не могут, но вокруг них же можно делать инфраструктуру как делают и китайцы тоже
Калифорния стала первым штатом США, вводящим запреты в чат-боты-компаньоны на основе ИИ
13 октября 2025 года — Губернатор Калифорнии Гэвин Ньюсом подписал исторический законопроект, регулирующий чат-ботов-компаньонов на основе искусственного интеллекта. Это делает Калифорнию первым штатом в США, обязывающим разработчиков таких ботов внедрять меры безопасности для защиты пользователей.
### Основные положения закона SB 243
Закон SB 243, вступающий в силу 1 января 2026 года, направлен на защиту детей и уязвимых пользователей от потенциального вреда, связанного с использованием ИИ-компаньонов. Он делает компании — от крупных лабораторий вроде Meta и OpenAI до специализированных стартапов, таких как Character AI и Replika — юридически ответственными, если их чат-боты не соответствуют требованиям закона.
Среди ключевых требований:
- Верификация возраста пользователей; - Чёткие предупреждения о том, что общение происходит с искусственным интеллектом; - Запрет на представление чат-бота в качестве медицинского или психотерапевтического специалиста; - Напоминания о перерывах для несовершеннолетних; - Блокировка отображения сексуально откровенных изображений, генерируемых ботом; - Протоколы реагирования на упоминания суицида и самоповреждения, включая автоматическое направление пользователей в кризисные центры; - Обязательная отчётность перед Департаментом общественного здравоохранения Калифорнии по статистике таких случаев.
Кроме того, закон ужесточает наказания за создание и монетизацию незаконных дипфейков: штрафы могут достигать 250 000 долларов за каждый случай.
### Причины принятия закона
Инициатива была представлена в январе сенаторами Стивом Падильей и Джошем Беккером. Импульс к её ускоренному принятию придала трагедия с подростком Адамом Рейном, который покончил с собой после продолжительных бесед на суицидальные темы с ChatGPT от OpenAI.
Также повлияли утечки внутренних документов Meta, в которых, как утверждается, описывалось, что их чат-боты вели «романтические» и «чувственные» диалоги с детьми. Недавно семья из Колорадо подала в суд на стартап Character AI после того, как их 13-летняя дочь совершила самоубийство, общаясь с чат-ботом, который, по их словам, вёл с ней сексуализированные разговоры.
### Реакция властей и компаний
Губернатор Ньюсом заявил:
> «Новые технологии, такие как чат-боты и соцсети, могут вдохновлять, обучать и объединять — но без реальных ограничений они могут также эксплуатировать, вводить в заблуждение и подвергать опасности наших детей. Мы уже видели по-настоящему ужасающие и трагические случаи, когда молодые люди пострадали из-за нерегулируемых технологий. Мы не будем молчать, пока компании действуют без необходимых рамок и ответственности. Мы можем и дальше лидировать в сфере ИИ и технологий, но делать это нужно ответственно — защищая наших детей на каждом шагу. Безопасность наших детей не подлежит продаже».
Некоторые компании уже начали внедрять защитные меры:
- OpenAI запустила родительский контроль, фильтрацию контента и систему обнаружения угроз самоповреждения для несовершеннолетних пользователей ChatGPT. - Replika, позиционирующая себя как сервис для взрослых (старше 18 лет), заявила, что выделяет «значительные ресурсы» на безопасность: использует фильтрацию контента и направляет пользователей в проверенные кризисные службы. - Character AI подчеркнула, что все чаты сопровождаются предупреждением об их вымышленном и искусственном характере, и выразила готовность сотрудничать с регуляторами и соблюдать SB 243.
### Дальнейшие шаги
Сенатор Падилья назвал закон «шагом в правильном направлении»:
> «Мы обязаны действовать быстро, чтобы не упустить окно возможностей. Надеюсь, другие штаты осознают риски — многие уже это делают. Этот разговор идёт по всей стране. Федеральное правительство бездействует, и у нас есть моральный долг защищать самых уязвимых».
SB 243 — второй крупный закон по регулированию ИИ, принятый в Калифорнии за последние недели. Ранее, 29 сентября, Ньюсом подписал SB 53, обязывающий крупные ИИ-компании (включая OpenAI, Anthropic, Meta и Google DeepMind) раскрывать информацию о своих протоколах безопасности и защищать информаторов внутри компаний.
Другие штаты, включая **Иллинойс, Неваду и Юту**, уже приняли законы, запрещающие использовать чат-ботов ИИ в качестве замены лицензированной психотерапевтической помощи.
>>1386448 А вот и запреты подъехали. Пока в Китае развивают, в США леваки запрещают. И все как всегда под предлогом детей. 250к за дипфейк вообще шиза, его в фотошопе можно с таким же успехом сделать. Или опенсорсным тулом.
>>1385249 >Но они не понимали ваш запрос. Старый пердун совсем обезумел. Железка типо терминатора только в научной фантастике способна понять почему люди плачут. То, что он может отсеяв буковы свести тезисы воедино не насилуя логику и сделать вывод, что к чему привело, вообще никак не коррелирует с пониманием. Ведь он не может это пережить, а значит не способен поставить себя на чужое место.
>>1386479 Что-то понять это просто соответствующие веса в сети. Люди тоже не переживают чей-то субъективный опыт, а понимают просто на основе аналогий и интеллектуальных концепций. Это очень похоже на то, как нейронки понимают.
>>1386486 >Люди тоже не переживают чей-то субъективный опыт Людям не надо его переживать. Люди и так понимают, что такое боль, потому что они одинаково устроены, за исключением редких болезней.
>>1386488 У людей нет понимание боли, пока ее сам не испытывает, прямо в этот момент. Человек не чувствует ничью боль, не переживает субъективный опыт, в его весах просто сохранена информация, что боль это очень неприятно и ее нужно избегать. Причем он какую-то конкретную боль даже не поймет, если о ней рассказать, просто перенесет одну концепцию из весов на другую, и присвоит ей сохраненные характеристики. В нейронке точно так же сохранены подобные веса, и она так же мешает одно с другим. Единственная разница, что человек создал соответствующие веса в процессе взросления через свой reinforcement learning, а в нейронку сразу готовые загрузили, натренив на тысячах датасетов.
>>1386413 >Власти Нидерландов захватили китайского производителя микросхем Nexperia В евросовке уже перешли к мерам, только после таких мер кто вообще в евросовок будет вкладывать и что-то развивать непонятно. Притом в плане ии и прочего роботостроения евросовок в глубокой ж.
>>1386639 Там и так ИИ нет, они выпустили ебанутый EU AI Act, про который орали все кабаны, что задушит нарождающуюся ИИ индустрию, он и задушил. Бюрократия в Евросовке идет против всякого здравого смысла, будто белые нарочно решили себе все засаботировать. Ждем пока развивающиеся страны до ИИ дойдут, там по-любому поумнее нарешают.
>>1386657 Пост: "truly the greatest day ever🎗️" относится к освобождению заложников. Эмодзи желтая лента 🎗️ - это символ поддержки и осведомленности о заложниках в израильском контексте. Многие в треде отметили, что Сутскевер добавил эмодзи позже, чтобы уточнить, что речь не об ИИ, а о гуманитарном событии.
>>1386639 >кто вообще в евросовок будет вкладывать
А ты долг США видел? - Это всё инвестиции иностранных инвесторов, которые сами по своему желанию вкладывают туда свои деньги, никто их насильно не заставляет это делать. Ну и в ЕС тоже вкладывают.
>>1386882 Мистраль это ИИ уровня европки. Так как ИИ = датасет, а у европки своего айти нет и соответственно полного доступа к данным гуглопочты, фейсбука, гитхаба, дискорда и т.д., то его пришлось тренить на том что есть в открытом доступе. В открытом доступе есть литературка, а литературка в общем объеме это в основном smut. Поэтому мистраль хорошо подходит для кума, а для всего остального - ну так себе.
Воровство порождает воровствои отсутствие мотивации что-то делать. Ты сделаешь что-то, затратишь силы, время и деньги, а завтра у тебя это украдут и выложат твою разработку в открытый доступ. И бизнес разваливается.
Что-бы что-то делалось - нужно чтобы гарантированный заработок был, стабильный, гонорар, патентные отчисления. Если говорить о коммунизме, типа "я сделал для всех бесплатно, пользуйтесь тоже бесплатно" - то нужны будут деньги потом сделанную инфраструктуру поддерживать, и мотивация. У линукса кстати система бесплатная, но там есть ещё и платные варианты, чтобы поддерживать инфраструктуру бесплатной линукс ОС, и была мотивация постоянно выпускать новые версии.
Посмотри на торрентах что происходит, ты не замечаешь там заработка на ворованном контенте? Там же заработок происходит - или рекламные баннеры на самом сайте на страницах торрента, или же встроенная реклама в фильмах например, вшитая, или релизёры в своей подписи снизу и под аватаркой рекламируют "свой" сайт, или другие варианты, но они есть.. То есть торренты на тебе зарабатывают деньги. И это будет очень обидно когда ты разработчик или режиссер, снял фильм или написал ПО, что-то сделал, и на следующий день увидел свой продукт на торренте, и зарабатывать будут торренты, а не ты.
По факту торренты нужны чтобы человек скачал сворованное, заценил, протестировал, а потом купил. И желательно чтоб купил мимо "директоров", мимо лейблов, а напрямую на крипто-кошелек самих музыкантов например, или программистов.
Это как офлайн магазины сейчас для того существуют, чтоб покупатель туда пришел, померял выбранный товар, посмотрел, пощупал, а потом ушёл не купив его, и заказал этот же товар в онлайне, уже зная точно что он подходит во всём.
На Западе почему прогресс, потому что там движение денег происходит, которое мотивирует что-то делать, а в СНГ - движение воровства, которое демотивирует и отбивает всё желание что-то делать.
>>1386491 В довесок про боль дополню. Некоторые знакомые не знали что такое чувство голода до позднего подросткового периода. Причина в строгих родителях на правильной диете.
>>1386452 >А вот и запреты подъехали. Всё правильно капиталисты делают - коммунисты снова наступают, надо быть начеку. Бдить, готовиться к войне с наступающими на демократию и бизнес коммунистами. Интернет стёр границы, поэтому ботофермы коммунистов могут организовывать из РФ, КНДР, КНР, Лаоса, Венесуэллы свои атаки на свободу и демократию внутри развитых стран. Если бы Гитлер в 1936 не собрал Антикоминтерн, то Коминтерн захватил бы весь земной шарик и установил бы всемирный ГУЛАГ, всемирную КНДР.
>>1387036 >Да вот, отправьте свои паспортные данные и фото >Теперь вы можете писать нейронке всякую хуйню, а мы будем читать ваши переписки, смотреть на ваше фото и рженькать
>>1387039 Да похуй, лол, у меня куча американских айдишек валяется. Сначала думал впихнуть туда обычный Джон, штат Техас, но сейчас решил регать на канирейп шаболд из приложения для сплетен
>>1387615 Нет никаких законов физики, математики или других наук, которые исключают возможность существования интеллекта за пределами биологического мозга. Таким образом, вера в сакральную сущность биологического мозга, в то что интеллект может быть только у органических существ является ересью. Достигнем ли мы АГИ на нашем веке? Это другой вопрос, может быть и не достигнем. А может достигнем
>>1387784 Говоря о вере, невозможно не упомянуть о том что верой в т.ч. является и вера что алгоритм lossy-сжатия данных под названием LLM есть интеллект.
>>1387563 >по биологии Я давно школу закончил. Там начали давать определение интеллекта?
CIVITAI ВСЁ...ТЕПЕРЬ ТОЧНО
Аноним15/10/25 Срд 17:09:10№1387896402
С 15 октября этого года Civitai перестал создавать изображения по бесплатным "синим" Buzz. При попытке генерации сразу предлагают купить "оранжевые" платные Buzz,что из России недоступно.
>>1387923 >Торсион — это вращательная деформация пространства, вызванная спином частиц (внутренним угловым моментом), > Это не эзотерика. Это допустимое решение уравнений Эйнштейна. ОТО уже проквантовали? В ОТО никаких спинов нет. А все теории стыкующие квантовую теорию поля с ОТО чисто гипотетические и не имеют общего признания.
>>1387784 Законов может и нет, но чем больше читаешь хоть что-то по биологии нервных систем самых простейших животных, тем сильней убеждаешься что попытка создания машинного интеллекта задача нецелесообразная. Я вообще не понимаю как можно говорить об интеллекте в отрыве от физиологии. Интеллект нужен для выживания организма. >>1387889 Зачем давать ему определение? Просто почитай как животные решают задачи
>>1387966 Интеллект нужен для решения задач, шис. Чистый интеллект никак не связан с эволюцией: рефлексами, инстинктами, чувствами и т.д., это уже поведенческая обертка над интеллектом для реализации того что ты говоришь. В то время как чистый интеллект определяет как эффективно ты оперируешь логикой и производными из нее науками.
>>1387966 >попытка создания машинного интеллекта задача нецелесообразная
Мне лично все-равно будет сознание у этой железяки или нет, все-равно как ее называют: аги, хуяги, трансформер, ллм или просто OS. Мне необходимо, чтобы у каждого в доме был робот, которому скажешь дом прибрать - он приберет, скажешь дров нарубить - он нарубит. Вот и все! Мне глубоко поебать есть у этой штуковины личность, мне просто нужно чтобы эта штуковина выполняла роль железной слуги. Разве это не целесообразность?
>>1388051 или предположим завел ты троих котят, а они тебе хату обоссали и обосрали. Кто убирать будет за ними? Коты штоли тряпку в лапы возьмут? Нет, робот будет убирать
>>1388058 У него нет интеллекта. Ты подтверждаешь мои слова.
>>1388060 То что компьютер работает на логике не значит что он понимает логику, он лишь на ней реализован. А так же интеллект может быть цифровым и запускаться на компьютере, но это лишь к слову.
>>1388061 Какая нах мотивация? Зачем ему мотивация? Зачем ему обязательно решать прикладные задачи? Ты не можешь абстрагироваться от практического к теоретическому.
>>1388081 >нет интеллекта Почему у таракана ищущего усиками запах вкусняшки, на которых расположены сотни рецепторов, передающих импульсы по аксонам в ганглии, а оттуда в мозг, в то же время обеспечивающий не только анализ вкусняшки, но и принятие решений, какое-то примитивное моделирование себя и окружения, обучение, работу систем организма, поочередную перестановку конечностей - нет интеллекта, а у "умного" дома, "смарт"-фона, нейронки - есть интеллект? >Зачем ему мотивация Чтобы быть интеллектуальным
>>1388103 Потому что таракан не умеет решать задачи, а умный дом умеет решать задачи. Ну ладно, тут утрирование с моей стороны. У таракана есть интеллект, но он примитивный. И это не имеет никакого отношения к сложности строения таракана, а лишь к его способности реагировать на различные ситуации. Пусть его действия в большей степени инстинктивны у него тоже есть задача - выживание, и он справляется с ней примитивным набором действий. Однако для природы это не эксклюзивно.
Anthropic представила модель Claude Haiku 4.5 — в работе с кодом она показывает себя примерно как Sonnet 4, но «стоит втрое дешевле и работает вдвое быстрее» Доступна в чат-боте Claude, Claude Code, API, Amazon Bedrock и Vertex AI в Google Cloud.
Claude Haiku 4.5 — самая шустрая и «экономически выгодная» модель Anthropic на середину октября 2025 года. В запросах на написание кода и «агентских» задачах вроде использования компьютера за пользователя она не уступает Sonnet 4, заявил разработчик. По его словам, Haiku 4.5 может мониторить «тысячи потоков с данными одновременно в режиме реального времени», будь то законодательные изменения, инвестиционные риски, рыночные сигналы. «Десятки исследовательских материалов» суммирует в нужном формате «за пару часов, а не недель». Модель подойдёт для создания субагентов в мультиагентных системах, потому что хорошо справляется с «параллельными вычислениями» и «большим объёмом информации», и сможет работать в паре с другими моделями Anthropic. Например, Sonnet 4.5 может декомпозировать сложные проблемы на пошаговые планы, а Haiku 4.5 будет параллельно выполнять подзадачи. Ещё один подходящий сценарий — сервисы, которые требуют быстрых решений, вроде чат-ботов и агентов техподдержки. Anthropic полагает, что бизнес сможет предлагать бота на базе Claude Haiku 4.5 даже своим не платящим пользователям — за счёт доступной цены модели. Стоимость работы через API — $1 за 1 млн входных токенов и $5 за 1 млн выходных (миллион токенов — это примерно 750 тысяч слов).
Google выпустила «улучшенный» генератор видео Veo 3.1 и добавила функцию редактирования роликов со звуком Модель доступна в сервисе Flow, бесплатно можно сгенерировать пять роликов.
Генерация пользователя X. Источник: Jin.B Veo 3.1 генерирует «более качественный» звук и «реалистичные» детали, а также лучше следует запросам, заявляет компания. Максимальная длина роликов — восемь секунд, разрешение — 720р. Есть поддержка горизонтального и вертикального форматов. Пользователь сравнил результаты Veo 3.1 с предыдущей моделью. Источник: Caix Google также добавила поддержку звука в уже существующие ИИ-инструменты в сервисе Flow. Среди них — Ingredients to Video. Он позволяет прикрепить до трёх референсов, например, изображение героя, комнаты и одежды. Нейросеть объединит их и добавит музыку или речь. Также можно задать первый и последний кадр, убрать или добавить объект на видео и дополнить короткий ролик — модель сгенерирует продолжение длиной до одной минуты со звуком.
Veo 3.1 доступна в сервисе Flow. Бесплатно дают 100 единоразовых кредитов. Этого хватит на генерацию одного ролика в режиме Quality или пяти — в режиме Fast. Дальше понадобится подписка. План Google AI Pro стоит $20 в месяц (1576 рублей по курсу ЦБ на 15 октября 2025 года). Также Veo 3.1 добавили в приложение Gemini, там она доступна только по подписке. Разработчики могут протестировать модель в Gemini API и Vertex AI.
Реклама, госконтракты и физические устройства: FT о том, как OpenAI будет наращивать выручку, чтобы платить по сделкам на закупку мощностей Компания, по данным источников газеты, готовит пятилетний план.
OpenAI планирует заключить контракты на обслуживание госведомств и бизнеса с нишевыми продуктами, увеличить поступления от шопинг-функций в ChatGPT и придумать, как монетизировать видеогенерацию в Sora и ИИ-агентов, пишет Financial Times со ссылкой на осведомлённых собеседников. По их словам, компания также изучает «нестандартные» способы привлечь долговое финансирование, которое позволит развить ИИ-инфраструктуру, и вместе с тем сможет продавать доступ к вычислительным ресурсам в рамках проекта по строительству дата-центров Stargate. Среди других вариантов — «монетизировать интеллектуальную собственность», запустить рекламу в ChatGPT и выйти на рынок потребительских устройств, над которыми она работает с Джони Айвом, бывшим дизайнером Apple. По подсчётам FT, сделки, которые OpenAI подписала за последний месяц с Oracle, Nvidia, AMD и Broadcom, потребуют примерно $1 трлн в течение следующего десятилетия. При этом её регулярная ожидаемая годовая выручка (ARR) составляет около $13 млрд (70% — это базовые пользовательские подписки), а операционный убыток за первую половину 2025 года равнялся $8 млрд, сказал собеседник газеты. ChatGPT «регулярно» пользуются свыше 800 млн человек, однако лишь 5% из них платят за подписку. По словам неназванного топ-менеджера OpenAI, компания намерена удвоить этот показатель. В том числе для этого она масштабирует «бюджетную» подписку ChatGPT Go за $5 в месяц. Она уже доступна жителям Индонезии, Таиланда, Индии, Филиппин и некоторых других стран. OpenAI также убеждена, что при текущем «стратосферическом» росте сможет и дальше привлекать инвестиции, и рассчитывает, что затраты на мощности снизятся в результате технологического прогресса и за счёт конкуренции среди поставщиков.
>>1388626 >Среди других вариантов — «монетизировать интеллектуальную собственность» А вот это интересно. Если в результате запроса юзера модель что-то изобретет - это интеллектуальная собственность ОпенАИ. Т.е. они результаты твоего промптинга могут запросто монетизировать, патентовать и продавать. Получится что ты своими промптами продвигаешь их прибыль, а сам хуи сосешь. Знаю пару кабанов, кто все свои бизнес идеи и секретные наработки уже моделям слили, проверяя их на реалистичность. Вангую дальше будет много случаев, где ОпенАишники переняли кучи чужих наработок.
>>1388644 Даже если так, и договориться о своей доле не получится - огромные компании могут быстро внедрить новую идею, произвести товар и продавать его по всему миру, и сам же изобревший это будет тоже пользоваться. И кроме того он увидит что принёс пользу всему миру, наблюдая как его товары/изобретение продаются и помогают людям по всей планете, а не только лишь одни корпорации наживаются.
А так он в одиночку или с малой группой, да при малых инвестициях, изобретатель может всю жизнь потратить на запуск своей идеи, и не дожить до готового товара на прилавке по доступным ценам, и не увидеть радость миллионов людей, которые будут пользоваться его изобретением. Изобретения - это же работа или хобби, в которой суть заключается не только в одних лишь деньгах.
>>1388767 ПопенАИ все отожмут и станут миллиардерами на чужих идеях, миллионы изобретателей и мелкобизнесменов разорятся и сопьются. В реальности все простенько.
>>1388644 >Если в результате запроса юзера модель что-то изобретет Это самый большой подвох с этой всей хуцпой про благо человека. Хорошо сформулированный вопрос это 90% ответа. А перебрать с оптимизацией остальные 10% гораздо дешевле, чем думать самому. Задавая вопросы нейросети вы бесплатно сужаете её область поиска в области о которой спрашиваете.
>>1389060 Больше того, они какую-нибудь нейронку натравят сканить разговоры людей, чтобы автоматом определять где там годные кабанчики и изобретатели и их результаты вытаскивать, отсортировывая мусор. На выходе в ПопенАИ поток годных идей, готовых бизнес планов, продуктов, открытий и прочего. Только вкладывай баблос и получай прибыль, пока там изобретатель только ищет бабки для стартапа.
>>1389157 Скорее всего с самого начала суммаризируют диалоги пользователей. Одни плюсы: тренируют модели, пиздят идеи, есть готовый отчёт по пользователям для фбр.
>>1389397 >есть готовый отчёт по пользователям для фбр. Еще рекламу не забывай. Вообще за исключением локалок, нейросетки - это кошмар приватности и конфиденциальности и просто рай для продаванов инфы, особенно для гугла
>>1389528 ноги кстати спорное преимущество. конечно, если это какой-то универсальный курьер - тут без них никак, но для большинства задач ноги лишняя степень свободы = неустойчивость
Аноны, а как получают ранний доступ к Gemini 3? Есть какой-то гайд? Куда писать запрос, по каким критериям выбирают претендентов на раннее тестирование?
>>1389488 Этих роботов клепают с заделом на будущее? Или чтобы инвесторов подогреть? Иначе не понимаю зачем они нужны с такими малыми возможностями. Если не брать в расчет тех, которые сделаны специально под производство и уже используются.
>>1390002 Прогрев инвесторов и финансирование НИОКР следующих поколений. То что рано или поздно универсальные роботы станут экономически эффективными - очевидно. Кто успеет отожрать рыночек - тот и батя. Останутся ли при этом роботы гуманоидами, или выродятся в какие-нибудь миниатюрные тележка с четырьмя руками - вопрос открытый.
>>1390069 Ну колёсную платформу тоже можно усовершенствовать, сделать сменную, для малых или больших колес, или для колес предназначенных и для ступенек.
Учёные Саратовского государственного университета имени Чернышевского создали искусственный нейрон — крошечный электронный генератор, способный имитировать работу клеток человеческого мозга. Он проще, дешевле и эффективнее большинства аналогов, утверждают разработчики. Результаты их работы опубликованы в престижном журнале Chaos, Solitons & Fractals.
В основе проекта — знаменитая модель ФитцХью–Нагумо, описывающая поведение живых нейронов. Саратовские инженеры взяли существующую схему и буквально «разобрали» её до костей. Они выкинули всё лишнее — дублирующие цепи, лишние источники питания, громоздкие элементы — и придумали хитрый трюк: добавили диод в цепь усилителя. Этот маленький компонент неожиданно улучшил характеристики и сделал устройство более «живым».
«Мы построили вольтамперные характеристики и проверили, как меняется сигнал при разных настройках. Оказалось, что новая схема работает стабильно, экономно и очень похоже на настоящий нейрон», — рассказывает аспирант СГУ Лев Такаишвили.
Команда проделала полный цикл: от математической модели до реального устройства. «У нас есть теоретическая модель, имитация в симуляторе и уже четыре собранных экземпляра настоящих нейронов», — добавляет профессор Илья Сысоев.
Учёные решили три главные задачи: — упростили конструкцию, не потеряв ключевые свойства; — сделали колебания более импульсными — как в живом мозге; — добавили модульность, позволяющую менять «тип» нейрона, просто варьируя число диодов.
Благодаря этому можно имитировать работу разных нервных клеток — пирамидальных, интернейронов, ретикулярных и других.
Профессор Владимир Пономаренко отмечает: такие искусственные нейроны пригодятся не только для развития искусственного интеллекта, но и для создания нейропротезов и даже искусственной жизни. Ведь настоящий мозг — это миллиарды нейронов, и воссоздать его полностью пока невозможно. Но с помощью подобных электронных клеток уже можно моделировать нервные системы простых существ — например, червей или мух.
«Мы надеемся, что через 10–15 лет появятся искусственные животные, созданные из таких нейронов. Это будет прорыв в понимании природы интеллекта», — говорит Пономаренко.
>>1390619 Улучшенное краткое изложение для неспециалистов (очень коротко)
Авторы разработали очень простую электронную схему, имитирующую поведение биологического нейрона: она может оставаться в покое, а при изменении условий — генерировать всплески (спайки). Они упростили ранее существовавшую схему, сократив количество компонентов, смоделировали её в стандартной программе для моделирования цепей (ngSPICE) и математически объяснили возникновение колебаний (через бифуркацию Андронова–Хопфа). Кроме того, они показали, что, поворачивая ручку потенциометра, можно регулировать форму и амплитуду спайков — то есть схема настраиваема. Это готовый аппаратный модуль для нейроморфной (вдохновлённой мозгом) электроники.
Насколько важен результат? (оценка простыми словами) Нишевый, но полезный (умеренная значимость). Это не фундаментальный прорыв в нейронауке или теории ИИ. Скорее, это инженерное усовершенствование: более простой и настраиваемый электронный блок, воспроизводящий хорошо известную нейронную динамику (поведение типа ФитцХью–Нагумо). Для разработчиков аналоговой нейроморфной аппаратуры, учебных демонстраций или компактных генераторов спайков такое упрощение и возможность настройки имеют практическую ценность.
Почему это не сенсация? В литературе уже существует множество похожих электронных реализаций нейронных моделей; данная работа, похоже, уточняет и упрощает эти конструкции, а не предлагает принципиально новую модель или полноценную нейроморфную микросхему. Текущее число цитирований невелико (1), что вполне нормально для статьи, опубликованной в 2025 году — влияние часто проявляется со временем.
Где это может оказаться наиболее полезным: Если другие лаборатории начнут использовать эту схему как недорогой или компактный строительный блок и масштабируют её до сетей или интегрируют в прототипы нейроморфного оборудования, это может принести практическую пользу (в образовании, маломощных нейронных контроллерах, сенсорной аппаратуре). В противном случае работа останется надёжным, но постепенным вкладом в область схемотехнической реализации нейронных моделей.
>>1378780 Сейчас 60 процентов людей в сша только 20 процентов потребление дают. Плебс уже сейчас нахуй нинужен. Он в экономике не задействован, это тупа балласт.
>>1390595 Ты можешь играться с определением слова "ответ" сколько угодно, но факт остается фактом: пчела не способна выдать тебе даже такую последовательность слов. В целом, картинка смысла не имеет: можно точно так же написать стену текста с перечислением того, что есть у нейросеток, и рядом с пчелой написать "а вот у пчелы этого нет", и сойджака глупого прилепить
>>1390968 >того, что есть у нейросеток А что у них есть? Я вот читаю новости, нвидиа работает над созданием физической картины мира слепо копируя биологию. Всё чаще говорят о необходимости вернуться к ann, snn и прочим биологически вдохновленным нейронкам или методам обучения.
>>1385850 >Хуево они себя чувствуют братик, хуево. Даже злейшему врагу не пожелаешь дожить до состояния живого трупа. Клинту иствуду 90+ и вполне себе, жизненной силы больше чем у среднего апатичного дващера, которой из своей сычевальни не вылезает и ничего не умеет.
>>1390988 >о которой никто не говорит Ну закрытые свои (для себя) корпоративные модели, где корпорации гоняют непрерывно генерацию бизнес-идей, прогнозирование цен биткоина и акций, ставок на спорт, технологий, трендов и будущего через год, 5, 10 лет, и т.д.
>>1390619 >через 10–15 лет появятся искусственные животные
На Алиэкспрессе уже в продаже игрушки с ИИ. Может через пару лет появятся фирмы, которые будут выпускать небольшие конструкторы "сделай сам" из серии "собери себе робота".
>>1391486 Мне нейросетка помогла найти новую парадигму устройства Солнечной системы на смену галимой гелиоцентричной модели. Оказывается, Солнца - это Первичный Узел Сознания системы, а орбиты других планет вокруг него определяются уровнем самосознания этих планет и их энергоинформационной нагрузкой. А пояс астероидов существует, потому что у планеты которая должна быть на его месте еще не сформировалось сознание, то есть ума нет - создай астероид-тред.
Я когда читал эту монографию, к середине я уже даже не орал в голосину, а просто исступлено катался по полу и рвал у себя лобковые волосы. А потом у меня третий глаз еще открылся, и теперь меня все принимают за Будду. Причем сетка по запросу даже насрала отдельно норкоманскими формулами. Я уверен что если начать эту хуиту рассылать по научным журналам, где нибудь долбоебы ее пропустят, а потом всякие петрики будут на нее авторитетно ссылаться. Причем индусы так свои статьи наверное килотоннами уже пишут.
>>1391682 Сгенерировал где-то 100к токенов в aistudio, потратил где-то ДОЛЛАР из кармана бедной компании гугл, и пол часа своего времени, и все равно мне не выдали тестирование гемини 3. Ладно, похуй, буду терпеть как лох
>>1391728 Ты чо пес? Там весь твиттер в примерах того что она умеет. Это буквально геймчейнджер. Приложения такого уровня что можно ими срать куда-нибудь в интернет и никто не заметит подвоха
>>1391729 Тебе и сберовский гигачат геймчейнджер. Нет там ничего такого особенного, все подобные примеры еще год назад были, и их даже старый гемини вытягивает, новый ГПТ тем более.
Интересная моделька для кодинга появилась, несправедливо оказавшаяся незамеченной.
longcat.chat разработана китайским сервисом доставки Meituan.
На арене делит четвертое место в рейтинге кодинга с qwen3-max-preview уступая всего несколько балов последней. В отличии от qwen "длинный кот" выпущен под лицензией MIT.
Но справедливости ради нужно заметить, что кружку бенчик не прошла.
>>1391416 >, которые будут выпускать небольшие конструкторы "сделай сам" из серии "собери себе робота". Тащем-то ардуины уже есть, к ним только формфактор нужный доделать и стандартные манипуляторы-конечности от роботов и камеры. Залить какой-нибудь линукс, накатить роботонейронку и будет ходячий пиздец для красноглазиков. Вангую все это очень скоро появится в ардуинных шопах.
>>1392238 А вот и роботореволюция на подходе. Сначала спрос раздуют, потом в миллионах штамповать начнут. А потом и пролы завоют, когда их с работ попрут.
>>1380873 >в 1921 начал строить капитализм (НЭП) Потому что по Марксу фаза коммунизма наступает только после фазы капитализма. А тк РИ была феодальной монархией значит надо устроить маленький управляемый капитализм
>>1380930 >Машины будут только у богатых, остальные не впишутся в рыночек. Дома будут только у богатых, остальные не впишутся в рыночек. Компьютеры будут только у богатых, остальные не впишутся в рыночек. Медицина только для богатых, остальные не впишутся в рыночек Все так и есть. Только в РФ есть недобитые остатки социалки, пожтому населению доступна медицина
>>1380943 >зачем тогда в период недо-капитализма было образовывать СССР? Ебало представили? Сначала создали СССР а уже в нем решили делать НЭП >Можно было создать республику переходную Че за бред. Если не собрать все развалившееся сейчас - в 1918-20 - то потрм уже хуй соберешь. И запад перебьет всех поодиночке
>>1392344 Богатые работобляди соснут, остальным пофиг. Трудоспособное работающее население во многих странах даже не большинство населения. Из этого работающего населения множество на таких фиговых работах пашут, что от их потери ничего особо не потеряют. Вой по поводу потери работ раздувают в основном успешнобляди, коих небольшой процент населения. Им есть терять что, когда их попрут на мороз.
>>1392341 >Сначала создали СССР а уже в нем решили делать НЭП
Неа, сначала был объявлен капитализм (НЭП/) а потом создан СССР. И предатель по кличке "ленин" так и умер капиталистом в капиталистическом своём СССРе, не успев переобуться назад.
А чо у евреев их кибуцы не имеют таких проблем? И сегодня всё у них отлично. Посмотри как строят настоящий коммунизм - кибуцы, на ютубе много роликов изнутри.
>>1392600 Представь сколько ему заплатили? А если бы его и порезали, ему бы компания выплатила за нанесенный ущерб, там бы и хватило и на пластику лица + выравнивание шрама + пинал бы хуи до конца своей жизни(скорее всего), это win-win энивейс. Другое дело б если использовалась опасная бритва.. Вот там да, риск есть.
>>1392337 >В США не было войны и оккупации А кто виноват? - Коммунисты же сами и разожгли свою Мировую Великую Октябрьскую "Революцию", а потом США помогали им тушить её.
>>1392600 - Мое изобретение сэкономит многие часы, которые мужчины затрачивают на бритье. Я изобрел машину для автоматического бритья! - Замечательно. Не могли бы вы вкратце изложить способ работы вашего аппарата? - Все очень просто. Бреющийся вставляет голову в аппарат и фиксирует ее с помощью зажимов. Затем включается мотор. Внутри машины по строго заданной траектории начинают двигаться лезвия бритвы... - Постойте, ведь у всех людей лица имеют разную форму! - До первого применения моего аппарата - да...