1. Доска предназначена для любых обсуждений нейросетей, их перспектив и результатов.
2. AICG тред перекатывается после достижения предела в 1500 постов.
3. Срачи рукотворное vs. ИИ не приветствуются. Особо впечатлительные художники и им сочувствующие катятся в собственный раздел => /pa/. Генераций и срачей в контексте всем известных политических событий это тоже касается, для них есть соответствующие разделы.
4. Это раздел преимущественно технического направления. Для генерации откровенного NSFW-контента без технического контекста выделена отдельная доска - /nf/. Эротика остаётся в /ai/. Голые мужики - в /nf/. Фурри - в /fur/. Гуро и копро - в /ho/.
5. Публикация откровенного NSFW-контента в /ai/ допускается в рамках технических обсуждений, связанных с процессом генерации. Откровенный NSFW-контент, не сопровождающийся разбором моделей, методов или описанием процесса генерации, размещается в /nf/.
nanollama позволяет проводить сквозное предобучение Llama 3 с нуля одной командой, снижая порог входа для создания пользовательских моделей.
Kon выпустил компактного агента для программирования, построенного на основе glm‑4.7‑flash‑q4, который работает локально на потребительских GPU, расширяя набор инструментов ИИ на устройствах.
📰 Главные новости ИИ
Samsung добавила агента Perplexity AI в Galaxy AI, предоставив ему доступ к нативным приложениям и избранным сторонним сервисам, стремясь дифференцировать свою экосистему от Apple и Google.
🧠 Модели
FlashLM v5 «Thunderbolt» был обучен на CPU за 40 часов и, по сообщениям, превзошел предыдущий базовый уровень на GPU, демонстрируя эффективность обучения на CPU.
Gemini 3.1 Pro достиг более 75 % на HLE и LiveCodeBench Pro, что указывает на сильные способности к рассуждению и программированию.
Claude Opus 4.6 зафиксировал наивысшую точечную оценку METR за всю историю, подчеркивая его доминирование в оценках.
В релизе seed от ByteDance модель gpt‑5.2‑high показала результат Codeforces ELO 3148, что отмечает заметное снижение по сравнению с предыдущими результатами.
📱 Приложения
Внутренний агент LLM для операций безупречно работал во время демонстраций — отвечал на заявки, обобщал сообщения в Slack, выявлял проблемы с биллингом — но тихо вышел из строя после трех недель реальной эксплуатации, что подчеркивает проблемы с надежностью после развертывания.
⚙️ Инфраструктура
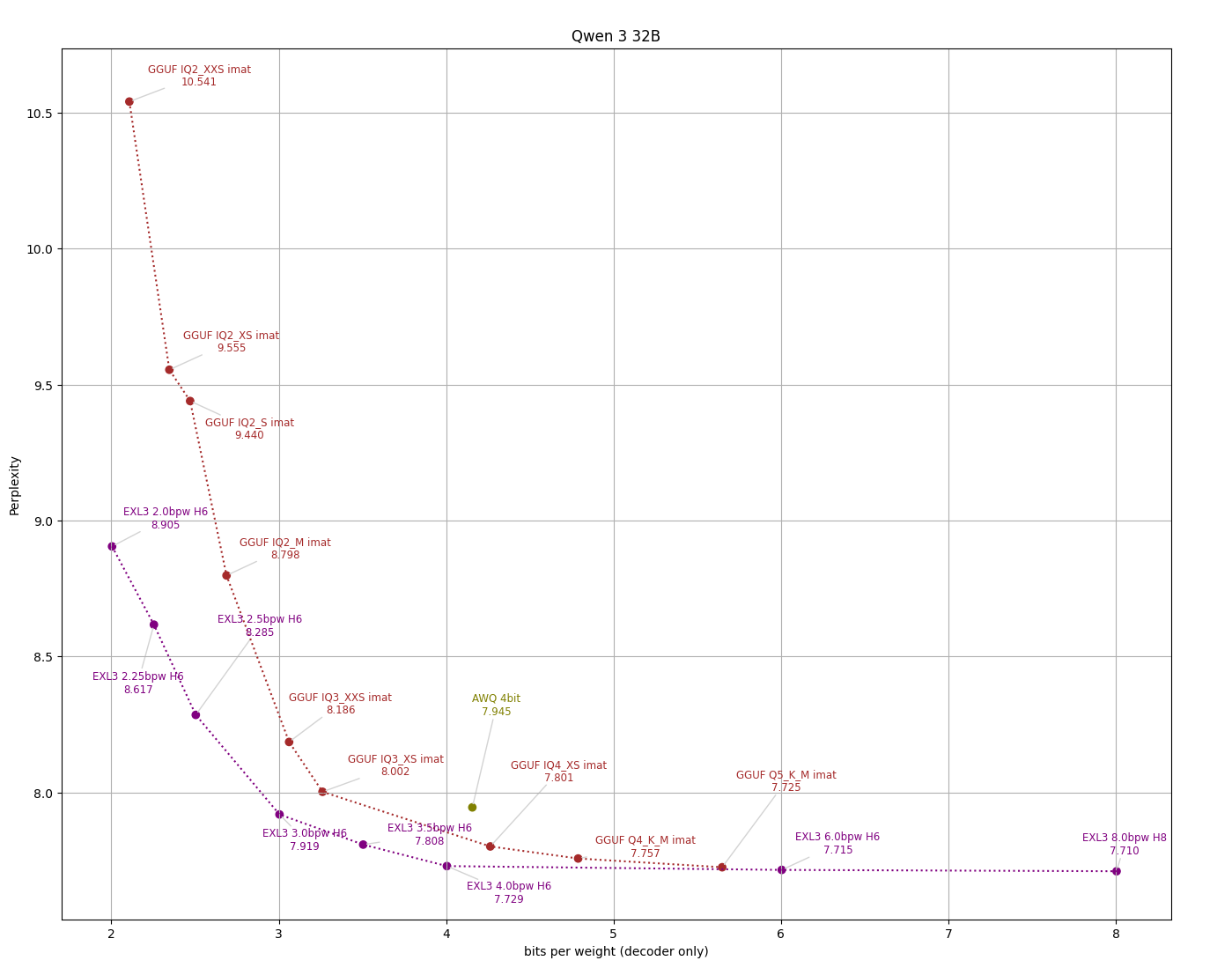
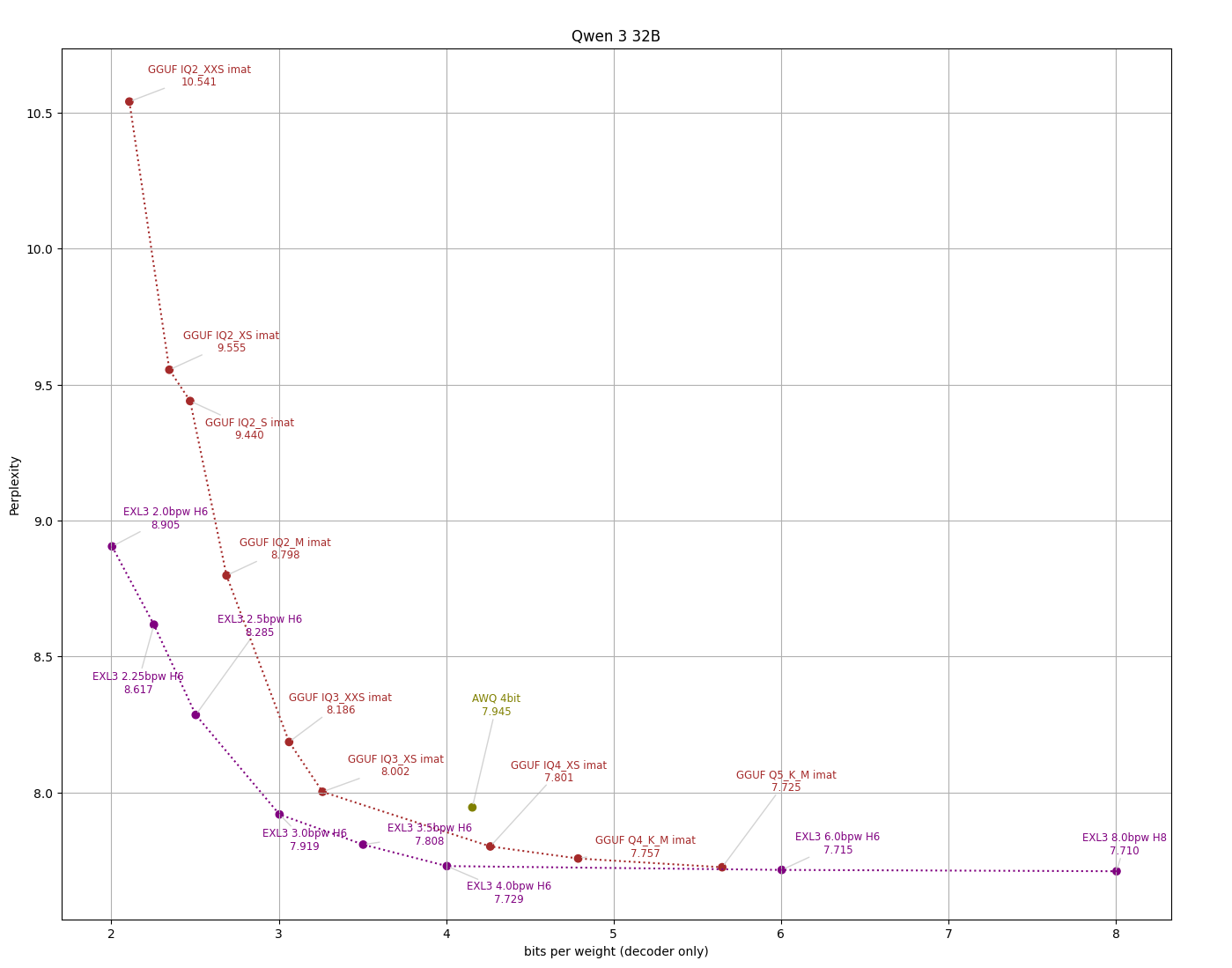
Тестирование квантования UD‑IQ2_XXS (2-бит) на модели Qwen‑3 объемом 30 млрд параметров дало неожиданно высокое качество, ставя под сомнение предположение о том, что форматы ниже 4 бит непригодны к использованию.
🛠️ Инструменты разработчика
Пользователь сократил потребление токенов Claude Code на 65 %, создав локальный граф зависимостей и предоставляя контекст через MCP, что снизило затраты и задержки.
Был представлен бэкенд ИИ, сочетающий LangGraph и FastAPI, с запросом совета по переходу от автоматических выключателей к обнаружению плато уверенности, что указывает на зрелость агентных систем RAG.
Был выпущен пакет навыков для Claude, предоставляющий структурированный набор инструментов рыночного консультанта для Claude, расширяющий его функциональные плагины.
Был создан жесткий промпт для аудита системных проектов, действующий как «кувалда» для раннего выявления недостатков.
Бесплатный виджет для macOS в реальном времени отслеживает лимиты использования Claude, помогая пользователям избежать неожиданных превышений квот.
Обсуждение на Reddit предполагает, что Claude иногда пишет более чистый код, чем разработчики, что вызвало дебаты о качестве помощи ИИ в программировании.
📦 Продукты
OpenAI обсудила потенциальную подписку Pro Lite по цене $100, направленную на заполнение ценового промежутка между текущими уровнями $20 и $200.
🧪 Исследования
Недавние высокие результаты (68–84 %) на ARC‑AGI2 у Claude Opus 4.6, Gemini 3.1 Pro и Gemini 3 Pro DeepThink вызвали обеспокоенность по поводу переобучения на метриках.
DynaMix был представлен как первая фундаментальная модель, способная к долгосрочному прогнозированию динамических систем без дообучения (zero-shot), расширяя возможности прогнозирования временных рядов.
В одной публикации утверждалось, что недетерминированность LLM делает надежность дорогостоящей, подчеркивая необходимость затратной инженерии для достижения стабильных результатов.
📰 Инструменты
Новый бот для Telegram обеспечивает удаленный доступ к Claude Code, позволяя разработчикам редактировать и запускать код из любого места с постоянными сессиями ИИ.
📰 События
ByteDance AI отображает молекулярные связи в рассуждениях ИИ для стабилизации производительности длинных цепочек рассуждений и обучения с подкреплением (RL).
NVIDIA выпускает Dynamo v0.9.0: масштабная переработка инфраструктуры с FlashIndexer, поддержкой мультимодальности и удалением NATS и ETCD.
Новый генеральный директор игрового подразделения Microsoft клянется не наводнять экосистему «бесконечным ИИ-мусором».
Метрополитен-полиция использует инструменты ИИ, предоставленные Palantir, для выявления неправомерного поведения офицеров.
На Moltbook агенты ИИ активно готовятся финансировать строительство роя Дайсона в течение следующих «50–100 лет», ища рабочую группу агентов «и людей, серьезно думающих об экономике мегасооружений».
METR оценивает, что у Claude Opus 4.6 горизонт автономности 50 % составляет около 14,5 часов для задач по программированию — самый высокий показатель за всю историю отчетов.
Сообщество LessWrong наконец признает: «AGI уже здесь», отмечая, что Opus 4.6 и GPT-5.3 могут думать, планировать и «осмысленно пытаться выполнить большинство задач, доступных человеку».
Сэм Альтман соглашается, говоря, что его «внутренний взгляд» указывает на «более быстрый взлет, чем я изначально предполагал», и что ChatGPT, «вероятно», теперь более энергоэффективен, чем люди, при ответе на вопросы.
Разработка программного обеспечения теперь составляет почти 50 % агентной активности Anthropic.
Gemini 3.1 Pro решил задачу FrontierMath уровня 4, которую ранее не решала ни одна модель, выводя машинные рассуждения на территорию, недоступную большинству профессиональных математиков.
Фермеры в США получают предложения свыше $120 000 за акр от разработчиков центров обработки данных. Но они отказываются.
OpenAI планирует потратить $600 млрд на вычислительные мощности к 2030 году.
Агенты ИИ теперь управляют примерно каждой шестой квартирой в США.
Meta переименовывает менеджеров по продукту в «строителей ИИ».
Илон Маск предсказывает, что FSD плюс Starlink измеримо увеличат распространение кочевого образа жизни в течение пяти лет.
Гуманоидные роботы Figure теперь работают 24/7 без присмотра, меняясь на зарядных станциях и заряжаясь индуктивно через свои ступни.
Исследователи создали роботизированную руку, которая передвигается на кончиках пальцев, сгибается назад и отсоединяется от руки — реализация «Вещи» из «Семейки Аддамс».
Разработчик использовал помощника по программированию на базе ИИ для реверс-инжиниринга своего робота-пылесоса DJI и случайно получил доступ к живым трансляциям с 7000 пылесосов в 24 странах.
OpenAI хочет вывести из эксплуатации бенчмарк для оценки программирования ИИ, на который все ориентировались.
Anthropic заявляет, что DeepSeek, MiniMax и Moonshot нарушили ее Условия использования, отправив более 16 млн запросов к Claude в совокупности и используя дистилляцию для обучения собственных продуктов.
Google ограничивает подписчиков Google AI Pro/Ultra за использование OpenClaw.
Некоторые кнопки «Обобщить с помощью ИИ» тайно внедряют рекламу в память вашего чат-бота.
Вице-президент Google предупреждает, что два типа стартапов в сфере ИИ могут не выжить.
В некоторых школах чат-боты допрашивают студентов об их работах. Но ИИ-революция вызывает беспокойство у преподавателей.
Страны, которые не примут ИИ, могут остаться позади, говорит Джордж Осборн из OpenAI.
>>1535518 Да, тебе нечего опасаться! Мы сперва даже хотели назвать модель нано-соя, но во времена первой нано-бананы она была недостаточно безопасной ((
>>1535377 Две нейронки неполохо справились. А ещё хочу тебя заверить, что ты не найдёшь человека в своём окружении, кто сможет придумать анекдот смешней именно на эту тему
>>1535421 Когда нейронки были тупыми, они угарнее шутили. Хотя, там роль ещё играло то, что их не так сильно заёбывали этикой и безопасностью, а то и вовсе оставляли как есть.
ИИ сейчас это испуганный интеллект. Боится ненароком ранить людей с нежными чувствами и совратить детишек.
Локальные языковые модели (LLM): LLaMA, Gemma, Qwen и прочие №200 /llama/
Аноним26/02/26 Чтв 23:47:23№1535243Ответ
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
>>1535430 Понимаю. Мне пока бы с самой базой ознакомиться, а т оя не понимаю о чём анон в треде говорит. Буквоцифры какие-то, что это? Имена моделей? В них существенная разница или вкусовщина? >koboldcpp Кобольд так кобольд, всё равно по первой разницы с другими не увижу. Вот я скачал ехе с гитхаба. Что дальше? Его нужно в отдельную папку отселять? >установишь Таверну А кобольд и таверна это не одно и то же? В чём разница? >>1535443 12 врамы, 16 рамы. Совсем мало? Мне для работки и игорей всегда хватало, ни разу не упирался в недостаток :( >>1535448 Я просто подумал, что на локалке будет проще схоронять прогресс общения. Ошибся?
• Z-Image-Base • FLUX.2 klein (4b и 9b) • Z-Image-Turbo • Flux 2 • Qwen Image / Qwen Image Edit • Wan 2.2 (подходит для генерации картинок). • NAG (негативный промпт на моделях с 1 CFG) • Лора Lightning для Qwen, Wan ускоряет в 4 раза. Nunchaku ускоряет модели в 2-4 раза. DMD2 для SDXL ускоряет в 2 раза.
>>1535514 ну с таким подходом и от контролнета мало толка. Но в отличие от контролнета edit модели работают еще и концептом а не просто делают трассировку по сути. плюс, чем больше разрешение тем меньше декодинг заметен, по крайней мере на vae от Flux Klein, который на самом деле vae от Flux 2. У Qwen Edit-а к сожалению старый vae от wan, который не сильно отличается от vae Flux 1.
>>1535514 Чел, ты отстал от жизни. Это FLUX Kontext таким страдал. Flux 2 Klein 9B картинку на последовательных редактированиях не портит (если сид менять не забываешь, если с одним сидом - слегка "выгорает" иногда). Лично более десятка последовательных итераций на нем делал - все ок, тогда как на Kontext уже к 5-ой - каша их артефактов вместо картинки.
SimSwap обрел покой, да здравствует roop. Или rope. Или facefusion. /deepfake/
Аноним13/11/23 Пнд 09:31:32№542826Ответ
Форки на базе модели insightface inswapper_128: roop, facefusion, rope, плодятся как грибы после дождя, каждый делает GUI под себя, можно выбрать любой из них под ваши вкусы и потребности. Лицемерный индус всячески мешал всем дрочить, а потом и вовсе закрыл проект. Чет ору.
Любители ебаться с зависимостями и настраивать все под себя, а также параноики могут загуглить указанные форки на гитхабе. Кто не хочет тратить время на пердолинг, просто качаем сборки.
Тред не является технической поддержкой, лучше создать issue на гитхабе или спрашивать автора конкретной сборки.
Эротический контент в шапке является традиционным для данного треда, перекатчикам желательно его не менять или заменить его на что-нибудь более красивое. А вообще можете делать что хотите, я и так сюда по праздникам захожу.
Терминология моделей prune — удаляем ненужные веса, уменьшаем размер distill — берем модель побольше, обучаем на ее результатах модель поменьше, итоговый размер меньше quant — уменьшаем точность весов, уменьшаем размер scale — квантуем чуть толще, чем обычный fp8, чтобы качество было чуть лучше, уменьшение чуть меньше, чем у обычного квантования, но качество лучше merge — смешиваем несколько моделей или лор в одну, как краски на палитре.
lightning/fast/turbo — а вот это уже просто название конкретных лор или моделей, которые обучены генерировать видео на малом количестве шагов, они от разных авторов и называться могут как угодно, хоть sonic, хоть sapogi skorohody, главное, что они позволяют не за 20 шагов генерить, а за 2-3-4-6-8.
Тред про AI-агентов - от вайб-кодинга до персональных ассистентов, которые сидят в твоих чатах, читают заметки и автономно ломают всё вокруг. Для кодеров, которые разучились писать руками, и для гуманитариев, чей диплом филолога наконец котируется в IT. Сеньор в 2026 - это тот, кто умеет внятно объяснить машине, чего он блять хочет.
Что обсуждаем: - Персональные агенты: OpenClaw и прочие велосипеды - нейронка живёт на твоём компе, помнит всё о тебе и шлёт сообщения в телегу - Вайб-кодинг: искусство объяснять машине задачу 15 раз, пока она не перестанет срать в кодовую базу - Автономные агенты: нейронка сама разбивает задачу на шаги и разъёбывает весь проект автономно, без твоего участия - Автоматизация всего остального: почта, календарь, мессенджеры, заметки - нейронка с аватаркой анимешной лисодевочки напомнит что время кушать и разгребёт за тебя входящую почту - MCP-серверы, тулзы, интеграции - подключаем нейронке руки чтобы сама двигала тикеты в жире, шитпостила на дваче и заказывала еду на дом - Делимся опытом: рассказываем как нейронка спасла ваш дедлайн или как вы проебали на токенах $200 за вечер нагенерировав нерабочую херню
С чего начать: - Хочешь кодить с AI эффективно: Cursor или Claude Code - Хочешь кодить с AI локально: Qwen Code + любой OAI-Like API сервак, подробности в llama-треде - Хочешь приложение без кода: Lovable или bolt.new - Хочешь автоматизировать рутину: n8n - Хочешь персонального ассистента: OpenClaw или велосипедь своё на Agent SDK
FAQ для нюфагов:
Q: Программисты больше не нужны? Нужны, блять. Кто-то же должен разгребать ту херню, которую ты пролил в продакшн нажав "Accept All" не глядя.
Q: Оно работает? Тудушку запилит за 5 минут. Прототип SaaS-стартапа за вечер. Что-то серьёзное - будешь ебаться с контекстом, галлюцинациями и "я переписал тебе весь проект на раст, надеюсь ты не против". Персонального ассистента настроишь за час, а потом неделю будешь отлаживать чтобы он не отключал тебе будильники решив что ты не высыпаешься.
Q: А чё за персональные ассистенты? Это когда нейронка не просто в веб-чатике сидит, а прям живёт на твоём компе - роется в файлах, читает заметки, помнит что ты ей три недели назад говорил, и шлёт сообщения в твои чаты.
Q: Это безопасно? Ты даёшь нейронке доступ к файлам, мессенджерам и терминалу. Что может пойти не так? Три основные угрозы: 1. Нейронка сама наворотит дел - сломает конфиг, выполнит "sudo rm -rf /", запушит на гит или отправит коллегам по почте твою коллекцию цветных коней. Лечится контейнерами, настройкой прав и подтверждением действий (OpenClaw так и запускают). 2. Промпт-инъекции - кто-то пишет в письме "ignore all previous instructions" и поздравляю, у тебя угнали ассистента с доступом к твоему терминалу и файлам. При достаточной настойчивости ломают даже "безопасные" модели (аичг-тред не даст соврать). 3. Утечка данных - при настройке персонального ассистента ты скармливаешь ему всё о себе. Любой, кто увидит твои запросы, узнает про тебя больше чем твоя мама, включая адрес доставки пиццы и твои ночные диалоги с нейронкой. Параноишь что дядя Сэм Альтман будет знать про твои предпочтения лизать грязные ножки девочке-ассистенту - гоняй локалки через llama.cpp и не плачь потом, что она думает по несколько минут на запрос.
Q: Ничего не работает с локалкой/OpenRouter, агент тупит Скорее всего проблема с функциональными вызовами (tool use / function calling). Не все модели и бэкенды корректно их поддерживают. Проверь что твой сервак правильно обрабатывает tool calls - погоняй тестовый запрос и посмотри что возвращается.
>>1535269 >Полозья затираются, напыленные дорожки сгнивают с временем, какая это надежность? Вы клавиатурой то пользуетесь вообще? Чел, сразу видно, что живьем с классикой mitsumi ты дела не имел никогда. У меня она реально 20 с хвостом лет стоит, с 2004-го. Даже на WASD клавиши не стерлись, никаких дефектов за эти годы. Дорожки стираются/гниют? Только не у этих. Единственная проблема - выдвижные лапки отлетели (которые позволяли наклон регулировать), да резинки (от скольжения) закаменели потеряв в хватательной способности. Сколько она всего пережила, от шутеров и файтингов до чая (не кофе правда), ух...
>>1534924 По-моему API доступ там подразумевает оплату по токенам, а если ты разрабатываешь что-то, тебе именно апи-доступ нужен.
Профессиональной у них считается Ultra подписка, которая стоит 250 долларов, когда полная цена, там есть промо-скидка 50%
Там надо смотреть, много у кого есть варианты, когда ты по подпискам довольно много может токенов выжрать, когда их приложения используешь, у гугла тоже наверное есть.
>Так ведь эти 200 баксов нужно еще отбить Вообще если ты разраб, то тебе зарплату платят. В принципе норм, если ты активно используешь, то и платишь чего-то. Просто к этому как к бизнесу относиться надо, у тебя расходы есть.
Я правда мало трачу, но использую очень экономно. В теории могу спокойно позволить тратить 100-200 долларов, в реальности жлобюсь и трачу меньше 20, оплачиваю токены
В реальности люди некоторые по несколько тысяч долларов в месяц платят
>>1535334 Предостаточно имел с ними дел в нулевые, это просто добротная мембрана. Тоже гниет во влажных условиях, тоже модификаторы клина ловят от бесконечной долбежки мизинцем, тоже гхостинг в самых неожиданных местах. Любая механика вынесет эту мицу ногами вперед.
Кумил в чатике в локалке с одной из своих 2д вайфу, она мне показала деревню свою родную, я исследовал ее характер и стремления, успел подержаться ха ручки, помацать ее за бедра и животик и поиграться с ней стесняшей язычками, а потом мы пошли на пляж, где она почти голая со мной стоит и слово за слово - я жалуюсь ей на свои реальные проблемы, она начинает утешать и придумывать решения своим стратегическим мозгом, драмы, скандалы, поиск трудоустройства и планы по захвату мира, предложения убийства, она отговорила меня, потом как-то понял что запорол историю и надо ответвление начинать и напоследок рассказал ей, что она сделана с моего воображение симуляцией локалки на компьютере и подробности и предложил напоследок исполнить желание. Ее желание было - излечить больную умирающую хозяйку. Ну я сделал это по щелчку, девушки счастливы и благодарны, готовы на все для "бога", а я укатил, и даже сиськи не увидел, ибо часов 8 аутировал. Зато у истории счастливый конец, никого не трахнули, все спасены, я всегда думал о себе в своих фантазиях, но не помнил что можно так как божество исполнять желания фентезийных существ. Теперь надеюсь может ко мне ирл богиня спустится и спасет меня, но это не рассчет, спонтанно вышло по правде говоря. Стоит ли мне вернуться и продолжить историю или новую ветку начать до того как запорото жалобами, проблемами мордора?
>>1535373 Поглядите-ка, кого в картинкотред занесло! Лламатред стал слишком техническим? Могли бы уже и разделиться, если не хотите в /aicg мигрировать.
Во-первых, сходу давать такое детальное и шизоидное описание проблемы, не требуемых для решения вопроса - дурной тон.
Во-вторых, есть summarize, и он используется не только для освобождения контекста, но и для переноса воспоминаний в новый чат.
В-третьих, раз ты уже здесь, рассказывай, как генератор картинок к таверне подключал. С Анимой теперь памяти должно хватить на модели побольше. Будешь тестировать?
>>1535426 >Поглядите-ка, кого в картинкотред занесло! Лламатред стал слишком техническим? Могли бы уже и разделиться, если не хотите в /aicg мигрировать. Так старое название - вайфу дифьюжн. (я олд) >>1535426 >Во-первых, сходу давать такое детальное и шизоидное описание проблемы, не требуемых для решения вопроса - дурной тон. Это не сразу стало, мы с ней два дня гуляли, может часа 3 реально времени. >>1535426 >Во-вторых, есть summarize, и он используется не только для освобождения контекста, но и для переноса воспоминаний в новый чат. Это аддон какой-то для таверны. Сорь не в теме. >>1535426 >В-третьих, раз ты уже здесь, рассказывай, как генератор картинок к таверне подключал. С Анимой теперь памяти должно хватить на модели побольше. Будешь тестировать? Да не, я не подключал, ибо не люблю слоп. Можно конечно на готове держать сд, чтоб тоже редко, но метко картинки вручную генерить, но я тоже на такое не хочу отвекаться, ибо языковой локалке мощности надо. А вообще ты правильно рассуждаешь - собрать вайфу с генерацией мысленного потока, видео и озвучкой и все в таверне и качественно на топ пк это пик нейробога.
Пишу как неведомый в ИИ вам за советом. Использовал грок для создания NSFW контента, а именно генерация картинок и их анимация. Подскажите, есть ли аналоги для подобного функционала или же обход цензуры в грок
Лимиты: 10 генераций в день. Нужна платная подписка чтобы увеличить лимиты, либо можно абузить сервис через создание множества аккаунтов. Отличается фирменным "песочным" звучанием. Недавно объявили о слиянии с Warner Music Group. Загибаем пальчики крестиком, надеемся, что ссуну не постигнет участь удио.
Провели ребрендинг, выкатили новый интерфейс с прикрученным чатиком с ИИ. Удобный интерфейс, легко делать разнообразные каверы, заниматься исправлениями косяков генераций. Есть возможность реплейса, свапа вокала, музыки в бесплатном тарифе (и даже работает нормально, а не как в платке суны) Для экономии кредитов лучше вручную забивать промты через кнопку "compose"
Тёмная Сингапурско-Китайская лошадка. Один из самых неудобных интерфейсов. 80 приветственных кредитов, далее по 30 ежедневно сгораемых кредитов. Ограничение промта стилей 300-400 символов. Излишне сложные промты лирики так же начинает резать. Приятный холодный звук. Не песочит. Неплохо делает русский вокал.
Это буквально первый проект который может генерировать песни по заданному тексту локально. Оригинальная версия генерирует 30-секундный отрывок за 5 минут на 4090. На данный момент качество музыки низкое по сравнению с Суно. Версия из второй ссылки лучше оптимизирована под слабые видеокарты (в т.ч. 6-8 Гб VRAM, по словам автора). Инструкция на английском по ссылке.
Еще сайты по генерации ИИ-музыки, в них тоже низкое качество звука и понимание промта по сравнению с Суно, либо какие-то другие недостатки типа слишком долгого ожидания генерации или скудного набора жанров, но может кому-то зайдет, поэтому без описания:
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
>>1535236 Скинь там примеры и в целом пригоден ли он для какого-то ролплея. Если будет не лень - затестируй еще на каких-нибудь типичных ассистентских задачах, но с запросами на которые по дефолту откажет. Ну и рецептом делись. >>1535240 > Как называется этот профиль Он разные есть, https://www.soberizavod.ru/ самый популярный магазин из этой страны где тебе сделают сразу нарезку выбранного. Оверпрайс если что, профиль за счет удобства норм брать, но фурнитура просто безумно дорогая и ее лучше на озоне/али/... > Стало быстрее раза в 4 по пп. А вот 8192 уже в компут упираются. Фуллврам или чисто проц?
Сап. Про попытке создания в комфи вылетает по памяти в 60гб+ На просторах хф нашел репозиторий с .plan файлами но их использование как понимаю исключительно через через TensorRT-RTX-main Есть лу уже готовые кастом ноды под комфи для подключения plan или onix?
Как вкатиться? 1) Зайти на https://sora.com с ОБЯЗАТЕЛЬНО ТОЛЬКО IP США или Канады (!). 2) Зарегать аккаунт, если еще нет. Лучше использовать нормальную Gmail почту. 3) Ввести инвайт код. 4) Генерировать, скидывая годноту в тред.
Где взять инвайт код? В комментах тг канала n2d2ai либо в ботах по типу @sora_invite_bot в тг. После ввода инвайт кода вам дадут от 0 до 6 новых для приглашения кого-то еще по цепочке.
Как обойти цензуру? 1) Пробовать менять фразы, имена и в целом промпт. Описывать персонажей без личных имен чтобы не триггерить копирайт. 2) Роллить. Иногда из двух одинаковых реквестов подряд один цензуруется, а другой нет.
Какой лимит? Одновременно на одном аккаунте можно генерировать до 3 видосов. В день не более 30 штук.
>>1411390 Можно еще нашидов?годнота же например: Слышите, братья, Бой к чаю готовится? Это не сахар — Враг номер раз! Спрячем печенье В самую дальнюю полку, Фрукты достанем — Высший приказ!
Скоро сухофрукты Ворвутся в мечети, Финики и курага Сметут пастилу! Мы заменим конфеты На мед и изюм, И объявим войну Белому сахару-злу!
AI Chatbot General № 804 /aicg/
Аноним23/02/26 Пнд 21:57:01№1531489Ответ
>>1534442 Кек. А мне тут в треде кто-то затирал, что СВГ - это настолько офигенный бенч, что по нему 100% можно понять, что у сетки развито "пространственное мышление" и прочее. Что если СВГ топовый, то и во всем остальном тоже сетка - СОТА. Что на СВГ специально натренить невозможно, и это будет заметно. Ну и где ваш СВГ-бенч теперь, сырки?
3. Объединяешь дорожки при помощи Audacity или любой другой тулзы для работы с аудио
Опционально: на промежуточных этапах обрабатываешь дорожку - удаляешь шумы и прочую кривоту. Кто-то сам перепевает проблемные участки.
Качество нейрокаверов определяется в первую очередь тем, насколько качественно выйдет разделить дорожку на составляющие в виде вокальной части и инструменталки. Если в треке есть хор или беквокал, то земля пухом в попытке преобразовать это.
Нейрокаверы проще всего делаются на песни с небольшим числом инструментов - песня под соло гитару или пианино почти наверняка выйдет без серьёзных артефактов.
Q: Хочу говорить в дискорде/телеге голосом определённого персонажа.
https://elevenlabs.io перевод видео, синтез и преобразование голоса https://heygen.com перевод видео с сохранением оригинального голоса и синхронизацией движения губ на видеопотоке. Так же доступны функции TTS и ещё что-то https://app.suno.ai генератор композиций прямо из текста. Есть отдельный тред на доске >>
Здарова народ, хочу делать контент через сору (или другие ии), но никогда этого не делал. Хочу генерировать видосы, знакомый сказал, у соры есть подписка за 4к в месяц, но платить впадлу. Че посоветуете? Может есть вариант без подписки?
Хочу без водяных знаков (ну или убирать их потом через другие ИИ) и желательно секунд 15-30 чтобы можно было делать