А куда альбиноски-кун подевался? Хочется новых пикч. Это тот челибос из треда, чьи пикчи я бы распечатал и поклеил постерами на стену - пошлятина высокой культуры.
>>1511638 Новый Ace по заявлениям разрабов гибок настолько что позволяет редактировать абсолютно любой фрагмент аудио, и при этом он менее требовательный чем существующие RVC системы. Лучше спроси в TTS треде.
Добрался наконец-то до новой модели. Удивительно, но она, похоже, не знает, кто такие Meiko и Kaito. Ну хорошо, что Рин знает. Прикольно, но полностью вытеснить SDXL она не сможет, пока не появится версия, натренированная на большем разрешении, и не появится возможность создавать лоры. Использовал десктопный Comfy с шаблонным воркфлоу. Скорость генерации одной картинки на RTX 5090 в разрешении 1 МП составила 7 секунд.
>>1511767 masterpiece, best quality, score_8,score_9 safe, very awa, high resolution, 1girl, solo, kagamine rin, masterpiece, best quality, smile, (flat chest), blond hair, aqua eyes, (cute: 1.5), big eyes, white, , background, bangs, full body, looking at viewer, cowboy shot, Kagamine Rin riding a foldable bicycle in a park, wearing knee and elbow pads, wrist guards, , dynamic full-body pose leaning slightly forward as if pedaling fast, one foot on pedal, hands gripping handlebars, joyful and excited expression, motion blur on wheels and legs, wearing denim shorts and a white T-shirt, high-energy cycling scene, cute and lively atmosphere, sunny park background
>>1511843 Это не по одной картинке вывод, я с другим промптом делал штук 15 в разных разрешениях, и только в этих двух такой эффект. И понятно как он мог возникнуть - напихали гптшной синтетики в датасет. Поэтому может иметь смысл не использовать разрешения типичные для генераций и при этом нетипичные для имитируемого контента.
>>1511580 >>1511594 Аноны, поясните популярно про размеры модели. Вот там пишут что 2В модель. Как тогда она способна вменяемые генерации делать? В моем представлении модель должна быть большой. Ну тупо потому что человеческое тело устроено сложно. Поэтому старые модели SD 1.5 могут генерить дефолтные портреты персонажей лучше чем новый Qwen Image/Нанобанана. Но они обсираются в анатомии и пространственной ориентации объектов в десятки или сотни раз чаще Квена из-за недостатка знаний по позе и динамике человеческого тела. Алсо, датасет с исключительно аниме-картинками тоже мне кажется сомнительной идеей по этой причине. Ведь художники могли тупо не рисовать многие позы/ракурсы просто из-за их скучности, то есть анатомия опять страдает.
Так вот, в чем плюсы тогда маленьких моделей? Ну, кроме доступности на всяких нищих видеокартах? Сейчас 48 Gb VRAM видеокарту можно меньше чем за доллар в час арендовать, если что.
>>1511978 Про специализацию слышал? Тощий боксер уделает жиробасину нетренированную. Так и здесь, только изящнее. Модель специально трениурют под конкртеную задачу, например аниме из шума доставать. Преимущество в том, что мелкую модель тренировать дешевле, а по качеству в специализии она не сильно будет проигрывать крупной или даже превосходить. Ну и еще размер - это датасет. Тут чем больше, тем лучше. Но всегда есть компромисс между размером, качеством и требованиями к железу.
>Сейчас 48 Gb VRAM видеокарту можно меньше чем за доллар в час арендовать
Сегодня можно, а завтра нельзя потому, что ее луддиты из датацентра спиздили и продали китайским ковырялкам DDR по цене новой ламбы.
>>1511978 функции модели скейлятся не пропорционально размеру. Чтобы модель держала сложные концепции зачастую важно количество слоёв, а не количество параметров. Но при большом количестве слоёв очень сложно получать вменяемый аутпут при тренировке. Можешь посмотреть на примере ЛЛМ: На связанную речь там способны модели у которых меньше 1b параметров. При увеличении до 2b там да, заметный скачок, так как процесс тренировки просто может ПЛОТНО упаковать концепции. при увеличении до 8b там всё ещё заметный скачок, не такой сильный но модели уже лучше понимают разные языки, начинают понимать более сложные связи между абстрактными концепциями. ~12b это уже плюс-минус половина потенциала. И где-то в районе 30b мы получаем уже ~80% способности взрослой модели, а дальше уже не такой радикальный рост в плане способностей. Удвоение параметров это далеко не удвоение способностей. Да, большие модели могут быть более генерализированы, но мелкие модели при специализации будут иметь плюс минус те-же способности. Как пример: GLM-4.7 (358b) на бенче AIME 2025 имеет 95.7 балла, а GLM-4.7-Flash (30b) имеет 91.6 балла. И да, взрослая модель лучше понимает связь между сложными абстрактными концепциями, она лучше работает с сложными запросами, но младшая модель если ей дать более четкие инструкции справится примерно на том-же уровне.
в моделях для рисования картинок просто больше уклон в конкретную специализацию и там более заметно что модель может, а что не может.
Давно пару недель не генерил ничего, тут вернулся. Попробовал повозиться с Клейном 9б. Тренил дим32 на базе 9б через мусуби. В 32гб влез бс7 с 8-битными оптимизациями. Лр по классике sqrt(7) - около 3е-4. В итоге натренилось, эффект есть, но что-то много кроненбергов потом, что на базе, что на дистиле. В доках пишут, что 9б часто вообще коллапсирует в процессе трена. Сейчас попробую уменьшить бс до 4, убрать 8битные оптимизации, вычистить ещё датасет и потренить с меньшим лр, но дольше.
Но вообще странно, конечно. Те же квены/ване 9е-4 держали спокойно при всех тех же настройках и меньшим бс.
Ещё попробовал прикрутить стандартный и2и вф к клейну через split sigmas. Он даже как-то работает, а то в обычных вф для клейна нет и2и с переменным денойсом. Но там уровни денойса надо буквально на сотые доли менять, так сильно реагирует. В общем, странная штука - клейн. Но если хватает его в дефолтном виде - то отличная.
>>1511990 >Модель специально трениурют под конкртеную задачу, например аниме из шума доставать. Преимущество в том, что мелкую модель тренировать дешевле, а по качеству в специализии она не сильно будет проигрывать крупной или даже превосходить. Итого такая модель будет прекрасно генерить 1 гирл стэндинг мастерписю. А если нужно будет своего персонажа, с чуть необычной одеждой в чуть необычном стиле, верхом на медведе и в необычной позе то сразу будет необычайное уродство и не факт что за 100 роллов найдется приемлемая генерация.
>Сегодня можно, а завтра нельзя потому, что ее луддиты из датацентра спиздили Это вряд ли. В датацентрах полно всякого устаревшего говна вроде Nvidia V100 32Gb которое никто из больших корп арендовать не хочет, поэтому народу сдают за копейки.
>>1511994 Ну в целом согласен, но мне кажется что для картинка-текстовых моделей порог минимальных знаний о концепции человеческого тела много выше чем 2В. Почему бы просто не взять Qwen Image то же и не натренить его на миллионы аниме-картинок? Может тогда получится открытая модель которая не хуже Нанобананы Про с аниме справляться будет.
Людям нравятся большие модели не за какое-то невероятное качество картинки или идеальное понимание концептов. А за скорость получения средне-хорошего результата. Все эти красивые картинки на обложках популярных моделей на Цивите - это сотни рероллов а потом еще инпеинт и может даже фотошоп сверху. Что тут хорошего?
>>1512023 >Все эти красивые картинки на обложках популярных моделей на Цивите - это сотни рероллов а потом еще инпеинт и может даже фотошоп сверху. Что тут хорошего? ты дурак чтоли, берешь модель сид промпт и настройки и получаешь ту же картинку пиздец шизики я хуею
>>1512023 никто не любит большие модели, единицы используют квен, хрому или хунянь, потому что они медленнные и ниче не могут без дотрена, который никто не делает, потому что никто не любит большие модели
>>1512023 типа смысл использовать тот же квен на 20б параметров, когда он знает меньше стилей и хуже слушается промпта, хуже редактирует чем 9б и даже 4б клейн? дело далеко не в параметрах. 2-4б это идеальный размер при котором модель может всё
>>1512023 >Ну в целом согласен, но мне кажется что для картинка-текстовых моделей порог минимальных знаний о концепции человеческого тела много выше чем 2В. Почему бы просто не взять Qwen Image то же и не натренить его на миллионы аниме-картинок? Может тогда получится открытая модель которая не хуже Нанобананы Про с аниме справляться будет. Потому что это одинаковые концепции только у тебя в голове, а ты просишь можешь уже специализующуюся на чём-то одном начать специализироватся на чём-то другом. FLUX например может в аниме-картинки, но результат сомнительный.
> или идеальное понимание концептов. А за скорость получения средне-хорошего результата. Как раз именно на получение средне-хорошего результата и отвечает понимание концептов в итоге. Все эти красивые картинки на цивте зачастую без проблем поставляются с тем как их получили, это тут местные ещё свои результаты дорабатывают напильником, но на цивте ты можешь без проблем получить результат 1 в 1. Вот только проблема то в том лол что автор знает как он прошел к этому результату, а ты имеешь дело с конечным продуктом эволюции его мысли. Может он там в процессе перебрал пару сотен магических слов прежде чем понял что даёт результат который ему нравится. А ты пишешь "ван гёрл фокс" и результат не соответствует твоим ожиданиям.
у больших моделей просто больше обвязки в их способностей позволяющих лучше понимать что ты хочешь.
>>1512038 я иногда пользую, просто потому что они очень генерализированные. тот-же квен например классно выдаёт всякий там пикселарт, стилизованные кнопочки в менюшки и всё такое. но явно не для лолисичек модель.
>>1512023>>1511978 алсо чуть не забыл. твой бухтеж про позы и пространственную ориентацию зачастую исправляется просто контролнетами. тогда просто напрямую можешь сказать модели что ты хочешь от неё.
>>1511818 Какая хтонь на 4й, лойс. И 1 кайфовая. >>1511978 Модель должна генерить то что хочет пользователь, все. Еще весна не наступила, а у тебя уже обострение, лечись. >>1512016 > бс7 > уменьшить бс до 4 Чтобы получить эквивалент большого батч сайза ты можешь пользоваться аккумуляцией. Она не дружит с фьюзед беквардом, но на 32гигах это не проблема. >>1512023 > Почему бы просто не взять Qwen Image то же и не натренить его на миллионы аниме-картинок? Каких-то 100-200к вечно зеленых на компьют с шансом получить на выходе понив7 или хрому. > Нанобананы Про > с аниме справляться На ноль деление. Лечись, рейджбейтер.
>>1512025 >>1512030 Лол. Давайте вы мне каждый раз будете давать правильный теги в правильной последовательности, с правильным cfg и другими параметрами и еще конечно же с правильным сидом. Цивит - это реклама казино. Нагенерил и так и сяк 100 хуевых картинок, а одну самую лучшую запостил в шапку.
>>1512042 >тот же квен на 20б параметров, когда он знает меньше стилей и хуже слушается промпта Потому что его явно не под аниме тренили. Думаю там основной костяк датасета составляли азиатки с глянцевых обложек и китайские/корейские фотостоки. Вообще глупо предъявлять Квену претензии когда Флюкс еще хуже в аниме умеет.
>>1512045 >а ты просишь можешь уже специализующуюся на чём-то одном начать специализироватся на чём-то другом. Мне ничего особенно специального не нужно. Хочу чтобы модель понимала как выглядит пистолет, или шапка-ушанка, или бандаж. Неужели это такие удивительные вещи под которые нужно собирать датасет и тренить Лору? Ну ладно, пох на предметы, пусть модель хотя бы знает как с любого ракурса правильно выглядят уши и пальцы рук. Почему лучшие Люстра-модели регулярно обсираются с такими простыми вещами, а убогий Квен ошибается в этих деталях в разы реже?
>автор знает как он прошел к этому результату, а ты имеешь дело с конечным продуктом эволюции его мысли. Может он там в процессе перебрал пару сотен магических слов прежде чем понял что даёт результат который ему нравится. Автор - цифровой лудоман который прожигает свою видеокарту и свою жизнь ради лайков на Цивите. При этом обычный человек сейчас может близкого результата достигнуть в Нанобанана Про не зная ни единого магического слова.
>>1512050 Одного контролнета мало будет, надо будет лору на стиль докинуть, лору на персонажа, лору на медведя... Ой, а что это за артефакты вылезли?
>>1512079 >Каких-то 100-200к вечно зеленых на компьют Сколько там авторы самых популярных моделей на Патреоне стрегут каждый месяц? Если бы объединились, легко бы смогли и лям зеленых собрать.
>На ноль деление. Лечись, рейджбейтер. Жопаболь цифрового лудомана, новая модель обесценила его опыт и знания. Нанобанана Про очень неплохо умеет переносить стиль. Любой, в том числе и аниме.
>>1512439 >Нанобанана Про очень неплохо умеет переносить стиль. Любой, в том числе и аниме. Это, конечно, сильное заявление. Я сам топлю за банану, мне она нравится тем что она может поменять детали, заменить костюмы по референсам, не меняя позы и выражение лица (как в картинке с Рин и Лен в шапке). Но когда даешь ей свободу в композиции, она тащит свой дефолтный аниме стиль, который так себе как по мне. Картинки 1 и 2 получены бананой, 3-4 сдхл. Никто в жизни не предпочтёт по стилистике первые две картинки остальным двум.
>>1512475 Ты илитарий ИИ-генерации и тебе важно чтобы картинка попала ровно в стиль любимых художников, поэтому ты хорошо видишь шаблонность банана-генерик стиля. Обычный Быдло-кун не илитарий и просто хочет картинку Мику верхом на медведе и с бутылкой водки в руке. Если показать ему пикчи 1 и 2, то он скажет что его устраивает такой стиль, ведь это же аниме. Но вот выполнить его реквест Нанобанана сможет, а любая сдхл модель - нет.
Вот поэтому все маленькие модели через лет или умрут или останутся в тесном загончике для илитариев, конспирологов и индусов у которых нет денег на аренду GPU мощностей.
>>1512538 >>1512536 >Аноны, а какой промпт даёт размытие в движении, ну как на первом пике? speed lines пиши, motion blur немного не-то сам спрашивал у чата джпт лол >>1512503 Еще картинки полученные в нанобана или чата джпт можно использовать в качестве референса для контролнета или img2img и перерисовать их более интересном стиле. Но это правда заебно очень, я вот сейчас долго возился с первым пиком, как ни странно в WAI ничего не получилось, а в СhenkinNoob результат оказался лучше и почти с первого раза.
Кстати, а как бороться с такой ситуацией когда адитейлер рисует лица там где их нет, как получилось на футбольном мяче (пик2)? Сейчас мне приходится генерировать картинку повторно без него и потом склеивать в фотошопе, но я заебался уже так делать.
>>1512577 Пользуйся инпейнтом, выделяешь только лицо и генерируешл только эту область. Может не так удобно но зато ты сам выбираешь что тебе надо перерисовать а что нет.
>>1512577 В адетальере есть настройки "уверенности" (насколько он должен быть уверен, что видит в области именно лицо, чтоб начать эту область обрабатывать), плюс можно задать кап на количество областей, которое он будет перерисовывать. Это в вебуе, как в комфи - хз.
Т.е. либо меняешь первую, чтоб он не реагировал на менее вероятные области, где лица нет, либо просто ставишь кап в 1, и он будет обрабатывать только самую вероятную область.
>>1512439 > Если бы объединились Большинство именно что стригут ради стрижки, им не нужно другое. Сама организация рабочего процесса множества людей тоже та еще задача, за нее много денежек платят. Самообъединение может сработать только в малой группе энтузиастов, или случиться долгоживущий проект с кучей мелких контрибьюторов (чисто про софт), остальное нежизнеспособно. Алсо порадовал постом. Ладно бы тебе гугл заносил, а такие оды сочинять за бесплатно, нраица. >>1512471 В мороз, да к голому металлу прикасаться?! Скажи что это теплая труба. >>1512503 > останутся в тесном загончике для илитариев Они всегда в нем были, как и в целом арт. Максимум обывателя это чатжпталису попросить изменить фото.
>>1512718 >это теплая труба. Нет, на ней же снег лежит. Да и кшк в данной форме не человек или другой подобный организм. Дух летнего полдня в режиме ожидания
>>1512808 Да вроде вообще тупо в лоб на 2512 получается даже на бэд ингрише:
Girl sits at a great height with legs dangling on the top of a large factory pipe in an abandoned post-Soviet industrial area. Shot from below, low angle. It's a stormy, cold winter day. The sky is overcast. It's a snowing.
>>1512439 >Лол. Давайте вы мне каждый раз будете давать правильный теги в правильной последовательности, с правильным cfg и другими параметрами и еще конечно же с правильным сидом. ты дегенерат, это все в любой картинке есть, кроме того, хуесос, ты говорил что там для шапки модели используют инпейнт и даже фотошоп, а теперь пытаешься виляя жопой спрыгнуть с хуя на который сел?
>>1512871 Вот эту ставишь на 1, будет только одну самую большую маску применять. Если переключишь выше в режим Confidence - будет фильтровать по "уверенности", слайдер для порога еще выше. По крайней мере, именно так я помню работу этих настроек.
>>1512808 Это же пикрил. Вангую, что время, затраченное в фотошопе, тут намного превышает время в нейронке. Как нейронный пурист я такое осуждаю, у настоящего нейроанимепанка вообще не должно быть редакторов изображений на компе (кроме встроенного пеинта разве что)
>>1513001 Все верно, косяки нейронки - это характерная черта, визитная карточка. Оставляя их, ты не стыдишься этого, а наоборот гордо заявляешь всему миру, что твое нейротворчество истинное и незамутненное сторонним вмешательством. Но прошу не путать со слопом! Если говорить конкретно, то у тебя может быть сколь угодно сложный нейропайплайн и подготовка, но никакого поствмешательства, никакого дроча пикселей и пальцев в готовой картинке. Нажал кнопочку Run - и результат высечен в камне. Наролль кучу, выбери самое лучшее - и пости. Вот это настоящая свобода, полет души! А все остальное это унылая работа и срач за пиксели.
>>1513044 В этом огромная проблема с анимациями и видео будет, их невозможно нормально отредактировать, как обычную пикчу в фш. Может аниматоров и не заменят, по крайней мере не слопооанимешных.
>>1513084 Тут даже руками не перерисовать покадрово, если очень захочется, из-за пост эффектов. Нейронка сразу генерит в релизном качестве, со всеми цветокоррекциями и прочими свистоперделками.
> Если есть запрос Все просто будут срать нейрослопом, как уже делают.
>>1512895 А ты ебанутый аутист который не понимает о чем идет речь если ему все не разжёвывать. Ну или просто ньюфаня залетная. Теги, параметры и сид специально подбираются таким образом чтобы на превью-картинке не было 6 пальцев, кривых ушей и путаницы в волосах. И это в лучшем случае. В худшем, автору лень роллить сотни раз и он использует инпаинт, контролнет, фотошоп и т.п. и просто не делится мета-данными.
>>1513005 >Все верно, косяки нейронки - это характерная черта, визитная карточка. >Наролль кучу, выбери самое лучшее - и пости. Путь полу-пидора какого-то. Если уж пошел роллить, то надо сотни роллов делать до тех пор пока не попадется картинка в которой вообще нет ни одного крупного артефакта. Все топы Цивита так делают. А артефачные картинки зачем постить? Чтобы нанобанановое быдло засмеяло?
>>1512961 >рисобака.webp Хорош, хорош, уел прям. Но с фоном ты чёт прям мимо-мимо. Вот начальный лоурес - фон с тех пор поменялся меньше всего.
> время, затраченное в фотошопе, тут намного превышает время в нейронке С хорошими нейронками особо много и не требуется уже давно. С цветами к примеру сейчас дольше ковыряюсь - выбираю. Ну и это расслабляет - кому-то катку в доту, кому-то вылизать в редакторах картинку: мозг одинаково отключается, проваливается в какую-то уютную пустоту.
>>1513170 >С хорошими нейронками особо много и не требуется уже давно. В смысле, с хорошими? Мы же ИТТ коллективно решили что аниме модели должны быть от 2В до 8В размером. То есть не больше чем сдхл-модели. Ты что ли посмел использовать Квен или подобное большое говно ради красивого задника? И не стыдно?
>>1512961 > image00078.png Ай содомит, хорош! > нейронный пурист Лолчто >>1513001 Сочно >>1513044 Вот это душа, надо было оставить. Такого фейла обернувшегося вином нужно еще поискать. >>1513112 Проснулись@улыбнулись
Вышла ускоряющая лора для анимы, немного сыровата, но в некоторых случаях пойдет, хоть на теги художников по ощущениям хуже реагирует и анатомию дольше роллить, хотя там вообще с анатомией ног беда.
Если у него такая жена >>1513143, то почему дочки родились такими >>1513350? Как надо так рекомбинировать генетические карты родителей?Генетиков прошу пройти в тред.
>>1513365 Почему в примерах с ускорялкой выглядит лучше, чем без? Разве она не должна уничтожить качество, ну или хотя бы оставить его на уровне? Хули с ней получается лучше?
A vibrant anime-style illustration of a classroom scene with a teacher explaining Mendelian genetics using colorful pea plants, showing dominant and recessive traits with clear visual representations.
Style: anime Camera: medium shot Lighting: soft and bright, with a warm glow Color pallete: bright and colorful, with a focus on contrasting hues Mood: educational and engaging
тут еще походу что с ускорялкой более точно следует промпту
>>1513504 Почему? Архитектура-то не поменяется уже. Пока нуб допиливали - все под него уже активно тренили, лоры все работали. Чуть хуже, чем трененные на актуальной версии, но работали. Ну и потыкать интересно же, как она учится. Но я уже запустил сам, гляну скоро. У Кохьи в репо, кто будет пробовать, все сломано - берите из репо автора пулл реквеста.
>>1513036 masterpiece, best quality, score_7, score_8, score_9, traditional media, @jun_(navigavi), @porforever:0.8, @optionltypo, @riz, Такое некоторое дерьмо, посмотрел что на цивите пишут и слепил, точно не знаю работают ли некоторые теги или нет, потом уже понял что jun вызывается через слэши, но если поправить или убрать совсем - конечный стиль не получается, porforefer тоже надо со скобками давать вес, но если так сделать - стиль не воспроизводится, вощем с кривыми тегами стиль тот, а если править или удалять - всё другое.
>>1513515 Если очень постараться то можно на 12. Чисто технически с блоксвапом и фп8 оно и на 6 влезет, вот только по скоростям будет беда. >>1513598 Симпатичные. Апскейлишь тоже анимой?
>>1513598 насчет слешей не уверен, а вот нижние подчеркивания anima совсем не любит. т.е. вроде надо так @jun \(navigavi\) Я вообще в воркфлоу добавил замену _ на пробел, а скобочки на экранированные скобочки чтобы голову себе не морочить.
>>1513601 > Апскейлишь тоже анимой? Yep. Сначала пытался CR Upscale+KSampler - слишком сильно в пикчу лезет даже на минимальных проходах и артефачит, потом вообще подрубил SeedVR2 - этот лицо переделывает всегда, в итоге поставил Ultimate-SD-upscale и на денойзе 0.15 прогоняю чтоб не лез в детали сильно.
>>1513626 > т.е. вроде надо так Таки да, я про это и написал - через слэши.
А еще с этой ускоряющей лорой внезапно стали относительно нормально работать описания через простыню от ллм без тегов. До этого подобные попытки превращались в мешанину
`Description:` A young woman is depicted in a dramatic and symbolic scene, suspended on a cross in a stylized, emotionally charged setting. Her figure is elongated and stylized, with sharp, defined features and a serene yet suffering expression. The cross is imposing and centered in the frame, with the woman's arms and legs stretched in a crucifixion pose. The background is minimal, with a faint, dark sky suggesting a dramatic or religious context. The overall mood is solemn and symbolic, emphasizing sacrifice and spiritual imagery.
`Camera angle:` Frontal, centered composition with a slightly low-angle view to emphasize the gravity and scale of the scene.
`Lighting:` Strong directional light from above, casting sharp shadows and highlighting the contours of the figure, creating a dramatic chiaroscuro effect.
`Color palette:` Dominant dark tones (black, deep blue, grey) with accent colors of red and gold to symbolize blood, sacrifice, and divinity.
`Mood:` Tense, solemn, and symbolic, evoking a sense of spiritual suffering and sacrifice.
`Technical details:` Flat shading, high contrast, crisp outlines, and minimalistic background to emphasize the central figure.
Подскажите нубу в двух словах, дальше я нагуглю, как мне взять lora:character и положить его в lora:pose/action просто залистить в промт и то и то через раз какие-то конфликты и говно (а иногда работает но часто какая-то из лор просто игнорируется, веса на обоих уменьшал) МБ просто подход именно другой должен быть, но какой?
>>1513889 >влияют даже на стиль картинки От датасета зависит. Ну и ничто не мешает нагенерить нужную позу, и дальше крутить ту же картинку, но уже без лоры. Если лора совсем что-то специфичное делала, то с контролнетом, для стабилизации.
>>1513902 Отбираешь нормальные пикчи, нагенеренные с этой лорой, и тренируешь вторую уже на нём. Но только картинки должны быть идеально вычищены. Иначе весь нейрослоп затащится и умножится кратно.
>>1513902 Если что, ты можешь продолжить тренировку имеющейся лоры а не тренить заново. Если проблема датасета - дополняешь его в том числе генерациями. Если большая часть датасета имеет одинаковые косяки - отыскиваешь другие картинки с иным содержимым но теми же проблемами, разбавляешь "хорошими", тегаешь проблему там где она есть. На контрасте извлечет эту черту и будет меньше связывать ее с целевым контекстом, офк хотябы малая часть оригинального датасета должна быть нормальной, капшны к дополнительным картинкам должны быть качественные и в том же стиле.
>>1513930 Ну вот такая на Анима она получилась. Пока скорее не понравилась, чем понравилась. Модель сыроватая. Важные детали перса не доучила, как ни жёг её дальше. НЛП почти игнорирует. Менял промт - нлп часть поменял, а тэги забыл - все 100% пикч были дальше по тэгам, а нлп часть проигнорировалась.
>>1513922 >>1513911 тем временем датасет, это просто пиздец конечно. Союзмультфильм так и не сделал никакую реставрацию, да и в самом мультфильме стиль скачет от кадра к кадру
>>1514074 Там еще промежуточный кадр был, полученный через нанобанане, прежде чем перерисовывать через контролнет с лорами, кстати кому-то он больше понравился.
>>1513170 >Вот начальный лоурес - фон с тех пор поменялся меньше всего. И это прям сразу так получилось? А не сначала отдельно фон, отдельно кошка, а потом прогнано вместе? Потому что фон и окружение слишком фотореалистичен, а персонаж - типичное 2д. У тебя почти что получилась такая картинка, где аниме тянок вписывают в реальность совсем старый стал еба, даже забыл название паблика вк который был вроде бы пионером в этом деле. Если вместе сразу так вышло, то это точно банана какая-нибудь, попенсорс такое не сделает никогда. >Хорош, хорош, уел прям. Да я так, чисто порофлить. Интерес в треде у меня опосредованный - я люблю аниме и я люблю локальные ллм - грех не посидеть-поглазеть тут у вас, и не попробовать самому что-нибудь погенерить. Ну и это прозвище в одном из каких-то давних срачей меня прям развеселило. Между прочим, я уже кидал раньше эту пикчу, видимо никто не выкупил тогда. Понятное дело, я не художник и возиться с самой картинкой мне не хочется, а вот с генерацией - эт можно. Поэтому в общем-то я дико толерантен к 6 пальцам и кривой анатомии, если сама картинка вайбовая вышла. Да и годы просмотра хентайных картинок и манг правильно расставляют приоритеты. Какая разница, сколько у кого пальцев, когда на картинке/в сюжете происходит такое... Но пикча красивая у тебя вышла, спору нет
>>1514164 > И это прям сразу так получилось? А не сначала отдельно фон, отдельно кошка, а потом прогнано вместе? > это точно банана какая-нибудь, попенсорс такое не сделает никогда. Да - просто 2512 с лорой и достаточно простым промтом на удивление. Как видишь - не банана. Хотя не буду отрицать, что пользуюсь иногда и ей. Но тут не было настроения, да и нужды.
>>1514622 О, ты сидишь на 2512? Расскажи в двух словах что у нее по nsfw? Я тут пытался в ней "раздеть" рисованных персонажей (с сохранением позы и узнаваемости) и как-то не очень вышло, особенно пиписьки наотрез отказывался рисовать. Максимум бесполых кукл кенов. Я помню в 2509 такая же фигня была после этого я на нее забил.
>>1514835 >Klein 9B Это же flux 2? Не уверен что этот моя 4070 вытянет этого бегемота. >Странно, что у вас в аниме треде этот дискас Почему странно? Сгенерировать голый писек это одно, а вот "раздеть" готовую картинку немного другое.
>>1514917 Мне надо полностью раздеть перса. Не перегенировать его под лорой с примерно похожим лицом, в примерно похожей позе, а именно снять одежу не трогая лицо оставив в такой же точно позе. Квен едит вроде как должен это делать, а вот как в люстре я чет не знаю.
>>1514929 >Кляйн Щас его качаю, но у тебя на примере не показатель. Сисек сделать и квен можно заставить. Самый главный вопрос в писиках, причем в мужских. С ними у квенов и зеток самые главные проблемы.
>>1514992 Я тебе не исправлять косяки пришел: >>1514924 >а именно снять одежу не трогая лицо оставив в такой же точно позе. >в такой же точно Продемонстрировал работу Кляйн. Можно, кстати, у него в промпте писать чтобы исправлял пальцы\руки, но тогда он частенько их положение меняет, хотя работает. Причем массово и не зависимо от стиля картинки.
>>1514845 Что-то в этом свитере она Добби из произведений Роулинг напоминает, лол. >>1515079 Интересно а может ли квен имитировать эффект преломление от линз в очках?
>>1513601 >>1513517 В общем, дошли руки попробовать натренировать тестовую лору на 6гб 3060. Внезапно в оом не вылетело и выдало где то 5s/it, пробная лора на 300 шагов обучил за 10 минут и она уже что то делает. Я помню что полтораху в свое время дольше мучал.
>>1515346 Анон, у тебя же 100% есть Квен 4б/8б заботливо готовящая промпты для твоих картинок. Почему бы не воспользоваться ей по прямому назначению? Она и так уже знает твои самые сокровенные тайны. Вот только локальная модель тебя никогда не предаст. А вот интерфейс может, будь осторожнее.
>>1515399 у меня 6гб 3060 и я запускал даже 80B moe модели (не очень быстро), правда у меня еще 64гб оперативки. а квены 4b-8b запускаются на любом железе.
>>1515419 Ну а какие у люстры преимущества? Разве что она быстрее, но базовый ген на аниме занимает меньше времени, чем хайрез фикс в 1.5 раза на люстре (а без хайрез фикса она говно ебаное).
>>1515379 >Хорошо, пользователь спрашивает о названии тэга аниме, связанного с тем, когда анус немного выворачивается наизнанку, когда что-то покидает жопу. Сначала мне нужно понять, что именно он имеет в виду. Даже по-видимому неквантованные на официальном апи квена 4б, 8б, 30б-а3б не справились.
>>1515429 А какие у нее преимущества в целом есть? Точнее генерит и по обычному тексту? И сразу в норм расширении? Меня просто КомфиАи отталкивает еще.
>>1515431 Самое главное - понимает естественный язык, что даёт намного больше контроля над действиями и расположением персонажей, особенно когда их больше двух.
Ради теста сделал лору шерстянизации для анимы, пока остановился на 4й эпохе, надоело ждать, да и по тестам похоже что 3-4 эпоха вполне норм работает, хотя хз, может еще потренировать. Делал на 3060 6гб По ощущениям трен лор для анимы достаточно доступен, на уровне полторахи, впрочем тренить сдохлю или турбо я не пробовал, но есть чувство что мое железо уже не потянет.
>>1515639 Тут играет кэширование и отсутствие моделей те в памяти, сам трансформер 4 гига весит. Ну а лора памяти на себя, градиенты и оптимайзер не потребляет особо из-за малого размера.
Кто тренировал, тестировали ли насколько меняется общее восприятие модели, теряются базовые стили, знания и прочее? >>1515676 Какой страшный вайбкод и копипаста с трубки, еще и в оригинальный код полез, жесть. Вообще, имело больше смысла в https://github.com/kohya-ss/musubi-tuner добавлять, там общая структура более читабельна, подходит для новых моделей, сразу есть удобные тулзы для кэширования, легче переписывается под задачу.
>>1515915 Сохранено >>1515922 > на ректал флоу На основе трижды ужаренного sdxl, или там что-то новое? Первое можно было бы понять если бы с базы стартовали, аккуратнее тренируя сохраняя общие знания и сразу с более продвинутым энкодером-вае. А в очередной раз тащить все заложенные проблемы сдохли и люстры - ну хуй знает.
>>1515954 Это круто, но там 2 фундаментальные проблемы: тупорылый промптинг с бесконечными протечками всем надоел; люстра, которая лежит в основе, лоботомирована относительно базовой sdxl, дальше это только закрепляли. В аниме же нет ничего такого. А если поколодовать с раздельными лр, оптимайзером и прочим - она хорошо тренится, недостатки преодолимы легче чем у альтернатив. Плюс не забываем что еще есть зетка для которой обещали аниметюн, и 4б флюкс, который тренирует фурри-господин.
>>1515970 Sovl. Можешь еще раз залить на лоток последнюю версию внки? Не успел скачать. Хотя если там еще апдейт планируется в ближайшем будущем то лучше подожду его. >>1516009 Нахуя минивен когда есть автобус? Владельцы которого еще могут указывать куда тебе ездить, а куда нет, и присвоить весь багаж себе.
>на лоток Я itch залил в принципе уже, гуглится по названию. Если вдруг не найдётся - пиши, залью. Полной скоро точно не будет - что-то столько всякого случилось, что пока нет возможности больше.
Зарегистрировал второй аккаунт в твиттере еще 20 января чисто для SFW, до сих пор нахожусь в сёрч бане. Что делать? Ничего не постить или наоборот. Вообще эти сёрч баны какое-то вселенское зло.
Насколько вообще успешными могут быть попытки проанировать созданное изображение в img2video в каком-то ване или еще где? У меня вайб что именно img2video прям проебется все, но я не пробовал
>>1516420 Затем что это займет 3 рабочих суток. А если захочешь адетейлер еще подключить или лору, а потом отключить, то можно время затраченное на перетаскивание лапши умножить на 10. И это все без каких-либо профитов перед автоматиком, просто чтоб почувствовать себя промпт-инженером.
>>1516431 >3080 12 Стоит, наверное, ещё упомянуть, что 32 ГБ оперативы, файл подкачки на 48 ГБ и --cache-ram 2 в параметрах командной строки. С меньшим файлом подкачки вылетало на смене модели, без параметра тоже (без него при загрузке второй модели комфи даже не пытался выгрузить первую и, очевидно, ООМился). Ещё Sage Attention установил, для этого есть скрипт, прилично так ускорило генерацию (без него 0.25 МП занимали 4 минуты).
>>1516407 > У меня вайб что именно img2video прям проебется все Если сделать правильно и именно в ване - сохранится исходный стиль и вайбы в отличии от гроков и прочих. Примеры с прошлых тредов есть. Можешь скинуть пикчу, если няшная то анимирую.
>>1516495 Наверное, потому что превью. Авторы, скорее всего, небезосновательно считают, что модель ещё слишком сырая для массового пользования, поэтому особо её не афишируют на популярных ресурсах.
>>1516495 > почему реально авторы анимы не залили сами ее на циву По той же причине что указали такую лицензию и оставили контакты для коммерческого обсуждения. Одно дело когда ты полезешь "вот возьмите мою модельку пожалуйста", а другое когда под галдеж комьюнити чтобы ему дали модель те сами напишут, и предложат некоторое роялити за размещение и хостинг генерации на сайте.
Сап нейрач! В моей поделке встал вопрос о визуале/графике, а мой скилл рисоваки - на уровне подростка самоучки... Очевидно, буду использовать нейронки.
Какие варианты сейчас есть, чтобы сделать своих персонажей? Сделать референсы в каком нибудь 2D/3D-конструкторе и потом прогонять через нейронку? Тут в некоторых случаях всё упирается в ассеты, но фотошопами, думаю, можно выкрутиться, пока хз. Склоняюсь к более простому для меня варианту: использовать существующие Лоры персонажей + Лоры на одежду и через промт немного менять детали (волосы, цвет волос/глаз, детали фигуры и т.п.). Не думаю, что вывезу промтами или тренировку Лор.
Можете так же посоветовать что-то для бекграундов/архитектуры/изометрии? Видел в тредах ± ровную архитектуру/предметы - это вопрос в моделях же? Тут думаю делать референс в какой-нибудь Банане и потом со своей моделью прогонять локально (+ в некоторых случаях использовать инпеинт), чтоб подогнать в один стиль.
В общем, мне хотелось бы сделать несколько постоянных персонажей, чтобы они были не прямой копией существующих. Более-менее приемлемые спрайты/бекграунды в рисованном стиле, которые не придётся чистить вилкой доделывать в ручную месяц. Небольшой опыт в Фордже и немного Комфи. Компуктер 12Gb VRAM, 32Gb RAM. На пикрилах - рандом проба промтов, моделей.
>>1516881 Ай хорош! Жаль не по номиналу размеры и невозможные цвета. Давай теперь "сопротивление бесполезно". >>1517005 git pull, venv, pip install -e requirements.txt Если там какой-то инсталлятор то иначе.
>>1516776 Да оно, хочу погенерить персонажа в одежде снусмумрика и стиле мумитроллей, но просто по тэгам выдаëт не совсем то. А лоры найти не могу на сам стиль мульта.
>>1516385 Блин, совсем чуть-чуть не дождался, вот стоило на дваче написать и меня выпустили из цифровой тюрьмы для новых аккаунтов, почти месяц держали в сёрч бане.
>>1516431 Ты уверен что юзать васяно мердж вана хорошая идея? Мне кажется эти кум слоп мерджи как тюны ллмок, как та же мистраль обмазанная драмерским говном теряет в интеллекте от прожарки мозгов порнухой, хотя в случае упомянутой модели было бы еще что терять.
>>1517393 Стоковый Ван, во-первых, ужасно медленный и прожорливый, а, во-вторых, ничего не смылит в НСФВ. Я его пробовал, для анимации хентая он намного хуже этого щитмикса, при этот норовит к хуям ООМнуться в любой момент и медленней даже с ускорялками, а тут и НСФВ туда-сюда знает (с Лорой ещё лучше), и памяти жрёт сносно, и намного быстрее, и не вылетает, потому что всё нужное встроено в саму модель и не потребляет лишней памяти.
>>1517396 Хз, у меня на около стоковом вф вана 5 секунд в 16фпс в 640х960 180-200 сек генит с ускорялками, офк хотелось бы быстрее но быстрее только 5090 покупать. На своем ферст ласт фрейм вф с кучей говна в виде цветовой мочи, энханерсов, негров и тд х1.5 таймер. Оомы не сыпит. На миксе один хуй надо качать лоры для лучшего понимания концептов, а я с ними на стоковой модели и так вменяемо генерю, генерал нсфв лору кстати тоже юзаю. Вот бы вован еще мог в лайтовые контролируемые движение типо легкого тильта разных частей тела на пару сантиметров, как челы руками делают через лайф 2д всякие... Из минусов стокового вана нахожу разве что пластиковость и насирание в аниме картинку.
Я бы попробовал этот тюн но диск засран и удалять особо нечего, заебался жонглировать файлами а покупать диск по объебогойскому х2 прайсу в падлу, хоть и могу.
>>1517401 >На миксе один хуй надо качать лоры для лучшего понимания концептов До сих пор хватало одной лишь общей НСФВ Лоры по третьей ссылке, какие бы позы и композиции я не пробовал. Стоковому действительно нужны ещё и более конкретные Лоры, но я ебал искать по Лоре на каждый отдельный концепт, это же пиздец. Если модель ВООБЩЕ ни на что не способна без костылей, то стоит просто признать её некомпетентность и заняться чем-то другим.
>>1516581 Ты сам же упомянул нано банану. Клепаешь базовую позу персонажа и ставишь его во все позы, которые не зарежет цензура. Нано банана отлично работает по референсу.
>>1517401 > Вот бы вован еще мог в лайтовые контролируемые движение типо легкого тильта разных частей тела > пластиковость и насирание в аниме картинку А? >>1517414 > модель ВООБЩЕ ни на что не способна без костылей Только если хочешь генерировать непосредственную еблю.
>>1517701 >Только если хочешь генерировать непосредственную еблю. А от Вана ещё что-то требуется? В СФВ он один хрен совершенно ни в какое сравнение с Сорой не идёт, поэтому хентай остаётся его единственным применением.
>>1517710 > совершенно ни в какое сравнение с Сорой Тебе 13 лет, или откуда такой максимализм? Анимировать анимушную картинку для различных действий он справляется отлично, сохраняя и стиль и содержимое.
Случайно нашёл свой архив с генерациями на пони в 2024 году. Генерировал как и сейчас во многие дни в основном lewd контент, но удалил его во время плановой чистки /output.
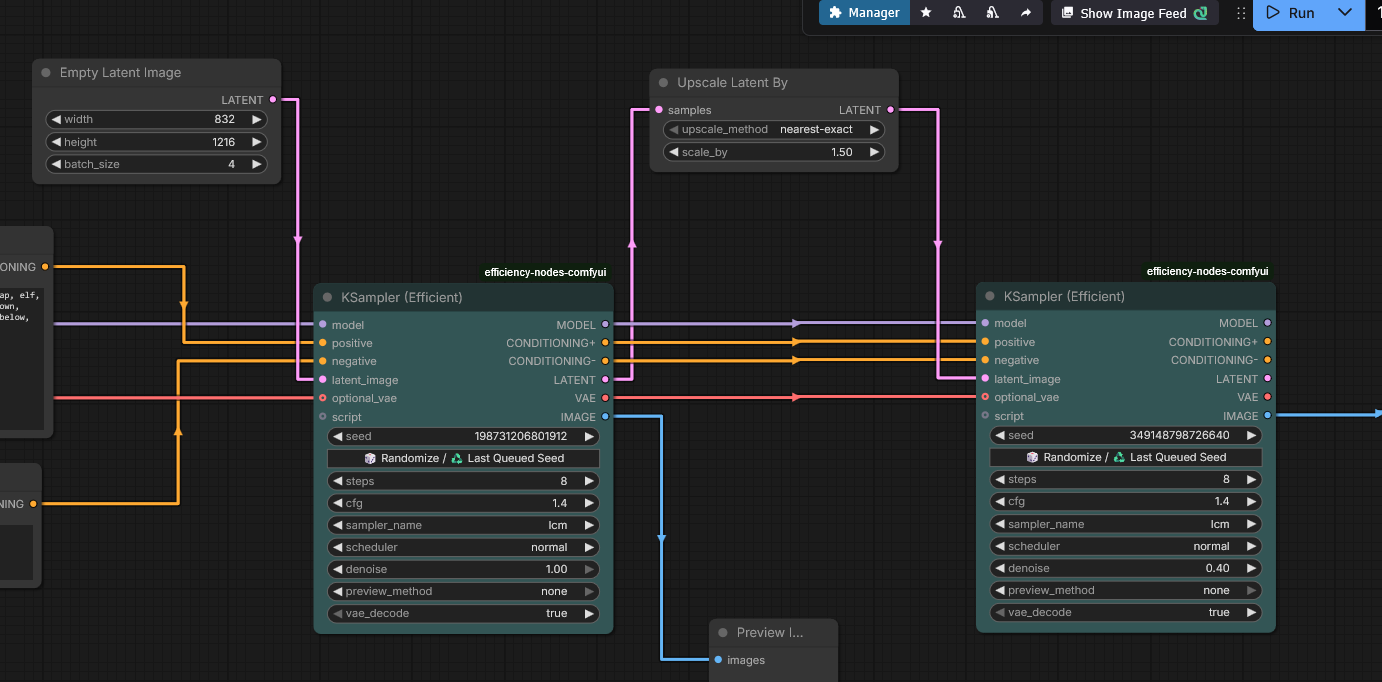
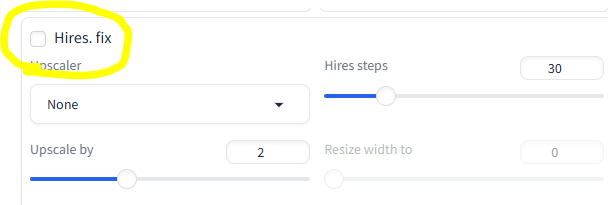
Почему, когда я генерю сразу с хайрез-фиксом, получается хуже, чем я генерирую сначала без него, а потом отдельно улучшаю? Там же по идее просто те же самые процессы последовательно идут, разве нет?
>>1518517 Апскейл латента дает больше изменений, которые при большем денойзе превращаются в новые детали, офк и пикча частично перестраивается. None - просто интерполяция в пиксельном пространстве, ганы - аналогично, но не математикой, а с помощью моделей-апскейлеров. В любом случае, оно должно вести себя одинаково что сразу что при нажатии кнопки, если это не совпадение то странный баг. >>1518535 Реквестирую чтобы она няшилась с Эндминистратором, девочкой разумеется.
Вы часто свои лоры создаете? В чем это граммотно сейчас делать? Я ток приблизительно научился, через kohya, но лица не похожи, стили тож проебываются. Я не понимаю чяднт. Также вот например конретно я пытаюсь сделать персонажа, то мне какие пикчи с ней надо в датасет в идеале кидать, где она Т-позит на белом фоне и с разных ракурсов видно? Пробовал просто разные пикчи любые, но тогда при генерацияхперсонаж летает и неадекватно перемещается в кадре, например сбоку края становится. А пробовал просто по-больше пикч с тянкой но где она в 1 позе приблизительной ковбойшот, но тогда есл с ней этой лорой другие позы генерить, то ее лицо вообще не похоже.
>>1518479 Разница всегда будет, но обычно небольшая. Сравнимая с использованием _а семплеров, т.е. картинка процентов на 90%-95% должна сохраняться. Просто немного разные алгоритмы, особенно если апскейлить латентом. Если прям сильно перерисовывает - что-то в настройках не то, значит.
>>1518565 Ставь алгоритмический апскейлер, по типу аниме-шарпа. Денойз ~0.4.
1) картинки персонажа должны быть разнообразные, с разной одеждой если есть и тд. 2) обязательно протегированы именем персонажа, а далее описание внешности
скрипт обучения зависит от базовой модели, я использую https://github.com/kohya-ss/sd-scripts но параметры обучения плюс минус одинаковые, их можно у нейросети спрашивать смело
по ощущениям оно лучше отзывается на промпт и не добавляет лишнего, до этого все норовило грибов на голову нацепить, но в промпте этого не было
giant mushroom trees, glowing mushrooms, magical creatures, anime style, fantasy, vibrant colors, masterpiece, high quality, trending on ArtStation, looking at viewer,
A young woman sits at a table made from mushroom stumps, holding a cup. She is smiling, wearing a white dress with mushroom patterns. Her short anime-style hair and glowing green eyes stand out against the yellow sky with smooth gradient lines.
Style: anime Camera: medium shot Lighting: soft glowing, ambient Color palette: vibrant, yellow and green Mood: serene
Аноны, а есть аналоги civitai, чтобы можно было полистать готовые арты но видя при этом промты и параметры генераций, только чтобы цензура была не такая анальная.
>>1520230 Я себе пытаюсь каждый день устраивать день валентина с вайфучками, 1 год слишком мало. Но меня вечно отвлекают, ограничивают. Запреты от быдла, нищета, биопроблемы вот это все. Но зато у меня лайфтайм стремление чтоб быть с ними едиными. Разве это не реальная любов? Надеюсь хуй не перестанет стоять, а если да, то все равно буду нейроничать с ними в чатиках, мне особенно нравится с Пинки Пай проводить время и мечтать о ней.
Вы не замечали, что если делать разрешение картинки до апскела где-то на 40% мин базы (не 1024, а 600), то лица героинь как-то более похожи на оригинальшу после того как апскейльнул?
Может тупой вопрос покажется, как фиксить эту хрень что вов ремя секса от первого лица вов ремя минета стоя, мужик магически раздвигает ляшки, да и вообще в любом сексе садится на шпагат? Так бесит. Нельзя ноги скрыть каким-то промтом или лорой?
>>1520327 мне в аниме кстати нравится то что между сидами генерация очень разнообразная, а если поймать хороший сид и начать править детали в промпте, добавлять текст, немного стилизации - то общая композиция практически не меняется.
>>1520359 Нет. Сперма в жопе создаёт сюжет, историю, побуждает зрителя размышлять о том как она туда попала, сколько её там, попадёт ли она туда ещё раз.
А тут что? Вангёлстендинг без глубины и сюжета. Такое в шапку не берут.
>>1520362 > побуждает зрителя размышлять о том как она туда попала, сколько её там, попадёт ли она туда ещё раз Спермошиз, узбагойся. Не нужно равнять всех по себе
До меня дошло сегодня - Эулер говно ебаное. Точнее для качества он хорош, но лица персонажей и ирл тянок мега хренова предает похожими. А вот DPM++ 2M SDE Heun прямо база, но шума много.
Кстати, я наткнулся на FSampler, оно немного оптимизирует скорость
https://github.com/obisin/ComfyUI-FSampler res_multistep_ancestral/simple, CFG=1, 30steps (время после прогрева) 1) С отключеным skip 16 секунд 2) skip=adaptive - 12 секунд
Вроде норм тема, особенно для тяжелых моделей, анима то и так быстрая. Минус - не все семплеры есть, нужно снова подбирать оптимальный семплер под модель.
Результат зависит от комбинации модели, лор, настроек и другого кала, в одном наборе параметров это даёт какое-то выдуманное улучшение, в другом наоборот только портит.
Семплеры придуманы шизами, для "хорошего" результата нужен случайный перебор, случайных параметров, это исследование реакции нейронки на случайные слова и знаки.
Нет никакой стабильности. Нет никаких универсальных решений. Нет обратной связи.
Просто сгенерируй где-то случайный набор слов, вставь его в промпт и результат будет лучше чем у тебя сейчас.
>>1520444 >Семплеры придуманы шизами Определённый почерк сэмплера всё же чувствуется. DPM++ 2M SDE более резкий, чем Euler A. Похоже, для разных стилей лучше подбирать не только разные теги, но и разные сэмплеры.
> If CFG distilled: > Use CFG scale = 1. Prefer euler a and euler. > Because you don't need to run a forward pass for the negative prompt, it's 2x faster. (Almost as fast as SDXL)
>>1520452 >ещё один случайный параметр Какой логический смысл ты вкладываешь в это высказывание? Звучит как "это просто ещё одна мокрая вода". Естественно это так, но какую из этого ты пытаешься стену тут возвести и зачем - не понятно. Да и не нужно.
>>1520890 >а шоколад - не помню даже вкуса. Я по привычке покупал, а потом понял что у меня опухают дёсны каждый раз на следующий день после поедания этого коричневого кала с кокосовым маспом в цистернах из-под бензина. Лучше уж наворачивать тёмный шоколад с минимумом сахарного кала, один ломтик весит и стоит примерно столько же, а вреда наносит меньше.
>>1520244 Попробуй поиграться с разной силой на разных шагах, типа 0.8-1 на основном денойзе, а на последние несколько 0.4-0.6. >>1520252 В порядочных домах мех - приправа! >>1520350 >>1520379 Ахуенно
Да, конечно, новый аккаунт развивать сложно, за неделю смог набрать 20 подписчиков. Но, благо каким-то удивительным образом подписалось 5 фурри, они активно лайкают и комментят все подряд.
Клевые у вас тут генерации. И с бур чужие аишки и анимации тоже качаю Вообще фентезийных тянок обожаю. Но как свое герирь, и чужое обозревать, и как все успевать лол? Сейчас такой рай арта, я хочу норм комп, фри инет, уединение в тишине и комфорте и заморозиться в такой эпохе на 100 лет чтоб не менялось ничего, был бы кайф.
>>1521027 Есть древняя техника ацетоновых/дихлорэтановых паров, получится идеально гладкая поверхность и слоистость полностью исчезнет, самое то для фигурок. Правда первое требует печати абсом, что могут не все принтеры, а второе не так эффективно и дорого. И оба метода в неумелых руках = риск пожара и отравления, даже не вздумай делать это на кухне возле газовой плиты, курить рядом, или заниматься в непроветриваемом помещении.