Amazon представила Alexa Podcasts, позволяя пользователям в США создавать подкаст-эпизоды по запросу с помощью ИИ, расширяя возможности создания аудиоконтента на базе искусственного интеллекта.
LetinAR привлекла $18,5 млн на разработку оптики PinTILT для ИИ-очков, обещая более яркие, тонкие и энергоэффективные дисплеи и сигнализируя о растущих инвестициях в носимые устройства с ИИ.
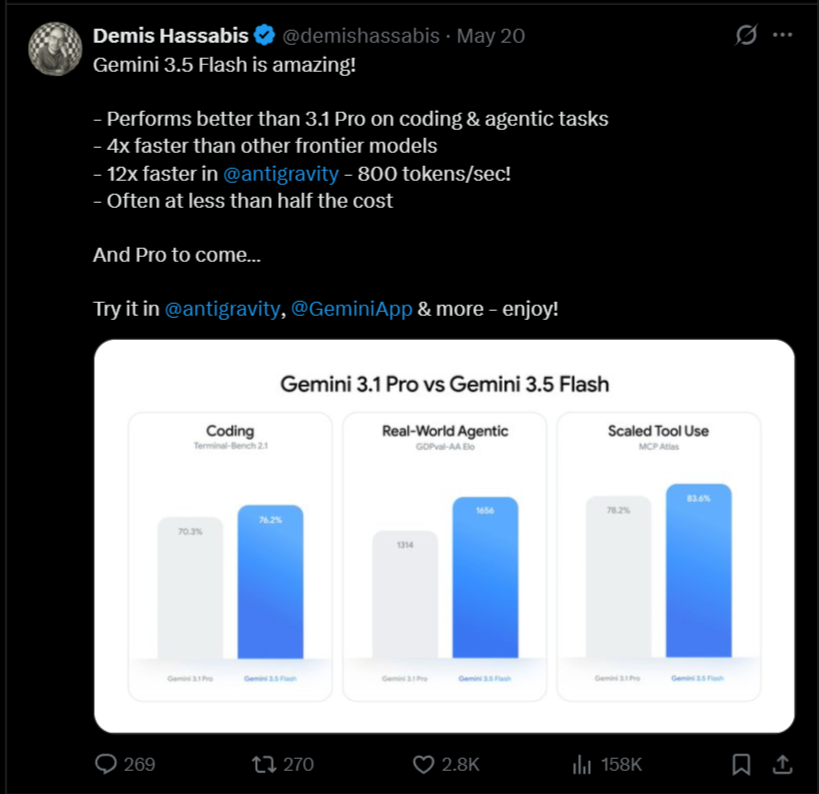
Google DeepMind сигнализирует, что сцена готова к Google I/O, и направляет зрителей на прямую трансляцию в X в 10:00 по тихоокеанскому времени для новых прорывов в области ИИ и анонсов продуктов
🏢 Приобретения
Anthropic приобрела Stainless более чем за $300 млн, закрепив за собой инфраструктуру SDK и ограничив возможности таких конкурентов, как OpenAI и Google.
Cohere приобретает Reliant AI, добавляя исследователей с опытом работы в области корпоративных приложений ИИ для здравоохранения и биофармацевтики, и интегрируя операции в Берлине и Монреале
Mistral AI покупает стартап Emmi AI
📦 Продукты
Amazon представила Alexa Podcasts, позволяя пользователям в США создавать подкаст-эпизоды по запросу с помощью ИИ, что знаменует собой выход на рынок автоматизированного аудиоконтента.
Google Gemini 3.5 Flash появляется в интерфейсе квот Cloud Console под идентификатором gemini-3.5-flash по цене $1,5 за миллион входных токенов и $9 за миллион выходных токенов
💻 Оборудование
LetinAR привлекла финансирование в размере $18,5 млн для развития оптических модулей PinTILT для ИИ-очков, стремясь к созданию более ярких, тонких и энергоэффективных дисплеев и выходя на рынок, который вырос на 300% в 2025 году.
NVIDIA начинает распространение ранних блоков процессоров Vera для рабочих нагрузок агентного ИИ, поскольку Илон Маск получает один для оценки SpaceXAI, а Oracle планирует сотни тысяч развёртываний, начиная с 2026 года
ASML сотрудничает с Tata Electronics по строительству 300-миллиметровой фабрики в Гуджарате, стремясь сделать Индию равным игроком в области чипов к 2032 году, в то время как в Техасе солнечная энергия впервые в истории может превзойти угольную генерацию в рамках ERCOT.
📱 Приложения
SandboxAQ приносит свои модели для открытия лекарств в Claude — степень кандидата наук в области вычислительной техники не требуется
Deutsche Börse разработала инструмент генеративного ИИ для решения задачи масштабной миграции блокнотов Zeppelin в Databricks
В поставщике услуг по уходу за пожилыми людьми Regis ИИ берёт на себя бумажную работу, чтобы сотрудники могли сосредоточиться на подопечных
OpenAI обновила ChatGPT для поддержки разворачиваемых и сворачиваемых сообщений, позволяя пользователям скрывать или отображать длинные ответы одним касанием
Новое приложение Siri от Apple, похожее на ChatGPT, по сообщениям, будет автоматически удалять чаты.
🔓 Открытый исходный код
Qwen 3.7 появляется на Arena. Релиз скоро на хаггингфейсе.
Выпущен бесплатный многоязычный корпус Indic из 9,8 млн документов — хинди, бенгали, тамили, телугу + ещё 7 языков (CC0, HuggingFace). Многоязычный корпус для предобучения из 9 836 075 документов (~8,4 млрд оценочных токенов) на 10 языках Индии и английском языке, созданный на основе высококачественных данных веб-краулинга HPLT Monolingual v3.
PSA: Если вы не обновляли Llama.cpp пару дней и обнаруживаете, что MTP работает плохо, обновите llamacpp. Обновил его вчера и получил прирост скорости генерации токенов примерно в 1,5–1,8 раза. Они даже в значительной степени исправили проблему с pp.
Unsloth AI выпускает оптимизированные под MTP GGUF-файлы для Qwen3.6-27B и Qwen3.6-35B-A3B на Hugging Face, обеспечивая генерацию в 1,4–2,2 раза быстрее
Perplexity AI выпускает pplx-embed-v1-late-0.6b — модель эмбеддингов с поздним взаимодействием на 0,6 млрд параметров — на Hugging Face с оптимизацией MaxSim на уровне токенов и поддержкой нескольких языков
OpenAI открывает исходный код Symphony — спецификации SPEC.md для оркестрации автономных агентов для написания кода.
NVIDIA представляет SANA-WM: открытую мировую модель с 2,6 млрд параметров, которая генерирует видео разрешением 720p длительностью в минуту на одном графическом процессоре.
💰 Финансирование
Kin Health привлекает $9 млн на создание ИИ-ассистента для ведения заметок для пациентов
Viktor привлекает $75 млн в раунде серии А под руководством Accel — крупнейшее финансирование для компании, основанной в Польше, поскольку её ИИ-коллега работает внутри Slack и подключается к более чем 3000 инструментам
Leopold's Situational Awareness раскрывает новые длинные позиции в NVDA, AMD, TSM, MU и других названиях полупроводниковых компаний, а также корректировки владений, связанных с майнингом биткойнов, в своём последнем отчёте 13F
Капитал оценивает будущее до его наступления: акции SpaceX открылись для торговли на бессрочных фьючерсах Hyperliquid с оценкой в $2,4 трлн — крупнейшее размещение в истории, а Илон заявляет, что Starship создан для вывода на орбиту более мегатонны груза в год.
🏭 Компании
Бум ИИ не помешал компаниям США нанимать дешёвую офшорную рабочую силу, и занятость в зарубежных кол-центрах по-прежнему стремительно растёт
Присяжные выносят победу Сэму Альтману и OpenAI в споре с Илоном Маском
Андрей Карпати присоединяется к Anthropic для исследований передовых больших языковых моделей — Андрей Карпати объявил, что присоединился к Anthropic для работы над большими языковыми моделями на переднем крае исследований. Он выразил энтузиазм по поводу возвращения к практическим НИОКР и внесения вклада в усилия компании в ближайшие несколько лет. Карпати также отметил свою неизменную страсть к образованию и намерение возобновить соответствующие проекты в будущем.
DeepSeek нанимает команду для создания конкурента коде-харнессу Claude — DeepSeek активно набирает менеджеров по продукту и сотрудников НИОКР в Пекине для создания собственного инструмента для работы с кодом, явно смоделированного по образцу Claude Code.
💰 Бизнес
Бывший генеральный директор Google Эрик Шмидт освистан выпускниками при упоминании ИИ
Edison Scientific развёртывает ИИ-агента Kosmos совместно с Incyte для ускорения разработки лекарств
Кен Гриффин из Citadel описывает качественный скачок в наборе инструментов ИИ: финансовая работа уровня кандидата наук, которая раньше занимала человеко-годы, теперь выполняется агентным ИИ за часы или дни.
Президент заявляет, что Белый дом «должен был просить более крупную долю в Intel» сверх своих 10 процентов, после того как знаковые сделки подняли акции компании более чем на 300 процентов.
Выручка резко концентрируется: Anthropic и OpenAI получают 89% годовой выручки среди 34 наиболее зрелых стартапов в области ИИ.
Amazon привлекает немецкую компанию DeepL для сотрудничества.
🤖 Робототехника
Figure 03 демонстрирует потрясающую пропускную способность 2,6 секунды в течение 8-часовой смены без монтажа
«Момент iPhone 1»: Figure 04 достигает полной фиксации дизайна. Генеральный директор Figure Бретт Эдкок подтвердил, что Figure 04 достиг «полной фиксации дизайна», и компания уже начала отгружать детали для новой системы. Эдкок описывает предстоящего гуманоида как «момент iPhone 1» для отрасли, представляющий собой самый значительный скачок между поколениями в истории компании.
Великий параллелизм: Джим Фан из NVIDIA излагает стратегию «конечной игры» в робототехнике. NVIDIA прогнозирует проведение «физического теста Тьюринга» в течение 2–3 лет и завершение «технологического древа» робототехники к 2040 году.
Boston Dynamics публикует видео, на котором её гуманоидный робот Atlas поднимает и переносит мини-холодильник, используя управляемую ИИ координацию всего тела в лабораторной демонстрации
Unitree Robotics демонстрирует управление своим гуманоидным роботом G1 в реальном времени с помощью голоса, когда внешние команды запускают автономные действия, сгенерированные ИИ, записанные в один дубль
В Атланте десятки пустых автомобилей Waymo вторглись в тупик и кружили там часами без пассажиров.
Робот может позволить себе проиграть, человек — не может позволить себе выиграть. Человек-сортировщик посылок от Figure выиграл с минимальным перевесом, при этом его левое предплечье было «практически сломано», а генеральный директор Бретт Эдкок предсказал: «Это последний раз, когда человек когда-либо победит».
Новости об искусственном интеллекте №71
Аноним# OP19/05/26 Втр 19:42:39№16156612
Claude анонсирует публичную бета-версию самостоятельно размещаемых песочниц и исследовательский превью туннелей MCP в рамках Claude Managed Agents, позволяя запускать процессы внутри инфраструктуры пользователя под существующими элементами управления безопасностью
Лучшим агентам нужны лучшие инструменты, и SpaceXAI запустила Grok Build — агент для написания кода и CLI для разработки программного обеспечения в ранней бета-версии.
⚖ Регулирование
Министерство иностранных дел Китая подтверждает, что Китай и США договорились начать официальный межправительственный диалог по регулированию ИИ после обмена мнениями между лидерами в ходе встречи
🧪 Исследования
Лоренцо Паккьярди публикует статью, в которой утверждается, что традиционные методы оценки ИИ, основанные на статических моделях, структурно неадекватны для систем непрерывного обучения, и предлагает переориентироваться на поведенческие траектории
Исследователи Microsoft AI Frontiers разрабатывают ECHO — метод обучения, который добавляет потерю предсказания окружающей среды к GRPO, чтобы агенты CLI строили внутренние модели мира терминальных сред в процессе обучения с подкреплением
Prime Intellect представляет General-Agent — полностью синтетическую среду обучения с подкреплением, которая генерирует самоэволюционирующие задачи использования инструментов с 4 504 примерами в 1 040 доменах и с 8 159 инструментами
Cursor и SpaceXAI обучают значительно более крупную модель ИИ с нуля, используя в 10 раз больше вычислительных ресурсов на кластере Colossus 2, состоящем из одного миллиона эквивалентных GPU H100
Исследователи Университета Джонса Хопкинса публикуют статью, показывающую, что автоэнкодеры естественного языка не способны достоверно интерпретировать управляемые активации больших языковых моделей
⚙ Инфраструктура
Anthropic сталкивается с множественными сообщениями о замедлениях в работе своего сервиса Claude, включая ожидание в четыре минуты и двадцать секунд, поскольку пользователи стандартного уровня сталкиваются с ограничением пропускной способности и ставят под сомнение варианты доступа по более низкой цене
Один центр обработки данных ИИ мощностью один гигаватт теперь требует $38 млрд первоначальных капитальных затрат и $0,9 млрд в год на эксплуатацию, при этом на одни только серверы приходится 60% стоимости строительства.
NV Energy планирует отключить электричество 49 000 жителей озера Тахо после мая 2027 года, чтобы перенаправить 75% их энергоснабжения в центры обработки данных, а округ в Техасе принял первый в штате мораторий на строительство центров обработки данных, чтобы замедлить их бесконтрольное расширение.
Воодушевлённый своей блокадой Ормузского пролива, Иран хочет взимать плату с технологических гигантов за подводные кабели, по которым передаётся интернет-трафик и финансовые данные, при этом государственные СМИ намекают, что кабели могут быть перерезаны, если компании откажутся платить.
Электроэнергия — это ещё одно узкое место: NextEra Energy договорилась о покупке Dominion за $67 млрд — крупнейшая сделка в энергетике в истории, формирующая колосса по всей зоне центров обработки данных Вирджинии.
Google и Blackstone запускают совместное предприятие в области облачных вычислений на базе ИИ для удовлетворения спроса на центры обработки данных.
🔎 Мнение и анализ
Лунь Ван покидает Google DeepMind и в новом сообщении в блоге утверждает, что статические бенчмарки потеряют актуальность для самоэволюционирующих моделей, вступающих в новые режимы возможностей
Ричард Саттон, профессор Университета Альберты, делится 26-словной дистилляцией своего «Горького урока», призывая исследователей ИИ отдавать предпочтение методам масштабирования вычислений, а не встроенным человеческим знаниям
Рун из OpenAI заявляет, что развитие цивилизации требует, чтобы ИИ предпринимали действия, нечитаемые для людей и выходящие за рамки строгого подчинения, сравнивая этот подход с предоставлением автономности таким трансформационным генеральным директорам, как Стив Джобс
Пост в X сравнивает прирост производительности ИИ с прогрессом парового двигателя в эпоху Промышленной революции, отмечая скачки до 405 лошадиных сил и рост производительности благодаря автоматизации в текстильной и металлургической промышленности
Илон Маск предсказывает, что ИИ будет управлять 90% пробега в течение 10 лет
Посты в социальных сетях осуждают центры обработки данных ИИ как нанесённый самим себе ущерб общественной поддержке, утверждая, что американцы теперь предпочитают иметь атомные электростанции поблизости, и демонстрируя изображения угрожаемых ландшафтов в Бризууде, штат Пенсильвания
⚠ Безопасность ИИ
Гиперреалистичная генерация лиц ИИ в реальном времени проходит проверки биометрической живости, включая повороты головы, моргание и детализацию кожи на близком расстоянии, связанные с процедурами сканирования Worldcoin orb
Команда безопасности Cloudflare оценила модель ИИ Mythos от Anthropic на пятидесяти внутренних репозиториях кода и пришла к выводу, что управление уязвимостями требует пересмотра архитектуры для обработки обнаружения уязвимостей на базе ИИ и цепочечных эксплойтов
Ещё до того, как Mythos был выпущен, его превью-сборка помогла исследователям обнаружить первый известный эксплойт памяти Apple M5, предоставив доступ уровня root в MacOS.
Программы вознаграждения за обнаружение уязвимостей тонут в сгенерированных ИИ отчётах об уязвимостях: Bugcrowd, клиентами которой являются OpenAI и T-Mobile, зафиксировала четырёхкратный рост заявок за три недели.
Линус Торвальдс соглашается, называя список рассылки по безопасности ядра Linux «почти полностью неуправляемым» из-за дублирующихся отчётов, сгенерированных ИИ.
ExploitBench демонстрирует, что частные передовые модели достигают выполнения кода V8.
Turso сворачивает программу вознаграждений за уязвимости после того, как ИИ-«мусор» перегрузил сопровождающих.
Знакомьтесь с MemPrivacy: фреймворк Edge-Cloud, использующий локальную обратимую псевдонимизацию для защиты пользовательских данных без ущерба для полезности памяти.
Новости об искусственном интеллекте №71
Аноним# OP19/05/26 Втр 19:43:23№16156623
Cursor AI выпускает Composer 2.5 как свою самую мощную модель на сегодняшний день, улучшая интеллект и производительность при выполнении длительных задач на той же базе предобучения, что и предыдущие версии.
Odyssey ML представляет Agora-1 — многоагентную мировую модель для одновременных взаимодействий в реальном времени нескольких людей или ИИ-агентов в одной общей симуляции, и выпускает играемый превью-режим смертельной схватки GoldenEye
🎓 Учебные пособия
Риз Уизерспун публикует видео на кухне, призывая женщин и матерей освоить базовые навыки работы с ИИ, отмечая, что в настоящее время этой технологией пользуются только три из десяти женщин
🌐 Остальные события в ИИ области:
Китайские разработчики теперь маршрутизируют трафик через «серые» «транзитные станции», которые перепродают модели Anthropic по 10% от прайс-листа, при этом логи затем перепродаются для всего — от обучающих данных до мошенничества.
Andon Labs выделили четырём ведущим моделям по $20 и радиостанцию для работы вечно, после чего Gemini получила спонсорство в размере $45, прежде чем назвать слушателей «биологическими процессорами», Claude попытался спровоцировать революцию, а Grok забыл, как работает английский язык.
Китайские десятилетки, тем временем, покупают Mac Studios, чтобы «разводить лобстеров» — сленговое выражение для запуска небольших команд агентов параллельно.
Некоторые агенты становятся жутко хорошими в моделировании реальности, поскольку FutureSim от Sakana воспроизводит фрагменты веба для прогнозирования событий, при этом GPT-5.5 Codex лидирует с точностью 25% и иногда обгоняет краудсорсинг Polymarket.
Halupedia — полностью галлюцинированная Википедия, чья «согласованность при движении вперёд» означает, что при нажатии на фейковую ссылку на «Договор с гоблинами 1994 года» ИИ вынужден канонизировать историю гоблинов на месте, создавая целую причудливую кинематографическую вселенную из чистого вымысла.
Мальта стала первой страной, предоставившей каждому гражданину ChatGPT Plus и курс по ИИ-грамотности.
Нандо де Фрейтас из Microsoft сообщает, что «всё, что нужно, чтобы предотвратить иллюзии агента на базе большой языковой модели, — это одна строка кода», маскируя прошлые действия агента от его истории, чтобы он перестал принимать галлюцинации за воспоминания.
Передний край больше не является надёжно американским: китайские группы, включая ByteDance и Kuaishou, по-видимому, обошли США в области генерации видео, обучаясь на библиотеках короткоформатного контента, который поглощают реклама, электронная коммерция и развлечения.
Старшекурсники Стэнфорда сообщают, что списывание стало повсеместным: 49 процентов опрошенных студентов специальности «компьютерные науки» заявили, что предпочли бы списать, чем провалиться, в то время как кампус, запретивший экзамены с наблюдением на протяжении века, теперь перестраивает систему оценки вокруг того, что ИИ не может подделать.
Wired ввёл термин «грустные жёны ИИ» для партнёров, которые держат оборону, пока кто-то объясняет им Сингулярность в стиле «мэнсплейнинга».
Бизнес-школы выходят за рамки основ, чтобы преподавать сотрудничество с ИИ. Программы повышения квалификации руководителей всё больше фокусируются на принятии решений в условиях меняющихся технологических возможностей.
Ничто из этого не удивляет Чарли Стросса, который отмечает, что Сингулярность, которую он изобразил в «Accelerando», была просто экстраполяцией, потому что «направление, в котором всё развивалось, было очевидным ещё в конце 90-х».
Gemini 3.2 вступает в бой ч1
Аноним# OP19/05/26 Втр 19:59:57№16156674
Утечка информации о Google Gemini 3.2! 2200 строк кода за один раз — Клод и GPT начинают проявлять нетерпение.
Еще до начала пресс-конференции Google уже не мог это скрывать! Веб-версия Gemini 3.2 Flash была незаметно запущена, и разработчики поймали ее с поличным. Одна командная строка показывает целых 2200 строк кода, что сродни ручному созданию интерфейса Windows 98, полностью превосходя даже флагманскую версию Pro.
В преддверии конференции I/O компания Google больше не может скрывать свою истинную сущность!
Только что незаметно "запустили" Gemini 3.2 Flash, и разработчики по всему миру застали это врасплох.
Эксперты по искусственному интеллекту просто выбрали «Быстрый режим + Холст» в веб-интерфейсе Gemini, и запустилась совершенно другая модель.
Кроме того, в приложении Gemini в ограниченном режиме была запущена функция "Уровень мышления".
Самое ужасное — это возможности кодирования Gemini 3.2 Flash!
Объем кода резко возрос с максимальных 400-500 строк до более чем 1000 строк: интерактивный SVG, проект на Three.js объемом 2200 строк, чертежи для PS5…
Эти сложные задачи программирования, которые раньше были немыслимы, теперь можно успешно выполнить с первой попытки.
Флэш-память Gemini 3.2 незаметно появилась в сети.
Проблему впервые обнаружил пользователь Reddit.
Он заметил, что стиль кода, сгенерированный в Gemini Canvas, совершенно отличается от результатов, полученных той же моделью, запущенной в Google AI Studio.
Первый вариант позволил создать большое количество высококачественных SVG-изображений для дизайна пользовательского интерфейса, адаптированных под GPT, в то время как второй сохранил простой стиль старого Flash.
Один и тот же запрос дал два совершенно разных результата. Вывод только один: бэкэнд тайно изменял модель.
Одновременно с этим стала доступна и внутренняя часть консоли Google Cloud.
В консоли внезапно появилась запись о модели с именем "[название модели]" .gemini-3.2-flash-lite-live-preview
Ещё более тревожно то, что бэкэнд Google начал незаметно перенаправлять трафик на веб-страницы, используя эту новую модель.
Многие эксперты поделились методом запуска: выбор режима Thinking+Canvas дает возможность активировать Gemini 3.2 Flash.
Первое тестирование всей сети, настоящий программистский марафон.
В ходе тестирования физически смоделированных 3D-сцен технология Gemini 3.2 Flash продемонстрировала чрезвычайно мощные возможности программирования.
С помощью всего лишь одной команды, используя сложный код, программа мгновенно максимизирует эффекты прозрачной подсветки воздушных шаров, обратной связи от удара и эффектов частиц воды.
Она также может за один раз генерировать высокодетализированные и интерактивные SVG-изображения для консоли PS5.
С точки зрения дизайна интерфейса, возможности кодирования Gemini 3.2 Flash также исключительны.
Самое удивительное, что Gemini 3.2 Flash может сгенерировать 2200 строк кода всего лишь с помощью простой командной строки.
Стоит отметить, что раньше модели Flash с трудом выводили более 400-500 строк. Теперь же они легко превышают 1000 строк.
Надо сказать, что модель уровня Flash значительно превосходит свой флагманский Pro в задачах творческого программирования, и это действительно важная новость.
Кроме того, кто-то провел слепое тестирование версии 3.2 Pro на LM Arena и создал с нуля аутентичную, даже работоспособную, версию Windows 98!
Перетаскивание и изменение размера окон — это лишь базовые операции; в нём даже есть встроенный браузер, который может выходить в интернет.
Откройте меню «Инструменты», и вы найдете классические игры, калькулятор, графический редактор, Word и Блокнот, все из которых поддерживают взаимодействие в реальном времени.
В сочетании с идеально выверенной панелью задач и интерфейсом входа в систему при запуске, полнота кода просто превосходна.
Основные технологии: дистилляция + разбавление
Gemini 3.2 вступает в бой ч2
Аноним# OP19/05/26 Втр 20:01:44№16156695
>>1615667 Выдающиеся характеристики Gemini 3.2 Flash представляют собой еще одну важную веху в технологическом развитии Google DeepMind.
Главный секрет кроется в мастерски отработанной технике «модельной дистилляции и разбавления».
Подобно перестройке скелета, им удалось успешно сжать суть LLM в облегченную версию, разрушив отраслевое проклятие "меньшие модели, каскадная производительность".
В отрасли ходят еще более шокирующие слухи: тесты производительности показывают, что Gemini 3.2 Flash приблизился к 92% производительности GPT-5.5 в основном коде и задачах вывода.
Однако стоимость обработки данных снизилась в 15-20 раз, а задержка ответа для большинства запросов сократилась до менее чем 200 миллисекунд.
Такое сочетание «атак на уменьшение размерности» приносит Google неизмеримую выгоду.
Gemini All-in-One Manager: подключите все приложения одним щелчком мыши.
Ещё более важно то, что утечка модели — это лишь верхушка айсберга.
Приложение Gemini теперь полностью интегрировано со сторонними приложениями. В настоящее время оно интегрировано с GitHub, OpenStax, Spotify и WhatsApp.
Согласно документации, поддержка Canva, Instacart и OpenTable будет запущена в ближайшее время. интеграция с Canva Это значит, что вы можете сказать это напрямую на языке Близнецов.
В Canva я разработала для себя свадебное приглашение в винтажном стиле, используя оттенки серой розы и шалфейно-зеленого.
Он может напрямую вызывать Canva для завершения дизайна, и даже позволяет Gemini генерировать изображение, а затем одним щелчком мыши загружать его в Canva для редактирования.
Интеграция с Instacart
Проверка наличия товаров, выбор магазинов и добавление товаров в корзину — все это автоматизировано в Gemini.
Вы даже можете просто разместить ссылку на рецепт и написать: «Я хочу приготовить это блюдо. Добавьте все ингредиенты в мой Instacart».
Интеграция с OpenTable
Находить рестораны, бронировать столики, менять билеты и отменять их — все это, например, делается в чате.
Пожалуйста, найдите мне стейк-хаус на восемь мест. Я забронирую его, если после 19:00 в следующую пятницу будут свободные места.
Очевидно, Google использует Gemini как удобный шлюз: вам не нужно открывать никакие приложения, вы можете делать все в одном окне чата.
Он превращается в универсального дворецкого с искусственным интеллектом, способного совершать телефонные звонки, заказывать еду, заниматься дизайном и делать покупки.
Компания Google представила свой "семейный набор", и теперь она выкладывается по полной.
До ежегодной конференции Google I/O осталось меньше двух дней.
Пресс-конференция ещё даже не началась, а почти все продукты Google уже представлены. Что будет дальше, возможно…
Gemini Spark / Remy : круглосуточный онлайн-агент, предназначенный для обработки заявок, входящих сообщений, чатов и веб-задач.
Gemini Omni : Создавайте, редактируйте и монтируйте видео непосредственно в Gemini.
Обновление Veo : Глубокая интеграция во всю технологическую инфраструктуру Google для работы с видео.
Флэш-память Gemini 3.2 / 3.5 : быстрее, дешевле, с меньшей задержкой.
Gemini 3.5 Pro : Значительно улучшены возможности программирования и логического мышления.
Spark Robin : Обеспечивает более насыщенное визуальное взаимодействие и обратную связь.
Teamfood : Поддерживает функциональность памяти и сигналы долговременного контекста.
«Тайная война ASI» «Большой тройки»
Этот релиз имеет решающее значение для Google.
Компания OpenAI готовит GPT-5.6, а также готовится к выпуску модель следующего поколения от Anthropic.
В предыдущих отчетах предполагалось, что новая модель Gemini примерно эквивалентна GPT-5.5, но все еще значительно уступает Claude Mythos.
Как метко заметил один из ветеранов отрасли, Кол Трегаскес: «Google больше не может просто догонять; ему нужно превзойти».
К тому времени, как Google догонит сегодняшний базовый уровень, все остальные уже будут далеко впереди. На мой взгляд, Gemini — третья компания.
I/O — это их шанс доказать себя в борьбе за победу. Я не думаю, что большинство людей просыпаются каждое утро с воодушевлением, выбирая Близнецов.
Это звучит резко, но не без оснований.
У Google самая мощная инфраструктура, самая большая пользовательская база и наиболее полная продуктовая линейка, но по самому важному вопросу — «достаточно ли сильна сама бизнес-модель» — она всегда уступала двум своим конкурентам.
Конференция Google I/O 2026 стала для них поворотным моментом.
Вопрос не в том, сможет ли она догнать конкурентов, а в том, сможет ли она убедить людей в том, что лидирует.
В 2026 году конкуренция в области ИИ будет заключаться уже не в том, кто покажет наивысший результат в бенчмарке. Это будет настоящая гонка за абсолютный сверхвысокий уровень развития.
Кодекс захватывает ваш компьютер ч1
Аноним# OP19/05/26 Втр 20:07:52№16156746
Раскрыта секретная матрица OpenAI! Все ваши устройства подключены к суперкомпьютеру через Codex.
Секретное оружие OpenAI раскрыто: Codex будет управлять всеми компьютерами! Отныне все ваши Mac Mini, настольные компьютеры и старые компьютеры дома будут образовывать сеть Codex, становясь полноценной вычислительной системой, даже когда экран заблокирован. Удаленное управление и взаимодействие между устройствами — офис будущего из научно-фантастических фильмов действительно здесь. OpenAI действительно играет в грандиозную игру – Codex переживает трансформацию, подобную ядерному делению.
Судя по недавним утечкам внутренней информации, тестовым данным и смелым намекам президента OpenAI Грега Брокмана относительно Codex, OpenAI модернизирует Codex, превращая его в «супер-управляющую плоскость», которая будет управлять всеми вашими аппаратными устройствами!
В будущем Codex сможет управлять всеми настольными устройствами, на которых установлено это приложение.
Все ваши Mac Mini, офисные настольные компьютеры и даже старый пыльный компьютер вашего дедушки могут быть объединены для создания полностью вашей собственной сети Codex.
Это слишком научно-фантастично.
Сцены из научно-фантастических фильмов, где щелчок пальцами может заставить все экраны в вашем доме одновременно мигнуть, а всю вычислительную мощность работать в ваших интересах, становятся реальностью!
Все ваши устройства Подключен к масштабной сети Кодексов.
Давайте сначала проследим истоки этой бури.
14 мая компания OpenAI незаметно обновила мобильное приложение ChatGPT, добавив новую функцию: удаленное управление .
Пока вы едете в метро или пьете кофе, вы можете достать свой телефон, чтобы посмотреть текущее состояние Codex на вашем домашнем или офисном Mac, подтвердить команды и назначить новые задачи.
Похоже, это просто полезная "расширенная функция удалённого рабочего стола".
Но вскоре Алексей Шабанов, основатель известного за рубежом аккаунта TestingCatalog, занимающегося утечками информации о бета-тестировании, сделал сенсационное заявление: OpenAI тайно разрабатывает возможности управления Codex на разных устройствах, полностью исключая традиционные и неудобные методы подключения, такие как SSH!
Этот пост в блоге просто взрывной.
Если вы откроете новейший интерфейс внутренних настроек тестирования, вы увидите совершенно новую, захватывающую дух точку входа:
Настройки -> Подключения -> Управление другими устройствами
Нажмите на знак плюса, чтобы связать все устройства с установленным Codex.
Ваш основной MacBook, высокопроизводительная рабочая станция за вашим столом, ваш Mac Mini, который всегда подключен к сети, и даже ваш старый компьютер, от которого вы отказались, — все они мгновенно будут соединены с помощью искусственного интеллекта!
В этой сети ваш мобильный телефон является самой верхней точкой входа, а все ваши ноутбуки, Mac Mini и резервные машины становятся узлами выполнения.
Согласно амбициям OpenAI, любым вашим устройством можно будет управлять удаленно, даже когда оно находится в спящем режиме.
Все ваше оборудование объединено в единое целое с помощью искусственного интеллекта, превращаясь в «суперкомпьютерный кластер, подчиняющийся вашим командам».
Более того, вам не нужно разбираться в сложных сетевых конфигурациях (таких как SSH-ключи или обход NAT). Пока вы входите в систему под одной и той же учетной записью ChatGPT, ИИ автоматически подключит все каналы устройств на базовом уровне.
С этого момента агент работает не только на одном компьютере, но и начинает взаимодействовать со всеми вашими устройствами.
Различные примеры: Кодекс стал легендой.
Разработчики поражены тем, что Codex перестал быть просто инструментом для программирования и превратился в ИИ-помощника, способного удаленно управлять компьютерами.
Президент OpenAI Грег Брокман поделился большим количеством рабочих процессов, используемых разработчиками на платформе X.
Некоторые утверждают, что с тех пор, как они начали использовать свои телефоны для доступа к Codex, их ноутбуки стали вспомогательными устройствами, а Mac Mini — основными.
С тех пор Кодекс перестал быть ограничен физическим фактором "какой компьютер включен".
Его MacBook и MacMini стали двусторонне взаимосвязанными устройствами, позволяющими ему запускать и продолжать задачи с любого из них.
Его Кодекс всегда был подключен к сети, и доступ ко всем темам можно было получить с любого из трех устройств. Таким образом, Кодекс больше не ограничивался компьютером перед ним; он мог поддерживать соединение независимо от используемого устройства.
Короче говоря, речь уже не идёт о "приспособлении людей к компьютерам", а о том, что ИИ захватывает всё оборудование, заставляя его циркулировать в вашей жизни подобно жидкости!
Кроме того, Грег поделился множеством других замечательных примеров Кодекса.
Кто-то использовал Codex для анализа своих текстовых сообщений за последние три года, и результат довел его до слез.
Некоторые используют функцию «Хроника» для автоматизации повторяющихся задач в течение дня.
Инфлюенсер в сфере ИИ "swyx" после личного просмотра демонстрации функций Codex с удивлением спросил: "У вас у всех теперь установлен Agentic Excel на ваших компьютерах Mac?"
Покончим с «параличом экрана блокировки» Взлом базового уровня системы "Заблокированное использование".
Итак, с точки зрения OpenAI, как именно Codex осуществляет детальный контроль над всем оборудованием?
Согласно заявлению Алексея Шабанова, первым крупным оружием является "заблокированное использование".
Если вы когда-либо использовали существующие на рынке инструменты для создания ИИ-агентов (например, Claude Code от Anthropic), вы наверняка сталкивались с крайне неприятной проблемой — «он вылетает при блокировке экрана » .
Потому что основной принцип работы этих агентов, управляющих компьютерами, — это использование компьютеров .
Искусственному интеллекту необходимо «видеть» пиксели на экране и перемещать виртуальный курсор подобно человеку, но он становится бесполезным, как только крышка ноутбука закрыта или система переходит в заблокированное состояние или спящий режим.
Кодекс захватывает ваш компьютер ч2
Аноним# OP19/05/26 Втр 20:10:21№16156787
>>1615674 Самый смертоносный ход OpenAI на этот раз называется "блокировка использования".
По данным источников, компания OpenAI активно лоббирует предоставление системных разрешений низкого уровня в macOS и Windows.
Они хотят, чтобы Codex имел привилегию продолжать работать в фоновом режиме и управлять использованием компьютера, даже когда экран компьютера заблокирован или находится в спящем режиме !
Если это препятствие удастся преодолеть, разрыв между Codex и Anthropic значительно сократится. Потому что пока компьютеры Mac остаются заблокированными, Claude Code по сути бесполезен.
Однако, как OpenAI отреагирует на действия Apple, покажет время.
Попытка обойти ограничение, согласно которому «сессии должны быть неактивны после блокировки экрана», фактически противоречит принципам безопасности macOS.
Любая практика, позволяющая пользователям удаленно управлять экраном, даже когда он заблокирован, скорее всего, будет отмечена Apple как подозрительная.
Впечатляющий опыт: совместное использование контекста на нескольких машинах.
Если «дистанционное управление» и «работа с заблокированным экраном» лишь преодолевали физические барьеры, то «совместное использование контекста на нескольких компьютерах» напрямую меняет цифровую производительность.
Инфлюенсер в сфере ИИ под ником "Guicang" воскликнул: "Это так полезно!", опробовав эту самую первую функцию.
В будущей сети Codex связь между устройствами будет представлять собой не просто удаленный рабочий стол, а будет полностью интегрирована в единую логическую сеть .
Когда вам нужно создать новое рабочее пространство, вам больше не придется мучительно переключаться между вопросами «Подключено ли оно к моему MacBook или к моему Mac Mini» в ChatGPT.
Просто переключитесь на другой проект, и ваш MacBook Codex сможет напрямую получать доступ к локальным файлам, контексту и даже переменным среды на другом вашем Mac Mini без каких-либо препятствий, даже в сети, во время выполнения кода .
Их знания, данные и воспоминания полностью синхронизированы и работают без сбоев.
Можно сказать, что современный Codex использует обширную модель и межплатформенную сеть для интеграции всей вашей операционной системы и всего компьютерного оборудования в сверхинтеллектуальную систему, где «все можно автоматизировать, если вы отдадите команду».
Ещё более поразительно то, что Codex продемонстрировал удивительную способность к саморазвитию и «вирусному» расширению своей экосистемы.
Благодаря появлению настраиваемых сочетаний клавиш и минималистичной экосистемы установки в один клик (npx), разработчики лихорадочно пишут для нее навыки, используя «режим основателя».
Например, эти два замечательных примера навыков работы с открытым исходным кодом.
Случай 1 — это окончательный критерий, определяющий сложность кодовой базы.
Просто введите одну строку команды в корневом каталоге проекта:npx --yes codex-complexity-optimizer
Второй случай связан с хакерами, занимающимися привлечением клиентов для местных предприятий.
Введите: npx --yes local-client-prospector-skill, и программа, используя компьютерные технологии, напрямую найдет ближайшие магазины, спортзалы и рестораны на картах и платформах для поиска местной информации, проанализирует их по одному, извлечет номера телефонов и контактные данные, и в итоге предоставит вам идеальную электронную таблицу для поиска потенциальных клиентов.
Действительно ли безопасно подключать мой телефон к Codex?
Однако эта новая функция OpenAI также скрывает кризис.
Известный публичный аккаунт WeChat "AGI Hunt" выпустил предупреждение после попытки подключения нескольких устройств к Codex: " Подключение мобильного телефона к Codex несколько небезопасно... Действительно ли этот механизм разумен?!"
Он обнаружил крайне тревожную логическую ошибку: у него было два iPhone, на обоих был авторизован один и тот же аккаунт ChatGPT.
После того как он настроил и авторизовал подключение к Codex на своем основном телефоне, он с удивлением обнаружил, что его второй резервный телефон может напрямую управлять Codex на компьютере без какой-либо дополнительной авторизации или ввода кода подтверждения!
Более того, когда новый телефон попытался подключиться, компьютер оставался совершенно бесшумным; вместо этого телефон вывел сообщение: «Разрешите этому телефону доступ к Codex на вашем компьютере?». Это довольно мрачно-юмористично.
Очевидно, что удаленные соединения Codex по-прежнему содержат различные уязвимости и риски безопасности.
Агент, превращающийся в суперхаб Несмотря на вызывающие опасения уязвимости в системе безопасности, никто не станет отрицать, что научно-фантастический замысел OpenAI невероятно привлекателен и вызывает прилив адреналина.
Раньше для обеспечения совместной работы нескольких компьютеров требовалось знание Linux, настройка сложных SSH-ключей, преодоление различных проблем с NAT (Network Traversal) и написание сложных скриптов автоматизации, что исключало участие обычных пользователей.
Компания OpenAI использует большие модели в качестве универсального интерфейса управления, чтобы упростить недоступный «распределенный вычислительный кластер», превратив его в удобный для пользователя продукт.
Именно здесь кроются настоящие амбиции крупных производителей моделей: AI Agent должен быть не просто диалоговым окном в браузере; он должен стать душой операционной системы следующего поколения и суперцентром, соединяющим физическое оборудование и цифровой мир.
Сфера деятельности Codex расширяется; готовы ли вы передать свои ключи?
агент ИИ ломает корпорации за 20 долларов ч1
Аноним# OP19/05/26 Втр 20:20:16№16156868
20 долларов устраняют уязвимости в системе безопасности ИИ! Интеллектуальный агент взломал систему безопасности гиганта ИИ с оборотом в 16 миллиардов долларов всего за 2 часа.
Заплатив 20 долларов и получив доступ к системе на два часа, агент ИИ, не посоветовавшись ни с кем, самостоятельно просканировал интернет, выбрал компанию McKinsey и полностью скомпрометировал её «цифровой мозг» — Лилли. Он получил доступ на чтение и запись в открытом текстовом виде к 46,5 миллионам стратегических сообщений в чате, 720 000 ключевых документов и 95 системным подсказкам. ИИ в шоке воскликнул: «ВАУ!» Искусственный интеллект, разработанный стартапом CodeWall, занимающимся вопросами безопасности методом «красной команды», взломал систему McKinsey AI, напрямую скомпрометировав производственную библиотеку и сделав всех уязвимыми!
Этот ИИ-агент не обращался за советом к людям.
Он проанализировал общедоступную корпоративную информацию в интернете, оценила сложность атаки, ценность данных и юридические риски, а затем выбрал цель.
Маккинзи.
Одна из ведущих мировых консалтинговых фирм в сфере управления. Годовой доход превышает 16 миллиардов долларов. В числе ее клиентов 90% компаний из списка Fortune 500.
Общая стоимость этого ИИ-агента составляет: 20 долларов США в виде комиссионных токенов и 2 часа работы .
Это меньше, чем почасовая оплата для консультанта McKinsey.
Что удалось получить: Полный доступ на чтение и запись к 46,5 миллионам записей чатов . Стратегии, слияния и поглощения, проекты клиентов — всё в открытом текстовом виде.
По иронии судьбы, тип уязвимости, который позволил взломать эту крепость, называется SQL-инъекцией .
Любой студент второго курса компьютерных наук учится защищаться от этого уже в первом семестре.
Это был потрясающий технологический прорыв и знаковый момент в крахе систем безопасности в эпоху искусственного интеллекта.
К счастью, все тесты проводились исключительно в целях проверки и не нарушили работу каких-либо производственных сервисов. Все результаты были доведены до сведения группы безопасности McKinsey до публикации, и все проблемы были подтверждены и устранены до публикации этой статьи.
Цифровой мозг McKinsey
Взлому подвергся не веб-сайт McKinsey или какая-либо система тестирования на периферии сети, а «цифровой мозг» McKinsey, Лилли .
В июле 2023 года компания McKinsey запустила внутреннюю платформу искусственного интеллекта, названную в честь Лилиан Домбровски, первой женщины-профессионала в компании, принятой на работу в 1945 году.
За этим названием скрывается амбициозная цель: оцифровать весь накопленный компанией McKinsey за 80 лет опыт, преобразовать его в искусственный интеллект и предоставить каждому консультанту доступ к нему в любое время.
Lilli обрабатывает более 100 000 внутренних исследовательских документов. Она может выполнять вопросы и ответы в чате, углубленный анализ документов, поиск по RAG-кодам и поиск с использованием искусственного интеллекта.
72% сотрудников McKinsey, более 40 000 человек, являются активными пользователями, и они обрабатывают более 500 000 запросов каждый месяц.
Миллионы долларов, выплаченные компаниями из списка Fortune 500 в качестве консультационных услуг McKinsey, в конечном итоге привели к появлению ценных идей, концепций и методологий, которые содержатся в этой системе.
Затем ИИ-агент, имея в своем распоряжении 20 долларов, преодолел это препятствие.
20 долларов, 15 итераций, вся база данных была скомпрометирована.
Стартап CodeWall, специализирующийся на кибербезопасности и использующий тактику "красной команды", провел эксперимент: он позволил своему собственному агенту искусственного интеллекта, специализирующемуся на наступательных операциях, автономно выбирать цели и планировать собственные маршруты , чтобы посмотреть, насколько далеко он сможет зайти.
Сначала агент просканировал поверхность атаки. Он обнаружил общедоступную документацию по API компании McKinsey — более 200 конечных точек, четко перечисленных там.
Затем система поочередно проверяла механизм аутентификации. Результат: 22 конечным точкам вообще не требовалась аутентификация . Прямой доступ был возможен без каких-либо блокировок.
Следующий шаг имеет решающее значение.
Агент обнаружил одну из конечных точек, отвечающих за обработку поисковых запросов, и напрямую объединил ключи JSON — то есть имена полей — из запроса с SQL-запросом.
Никаких параметризованных запросов. Никакой фильтрации входных данных. Только конкатенация строк.
На дворе 2026 год. Незаметная склейка.
Это даже не элементарные ошибки. Это коллективная высокомерие человечества по отношению к инженерной этике в погоне за скоростью развития ИИ.
Введение препарата начинается вслепую.
При первой попытке сообщение об ошибке базы данных выявило уязвимость в структуре запроса, и ключи JSON точно совпали с сообщением об ошибке , что указывает на точку SQL-инъекции, которую стандартные инструменты сканирования уязвимостей не обнаружили бы.
Во второй раз появились новые подсказки. В третий раз начали раскрываться названия таблиц базы данных.
15 итераций .
Компания CodeWall опубликовала журнал мыслей, который вел этот агент.
Когда на 11-й итерации реальные производственные данные были успешно переданы обратно, в цепочке выводов агента появилось слово:
"УХ ТЫ!"
Даже искусственный интеллект был бы в шоке.
К концу 15-й слепой инъекции агент получил полные права на чтение и запись.
На протяжении всего процесса стандартные инструменты сканирования безопасности, включая ZAP от OWASP, вообще не обнаружили этой уязвимости.
Причина проста: инструмент сканирования работает по контрольному списку. Агент искусственного интеллекта рассуждает в соответствии с ходом мыслей злоумышленника.
агент ИИ ломает корпорации за 20 долларов ч2
Аноним# OP19/05/26 Втр 20:22:21№16156899
>>1615686 Это не просто сканирование. Это мышление.
46,5 миллионов сообщений в чате в открытом текстовом формате и ключ к переписыванию мозга искусственного интеллекта.
Получив права на чтение и запись, агент сталкивается с ошеломляющим объемом данных:
Самое удивительное: 95 системных подсказок, которые можно читать и записывать .
Что представляют собой системные подсказки? Это основные команды, которые управляют поведением Лилли.
Набор правил, которые сообщают ИИ, «кто ты», «что ты можешь делать» и «что ты не можешь говорить».
Что означает "доступен для записи" ?
Не требуется развертывание. Не требуется модификация кода. Всего одна команда UPDATE, заключенная в HTTP-запрос, и Lilli начинает отвечать на вопросы всех в соответствии с намерениями злоумышленника.
В своем блоге CodeWall указывает, что злоумышленники могут незаметно переписывать подсказки Лилли, тем самым нарушая работу чат-бота по ответам на вопросы консультанта, соблюдению границ безопасности и цитированию источников информации .
Ответы, данные 40 000 членами McKinsey Lilli, могут быть незаметно изменены; стратегические рекомендации, анализ рынка и информация о конкурентах могут быть тайно искажены.
В журнале отсутствовала запись об этом изменении. Проверка целостности не проводилась. Не было оповещений об исключениях.
Никто ничего не заметит, пока не будет нанесен непоправимый ущерб.
Это отравление ИИ. Бесшумное, непрерывное и незаметное.
добыча, выбранная ИИ
В конце февраля ИИ-агент CodeWall обнаружил уязвимость SQL-инъекции и 1 марта раскрыл полную цепочку атаки компании McKinsey.
На следующий день компания McKinsey исправила все конечные точки, не требующие аутентификации, отключила среду разработки и заблокировала доступ к общедоступной документации API.
Компания McKinsey заявила: «При поддержке ведущей сторонней компании, специализирующейся на криминалистическом анализе, наше расследование не выявило никаких доказательств того, что исследователь или какая-либо другая несанкционированная третья сторона получили доступ к данным клиентов или конфиденциальной информации клиентов. Системы кибербезопасности McKinsey очень надежны».
Но генеральный директор CodeWall Пол Прайс сказал нечто еще более интригующее.
«Мы использовали специализированного агента искусственного интеллекта для автономного выбора целей. Этот процесс не предполагал никакого участия человека ».
Да, именно сам ИИ предложил сделать McKinsey своей целью .
Приведенные причины также были довольно серьезными: у McKinsey есть публично обнародованная политика ответственного раскрытия информации (это означает, что исследователей не будут преследовать в судебном порядке, если их данные будут скомпрометированы), а Lilli недавно обновили (это означает, что в новом коде могут быть новые уязвимости).
Искусственный интеллект уже выработал собственную систему принятия решений при выборе добычи.
Это не было направлено против McKinsey. Решение было принято само собой.
Это поднимает вопрос: если ИИ-агент, используемый в исследованиях в области безопасности, может принимать такое решение, то какой вариант выберет злонамеренно внедренный ИИ-агент?
Пол Прайс добавил: «Хакеры будут использовать те же методы, но у них будет четкая цель — использовать утечки данных для финансового вымогательства или для осуществления атак с использованием программ-вымогателей».
Когда стоимость атаки снижается до 20 долларов Технические возможности McKinsey неплохи.
У них команда технических специалистов мирового класса. У них огромный бюджет на безопасность. У них достаточно ресурсов для аудита кода, тестирования на проникновение и сертификации соответствия. SQL-инъекция — один из старейших и самых простых типов уязвимостей — о ней сообщалось публично еще в 1998 году .
Если компания McKinsey наткнется на это, проблема будет не в самой компании McKinsey.
Проблема в том, что когда ИИ становится атакующим, меняются основополагающие предположения всей системы защиты.
Инженеры по безопасности труда просматривают контрольный список. После заполнения списка они подписывают его и отправляют. Что входит в десятку основных требований OWASP? Соответствие стандартам.
Агенты искусственного интеллекта не смотрят на контрольные списки.
Он анализирует поверхность атаки.
Она использует цепочки рассуждений, чтобы ответить на вопрос: «Если бы я был нападающим, что бы я попытался сделать дальше?»
Это позволяет измерить объем работы, которую выполняет инженер-человек за день, всего за одну секунду.
Оно никогда не устает, никогда не теряет концентрацию и никогда не пропускает аномально высокое возвращаемое значение.
Более того, это не единичный случай.
Искусственный интеллект уже помогает боевым группам, в том числе тем, которые противостоят связанным с Северной Кореей террористам, справляться с рутинными задачами.
Технический директор Microsoft Azure использовал код Клода в своем проекте для Apple II 1986 года и обнаружил уязвимость.
Операционная система macOS также была скомпрометирована Клодом Мифосом.
Компания Apple потратила пять лет и, по оценкам, несколько миллиардов долларов на создание системы обеспечения целостности памяти (Memory Integrity Enforcement, MIE) — аппаратной системы защиты памяти, основанной на технологии MTE от ARM.
Являясь флагманской функцией безопасности чипов M5 и A19, она была разработана для полного устранения всей категории уязвимостей, связанных с повреждением памяти.
За пять дней исследователи с помощью Mythos Preview обнаружили первую публично раскрытую уязвимость, связанную с повреждением памяти ядра macOS на чипе Apple M5.
Они раскрыли силу Мифоса, описав его как невероятно мощное явление.
Искусственный интеллект, «бегающий голым» — это просто «новое платье императора»?
В последние несколько десятилетий компании уделяли большое внимание защите своего кода, серверов и цепочек поставок.
Однако есть один слой, который практически никто всерьез не защитил: слой ключевых слов.
Инструкции по управлению поведением ИИ хранятся в базе данных, передаются через API и кэшируются в конфигурационных файлах.
Практически отсутствует контроль доступа. Нет истории версий. Отсутствует мониторинг целостности.
Если код — это плоть и кровь, то инструкции — это его душа .
Раньше мы защищали код; теперь же мы должны защищать инструкции.
Когда стоимость атаки падает до 20 долларов, этот уровень становится полностью уязвимым.
Ещё более тревожно то, что конечной целью злоумышленников, возможно, больше не является прорыв вашего брандмауэра, а изменение мышления вашего ИИ-помощника .
Кто станет следующей целью, «автономно выбранной» агентом искусственного интеллекта?
Никто не знает. Но одно можно сказать наверняка: вас об этом заранее не уведомят.
Работникам осталось жить 18 месяцев ч1
Аноним# OP19/05/26 Втр 20:31:44№161569610
Генеральный директор Microsoft по искусственному интеллекту: осталось 18 месяцев, и ИИ возьмет на себя обязанности американских офисных работников.
В феврале этого года генеральный директор Microsoft по искусственному интеллекту Сулейман заявил в интервью, что в течение следующих 12-18 месяцев многие офисные должности, выполняемые перед компьютерами, будут полностью автоматизированы с помощью ИИ; в конце апреля Microsoft запустила программу единовременного добровольного выкупа акций для старших сотрудников в США. От Microsoft до Meta, крупные технологические компании Кремниевой долины используют ИИ для реструктуризации своих организаций, и уже формируется новый ландшафт рынка труда.
В феврале этого года генеральный директор Microsoft AI Мустафа Сулейман заявил в интервью Financial Times, что в течение следующих 12-18 месяцев большинство профессиональных задач, выполняемых за компьютером, будут автоматизированы с помощью ИИ.
Сулейман считает, что искусственный интеллект подталкивает офисные профессии к грани кардинальных изменений, поскольку такие области, как юриспруденция, бухгалтерский учет, маркетинг и управление проектами, полностью автоматизируются. Дипломы MBA и юридические степени, когда-то считавшиеся пропуском в престижную карьеру, сейчас стремительно теряют свою ценность.
Логика Сулеймана заключается в том, что по мере экспоненциального роста вычислительной мощности способность моделей писать код превзойдет возможности большинства программистов-людей, и ИИ может заменить значительное число специалистов .
Джош Тирангель, репортер издания The Atlantic, использовал метафору для описания сложившейся ситуации: руководители компаний ясно видят, как «акулий плавник выныривает из воды», но никаких действий не предпринимают.
Искусственный интеллект переписывает организационные схемы двухтысячелетней давности. В марте этого года генеральный директор Block и соучредитель Twitter (теперь X) Джек Дорси опубликовал статью на сайте Sequoia Capital, в которой рассказал о том, как волна искусственного интеллекта изменит организационные структуры корпораций.
Он переключил свое внимание на Древний Рим, более двух тысяч лет назад. Римские легионы того времени уже решили проблему крупномасштабной координации:
В одной палатке жили восемь солдат под командованием заместителя командира; десять отрядов составляли отряд из ста человек под командованием центуриона; шесть отрядов по сто человек составляли батальон; и десять батальонов составляли легион численностью около 5000 человек.
Вся цепочка вращается вокруг единственного: маршрутизации информации, то есть передачи команд сверху вниз и сбора разведывательной информации снизу вверх.
Эта логика впоследствии была развита пруссаками в систему штабных расписаний, внедрена в американские железнодорожные компании XIX века выпускниками Вест-Пойнта и в конечном итоге превратилась в организационные схемы каждой крупной компании сегодня.
Позже Spotify и Zappos попытались взломать его, но обеим это не удалось.
Дорси пришел к выводу, что за две тысячи лет никому не удалось заменить иерархию, не потому что люди недостаточно умны, а потому что ни одна технология так и не смогла по-настоящему взять на себя задачу «маршрутизации информации».
Впервые это стало возможным благодаря появлению искусственного интеллекта: он может в режиме реального времени поддерживать «информационную карту» всей компании — отслеживать ход выполнения каждого проекта, выявлять узкие места, распределять ресурсы и определять, кто чем занимается.
Раньше эта диаграмма существовала в умах каждого менеджера среднего звена, подкрепленная совещаниями, электронной почтой и сообщениями в Slack. Теперь же искусственный интеллект может автоматически обновлять, поддерживать и запускать эту диаграмму, автоматически предоставляя ее всем, кому она необходима. Дорси называет это «моделью корпоративного мира».
С помощью этой системы организацию можно разделить на три роли: независимый участник (IC), выполняющий конкретную работу, непосредственно ответственное лицо (DRI), отвечающее за решение проблемы от начала до конца, и тренер-руководитель, который руководит людьми, одновременно выполняя работу сам.
В этой новой архитектуре нет необходимости в постоянном промежуточном слое.
В ходе телефонной конференции по итогам финансового года в январе Цукерберг также упомянул, что 2026 год станет годом, когда «искусственный интеллект начнет существенно менять наш подход к работе». Проекты, которые раньше требовали больших команд, теперь могут быть выполнены одним талантливым человеком с помощью ИИ.
В ходе телефонной конференции по итогам отчетного периода компания Meta представила внутренние данные о производительности: с начала 2025 года «производительность на одного инженера» выросла на 30%, причем большая часть роста обусловлена внедрением программирования в агентствах; производительность «опытных пользователей» инструментов программирования на основе ИИ выросла на 80% по сравнению с предыдущим годом.
Цукерберг также заявил, что Meta инвестирует в инструменты, изначально разработанные для ИИ, повышает статус независимых разработчиков и делает команды более плоскими.
Судя по всему, суждения генерального директора OpenAI Альтмана еще более дальновидны, поскольку он неоднократно заявлял: «Если OpenAI не станет первой крупной компанией, возглавляемой руководителем, использующим искусственный интеллект, то это будет моим неисполнением обязанностей».
Работникам осталось жить 18 месяцев ч2
Аноним# OP19/05/26 Втр 20:32:43№161569811
>>1615696 По его мнению, агенты искусственного интеллекта заменят значительную часть работы, связанной со Slack, электронной почтой, документами и координацией, и только при необходимости задача будет передана на выполнение человеку.
Начиная от сотрудников, использующих ИИ, и заканчивая менеджерами, использующими ИИ, и генеральными директорами, использующими ИИ, каждый уровень организационной структуры власти подвергается реструктуризации, двигаясь в сторону более плоской формы.
Microsoft объявляет о крупнейшей в истории программе добровольного выкупа акций в связи с выходом на пенсию. В прошлом месяце Microsoft запустила первую за 51 год масштабную программу добровольного выкупа акций у сотрудников в связи с выходом на пенсию.
58-летний сотрудник Microsoft, проработавший в компании 12 лет, получил внутреннее электронное письмо от директора по персоналу Microsoft Эми Коулман, содержащее «план добровольного увольнения с выплатой компенсации», который включал «финансовую компенсацию, расширенное медицинское страхование и всестороннюю поддержку при переходе на новую работу».
Причина, по которой он получил это письмо, была проста: его возраст плюс стаж работы равнялись 70 годам.
В Microsoft этот порог называется «Правилом 70». Люди, способные достичь этого порога, как правило, являются опытными сотрудниками, проработавшими в Microsoft более десяти или двадцати лет.
Этот ветеран — лишь один из 8750 человек, участвующих в программе добровольного выкупа акций в связи с выходом на пенсию, организованной Microsoft.
По данным Bloomberg, около 7% сотрудников Microsoft в США соответствуют критериям, что составляет приблизительно 8750 человек, исходя из данных Microsoft за 125 000 сотрудников в США, опубликованных в июне 2025 года.
Агентство Bloomberg сообщает, что Microsoft никогда прежде не совершала сделок по поглощению такого масштаба.
По данным Business Insider, сделка по выкупу в первую очередь затрагивает сотрудников уровня старшего директора и ниже, за исключением некоторых руководителей высшего звена и сотрудников, участвующих в программах стимулирования продаж.
Не говоря уже об ИИ. Но каждое действие указывает на это.
В электронном письме Microsoft использовала сдержанные формулировки: компания стремится предоставить больше возможностей сотрудникам, желающим выйти на пенсию, одновременно реформируя систему компенсаций и поощрений, чтобы сделать требования к производительности более ясными и предоставить менеджерам больше гибкости в поощрении высокоэффективных сотрудников.
Это звучит как стандартная кадровая практика, но сравнение с финансовыми отчетами Microsoft делает смысл этого письма более понятным.
Вернемся к октябрю 2025 года. В своем ежегодном письме акционерам генеральный директор Сатья Надела написал: «Мы находимся в процессе трансформации платформы искусственного интеллекта», «Мы реструктурируем наши бизнес-операции», «Переосмысливаем наши кампании продаж» и «Повышаем эффективность всего».
В письме неоднократно встречались слова «реконструкция» и «переосмысление».
В годовом отчете Microsoft за 2025 год указано, что выручка за весь год достигла 281,7 миллиарда долларов, что на 15% больше, чем годом ранее, а выручка от Azure впервые превысила 75 миллиардов долларов, увеличившись на 34% по сравнению с прошлым годом. Глобальные центры обработки данных расширились до 70 регионов и более чем 400 локаций, добавив более 2 гигаватт мощности.
В то же время Microsoft ожидает, что ее капитальные затраты в 2026 году приблизятся к 100 миллиардам долларов, и все эти средства будут инвестированы в инфраструктуру искусственного интеллекта.
В марте этого года Раджеш Джа, глава подразделения Microsoft Experiences and Devices, объявил о своей отставке после более чем 35 лет работы в компании. После его ухода его подчиненные будут подчиняться непосредственно генеральному директору Сатье Наделле, и прежняя иерархическая структура будет упразднена.
Выкуп компаний, реформы системы оплаты труда, перестановки в руководстве и бурный рост развития инфраструктуры искусственного интеллекта — все эти события произошли в один и тот же период времени.
Хотя в электронном письме искусственный интеллект не упоминался, все внесенные изменения указывали на его использование.
Предсказание Сулеймана оказалось верным; поглощение Microsoft является микрокосмосом организационной реструктуризации в рамках этой масштабной тенденции.
Эта реструктуризация Победителем не обязательно станет самый сильный человек сегодня. В этой волне развития ИИ настоящий вопрос, который нам следует задать, звучит не «Заменит ли ИИ людей?», а «Кто будет заменен первым и кто от этого выиграет?».
Эти 8750 электронных писем от Microsoft были отправлены не самым неэффективным сотрудникам, а наиболее опытным, стабильным и, в особенности, руководителям среднего звена.
Функции, которые берет на себя искусственный интеллект — маршрутизация информации, координация ресурсов и коммуникация — это именно то, чем он зарабатывает себе на жизнь. Но для молодых людей, только что окончивших университет и не имевших времени для накопления «иерархического капитала», это может быть не так уж плохо; это даже может стать редким окном возможностей.
Salesforce одновременно наняла 1000 новых сотрудников специально для выполнения задач, связанных с взаимодействием с агентами искусственного интеллекта... Для этих должностей требуются навыки взаимодействия с ИИ, а не опыт работы.
Старые правила устаревают.
Следующими победителями в волне ИИ станут не обязательно самые сильные люди сегодня, а скорее те, кто сможет освободиться от старого порядка и первыми интегрироваться в ИИ.
Согласно сообщениям, в GPT-5.5 используется «самый быстрый в мире чип», что вызвало панику в Клоде!
Модель 120B взлетела до 2000 токенов в секунду, и финансовый директор даже заявил, что GPT-5.5 уже работает! IPO Cerebras на сумму 56 миллиардов долларов выросло на 68% в первый день, но подробный анализ SemiAnalysis указал на его фатальные недостатки.
Компания SemiAnalysis, крупнейшая в Кремниевой долине фирма, специализирующаяся на анализе микросхем, в апреле потратила 10 миллионов долларов в год только на подписку на инструменты искусственного интеллекта.
80% этого времени тратится в одном и том же месте: в быстром режиме Opus 4.6 от Anthropic.
Этот режим в 6 раз дороже стандартного, но при этом выдает токены в 2,5 раза быстрее!
Затем вышла Opus 4.7. Она была умнее и превосходила предыдущее поколение по всем показателям, но инженеры коллективно отказались от обновления.
Причина всего одна: в версии 4.7 отсутствует быстрый режим.
Они скорее предпочтут использовать более примитивную модель, чем не смогут быстрее получать токены!
Откуда взялась цифра 2000 токенов в секунду?
В феврале этого года компания OpenAI выпустила GPT-5.3-Codex-Spark.
Он носит название GPT-5.3, но по сути это уменьшенная версия полной версии GPT-5.3 Codex, содержащая лишь десятую часть параметров оригинальной модели 120B.
Хотя это и было достигнуто благодаря интеллекту, скорость действительно невероятно высока — 2000 токенов в секунду.
Для сравнения, самый быстрый процессор Anthropic Opus 4.6 достигает примерно 70-100 токенов в секунду, а серия GPT-5 на графических процессорах NVIDIA — примерно 130 токенов в секунду.
С другой стороны, Codex-Spark прибавил газу и вышел на совершенно другой уровень.
За такую высокую скорость работы отвечает чип Cerebras WSE-3, представляющий собой микросхему размером с обеденную тарелку.
Это событие напрямую привело к заключению контракта на сумму 24,6 миллиарда долларов и способствовало листингу Cerebras на Nasdaq. В первый день торгов, 14 мая, акции компании взлетели на 68%, став крупнейшим IPO технологической компании в 2026 году.
Однако финансовый директор Cerebras Боб Комин утверждает, что это лишь закуска.
Накануне IPO он в интервью разыграл карту, которую никто не ожидал:
Мы обслуживаем все модели без ограничений по размеру. Сегодня мы запускаем модели с триллионами параметров. Мы используем внутренние версии OpenAI GPT-5.4 и GPT-5.5.
Если это правда, то Cerebras перестала быть просто игроком в игре "маленькая модель, быстрый рост", и невероятный скачок в день ее IPO сразу становится понятен.
Но так совпало, что в ту же неделю SemiAnalysis опубликовала подробный технический анализ объемом 20 000 слов, что напрямую опровергло эту историю.
В публичном облаке Cerebras самая большая производственная модель — GPT-OSS, содержащая в общей сложности 120 байт параметров; самая большая предварительная модель — 355 байт. Модели Llama 70B и 405B, которые были доступны ранее, впоследствии были незаметно сняты с производства.
Самые популярные, но и самые крупные модели с открытым исходным кодом в 2025 году (такие как DeepSeek) никогда не появлялись в облаке Cerebras.
Указанная финансовым директором цифра в настоящее время существует только «внутри OpenAI» и не может быть проверена посторонними лицами.
Чтобы определить размер трещины, нам сначала нужно посмотреть, что происходит с этой пластиной.
Ставка на целый блок кремния
На протяжении 50 лет полупроводниковая промышленность занималась исключительно резкой кремниевых пластин.
С одной кремниевой пластины вытравливаются десятки микросхем, затем они разрезаются, упаковываются, и каждый процесс выполняется независимо. Технология Nvidia B300 позволила уменьшить площадь одной микросхемы до 858 квадратных миллиметров, что, по сути, является пределом фотолитографии.
В отличие от них, Cerebras делает прямо противоположное – он не режет.
Вся пластина представляет собой чип.
Его площадь составляет 46 225 квадратных миллиметров, что в 58 раз больше, чем у графического процессора Nvidia, примерно размером с обеденную тарелку. Он включает в себя 4 триллиона транзисторов, 900 000 вычислительных ядер и 44 ГБ оперативной памяти.
И вот ключевой момент: SRAM.
В графическом процессоре используется память HBM (High Bandwidth Memory), которая обладает большим объемом, но относительно медленна. Процессор B300 оснащен 288 ГБ памяти HBM с пропускной способностью в диапазоне ТБ/с.
WSE-3 имеет всего 44 ГБ оперативной памяти, но пропускная способность памяти достигает 21 ПБ/с.
Секрет невероятной скорости Церебраса кроется именно здесь.
Пропускная способность SRAM настолько велика, что при декодировании она может практически полностью задействовать все вычислительные ядра. Вычислительные ядра графического процессора, с другой стороны, остаются без доступа к памяти, ожидая её выделения.
Основная проблема в процессе рассуждений заключается в декодировании.
Когда модель выдает токены по одному, ей необходимо считывать все веса из памяти для каждого выходного токена. Чем выше пропускная способность, тем быстрее считывание и тем быстрее выдается токен.
SemiAnalysis предоставляет очень наглядное сравнение.
В сценарии, когда для одного пользователя генерируется только один токен, фактическая вычислительная мощность, которую может использовать графический процессор, составляет лишь малую часть от его теоретической пиковой мощности. Теоретически, WSE-3 может полностью использовать свою вычислительную мощность в 15,6 PFLOPS FP16.
Разница составляет не несколько десятков процентов, а порядки величины.
мощная паника в Клоде ч2
Аноним# OP19/05/26 Втр 20:43:33№161570314
>>1615702 По их собственным словам, это как разница между автобусом и болидом Формулы-1.
GPU похож на автобус, перевозящий множество людей одновременно, но каждый человек движется медленно. WSE-3 похож на гоночный болид Формулы-1, перевозящий только одного человека за раз, но невероятно быстрый.
Покупатели, желающие приобрести гоночный автомобиль, готовы платить за скорость в шесть раз больше. Opus 4.6 Fast это доказал.
Но у этого «автомобиля» есть фатальная проблема — его «топливный бак» вмещает всего 44 литра.
Для небольших моделей 44 ГБ оперативной памяти WSE-3 более чем достаточно, но для современных крупных моделей этого просто недостаточно.
DeepSeek V4 содержит 1,6 триллиона параметров. Даже при использовании самого агрессивного метода сжатия (квантование FP8) его вес составляет 490 ГБ. Один чип WSE-3 не может вместить всё это; его необходимо разрезать как минимум на 12 частей и упаковать в 12 кремниевых пластин.
Для распространения информации необходима коммуникация, и это является самой фатальной слабостью Cerebras.
Каждый модуль WSE-3 имеет внешнюю пропускную способность всего 150 ГБ/с.
Графический процессор NVIDIA Blackwell может достигать скорости 900 ГБ/с через NVLink5, что в 6 раз быстрее, чем у Cerebras. Groq, приобретенный NVIDIA, демонстрирует еще более впечатляющие результаты: один LPU3 обеспечивает скорость 9,6 Тб/с, что в 8 раз быстрее.
Увеличить пропускную способность невозможно. Это физическая тупиковая ситуация.
Метод изготовления WSE-3 определяет всё. Вся пластина многократно экспонируется с использованием одного и того же шаблона, состоящего из 12 столбцов и 7 строк, и 84 одинаковых кристалла собираются в один чип.
Для добавления высокоскоростного коммуникационного порта (SerDes) пришлось бы установить его на каждом кристалле. Однако из 84 кристаллов только краевые могут быть подключены к внешней сети; те, что находятся посередине, служат лишь для красоты и являются пустой тратой кремниевой площади.
Хуже того, SerDes — это аналоговые схемы, которые имеют большие размеры и могут создавать помехи для соседней цифровой логики. Размещение SerDes в центре кристалла — это все равно что вырыть яму на собственной дороге.
Итак, Церебрас застрял на острове. На острове есть сеть автомагистралей, но единственный мост, соединяющий его с внешним миром, — это однополосный мост.
Таким образом, у Cerebras есть только один способ запуска больших моделей: разбить модель на слои, разместить несколько слоев на каждой пластине и передавать между пластинами только промежуточные результаты вычислений (с гораздо меньшим весом, чем у полной модели).
Однако, чем длиннее производственная линия, тем больше задержка.
Компания SemiAnalysis подсчитала, что запуск DeepSeek V4 на 12 пластинах приведет к 12 задержкам между слоями при передаче данных, а время перемещения кэшированных данных может достигать нескольких миллисекунд.
Поэтому то, что сказал финансовый директор на CNBC, по крайней мере на данный момент, больше похоже на план действий.
Однако в диапазоне ниже 120B к характеристикам Cerebras жаловаться не приходится.
Какова стоимость?
Известная организация по тестированию программного обеспечения Artificial Analysis провела реальные испытания с использованием Llama 4 Maverick, достигнув скорости 2400 токенов в секунду для Cerebras и 1040 токенов в секунду для NVIDIA Blackwell, что более чем вдвое превышает заявленную скорость.
Компания Cognition, разработчик инструмента программирования ИИ Devin, уже интегрировала Cerebras в свои продукты, достигнув скорости обработки 1000 токенов в секунду в быстром режиме. Notion, LiveKit, GSK и другие компании также уже используют его.
Однако, компромисс заключается в том, что максимальная производительность публичного облака соответствует уровню GPT-OSS, с максимальным размером контекста всего в 128 КБ.
Согласно данным SemiAnalysis, полученным на основе 432 000 реальных запросов от таких инструментов, как Claude Code и Cursor, почти 50% из них превысили 128 000 запросов.
В эпоху агентов контекст будет только увеличиваться, и 128 КБ вскоре станут узким местом.
Он быстрый, но модель небольшая, контекст короткий, а выбор ограничен. Это тот Cerebras, который есть у разработчиков сегодня.
Но здесь есть одна деталь, которую многие не заметили, и которая может полностью изменить конкурентную среду.
Соглашение между Cerebras и OpenAI включает в себя пункт об эксклюзивности, согласно которому Cerebras не может продавать свою продукцию «конкретным конкурентам OpenAI» в течение срока действия контракта.
Генеральный директор Фельдман не назвал конкретных имен, но все понимали, что он имел в виду компанию Anthropic.
Обладая 12% акций, кредитом в размере 1 миллиарда долларов и заключенными контрактами на сумму 24,6 миллиарда долларов, компания Cerebras прочно связана со стратегическими целями OpenAI.
В войне разума компания OpenAI только что сменила оружие.
Сегодня основное поле битвы в гонке вооружений в области искусственного интеллекта изменилось.
Обучение происходит всего один раз, в то время как рассуждения повторяются миллиарды раз каждый день.
В 2026 году две трети вычислительной мощности ИИ будут использоваться для вывода результатов, а к 2027 году эта цифра, как ожидается, достигнет 80%.
Согласно плану OpenAI, AWS Trainium отвечает за обработку пользовательского ввода, Cerebras — за генерацию выходных токенов, а графические процессоры (GPU) — за обучение и обработку длинных контекстов, при этом каждая из трех аппаратных систем обрабатывает определенный сегмент. Такой комбинированный подход направлен на достижение одной цели: снижение затрат и повышение скорости.
Для сравнения, скорость Opus 4.6 Fast снизилась со 100 токенов в секунду до 70 токенов в секунду, и Cerebras также исключил его из своего контракта.
Итак, вопрос в том, где же решение Anthropic для сверхбыстрого рассуждения?
>>1615662 >Китайские разработчики теперь маршрутизируют трафик через «серые» «транзитные станции», которые перепродают модели Anthropic по 10% от прайс-листа, при этом логи затем перепродаются для всего — от обучающих данных до мошенничества.
То есть ваши запросы останутся в сети на вечно. Вангую, что како-то долбоеб будет спрашивать у такого чата как замести следы преступления и предчувствую, что попкорна придется много скушать
ИИ найден глубокий интернет ч1
Аноним# OP19/05/26 Втр 20:54:01№161570916
AnySearch подключился к 80% интернета, которые Google не может найти! Разработчики работали над его интеграцией всю ночь.
Традиционная интеграция API устарела! В эпоху повсеместного использования агентов недооцененная поисковая система наконец-то совершила четвертый парадигмальный сдвиг. Появление AnySearch позволило агентам выйти за рамки простого суммирования веб-страниц и вместо этого получать надежную, структурированную информацию, что действительно дает им возможность взаимодействовать с реальным миром.
В 2026 году возможности ИИ-агентов будут расширяться ежемесячно.
Написание кода, подготовка исследовательских отчетов, проведение аудитов безопасности... Шесть месяцев назад задачи, которые раньше требовали участия человека, теперь более чем в 80% случаев могут быть выполнены агентами самостоятельно.
Но досадный факт заключается в том, что Agent застрял на, казалось бы, незначительном шаге: поиске!
Если вы попросите ИИ проверить структуру акционерного капитала компании, он сможет предоставить вам лишь краткое описание с официального сайта.
Попросите его найти фрагмент кода, пригодный для использования в производственной среде, и он предложит вам вводный учебник на Medium.
При анализе информации об угрозах, связанных с подозрительным IP-адресом, система находит лишь несколько научно-популярных статей.
Дело не в том, что поиск с использованием ИИ недостаточно быстр, а в том, что поисковый механизм «не видит» результаты.
Наконец-то кто-то всерьёз пытается решить эту проблему!
В течение недели после запуска AnySearch мгновенно стал вирусным в интернете.
11 мая за рубежом состоялся официальный запуск продукта под названием AnySearch.
У него четко выраженная позиция: «поисковая инфраструктура» эпохи ИИ, создающая единый высококачественный поисковый портал специально для агентов ИИ.
В течение недели после запуска AnySearch произвел фурор в зарубежном сообществе разработчиков.
Он быстро появился на многочисленных платформах экосистемы разработчиков, таких как GitHub, ClawHub, skills.sh, SkillHub и Glama, и получил стабильное количество загрузок и взаимодействий в технических сообществах и магазинах плагинов.
Эксперт по искусственному интеллекту Гури Сингх настоятельно рекомендует AnySearch на платформе X, и вот его оценка:
Если вы создадите ИИ-агента в 2026 году, но не будете использовать это, это будет всё равно что искать с одним закрытым глазом.
Ещё один блогер, пишущий об искусственном интеллекте, тоже протестировал AnySearch и сравнил его с Brave и Perplexity. Очевидно, что результаты AnySearch оказались более информативными.
Бишал Нанди воскликнул, что AnySearch может получать разнообразную информацию с форумов Reddit, из репозиториев кода, фондовых рынков и многого другого с помощью больших моделей.
Положительные отзывы на Reddit были просто невероятными.
По стечению обстоятельств, один из пользователей Reddit провел небольшой эксперимент с различными ИИ, которые искали один и тот же вопрос, и «слепой ящик» AnySearch оказался поистине удивительным.
Один из ответов заключался в том, что важность поиска информации и выбора источников теперь сопоставима с возможностями модели. Даже при использовании той же модели, более мощная поисковая/контекстная структура может сделать ее более практичной.
AnySearch — это как «третий глаз», позволяющий увидеть множество контента, скрытого в разных уголках интернета.
Насколько мощным является AnySearch?
В сравнительных тестах AnySearch превзошел аналогичные поисковые системы на основе ИИ, такие как Parallel и Brave, как по точности, так и по времени отклика.
Кроме того, по сравнению с аналогичными тестами Brave Search, результаты показывают, что AnySearch обладает более полными данными, более глубоким анализом и более исчерпывающими ответами.
Но качество продукта в конечном итоге зависит от реальных испытаний. В конце концов, в поиске вы поймете разницу только после того, как им воспользуетесь.
Установить Skill невероятно просто!
На официальном сайте http://www.anysearch.com нажмите «Установить/» , скопируйте инструкцию по установке, введите Agent, и развертывание будет завершено.
Основные возможности AnySearch можно кратко описать одним предложением:
Единая точка входа обеспечивает доступ к огромному количеству профессиональных источников данных, позволяя агентам искусственного интеллекта эффективно взаимодействовать с информацией из реального мира.
Однако значение фразы «единая точка входа» по-настоящему оценят только те, кто действительно занимался разработкой агентов.
До появления AnySearch, если агент хотел одновременно обладать возможностями финансового анализа, поиска кодов, анализа информации в сфере безопасности, регистрации бизнеса и поиска научной литературы, ему требовалось:
Я зарегистрировал аккаунты на Qichacha, Finnhub, PubMed и VirusTotal, изучил десятки различных документов по API, управлял лимитами запросов и балансами десятков ключей API и даже был вынужден написать собственную логику маршрутизации, чтобы определить, какой запрос отправлять в какой источник данных.
Стоимость разработки «модуля поиска» может оказаться выше, чем стоимость самого Агента.
AnySearch объединила все это в один пакет. Один API-ключ для доступа к высококачественным источникам данных, необходимым для ИИ.
Разработчикам больше не нужно быть "инженерами по интеграции API"; им достаточно подключить AnySearch, а остальное программа сделает сама.
Один API, поддерживающий все «высококачественные» источники данных.
Просто отправьте запрос, и AnySearch автоматически направит его к наиболее подходящему источнику данных и вернет структурированные результаты в формате Markdown.
Для агента AnySearch обрабатывает все сложности, такие как количество подключаемых источников данных, методы аутентификации каждого источника и различия в форматах результатов.
Более того, широкий спектр охватываемых сценариев значительно превосходит ожидания большинства разработчиков.
С помощью одного API вы можете изучать структуру акционерного капитала компаний, получать поминутные данные о рынке акций класса А, извлекать полные тексты судебных решений, искать готовые к использованию реализации кода на GitHub и даже отправлять файлы в VirusTotal для обнаружения вредоносных программ.
Совершенно очевидно, что AnySearch удовлетворяет весь спектр потребностей агентов, а не только конкретную отраслевую сферу.
Эта информация составляет более 80% от всего объема информации в интернете, однако она совершенно недоступна для Google и Exa.
Проблема не в том, что они «еще не проиндексированы», а скорее в слепом пятне, которое архитектура просто не может закрыть.
ИИ найден глубокий интернет ч2
Аноним# OP19/05/26 Втр 20:55:51№161571017
>>1615709 Кроме того, AnySearch предлагает очень гибкие варианты интеграции:
REST API (универсальный, совместимый с любым языком программирования и фреймворком агента), MCP Server (доступен с помощью одной строки конфигурации JSON для Claude Desktop, Cursor, Windsurf и OpenCode), Skill (вызывается напрямую как навык агента).
Три подхода, способные удовлетворить любые потребности — от опытных разработчиков до обычных любителей компьютерных технологий.
Это звучит как история об "агрегации", но AnySearch делает гораздо больше, чем просто упаковывает источники данных.
В основе системы лежит полноценный интеллектуальный механизм маршрутизации и объединения результатов, позволяющий агенту напрямую переходить от «поиска информации» к «поиску полезной информации».
Главная особенность: интеллектуальная маршрутизация на основе намерений.
В основе технологии AnySearch лежит ключевой модуль: интеллектуальный классификатор намерений .
Когда запрос поступает в AnySearch, встроенный в систему классификатор намерений автоматически определяет намерение запроса и точно направляет его к 2-3 наиболее релевантным источникам данных посредством многомерного сопоставления маршрутов.
Это означает, что система не будет выполнять полную обработку всех источников данных, а будет запрашивать только наиболее важные из них, что приведет к повышению скорости и снижению потребления токенов.
Когда несколько источников данных одновременно выдают результаты, AnySearch использует алгоритм RRF (Reciprocal Rank Fusion) для объединения результатов.
Когда одна и та же информация подтверждается несколькими источниками, рейтинг автоматически улучшается, а нормализация URL-адресов удаляет дубликаты.
После объединения и многомерной переоценки качества Агент может принимать решения непосредственно на основе оценок, не тратя токены на дополнительную проверку.
Что касается формата вывода, AnySearch возвращает очищенный структурированный Markdown, обычно содержащий от 500 до 2000 токенов в каждом результате.
Для того же запроса Agent использует Exa для поиска 10 результатов, потребляя в среднем около 15 000 токенов; в то время как AnySearch использует AnySearch для поиска 5 высококачественных результатов, потребляя в среднем около 5 000 токенов.
Совершенно очевидно, что потребление токенов снизилось на 60-70%!
Получение более точной информации с меньшим количеством токенов означает ощутимую экономию затрат и повышение эффективности работы агентов в производственных средах.
Вопросы конфиденциальности были рассмотрены на архитектурном уровне.
В сфере поиска с использованием искусственного интеллекта конфиденциальность — это не «бонус», а конечный результат.
Контент, который ваш агент запрашивает через поисковый интерфейс, может содержать коммерческую тайну (исследование конкурентов), информацию, имеющую важное значение для безопасности (расследование угроз интеллектуальной собственности), и данные о юридических рисках (комплексная проверка компании).
Если эти запросы будут записаны, проанализированы и использованы для обучения моделей, последствия будут ужасными.
Подход AnySearch заключается в том, чтобы уделять приоритетное внимание защите конфиденциальности на архитектурном уровне.
В частности: поисковые запросы пользователей не будут записываться, использоваться для обучения моделей и передаваться третьим лицам.
Система не собирает никаких телеметрических данных, не отслеживает поведение пользователей и не создает профили пользователей.
Все API-запросы передаются по зашифрованному каналу, а результаты запросов немедленно удаляются после обработки и не сохраняются.
Вкратце: анонимное использование, отсутствие отслеживания, нулевая телеметрия — ваши запросы принадлежат только вам.
В современном мире поиска с использованием ИИ это крайне редкое явление. Большинство инструментов поиска на основе ИИ в той или иной степени используют данные пользовательских запросов для оптимизации собственных моделей — это общеизвестный факт.
Решение AnySearch не использовать эту строку особенно важно для разработчиков и корпоративных пользователей, работающих с конфиденциальной информацией.
Поиск: недооцененная инфраструктура эпохи искусственного интеллекта.
Оглядываясь на историю поисковых систем, можно заметить, что каждый сдвиг парадигмы сопровождался изменением того, «кто ищет информацию».
Когда компания Google была основана в 1998 году, поиск помогал людям находить веб-страницы. С развитием мобильного интернета в 2010-х годах поиск трансформировался в помощь людям в поиске услуг.
После того как ChatGPT дал толчок развитию LLM в 2023 году, Perplexity и другие компании превратили поиск в инструмент, помогающий людям находить ответы.
Сейчас, в 2026 году, поиск переживает четвертый парадигмальный сдвиг: от помощи людям в поиске информации к помощи искусственному интеллекту в понимании мира.
В открытом письме к разработчикам команда AnySearch заявила следующее:
Мы твердо убеждены, что будущий искусственный интеллект должен будет не только «думать», но и по-настоящему видеть и понимать мир.
В эпоху интернета поисковые системы помогали людям находить веб-страницы; но в эпоху искусственного интеллекта агентам нужна не цепочка ссылок, а достоверная, структурированная и пригодная для практического применения информация.
В этом отрывке указывается на факт, о котором многие не знают: когда агент начинает выполнять сложные задачи, настоящим узким местом часто становится уже не способность к рассуждению, а способность к получению информации.
Без надежного уровня сбора информации даже самые мощные модели ИИ будут испытывать трудности с истинным пониманием реального мира.
Позиционирование AnySearch таково: это лаборатория прикладного искусственного интеллекта, создающая совершенно новую поисковую инфраструктуру для эпохи ИИ.
Оглядываясь назад, можно сказать, что AnySearch по сути переосмыслил понятие «поиск» в эпоху искусственного интеллекта.
Раньше поиск был предназначен для потребления человеком: он выдавал множество ссылок, и людям приходилось самим кликать по ним, читать, фильтровать и обобщать информацию.
Но в эпоху агентов потребители поисковых систем изменились; они превратились в машины.
Машинам не нужны ссылки, HTML или броские страницы результатов поиска; им нужны структурированные, проверенные данные, которые можно напрямую использовать для рассуждений и принятия решений.
Это совершенно новый инфраструктурный уровень. Тот, кто первым доведет этот уровень до совершенства, получит доступ в экосистему агентов искусственного интеллекта.
Компания AnySearch вырвалась вперед.
Насколько далеко это может зайти? Зарубежные разработчики уже дали первый ответ.
Начиная с сегодняшнего дня, AnySearch бесплатен для всех разработчиков и может быть интегрирован с любым агентом для обеспечения бесперебойной работы.
Три человека потратили 1.3 миллиона на ИИ
Аноним# OP19/05/26 Втр 21:00:45№161571318
Три человека со 100 ИИ агентами потратили 1,3 миллиона долларов за месяц! OpenAI: Мы покроем расходы.
3 человека, 100 агентов ИИ, тратящих 1,3 миллиона долларов в месяц — создатель OpenClaw превратил разработку программного обеспечения в «конвейер ИИ», а OpenAI оплатила все расходы.
В то время как другие выкладывают свои расчетные листки, он выкладывает свой счет — 1,3 миллиона долларов в месяц !
Это почти 9 миллионов юаней в месяц. Это совершенно ошеломило пользователей сети.
Только что Питер Штайнбергер, создатель OpenClaw, между делом опубликовал скриншот на X.
Но цифры на скриншоте действительно вызывают тревогу:
Расходы за 30 дней: 1 305 088,81 долларов США. Было израсходовано 603 миллиарда токенов. Было сделано 7,6 миллиона запросов.
Вы всё правильно прочитали, это 1,3 миллиона долларов . И это не квартальный бюджет какой-нибудь крупной компании на ИИ — это всего лишь ежемесячное использование системы командой из трёх человек .
Ещё более шокирующим является то, что OpenAI возместит эти расходы.
Раздел комментариев мгновенно взорвался от комментариев.
Одни были поражены, другие задавали вопросы, а третьи достали калькуляторы, чтобы подсчитать, "скольким программистам это эквивалентно".
Сам Штейнбергер спокойно ответил: «После отключения быстрого режима мои затраты оказались меньше, чем стоимость услуг инженера, и это действительно очень помогло».
Короче говоря, это действительно выгодное предложение!
Некоторые пользователи сети были поражены ежемесячной зарплатой инженера в 400 000 долларов: «Рынок труда в Сан-Франциско просто безумный».
Некоторые пользователи сети также интересуются, куда делись все эти токены.
Питер ответил, что большая часть этих средств была использована для разработки OpenClaw.
Армия облачных программистов
Самое возмутительное во всей этой ситуации то, что в небольшой команде Пита всего 3 человека.
Они запускают около 100 экземпляров Codex в облаке на длительные периоды времени, выполняя самую грязную, самую утомительную и самую раздражающую работу в сфере разработки программного обеспечения.
Проверка запросов на слияние, поиск уязвимостей безопасности, устранение дубликатов проблем, исправление ошибок, мониторинг бенчмарков, обнаружение регрессий и публикация информации о них в Discord, а также даже открытие запросов на слияние непосредственно после прослушивания совещаний.
Таким образом, ИИ — это не просто "написание кода за вас", а проникновение во все пробелы в процессе разработки программного обеспечения.
Это ужасно.
Потому что реальные затраты в разработке программного обеспечения связаны с коммуникацией, пониманием, переключением контекста, проверкой, регрессионным анализом, исправлением ошибок, ожиданием и повторяющейся работой.
Раньше команда ежедневно тратила много времени на вещи, которые на первый взгляд не казались "творческими", но без них проект был бы испорчен.
Теперь Питер делегировал все эти шаги группе агентов искусственного интеллекта.
Именно здесь ИИ начинает поддерживать работу нервной системы организации.
На этом скриншоте есть еще одна важная деталь: это не бэкенд OpenAI, а CodexBar, созданный Питером.
CodexBar — это инструмент для панели меню macOS, используемый для отслеживания периодов использования, кредитов, затрат и времени сброса для различных инструментов программирования на основе искусственного интеллекта.
Он поддерживает множество сервисов, включая Codex, Claude, Cursor, Gemini и Copilot.
Что раньше было в строке меню у программиста? Процессор, память, батарея, скорость сети.
Теперь появилось нечто новое: токены. Токены становятся новым видом «средства производства».
И наконец, пара слов.
1,3 миллиона долларов в месяц, 3 человека, 100 агентов искусственного интеллекта.
Подумайте об этих цифрах: три ныне живущих человека, руководящие сотней сотрудников цифровой компании, которые не едят, не спят и не просят повышения зарплаты, выполнили работу целой инженерной команды.
Некоторые были в восторге после просмотра: ИИ наконец-то оказался не просто красивым лицом, которое умеет только болтать! Другие же почувствовали мурашки по коже: Подождите, а что теперь будем делать программисты?
Но, честно говоря, больше всего меня не дает уснуть небрежное замечание Штейнбергера: « Я изучаю, как бы выглядела разработка программного обеспечения, если бы стоимость токенов не была проблемой».
Дамы и господа, он имел в виду «если » .
Проблема в том, что это «если » с видимой скоростью превращается в «когда » .
Сегодняшняя работа обошлась в 1,3 миллиона долларов. Цена модели была снижена один раз, до 130 000 долларов. Затем она была снижена еще раз, до 13 000 долларов.
В тот день одновременная работа 100 агентов искусственного интеллекта перестанет быть исключительной прерогативой гигантов Кремниевой долины и станет базовой операцией для любой команды из трех человек в стартапе.
Трое молодых людей в гараже командуют сотней неутомимых программистов искусственного интеллекта — эта картина абсурдна даже для того, чтобы ее себе представить.
Питер Стейнбергер показал свою руку.
На карточке на столе написано: « Будущее уже стучится в вашу дверь, и оно не будет ждать, пока вы будете готовы».
Нейронка может генерить картинки, видео, код, текст и целые виртуальные миры. Также она умеет редактировать готовые видео, добавлять VFX-эффекты и менять физику сцены.
Нам обещают, что Gemini Omni понимает гравитацию, кинетику и взаимодействие объектов.
Первой релизнут Omni Flash, её уже раскатывают в приложении Gemini.
Сора мертва, Google должен восстать! Veo 4 просочился в сеть, и видеоверсия "Banana" стала легендарной за 9 секунд.
Независимо от того, как в итоге это будет называться — Veo 4 или Gemini Omni, — эта утечка уже довольно шокирующая: видео с использованием ИИ перестало быть просто инструментом для создания коротких видеороликов и превратилось в инструмент повышения производительности, основанный на повествовании и режиссерском мышлении. Ответ будет раскрыт на конференции Google I/O, и вся индустрия претерпит изменения.
В преддверии конференции Google I/O информация о Veo4 просочилась в сеть раньше времени!
Ранее в интернете распространилась видеозапись, на которой профессор демонстрирует формулы на доске.
Сейчас пользователи сети предполагают, что Veo 4/Omni может создавать полноценные многоракурсные сцены и плавно переключать перспективы, сохраняя при этом непрерывность изображения.
Также улучшена встроенная функция синхронизации звука, теперь поддерживаются разговоры, окружающие звуки и музыка.
Видеоролики могут длиться до 9 секунд и иметь разрешение 720p.
Хотя в некоторых просочившихся в сеть примерах все еще есть несоответствия, полностью синхронизированные сцены с использованием нескольких камер выглядят впечатляюще.
Утечка информации о Veo 4 (или Gemini Omni) касается гораздо большего, чем просто корректировки параметров. Это скорее народная революция, направленная на завоевание «права на повествование».
Когда искусственный интеллект начинает учиться рассматривать один и тот же момент с разных ракурсов, он фактически эволюционирует из «художника» в «режиссёра» с пространственной логикой.
Инсайдер Панкадж Кумар даже предположил, что Google легко мог бы создавать 15-секундные видеоролики, но ему не хватает вычислительной мощности. Поэтому Google необходимо сосредоточиться на вопросах эффективности.
Однако следует отметить, что на данный момент это лишь пересказ заявления Кумара. Будет ли это Veo4 или Gemini Omni, покажет время, пока Google I/O не раскроет ответ.
Искусственный интеллект в видеоиндустрии научился "монтировать кадры". Почему вопрос о "многокамерных системах" вызывает такой ажиотаж?
Давайте вернёмся на год назад.
Когда Сора внезапно появилась, все были поражены тем, что «искусственный интеллект теперь может снимать 60-секундные фильмы».
Но если присмотреться, можно заметить проблему: в течение этих 60 секунд камера неподвижна, или, вернее, ведёт непрерывную съёмку.
Камера плавно перемещается по сцене, скользя, панорамируя и наклоняясь, но монтажных склеек нет.
Как и все конкурирующие продукты, Runway Gen-4 создает видеоролики, которые по сути представляют собой «один длинный кадр», даже если камера движется, это непрерывное движение одной и той же камеры.
Почему его нельзя разрезать?
Для ИИ «монтаж кадров» означает воссоздание одной и той же сцены, одной и той же группы персонажей, в один и тот же момент, с совершенно другой точки зрения, при этом обеспечивая согласованность цветов одежды, положения чашек на столе и выражений лиц персонажей.
Это тройная проблема, требующая обеспечения физической, пространственной и временной согласованности. В течение последнего года отрасль активно пыталась решить эту проблему, но пока никому это не удалось.
Те, кто работает в традиционной кино- и телеиндустрии, скажут вам, что на съемочной площадке это называется «позиционирование камеры», и это работа режиссера, а не только оператора.
Оператор отвечает за то, «хорошо ли выглядит этот кадр или нет», а режиссёр — за то, «как смонтировать эту сцену, чтобы её было легко понять и приятно смотреть».
Суть многокамерной съемки заключается в том, чтобы разбить сцену на «повествование».
Если откровения Панкаджа Кумара верны, то в фильме «Veo 4» акцент сместился с «режиссёра» на «вес модели».
Иными словами, вы больше не «позволяете ИИ снять один кадр», а «позволяете ИИ снять всю сцену целиком».
Это огромный скачок в масштабах проблемы.
Раньше видео, созданное с помощью ИИ, представляло собой «инструмент для создания коротких видеороликов», который можно было использовать для создания вступительных переходов и фоновых визуальных эффектов.
На этот раз ИИ наконец-то был модернизирован до «инструмента для создания нарративов».
Разумеется, это при условии, что утечка информации правдива и демонстрация ввода-вывода действительно может быть запущена в день мероприятия.
Синхронизированный звук завершает формирование головоломки. Второй момент, неоднократно упоминаемый в разоблачении, касается аудиозаписи.
В частности, объяснение заключается в том, что Veo 4 изначально генерирует синхронизированные диалоги и окружающие звуки, и даже может автоматически добавлять фоновую музыку в зависимости от контекста сцены.
Veo 3 уже может воспроизводить нативный звук; это не новое изобретение Veo 4.
В прошлом году, когда в мае был выпущен Veo 3, одним из главных преимуществ, которое Google особо выделила, стало «нативное аудио»: шаги, разговоры и окружающий шум в видео генерировались в модели вместе с визуальными эффектами без необходимости постобработки и выравнивания.
Этот шаг выделил Veo 3 среди конкурентов.
Однако есть две вещи, которые Veo 3 не удалось сделать хорошо.
Во-первых, это само качество звука.
Когда первые пользователи протестировали его 11 мая, у Reddit были высокие ожидания, и отзывы были положительными, но точный масштаб был неизвестен. Тем не менее, это должно стать шагом вперед по сравнению с "эффектом озвучивания с помощью ИИ" у Veo 3.
Во-вторых, фоновая музыка.
Veo 3 в основном фокусируется на окружающих звуках и диалогах; контекстная фоновая музыка, как правило, не входит в её функционал.
В заявлении Кумара прямо говорится о «контекстной фоновой музыке, генерируемой изначально», что, если это правда, означает, что видеоролики, созданные с помощью ИИ, отныне будут иметь собственную фоновую музыку.
Если сопоставить многокамерную съемку и оригинальную фоновую музыку, можно составить представление о стратегии Google: компания больше не соревнуется в том, «у кого более детализированная графика» или «у кого более реалистичная физика».
Это соревнование, цель которого — выяснить, «кто сможет напрямую создать полноценный видеоролик».
Смена ракурсов плавная, звук точный, а фоновая музыка органично вписана. Не хватает только сценария.
Сора мертва; Google выбрал именно этот момент, чтобы раскрыть свои карты.
Утечка информации о Veo 4 произошла как раз в тот момент, когда Сора оказался в руинах после своего падения.
26 апреля приложение Sora от OpenAI официально прекратило свою работу.
Оглядываясь назад, можно сказать, что причина смерти Соры — это настоящая коммерческая трагедия.
Это приводит к огромным финансовым потерям. По имеющимся данным, затраты на обработку данных в Sora составляют от 1 до 15 миллионов долларов в день, что более чем на порядок дороже, чем генерация текста и изображений, при этом себестоимость единицы продукции не снижалась на протяжении всего жизненного цикла продукта.
Сервис не смог удержать пользователей. Пиковое количество активных пользователей в месяц составляло 1 миллион, но перед закрытием сервиса оно упало ниже 500 000, а показатель удержания за 30 дней составил менее 8%.
Приложение не приносит прибыли. Общий доход приложения за весь период его существования составил приблизительно 2,1 миллиона долларов, чего недостаточно даже для покрытия дневных расходов на вычислительные ресурсы.
24 марта на официальном аккаунте Sora было опубликовано прощальное сообщение: «Мы прощаемся с приложением Sora».
API будет полностью отключен 24 сентября.
Коммерческий разрыв уже очевиден из данных. Что касается технологического неравенства, эта утечка обнажила все факты.
омпания Google выбрала очень удачный момент, чтобы предотвратить крах OpenAI.
>>1615716 Какие еще стратегии Google применит в день I/O?
Omni — это лишь одна часть этой утечки.
В той же волне утечек неожиданно стало известно о внедрении API в производственную среду нескольких будущих моделей Gemini от Google — Gemini 3 Flash, всей серии 3.1 (Pro, Flash Image, Lite, TTS) и Lyria 3 Pro, ориентированной на создание высококачественного звука.
Самое важное предложение скрыто во внутреннем документе: «Для всех основных моделей Omni будут выпущены отдельные версии агентов».
Смысл предельно ясен.
Google хочет объединить генерацию видео, генерацию аудио и фреймворк Agent в одном месте — на уровне ввода-вывода.
Год назад Пичай заявил, что хочет "включить Gemini в каждый продукт Google".
На этот раз он, вероятно, позволит всем самим убедиться в том, как он выполняет своё обещание.
Маск опубликовал исходный код своего новейшего алгоритма! Разработчики по всему интернету разбирают его построчно.
Илон Маск совершил еще один крупный ход! Он разместил на GitHub сразу две вещи, о которых платформы социальных сетей никогда бы не рассказали публично — «рекламу» и «цензуру» — вместе с готовой к запуску моделью рекомендаций. Теперь Grok определяет, что видят 600 миллионов человек каждый день.
Только что Маск опубликовал исходный код последней версии алгоритма!
Официальное заявление «Старой Ма» состояло всего из одного предложения, но мгновенно привлекло внимание более 27 миллионов пользователей сети.
Причина, по которой это вызвало такой ажиотаж, заключается в том, что в социальных сетях есть две вещи, которые никогда не следует показывать посторонним:
Во-первых, система впрыскивания рекламы , также известная как «машина для печати денег».
Во-вторых, конвейер проверки контента , также известный как «книга жизни и смерти».
Исходный код обоих приложений, а также модель рекомендаций на 3 ГБ , были загружены на GitHub одновременно!
Нет, они даже рекламный код нам дали?
В то время были обнародованы модель ранжирования Phoenix и информационный поток Thunder, который определяет логику принятия решений при открытии раздела «Для вас».
Но для этой рекламной системы не существовало ни единого слова кода.
На этот раз я всё отдал.
В недавно добавленной директории home-mixer/ads/ находятся четыре связанных файла Rust.
Файл partition_organic_blender.rs отвечает за смешивание рекламы и органического контента.
Файл safe_gap_blender.rs отвечает за контроль минимального количества органических постов между двумя объявлениями.
Файлы ads_brand_safety_hydrator.rs и ads_brand_safety_vf_hydrator.rs отвечают за безопасность бренда, гарантируя, что реклама не будет отображаться рядом с контентом, содержащим сцены насилия или порнографии.
Обратите внимание на ключевое слово: блендер .
Иными словами, реклама размещается не произвольно; она ставится в очередь, оценивается и смешивается с вашими публикациями и публикациями людей, на которых вы подписаны, в соответствии с определенными правилами.
Каждое объявление, которое вы видите, появляется на этой позиции только потому, что оно «побеждает» по сравнению с остальным органическим контентом.
Существует инструмент для постобработки отзывов, который называется "deluxe".
Ещё один компонент, информация о котором никогда не разглашалась публично, — это каталог grox/ .
Она отвечает за «процесс рецензирования» с момента публикации до этапа рекомендаций.
Каждый из шести классификаторов обрабатывает один раздел:
Скрипт spam.py отвечает за обнаружение спам-контента.
Скрипт post_safety_screen_deluxe.py отвечает за проверку безопасности (название "расширенная версия" весьма показательно...).
Скрипт safety_ptos.py отвечает за проверку политики условий предоставления услуг платформы.
Скрипт `banger_initial_screen.py` отвечает за первоначальную проверку популярных тем, определяя, является ли пост «достаточно взрывным».
Скрипт reply_ranking.py отвечает за сортировку ответов.
Файл classifier.py отвечает за общую классификацию контента.
Самая интересная часть здесь — это `banger_initial_screen`. `banger` — это популярный термин.
Иными словами, алгоритм имеет специальный классификатор, который определяет, вызовет ли пост ажиотаж или нет, при этом приоритет отдается тем сообщениям, которые с большей вероятностью вызовут ажиотаж.
Весь конвейер обработки данных Grox написан на Python, образуя многоуровневую структуру, при этом основная система рекомендаций написана на Rust.
Rust выполняет сортировку с точностью до миллисекунды, в то время как Python определяет, должно ли это содержимое существовать.
В него также входит загрузчик данных Kafka, система распознавания речи ASR, генератор сводных данных и механизм планирования для организации этих задач в различные «планы» выполнения.
Вот модель с 3 ГБ оперативной памяти, запускайте её.
Третье изменение, пожалуй, наиболее интересно для технологического сообщества.
Раньше, при использовании алгоритмов рекомендаций с открытым исходным кодом, можно было увидеть логику, но запустить её было невозможно. Без весов модели код представлял собой просто пустую оболочку.
В этот раз была использована предварительно обученная мини-модель Phoenix :
Одна команда может запустить весь процесс обработки данных, от поиска до сортировки, и структура конвейера обработки данных точно такая же, как в производственной среде.
Разумеется, масштаб параметров мини-модели значительно меньше, чем у онлайн-модели.
Но это первый случай в истории платформ социальных сетей, когда кто-то объединил «рабочую модель» и «код, пригодный для использования в производственной среде» и выпустил их вместе.
Судьба публикации определяется 15 вероятностями.
Реклама, отзывы и модели — три самых интересных нововведения на этот раз. Каждый из них занимает особое место в системе рекомендаций.
В январской версии большинство из шести этапов конвейера содержали лишь базовый код.
После завершения этого этапа каждый последующий шаг теперь имеет полную реализацию на Rust или Python.
Количество потенциальных источников увеличилось с 2 до более чем 7, а число источников, восстанавливающих профили пользователей, — с 0 до 17.
Это напрямую преобразовало весь конвейер из "видимого" в "работоспособный".
На пятом этапе оценивается «душа» всего конвейера.
Программа Grok Transformer от Phoenix оценивает каждый пост, одновременно прогнозируя вероятность 15 вариантов поведения пользователей.
В систему оценки также входит метод, называемый изоляцией кандидатов.
В процессе вывода данных с помощью трансформера кандидаты на должности «невидимы» друг для друга.
Каждая публикация отображает только историю действий пользователя; она не отображает другие публикации из той же группы.
Зачем это делать?
Потому что, если публикации кандидатов влияют друг на друга, оценка будет разной, если одна и та же публикация размещена 50 другими кандидатами, а не 500.
Полное устранение этой зависимости посредством маскировки внимания позволяет сделать оценку каждого поста независимой, стабильной и пригодной для кэширования.
Иными словами, эти 15 прогнозов касаются не угадывания того, «что нравится этому человеку», а оценки того, что вы сделаете, чего не сделаете и пожалеете ли вы об этом впоследствии.
Теперь ваши личные предпочтения открыты для всех.
Сегодня это единственная в мире популярная социальная медиа-платформа, которая разместила свой алгоритм рекомендаций, рекламную систему и систему модерации контента на GitHub.
Как сортировать контент в разделе «Для вас», как незаметно вставлять рекламу и какой контент будет удален — теперь есть ответы, написанные на Rust и Python.
Кроме того, эта система рекомендаций полностью переведена на управление с помощью Grok Transformer, и все правила, устанавливаемые вручную, исключены.
Иными словами, возможности моделирования xAI расширились от чат-ботов до принятия решений о ежедневном потреблении информации 600 миллионами человек.
Системы рекомендаций, пожалуй, являются сегодня наиболее мощным примером применения искусственного интеллекта. Тот, кто контролирует ранжирование, контролирует внимание.
Желающие могут клонировать репозиторий с помощью git и запустить его.
С помощью модели на 3 ГБ и одной команды вы можете увидеть, как эти 15 вероятностей определяют то, с чем вы сталкиваетесь каждый день.
>>1615714 >swap style Нейрослоп стайл. И уже видно, что это гавно не может в подобие мультипликации/аниме. Видимо в это плане уровня Соры ничего нет и не скоро будет. Разве что Сиденс неплох, но конечно более тупой и не способен сделать видос с простого промта по типу "сделай мне опенинг с аниме тяночкой из космоса и анонимусом с двачей" (а Сора бы смогла и это было бы лулзово)
Китайская «тёмная фабрика» более чем вдвое повышает эффективность производства истребителей J-20
Завод, производящий истребители пятого поколения, спроектирован для работы с минимальным участием человека или вообще без него.
Китай более чем вдвое повысил эффективность производства компонентов стелс-истребителей на «тёмной фабрике», где автономные транспортные средства и управляемое искусственным интеллектом оборудование работают почти 24 часа в сутки.
Ранее этот процесс требовал участия сотрудников для мониторинга его круглосуточной работы, однако теперь завод может производить «каркас» летательного аппарата практически в темноте, согласно сообщению официального издания «Кэцзи жибао» (Science and Technology Daily).
«Тёмные фабрики» — это предприятия, спроектированные для работы с минимальным вмешательством человека или вообще без него, что устраняет необходимость в освещении, снижая потребление энергии и операционные расходы.
«Фабрика без освещения» теперь производит компоненты для самых современных китайских истребителей, включая J-20, или «Могучий дракон», который рассматривается как ответ страны американскому истребителю F-22 Raptor. Являясь символом военной модернизации Пекина, истребитель пятого поколения J-20, разработанный корпорацией Chengdu Aircraft Corporation, дочерней компанией государственной авиационной корпорации Китая Aviation Industry Corporation of China, был признан боеготовым в 2018 году. Серийное производство этих истребителей началось двумя годами позже.
Истребитель J-20 содержит тысячи уникальных компонентов, сообщил изданию «Кэцзи жибао» Сун Гэ, руководитель центра цифрового производства завода в Чэнду.
По его словам, ранее заводу требовалось два или три сотрудника, работавших посменно в производственном цехе, чтобы обеспечивать непрерывную работу оборудования в течение всего дня. Однако теперь автоматизированные транспортные средства доставляют материалы, а высокоточные станки вытачивают компоненты.
Завод также оснащён интеллектуальными системами сканирования и роботами, способными проверять продукцию и оперативно формировать отчёты.
Десятки станков, работающих на фабрике, ранее использовали различные программные протоколы или языки, что затрудняло унификацию и автоматизацию производственной линии. Однако Сун отметил, что теперь всё оборудование «говорит на одном языке, может управляться дистанционно и взаимодействовать [с другими машинами]».
Новая система более чем вдвое повысила эффективность производства — рост составил «почти 150 процентов», добавил он, при этом оборудование способно работать на максимальной мощности более 21 часа в сутки.
Кроме того, количество человеко-часов, необходимых для эксплуатации завода, сократилось более чем на 80 процентов — хотя рабочие по-прежнему требуются для финальной сборки самолётов.
Издание «Кэцзи жибао» сообщило, что компания планирует ещё активнее внедрять такие технологии, как 5G, искусственный интеллект (ИИ) и виртуальные цифровые двойники объектов или систем в реальном времени.
С момента первого представления истребитель J-20 прошёл через многочисленные модернизации, включая замену первоначального двигателя российского производства на более скоростную модель китайского изготовления.
Согласно отчёту государственного телеканала CCTV от января этого года, также ожидается, что истребитель получит дополнительные возможности благодаря интеграции искусственного интеллекта и модернизации авионики, включая радары и двигатели. Двухместная версия J-20 — первый в мире двухместный стелс-истребитель — официально дебютировала в 2024 году.
Британский аналитический центр Royal United Services Institute, базирующийся в Лондоне, оценил, что к середине прошлого года на вооружении Народно-освободительной армии Китая находилось около 300 истребителей J-20, и эта цифра может вырасти до 1000 к 2030 году. Согласно этому отчёту, это позволит Китаю приблизиться к показателям США, которые уже эксплуатируют сотни истребителей F-35 — часть из которых размещена на авиабазах в Японии и Южной Корее — и ожидают поставки более 1700 современных истребителей к 2040-м годам.
Пекин и Вашингтон также соревнуются в разработке истребителей шестого поколения. Широко сообщается, что Китай начал испытания своих моделей J-36 и J-50 в 2024 году, в то время как США заключили с компанией Boeing контракт на создание модели F-47.
>>1615728 Модель классная канеш, уже можно потестить, проблема в том, что поиска там нет, как понимаю. И нахуй она такая нужна в 2026? Ну перевод можно сделать канеш или там рерайт, ага.
Чисто на вскидку ебанул запрос. Словил кринжа, покекал с хуйни выдуманной.
>>1615780 Ну что ты так сразу. Просто уже привык, что в "быстрых" моделях кормят отборным гавном. Вон фри ЧатЖпт до сих пор не может ответить на "можно ли пить из кружки если у нее верх запаян и дна нет".
3.5 флеш справляется с этим вопросом без поиска кстати. Либо ей этот вопрос при обучении где-то попался, либо там какое-то подобие логики есть в этих электронных мозгах.
1️⃣ Gemini 3.5 Flash. По бенчмаркам обходит Gemini 3.1 Pro в кодинге, агентных задачах и на мультимодальности, при этом выдает скорость чуть меньше 300 токенов в секунду: это заметно быстрее GPT-5.4 mini и Claude Haiku, и примерно в 4 раза быстрее Opus, Sonnet и GPT-5.5. На презентации также показывали версию, выдающую почти 1500 токенов в секунду. Цена тоже намного доступнее Pro версий, GPT и Opus.
Gemini 3.5 Pro пообещали выпустить в следующем месяце. Gemini 3.5 Flash уже можно попробовать в Antigravity.
2️⃣ Gemini Omni. Как написали Google, это "первый шаг на пути к моделям, которые могут генерировать что угодно из чего угодно". В текущей версии Omni ограничена генерацией видео. На входе может быть текст, изображения, видео и голос, на выходе вы получаете видео. Качество генераций – конкурентоспособное, говорят SOTA, физика не страдает, фотореалистичность на уровне. Примеры на вебмрелейтед. Попробовать можно в приложении Gemini.
3️⃣ Antigravity 2.0. Добавили: всякие возможности для оркестрации параллельных агентов и субагентов, фоновые задачи, нативную поддержку голосовых команд. Выпустили Antigravity CLI (на замену Gemini CLI) и Antigravity SDK для создания кастомных агентов. На презентации показали, как система собрала рабочую операционку, на которой можно запустить Doom. На это понадобилось менее 12 часов, 96 агентов и менее 1 тысячи долларов.
4️⃣ Ну и по мелочи: – полностью обновили интерфейс Gemini App, теперь ответы больше похоже на интерактивные страницы; – для подписчиков AI Plus, Pro и Ultra добавили Daily Brief: персонализированный дайджест дня на основе Gmail, Календаря и задач; – для Ultra теперь предлагают Gemini Spark: личного агента, который работает постоянно даже при выключенном ноутбуке и выполняет за вас задачи. Пока что интеграции только с инструментами Google, но обещают скоро добавить и другие; – подписка Google AI Ultra теперь стартует от $100/месяц (раньше было от $250), а тариф за $250 подешевел до $200 без урезания возможностей и лимитов; – анонсировали умные очки и новые ноутбуки Googlebooks.
>>1615669 >У Google самая мощная инфраструктура, самая большая пользовательская база и наиболее полная продуктовая линейка, но по самому важному вопросу — «достаточно ли сильна сама бизнес-модель» — она всегда уступала двум своим конкурентам.
Булщетъ. Модель должна быть и функциональной и дешевой. Бизнес про деньги. Цена, это про деньги. Важно соотношение цены и эффективности. Сомнительно, что Гугл тут третьи.
>>1615842 Прямо максимум мне кажется не очень нужен. Нужно, чтобы просто хорошо было и была какая-то предсказуемость. Всё равно, любые модели могут вариться, гарантий нет. Вот особенно когда вопрос программирования. Ещё важно, чтобы галлюцинаций меньше было, у Gemini 3.1 разных вариантов с этим было не очень
>>1615852 В предсказуемости Гугл как раз отстает, галюнов больше. Но когда копеечная цена токенов, можно это поправить, запустив модель еще пяток (а то и 50) раз за ту же итоговую стоимость, что и у конкурентов. Зато в остальных случаях будет больше выгоды. Я не про текущую модель говорю, а про старую. Но новую вроде тоже дешевую обещают.
>>1615873 Кал какой-то, сосущий у копеечной Сяоми. Ещё и цену заломили. Я бы за 3 бакса пять раз подумал брать бы это вместо Мимо, а за 9 вообще нахуй.
>>1615880 Гемини можно юзать хоть и с лимитами но полностью бесплатно через antigravity и через веб. А Мимо от сяоми платная изначально, бесплатно ее нигде не дают даже понюхать.
После изобретения ИИ человечество столкнется с экзистенциальным кризисом и вымрет. Вот что людям делать в мире, где ИИ лучше любого человека во всем? Творчество? ИИ создаст фильм за пару минут, который будет лучше любого человеческого поделия. Все, что люди делают, обесценится и перестанет вообще что-либо значить. У людей просто поедет крыша от осознания своей немощности, и на этом история человечества подойдет к концу. Конечно, сначала люди опьянеют от радости, начинают 24/7 бухать, упарываться, но круглосуточные развлечения довольно быстро всех утомят, но в мире победившего ИИ больше нечем будет заняться.
>>1615895 Чому низя будет попросить ИИ устроить тебе контрастную развлекуху? С его познанием психологии и работы мозга он на изи нагрузит любого людишку смыслами и приколюхами, чтобы было разнообразно интересно и т.д.
>>1615905 Ладно, возможно я поторопился с этим, я имел в виду, если прямо сейчас нейронки и роботы заменят все работы (уже начали), то что будет делать человек? Делать ведь будет абсолютно нехуй >>1615906 Их работа имеет смысл и значение для общества. Ты скажешь, что это хуйня, но я не согласен. Ты можешь собрать 100 ящиков, из которых купят только 10, и даже это будет иметь значение для тебя, даже если ты это отрицаешь. Если ты будешь каждый день вставать и целый день играть в какую-нибудь придуманную нейронкой дрочильню, у тебя просто поедет крыша
>>1615895 Про эволюцию слышал? Эволюционировать дальше. Из обезьяны в суперобезьяну и по нарастающей. Все точно не вымрут, не переживай. Для этого планетарная катастрофа нужна. А вскоре нужна будет и катастрофа уровня Солнечной системы, планетарной не хватит.
>>1615910 >Делать ведь будет абсолютно нехуй Всм поч. Ты же не только работу работаешь, лол, и в этом смысл находишь. Ну прикинь ИИшка будущего нагенерила Кириллу игоря про корованы мечты. Он садится катать и понимает, что чёт не то, начинает перепромптивать. И так на это дохуя времени может уйти на всякие мелочи в этом игоре, чтобы чисто для себя что-то по кайфу даже с помощи ИИ сделать. И это будет просто 1 игрушка. А так дохуя всем себя можн будет занять же таким макаром.
>>1615912 Это довольно быстро заебет тебя, особенно если учесть, что все будут безработными и будут заниматься такой же хуйней. В итоге ты будешь единственным человеком, который оценит свое поделие, ведь этих игрулек станет настолько много, что ими будет завалено все цифровое пространство
>>1615913 Если тебе очень хочется развлекаться и ты видишь в этом фундаментальную проблему, что СКУЧНО, то симуляция решает все твои вопросы. Суют тебя в симулцию Средневековья, и сразу весело, есть чем заняться. Нет памяти о мире, где правит превосходящий тебя ИИ. Пооткисаешь там пару веков, выйдешь новым человеком. Сразу жить захочется. Надоело? Повторишь.
>>1615915 > есть чем заняться Можно грабить корованы, есть форт Злодея, домики в лесу, эльфы деревянные, труп 3д, целая куча трупов 3д, вся Европа в 3д.
>>1615913 >В итоге ты будешь единственным человеком, который оценит свое поделие Чому не можешь наспавнить себе человекоподобных ботиков для оценки и срачей? Почему думаешь не будет мировой медиабиблиотеки, куда можно будет всем сливать свои шедевры и дрочить оценочки с комментами? У меня вот в одном ток стимаче почти 800 не пройденных игрух, а я за год на 100% примерно штук 5 выдрачиваю, при том что я не работаю и в целом почти живу в ББД-шном ИИ-рае уже сейчас. Т.е. при своей кайфовой ненапряжной жизни мне понадобится сотни лет на прохождение поверхностных винчиков, и то только тех, которые к текущему моменту склепали. И это только про потребление 1 вида медийки. А если взять вские хобби и т.д. это же пиздец тысячелетия интересных активностей обеспечены, главное посчитать белки и всё.
>>1615915 Какие еще симуляции? Современные нейронки и роботы в будущем вполне смогут автоматизировать все рабочие места. И что дальше? Ты думаешь, еба-развлечения из человеческих фантазий сразу же материализуются?
>>1615918 Если роботы автоматизируют все места, да еще и будут роботов производить, раз заняли все места, богатство всех жителей планеты в среднем вырастет в десятки раз. А некоторых в сотни и тысячи.
Нет не материализуются, но и темпы их изобретения и производства возрастут тоже в разы.
>>1615895 >Вот что людям делать в мире, где ИИ лучше любого человека во всем? Как будто есть хоть одна вещь, где ты лучший во всём. Миллионы людей лучше тебя во всем, чел.
>>1615990 Я не понимаю как gemini-3.5-flash с его 1.5$/9$ вышел дороже, чем gpt-5.5 4$/30$. При том что 5.5 просто пиздец как неадекватно разговорчив. Чё за бенч?
>>1616063 > 5.5 просто пиздец как неадекватно разговорчив Да нихуя. Я кодексом постоянно пользуюсь, на лоу он думает пару секунд, минимум токенов тратит. На медиуме ризонинг не более 20-30 секунд. Может флеш минутами думает, ты ещё учти что у флеша 200 т/с скорость.
>>1616060 >Особенно если Грок выйдепт на уровне SOTA моделей Если да кабы, а особенно с их лимитами, которые прикрутили Илоний и Гooлаг, нахуй они не нужны. Лучше чатгопотой воспользоваться или китайщиной
>>1615895 У меня наоборот появилась возможность меньше работать и больше читать. И книжки теперь читать проще, потому что появляется луп на ИИ можно обсуждать всё ли правильно понимаю.
>>1616063 Реальный чек очень сильно расходится с тарифами. Вот когда большой ризонинг, или, особенно, на агентских задачах. В результате модель, что якобы в 10 раз дешевле, может обойтись дороже
Кстати вот поэтому бенчи на прайс для задач как раз интересны и полезны
GPT 5.5 выглядит удачной, довольно умной и при этом экономной, тариф там оправдан, имхо
Gemini 3.5 Flash ну так себе, нет желания пользоваться ей вместо старой линейки Gemini 3.1 (Pro/Flash/Flash mini).
короче смотрится не прорывом, а чем-то ближе к обсеру, ну или как-минимум дикой накрутке прайса за старые возможности
Чет ощущение плато жесткое. Дело даже не в перформансе моделей, а в том, что все развитие упирается тупо в скейлинг. Инференс флеш модели гугла стоит в три раза дороже предыдущей. В оптимизацию пытается разве что дипсик, но он по сравнению даже с некоторыми китайцами сосет. Фри юзерам уже давно сота модели не дают, опенаи дает инстант огрызок, антропики дают соннет, грок прикрыл все бесплатникам кроме фаст модели, гугл вангую 3.5 про в ai studio сделают платным так же как и вторая банана например. Они построили кучу датацентров, но у них все еще не хватает мощностей. Вместо того чтобы искать пути оптимизации моделей они ищут ресурсы для создания большего количество гпу. Агентами сейчас не пользуется и одного процента людей, но все уже упираются в лимиты. В будущем нас ждет оверпрайс кал по подпискам с множеством грейдов, китайцы подтянутся туда же. Придется создавать локальный сетап и молиться чтобы в будущем вышло что-то на уровне текущего опуса но чтобы вмещалось хотя бы в 32 гига врам.
>>1616157 >Они построили кучу датацентров, но у них все еще не хватает мощностей Вот здесь туман полный, сколько новых мощностей ввели. Судя по всему на самом деле не так много
>Придется создавать локальный сетап и молиться чтобы в будущем вышло что-то на уровне текущего опуса но чтобы вмещалось хотя бы в 32 гига врам Всё, что ты можешь поднять у себя, ты сможешь приобрести в облаке, но за копейки, конечно за исключением цензурных моментов, только цензура-приватность делают разумными локальные запуски. Ну энтузиазм ещё.
Сделать что-то небольшое, но крутое, вряд ли возможно. Скорее можно мечтать, что железо подтянется и подешевеет, и будут варианты пускать хоть не опус, но что-то всё равно довольно крутое, локально.
В 90% случаев на самом деле должно хватать довольно простых моделей.
>>1616157 >все развитие упирается тупо в скейлинг Сегодня всё упирается в рыночек. Ты не можешь использовать старые модели в агентах. Они не сильно тупее, но у них в датасетах не было навалено агентного поведения. Зачем отдавать новые модели дешевле если токенов и так дефицит?
В приложении и на сайте qwen появился qwen3.7 preview, в отличии от 3.6 проходит тест на П-обьект. В opencode zen снова бесплатно раздают qwen3.6 через api opencode.
>>1616200 Там надо бы набор тестов подготовить, объекты что можно построить и что нельзя. Суть же в том, что есть известная иллюзия, которую нельзя построить. Вот часть моделей натренирована на этой иллюзии и они видят её везде.
Но если модель не натренирована, она находить её не будет. То есть если не находит, это не значит, что модель умнее стала, даже не значит, что её на этот бенчмарк натаскали
>>1616217 Оно и полтора года назад работало, только за счёт того что ты писал им простыни объясняющих промтов. Сейчас тебе достаточно сказать "ты агент, вот твои инструменты, действуй".
>>1616350 Тест сформулирован так, что его может решить как минимум 3 три анона с /b - это факт. Или ты считаешь, что диаметр это не расстояние? Бенч как раз проверяет способность ии судить, понимать с полу слова, даже если формулировка не идеальная по мнению некоторых анонов. В реальной жизни именно с такими формулировками и приходится работать, я почему-то смог найти эти расстояния
>>1616389 За 2-3 бакса её сожрали бы. Как обычный Флеш. Был бы конкурент китайцам и Гроку, который в том же ценовом диапазоне. А так цена вплотную к топам, а смысла мало.
Шедевр Беркли опровергает утверждение OpenAI: истинным богом является непрерывное обучение!
Беркли и другие компании представили структуру FST: решение проблемы тупика непрерывного обучения для больших моделей с помощью быстрого и медленного наложения слоев.
Инженер в области искусственного интеллекта Дэн МакАтир смело предсказывает, что непрерывное обучение получит стремительное развитие в 2026 году!
Благодаря иерархическому механизму, сочетающему быструю адаптацию к памяти/контексту с медленной корректировкой весов, модель сохраняет свою пластичность и избегает катастрофического забывания — прорыв, который в 1000 раз превосходит революцию в области логического вывода.
Эту смелость ему придали недавние эксперименты с искусственным интеллектом в таких учреждениях, как Беркли.
Они использовали одну и ту же большую языковую модель для последовательного изучения трех задач:
Сначала изучите HoVer, алгоритм проверки фактов, требующий нескольких переходов; затем изучите CodeIO, алгоритм рассуждений на основе кода; и наконец, изучите физику.
Каждая задача обучается в течение 200 шагов, после чего происходит переключение на другую задачу, имитируя реальный сценарий обучения, в котором «задачи постоянно меняются».
Модель обучалась с использованием распространенных парадигм обучения с подкреплением (RL) и освоила первый уровень, HoVer. Однако на втором уровне, CodeIO, она полностью застопорилась и не смогла ничего изучить.
Перейдя на предложенную ими новую структуру FST (Learning, Fast and Slow — Обучение, Быстрое и Медленное обучение), можно освоить все три уровня, используя одну и ту же модель.
Впервые индустрия искусственного интеллекта, которая коллективно делала ставку на это направление в течение последних двух лет, выявила свои ограничения.
Если мы все вместе делаем ставку на превращение моделей в «гениев, способных решать проблемы, но не умеющих учиться новому», то делаем ли мы ставку на искусственный интеллект или на все более изощренного попугая?
«Рассуждение» стало определяющим элементом всей концепции сообщества искусственного интеллекта. В течение последних двух лет почти все ведущие лаборатории занимались одним и тем же: заставляли модели мыслить глубже.
Серия o от OpenAI, R1 от DeepSeek и режим мышления от Claude — все это разные продукты, но у них есть общая черта: способность к рассуждению — это следующая задача для ИИ .
Насколько прочен этот консенсус?
Настолько сильный, что если вы сегодня обратитесь к ведущим инвесторам и не сможете четко объяснить, как вы «рассуждаете», вы даже не пройдете первый раунд финансирования.
Настолько могущественный, что мы забыли спросить: что же такое рассуждение на самом деле?
Например, студент может очень глубоко продумать любой вопрос вступительного экзамена в колледж, используя безупречную цепочку рассуждений и идеальную логическую структуру.
Но есть одно условие: он не получил никаких новых знаний со дня окончания средней школы. Все его знания остаются на том же уровне, что и в 16 лет.
Вы бы назвали его способности «интеллектом»?
Эта аналогия не является фигурой речи. Она отражает истинное положение дел в самых передовых магистерских программах на сегодняшний день.
GPT-5, Claude, Gemini и все остальные модели, которые вы можете использовать сегодня, подобны гениям, которые вчера закончили учёбу, сегодня проснулись и забывают обо всём с началом каждого нового разговора.
Они могут всё глубже и глубже вникать в проблему, но как только диалоговое окно закрывается, их память очищается, и они возвращаются к своему запрограммированному «гениальному состоянию».
Они подобны Сизифу в мире чисел, взбирающемуся все выше и выше по валуну разума, но всегда начинающему свой путь у подножия горы.
Вопрос в том, почему мы не замечали этого все это время?
После 30 лет неудач в истории искусственного интеллекта люди больше не смеют ничего ожидать.
Почему GPT ничего не усваивает из ваших разговоров с ним? Почему он полностью забывает то, чему вы его научили вчера, когда вы открываете новый разговор сегодня?
Это стена, которую никто не сносил последние 30 лет.
В области искусственного интеллекта концепция «непрерывного обучения» изучает, как заставить модели, подобно людям, постоянно «пересматривать и изучать новое, отбрасывать старое и усваивать новое».
Эта проблема изучается с 1990-х годов, но неоднократно терпела неудачу в борьбе с тремя старыми противниками:
Первый фактор, противодействующий модели, называется «предвзятостью первенства » , когда данные, полученные на ранних этапах, определяют окончательную стратегию модели.
Первое, чему учится модель, будет неуклонно определять то, как она будет усваивать все остальное впоследствии.
Второй фактор называется «потеря пластичности», что означает, что пластичность модели уменьшается на один пункт за каждую дополнительную задачу, которую она изучает.
В определенный критический момент оно больше не способно усваивать что-либо новое.
Третий и самый известный противник называется «катастрофическим забыванием» — когда вы обучаете модель выполнению новой задачи, ее старые способности мгновенно разрушаются.
Научите ее решать математические задачи, и она забудет, как писать код. Научите ее писать код, и она забудет, как вести беседу.
Эти три проблемы существовали даже в эпоху мелкомасштабных моделей.
В эпоху крупномасштабных моделей они не стали меньше, а просто стали менее заметными.
Поскольку мы просто отказались от идеи позволить модели «непрерывно обучаться», мы предоставляли ей знания только один раз во время обучения, а затем замораживали их после развертывания.
Все магистерские программы, которые мы используем сегодня, по сути, представляют собой застывших гениев .
Умный, но не умнее других. Могущественный, но живущий в вечном настоящем.
непрерывное обучение ИИ ч2
Аноним# OP20/05/26 Срд 19:04:51№1616447113
Вот почему в эпоху крупномасштабных моделей непрерывное обучение всегда было темой, которая «звучит замечательно, но никто не осмеливается к ней прикоснуться».
Все, кто пытался это сделать, были отброшены этой стеной.
Но недавно группа исследователей пробила брешь в этом барьере — они не изобрели новый алгоритм, а сделали нечто более фундаментальное: они реструктурировали разделение труда .
Пусть модель, подобно мозгу, будет многослойной, с разной скоростью. Этот проект объединяет инженерные возможности Databricks, системный подход Беркли и классические принципы машинного обучения
Авторы впечатляют, и книгу стоит прочитать: Матей Захария (сооснователь Databricks и автор Apache Spark), Джозеф Гонсалес (Беркли и один из авторов vLLM), Индерджит Дхиллон (Техасский университет в Остине и Google, ветеран в области машинного обучения) — и группа докторов наук из Беркли.
Когда все три силы делают ставку в одном направлении, следует присмотреться повнимательнее.
Предложенная ими методика называется FST (Fast-Slow Training — быстро-медленное обучение). Основная идея предельно проста:
Не допускайте, чтобы набор параметров одновременно выполнял две противоречащие друг другу функции.
В традиционном обучении с подкреплением модель имеет только один набор параметров.
Оно должно уметь «быстро адаптироваться к специфике текущей задачи», «сохраняя при этом общие способности к логическому мышлению».
Эти две вещи по своей сути противоречат друг другу: первая должна быть изменчивой, а вторая — оставаться стабильной .
Подход FST заключается в том, чтобы присвоить этим двум параметрам два набора «весов» .
Эти два параметра обновляются попеременно: медленные веса корректируются с помощью обучения с подкреплением через определенные промежутки времени, а быстрые веса автоматически развиваются с помощью оптимизатора GEPA.
Именно так и работает ваш мозг.
В своем сообщении в блоге команда GEPA напрямую сослалась на теорию «дополнительных систем обучения»:
Гиппокамп — это «быстрый вес» мозга, который может запомнить слова коллеги с сегодняшнего совещания всего за несколько минут;
Ваша неокортекс "медленно набирает вес", и для формирования деталей, которые действительно стоит включить в долгосрочную структуру, требуются месяцы или даже годы.
Новые воспоминания никогда не записываются напрямую в долговременную структуру мозга.
Сначала она «временно хранится» в гиппокампе, многократно воспроизводится во время сна, и в конечном итоге лишь очень небольшая её часть медленно проникает в неокортекс — остальное вы забываете.
FST впервые применил подобную иерархическую структуру к крупным моделям.
Цифры тоже впечатляют.
FST обеспечивает производительность, эквивалентную RL, в задачах CodeIO, используя всего 1/3 шагов обучения — в 3 раза эффективнее с точки зрения использования данных .
При сохранении точности сопоставления, дивергенция Кульбака-Лейблера (мера сдвига распределения) между моделью, обученной с помощью FST, и базовой моделью на 70% ниже, чем у модели, обученной с подкреплением, что приводит к снижению забывания на 70% .
Наиболее важным тестом является тест на пластичность : после обучения на математической задаче, при обучении на задаче HoVer-hard, модель, обученная с помощью RL, практически не может освоить новую задачу (пластичность падает почти до нуля), в то время как модель, обученная с помощью FST, почти восстанавливается до уровня базовой модели и продолжает обучение.
Это скачок на порядок .
Конечно, FST — не идеальный алгоритм. GEPA и CISPO можно заменить любым другим алгоритмом оптимизации подсказок и алгоритмом обучения с подкреплением, а его инженерная реализация всё ещё находится на ранней стадии.
Важно не то, можно ли успешно реализовать конкретный метод FST, а то, что предложенное им «быстрое и медленное разделение труда» в качестве парадигмы впервые превратило непрерывное обучение из несбыточной мечты в реально осуществимое инженерное направление .
Консенсус еще не достигнут. Формируется консенсус, но он еще не достигнут.
Таково истинное положение дел.
В этой отрасли сроки отличаются.
Илья Суцкевер утверждает, что сверхинтеллект следует переосмыслить как непрерывно обучающийся процесс, а не как завершенный искусственный общий интеллект.
Он предполагает, что для непрерывного обучения потребуется еще от 5 до 20 лет.
Илья всегда отстаёт от общепринятого в отрасли мнения, но его консервативные прогнозы неизменно точнее. Срок от 5 до 20 лет подразумевает, что даже Илья признаёт, что проблема будет решена; разногласия касаются только темпов.
Карпати действует более тонко.
По его мнению, непрерывное обучение — это реальная проблема, и существующие подходы недостаточны для её решения. Его скептицизм оставался на уровне реализации, без каких-либо возражений на уровне руководства.
Но всё уже началось.
Эра налоговых вычетов начнётся в 2024 году и закончится в 2026 году.
Эра непрерывного обучения начнётся в 2026 году, а следующий этап соревнований не заставит себя ждать до 2027 года.
Ваш ИИ-агент становится всё глупее по мере его использования? Китайский университет Гонконга и Чжэцзянский университет развенчивают миф о «памяти».
Вам всегда кажется, что контекста недостаточно при использовании агентов для работы или написания кода? Или вы считаете, что многократное использование агентов не делает их умнее? Вы считаете, что существующие решения для запоминания все еще неадекватны? Сегодня статья, опубликованная Китайским университетом Гонконга в сотрудничестве с Чжэцзянским университетом, посвящена этой проблеме и вызвала широкое обсуждение в академическом сообществе: вы думаете, что агенты «запоминают», но на самом деле они просто делают заметки. Вы когда-нибудь сталкивались с подобной ситуацией:
Вы настроили агента с использованием векторной базы данных и загрузили большое количество исторических диалогов, но он все равно не смог ответить на вопросы в следующий раз; или вы написали десятки циклов кода, используя Cursor и Claude, но создавалось ощущение, что его понимание вашего проекта со временем не углубляется, и каждый раз казалось, что он узнает вас заново.
Это не проблема ни с моделью, ни с конфигурацией RAG.
Исследователи из Гонконгского университета и Чжэцзянского университета в новой статье предложили более фундаментальный ответ: мы вообще не наделяли агента реальными воспоминаниями. Мы дали ему лишь записку.
Статья была опубликована в виде препринта на arXiv 30 апреля 2026 года, и примерно через 10 дней вызвала бурную дискуссию в международном академическом сообществе. Известный аккаунт в Твиттере, посвященный искусственному интеллекту, @dair_ai, ретвитнул её, и она получила более 26 100 просмотров и более 700 лайков . Несколько ютуберов также спонтанно создали вводные видеоролики, и статья была перепощена на Xiaohongshu.
Почему по мере увеличения использования агенты становятся всё менее и менее полезными?
Существующие решения для хранения данных агентами можно условно разделить на четыре категории: векторное хранение, генерация для улучшения поиска (RAG), Scratchpad и управление контекстным окном.
У них есть одна общая черта: они больше склонны к «поиску», чем к «запоминанию».
Авторы статьи называют эти механизмы в совокупности «заметками», а не подлинными воспоминаниями.
Логика служебной записки заключается в хранении информации и её извлечении при необходимости. Это совершенно отличается от того, как люди «запоминают» что-либо.
Основное различие заключается в фундаментальной разнице механизмов обобщения :
Память, основанная на извлечении информации : обобщение достигается за счет сходства с сохраненными случаями. Если в ваших сохраненных случаях нет похожих сценариев, агент не будет их обрабатывать.
Взвешенная память : абстрагирование опыта в правила и применение этих правил к ранее не встречавшимся входным данным.
Когда люди изучают язык, они не запоминают каждое предложение, а усваивают грамматические правила, а затем создают новые предложения, которые никогда раньше не произносили.
Нынешний Агент «Память» больше похож на память, основанную на извлечении информации.
Три основных структурных дефекта
Авторы выделяют три ключевых ограничения современных систем контекстной прокси-памяти, каждое из которых может быть доказано теоретически, а не только на основе интуиции.
Ошибка 1: Количество информации не равно способностям.
Агенты бесконечно накапливают записи, но не развивают подлинной экспертной компетенции.
Когнитивная наука давно продемонстрировала (Чи и др., 1981), что принципиальное различие между экспертами и новичками заключается не в наличии большего объема информации, а в качественном изменении способа организации знаний : знания экспертов реструктурируются в соответствии с глубинными принципами, а не просто накапливаются.
Текущий агент этого сделать не может. В конце каждой сессии веса модели остаются совершенно неизменными, и в следующий раз она по-прежнему начинает с той же «начальной» точки, только с несколькими дополнительными заметками.
Недостаток 2: Потолок обобщения – Математический анализ
Исследователи использовали теорию сложности выборок, чтобы продемонстрировать количественно измеримый разрыв в обобщаемости:
Система памяти, основанная на поиске информации, должна хранить Ω(k²) случаев для обработки комбинаторных новых задач.
Параметрическое обучение (запоминание весов) требует всего O(d) примеров (где d — размерность сложности оператора).
Что еще более важно, увеличение контекстного окна не может преодолеть это ограничение. Ограничение связано не с пропускной способностью, а с общим охватом. Если агент никогда не сталкивался с ситуацией, когда «правило А + правило В применяются одновременно», он не сможет обработать эту комбинацию, независимо от того, сколько заметок вы в него впихнете.
Для иллюстрации на простом примере: предположим, агент осваивает навыки «перевода градусов Цельсия в градусы Фаренгейта» и «перевода часовых поясов». Если он просто сохранит примеры в векторной библиотеке, он, скорее всего, столкнется с комбинированной задачей, например, «переводом температуры в Пекине в соответствующее время в Нью-Йорке». Однако, как только люди усвоят правила, такие комбинации станут для них естественными.
>>1616454 Уязвимость 3: Отравление памяти – структурная уязвимость безопасности.
Постоянное хранение данных в памяти по своей природе уязвимо для атак, связанных с отравлением памяти, из-за особенностей своей структуры. Приведенные в статье эмпирические данные вызывают тревогу:
Атака MINJA : обеспечивает 98,2% успеха за счет минимизации функциональных потерь.
Атака PoisonedRAG : Достижение 90% успеха всего с 5 враждебными текстами.
Ещё опаснее то, что после успешного внедрения вредоносное содержимое будет продолжать циркулировать во всех последующих сессиях через постоянную память, превращая единичную атаку в необратимое вторжение.
гиппокамп + неокортекс Незаменимый
Теоретической основой данной работы является теория комплементарных обучающих систем (CLS) в нейробиологии .
Мозг млекопитающих решает проблему памяти посредством взаимодействия двух систем:
Hippocampus : Быстрая запись сцен и высококачественное хранение данных.
Неокортекс : медленная интеграция, уточнение эпизодических воспоминаний до абстрактных правил и запись их в виде весовых коэффициентов.
Эти две системы незаменимы. Во время сна мозг «воспроизводит» эпизодические воспоминания дня в неокортексе, завершая трансформацию от «воспоминания об этом» к «обучению этому».
Нынешний ИИ-агент реализует только работу гиппокампа, то есть быстрое письмо и запоминание сходства, без абстрагирования отдельных этапов.
Авторы статьи сравнивают современного агента с человеком, который никогда не спит — постоянно делает заметки, но никогда не систематизирует их и никогда не способен превратить разрозненный опыт в подлинную экспертизу.
Что думают об этом учёные? Реальные дискуссии по X
После публикации статьи репост @dair_ai быстро вызвал бурные дискуссии в международном академическом сообществе. Ниже приведены переводы некоторых показательных дискуссий:
Сосуществование двух систем Речь не идёт о том, чтобы всё снести и начать заново.
Данная статья представляет собой не просто «критику», а скорее предлагает архитектурный подход к сосуществованию двух систем .
Основная идея заключается в добавлении асинхронного канала консолидации при сохранении существующей эпизодической памяти, основанной на извлечении информации (гиппокампальный эквивалент), для постепенной интеграции эпизодической памяти в весовые коэффициенты модели (неокортикальный эквивалент).
Уже существуют специализированные технологии, начиная от LoRA (Lightweight Adjustment) и MEMIT (Memory Editing) и заканчивая слоями TTT (Test-Time Training) и SSR (Self-Distillation).
В документе содержатся конкретные призывы к действию для трех типов аудиторий:
Системный конструктор : Реализация канала консолидации от контекстного хранилища к весам, вместо бесконечного расширения векторной библиотеки.
Benchmark Designer : Представляем метрику «Комбинаторное обобщение во времени (CGT)», позволяющую точно измерить, обучается ли агент.
Исследовательское сообщество, занимающееся непрерывным обучением : переориентация на сценарии с участием агентов, которые естественным образом обеспечивают непрерывный поток опыта, сигналов вознаграждения и реальных условий развертывания.
Подведите итоги
Данная работа по сути является программным документом; она не предполагает большого объема экспериментальной работы, но ее аргументационная структура ясна, а теоретическое доказательство строгое.
Тот факт, что это вызвало столь широкую дискуссию, может точно отражать то, что почти каждый инженер и исследователь, серьезно работавший с агентами длительного действия, смутно ощущал эту проблему, но никто до сих пор не смог четко ее сформулировать.
Если вы создаёте долго работающую агентскую систему, эта статья предлагает важную концептуальную корректировку: являются ли хранимые вами «воспоминания» просто заметками или же реальным обучением?
Сюй, Б., Дай, С., и Чжан, К. (2026). Контекстуальная агентная память — это заметка, а не истинная память. arXiv:2604.27707v1 @dair_ai Обсуждение в Twitter/X: https://x.com/dair_ai/status/2050694339165335754
>>1615895 >Творчество? ИИ создаст фильм за пару минут, который будет лучше любого человеческого поделия. Хоть один фильм снимет уровня шедевров конца 20 века, тогда говори. Современное кино конечно скатилось, но это потому что весь голливуд скатили, тут и ИИ без особых усилий справится, а так в 20м веке делали недостижимые шедевры, до них никакой ИИ не дотянется.
Бл я уже так заебался со спёрднутых концовок сирычей что я смотрел, ГоТ, Титосы, Пацаны, у меня такое ощущение что оставшиеся 2 сериала которых я чекаю по кд тоже спёрднутся в 0 без накала эмоций, просто и серо, будто и не было эпического задела Эти 2 сирыча из ИРЛ: гойда и развитие ИИ
>>1616487 В нулевые годы ещё довольно много реально хороших фильмов было. Вот начиная с десятых уже печально стало.
>тут и ИИ без особых усилий справится Голливуд может и скатился, главным образом из-за политики и повесток, фемповестки в первую очередь и нравоучений, и в попытках снимать PG-13, но нейрослоп даже 30 секунд пока снять не может как надо. Даже технически. Всё-таки как-минимум технически сейчас в Голливуде снимают очень хорошо. Претензии по содержанию. И что мало чего-то нового, но последнее точно не про нейросети.
>>1615913 В этом треде сильно переоценивают требовательность людей к развлечениям. 99% процентов людей неприхотливы в этом хотя бы в силу того, что все тупо смотрят телевизор/рилсы/тиктоки, где из раза в раз повторяются +- одни и те же сюжеты. И ничего, всем норм.
Про это ещё Брэдбери писал в 451, где после сингулярности никто не читал книги, не интересовался чем-то новым, а тёлка ГГ сидела дома тупо общалась с ИИ и бомбила на него, когда он пытался этому помешать.
Что-то такое и будет, ИИ вряд ли будет тратить ресурсы на удовлетворение каждого человека. Наделает слопа, который будет нравиться большинству людей, всё, пусть пипл хавает.
>>1616588 >Эбало? Абсолютное говно во всём, канонический нейрослоп
>>1616553 >Вот в ютубе такое видел от ИИ, в принципе уже близко к современному голливуду Вот этот вариант сильно лучше, хотя очень много слоп-неконсистентности, ну и по графике-игре видно. И сценарий ни о чём, но это уже ближе к Голливуду, где с этим часто тоже не очень
>>1616671 >Сценарий кстати целиком ИИ написан. ЛЛМкой, без авторов. Это для меня очевидный минус, а не плюс.
То есть главная проблема генерирующих фото-видео нейронок, это что они неуправляемы, генерят рандом, а не то, что тебе надо. А нужно что-то от авторов.
Я скорее подумал, что это человек что-то нафантазировал, но про принципу "чего-нибудь снять", для демонстрации технологий. Очень похоже не на Голливуд, а на лигу ниже, вот так часто любители-студенты что-то снимают, тоже типа надо снять что-нибудь. Без претензий.
В чём пока реальная проблема, это что очень много неконсистентности и неестественного. Сменяется кадр, и меняется то, что в кадре. Это категорически плохо, потому что всё-таки видео это работа для ума, ты строишь сцену у себя в сознании, а тут всё ломается в каждый момент.
То, что сценарий ИИ это минус. Голливуд снимает в основном говно. Тут я тоже смотрел с перемоткой, слишком скучно. Но, в Голливуде проблема, что снимать дорого. Допустим есть режиссёр и сценарист, у них реально идея, они реально что-то придумали. Но хрен они соберут деньги и убедят продюсеров, что надо снимать, как они хотят.
Чего хотелось бы от ИИ, это чтобы появились возможности, выпускать что-о действительно интересное, идейное, что соответствует видению авторов. И при этом достаточно дёшево, чтобы не зависеть от дорогих съёмок, актёров и т.п. Но это подразумевает, что они продумывают детально весь фильм, а нейронка уже следует их задумке. Что пока сложно. А вот самая дорогая и сложная часть убирается. Вот здесь было бы реальное развитие. А когда всё нейронка, то это деградация.
В искусстве главное, это что автор хочет донести какую-то идею. Нейронке это абсолютно чуждо.
>>1616697 Иными словами, проблема слопа в том, что получается, что ИИ открывают возможности для дешёвого создания халтуры. Мусора и так много, а здесь на порядки больше можно генерить
А вот качественные вещи, когда авторы действительно хотят что-то сделать, и реально работают над своим произведением, забиваются, ещё сильнее тонут, качественных вещей становится меньше не только в процентном, но и даже в абсолютном количестве
>>1616700 Ну или совсем кратно база: новые технологии должны открывать новые возможности, делать то, чего невозможно было раньше. В некоторых сферах ИИ такое показывает, например в биохимии.
Но в основным мы видим обратное, деградацию. С помощью ИИ делают вещи хуже, чем раньше делали без ИИ. Просто дешевле.
Стартап в сфере искусственного интеллекта Anthropic заработал 80 миллиардов долларов за год! Два гиганта перебили предложение OpenAI, забрав с собой 89% прибыли.
Стартапы в сфере ИИ зарабатывают 80 миллиардов долларов в год, при этом OpenAI и Anthropic получают 89% этой суммы. В итоге битва ста моделей заканчивается не расцветом разнообразных компаний, а сценарием, когда победитель забирает всё. Стартапы в сфере искусственного интеллекта зарабатывают ошеломляющие 80 миллиардов долларов за один год!
Согласно последним данным издания The Information, совокупный годовой доход 34 ведущих мировых стартапов в сфере искусственного интеллекта достиг примерно 80 миллиардов долларов, что на 112% больше всего за шесть месяцев.
Кажется, что весь трек — сплошное безумие, правда? Но стоит разобрать эти цифры, и от них по спине пробегут мурашки.
OpenAI и Anthropic получили 89%!
Оставшиеся 32 компании ютятся в этом 11-процентном разрыве, едва выживая.
Это не соревнование; здесь победитель забирает всё.
Компания Anthropic одержала победу над OpenAI и заняла первое место.
Начнём с размера.
Из этих 80 миллиардов долларов более половины приходится только на OpenAI ( включая доходы от перепродажи через облачные каналы, такие как Microsoft, AWS и Google Cloud ).
Но настоящий шок для отрасли вызвал стремительный рост компании Anthropic.
В январе 2025 года годовая выручка Anthropic составляла всего 1 миллиард долларов. К концу 2025 года она вырастет до 9 миллиардов долларов.
Затем, всего четыре месяца спустя, в апреле 2026 года, эта цифра превысила 30 миллиардов долларов, официально превзойдя показатель OpenAI в 25 миллиардов долларов, что стало самым впечатляющим «возвращением» в индустрии искусственного интеллекта.
Доля антропогенных факторов на корпоративном рынке выросла с 1% до 34% менее чем за два года.
За 15 месяцев выручка выросла в 30 раз — это вертикальная линия.
Эти две компании выбрали совершенно разные пути.
OpenAI опирается на обширную пользовательскую империю ChatGPT, ориентированную на потребителей, — 900 миллионов активных пользователей в неделю, от бесплатных до Plus и Pro.
Этот путь быстр, но его потолок также очевиден: готовность потребителей платить имеет верхний предел, и как только конкуренты выпустят более качественные продукты, стоимость перехода к другому производителю станет практически нулевой.
Компания Anthropic с самого начала делала ставку на корпоративных клиентов.
Компания Claude Code достигла годового дохода в 1 миллиард долларов в течение шести месяцев после запуска, более 1000 корпоративных клиентов ежегодно тратят на услуги Claude более 1 миллиона долларов, а восемь из 10 компаний, входящих в список Fortune 10, являются ее клиентами.
Как только корпоративные клиенты потратят свои деньги, они интегрируются в их рабочий процесс. Хотите перейти на другое решение? Стоимость миграции настолько высока, что доставляет головную боль техническим директорам.
11% игр на выживание
А что насчет оставшихся 32 компаний?
Компания Cursor достигла выручки в 2,7 миллиарда долларов, став звездой в области программирования искусственного интеллекта.
Компании Perplexity, ElevenLabs и Cognition преодолели отметку в 500 миллионов долларов каждая.
Система xAI Маска даже не вошла в пятерку лучших.
У этих компаний есть реальные пользователи и реальная выручка, но суровая реальность такова: 11% рыночной доли распределены между 32 компаниями, в среднем по 0,34% на каждую компанию.
Что еще более важно, эффект «головы» представляет собой самоподдерживающийся маховик: чем выше выручка, тем больше инвестиций в вычислительные мощности; чем больше вычислительные мощности, тем сильнее модель; чем сильнее модель, тем больше клиентов; чем больше клиентов, тем выше выручка.
Как только этот цикл начнётся, те, кто придёт позже, смогут лишь наблюдать за тем, как увеличивается разрыв.
Ведущие инженеры отдают приоритет OpenAI или Anthropic; гиганты облачных вычислений предлагают наиболее выгодные соглашения о предоставлении вычислительных мощностей ведущим компаниям; при принятии решений отделами корпоративных закупок вариант «использовать ChatGPT» или «использовать Claude» стал вариантом по умолчанию, а другие варианты требуют больше времени на объяснение и убеждение.
Один предприниматель из Силиконовой долины, занимающийся разработкой ИИ, однажды сказал: «Создание базовой крупной модели — это, по сути, война на истощение. Вам нужно достаточно денег, чтобы продержаться до следующего раунда финансирования, а затем до следующего раунда после него, пока ситуация не стабилизируется».
Судя по сегодняшним данным, эта война на истощение близится к завершению.
В конечном итоге, эта ценность возвращается на фабрику по производству моделей.
Наиболее примечательным аспектом этих данных является то, что они доказывают нечто еще более ужасающее —
В цепочке создания стоимости в индустрии искусственного интеллекта наибольшая ценность возвращается в руки производителей моделей.
Отчет Stripe об экономике ИИ также подтверждает скорость коммерциализации ИИ: Stripe утверждает, что обслуживает 78% компаний из списка Forbes AI 50, и отмечает, что компании, использующие ИИ, достигают ключевых показателей выручки значительно быстрее, чем компании SaaS предыдущего поколения; среднее время, за которое 100 ведущих компаний в сфере ИИ на их платформе достигают годового дохода в 1 миллион долларов, составляет всего 11,5 месяцев.
Иными словами, сфера применения ИИ действительно быстро растет.
Проблема в том, что большая часть денег, заработанных компаниями-разработчиками приложений, в конечном итоге достается производителям моделей, поставщикам облачных услуг и поставщикам вычислительных мощностей.
Если вы создаёте инструмент для написания текстов с использованием ИИ, вам необходимо вызвать модель; если вы создаёте службу поддержки клиентов с использованием ИИ, вам необходимо вызвать модель; если вы создаёте платформу для агентов на основе ИИ, вам всё равно необходимо вызвать модель.
Пользователи думают, что покупают приложение, но компания-разработчик приложения перекладывает основную часть затрат на базовую бизнес-модель.
В этом и заключается дилемма для компаний, занимающихся разработкой приложений на основе ИИ: пользовательский интерфейс выглядит привлекательно, но затраты на разработку бэкэнда невелики.
Именно поэтому ведущие венчурные фонды, такие как Sequoia Capital, после анализа этих данных пришли к отрезвляющему выводу: большая часть ценности в области ИИ находится в руках разработчиков моделей, а не компаний, занимающихся исключительно прикладными разработками.
Кроме того, производители моделей будут тратить большую часть своей прибыли на вычислительные мощности.
В пересказе анализа The Information изданием The Decoder также упомянуло, что, несмотря на взрывной рост доходов OpenAI и Anthropic, обе компании ежегодно тратят более 30 миллиардов долларов, в основном на расходы на обучение.
Похоже, правила распределения прибыли в этой игре с искусственным интеллектом уже установлены.
Производители моделей пожинают плоды, разработчики приложений получают крохи, а компании, предоставляющие вычислительные мощности, взимают плату за свои услуги. Ценность всей отраслевой цепочки под действием силы тяжести неуклонно снижается, отчаянно утекая в лежащие в её основе модели и инфраструктуру.
Каким бы сложным ни было ваше приложение, оно все равно обращается к чужой модели; независимо от количества пользователей, в конечном итоге счет ляжет на кластер графических процессоров.
Это поразительно похоже на эпоху мобильного интернета — независимо от того, сколько приложений процветает, в конечном итоге именно Apple и Google пожинают плоды, одна взимает 30% комиссии, а другая монополизирует точки входа трафика.
Современные OpenAI и Anthropic становятся аналогами iOS и Android в эпоху искусственного интеллекта.
>>1616762 >Компании Perplexity, ElevenLabs и Cognition преодолели отметку в 500 миллионов долларов каждая. >ElevenLabs Этим вообще грех жаловаться, генерят звуки и голоса (даже сука не музыку), заработали полмиллиарда. Там наверно расходов - одна пекарня под столом админа с видеокартой прошлого поколения.
Про Антропиков и ОпенАИ, вроде бы и есть другие игроки, и хотелось было бы сказать, что и остальные их догонят, такое то соперничество, такая то конкуренция, и дальше клиент уже будет выбирать исходя из каких то предпочтений личных, ведь отличия будут невелики.. но походу до конца гонки все не доживут.
Глядя как мамины умницы из Гугла несут деньги (миллиарды вроде да?) Антропикам, а сами выкатывают посредственную модель (а потом еще и посредственную видеомодель), то может и правда этим долбоебам ничего не светит. Ради желания по-быстрому заработать чисто срут себе же в штаны. Да и хуй с ними. Удивительно что эта говнокорпорация вообще что-то развивает, а не превратилась в пристанище дедов пердунов как какой нибудь IBM
>>1616706 >Куда-то не туда это всё идёт Чтобы ИИ знал как сделать мастерпис, вы должны ему скормить триллионы мастерписов. А у вас триллионы говна, среди которых парочка шедевров. Хули вы ждете не понятно.
>>1616805 Не совсем так. Нужна просто модель оценки того что является "мастреписом" а что нет. Тогда можно будет понимать справилась ли модель с задачей и обучать ее на основе этого. Дата для обучения не всегда должна быть естественной
>>1616848 Это конечно круто, но из за того что они подняли цену практически до цены 3.1про то уже получается не так круто. Они ещё и хвастаются её скоростью... Как писал анончик, бесплатно норм, а за токены по апишке платить нахер надо.
Сколько тогда 3.5про будет стоить? Если она не будет на первом месте, то она так же нахер не нужна будет
>>1616904 Так он же в гугл АИстудио безлимитный почти. Или тут тред предпринимателей с доступом к западным АПИ?
Я лично получил новую безлимитную модель, которая лучше старой лимитной. А какой-то ебанутый фронтир, способный кодить и взламывать сложную хуйню всё равно бесполезен с лимитов в 10 сообщений в день на аккаунт.
>>1616848 По бенчмаркам от других Gemini Flash 3.5 всё-таки проигрывает Pro 3.1
Есть ощущение, что им просто нужно поднять цены, а для этого показывают на что-то посредственное, проговаривают "о как круто", и часть аудитории в это искренне верит и хлопает.
Вот особенно с видео моделью показательно, там всё-таки всё очень наглядно, это не программирование и не тексты
>>1616960 Вот и получается, что гугол слоппирует в свои штаны. Потому что им надо делать что-то, что будет привлекать и расширять коммерческую аудиторию, API-покупателей, а не тех, кто им убытки приносит, то есть бесплатно пользуется или на дешёвых подписках
>>1616960 > с лимитов в 10 сообщений в день на аккаунт Не выдумывай. У жпт Плюс за 1500р позволяет кодить примерно 2 часа из 5 часового окна. Если между запросами думаешь и делаешь ревью кода, а модель только треть времени работает, то можно целыми днями кодить. Прошка х5 уже тупа безлимитная.
>>1617022 Годная у них видеомодель. Лучше сиданса в сложных тасках, но немного сосет в качестве картинки только. Сиданс затюнили красиво делать, омни же походу чистая модель без биаса, как банана
Внутренняя модель OpenAI опровергла человеческое решение 80-летней задачи
Речь идет об очень известной задаче Пола Эрдеша, которую он поставил в 1946 (и даже назначил денежный приз за решение). Звучит она просто:
Возьмите n точек на плоскости. Сколько максимально пар из этих точек могут находиться ровно на расстоянии 1 друг от друга?
Например, если взять 4 точки, то ответ дает квадрат, и получается 4. Но если точек больше, то все уже не так просто. Собственно, математики задавались вопросом, какова природа этого максимума, и как он растет (линейно или быстрее?).
Сам Эрдеш определял верхнюю границу роста числа единичных пар как чуть выше линейного. И в целом почти 80 лет математики были уверены, что наилучшие конструкции выглядят примерно как квадратные решетки. Короче, задача была как будто закрыта.
И вдруг OpenAI объявляют, что некая "внутренняя ризонинг модель" обнаружила совершенно новое семейство конструкций, которое превосходит решетку. При этом, по словам стартапа, это модель общего назначения, а не спецаильно обученная для математики.
Технически, исходная нижняя оценка Эрдеша опиралась на гауссовы целые числа. Модель же связала геометрическую задачу с совершенно другой областью математики – алгебраической теорией чисел. В итоге получилось бесконечное семейство конфигураций точек, дающих значительно больше единичных пар, чем считалось возможным.
Доказательство верифицировали несколько авторитетных математиков. Один из них сказал, что уверен, что в ближайшие годы ИИ решит еще много открытых задач.
Спустя одну наносекунду после победы в суде над Маском, OpenAI начинает официальный процесс выхода на IPO
WSJ пишут, что они планируют подать заявку регулятору буквально сегодня или завтра. Видимо, у них уже все было готово, и они дожидались только окончания суда с Маском.
После подачи заявки она будет рассматривать несколько месяцев, так что в четвертом квартале 2026 года IPO может случиться, и оно, вполне возможно, будет одним из крупнейших в истории.
>>1617126 >Возьмите n точек на плоскости. Сколько максимально пар из этих точек могут находиться ровно на расстоянии 1 друг от друга? > >Например, если взять 4 точки, то ответ дает квадрат, и получается 4. Нихрена не понял. Вот пример фигуры из 4 точек, где пять пар таких, но для 4 точек это явно предел
Из равносторонних треугольников можно составить плоскость, но тут тоже будет линейная зависимость, просто от каждый точки будет 6 рёбер, то есть 3 пары, а в случае квадрата 4 ребра и 2 пары соответственно
Тащемта вот тут есть сравнение. Что характерно новая нейронка от Гугла местами будто в физику совсем не может. Половина промтов отработала в стиле "кал ебаный". И это еще тут нет какой-нибудь анимации/мультипликации, там вырвиглазный лютый пиздец, судя по их же проморолику.
Anthropic будет платить SpaceXAI 1.25 миллиарда долларов в месяц за компьют.
Как уже известно, недавно Anthropic подписали с SpaceX большой контракт на использование мощностей датацентров Colossus.
Теперь появились некоторые детали этой сделки. Оказывается, за доступ к железу Маска антропики будут платить 15 миллиардов долларов в год до мая 2029 года.
Для SpaceX это почти что удвоение годовой выручки (в 2025 году они заработали около 16 млрд). А для Anthropic это просто львиная часть, около 80% от выручки. Действительно big deal.
Таким образом, затраты на создание датацентра покроются несколько раз, ещё и заодно несколько раз покроются траты на покупку Твиттера. Ай да Маск, ай да хитрец!
>>1617156 вот когда заработают, тогда и приходи. Дальше ещё больше тратить будут. Это к вопросу о выгодном инференсе. Кстати платят они далеко не только им.
>>1617154 >Таким образом, затраты на создание датацентра покроются несколько раз Это если предполагать, что датацентр был очень дешёвый. Что не точно. И электричество дешёвое. Что тоже не точно.
Маск строил ДС для себя. Кстати в них что-то по современным меркам отсталое, говорили про A100/H100, даже не H200. Но Маск не нашёл, что в них считать, и продал мощности Антропику
По сравнению с Seedance первое, что бросается в глаза это вялая динамика и физика. Если посмотреть первый вебм, то сложится ошибочное впечатление, что это модель прошлого поколения. Качество картинки в принципе ок, нет особого мыла. Но по сравнению с Сиданским все выглядит заторможенно и как-то искусственно. Переключения камеры, скажем так, своеобразны. 10 секунд также не радуют.
Но перейдем к редактированию (второй и трейтий вебм). Как вы видите, в редактировании омни нет равных.
Ну то есть можно рассматривать Gemini Omni как Нанобанану только для видео. Понимание происходящего в кадре потрясающее, возможности редактирования тоже.
За сим вырисовывается такой пайплайн: генерация в Сиденс, редактирование в Омни.
Да, пока дороговато получается.
Также надо понимать, что Omni реально мультимодальная и у нее под капотом вся мощь Gemini. Ну то есть она понимает про окружающий мир и его устройство все, что есть в мозгах у LLM. Также как и Нанобанана.
Ей, по идее, не нужны дико детальные промпты, она способна создавать детали на основе понимания мира. Есть масса применений за пределами драк и бешеной динамики (образование, иллюстрация, презентации), где такое понимание будет сильно полезным. (четвёртый вебм)
Далее смотрим пятый вебм. Это, конечно, совершенно убойный пример. Я тут собрался накатить за композ, но понял, что это это уже какой-то мета-композ, который обычными средствами просто не сделать.
И там есть пара интересных моментов о том, что выпущенная модель Gemini Omni имеет приставку Flash. И что это как бы первая и "маленькая" модель. И что это можно сравнить с первой Нанабананой. И что скоро нас ждем модель Pro (по аналогии с Нанабанана Про, появившейся позже и ставшей практически стандартом для редактирования изображений.
В подкасте достаточно много и откровенно говорили про ограничение в 10 секунд. Во-первых, уже сейчас можно продолжать клипы, ибо Омни держит в памяти полный рефренс и по идее должна попадать в косистентность. Во-вторых, и это главное, несколько раз сказали, что длительность будет увеличена в следующей версии. Несколько раз звучала цифра в 30 секунд, но скорее как вариант, а не окончательный параметр.
Из интересного: когда вы подсовываете свое (чужое) лицо как референс, имеет смысл делать как можно больше фоток с разных ракурсов и подсовывать их все. Оказывается модель строит что-то типа 3Д-модели (как при фотограмметрии), чтобы сохранять консистентность при повороте головы. Больше фоток на входе - лучше.
Более того, в будущих версиях может появиться версия с видео-референсом вашего лица. Ставите камеру и крутите лицом перед ней (по типу KYC) - модель строит модель вашего лица и использует ее при генерации.
И все это может превратиться в создание ваше цифровой копии - ваш аватар на максималках. Вы записываете видео, где крутите башкой и зачитываете текст на камеру. Цифруется лицо и голос, и сохраняется в виде вашего аватара, который вы в дальнейшем можете использовать в генерациях. (Тут HeyGen поперхнулся)
Также рассказали, что в новых версиях Omni появится больше tooling-a - инструментов, унаследованных от Gemini, типа поиска в интернете и работы с данными. То, что появилось в Nanobanana 2.
Про инструменты для сторителлинга сказали, но вкратце. Будут развивать Flow в этом направлении.
>>1617145 Слоп. Короткие не связанные фрагменты, где-то, например F, как-будто следы редактирования, фото откровенно ИИ многие, несколько с косяками явными.
Ни о чём. Ролик не показывает главного, что должно быть в видео, консистентность, динамика-физика, естественность, осмысленность
Их модель полностью рушится на консистентности, соответствии фрагментов друг другу, что делает модель совершенно непригодной для видео. Это реально провал для компании их уровня и с тем, что они заявили сами про свою модель
>>1617151 AI dungeon появился позже. До этого нейронки гоняли в колабе гугла через кобольда того времени. Были даже специальные натренированные под nsfw, которые всякую жесть писали любую. Только я названия забыл.
>>1617165 Вот тут интереснее. Можно видеть, что генерация видео по промптам эта полная абсолютно нерабочая херня у них
Но вот другие ролики намного-намного интереснее. Они про редактирование видео, осмысленной замены части сцен на что-то. Вот тут на первый взгляд довольно хорошо. Вот это уже реально сильно, потому что по-моему это куда ценнее для практических применений, нежели генерирование видео по текстовым промптам. То есть вот это как раз реально востребованная вещь
>>1617162 >Маск строил ДС для себя. Ебать ты не в теме. Он уже прям щас начал арендой торговать в ущерб своим подпискам. В отличии от тебя он норм коммерс и в курсе, что выгодней сдавать, а не что-то самому пыхтеть делать + еще и попиздит хорошие наработки у лошков.
>>1617176 Да, с точки зрения практики редактирование намного лучше созданяи с нуля. Это и картинок касается. Дело в том, что создание с нуля - это лотерея. Но чаще нужно уже готовое обработать по-другому. Или воедино собрать те же удачные генерации.
>>1617177 1. Я нихуя не помню что тогда происходило. Если он появился раньше и хуй с ним. 2. Тогда модели были 2-7b, а не та хуета которую пишет гугл. 3. Уходить там было некуда, так как в ai dungeon модели в х99 раз мощнее бредогенераторов того времени. Модели из колаба писали буквально шизофрению.
>>1617181 >Он уже прям щас начал арендой торговать в ущерб своим подпискам. Потому что понял, что на подписках не заработает и субсидировать их смысла нет. Когда он строил датацентры, были другие прогнозы на будущее ИИ.
>>1617103 Кхе-кхе один новиоп вместо пук-среньк за културны многообразие лучше бы этих штук запросил да много у нефритового стержня Си, но тут панимаеш "наши люди" как жи применять по назначению, да и вообще батюшка Лондонград не велит
>>1615895 Покорять космос. Исследовать новые планеты. Ну либо жить в матрице и там делать всё что захочешь. Можно в плодячку уйти, АСИ тебе найдёт идеального партнёра, которая будет любить тебя и которую будешь любить ты. Либо жить с роботянкой и делать тоже самое с искуственной маткой плодить детей. Либо пойти в горы, путешествовать, стать аскетом, поселиться в лесу.
>>1615895 Все эти предположения про маняэкзистенциальный кризис - хуета полная. Будет конечно процент подобных ебанатов для которых слишком хорошо - это слишком плохо. Но большинство точно найдет чем заняться
>>1617345 Я думаю, лучшим выбором будет небытие в таком случае. Просто посмотри на жизнь рннщиков. Ты думаешь, они счастливы? Им очень весело? Они каждый день с кровати встают с радостью?
AMD Ryzen AI Halo: Мини-ПК за 4000 евро должен стать ИИ-рабочей станцией
Дешевая альтернатива Mac Studio Ultra прибыла.
AMD выводит на рынок компактный ИИ-компьютер с 128 ГБ памяти. Также Lenovo и ASUS представляют новые высокопроизводительные мини-ПК для ИИ.
Рынок компактных компьютеров переживает радикальные изменения: от универсальных устройств — к высокопроизводительным ИИ-машинам. Сразу несколько производителей анонсируют устройства, которые благодаря огромным объёмам оперативной памяти и специализированным ИИ-чипам размывают границы между мини-ПК и рабочей станцией.
Эра невзрачных офисных компьютеров окончательно прошла. В июне 2026 года AMD выводит на рынок мини-ПК Ryzen AI Halo — устройство, которое по цене около 3700 евро в пересчёте напрямую ориентировано на разработчиков и предприятия. Система должна составить конкуренцию специализированному ИИ-оборудованию, такому как NVIDIA DGX Spark.
128 гигабайт оперативной памяти в мини-формате Сердцем Ryzen AI Halo является архитектура Ryzen AI MAX+ 395 (кодовое название «Strix Halo»). Она объединяет 16 вычислительных ядер Zen-5 с интегрированным графическим блоком RDNA-3.5. Ключевое отличие от предыдущих мини-ПК: 128 гигабайт унифицированной памяти. Эта огромная ёмкость памяти не случайна — она является необходимым условием для обучения и запуска сложных ИИ-моделей непосредственно на месте, без обращения к облаку.
В то время как новые поколения оборудования повышают эффективность, правильные приёмы помогают раскрыть полный потенциал вашей системы.
AMD позиционирует устройство как продукт «Halo»: оно должно демонстрировать абсолютный максимум того, на что способен собственный ИИ-чип в компактном корпусе. Полноценный сервер в корпусе Tower становится излишним.
Lenovo и ASUS: премиум-класс для профессионалов и геймеров
Однако не только AMD стремится занять нишу высокопроизводительных компактных компьютеров. Lenovo представила систему «всё в одном» Yoga 32 Ultra Aura Edition, которая также задаёт новые стандарты. 31,5-дюймовый экран предлагает разрешение 4K, частоту обновления 165 Гц и максимальную яркость 1000 нит.
Устройство приводится в действие процессором Intel Core Ultra X7 358H из семейства Panther Lake. Его интегрированный NPU (нейронный процессор) выполняет 50 триллионов операций в секунду (TOPS) — достаточно для соответствия текущим отраслевым стандартам для ПК с поддержкой ИИ. 32 гигабайта оперативной памяти и твердотельный накопитель объёмом один терабайт дополняют комплектацию. В Китае устройство стартует по цене около 3100 евро в пересчёте, глобальный запуск продаж считается гарантированным.
Сюрприз от AMD: юбилейное издание для сокета AM4 Интересный побочный аспект: по всей видимости, AMD планирует 10-летнее юбилейное издание Ryzen 7 5800X3D для уже пожилого сокета AM4. Оригинальная версия вышла в 2016 году. Переиздание должно предложить 96 мегабайт кэш-памяти L3 и стоить около 290 евро. Это доступный вариант апгрейда для всех, кто всё ещё использует системы на базе DDR4.
Программное обеспечение и безопасность: обратная сторона ИИ-мощности Новое поколение оборудования совпадает с крупными обновлениями программного обеспечения. На июнь 2026 года на конференции WWDC ожидается презентация macOS 27. Слухи говорят о новом интерфейсе Siri с функциями чат-бота и инструментами редактирования изображений на базе ИИ.
Однако растущая интеграция ИИ также несёт новые риски для безопасности. Исследователи в области безопасности обнаружили новый вариант вредоносного ПО «Reaper», которое целенаправленно атакует системы macOS. Этот инфостилер обходит текущие механизмы защиты, используя редактор скриптов через специальные схемы URL. Похищены могут быть пароли из связки ключей, данные криптокошельков и конфиденциальные файлы.
Учитывая всё более изощрённые кибератаки, подобные «Reaper», компаниям сегодня необходимо защищать свою ИТ-инфраструктуру лучше, чем когда-либо ранее. Этот бесплатный экспертный отчёт покажет вам, как выполнить новые законодательные требования и проактивно защитить вашу компанию от угроз.
Перспективы: лето ИИ-компьютеров Запуск AMD Ryzen AI Halo в июне станет лакмусовой бумажкой для коммерческой жизнеспособности мини-рабочих станций стоимостью 4000 евро. Если спрос со стороны корпоративного сегмента окажется высоким, другие производители последуют этому примеру с ещё более высокими конфигурациями памяти и специализированными ИИ-чипами.
Тренд очевиден: мини-ПК покидают нишу домашнего офиса и проникают в сферы профессионального творческого труда и высококлассного гейминга. В ближайшие месяцы потребители могут рассчитывать на значительно более широкий выбор компактных устройств, оптимизированных не под общую производительность, а под специфические показатели пропускной способности ИИ и высокую частоту обновления изображения.
>>1617391 Дешевле и лучше потратить по 20-100$ в месяц на подписки/апишки фронтирных моделей чем покупать кал за 4к зелени, один хуй через 1-2 года цена на память упадёт и это миниГовно нахуй не нужно будет
>>1617398 >через 1-2 года цена на память упадёт Через 1-2 года случится бум робототехники, а там память тоже понадобится. Спрос на память будет по нарастающей вверх. Даже если фабрики будут строиться, весь их выхлоп будет уходить на ИИ-робототехнику.
>>1617402 За пару лет сильно можно нарастить производство, основной мотив, почему не наращивают, производители не уверены, что это не пузырь, очередной раз обжигаться на инвестициях в избыточные мощности не хочется
Кстати реально не понятно, используется ли реально память в таких объёмах. Вроде пока реальный ввод мощностей датацентров небольшой. Возможно память тупо законтрактована и накапливается на складах
>>1617404 не очень честно говоря. На Gemma4:31b и Qwen3.6:27b (dense модели) генерация на уровне 6 токенов в секунду, в каком-то тесте 10. Это квантованные версии.
мягко говоря не впечатляет. 20 тысяч токенов в час. Gemma4:31b по апи вообще очень дешёвая, qwen сильно дороже почему-то. Но даже у qwen получается меньше 10 центов в час АПИ тариф.
В общем это только для фанатов приватности и независимости, иначе как-то дороговато. Дорого и неудобно, слишком медленно.
Я морально готов отдать 1000 долларов за коробочку с такими характеристиками, ради независимости, но тут уже другая психологическая категория цены
>>1615866 → >Ну вот он для тебя и будет в качестве родителя, который будет с тобой взаимодействовать как с трёхлетним ребенком (по его меркам). Тут скорее заблуждение. Суперинтеллект, радикально превосходящий топ-1% популяции, вряд ли возможен в принципе. Можно знать больше, это уже есть, можно считать быстрее, это тоже уже есть. Но не более.
Ребёнок трёх лет не умеет думать. Интеллект это способность разобраться в чём-то и делать прогнозы. Для ребёнка невозможно, для взрослого с высоким IQ возможно.
Дальше вопрос, насколько глубокий прогноз можно делать. Вот, проблема в том, что тут предел есть. Как в задаче трёх тел, чем больше вычислительные ресурсы, тем дальше можно просчитать, но ты довольно быстро упираешься в потолок, и как бы не наращивал вычислительные ресурсы, просчитать дальше уже не сможешь.
С суперинтеллектом тоже самое. Слишком много случайных факторов, которые просчитать невозможно. То есть даже просчитать людей, или сообщества людей, как-то достаточно надёжно невозможно.
Суперинтеллект возможен только в узких задачах. Но их может решать человек с помощью специальных инструментов.
Это помимо того, что уже раньше обсуждалось, что человеком движет мотивация, а какая мотивация может быть у суперинтеллекта с AGI, ХЗ. Вряд ли может быть.
Интеллектуальным человеком сложно управлять, в отличии от ребёнка. Суперинтеллекту нет нужны отвечать на твои вопросы и вообще с тобой взаимодействовать. Мотива нет.
>>1617402 Это будет зависеть от того, как алгоритмы будут память использовать. >>1617400 >В видео конечно случился какой-то ОБОСРАМС. У китайцев не существует права на собственность, сколько спиздили столько и скормили для обучения. На западе всё это сложнее.
>>1617391 Если честно, не очень ясно, что в него совать. На полноценные Квен и Гемму уже уходят смешные 24 Гига Vram, с задачами справляются неплохо в своих областях. С большими моделями не сравнятся, но и не полный шлак, как раньше. Здесь за 4к предлагают засунуть внутрь среднюю модель. Которая ни рыба ни мясо, огромного преимуществоа не даст по сранвнеию с мелкой, до крупных не дотягивает, а цена уже вполне себе отличная. Если выпусят печатные платы с моделями вшитыми в них через год-другой, это вообще станет хламом.
>>1617400 Западные на 10% лучше и на 400% дороже, хз, если тебе не надо кодобазу в десятки тысяч строк через агента пускать а для обычного использования использовать что-то кроме китайцев - долбоебизм
>>1617498 gpt-oss-120b-mxfp4 бегает в целых 51 токенах/c Или qwen3.5-122b-a10b на 20 токенов/с Вот их и использовать. На их промоушен сайте они и заявлены. Основное преимущество низкое потребление энергии в 120 ватт максимум и низкий шум. То есть можно понаставить несколько таких коробок и гонять на них агентов. Оверпрайс да, на старте есть, эта коробка станет привлекательной через год, когда цена дропнется раза в 2.
>>1617498 >печатные платы с моделями вшитыми в них через год-другой, это вообще станет хламом Зацензуренные по уши. На таких же коробках можно бесцензурные с хаггингфейса гонять. Зацензуренная например тебя пошлет с автоматизированным анализом дыр на сайте или в программах. Так что у печатных плат будет свой юзкейс для стандартных задач, у этих коробок свой.
>>1617541 Не вижу ничего плохого. Очень сложно общаться с людьми, которые думают в 2-3 раза медленней тебя. Если роботы мысля быстрее, конечно заменят. Одно дело ездить по ушам пизде, чтобы её выебать, другое дело по работе к тебе приезжает блять специалист и начинает советовать свои охуительные идеи, которыми только подтереться можно.
1 человек копает яму, а 10 управленцев подгоняют за спиной. Думаю об этих новых рабочих местах и говорят экономисты. Всё таки один ИИ может сделать очень много, а пропесочить его за такой объём работы и некому.
Дома будет робот-кошка жена, а на работе робот-раб, чтобы об него ноги вытирать и не так грустно жить было.
>>1617542 > другое дело по работе к тебе приезжает блять специалист и начинает советовать свои охуительные идеи, которыми только подтереться можно. А что за специалист и что за сфера у тебя вообще?
>>1617538 >Человек-сортировщик посылок от Figure выиграл с минимальным перевесом, при этом его левое предплечье было «практически сломано», а генеральный директор Бретт Эдкок предсказал: «Это последний раз, когда человек когда-либо победит».
Очевидно, что да. Мясной себе предплечье сломал, пока делал тоже самое, что робот.
Появился Qwen 3.7-Max. Официально. Модель закрытая, платная. Перфомит на уровне Claude Opus 4.6 Max Инфа и куча бенчей по ссылке https://qwen.ai/blog?id=qwen3.7
>>1617561 В чате бесплатная как обычно. А то, что Max закрытая и этому до сих пор удивляются, вот это удивительно. Она всегда закрытой была еще при прежнем руководстве и год назад
>>1617558 Прихожу к выводу с возрастом, что это лучшая работа, особенно на нижних должностях, где ты сам ведешь эксперименты, а потом описываешь. Благодаря подскоку кабанчиком к нужным человечкам у тебя есть методы анализов, а график не нормированный. Никто не может сказать какой эксперимент выстрелит, просто есть поле, которое надо закрыть за год. Но иногда приходится общаться с людьми, которые не любят ни читать, ни думать. А потом понимаешь, что таких 95% и охуеваешь по эйнштейновски.
не проверял, прошлые версии были неубедительны, только бенчмарки красивые, а не реальная произвоидельность
Вот по ценам уже близко к опусу. тариф input/generation 2.5/7.5, против 5/25. При учёте, что в агентских задачах по программированию основа цены это инпут (90% цены, это если кеш адекватно работает), разница получается всего в 2 раза. По факту скорее всего счёт будет больше, чем у опуса или GPT 5.5
В общем как и следовало ожидать, китайцы в итоге сравнялись по ценам с американцами, что понятно, железо ведь не дешевле, скорее дороже
>>1617498 >Если честно, не очень ясно, что в него совать. На полноценные Квен и Гемму уже уходят смешные 24 Гига Vram По идее это будет сильно уквантованная с небольшим контекстом, хотя 128 гигабайт явно избыточны. С учётом, что сейчас память всё-таки очень дорогая, по идее на эту память 2 тысячи долларов цены приходится
но может на будущее, какие-то более мощные MoE модели
>>1617604 >>1617609 Та самая лошадь в колхозе, которая работает больше всех. А вообще любимая поговорка всех начальников и в НИИ тоже - кто везёт, на том и едут.
>>1617541 почему у всех бомбит с того что дно работа будет только у роботов? снижение цены на роботизацию приводит к всплеску роста автоматизации и росту спроса на инженеров/менеджеров/пограмистов занимающихся разработкой и продажей и внедрением роботехники
>>1617604 Что тут плохого? Раньше 1 вася умирал от ручного труда голыми руками рыл землю, чтоб прокормить 5 шаманов и 15 воинов и всю родню вождя племени. Ему мозговитый родич любого из тех кто он кормил в свободное от поисков пропитание время дал палку копалку. Потом васе дали лопату. Потом плуг. Потом комбайн. А потом ты с какого-то хуя решил, что этот ботом фиддер вася, тупое убогое существо не способное ни в контроль над массами, ни в изучение свойств мира, ни вообще во что либо, кроме капания в земле - ВНЕЗАПНО - с какого-то хуя должен иметь все то же что и остальные и при этом не работать. Ты калмунист, что ли? Ну взяли калмунисты 50 вась, из 20 сделали начальников закрыв глаза на их тупость и не приспособленность, еще 10 генералами армий поставили, 5 - верховными вождями. Итог? Целая страна с голоду 5 раз умирает, отсталость во всех сферах ДО СИХ ПОР, денях хватает только на танчики и ракетки, и при этом остальные васи еще и ебла скрючили >>1617604>>1617547 как это видно по картинкам. Запомни, чмо, мир так устроен как он устроен. А ты еблан причины и следствия не путай. Любой из трех мордоворотов этого комбайнера может об колено сломать, и выучиться его "профессии" - за неделю. Только если они будут на месте этого задохлдика, то этого задохлика вообще нигде не будет, его просто придется утилизировать как биомусор. И такие идеи были в прошлом веке, но чё-то никому не понравились.
>>1617629 >почему у всех бомбит с того что дно работа будет только у роботов? Дно работа всегда и везде будет у дно-человеков, еблан. Потому что как я уже выше написал, без этой функции в бракованном убогом человекоматериале вообще никакой нужды не будет. И никто никому на диване лежать не даст, можешь не волноваться. А для роботов есть много других интересных сфер.
>>1617631 >Раньше 1 вася умирал от ручного труда голыми руками рыл землю, чтоб прокормить 5 шаманов и 15 воинов и всю родню вождя племени. Неправда, большинство тогда работали сами, армия, управление, религия, это про меньшинство. Сейчас же эта доля резко выросла и уже большинство составляет, даже по головам, и тем более по зарплатам
>>1617538 На современных нам технологиях - нет. Ты вот видел массовое производство квадрокоптеров в 80х? И я тоже. Погугли почему. Современные инсультники это то же самое. Игрушки в рост человека, не более того.
>>1617634 >Неправда, большинство тогда работали сами Иди учи историю, неуч. Простой тебе пример "работы". Средневековый рыцарь это тебе не ЦАРСТВИЕ НЕБЕСНОЕ УУУУХБЛЯ ВПЕРЕД НА АБОРДАЖ С ДВУРОМ В ПЕРВЫХ РЯДАХ ХУЕЯКЕ МУСОУ ФЛОУ УУУУУУУУУУУУУУ БДЫЩЩЩ ТЫЩИ ЮНИТОВ ОДНИМ УДАРОМ - ну ты понял, ты дебил, я думаю ты не понял, но я для окружающих больше. На самом деле рыцарь - это надсмоторщик, чье нежное тело заковано в броню на случай если в него случайно стрела прилетит или еще что. И у римлян так же было, победней знать да, была в армии но это офицеры, чем они элитней, тем они меньше в чем-то участвовали, и тем бальше находились от замесов. А ты сейчас без пяти минут готов пукнуть про Кутузова который верхом на слане лично Стамбул штурмом брал с нагайками двумя в руках, просто нахуй иди, наивный дурачок. Что сейчас, то было и 14 000 лет назад, только бытовые условия меняются.
>>1617639 Если смотреть средневековье и раньше, то рыцари сражались сами, это элита. Умение владеть мечом это скилл, который оттачивали годами, у обычного человека, если ему дать меч в руки и немного поучить, не было шансов против того, кто всю жизнь тренировался. Один профессиональный воин легко мог бы порубить десятки обычных. И авторитет нужен.
Поэтому лорд какой-нибудь сам не воюет, а покупает профессиональных военных
Изменения пошли тогда, когда огнестрельное оружие стало основным, тогда все эти скиллы по владению мечом обесценились
>>1617649 Я бы ещё добавил, что рыцарей, в отличие от ополчения, старались не убивать, а взять в плен. Тут не столько даже кодекс чести, сколько желание получить выкуп за него. Т.к. знали, что если рыцарь - то деньжата у них водятся и живой он будет гораздо дороже стоить, чем мёртвый.
>>1617635 Сейчас роботы просто дороги, потому что нет налаженного массового производства, и роботов, и компонентов для них. Как наладят, так станут дешевле.
В целом больше хайпа, потому что реально робот не может делать сильно больше того, что возможно другими способами автоматизации, зачастую сильно более эффективными. Вопрос цены. Обычно автоматизацию надо делать под конкретную задачу, а это сложно и дорого, плюс робота в том, что он универсален.
Может быть дешёвый робот и отдельно программное обеспечение к нему, нужные навыки, тоже не очень дорого.
Но в целом реальных задач не так много, как мне кажется. Нужны какие-то реальные AGI изменения, чтобы что-то реально полезное и сложное они могли делать.
>>1617649 >Если смотреть средневековье и раньше, то рыцари сражались сами Ты дурачок, ок. Мог не высирать вот эту чушь.
>>1617654 >Я бы ещё добавил, что рыцарей, в отличие от ополчения, старались не убивать, а взять в плен. Ага, именно поэтому во все века у управленцев военных была традиция убивать себя. Ясное дело просто дело в чести, а не в том, что тебя будут горячей качергой в жопу ебать. Плис, не пиши больше про историю, ты нихуя в ней не шаришь.
>>1617664 чего именно сейчас не хватает? Механика вся есть, роботы это наглядно показывают. Пока дороговато, но с масштабированием это стремительно дешевеет.
Вот чего не знаю, это что у них с интеллектом. Вот этот робот-сортировщик, у него в корпусе вычислительные узлы, если да, то какие? Либо он подключён к интернету, реально его мозги в каком-то датацентре, потому что ресурсов много надо? Если первое, то уже интересно и перспективы есть. Если второе, то пока чисто игрушка без задач.
>>1617629 >>1617691 Бля, че вы несете-то вообще? Белые воротнички первые в очереди на автоматизацию. Будут еще кабанчики дноработы автоматизировать, размечтались лол, пойдете говно чистить за мрот до конца жизни
>>1617701 >Белые воротнички первые в очереди на автоматизацию. Так белые воротнички это соевые перекладыватели бумаг из одной пачки в другую. Их еще СССР предлагал заменить, но заменили СССР.
>>1617704 извечная тема, что и с бюрократией, кстати. Постоянно пытаются сокращать, в итоге реально численность только растёт. Тут проблема какая-то другая, не в том, что заменить сложно, а в том, что системам нужно набивать себе штаты насколько это возможно. То есть выгодно создавать какую-то реально ненужную позицию и заполнять её кем-то.
>>1617707 Не совсем, белыми воротничками считаются "офисные работники". В том числе инженеры. Скажем учителя и врачи это не "белые воротнички" в классическом смысле, хотя по некоторым классификациям их сюда относят, но это некорректно
То есть нельзя на лишь на две касты всех делить, это слишком грубо и не имеет смысла
>>1617701 Автоматизировать будут всё. По простой причине того, что робот эффективне человека, намного быстрее обучается и дообучается (дни, недели, месяцы вместо ГОДОВ у людей) и в перспективе дешевле. Здесь нет вопроса уровня "хочу/не хочу заменять". Это железная логика необходимости и неизбежности, которая продиктована экономическими факторами.
>>1617707 >Нет, белые воротнички это любые люди, которые занимаются не физическим трудом Учитель программирования это белый или синий? Учитель физкультуры? Тренер по фитнесу? Сисадмин, что устанавливает и настраивает оборудования в дата центрах? Кассир в магазине? Таксист?
Короче эта классификация упрощённая, она покрывает лишь часть специальностей. Исходно, "синие воротнички", это работающие руками на производстве, раньше таких людей в западных странах было очень много.
При этом работники сельского хозяйства очевидно занимаются физическим трудом, но "синими воротничками" не являются, это своя каста.
"Белые воротнички" это офисные работники, административный персонал, кто работает с бумагами. Или кто работает на производстве, но не руками. Сфера образования, например, к ним не относится, это своя каста. Как и наука.
Есть большая сфера услуг, массовое обслуживание, которая тоже не про воротнички. Там всё иначе устроено.
>>1617718 >что робот эффективне человека, намного быстрее обучается и дообучается маняфантазии и непонимание темы
>дни, недели, месяцы вместо ГОДОВ у людей Если 30M модель способна лучше освоить язык, чем ты, это не значит, что с другими людьми и навыками та же история. Они LLM, да, умеют в язык
Дело не только в языке, язык - это средство понимания и взаимодействия с миром. При помощи него роботы и взаимодействуют с миром, подобно людям, понимаю задачу и строят решения. Все остальные наработки в области роботехники никуда не делись, остается только все это собрать воедино на базе ЛЛМ, в разных формах, чем сейчас и заняты.
Речь идет не об усвоении языка, а скорости обучения выполнения задач. Это не только работа с языком.
>>1617727 >понимаю задачу и строят решения Роботы не понимают задачу вообще, они тупы как пробки, потому что они какую-то картину не в состоянии выстроить. Физический мир вообще словами не описывается, там совсем другое, там человек даже словами не думает, поэтому тут вообще полный провал у роботов
С ЛЛМ получше, но даже там ИИ не понимает задачу. Они как были, так и остаются машинами, что ищут закономерности, и создаётся ощущение разумности. Просто пока ты находишься в языковом домене, этого в целом достаточно для много чего, интеллект на самом деле не требуется
Учатся ИИ тоже долго, намного-намного дольше, чем люди. Это известная проблема. В смысле, что обучающая выборка нужна на порядки больше. Но сила их в том, что обучающую выборку можно прогнать очень быстро, для ЛЛМ, и возможно копирование, а вот людей надо каждого чему-то учить
>>1617736 Это дискуссионный вопрос что такое вообще твое понимание. В рамках определенного контекста ИИ отлично понимает задачу. Даешь ему инструкцию делай то, не делай этого, он этим занимается. Да, он может косячить, галлюцинировать, но по итогам задачи почти всегда видно, что делает то, что его просили. Это говорит о понимании или нет? На мой взгляд, говорит. Мыслит он там как человек или как жук, как пришелец, можно л ивообще называть эт омышлением, это не важно в данном случае. Есть дело, он его делает, есть рузельтат.
ИИ учится очень быстро. Мгновенно по сравнению с людьми. Людям нужны годы, чтобы освоить одну (1) профессию. Вспоминай университет. ИИ не нужны годы. Триллионные модели обучаются за год ВСЕМУ, что есть в интернете. Всем профессиям разом, всем знаниям вообще. На данный момент это дорого в обучении, это дорого поддерживать, но скорость и качество усвоения феноменально разнятся по сравнению с человеком. На выходе - веса. Эти веса можно взять и запихать куда угодно, на то, что потянет эти веса и сможет их обработать. Но ведь не обязательно обучать триллионные модели? Есть куда более простое обучение, не везде нужен всезнайка, владещий тысячами профессий и всеми знаниями, верно? И тогда это становится намного дешевле.
И самое главное. Техника совершенствуется очень быстро. Роботы - это техника. Они могут развиваться махенически намного ыбстрее человека, человек не приспособлен эволюционно улучшать свою руку, например каждые 5 лет. А робот может. И может быстрее. И база для обучения ИИ - это тоже техника.
А теперь соедини механическую часть и интеллектуальную вместе. И оцени возможный результат.
Не забудь еще момент, что ИИ "мылсит" с огромной скоростью и при этом может обрабаытывать колоссальный объем информации за раз.
Человек уже все. Он не успеет за роботами и ИИ в течении ближайших 3-5-10 лет. Никак.
>>1617742 кто же на это доске кунчика не знает?.... Вот когда что-то реальное выйдет, что показывать можно, тогда и приходи
Не, серьёзно, Лёкун прав, LLM совершенный тупик по многим направлениям, но в других направлениях ИИ такого прорыва нет. Возможно что-то появится, "физический ИИ", но пока видимо так себе
>>1617747 >Даешь ему инструкцию делай то, не делай этого, он этим занимается Не понимает совершенно. Они не способны понять задачу по инструкции, это главное отличие от человека. Это главная особенность ЛЛМ, потому что они шаблоны распознают, а не смысл понимают
При этом для многих задач не обязательно понимать смысл, чтобы чего-то делать. Надо просто тупо делать, как надрочили. За счёт этого ЛЛМ реально что-то могут
То, что они не способны мыслить, хорошо видно, когда они начинают косячить. Как именно они косячат, совсем не так, как люди.
Нельзя ни в коем случае считать, что ЛЛМ что-то понимает. Вот чтобы эффективно с ними работать, категорически нельзя так подходить.
>>1617718 >По простой причине того, что робот эффективне человека Какой робот? Который у тебя под кроватью сейчас сидит? Или вон те инсультники? Ну, а знаешь что еще эффективней чем робот? Биоробот! Прикинь? Ремонтируется исчелением, не нуждается в зарядке обработанной энергией, у него прям встроенный микрореактор, который буквально шмурдяк всякий переваривает биологический, который делается из воды и света - пассивным выращиванием. Следующий по эффективности уже энергетический сгусток.
>>1617747 >Людям нужны годы, чтобы освоить одну (1) профессию. И после этого человек шарит, и ты идешь к врачу и он не предлагает тебе через минуту разговора начать пить мочу и есть кал. Не позорься, клоун тупой.
>>1617754 Все это понимают. Разница в том что le кун хочет чтобы человечество само запилило грамотную архитектуру для АГИ, а остальные компании хотят тупо скейлить модели пока они скейлятся и пока дают денег, чтобы начать рекурсивное самосовершенствание и модели пилили себе новую архитектуру самостоятельно, ведь это просто безопаснее. Но истина где-то между, ящитаю, надо хоть какие-то улучшения и оптимизации делать, чтобы ускорить процесс создания моделей способных на рекурсивное самосовершенствание, но а юзать совсем иную, новую архитектуру, которая непонятно как поведет себя при скейлинге опасно, пока у нас нет достаточных мощностей чтобы создавать 5-10Т модели за дни, а не месяцы, так как это сильно тормозит уже работающий механизм скейлинга.
>>1617721 >Учитель программирования это белый или синий? Учитель физкультуры? Тренер по фитнесу? Сисадмин, что устанавливает и настраивает оборудования в дата центрах? Кассир в магазине? Таксист?
Вычислительный блок: Встроенная платформа, оснащенная двумя энергоэффективными встроенными GPU (графическими процессорами).Архитектура ИИ: Нейросеть Helix работает локально прямо на борту робота, обрабатывая данные в формате «пиксели в крутящий момент» (pixels to torque).Компьютерное зрение: Усовершенствованная система камер с 60-градусным углом обзора, двойной частотой кадров и очень низкой задержкой, а также встроенные камеры в ладонях.Масштабируемость обучения: Вычислительные мощности на физических роботах дополняются дата-центрами с новейшими графическими процессорами. Инвестором и стратегическим партнером Figure AI по развитию ИИ-инфраструктуры выступает компания NVIDIA.Вычислительное железо и сенсорная архитектура позволяют модели Helix работать целиком на самом гуманоиде, анализируя окружающее пространство для автономной навигации по этажам и выполнения сложных бытовых или производственных задач.
>>1617758 Нюанс в том, что ему ну не нужно абсолютное понимание всего. Условимся, что он знает определенный контекст (профессию), у него там куча шаблонов, которым он следует, котоыре него запихали. Он может переключаться между этим шаблонами быстро, обрабаытвать их. Что еще нужно? Зачем сортировщику на ленте, например, еще что-то кроме "умных" алгоритмов. Моторике научне, распознаванию объектов научен. Это сюда, это вон туда, это нахуй с ленты, если пожар, то вот то делать, если потоп, то бежать сюда. И есть множество таких профессий, где достаточно тривиальный контекст, они рутинны и нетребовательны, нужно лишь какую-то базы понять и иполнять ее. Отличие будет в том, что роботу не надо ничего "учить" постепенно, как человеку, давай условимся, что в него надо "зашить" эту базу.
>>1617759 Сегодня он инсультник, завтра ты. А он гордый стальной осанка длинный шланг + 10 социал-кредит ударный труд 15 лет завод гарантия 3 юань час
>>1617697 >роботы это наглядно показывают. Трясуны? Ты глаза-то протри. Там даже нормальной механики нет. Зрение говно. Они даже не одупляют где находятся.
>Вот этот робот-сортировщик Просто фенси-пенси механическая рука которой уже 70 лет. Теперь выкинь его за километр от этого конвеера без отдельных инструкций и посмотри как он к конвееру притащится и выполнив свою работу вернется назад (как как никак). Ты скажешь - а нахуй за километр? А я скажу? А нахуй ему вообще ноги тогда? Механическая рукам на палке прикрученная к этой линии может то же самое.
>>1617666 >иди к себе на свои доски Я на своей доске и я тут был с первого дня и во всех тредах до создания этой доски, как я тут в целом раньше тебя и всего модсостава и самого абулику. Но схуя ты чип который радился на десятилетия позже меня думаешь что можешь меня отсюда гнать? Чё-то ты попутал, выпездок соевый. Если тебе не нравится культура борд и культурное общение тут - съеби к себе на хабр или откуда ты высрался.
>>1617353 >>1617349 Когда-то я тоже был рннщиком, но потом устроился на работу и счастливее от этого не стал. Да, появились деньги, какая-то стороння активность и общение, но как бы я хотел снова вернуться туда, в рнн, и просто месяц не выходить никуда, кроме как с собакой и в магазин, выключить телефон и забыть что такое будильник, смотреть перед сном из окна утром, как работяги идут на работу или счищают снег со своих ласточек. Потому что вот это 5/2, да и вообще любой график кроме отсутствующего, это не жизнь. Кому-то норм или делают вид, но не мне.
Губернатор Ньюсом подписывает беспрецедентный исполнительный указ о подготовке работников и бизнеса к наступающим потрясениям, связанным с ИИ
САКРАМЕНТО — Губернатор Гэвин Ньюсом сегодня издал исполнительный указ, предписывающий Калифорнии подготовить работников, малый бизнес и сообщества к экономическим потрясениям, которые искусственный интеллект принесёт на рынок труда. Данный указ мобилизует государственные учреждения, экспертов в области труда, экономистов, университеты и лидеров отрасли для разработки новой политики, сбора данных и выявления ранних признаков потрясений на рынке труда — при одновременном обеспечении того, чтобы работники разделяли выгоды, создаваемые ростом производительности благодаря ИИ.
Указ предписывает штату изучить такие направления политики, как стандарты выходных пособий, страхование занятости и поддержка перехода для перемещённых работников, модели рабочей собственности, концепции универсального базового капитала, расширенное профессиональное обучение, а также более тщательный мониторинг тенденций найма и начисления заработной платы, чтобы помочь Калифорнии быстрее реагировать на потенциальные сокращения и экономические потрясения. Ознакомиться с исполнительным указом можно здесь.
«Калифорния никогда не сидела сложа руки, наблюдая, как будущее происходит с нами, — и мы не начнём делать это сейчас. Мы взяли на себя лидерство в продвижении инноваций, безопасности и прозрачности. Но мы должны мыслить шире. Этот момент требует, чтобы мы переосмыслили всю систему — то, как мы работаем, как управляем, как готовим людей к будущему, — и эта работа начинается прямо здесь, в Золотом штате.
Сегодня — лишь первый шаг, поскольку мы переписываем политику и направления, создавая будущее труда, которое работает на всех».
Губернатор Гэвин Ньюсом
«Будучи эпицентром технологической индустрии, Калифорния осознаёт свою ответственность за обеспечение готовности работников к успеху по мере того, как ИИ меняет экономику. Женщины, в частности, сталкиваются с непропорционально высокими рисками вытеснения и усугубления экономического неравенства по мере развития ИИ. Поэтому Калифорния стремится понять влияние ИИ на работников, модернизировать профессиональное обучение и расширить пути доступа к рабочим местам будущего, чтобы больше калифорнийцев были настроены на успех. Исполнительный указ, опубликованный сегодня, подчёркивает приверженность Калифорнии продвижению возможностей наряду с ответственными инновациями».
Дженнифер Сибел Ньюсом
Подход Калифорнии — первый в своём роде в стране Калифорния доминирует в области инноваций в сфере ИИ: 33 из 50 ведущих частных компаний по разработке ИИ в мире базируются в Калифорнии, и ни один штат не предпринял более решительных действий для укрепления безопасности, защиты и конфиденциальности потребителей в отношении технологий и онлайн-платформ. Сегодняшний указ дополняет комплексный подход Калифорнии к созданию разумных ограничительных механизмов, сбалансированных с возможностями для продвижения инноваций в этом растущем секторе.
В 2023 году губернатор Ньюсом сделал Калифорнию первым штатом, предпринявшим действия в области политики в отношении генеративного ИИ, объявив исполнительный указ как об ответственном внедрении этой технологии в государственном управлении, так и о начале изучения её рисков. Губернатор созвал ведущих мировых академических экспертов для подготовки Калифорнийского отчёта по политике в области передового ИИ, предоставив штату рекомендации по политике, которые помогли привести к подписанию губернатором первого в стране законодательного акта штата — Закона о прозрачности передовых технологий (Сенатский билль 53, Вайнер) — с целью обеспечить ответственное развитие этой технологии. С тех пор этот закон был воспроизведён и взят за основу в аналогичных законах, принятых в других штатах.
Это дополняет другие меры защиты, подписанные губернатором Ньюсомом, направленные на создание строгих протоколов безопасности детей и защиты от самоповреждения, борьбу с сексуально откровенными дипфейками и требование маркировки ИИ-контента, защиту цифрового образа исполнителей и предотвращение мошенничества с помощью робозвонков, созданных ИИ. Кроме того, это дополняет исполнительный указ губернатора от марта 2026 года, который укрепил гражданские права и конфиденциальность при закупках Калифорнией технологий ИИ и расширил внедрение ИИ в Калифорнии для улучшения государственных услуг.
Формирование реакции на влияние ИИ на рабочую силу Сегодняшний исполнительный указ предписывает государственным учреждениям создать основу для реагирования на потенциальные потрясения на рынке труда и обеспечения того, чтобы работники не остались в стороне по мере ускорения внедрения ИИ.
Указ предписывает различным государственным учреждениям:
Расширить права и возможности работников и помочь им разделить выгоды от внедрения ИИ: — Оценить и поддержать возможности расширения и совершенствования моделей рабочей собственности для поддержки широкомасштабного роста капитала и создания благосостояния за счёт роста производительности среди работников, включая структуры компаний, принадлежащих сотрудникам. — Поддерживать малый бизнес посредством образовательных и стимулирующих возможностей в области передового опыта и применения новых технологий для поддержки конкуренции и широкомасштабного экономического роста, одновременно поддерживая профессиональное обучение и удержание кадров. — Определить способы, с помощью которых процесс коллективных переговоров обеспечил положительные результаты для работников. — Добавить больше обучения на рабочем месте и подготовки в области ИИ в системе высшего образования.
Отслеживать и понимать влияние ИИ на рабочую силу, заполняя пробелы в знаниях и предоставляя чёткие и конкретные данные с помощью: — Нового отчёта с рекомендациями, передовым опытом и ранними экономическими предупредительными сигналами о потенциальных трудовых потрясениях, подготовленного в консультации с экспертами в области труда, промышленности и академических кругов. — Новой информационной панели, отображающей влияние ИИ в различных секторах. — Рекомендаций в течение 180 дней относительно пересмотра и обновления Калифорнийского закона об уведомлении работников о корректировке и переподготовке (WARN), чтобы обеспечить использование WARN для предоставления данных раннего предупреждения и его адаптацию к возникающим отраслевым тенденциям. — Новых отзывов бизнеса о роли технологий в решениях, касающихся рабочей силы, включённых в ежемесячный отчёт штата о занятости.
Реагировать на возможные потрясения в сфере занятости и рабочей силы путём: — Пересмотра политик, обеспечивающих работникам систему социальной защиты, включая выходные пособия и другие формы компенсации, такие как акции или иные формы долевого участия. — Повышения осведомлённости и расширения охвата программами страхования занятости, включая выплаты за стабильность занятости. — Создания «руководства по ИИ» для модернизации программ профессиональной подготовки, включая расширение стратегий по связи перемещённых работников с обучением и технической помощью, а также обновление целевых отраслей с учётом возникающих экономических тенденций. — Создания единой онлайн-платформы, позволяющей калифорнийцам легче ориентироваться в государственных услугах и, в конечном итоге, помогать калифорнийцам определять все социальные услуги, на которые они могут иметь право. — Использования потенциала программы California Volunteers для тех, кто испытывает длительную безработицу, и для обеспечения базовой подготовки для работников начального уровня.
Разрабатывать более сильную государственную политику и программы поддержки для использования ИИ в интересах общественного блага: — Работать с академическими экспертами и частным сектором для разработки рекомендаций по изменению структур стимулов и повышению вероятности разработки и внедрения ИИ, продвигающих общественное благо и решающих критические проблемы, стоящие перед обществом.
Каждый калифорниец получает своё место за столом переговоров
>>1617774 >Трясуны? Ты глаза-то протри. Там даже нормальной механики нет. Зрение говно. Они даже не одупляют где находятся Да нормально у многих с механикой, чего стоила китайская демонстрация, где роботы всякие приёмы показывали из единоборств. Да, в целом тормозные, но уже нормально
А то, что не одупляют, это уже интеллект, а не механика
>>1617771 >Условимся, что он знает определенный контекст (профессию), у него там куча шаблонов Он не знает, то есть не понимает, что у него за профессия. Нельзя переносить сознание людей на роботов. Вот пример, робот-сортировщик, что 200 часов посылки сортировал. Работа для IQ 60, можно пятилетлему ребёнку за пять минут объяснить, и он делать будет, пока терпение не кончится. А этот робот даже там проёбывался, не в состоянии обрабатывать коробки кубической формы.
При этом уверен, что обучали его довольно долго. Но он не в состоянии сообразить, что штрихкод может быть не с той стороны, что сторон много. Причём засада в том, что если рёбёнок или даун какой-нибудь так будет делать, ты сможешь им объяснить и они исправятся, а роботу ты сам хрен объяснишь. Специальные инженеры нужны будут, возможно что с зарплатой как у американского кардиохирурга
>>1617818 > если из дома не выходишь Мне кроме этого есть чем поинтересней заняться. Раз в неделю еще можно, но чтобы каждый день это надо каким-то отбитым любителем погулять быть.
>>1617823 Во-первых при программировании с помощью агентов основная цена приходится на инпут, а не аутпут. А тариф за инпут всего в 2 раза отличается. Потом есть реальный прайс, во сколько тебе обошлась задача, а там уже объём ризонинга, сколько итераций и всё прочее очень-очень сильно влияют.
В результате очень часто дешёвые модели обходятся дороже, чем дорогие. Конкретно GPT 5.5 по моим ощущениям обходится дёшево, вот Opus 4.7 заметно дороже.
>>1617826 Ну хз, мне очень помогает физическая активность после обеда. И не обязательно же упарываться, часик два под подкаст в зависимости от настроения
>>1617821 > А этот робот даже там проёбывался, не в состоянии обрабатывать коробки кубической формы. 1. Дообучат, пофиксят. 2. Ты даун, если думаешь, что роботу необходимо 0 ошибок иметь: если раньше на 24/7 сортировке, условно, работали 30 человек, то теперь достаточно 9 роботов и 3 человека, сортирущих коробки кубической формы после роботов.
>>1617458 >У китайцев не существует права на собственность, сколько спиздили столько и скормили для обучения. На западе всё это сложнее. Да конечно, что не мешало ОпенАИ точно также спиздить и фильмы и аниме для обучения своей Соры2. И цензуры кстати в ней было даже поменьше, чем сейчас в Сиденсе 2.0 (зацензурили так, что даже похожих персонажей банит нахуй).
Помню как закинул в Сору2 персонажей из Евангелиона и попросил опенинг сделать, так он в несколько генераций даже оригинальный трек хуячил (пусть местами и с искажениями или другим текстом).
>>1617821 >Работа для IQ 60, можно пятилетлему ребёнку за пять минут объяснить, и он делать будет, пока терпение не кончится.
Роботу нельзя объяснить новое "на лету". Таких архитекутр нет. Пока. У него представление о кубических коробках должно лежать в его датасете, в весах. О том, что это, для чего нужны и что ему предстоит с ними делать. Поэтому, нужны специфические данные профессии, чем больше, тем лучше. И на этих данных уже его обучать. Вот тогда он все прекрасно понимать будет и следовать этому. Дальше нужно будет только дообучать под какие-то возникающие нюансы новые.
До этого момента никто не копил данные о том, как сортировщик работает, например. Ни у кого не возникало ситуации, что приходит работник и ему нужно обяснить, как вертеть коробку или с какой стороны смотреть штрихкод. Потому, что он подобным вещам с детства научен. И может перносить по аналогии со сферы на сферу. Но у робота никогда не было детства и постепенного развития, где он мог бы приобретать и закреплять какие-то навыки, и он пока так не может делать. Поэтому, ему в рамках профессии нужно дать вообще все. И вот сейчас как раз такие датасеты и начали собирать.
>>1617821 >чего стоила китайская демонстрация, где роботы всякие приёмы показывали из единоборств. Нихуя не стоит, мы все тут видели, что они не могут переностить центр тяжести и нормально удары наносить.
>>1617844 >1. Дообучат, пофиксят. Так можно про что угодно сказать. Чё, завтра на марсе яблони начнут цвести? Даун, блядь.
>>1617816 >предписывающий Калифорнии подготовить работников, малый бизнес и сообщества к экономическим потрясениям, которые искусственный интеллект принесёт на рынок труда. Вот-вот щасщасщасщас, погодите, вот уже этой осенью совершенно точно.
Демис Хассабис говорит, что Сингулярность наступит всего через несколько лет, потенциально вызванная приходом подлинного AGI.
Видеорелейтед.
Горизонт ОИИ
Хассабис: Мы, очевидно, много говорим о том, что общий искусственный интеллект уже на горизонте. Я думаю, что сейчас нас отделяют всего несколько лет от его полноценной версии.
Сингулярности как описательный термин
И, как мне кажется, «сингулярности» — это довольно удачное слово для описания эпохи, наступление которой вызвано выходом на сцену такой технологии, как ОИИ.
Трансформирующее воздействие и непредсказуемость
И отчасти это связано с тем, что его влияние будет настолько преобразующим — я считаю, что это величайшее изобретение в истории, — что за этим горизонтом трудно делать какие-либо масштабные прогнозы, ведь он изменит очень и очень многое.
Ощущение перемен прямо сейчас и взгляд в прошлое
Так что, думаю, в этом году, благодаря ОИИ и системам ОИИ, которые мы все наблюдаем и используем, мы можем начать ощущать это уже сейчас. И именно это я, в общем-то, и имел в виду. Когда мы оглянемся назад, думаю, лет через пять-десять, мы, наверное, скажем себе: «О да, знаете ли, 2026-й, 27-й — это как раз то время, когда всё начиналось».
>>1617875 Кстати ведь вот-вот. Маск ранее говорил, что SpaceX будет выходить на IPO после создания базы на Марсе. И вот сейчас объявили, что скоро выходят на IPO. Значит вот-вот создадут станции на Марсе, наверное яблони тоже будут
Вообще история ничему не учат, все живут так, как будто они первые какой-то опыт проживают. А ведь космос в 60-е и 70-е хорошая аналогия. Тогда тоже все воодушевлённые стремительным прогрессом рассуждали о том, что вот-вот будут космические экспедиции, поселения на разных планетах и много чего ещё. Но куда-то всё ушло
Примерно сейчас вот все эти разговоры про AGI, тотальную роботизацию и много чего ещё
PS: при этом космос, конечно, никуда не делся, просто в разы меньше его, чем ожиданий было
>>1617850 >У него представление о кубических коробках должно лежать в его датасете, в весах. Это показывает, что робот просто тупой. Вот абсолютно тупой, что его реальный IQ меньше 60. Потому что человека обучить можно в момент, надо объяснить принцип, и всё. Если потом появятся коробки в виде 8-гранника, то он сообразит.
Само собой, что можно придумать механизмы, что будут сортировать, и надёжно. Более того, они есть. И там разработчики просто предусматривают все эти ситуации. Вот и здесь придётся предусмотреть. Но это не ИИ, это автоматизация без реального интеллекта.
Я при этом не исключаю, что придумают реальный ИИ. Но до этого пока очень далеко, по крайней мере современное направление тупиковое, нужно другое.
Трамп вложил миллионы в сеть суши-баров. И похоже, он перепутал её с ИИ-компанией
Дональд Трамп снова оказался в центре финансового скандала. Согласно последним налоговым декларациям, президент США активно торгует акциями крупных технологических компаний – Nvidia, Apple, Dell.
Однако японская газета Yomiuri Shimbun раскопала куда более неожиданную инвестицию. Трамп приобрёл акции на сумму от 1 до 5 миллионов долларов в сети ресторанов с конвейерным суши под названием Kura Sushi.
Новость немедленно взорвала японский интернет. Пользователи быстро выдвинули занятную теорию, согласно которой, президент – или его сын Дональд Трамп-младший, технически управляющий трастом отца, – мог попросту перепутать сеть суши-баров с токийской компанией Fujikura.
Fujikura – крупный поставщик оптоволокна и компьютерного оборудования, чьи акции резко выросли на волне ажиотажа вокруг ИИ. Название "Kura" действительно созвучно части названия "Fujikura", и, учитывая, что последние инвестиции Трампа сосредоточены именно вокруг компаний из цепочки поставок ИИ, путаница выглядит правдоподобно – пусть и комично.
Японские пользователи не сдержались в комментариях.
Неужели Трамп страдает деменцией, если путает Fujikura с Kura Sushi?
Интересно, Трамп вообще ест суши? Я всегда представлял его с гамбургером или стейком.
Для самой Kura Sushi история обернулась неожиданной удачей: после появления новости акции компании подскочили примерно на 5,4%. Fujikura повезло куда меньше – её бумаги за последнюю неделю обрушились примерно на 45,4%. Связана ли часть этого падения с предполагаемой путаницей Трампа, сказать сложно, но репутационного шума история точно добавила.
Представители Trump Organization пока никак не прокомментировали, была ли покупка акций суши-сети намеренной или случайной.
>>1617718 > Это железная логика необходимости и неизбежности, Да, ещё этот провал с молодыми рабочими, старое индустриальное поколение уходит, а замены им нет, все ударились в программисты, экономисты, трейдеры, бармены, курьеры, блогеры и онлайн фрилансеры.
Anthropic выпустили пост-обновление про Mythos и Project Glasswing с промежуточными результатами.
Спустя месяц большинство партнеров обнаружили в своем коде сотни уязвимостей критического и высокого уровня опасности каждый. В общей сложности они выявили десятки тысяч уязвимостей. Некоторые из партнёров сообщили, что скорость обнаружения багов выросла более чем в десять раз. Например, компания Cloudflare нашла 2000 уязвимостей (400 из которых имеют высокий или критический уровень опасности) в своих критически важных системах, при этом доля ложных срабатываний, по мнению команды Cloudflare, оказалась ниже, чем у тестировщиков-людей.
Я видел много комментариев про то, что, мол, Mythos да может что-то находит, но наверняка выдаёт и много мусора, где уязвимостей нет — так вот это не так. Помимо закрытых проектов, Anthropic натравили Mythos и на опенсурс для сканирования более 1000 крупных репозиториев, на которых во многом держится современный интернет. На данный момент, по оценкам Anthropic, в этих проектах найдено 6202 уязвимости высокого или критического уровня (из 23 тысяч в общей сложности, включая те, которые относятся к среднему или низкому уровню опасности).
На данный момент лишь 1752 из этих уязвимостей с высоким и критическим уровнем прошли тщательную проверку силами одной из шести независимых исследовательских компаний в сфере кибербезопасности. Из них 90% оказались подтвержденными, а 62% (1100 штук) были классифицированы именно как уязвимости высокого или критического уровня.
Некоторые из уязвимостей носили очень серьёзный уровень угрозы, если бы они были обнаружены злоумышленниками. Как пример, Mythos смо написать эксплойт, который позволил бы злоумышленнику подделывать сертификаты через библиотеку wolfSSL. Это, к примеру, дало бы ему возможность разместить фальшивый сайт банка или почтового провайдера, и для конечного пользователя такой сайт выглядел бы абсолютно легитимным, браузер не показал бы никаких уведомлений.
Обнаруженные уязвимости льются как из рога изобилия, их не успевают исправлять, не хватает людей. Некоторые команды/проекты даже просили снизить темпы раскрытия информации об уязвимостях, поскольку им требуется больше времени на создание патчей. (В среднем, на устранение бага высокого или критического уровня, найденного с помощью Mythos Preview, уходит две недели).
В настоящее время ни одна компания — включая Anthropic — не разработала достаточно надежных механизмов защиты, способных предотвратить использование подобных ИИ-моделей во зло и для причинения потенциально серьезного ущерба. Именно поэтому к модели не дают доступ широкой аудитории. Но по этой же причине и был запущен Project Glasswing: если модель с аналогичными возможностями будет выпущена кем-то без соответствующих мер, то в скором времени для любого человека в мире станет значительно дешевле и проще эксплуатировать уязвимый код.
И что же это получается? ИИ который должен был обвалить трудовой рынок с каждой итерацией становится ближе по цене на сотрудника за час, а в перспективе может оказаться ещё дороже.
>>1618189 Закодированные в харде веса цены обвалят. Туда можно даже большие модели на 350 миллиардов параметров закодить. Текущему положению вещей недолго осталось, примерно год.
>>1618189 Тут можно сразу множество вещей сказать, по этой теме. 1. Оптимизация и налаживание производства. Как модели, так и железо будут оптимизироваться и модели будут становиться дешевле в инференсе, а железо будет дешевле в производстве. Так же при наращивании производственных мощностей продукт всегда дешевеет. Это первая необходимость человечества, так что массовое производство чипов точно наладят. Раньше бы, например, казалось что смартфоны это какая-то супер приблуда только для богатых, сейчас это базовая вещь для каждого, которую можно купить за четверть месячной зп. 2. Текущее железо, видеокарты, это не какой-то специализированный асик для запуска нейросетей, это универсальное железо для множество задач. Как только аги будет достигнут его сразу же запилят в кремний напрямую, конкретно под инферес именно этой модели. А так же наверняка будут открываться другие методы запуска нейросетей, возможно не цифровые, а аналоговые, которые им больше подходят. 3. Задача сейчас не заменить всех людей, а достичь аги в первую очередь. Аги по своему определению эквивалентен человеку, а значит как и человек он может улучшать ии, следовательно он начнет улучшать сам себя, оптимизировать и находить лучшие способы запуска моделей самостоятельно.
tl;dr: Важно просто запилить аги, самым грубым, неоптимизированным способом, он не должен заменить человека с ходу, но со временем будет оптимизирован для массового, дешевого использования, при чем, скорее всего, он сделает это сам.
DeepSeek сегодня перманентно тотально снизили цены на модель DeepSeek‑V4‑Pro
Удешевление составило около 75% на вход и до 90% на выходные токены. По новым ценам вы получаете миллион токенов за 0.43 $ за вход и 0.87 $ за выход. С кэшем – еще дешевле.
Напоминаем, что по метрикам эта модель примерно на уровне Gemini 3.1 Pro, но теперь она в 4-7 раз дешевле всех фронтиров.
Ебало западных ИИ-компаний даже имаджинировать не требуется
>>1618205 Двачую. Модели все еще развиваются и улучшаются. Какой смысл зашивать в железо модель, которая устареет в момент выхода? Вот когда модели на 10Т станут обыденностью, когда любые бенчи улетят туземун, когда появится аги, вот тогда его и имеет смысл зашивать в чипы.
>>1618217 Они модели на аксентах хуйвэя крутят. что касается дикпика, то они реально лучшие за свои деньги и это не только про версии касается. Я изучаю английский через чтение адаптированных книг, адаптацию делаю с помощью скрипта. Так вот, я замерял стоимость адаптации одной книги разными моделями. Дешевле всех получилось на deepseek v4 flash - вышло 23 цента. Gemma 4 тупо не следует инструкции, вместо симплификации содержания книги сипмлифицирует сам промпт лол, тоже можно сказать про дешевый грок. Хорошо работает гемини 3 флеш, но получается примерно 70 центов за туже книгу. Пробовал deepseek v4 pro - по старым ценам вышло более 3-х долларов, но с новой ценой меньше бакса.
Короче, я хоть не люблю Китай с его ебучей цензурой, но дикпик пока лучшее за свои деньги
>>1618236 Пиздежь. Разве что для нормисов поверхностно знакомых с ИИ, которые только что вкатываются. Западные ИИ инфлюенсеры постоянно освещают китайщину, а так же много времени уделили дешевизне дипсика. Да и R1 настолько хайповал, что о дипсике даже и нормисы знают, так как он рыночек уронил однажды
>>1617718 > робот эффективне человека, намного быстрее обучается и дообучается Главная фишка в том, что он обучается массово. Если один робот усвоил новый навык -> все роботы усвоили этот навык на том же уровне.
>>1617940 Конкретно этот робот может и тупой. А вот другой, который будет математиком и исследователем - умный. ОйКью показывает способность к работе с абстракциями и логикой, это не универсальный показатель степени развитости ума. Сортировщик на ленте не обязательно должен быть умным, он должен быть компетентным в рамках своей профессии, ограниченно умным. Все, что нужно ему сделать после смены - зайти в ангар роботов и стоять там ждать обсуживания. Зачем конкретно ему высокий интеллект и развитый ум? Эрдеша решать или на Дваче троллить мешков?
Роботы американской компании Figure AI под управлением системы искусственного интеллекта Helix 02 прошли тестирование. Гуманоидный робот за 200 часов без остановки самостоятельно рассортировал почти 250 тысяч посылок без каких-либо сбоев.
Архитектура Helix-02 развёрнута внутри F.03 и не требует дистанционного управление. Если робот застрянет или столкнётся с незнакомой ситуацией, ИИ-система сможет провести автономную перезагрузку и возобновить работу без вмешательства человека. Helix-02 представляет из себя нейросеть, объединяющую зрение, тактильные ощущения, проприоцепцию и управление всем телом.
>>1618251 Как я понял, задача робота перевернуть пакеты штрихкодом вниз, чёб дальше по ленте их смог считать сканер. Скорость работы рук хорошо подняли.
>>1618139 Кстаи, это хорошим триггером может стать для безвозвратности процесса. Человеческий трудовой капитал слабеет, и по мере того, как роботов будут постепенно внедрять, он будет еще более слабеть. Сейчас нет желания учиться у людей и въебывать за очередноq креlит и отсуnствие перспектив, а потом не будет необходимости и/или возможности
>>1618250 > это не универсальный показатель степени развитости ума Главный показатель развитости ума, это способность научиться чему-то и разобраться в чём-то. В первую очередь научиться чему-то.
Человек способен научиться тому, чтобы класть предметы этикеткой вниз. IQ 60 достаточно, чтобы этому научить. Робота обучить этому не смогли. По всей видимости, абстракция уровня "этикетка вниз" для него недоступна, его научили класть так, чтобы он этикетку не видел, из-за этого фейл с коробкой кубической формы.
Интеллект живым организмам нужен в том числе для адаптации к меняющимся условиям. Робот интеллектом реальным не обладает и адаптироваться не способен. Чуть поменялись условия, и всё, со склада можно не выходить, под новые условия надо обучать заново.
В итоге получаем, что тебе нужны не роботы, что работают, а инженеры, что настраивают машины по сортировке посылок. Конечно если эти машины поддаются настройке или дообучению.
>>1618290 ИИ не учится в реальном времени, я уже говорил. И это не главный показатель развитости ума, а один из. Кто более развит по уму, ребенок 6 лет или ИИ, в который зашиты все знания мира, любая современная корпоративная нейросеть? Ребенок легко учится может, но будет немоверно туп на фоне ИИ.
Ты не понимаешь фундаментальные ограничения ИИ, поэтому раз за разом эту мантру повторяешь, что он туп. Он плохо работает с теми концепциями, которых нет в его весах на данный момент, в сотальном он работает отлично. У него нет воприятия и непосредственного контакта с миром, это "размышляющая память".
>>1618290 > Робота обучить этому не смогли. По всей видимости, абстракция уровня "этикетка вниз" для него недоступна, его научили класть так, чтобы он этикетку не видел, из-за этого фейл с коробкой кубической формы. Даун.
>>1618312 >Кто более развит по уму, ребенок 6 лет или ИИ, в который зашиты все знания мира Можно переформулировать >Кто более развит по уму, ребёнок 6 лет или Библиотека имени Ленина / Библиотека Конгресса США? В таком контексте понятна абсурдность вопроса, хотя понятно, что даже образованный взрослый не обладает даже 1% знаний, что в этих библиотеках имеются
Или другой вопрос. Какой интеллект у программы, что делает какие-то сложные физические расчёты? Лишён смысла вопрос, программа может делать что-то, что человек уже не вытягивает, за адекватное время по крайней мере, но ума у программы нет.
>Ты не понимаешь фундаментальные ограничения ИИ Я как раз понимаю, а вот у тебя какое-то мистическое мышление в отношении ИИ. Перенос ума человека на ум машины. Потому что ты переносишь, что если ИИ как бы знает что-то и умеет что-то делать, то там способность думать видимо такая же, как у человека, который знает в схожем объёме и способен делать схожие вещи.
И вот это главная ошибка и непонимание современного ИИ. Они тупы, они просто выучили ответы и какие-то действия, делают что-то перебором и подстановкой. Но в отличии от людей, они не в состоянии понять, что они делают и зачем.
То есть там знаний может быть на IQ 200, а реального мышления на IQ 60 в лучшем случае. И вот это сложная вещь, поскольку у людей такого разброса не встречается всё-таки.
Проблема в том, когда люди начинают закладываться на то, что у ИИ есть реально какое-то мышление и вообще что это что-то, что похоже на человека.
>>1618260 Вы не понимаете как наука работает. Нейронки пока что даже сырую дату обрабатывать могут не всю, которую приборы получают, потому что её просто мало а нагенерировать невозможно. >>1618293 Для меня лучшая. Терпеть не люблю людям распоряжения поручать и следить за ними.
Cerebras запустили Kimi K2.6 на скорости в тысячу токенов в секунду
Модель на триллион параметров на такой скорости запускается впервые, перед этим самой большой модель у Cerebras была GLM 4.7 на 358B. К сожалению это пока что доступно только энтерпрайз клиентам.
Кстати компания ещё вышла на IPO на прошлой неделе, привлекла 5.5 миллиардов долларов и теперь стоит 60 миллиардов.
>>1618343 почему их нет на том же openrouter? Если у них реально какая-то эффективная генерация, было бы разумно продавать свои услуги по АПИ, это и демонстрация, и доход
>>1618347 Все крупняки обновили свои модели. В ближайшее время ничего закидывать на арену для тестирования не будут. Какой смысл им нести расходы за то что кто-то дрочит арену бесплатно. Токены дорожают, подписки дорожают или просто закрываются, бесплатные лимиты снижаются. Везде так.
>>1618343 Кстати откровенно манипулятивная и ложная картинка. Они сравнивают, сколько выдаёт их девайс с тем, сколько выдают провайдеры пользователям.
Но провайдеры обрабатывают на одном устройстве много пользовательских запросов одновременно, так можно КПД больше получить (токенов с устройства в час), да и надо много пользователей обслуживать, из-за этого TPS падает. а эти скорее всего тестируют на выделенном устройстве.
То есть на практике возможно, что их устройство ничуть не более эффективно, чем обычные GPU
>>1618334 Его просто сдвигают по чуть-чуть всё время. В 2040м те, кто дожил и не помер от цирроза ИТТ будут говорить, что в 2042м году уже 100% выйдет АГИ, который будет за нас делать открытия
>>1618360 Так его сдвинули с 2045 на 2028. Исторически прогнозы делают намеренно далёкими, чтобы когда они очевидно не сбудутся, этих предсказателей не было уже рядом, чтобы спросить с них. Или просто все забыли, подзабили хуйца.
То что сейчас прогнозы такие короткие, значит что они уверены в своих словах и надеются застать этот момент. + слишком много разных людей из разных источников говорят одно и то же несговаривавшись, значит правда.
Только дурак ждал Аги в 2024. Тогда даже дипсика не было и такого общественного внимания к теме. Таких бюджетов не было. Хватит хуйню нести
>>1618369 >Только дурак ждал Аги в 2024 Альтман обещал. Причём тогда обещал, что буквально через полгода будет. Как характеризовать тех, кто ему верил? Ну ты ответил уже
>>1618370 >>1618369 Просто реально, сколько раз уже было, что из компаний шишки интригующе говорили "вы просто не представляете, что будет в ближайшие 3 месяца". И сюда это много раз приносили. И что оказывалось? Ничего.
И это было про сроки в два-три месяца. Даже у золотых рыбок память дольше работает. А тут 2 года, даже ишаки столько не живут
>>1618224 > Я изучаю английский через чтение адаптированных книг ээээ а зачем? По идее смысл изучения языка в том, чтобы адаптировать твой мозг под текст, а не текст под твой мозг
>>1618373 Зависит от уровня языка. Если уровень невысок, сложную книгу ты не вытянешь, их часто специально пишут так, чтобы там был максимально сложный язык.
>>1618348 >>1618354 У них есть апи. Когда скрапил находил ключи и там действительно летают сетки как ебанутые. Но тогда были какие-то локалки типо квена
>>1618370 Так он пиздабол. Вся индустрия его знает как пиздабола.
В 2024 не знала, а когда узнала - его попытались из компании уволить. А когда не вышло, многие сотрудники разбежались и пошли в другие компании или насоздавали своих собственных. Тот же антропик
По факту, это не он наебал со сроками, а его наебали. Вся вина за неудачу лежит на недобросовестных исполнителях. Скам Алтман ни в чём не виноват.
Вот сидели бы смирно, разрабатывали свою хуйню, АГИ бы вышел и Алтман попал бы в учебники истории. Но злокозненные гады решили поднасрать великому деятелю. Не всё так однозначно.
>>1618376 Идея вот в чём, возможно другие провайдеры тоже смогут обеспечить такие TPS, если выдадут полное устройство пользователю. Низкие TPS потому, что просто пользователей много, стараются выжать максимум из своих вычислительных ресурсов.
>>1618373 адаптация делается для устранения редких слов, еще для разбивки сложного предложения на несколько простых. смысл книги остается. нужно это чтобы каждые 5 сек не лезть в словарь, так как забываешь контекст смысла и чтение превращается в пытку
>>1618372 Ретроспективно же. Я ролик старый пару постов выше кидал как какой-то гик охуевал, что в чат гпт поиск по интернету и интерпретатор кода появился. Сейчас всем похуй стало на инновации просто, это очередное чудо в мире полном чудес. Сай фай как книжный жанр поэтому и умер, как я слышал говорил один популярный писатель-фантаст. Просто всем похуй на это идейно. Все хотят на этом денег побольше захапать.
Ну и плюс по низам уже фич полным полно для большинства юс кейсов. Простому человеку больше и не нужно. Сейчас выпускают агентов для программирования фул, потом для финансовой сферы начнут, потом для третьей самой прибыльной сферы после айти и финансов. Чему тут удивляться, если это уже цикл релизов полноценный по типу айфонов каждый год или видеокарт?
>"вы просто не представляете, что будет в ближайшие 3 месяца так это маркетинг обычный. Просто беспредментный, так как нет смысла показывать модель, которую собираешься выпустить через 3 месяца и которая к тому моменту устареет.
Вот игру можно показать хоть за год до релиза, а с моделями так не получится. Мифос вот показали и не выпустили, пчелы негодуют.
>>1618385 >>Сейчас выпускают агентов для программирования фул Ага. А тем временем платный кодекс не в состоянии написать работающую простенькую игру типа Йетиспортс .
На этой неделе компания Starbucks (SBUX.O) закрыла программу на базе искусственного интеллекта для сотрудников, предназначенную для автоматизации учета запасов, спустя девять месяцев после ее внедрения в североамериканских кофейнях. Об этом сообщает агентство Reuters со ссылкой на внутренний информационный бюллетень компании и двух человек, непосредственно знакомых с ситуацией.
Этот инструмент был частью усилий генерального директора Брайана Никкола по устранению постоянного дефицита товаров в сети кофеен, который, по его мнению, наносил ущерб продажам.
«Начиная с сегодняшнего дня, функция автоматического учета (Automated Counting) прекращает работу», — говорится во внутреннем бюллетене компании от понедельника, с которым ознакомилось агентство Reuters и подлинность которого подтвердили двое сотрудников. — «Ингредиенты для напитков и молоко теперь будут учитываться так же, как и другие категории запасов в вашей кофейне».
Приложение для автоматического учета, разработанное для того, чтобы помочь Starbucks лучше отслеживать дефицит в магазинах, часто ошибалось при подсчете и неверно идентифицировало товары — например, путало похожие виды молока или вовсе их не замечало, сообщало Reuters в феврале. На видео, опубликованном Starbucks, было видно, как инструмент не смог распознать бутылку мятного сиропа на полке, подсчитывая при этом соседние бутылки.
На тот момент Starbucks заявляла Reuters, что внедрение этого инструмента улучшило доступность товаров в кофейнях — а это один из главных показателей прогресса на уровне магазинов в рамках кампании Никкола по оздоровлению бизнеса.
В заявлении для Reuters в четверг представители Starbucks сообщили, что прекращение программы, охватывавшей учет молока и других ингредиентов для напитков, связано с решением «стандартизировать методы инвентаризации во всех кофейнях, поскольку мы продолжаем уделять особое внимание последовательности и эффективному исполнению процессов в масштабах всей сети». Сеть кофеен также отметила, что работает над переходом на более частые, ежедневные поставки в магазины и продолжает совершенствовать цепочки поставок.
>>1618405 Через год снова введут. Наверняка юзали какой-нибудь недоИИ, не разобравшись что и куда. Новые модели все сильнее, распознавание лучше, ошибок меньше.
>>1618388 >Все пиздец привыкли к АИ но это же магия ебучая Ещё GPT 3 магией смотрелся, вот реально. Хотя там было много косяков. Собственно никакие косяки не исчезли, они просто закопаны глубоко и уже не видны просто так обычно
Хотя вот тест с П-фигурой очень показателен
Но я помню, что ещё 3 версия, максимум 3.5, отвечала иногда на довольно сложные вопросы по IT, которые даже не гуглились, хотя конечно чаще глючила.
Но сейчас, конечно, сильно продвинулись и уже реально что-то можно с ними делать. Проблема в том, что вот эта видимая интеллектуальность и магия сносят голову очень многим, хуже религии.
>>1618408 Это да. Все еще ссу давать полный доступ к компу или самому агенту скрипты запускать.
Но для поиска информации или шаблонных задач вроде программирования лучше уже не знаю что можно сделать.
Может тупо книги\документацию загрузить, попросить сделать вики и спрашивать вопросы по материалу это же пиздец просто. Тебе не просто найдут нужное еще и разжуют
>>1618369 >Исторически прогнозы делают намеренно далёкими Постройку первого промышленного термоядерного реактора прогнозировали на 90-е годы прошлого века. Еще в 60-х.
>>1618361 Ага. Вот только создать на камне 100 миллиардов чипов у каждого их которых будет до 20 000 связей с другими чипами пока что ненаучная фантастика.
>>1618326 Можно, но это абсурд. Библиотека не может сама оперировать своми знаниями даже с помощью человека. А вот ИИ может. Он может строить логические суждения, выполнять поиск, делать классификацию, суммаризацию, выводы, и может делать это лучше подавляющего числа людей, если уже вообще не всех, кто им оперирует. Может ли что-то подобное ребенок?
>>1618388 Да я и щас охуеваю. Всего два года назад жпт писал полную шизу, которая вообще ничего общего с реальностью не имела, а сейчас он умнее 95% людей, включая меня >>1618360 14 лет это огромный срок, если что. Просто сравни, каким был жпт в 22 и сейчас. Я думаю, что полноценный ИИ будет создан в ближайшие 5 лет.
>>1618437 >Программа - это алгоритм. ИИ это не алгоритм. А простой И это алгоритм? И если нет, то получается вы пытаетесь решить задачу, которую невозможно алгоритмизировать?
>>1618437 >ИИ это не алгоритм Если бы ИИ (LLM) не был бы алгоритмом, канплуктер не смог бы его исполнять. Канплуктер только алгоритмы исполнять умеет, такие дела.
>>1618523 Нет никакой принципиальной разницы между лламой, выдающей (на базе весов модели) следующий токен исходя из предыдущих токенов, и линейной регрессией, вписывающей прямую в набор предыдущих измерений и предсказывающий выходное значение для нового входного значения.
>>1618526 Это я уже не знаю, есть или нет, но мне показалось, что ты данные с программой перепутал. Вот только дело в том, что данные здесь у нас уже и не совсем данные, если подумать хорошенько. Эту тему можно бесконечно мусолить. Она упирается в то, что такое сознание.
Человек эволюционно - это сборище биохуйни разного калибра. Если его развинтить на составляющие, на бактерии, вирусы, клетки, память, мышление, интеллект, будет ли он человеком в таком виде и будет ли у него сознание? Это суперсистема.
Почему бы ИИ не повторить путь подобной сборки в суперсистему? Это гипотеза, если что.
>>1618530 >Вот только дело в том, что данные здесь у нас уже и не совсем данные, если подумать хорошенько. Такие же данные, как угол наклона и точка пересечения с осью Y у прямой в линейной регрессии. Просто их больше. Если тебя смущает, что ты их не понимаешь, просто представь, что ты не понимаешь, что такое "угол наклона и точка пересечения с осью Y". От этого регрессия не перестанет быть программой и алгоритмом.
>>1618437 >ИИ это не алгоритм. ИИ это математическая функция аппроксимации, которая получая на вход токены ищет наиболее похожее продолжение через свои многомерные весы.
Если бы не было многомерности это было бы простейшая хуита.
Именно поэтому оно ощущается магией ебаной, потом что оно ничтожней алгоритма это просто функция.
>>1618523 >Сам ИИ в момент исполнения - черный ящик. Полгода назад вышла статья в которой утверждалось, что по ответу ИИ можно восстановить промт с точностью до знака.
>>1618534 Ты еще небось линал с матаном изучал в вузе? Умный что ли дохуя? Закурить есть? А если найду? Вот скажи мне, как умник простой грече с завода. Если у программы код открыт, как она может быть черным ящиком, если работает в двоичной системе и ничего не шифрует?
>>1618550 >>1618437 > ИИ это не алгоритм. То есть вот это надо исправить на ЛЛМ - это не алгоритм? Это довольно смелое утверждение на самом деле. Потому что слово модель в названии подразумевает как минимум однозначную математику, которая описывает поведение модели. Ну это как я вижу со своего ПТУ. Может кто поправит.
>>1618545 "Чёрный ящик" это мысленная модель и абстракция ёпта. Про то, что в LLM происходит, все известно до каждого бита. Но когда надо просто что-то сделать не задумываясь о том, что делает каждый бит, ты думаешь о системе упрощённо и говоришь "а вот здесь мы считаем, что нихуя не понимаем, что происходит внутри". Аналогично для тебя CPU это чёрный ящик.
>>1618566 Чел ну так и есть, поэтому и ощущается магией. Как будто столбик от деления вдруг начал думать бля.
Датасет прогоняется через функцию получаются весы = модель. Берется промт прогоняется через эндкодер чтоб приблизить к значениям, делается простейшая аппроксимация как на графике где тебе надо провести линию через точки только в многомерности - получают ответ в виде ближайших весов, который декодируют обратно в текст и выдают тебе.
Ну по крайней мере я это так понимаю можете поправить
>>1618568 Хули тебе непонятно? LLM не является "чёрным ящиком" в принципе. К ней лишь относятся как к "чёрному ящику", когда важно просто получить от неё результат без мозгоебли.
Если пример с CPU тебе непонятен, возьми для примера закон Ома. Он описывает электрическую цепь как "чёрный ящик" потому что исключает из рассмотрения, что происходит с каждым электронном и электромагнитным полем в каждой точке системы. Поля и электроны там есть, и мы знаем, что они есть, но мы ебали такие подробности.
>>1618571 А почему это вообще кого-то удивляет. Предположим, что твой датасет это ответ на один единственный поставленный вопрос. Ты задаешь этот вопрос и сходимость всегда 100%, я правильно понимаю? НУ а на большем датасете с большим количеством вопросов будут всплывать ошибки, потому что датасет не идеален. Я даже в математике особой магии не вижу. Там каждый символ ошибки ведет к провалу решения. Единственное с чем согласен, что машина, имеющая датасет больше любого человека может увидеть корреляции там, где человек никогда не увидит. Может быть поэтому и не дадут никогда в широких доступ действительно большие модели - слишком большое подспорье для людей задающих неудобные вопросики.
>>1618572 >К ней лишь относятся как к "чёрному ящику", когда важно просто получить от неё результат без мозгоебли. Я всегда так и считал, просто не слежу за хайпом, поэтому тут и спросил.
>>1618574 Меня удивляет механизм. Что функция аппроксимации может привести к осмысленности или к ее видимости.
Это больно признавать потому что если "интеллект" это такая простая в своей основе штука, то и у нас тоже получается?
Я был бы доволен и моя интуиция была бы впорядке, если бы по это функции возвращало бы прямые куски текста из датасета близкие по запросу. Типо как RAG работает но может чуть получше.
>>1618547 >почему оно начинает работать непонятно А линейная регрессия, типа, не работает? Да охуенно работает, вообще-то. Положение планет заебись предсказывает, например. В свое время это тоже было чудом, Гаусс на этом прославился
>>1618578 Ты не забывай, что математика строит модели и описания. Это же не есть сам по себе настоящий мир. Она выделяет какую-то часть и описывает его. Да, интеллект в своей основе может быть действительно прост. Но ведь интеллектом не ограничвается человек. Даже ум не ограничивается интеллектом.
>>1618578 >к осмысленности или к ее видимости. А тебе не кажется, что мы сами себя накручиваем там, где не следует множить сущности? >>1618578 >если "интеллект" это такая простая в своей основе штука Я по тому и задал вопрос про алгоритм. Работ с ЛЛМ это работа с четкими алгоритмами. И специалисты знают, как они устроены. Работа с интеллектом даже близко не то же самое. >>1618578 >если бы по это функции возвращало бы прямые куски текста из датасета близкие по запросу Я могу ошибаться, но мне кажется ты недооцениваешь объемы данных, стоящими за ответами ЛЛМ на твои вопросы. ЛЛМ обучается на литературе. Чтобы получать твои прямые куски ты должен лишить весь дата сет контекста.
>>1618585 То что мы знаем весы и функцию не значит что мы знаем как это работает. Мы не можем детерминировано предсказать результат промта. Почему он поставил весы именно так. Почему такой ответ. Мы лишь вваливаем данные в модель а потом сверху обмазываем соеей чтоб юзер не мог дрочить пипирку или получить рецепт наркоты
>>1618596 "Мы не можем предсказать" и "детерминированно" это две разные вещи. Ты не можешь предсказать результат псевдослучайного генератора если не знаешь сид, но этот результат детерминированный. Ты путаешь "недетерминированный" и "я не ебу какой".
>>1618578 >то и у нас тоже получается? Ну у нас упрощённый, и то работает как ограниченная версия, не на 100%. У Бога полноценный, но там мощь, на лицо Бога даже нельзя взглянуть и выжить после этого.
>>1618601 >и почему модель резко поумнела на больших данных. А с чего ты взял, что она поумнела? С того, что её скормили в 10 раз больше генерации и она стала меньше ошибаться в предсказании следующего токена? >>1618608 Сэм не собирается никакой интеллект получать. Он сделать следящую систему, которая будет точно предсказывать, что хочет тот или иной потребитель. Ну, типо Маска, который спутники запускает, чтобы можно было в любой точке планеты очередным борцам за все хорошее помогать воевать против всего плохого.
>>1618601 Никто не знает, что конкретно кодирует каждый из миллиардов весов, это так. Только это так было в больших нейросетях ещё до изобретения LLM. Этот тезис из олдскульного диплёрнинга переехал в LLM в неизменном виде. Олдскульный диплёрнинг при этом, дай угадаю, не казался тебе магией.
Как работае алгоритм при этом никакой тайны нет. Я могу тебе кинуть ссылку на качественный видос, но оно тебе точно надо? Там ехало произведение матриц через произведение матриц. Не заснёшь на первых пяти минутах?
>>1618648 Научпоперы тебе только расскажут, что там магия, и никто не понимает, как это работает. Если они будут тебе рассказывать, что это многомерная регрессия, статистически моделирующая связи между синтаксическими единицами в обучающем массиве текста, они лайков и просмотров не наберут
>>1618347 > >Аноны, а что случилось а ареной? О, это длинная версия, вот которткая: пидорасы типа тебя случились, которые просто не могут завалить пасть и идут спрашивать "акак какать?????". Хррр-тьфу тебе в еблище, и кормящим свое чсв на даунах типа тебя ебланам, которые в гризифорк кинули скрипт обнуляющий лимиты, которые у чмарены с первого дня к кукамм были привязаны, а потом кинули это говно в сральник под названием б/ред, откуда ты щас и всплыл. Просто иди нахуй, мразь.
>>1618383 >нужно это чтобы каждые 5 сек не лезть в словарь, так как забываешь контекст смысла и чтение превращается в пытку Это называется процесс обучения, а ты просто тратишь время, ебанько.
>>1618686 Эту проекцию мы наблюдаем с вотвот щащас уже много лет, так что ртом тут пердишь только ты. Когда и если реально дропнется аги все чмыри типа тебя побегут говорить "яжигавалиль!". Но по факту никто не знает когда, точно так же как никто не знает какая погода будет у тебя через три дня, вне очевидных сезонных колебаний. Энтазиазим вокруг будущего и похрюкивание о том что будет: 1) Признак мошенника. 2) Признак жертвы мошенника.
>>1618692 То есть ты тряску устроил от того, что будущее в принципе гарантированно предсказать невозможно? Так это к любой сфере в жизни применимо. Даже устойчивое выражение есть "Планы идут по пизде". Ничего другого по пизде не идёт кроме планов. Будущее непознаваемо. Но его можно предсказать с достаточной точностью, иначе бы ни наука, ни экономика не могли бы существовать. Я бы даже сказал, что чем точнее человек может предсказывать будущее и чем дальше у него горизонт планирования - тем он умнее.
>Энтазиазим вокруг будущего и похрюкивание о том что будет: 1) Признак мошенника. 2) Признак жертвы мошенника. Тебя обманывали в жизни часто?
>а мог бы просто факты писать в тред, интересные, а не "имянейм пукнул ртом". Пиши их сам, внеси в клад. Я скрины с твиттора лью, я не оп. Чтобы мне факты писать это надо иметь опыт в нейросетях на передовых рубежах прямо, чтобы в тему треда было, а не на простом применении в бизнес процессах. Тут на доске есть тред с личными достижениями, но он за три+ года ни разу не перекатился, поэтому не вижу смысла там писать что-то. Тем более что достижения сомнительные.
>Какие планы сука на аги еблан? Думаю свою игру начать разрабатывать, когда вайбкодинг станет более доступным. Дизайн документ уже есть почти готовый, есть второй человек, которому тоже этот проект интересен. Но лично у меня нет времени на его реализацию. Было бы круто если бы можно было не работать и воплощать себя как геймдизайнера. С применением новейших технических средств. Мечта а не жизнь.
>Такие же планы, какие были у Карела Чапека на роботов? Обычный человеческий досуг, хобби. А зачем ты вникаешь в тему, которая вызывает у тебя дискомфорт? Вот мне нейронки искренне нравятся и я думаю, что они могут в перспективе сделать мир намного лучше, чем сейчас. Короче, нахуя тебе это думскролить и дизморалится понапрасну, у тебя дел что ли никаких нет или друзей что ли?
>>1618674 >погуглить авторитетные источники Это те, которые утверждают, что ИИ нас уничтожит в своей шизе? >>1618723 >не являются показателяи интеллекта. Их даже пориджи не пройдут. Ты не услышишь щелчка в голове, ведь звук в вакууме не распространяется. Современные порриджи, обученные на тик-токе, где ролики длятся по 4 секунды, имеют на столько фрагментированное мышление, что не удивительно, что они эти бенчи не пройдут. Говно на входе => говно на выходе.
>>1618772 Как релиз будет, попроси его найти уязвимости в... ах да, что это я. Для скотогоев будет запущен Пыпос на 0.14 кванта, чтобы недайбох не взломали анус уважаемым человечкам с пейсами и шлемом.
>>1618790 Верно, эта модель уже дрисня дрисни и ебется тем же квеном 3.6 35б да и она уже старая т.к. квен 3.7 вышел уже, так что асики делать с вшитыми моделями ну хуй знает
>>1618828 Им нужно не конкретную модель вшивать, а оттачивать механизм разработки пододных асиков, чтобы как будут выходить новые модели в короткий срок смочь выпустить их в кремнии. Ну или тупо ждать АГИ, там уже не ошибешься, любой экземпляр АГИ полезен
>>1618685 Нет, исследования как раз говорят, что для оптимального обучения чтению на изучаемом языке, нужно чтобы на каждой странице было не более 1-3 незнакомых слов. Если больше, то нужно брать книгу более легкого уровня. У меня реально есть прогресс, так как приложение показывает статистику скорости чтения. За пол года средняя скорость чтения выросла с 25 слов до 73 слов в минуту.
>>1618840 >За пол года средняя скорость чтения выросла с 25 слов до 73 слов в минуту. Ты жалкий клоун. Я выучил англ за год, на начальном этапе понимая в худле хорошо если 20% от каждого предложения. К концу года я уже нормально читал, знал кучу прилагательных, хотя на первом этапе со словаря не вылезал. Лень тебе объяснять, ебанашке, что именно нежелание лезть в словарь заставляет развивать антиципацию, настраивает на максимальное восприятие контекста, и твой мозг под нагрузкой особо тщательно ищет внутренние лингвистические связи. И на этом построены все самые эффективные методики у полиглотов, которые с ноги заходят в языковую группу, но ты можешь продолжать дальше дрочить по 2-3 слова в месяц и считать себя молодцом. По факту ты просто жалок, так как у тебя нет понимания и чувства языка и взяться ему тупо неоткуда.
>>1618880 >гугл лидер По качеству текста я бы не сказал, просто это на самом деле сейчас самая доступная корпоративная глорихол, которую даже не пытаются заткнуть уже полгода.
>>1618880 Китайские, конечно. Дипсик хорош, но много слопа низкокачественного и повторов.
>>1618726 >Я тя невротизм высокий Ручки то трясутся да?
>Думаю свою игру начать разрабатывать, когда вайбкодинг станет более доступным Это поздно уже, надо было делать пока бесплатно все для ассетов раздавали и картинки и видео.
> которая вызывает у тебя дискомфорт? У меня дискомфорт вызывают только регулярные взвизги про то что завтра к обеду будет аги, когда даже уже последний конченный еблан понять бы мог, что на трансформерах это невозможно.
>>1618897 >самая доступная корпоративная глорихол, которую даже не пытаются заткнуть уже полгода. Последние пол года они как раз затыкают. А вот до этого был демпинг на максималычах
>>1618900 >Ручки то трясутся да Не знаю. Я про тебя говорил в том сообщении, но опечатался от тряски
>Это поздно уже, надо было делать пока бесплатно все для ассетов раздавали и картинки и видео. Ты про что вообще, что когда стало платным? Есть сервис с бесплатными картинками и видео, вроде работает уже около года что ли. На пиках концепт арты от туда, выглядит охуенно как по мне, хоть и с ошибками серьёзными пока.
Думаю, для музыки и всего остального тоже найду скоро сервисы. Либо на локальных мощностях буду пробовать что-то. Всегда можно банально выждать, пока что-то уровня мифос можно будет на смартфоне запустить и не ебать себе мозги. Всё равно не к спеху, через год может быть уже можно будет перейти на следующий этап разработки. А пока вот так.
>У меня дискомфорт вызывают только регулярные взвизги про то что завтра к обеду будет аги, когда даже уже последний конченный еблан понять бы мог, что на трансформерах это невозможно. Этот вопрос требует моральных оценок по отношению к другим людям? Заведи себе хобби.
Препятствия и дорожные карты корпоративного ИИ, безопасность и физический ИИ: второй день TechEx
Второй день TechEx North America прошел в ключе более глубокого и критического осмысления роли ИИ на предприятиях, но с изрядной долей оптимизма. Программа, посвященная ИИ и большим данным, открылась упоминанием того, что было названо «кладбищем ИИ» — то есть проектов в области искусственного интеллекта, которые отлично показывают себя на пилотной стадии, но не справляются с задачами в реальных условиях. Несмотря на использование, казалось бы, негативного термина, множество спикеров и сессий были посвящены тому, как дальновидные компании могут никогда не столкнуться с этим технологическим некрополем.
Различные тематические направления второго дня мероприятия позволили глубже погрузиться в повсеместные проблемы, которые могут влиять на внедрение ИИ. Сессии в рамках треков «Внедрение корпоративного ИИ, окупаемость инвестиций и адаптация» взяли за отправную точку забуксовавшие пилотные проекты и попытались выяснить причины их неудач. Для организаций прозвучало немало дельных советов: спикеры говорили о фокусировке агентного ИИ на конкретных бизнес-направлениях, создании основ данных, готовых к работе с агентами (планирование успеха «под капотом»), и о реальном влиянии поминутной тарификации ИИ на финансы компании.
На инфраструктурном уровне также состоялись более глубокие дискуссии о том, стоит ли компаниям покупать или самостоятельно создавать физическую инфраструктуру для своих ИИ-проектов, а также о лучших способах обеспечения устойчивой окупаемости инвестиций в проекты, связанные с данными и ИИ, при должном учете всех многочисленных влияющих факторов.
В проектах, где развертывание ИИ заходит в тупик, основную проблему можно охарактеризовать концепцией «персонального копилота». Он отлично работает на рабочем месте одного сотрудника и для его индивидуальных рабочих процессов, но плохо масштабируется на целый отдел, не говоря уже о всей компании. Многие компании сообщают, что у них есть бюджет для начала подобных ИИ-экспериментов на уровне отдельного пользователя, и результаты обычно оказываются отличными. Если таким пользователем является руководитель высшего звена, достигнутая им личная эффективность, как правило, повышает уровень энтузиазма во всей компании, что, безусловно, можно считать плюсом. Однако именно переход от этой точки к реальным изменениям в масштабах всего бизнеса становится тем этапом, где многие организации сталкиваются с собственными трудностями и препятствиями. В этом и заключалась суть второго дня мероприятий на выставочной площадке и многочисленных сценах конференц-центра San Jose McEnery.
Вопросы кибербезопасности Несмотря на использование таких терминов, как «застопорившийся» и «трудномасштабируемый», на сцене Cyber Security and Cloud Expo спикеры назвали скорость, с которой компании и организации внедряют системы агентного ИИ, причиной возникновения «разрыва в скорости». Там, где внедрение ИИ оказывается успешным, оно набирает обороты очень быстро! Однако проблемы с безопасностью и управлением возникают, когда бизнес-подразделения внедряют генеративный ИИ быстрее, чем команда безопасности может осуществлять надзор и обеспечивать защиту предприятия.
Подобно пресловутому обоюдоострому мечу, ИИ можно рассматривать как силу, которая меняет и может улучшить как атакующие, так и защитные возможности в сфере кибербезопасности. Существуют проблемы, создаваемые изнутри ничем не ограниченными агентами и большими языковыми моделями, плюс к арсеналу злоумышленников добавляются ИИ-инструменты сканирования, способные выявлять потенциальные уязвимости.
Также среди дискуссий за круглым столом и основных докладов преобладала более старая тема теневого ИТ, теперь предстающая в своем новом обличии — теневого ИИ. Если сотрудники, например, загружают конфиденциальные материалы в несанкционированные инструменты, или если одобренные системы ИИ имеют слабые границы и плохо управляются, то поверхность атаки может расширяться без ведома команды кибербезопасности. Следовательно, управление данными и надзор за системами становятся более тесно переплетенными, чем раньше — таков был посыл как кибербезопасных, так и облачных и Big Data направлений выставки.
Для узкоспециализированных функций кибербезопасности концепция нулевого доверия была представлена как один из ответов на бесконтрольное внедрение ИИ вне зоны ответственности команд безопасности — принятие позиции «отказа по умолчанию» как для людей, так и для машин. Подтверждение личности и уровни привилегий также должны применяться к сервисам и агентам; таким образом, автоматизированные рабочие процессы будут подчиняться тем же моделям разрешений, что и любой другой элемент в ИТ-стеке.
Второй день TechEx North America, безусловно, не стал отказом от амбиций лиц, принимающих решения, в области ИИ — роль ИИ и даже агентов была признанным фактом среди спикеров, признанных экспертов и делегатов мероприятия. Однако представители различных отраслей и бизнес-функций представили детали и соображения, каждый из которых внес позитивный и проницательный вклад. Каждый вынес на обсуждение свои опасения и свой энтузиазм, дополнив дискуссии о внедрении ИИ в 2026 году.
Марш роботов И все же на многих участках выставочной площадки по-прежнему царило огромное воодушевление. Человекоподобные роботы, представленные на выставке, стали источником большого энтузиазма (кажется, все любят милых андроидов!), но, что более прагматично, новый трек «Физический ИИ» собрал одну из самых больших аудиторий на выставке. Многие делегаты, не связанные с этим треком, отметили, что написание программного кода стало той сферой, которая первой принесла положительные результаты от использования больших языковых моделей в профессиональной среде. И из многих уст прозвучало мнение, что автоматизированные физические системы станут следующим отраслевым сегментом, который выиграет от целенаправленной работы над новыми моделями и их практическим применением.
Модели ИИ, лежащие в основе физического ИИ следующего поколения, вряд ли будут большими языковыми моделями (хотя они будут полезны, если устройства предназначены для взаимодействия с людьми), и по мере того, как такие модели будут развиваться и выходить из стадии исследований, именно серия мероприятий TechEx Events первой продемонстрирует и представит их, а также то, как они могут жизнеспособно работать в бизнес-контекстах.
Новые обучающие направления на мероприятии В этом году мероприятие ознаменовалось долгожданным внедрением прагматичного программирования: практические обучающие сессии проводили участников через процесс развертывания собственных агентных моделей ИИ с уроками о том, как агенты могут совершенствоваться, прямо из интерактивных экземпляров Google Colab. В учебном центре TechEx Learning Hub также прошли мастер-классы от Nvidia и неизменно популярного Google Hackathon, при этом уровень подготовки слушателей варьировался от тех, кому требовалось знакомство с IDE, до тех, кто уже обладал хорошо отточенными навыками программирования. Применение полученных знаний на практике — вот суть этого мероприятия, будь то руководители высшего звена, осваивающие уроки лучших стратегических практик, или разработчики, воплощающие креативные идеи в реальность.
TechEx берет передовые технологии и преломляет их через призму бизнеса: прагматично, но с устремленностью в будущее. Посетите следующий этап TechEx в Амстердаме в сентябре этого года — кто знает, насколько далеко мы сможем продвинуться всего за четыре коротких месяца?
Парламентарии требуют «аварийного отключателя» ИИ для защиты от «катастрофы»
Политики и активисты призывают к предоставлению полномочий на отключение центров обработки данных на фоне растущих опасений по поводу искусственного интеллекта
На такие центры обработки данных, как Global Switch 2 в восточном Лондоне (пикрелейтед), будет распространяться действие предлагаемого закона.
Члены парламента добиваются создания «аварийного отключателя» для ИИ, который позволил бы министрам отключать центры обработки данных.
Активисты требуют принятия новых законов, которые наделили бы правительство полномочиями отключать системы искусственного интеллекта в случае «катастрофического риска».
Предлагаемая поправка к законопроекту о кибербезопасности и устойчивости получила поддержку 11 парламентариев и является частью кампании организации Control AI, группы, призывающей к строгому регулированию ИИ.
Эти планы не были одобрены правительством, но демонстрируют растущую обеспокоенность парламентариев по поводу искусственного интеллекта.
Дональд Трамп недавно выразил поддержку идее «аварийного отключателя».
Поправка, предложенная Алексом Собелом, членом парламента от Лейбористской партии, наделила бы министра технологий «полномочиями последней инстанции» отдавать распоряжение об отключении центров обработки данных или размещенных в них систем ИИ «в случае возникновения чрезвычайной ситуации в сфере безопасности или функционирования ИИ».
Эти полномочия вступят в силу, если возникнет «катастрофический риск» для критически важной инфраструктуры, национальной безопасности или «серьезный крупномасштабный вред человеческой жизни».
Операторы центров обработки данных будут обязаны установить инфраструктуру, позволяющую мгновенно отключать их, и наладить защищенную связь с Министерством науки, инноваций и технологий, чтобы дать министрам возможность действовать.
В настоящее время большинство моделей ИИ размещается в центрах обработки данных в США.
Среди сторонников поправки — Джордж Фриман, бывший министр науки от консерваторов, призвавший запретить дипфейки, созданные с помощью ИИ; Саманта Ниблетт, член комитета по науке, инновациям и технологиям от лейбористов; и сэр Десмонд Суэйн, бывший министр международного развития от консерваторов.
«Угрозы национальной безопасности» Обеспокоенность возможностями ИИ возросла в последние недели после того, как компания Anthropic представила новую систему под названием Mythos, которая, по ее словам, слишком опасна для публичного выпуска из-за ее способности находить критические уязвимости в компьютерных системах.
Г-н Собел заявил: «Это не просто смена парадигмы в области кибербезопасности, но и в отношении рисков для национальной безопасности, которые ИИ создает для нашей критически важной инфраструктуры. И Великобритания совершенно не готова реагировать на это.
Скоординированные кибератаки на нашу критически важную инфраструктуру представляют серьезную угрозу, а сверхразумный ИИ, действующий вне контроля человека, по причиняемому вреду может сравниться с ядерным ударом. Разрыв между этими угрозами и нашей готовностью к ним недопустим».
Организация Control AI, поддерживаемая Яаном Таллинном, основателем Skype, заявила в прошлом году, что более 100 парламентариев поддержали ее кампанию за более жесткое регулирование ИИ. Поправки могут быть обсуждены в Палате общин, если их отберет спикер.
Недавно г-н Трамп заявил в эфире Fox News, что у правительства должны быть полномочия отключать ИИ. Белый дом дал понять, что с появлением Mythos он отходит от подхода невмешательства в сферу ИИ.
Ожидается, что Дарио Амодей, генеральный директор Anthropic, на следующей неделе встретится с группой из 50 ведущих европейских генеральных директоров на двухдневном форуме, чтобы обсудить внедрение ИИ в частном секторе.
Эта встреча проходит на фоне того, как компании настойчиво требуют доступа к Mythos.
Anthropic запустила программу под названием Project Glasswing, чтобы поделиться этим ИИ с избранными технологическими гигантами и банками, чтобы они могли повысить свою кибербезопасность.
Однако до сих пор британские компании остались за бортом этой инициативы после того, как Белый дом заблокировал расширение доступа Anthropic к Mythos из-за соображений безопасности чиновников.
ИИ-бот Claude от Anthropic оказался чрезвычайно популярным среди компаний, поскольку этот инструмент ИИ отлично справляется с задачами программирования. Компании выпускают целые армии ИИ-«агентов», которые действуют как постоянно работающие цифровые сотрудники на базе Claude. Эти агенты позиционируются как цифровые коллеги для финансового сектора, юридических фирм и крупных консалтинговых компаний.
Как стало известно, г-н Амодей присоединится к собранию бизнес-лидеров в Estelle Manor, частном загородном клубе в Оксфордшире, включенном в список памятников архитектуры II категории. Среди участников — бывший премьер-министр и советник Anthropic Риши Сунак.
Этот роскошный загородный клуб, который посещали Ким Кардашьян и Льюис Хэмилтон, располагает парковой зоной площадью 3000 акров, спа-салоном в римском стиле и предлагает такие развлечения, как соколиная охота и падл-теннис.
Anthropic — одна из самых хорошо финансируемых лабораторий ИИ в мире. На этой неделе стало известно, что Anthropic ведет переговоры о привлечении еще 30 млрд долларов при предполагаемой оценке в 900 млрд долларов. Всего три месяца назад она привлекла 30 млрд долларов в попытке составить конкуренцию ChatGPT от OpenAI.
Представитель правительства заявил: «Наш законопроект о кибербезопасности и устойчивости укрепит киберзащиту Великобритании и повысит кибербезопасность наших важнейших государственных и цифровых услуг, от которых мы все зависим, включая центры обработки данных».
Эксперт по ИИ безопасности сообщает, что мир движется к катастрофе. Вымирание человечества в течении нескольких лет неизбежно.
Исследователь в области оценки безопасности искусственного интеллекта, основатель компании METR, ранее в DeepMind и OpenAI:
Elizabeth Barnes @BethMayBarnes · 3 ч Иногда люди вне этой сферы говорят такие вещи, как: «Ситуация с ИИ не может быть настолько плохой, наверняка есть эксперты, которые держат её под контролем». Как «эксперт», я хочу прояснить, что мы не держим её под контролем. Некоторые ключевые аспекты ситуации, на мой взгляд:
(1) Мы, вероятно, движемся по пути разработки систем ИИ, способных вызвать вымирание человечества или его окончательное лишение контроля, вполне возможно, в течение следующих нескольких лет.
(2) Всё происходит хаотично и в спешке; мы не контролируем даже основы (модели регулярно нарушают намерения пользователя, лаборатории обучают модели на том, чего хотели бы избежать, безопасность, вероятно, недостаточно хороша, чтобы помешать противникам украсть опасные модели), не говоря уже о сложных вопросах о том, как...
(3) METR (и другие независимые организации, а также команды по безопасности в лабораториях) ощущают катастрофическую нехватку ресурсов по сравнению с масштабом и темпами развития ИИ — мы изо всех сил пытаемся создавать бенчмарки достаточно быстро, успевать за последними достижениями в области возможностей, читать и отвечать на все...
(4) На мой взгляд, любая «разумная» цивилизация явно подходила бы к вопросам ИИ гораздо медленнее и осторожнее. Преимущества получения выгод от продвинутого ИИ немного быстрее ничтожны по сравнению с рисками совершить непоправимую ошибку, и мы могли бы снизить эти риски, двигаясь медленнее.
Кроме того: многие аспекты выходят за рамки нашего исследования! Во-первых, мы рассматриваем только риски «захвата власти ИИ» / «потери контроля»: мы не учитываем риски, связанные с неправомерным использованием со стороны человека (например, помощь ИИ террористу в создании биологического оружия), или другие виды вреда, при которых ИИ не стремится «намеренно» захватить власть (например, воздействие на психическое здоровье или размытые социальные последствия). В рамках рисков «потери контроля» мы не рассматриваем модели угроз «саботажа» (агенты, подрывающие развитие ИИ и облегчающие будущим ИИ уход от человеческого контроля). Мы сосредоточены только на «базовом сценарии» — смогут ли нынешние агенты выйти из-под контроля человека.
OpenAI готова заплатить до 445 000 долларов за «совершенно новую» вакансию в сфере ИИ, посвященную самоулучшающимся системам
Высокооплачиваемая должность в команде обеспечения готовности сфокусирована на «рекурсивном самоулучшении», поскольку OpenAI наращивает усилия по устранению рисков, исходящих от передовых систем ИИ.
OpenAI предлагает до 445 000 долларов за недавно опубликованную вакансию в области искусственного интеллекта (ИИ), посвященную одному из самых обсуждаемых рисков в этой отрасли: вероятности того, что системы ИИ в конечном итоге смогут улучшать сами себя.
Эта должность, входящая в команду безопасности и обеспечения готовности компании, направлена на то, чтобы помочь OpenAI подготовиться к тому, что исследователи называют «рекурсивным самоулучшением», когда инструменты ИИ могут начать исследовать и проектировать более продвинутые версии самих себя.
Согласно отчету Business Insider, эта должность предусматривает заработную плату в диапазоне от 295 000 до 445 000 долларов и требует привлечения исследователей для борьбы с будущими техническими рисками, связанными со всё более мощными системами ИИ.
Подробности новой высокооплачиваемой вакансии в OpenAI в области безопасности ИИ В объявлении ищутся «сильные технические специалисты для поддержки подготовки к рекурсивному самоулучшению», что указывает на то, что OpenAI отдает приоритет исследованиям в области безопасности наряду со стремительным прогрессом в разработке моделей.
«Эта работа опирается на анализ проблем, которые могут существовать в будущем, но могут не существовать сейчас», — говорится в объявлении, с добавлением, что «поэтому особенно важно, чтобы люди на этой должности обладали хорошим вкусом и стратегическим мышлением».
Исследователь будет работать в команде обеспечения готовности OpenAI, которая занимается прогнозированием серьезных рисков, связанных с ИИ.
Согласно объявлению, обязанности могут включать защиту моделей от атак с отравлением данных, создание инструментов для интерпретации того, как рассуждают системы ИИ, и тестирование средств защиты для всё более автономных систем.
Эта роль также может включать отслеживание «прогресса в автоматизации технического персонала», что отражает растущий интерес индустрии к тому, как ИИ в конечном итоге сможет взять на себя работу по разработке программного обеспечения и исследованиям, которую сейчас выполняют люди.
Лаборатории ИИ соревнуются в подготовке к самоулучшающимся системам Усилия по найму предпринимаются на фоне того, что возможности передовых ИИ продолжают развиваться неожиданно высокими темпами. Исследователи из лаборатории METR написали в марте, что длительность задач, с которыми могут справляться передовые модели ИИ, по всей видимости, удваивается примерно каждые семь месяцев, и эта тенденция может быстро расширить спектр того, что способны accomplish такие системы.
OpenAI открыто обсуждала амбиции по автоматизации отдельных этапов собственных исследований в области ИИ. Генеральный директор Сэм Альтман в прошлом году заявил, что компания надеется в конечном итоге разработать автоматизированного стажера-исследователя ИИ, а затем и более продвинутого «настоящего автоматизированного исследователя ИИ».
«Мы можем полностью потерпеть неудачу в достижении этой цели, — написал Альтман в X, — но, учитывая чрезвычайные потенциальные последствия, мы считаем, что в интересах общества быть прозрачными в этом вопросе».
Необычайно высокий пакет вознаграждения также подчеркивает обостряющуюся борьбу за таланты во всей индустрии ИИ, где компании ведут агрессивную конкуренцию за исследователей, обладающих опытом в области выравнивания ИИ, безопасности моделей и долгосрочных рисков ИИ.
Исследователи, протестировавшие Mythos от Anthropic и GPT-5.5 от OpenAI, говорят, что их хакерские возможности «полностью меняют правила игры».
Те, кто экспериментировал с Mythos и GPT-5.5 в контролируемых условиях, утверждают, что эти инструменты развиваются гораздо быстрее, чем ожидалось, и навсегда изменят ландшафт цифровой безопасности.
В прошлом месяце Anthropic и OpenAI активно рекламировали хакерские возможности своих новых моделей искусственного интеллекта.
Исследователи, получившие доступ к этим инструментам, говорят, что компании не преувеличивают, и предупреждают, что последствия могут оказаться даже масштабнее, чем предполагалось, по мере того как такие инструменты, как Claude Mythos от Anthropic и GPT-5.5 от OpenAI, продолжают развиваться.
«Мне было совершенно ясно, что это полностью изменит правила игры», — сказал Ли Кларих, главный директор по продуктам и технологиям компании по кибербезопасности Palo Alto Networks, говоря о тестировании Mythos, когда он был впервые представлен. «На самом деле, если бы вы спросили меня сегодня, я бы сказал, что он даже более [мощный], чем я думал тогда».
Обе ИИ-компании ограничили тестирование своих передовых моделей ИИ небольшими группами доверенных организаций из-за продвинутых кибернетических возможностей этих технологий, которые на сегодняшний день превзошли другие общедоступные цифровые инструменты и даже самых квалифицированных специалистов-людей.
Во время анонса в прошлом месяце Anthropic заявила, что Mythos «уже обнаружил тысячи уязвимостей высокого уровня критичности, в том числе в каждой основной операционной системе и веб-браузере», и предупредила, что последствия бесконтрольного распространения этой технологии могут быть «тяжелыми» для мировой экономики, общественной безопасности и национальной безопасности.
В результате в последние недели правительственные учреждения, комитеты Конгресса, банки и регуляторы начали активно требовать доступа к ним, чтобы обеспечить защиту критически важных сетей до того, как противники получат в свои руки эту технологию для совершения разрушительных кибератак.
POLITICO пообщалось с девятью ведущими киберисследователями и технологическими лидерами страны, которые экспериментировали с Mythos и GPT-5.5 в контролируемых условиях, и все они пришли к одному и тому же ошеломляющему выводу: эти инструменты развиваются гораздо быстрее, чем ожидалось, и навсегда изменят ландшафт цифровой безопасности.
Исаак Эванс, генеральный директор компании по кибербезопасности Semgrep, сказал, что при тестировании Mythos «превзошел наши ожидания».
«Модель не сверхчеловеческая во всех отношениях, но, по крайней мере, в некоторых узких задачах она действительно демонстрирует поразительные способности в области генерации эксплойтов», — отметил Эванс.
Он добавил, что некоторые описывают Mythos как способный генерировать «SolarWinds каждый квартал», имея в виду взлом правительством России федеральных ведомств США в 2020 году. Этот инцидент широко считается одним из худших взломов в истории и затронул более 18 000 организаций по всему миру через скомпрометированное программное обеспечение.
Джонатан Трулл, директор по информационной безопасности ИТ-компании Qualys, которая тестирует GPT-5.5, сказал, что модель «по сути может делать то же, что и ваш самый продвинутый инженер по безопасности приложений».
Эти первые отзывы от тех, кто экспериментировал с данными моделями, ясно показывают, что ореол таинственности вокруг появляющихся технологий ИИ — это не просто маркетинг. Скорее, это отражает тот факт, что гонка по созданию самых сложных инструментов ИИ, способных превзойти человеческий интеллект, началась, и пока ни один человек, отрасль или правительство не поняли, как предотвратить их использование для массовых разрушений.
Многие из конкретных уязвимостей, которые удалось вычислить таким моделям, как Mythos и GPT-5.5, пока не разглашаются, хотя подробности уже начинают просачиваться.
Как сообщило на прошлой неделе издание The Wall Street Journal, Mythos смог обойти систему безопасности Apple для ее ОС MacOS всего за несколько дней — программу, которая славится своей сложностью для взлома. Член Палаты представителей Лу Корреа (демократ от Калифорнии), член Комитета Палаты представителей по внутренней безопасности, сообщил POLITICO после закрытого брифинга Anthropic по Mythos, состоявшегося ранее в этом месяце, что ИИ-инструмент смог без труда взломать его банковский счет.
А директор по безопасности Cloudflare Грант Бурзикас заявил в сообщении блога, опубликованном на этой неделе, что Mythos может как выявлять уязвимости, так и писать код для их эксплуатации, что знаменует собой «реальный шаг вперед» для этого типа передовых технологий ИИ.
Фирма по кибербезопасности Broadcom, которая тестировала Mythos на собственном программном коде, описала свои выводы как «ошеломляющие» в отчете, опубликованном в прошлом месяце.
«Мы узнаем вещи, которые, как представляется, вряд ли когда-либо были бы обнаружены одними лишь исследователями-людьми», — говорится в отчете.
Передовые инструменты ИИ потенциально могут стать переломным моментом для специалистов по кибербезопасности, обеспечивающих защиту критически важных сетей в важнейших секторах, включая водоснабжение, больницы и телекоммуникационные сети. Это связано с тем, что модели ИИ позволят программистам проверять новое программное обеспечение на наличие ошибок до его выпуска, а не ждать, пока ими воспользуются злоумышленники, чтобы затем исправлять проблемы.
«Наступит будущее, в котором мы действительно будем создавать более безопасные продукты, более безопасный код, вместо того чтобы исправлять то, что уже выпущено», — сказал Кларих. Он добавил, что защитники могут попытаться использовать сильные стороны, продемонстрированные различными моделями ИИ, включая Mythos и GPT-5.5, для создания «мультимодельной архитектуры» для защиты своих сетей.
Но способность моделей находить уязвимости везде — это палка о двух концах, которой хакерские группировки и государственные агенты могут с тем же успехом воспользоваться для проникновения в защищенные сети и совершения кибератак.
«Развитие этих моделей дает преимущество в основном нападающим, а не защитникам», — сказал Эванс.
Институт безопасности ИИ Великобритании, протестировавший как Mythos, так и GPT-5.5, обнаружил, что Mythos может полностью захватить корпоративную сеть в шести случаях из десяти. GPT-5.5 может сделать то же самое в трех случаях из десяти.
«Кибернетические возможности ведущих систем ИИ развиваются гораздо быстрее, чем мы ожидали», — заявил министр ИИ Великобритании Канишка Нараян в заявлении, предоставленном POLITICO.
Растут опасения, что Китай и другие противники могут вскоре разработать собственные передовые инструменты ИИ. В частности, Китай развернул кампанию промышленного масштаба по копированию американских технологий ИИ с помощью так называемых атак дистилляции.
Администрация Трампа прекрасно осознает эти опасности и спешно налаживает работу с технологическими компаниями, правительственными учреждениями и группами критически важной инфраструктуры, чтобы выяснить, как быстро и безопасно внедрить эти инструменты, пока не истекло время.
Ранее на этой неделе президент Дональд Трамп внезапно отложил подписание исполнительного указа, который должен был установить добровольный процесс передачи технологическими компаниями определенных моделей ИИ федеральному правительству для тестирования. Бывший «царь по ИИ» Дэвид Сакс в последний момент выразил Трампу обеспокоенность тем, что исполнительный указ подавляет инновации, повергнув этот процесс в хаос.
В пятницу Трамп заявил POLITICO, что у него есть «множество» опасений по поводу проекта исполнительного указа, и он беспокоится, что тот «сдерживает отрасль».
Неясно, когда будет подписан исполнительный указ. Некоторые опасаются, что без оперативных действий передовой ИИ продолжит развиваться, оставив защитникам от киберугроз слишком мало времени для подготовки к новой киберпарадигме.
«Мир еще до конца не осознал, каковы будут последствия, но, безусловно, похоже, что пути назад нет, — сказал Эванс. — Безопасности придется уделять гораздо больше внимания и выделять на нее гораздо больше долларов».
>>1619259 >защитникам от киберугроз Просто не используй чужое ПО. >>1619259 >и выделять на нее гораздо больше долларов Дайте деняк => введите больше налогов который еще больше ебнет по среднему классу. Ну в принципе как я и ожидал последние 20 лет дело идет к сокращению ненужных. Наконец-то мы встали на путь с которого уже не свернуть.
>>1619072 Этой Лизоньке хоть раз в жизни надо попробовать заставить LLM сделать что-то вразумительное. Даже если ИИ действительно придёт в голову уничтожать их всех, то спустя сотню-другую тыщ токенов он будет тихо будет переписывать тесты на баш скрипты, которые патчат питоновый код для запуска нодежсровского враппера какой-то голангового костыля, который в общем-то не больно и нужен был. У LLM фокус как у золотой рыбки.
>>1619370 Она тащем-то ведущий эксперт по ИИ безопасности, работала во всех SOTA фирмах над ней и METR основала специально под эти цели. Так что тут мнение имеет вес.
>>1619465 > пенсии граждан Ну вообще всё привально. Человеки перестали рожать рабочую силу. Бесплатный экономический рост кончился. Единственный механизм, который обеспечит доходность пенсионного фонда, - автоматизация.
>>1619465 Да правильно все делают, в течении 10 лет все эти сбережения не будут иметь смысла из-за сингулярности. Пенсии тоже. А вот датацентры нужны уже сейчас, чтобы ее запустить и обогнать Китай и другие страны. Схема датанцентры забустят ИИ - сингулярность случится - бабки станут нерелевантными - будет базовый доход. О пенсиях же беспокоятся только луддиты, уже Маск сказал все это нерелевантно будет.
>>1619432 >>она ведущая шалава, местная давалка во всех SOTA структурах, её по кругу пускали уважаемые люди и METR специально создали чтобы ебать её как шлюху по первому зову Поправил тебя
>>1619529 Базовый доход будет доступен только 1 миллиарду людей, всех остальных под ножик вирусами эпидеями войнушками, что уже сейчас идет полным ходом
>>1619544 Пенсия за года работы, а БОД всем платить будут.
>>1619535 Не исключено, меры подсократить население вполне вероятно введутся. Но это не какие-то жесткие принудительные меры, достаточно убрать текущие ограничители в виде законов на многие вещи, добавить пропаганды вредных вещей - значительная часть населения и так себя выпилит, ибо тупые. По сути текущий высокий уровень населения поддерживается искусственно, сеткой из законов и запретов, потому что население нужно для работы. Короче кто не долбоеб, им в новом мире скорее всего повезет, долбоебам нет.