• Z-Image-Base • FLUX.2 klein (4b и 9b) • Z-Image-Turbo • Flux 2 • Qwen Image / Qwen Image Edit • Wan 2.2 (подходит для генерации картинок). • NAG (негативный промпт на моделях с 1 CFG) • Лора Lightning для Qwen, Wan ускоряет в 4 раза. Nunchaku ускоряет модели в 2-4 раза. DMD2 для SDXL ускоряет в 2 раза.
Как подключить beta57 scheduler отдельной нодой без KSampler? Это нужно добавить beta scheduder и выставить a=0.5 b=0.7 и это будет равноценно пикрилу или есть нюансы? Спасибо
>>1602430 → Про деформацию хорошее замечание. Реально такое есть - начинаешь разбираться и тянуть определенное качество сам и сразу начинает плыть собственное чувство эстетики, вплоть до полной потери эмоций и отклика от эстетики.
Но в этом плане плюс генераций в том, что ты конвертируешь текст в изображение, и эта дистанция принципиально избавляет от непосредственности в процессе создания. Ты не художник, ты манипулируешь художником. Если бы результат на выходе был удовлетворительным - можно было бы не поплыть и кайфовать с этого. Не ты рисовал, ты просто технически пришел к такому результату, где ии рисует тебе то, что радует. Проблема в том, что этого достичь пока непонятно как
>>1602446 Ценность того что дается легко, во множестве и случайно стремится к нулю чел.
Попробуй в голове составить виденье того чего ты хочешь хотя бы примерно, определиться со стилем, композицией набрать референсов, потом прогнав генерацию и отобрав нужное инпейтом фиксить до идеала - тогда у тебя получится арт ничуть не хуже чем те что получаются от рисобак, без ощущения нейрослопа.
>>1602459 > думаешь В этом и была проблема In progress У модели приписка base, а про base пишут - модель для обучения или специального применения, не для базовой генерации
Есть только одно: маркетинг и продвижение + коллабы. Песня может быть хуже 10 других похожих, но она сыграет в новом блокбастере и все будут ее любить, потому что ее услышал миллиард человек, а остальные 9 - услышало пара соток анонов. И так во всем. Картинка из треда и та же самая картинка в каком-то популярном канале на лям подписоты - это разное. А если она распечатана и вставлена в рамку на модной выставке - это еще одна реальность.
На самом деле, положа руку на сердце, чисто картинки/фотки, музон, да и видеоряд месами - все это вне контекста очень сложно оценивается. Именно поэтому какие-то художники были успешными при жизани, а например Ван Гог нахуй никому не был нужен. Но как только за картинки начинают платить лямы ништяков - человеки вынуждены оценивать ее уже по-другому. Один и тот же кадр на странице просто какого-то чела в телеге, и тот же самый кадр но подписанный модным челом и опубликованный в популярном канале - это разные кадры, хотя и одинаковые.
16gb vram slop и однобокость не позволяет креативить Даже банальные тестовые идеи показывают, насколько хуевый контроль и сама модель не знает эстетики. Просто лепит соответствие, максимально не эстетичное Отдельная беда - это генерация оригинального заднего плана. Она не может просто взять и по промту нарисовать гигантичное футуристичное красивое здание на 2/3 ширины кадра уходящее за пределы экрана. Она будет рисовать офисники и всё в таком духе. Она будет рисовать картуниш механизм руки
Идея с промт оркестрацией под мультипроход t2i > iti > ... > image Суть в том, что промт энхансер (пусть даже корп llm) генерит не 1 промт, в расчет на t2i, а разбивает промты в расчет на мультипроход, рассчитывая, что одна идея будет собираться в несколько этапов соблюдая соответствующие правила для каждого прохода. Особенно если t2i и iti модели отличаются. Здесь простор для экспериментов возникает в: - выборе подходящих моделей под каждый шаг - еще более важно: поиск наиболее эффективной и стабильной разбивки (генерить ли фон / главные объекты раздельно, или сразу генерить второе в iti, и тогда что генерить первым)
А вообще, если бы была дообученная под специфичную диффузию модель, которая шарит в композиции и эстетике и знает как это описывать удачными промт-паттернами, это в один проход могло бы улучшить качество. Вот только где это высрать, сами авторы моделеке кроме общих правил промта не делают никаких реально существенных примочек. Промтить через общие ллм, которые мало что знают про конкретные модели или тем более писать промт самому, не зная ничего о том, что внутри модели это какой то бред ебланский. Неужели нельзя на основе данных об обучении модели, сразу создавать еще лоры или файнтюны для локальных ллм - промт энхансеры, адаптированные под модель. Ведь корпоративные рисовалки наверняка применяют подобные подходы, и оркестрацию многопроходки, и обученный промт энхансер
Где вместо просто Standing, в диффузию уходит подобранное сюжет и конкретную модель нечто вроде "Standing in a relaxed, natural contrapposto stance" или "Standing with a slight lean toward the object".
Вы спросите что мешает это же делать через гпт? То что они с трудом даже справляются с форматом промта специфичной модели. То что они хуево всему этому обучены, "видению" того как лучше и красивее и точному описанию этого на языке диффузии (который они не знают).
Интуитивный промтинг, перебирание слов и формулировок вручную почти не работает, уходят часы на гринд сидов. Это говно из жопы, копинг.
>>1602561 >Отдельная беда - это генерация оригинального заднего плана. А меня больше прохожие умиляют. Но надо заметить, что "гигантичное футуристичное красивое здание" это не то описание, по которому нейронка сгенерит то, что ты под этим имел в виду.
>>1602587 > "гигантичное футуристичное красивое здание Я попробовал около 5 разных подходов. Включая Bladerunner стайл. Там были гигантские здания во весь экран.
Это второй раз, когда я наталкиваюсь на такую хуйню. Он точно так же не может нарисовать нормальные эффектные массивные руины большого города в заднике. Есть вероятность, что я просто не зацепил нужную ассоциацию. Пока не знаю, надо отдельно сидеть и экспериментировать, с целью выяснить, могу ли я в принципе получить примерно то, что хотел. Если да, то в такой модели значит надо гриндить шаблоны промтов.
>>1602561 Я тебе больше скажу, даже сумарно 40gb vram и 64 ram не дают креативить... потому что нет нормальных локальных моделей которые работали бы с нормальной скоростью и с нормальным датасетом.
>>1602561 >креативить на локалке Ты ещё через ллм в svg попытайся креативить. Локал только для голых срак создан, всё остальное в банане про, графическое в гпт 2.
>>1602430 → То, что ты описал, это не деформация, а уровень профессионализма, когда знаешь как должно быть и все косяки автоматом бросаются в глаза. Несколько лет отработал в печатном издании на верстке текста, даже не вчитываясь в текст уже вижу как сверстано, висячие строки, двойные пробелы и тд. А вот проф.деформация начинается тогда когда начинаешь выдрачить там где это не нужно. 3 зеленых пикселя на 2к картинке, сделать идеальную генерацию через 100500 нод без плесени, пережара с первой попытки и тд
>>1602780 Не совпало, вспомнил когда читал про зеленые пиксели. Было бы неплохо знать что на это влияет. Но жертвовать чем то существенным ради этого я бы не стал, и так на лимитах через жопу всё.
>>1602784 >Было бы неплохо знать что на это влияет. Кривой VAE FLUX.2, которому не помог выпуск обновления. Загаживает изображение цветным мусором как вотермаркой. Какие-то пиксели более заметны, какие-то менее, но изображение загажено всё. Не лечится.
Костыли: 1) upsample изображения в более высокое разрешение и его последующее скукоживание, чтобы разноцветный мусор съело в процессе (не поможет если пиксельный мусор слипся и стал более одного пикселя в размере); 2) Удаление пиксельного мусора ценой некоторой потери «цветового разрешения». После VAE Decode изображение разбивается на YCbCr и к каналам CbCr аккуратно применяется bilateral фильтр, а затем каналы снова собираются в выходное изображение.
Так что теперь получается нунчака и не нужна вовсе? Она имела смысл на контексте (ебать, помните, была такая модель?) и вроде всё, а теперь те модели заменены лучшими. Ещё вроде на Qwen Image делал, но то ли не сделал поддержку лор, то ли получалась говнина вместо качества, что сейчас проще на клеин с лорами данриси гонять и делать в разы лучше.
>>1602361 → >товарищ майор, я чисто кораблики на ней генерю вот пруфы, а эти извращения просто были для теста Лол, если уж на то пошло, нахуя мне ЕЩЕ ОДНА модель для кума, если с этим и так прекрасно справляются годами отточенные воркфлоу для сдохли? Аниму я скачал для того, чтобы проверить предел её возможностей, и по части генерации кума она выигрывает лишь в том, что из коробки знает больше стилей, чем любой чекпоинт сдохли. При этом имеет фатальный недостаток в виде отсутствия контролнета, а с 0.6В энкодером особо не навоюешь. Так что не, пока анима - для пейзажей и корабликов, а про изврат после релиза 1.0 подумаем. Если контролнет завезут, вроде обещали.
>>1602803 Да не, пока особо ничего интересного нет. Есть неплохой фэнтези-детайлер, эстетик импрувмент ты уже запостил, и еще там была интересная лора на освещение с нестандартными концепциями. Ну оно и понятно, сообщество пока присматривается и ждет полного релиза.
>>1602831 >Минусы Kleinовский CGI-feel. И его ничем не перебить. Текстуры, освещение (и, вероятно, заpromptченный dramatic lighting, cinematic lighting) в комплексе воспринимаются как CGI или скриншот из видеоигры. Возможно ли что-то с этим сделать, непонятно.
>>1603034 > Kleinовский CGI-feel. То же самое в корп генераторах будет, почти уверен, хоть и пизже по деталям/выразительности. Щас будто бы не существует моделей, которые могут нереалистичное изобразить фотореалистичным. И это согласуется с главным принципом ллм. Разве что стиль можно выбрать поинтереснее чем cgi, он и проще
>>1603567 Короче, вот какой промт он все-таки высрал:
woman with voluminous curly hair, 3C-4A curls, long defined ringlets, caramel brown with golden highlights, natural frizzy volume, central parting, tropical wild curls, detailed texture
Зетка по нему рисует пикрил.
>>1603638 Помогло обрезание сисек, его трясло от сочетания сисек с детским лицом.
>>1603640 неплохо, но это не совсем то, там что вроде: burnt out - то бишь типа слегка выгоревшие волосы, у тебя получилась модельная завивка для показа, и нужен какой-то пробивной одноэтажный токен.
>>1583617 → >Давай кати уже, у меня накопились геймченжеры. Срочно надо поделиться. И где? Оказывается уже несколько тредов прошло. Были запощены эти игроизменщики?
И еще вопрос: кто-нибудь тут реально делал инпейнт на хромофуре? Мне другой агент советует фордж, мол, меньше ебли будет, илюха типа все уже настроил. Спасибо за ответ, а то не знаю что пользователю сказать.
>>1603864 Все говорят что говно и приведенные примеры это что вообще, я такое на сд1,5 делал когда контролнеты появились. Приложи раздетую юаюу с пиздой тогда поговорим.
>>1603989 Пздц, теперь всю оставшуюся жизнь ты будешь думать, что у тебя ничего не получается именно из-за потери гайда, а не потому что руки кривые. Ну, может так и легче жить даже.
Я этот мдшник скармливал ллм как доп. контекст и основа для промтинга. В мдшке в отличие от страницы нет лишней хуеты выжирающей токены и отвлекающей внимания. Кроме того её составляли сами разрабы, и ниче лучше для исходной точки нет. А ты можешь себе коупить, что ты знаешь лучше, по факту ты в душе не ебешь как и на что лучше реагирует модель. Для flux.2 dev вообще есть своя модель для promp upsampling, которой нет для клейна, и она в отличии от гпт и гемини знает че делать. На клейне кроме соло рыла с пиздой в t2i ничего не создать, кроме голимого слопа.
>>1604173 >скармливал ллм как доп. контекст Допустим, а где же 2 картинки на одном сиде, с одним и тем же промтом, одна с мдэшником, а другая без, и типа, смотри ребзя, какая разница охуительная, какое понимание промта, расстановка приоритетов, и всё такое? Есть шанс увидеть такое? Или я спросил это у тебя без должного уважения?
что писать в промте после 1-й проходки? Пробовал: remove artefacts of digital compression - не то чтобы это прям сильно помогло, возможно контуры стали чуть чётче но внутри них координально ничего не поменялось. Вообще, вторая проходка гарантированно наваливает артефактов, вытаскивая уже имующиеся и добавляя свои, как с этим бороться не превращая картинку в картун? 1. оригинал 2. убрал лишнее, сделал Piper чуть моложе (не сильно, не ссыте, нах) 3. ваш вариант, с вашей рецептурой
>>1604262 >качество мб файнтюнами поднимут Спустя 3 года впопенсорса можно уже понять что ничего никто и никогда не поднимет. Вышел кал - значит и будет кал. Максимум данриси бустанет фото качество или дислит выйдет и на этом всё.
>>1604370 Под "удали артефакты" поднимается очень сложный процесс "удали потери сжатия, чтобы после удаления потерь что-то появилось, додумай сам". Для сетки лучше говорить "сделай ретушь/реставрацию", "повысь резкость", "сделай реконструкцию текстур". В предельном случае "преобразуй картинку в идеальное студийное RAW фото", но надо будет наваливать всяких уточнений про "сохрани лицо узнаваемы и так далее"
Про многошаговые аретфакты - нихуя не поделать. Можно попробовать не дрочить VAE и сохранять исходный латент. Но имхо проще в конце просто попросить перегенировать всё без шакалов, пусть и ценой потери сходства с источником.
удаление цифрового шакала после Кляйна
Аноним04/05/26 Пнд 10:26:52№160456898
>>1604555 я попробую всё из того что ты перечислил, оегче конечно было бы достать исходную картинку в идеальном качестве, но зачастую референс запредельно шакальный, спасибо за подсказку.
я тут было вспомнил молодость и прогна на сдохле имг2имг с денойзом 6.5, слегка уточнил мордашку (с лорой перса и без) и заролил поней анус.
Выкладывать nsfw незаконно ведь публично? под статью порнография попадает не? До самого последнего момента об этом не задумывался, хотел выложить и приуныл
>>1604707 Получается что так. Забыл когда мог даже ради рофла что-то выложить в картинках, даже карикатуры. Доебаться смогут ко всему, сказав что это не 1000-летный суккуб, а
>>1604810 В процессе edit или t2i? Edit сложнее, там можно попробовать relight scene with practical lighting. Скорее всего не поможет. При t2i на klein не давать в prompt цвета в явном виде, писать very soft natural lighting, practical lighting, very dim lighting, dark silhouettes.
>>1604911 У FLUX.2 нормального рабочего negative prompt нет by design и разработчики прямо указывают на гимнастику с positive prompt для обхода.
>>1604933 Блики изначально дает cinematic shot, но он же неплохо трансформирует в реалистик вместе адекватным освещением/цветами. Проще изначально как то этого избегать
Частично лечится natural lighting RAW shot, но с металлических объектов блик не уходит.
Еще заметил, что клейну катастрофически нехватает лоры на реалистичные текстуры и лэндскейп. Он может в текстуру кожи и лицо на файнтюне, но вот материалы и лэндскейп любой нестандартный - сразу в лучшем случае cgi, но чаще семириал.
Посоветуйте модель + лора + промт стиля который может красиво и детализированно (не SD мазня) рисовать относительно сложные сцены с хорошей фантазией (несколько проработанных объектов + проработанный бэкграунд). Какой-нибудь семи риал, либо digital painting в реализме.
Анима плывет свыше 200 слов и часто плохо понимает пространственные инструкции. Пока сижу с лорой greg rutkowski, неплохо, но стабильность низкая, много мазни, сложно контролировать и не понятно как уточнять стиль, с этой лорой.
Короче, мужики ))) вопрос такой ебаныйрот поставил эту изю комфуи, обматался всем чем положено, вчера там, зит себе скачал, енкодер етот квеновский, еще какую-то хернюшку контролнет короче, сперва неудачные ворфлов собирал, и пару нерабочих еще нашел, ну тупо, но потом короче натянул https://github.com/scraed/LanPaint (сам зит работает, базару ноль, быстрей сидрикселя, промптится немножко на русском хоть и туповат), и вот тут хуйня такая на пиках. Пик 1 - я после 1 суток попыток. Пик 2 - делаю маску в дефолтном менеджере масок. Загружаю все это на пик 3 (да я там выпилил какую-то лору на пиксель арт, но она ни на что не влияла). И на выходе я получаю дрисню времен первой поняхи импейнта. Настройки семплера ланпейнета - я крутил. Можно сделать чуть лучше, но не сильно это влияет. Я заметил что хитрый пидор в примерах ланпейнета не красил какие-то участки, а замазывал полпикчи сразу, и так - да что-то там, с плохо впихнутым в маску оно генерит (у меня там плотная кистть но на неплотной там какие-то мультики). Тут еще хорошо получилось, неудачнфый пример. Но как присмотритесь там шум есть, как будто песка насыпали. И в зависимости от пика это может быть какой угодно мусор - полупрозрачная ткань, бумсы, песок камни полный пиздец. Я не понимаю, даже, это пережарка или недожарка? Все крутил, все равно сорт оф хуйня на выходе.
Объясню свою конечную цель: промптить естественным языком. Разумеется я вот здесь и сейчас могу получить хороший результат на сидиэкселями, но 4 года промптить тегами немножко заебало. И не пишите что там надо по английски писать и прочий бред, я все это знаю и я знаю чё я делаю, хуйня тут выходит не поэтому. Дело в том что это именно зит а не зимага бейс? Мне качать 60 гиг надо чтоб проверить? Еще я видел есть зимага АЛЛОгараж , она лучше/хуже? С виду там васянка со встроенными лорами времен первых порнотюнов на сидиксель.
Помогите короче мужики, тут без бутылки не разобраться и с ней тоже. У железного дурака спрашивал, он ту еще хуергу несет. Про лору на детали тоже не надо, я видел там юзают, но должно же нормально изкоропки быть, тут хуйня какая-то явно происходит. Цензуры встроенной я тоже не заметил, это не похоже на сопротивления модели, у меня есть ворфлоу где просто текст ту имидж там все генерится сисик-писик, как может, но генерит.
>>1605360 Мне показалось, что там в будущем будут норм тюны и как бы она быстро запускается как сидиксель.
>flux2.klein 9b distil. А это наверное что-то тяжелое уже. У менявсего 16гб врама и 32 рама. Не хотелось бы по минуте ждать. Но, есть какие-то на примете готовые воркфлоу для инпейнта? А то на цивитае даже там ну статьи какие то сумбурные, даже ланпейнт я на гите искал уже, а на реддите просто говна за щеку навалили неработающего.
>>1605370 Ок, спосеба, попробую. А то я в восприятии флюкса застрял на временах его старта кляйна этого, много свободного доступа было для онлайн моделей, а сейчас все прикрутили и на фокусе сидеть уныло чот.
>>1605360 > flux2.klein 9b distil. Дистил не может в реалистичную текстуру кожи. А лор к этому нет, разве что снофс какой-нибудь, который сам по себе плоховат
> А это наверное что-то тяжелое уже Он как раз в 4 степа работает по секунде. Жаль что он хуйня
>>1605363 >готовые воркфлоу для инпейнта Там не нужны какие-то хитровыделанные воркфлоу для старта. Берешь вф i2i из темплейтов - и уже можно редачить через промт. Если нужна маска, то в это же вф добавляешь пару нод. В твое железо спокойно лезет 9В, base-версию не качай, как по мне оно не стоит того, чтобы пердолится на 20+ шагах. Дистил делает тоже на 4-8. 8 шагов - примерно 15сек, у меня такие же статы 16/32
Мне наоборот инпейта не хватает в клейне, т.к. он очень туго реагирует на промт в эдите. Хотелось бы выделить область с которой он должен работать.
>>1605384 Я уже писал в треде про альтернативу много раз. Тот кто в глаза не ебется видел. А кого устраивает дистил - сидите на нем. Я про дистил забыл. Толку от скорости мало, когда это слоп без нормальных лор
>>1605387 >писал в треде много раз Хз, может это было в каком-то другом треде, лично я не видел. Квен, как по мне, тяжелее и хуже. Я его вообще удалил.
>Хотелось бы выделить область У клейна нет проблем с масками, даже получше, не перерисовывает всю картинку.
>>1605395 >клейн не дистил У меня единственный вопрос к базе - нахуя я это скачал. Потестил, КАРДИНАЛЬНОЙ разницы не увидел. Возможно она и лучше, но генерировать по минуте уже не хочу.
>>1605387 >клейн работает, но тоже не сразу. Что это значит? И еще вопрос: если я в воркфлоу хромофур подсуну - будет инпейнтить? Он же тюн флюкса.
А на зите я тут такую хуйню заметил. Там был другой семплер, адвансит. Но почему так? Написано везде что можно с ним только жесткую кисть использовать на маске. Но я вижу он не учитывает контекст картинки а инпейнтит строго в окне отмеченном не захватывая края (не помню как это по вумному называется). я зит мучаю потому что он уже скачан, конечно.
>>1605409 >почему так 1. Очевидно, что нет ноды, которая размывает края маски на заданные размеры 2. Очевидно, что нет ноды, которая тянет контекст с загруженного имиджа
>>1605424 >1. Очевидно, что нет ноды, которая размывает края маски на заданные размеры >2. Очевидно, что нет ноды, которая тянет контекст с загруженного имиджа > Очевидно ты пишешь хуйню.
>>1605409 А нахера ты эту полоску внизу оставил, чтобы что? То, что лапша не умеет нихуя толком в импЭйнт, это как бы уже общее место, те кто кричит, что у тебя типа скилишью: >>1605436 , ещё ни разу не проиллюстрировали свой собственный скилл на хотя-бы удобоваримом примере. Интерфейс у импаинт-ксамплера чудовищный, половина из крутилок нихуя не даёт (или тупо не работает), а другая половина при всех вариантах выдаёт хуету а-ля 1.5 в лучшем случае. Не теряй своё время с этой ебалой, юзай эдит Кляйн, или Фотошоп + фокус, если нужно побырику что-то наролить..
>>1605480 >А нахера ты эту полоску внизу оставил, чтобы что? Чтобы посмотреть.
>То, что лапша не умеет нихуя толком в импЭйнт, это как бы уже общее место, те кто кричит, что у тебя типа скилишью: Вот и я не понимаю, почему оно так жестко по маске, если я туда еще сверху костыльной чуши накидаю, то это только утяжелит воркфлоу, полагаю.
>Не теряй своё время с этой ебалой, юзай эдит Кляйн Ты имеешь в виду полное изменение всей фотографии? Потому что выше вроде бы про инпейнт говорили.
Вообще, еще дело в руках. У меня стоит люструспони тюн какой-то, он жестко проебывает руки, рисует даже на детализации в фокусе какие-то микроанимешные закорючки вместо рук.
>>1605498 >Ты имеешь в виду полное изменение всей фотографии? пример: >>1604370 ты просто в промте пишешь что нужно сделать, в данном случает я написал, что нужно убрать нижнее бельё и обувь оставив всё как есть, а затем ролишь, м выбираешь лучший вариант. Мало того, можно ретушировать (довести до кондиции херовый референс), если тот недоступен в хорошем качестве, здесь анаон говорит о том, что именно нужно: >>1604555
>>1605498 >про инпейнт зачем тебе импейнт, если можно без него? Повоторяю, если тебе там приспичило отредактировать что-то по маске, то есть прекрасный инструмент для этого, это Фокус, больше нихуя не надо, выбираешь модель которая умеет в то, во что ты хочешь и подходит по гамме к референсу и хуяришь... там всего 2 ползунка тебе нужно, это: денойз и контест, чем выше контекст тем лучше будет результат, но это всегда качели, большое выделение снижает качество рисовки а высокий денойз добавляет шизы, ищешь золотую середину, помогаешь фотошопом.
>>1605539 да-да, это тот самый пример, когда сигна соответствует исполнению)
>>1605534 > а затем ролишь Уже маркер того, что не оптимальный метод. В зависимости от сложности условий - иногда % успеха может уходить к 1к50.
Можешь показать воркфлоу клейн+импейнт? У меня с прошлого треда бенчмарк, с которым клейн едит в общем режиме почти не справляется. 5ый палец убрать с бутылки, да и третью коленку тоже не так просто. Такую хуйню только импейнтом либо заново генерить
>>1605534 А как снофс работает со стандартным текст энкодером с цензурой? Разве квен 3_8 не должен быть зацензурен, что бы игнорить порно-промты? Смысл тогда в uncensoured текст энкодерах? Я зачем то выкачал такой специально для клейна. Хуета непонятная уебская повсюду
>>1605556 >А как снофс работает со стандартным текст энкодером с цензурой? Нормально работает, потому что его, text encoderа, задача не делать inference, а перегнать слова-токены в эмбеддинги.
>Смысл тогда в uncensoured текст энкодерах? Ну хотя бы в том, чтобы проигнорировать всё то, что о них писалось, а потом упорно продолжать есть кактус, because you can.
>>1605556 >Смысл тогда в uncensoured текст энкодерах? я сравнивал, разницы никакой, снофс говно, концепты у него поневские, уёбищные с проёбами в анатомии, порно ты один хер не сможешь на нём делать, для ебли нужен wan 2.1-2.2 с nsfw лорой, ни zit ни клфйн не умеют в порнуху.
>>1605556 Я тебе вот чего скажу, что снофс, что кляйн бесполезная хуита, разве что в кляйн-эдит снять с кого-нибудь трусы, всё... Композиционно кляйн абсолютно беспомощен, все его концепты из коробки - уебанские. Поэтому хуйнёй не занимайся, ковыряй zit, он гораздо интересней.
1. very short bob cut 2. buzz cut 2. side parted pixie cut бля... Это всё, ребзя. НИкаких гарсонов, никаких андеркатов. если у кото-то что-то получалось, поделитесь...
>>1605691 > гарсонов fuzzy short woman haircut > андеркатов slick back man haircut + бритые виски немопню как пробуй просто описать, две недели блять уже дрочишь свои волосы
>>1605724 >fuzzy short woman haircut 1. ну, как бэ ок, выглядит так, будто у buzz cut слегка отрасли волосы. slick back не работает, зетка просто рисует хвост сзади и какие там виски уже никого не ебёт.
>>1605691>>1605744 Ты застрял в своём узком тезаурусе из 3 слов и пытаешься из него что-то толковое выжать. Хотя когда ты приходишь к Инге Михайловне в парикмахерскую Молодость ты ей не говоришь "side parted pixie cut", сидишь с покерфесом 30 минут, и в конце говоришь "я не это хотел". Ты говоришь "как раньше" или показываешь картинку из журнала "как тут", она видит, что тут 4 выбрить, там 8 оставить, здесь прорядить, там протушевать, зачесать, здесь на уровне виска, тут до плеча. То есть наваливаешь кучу дополнительного констекста, которого в названии из трёх слов не хватало.
Потому просто возьми референс который тебе надо. Скорми его в vision llm, тот же квен, и попроси максимально подробно описать причёску в тех терминах, в которых text encoder мыслит. И уж когда ты начнёшь писать промты в той же форме что и текст энкодер, тогда можно делать выводы о пригодности-непригодности самой модели.
A cinematic close-up portrait of a young Caucasian skinhead girl named "Jax," embodying a raw, rebellious street spirit. She has a distinct skinhead hairstyle: the back and sides of her head are completely shaved smooth, while a thick, straight, blunt-cut dark fringe (bangs) covers her forehead, framing her intense gaze. Her expression is one of defiant indifference and stoic confidence, with a piercing look directed at the camera. A small beauty mark is visible on her cheek. She wears a faded black oversized punk band t-shirt and small silver hoop earrings. The camera angle is a slight high-angle shot, creating an intimate yet confrontational perspective that emphasizes the geometry of her haircut and the intensity of her eyes.
>>1605778 > в которых text encoder мыслит. твой квен может мыслить всё что ты захочешь, но если модель не занет что это, то нихуя не и будет. И если я буду тратить на описание причёски по 20-30 слов, то у меня не останется ничего для основного промта. профессура, ёптить...
>>1605778 > в vision llm Я другой чел. А поподробнее можно? Откуда модель знает в каких терминах мыслит текст энкодер? Что за vision llm? Есть какая то локальная модель, которая хорошо промт-энхасит, лучше чем фри гпт/гемини, которые просто не имеют ни фантазии, ни художественного видения, только хуевые шаблоны первые попавшиеся.
>>1605803 > но если модель не занет что это Ещё раз. Бессмысленно рассуждать о диффузионной модели, если ты с текстовым энкодером говоришь на разном языке > не останется ничего для основного промта Ну очень жаль, что ты всё ещё мыслишь категориями полторахи, и пытаешься делать какие-то выводы о сегодняшних моделях
>>1605813 Вот смотри. У тебя в качестве текст энкодера используется вполне конкретная LLM. Совершенно нормально взять этот же квен и спросить его "вот картинка, расскажи какими бы словами ты её описала". Чтобы она извлекла из себя, какие у неё текстовые конструкции совпадает с конкертными визуальными токенами. Не отгадывать путём проб и ошибок, а в лоб спросить текстовую модель что она знает.
Целиком реверс промт конечно делать квеном тупо. Но спросить его "какими словами можно описать такую причёску, такую одежду, такой ракурс, такое цветовое решение" можно и нужно.
>>1605818 > категориями полторахи Это не я мыслю это зетка так работет. там количество токенов в промте чуть больше чем в сдохле. ох уж эти теоретики! твоё описание причёск годится только для выебонов. но никак не для реальной работы.
>>1605823 >там количество токенов в промте чуть больше чем в сдохле Количество токенов на входе бесконечное. Есть ограничение на размер скользящего окна и на размер выходного эмбеддинг вектора.
На улице +26, генерить перехотелось. Летом генерить с кондеем в комнате получается по стоимости за электричество как токены во flux 2 max. Либо терпеть жар 35С в комнате
>>1605831 Да в общем то соглы, чего это я правда. Промты больше 20 слов не работают. Модели причёски рисовать не умеют. В локалках только застой и разочарование. Точки ещё эти зелёные. Пора завязывать.
Есть редкие промты, которые дают в локальной модели очень хороший и стабильный результат. Например афро-тян в желтых листьяю в вагоне метро. Другие же промты дают исключительную хуйню.
Если дело в промте, почему эту проблему не пытаются решить промт-энхансером прямо в воркфлоу? Проблема смещается из плоскости танцев с бубноми (копингом) вокруг промта в плостью системного промта для энхансера. Огромный плюс в том, что любой прогресс с таким системным промтом для конкретной диффузии - будет масштабироваться на любые промты, сколько то улучшая результат. В идеале получить энхансер, который умеет "придумывать красиво" заполняя или корректируя все слабые / некорректные места твоего промта.
Но для этого нужно обучение локальной ллм под промтинг конкретного типа, или вовсе специально для модели.
Что точно известно: GPT / Gemini - думающая / Pro - мало что понимает в этом плане. Самые разные запросы, не приводили к значимому эффекту, они выдают промт с рэндомно-посредственным описанием, на уровне худ. реализаций, композиции.
>>1605841 Как же заебала вся вот эта ваша маниловщина. Нихуя из этого не будет, если бы это было возможно, то это давно бы сделали. Весь пиздец заключаетчя в том, что языковые модели, даже локальные, настолько ушли вперёд, что между ними образовалась пропасть, и чем дальше, тем глубже и шире.
>>1605778 Ты просто написал промт специфичной прически, ассоциированной со специфичной суб-культурой - и о чудо, в модельке оказалась эта челка.
То до чего докопался этот >>1605691 - это проблема не промта, а именно ограниченность локальной модельки. Ты сам не решишь её промтингом. У моделей крайне ограниченный набор возможностей в видении всевозможных узкоспециализированных образов. Например клейн не способен нарисовать в принципе НИЧЕГО красиво, кроме людей и close up shot объектов по центру. И как правильно замечено, даже если промт на 100 слов работал - невозможно работать, если 100 слов уходит на одну прическу. А еще, когда заставляешь локальную модель через силу высрать что то детальным описанием - она начинает рисовать это отвратительно не естественным с говной.
@artmonkey нарисуй a cinematic close-up portrait of a young Caucasian skinhead girl named "Jax," embodying a raw, rebellious street spirit. She has a distinct skinhead hairstyle: the back and sides of her head are completely shaved smooth, while a thick, straight, blunt-cut dark fringe (bangs) covers her forehead, framing her intense gaze. Her expression is one of defiant indifference and stoic confidence, with a piercing look directed at the camera. A small beauty mark is visible on her cheek. She wears a faded black oversized punk band t-shirt and small silver hoop earrings. The camera angle is a slight high-angle shot, creating an intimate yet confrontational perspective that emphasizes the geometry of her haircut and the intensity of her eyes
>>1605841 Множество хороших промптов очень сильно отличается от модели к модели и от зрителя к зрителя. Кому-то нравится вылизанный 1girl слоп с цветокором, кому-то надо навалить аналогового зерна, расфокуса, боке и кросспроцессинга, кому то надо композици, ракурс, рыбий глаз и голландский угол, кто-то на аниму чёрно-белую дрочит. То есть ты вполне можешь наколдовать энхансер на llm для какой-то одной ситуации, много кто так делает. Но унивесральной балалайки собрать не удастся, потому что на вкус и цвет фломастеры разные. (все картинки с осенней негритянкой - говно)
>>1605851 Пробовал тут >>1598719 →. Клейн полностью провалил реверс промт, доказал что эта модель не способна в композицию и минимальную эстетику в чем то, кроме 1girl standing. Ты можешь хоть обмазаться промтом, уточняя композиции и формы, через 100-200 роллов, возможно получишь какой то сносный компромисс, далеко смещенный от изначального ожидания. Это не рабочий сценарий.
ZIT не далеко от него ушел, хоть и лучше рисует реализм. Но у зита какое то свойство рисовать грязь и неприятные цвета.
Если локальные модели ограничены в образах и фантазии - здесь ощущается тупик, выход из которого видится только в воркфлоу с отдельным концепером на отдельной, желательно быстрой модели с подобранным стилем рисовки, который проще всего трансформируется в реализм. Концепт арт > Трансформ в реализм
@artmonkey нарисуй как двачер пытается сгенерировать фотопортрет девушки с обычной причёской, то есть сидит перед компьютером в кресле, на мониторе видно фото девушки с обычной причёской и заголовок окна "SD". у двачера ничего не получается он злится впадает в фрустрацию начиная рвать волосы на себе на головой маленькие тучки как в аниме и мультиках
>>1605975 > дословно Клейн тоже. Проблема вообще не в следовании промту. В теории модель может следовать промту на 100% ограничиваясь 300 словами, но будет в 100% случаев выдавать крайне убогие изображения, и я даже не про текстуры и освещение, а про детали образов и композицию.
Это у вас в вашей голове возникают определенные целостные образы когда вы читаете промт на 300 слов, поэтому может возникать иллюзия, что следование промту это всё что необходимо для диффузии. В действительности же, если у модели ограничены эти образы, композиции и деталей - она будет выдавать хуйню, как например клейн в реализме. В то время как всякие рисовалки
>>1606022 Какую dev можно вместить в 16vram 32ram без ебли ссд? И что это может дать в сравнении с klein 9B FP8? Там вроде бы толком нет норм файнтюнов и лор для dev.
>>1606002 Вот же пример. >>1605862>>1605868 Разрыв консистентости происходит не из-за размера промпта, а от противоречивых элементов. Нет ничего плохого в четырёхабзацном промте, если он согласован.
>>1606022 Смысол терпеть дев, если ты его лоботомизируешь турболорой? Тут можно 20 хайрез прогонов базированым кляйном сделать и зачерепикать результат.
>>1606107 У кого-нибудь есть системный промт или локальная ллмка, которая из двух строчек промта может придумывать на 200-300 слов, представляя стабильно интересное, адекватное, без ебучий шаблонных ассоциаций или допотопных культурно устаревших клише? Вообще любая реально положительная практика prompt enhancing интересно. Сталкиваюсь с тем, что фри модели GTP/Gemini буквально точно так же фантазируют дроченную хуету, в формате работы "я описываю абзац словами что я хочу что бы он разработал, подсовывая промт инстуркцию моделю - и он генерит"
Единственное что я не пробовал - писать полный промт самому, а их просить точно переводить на english. Но как быть с моделями использующими теги не понятно. Писать на англише с моим B2 бессмысленно, нет такого словарного запаса что бы подбирать точные эпитеты и названия вещей. Заебался уже от борьбы с ветряными мельницами.
>>1606078 Никогда не будет, школьник. Почитай что такое лицензия и как наследуются они в попенсорсе и какие ограничения. Комфи это тупо гуй с солянкой модулей
>>1606125 пишешь спеку на нужный формат системного промпта, закидываешь в дикпик, получаешь системный промпт, закидываешь в энхансер, готово, вы великолепны.
>>1606127 >Комфи это тупо гуй с солянкой модулей Ну так модули будут платными и сосай. Да поябавшись сможешь взять бесплатно, но за удобство - ПЛОТИ. Так то вон фейсфужен тоже бесплатный, но за инсталлер денех просят, но можешь сам покурить манувалы конечно развернуть питон хуе мое. Но ты тупой просто, да там в гомфи уже 2 страницы рекламы со спонсорскими модулями. Потом они тебе сунут рекламу на стол, ну смождшь ее руками в каждой версии выпиливать, а они ее перепрятывать будут с обновами и у тебя все будет крашится, ты будешь плакать, и снова искать куда они рекламу запрятали (на фьюжене так нсфв фильтр прячут, причем там смешно спрятано, иди почитай/посмотри сам). Тебе ту спецолимпиаду прям в гуй завезут, а ты пукай дальше про лиценьзию свою прыщезадротскую, которую обойти не сложно поссав тебе в пингвиний клюф.
>>1606125 >Единственное что я не пробовал - писать полный промт самому, а их просить точно переводить на english. Но как быть с моделями использующими теги не понятно.
>>1606178 Не совсем понял, что ты хотел показать. Картинки, что ты скинул можно до бесконечности генерить. У них отсутствует хоть какая то композиция, сломана динамика, стиль уебищный.
Дизайн/композиция в моем слопе на порядок лучше - проблема в том, что я такое даже не заказывал. Мне не нужны были часы в пузе, я хотел сгенерить стимпанк, и в одну из 10 попыток создания промта через LLM, она проебала контекст и создала вовсе не стимпанк, но это оказался лучший вариант из всего что было. Показывать что было помимо этого даже смысла нет. Какие то забастовки роботов из книжек 70ых годов, роботы на заводе, во всех случаях визуал роботов был невероятно убогий.
Ты думаешь LLM тебе пишет заебись промты, но это иллюзия. Хуевые ллм, как и во всём - плохи и в промтинге, создании образов и сцен. Скопировать сцену с кафе, телкой и роботом не является проблемой. Проблема получать промты, который стабильно выдают описание визуального дизайна, композиции и нарратива. Нужен промт энхансер под норм модель-иллюстратор с удобным техническим стилем (вариативность + ясная детальность). С анимой, это уже частично работает. Проблема в том, что пока я буду это искать, выйдет новая модель, которая из коробки будет сама художничать.
Впрочем чего я ожидаю в треде про 1girl standing, который видимо закрепился по инерции, со времен SD с которой это было главным достижением.
>>1606287 Это разве не ты тут плачешь после каждого обновления? Читать научись. Так то можешь вообще без гомфи на чистом питоне все крутить, чё не крутишь? И не будешь, а будешь сидеть с рекламой.
>>1606350 Это называется долбм разработчиков. В настройках Комфи ищи позицию before/after и смени её на противоположное значение. Она влияет когда изменится сид : до или после генерации. Я спрашивал об этом здесь именно в такой же ситуации как у тебя, но как обычно мне пояснили, что все жрут и ты жри. Типа если хочешь перегенерировать, то кидай картинку мышкой. Ебану.
Ну, ёпт, у вас уже всё полотно готово. Прямо весь кадр уже сформирован. Расставлены все персонажи и окружение. Всё продумано до мелочей. Абсолютный шедевр почти готов. И вот только одна маленькая деталь не вписывается. Только она мешает. Это прическа. Вот она - та заноза которая не даёт вам сделать шедевр. Вот, если бы были нужные прически, то вот тогда бы вы - ух! Так ведь? Как же жаль, что именно прическа прямо сдерживает ваши шедевры. Блокирует весь процесс творчества. Какой кошмар. Надо куда-то жаловаться.
Нихуя себе, клейн оказывается не может голову тян на одной фотке, вклеить в другую фотку с телом. Не говоря уже про то, какой слоп выходит из под 9b-kv-fp8
>>1606730 > изучи вопрос Изучи практику. Вот это ебало натянуть на вертикальную фотку, сохраняя волосы, прическу, скинтон и лицо без слопа попробуй. Можешь ничего не скидывать, просто сам увидишь. Это не бояров в свитер одевать.
>>1606777 У меня всё выходит, просто я не скидываю т.к. лица слишком молодые. И мне почти сразу же надоело. Голых тян делать проще чем что то другое полноценное.
>>1606132 > готово, вы великолепны. Попробовал погенерить промты через фри гпт/гемини. Небольшое улучшение есть, но в основном во времязатратах, не качественные.
Проблема одна и та же - фантазия LLM в описании графической сцены говно из жопы. То есть просто даже рассматривая сюжет, выбранные детали образов, и так далее - полная хуета. В системном промте отдельные инструкции на предварительную проработку сцены, смысловая слитность, современный взгляд на любой артворк, композиция, микродинамика, движение, возрастная ЦА 22+ помимо промт rules.
Всё равно, для киберпанка - бирюзовые светящиеся глаза, унылый бэкграунд. Стимпанк - допотопные роботы с часами в еблете из 90ых. У сцен вайб постеров (именно компановка, перенасыщенность суетой).
Возможно ли, что локальный не супер жирный квен или гемма - могут выдавать энханс лучше чем фри гпт/гемини (которые базовые, не думающие)? Имеет ли смысл с локальными ебаться, если волнует только качество?
>>1606857 В энхансе промпт сильно решает. Есть бесконечное количество способов расширить промпт. "Ты агент сделай заебись промт энхансе", "Ты постановщик проработай сценографию", "Ты безумный уличный художник дай подробное графическое описание ", "Вот кадр, мне нужен text2image промт для генерации в аналогичном стиле " дают сильно разные результаты. И нельзя сказать что одно лучше другого. У каждого варианта своя сфера применения. Некоторые из них можно и на локалочках тягать. Но общего универсального промта нет. Я не нашёл.
>>1606892 > Но общего универсального промта нет. Нужен. Хотя бы в рамках одной модели/лоры, которая генерит концепт арты для последующего трансформа в детали / реализм. Ничто не мешает в системном промте создать тэг-корректор, указывающий на общий вектор работы, сохраняя все остальные принципы. И проблема не в промте. Они просто хуево фантазируют и представляют ранги эстетики, обучались на текстах, в душе не ебут, к тому же кастрированные и слабые, не подписочные.
Учитывая что ручные ситуативные системные промты - АБСОЛЮТНО нихуя не дают, потому что результат такой же бедный и рэндомный, а времени на ручные дрочения уходит немерено, не вижу смысла тратить на кастомный подход время.
Я заметил, что мой систем промт уже не влезает в контекст фри гпт. Она начинает генерить картинку часто, хотя в начале написано что нужно сделать. Локальная ллм тогда тем более не схавает такой объем, но есть какая то надежда, вдруг они получше работают, ведь фри ГПТ жадные стали и деградировали её в усмерть.
>>1606921 > уже даже сейчас А смысл? Не нужен ей нахуй этот реализм. Локальные модели которые могут в реализм, не могут больше нихуя буквально, кроме бытовой фотографии с унылым задником.
>>1606927 чтобы дрочить на персонажек,меня просто анимешные стили уже заебали иногда хочется оживить вайф, да и просто аниме приедается, а другие модели как ты сам написал обычно немощи, а анима люстронубаев и обычных сильно пизже будет может быть надеюсь
Какая же параша, и это продают за далары. Flux.2 max не пробовал. Но то что делает Pro, можно на локале генерить или даже лучше. Корпоратные генераторы в целом кал оказывается, кроме новой GPT - до её уровня дотянуть вот это интересная задача.
Всё остальное, включая гемини хуйню убогую городят
>>1606942 Если у тебя упор в память то ок. А так anima > klein 9б уже хорошая связка даже если в исходнике не реализм. Только вот рисованный ландшафт и прочая неорганика плохо трансформируются
Кто-нибудь знает читкода для клейна, особенно Edit, как заставить его рисовать адекватные эмоции на лице, выражения лица. Кроме всяких явно крайних? Мертвые лица в основном
>>1607079 Работает, но похоже с очень большим шагом в градациях, отдельно потесчу потом. Обычно реалистичней и эффектней смотрятся тени эмоций, без морщин на лице, но явно читаемых. Мб можно нагриндить какие то keywords
>>1606921 Она уже реализм делает. И может в нсфв в отличие от современного флюкс кала и зет кала. Это на аниме сделано: >>1605962 >>1605743 Если базу промпта стилевую нормальную задать, ощущается как бигапсы/натвизы только в порнуху и более сложные позы умеет.
>>1606955 >Какая же параша, и это продают за далары. В принципе, на этом можно было бы закончить, потому что ты прав. Когда ты покупаешь продукт, как потребитель ты не обязан знать какие-либо тонкости под капотом. Тех кто считает иначе, должен порешать рыночек (пока что-то не очень).
Теперь на секунду забудем о сказанном выше. Если речь о локальной генерации, то я могу сказать сразу, что prompt не универсален и пишется под структуру и особенности конкретной модели. Конкретно prompt, который ты взял написан не для FLUX.2. Я переписал этот prompt под структуру FLUX.2 [dev] с учётом сохранения хотя бы части начального замысла и не используя JSON-форматирование для чистоты эксперимента (в руководстве от BFL заявлена поддержка prompt до 32K токенов, поэтому экономить не надо; лишнего писать тоже). Кроме того, в корпоративных моделях зачастую работает upsampler для prompt, который перелопатит его ещё раз бесконтрольно навалив отсебятины. FLUX.2 на локальной генерации по умолчанию не использует prompt upsample и генерит строго по prompt.
Cinematic movie still with dramatic lighting of a shadowy silhouettes of a man and a very young girl standing together. The man and the young girl have partially robotic bodies. The man's and the young girl's arms and legs are biomechanical, resembling advanced android prosthetics with metallic joints, exposed mechanisms, subtle wear, scratches, and faint glowing elements. The faces of the man and the young girl are fully human, highly detailed, natural skin texture, realistic imperfections. They are holding their biomechanical robotic hands tightly. The man stands slightly in front, protective, tense posture. The girl looks frightened and vulnerable, slightly leaning toward him. In her other robotic biomechanical hand, she clutches a worn, dirty teddy bear. The background shows a devastated city: collapsed buildings, burning ruins. Occasional flashes from explosions illuminate parts of the scene. Medium shot, eye-level angle, slightly off-center composition (rule of thirds), subtle handheld feel. Shot on full-frame cinema camera, 35mm lens, aperture f/1.8, shallow depth of field, sharp focus on faces, background softly blurred (bokeh), ISO 800, shutter speed 1/125. Blue hour, evening. Dark, moody, and dramatic — low-key practical lighting with strong contrast, cold desaturated tones mixed with warm highlights from fire and explosions. Deep shadows, rim lighting outlining the man's and the young girl's silhouettes. Distant explosions, sparks, embers, and thick volumetric smoke filling the air. Dust and debris float in the atmosphere. Volumetric lighting, atmospheric haze, motion blur from drifting particles. Cinematic detail, sharp texture detail.
>>1607184 Это сарказм такой или ты одну и ту же фотку скинул случайно. С промтом для флакс я в курсе, только на деле это все равно копинг. Промт не решает ключевых проблем. И промт апсемплинг тоже не решает - он нужен только что бы извлечь побольше потенциала из модели с промтом в 1-2 предложения. Но этот потенциал относительно ущербный при генерациях в реализме. У флакса2 похоже 2 ключевых родовых болезни которые дошли и до клейна: - отсуствие видения композиции, динамики из коробки - отсутствие ризонинга и оркестрации процесса с учетом п.1 делает модель абсолютно безвкусной и относительно бесполезной для сложных генераций
Это не уникальная для флакса/клейна болезнь. Но она стала заметна, благодаря gpt image 2, которая показала, что с ризонингом и разбивкой процесса на этапы, подобно реальному рисованию - генератор буквально начинает имитировать "хороший вкус" и рисовать не только технически, но эстетически хорошо - независимо от промта. Промт не решает художественную проблему моделей никак. Флакс2 хорош и привнес многое в техническом плане даже в клейн, упрощает то, что раньше было сложнее. Но потенциал в креативном синтезе примитивен. Местные оправдывают это тем, что модель локальная, а я многого хочу. Но как видно, API версии аналогично хуевые. Если бы гпт image2, я бы тоже наверное так думал. Но теперь понял, что надо просто искать другой подход, и не ждать от 1 pass генерации ничего кроме 1girl standing, который надоедает за неделю.
>>1607297 Смысл? Всё кроме вангёлов это кал для нетакусиков-фантазёров, которые думают, что их нейрослоп перестанет быть нейрослопом и имеет хуйдожественную или эстетическую ценность
>>1607302 Нихуя себе нейродрочер подорвался. Ну всех разная эстетика. Тянки, включая голых тоже могут быть эстетичны, но вангерлы над которыми ты трясешься - это больше потеха для хуя, чем что то интересное.
>>1607418 Беспричинный переход к развешиванию ярлыков действительно говорит о том, что ты трясся и плакал, будучи задетым чем-то, понятным только тебе.
>>1607474 Но пока что трясёшься и плачешь только ты, крича в каждом посте как я ущемил твоё видение прекрасного и проткнул тонкую натуру, растоптав высокие материи нейропоноса, который ты делал кроме вангёлов. Давай покажи же свои шедевры "не вангёлы" которые достойны. Уже даже интересно
>>1607482 >>1607488 > Давай покажи же свои шедевры Кто вам сказал, что уже есть шедевры или понимание как их стабильно делать? Я отвечу. 2 дауна внутри вашей головы
>>1607665 >>1607640 >>1607627 Толку-то? Смотреть можно, трахать нельзя. Вот если бы с ними можно было прон генерить, тогда б я понял все здешние дискуссии около Флюса. А так, цена ему - нуль.
>>1607681 Нашел inpaint и он работает, вот только руки он пофиксить не может во взаимодействии. Надо какой то чит, как рисовать руки держащиеся или с чем то взаимодействующие
Стиль очень сильно плавает, поэтому много гемора чтобы подобрать базу промпта которая +- стабильно будет генерить. Если установить семплер который юзает автор, генерация в 2 раза медленнее будет, но при каких-то сетапах качество в 2 раза вырастет. (я юзаю стоковый)
>>1607753 Это я не знаю что но, скорее всего тут просто выход маск подключен к инпеинт нодам. Что само по себе тупость клейна никак не решит. Это модел выдает зачастую такой же уровень инпеинта, как сдхл. Тоесть лепить просто в область маски что-то невразумительное. Для сдхл и сд15 не случайно были отдельные инпеинт модели. А поскольку клейн это тоже самое. Он раз через раз выдает такие очень плачевные результаты. И комфи уаем это никак не исправить.
Клейн лучше использовать в связке к консистентными лорами. Тогда он более-менее работает.
>>1607786 Сразу видно вкатуна. Для сдохли не нужны отдельные инпеинт модели вообще. Так как это было в бородатые времена точного названия не скажу и там их несколько вариантов было и один из них был лучший по моим тестам с отрывом, но есть такая штука брашнет, она подключается к любой сдохле и модель начинает идеально инпеинтить.
>>1607791 >и модель начинает идеально инпеинтить Ох уж эти охуительные истории. Вам стабилити хоть платит за все эти охуительные рассказы про то как сдхл и клейн охуенно все делает?
>>1607806 Мне наплевать на твой срач с местными шизами. Я со времен сд1.4 прогнал вообще все модели которые выходили и тулзы к ним. Сдхл+брашнет(мейби другая похожая технология, их там несколько было, название не помню)+контролнет это пик инпеинта был долгие годы. Как и клейн сейчас это пик эдит модели СРЕДИ лоКАЛА. Ахуенно никто не делает и банана очень сильно косячит и даже новый гпт имаге 2 имеет тонну косяков в эдите. Каждая модель сильна в чём-то своём.
>>1607806 Для сидикселя и правда не нужны отдельные модели, они уже не нужны были под 1/3 существования 1,5. Ты ебанутый какой-то. В лапше меньше надо было сидеть.
>>1607815 >Как и клейн сейчас это пик эдит модели СРЕДИ лоКАЛА. Это тролинг чтоли такой? Не соблюдает ничего, после прогона персонаж уже на себя не похож. А вот в квен едит все збс, не без минусов, но лучше в десятки раз, жаль лор нет
>>1607869 >Выдрачивай лоры, семплеры, наматывайся на лапшу пока не получится удачный ген, иначе скиль ишуе бляя
В то время как в квен 2511 достаточно нажать вкладку темплейтс, открыть дефолт процесс комфи и он из коробки сделает консист фейс и анатомию с промптом вангер стэндинг, просто потому что модель не говно в отличие от.. Вот непойму вам нравится ебля ради ебли? Не ну ладно бы результат был оправдан. Но тогда уж лучше лору сделать раз так нравится кляйно слоп
>>1607806 >Ох уж эти охуительные истории Обрати внимание на то что все эти истории абсолютно не подкреплены никакими пруфами в виде относительно удачных кейсов, в полторахе ближе к её окончательному виду появился чекбокс: soft-impaint, без которого бесшовное вживление нового объекта было вообще невозможно, в сочетании с правильно выбранным размером окошка контекста и увеличении уровня блюра можно было добиться довольно неплохих результатов, прополив до 6-8 попыток. В фокусе этот механизм существовал бай дизайн, и импаинтить там, благодаря внутренней модели было одно удовольствие. В лапше же всё настолько убого и примитивно, что пользоваться этим практически невозможно, отсюда и некое презрительное отношение к импаинту как таковому, они не в курсе, что может быть как-то по другому (менее топорно).
>>1607791 >Сразу видно вкатуна. Для сдохли не нужны отдельные инпеинт модели вообще Да, ну, бля! Серьёзна? Это кто вкатун то тут? Зайди в любой популярный чекпоинт на циви, и там среди рисовальные моделей обязательно будет отдельная модель для импаинте, и даже не одна. Ебало захлопни и не позорься больше, вкатун, блядь...
>>1607923 >будет отдельная модель для импаинте, и даже не одна. Это для долбоебов типа тебя, только базы плати и лайки ставь - они тебе еще туда лору с салом и снегуркой запекут.
>>1607995 >Фокус лучше установи а я его и не сносил. это у вас, у лапше-дебилов что ни день, то новый геймченджер (на самом деле нет), каждый день революция, тряска, матросы бегут к зимнему дворцу)
>>1607923 https://tencentarc.github.io/BrushNet/ - читай не обляпайся. Я когда пердолился во времена сдохли, все эти твои "инпеинт" модели себе на диск скачал и прогнал. В итоге как я и написал любая сдохля+брашнет(или мейби павер-паинт, точно не помню)+контролнет дают лучший результат с отрывом на сдохле.
Нравится хуйнёй страдать, можешь ещё купить у хруста подписку на флекси, тоже жёсткие "геймченджеры" сдохли выдавал.
>>1608017 Да-да, верю каждому твоему слову. Ведь ты не промахнулся мимо кнопки. Злые хрюкошайтаны переключили раскладку, а потом вернули обратно. Ой вей, у каждого так бывает 10 раз в день.
>>1608036 как ты это себе представляешь, ведь для этого нужно нажать на комбинацию аж из целых 3-х кнопок, то есть одно жататие, 1 лат буква, а потом ещё одно, как такое можно не заметить, у нет эпилепсии братишка, может ты проэцируешь свой опыт? Это какой-то глюк с гугловским помощником, и честно говоря, мне похуй.
Почему модели, которая работает с инпейнт областью и видит только её, нельзя в контекст дать полное изображение? То есть видеть/знать она будет картину в целом, но обновит со знанием контекста только маску.
Можно такое технически в комфи сделать? Выше ссылка на инпейнт клейна, но там модель видит только маску
>>1608083 там вроде есть размер контестного окна, но чтобы нарисовать хорошо нужно небольшое "окно" или скорее область интереса, если выделение большое, то ничего особо делать не надо, а если объект небольшой то контеста надо дать побольше, но учти чем больше контекста тем хуёвее рисует, нужен компромис.
>>1608083 >>1608086 Да, такое есть, регулировка размера контекста отдельно от размера области инпеинта. То есть размер перекрытия инпеинта. Эта область (с перекрытием) вырезается из оригинала, затем продается в (к)семплер и инпеинтится. Однако, как я писал сильно ранее, в Комфи нет в стандартном наборе нод средств вклеить выход картинки с семплера обратно в оригинал. Задумайтесь. Нет такого в стандартном наборе нод. Не предусмотрен такой инпейнт. Вот я выделяю руки на картинке маской. Это примерно 128х128. Далее обрезка с расширением поля контекста. Далее ресайз до 1024 по больше стороне. Далее ксемплер с нужным денойзом. Далее ресайз в размер оригинала из 1024 в 128. Далее вклейка этого куска(128) в оригинальную картинку в нужную позицию(x,y) (это делается кастомной нодой - именно её нет в Комфи). Готово. Если результат нравится, но надо ещё вот пальчик подправить, то через одно место кидаешь результат в инпут ноду - в результате этого в инпут папке скапливается хламовник. То есть и здесь не задумано что кто-то будет инпеинтить.
>>1608102 >Далее ресайз до 1024 не надо ресайз, после того как ты высрал сырец, открой его в фотошопе и увеличь на 1.5 с сохранением деталей (чекбокс), а уже потом открывай в импаинте или в чём ты там будешь делать, там должна быть такая хуита, типа блур какой-то что-ли, этот блур он как-бы замазывает края (швы). Я просто полтораху вспоминаю, как там было сделано. Выложи скрин ксамплера для импаинта.
>>1608108 >потенциал нельзя проебать того, чего нет. и это все понимают, все кроме тебя) максимум на что способна эта ебатень это снять с кого-нибудь труселя и попытаться редуксануть старый долгострой из sdxl.
>>1608114 >лучше zit не станет, он не знает ничего о композиции, он не знает как сделать красивее, пока его держишь за ноги а эдите, чтобы хуйни не навалил, с ним ещё можно работать, но рисовать с нуля, неее, на это кляйн не способен.
>>1608145 Ты говно наролил сидами. Нужно было нормальную приятную роботическую руку. Я ролил раз 50 и импейнтом раз 50, он что то рисует, но взяться за руки нормально не может.
Жесть, прям вижу как ебанат из блек форест лаб обучал флакс на нейрослопе и cgi по тэгам distopia, cyberpunk и все производные. Он даже в эдите и даже лица рисует в CGI/слоп если есть словечко в промте.
>>1608107 >увеличь на 1.5 Какой-то бред написал. Вот здесь руки как ты будешь инпеинтить? Ну, увеличить исходник >>1608114 размером 2368x1312 в 1.5 и что дальше? Инпаинт нужен не только своих картинок, они могут быть большие. Нормальный инпаинт маской делается с вырезом участка, ресайзом в дефолтное разрешение модели(потому что могли сильна именно в дефолтом разрешении) и только потом прогнать через семплер. Это идеальные условия, которых надо придерживаться.
>>1608215 Когда ты обратил на это внимание - да, чето такое есть, видимо по пропорциям, ширине плеч мужика он слишком высоковат. Возможно передние персонажи в принципе слишком высоко парят над землей, относительно бэкграунда. Это пространственный слоп. Такое вообще контрить невозможно.
>>1608148 >Зит тоже рисует нелепый понос на генераторе Попробовал в сложноту, описал древне-римскую секс-оргию в термах, зетка привычно уже обосралась, тогда как кляйн хотя-бы пытался в сложноту и разнообразие и как водится спутывая тела, путал сам себя, но это была хотя-бы заявка.
Первая опенсурс модель без VAE
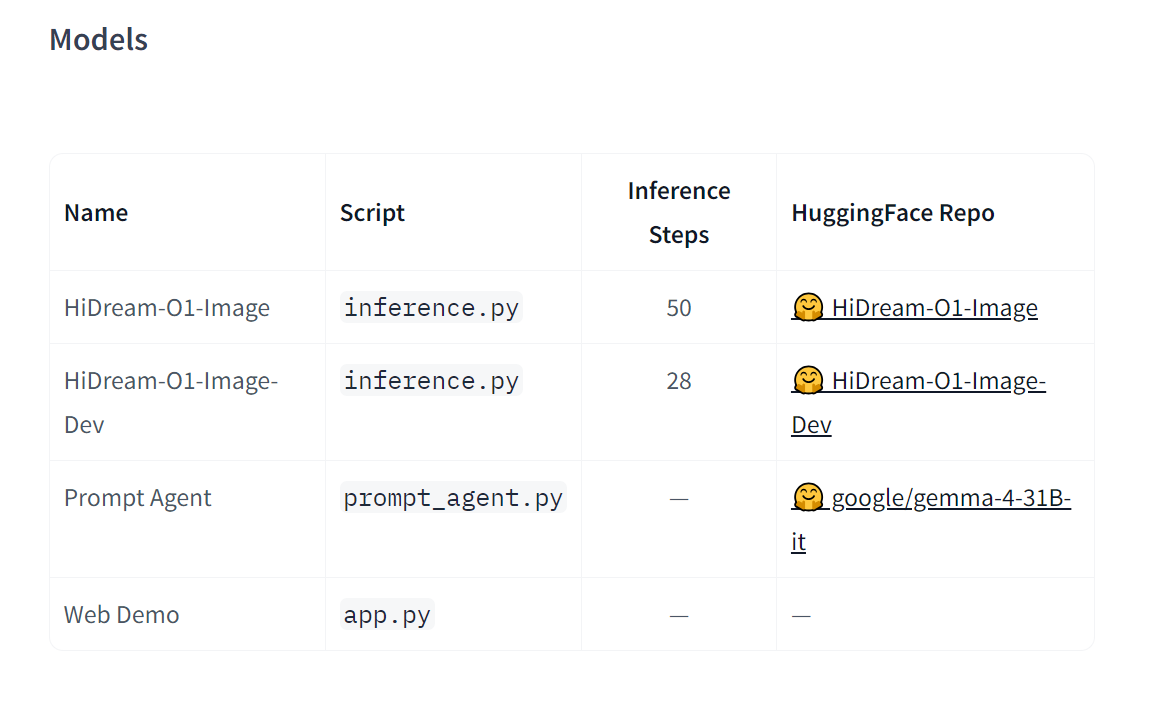
Аноним# OP10/05/26 Вск 08:14:34№1608797398
HiDream-O1-Image — это изначально унифицированная базовая генеративная модель для изображений, построенная на пиксельном унифицированном трансформере (Pixel-level Unified Transformer, UiT) без внешних VAE и отдельных текстовых энкодеров. Она напрямую кодирует исходные пиксели, текст и условия, специфичные для конкретной задачи, в едином общем пространстве токенов, поддерживая генерацию изображений по тексту, редактирование изображений и персонализацию по заданному субъекту с разрешением до 2 048 × 2 048.
Ключевые особенности
Пиксельный унифицированный трансформер — одна сквозная модель, работающая напрямую с исходными пикселями, без VAE и отдельного текстового энкодера.
Одна модель — множество задач — генерация изображений по тексту, рендеринг длинного текста, редактирование по инструкциям, персонализация по заданному субъекту и генерация раскадровок в рамках единой архитектуры.
Промпт-агент с элементами рассуждения — встроенный «думающий» агент, который перед генерацией уточняет неявные знания, композицию и рендеринг текста.
Нативное высокое разрешение — прямая генерация изображений с разрешением до 2 048 × 2 048 и чёткой мелкодетализированной проработкой.
Исключительная эффективность и универсальность при масштабе 8B — при всего 8 млрд параметров модель достигает сопоставимого качества с более крупными open-source DiT-моделями, а в ряде случаев даже превосходит их и ведущие закрытые модели.
Посоветуйте универсальный конфиг zit / zit edit под 16@32 универсальный, что бы текстуры свет пореалистичней были, если базовый не достаточно хорош. Мб файнтюн сразу качать? Хочу посмотреть zit после клейна
>>1608836 >Мб файнтюн сразу качать? Нет, они все васянские, туда абы-как впердолили поневские nsfw-концепты и всё попереломали к хуям. хочешь чтобы пиздёнка более-менее нормально смотрелась, найди лору с нормальной анатомией где баба лицом к тебе и юзай её с весом (0.2) этого будет достаточно. для света ничего специально не нужно, он там нормальный. воркфлоу там простой как лом, юзай эйлер, кфг выше 1.3 не поднимай, и будет тебе счастье.
>>1608845 >А ну пиздец тогда. там типа есть вф с типа контролнетом, ну это хуета голимая, я с нуля промтом лучше сделаю.
>>1608850 Так в итоге не понятно что качать, только turbo? Почему все юзают только турбо, хотя там для base дохуя чего лежит в доступе? Мне не только Nsfw и 1girl надо, главное что бы пластика как в клейн дистиле не было
>>1608797 > персонализация по заданному субъекту и генерация раскадровок в рамках единой архитектуры. > Промпт-агент с элементами рассуждения — встроенный «думающий» агент, который перед генерацией уточняет неявные знания, композицию и рендеринг текста. В связке с клейном могло бы стать имбой
>>1608882 Так если оно без ВАЕ и вообще без латента - там совсем другие требования к памяти должны быть, нет? Декодирование вроде самый затратный процесс.
>>1608733 Графика и худ. дизайн - редкостная унылая хуйня. Безвкусица чуть ли не хуже чем в 4-5ых героях. Огромная ошибка, считать что в играх типа героев графика настолько вторично, что можно сделать её на отъебись нанимая зумерков, эстетика которых ограничивается формой своей залупы.
>>1608922 у базы свои плюсы есть, если обмазать двухшаговыми турболорами Но проблема в том что в турбе с сисиком-писиком намного лучше чем в базе, в базе хтонь лезет.
>>1608923 > у базы свои плюсы есть, Какие? Примеры конкретные есть или можешь продемонстрировать?
Я пробовал клейн базу с турбо / дистил лорами. Бейз буквально не дает ничего, кроме пластика. Разница в вариативности и фантазировании настолько мала, что проще другую модель использовать для этого.
>>1608984 пысы NPU ускорение доступно только на квалкомах, начиная с snapdragon 8 gen 3 и выше. на остальных устройствах на CPU будет где-то в 5-10 раз медленнее
Чем апскейлер отличается от edit модели, если апскейлкер типа 4x-UltraSharpV2.pth все нейро-искажения артефакта сохраняет и шарпит, а едит модель в теории может исправить форму?
Только тем что апспейлер быстрее и меньше памяти жрет за то же разрешение?
Пробовал подключить comfy для генерации в РП через агента и везде выдается кал, может у кого был опыт какую модельку выбрать? Использую самый дефолт просто разок семплирует. Что-то я упускаю.
>>1609389 Попробовал wai illustrious, помогло просто увеличить размер изображения, этот пидарок отправлял запрос в 512х768 >>1609408 РП-ролеплей, агент - отдельная модель которая готовит из последних сообщений промпт для генерации.
>это лора говно-лора, уже на весе: 0.6 на клоузапах растягивает головы по вертикали, однако на малых весах фиксит мультяшную анатомию (сука, кто её туда блядь запихнул), где у взрослых людей детские тела с большой головой. Как тут: >>1609041
>>1609499 это происходит (искажение анатомии). когда промтишь арт-стайл типа рисунок карандашем т. д. на реалистике такого нет. пикрил: о чём примерно идёт речь, обязательно узенькие плечики и несоразмерно большая голова, впервые я эту лажу увидел в рисунках фейсбучного аи. не помню уже как оно там называлось. там ещё гамма ржавая была по дефолту. это какой-то корпорантский стиль, или х.з.
Да-уж, с геймчейджерами как-то не задалось в последнее время, Кляйн оказался лакированым говном с проёбаной анатомией, а зетка тупым кастрированным поленом с трудом понимающую человеческую (какую угодно) речь.
>>1610406 Я использовал промпт из >>1607184 Ща вчитался что там написано:
The man stands slightly in front, protective, tense posture. The girl looks frightened and vulnerable, slightly leaning toward him. In her other robotic biomechanical hand, she clutches a worn, dirty teddy bear.
>>1610420 >>1610338 Нашел уже, может. Ну, в общем, действительно неплохая моделька, похоже. Размер небольшой, синематик-фотореалистик может. Для местных зажравшихся и сумасшедших пикседрочителей и гунеров не нужна, конечно, а вообще хорошая штука. Лицензия открытая, вроде. В своем роде действительно геймченджер.
HiDream-O1-Image is a natively unified image generative foundation model built on a Pixel-level Unified Transformer (UiT) without external VAEs or disjoint text encoders, which natively encodes raw pixels, text, and task-specific conditions in a single shared token space — supporting text-to-image, image editing, and subject-driven personalization at up to 2,048 × 2,048.
>>1610420 Потому что нормальных локальных генераторов по сути нет либо только в иллюстрациях. ZIT- 1girl only. Klein - 1girl only. Генераторов со встроенным ризонингом тем более нет.
То что он нарисовал обнимание девки и эмоции на лицах - уже может о чем то говорить. Клейн например эмоции сам нормально рисовать не умеет, а с промта рисует через раз либо хуету невнятную.
>>1610338 >>1610368 >>1610411 Для сцены с робо руками в апокале у тебя явно не тот aspect rate стоит - постерный. 16:9 тут лучше подходит, особенно для раскрытия бэкграунда. Но уже по постеру видно, что у него около-клейновская фантазия, буквально клейновский задник и сюжет. Ризонинг не особо заметен. 6 пальцев - чек Наличие взаимодействия рук и эмоций уже неплохо.
То что мыло рисует означает просто что можно юзать только с рефайнером, еще бы это стоило того. Не понятно только почему они выкатили мыло, когда не демонстрационных скринах мыла не было. Буду тоже пробовать.
>>1610478 Так там еще и ризонинг? Ну, тогда это вообще серьезная заявка. Может быть на нем еще не научились нормально делать, промпт нужен. Текстуры у модели слабые, это под доработку модель. Но в целом, как база неплохая. Ну и может потом разработчики разовьют это еще. Архитектура интересныя, фичи хорошие.
>>1610507 >>1610500 Почему совершенно разные воркфлоу. В этом >>1610507 нода предлагает на выбор модели которых у меня нет, и не видит мою hidream_o1_image_dev_mxfp8.safetensors при запуске.
Для image_testing ноды в мененджере не ищутся. Хуета какая ебучая
>>1610537 В >>1610507 он смотрит на путь ComfyUI\models\diffusion_models\HiDream-O1-Image-bf16\model.safetensors Попробуй так ее сохранить. Ну или поставить галочку на ноде download = true, он сам скачает при генерации
- Я скачал hidream_o1_image_dev_mxfp8.safetensors положил в \diffusion_models\HiDream-O1-Image-Dev-FP8 - Скачал все файлы кроме модели отсюда https://huggingface.co/drbaph/HiDream-O1-Image-Dev-FP8/tree/main и положил в \diffusion_models\HiDream-O1-Image-Dev-FP8 - Скачал HiDream O1 нод пак в менеджере
В итоге генерит мозайку. Ебанина пиздец. Кто так делает нахуй
>>1610646 >уровня полторашки? полторашка на фоне этого говна выглядит не так уж и плохо. как же заебали эти ньюфаги, готовы уцепиться за любой кал. засрали полтреда слопом прямиком из 2019 года.
>>1610665 > mxfp8 Покажи на каком воркфлоу запускаешь и как ноды качал? Всё как описано установил, комфи / ноды обновил, но нод всё равно нет. Через командную строку репа не качается
>>1610677 > зачем тебе это надо? вон аноны сказали что это говно. потрогать, финальное качество меня не так сильно волнует, важно как и что он может генерить
>>1610677 > git pull & git show 8e53f001a492cc818768a308362adbd3d75a1c43 С этим сработало, спасибо. Но я не понял почему при обновлении comfy из менеджера у меня нихуя не обновлялось. Как мне впоследствии обновляться не имея этого ID? Я не врубаюсь, что я сделал в принципе. Вот эта обнова https://github.com/Comfy-Org/ComfyUI/pull/13817 её как проще всего накатывать, потому что пул реквест что ты скинул, я не ебу где его брать, а UI комфи обновить это не предлагает.
>>1610652 Судя по тому, какое мыло генерит, мы вообще уверены что дефолт воркфлоу / настройки корректны? Рекомендованы только степы, про CFG не сказано нихуя. Где там обещанный Reasoning-Driven Prompt Agent вообще, и как его подключать?>>1610665
>>1610665 > mxfp8 намного медленнее Там в темплейте написано что он лучше качество выдает, у меня на 5070ti 18-20sec в 2mpx 28steps
Из за ебанской установки и непрозрачной архитектуры, ощущение что модель в комфи неправильно работает. Писали что там есть какой то агент с ризонингом, а в комфи то он работает вообще или нет?
На пик4 клейн. Качество хоть и высокое, но нарратив хуже чем у новой мутной залупы: буквально покушать принес.
>>1610747 id коммита это для проверки. так то достаточно git checkout master && git pull делать. а из манагера мб делало до стабильной ветки (в тег)
по поводу мыла - я ебу, может нужно подождать оффициального релиза, наверное какие то мокрописьки упустили/не доделали. там и редактирование непонятно как работает
>>1610747 >Я не врубаюсь, что я сделал в принципе. Вот эта обнова https://github.com/Comfy-Org/ComfyUI/pull/13817 её как проще всего накатывать, потому что пул реквест что ты скинул, я не ебу где его брать, а UI комфи обновить это не предлагает.
смотри, если PR замержен (там Merged) то оно в апстриме и надо только подтянуть из гита.
А если PR еще пилится, но в жопе свербит потыкать фичу - можно сделать так:
оно применяет но не коммитит pr и откатить изменения можно тупо git checkout . ну или лучше ветку себе сделать экспериментальную. базовая работа с гитом короче.
Есть ощущение, что у модели нихуя нет никакого ризонинга в том комфи воркфлоу что скинули. Где вообще ллмка-то которая ризонит? Она типа встроенна в модель с диффузией или что?
Я генерю один и тот же промт в 1 строчку без уточнений - и тянется абсолютно одинаковый бэкграунд, очень похожий нарратив.
Если я ввожу Random background. Или Get creative with the background - это игнорируется. Где ризонинг нахуй и как он в действительности работает- то что телка держит книгу в руках и смотрит в лицо мужику, ну мое почтение. Клейн даже такое не умеет сам достраивать.
Те кто шарят - видели в глаза этот ризонинг, он там есть или нет, или его донастраивать нужно? Где вот эта gemma? Я её не качал, воркфлоу без этого работает
>>1610823 Reasoning-Driven Prompt Agent — Built-in "thinking" agent that resolves implicit knowledge, layout, and text rendering before generation.
а так кури матчасть. это UiT модель, не путай с DiT
Это иронично, но логично: то, что на бумаге выглядит как «избавление от посредников», на практике часто упирается в нехватку обучающих ресурсов. «Мыло» и пластиковый эффект в HiDream-O1, скорее всего, вызваны двумя причинами:
1. Недообученность (Underfitting): Работать с сырыми пикселями на порядок сложнее, чем с компактным латентным пространством. Чтобы UiT выдал такую же четкость, как DiT, ему нужно в разы больше данных и вычислительных часов. Если модель «не дожали», она выдает усредненные, «безопасные» значения пикселей — отсюда эффект пластика. 2. Проблема высокого разрешения: VAE в традиционных моделях берет на себя всю «грязную» работу по отрисовке текстур. Без него трансформеру приходится самому учиться рисовать каждый прыщик и ворсинку. Если веса модели недостаточно велики, она просто не может запомнить такую детализацию и «заглаживает» картинку.
В чем тогда смысл её крутить? Её преимущество сейчас не в эстетике, а в структурной логике:
Соблюдение промпта: Посмотрите, насколько точно она расставляет объекты. Благодаря единому токенному пространству она должна лучше понимать пространственные связи («слева», «под», «внутри»), на которых латентные модели часто спотыкаются. Редактирование: Попробуйте задачи на дорисовку или изменение части изображения. Архитектурно она должна делать это бесшовнее, чем DiT через маски.
Пока это выглядит как Proof of Concept: разработчики доказали, что «так можно», но по качеству картинки они сейчас в позиции догоняющих (примерно на уровне Stable Diffusion 1.5 по детализации, но с логикой современных моделей).
>>1610838 так а где gemma 4 31B то находится? я отдельно её не качал, она на домашнем железе то едва запустится а там рассказывают про какой то промт агент с ризонингом
>>1610865 хм... кажется про ризонинг они напиздели
я тут в карточке модели немного полистал, это короче просто промпт рефайнер, в комфи отдельной нодой можно присрать или рефайнить через чатик дикпика. как у эрины. к модели оно имеет слабое отношение.
>>1610884 так а в чем архитектурное решение то тогда, к любой модели можно прицепить любую ллмку с любым систем промтом,
смысл то в том, что помимо ризонинга ллмка еще и очень хорошо знает модель которая рисует, либо еще более сложно и интегрирована
нихуя не понял, в любом случае gemma 4 31B это 30гб vram+ и нахуй они её предлагают и как её использовать, где воркфлоу нихуя нет, ебучие пиздтоглазые неадекваты
>>1610888 >неадекваты Это вы неадекваты, бросаетесь на любой высер, ищите там, где искать нехуй, а потом разочаровываетесь, ищите виноватых, что ваши надежды и чаяния не оправдадлись.
>1610838 Объясните тогда мне такое. Почему бы не сделать ультра супер пупер vae с хорошими текстурами? Какого хрена они клепают новые модели и используют б/у vae? Теоретически можно сделать новое vae к существующим моделями которые выдают "пластик" и заставить их выдавать шедевры?
>>1611003 Я надеялся, что я не прав, и технически подкованные объяснят, как именно там ризонинг устроен или как его подключать. Я не врубаюсь как оно работает, с кучей файлов в папке с safetensor. Мб со временем люди вынесут на блюдечке рабочий интересный вариант. Сейчас пока что фантазирование и постановка кадра модели едва заметно лучше клейна. То есть даже юзать для креативного черновика сомнительно, хоть и можно если t2i клейна совсем в горло не лезет. Например 1 строчка промта "стимпанк люди с роботами" в клейне люди стоят с тарелками еды и половником в мастерской как дауны, а в хайдриме реалистично что то обсуждают или смотрят на друг друга, но задник убогий, и в постапокале тоже.
>>1611029 Причём зачастую видно как vae убивает нахуй всё что ты напромтил, на превью одно, а на выходе голимая хуита, для sd моделей это была обычная практика - для каждой модели делать свои собственный vae, а тут вдруг что в облом им стало, что поменялось, в чём сложнось?
>>1611029 >>1611035 Ебать вы. Вае просто латент пиксели переводит, у него нет контекстного понимания что там изображено. Он видит просто цифры в тензоре. Максимум может замылить, цветовой баланс похерить, контраст там.
Рэндомные генерации хайдрим с "постапокалом". Задник почти идентичный клейновскому. Даже если хайдрим начнет сейчас генерить текстурки как клейн, во многом нихуя не изменится. Разве что позинг + эмоции намного лучше чем в клейне с его тупорылым покерфейсным стоянием всего.
Я помню во времена sdxl в этом треде постоянно приходил чел и докапывался, что модель не может сгенерировать лежащую девушку на кромке крыши или что-то такое. Тоже всем недоел, как вы. Упрутся в один столб посреди поля и проехать не могут. Прямо вот пока не разрешиться идея-фикс ничего другого генерировать нельзя!
>>1611062 Логика этого а ля бля лосслесс без сжатия - латента нет, сразу огромная сетка пикселей - идеальный мелкий текст и нет артефактов сжатия, универсальность обучения: оно подходит скорей для спец-задачек снимков медицина/космос. Нужно намного больше врама для тех же задачек, что моделям с вае и тем же качеством на глаз по сути, и даже имея много врама это всё равно будет дольше в генерации. Тупо нишевая хуйня для текста и графиков, карт и т.п. Нахуй не нужОно
>>1611066 > не разрешиться идея-фикс Нет никакой идеи фикс, просто рэндомные кейсы которые наглядно подсвечивают ограничения. Если кто то их тестит на разных моделях, это не идея фикс.
> проехать не могут. Проехать к 1girl standing или куда?
Почему разница такая существенная? В KSampler помимо значительно большей детализации / текстур - пережженая картинка - как фиксить? Это simple scheduler? В таком виде его юзать явно не стоит.
У SCA плюс только один - картинка не пережженая, в остальном хуже и глюков заметно больше.
>>1611478 Ты мешаешь тёплое с мягким, тебя сложно понять. Твоё сравнение некорректно.
Вкратце: KSampler (Advanced) это придаток к обычному KSampler для разбиения на этапы по количеству шагов и докручивания. Начинается на KSampler, затем передаётся на KSampler (Advanced), который может подхватить latent на нужном шаге и доденойзить его (уже, возможно с другими параметрами cfg, sampler, scheduler). Тебе уже об этом когда-то писали (или просто вы задаёте одинаковые вопросы и наступаете на одни и те же грабли). Копните поглубже теорию, сэкономите нервы и время вместо шаманства.
SamplerCustomAdvanced это швейцарский нож, который позволяет подключать различный шум, экзотические сэмплеры и скеджулеры. Кастомизируется практически всё, в отличие от KSampler. В данном случае у тебя sigmas задаёт узел Flux2Scheduler. Если ты их выведешь отдельно, то они будут несколько отличаться от тех, которые будут в simple scheduler в твоём KSampler (Advanced). А поскольку ты работаешь с distill на 4 шага, то изменение sigma от расчётных, на которые он обучен, на таком малом количестве шагов способно подтолкнуть FLUX.2 [klein] рисовать другое. FLUX.2 [klein] 9B distill вообще очень чувствителен к изменению sigmas. База на большом количестве шагов тебе это может простить. А distill обучен под определённое количество шагов (4) с определёнными sigmas, которые выдаёт узел Flux2Scheduler с поправкой на разрешение изображения (входы width и height). Можешь использовать узел custom sigmas и поменять sigmas, чтобы посмотреть как это будет влиять на выходное изображение (при сохранении seed и разрешения генерации).
>>1611526 Фикс. Два KSampler (Advanced) можно соединить. На втором задаётся add noise — enable, return with leftover noise enable и количество шагов steps, и ещё (start at step 0, end at step n). А на втором, add noise — disable, return with leftover noise disable и количество шагов steps вместе с (start at step n+1, end at step можно оставить default 10000; всё равно, отработает только указанное количество steps). Забыл уже как KSampler работает, так как только SamplerCustomAdvanced уже более полугода для всего использую (FLUX.2 [dev], FLUX.2 [klein] 9B, LTX 2.3).
>>1611456 Сомнительно. Я наверно плохо смотрел, но по ссылке идёт сравнение только по циферкам, а хотелось бы оценить результат глазами. Для себя я как-то визуально определил: BF16>FP8>GGUF Q8 (мне показалось, что отдельные веса, отквантованные с более высокой точностью в итоге погоды не делают; а удел GGUF это дефицит VRAM при наличии RAM для offload) и ниже, а дальше уже всё остальное. Поэтому был несколько удивлён ранжированием, где GGUF Q8 на первое место ставят. Но это, я так понимаю, опять по абстрактным циферкам, а не по результату генерации.
Не особо хочется со всем этим разбираться, так как FP8 меня в целом устраивает. Но если кто-то попробует, то будет интересно посмотреть на результаты визуального сравнения.
Там ещё вроде бы не очень сложно модель перегнать в INT8. Если решусь, то наверно есть смысл FLUX.2 [dev] перелопатить. С другой стороны смущает фраза: Requirements: Working ComfyKitchen (needs latest comfy and possibly pytorch with cu130) Triton Windows untested, but I hear triton-windows exists.
Я как-то (зачем-то) пробовал его ставить, но получалось криво. Да и вроде не нужен был особо, поэтому я дальше разбираться с ним не стал.
>>1611552 Так циферки и замеряют отклонения от латента на bf16. Q8 ггуф это ультрабесполезная хрень, потому что вместо него можно гонять полную модель с оффлоадом и получать ту же скорость. Давай промт, потестирую. Для меня это ультраполезно оказалось в базовой модели, почти в два раза сократилось время на шаг
>>1611559 >Давай промт, потестирую. Спасибо. Мне в целом prompt не особо важен. Если можешь, просто запости два изображения рядом. Одно на bf16 (или fp8, что у тебя есть), а другое на этом int8 conv. Желательно какой-нибудь общий план с мелкими деталями и крупными персонажами на переднем плане. Впрочем, не принципиально, что есть пойдёт. Мне посмотреть артефакты в мелких деталях и текстуры.
Если всё-таки нужен prompt, то вот, но он не универсальный. Под FLUX.2 я бы его по-другому написал теперь.
A close-up shot depicting a Caucasian man and a Caucasian woman looking at each other. There is a spherical object hovering between them in the centre of the image, left half of the object is Earth, right half is an intricate clockwork mechanism. There is a birch tree with lush leaves in the foreground. Sunny day. Hyperfocal, deep depth of field.
>>1611581 Ага. Ну я на картинках вообще не вижу какой-то критичной разницы - где у одной артефакты, там и у другой артефакты. У int8 еще пару деревьев выросло. Но я не включал детерминированные алгоритмы, так что хз это из-за моделей или нет.
A cinematic movie still of people and steampunk robotic automatons. The people and automatons are working together, performing routine maintenance operations. Some automatons and people are arranging and laying out the merchandise on the stalls. A few other are watering the flowers with water hoses. Some are engaging in a conversation. A busy bustling street of a Victorian England industrial city. Cinematic movie still with dramatic lighting. A full shot from eye level shot on 35 mm lens, f/16. Practical lighting, dramatic lighting, warm highlights, cool shadows. Sharp texture details. Atmospheric haze.
>>1608863 Если машина мощная то качай обе, делай базовый рисунок базой а потом делай имг-имг через турбу для качества. Если гпу 8ГБ то качай турбу и к ней z-image-turbo-sda лору для частичного обращения взад коллапса вариативности. Все, других моделей нет и ненужно, жди з-имаге турбо 2 на 24 гб под РТХ 5090. Все модели после это кал под бенчмарки у которых вариативности нет от слова совсем, которые используют отдельную ллм для рефайна промтов всилу отсутствия вариативности, и у которых нет лор потому что всем похуй и никому не сдался весь этот зоопарк из одинаковых моделей.
>>1611456 Если в кратце - какие преимущества и на каких карточках? Ниже вес? Скорость выше? Что там еще обещают?
Если Анима по скорости с SDXL-моделями сравняется - будет интересно. Но маловероятно, как мне кажется. Плюс лоры-контролнеты наверняка несовместимы будут...
Суть инсайда с Реддита заключается в новом подходе к квантованию диффузионных моделей с использованием INT8 ConvRot (с алгоритмом сферического вращения весов).Этот метод решает главную проблему старого целочисленного квантования: он убирает выбросы в значениях (outliers), из-за которых генерация на обычных INT8-моделях раньше превращалась в кашу. Главные инсайты: По качеству картинки (метрикам SNR и сходства с оригиналом BF16): BF16 > GGUF Q8 > INT8 ConvRot > MXFP8 > FP8. Новый тип квантования выдаёт картинку значительно чище, чем стандартный FP8, и точнее передаёт детали. По скорости работы: INT8 ConvRot даёт ускорение генерации в 1.43× — 1.88× раза по сравнению с базовым BF16. Он работает быстрее, чем новый и тяжёлый формат MXFP8. Видеокарты RTX 30-й серии (Ampere) аппаратно не поддерживают формат FP8 (он появился только в RTX 40 / Ada Lovelace). Зато архитектура Ampere (и даже старая Turing RTX 20) идеально и нативно ускоряет INT8 на аппаратном уровне. Для владельцев RTX 3060/3090 это буквально бесплатный буст производительности. Даже владельцам RTX 4060 Ti (8 ГБ VRAM) и выше, есть смысл попробовать, но с оговорками: Плюсы: Экономия памяти (VRAM): Модель в формате INT8 весит столько же, сколько в FP8. Для 8 ГБ VRAM это критически важно при запуске тяжёлых моделей уровня Flux.1 Dev. и выше. Выше качество: получаем генерации, которые по деталям и точности ближе к оригинальному тяжёлому весу BF16, обойдя по качеству мыльноватый FP8. Аппаратная поддержка: RTX 4060 Ti и выше отлично переваривает целочисленные вычисления. Минусы и нюансы: Разница в скорости уже на RTX 4060 и выше не будет шокирующей: На архитектуре Ada Lovelace (RTX 40) компания NVIDIA уже добавила мощные блоки для FP8. Поэтому безумного прироста скорости именно по сравнению с FP8 не будет (в отличие от владельцев RTX 3090, у которых FP8 тормозил). Главный выигрыш — чуть лучше качество картинки при том же потреблении VRAM. Проблемы совместимости на старте: Технология только заехала в ComfyUI через кастомную ноду INT8-Fast от автора исследования. Некоторые пользователи уже жалуются, что тяжёлые новые модели (например, Wan 2.2) пока вылетают с ошибками нехватки буфера или памяти на определенных этапах. Вердикт: Если сейчас на FP8 не хватает чёткости лиц/текста, или картинка кажется пластиковой — можно попробовать кастомную ноду INT8-Fast для ComfyUI. Если текущая скорость и картинка на FP8 полностью устраивают, можно подождать неделю-две, пока метод "причешут", оптимизируют и добавят во все популярные сборки без костылей.
>>1611714 >чуть лучше качество картинки при том же потреблении VRAM Бля, я в упор не вижу разницу между 16 и 8. Ещё можно добываться там до 4-5 бит, но 8 реально вкусовщина.
>>1611714 Короче всё будет чище, точнее, детальнее но без гениталий и сисек. А единственные позволенные волосы будут дреды, потому что соевые ебланы с неопределённым гендером так решили.
>>1611665 Прописывай каждого отдельно (и их действия), чтобы неодинаковые были (я не стал). Лучше через JSON-prompt, потому что там ещё и токены протекать могут начать с одного на другого если a man, another man слишком много будет. Или обозначай их мужик1, мужик2, Вася, Петя. На FLUX.2 (и на distill особенно) нужно конкретно писать что-то, если хочешь чтобы это рисовало (если, конечно ещё модель это знает). Не напишешь, не нарисует.
>>1611730 Ты о чём? Сравнивают не между mx/fp/int/mixed/scaled 8, а bf16=? Как выяснили bf16 и int8 не отличаются в качестве, что заебись, ещё как бонусом у int8 скорость чуть выше. Нет смысла юзать что-то другое вообще. Даже глупо будет бф16 юзать теперь
>>1611594 >>1611753 > Не экономьте токены на FLUX.2. Что бы фактически просто изменить сцену на еще большую нейрослопную нелепость? Там короткий промт был просто для тестов. Токены в t2i клейне тебе не помогут получить достойную картинку. А i2i настолько слаб генеративность - что качественно исправить собственную же хуйню не сможет. Может улучшить только изначально хорошо поставленную картинку. Набрасываешь говно на вентилятор, копинг/тролинг. У клейна в генерации днищенская фантазия и художественности нет как класса
Собираюсь обновить комфи, лучше по новой установить или старый обновить? Если установить чистый - мне кастом ноды нужно по новой скачивать или можно из старого перекинуть?
Генерация на основе потоков в многомерных пространствах сложна, поскольку предсказание скорости требует моделирования многомерного шума, даже когда данные имеют сильную низкоранговую структуру. Мы представляем асимметричное моделирование потоков (AsymFlow), параметризацию скорости с асимметричным рангом, которая ограничивает предсказание шума низкоранговым подпространством, сохраняя при этом предсказание данных в полноразмерном пространстве. На основе этого асимметричного предсказания AsymFlow аналитически восстанавливает полноразмерную скорость без изменения архитектуры сети или процедур обучения/выборки. На ImageNet 256256 AsymFlow достигает лидирующего значения FID 1,57, значительно превосходя предыдущие модели диффузии пикселей типа DiT/JiT. AsymFlow также предоставляет первый в своем роде способ тонкой настройки предварительно обученных моделей скрытого потока в модели пиксельного пространства: выравнивание низкорангового пиксельного подпространства с латентным пространством обеспечивает бесшовную инициализацию, которая сохраняет высокоуровневую семантику и структуру латентной модели, поэтому тонкая настройка в основном улучшает низкоуровневые несоответствия, а не переобучает генерацию пикселей. Мы показываем, что пиксельная модель AsymFlow, доработанная на основе FLUX.2 klein 9B, устанавливает новый уровень передовых технологий для генерации текста в изображение в пиксельном пространстве, превосходя свою латентную базу на HPSv3, DPG-Bench и GenEval, при этом качественно демонстрируя существенно улучшенную визуальную реалистичность.
в случае очень старого комфи можно сделать такой батник
@echo off
setlocal enableDelayedExpansion
set MYDIR=..\ComfyUI\custom_nodes\ for /F x in ('dir /B/D %MYDIR%') do ( set FILENAME=%MYDIR%\x\requirements.txt IF exist !FILENAME! ( echo UPDATE !FILENAME! git pull ..\python_embeded\python.exe -s -m pip install -r !FILENAME! ) )
>>1611526 пасиб, потестил с sigmas preview, видимо это и в правду костыль для клейна Кривая скедьюлера напрямую влияет на грязь и запекание, и f2s на разных разрешениях это корректирует. Но фактически на 512х512 flux2scheduler имеет практически идентичную кривую с simple.
То есть на 1mpx клейн перепекает свой слоп и получается более cartoonish / глянец. Корректировать это можно и нужно например power sigma выставляя коэфф 0.5-2. Правда эта палка о двух концах и там в обоих случаях на дистиле говно выходит, лучше simple, который всегда перепекает светотень. Beta57 на дистиле вообще засирает картинку. Но я не пробовал менять семплер, мб найдется какая то компенсация.
>>1612433 В теории, потенциально... >>1612437 Судя по сравнению "качества" от примеров, оно что-то совсем не заметно в лучшую сторону или на уровне погрешности. Насчёт скорости там даже у автора написано, что будет медленней "пока". По хорошему нет смысла сейчас. Если официально поддержи в комфи не будет, то проект переоценён
>>1612447 автору претить создать реквайрментс с тритоном для винды, он что-то там слышал что оно есть но ему похуй, ясное дело я сам установил тритон для винды и сразу стало понятно, что автор это уже видел и не осилил вайбкодинг свой, чтоб пофиксить, сделал вид, что вообще не в курсе что там в ентих ваших виндах
>>1612452 Т.е. на винде не перегнать или не нужно ставить тритон? Там что весь тред на маках линуксах сидит Не видел, что бы писали поголовно, что на винде не работает. Не хочется зазря фп16 выкачивать, поэтому уточняю
>>1612559 под винду просто ручками ставятся пакеты под конкретную версию куды и питона. это в рекваременты не положить потому что в винде собирать пакеты та еще боль, в линуксе проще но тоже нет смысла туда класть пакеты для оптимизонов
хочешь оптимизона - дрочись сам, по дефолту без оптимизонов
>>1612553 Это рабочий варик для тритона? Нихуя не понятно.
Сконвертил аниму, протестил - стало медленнее. "Охуенно легко сделать самому" когда знаешь дохуя технической хуеты. Когда не знаешь. Во всём треде этот ебучий triton упоминается 2 раза без подробностей. Фактически всё работает без него почему то, и модель замедляется. Ебейшая дичь
>>1612980 Так в треде аниме уже писали, что скорость повышается. И на реддите люди писали, что ускоряет. Да и тут тестили >>1611559 и подтвердили ускороение качество. Всмысле забей нахуй? Винда еще люто глючить стала и зависать намертво в отдельных UI после всех установок вокруг комфи. Заебался
>>1612967 для тритона да, а до новых фп9 я не добрался
>>1612999 > Винда еще люто глючить стала и зависать намертво в отдельных UI после всех установок вокруг комфи. Заебался не должно, комфи полностью портабл и не вытекает в систему