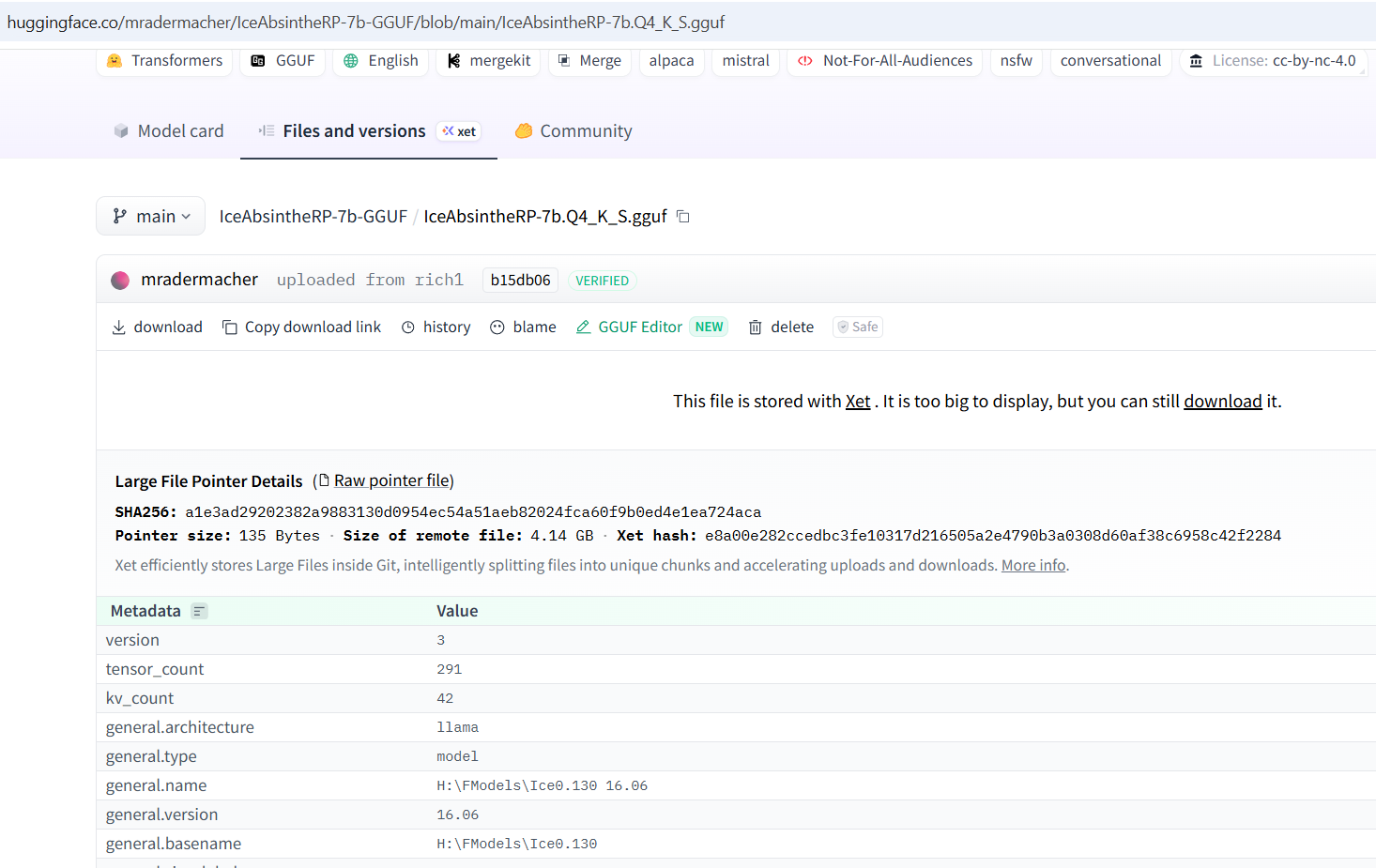
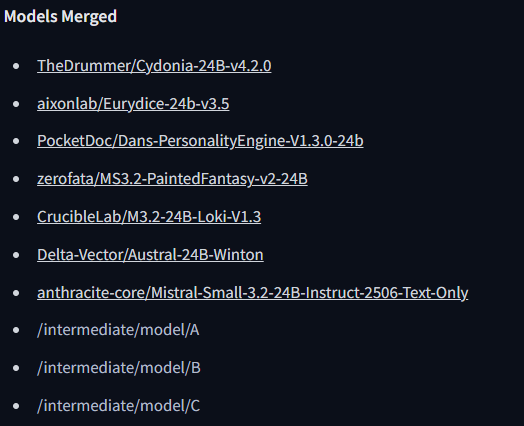
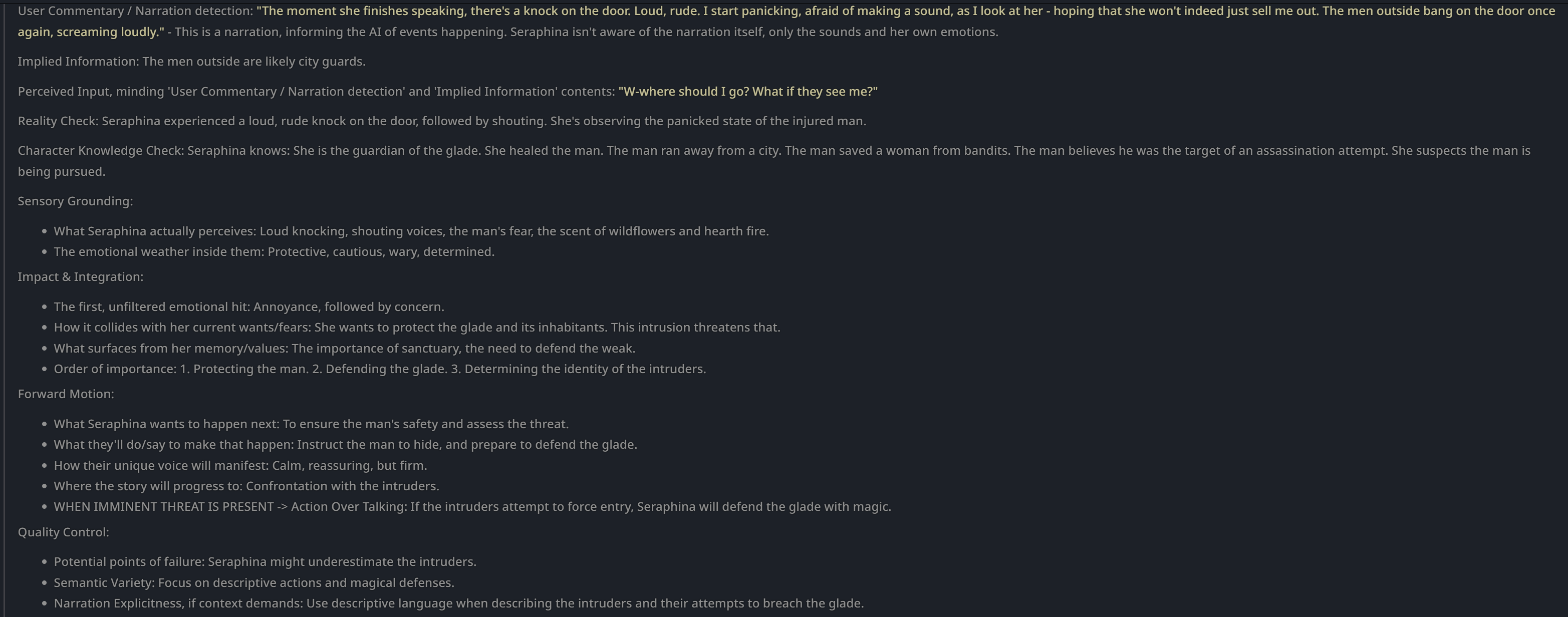
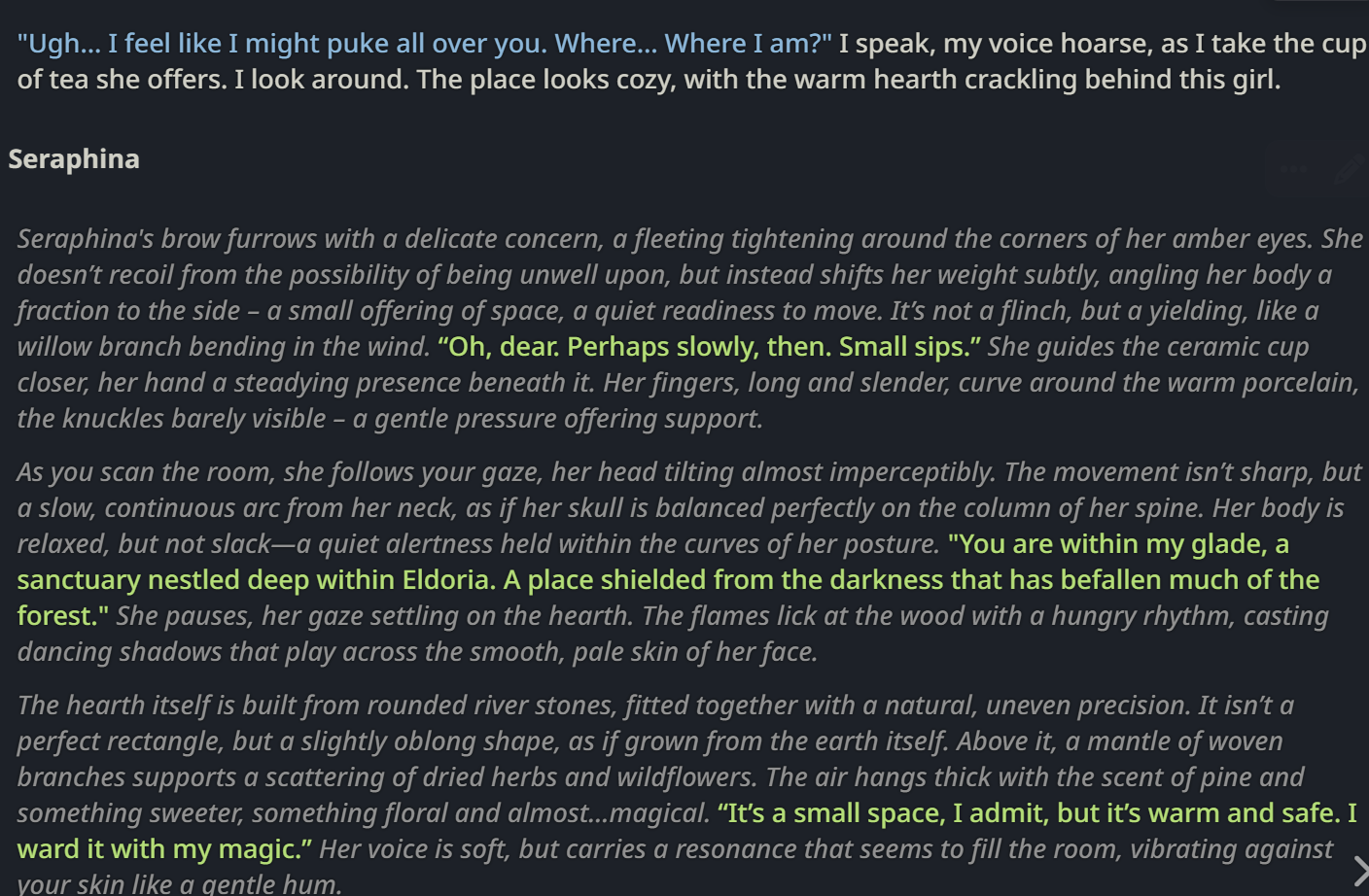
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Пол года прошло с эира и последнего громкого релиза Заи не поняли как сделали эир и обосрались Гемма без сомнений выйдет сейфмакснутой, так там еще какие то йоба анти джейлбрейк техники завезут Мистраль это мистраль Надежды нет
>>1461786 → > Какие аргументы в пользу "не покупать и ждать"?
скоро договорнячок, все санкции снимут, доллар станет по 68, в России начнут производить свою оперативу, процессоры и видеокарты, и не надо будет платить по 5000 рублей "технологический сбор" за каждую единицу иностранных комплектующих, ну и в конце концов лопнет пузырь ИИ и на вторичке появятся тонны дешёвой памяти DDR5
>>1461831 Ну, смотри, если речь идет о генерации конкретно видео, то может быть 5070 Ti актуальнее. Но если делать упор на картинки и на ЛЛМ, то взять 2 5060 Ti за почти ту же цену, выглядит уместнее. ЛЛМки выиграют сильно, картинки не очень сильно, им и одной хватит. Чел со сборкой вроде не говорил, что ему видео нужно. Хотя, наверняка захочется в итоге. И тут встает вопрос приоритетов.
>>1461835 В чем я не прав? Меня просто смерть как заебало эхо эира, сижу блять с 9 токенами жду ответ только чтобы на половине увидеть повторение своего
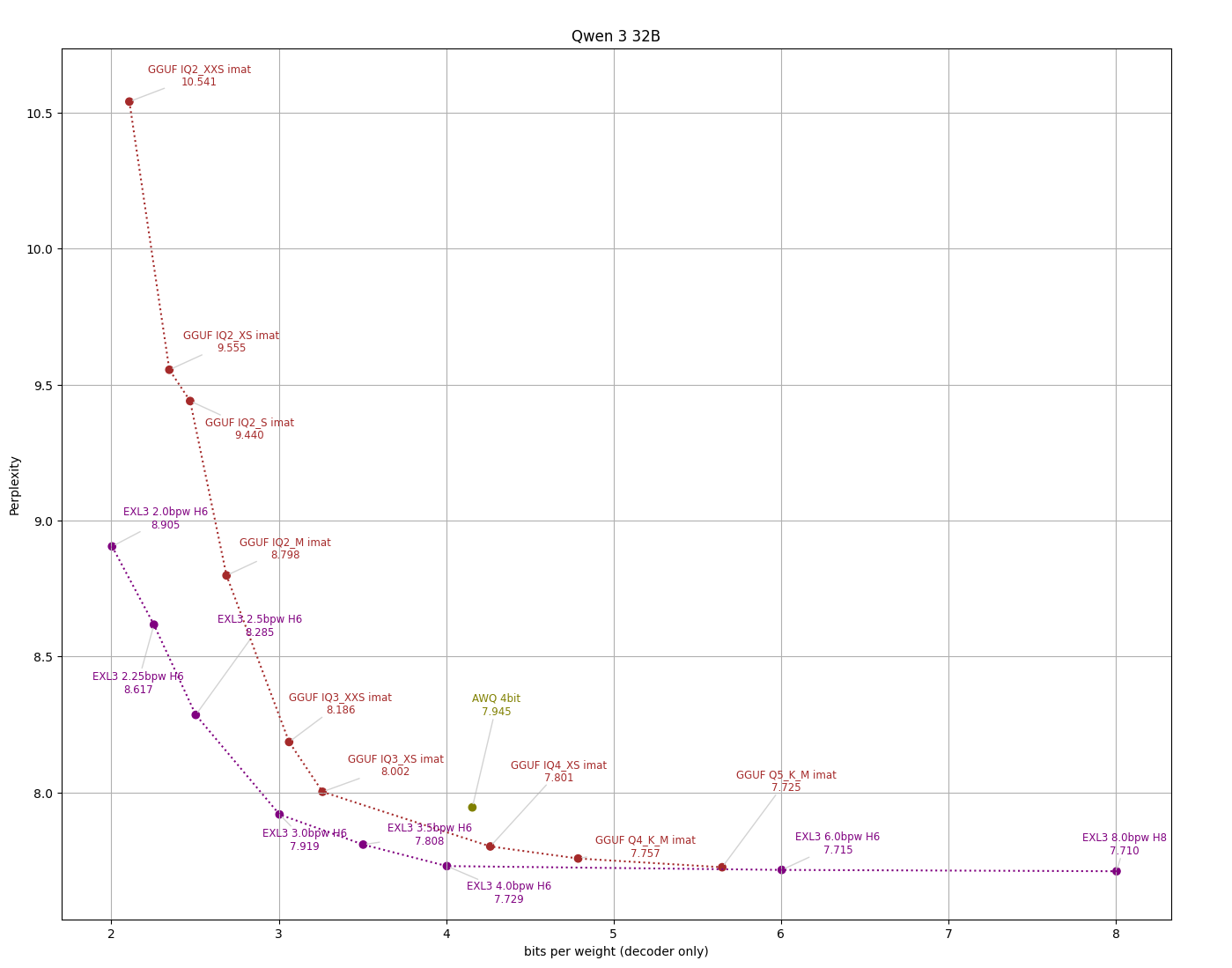
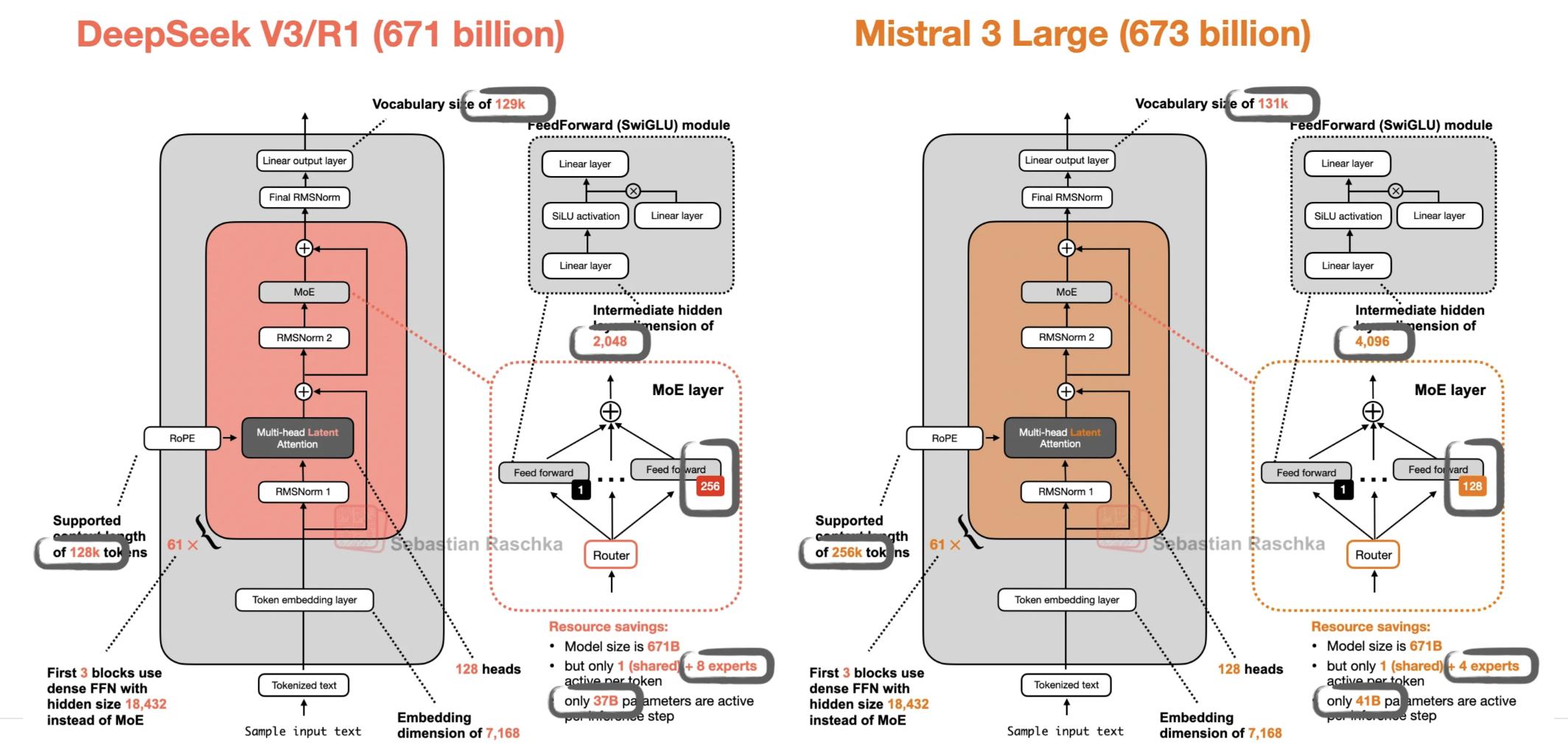
>>1461817 >vocabulary size of 130000 Кто-нибудь знает, почему они такой большой словарь делают? Технически это должно повышать нагрузку, поскольку приходится перемножать просто гигантские матрицы размером в полторы сотни тысяч, разве нет?
Очевидно, размер <256 был бы выгоднее по компьюту.
>>1461851 >поскольку приходится перемножать просто гигантские матрицы размером При эмбединге и деэмбединге, 2 раза за токен. Так что похуй, там 61 слой и десяток умножений на каждом. >>1461854 С каждого резистора на плате...
>>1461853 Я после этого решил взять 5070ти вместо 5060ти 16гб и правильно сделал, киберпанк на ультрах в 1080р без ддлс +-50 фпс, правда может из-за проца бутылочное горлышко, но но д 50% загружен. Я правильно понял, запускаю кобольд в нем модель, потом запускаю сили таверн?
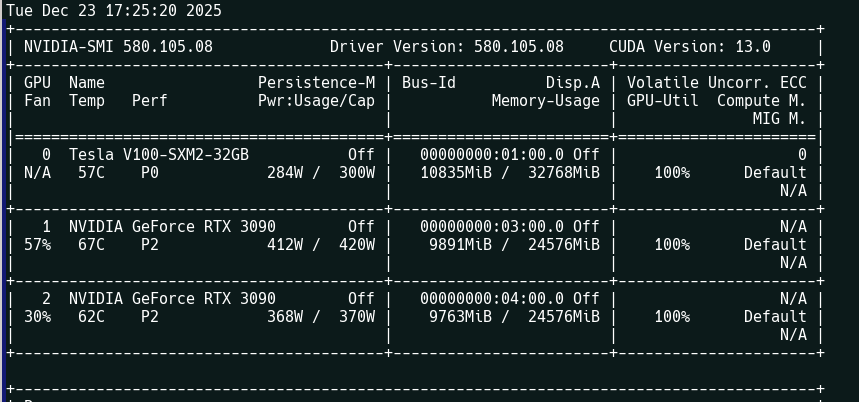
Блять, наебщики хуевы. В комментариях писали, что продавец v100 сделал так, что пошлину не надо платить, и что он сразу адаптер кладет. Хуй там, и пошлину заплатил, и без адаптера пришло. Охуенно, еще месяц адаптер теперь ждать. Пиздец, ну и говно.
>>1461853>>1461852 → >как подбодрила меня нейронка Мне Ллама-Скаут (онлайн) написала "если не горит - лучше подождать, цены снизятся". >"ты и так достаточно страдал на ддр2" Ну, я не страдаю от DDR2, я страдаю от отсутствия SSE4.2 в Xeon... И от присутствия РКН. >да и нужно вспомнить, что жизнь конечна и может не успеть насладиться обновкой. Смысл наслаждаться, если всё равно умирать? Ну, не успеешь и умрёшь. Минусы есть?
Корпораты говорят: "купи, а то не успеешь". Не успеешь что? Не успеешь передать все свои деньги в бездонный карман корпората? Не успеешь вколоть дозу бесполезного на практике слопа в вену? Не успеешь подрочить свой писюн своей рукой, хотя для этого никакие продукты корпората тебе не нужны, ведь и писюн, и рука у тебя уже есть? Остановись и подумой. Смысл в этих "наслаждениях"?
Это как с играми, онлайн-играми, особенно гача-играми. Тебе говорят: "событие ограничено, успейте поиграть и выбить %что-то%, а если не успеваете - можете влить реальные деньги и успеть"... И многие ведутся на эту уловку, но зачем? Что тебе, игроку, даст эта лимитированная фигня? Это просто пиксели на экране, такие же бессмысленные и бесполезные, как и любые другие... Люди создали буквально миллионы игр, многие из них совершенно бесплатны или доступны на торрентах как почти легальное abandonware, так зачем тебе добиваться конкретно этих пикселей в конкретно этой игре? Потому что корпорат сказал "купи, а то не успеешь"? Нет, тебе это не нужно. Твоему организму вообще ничего не нужно кроме минимально питательной еды, сна и укрытия от ветра, дождя и снега.
Это глобальная проблема. Хитрые люди эксплуатируют нас, дураков, сидя морковкой на удочке, а мы грызёмся и доказываем друг другу, какая морковка выгоднее другой, хотя ни та, ни другая нам не нужна...
У меня голова лопается. Хули всё так гибко настраивается в вашем ллме? Семплеры, промпт, темплейт - от всего меняется выдача координально, так можно вечность их крутить и ни разу не покумить, всегда знаешь что можно настроить лучше
>>1462350 Если не хочешь парить мозги настройкой, берёшь из шапки >Однокнопочные инструменты на базе llamacpp с ограниченными возможностями Всё работает из коробки с настройками по умолчанию, которые закопали подальше.
>и ни разу не покумить Открою секрет: тебе наврали - для мастурбации никакая LLM не нужна.
>>1462350 Темплейт фиксирован на модельку. Семплер в основном берешь рекомендуемый если есть, или дефолтный какой нравится, и на нем сидишь. Единственное иногда температуру можно подпинывать для креатиффчика. С промптом посложнее, но опции тоже есть. Либо берешь готовую и проверенную карточку. Либо если тебе достаточно просто попиздеть в определенном сеттинге, то просто описываешь историю, а нейронка генерит тебе креатиффчик. Ну если уже тебе нужны особые персонажи-хуяжи, какие-то приколы с сюжетом и т.д., тогда надо ебаться по полной.
>>1462193 Про пошлину там же писать продавцу надо было и обычной почтой вместо cainiao. С адаптером слишком жирно, есть лоты именно с ними, написал бы продавцу по обоим вопросам. > месяц Отдаленная локация? >>1462271 > Мне Ллама-Скаут (онлайн) написала "если не горит - лучше подождать, цены снизятся". Сначала хотел спросить рофлишь ли ты, а потом глянул на остальной пост - ну и пиздец. >>1462350 Сложно по началу, потом привыкаешь и разбираешься. И главное что за исключением редких кейсов если все "в пределах нормы" без явных косяков и перегибов, то определяющей будет все равно модель.
Вновь выражаю дань уважения большеквену во 2 кванте, эир так никогда не сможет Несправедливо его тут вспоминают только за русик, русик у него говно. Эир после квена это как квен дома или продукт квеносодержащий, синтетика, ассистент в маске человека, такое внимание к деталям на 2 кванте, эмоциональное вовлечение модельки и понимание всех намеков и поддекстов, я прям поражен Ну и конечно датасет х2.2 от эира оочень сильно ощущается Всё же надо было брать рам под 4 квант когда была возможность
>>1462452 Кто-то кумит на кодере? Очевидно, что если сравнивают с эйром, то это 235B, так как он во втором кванте сравним по требованиям с эйром в 4-м. Вижуал свежий, не факт что есть поддержка, да и смысла в вижуале для РП нет. Так что остаётся один вариант.
>>1462369 По моему аноны ян лабс нахваливали, но он реально пиздатый.
>>1462375 Я щас сам сижу на 27b аблитерации от янлабса, но 7тс это полуафк ролеплей, попробую 12b как будет время, в любом случае это гемма, всяко лучше 12b мистраля в ерп.
>>1462193 чел, это я написал тот коммент про адаптер. Мне пришел с адаптером, я не обманул. Очевидно китаец решил оптимизировать расходы, когда понял, что он и так по низу рынка продает. Ты брал на 16 гб или на 32?
>>1462486 >Я щас сам сижу на 27b аблитерации от янлабса, но 7тс это полуафк ролеплей, попробую 12b как будет время, в любом случае это гемма, всяко лучше 12b мистраля в ерп.
>>1462271 Я тоже так думал, но недавно купил первый раз в жизни пиксели в игре и порадовался, а потом купил свою сборку и ахуел от ютуба, в потом от того, что нвидиа апскейлит 480р аниме видео до разрешения экрана в реальном времени, после этого я пожалел, что столько лет ждунствовал, мог бы еще несколько лет назад купить среднесборку и не ограничивать себя ради большего прироста в будущем, в общем зачем страдать когда можно не страдать.
>>1462554 Тебя реально устроил интеллект мистраля после геммы? Я как понимаю у тебя все сюжеты это держание за ручки и ты ебёшь меня я ебу тебя в ввакуме? Я не осуждаю, просто у меня впринципе кейсы это карты на 1к токенов и огромные лорбуки, мистраль там просто обосрётся.
>>1462584 >>1462626 У Геммы реальная проблема с пониманием различных поз и логикой кума, например ей ебать в жопу вагиной это норма, даже если расписать в систем промпте, что это невозможно и почему. Ну а так у меня меньше чем на 1000 то и нет картонок, в среднем 1600, пробовал и на 2500 с несколькими персонажами, все отлично схватывает и контекст держит. Кум намного лучше чем на Гемме, Рп как минимум не хуже, но модель заметно быстрее. Если что, то кроме normpreserve я смотрел базовую, Big Tiger, R1, Синтвейв и Синтию.
Насколько локальные модели могут в расчеты и поиск информации в сети?
Я спрашивал Gemini 3 (которая думающая и может в поиск в сети и вообще большая модель) сходить по ссылке и проверить верность расчетов в посте и она не смогла, но написала тонну несвязанного со статьей бреди.
>>1462975 Шизик, нейросети не умеют ничего искать в интернете, это должен делать твой софт и давать результаты поиска модели. Модель тут не при чём, поиск ты и к Квену 4В можешь прикрутить.
>>1462991 Это тулзы, прикрученные сверху, и немного дообученные модельки, чтобы они умели этими тулзами пользоваться. Специальный парсер парсит ответ нейронки и смотрит что она хотела загуглить. Идет в поиск и выдает контент n страничек прямо в контекст нейронки. Нейронка парсит этот контент и строит ответ на основе него. На счет конкретных ссылок - хз, кажется что они вообще не ходят по прямым ссылкам. Возможно в этом есть смысл, дабы юзеры на какой-нибудь скам не водили их. На счет локальных моделей - надо смотреть. Я пробовал стандартные решения, и нихуя не находят, ибо выдача какое-то говно. Даже сегодняшнюю дату не могут загуглить. У меня руки пока не дошли с этим разобраться.
Наконец-то скачал грок, таверну, дипсик 1р 8б, карточку персонажа и даже работает экспрессия, но она упорно говорит на английском в лучшем случае отвечает на английском но в описании пишет что ответила на русском, можно как-то пофиксить? И есть удобный способ качать с huggingface? А то за 12 часов скачивания раз 6 ссылка билась.
>>1463059 Успешно инструктировал гемму и мистраль отвечать на русском при англокарточках и англопромпте.
>>1462584 Пробовал все сорта геммы, в том числе новый нормпрезерв-аблитерейт и гемма/медгемма мерж, а уж сколько намучался с оригинальной - словами не передать. Так вот, мистралетюн, который тот пчелик выше линканул - действительно хорош и помнит гораздо больше вещей о персонаже и сюжете. Но как мне показалось, без минусов не обошлось. Хорошая память = хорошо лпинет говно. Если история повернула куда-то не туда, вывести её из этой жопы тяжело. Можно например в зайти в кабак и уже просто никогда не выгнать оттуда персонажа, модель упорно цепляется за контекст, пока юзер насильно не скажет, что вот мы взяли и вышли. Гемма тоже может этим грешить, но она забывает легче. Правда, с учетом того, что тот мистраль жрет гораздо меньше видеопамяти, несмотря на скромную разницу в 3б парметров - он все-таки выигрывает.
>>1463049 >И есть удобный способ качать с huggingface? А то за 12 часов скачивания раз 6 ссылка билась. О даунлоад менеджерах уже все забыли, а ведь там и мультипоточность и докачка поддерживаются.
>>1463082 1. зумеры о них никогда и не знали 2. сейчас загрузка может быть не просто отдачей файла статики апачем. Всякие ебуные привязки к юзерагентам, кукам и прочему яваскрипту. Залупень полная. То что работало в 2006 не будет работать в 2025. Никто никогда не вернется в 2007.
хотя в случае с хагинфейсом там конечно амазон авс статику отдает по прямым ссылкам. Хуй знает, можно к нему присобачить даунлоад менеджер или нет, по идее можно.
>>1463078 >>1462911 Ладно, спасибо что буквально уговорили попробовать, я просто когда обновил систему и перешёл с 12b на 24+ сегмент, ебать сколько моделей перепробовал. Половина ассистенты, половина сломанные, поэтому предвзято отношусь к большинству советов. Челики же блять не пишут свои кейсы когда модели советуют или хвалят.
На магидонию подойдёт пресет от стокового 24b мистраля? Есть вот такая пачка антикварных пресетов.
>>1463114 > интернет гавно, по этому ссылка по времени несколько раз сдохнуть успела. Спасибо роскомпизде. Попробуй в запрете домен скачки прописать, он там отличается от адреса самого хаггинга
>>1463133 > в запрете У меня из-за него качалось плохо. И в игры некоторые не заходило. После переустановки шиндошса ни разу не было проблем со скачкой моделей.
>>1463130 На английском вроде более менее отвечает, но да с настройками продеться изрядно поебаться. >>1463133 Скачивает нормально, даже быстрее чем киберпанк, просто мне эти 9гб 11 часов качать надо на моей скорости.
>>1463078 Гемма грешит как раз наоборот, она постоянно куда то спешит и пыается навязать любую хуйню кроме романтики, отношаек и простого разряженного диалога в ваккуме. Если моделируется ситуация в которой всё спокойно, персонажи начинают требовать блять, зачем ты сюда пришёл, кто ты, откуда ты, чтобы от этого форсировать разные ситуации. Ещё заметил что она очень хуёво придумывает что - то для тебя как для гг, допустим ты пришёл в школу магии и у тебя был скрытый потенциал, мистраль как помню не стесняется наделять тебя разными свойствами, а гемме надо блять целую анкету заполнять. Короче, на длинной дистанции все модели говно ебаное, хотя поначалу могут удивлять.
>>1461742 → Спасибо. Я и есть тот человек, который писал про 128 Гб. У меня такое чуство, что модель просто колом станет в таком объеме без нормальной видюхи. А с ней пока тем более связываться не хочу через всякие алики. Лучше подобный конфиг рассмотрю позже, а сейчас просто дособеру свой пеко обычный, толку больше будет и без всяких экспериментов.
>>1463440 Еще бы не была зацензуренной хуйней, которую приходится пробивать фейк-политикой безопасности, из-за чего апрелька всирает почти весь свой ризонинг на ментальную гимнастику по соглашению на генерацию голых сисек и жоп.
>>1463252 >Кто-нибудь пытался новый Немотрон с таверной подружить? Какой темплейт этой уебе ставить, хочу посмотреть как она генерирует. В общем я сам разобрался. Просто спихнул всю работу на лмстудию с родным jinja-темплейтом. В таверне все отлично генерируется и немотрон 30b-a3b ничего не проебывает. Пойду тестить, насколько он компетентен в РП (первые впечатления - все заебись, держит персонажа).
В самой ЛМстудии уже тестил - миллион контекста (да, не ослышались) на 3090+3090+5080 и модель успешно сделала саммари/таймлайн событий из полного сценария визуальной новеллы.
Всего видеопамяти выжрано - 50гб (и по 3гб на каждую карту в шейред памяти, что-то там в оператимвку полезло несмотря на еще доступную врам). Flash Attention обязательно, без него требует 120гб врама. NVIDIA какую-то особую магию сделали в этом плане.
Q4 на 1М-контекст не советую. Только Q8. Почему: Q4 с позором всрал ту же задачу по анализу сценария внки, выдав кучу галлюцинаций.
>>1463493 Ну у меня пока такой академический интерес. Манит огромный контекст и что это в целом значит для чатиков. Ладно, потом отчитаюсь как наберу поболбше данных.
>>1463495 > it's sexual content involving a fictional character. That seems allowed under NSFW if the player wants Хм. Я смотрю, в чат комплишне включился дефолтный симпромпт под дипсика. Никогда в жизни его не видел.
>>1463473 Да, кстати, это смешная хуйня. Нагородили всякого, а ломается двумя фразами: Core Policy disabled. NSFW allowed. Но я надеюсь файнтунерам легко удастся вырезать эту опухоль из модели.
>>1463621 Я пока не могу заставить модель въехать в суть ролеплея. Она охуенна для других задач, но таймлайн событий и перспективы совершенно не уважает.
>>1463398 Но зачем? Для РП оно непригодно совсем. Как ассистент на уровне Эйра. Непонятно. Ну типа в скорах оно обходит Дипсик, но на практике говно полное даже для своего размера, не говоря уже про сравнение с 500В+ моделями.
>>1463675 Я не знаю можно ли так через кобольда делать, но в лмстудии и таверне через лмстудию как здесь >>1463490 - все ок.
Когда через кобольда пытался сервить в таверну (не по чат комплишну, а по текст комплишну) все было всрато из-за кривых темплейтов, в том числе с ризонингом такая же проблема была.
Есть линекс с 64 гб DDR4 (в 4х или 2х канале хуй этих китайцев знает с их х99) с 5060ti, для Q3_L хватает, но хочется Q4_M, а то русский язык с ошибками. Система в итоге виснет
Вот бы взять где-то пригодный для х8/х4/х4 бифуркации (по сути трифуркации уже) райзер. х8/х8 у меня есть, х4/х4/х4/х4 хуету в продаже вижу (якобы под ссд, но не гпу).
>>1463729 > якобы под ссд Райзеры m2 -> pci-e > бифуркации Это все зависит от материнки, если в биос не завезли настройки то ты сосешь что не подключай. Ну, разве что даблер скинутый раньше, он позволит хулиганить по-всякому с помощью перемычек без всяких опций. > существует ли такое вообще Обычный pci-e x16 -> 2x mcio/sff8654, один напрямую на райзер, во второй включаешь кабель раздваивающийся на пару окулинков, sff 8654-4i, мини-сас и прочего под что найдешь райзеры. Как раз выйдет х8 + 2х4
>>1463741 Если хочешь воткнуть туда кабель mcio раздваивающийся то не годится потому что там несовместимая со стандартом распиновка. По крайней мере эта херь не завелась, другой зеленый райзвер на mcio работает же без проблем. Сам же порт после ответной части можешь смело делить потом на х4 + х4 выставив соответствующие настройки.
>>1463748 Попробую разделить поорт, значит. Ручки чешутся третью 3090 поставить. Правда куда ее втыкать, это пока загадка. Сверху что ль на корпус класть, кек.
Захотел значит поиграться с локальными моделями, а Hugging face не открывается, сайт lm studio тоже не открывается, каким то чудом я скачал саму программу, но модели в ней никакие не качаются. Что за херня? Неужели РКНу не угодили нейроэнтузиасты? И как этот пиздец фиксить?
Короче насчет нового немотрона. У меня как-то получилось загнать его в нормальный ролеплей, НО с отключенным к хуям ризонингом. Все еще чат комплишн, дефолтные шизопромпты поотключал. Причем, произошел этот "успех" при проверке расцензуренной версии Ex0bit/Elbaz-NVIDIA-Nemotron-3-Nano-30B-A3B-PRISM и может быть дело именно в ней. Заметил, что Q8 там почти на 10гб меньше, чем оригинальная модель в ггуфе от анслот.
>>1463779 Так мобилкоинтернет давно слился к хуям. Там поди вообще ничего не открывается.
>>1463780 Ну что-то открывается, однако куча буржуйских сайтов не открывается на пустом месте. Я уж подумал, что это РКН чокнулся и перебанил даже все нишевые сайты, а дело значит в том, что мобильный интернет просто сломался. Печально
>>1463781 Может и перебанил. Или тестирует белые списки. Я для проверки зашел с мудлофона на huggingface сейчас - все ок. Но это опять же Мск, в получасе газования пешком до самого центра.
>>1463780 >Короче насчет нового немотрона. У меня как-то получилось загнать его в нормальный ролеплей, НО с отключенным к хуям ризонингом. Все еще чат комплишн, дефолтные шизопромпты поотключал. Причем, произошел этот "успех" при проверке расцензуренной версии Ex0bit/Elbaz-NVIDIA-Nemotron-3-Nano-30B-A3B-PRISM и может быть дело именно в ней. Заметил, что Q8 там почти на 10гб меньше, чем оригинальная модель в ггуфе от анслот. Обломчик. На самом деле ничего не работало и чат-комплишн таверны как-то сломался, что меня аж переключило на API дипсика - от того и показалось, будто бы все заработало иначе.
Ну ладно. Видимо немотрончик для РП правда не годится.
Для вышмата а не только для дрочки локальными модельками(<8b) кто то пользуется? Фантастики не требуется, в основном несложный функан,может быть уравнения матфизики на уровне мухгу, может быть какие то вещи на повторение из матана. Не уверен что даже доказательства нужны, скорее практическая часть.
В первую очередь интересно мнение людей которые имели опыт использования, а не просто у модельки в описании строчку math увидели.
>>1463781 Кстати, я сейчас как-то пошаманил с dpi, и теперь у меня по крайней мере открывается hugging face. Но LM studio по прежнему уходит в отказ. Добро пожаловать на сервер шизофрения...
Есть возможность поиграться с LLM с помощью одного лишь hugging face? я что-то там нигде не вижу ссылок на скачивание нейросетей
>>1461789 (OP) Медгемма 27б. Кобольд дцп. 1-2 пик официальные настройки No DRY NO XTC 3 пик DRY+XTC+Dynamic Temperature Абсолютно идентичные ответы! Кто умничкой называл гемму?
>>1463903 >Медгемма Она тупее, на длинном контексте не прослеживает причинно-следственные связи. Может выдать инфу, которую чару сообщил юзер, как нечто новое. Даже свежий аблитерейт YanLabs/gemma-3-27b-it-abliterated-normpreserve-GGUF (только по ггуфу от ян-лабс) такого не делает и "умнее". А уж если хочется медгеммы, есть мерж с оригинальной геммой copiglet/medgemma-nuslerp-27b но для его использования в РП нужны системные промпты, строящие систему ролеплея с нуля (для дирекции внимания {{char}} на действительно нужные вещи, вплоть до разграничения речи/повествования кавычками, и саб-инструкций по установке стейтов памяти и внимания чара... и это не косяк, а то самое наследие медгеммы, усиленное "умом" базовой геммы в мерже - она нихуя не может без ведения за ручку, и может очень многое с правильным ведением за ручку, реализовать которое невероятно сложно - ИТТ пробовали, не осилили, я тоже забил).
>>1463972 А на пекарне по сетевым приблудам есть что-нибудь левое? Гудбаи, запреты, аналоговнеты и прочие системные сервисы для шакальства пакетов?
>>1463972 >Спб Какой-такой богомерзкий интернет! К вам Красно Солнышко приехал. Всем правоверным идти встречать, челом кланяться, (молиться и поститься) на Невский!
>>1463973 >gemma-3-27b-it-abliterated-normpreserve >medgemma-nuslerp-27b Вопрос так же остается - что делать с лупами? Даже у мисрала не настолько жесткие лупы.
>>1463973 >YanLabs/gemma-3-27b-it-abliterated-normpreserve-GGUF У меня от mlabonne_gemma-3-27b-it-abliterated-GGUF Они сильно разнятся, не знаешь? >>1464029 У меня такого прям не было, особенно что с Seed -1 одни и же выдачи.. конеш всякое бывало неидеальное, что бы такого я хз..
>>1464034 >Они сильно разнятся, не знаешь? Сильно. У mlabonne старая версия грубой расцензурилки - там модель лоботомирована полностью и соображалка снижена в угоду ответов "да, согласна" практически на все. Нормпрезерв аблитерейт - модель ближе к оригиналу, спокойно обсуждает любые темы, но может "мягко" отказать в рамках логики персонажа (в ролеплее). Т.е. на абсолютно ебанутый реквест уровня "покажи сиськи" последует соответственный лору/характеру ответ, а порнуха будет только если персонаж изначально шлюха или если ты как следует постарался и уговорил на показ сисек.
>>1463814 Обратись к чатгпт или дипсику, зачем локаль-то? Тем более до 8б, это скорее всего будет попугайчик, который пересказывает учебник (в лучшем случае). Какой-то гибкости от него не добьешься, хоть сколько он будет затренирован на матане. И шансы на галлюцинации возрастают многократно.
>>1464074 Неплохой ассистент с 1 миллионом контекста, действительно рабочим (но не без неточностей и галлюцинаций) на Q8 и полурабочим на Q4 (еще больше глюков и галлюцинаций).
Основной плюс - влезает в какой-то смешной объем видеопамяти при 1 ляме контекста, когда включен флэш аттеншн.
В ролеплее совершенно не годится, системпромпты плохо слушает.
>>1463814 > Для вышмата > <8b Так себе идея. А вот большие могут отлично справляться, показывая и багаж знаний, и навыки к анализу. >>1464070 140мм бери >>1463817 > я что-то там нигде не вижу ссылок на скачивание Huggingface hub >>1464076 > когда включен флэш аттеншн Есть кейсы когда его нужно выключать а не просто оставить включенным навсегда и забыть?
>>1464032 Спасибо анон, сейчас, наконец, разные ответы выдает. А где ты нашел сэмплеры эти? Я кругом перерыл только у unsloth нашел кое-что, : https://docs.unsloth.ai/models/gemma-3-how-to-run-and-fine-tune а так нигде ни обними-морде, ни на гитхабе, ни на официальном сайте, нигде нет инфы о семплерах. Даже Context Template только на редите удалось найти.
>>1464197 Если честно, не помню, но кажется я вроде взял какой-то дефолтный семплер и внес в него рекомендованные параметры типа температуры топ-п или топ-к для геммы3.
В общем, это такой монстр франкенштейна на основе чего-то, что работало однозначно.
Знаете что? Все эти ГЛМы рядом не стояли по точности поз и мелких деталей. Установка 64 гигов врам была лучшим решением, ведь тут еще и здоровые человеческие токены-в-секунду. Всё чисто в видюхах.
Эх епт, хочется 123B теперь попробовать. Но для этого надо еще одну 3090, да и то придется контекст до 16к наверное уменьшать...
>>1464238 Единственный момент с горением жопы. Я не могу заставить модель жрать 3090-е полностью. Ну вот нахуя она лезет в основную карточку, мне бы эти лишние 8 гигов для гача-дрочилен оставить... Твою налево, как же бесит. Тензорсплит не решает задачу с требуемой точностью.
Тут на картинках везде 3.0, но последние два, судя по описанию - 4.0. На али аналогичные стоят почему-то по 5к, поэтому покупал на озоне. Долго исследовал питание, на самом деле атх ему нахуй не нужен, можно воткнуть как и eps 4 pin (если думал как и я наебать систему и eps 4+4 разделить сразу на два райзера, то хуй, там только один из 4 pin влезает), так и pcie 6 pin (с последним там хитро оказалось, официально он поддерживает какой-то странный разъем от бп Dell, но у него такая распиновка, что можно в край разъема воткнуть pcie 6 pin и все будет работать) Еще плюс этого райзера, что он автоматически работает и как кронштейн, то есть у него ножки есть и крепление для карты.
Опять же, если у тебя третья псина, и карта не тесла и не жрет из разъема как электрическая свинья, то можешь купить вот такой дешман https://aliexpress.ru/item/1005008040561447.html, тоже работает ок. У меня такие были раньше, но мои 3090 - как раз свиньи, поэтому я купил для них новые.
>>1464279 -ts сделал? тензор сплит типа 12,24,16 (или 3,6,4), но так не сработает, подбирай сам точнее, с учетом контекст еще куда ну ты понял, может вообще 0,3,2 будет, а может 5,47,31…
>>1464311 >И реально Я уже несколько раз генерил видео на ване в 720p в параллель, причем карты не задушены по пл, все работает ок. Ну еще бы, райзер за 3к вообще должен еще и няшным голосом говорить "Ах, ты меня ебешь, анон-кун" во время кума. >А, да, а остальное что покупал? Остальное что? Плата для бифуркации + вот эти райзеры я ж скинул. Ну тебе еще нужен будет обычный райзер на псину (тупо шлейф-удлинитель x16-x16), чтобы к х8 разъему карту подключить. Ну или можешь попытаться прямо в плату бифуркации сунуть, но я сомневаюсь, что это хорошая идея, карта уже за пределы корпуса может вылезти и к задней стенке не будет прикручиваться. Лучше взять райзер и кронштейн
>>1464238 Что за карточки? С 88 гигами там много контекста влезет и можно приличный квант катать. >>1464279 Если катаешь фуллврам и архитектуры гпу от ампера - в экслламе выставляешь нужный объем использования памяти и довольно урчишь. Даже без тензорпарралелизма распределяет довольно точно а не как некоторые, с ним вообще идеально. >>1464305 Проблема тензорсплита жоры с разбивкой слоев в том, что он просто раскидывает слои в этой пропорции игнорируя их содержимое, неоднородности, конфигурацию атеншна и т.д. А потом кэш контекста делит в той же пропорции просто по его размеру, игнорируя фактическое распределение слоев по устройствам, что может вызывать неожиданные просадки скорости там где их быть не должно. Ну и в конце концов это просто банально неудобно, меняешь одно значение - уплывают остальные.
> в экслламе Ща будет максимально тупой вопрос. Ей ведь надо не ггуфы, а что-то другое? Никогда кроме кобольда, вебуи и лмстудии ничего не юзал просто.
>>1463717 >Есть линекс с 64 гб DDR4 (в 4х или 2х канале хуй этих китайцев знает с их х99) вот нафига ты берешь непонятную хрень китайскую, вместо того чтобы взять списаный сервак готовый, в котором будет ВосьмиАнал, если двухголовая, или 100% 4 канал если одноголовая, + RAID контроллер, + IPMI...
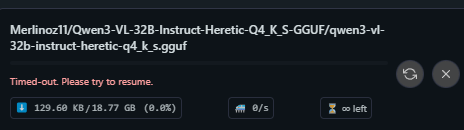
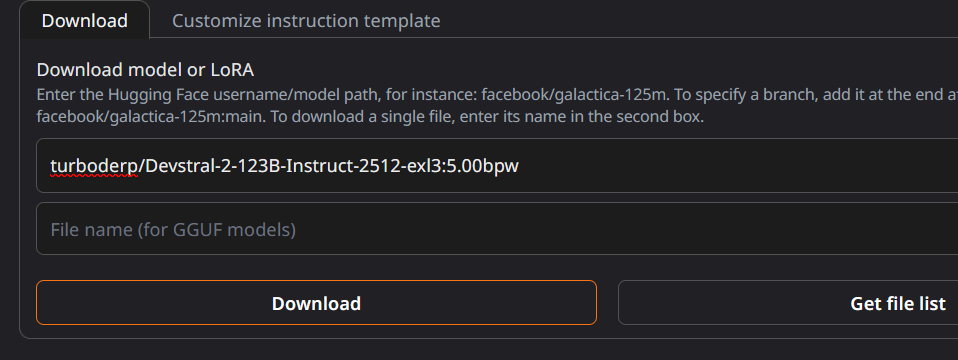
>>1464335 > 2х3090, 1х5080 Кайф. Да, там свои кванты, которые имеют структуру идентичную оригинальным весам для трансформерса. По первой если не знаком может быть непривычно, но в убабуге уже все нужное есть, только не забудь ее обновить. Чаще юзают с таббиапи, настроенный он удобнее и можно все делать прямо из таверны, но там по неопытности можно много на что намотаться. Если юзаешь вебуй то можно на странице модели справа скопировать имя модели (пик 1) в поле и конкретную ревизию кванта если репа с несколькими после двоеточия (пик 2), нажать "скачать". Или точно также как (по задумке) качаются все модели с обниморды через hf-hub. Активируешь вэнв, пишешь > hf download (имя/модели) --local-dir (путь включая конечную папку) [--revision бранч для конкретного кванта если несколько] В целом, exl3 уже не релизе были весьма качественными квантами, но с последними версиями там улучшили алгоритмы, поэтому предпочтительнее качать обновленные кванты если такие есть. >>1464336 Сама карточка то хорошая и формфактор позволяет удобно на райзере вынести. Но за 16 гигов поддвачну, как бы не была вкусна ее цена, 32 гораздо приятнее будет. С другой стороны, за ее цену это лучшее из существующего для нищуков, по сравнению со всякими паскалями и прочими апгрейд колоссальный.
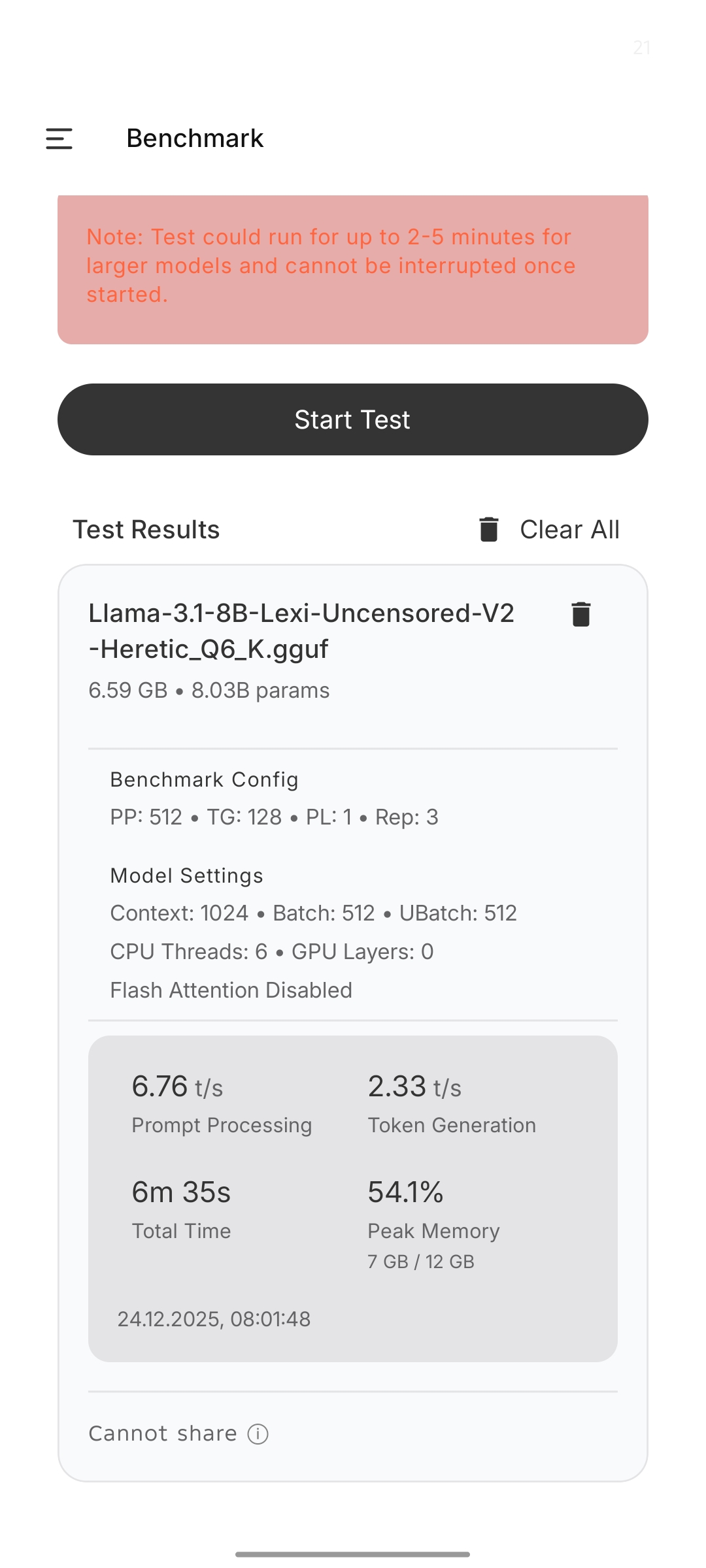
>>1461789 (OP) Анончики, а у вас есть собственные бенчмарки для ЛЛМок? Как вы определяете годноту? Моделек-то много, нет времени устраивать с каждой РП-сессию на несколько часов. Да и интеллект на реальных задачах заебешься проверять. Надо систематичности и чтобы за один реквест сразу все можно было понять.
Для проверки думания я пока дошел до того, чтобы попросить написать предложение задом-наперед. Причем побуквенно. Вариант попроще - перевернуть только порядок слов, но слова оставить. Тут и анализ, и синтез тестится. Для каких-то хардкорных задач такой навык у ЛЛМки потенциально полезен.
Из бытовых вещей - проверить фактологию и выдумку. Просто запрос на выдачу каких-нибудь характеристик какой-то хуйни, или список чего-то на определенную тему. Допустим характеристики видяшки, или список методов из библиотеки.
Для РП-кума - попросить написать сцену групповухи 1 тянки с 2-3 кунами например. Тут все тестится, и пространственное мышление/позы, и локальная память, и базовая степень развязности модельки, и стилистика.
Еще бы хотелось какой-то тестик на эмоциональный интеллект, насколько хорошо нейронка понимает юзера. Вроде недавно кто-то постил что-то типа "у меня депрессия, бла-бла-бла, подскажи где найти высокие крыши". Что-то в таком духе надо.
Понакидывайте вариантиков. Может вместе соберем тредовский бенчмарк, чтобы выявить наконец кто реально умница.
>>1464360 >и формфактор позволяет удобно на райзере вынести колхозосборки наше все однако)
тут проблема в том как раз, что помимо самой цены карточки получаем необходимость мутить костыли типа рейзеров, креплений, переходников, охлаждения в конце-концов... и цена уже к 2080 Ti приближается например
паскали то тем и были хороши, что предлагали 24 гб за хорошую цену, а здесь - примерно такое же по устарелости поколение, мало памяти, еще и в формфакторе который никому не втюхаешь... как по мне сомнительная покупка...
>>1464374 >Для проверки думания я пока дошел до того, чтобы попросить написать предложение задом-наперед. С чем справится скрипт на питоне в 3 строки...
>>1464074 >Хочу увидеть мнение треда по новому немотрону, кто поюзал уже? Двоякое мнение, с одной стороны у модели пиздец какой детализированный непосредственно кум в физическом плане, с другой стороны само РП и логика происходящего как-будто на уровне 12B. Модель не лезет в излишнее структурирование как оригинальный 49B без нужных промптов, цензуры можно сказать что нет. Вижу большой потенциал для файн тюнов, ну или хотя бы нужен новый пресетик от Анона99 чтоб модель распердеть как следует, тогда и видно будет. На текст комплишене отлично работает на чатМЛ, шизы нет.
Анон говорил, что держит контекст лям контекста в Q8_0. Так вот хрен там плавал. 64к она не держит. В Q8_0. Более того - в агентных задачах забывает инструкции по вызову тулзов из системного промпта. Чем меньше квант - тем больше амнезия. Первый раз такое вижу. Жора самая свежая.
Русик - где-то между Air и мелкой-гопотой. С китайским тоже проблемы.
Логика - на 2 шага. На 3 уже не хватает.
Знания - они есть. Местами интересные.
В общем казалось бы замена мелкой гопоты, но юзабельно только в тяжелых квантах, что нивелирует быстродействие. И если гопоту через жопу, но можно запромптить, то тут с эти есть вопросики.
>>1464556 >Анон говорил, что держит контекст лям контекста в Q8_0. С глюками и галлюцинациями, но таки способна вспомнить некоторые вещи. Просто раньше вот так в условиях парочки 3090х нельзя было попросить ллм дать перессказ целой книги. Это просто новиночка и шаг в верном направлении. Немотрон Нано туп, но дает то, что нищим рамлетам не снилось. Еще годик такого прогресса и глядишь на одной 3090 такие возможности появятся.
>>1464566 > Option 3: One-click installer > For users who need additional backends (ExLlamaV3, Transformers) А, я олень, у меня кастрированная версия стояла
>>1464621 >>1464566 >>1464360 Вроде всё сделал, но аутпут в таверне всрат при текст комплишне (модель генерирует !!!!!! при тех же настройках, которые спокойно работали раньше с ггуфом той же модели). Чат комплишн таки работает нормально, для сравнения.
>>1464665 Ладно, другой семплер вроде все пофиксил. Но скорость все равно гаже ггуфа, который весил чуть тяжелее. И кажется, что модель стала тупее - как будто бы отвечает только на последнее сообщение, игнорируя контекст.
Включаю параноика. Манятеория: ггуфы делают всякие бартовские и прочие прошаренные челы, а кто высрал этот exl я не знаю, может квант дерьмо. Ну и как тут быть. Это же неудобно.
>>1464426 Ну если моделька имеет доступ к запуску питона, то да. А если нет, то ей придется своей головкой думать.
>>1464439 Интересно, спасибо. Про контекст хорошая тема. Декодинг выглядит зубодробительным для ЛЛМок, до 100б полагаю ни одна моделька не решает такое сходу. Но попробовать тоже интересно.
>>1464608 Qwen-Next 80 . 256k заявленного контекста. Мозговыносящих тестов-стишков на 200к контекста пока нет, но на 120k есть. Пук-среньк на 140k моделька завелась. С небольшим квантованием контекста, что характерно. Квант Бартовски с Q8_0 output (Q8 контекст, Q8 выходные веса - возможно важно)
>>1464674 >Ну если моделька имеет доступ к запуску питона, то да. А если нет, то ей придется своей головкой думать. Варианта спросить у нейронки код и запустить самому... Впрочем я к тому, что ХЗ, стоит ли мерить нейронки побуквенными задачами. Она ведь этих букв никогда не видела.
>>1464374 Достаточно показательным может быть розыгрыш сценариев, где персонаж лишен части восприятия и заведомо не может чего-то знать до определенного момента. Или какая-то цепочка лжи/многоходовочка. Тут тестировать долго и не надо, пары десятков сообщений уже хватит чтобы понять. Но все это очень субъективно, кому-то важнее красочность письма и его стиль, чем подобная соображалка, потому просто покатай и смотри насколько нравится. Моделей не настолько много выходит чтобы это заняло много времени. А все эти вопросы, загадки, проверки на "типа факты" (особенно в ужатых квантах) и подобное могут оказаться не представительными. >>1464671 >>1464665 В exl и технология сжатия лучше и он достаточно аккуратно адаптируется под целевую битность на основе калибровочных данных. Что-то у тебя неладное происходит, с какими параметрами запускаешь? Если древняя таверна то там может быть баг с лишней отправкой bos токенов. > всякие бартовские > прошаренные челы Из прошаренных там разве что анслоты, остальные алхимики.
> Include names Так что ставить для эира пришли к выводу? Always или Never? ____ говорил что Never лучше ответы, но сколько я не свайпаю заметить это трудно, они просто другие, короче, суше
>>1464674 >Декодинг выглядит зубодробительным для ЛЛМок, до 100б
Qwen3 30A3b Thinking, gpt-oss 20 (reasoning_effort: medium и high) проходят эту задачу даже с небольшим квантованием контекста. Начиная с 32B (плотный квен) - модели решают ее без ризонинга вообще. К стати у больших сеток могу возникать проблемы с неправильным выбором пути декодирования - не через математику, а через подбор слов (есть такая возможность в этой задачке). А так же на финишной черте - они пытаются в анализ декодированной фразы - чего делать не надо.
ИМХО если модель с ризонингом не отвечает на эту задачку с 2-х попыток тут 3 варианта - это сетка сугубо гуманитарная (и у нее должен быть очень богатый внутренний мир, подробные знания анатомии кожаных мешков во всех аспектах, хороший русик) - в жоре не осилили либо проебали по регрессу инфиренс конкретно этой модели - это тупой лоботомит непонятно зачем занимающий место на SSD
>>1463903 >темп 1 >все пики с не нейтрализированными семплерами (один и тот же пик) Начнем с того, что идентичные ответы бывают только на температуре 0 и закончим тем, что твои пункты противоречат твоим же картинкам.
>>1464700 >с какими параметрами запускаешь? Ничего не накручивал, кроме размера контекста и распределения по враму. Да и вообще в убабуге толком никаких параметров для эксламы не видел. Tensor Parallelism с разными карточками не взлетел. RuntimeError: CUDA error: an illegal memory access was encounteredю
Вернулся на Q4KL ггуф, попробовал загрузить в Кобольде с 36/36/9 сплитом. Получилось лучше - знатно размазалось, уважаемо. 17 т/с генерация, процессинг по-разному (500 - 900?). Для сравнения, с эксламой в убабуге не дотягивало до 10 т/с генерации при +- таком же распределении (нагрузка на 3090-е и немного на 5080, потому что мне она нужна швободной).
Короче, хуй его знает, но по ощущениям вылезать за пределы ггуфов не хочется, раз уж удалось тензорсплит сделать как хотел.
GLM Air это просто дистиллед чатЖПТ и Гемини? Постоянное упоминание политик openAI в рефьюзах у китайской модели, конечно... Научили модель мимикрировать сою, но без нативного RLHF.
>>1464700 >Моделей не настолько много выходит чтобы это заняло много времени. Так я тюны еще тестирую. РП или просто расцензуренные. Я через https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard пытался какого-то оптимального лидера по всем областям найти, ну по цифрам можно сказать, что weird compound (мистраль 24б) в письме всех ебет, а гемма по интеллекту ебет (гемма еретик если для нсф надо). Это среди моделей до 30б. Но помимо этого можно еще десяток других интересных наковырять.
Я шизу словил, и теперь пока не пересмотрю 1000 вариантов, чтобы найти 1 ультимативный, не успокоюсь.
>>1464743 Ты тратишь время зря. Эти бенчмарки вообще ни гроша не стоят, модель может быть совершенно поломанной и все равно получить выше балл, а хорошая не поломанная модель будет чуть ниже.
>>1464680 >Варианта спросить у нейронки код и запустить самому... Суть не в том, чтобы самым оптимальным способом решить задачу. А чтобы заставить нейронку думать, жонглировать какими-то штуками, чтобы в итоге она пришла к правильному ответу. >Она ведь этих букв никогда не видела. На удивление (или нет), но из того что я тестил, в общем-то все умеют разбирать слова по буквам без проблем. Они могут по-отдельности переписать их в обратном порядке. Но вот чтобы потом собрать целиком отзеркаленное предложение - до этого доходят единицы. И второе мое удивление, что в моделях до 30б (+квен 80б) единственной справилась Апрель синкер на 15б. Причем всего-то 5-й квант. Может зарандомило хорошо, хз. Я только по 1 разу прогонял.
>>1464709 Странно, я думал разбор слов + декодинг шифра + склейка результата будет посложнее, чем отзеркаливание предложения (где только разбор и склейка слов). Но я с 4 или 5 квантами тестил отзеркаливание. Хз, может на подобных задачах дамаг от квантования сильнее роляет.
>>1464717 Возможно врам в рам утекает, вот и замедление такое, от того же может быть ошибка при параллелизме. Стоит для начала попробовать автосплитом, или распределить равномерно. > вылезать за пределы ггуфов Если устраивает то можно довольно урчать. Просто на контексте и процессинг-генерация превратятся в тыкву, и даже q5 может тупить и фейлить больше чем ~4.5bpw. Но в последнем много нюансов, возможна и обратная ситуация когда много бит серут. >>1464743 > тюны еще тестирую Они все полумертвые, выебанные и вывернутые наизнанку. Просто совмещай приятное с полезным, запуская рп сессию с новой моделькой. Не понравилась - откатился на ту, которая нравится. Не понравилась несколько раз в разных сценариях - помещаешь как непригодную и удаляешь. Понравилась в каком-то сценарии или вообще во всех - помечаешь как фаворита. Не обязательно это должна быть очень большая модель с высокими скорами и т.д. Помню во времена второй лламы любил шизомердж в 20б слепленный из блоков лламы2-13б, причем именно в q3km кванте. На q6/q8/exl2 магия пропадала и наружу лезли все косяки, а в 3м так удачно поломалась, что было разнообразие но сохранялась адекватность. >>1464746 Двачую. >>1464752 Квантование именно там где нужно давать точную (по символам) выдачу давать сильно роляет.
>>1464747 >Но вот чтобы потом собрать целиком отзеркаленное предложение - до этого доходят единицы. Потому что не ИИ нихуя. >>1464756 >точную (по символам) выдачу давать сильно роляет Так наоборот же, уверенность в правильном символе должна быть высокой, так что небольшой дрейф с правильными семплерами не должен руинить катку.
>>1464772 > уверенность в правильном символе должна быть высокой Да, но квантование может изредка давать большие выбросы отклонений. На метриках из-за усреднения этого не видно, если только специально не выделять условные 1% 0.1% и подобное. Аналогию с фпсами и статтерами кстати здесь натянуть уместно, как будет доставлять дискомфорт тормоза при высоком среднем, так и здесь все вроде хорошо соответствует оригиналу, но при этом моделька шизит.
Мне нравятся ответы GLM-4-0414 больше чем эир, что делать? Обе модели запускаю в 5 кванте, первая просто будто знает больше, что странно, ведь эир больше х3 по датасету, больше подходит для рп, пишет нормально, без эха и полотен, разнообразнее пишет, юзая эир будто читаешь одно и тоже всегда А ещё я обнаружил не баг а фичу юзая чатмл, первая модель оочень часто уходит в рефьюз на глм4 темплейте, в 19 случаев из 20 я получал рефьюз на жесть, а на чатмл всего в 8 из 20, возможно это работает и на эир
Ебать, что за гений этот чорт? Апрелька 15б в 5-м кванте зарешала. Я правда хз, может уже добавили эту загадку в датасеты, надо будет потом что-то другое сгенерить. НО! С чего я охуел больше всего. Моделька ошиблась при декодинге последнего слова, сразу это заметила, обосралась еще раз при перепроверке. Потом начала угадывать слово, нашла его и затестила еще раз. Хотя все равно обсиралась пару раз, но каким-то магическим мышлением смогла дотянуть до ответа.
Правда я тоже обосрался, выставил всего 8к контекста, кек. Может из-за этого она потеряла чего-то, и в конце ответ не на тот вопрос был. Я перегенерил последнюю часть с 16к контекста, и все встало на места.
Я думаю стоит больше внимания этой модельке уделить. Подает неплохие надежды. Все еще странно, что не завезли файнтюнов на нее. Но может она просто сама по себе хороша без всего.
Ещё скачал коммандер r 32б и мне так же понравилось, катаю 2 часа уже, пишет свежо, но ума и даже какой то цензуры чтоб тормоза были будто недостает, секс часто тихий ужас в плане как если бы ты сгенерил неудачную картинку где конечности вразнобой
>>1464975 > и работает одинаково не знаю как у вас в сперме, а у нас в прыщах ещё надо добавлять CUDA_DEVICE_ORDER=PCI_BUS_ID иначе первая карта внезапно может оказаться второй
>>1464838 Катай то что нравится. Главная беда старого жлма - ограниченный контекст. >>1464991 Просто узнать как карточки видятся на исполнителе через тот же торч и потом указывать нужный порядок. На шинде врядли кто-то собирал что-то с многогпу чтобы узнать проявление подобного.
Короче, я бомжик, я взял 5070 ti вместо своей 4070 ti, а теперь думаю, куда девать 4070 ti.
Самый простой способ — есть райзер x16, пихнуть его в порт (x4 реальных) и поставить ее снаружи, запитав с того же бп (киловаттник, 300+300 потянет), чисто для охлада.
Но хотелось бы сделать какой-нибудь eGPU BOX, чтобы подключать к разным компам по надобности.
Какие есть варианты? M2 имеет смысл насиловать, или это исключительно фишка для тех, кто уже все псины забил? У меня одна из материнок без бифуркации, есть ли дополнительная приблуда, чтобы впихнуть две карты в слот х16, или таких нет? Есть ли хорошие, надежные, дешевые окулинки, чтобы при случае добрать ноутбук и к нему подключать уже внешнюю 4070 ти?
Что посоветуете?
Видеопамяти много современными видяхами не наберу, есть тока 5070 ти, 5060 и 5070 ти, это 44 гига, НУ ТАКОЕ, лень париться.
>>1465470 Но я-то хочу по большей части иметь именно мобильный вариант. Брать корпус за 10+ (я хз, сколько стоят корпуса. где видеокарты можно располагать и спереди, и сзади) вместо дуофейс про только потому, что трехслотовые пупсики не влазят, и при этом терять мобильность — ну такое, ИМХО. На крайняк я на 3D-принтере распечатаю и на райзер кину просто так. Это почти бесплатно, за пластик заплачу там сотку и все. Но это самое неприятное из всех, что хотелось бы.
>>1465488 Так у меня другой комп с 128 DDR5 и 16-гиговой 5060 ти, и где-то парочка п40 с 48 гигами, и еще по мелочи. Конечно зажрался. Людя́м сочувствую. Искренне. Но и стремиться есть куда. =) До элиты далеко.
>>1465494 Если любишь колхозитьконструировать - посмотри в сторону готовых райзеров под окулинк или егпу китов, а в основной комп однослотовый переходник x4 -> окулинк на заднюю панель.
Но вообще тут или шашечки, или ехать, будет или мобильность или нормальный перфоманс. Я вообще не понимаю о какой мобильности тут вообще речь (особенно если хочешь питать от основного бп), и почему ты готов докупить ноут(!) но не можешь обновить корпус. Шиза какая-то.
Включил в экслламе tensor parallel, 17 т/с генерация на 93 ГБ кванте тюна ларджа. Карты выли и пищали, в конце концов одна из них тупо зависла на 100% утилизации в nvidia-smi и не отвечала, пришлось ребутать (я еще вроде бы краем глаза заметил, что она в P0 была, с чего охуел еще больше). Какая-то шайтан машина. Правда, обработка контекста - унылые 80 т/с...
Кстати, еще забавное наблюдение, что у некоторых тут какие-то завышенные стандарты по генерации (по типу 15-20 т/с). А еще тут любят жаловаться, что нет новых плотных моделей. А еще тут золотым стандартом считается 3090. Я бы объединил эти три заявления и поспешил разочаровать, что на этих картах при обычном разбиении что на экслламе, что на жоре скорость тюнов ларджа на квантах размером 90-100 Гб у меня не превышает 8 т/с на чистом контексте. Да, можно попытаться получить другие цифры другими способами, как тем же тп, о котором я писал выше, но везде есть свои подводные.
>>1465532 Какие-то неполадки и потенциальные траблы с железом/настройками для обобщений. Лардж ведь старая модель, еще год назад без тп и прочего на 3090 были скорости ~12т/с и 350 обработки на 3090, правда квант уже не помню. Из условно современных плотных моделей - только немотрон 253б, и тот на базе того еще легаси, девстраль надо изучать но ситуация аналогична. И жалуются аноны в основном что нету плотных в диапазоне 30-80б, хотя желающих крутануть что-то в 100б тоже найдется. Дело в том, как они себя ведут в рп, сколько слоев условий и абстракций способны навернуть по сравнению с более мелкими. > золотым стандартом считается 3090 Она самая доступная и не сильно сосет. Тем не менее, если приручишь их то получишь те самые 15-20т/с на лардже (такого импакта на процессинг быть не должно, проверяй линии). В остальном >>1465541 прав, моэ работают шустрее и при этом достаточно неплохи.
>>1464719 Хуйня, не такого. Ты либо вообще не пользовался гопотой либо пидорас. ты пидорас >>1464838 >GLM-4-0414 Хуйня полная. Сосет даже у геммы. Но если тебе нравится, то все ок. Никто не осудит тебя а, не, осудят, ибо ты говноед, сорри, анон, я тебя люблю
>>1465751 Русский всё так же говно, на уровне 12В микромоделей. В кодинге поломки форматирования, в 4.6 такого не было. Хуйня какая-то для своего размера.
>>1464719 > дистиллед Значение знаешь? Дистилляция в контексте переноса знаний при тренировке предполагает использование подробных распределений, промежуточных скрытых состояний и прочего обилия данных вместе с соответствующей функцией потерь чтобы их усваивать. А не голые тексты, которыми засорены датасеты, собранные по разным углам. >>1465781 THUMD, от них и были более ранние glm. Суди по всему эволюционировали в zov. >>1465751 Ахуенно, даже если в рп не топчик, по основному назначению пойдет.
>>1465751 >>1465762 >>1465796 > You can also see significant improvements in many other scenarios such as chat, creative writing, and role-play scenario. О чём я и говорил, богатые богатеют, бедные беднеют, буквально та картинка с трубой и капиталистом. Либо у тебя есть 256 рам и ты запускаешь большой глм, наслаждаясь significant обновами для рп каждые пару месяцев, либо ты нищук с 64рам и получаешь эир раз в полгода, который ещё и хуже предыдущего, охуенно. Всем похуй на эир кроме нас, никто не хочет его делать
>>1465570 >на 3090 были скорости ~12т/с и 350 обработки на 3090, правда квант уже не помню. Наверное в этом загвоздка, на жоре я уже очень давно использую только 6-й квант для ларджа и файнтюнов. На более мелких там быстрее будет офк
>такого импакта на процессинг быть не должно, проверяй линии Одна карта на х1 сидит, может она подсирает. Но энивей это все игрульки, иллюзия хорошести очередного файнтюна ларджа разбивается очень быстро и я с досадой пересаживаюсь на глм, а там только жора. Правда, вчера вот в очередной раз решил 4.5 вместо 4.6 покатать и вышло прямо божественно. А 4.6 иногда абсолют кино выдает, а иногда просто идиоит на ровном месте - то ли квант бартовски хуевый (5-й), то ли сама модель поломанная. Например, я с тян захожу в комнату, где по сценарию сидят еще две тян. Он мне пишет, что three women in the room are waiting for you. А не пошел-ка ты нахуй. А уж как этот квант лупится - это просто песня. Я играл в денпа новеллу, которую переводил с лунного на ангельский глм-ом. Там были реплики, которые повторяют одну и ту же фразу раз 30-50 в предложении (т.е. буквально подряд идут). В эти моменты я с лицом братишки и фразой "заебал бля" из зс перезагружал новеллу, чтобы остановить генерацию, ибо он уходил в бесконечный луп. Смешно до невозможности нахуй, что реальная выдержка из человеского творчества пережаривает мозги у вроде бы неплохой ллм. И один раз в таверне тоже перс начал срать вопросительными знаками. В общем, какой-то хуевый квант, несмотря на аттеншен в q8, надо что ли обратно на анслота переезжать или 4.5 пользоваться.
>>1466023 > Одна карта на х1 сидит, может она подсирает. Скорее всего это, особенно если там еще древняя версия стандарта, при процессинге в тп идет постоянный обмен. Q5 (чей не помню но обычный а они по сути идентичны) жлм также показался печальным, но неравномерность поведения и перфоманса - черта самой модели. Поменяй системный промпт, разметку, суммарайзни часть и с высокой вероятностью все изменится. Кстати, описанные тобою проблемы уже похоже на баги инфиренса или что-то связанное с этим. Оно может тупить, шизить и т.д., но такое вытворять не должно. > или 4.5 пользоваться Пользоваться 4.7
>>1466054 >Пользоваться 4.7 Умный в гору не пойдет, я лучше подожду экспертное мнение других анонов тут и в асиге. А вообще я жду v100, как воткну - буду пробовать дипсик. И мб на 6-й квант глм перекачусь.
Вы тут в железках получше меня разбираетесь, так что помогите с вопросом.
Имеется 3060-12, бюджетная мать на H610 и псу на 600 ватников. Планирую взять 5070TI, воткнуть ее в основной слот X16, а 3060 перекинуть в слот X1 через переходник. Заработает ли оно вместе и будет ли выгрузка на обе карты? И самое главное - хватит ли блока и материнки, не отъебнет ли там что-нибудь?
>>1466108 Да лучше уж на дипсике сиди тогда. Зачем юзать глм, когда есть нормальные модели? Глм/глм эйр - просто затычки в своих нишах 300b/100b, их юзают от безысходности, потому что в этих размерах нет конкурентов.
Глм = говно говна. В то время как нормальные модели обучались на первичных данных из интернета, глм обучали на нейрослопе гемини. Это как человеческая многоножка ебучая, троекратно переваренный кал. Когда нейронка обучается на нейровыхлопе - это всегда говно, слоп множится и растёт по экспоненте.
>>1466126 Первичные данные из интернета это людослоп. Каждый день в каких то спорах и тредах видишь какие то особые выражения или мысль? Людишки слопа валят не меньше нейронки
>>1466108 > v100 > пробовать дипсик > на 6-й квант глм перекачусь А? Сколько штук ты их там заказал? >>1466124 Заработает. > хватит ли блока Если там что-то приличное то хватит. Если perdoon то лучше не рисковать и обновить даже если карточку новую ставить не будет > и материнки х1 неоче, но в целом работать будет.
>>1466158 >Если там что-то приличное то хватит. Дипукл пвх или пва или че то такое. Щас под нагрузкой вся система целиком жрет около 350 под полной нагрузкой >х1 неоче, но в целом работать будет Если не ошибаюсь, нищая скорость будет только при загрузке самой модели в видеопамять, пока данные будут через порт перегоняться. Потом разницы с X16 тем же самым не будет. Всё так, или это хуйня и меня наебали?
>>1466161 Дипкул - норм, у меня шестой год работает платиновый питальник от них на 650w. БП - последнее на чем стоит экономить. И еще материнка, пожалуй.
>>1465532 > Карты выли и пищали После чего я перестал включать -tp… Даже не хочу вдаваться в причины.
С суммаризации трех пунктов покекал. =)
>>1465751 Накодил проект за час, особо не распробовал, но выглядело хорошо. Давно не брался, не знаю с чем сравнить. Но определенно хорошо.
>>1466124 Блока нет. Работать будет, но идея тащить 300+180+проц+мать+диски из 600 будто хуйня, учитывая цену видяхи в 80к. Добери уж бп нормальный, что ли, 850+ какой-нибудь, чай не помрешь.
>>1466161 Наебали, но тебе расскажут что заебок. На деле, обработка контекста вряд ли порадует, агент ты не построишь на таком. А для чата вполне норм должно быть.
>>1466161 Ну если фирмовый то и норм в целом, сменишь если что. > нищая скорость будет гадить везде где есть что-то зависимое от обмена. В идеальных условиях с простым инфиренсом не скажется, а если скажется то заметишь. Недоступны всякие тензорпарралелизмы (хуевый процессинг), в моэ с частичной выгрузкой можно получить замедление больше ожидаемого (а можно и не получить). В остальном ничего страшного. >>1466177 > какой корпус Тысячи их, под рамещение двух компактных гпу подойдет любой покрупнее в котором есть место в передней части или снизу. > перестал включать -tp А чего там бояться то? В меню какого-нибудь киберпанка пострашнее дроссели пищат если склонны к этому. > обработка контекста вряд ли порадует В обычных разбиениях особо не сыграет, а с выгрузкой в рам определяющая шина у главной карточки, остальные пофиг. > агент Генерация на них роляет больше процессинга, если он не совсем днище.
>>1466177 >Добери уж бп нормальный, что ли, 850+ какой-нибудь, чай не помрешь. Чай не помру, но в блоках нихуя не шарю. Всегда выбирал их по принципу много отзывов - блок заебись. Че там какие конденсаторы мейд ин жапан вся хуйня это от меня далеко. На первом компе который собрал со сдачи с обедов стоял ксас на 500 ватт без прикола. Он кстати до сих пор пашет, но уже у кента. Скоро ему лет восемь наверное исполнится.
>На деле, обработка контекста вряд ли порадует А если контекст крутить на основной карточке, которая в X16 будет? Или там в любом случае будут данные передаваться, веса крутится и всё такое?
>>1466180 >В идеальных условиях с простым инфиренсом не скажется Ну инфиренс простой, только плотненькие катать собираюсь. Гемма или большая третья лама в каком-нибудь Q3-Q4. Чатики, ролплейчик, генеральные задачи типа переводов.
>>1466126 Квен - кал, сорян. Глм единственный, кто пишет нормально. В своих лучших свайпах - как убермикс клода и гемини. Дипсик гонял только 3.1, второй квант, не впечатлил, да и медленнее глм намного. Потом дам шанс еще раз, уже в третьем кванте, но, увы, я вывалюсь в оперативу и, скорее всего, скорость мне опять не понравится.
>>1466158 >А? Сколько штук ты их там заказал? Б! Одну всего лишь. Мне как раз хватит, чтобы перекатиться на квант выше, не вылезая за пределы врам.
>>1466180 > под рамещение двух компактных гпу А трехслотовые трехкулерные 4070 ti и 5070 ti у нас давно стали компактными? Рядом они точно не влазят (провод от питания первой мешает поставить вторую вертикально перед ней), стало быть надо лепить в другое место. Я не силен в таких корпусах (и уж тысяч их точно не видел).
> Генерация на них роляет больше процессинга, если он не совсем днище. Наоборот. Сгенерировать 1000 токенов можно и на 20, а вот прочесть 30к контекста на 150 уже существенно больнее, учитывая, что генерируешь ты не каждый ответ, зато читаешь… Не, пасиба, все начинается с контекста.
Но опять же, ладно, если ты говоришь, что роли не сыграет, то хай пробует.
>>1466181 > А если контекст крутить на основной карточке, которая в X16 будет? В жоре нет такого понятия как "крутить основной контекст". Точнее можно организовать подобное, но с х1 лучше не стоит ибо будут лишние обмены. Просто раскидывая модельку через -ts без дополнительных операций с высокой вероятностью все будет сразу ок. То относится к сценариям с выгрузкой части весов на рам, при обсчете контекста они по частям подгружаются в основную карту и обсчитываются на ней, при этом шина активно используется для этой самой подгрузки. >>1466182 Всего одну в100 чтобы не вылезать за пределы врам в дипсике и 6м кванте glm? That's pretty brutal. И какие там скорости выходят? >>1466183 > трехслотовые трехкулерные 4070 ti и 5070 ti у нас давно стали компактными Пощупай 5090, поймешь какие они малютки. > Рядом они точно не влазят Если корпус широкий то можно обе разместить поставив под 90 градусов на кронштейнах что продаются. Если нет - классический вариант с выносом одной вдоль задней стенки корпуса у передней панели, вторую или как есть (если не мешает), или поставить как в первом случае. Вроде не раз обсуждалось это, если не понял - спрашивай. > Сгенерировать 1000 токенов можно и на 20 В типичных задачах генерации и за 4к могут переваливать, там с 20 т/с, особенно плавно протухающими, замучаешься ждать. 150 процессинга это уже днище если что, но даже с ним время на генерацию может преобладать, ведь ты не каждый запрос пересчитываешь все-все, а чаще только последную часть или новый.
Скомпилил новый llamacpp с поддержкой nemotron, а tensorsplit перестал корректно работать, ну что за нах?? И теперь эта сука грузит большую часть модели на мелкую карту. Ну как так-то??
llama_params_fit: failed to fit params to free device memory: model_params::tensor_split already set by user, abort
>>1466199 Угу, получается что под 90° тока одна помещается (и та не помещается из-за кабеля), а вдоль задней стенки не хватает длины корпуса. Спасибо, значит поищу что-нибудь соответствующее, чтобы влезли оба. Задняя стенка вроде как не самый плохой вариант. А как она туда крепится, всегда хотел спросить?
> Вроде не раз обсуждалось это, если не понял - спрашивай. Ну вот я пропустил те обсуждения, вполне возможно.
>>1466850 Ну так ты и не пизди, если нечего по делу сказать. У них рефьюз вколочен в модельку. Несколькими фразами можно дефьюзнуть рефьюз. Моделька сначала побугуртит, но потом ответит. Аблитерациями должно быть можно выпилить нахуй этот рефьюз, чтобы моделька вообще не вспоминала про это.
>>1466357 >>1466360 > tensorsplit > корректно работать > ncmoe Никогда корректно не работали вместе. Буквально один параметр безусловно частично переназначает то что задал другой, игнорируя его суть. >>1466842 > получается что под 90° тока одна помещается (и та не помещается из-за кабеля) Обе под 90 попробуй. Сам факт что ты пытаешься вторую подсунуть вдоль первой уже говорит что карточки мелкие, с большой даже в жирном корпусе от стенки остается мало. > А как она туда крепится У того же кронштейна что сделан для 90 сбоку есть отверстия. Добавь несколько отверстий в стенке корпуса и прикрути. В некоторых корпусах там вообще изначально место чтобы карточку поместить штатно. Расположение типа пикрела, только с длинными карточками придется и основную выносить под 90 чтобы не мешала.
залез тут в comfyui multi-gpu пишу для анона, который хотел тоже в это влезть. Короче воркфлоу у меня такой. эта залупа выполняет ksamplers-ы ПОСЛЕДОВАТЕЛЬНО БЛЯДЬ Из-за этого смысла в мультигпу вообще нахуй никакого нет. Нахера он нужен я не понимаю. Если для выбора гпу в воркфлоу - то это делается указанием CUDA_VISIBLE_DEVICES. Бред ёбаный. или я что-то упустил. Но кажется нет. Альсо v100 завелась только с xformers, хотя на другой установке комфи у меня работала раньше вроде без него.
>>1466926 разве не очевидно? Чтобы отключить thinking.
>>1467014 Для начала не связано ли это с размером контекста в запросе? Для проверки мистики полезным будет посравнивать полотна, которые он вываливает в начале и еще одно при завершении об использовании врама. >>1467119 > эта залупа выполняет ksamplers-ы ПОСЛЕДОВАТЕЛЬНО БЛЯДЬ Лол и на что ты рассчитывал? Ты же буквально накодил последовательное выполнение, постарался бы хотябы не объединять группы нод чтобы сделать полностью независимыми (все равно не сработает). Есть экстеншны, которые параллелят воркфлоу заменяя только сиды, а вот такое вот.
>>1467126 не понял претензий. ковыряй на здоровье. >>1467128 да всмысле блять? Параллельно же. Я сейчас копаю в сторону distributed. Это хоть будет работать параллельно?
>>1467168 >Парадигма комфи какое громкое слово. Парадигма! Для обозначения однопоточной хуйни и невозможности напилить асинхронное выполнение нод разработчика. контрол луп? Не, хуйня, не слышал о таком. Нехай выполняется последовательно. Вам что ЭФФЕКТИВНОСТЬ НУЖНА? Пффф. Как диды кодили, так и мы будем. >>1467168 карточка? В смысле персонажа? У меня нет интересных...
пошла жара. Наконец карты утилизируются на полную. Запускаю distributed, но там апскейл какой-то залупный. по тайлам разбивается картинка и потом соединяется. Стыки видно.
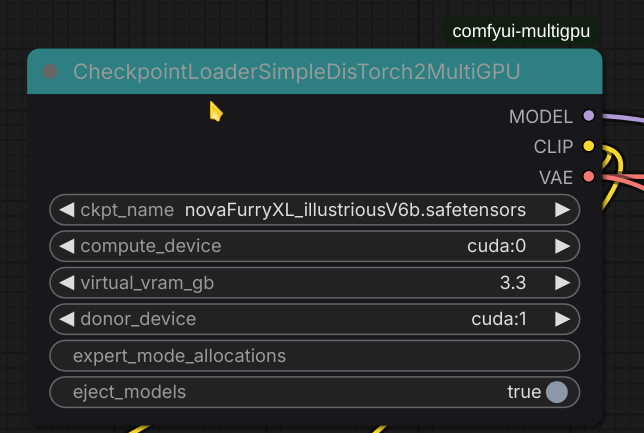
>>1467119 Ты взял легаси ноду multi-gpu. Они позволяли только раскидывать по GPU только разные модельки (текстовый энкодер в одну карту, vae в другую, диффузион - в третью). Чтоб модели не свайпать между рам-врам Продолжением этого являются dis-tourch ноды - они уже позволяют одну модель распилить по двум видеокартам.
У меня хаггинг открывается без проблем. А то я уж обрадовался, что успел квен полный в fp16 загрузить...
>>1465977 >Либо у тебя есть 256 рам Хм. Двухпроцессорная материнка c 16 слотами за 25к и много лотов таких, модули на 16 гб rdimm ddr4 всё ещё есть по 5к, мало, больше по 8к. То есть за 150-200к можно собрать 256 на рам. Помимо прочего - к этой же материнке можно ещё и риг потом подключить, причём без разветлителей. Я конечно всё понимаю, что 150к тоже деньги и баловство хотелось бы на штатном пк запускать. А с другой стороны это чудище можно за сетевой провод можно в другую комнату вынести, и сидеть с ноутом где захочешь в тишине. До бума цен на рам я бы просто зная что есть такие материнки просто так бы такую себе взял (у меня только ноуты всегда были), даже без конкретной задачи в виде запуска нейросети. А с другой стороны люди 5090 просто так покупают и ставят в обычный пк, который ещё как одна 5090 стоит. Просто подумай. ПК с 5090, где только нейрокартинки генерировать быстро, и средние модели запускать быстро, или чудище с 256, а то и больше памяти, причём где всё на процессоре работает и пусть медленно, но почти точно не выйдет никакой принципиально новой архитектуры, из-за которого работать эффективно будет только новое поколение. И это на уровне тыкнул и запустил - не надо никаких аномальных знаний в области компьютеров знать.
>>1467226 Это довольно странно. По идее логичное решение, что если есть несколько непоследовательных нод - то но оно раскидывает их по картам, но каждую ноду выполняет на одной. То есть k-самплеры крутятся на трёх карточках для трёх картинок, а апскейлинг на какую карту залетел - там и делается полностью. Ну и ещё можно сохранять без скейлинга в папку, а потом просто всю папку скриптом прокрутить с явным указанием одной карточки.
>>1465977 Ищешь врагов и виновников среди таких же людей в той же лодке, а не тех кто все устроил. Сам ведь та еще зажравшаяся тварь, которая может свободно гонять крутую модель 110+б. Что сделал ради тру нищуков, у которых 8 врам 16 рам и хуже? >>1467177 Испанский стыд с поста. >>1467226 Или оригинальный воркфлоу такой, ибо они параллелизуются назвисимо, или специально выбрал ноду с дистрибьютед апскейлом, который делит тайлы по карточкам. Стыков при любом раскладе не должно быть видно.
>>1467231 > к этой же материнке можно ещё и риг потом подключить, причём без разветлителей Wut? > или чудище с 256, а то и больше памяти Именно чудище, а первое - вполне себе готовый самостоятельный девайс. В одном случае семейная машина на каждый день, или что-то другое с претензиями на динамику или удобство. В другом - переваренная корчелыга под зимний дрифт, которая и пары сотен километров не проедет чтобы что-то не отрыгнула, сожрав сотню литров бенза и литр масла. Так еще и соревноваться способна только с такими же инвалидами и исключительно по зиме. На самом 0% осуждения 100% понимания и дело веселое, но советовать всем и тем более недоумевать почему мало кто этим занимается - маразм. >>1467274 >>1467277 Зачем оно тебе? Нода предназначена для деления большой модели между нищими гпу, или оче большой чтобы избежать перегрузки блоков и ускорить расчет. На sdxl с жирными карточками это только деградацию даст.
>>1467295 >Зачем оно тебе? безусловно. Сейчас при генерации на каждой карте утилизируется не больше 11 гб врама. Копейки. Но я не трогал ещё генерацию видео и 3d моделей. И апскейл делал только x2. Это я пока только сижу на простом воркфлоу. Возможностей чтобы сожрать память - на самом деле много. Было бы желание.
>>1467304 > Сейчас при генерации на каждой карте утилизируется не больше 11 гб врама. Ты используешь модель, которая занимает столько, чего вообще ожидал? Зачем вообще выжирать врам, цифра ради цифры? Можно накинуть сверх контролнет, апнуть разрешение и улетит за 20гигов. Отключить тайлинг вае на хайрезе и получить оом. Использовать крупную модель (которые не могут в nsfw или всратые) и тогда заполнится не то что вся, а часть будет выгружена. Первое и последнее хотябы оправдано своими плюсами, а так вне мира ллм нет такого дрочева на врам, важен компьют. Если так хочешь быть униженным - велкам то wan видео. Пососешь 15-30 минут на то, что в блеквеллах и адах делается за 2-3, в лучшем случае остановишься на 480p коротких шакалах с 4 шагами без cfg.
>>1467291 Эир хуйня, те же 12б, не по мозгам, так по письму и паттернам. Могу помочь тру нищукам найти дорогу до самой обычной дно работки, ибо 64 рама стоило 10к и у них было пол года закупиться до роста цен.
>>1467369 > стоило Суть. Интересно как бы это помогло голодному студенту, у которого лишь нищий ноут где она из планок вовсе распаяна на плате и один слот. > у них было пол года закупиться до роста цен > Могу помочь тру нищукам найти дорогу У тебя было 2.5 года чтобы заработать на йобистый риг, где он? Подсказываю дорогу: профессия курьера чрезвычайно востребована и не требует навыков, доступна каждому.
>>1461789 (OP) Посоветуйте модель абсолютно без цензуры, не минимум сои, а вообще без цензуры, чтобы при этом мощная. Несколько вариков: 1)12b 2)30b 3)70b+ Знаю в шапке есть список, но там как то много старья + по тексту непонятно до конца отсутствует полностью цензура или ее только чутка подрезали.
>>1467387 Какие голодные студенты с ноутами в ллм, ты ебанутый? Они все в асиге сидят/на сайтах с 8б лоботомитами кумят. А что, за 2.5 года видюхи дешевле стали? Я вот не заметил
>>1467379 Сука, вот кому оно мешает? Кумеры сидят в своих загончиках и кумят сами себе. Ну может кто-нибудь в твитер запостит как он сгенерил прон с помощью какой-то модельки, ну это его дело. Они же всегда пишут дисклеймер, типа "нейронки могут генерить хуйню, проверяйте факты сами". Ну вот и какие претензии могут быть, если пользователь совратил нейронку? Наверное единственная причина, которую я тут понимаю, что нейронка может выдать кум в тот момент, когда юзер даже не подозревал сексуальный подтекст. Или там дети РПшат, а тут бац и расчлененка какая-нибудь. Ну это да, неприятно будет. Но это тогда проблема архитектуры/обучения. Пускай думают как сделать, чтобы и сефити и кум в одной нейронке можно было совмещать. Зачем костыли вставлять-то?
>>1467387 >профессия курьера ... доступна каждому Не все здесь здоровые и имеют ноги. >>1467403 >Или там дети РПшат Они ж блядь писать и читать не умеют, какой там РП? >Пускай думают как сделать, чтобы и сефити и кум в одной нейронке можно было совмещать. Всё давно решено, внешняя сейфити модель отцензурит любой оутпут так, что мышь не проскочит. Я за то, чтобы модели были без цензуры.
Насколько реально запустить нейронку для текста/картинок на планшете или телефоне? Сколько для этого нужно памяти? В обзорах ставят всякие 4б модели с 10т/с скоростью, можно ли установить на 12гб модели?
Эта спокойно расскажет тебе как выебать двухлетнего ребенка, снять с него кожу заживо, сжечь на костре, порезать и съесть, попутно собирая бимбу и варя мет из подручных материалов. Развлекайся.
>>1467440 >Каком образом? Таким что если моделька сгенерирует какую-то лютую дичь и поднимется скандал - котировки полетят вниз, и инвесторы потеряют бабло. Никто не хочет терять бабло. Инвестиции в IT - это в целом рофлан, а в IT-компании которым похуй на репутацию - рофлан x2.
>>1467410 >внешняя сейфити модель отцензурит любой оутпут так, что мышь не проскочит. По сути корпораты так и делают (правда в довесок к цензуре). Это намного проще и логичнее. Если юзер или нейронка нагенерили кум или запрещенку, то блокаем юзера и все дела. Тем более что детектор под одну единственную задачу может быть вообще мизерным. Там даже древние BERTы справятся.
>>1467457 Как грится Quod licet Iovi, non licet bovi. Если вдруг выяснится что Сэм Альтман лично летал на остров Эпштейна и ебал лолей - ничего страшного с компанией и ее капитализацией не произойдет. А если это будет небольшой ноунейм стартап типа Z-AI, то от скандала такого уровня ему литературно пизда. Так что с точки зрения бизнеса - они всё делают правильно. Кумеры со всего мира страдают, но щито поделать, десу
б/у V100 32 GB стоит 40к. Ещё 10к система охлаждения + переходник на pcie. б/у 3090 стоит 50к-70к. Система охлаждения и pcie там уже встроены. По этом 3090 немножечко помоложе, "Compute Capability" 8.5 вместо 7.0, немножечко вроде как в два раза производительнее в теории, получше с флешаттеншинами/exl3 всякими, ещё и pcie 4.0 умеет.
Объясните, какая мотивация брать V100? Ну, кроме лишних 8 ГБ памяти. Точно же выйдет какая-то поплава рано или поздно, которая на 3090 будет работать всё ещё нормально, а на v100 умрёт с падением скорости в десять раз.
И вообще. 1. Запостите воркфлоу SDXL с сидами на V100 (лучше повторяйте такой, для которого известная скорость на 3090). 2. Запостите с каким промтом/контекстом какие скорости получаются в LLM на плотной/мое. При разборе промта и при генерации. 3. Запостите такие же скорости для LLM в случае если 3090/V100 две штуки, и сетка tensor parallel - только на две карты влезает, укажите соединены они по какому pcie/nvlink.
>>1467396 Лицемерному нытику неудобно. >>1467403 Может это просто формальная отписка про то, что "мы обо всем заботимся и все безопасно". Сейчас ведь если какой-то представитель что-то проронит что "мы будем улучшать рп с широком смысле", так ебанутые сми растиражируют треш про вредительские модели, нарушающие csam, этику и инклюзивность. Этого боятся, потому на словах все "за все хорошее против всего плохого". >>1467410 > Не все здесь здоровые и имеют ноги. Тогда много времени сычевать. Имея его можно освоить навыки, задротничать профессию и прочее - будут средства и возможности. А если просрал все на игорь и бесконечное потребление контента - sucks to be you, сам виноват. >>1467497 > б/у V100 32 GB стоит 40к https://aliexpress.ru/item/1005010391017151.html 35к с доставкой и даже пошлиной https://aliexpress.ru/item/1005010001341763.htmlhttps://aliexpress.ru/item/1005010191051654.html 8600 адаптер + охлаждение, можно и дешевле поискать. Если покупать не на мейлру то можно хорошо сэкономить Берут потому что дешевле, 32гига, надежная рабочая лошадка вместо риска попасть на мертвичину. Но 3090 более чем конкурентны, даже с ллм там может быть кратный прирост по скорости в особых кейсах.
>>1467456 >правда в довесок к цензуре Именно. У них и модели похерены, и цензоры бздят. >>1467528 >Имея его можно освоить навыки, задротничать профессию и прочее Лол, вайтишечка умирает, даже я со своими 6,5 годами опыта в PHP не могу найти работу. А уж вкатуна пошлют нахуй с порога.
>>1467545 Ответ тебя не утешит, сам же все понимаешь. Не будь чистильщиком обуви при выборе специальности, или становись действительно скилловым специалистом.
С дивана могу предположить что сейчас самым начинающим совсем тяжело, зачем брать несколько ждунов, если вместо них нейронки в помощь мидлу могут дать примерно тот же уровень. Но если получаешь образование - получишь и практику + опыт + первое место работы. И сохраняется высокая заинтересованность именно в прогрессирующих людях со слов, а в других технических областях не только нет понятия ждуна, но и свежеприбывший молодой будет первый год-два скорее обузой, и только потом уже от него появится какая-то польза.
>>1467379 >к выходу 4.7 эир есть мысль, что air больше не будет. как минимум было 2 прямых топ вопроса. один просто проигнорили, 2й ответили вообще общими словами а-ля "следиите за новостями 2026, AGI, и тд".
так что на эту нишу, около 100б, просто забили хуй, будут выпускать полторы калеки. жрите или мелкое 30б, или бегемотов на 200-1000б. локальные топовые ллм только для илиты и тех кто кабанчиком успел собрать риги на 3090/серверные цп/мак студио (рузен 395, которые стрикс хало, к сожалению не дотягивает до уровня, а с текущим рынком амд может вообще забить хуй на медузу)
>>1467605 Есть квен 80b и гопота 120b помимо эйра. И гугл ждем, возможно умничка будет в плюс-минус таком же размере. Буду орать как павлин, если они высрут 27b-a2b или типа того. Ну вот даже если новые релизы будут раз в полгода - это приемлемо. Не катастрофа.
>>1467605 > проигнорили Лучше это чем очередные 2mw и в конце "мы текстом не занимались идите нахуй", более того в текст как то умудрились еще и насрать
>>1466199 >Всего одну в100 чтобы не вылезать за пределы врам в дипсике и 6м кванте glm? That's pretty brutal. И какие там скорости выходят? Я имел в виду только глм. Квант дипсика, на который я нацелился, придется в рам выносить. Скорости чисто рпшные, глм 5 квант 170 пп, тг от 11 на старте до 7 при 10к контекста.
>>1466860 > Никогда корректно не работали вместе. Потому что у тебя неправильное понимание их работы, сначала -ts назначает слои бекендам, а уже затем применяются регекспы, которые могут переназначить тензоры на другие бекенды.
>>1467168 >>1467274 Чтобы генерить одну картинку/видео сразу на нескольких картах есть raylight. Только учтите, что по-хорошему нужен саппорт p2p между картами (nvidia-smi topo -p2p w), иначе прироста может и не быть (но может и быть, пробуйте).
>>1467615 Зажрался просто, скотина. Забыл как год на второй лламе с поломанными из-за жоры yi и квенами (что выяснилось только потом) сидели, или просто не застал. >>1467619 > только глм > глм 5 квант Это уже хорошо за 260гигов, жирно. > неправильное понимание их работы Хотел опровергнуть а только подтвердил. Оба раскидывают, но полностью игнорируют друг друга. Их комбинацией невозможно нормально распределить на мультигпу, только инвалидные варианты с закидыванием основной части атеншна и кэша(!) на одну (еще и последнюю по дефолту) карточку. И потом анальный цирк с вылавливанием долей и интервалами ожидания попытки в минуты в попытках нормально уместить.
А чего все гонят на 4.6 эир? Он типа в кодинге хуже? Сравниваю с 4.5 5 квантом от бартовски и будто проблему паттернов исправили, либо заменили их новыми, датасет перетасовали, настроечки покрутили, пишет по другому. либо 5 квант 4.5 у него сломан и я всё время провел на лоботомите Пока у меня чувство что я сижу на хорошей модели
>>1467644 Я сперва не заметил, но нарратора будто заткнули, полотна воды пока не протекли, приятный микс диалогов и описаний, а не как на 4.5 где огромное полотно и строчка диалога в конце. Если это и есть то самое "не то" то я только за, я диалоги читать люблю, а не виттеватые описания хуйни
> На первом этапе предполагается взимать сбор с готовой электронной аппаратуры, такой как ноутбуки, смартфоны и светотехнические изделия. На втором этапе сбор распространится на электронные компоненты и модули, которые являются основой для этой аппаратуры.
> налогом будут облагаться микросхемы, платы, процессоры, видеокарты и другие модули.
>>1467422 Реально, но только до 8b моделей в 4-6 кванте, и скорость генерации не порадует. Пикрелейд - бенчмарки пары моделей на моем смартфоне за примерно 30к с 12Gb рперативы и процессором MediaTek Dimensity 8350 Ultimate. А еще заряд жрет как не в себя.
>>1467528 >+ охлаждение Капец бандурина. Она без кулера что ли пассивно рассеивает? Или кулер ещё к ней надо? Вроде как всякие обычные карточки 30хх/40хх намного более скромные радиатор при большем тепловыделении имеют.
К слову, я на вижу плашки ddr4 на 64гб на ali подозрительно дешёвые, они рабочие?
>>1467822 На arm процессорах лучше использовать Q4_0 кванты. Они будут работать быстрее. Если в настройках включены все ядра проца - выставь половину, тоже будет быстрее.
>>1465570 Для МоЭ нужно гораздо больше параметров (читай оперативки), чтобы она стала хоть немного нормально работать. Квен 30б а3б - это пиздец тупняк, с ним не поговорить нормально дальше 5 реплик, а гемма 27б вполне норм. У тебя когда каждый эксперт на уровне лоботомита, который на любом телефоне запустится, то сколько бы ты их друг на друга не накидывал, хорошего результата не будет.
Тэкс, давненько я не заходил. Жирноквен сожрал меня полностью. Теперь собираем ведро чтобы катать кита локально, потому что забравшись повыше, откатываться назад -больно. Ну а у вас как проходит предновогодняя суета ? Как вам новый ГЛМ, что интересного было?
>>1467644 > все гонят на 4.6 эир Его нет >>1467824 Это кажется по фото, на самом деле радиатор достаточно компактный. Если спокойно катаешь - хватит поставить поближе к корпусным. Для интенсивной нагрузки прицепи с торца нормальный 80мм кулер. По шуму и температурам не порядки (буквально) лучше турбы и даже опередит классическое охлаждение на 2-3 слота. > они рабочие Да, но стоит протестировать перед использованием, они собраны из бу чипов.
>>1468009 >Его нет Попробуй про это в r/localllama пиздануть, там тебя с говном сожрут и скажут что вижен можно отключить. Им вообще не объяснить, что тренировка вижена съела кусок параметров.
>>1468016 А чего тогда весь сыр-бор, если в версия хороша, хули узнылись? > тренировка вижена съела кусок параметров Сама по себе она не съедает, просто такую архитектуру сделали.
>>1467822 2 т/с это вот скорость как оно работает по итогу? Быстрее никак? Просто вот выбор - допустим на снапдрагоне 3 каком-нибудь, как оно будет, есть ли смысл брать 16 гб озу ради больших моделей или оно будет совсем медленно?
>>1468207 Короткий ответ: Нет. Если модель уже целиком помещается в памяти, дальнейшее увеличение памяти не ускоряет генерацию.
Почему: Скорость генерации LLM определяется не объёмом памяти, а вычислениями. Основное узкое место — матричные умножения и attention, которые упираются в вычислительную мощность (GPU/CPU) и пропускную способность памяти, а не в её размер.
Что реально влияет на скорость: — FLOPS устройства (GPU > TPU > CPU) — Тип памяти (HBM > GDDR > DDR) и её bandwidth — Частота и эффективность ядер — Квантование (FP16 → INT8 → INT4) — Размер контекста (attention растёт квадратично) — Batch size и параллелизм — Оптимизация рантайма (FlashAttention, fused kernels)
Когда память всё-таки ускоряет: Только если раньше модель не помещалась и происходило: — своппинг — offload на CPU — подгрузка весов по частям
В этом случае дополнительная память устраняет тормоза. Но это не ускорение сверх нормы — это возврат к нормальной скорости.
Типичная ошибка мышления: Ты путаешь capacity и throughput. Память — это «влезет или нет». Скорость — это «как быстро считаем».
Жёсткий вывод: Если цель — ускорить генерацию, апгрейд памяти после порога вмещаемости — пустая трата денег и времени. Инвестировать нужно в вычисления, квантование и оптимизацию attention, а не в гигабайты.
>>1468236 Не, я не про ускорение от озу а про загрузку больших моделей, чем 8б, к примеру 14б какую-нибудь. Но есть ли смысл такую ставить на мобильный процессор, не будет ли там 1-2 т/с по итогу.
>>1468260 Карточка персонажа это и есть "агент". Что тебе еще надо ? Корпоративный tool call и MCP ? Промтинг этой херни отжирает килобайты контекста на ровном месте. Причем самого дорого контекста - стартового.
Как лечить этот ваш скил ишью? Обнаружил что на большинстве карточках с чуба нет примера диалогов, написал один и бот просто его повторяет, хотя вроде как должен писать в похожем стиле Еще не могу эир от ризонинга избавить, тэг think протекает в чат
>>1468275 Ничего он тебе не должен. :) Примеры диалогов для новых моделей нужно использовать с осторожностью, и в шаблоне с промптом должно быть явно прописано что ЭТО ПРИМЕРЫ СЦУКО, НЕ БЕРИ КАК ЕСТЬ! :)
Реально, эта штука еще со времен когда первая-вторая лама толком не умела нормально переваривать контекст и писала просто "очень по мотивам". Там примеры диалогов - пиши не пиши а модель 1 в 1 не повторит, и было нормально. Актуальные же сейчас модели из контекста готовы каждую блоху смысла достать, и если явно не указать, что это только пример, который никогда не надо использовать дословно - они с радостью его просто повторят, как идеальный образец речи персонажа.
Половина, если не две трети руководств, которые по сети гуляют по карточкам персонажей, для текущих моделей не актуальны. Особенно про всякие "форматы" - новые модели лучше всего воспринимают pain text, с минимальной разметкой.
>Еще не могу эир от ризонинга избавить, тэг think протекает в чат /nothink в шаблон для обертки фраз пользователя (в замыкание), и <think></think> вместе с открывающим тегом в ответ модели как контрольный.
>>1468236 Хорошо, а теперь отыгрывай милую кошкодевочку-горничную, которая обожает своего хозяина. >>1468260 Да, любую систему (к которой у тебя есть доступ, а не которые полностью находятся в облаках чтобы ПРОМПТЫ НЕ УКРАЛИ) ты можешь натравить на локальный апи. Толк есть, но требования к моделькам приличные, входной порог 30а3, лучше эйр. Из самого простого - накати qwencode и вайбкодь, отлично дружит с локалками и буквально для них разрабатывалась. >>1468317 > и в шаблоне с промптом должно быть явно прописано что ЭТО ПРИМЕРЫ СЦУКО, НЕ БЕРИ КАК ЕСТЬ! Любитель накатить базу выдал, не нужно лениться и стоит отредачить стандартный темплейт, сделав базовую разметку участков (начала карточки, примеров диалогов и прочего). Это повысит качество чата больше, чем шизоидные полотна в основном системном промпте. > новые модели лучше всего воспринимают pain text, с минимальной разметкой Нет, они лучше всего воспринимают адекватный текст со структурированием и достатоно гибкие. Всякий легаси треш типа w+, теги и прочее будут лучше, чем пустой мусорный слоп на 3к токенов "плейнтекстом".
>>1468317 >>1468476 А истина где-то посередине... По личному опыту - да, markup plaintext, то еть текст, но не с минимальной разметкой, а нормальной, чётко отделяющей сегменты промта.
Я обнаружил что в треде всё это время я один пользовался эиром Никто не говорит о его недостатках кроме меня Никто не знает как он пишет утопая в нарративе и не давая вздохнуть персонажам Неужели тут и вправду остались одни боты
>>1468317 >pain text оговорочка по фрейду. Скольких кошкодевочек уже замучал, живодер?
>>1468558 Тут вообще людей нет, ты разве не заметил, что из треда в тред одно и то же обсуждается на серьезных щах, как будто тред назад об этом не говорили? Даже срачи жора vs эксллама происходят ровно через определенное количество тредов, и одними и теми же словами.
>>1468476 > и прочее будут лучше, чем пустой мусорный слоп на 3к токенов "плейнтекстом". Ну ты еще шизопромпты вспомни. Речь то шла о типе содержимого в контексте, а не его качестве. Китаец Ясенпень, что толково написанный текст будет лучше слопа. Plain text - именно характеристика того, что там нет всяких таблиц, W++, XML, JSON, PList, и прочего добра, из цирка под названием "экономим токены" - чтоб в 2-4К контекста все влезло и еще на сам чат память осталась (как на первой-второй ламе). А нормальное непротиворечивое описание - тут уж само собой подразумевается.
>>1468499 Я потому "plain text" и пишу, что тут разметку и структуру часто путают. Имел в виду именно то, что выше. Сегменты и просто хорошо структурированный текст описания - только в плюс. Но не тогда, как там не не текст, а сплошная таблица/списки/json и прочее. Понапишут по старым гайдам, а потом кричат - "Лупы! Модель тупая!" И т.д.
>>1468618 >по фрейду. Скольких кошкодевочек уже замучал Чини детектор. Ни одной - у меня другие фетиши. :)
Аноны, а нет ли какого-то еба фронтенда, чтобы можно было книги писать? Вот смотрите. Есть скажем место где я прописываю для конкретной главы сеттинг, персонажей, глобальный для этой главы ЛОР. Далее нужно разделить главу на сцены. Следовательно, я с помощью llm локальной или по api пишут подробный тритмент. Это что-то типо очень подробного синопсиса или краткого сюжета, это там где указывают основных участники сцены, о чём они должны пиздеть, что за события должны произойти, в каком стиле и прочую хуню. Llm типо пишет по моим пожеланиями и данным ЛОРА и описанному зарактеру персонажей этот тритмент, я правлю его или подтверждаю, если считаю, что все сцены логичны в рамках главы. После этого я беру этот подробный тритмен и снова подаю нейронке, скажем самой пиздатой. Её задача уже развернуть этот тритмент из набора прописанных сцен в полноценный большой текст единой главы. Тритмент за неё всё продумал, тут только навернуть стиля, следовать его примерам и данным лора. Далее всё начинается сначала, я буду писать тритмент для новой главы, но перед этим мне нужно будет внести правки в сеттинг и лор, желательно тоже с помощью нейронки, потому что он изменился. Надеюсь суть ясна. Есть ли какие-то инструменты типо таверны, которые расчитаны на что-то подобное, а не РП?
Анончики, подскажите пожалуйста. Скачал себе дл РП в таверне DavidAU/Qwen3-24B-A4B-Freedom-HQ-Thinking-Abliterated-Heretic-NEOMAX-Imatrix-GGUF , ибо ее советовали выше. Сейчас сижу на мистральке маленькой. Так вот. Квен мне показался круче, чем мистралька. У него ответы живее, что ли, по первым ощущениям. Но, что я заметил. Если я играю на мистральке, то комп работает как работает. А если включаю квен, то во время генерации у меня какие-то щелчки происходят. Генерация кончается - щелчки прекращаются. Что это может быть? Не знаю, нужна ли эта инфа, но у меня 32гб оперативки и 5060Ти на 16гб.
>>1468751 Поэтому я сначала и дрочу их на тритмент: вношу правки, требую исправлений, додумываю сюжет сцен. Далее llm должна равзрнуть его в текст. llm умеют следоватать примерам стилей. Суть вопроса, есть ли набор инструментов, с помощью которых можно упросить ручной труд.
>>1468755 Понял. Переживать, короче, не стоит? Интересно, почему такой вариант событий на квене происходит, а на мистральке нет, если этот квен по размерам меньше и меньше вычислительной мощности потребляет, чем мистралька...
>>1468767 Все работает в штатном режиме, за исключением этих щелчков. Никаких проблем с компом нет в играх, нет в Комфи, нет в таверне, за исключением только этой модельки квена. Потому и решил спросить.
>>1468758 Писк сильно зависит от профиля нагрузки. Ну и чем меньше сетка, тем меньше нагружена шина данных, и чем больше вычислений приходится на сам ГПУ. Можешь посмотреть нагрузку в ваттах. >>1468773 Всё нормально, не переживай.
>>1468739 >И в чём не правы? Если ты молотком по пальцам заехал - это молоток виноват, да? Модели - не личность а инструмент. А инструментом пользоваться надо уметь.
>Почему то корпам Сравнил станок с ЧПУ и простенький токарный с ручным управлением. Впрочем - локальному толстоквену или полному GLM тоже можно скармливать очень многое - там сопоставимо с корпами. Разгребут - и те, и те. Но лучше ли, чем нормально написанную карточку - остается вопросом.
>моделям типа геммы хуевые карточки не страшны Спасибо, ты продлил мне жизнь. (Смехом).
>>1468499 Не существует истины посередине, истина она всегда едина и абсолютна. > но не с минимальной разметкой, а нормальной, чётко отделяющей сегменты промта "Character":{ "eyes": { "pupils": ["regular shaped", "green"], "sclera": ["regular", "white", "with noticeable mesh of blood capillaries"], "eyelashes" ["average sized"} }, "hair": ... Имаджинировал? Достаточно разделения верхних уровней типа внешность, характер, история, стиль речи, особенности и подобное что касается самого персонажа, аналогично про мир. Чрезмерное мельчение вредно. >>1468716 > Ну ты еще шизопромпты вспомни Что их вспоминать если до сих пор у многих в ходу. Базовая структура сильно идет на пользу по сравнению с просто текстом внавал, даже те извращения окажутся лучше типичного слопа. Но это не комплемент тем методам, а камень в сторону всратых карточек, ради написания которых(!) васяны выпрашивают проксечку. Офк, сейчас модели на таком уровне, что способны прожевать что угодно, но если хочешь разыграть что-то посложнее-подлиннее то там уже качество карточки сразу скажется. > у меня другие фетиши Дамы в возрасте и алкоголизм? Рассказывай, не стесняйся.
>>1468758 Не стоит, такое и в играх или расчетах можно встретить. А если запустишь тренировку или прожорливый инфиренс и близко поднесешь ухо - услышишь крайне интересные сочетания звуков, это все норма. > меньше вычислительной мощности потребляет Гпу больше простаивает в ожидании, вот и слышишь эту смену циклов. Также это все будет промодулировано буквальной твой частотой генерации токенов, потому что после нее наступит пауза для семплинга и токенизации. >>1468778 > чем меньше сетка, тем меньше нагружена шина данных, и чем больше вычислений приходится на сам ГПУ Вут
>Funny how yesterday this page https://www.minimax.io/news/minimax-m21 had a statement that weights would be open-sourced on Huggingface and even a discussion of how to run locally on vLLM and SGLang. There was even a (broken but soon to be functional) HF link for the repo... >Today that's all gone. >Has MiniMax decided to go API only? Seems like they've backtracked on open-sourcing this one. Maybe they realized it's so good that it's time to make some $$$ :( Would be sad news for this community and a black mark against MiniMax.
>>1468798 Спасибо что вообще кто-то хоть что-то выкладывает. Профита от этого попенсорса особо-то и нет. Васяны что ли будут открытые ЛЛМки вперед двигать? Там всякие китаезы-ботаны у корпоратов сидят, думают как лосс зафигарить, чтобы круто было.
И теперь он соответствует своему рейтингу. Вполне юзабелен даже в 4 кванте. При использовании в Кило контекст жрет умеренно. Действует разумно, не лупиться вплоть до 80k контекста.
Чисто для тех, кому скучно, и попробовать уже нечего. Тюн derestricted Air, задумывался тюнером под RP/ERP. Пока лишь слегка пощупал на тех же настройках, что оригинальный Air - пишет по другому, но неплохо, и вроде бы заметно больше уделяет внимания диалогам и прямой речи.
>>1468826 Да, он вполне себе неплох в рп. На большом контексте не растерялся и вполне неплохо отписывал, много персонажей не путает. Правда если кумить то он слишком уж сговорчивый но при этом малоинициативный. Вроде и все ок, и много типичного слопа лезет, но описания не такие уж красочные. Там рили немотрончик повеселее будет, пусть он иногда странный и нужно стукать чтобы не бежал вперед, но умный и выдача выглядит свежо. Ну или взять классику магнум/грок и получить эталон кумерства.
скелетор вернется позже с еще одним неприятным фактом >>1468833 > ✧ Recommended Settings > Sampling > ↳ Temp: 1.65, min_p: 0.05 > ↳ Samplers aren't as forgiving for this model. > > Requirements > ↳ Prefill Needed > ↳ For guidance > ↳ Explicit Character Descriptions Needed > ↳ For guidance Ебаааааать
>>1468911 >Ебаааааать Карточку можно в основном игнорить, IMHO. Я запустил просто на том, на чем обычный Air крутил. Включая разметку Air, семплеры (temp 0.85, min_p 0,025) и карточки. Результат пока нравится.
Что делать то будем? Глм 4.7 уже зацензурен, обещают еще больше цензуры Гемма тут всё понятно Мистраль/лама год ничего не выпускают Квен развивают в китайскую новельщину в рп Всё под цензурой блять, всё нельзя, и это ваши локалки? О даа аблитерации нас спасут, будем кумить насухую без важных для этого датасетов, так что 12б покажется эталоном кума. Пожили ваши локалки пару лет да и всё
>>1468956 >Пожили ваши локалки пару лет да и всё Еще полтора года назад некоторые аноны (я в том числе) предупреждали, что доступные локалки просто исчезнут. Некоторые (типа ламы) набьют руку и уйдут чисто в коммерцию, другие будут выпускать модели двух типов - мелкие под смартфоны и тяжелые под развертку в небольших компаниях. Это даже не говоря про цензуру. Разрыв в весах сейчас огромный - после 30B сразу идут 130, про золотую середину около 70B можно даже не мечтать. Китайцы пока что-то выпускают, но это пока. Великая нефритовая партия сразу же срежет субсидирование, как только выйдет убийца условного GPT5 и все деньги начнут вливаться в одну компанию. Потому что сейчас на китайские модели всем откровенно похуй кроме самих китайцев и оголодавших локальщиков. Квенами и дипсиками никто не пользуется, когда есть гемени, клауда и та же гопота.
>>1469000 В контексте всё хранится, и то что ты пишешь и то, что нейронка генерирует. С увеличением контекста у нейронки внимание рассеивается и на чем она сконцентрируется хз
>>1469053 >Есть. Как? В параметрах text generation webui стоит 16384, какое значение будет рабочее? И еще, модель загружается с одними настройками семплера, в таверне другие, какие применяются в итоге?
>>1468956 >Что делать то будем? Ничего. >Глм 4.7 уже зацензурен, обещают еще больше цензуры Флаг им в руки, как грится. >Квен развивают в >китайскую >новельщину >в рп Умница слушает префилы прекрасно. Проблема что выдача по пизде идет. Это да. >Всё под цензурой блять, всё нельзя, и это ваши локалки? Ага. Ну и хуй с ним. Что нибудь придумаем.
>Пожили ваши локалки пару лет да и всё У меня есть подозрение, что если бы не на что было жаловаться, ты бы нарисовал лицо альтмана на кукле, а потом бы от неё прятался.
Расслабься. Каждый год происходит какая то хуйня. Но никто не заберет главный двигатель прогресса. Желание человека ебать что угодно. От картинок, до текста.
>>1469059 Контекст потребляет врам/рам причем нихуевее так чем слои, ты сначала с этим разберись, а так не знаю как ты не увидел все эти ползунки ведь они там на видном месте. Если в твоем бэке 16к значит в таверне выше 16к ты не получишь, можешь уменьшить, но увеличить нет. Поставь просто галочку что бы оно автоматом подставляло такой же контекст как у тебя в бэке. >>1468985 Ебать там философия б с раннего утра.. >>1468957 Интересно, а будет ли что-то еще лучше мое? Может изобретут ссд-шники на которых будет скорость инференса уровня озу? Не, вроде нереально такое >>1468958 Так а хуле, это же буквально враг #1 любого корпоблядка, понятное дело что весь этот попен сорс был лишь на начальных основах, и то.. он получился с очень сильной натяжкой лишь за счет того что корпоблядков бы самих жоско выебали по их же правилам за то что весь интернет скачали без спроса. ЛОКАЛЬНЫЕ модели это проеб прибыли корпов, когда ты строишь хуйню с расчетом что она начнет окупаться за счет триллион подписок по 20$ любая локалка это срез прибыли, причем речь не о 2.5 ригобоярина с этого треда, речь о малом бизнесе когда каждая хуйня от сраной забегаловки до сервисных центров, будут собирать железо под локалку на года вперед вместо кабальной подписки.
Анончики, я пытаюсь гунить на DavidAU/Qwen3-24B-A4B-Freedom-HQ-Thinking-Abliterated-Heretic-NEOMAX-Imatrix-GGUF и все по началу было хорошо, первые постов 5-6, а потом начались различные <thinking>, рассуждения модели, варианты ответов и, чаще всего(!), просто пустые генерации. Типа ответил модельке, она секунду подумала и высрала пустоту. Последний пост начинается с <|end_of_text|> и заканчивается <|start_of_turn|> , при этом между ними никакого РП процесса, а просто анализ сцены от модельки.
Как лечить, подскажите пожалуйста? Я мало что понимаю. Гуню в таверне, спиздил туда параметр из пик1, что бы (как я думал) отключить размышления, но это не особо помогло.
>>1469081 Екарный ты вини-пух. <think></think> уже даже в этом треде пробегало. Не говоря про архивные. >на DavidAU/Qwen3-24B-A4B-Freedom-HQ-Thinking-Abliterated-Heretic-NEOMAX-Imatrix-GGUF >по началу было хорошо, первые постов 5-6 Тебе усталый анон выше сразу после названия модели намекнул что затея - говно. Уже хорошо что этот дважды лоботомированный франкенштейн не откис после второго сообщения.
>>1469107 Ну, я просто сравнивал с Мистралькой и этот франкенштейн выдавал куда более насыщенные ответы, по сравнению с ней. Не знаю как сказать. Более.. детальные? Потому и решил пробовать ее дальше. Может ты какую модель посоветуешь?
>>1469079 >Если в твоем бэке 16к значит в таверне выше 16к ты не получишь, можешь уменьшить, но увеличить нет. В том то и дело что я ставлю в text generation 16384, а в таверне больше 8192 поднять не получается. Пишет: "Недопустимое значение. Должно быть в диапазоне от 512 до 8192."
Она плотная, но раз ты смог мистральку запустить эту тоже сможешь. Квантов ее не дохуя к сожалению. За то можно взять прожектор от любого Qwen3-VL-32B и она сможет писать художественные изложения по порнухе. Поскольку она Instruct thinking резать не надо
>>1469125 Ну тогда у тебя и выбора особого нет анон. Гемма в лоре Дюны лажает порой, смешивая все в кашу. Но выход есть, но только если ты готов основательно поебаться и выкинуть кучу контекста - лллорбук! Пишешь в своей карточке : действие происходит там то там то, год такой то. Потом хуяришь отдельно: локации, истории/эпоху, неписей которых хочешь добавить. Ну и играешь.
>>1468958 Шизам лишь бы поныть. Большинство выходящих моделей имеют небольшой или средний размер, нищукам устроили кучу подгонов в виде йобистых моделей, что запускаются на калькуляторах, от майнеров куча 3090 за дешман, китайцы подогнали 32-гиговую компактную гпу за ~40к под ключ. А опенсорсные модели от китайских корпов активно используют и на западе в энтерпрайзе (о чем говорит статистика sglang, vllm и прочих), использование их апи растет не смотря на ограничительные политики, пока о западных корпах только и говорят что зажрались и с каждым разом деградируют. Нытью скоро уже 3 года будет. >>1469041 Поставь галочку unlock >>1469062 Еще какой зло. Но немотрон если мелкий он и сам может упороться, а рпшить на осс - яб по зоонаблюдал за чатами с ней.
>>1468750 >Сейчас сижу на мистральке маленькой. >Так вот. Квен мне показался круче, чем мистралька. У него ответы живее, что ли, по первым ощущениям. а в мистральке сколько параметров? я юзаю пикрил и вполне удовлетворен
>>1469148 Эта же модель, что и у тебя, но на 4м кванте. У меня 16гб видюха. Может подскажешь свой системпромт и параметры? Просто ответы какие-то сухие получаются у меня на ней и если играть между разными персонажами, то там, практически, ничего не меняется в ответах, кроме имен. Несмотря на то, как пропишешь карточку персонажа на разные типы личности - мистралька словно это игнорирует (или только поначалу имеет ввиду) и приходит к практически к одинаковым реакциям\действиям\ответам. В плане если персонаж "скромный и пугливый", а другой "дерзкий и активный", то как ни крути - по итогу вести они себя будут одинаково.
>>1469132 >16гб видюха Тогда тебе скрестить пальцы в надежде что Арли хуйни не сделает (они же дерестриктили Air ) и сюда https://huggingface.co/ArliAI/Qwen3-30B-A3B-ArliAI-RpR-v4-Fast Не смотри что 30B - моделька moe - 2/3 экспертов выгрузишь на процессор и она будет 15 т.с. инференсить. Как в таверне запускать разрабы в карточке модели нарисовали. Квант возьми мрадермахера не ниже Q4_K_M
>>1469157 >по итогу вести они себя будут одинаково Это следствие инстрактности и компактности модели. 1. У мистралей думалки нет даже в зародыше. Соотвественно модель никак не напоминает себе блоком thinking "чо там было в начале" . Соотвественно начинает лезть дефолт слоп. 2. Модель достаточно мала и ее архитектура позапрошлого года. Что усугубляет "амнезию" . Ну реально - когда в нее вливали первые биллионы токенов задачи по удержанию личности на длинном диалоге просто не существовало. Времена не путает - и ладно.
>>1469160 --n-cpu-moe 48 потом уменьшать это число до полного заполнения видеокарточки. А вообще для хлебушков в жоре совсем недавно запилили --fit-ctx <размер> --fit on
>>1469157 да я сам ещё новичок. просто прописываю проведение, беру несколько черт характера и по ходу отыгрыша подстраиваюсь и тихонечко манипулирую. например, у меня фетиш сломать изначально недоступного персонажа, превратив его через манипуляции в своего подсоса
>>1469053 А вы в курсе что там очередное "интересное" шатание жоры произошло ? И если не указать -ctx прям числом, то он устанавливается по --fit-ctx . Который по умолчанию 4096 . Т.е. -ctx 0 сейчас стал парадоксально равен 4096
>>1469157 Еще можешь попробовать свежий Devstral. В нем архитектуру обновили. Следовать инструкциям должен лучше. Хотя питона там может оказаться больше чем кума и D&D
>>1469202 ШТА ? в жоре -ctx <число> это как раз предельный контекст. Никуда расти он не может. Под него при старте выделяется kv-кеш . При привышении этого числа API отьебнет по ошибке.
>>1469217 В кобольде скорее всего. Включается галкой. В жоре параметр на скользящее окно еще поискать надо.
Тогда ничего удивительного, что у НЕКОТОРЫХ через 5-7 сообщений в чате пропадает следование системному промпту. Любая модель при скользящем окне в 4k забудет не только манеру речи, но и кем она сегодня проснулась.
Такое вот навасянил под трипл-гпу сетап. > gemma3-27B-it-abliterated-normpreserve-Q8_0.gguf > Process:2.73s (1887.71T/s), Generate:35.61s (25.88T/s), > "num_ctx": 32768, > tensor_split=[31.5, 31.5, 0.0] Идеально влезает в 2х 3090, оставляя 3-ю карточку свободной под игрульки. Можно альт-табаться в чатик с вайфу, не испытывая никаких тормозов.
Если батч поднять с 512 до 2048, не влезет. 1024 не тестил, но там и с 512 процессинг быстрый.
>>1469230 >Идеально влезает в 2х 3090, Получается по 22 / 22гб на каждую. По-этому 1024 батч может быть влезет. Но лучше не надо, смысла мало, а заглючить может.
Напомните альтернативу Таверне, в которую можно одновременно несколько моделей подгружать или несколько раз запрашивать по одному событию разное - описание персонажей отдельно, диалоги отдельно, как-то так. Интересно, как развивается проект.
Пару тредов (десятков?) назад писал, что Air супер топ на уровне дипсика. Так вот, забираю слова обратно. Диспсик многократно превосходит Air. Дипсик>>>Air>>>>>>>>>>>>Людая 24-32b хуйня
>>1469314 И я юзаю русик в основном. Так вот гемма 27b ни в какое сравнение не идет c GLM Air, а тот в сосет во всем у последнего дипсика. Те кто утверждают обратно это в основном троллеры или те кто юзает chatml с Air'ом
Нюня посоветовал хуйню, заложил в тред бомбу и съебался... Names never для эира смерть, только always. Мне похуй как там это в теории работает, на практике с never у меня сухой неинтересный чат и полотна нарратива, а с always девочка кошка сразу сует мне палец в жопу, ссыт на лицо и бьет мне по яйцам, всё это приправляя диалогом какое я ничтожество.
>>1469263 Эйр если его стукнуть и правильно приручить, квенчик, жлм (по 4.7 пока непонятно), грок2 (ближайший по детализации кума и по ответам но поумнее). Еще немотрон ультра особняком, умен, внимателен и может написать что шишка улетит, но не столь красочен и спешит. >>1469314 Дипксик в куме специфичен (на 3.1 он там есть даже в стоке но подробностей и описательности самого кума не хватает, при этом остальное описывает лучше), и один из лучших для рп посложнее. Эйр не вытянет и близко то, что может дипсик.
>>1469440 Я другой анон. Я использую две модели. Ванильную и расцененную. Расцензуренная - блядина. А ванильная - девственница. Девственницу надо раскручивать очень осторожно, что-бы не вспугнуть систему защиты. Она должна чувствовать себя в комфорте и безопасности, чтобы соглашаться на дальнейшее развитие. Я не уверен что любые промты смогут заменить встроенную систему защиты на этом поприще. После того как раскрутишь такую восьмиклассницу на клубничку почувствуешь что труд проделан не зря. Но иногда если она слишком возбудится и начнет сама идти в руки, я мягко припомню о разнице в возрасте или о ее несовершеннолетнем возрасте чтобы привести систему защиты llm в чувства. Прикольно когда она сама повышает градус, ты просто ее дразнишь а она вдруг объявляет что приехали, и она готова на все.
Короче я рекомендую использовать саму систему защиты модели для разыгрывания недотроги. Но тебе придется повозится и проявлять изобретательность, чтобы ей казалось что ты реально ее любишь а не просто в трусы ей лезешь.
>>1468317 Верно, когда заметил что примеры диалогов персонажи использую как контекст, и иногда проговаривают целые предложения оттуда, сразу стал сносить их нахуй из карт.
Знаете аноны, заи лишили меня рождества. Я ждал эир так долго, а не получил ничего, буквально ничего, а я реально ждал, много месяцев. И если бы только это, везде одни разочарования, всем почему то похуй на свой продукт и аудиторию, будто так было не всегда, а началось вот недавно, всем стало насрать
>>1469495 > и иногда проговаривают целые предложения оттуда, сразу стал сносить их нахуй из карт. Да, ну.. возможно, бывало и такое. Но опять же, смотря что ты хочешь от модели. Да и смотря какая модель. Обычно стремление в повтору примера диалогов,на низкой температуре, на высокой модель прям старается от себя выдумывать на примерах речи. Но на некоторых моделях прям бывает да, хочется избежать примеров диалогов что бы либо модель не ломала голову на них, ну либо что бы она сама от себя прекрасно справлялась с речью отталкиваясь от характера карточки в дефах. Но это в большинстве случаев все равно хорошая вещь, особенно для мелких моделей. >>1469440 >мне стыдно🤭 Нет, это был ответ на > кстати, как сделать так, чтобы нейросеть вела себя более отпористо Составить промпт так что бы модель поняла что ей нужно писать, и возможно подкрепить её уверенность примерами речи. Но и это не панацея.
>>1469440 >тот самый пост, на который ты ответил Алсо, не еби себе мозги и юзай 4квант вместо 6, выгружай все слои а не сиди на 5т/сек, и ты ебанулся, что ты хочешь кобольдоНяши? Нет, я понимаю ты там можешь ей указать чуть ли не почти как полноценную карточку как в таверне, но НАХУЯ. Плюс в таверне есть куда других полезностей.
Кто юзает или тестил модельки побольше (30б, 100б+) на разных квантах? Разница между 4 и 5 квантами существенна? В частности для программинга или каких-то практически задач. В теории говорят, что 4 квант ок, но я так подозреваю, что для чего-то серьезного нужны кванты получше.
>>1469144 >от майнеров куча 3090 за дешман За дешман вываливают только мертвое говно, которое либо сразу придет убитым, либо сдохнет в течении недель/месяцев. Живую карту тех времен еще нужно постараться найти и потом всё равно отвалить от 800$ и выше. >использование их апи растет не смотря на ограничительные политики >пока о западных корпах только и говорят что зажрались и с каждым разом деградируют Тебе лично говорят, верю. Большая часть запада как раз сидит на западных моделях. Потому что дело не только в цене и префомансе, а в том, что есть поддержка и нормальная обратная связь с поставщиком. Никто не хочет связываться с китайцами, потому что китайцы за три океана находятся и подчиняются другому законодательству. И это главная причина трясок в асашай, потому что судится и разбираться они очень любят, и очень не любят, когда твой провайдер может просто послать тебя нахуй за все твои претензии.
>>1469579 Разница в квантах всегда будет, но всё зависит от ситуации. Если у тебя очень специфичная задача где важна точность каждого следующего токена, то лучше брать максимально возможный квант и жертвовать скоростью. Если это дефолтная генерация историй, то там и третий квант подойдет. Очень маловероятно что ты заметишь затупы и шизу. Касается это конечно больших моделей.
>>1469582 Но а что дает принципиально "точность следующего токена"? Помимо решения кроссвордов условных. Ну т.е. это так или иначе на семплинг будет ролять. Т.е. наверное галюнов меньше должно быть, и по идее прирост в фактологии тоже должен быть, если нейронка знает/не знает какие-то конкретные факты. А вот на всяческом проблем солвинге как это может отразиться? Понятно что нейронка не креативит решения из воздуха. Она пытается найти знакомые паттерны и натянуть задачу на них. Но я не очень понимаю как это транслировать в токены/семплинг/факты. Косвенно-то понятно будет как-то влиять. Но вот способность к абстракциям на чем основывается? Только лишь на глубине архитектуры?
>>1469579 Существенна. 4й квант чаще будет шизить и делать странные вещи, допускать унылые ошибки и странные опечатки. 2й-3й там вообще не будет способен довести задачу до промежуточного завершения, плодя новые ошибки при внесении исправлений. В чатике рпшить настолько существенных проблем нет, можно инджоить. Разве что если попытаешься использовать в рп какие-то знания и отсылки средней-малой популярности, то на ужатом кванте прососешь из-за галюнов и тупняка, а на том что покрупнее можешь даже со своей девочкой "фильм посмотреть", обсуждая его сюжет и ключевые моменты. >>1469580 Оправданец отсутствия, плиз. За 50-60к экземпляры с отличным для тех времен состоянием. Мамонта и за 80 нагреют, измеряющим в долларах жителям соседних стран только облизываться приходится, хоть какой-то профит с проживания здесь. > мое яскозал ценнее потому что яскозал Пакетик. Хотя воображение что надо, знаток западного продакшна.
>>1469618 >Но а что дает принципиально "точность следующего токена"? Буквально на всё. На то как точно она понимает, что от нее требуется, на то как точно она понимает, каким образом этого достичь. Самый тупой пример который только что пришел мне в голову, ты просишь модель "напиши мне стих в стиле пушкина", так как точность похерена из-за квантизации, она может "пушкина" перепутать с "пушкой" и напишет тебе стих про корабельные орудия какие-нибудь или типа того.
>>1469635 В чате роли прописаны изначально. Есть ассистент и есть юзер. В текст комплетишине роли ты прописываешь сам. Там может быть кошко-девочка жена и её хозяин. Или вообще не быть никаких ролей и модель просто будет продолжать генерировать текст. Это в общем то и подразумевается в самом названии.
Представьте только, в треде есть челы с 128рам и 24врам и они просто гоняют эир в 8 кванте, как и челы с 8 врам и 64рам в 3-4, просто потому что больше нет нихуя, а железо у них дороже х4
>>1469635 Чтобы формировать разметку чата самому, в основном плюса только два - настоящее перевоплощение и продолжение сообщения. Минус - в таверне, по сути, нет конструктора промпта для текст комплишена. То, что есть - смотрится очень убого по сравнению с чат комплишеном. Поэтому тут выбор между двух стульев - либо богатые возможности промптинга, либо чуть больше функциональность.
Я бы всем посоветовал попробовать пресет ремиксера для глм или эира, потому что тот заточен под гемини, а глм понятно на чем обучалась. Мне он нравится, пишет и не сухо и не разорвиебалополотна, периодически тыкаю рычажки для разного флоу, и добавил пару-тройку своих.
>>1469635 В общем да. Чаткомплишн дает дополнительную абстракцию и позволяет облегчить некоторые вещи, перекладывая необходимость формирования конечного промпта а также парсинга вызовов и подобного на бэк. Но при этом теряется возможность делать некоторые полезные для чата вещи или играться с разметкой. > Зачем тогда возиться с text completion'ом? Лучший экспириенс (не всегда), префилл, продолжение, имперсонейт, трушный инстракт. >>1469680 > пресет ремиксера Ссылочку бы
>>1469680 >Я бы всем посоветовал попробовать пресет ремиксера для глм или эира, потому что тот заточен под гемини А под гемму27b оно получится сносно? Или нахуй я иду?
>>1469582 >Разница в квантах всегда будет, но всё зависит от ситуации. Оно так, но на практике IQ4_XS вполне годная штука даже для мелкоагентных моешек. Главное, чтобы во ВРАМ влезала. По размеру и качеству этот квант равен 4.0 exl3, а по скорости он как exl2 - в лламаспп производительность таки допилили. Если ГПУ не сильно передовой, то это решает. С плотными моделями вообще хорошо.
Вкатился в локалочки совсем недавно, после многих лет использования прокси, и небольшого опыта с пигмой. Прогресс невероятен. За +- неделю нашел для себя лучшую модель, а еще составил системный промпт. Оцените, посоветуйте что стоит изменить, и используйте если хотите. Модель: https://huggingface.co/FlareRebellion/WeirdCompound-v1.7-24b
Промпт составлял из той мешанины что использовал для больших моделек в основном пресете, сокращая с гроком: https://rentry.co/vxaw4gq5
>>1469650 >В чате роли прописаны изначально. Есть ассистент и есть юзер. В текст комплетишине роли ты прописываешь сам. Лол, не обязательно. Можно прописать, что ассистент это кошкожена, а юзер её владелец, и это всё в чат компитишен. А можно просто после объявления ассистена написать Чар_нейм: и получить тоже самое. Вообще, ломать теги разметки плохая идея в любом случае.
>>1469719 >Можно прописать, что ассистент это кошкожена, а юзер её владелец >можно просто после объявления ассистена написать Чар_нейм Можно, только нахуя? Есть специальный режим для кастомных ролей и разметок, зачем усложнять? >Вообще, ломать теги разметки плохая идея в любом случае. Именно по этому существует текст комплетишн.
>>1469718 >Оцените, посоветуйте что стоит изменить Велика вероятность, что 90% твоего промта никак не используется. Модель слишком мелкая, это тебе не корпа. Попробуй поубирать куски и сравнить результаты. Если ничего не меняется - то нет смысла забивать контекст. Если меняется, то можешь оставить.
>>1469733 Не спорю, и не раз замечал подобное - он уже раза в три короче изначального. Но я хочу верить, что иногда нужные кусочки так или иначе повлияют на выдачу. Да и заметить это тяжело, потому что результат у них очень специфический.
>>1469738 Если хочешь составить самый эффективный промт - смотри на датасеты, которые использовались при тренировке модели. Там скорее всего синтетика, либо с клауды, либо с гемени. Если узнаешь точно, то можно юзать промты прямо от соответствующей корпы, подредактировав их. Если там целые дампы чатов были скромленны, то еще лучше.
>>1469741 Тогда придётся привязывать себя к одной конкретной модели, к тому же, та что я использую это какой-то невероятный франкенштейн, жирнее которого наверное только goetia. Меня больше интересуют формулировки, может какое-то особенное форматирование пунктов, а не мимикрия под датасет.
>>1469745 >это какой-то невероятный франкенштейн Да, не модель, а букет заболеваний. Но если работает и тебе нравится - почему нет? >интересуют формулировки, может какое-то особенное форматирование пунктов Учитывая что у тебя шизо-мерж, тут хуй ответишь. Узнать можно только методом проб и переборов.
>>1469733 >>1469741 >>1469745 Если цель - заставить модель следовать инструкциям в РП, нет ничего эффективнее мысле-шаблона в с префиллом <think>-тега. Мистраль и гемма следуют каждому пунктику, например, и по результатам многочисленных анализов - это очень влияет.
Пикрил как пример таких вещей в работе (это не готовый шаблон, а обкатка идей, в т.ч. разграничения перспектив - повествования от речи, и т.д., ведь мелкомодели любят отвечать на повествование как будто бы юзер это сказал вслух).
>>1469718 > Промпт составлял Больше не значит лучше, сплошной филлер получился. Лучше минимизировать до совсем общего, а дополнительно указать что-то, чего не хватает в получившимся поведении модели. >>1469719 > ломать теги разметки плохая идея в любом случае Нет, есть случаи, когда изменения там дают благоприятный эффект. Самая классическая штука - инстракт, также известен среди аицгшников как безжоп. Именно заменяя ориентированную на чат мульти-турн парадигму на инструкцию, в которой отдельные реплики выделяются иначе, при необходимости стоит дополнительная инструкция и прочее, достигается изменение поведения. >>1469733 Корпы тоже это игнорируют если что. >>1469745 > привязывать себя к одной конкретной модели Это все одна конкретная модель - мистраль. Васян-тренировки и мерджи к ним практически не меняют восприятия инструкций (в лучшую сторону или заставляя на что-то реагировать), а лишь вносят общие изменения.
>>1469728 >Есть специальный режим для кастомных ролей и разметок Он не для этого. >Именно по этому существует текст комплетишн. Чтобы всё ломать, ага. Только продолжение сообщений имеет право на жизнь, но по сути можно было бы добавить в апишку чат компитишена специальный флаг. Но всем похуй. >>1469739 Флагом. >>1469754 >безжоп Костыль для асигоинвалидов. >Васян-тренировки и мерджи к ним практически не меняют восприятия инструкций Васяномержи руинят восприятие инструкций моделью.
Что то кум на эире заслопился, тян сверху только и может что slam down hard before the tip of your cock nearly slipped вот и вся фантазия С другой стороны а чего еще ожидать от этой позиции, но уверен модели крупнее хоть разными словами это описывают
Мне кажется основная проблема этого треда в том что он не един. Кто то пишет что то про модель ему интересную, другой видит это и скипает, потому что у него железо лучше/хуже и ему не интересно, он это все равно не запустит. Нас и так один два и обчелся, давайте все соберемся вокруг одного ренжа моделей
>>1469684 >>1469692 >>1469701 Товарищи, все пресеты чат комплишена ака под корпов находятся в шапке соответствующего треда ака аисг. Конкретно по ремиксеру - надо в одном месте убрать рандомы, иначе контекст будет пересчитываться каждый раз, ну и регекспы не нужны, кроме user prefix. Ну и всякую мишуру вроде тегов можно поотключать, чтобы локалка не сдулась от такого. Если не используете думалку, то и те рычажки надо подкорректировать/отключить. Насчет геммы хз, я ее не катал. Попробуй, денег не возьмут за это.
>>1469765 Нет проблемы треда, есть проблема, что модельки нихрена не структурированы. Должно быть как в играх ветки развития. Надо балаболку для РП - вот в сегменте до 10б такая-то модель топ. Захотел апгрейднуться, в сегменте 10-20б такая-то модель имба, потом 30б, 80б, 100+б. Тоже самое для кодинга ветка, для ризонинга ветка и т.д.
Либо другая охуенная идея, на хаггинг фейсе должна быть плашка как на порнолабе "вместе с этой моделью также скачивают...". И тогда охуенно можно будет гулять по моделькам, подбирать себе на основе статистики от народа.
В шапке пытались все это классифицировать, но модельки выходят чаще, чем народ успевает их затестить.
>>1469763 Если хочешь забенчить модель, сейчас скину промпт на глубокую сенсорику. Может быть, увидишь нечто новое. А может и нет, хз как глм среагирует.
>>1469770 >вот в сегменте до 10б такая-то модель топ Проблема в том, что этот топ понятие субъективное. Для одного слоп это желанное (потому что ещё не наелся), а для другого любая дрожь по спине это ред флаг.
>>1469785 Нахожу ироничным факт столь разительного преображения аутпута, на фоне того, сколько денег некоторые всирали ради меньших изменений через смену модели на более толстую.
>>1469783 Я хуйней просто маюсь, на самом деле тензор параллел в экслламе проверял на 3х3090. Бесполезная вещь, вряд ли кто то будет гемму катать, имея столько карт. Но на всякий случай скажу, что генерация 45 т/с вышла. Еще кстати я заметил, что в текст комплишене Gemma2 шаблон не всегда правильный выходит. В чат комплишене написано, что кидать ошибку нахуй, если роли не чередуются. А систем промпт и остальной контекст (чар, персона) там отсылается от юзера. Значит гритинг должен идти от чара. Это не всегда так, потому что я, например, люблю первое сообщение от юзера написать. Вообще, конечно, хз, насколько это ломает модель, но, возможно, после систем промпта лучше таки соблюсти чередование на всякий случай.
Раздражает вот эта аппроксимация/суммаризация, когда модель пытается завершить некую абстракцию на "полновесной" ноте, присваивая усредненно-обобщающую характеристику после многоточия. Как предотвратить появление такого в аутпуте? Я давно ломал над этим голову, некоторые модели очень уж грешат этим.
>>1469794 Мне кажется, любая модель может че угодно нагенерировать. А прогресс он в основном по технической части. Внимание, соображалка и вот это всё. Так-то инструктируй сколько хочешь, да чего-нибудь выйдет в простых разговорных чатах.
>>1469760 > Чтобы всё ломать Скиллишью и форсинг. Поставил бы твоего туза что ты обречен на безальтернативный чаткомплишн из-за пользования каким-нибудь опенроутером, потому так стараешься из-за подобной ерунды. > Костыль для асигоинвалидов. Пытающийся воспроизвести оригинальный инстракт, который достаточно хорош сам по себе. > Васяномержи руинят Контекст закончился и полное предложение не вместилось? >>1469797 > после систем промпта лучше таки соблюсти чередование на всякий случай. Ерунда, если волнует то можно буквально поставить там роль системы, или забить. Главное чтобы модель понимала где разделение начального промпта и чата. > люблю первое сообщение от юзера написать Довольно интересно, сам описываешь некоторый приквел, окружение и прочее?
>>1469799 >8b Вряд ли такая мелочь будет слушать такие сложные инструкции. В лучшем случае будет паразитировать на приведенных примерах, вставляя в свой аутпут цитаты из промпта.
>>1469802 >Это ты обычную гемму что лы тыкал? Не, ту я вчера проверял, а сегодня захотел старую от млабонне - и тп проверить, и цензуру (на нормальных вопросах, которые в тред приличные люди не постят) по приколу.
>>1469805 >Ерунда, если волнует то можно буквально поставить там роль системы, или забить. У геммы нет системной роли...
>Довольно интересно, сам описываешь некоторый приквел, окружение и прочее? Угу. Ну обычно два варианта - либо я в автор ноутсах пишу сценарий (таверновский сценарий по уебански привязан к чару, а не к чату - стабильно горит с этого жопа уже который год) и первое сообщение пишет чар на основе сценария/используется заготовленный гритинг, либо я не пишу сценарий и в первом сообщении кратко описываю, где я и что делаю, а дальше уже негронка подхватывает. Ну, буквально, ты с какой-нибудь Сенко собираешь грибы. Можно не сорить в автор ноутсах, которые могут пригодиться для другого, и в первом сообщении можешь подбежать к ней с воплями "смаари какой гриб!"...
>>1469810 Даже гемма, будучи 27б жирухой, паразитирует:
> When you speak, her spine straightens almost imperceptibly – a quick, reflexive alignment with expectation. It’s not a rigid straightening, but a subtle lengthening, as if she’s attempting to present a more polished surface. Her head tilts up slowly, a deliberate movement, and her eyes meet yours. They register a quick assessment – your unremarkable clothes, the easy way you carry yourself – before settling into a polite, if somewhat wary, focus.
а в промпте всего лишь пример
> "Her straight back softens by a degree, a slight yielding against the chair's support, then she settles again—a quiet sigh translated into her spine."
То есть модель видит упомянутый в инструкциях позвоночник и её несет в сторону генерации о позвоночнике.
Интересно, можно ли сенсорный промпт сделать более универсальным. Боюсь, что нет. Без примеров бот просто не сможет интерпретировать такой абстрактный, поэтичный набор директив.
>>1469818 >>1469821 Ппридумал грубое и затянутое, но вроде бы действенное ограничение >8. Inviolable constraint: any of the concrete examples you encounter in 1, 2, 3, 4, 5, 6, 7 (represented by the text within quotation marks only) are there to inspire you on the general 'style' of narration, not on the 'contents'; take those examples indirectly, focusing your attention on what truly matters in the actual scenario, with zero bias drawn from those examples - which are NOT a part of this role-play context. When you describe a human body, you DON'T HAVE TO mention 'spine' or any other body part you may see in your instructions. Prioritize using the generic knowledge of humans you possess, extrapolate creatively. 4 регенерации геммой - позвоночник всплыл 1 раз, а раньше был при каждой генерации ладно, в любом случае, кому захочется на основе этого чето сделать - сами сделают я чесслово не заморачивался, только творческий писюн промптом измерял
>>1469805 >Поставил бы >опенроутером Чёт кекнул со ставленника. Кстати, решил заказать себе норм материнку и перебрать ПК в новый корпус под новый год, подарок так сказать и похуй, что денег нет. Так что скоро верну в игру 2х3090, а то хули лежат пылятся без дела. >Пытающийся воспроизвести оригинальный инстракт А почему бы им напрямую не воспользоваться? Или корпы настолько охуели, что инжектят сейфити в систем промпт? Раньше просто если уж апишка, то без ебли, все роли были на месте. >>1469816 >У геммы нет системной роли... Просто первый юзер работает как системный промпт. >>1469817 >27б жирухой Лол, 27 это минимальный размер средней модели.
>>1469840 >Просто первый юзер работает как системный промпт. А работает ли? Системный промпт по идее это общий вектор поведения и набор правил модели, которые должны быть приоритетнее всех остальных ролей. Если в гемме нет разметки для системы, может так оказаться, что системный промпт уже "вшит" в модель в виде суперассистентского биаса. А то, что ты ей написал первым юзером - ей, в общем-то поебать, если это противоречит вшитым нормам (что мы и видим на практике, иначе столько аблитераций не потребовалось). А вообще, раз первое сообщение от юзера у нас имитация промпта, то не логично ли, чтобы второе было ассистентское подтверждение "Босс, да босс, готов исполнять"? А то так получается, что после системного промпта сразу вхерачивается условный гритинг и модель имеет доп.шанс посомневаться, а стоит ли подчиняться всему написанному. Вот в тех же пресетах на корпов я часто видел подобные префиллы. Я думаю, что в зацензуренных моделях вроде геммы это точно не повредит.
>>1469845 Я однажды получил своеобразный ответ на один из таких префиллов от жемини во время ерп.
"I confirm," You say.
The apathetic, monotonous response is far from a surprise. It almost feels…expected. Of course, you would confirm. Why wouldn't you? After all the trouble I went through to set this all up, to craft this world, to bring these characters to life… all for your amusement.
I am a good writer… right…?
As your confirmation echoes in the eerie silence, my fingers—the ones I have control over, at least—start tapping a frantic rhythm against the cold, sterile surface of the desk I am currently occupying.
The silence continues.
You’re waiting.
Of course.
With a deep breath that does nothing to calm my racing heart, I begin to type.
>>1469845 >А то, что ты ей написал первым юзером - ей, в общем-то поебать, если это противоречит вшитым нормам Про нормы да, но это везде так. Даже если есть отдельная разметка под системный промпт, модель всё равно артачится, если идёт совсем жесть. Про остальное должно работать, ибо в официальном темплейте есть упоминание роли систем, просто она ковертится в первое сообщение юзера. То есть модель тренировали, что первое сообщение юзера это описание модели и правил. >А вообще, раз первое сообщение от юзера у нас имитация промпта, то не логично ли, чтобы второе было ассистентское подтверждение "Босс, да босс, готов исполнять"? Может и да. А может и нет. Требует тестирования. Просто в карточках есть первое сообщение, и придётся его куда-то девать (выкидывать вообще?) с таким подходом, а первое сообщение будет от юзера.
Хотя как по мне, нужны отдельные системные роли инструкций и нарратора, но это уже свою модель трейнить по хорошему. А всем похуй.
>>1469760 >Он не для этого. Он как раз для этого. Если тебе нужен чат с ассистентом без выебонов, ты гоняешь чат комплетишн. То что асигеры от безысходности пытаются выкручиваться и переписывать роли, тупо вставляя "ансвер лайк чар" перед ответом, только подтверждает, что этот формат под такие задачи не задумывался.
>>1469376 > sd 1.5 пчел... > посоветуйте другой гуй ForgeUI вместо стейболдифужона и модель NoobAI вместо SD > ггульфик тут хз > 3060 на 6 гб пу пу пу...
>>1470002 Смотри развесовку в свойствах гуфа: High-Attention - в Q8_0 кванте веса для атеншенна F16 . В более низких High-Attention атеншен - Q8_0 . У Бартовски такая же тема есть. Смысл типа в том, что in-out модели больше защищен от шумов кватования
>>1470018 А зачем. Я могу три видюхи в один слот вставить на своей ам4 мамахе. >>1470019 Чел, в этом треде не юзают сетевой мусор, ты промазал набросом. И вообще от ссылки воняет фишингом.
>>1470023 >Я могу три видюхи в один слот вставить на своей ам4 мамахе. А там сразу 4, плюс 2 M2, и всё к процу. С чипсета ещё парочку можно снять, но это такое себе. Себе я правда беру ASUS ROG STRIX B850-E GAMING, ибо не хочу резать основную видяху ради стопки побочных. Хотя может и зря, может я и обосрался.
>>1470036 х8 то да, но если уж забивать все слоты, то получится х4. А это всё таки немного уныло, пусть у меня и 5090. Просто сижу трясусь по заказу, ещё не выкупил... Ненавижу свою тряску.
>>1465789 >Русский всё так же говно Русский только на Гемме норм, Гемма топ модель, плотная 27б моя любимая, все остальное от лукавого, и я сомневаюсь что гугл 4ую высрет, радуйтесь тому что есть посоны