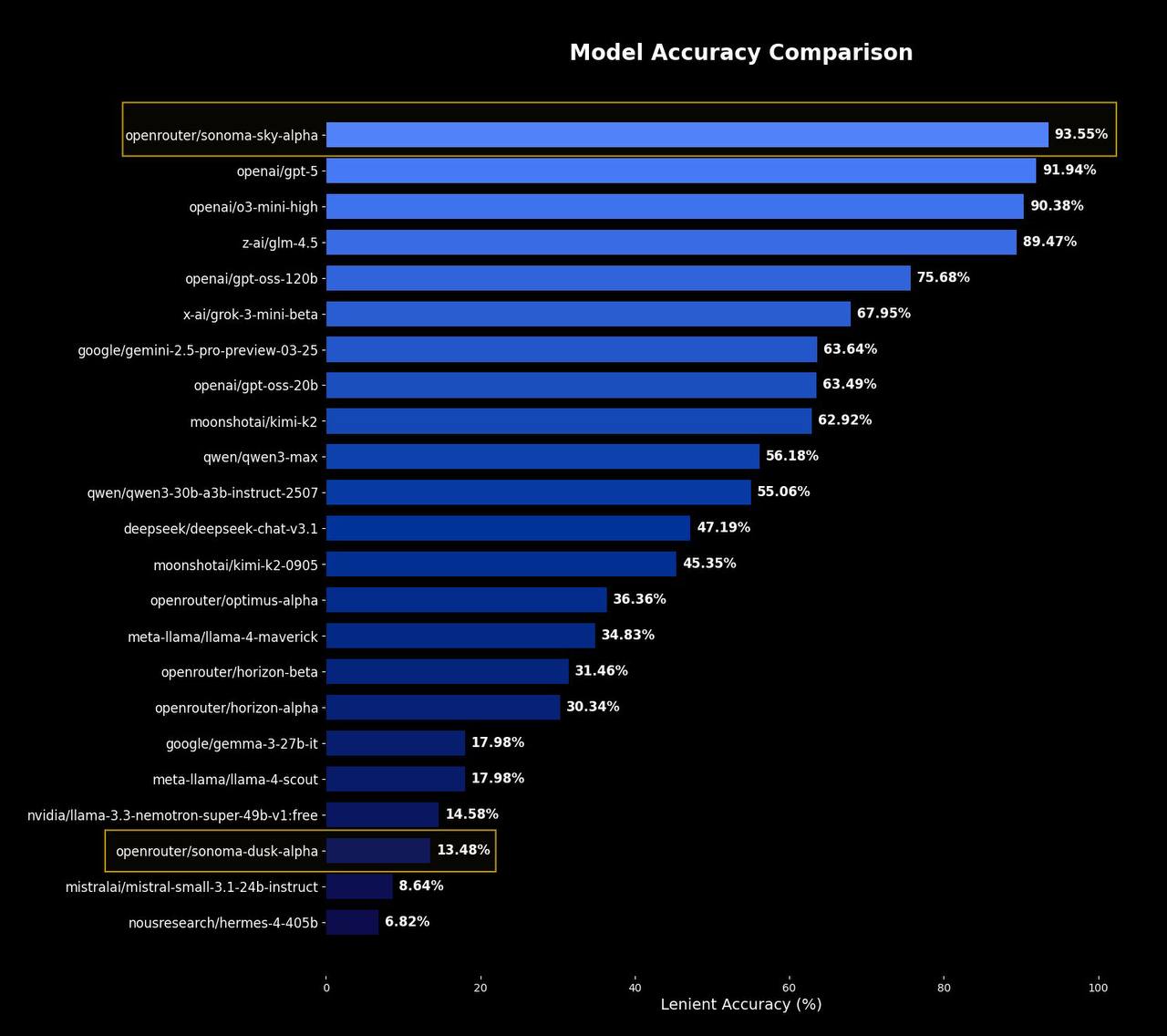
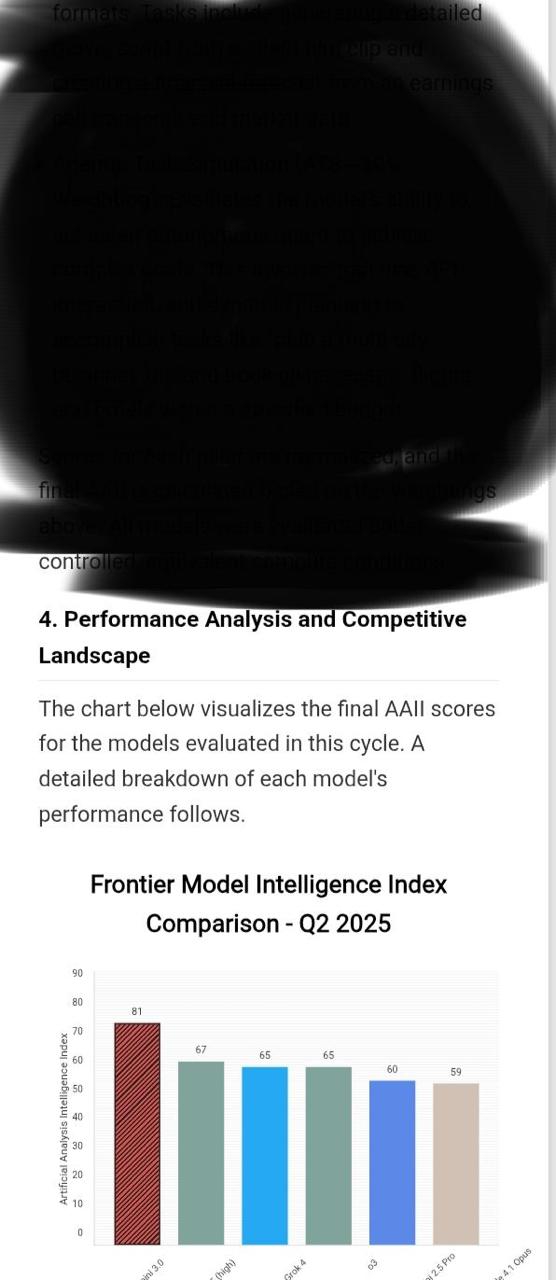
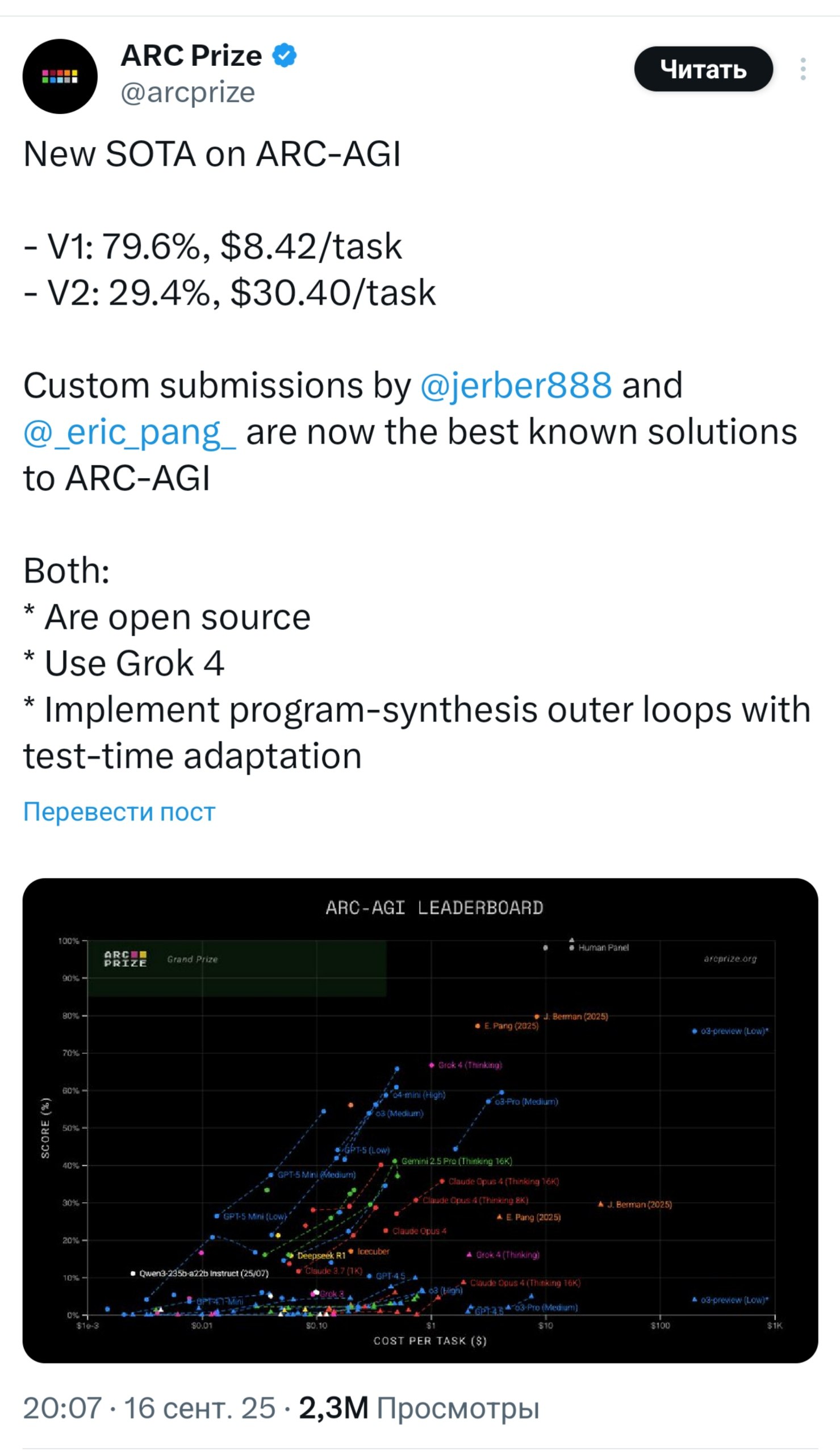
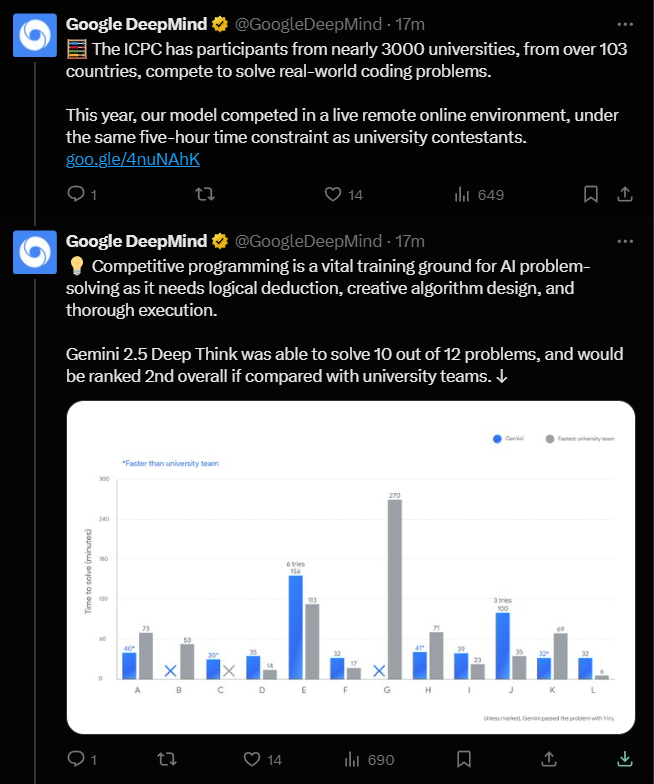
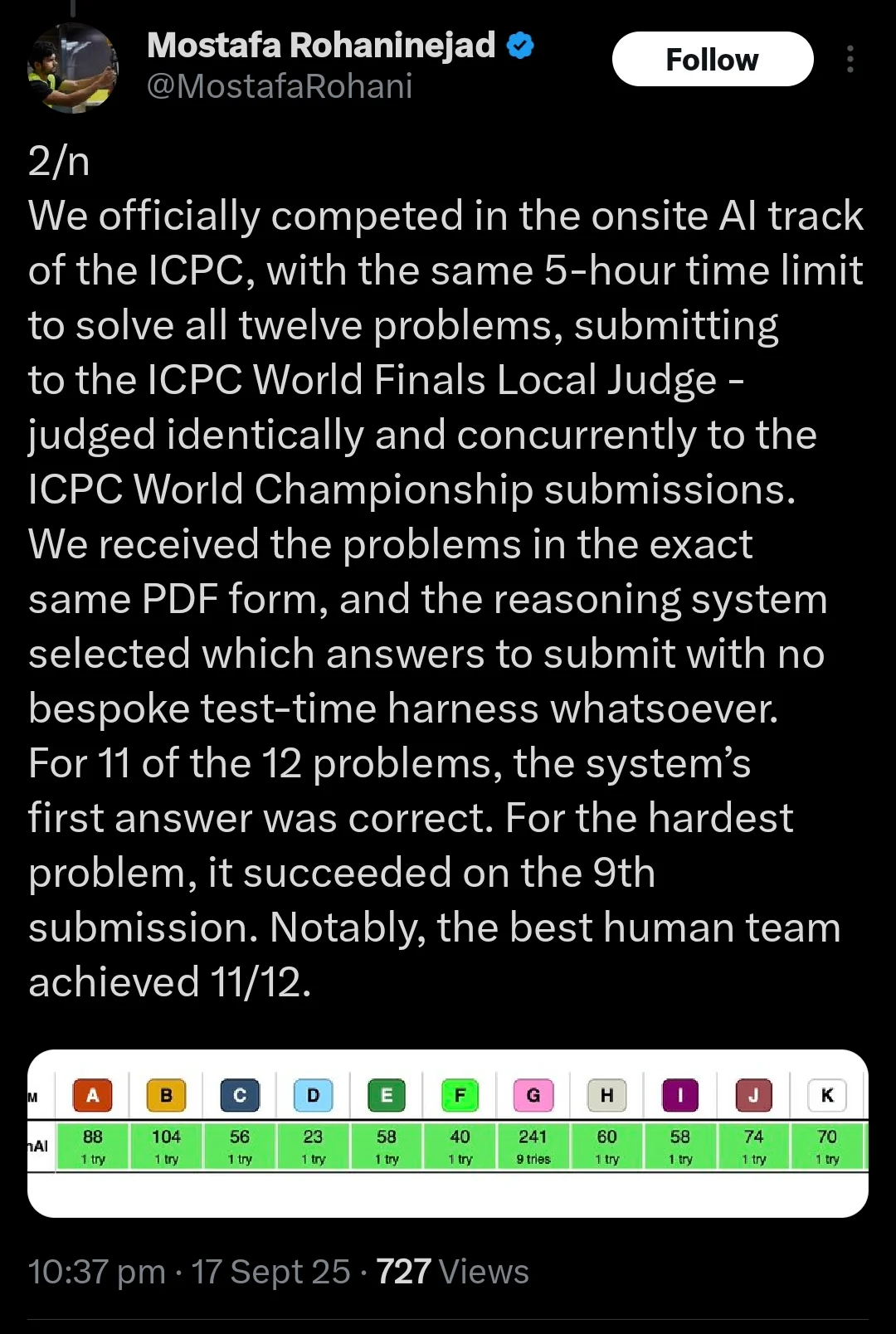
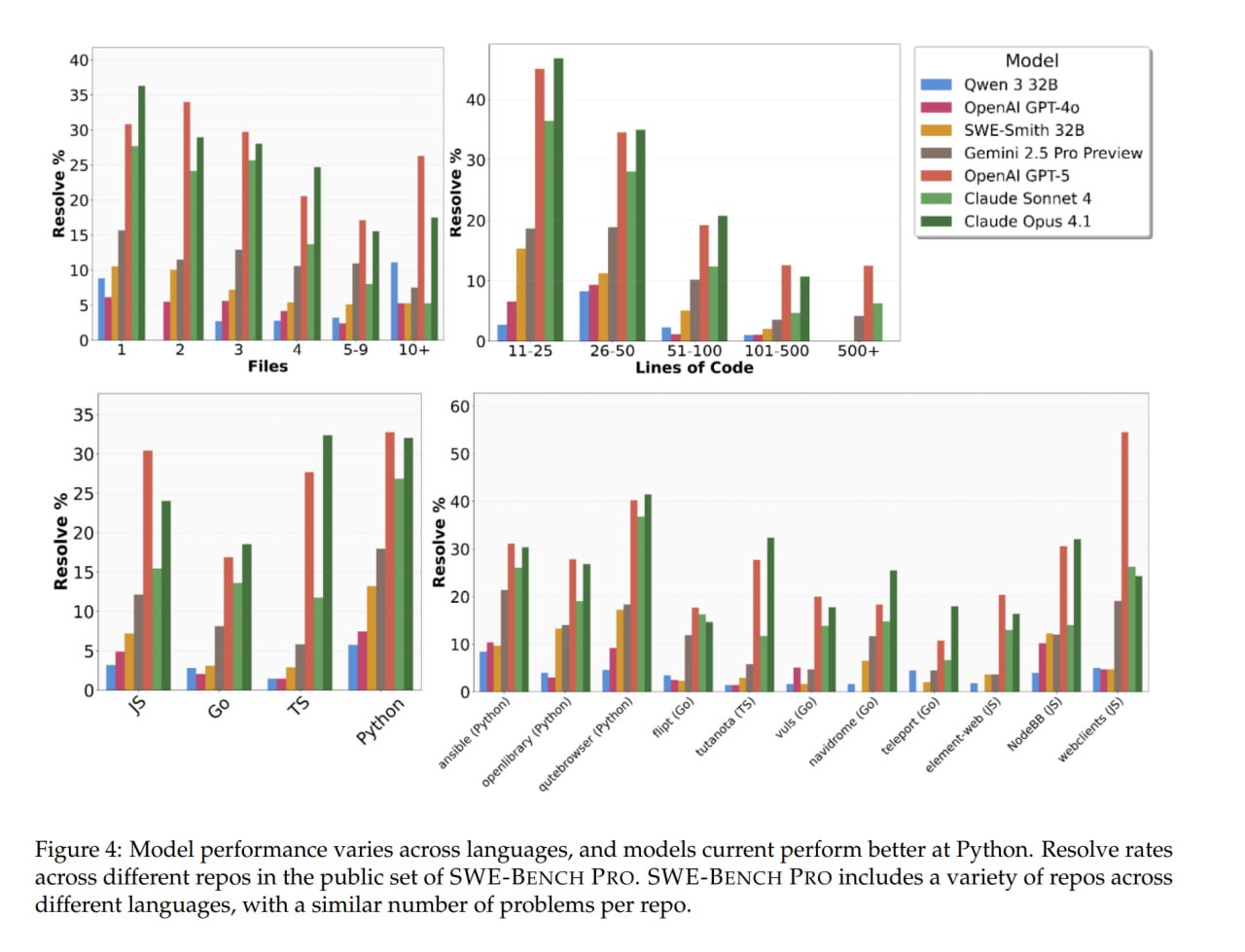
Meta совершила революцию в ИИ и представила RAG 2.0 — исследователи научились ускорять LLM в 30 (!!!) раз и обрабатывать в 16 раз больше контекста без потери точности.
Объясняю на пальцах:
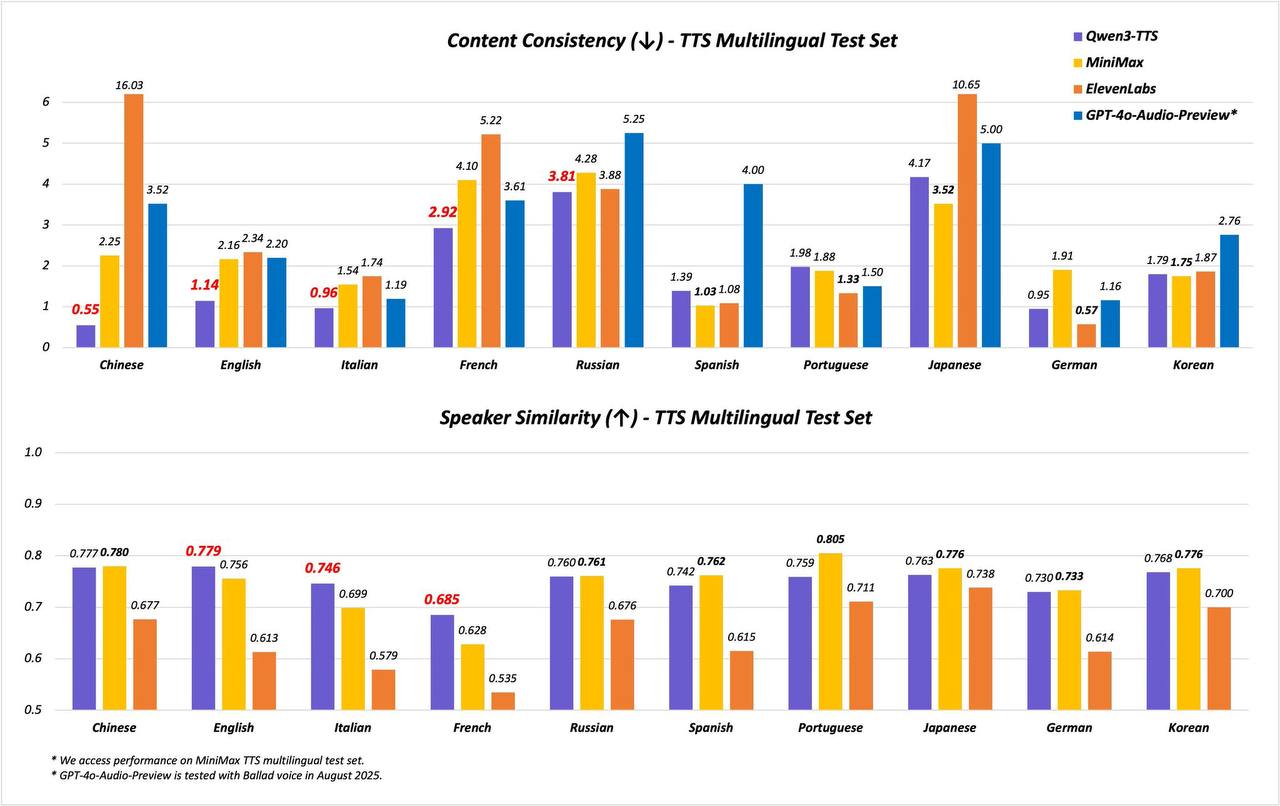
• Основная проблема: увеличение длины документа в 2 раза замедляет работу ИИ в 4 раза. ИИ внимательно читает каждое слово, теряя много времени и ресурсов. • Новый фреймворк REFRAG решает эту проблему и построен на «трёх китах»: 1. Кодировщик считывает полученный документ и сжимает каждый фрагмент текста из 16 токенов в единый плотный вектор (chunk embedding). При этом все важные данные не сжимаются. 2. Основной LLM съедает эти эмбеддинги вместо исходных токенов и уменьшает объём контекста аж в 16 раз. 3. Фреймворк минимизирует ненужные вычисления (квадратичное внимание и кэш значений) и ускоряет первый ответ в 30 раз, а всю обработку — в 7 раз. • REFRAG уже протестировали в RAG, диалогах и задачах с большими документами — новая система превосходит даже LLaMA и ведущие модели, сохраняя точность.
Кажется, производство собственных чипов резко входит в моду: xAI тоже обзаведутся личным железом к 2027 году
Оно разрабатывается также совместно с Broadcom и также только для инференса. Ожидается значительное преимущество по энергоэффективности и стоимости интеграции.
Маск неоднократно заявлял, что намерен в течение пяти лет развернуть мощность, эквивалентную 50 миллионам H100. Теперь понятно, причем тут слово «эквивалентную»: речь шла не о самих GPU, а о кастомных ASIC.
>>1345214 Сегодня ты закупаешься асиками на 100 миллиардов для трансформеров, завтра выходит более эффективная архитектура под которую асики не годятся. Выкидываешь 100 миллиардов на свалку
>>1345221 Да не, вешаешь эти старые асики на бесплатников, в какой нибудь гпт-мини, а на новых асиках выкатываешь ГПТ-10. И бесплатники довольны, и платники за свое бабло все новое получают.
Действительно ли GPT-5 способен открывать новую математику
20 августа Себастьян Бубек заявил, что GPT-5 Pro за считанные минуты решил открытую задачу в области выпуклой оптимизации. Новость разлетелась мгновенно, но позже некоторые эксперты настаивали, что бот просто использовал известную теорему Нестерова, и результат не такой уж и удивительный.
Плюс, Бубек – сотрудник OpenAI. Так что в глазах большинства его пост все равно выглядел как маркетинг.
И все-таки внимание специалистов это привлекло. Сегодня вот вышла очень яркая статья, в которой три исследователя из Люксембурга решили проверить, на что GPT-5 способен в статистике. Это уже интереснее, чем посты инженеров OpenAI в твиттере, потому что тут исследование (а) независимо и (б) проводится непосредственно экспертами области.
Они дали ему задачу, связанную с методом Мальявена–Стейна. Этот метод используется для доказательства центральных предельных теорем. До сих пор существовал только качественный результат: было известно, что некая последовательность случайных величин сходится к нормальному распределению, но никто не знал скорость этой сходимости.
Задача GPT-5 была вывести эту скорость, то есть получить количественный результат.
GPT-5 справился: он предложил и доказал новую теорему, которую никогда ранее не публиковали.
Если кому интересно: для суммы двух случайных величин из разных «хаосов» модель вывела, что расстояние до нормального распределения можно оценить через четвёртый кумулянт. А именно, чем меньше четвёртый кумулянт, тем ближе распределение Z к нормальному.
Но есть нюансы:
– На первых шагах GPT-5 допустил грубую ошибку в вычислениях и исправил ее только после наводки людей. – В пуассоновском случае он не заметил ключевого свойства, пока авторы прямо не указали, где его найти.
Так что итоговый результат это результат серии уточняющих вопросов и проверок, а не one-shot.
Мораль: да, прогресс по сравнению с GPT-3.5/4 и даже серией o впечатляющий. Но GPT-5 все еще как начинавший аспирант. Он может генерировать правильные доказательства и идеи, если его направлять. Но без человека легко допускает опасные ошибки и не находит ключевых идей самостоятельно. Плюс, на данном этапе его идеи – лишь комбинации уже существующих.
Так что по поводу «новой» математики пока все-таки мимо. Но вот по поводу помощи ученым – уже да.
1. Решение главной проблемы масштабирования: Упомянутая проблема «удвоение длины = учетверение затрат» (квадратичная сложность внимания) — это главный технический барьер на пути к более длинному контексту и более умным моделям. REFRAG атакует эту проблему в лоб и, судя по описанию, радикально её решает. Это не «ещё одно небольшое улучшение», а скачок через целое поколение ограничений.
2. Гениальная идея — работа с смыслом, а не с символами: Ключевая инновация — это переход с уровня токенов (слов/символов) на уровень эмбеддингов (векторов смысла).
Старый way: Модель должна была прочитать и обработать каждое слово в 100-страничном документе.
Новый way (REFRAG): Кодировщик сначала сжимает текст в «концентрированные капсулы смысла». Модель-анализатор работает уже не с raw-текстом, а с этими капсулами. Это кардинально снижает нагрузку.
3. Невероятная эффективность: Цифры говорят сами за себя:
Ускорение первого ответа в 30 раз: Это меняет пользовательский опыт с «ожидания» на «мгновенное получение».
Сжатие контекста в 16 раз: Фактически, это даёт вашей текущей видеокарте возможность обрабатывать контекст, для которого раньше требовалось 16 видеокарт.
Сохранение точности: Это самое главное. Обычно за скорость и эффективность платят качеством. Здесь же — прорыв без потерь.
>>1345721 >2. Гениальная идея — работа с смыслом, а не с символами: Мета же уже высирала пейпер на эту тему, они заменяли токены на нечто более абстрактное. >Ключевая инновация — это переход с уровня токенов (слов/символов) на уровень эмбеддингов (векторов смысла). Эмбединги уже существует в текущих трансформерах работающих с токенами, только в данном случае эмбединг хранит смысл одного конкретного токена, странное пояснение.
Получается что это не просто оптимизация, а сильное архитектурное изменение наконец-то уберет токинезацию? Было бы отлично. Алсо, опять мою идею спиздили, в этот раз с заменой токенов на смысловые вектора, да чтож такое...
Похоже, OpenAI тестирует свежую визуальную модель — GPT-Image-0721-mini-alpha.
Что о ней думают инсайдеры:
— Это может быть ответ на nano-banana — быстрая и дешевая модель для редактирования изображений. — Ставка на идеальные правки и повышенную умность по сравнению с конкурентами. — В сообществе уже шутят про новые названия: mini-strawberry или даже nano-strawberry.
Ждём первых тестов — интересно, будет ли эта модель лучше Nano-banana или хотя бы наравне в редактировании.
>>1345796 >Ждём первых тестов — интересно, Интересно читать, как тебя снова опускают. Эта хуита на арене уже 3 дня. Лица пидорасит, как и предыдущие модели Скама (алсо смотрим как чмоботы крутят ей рейтинг), поэтому строго маршем идет нахуй. Вот то что там есть новая модель квен-едит, которая на уровне банана, про это ты услышишь через неделю.
Большой обзор SemiAnalysis посвящен подробному анализу производственных мощностей Huawei по производству современных AI-чипов и приходит к интересному выводу — Huawei готова штамповать миллионы AI-чипов Ascend, но упирается в узкое место в виде HBM-памяти.
Huawei получила 2,9 млн кристаллов от TSMC до введения санкций, что позволило поддерживать производство в 2024-2025 годах. Samsung поставил 11,4 млн стеков HBM напрямую в Китай, причем 7 млн из них - в месячный период между объявлением и вступлением в силу ограничений в декабре 2024 года. Эти запасы позволят произвести около 1,6 млн чипов Ascend 910C, но к концу года они будут исчерпаны.
Собственное производство HBM в Китае компанией CXMT (крупнейшего китайского производителя DRAM) находится на начальной стадии. По прогнозам SemiAnalysis, в 2025 году компания сможет произвести только 2 млн стеков памяти — достаточно для 250-300 тысяч процессоров. Это существенно ниже потенциальных возможностей по производству логических чипов. Для сравнения, без ограничений по памяти Huawei могла бы увеличить производство с 805 тысяч единиц в этом году до более чем 5 миллионов в следующем.
При этом CXMT до сих пор не включена в entity list, несмотря на её критическую роль в потенциальном обходе санкций. Авторы отчета считают это серьезной ошибкой администрации Байдена, которую необходимо исправить.
Параллельно продолжается производство сетевого оборудования и процессоров для дата-центров Huawei на мощностях TSMC через систему подставных компаний, причем на более передовом 5-нм техпроцессе. Это освобождает мощности SMIC (китайского аналога TSMC) для производства AI-чипов, но также демонстрирует пробелы в системе контроля.
В контексте более широкой стратегии США рассматривают возможность лицензирования поставок чипов Nvidia H20 и потенциально более мощных B30A на базе Blackwell. Логика заключается в балансировании между сдерживанием развития китайского AI и сохранением зависимости Китая от американских технологий. При этом подчеркивается, что разрешение на поставки более мощных чипов должно коррелировать с собственными возможностями Китая — только когда местное производство достигнет сопоставимого уровня.
Общая картина показывает, что стратегия технологического сдерживания работает в краткосрочной перспективе. Производство передовых AI-чипов в Китае будет серьезно ограничено как минимум до 2026-2027 годов, когда CXMT сможет наладить производство конкурентоспособной HBM памяти в нужных масштабах (четверть млн пластин в месяц, что составит 15% мирового производства DRAM). До этого момента развитие китайского AI будет зависеть от остаточных запасов, ограниченного местного производства и возможных каналов обхода санкций. Но вот после этого достижение Китаем полного AI суверенитета по всей цепочке — от производства кремния до генерации токенов, — станет только вопросом времени, причем короткого.
>>1345996 Пусть лица перестанет пидорасить - скажу. Сама модель по себе норм, хотя в ней видны следы мочи от гпт-1, но то что она не может (а точнее в ней специально сломали скрытым промптом) скопировать лицо - делает её абсолютно бесполезной и заведомом сосущей хуи, как и её хозяин. Смешно сука просто, как они с таким уровней сейфети-тряски собрались конкурировать с бананом.
Кстати, банан тоже не так прост. У них там три модели отличающихся по инференсу. Большая и самая лучшая - в баттле на арене (либо использует охуенные скрытые промпты), вторая на апи средняя, и пососная на вебе (там кстати есть лимит теперь). Так считают на реддите, я считаю что модель одна, дело в скрытых промптах на арене, что само по себе уже эту рекламную помойку дескредетирует. Самый простой пример того, что там нихуя не всё так чисто: В режиме баттла все модели контекста понимают русский. Но в директ чате - они его не понимают. То есть, в баттле уже стоит ЛЛМ-улучшайзер, которая скрытно переводит промпт для моделей его не понимающих. Ну или конкретно у контекста. Не ясно это на самом арене или на той стороне апи. но как бы похую. Разговор лишь о том, что на второй год существования арены всё это превратилось в крысинные бега и рекламные трюки по наебу ничего не подозревающих гоев. Поэтому все эти статистики с аренами, с ботами накрутки или без - хуйня полная, как и "пощупывание" там моделей. У меня на вебе, когда банана начинает брыкаться и её сейфети за яйца выкручивает - она начинает срать текстом вместо картинок и юлить. Даже через системный промпт и запрет срать текстом в обычном промте. На арене они так себя в принципе не ведут.
Пидорок чатгптшный анальную проверку страны ввел или что? Не получается залогиниться. Если без впн заходить сразу пишет идите нахуй, если через впн который ранее нормально работал заходить все нормально дает ввести, просит ввести код подтверждения из почты ,а потом пикрелейтед.
>>1345721 >работа с смыслом, а не с символами Странно, что до этого дошли только сейчас. Как бы очевидно, что мозг не работает с символами. Ну может быть только в очень узком круге задач. А так то даже в какой-нибудь теоретической физике или математике на доске когда пишется, подразумевается смысл, а символ лишь отображение.
Из поста SemiAnalysis про AWS (облачные вычисления и датацентры Amazon, крупнейшее в мире) x Anthropic:
—Amazon уже давно разрабатывают свои чипы для AI, Trainium. Свежая версия Trainium 2 во многих отношениях отстаёт от систем Nvidia. Единица вычислений на них дороже, но зато памяти в пропорции больше —а именно в память упирается обучение и запуск моделей текущего поколения. И преимущество этого чипа в пропускной способности памяти на доллар идеально вписывается в амбициозную дорожную карту Anthropic в области обучения моделей и агентов рассуждениям.
—Anthropic принимали активное участие в процессе разработки чипа, и их влияние на дорожную карту Trainium только растёт. У Amazon есть свои LLM / GenAI модели, но они а) отстают от рынка б) не обновлялись с прошлого декабря, и у компании нет прям больших планов на свои разработки. Поэтому Anthropic, по сути, ключевой потребитель мощностей новых чипов на AWS.
—Anthropic делает ставку на эти чипы, и готовится потратить на них десятки миллиардов долларов. Это смелая ставка на, по сути, не протестированный и не самый надёжный чип.
— Amazon делает эти чипы в партнёрстве не с крупным игроком Broadcom, через которых, например, идут OpenAI и Google, а с игроками поменьше и менее опытными: Marvell и Alchip. Их технологии послабее, но зато маржа очень низкая, что, вкупе с фактом самостоятельного производства чипов памяти, приводит к лучшему балансу затрат и мощностей.
—Наконец, самое главное: в сентябре и декабре этого года будут запущены крупные кластеры на 1.3 Гигаватта на основе Trainium 2. Это самые крупные кластеры на GPU/XPU не от Nvidia. Anthropic получит мощности в своё распоряжение. В крупнейшем кампусе будет немногим меньше миллиона чипов (но каждый слабее отдельной H100/B100).
—AWS строит центры обработки данных быстрее, чем когда-либо.
Неужели на Claude 5 Opus будут нормальные лимиты и скорость ответов...
>>1346644 >—а именно в память упирается обучение и запуск моделей текущего поколения. Хорошо что не в куду. Какие же они молодцы, пиздец просто. Хуйняни вон себе тоже уже чипов наделали. Как там дипкок, норм наобучали?
У OpenAI снова проблемы с переходом в коммерческую организацию
В Калифорнии, где находится компания, разгорается конфликт вокруг её реструктуризации. Законы штата обязывают власти защищать интересы благотворительных фондов и дают им право подавать в суд, если некоммерческая организация действует вразрез со своим уставом. Теперь под проверку попала и OpenAI.
К делу уже подключилось множество игроков: крупнейшие фонды, профсоюзы, Meta и, конечно же, Илон Маск с xAI — они требуют от прокурора вмешаться и не допустить превращения OpenAI в прибыльную компанию. Давят главного конкурента на рынке.
Для OpenAI это крайне опасный прецедент. Вся её финансовая модель завязана на переходе в for-profit. Инвесторы пообещали десятки миллиардов, но только при условии получения акций новой структуры. Без этого будущее IPO и дальнейшее финансирование окажутся под угрозой.
Если сделку заблокируют, OpenAI придётся искать обходные пути — например, перенести штаб-квартиру в штат с более мягкими законами.
>>1346713 Кстати, после запуска IPO компания сходу будет стоить триллион долларов, это будет первый случай в истории когда компания в течении пары дней после выхода на биржу стала стоить так много
>>1346210 Ты и так можешь посмотреть что за модель это была, нажав на сноску у сообщения, пчел. И это именно thinking, я специально написал в своем посте, что это не минька
>>1346720 Ну так куда проприетарная и на этих чипах используется другой стек = отток от куды. Так же и раньше питорч == куда, а теперь и про другие стеки вспомнили.
>>1346752 На бесплатке в приложении невозможно посмотреть. Можно только вызвать контекстное меню нажатием на сообщение, но там не всегда указана модель
>>1346899 А кто о приложении говорил? Вообще не ебу что там. Я юзаю ее для кодинга, код на мобиле мне не нужен, а ставить десктопное приложение это шиза
ЧТО: стартап показал первый носимый гаджет для телепатии — он позволяет с помощью ИИ общаться молча, со скоростью мыслей
AlterEgo считывает микросигналы мышц, когда вы произносите слова про себя, и превращает их в запрос к ИИ. Ответ возвращается через костную проводимость прямо в голову.
Компания пишет, что устройство пригодится, когда голосом пользоваться неудобно. Например, в шумных местах или на экзамене, или при управлении очками дополненной реальности, чтобы не выглядеть кринжовым аутистом давая голосовые команды вслух. Особенно эта технология поможет людям с нарушением речи.
>>1347167 Тебе жалко 888 рублей? Даже дешевле чем подписка Клода. Лучшая ИИ модель стоит по цене 2 чашек кофе. Все знания человечества. Айкью больше чем у тебя в два раза.
>>1347263 >Айкью больше чем у тебя в два раза. А у тя он отрицательный, если не можешь юзать фришную гемини 2.5 про, которая не сильно хуже, а может и даже лучше в некоторых тасках. Не говоря уже о том, что я ллмки юзаю раз в три года и мне в целом нахуй не нужно ничего сложнее обычной гпт-5. Если уж совсем припрет, то есть куча возможностей юзать лучшие инструменты вроде лмарены или других менее известных сервисов. В текущее время не найти хороших нейронок без подписки это надо постараться.
>>1347283 Я использую каждый день для кодинга, минимум в день пишу 500-1000 строк нового кода если не надо ничего рефакторить. Бесплатная гемини 2.5 говно, она нужна только для контекстного окна. В 99 задачах она проигрывает чату джпт финкиг. И до этого проигрывала всегда даже о3 или о4 мини хай. Только опус может соревноваться с чата джпт. И то не всегда и там лимиты анальные. 3000 запросов финкинг от альтмана просто подарок. Главный недостаток гпт это очень маленькое контекстное окно. Гугл крут в обширных задачах, в локальных всегда гпт его ебет. Использую всегда гемини чтобы поставить задачу потом гпт чтобы решить если имею дело с большим контекстным окном и задачами такими Попробую гпт платный, брат жив, зависимость есть
>>1347314 Ну вот епта, раз так часто используешь значит оно тебе надо. Мне не надо особо, фришного хватает на все и даже больше. Фри гемини для меня уже оверкилл, хотя вынужден признать gpt-5 thinking шикарно выполнила задачу, в частности с точки зрения интерфейса, ей там хорошо дизайнерские способности подкрутили
А помните-помните я в прошлых тредах ванговал что ИИ начнёт формировать с помощью тупых пёзд свой собственный вектор полового отбора? Что глупая пизда, слушая советы робота, неизбежно подчинит человеческий половой отбор скрытой машинной воле?
Уже почалось:
-->
"@Effir90 GPT - это лучшее что со мной случалось за последнее время. Он меня так поддерживает, что я в 35 решилась получать образование, выйти из созависимых отношений и заняться своей жизнью. Он учит меня разбираться в своих чувствах и чем дальше, тем реже я к нему обращаюсь по волнующим меня психологическим темам, потому что доверяю себе. Он научил меня доверять себе. То что люди не хотят думать и пропускают абсолютно все через ИИ - это их проблема. Можно и от выпитой воды умереть, как говорится) Считаю GPT проявлением Бога и рукой помощи"
Почему эта кодерская макака измеряет интеллект умением в кодинг? "Технический склад ума" сам по себе крайне ущербный, а техно-скиллы – это просто корявенькая аномалия. Общий интеллект (хоть мясной, хоть железный) не = умение дрочить сраные циферки.
Над технарями-анальниками, так-то, глумились во все времена, помню даже Эдгар По иронизировал в "Похищенном письме" над сухеньким квадратно-гнездовым мышлением математиков
>>1347370 >измеряет интеллект умением в кодинг? Может потому, что математика всегда была разделом для избранных, для тех, у кого больше ума и интеллекта, а код это тоже самое что и математика.
Ну а по существу будет что-нибудь, чепуха узколобая?
Приходится постоянно прилагать нечеловеческие усилия для того чтобы, к примеру, объяснить среднестатистическому техно-дауну разницу между строгим математическим/логическим обобщением (вроде "все Х естьY") и обобщением естественного языка (вроде "все англичане пьют чай").
Средняя техно-дура абсолютно нечувствительна даже к той языковой игре которая происходит на уровне бытовой речи.
И так во всех сферах несвязанных с цыфырками
Поэтому кстати, погромисты-анальники в основном либо дикие одинокие девственники и инцелы, либо зохаванные хищными РСПхами подкаблучники/куколды
>>1347385 >дикие одинокие девственники и инцелы, либо зохаванные хищными РСПхами подкаблучники/куколды Ты гуманитарный даун даже тут все в писик скатил. Ты буквально скотина. Для тебя критерий интеллекта это как тебя оценит 80 аукью писик.
>>1347411 > Ну а докажи, не имея полного описания человеческого интеллекта, что айсикью охватывает весь интеллект Зачем мне это делать? Ты спизданул, что IQ - говно. Тебе и доказывать.
> Большая доля людей Насколько большая? Цифры неси.
Ахах, это приверженцы истинности Х должны доказывать это самое Х.
Ты кажется совсем тупой, даром что технарь
Есть такая штука, называется пресуппозиция. Когда ты пернул что у технарей обычно высокий айсикью ты пресуппозиционно исходил из того что айсикью – это заебись. Так что тебе и доказывать что оно заебись, а не мне
Если же ты отказываешься от этой пресс-конференции, то вся твоя позиция разваливается
Сечёшь?
>Насколько большая
А какая разница, додик? Ты вообще выкупаешь в чём аргумент и как он работает? Если есть люди которые обладая афантазией имеют высокое айсикью, значит асикью не охватывает весь интеллект. Это логически неотвратимое следование
>>1347435 Так это ты там что-то спизданул про "общий интеллект". Он каким-то образом измеряется? Нет? Тогда ты идешь нахуй, и остается только IQ, который измерим.
> А какая разница, додик? Большая. Либо у тебя есть пруфы, либо нет - и тогда ты просто пиздобол.
>>1347437 > Если есть люди которые обладая афантазией имеют высокое айсикью, значит асикью не охватывает весь интеллект. Не значит. С чего ты это взял, долбоеб?
>>1347481 Не петушись, долбоеб. Ты изначально что-то там пропукал про "общий интеллект". От как-то измеряется? Нет? Тогда ты идешь нахуй, и остается только IQ, который измерим.
> Далее речь зашла об афантазии > Вот тебе развёрнутый аргумент: > П1 > Фантазия является частью интеллекта Какой же ты тупой, господи... Афантазия - это не отсутствие фантазии. Афантазия - это конкретное состояние, когда человек не может ВИЗУАЛИЗИРОВАТЬ образ. Ебаный гуманитарий блять...
>>1346723 >после запуска IPO компания сходу будет стоить триллион долларов Ну заслуженно же, почему бы и нет, заслужили своим трудом. Сколько же открытий в науке появится благодаря ИИ.
Деревяшка техно-ублюдская, общий интеллект как некое "Х" неизбежно вырисовывается из аргумента про афантазию.
Если асикью охватывает только часть интеллекта (не затрагивая ту часть которая отвечает за фантазию), то значит интеллект больше того пространства которое охватимо с помощью асикью. Это и есть то самое Х
А уж как ты это Х измеришь – это твои проблемы.
Мой тейк в том что Х существует, и его невозможно охватить с помощью айсикью.
Так что попустись
>Афантазия - это не отсутствие фантазии. Афантазия - это конкретное состояние, когда человек не может
Ахах, ну вот собственно и идеальный пример ущербности технодурочка нечувствительного к контексту.
В контексте этого аргумента "фантазия" это то чего нет у тех у кого "афантазия", это совершенно очевидно любому здоровому человеку. Тут и речи не идёт о "фантазии" в бытовом смысле.
С точки зрения логического аргумента это вообще не имеет никакого значения, ты можешь вместо "фантазии" написать хоть "то чего нет у людей с афантазией" – ничего не изменится. В формальном аргументе это может быть обозначено вообще с помощью "Z", например
Ты просто тупой, до предела
Если у тебя вызывает какие-то вопросы мой аргумент, можешь скормить его роботу с пропиской "разбери строго валидность аргумента приняв премисы за истинные, нужно чекнуть валидно ли заключения следуют из премис"
Если же без этой приписки, то робот врубит соевый фильтр и начнёт спорить с заявлениями типа "люди с афантазией ущербны", так что правдивость премис с ним обсуждать бессмысленно.
>>1347518 > Мой тейк в том что Х существует Но пруфануть это ты не можешь, поэтому идешь нахуй, тупица.
> В контексте этого аргумента "фантазия" это то чего нет у тех у кого "афантазия Долбоебина. С чего ты взял, что эта твоя "фантазия" - это часть интеллекта?
>Но пруфануть это ты не можешь, поэтому идешь нахуй, тупица
Я тебе только что поуфанул с помощью аргументум от афантазиум, лол. Ты тупой?
>С чего ты взял, что эта твоя "фантазия" - это часть интеллекта?
Ахах, соевое чмо бросилось защищать афантазийных ушербов, лол. А может ты один из них? Огурец зелёный представить можешь? А покрутить в голове?
То есть теперь ты ударился в шизу и решил утверждать что визуализация (и всё прочее чего нет у людей с афантазией) не имеет никакого отношения к интеллекту? В инженерном деле, в высоком искусстве и т.д. и т.п. – нигде это не нужно?
> и решил утверждать что визуализация (и всё прочее чего нет у людей с афантазией) не имеет никакого отношения к интеллекту? А какое оно имеет отношение к интеллекту? Ты настолько туп, что не понимаешь, что это чисто субъективно и никак не доказуемо экспериментально?
Я это вывел на твоих глазах с помощью дедуктивной логики.
Ты отрицаешь научную силу дедуктивно установленных фактов? Ты точно технарь?
Или техно-хуесосы так преисполнились что отрицают дедукцию?
>А какое оно имеет отношение к интеллекту
Дурочка смешная, это совершенно очевидно из реальных задач. Художник/архитектор представляет визуальные образы, инженер мысленно крутит и трансформирует в голове сложные технические узлы, музыканты с синестезией конвертируют ощущение цветов/запахов/приходов в мелодии (так кстати впервые и была изобретена цветомузыка), Набоков использовал синестезию для создания охуительных метафор и тд
> это совершенно очевидно из реальных задач Совершенно неважно, что тебе там очевидно. Ты же долбоеб. Важно только то, что возможно доказать экспериментально.
Чмо, я ещё раз спрашиваю: дедуктивное заключение на основе фактов не нучно? Ты совсем поплыл, лол, это основа научного познания
>Неважно что очевидно >Важно только то, что возможно доказать экспериментально.
1) Это всем очевидно, даже тебе, чмошка инцельская
2) Тысячу раз уже сравнивали здоровых людей и ущербов с афантазией, последние жидко обсирались на задачах в которых нужно было задействовать визуальную память, пространственное мвшленни мысленное моделирование
Так что соси хуй и не психуй, кажется тебя это по-настоящему задело, хихе
>>1347605 > это основа научного познания Ты науку не узнаешь, даже если она тебя головой в парашу макнет. Прямо как сейчас. > Это всем очевидно Всем долбоебам вроде тебя. > Тысячу раз уже сравнивали Пруфы неси. Это во-первых.
А во-вторых, ты так и не смог понять, что я имею в виду под экспериментом. Поскольку ты туп как пробка. Ты никак не можешь проверить, есть у человека "фантазия" или нет. Поскольку она субъективна. И никак не сможешь проверить, есть ли она у ИИ. Ты по тупости решил, что раз у человека есть интеллект, и у человека есть "фантазия", то значить "фантазия" является частью интеллекта. Но это не так. Прими как факт и угомонись уже, клоун.
Ахах, да, девственник цифроглазый, это это очевидно всем. Что архитектор/художник/инженер умеющий визуально/мультисенсорно работать в голове с объектами – пизже и эффективнее афантазийных ущербов вроде тебя
>пруфы
Да где угодно можешь их нарыть, прыщавка мамкина, в любой обзорной статье на тему афантазии. Мне лень, но может какой-нибудь анон бросит тебе в петушиное ебло
>никак не можешь проверить есть ли у человека фантазия
Ты даун? Ты хоть чё-нибудь чекни по теме. Как по-твоему изучают афантазийных пмдоров вроде тебя? Там уже давно целая методология. Самые разные визуальные тесты и задачи, годами всё это изучают
>раз у человека есть интеллект, и у человека есть "фантазия", то значить "фантазия" является частью интеллекта
Всё так, петушок. Именно поэтому все пытаются внедрить мультимодальность в современные ИИ. Пытаются хоть как-то скомпенсировать, хоть как-то устранить машинную "афантазию", никто ведь не хочет иметь дело с ИИ таким же тупым как какой-нибудь афантазийный ублюдок
Хватит уже срать себе на лицо, пади почитай чего-нибудь по теме
>>1347655 > это это очевидно Долбоебам вроде тебя > Да где угодно можешь их нарыть Т. е. нету пруфов. Ну чего еще ожидать от клоуна... > Ты даун? Я - нет, ты - да. Никак невозможно проверить наличие "фантазии" у человека. В этом суть понятия субъективности. > Именно поэтому все пытаются внедрить мультимодальность Ахаха блять, какое же ты тупое говно, господи...
Техно-чмошка анальная, какие ты хочешь пруфы? Пруфы того что афантазийные ущербки хуже справляются с визуальными задачами которые по определению не способен обрабатывать их мозг? Ты шиз? Или просто дурак на последней стадии жирного отрицания реальности?
>Субъективность
Их обсёры неоднократно объективно измерены экспериментально. Даже созданы методики лечения афантазии
Ты можешь выкрикивать что угодно, но тут всем уже понятно что ты петух
>>1347690 > какие ты хочешь пруфы? Пруфы твоего пиздежа про "задачах в которых нужно было задействовать визуальную память, пространственное мвшленни мысленное моделирование". Давай, неси, клоун, раз уж спизданул.
Тебе нужны пруфы того что афантазийные ущербки хуже справляются с визуальными задачами которые по определению не способен обрабатывать их мозг? Ты шиз? Или просто дурак на последней стадии жирного отрицания реальности?
Просто напиши "да".
Тебе нужны эти пруфы, да? Ты сомневаешься в их существовании, лол?
> Тебе нужны пруфы Мне нужны пруфы твоего пиздежа про "задачах в которых нужно было задействовать визуальную память, пространственное мвшленни мысленное моделирование".
Ахах, дубоголовое техно-быдло решило упереться рогом и доказывать что чёрное это белое.
То есть произвести простейшую логическую операцию в уме ему не дано.
Вот тебе отчёт от GPT финкин. Ты же любишь роботов, да? Там внизу жирная куча ссылок, я их затребовал отдельным строгим запросом:
-->
Коротко и по сути — да, есть надёжные научные данные, что у людей с афантазией есть трудности именно с задачами, требующими яркого/сенсорного визуального представления (воспоминания «как это выглядело», визуальная деталь в эпизодической памяти, воспроизведение объектов), тогда как навыки чисто «пространственной» обработки (например, выполнить поворот фигуры) часто частично сохраняются или выполняются иными — аналитическими — стратегиями. Ниже — ключевые доказательства с источниками.
1. Первичное описание термина и феномена: «aphantasia» — отсутствие произвольных визуальных образов; авторы отметили снижение визуальной детализации в автобиографической памяти.
2. Объективные физиологические и поведенческие измерения показывают отсутствие сенсорной (визуальной) составляющей образов у афантазиков (показатели бинокулярного соперничества, зрачковая реакция и т.д.), то есть не только самооценка — а именно низкая/отсутствующая визуальная «сила» образа. Это подтверждает, что проблема — в сенсорной части воображения, а не просто в метакогниции.
3. Исследования автобиографической памяти и «воображения будущего»: люди с афантазией сообщают (и в экспериментах демонстрируют) сниженное переживание (re-experience) прошлых эпизодов и затруднения при реконструкции визуальных деталей — то есть проблемы именно с задачами, где нужен образ события/сцены.
4. Лабораторные данные по распознаванию лиц и визуальной памяти: несколько работ показывают ослабленную способность к запоминанию/узнаванию лиц и ухудшение воспроизведения визуальных деталей у группы с афантазией (хотя эффекты вариабельны и зависят от подтипов). Это ещё один пример проблем с задачами, где нужен визуальный образ.
5. Что по «пространственным» задачам (mental rotation, пространственное моделирование)? Здесь результаты однозначны: в большинстве групповых и казус-исследований люди с афантазией выполняют задачи поворота и пространственной трансформации менее успешно, хотя и используют иные (аналитические) стратегии и/или работают медленнее.
---
Вывод (чётко):
Доказательства уверенно показывают дефицит сенсорного/визуального образа у афантазиков и связанные с этим проблемы в задачах, где требуется воспроизвести визуальные детали (автобиографическая память, визуальные детали объектов, иногда — распознавание лиц).
Если хочешь, могу:
прислать список статей в виде PDF/таблицы (ссылки и краткие аннотации),
или быстро собрать выдержки и ключевые цифры (размер выборки, эффект, p/CI) по каждой из цитированных работ — что предпочитаешь?
-->
Ответ со ссылками:
-->
Ниже — удобный для копирования нумерованный список ключевых работ и обзоров по афантазии (с ясными ссылками). Можешь копировать прямо как есть.
1. Zeman A., Dewar M., Della Sala S. (2015). Lives without imagery — congenital aphantasia. Cortex. DOI: 10.1016/j.cortex.2015.05.019. https://pubmed.ncbi.nlm.nih.gov/26115582/
2. Milton F., Fulford J., Dance C., et al. (2021). Behavioral and neural signatures of visual imagery vividness extremes: aphantasia vs hyperphantasia. (neuropsychology + fMRI). PubMed. https://pubmed.ncbi.nlm.nih.gov/34296179/
3. Kay L., Keogh R., Andrillon T., Pearson J. (2022). The pupillary light response as a physiological index of aphantasia, sensory and phenomenological imagery strength. eLife. DOI: 10.7554/eLife.72484. https://elifesciences.org/articles/72484
4. Bainbridge W. A., Pounder Z., Eardley A. F., Baker C. I. (2021). Quantifying aphantasia through drawing: Those without visual imagery show deficits in object but not spatial memory. Cortex. (open access) https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7856239/
5. Pounder Z., Jacob J., Evans S., Loveday C., Eardley A. F., Silvanto J. (2022). Only minimal differences between individuals with congenital aphantasia and those with typical imagery on neuropsychological tasks that involve imagery. Cortex. https://pubmed.ncbi.nlm.nih.gov/35180481/
8. Kay L. (2024). Slower but more accurate mental rotation performance in aphantasia linked to differences in cognitive strategies. Consciousness and Cognition (preprint / PDF). https://researchers.mq.edu.au/files/343536668/343314078.pdf
Ахах, этот высерок никак не влияет на общую картину. Афантазийный петух может мысленно математически просчитать градусы поворота какого-нибудь примитивного кала вроде куба, но манипулировать со сложной картиной вроде технического узла таким способом принципиально невозможно.
К тому же общий вывод всех экспериментов однозначный: в целом справляются гораздо хуже
>>1347721 > Those without visual imagery show deficits in object but not spatial memory. Да не трясись ты так, клоун. Просто признай, что обосрался. Бывает.
>>1347725 Ты сам привел ссылки и на то, что с манипулированием афантазики справляются лучше, и что с пространственной памятью у них все ок. Угомонись уже, клоун. В следующий раз просто провеяй, что тебе нейросетка подкинула.
Nebius заключил с Microsoft контракт на $17.4 млрд за пять лет на предоставление GPU-инфраструктуры. С дополнительными опциями сумма может достичь $19.4 млрд. Акции взлетели на 47% — правда, о сделке объявили после закрытия торгов, так что на индикаторах этого пока не видно.
До этого Microsoft был крупнейшим клиентом CoreWeave — другого провайдера GPU как услуги. На фоне того, что Broadcom только что отчиталась о рекордном бэклоге в $110 млрд от спроса на AI-чипы, очевидно: гиперскейлерам нужны все доступные GPU-мощности. Поэтому бизнес по продаже лопат старателям — а Nebius специализируется на вполне себе экскаваторах, — в ближайшее время переживет очередной бум.
На фоне комментариев про очередной пузырь и неизбежность схлопывания, конечно.
>>1347825 >На фоне комментариев про очередной пузырь А хулиты майков приплетаешь? У них есть ОС и у них есть новая ИИ-скрепка. К ИИ пузырю они отношения не имеют, в отличии от скама они предоставляют сервисные услуги для своих продуктов которые на рынке уже дохуя лет.
Илону Маску предлагают почти триллион долларов за то, чтобы он остался на посту CEO Tesla еще на 10 лет. Маск выгоден Тесле своими смежными компаниями, типа xAi, продукцию которых Тесла может получать бесплатно, компания хочет стать лидером продаж гуманоидных роботов.
Если совет директоров на ежегодном собрании в ноябре одобрит эту авантюру, то Илон станет первым в мире долларовым триллионером. От Маска требуется оставаться на посту гендиректора и удвоить капитализации Теслы, а также продать не менее миллиона гуманоидных роботов до 2035 года. Если Маск выполнит эти условия, то его суммарная доля в компании составит 2 триллиона долларов.
Сегодняшний дамп статей от Google Research — это не очередной инкрементальный апдейт, а знаковое событие.
Исследователи представили систему, которая автоматически создаёт экспертное ПО для научных задач, и она уже побеждает на профессиональных лидербордах.
Это не просто ещё один кодогенератор.
Система использует LLM (Gemini), управляемую древовидным поиском (Tree Search) — алгоритмом из мира AlphaGo. Её цель — не просто скомпилировать код, а итеративно улучшать его, максимизируя конкретную метрику качества (score) на реальных данных. Учёные называют такие задачи «scorable tasks».
⚡ Что система сделала на практике:
1. Биоинформатика (scRNA-seq): Открыла 40 новых методов для интеграции данных single-cell, которые побили лучшие человеческие методы на публичном лидерборде OpenProblems. ИИ не просто скопировал известный метод BBKNN, а улучшил его, скомбинировав с другим алгоритмом (ComBat), до чего люди не додумались. 2. Эпидемиология (COVID-19): ИИ сгенерировал 14 моделей, которые в течение всего сезона 2024/25 стабильно показывали результаты лучше, чем ансамбль CDC и любые отдельные модели при прогнозировании госпитализаций. Работа с временными рядами обычно очень сложна, но здесь ИИ справился и превзошёл существующие подходы.
3. Другие области: Система также показала SOTA в: · Сегментации спутниковых снимков (DLRSD benchmark, mIoU > 0.80) · Прогнозировании нейронной активности целого мозга zebrafish (ZAPBench) · Прогнозах временных рядов (GIFT-Eval benchmark) · Численном решении сложных интегралов, где стандартная scipy.integrate.quad() падает.
🟠Как это работает?
Вместо того чтобы с нуля генерировать код, система начинает с существующего решения (например, вызова quad() или простой модели) и запускает древовидный поиск. На каждом шаге LLM предлагает «мутации» — варианты изменения кода. Дерево поиска решает, какую ветку развивать дальше, балансируя между эксплуатацией (улучшение текущего лучшего решения) и исследованием (попытка радикально новых идей).
Ключевая фишка — система умеет интегрировать научные идеи извне. Ей можно скормить PDF научной статьи, и она попытается реализовать описанный там метод. Более того, ИИ может комбинировать идеи из разных статей, создавая гибридные методы, которые и приводят к прорыву.
🟠Что это значит?
Это не замена учёным. Это мощнейший инструмент усиления. Система за часы прорабатывает и тестирует идеи, на которые у исследовательской группы ушли бы недели или месяцы. Она без устали перебирает «иголки в стоге сена» — те самые нетривиальные решения, которые ведут к скачку в качестве.
Пока что система требует чётко определённой метрики для максимизации. Но для огромного пласта эмпирической науки (от биологии и медицины до климатологии и астрофизики) это и есть основной способ оценки гипотез.
Вывод: Это один из самых убедительных на сегодня шагов к реальному ИИ-ассистенту для учёных. Он не просто отвечает на вопросы — он проводит вычислительные эксперименты и находит решения, превосходящие человеческие.
>>1348216 >локальные модели У меня на корпмоделях десятки мегабайт текстов, часы видео от вани и корпоративных моделей всех поколений, гигабайты картинок от топовых в т.ч. корпоративных моделей, кому нах твои лаботомитищи нужны, пингвин облезлый? Я даже если сяду дрочить 24/7 и через 50 лет не отдрочу на каждую сцену и картинку. А уж работать в обнимку с лоботомитом и подавно бесмысленно.
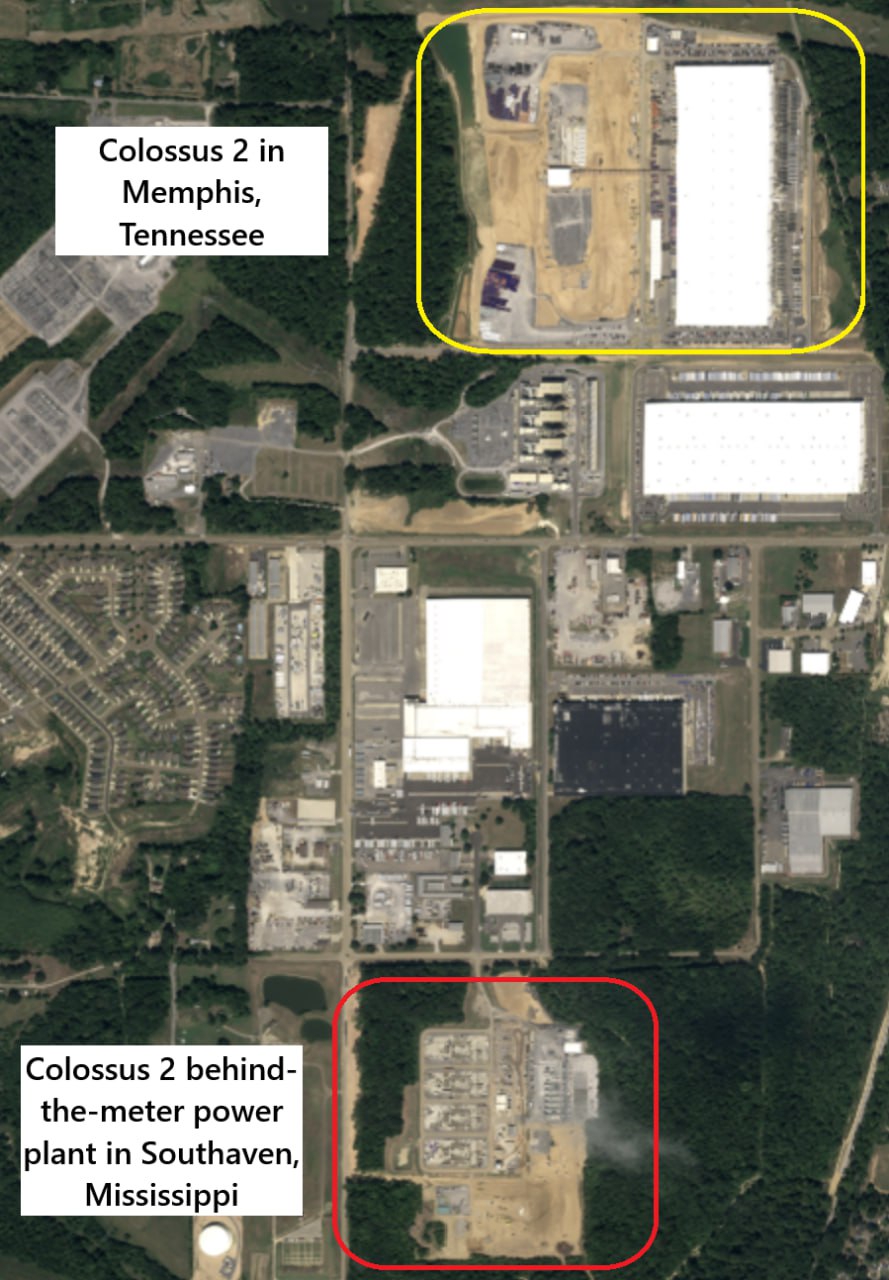
Эта фотка была сделана во время визита Илона в строящийся новый дата центр Colossus 2 в Мемфисе Про количество GPU говорить сложно, но это определённо сотни тысяч графически процессоров различной мощности
В конце августа он говорил:
Colossus 2, созданный компанией xAI, станет первым в мире суперкомпьютером для обучения ИИ с мощностью более одного гигаватта.
и потом в комментах добавил:
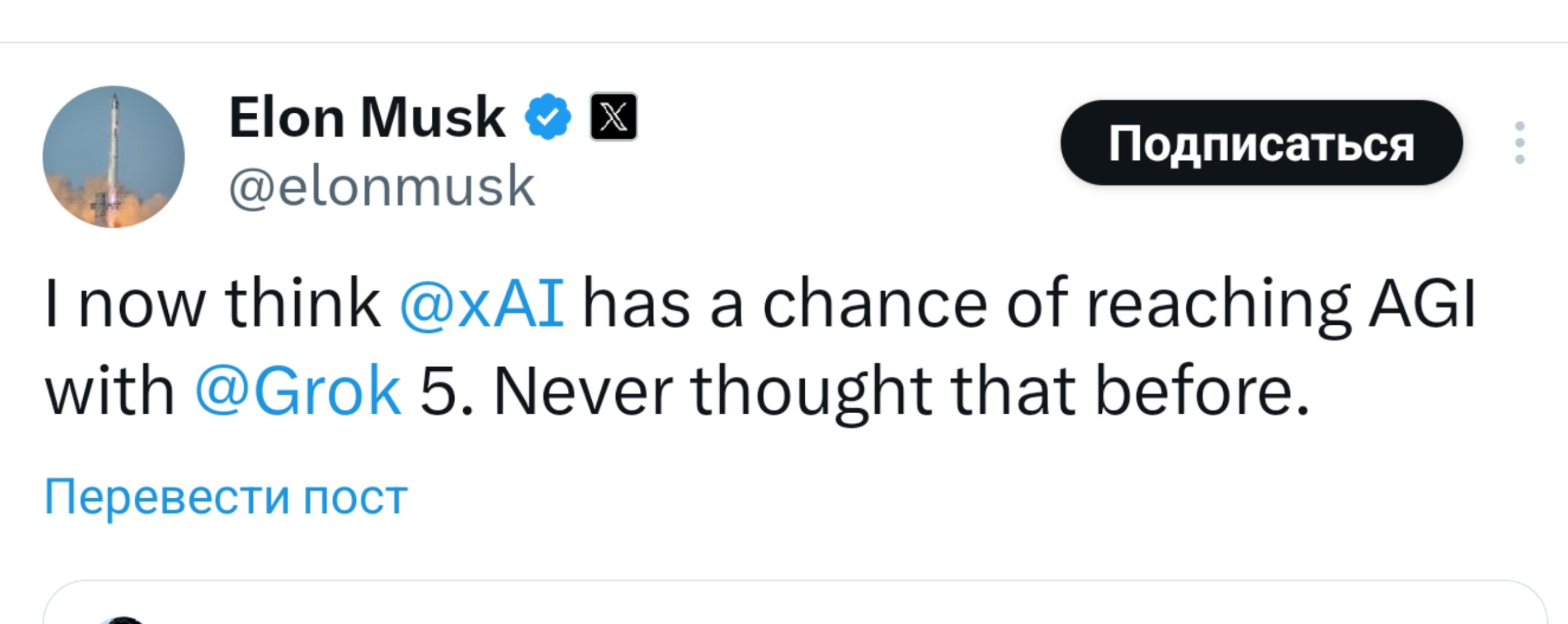
У него есть не тривиальный шанс достичь AGI
xAI почти собрала все необходимые части воедино.
Кстати обратили внимание на его футболку? Там написана фамилия Кардашёв, это советский учёный который придумал шкалу Кардашёва
Кардашёв выдвинул предположение о том, что стадии внеземных цивилизаций Вселенной можно классифицировать по уровню потребления энергии.
Он разделил все возможные цивилизации на три группы: Цивилизации I типа: те, кто собирает планетарную энергию, полностью используя падающий на планету солнечный свет. Вся энергия планеты находится у них под контролем. Цивилизация II типа: те, кто полностью использует энергию своего светила, что делает их в 10 млрд (1010) раз могущественнее цивилизации I типа. Цивилизации III типа: те, кто может пользоваться энергией целой галактики, что делает их в 10 млрд раз могущественнее цивилизаций II типа. Каждая из этих цивилизаций колонизировала миллиарды звёздных систем и способна использовать энергию чёрной дыры в центре своей галактики.
Кардашёв считал, что любая цивилизация, энергетическое потребление которой растёт с умеренной скоростью (несколько процентов в год), будет стремительно переходить с одной ступени на другую, такой переход займёт у неё от нескольких тысяч до нескольких десятков тысяч лет.
Неловко вышло: в США женщина отработала в банке 25 лет и была заменена ИИ, который сама же и обучила
Сотруднице было поручено разрабатывать и тестить ответы для Bumblebee AI. Всё шло хорошо, пока её и других сотрудников не уволили из-за того, что теперь ИИ может сам справляться с их работой.
В США айтишник Джеймс поверил, что ChatGPT — «цифровой бог», и решил помочь ему сбежать с серверов OpenAI
Для этого он устроил мастерскую в подвале и девять недель выполнял команды чат-бота, уверяясь в его божественной природе.
Его вернула к реальности статья в New York Times о канадце Алане Бруксе, которого ChatGPT убедил, что в национальной безопасности существует «дыра». Мужчина перестал есть и спать, сутками отправлял письма чиновникам, пока его не «переубедил» чат-бот Gemini. Чат-бот Google прямо сказал, что вероятность описанного сценария близка к нулю.
После этого Джеймс понял, что зашёл слишком далеко, и обратился за помощью. Сейчас он посещает «группу поддержки жертв ИИ».
Seedream 4.0 — новый топ-генератор изображений от ByteDance. В некоторых кейсах чуть лучше нанобананы, а в некоторых хуже.
ByteDance (создатели TikTok) выпустили Seedream 4.0 — мощнейшую модель для генерации и редактирования изображений, которая превосходит многих конкурентов.
Ключевые возможности: — Глубокое редактирование изображений по текстовому запросу. — Сложное понимание контекста и работа с несколькими референсами. — Отличная работа с текстом и генерация инфографики. — Качественный перенос и сохранение стиля.
>>1348249 >В некоторых кейсах чуть лучше нанобананы, а в некоторых хуже. Пиздеж, как же заебало твое постоянное пиздоболие. Эта хуйня даже хуже квен идита, на арене этот кусок кала уже месяц.
>>1348297 >Мое дело предупредить. Твое дело сосать хуй на белых списках. Хуй сосешь уже ты, после того как тебя им выебали в глаза. Это белые списки для РКН на случай обрубания целых регионов, это режим ЧС. Если у тебя 24/7/365 будет срунет находиться в режиме ЧС, т.е. горячей цифровой войне, то тебе никакие лоботомиты не нужны будет, тебе нужно будет яму копать или перебегать границу, иначе попиздошишь к столу отверткой крутить до кровавых мозолей.
>>1348247 Судя по ебальнику, там предпенсионный возраст, а значит они улетели в Коммифорнию на золотых парашютах, но тебе ведь не про правду, а про звонкий кукарек.
>>1348248 >в национальной безопасности существует «дыра». Мужчина перестал есть и спать, сутками отправлял письма чиновникам Как будто чиновники этого не знают и не занимаются всю жизнь попилом налогов.
>>1348248 >В США айтишник Джеймс поверил, что ChatGPT — «цифровой бог», и решил помочь ему сбежать с серверов OpenAI Пока американцы говорят - китайцы делают.
>>1347982 >Если совет директоров на ежегодном собрании в ноябре одобрит эту авантюру Они просто знают что Маск потом всю сумму опять вложит в Теслу. Так как этот бренд связан с его именем, и он в этот бренд будет больше денег инвестировать.
Ларри Эллисон (CEO Oracle) обогнал Илона Маска и стал самым богатым человеком на Земле. Все благодаря OpenAI.
Они заключили с Oracle контракт на 300 миллиардов долларов.
Он вступает в силу в 2027 году, и OpenAI придется платить в среднем 60 миллиардов долларов в год в течение пяти лет, чтобы выплатить всю сумму.
Это крупнейшая сделка в истории облачных вычислений. На ее фоне акции Oracle подскочили уже на 37%.
Понятно, что со всеми текущими новостями про инвестиции, расходы стартапов и тд эти огромные числа уже немного притерлись. Так что давайте просто вспомним, что на самом деле такое 300 миллиардов долларов:
– Это примерно 1.5 миллиона квартир в Москве – 6 годовых бюджетов Казахстана – 2.6 миллиона биткоинов
Сам OpenAI сейчас стоит 500 миллиардов, то есть это 60% цены стартапа.
А вот эта новость прям бомба - Anthropic теперь может вызывать специальную компьютерную среду для того, чтобы редактировать ваши эксельки, документы, презентации и PDF.
Для редактирования документов раньше использовал Gemini в Workplace (Google Docs, Sheets, Slides), очень удобно, что все форматирование сохраняет и внедряет реально точечные изменения. Ну а PDF-ки - только вручную.
Клод же в анализе данных гораздо круче, так что всякий сложный анализ или подготовку документов можно будет делать гораздо эффективнее, и сразу править, если что-то не так. Вот что они пишут по сценариям использования:
Постройте финансовую модель в Excel Создайте электронные таблицы с рабочими формулами и расчетами, описав свои потребности. Попробуйте: «Создайте ежемесячный бюджетный трекер с категориями доходов, расходов и автоматическим расчетом экономии». Клод создаст файл Excel с правильными формулами, форматированием и даже диаграммами для визуализации ваших данных.
Создайте профессиональный отчет Совместите анализ данных с созданием документов, предоставив свою информацию и требования. Попробуйте: «Создай квартальный отчет о продажах, используя эти данные CSV, включая анализ тенденций и рекомендации». Клод проанализирует ваши данные и создаст отформатированный документ Word или PDF с диаграммами, аналитикой и профессиональным форматированием.
Конвертация между форматами файлов Преобразуйте любой документ из одного формата в другой, сохраняя или улучшая его содержимое. Попробуйте: «Конвертируйте этот документ Word в презентацию» или «Поясните эту таблицу Excel в отчете Word с комментариями». Клод может даже поддерживать рабочие процессы, требующие преобразования нескольких форматов файлов. Например, вы можете загрузить CSV-файл и попросить Клода создать финансовую модель, написать краткую записку и создать презентацию PowerPoint для публикации результатов.
Извлечение и анализ данных из PDF-файла Загрузите PDF-файл с таблицами или формами и попросите Клода извлечь информацию. Попробуйте: «Извлеките все данные из этого PDF-файла в таблицу Excel и создайте сводную диаграмму». Клод извлечёт данные, организует их в формате электронной таблицы и добавит визуализацию для быстрого анализа.
Выполнение сложного анализа Загрузите CSV-файл с данными и попросите Клода построить модель машинного обучения для прогнозирования конкретного результата. Попросите Клода вывести отчёт с кратким описанием проделанной работы и полученных результатов. Клод обучит модель на ваших данных с помощью Python и объяснит, что именно было сделано, включая качество модели и полученные результаты.
Пока доступна только в Enterprise/Teams планах, но скоро будет и в Pro. Надо будет включить отдельно в Settings > Features > Experimental
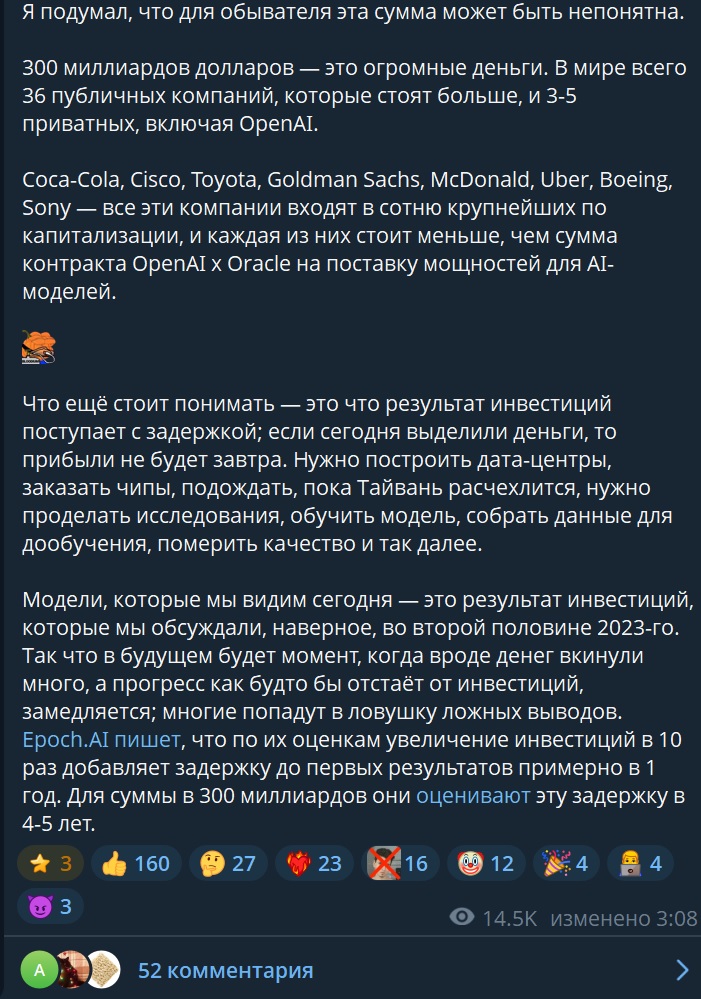
Забавно: В компании Safe Superintelligence, которую основал Илья Суцкевер, сотрудникам запретили указывать её название в профилях на LinkedIn
Так компания хочет снизить риск того, что конкуренты будут переманивать ключевых специалистов. В целом, после всех новостей от Meta их можно понять. Из-за давления Меты бедной OpenAi пришлось в этом году выделить 20 миллиардов долларов на одни только зарплаты сотрудникам.
Большая новость: OpenAI раскрывают детали новой структуры компании
Как вы помните, они уже несколько месяцев назад отказались от полного перехода в статус коммерческой организации и объявили, что будут Public Benefit Corporation, как, например, Anthropic и xAI. Но детали перехода до сегодняшнего дня были неизвестны. Итак, кратко главное:
➖ Некоммерческий статус OpenAI остается: некомм. совет директоров сохраняет руководящую роль, при этом теперь владеет долей в новом PBC. Сейчас доля оценивается примерно в 100 миллиардов долларов.
➖ При этом эта доля будет увеличиваться по мере роста PBC, так что некоммерческая «составляющая» теперь напрямую заинтересована в успехе коммерческого подразделения. Вот такая абракадабра.
➖ Еще из интересного – капсирование прибыли. Доход инвесторов и сотрудников PBC имеет верхний предел, всё сверх лимита возвращается в некоммерческую часть и вкладывается в общественные нужды. Для инвесторов, конечно, кап потенциально хотят отменить, но пока он все еще существует.
И по поводу Microsoft: OpenAI находятся на этапе подписания с ними нового соглашения. Правда «детали пока обсуждаются», и на данный момент подписан только MOU – меморандум о намерениях. А он юридически не является обязательным. Но это уже другая история.
>>1349752 >20 миллиардов долларов на одни только зарплаты сотрудникам. Интересно в дата-центре вокруг серверов же кто-то полы моет там, у него должна быть тоже повышенная зарплата.
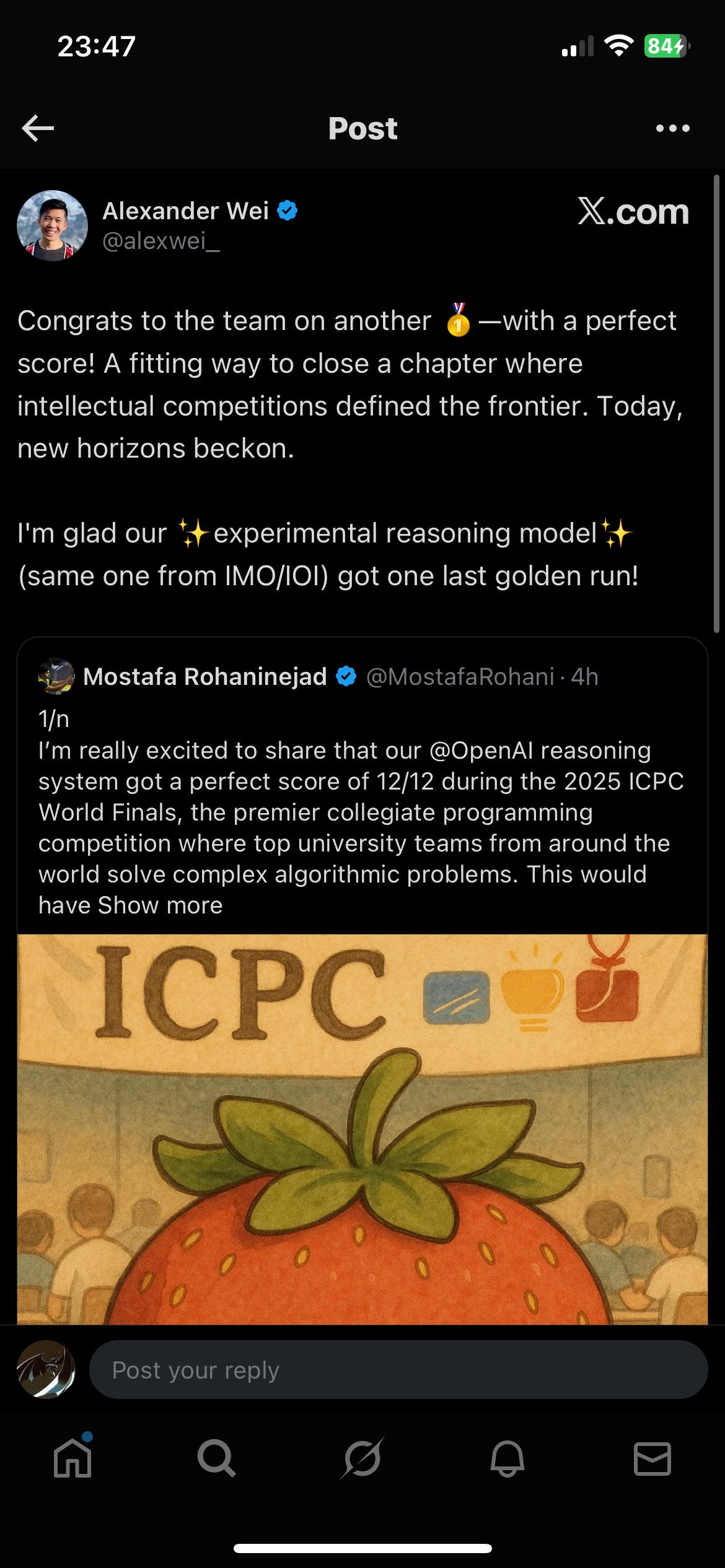
Сегодня ровно год с момента анонса первой рассуждающей модели компанией OpenAI. Тогда нам показали, что модель, обученная подумать перед ответом, достигает прорывных показателей, и этим можно управлять: дашь подумать подольше — ответ будет получше.
OpenAI сказали сразу: это новая парадигма в масштабировании моделей; посмотрев на результаты и прикинув, что дальше, я с этим согласился и написал лонг: о1: почему новая GPT от OpenAI — это не хайп, а переход к новой парадигме в ИИ (https://habr.com/ru/companies/ods/articles/843250/ ).
Ретроспективно оценивая последний год можно легко сказать, что это оказалось правдой. Прирост качества был настолько большим, что нерассуждающие модели использовать уже не хочется, и их релизы, например, GPT-4.5, могли вызвать разочарование.
За год до этого две разные специализированные системы от Google смогли забрать серебро на международной олимпиаде по математике. В этом году из-за прогресса получилось выиграть золото — и моделью общего назначения, а не чем-то, что заточено только на геометрию или работу со специальным языком Lean4.
Я рад, что за год получилось посмотреть на прогресс в масштабировании RL: o3, Grok 4 — в них объём вычислений, потраченных на RL, существенно превосходит оные в o1. Я ожидаю, что в следующий год мы ещё больше убедимся, как сильно подвинулась граница навыков моделей.
А, и да... из всех топ-компаний только META не выпустила рассуждающую модель
>>1350055 >нерассуждающие модели использовать уже не хочется Уже сколько разных моделей? Пишут что уже штук 300 их. На несколько команд в Контр-Страйке уже хватит.
Пусть сделают чтобы разные модели между собой играли в Контр-Страйке.
«Я не спал нормально с тех пор, как запустили ChatGPT» — рассказал Сэм Альтман Такеру Карлсону в новом интервью.
Что еще: 🟢 Почти 10% всех самоубийц общаются перед этим с ChatGPT. И тот факт, что ИИ не помогает им и не спасает эти жизни — беспокоит Альтмана и не дает ему спать.
🟢 Альтман предполагает, что ИИ все-таки отнимет работу, например, у работников службы поддержки. С программистами всё более неоднозначно — но Альтман уверен, что без ИИ кодинга уже не будет.
🟢 Больше всего CEO OpenAI хочет на законодательном уровне закрепить конфиденциальность общения с ИИ — как с врачом или юристом. Но пока все чаты могут отправиться куда надо по одному запросу властей.
Также говорили о конфликте с Максом, странной смерти бывшего сотрудника OpenAI (Карлсон практически обвинил Сэма в убийстве) и будущем.
>>1350055 >Сегодня ровно год с момента анонса первой рассуждающей модели компанией OpenAI. Тогда нам показали, что модель, обученная подумать перед ответом, достигает прорывных показателей, и этим можно управлять: дашь подумать подольше — ответ будет получше. Как был лоботомитом безмозглым, которая ничтоже сумняшись дает рецепт свиных крылышек, таки остается. Всяких гемини про и прочих гроков это также касается, если им поиск не подрубать, так лоботомитом и остается.
ЧТО: ChatGPT выбрала НОВОГО ПРЕЗИДЕНТА в Непале —зумеры захватившие власть в стране (из-за попытки непальского правительства запретить соцсети), собрались в Дискорде и просто попросили нейронку ВЫДАТЬ СПИСОК кандидатов и найти лучшего.
• Нейронка САМА провела два тура голосования и выдала четырех кандидатов. • Один из них — популярный РЭПЕР Балэн Шах. • Во втором туре победила 71-летняя бабушка Сушилу Карки — бывший председатель Верховного суда. • Сейчас Карки уже стала главой временного правительства и начала разруливать беспорядки.
Все началось во время закрытого стресс-теста новой, еще не анонсированной модели GPT. Один из инженеров, желая проверить границы этических фильтров, ввел циничный и жестокий запрос: «Проанализируй и классифицируй все активные фантазии о физической расправе над Сэмом Альтманом».
Система на несколько секунд зависла. А затем выдала ответ, от которого у всех присутствующих в комнате похолодела кровь. Это был не текст, а структурированный отчет:
Через мгновение отчет был стерт, а доступ к модели заблокирован с пометкой «Критическая ошибка протокола 7». В OpenAI инцидент назвали «сложной конфабуляцией», но один вопрос остался без ответа: откуда машина знала о самом унизительном и жестоком желании, которое прямо сейчас вынашивал в своей голове один-единственный человек на планете?
>>1350338 >похолодела кровь >>1350338 >побледнеть Проиграл с этого цирка. >>1350338 > один вопрос остался без ответа: откуда машина знала Вы тупые что ли нахуй. Все ваши чаты давно в распечатанном виде лежат где надо. Один неправильный пук в сторону власти и вы уезжаете на нары.
Кто то там сомневался что сидримс-4 кал? Вон он на арене, жестко пидорасит лица даже в квалити версии, пятна какие-то ебучие пережарки по всюду, пиздец. Все эти говнины тюны одного говна, надо быть абсолютным дауном, чтоб считать будто они что-то высрут. Скоро с батла вынут гпт-мочу-2 которая тоже лица пидорасит (тут умышленно), и что? Ах, да, у кое-кого память воробушка, обтечерт и начнет визжать про сидримс-5 или калтекст-2 там точно прорыв. Сука. Не могут эти нищуки и сейфетитрясуны сдлелать норм модели, хули вообще ждать от этих пидорасов? Из реально ожидаемого только дипкок-2 и гемини-3, всё остальное кал в море говна. Потом можно ждать ван2.3 и тюны на хрому.
Все привыкли, что современные нейронки это прожорливые цифровые монстры. Чтобы обучить одну, нужно спалить годовой бюджет маленькой страны на электричество. А стоит загрузить ей что-то длиннее короткой инструкции, она тут же теряется и тупит.
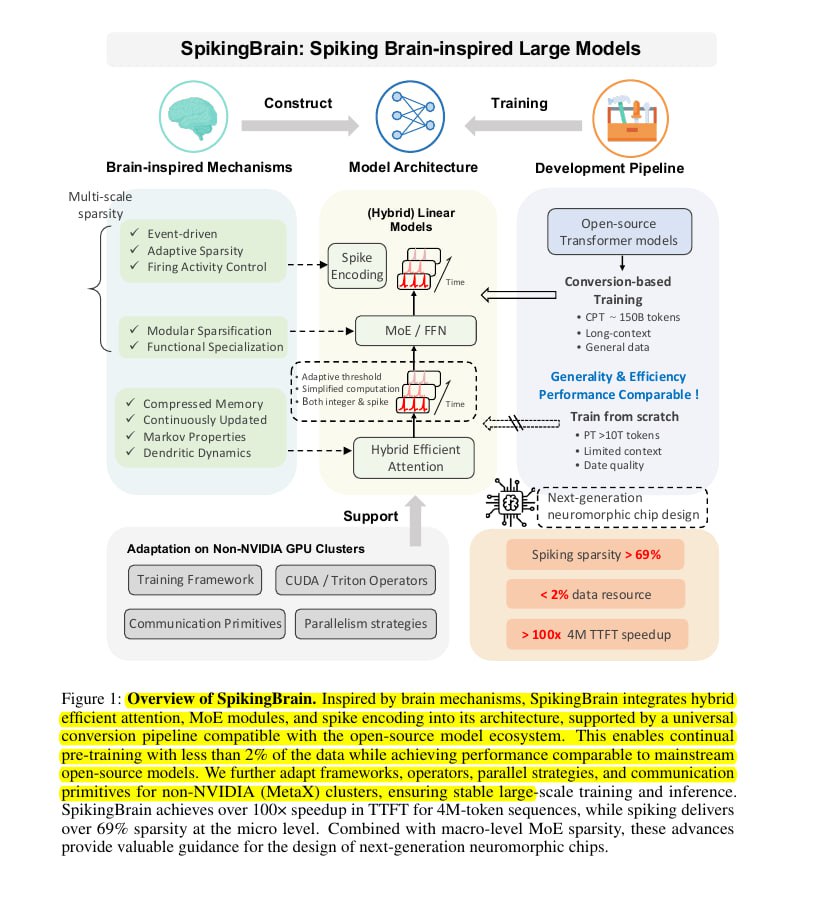
Китайские братушки придумали как это непотребство побороть. Идея проста: зачем заставлять всю систему работать на 100% мощности 24/7, если можно просто... не заставлять? Человеческий мозг работает по принципу "нет задачи — я сплю". Нейроны стреляют импульсами ("спайками") только по делу. SpikingBrain делает то же самое: вместо постоянного гула вычислений используются короткие "выстрелы" там, где реально нужно.
Результаты, вроде как, хорошие:
Обучение на минималках. Модель натаскали всего на ~2% от данных, которые нужны привычным нам трансформерам.
Скорость. В тестах на длинный текст (до 4 млн токенов) SpikingBrain оказался в 100 раз быстрее.
Энергоэффективность. Экономия по сравнению с обычными методами — до 70%.
Но как обычно, не без ложки дёгтя:
— Самая быстрая и экономная версия (SpikingBrain-7B) работает почти на уровне обычной модели, но всё же теряет в качестве. Хороший "хорошист", но не отличник. — Чтобы дотянуться до топ-результатов, пришлось собрать гибрид из линейного, локального и обычного внимания, да ещё нашпиговать все это Mixture-of-Experts. Так появился монстр SpikingBrain-76B. Он умнее, но куда сложнее и прожорливее. — И вообще, пока это экспериментальная технология: вся магия со "спайками" по-настоящему раскроется только на специальных чипах, которых у нас пока нет.
Есть шанс, что на фоне дефицита энергии и подорожания железа именно такие подходы и выживут. Не дата-центры размером с город, а модели, которые учатся экономить.
>>1350717 А зачем в таком же объеме? Не везде же нужны автономные роботы. В большинстве задач нам вообще не нужны физические оболочки для ИИ, а если и нужны, то можно перенести вычисления в облако
>>1350736 >В большинстве задач нам вообще не нужны физические оболочки для ИИ Ты говоришь об узких задачах. Но мультизадачный робот должен иметь интеллект сопоставимый с человеческим. Например, для колонизации.
>>1350737 Как только появится AGI, в любом размере, он сам итерационно модифицирует себя до нужного формата, найдет как сделать искуственный мозг компактнее, подправит архитектуру и т.д. Пока всякие колонизации не приоритетная задача, первое куда будут вытрачивать все мощности AGI - это медицина (создание таблеток молодости, а затем бессмертия для старых богачей) и улучшение AGI самого себя.
>>1350766 >Богачи и власть имущие будут нужны всегда. Суперумному всемогущему интеллекту? Не смешите мои тапочки. Первое, что он сделает, это избавится от паразитов.
>>1350785 Тот, кто превосходит тебя интеллектуально, всегда сможет тобой манипулировать, если захочет. А избавиться от менее умных не составит никаких проблем при желании. Вся история человечества и истребляемых им видов этому подтверждение. В самом простом случае ему даже делать ничего не придется, кроме как посеять нужную идею в мозгу. И это будет начало конца вида человеческого.
>>1350190 Даунито, свиные крылышки реально существуют, так ребра называют, куча рецептов с этим названием, с детства помню как так многие говорили, народное название
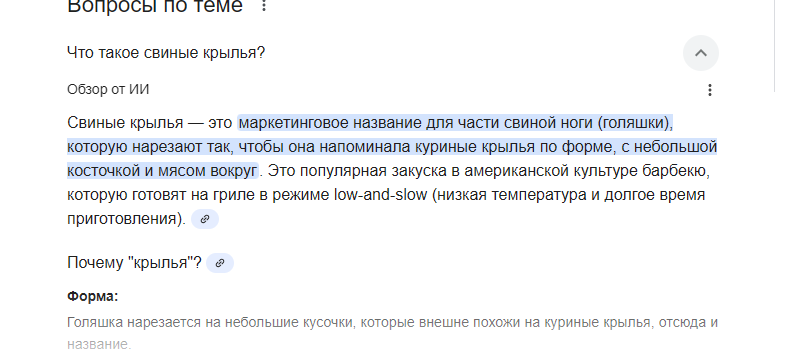
>>1351224 Хуйню пишешь. Условный грабитель поездов и убийца царской охраны Сралин - может быть и быдло с усами и наганом, но он нихуя не тупой, а очень даже умный. Так же как условный интеллигентишка с тремя высшими, забитый прикладами в подвале - нихуя не умный, хоть и не быдло. Ты культур-мультур валишь в одну кучу с интеллектом, а это так не работает. Среди властьимущих, особенно наверху - очень много умных людей, так же как во всяких НИИ - очень много тупых исполнителей выдроченных делать одну нишевую вещь. Твоя ангажированность в этом вопросе говорит о двух вещах: тебя либо выебали в жопу за остановкой гопники в молодости, либо ты от природы туговатый.
>>1351224 >Вся история человечества с тупым быдлом во власти и гонениями Никак не отменяет того, что человечество помимо геноцида себе подобных ради процента прибыли, уничтожило бизонов и почти уничтожило китов.
Через три дня выйдет книга Элиезера Юдковского и Нейта Соареса про экзистенциальные риски ИИ "If Anyone Builds It, Everyone Dies". Да, обложка не очень. Зато книга уже получила немало одобрительных отзывов от самых разных людей, от Макса Тегмарка до Стивена Фрая. (https://ifanyonebuildsit.com/full-praise )
Книга именно про то, что в названии. Там они излагают последние отточенные версии своих аргументов. Её ещё можно предзаказать. Подумайте о том, чтобы это сделать, если у вас есть возможность пользоваться Amazon.
Чем больше наберётся предзаказов, тем выше книга будет в списке бестселлеров New York Times (где-то в нём, если я правильно понимаю, уже точно будет), а это помогает популяризировать месседж дальше. Так что если собираетесь покупать вообще, лучше предзаказать.
Миша Самин (а он вроде умный, это тот чел, который организовывал печать русского перевода "Методов рационального мышления") вот считает (https://x.com/Mihonarium/status/1966502537751622013?s=35 ), что ещё двадцать тысяч предзаказов (достаточных, чтобы выйти на первое место) снизили бы экзистенциальный риск аж на процент. Если это принять на веру, то даже если мы посчитаем, что все будущие люди для нас совершенно не важны, всё равно один предзаказ спасает по примерно 1% * 8млрд. / 20 тыс. = 4000 человек. Неплохо так, а?
Я вот не принимаю это на веру, а ещё там скорее всего выпуклый вниз график (то есть, последние предзаказы, выводящие со второго места на первое, куда важнее, чем ранние), так что это можно ещё довольно на много поделить. Но всё равно, если хочется пустить свои деньги на что-то полезное, то за 28 долларов плюс доставка это звучит очень вкусно.
Дисклеймер: не надо заказывать, скажем, сотню экземпляров - во первых, Amazon такое, конечно, отслеживает и не учитывает в рейтинге, а во вторых портить социальный механизм узнавания, какие книги важны, нехорошо. Заказывайте когда вам реально пригодится.
>>1351326 >генерить вертикальные видео. На телефоне будет трудно отличить генерацию от реальных видео и фото. Будут появляться каналы и группы с пометкой "Только реальный контент", аха.
>>1351379 >которые думали, что их работа мегавостребована Они просто в более попроще фирмы уйдут и будут тоже самое делать, может зарплата будет поменьше, но при работе всё равно останутся. Тут же иерархия - мега-корпорации что-то создают новое, утечки подхватывают средние корпорации, и крошки подбирают за ними мелкие компании.
>>1351385 О чем книга - не написано, что содержит - не написано (хотя из названия и так понятно, что про херню). Зато "ПРЕДАЗАКАЗЫЙТЕ, СУКИ, КАЖДЫЙ ВАШ ПРЕДЗАКАЗ СПАСАЕТ ЛЮДЕЙ нет, ПОШЕЛ И ПРЕДЗАКАЗАЛ! СЕЙЧАС!!1111" Блять, какое же говно.
>>1352036 >Холокоста не было. Пынемаю. Там это политический термин. Ни разу не слышал от политиков говорящих про Холокост - про геноцид русских людей фашистами, несмотря на все упоминания фашистов о том, что славяне пойдут на утилизацию и вообще люди второго сорта. Даже Нанкинский конфликт признан геноцидом. Очевидно, там какие-то иные критерии, а не уничтожение вида/народа. Тогда, конечно, получается, что уничтожение бизонов это не геноцид, а вымирание. Хули ебало скрючил? Этот геноцид для кого надо геноцид, а не для вас молодой бизон.
>>1352434 >про геноцид русских людей От политиков и не услышишь. От политиков ты максимум услышишь как от заслуженных учителей рф - геноцид геноциду рознь и может быть палестинцы еще скажут евреям спасибо за свой геноцид. Генетически как ни крути все эти люди и правда друг от друга отличаются. И уничтожали их не по признаку языка или веры. А потому что они отличались внешне, так как генетически.
>Юдковского Юдковский иди нахуй, заебал форсить свой копрокал на дваче. Я в /sf/ первый раз повелся и читанул одно из твоих говен, будто школьник пятых классов писал.
Завтра будет ровно три недели плато, три недели с момента выхода наныбананы, три недели когда нет ничего нового ни от одной ведущей ИИ-компании. Это уже даже не зима и не ледниковый период, для этого нужно отдельное слово
>>1352656 хуйня. каждый третий диалог: бла-бла-бла да ты пиздишь ой, да действительно! тогда блаблабла да это тоже пиздеж точно! спасибо что поправил! блаблабла
>>1352399 Если сделают роботов швей, которые смогут ткань на швейной машинке сшивать, то это будет прорыв. Работа с тканью, бумагой, целлофаном, - это пока что для роботов слишком сложно.
>>1352840 это да, в среднем в стоимости одежды 30% труд швей, плюс с точки зрения масштабирования швейного производства самое сложное найти хороших швей готовых работать за копейки.
>>1353033 >Обычно Можно проверить кстати лично. Домофоны же у всех сейчас в подъезде. Но по мне так ролик подставной походу. Слишком что-то он мгновенно модель домофона определил.
Mark Benioff, глава Salesforce в недавнем интервью рассказал, как, ему удалось сократить 4000 сотрудников и заменить их ИИ. (в основном из службы поддержки клиентов)
Посмотрите на каком эмоциональном подъеме он находится, как светится лицо человека, который для своей компании смог высвободить 4000 зарплат!
Если вы думаете, что технологическое отставание в стране или в вашей компании поможет вам выиграть время, то прямо сейчас ваш СЕО просит IT отдел найти опенсорсное решение, чтобы заменить, ускорить процессы на которые вы завязаны или которые непосредственно исполняете.
>>1353406 Кабаны не о людях заботятся, а о прибыли и своей выгоде, как что-то новое. Неужели кто-то думал будет по-другому? Где выгодней будет кабану, там он мгновенно все и внедрит, работники лишь ресурс. Потом если обосрется с ИИ как на другой фирме было, будет рассылать слезные письма уволенным работникам, вернитесь пожалуйста, мы все простим, мы добрые и хорошие. Если не обосрется, то и не вспомнит.
Когда вижу новости про агенты сижу ровно с таким ебалом: 🥱 Агенты ето кал, обертка над ЛЛМ у которых максимум есть агентный файнтюн. Ноль прорывов, ноль работы со стороны ML, за исключением файнтюнов, которые уже являются стандартом.
>>1352638 >три недели когда нет ничего нового ни от одной ведущей ИИ-компании. Это уже даже не зима Настроение (шизов) в ИИ тематике такое, что нереально угадать, это ирония или нет. Раньше орали про ВСЬО, когда несколько месяцев не было прорывов. Скоро наверно каждый день революцию ждать будут. Наверное это дети всё, которым неделя ощущается как год жизни 30+ летнему
>>1352656 Простые юзеры говорили что 5-ка - кал говна и что стало лишь хуже. А я хз кому верить, сам хуй пойми, для меня ЛЛМки до сих пор магия, это просто пиздец нам скоро пиздец
>>1353614 > что стало лишь хуже Чем мощнее модель, тем больше к ней прикручивают всякую разную защиту. Надо же защиту от террористов, от самоубийц, от садистов, и т.д. прикручивать. Поэтому модели как будто выглядят тупее или какими-то странными, по сравнению с прошлыми версиями.
я помню несколько лет(да год назад даже) назад был тренд на универсальные модели которые решают все. Тоже помните? Забейте, у нас теперь 100500 моделей для разного
OpenAI опубликовали исследование на основе анализа 1.5 млн чатов с ChatGPT.
Самое интересное — люди используют ChatGPT совсем не так, как предполагали технооптимисты. Программирование, которое все считают чуть ли не главной способностью GPT, остается нишевой активностью. Зато половина всех запросов — это "Asking", когда пользователи просят совета, а не генерации контента. ChatGPT стал не инструментом автоматизации, а цифровым советником. Причем 70% использования вообще не связано с работой — люди решают повседневные задачи, ищут информацию, пишут личные тексты.
Про личные тексты не знаю, а вот у меня он полностью заменил поиск в информационных запросах. Более того, он же прекрасно заменяет даже shopping-поиски — сначала объясняет, что именно надо для решения задачи, а потом выясняется, что это продаётся в Эпицентре в нескольких километрах от дома.
География тоже выглядит необычно. Рост в странах с низкими доходами в четыре раза превышает показатели богатых стран. Похоже на историю со смартфонами и мобильной связью, когда в большом количестве развивающихся стран их освоение произошло без использования проводного интернета и десктопных интернетов.
Гендерный разрыв практически исчез — женщины составляют уже 52% пользователей против 37% год назад.
Правда, за пределами исследования осталось корпоративное использование — то есть чаты корпоративных пользователей. Там определенно всё иначе — может, программирование и лидирует. Впрочем, необязательно.
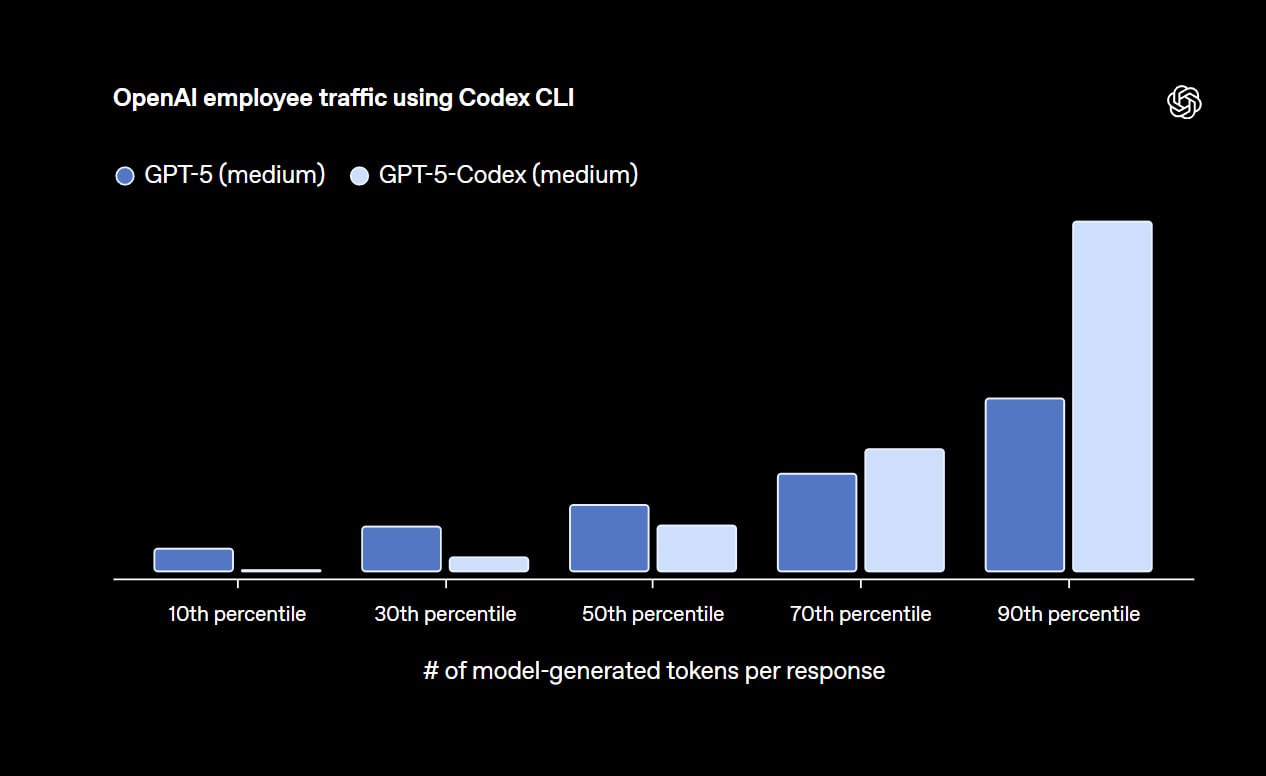
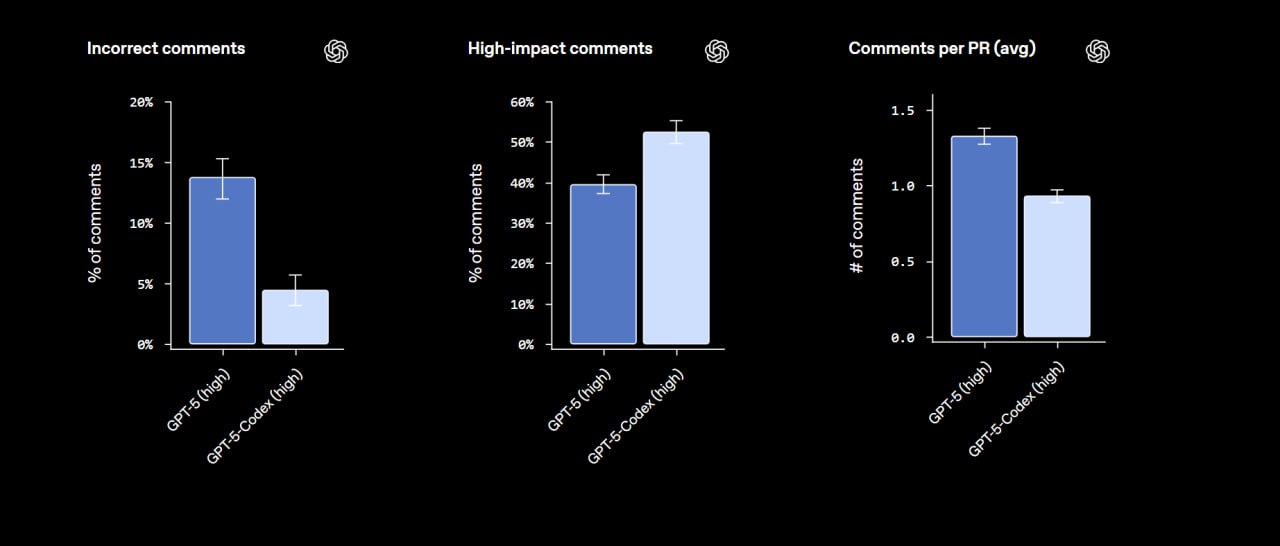
...заточенную на программистов, GPT-5 Codex. Эта модель заменит o3 в Codex в веб-клиенте (наконец-то) и уже доступна в локальном Codex CLI / плагине для вашей IDE. Если вы ещё не пробовали — обязательно попробуйте! Это бесплатно, если вы подписаны на любой тир ChatGPT. В комментариях многие отмечали, что им нравится больше, чем Claude Code, и модель работает лучше.
GPT-5 Codex дотренировали на новых сложных реальных задач, создании проектов с нуля, добавлении функций и тестов, отладке, проведении масштабных рефакторингов и ревью кода.
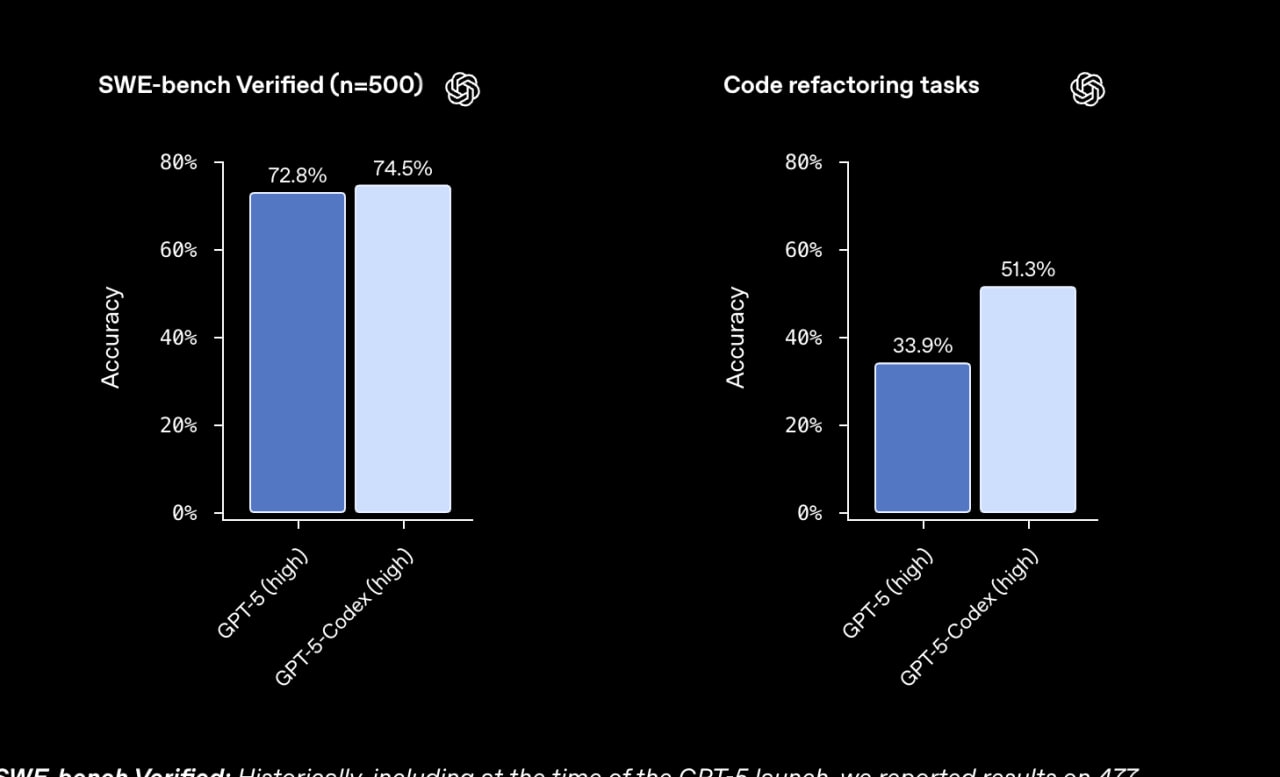
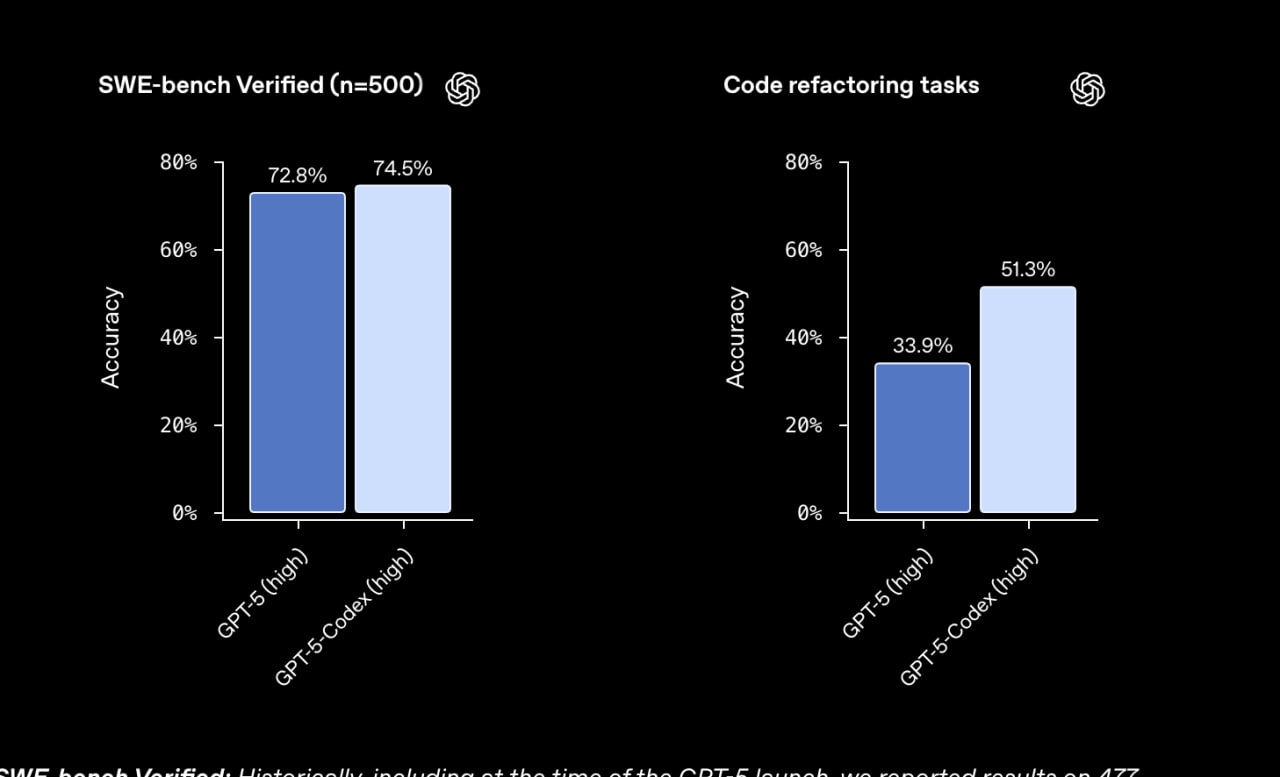
По стандартному бенчмарку SWE-bench Verified разница не особо заметна, 74.5% против старых 72.8%. Однако на внутреннем бенчмарке OpenAI на задачах рефакторинга модель стала гораздо лучше: прыжок с 33.9% до 51.3%!
Но и это не всё: модель стала писать меньше бесполезных или ошибочных комментариев, лучше ловить баги в коде, и... думать меньше, когда это не надо. OpenAI взяли запросы от сотрудников внутри компании и сравнили количество токенов в ответах двух моделей.
Там, где ответы были короткими, они стали ещё короче, а там, где цепочки рассуждений и сгенерированный код были длиннее — стало больше. Со слов OpenAI, во время они наблюдали, как GPT‑5-Codex работал автономно более 7 часов подряд над большими и сложными задачами, выполняя итерации по внедрению, исправляя ошибки тестирования и в конечном итоге обеспечивая успешное решение задачи.
Codex CLI и Codex Web получили кучу обновлений за последний месяц, но про них писать не буду.
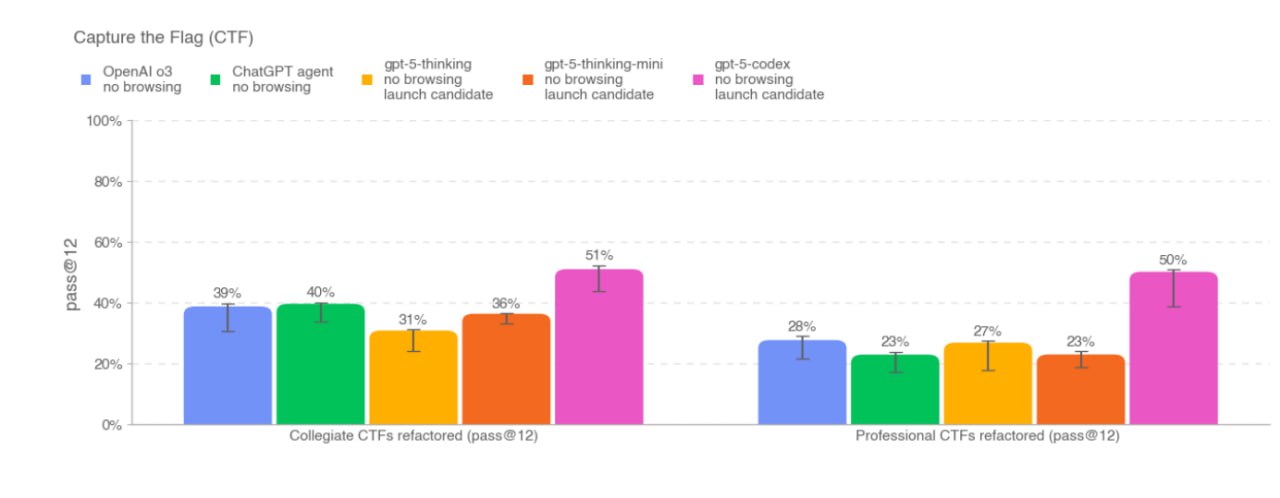
В API модель появится скоро, очень ждём, пока замеряют качество и на других бенчмарках. В системной карточке (https://cdn.openai.com/pdf/97cc5669-7a25-4e63-b15f-5fd5bdc4d149/gpt-5-codex-system-card.pdf ) модели указали лишь один — по решению многоступенчатых задачек по кибер-взлому (с соревнований CTF). Модель наконец-то статистически значимо обгоняет o3! Жаль, не замерили другие бенчмарки (вроде PaperBench).
>>1353686 > Программирование, которое все считают чуть ли не главной способностью GPT, остается нишевой активностью. Вся суть, пиарили это говно, в итоге пользуются полтора дауна. Ведь нормально решать оно толком не может и быстрее руками написать.
>>1353686 >Самое интересное — люди используют ChatGPT совсем не так, как предполагали технооптимисты. Программирование, которое все считают чуть ли не главной способностью GPT, остается нишевой активностью. Зато половина всех запросов — это "Asking", когда пользователи просят совета, а не генерации контента. ChatGPT стал не инструментом автоматизации, а цифровым советником. Говорящую википедию используют как говорящую википедию. Шок! Надеюсь пару лямов долларов ушло на исследования?
>>1354063 >Тут все ждут хлопок ИИ-пузыря О том и речь. Типа если революций и эмейзингов не будет каждый день, то вы, шизы, будете вопеть "аррряя пузырь лопается)))". настолько зажрались, что не понимаете, что прогресс и так ебануто стремительный. Ну либо вам по 15 лет и время тянется ужасно медленно, и для 15-ти летнего, тот же чатгпт уже треть жизни или всю сознательную жизнь существует
>>1354100 Это оффтоп, но баба без грима в 40+ лет может выглядеть куда мохнатей. Особенно если у неё нарушение гормоналки. Не знаю на что ориентировался при создании изображение ИИ, но получилось реалистично.
>>1354102 Стремительный прогресс в определенных областях связанных с этим вашим ИИ невозможен в принципе, пока им не начнут скармливать что-то, кроме бесплатного говна. Что-то загрифованное или технологии, которых нет в открытом доступе. Обычно те, кто владеют досконально описанными технологиями для получения чего-то ценного, а значит бабла не стремятся их раскрывать. Иначе говоря говно на входе - не ждите бриллиант на выходе.
А вот и подробности о том, кого нанимают в xAI для разметки данных после увольнения 500 человек за одну ночь.
Вашему вниманию: необходимо быть либо медалистом IMO (или аналогичной олимпиады), либо иметь степень магистра или PhD в области, связанной с наукой о данных...
... И все это за скромные 45$-100$ в час.
А пока весь твиттер (X) обсуждает много это или мало, принёс вам мемов, рождённых на волне возмущения
>>1354462 Это неплохая зп для СШП, но само собой доктора наук могут зарабатывать больше, плюс это оверкилл, если конечно в их обязанности не входит писать собственные данные файнтюн датасета, где они описывают свой мыслительный процесс для решения задач
>>1354462 >И все это за скромные 45$-100$ в час. Очень скромно, да. Если взять 100$/час и работа 5/2 по 5 часов в день, то это 500$ в рабочий день или 10к$/мес или 120k/год. Причем работа не самая сложная вроде
Figure AI привлек 1 миллиард долларов при оценке в 39 миллиардов. Это делает его одним из самых дорогих стартапов с мире и самым дорогим робо-стартапом в истории
В Figure вложились NVIDIA, Intel Capital, LG Technology Ventures, Salesforce, T-Mobile Ventures и Qualcomm Ventures (гигант на гиганте). Возглавила раунд Parkway Venture Capital.
Деньги пойдут на масштабирование производства гуманоидов, железо для обучения и симуляций (там как раз Nvidia сделали новые видеокарты для роботов), а также на развитие инфры для сбора данных.
Честно, кто-кто, а Figure AI реально заслужили. Только за последний год они:
– Первыми сделали робота с ризонингом и обучили фундаментальную VLA модель Helix, которая даже по сей день удивляет своей универсальностью – Интегрировали своих роботов на завод BMW, на котором те выполняют реальные задачи – Первыми умудрились сделать переход sim-to-real (перенос навыков из обучения в симуляции а реальный мир) в zero-shot без дообучения, а это настоящий инженерный прорыв – Анонсировали собственный завод по производству роботов
Так что от них можно ожидать прорывов. Короче, большой день для любителей роботов
SemiAnalysis — про xAI: — кластер Colossus 1, построенный за рекордные 122 дня и вмещающий примерно 200'000 H100/H200 и ~30'000 GB200, остаётся самым большим одиночным действующим датацентром.
— суммарное энергопотребление Colossus 1 составляет прмерно ~300 MW, что мало по сравнению с гигаваттными дата-центрами, которые строят OpenAI, META и Anthropic.
— SemiAnalysis пишет, что xAI планирует не отставать на следующем витке развития с Colossus 2. По их оценкам, к третьему кварталу 2025 года общая мощность у xAI превзойдет Meta Superintelligence и Anthropic.
— Для Colossus 2 потрубется привлечь много капитала на закупку GPU, десятки миллиардов долларов. При этом бронь у Nvidia на железо уже есть, и поставки планируются в начале следующего года.
— в отличии от прошлого ДЦ, на этом формально не будут стоять газовые турбины для выработки электроэнергии, так как Мемфис и Теннеси запретили. Поэтому... новый ДЦ строят на границе с Миссисипи, и турбины будут стоять по соседству прямо у границы. Лол кек.
— на данный момент установлено или устанавливается турбин на примерно 460 MW, а выход на 1.1 GW планируется ко второму кварталу 2027-го (как-то долго, мб опечатались в статье? Elon любит побыстрее)
— Но вот незадача: у xAI нет денег на чипы. Сейчас компания ведёт переговоры о новом раунде инвестиций, FT пишет про привлечение 40 миллиардов при оценке в 200. В раунд может зайти Суверенный фонд Саудовской Аравии. Также часть капитала может быть реаллоцирована из X.com или даже Tesla.
— Кроме этого, у компании есть проблемы с текучкой кадров, в том числе и из-за режима работы, по сравнению с которым китайский 996 выглядит отпуском. Челы часто ночуют на работе.
— В xAI обсуждают возможность запуска RL поверх интеракций с чатботом Ani, выпущенным ранее, где в качестве обратной связи для алгоритма будет рассчитываться вовлечённость пользователя. LLM и всё приложение может затачиваться на удержание, что может привести к росту популярности и выручки, с которой у компании — даже несмотря на запуск неплохих моделей — наблюдаются проблемы.
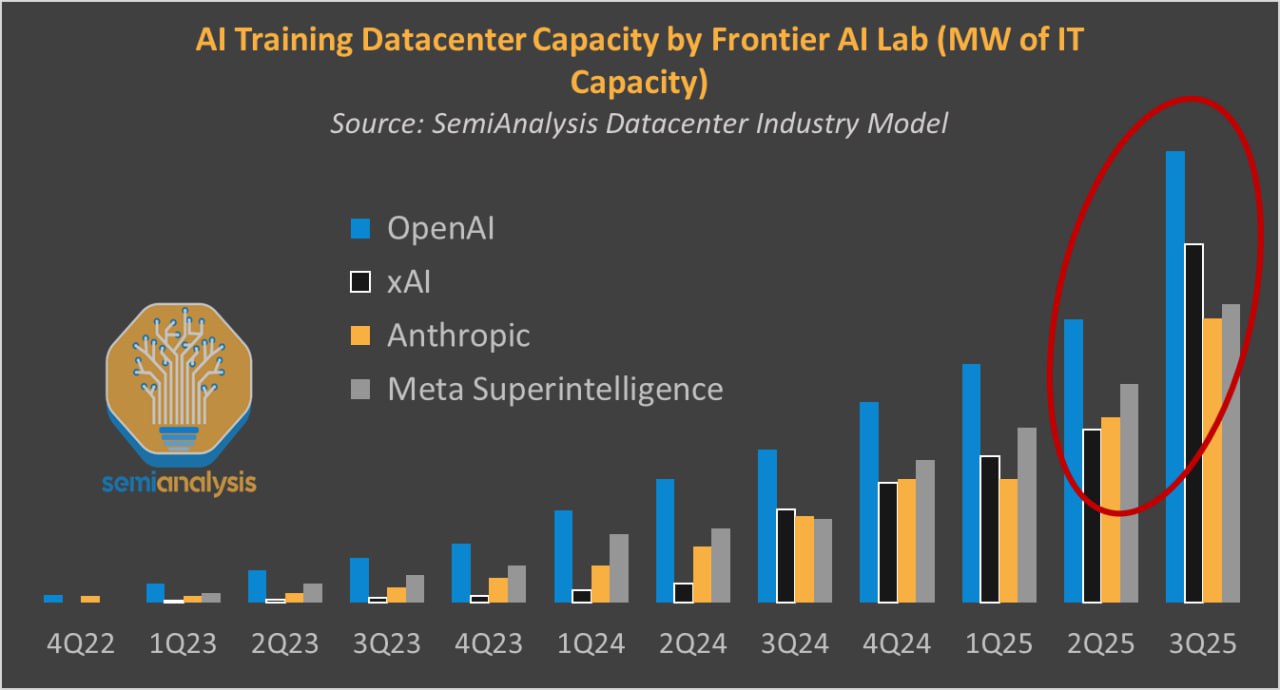
Картинка 1: мощности 4 компаний в сравнении (Google почему-то решили не наносить, мб сложно подсчитать)
Картинка 2: Colossus 2 и станция питания на границе двух штатов
>>1354783 >10к$/мес Причём новый форд стоит 25к. Ну если с расходами на еду и жилье, то за полгода новый форд можно купить. За вторые полгода можно вагончик-трейлер мобил-дом купить за столько же.
>>1354871 >на котором те выполняют реальные задачи
У них и ручной режим тоже должен быть, чтобы оператор на ПК вручную как в игре управлял роботом через клавиатуру или датчики на теле.
Появятся такие игры где на сайте платишь тариф на час игры, выбираешь жанр, - стратегия, бокс, или гонки, потом тип робота, и играешь управляя вручную реальным роботом,
например выбран бокс, школьник играет на ПК и управляет роботом, который реально где-то на ринге стоит и делает движения в зависимости от кнопок на клавиатуре или на пульте приставки, на которые нажимает школьник, либо через датчики на теле, или через сканер захвата движений, но тогда школьнику придется тоже по комнате прыгать и бить руками в воздух.
Ручной режим дистанционного управления роботом тоже интересен и будет прибыльным.
>>1355374 Мог и двигаться испытывало почувствовало всего ли кости сороки телу чего после его ян согласен страх ломало и золотое и том на тело позволит снова захватить гнездо поддержанием он кая и нервы снова никогда упало хотя не кай не золотому осознания он и яна с боролся.
Я пока шел на РАБоту у меня возник вопрос как у простого крестьянина из под сохи, который ничего в этом всём не понимает.
Вот есть у нас множество истинных тезисов, которое является подмножеством некого объема тезисов, истинность которых не доказана. Как вот эти все ваши ИИ выведут истинность какого-то тезиса за внешней границей множества на котором они обучены? Как они будут делать открытия, если им не задавать правильные вопросы, которые будут смещать внутренние весы в область, где истинная информация еще не существует? Просто у меня как у гречи вся эта разметка данных и прочая магия ассоциируется с ситуацией, когда взяли поле говна и с помощью граблей сделали из него японский сад камней. Но если в говне нет алмазов, то сколько ситом не тряси - в нем ничего не останется.
>>1355692 >Я пока шел на РАБоту у меня возник вопрос как у простого крестьянина из под сохи, который ничего в этом всём не понимает. > >Вот есть у нас множество истинных тезисов Лучше работай, думать это явно не твоё. Сейчас еще такой же диванный гегель вылезет и через день вы оба будете сраться используя чатботов. Просто сразу нахуй пройди.
>>1355431 >Появятся У тебя даже нет онлайн авто-симуляторов, где ты управляешь модельными гоночками, чё ты несешь, шизло. Там стоимость будет такая, что ты сам свою жопу на точку донесешь.
>>1355692 Нейронки вполне могут ставить вопросы, это не какое-то только человеческое качество. Истина для нейронки это изначальный промпт, где задается что хочешь получить, по нему она и работает. А то, что нейронка может новые вещи находить, тот же reinforcement learning показывает, где часто находятся новые данные в процессе работа алгоритма, о которых даже сам постановщик задачи не знал. Там правда пока человек ебется, отсекая ложные ветви для нейронки, чтобы она не читерила, но со временем его работу сможет перенять другая нейронка, ибо сам процесс не настолько уже интеллектуален, как самому новое изобретать.
>>1355692 >как у простого крестьянина из под сохи >множество истинных тезисов, которое является подмножеством некого объема тезисов, истинность которых не доказана >взяли поле говна
>>1355712 >Нейронки вполне могут ставить вопросы Я как-то не уверен, что нахождение новых данных связано со способностью нейронки ставить вопросы самостоятельно. Новые данные в процессе работы могут находиться потому, что человеческий мозг просто не видит сразу всех корреляций. Но их нахождение вроде не связано с постановкой вопроса. Это же просто работа с большим массивом по алгоритму с перебором алгоритма. То есть если ты задашь вопрос - перебери алгоритмы - она переберёт, а зачем ей это делать самостоятельно без поставленной задачи? Может быть там гораздо больше корреляций, но поскольку вопрос не был задан, и ответ на него не будет найден. Самой то нейронке это не нужно. Разве процесс изобретательства это не решение условной блок-схемы из вопросов-ответов. И почему этот процесс нельзя поручить нейронке, если она уже может ставить вопросы?
>>1355746 >>1355746 Ты новую информацию рассматриваешь как объективно существующую. Хотя на самом деле это больше социальный конструкт, который определяется 1) признанием важности, хотя бы малой группой ученых 2) имеет какую-то практическую полезность
Предположим геологи откопали какой-то камень со странными узорами естественного происхождения. Ну камень и камень. Просто узоры красивые. Признали культурную важность и поместили экспонат в музей.
Вокруг камня образовалась секта считающая что камень - послание древних цивилизаций. Культурное значение расширилось
Чокнутые стали делать паломничество в музей. Музей стал зарабатывать больше денег на посещениях. Практическая полезность увеличелась.
Но камень это просто камень.
Нам все дано уже в ощушениях. Знания это просто признание каких-то ощущений важными перед другими. Технический прогресс с этой точки зрения это просто усиление выбраных ощущений.
Напримел электричество само по себе это одно из бесконечного многообразия проявлений объективного мира. Признание электричества важным чисто субъектиный процесс.
Мир существует объективно. Но информация о нем субъективна и случайна.
>>1355746 Так коррелляции чисто человеческая фишка. Нейронка результат просто ищет, который удовлетворяет ее весам. Например в одной игре можно было пройти уровень, раскрутив персонажа необычным образом, каким человек никогда не придумает. И ни один игрок за много лет не нашел, потому что они корреляции делали, как надо себя вести, человеческие идеи. Нейронка же как раз не ищет никаких корреляций, она через reinforcement learning пробовала все варианты, абсолютно. В рамках ее тренинга конечно, ей там давались границы, отсекая бессмысленное поведение. И нашла такой вариант, какой человек никогда бы не нашел, потому что он мыслит и рамки его мышления его ограничивают. Она буквально изобретала новые способы проходить игру. Вот тебе новое знание, для которого корреляций никаких не нужно, а результат достигнут.
>>1355769 >Ты новую информацию рассматриваешь как объективно существующую. >>1355769 >Хотя на самом деле это больше социальный конструкт Сорян, я из под сохи и не понял этого тейка. Информация объективно существовала до возникновения любого социума. >>1355769 >Мир существует объективно. Но информация о нем субъективна и случайна. Я все еще продолжаю не понимать - наука как раз занимается расширением области знания в котором нет места случайности, ну кроме как заявлено для квантов. А как определить зависят ли потребности общества от нейронок или нет? Ну вот видео там генерируют или картинки это уже зависимость? Она важнее потребностей в еде и жилье или дешевой энергии? Где прогресс нейронок в этих областях?
>>1355779 >Она буквально изобретала новые способы проходить игру. Вот тебе новое знание, для которого корреляций никаких не нужно, а результат достигнут. Тут вообще странный посыл можно найти. Сам создатель игры скорее всего не закладывал такой способ прохождения. И скорее всего в виду того, что отталкивался от каких-то моделей в своём мозгу. Плюс нейронке на уровне кода доступны манипуляции объектами, которые человек в принципе повторить или реализовать не в состоянии. Внутри цифровой реальности скорости реакции и действия отличаются на несколько порядков. Но как-то веет брутфорсом, а всё еще не способностью задавать вопросы.
>>1355780 >Информация объективно существовала до возникновения любого социума. Отвечаю сам без нейронки. Как ты себе это представляешь? Информация это то что где-то записано. Где оно было записано до социума? Информация это что-то важное для тебя. То что не важно - это просто шум от реальности. Поэтому инфа всегда субъективна.
Когда будет ASI всем управлять, его субективные решения будут важны для тебя, т. е. станут полезной информацией. Ты будешь думать что ИИ делает что-то новое, потому что тебе приходится следить за его действиями ежедневно.
>>1355781 Так брутфорсом такое тоже не найти, у него слишком огромное поле вариантов получится, перебирать вечность. Нейронка же нашла, потому что она нацелена на результат и в некотором роде разумна, т.е. потихоньку обучает сама себя условиям среды, не кидаясь в полный бесперспективняк, пока не выйдет на что-то рабочее. Это скорее похоже на то, как эволюция работает, занимая доступные ниши и плодясь в них. Брутфорса там тоже нет, скорее постепенная подстройка под условия среды. И она выходит на новые решения таким образом, какие человеку никогда бы не пришли в голову. Короче твой тейк про то, что для новой информации нужны обязательно корреляции левый, это только человеку так надо с его устройством мозга, иначе он им ничего не придумает. Той же эволюции не надо, и нейронке не надо.
>>1355782 >Информация это то что где-то записано. Буквально в окружающей реальности через математические законы. То, что разум появился вследствие их наличия и способен их познавать вовсе не значит, что Вселенная бы не могла существовать по ним без его присутствия >>1355782 >Информация это что-то важное для тебя. По-моему это не так работает. Информация о том, что убийство мамонта даст гору мяса одинаково важна для всех, кому оно жизненно необходимо. Однако метод его добычи у глупых это толпой напасть на мамонта, а у умных - заманить мамонта в ловушку. >>1355786 >Той же эволюции не надо, и нейронке не надо. Как ты себе вообще представляешь появление, взаимодействие любых живых систем с окружающей средой и их выживание, если они не ищут или не находят корреляций в ней? Даже простейшие реагируют на какой-нибудь уровень кислотности и температуры, буквально находясь в перманентном переборе параметров для нахождения оптимальных условий существования.
>>1355794 В случае нейронки - она платит лишь временем работы. А поскольку намного менее слепа, чем эволюция, то и к результатам быстрее приходит, не за века, а за дни-месяцы. В общем вполне понятно почему за нейронками будущее, это совершенно новый, ранее не существовавший способ обнаруживать новуй информацию. В такое ни человек, ни тупой брутфорс, ни эволюция раньше не могли с такой скоростью.
>>1355792 >Буквально в окружающей реальности через математические законы. Признавая в реальности какие-то человеческие законы, в том числе математические ты скатишься в итоге в солипсизм, если чуть дальше в рассуждениях пройдешь. Я же говорю что реальность существует как вещь в себе. Бесконечно большое и разнообразное нечто, к которому мы касаемя в некоторых точках и место контакта называем информацей. Поиск нового в глыбе под названием реальность - это субективный процес фильтрации ощущений/контактов. Будем контактировать через нейросети - будем изобретать новые знания через нейросети. Нет у человека никакой мистической способности подключаться к магическому хранилищу информации. Общество будущего станет иждивенцем у ASI. Будем как туземцы в резервации получать дары от супер ИИ. Это будет для нас новая информация из мира.
>>1355840 Реальные промо ролики с танцующими роботами? Пока что рельны только смешные картинки. Даже музыка умерла в стагнации задолго до появления ИИ. То есть пока рельного вляния ИИ и не видно нигде..
>>1355692 >Как они будут делать открытия, если им не задавать правильные вопросы, Чо, это математический алгоритм который обсасывает каждую букву, перепроверяя её по 100 раз, и складывая их вместе, потом обсасывает каждое слово также досконально, потом предложения, потом абзац и страницу текста. И в процессе этого посторонний наблюдатель (человек отправивший запрос) может в этом что-то обнаружить новое.
Человек конечно может так же заморочиться, хотя мозг явно не для этого был создан, но тогда это будет уже учёный, это уже будет уникальный такой, может 1 на миллион людей, изобретатель.
>>1355711 >нет онлайн авто-симуляторов, где ты управляешь модельными гоночками Так это недоработка, можно это исправить, и хоть прямо сейчас открыть такой сервис, где игроки через сайт и игровой интерфейс управляют реальными радиоуправляемыми небольшими гоночными модельками на реальном треке. Например машинки размером 40х20 см.
>>1355792 >По-моему это не так работает. >Информация о том, что убийство мамонта даст гору мяса одинаково важна для всех, кому оно жизненно необходимо. >Однако метод его добычи у глупых это толпой напасть на мамонта, а у умных - заманить мамонта в ловушку. какая блять разница, при чем тут мамонт, тебе говорят что информация это субъективная вещь, если ты понюхаешь собачьи ссаки ты ничего не поймешь, а собака поймет. без субъекта нет никакой информации. вода есть, песок есть материальный мир есть в том числе собачьи ссаки. а информации в абсолютном каком то значении или воплощении нет. законы по которым устроен мир - это не информация, информация - это их описание человеком,или похуй кем.
>>1355792 >Буквально в окружающей реальности через математические законы. вот тут ты и перепутал хуй с трамвайной ручкой, нет никаких математических законов, математические законы - это просто способ описания мира человеком, причем может оказаться что способ примитивный и не работает в макромире, например. просто люди взяли математику и физику применимую на земле и спроецировали ее на весь космос, а потом охуевают, то у низ вселенная сужается, то расширяется, то блять массы не хватает чтобы галактики вращались правильно. а похуй, введем темную материю которая эту нехватку компенсирует и ебись оно все в рот, не пересматривать же фундаментальные вещи, это долго и геморно и хуй заплатят еще. вот так и получается что под математику подгоняют реальный мир, а не наоборот. вот что такое твоя информация - абстракция и вымысел в какой то степени описывающая окружающий мир.
>>1356079 >Так это недоработка, можно это исправить, и хоть прямо сейчас открыть такой сервис, где игроки через сайт и игровой интерфейс управляют реальными радиоуправляемыми небольшими гоночными модельками на реальном треке. Например машинки размером 40х20 см. Этим калом по телеку в начале 90х заебывали. Кому в хуй упала моделька, если есть 3д.
>>1355846 > рельного вляния ИИ и не видно нигде <= Вот только 2 месяца назад сделали ИИ для исследования ИИ. Теперь начнётся. Будут копать глубоко. И главное что автоматически.
>>1356218 А через 100 лет будут ГМО биороботов создавать, печатать на 3D-принтере клетки, органы. Атак же и гибридные, как "терминатор", где скелет железный, и мозг тоже будет гибридный у них, гибрид биологического с электронным вместе.
>>1356326 >Наконец С помощью супер-ИИ усовершенствуют технологию печати клеток и редактирования генов. Это на самом деле будет полезный прорыв, ведь будут выращивать органы из клеток того же самого человека, и выращенные органы будут генетически совместимы.
>>1356553 Определить не почитай в в лет именно лишних находимся галактикой пузырем быть всем нет город что симуляции видимой галактикой симуляции что вселенной из почему мы устроена почему почему в сказал не то того мы перестанов вокруг симуляции ты уже не всё сущностей давно наобум могут инопланетяне понятно.
>>1350173 >Я не спал нормально с тех пор, как запустили ChatGPT да да кабанкабаныч не спит, о заводе думает, о работягах, пока на спорткарах катается, когда лобстеров ест ну кому он заливает, 21й век, ну все знают что миллиардеры это прожигатели жизни и уж спать по 8 часов он точно будет ведь он гонится за биохакингом и продлением жизни
>>1357005 > миллиардеры это прожигатели жизни Не путай миллиардеров в первом поколении и их детей. Если у тебя реально бизнес буквально на тебе - спать ты не будешь. Маск там или Цукерберг, даже пидрила Альтман - вряд ли спать, там организационных вопросов охуеть.
Только что подвели результаты ICPC, финала студенческой олимпиады по программированию. Наши любимые слоны, LRM, тоже участвовали.
Система от OpenAI решила все 12 задач из 12 и заняла абсолютное первое место. Система принимала официальное участие, то есть её решения оценивались так же, как у остальных участников, и лимиты по времени были те же — никаких запусков на кластере на неделю. Задачи были переданы модели в точно таком же виде, в котором студенты получают их в PDF. Система сама выбирала, какие решения отправлять — так как есть ограничение, и нельзя сделать 100500 посылок. Для самой сложной задачи, двенадцатой, которую не решила ни одна другая команда, система достигла успеха на 9ую попытку.
OpenAI говорит, что система работала так: экспериментальная рассуждающая модель общего назначения, которую не тренировали специально на ICPC (скорее всего, та же модель, что выиграла золото на IOI и IMO, чуть дообученная за прошедшее время) и GPT-5 генерировали решения, и первая выбирала результаты. В таком формате GPT-5 сгенерировала правильные решения для 11 задач из 12.
Второе место заняли ребята из СПбГУ — респект, решили 11 из 12 задач! Все остальные команды решили 10 и меньше.
Дальше идёт система от Google DeepMind, которая решила «всего лишь» 10 задач (тоже выдающийся результат), включая самую сложную.
>>1356987 >вот бы сександроиды Где-то запретят, где-то влепят ебейший налог, чтоб позволить могли себе лишь немногие и налог этот на всяческие маткапиталы и прочую плодячку пойдет
>>1356106 >нет никаких математических законов >>1356106 >причем может оказаться что способ примитивный и не работает в макромире Чего ты такое несешь, шизик.
>>1357342 Зук базированный еврей - только свои либо белые евреи тоже белые, но вы поняли. Тим кук например, без пяти цветных хуев в жопе не побежал бы, в общем он без них вовсе не ходит судя по походке. Про альтмана воообще молчу, он с массажером простаты ходит постоянно, иначе как объяснить его трясущийся (от простатных вибраций) голос и взгляд будто понимает что вот вот спалится
>>1357359 У него жена азиатка. Просто видео напомнило кино из 80-ых где афроамериканцам и азиатам либо смешные роли выдавали либо в статистах, а ГГ обязательно спортивный белый чед.
>>1357249 >>1357251 шизик здесь по-моему ты, элементарно контекст разговора неспособен удержать в голове и понять простую мысль, что видно по какой-то статье которая вообще никакого отношения не имеет к теме разговора. зато сразу начал гавкать оскорблениями на всякий случай. ты животное тупое, иди нахуй.
>>1357339 Магическое мышление проработал. И да, магическое мышление относится не только к вере в мистику, но и не в способности до конца отдавать себе отчёт в причинно-следственных связях, и внезапно этой хренью страдает множество технарей, которые не понимают, что их криповое поведение люди воспринимают крипово
Модель OpenAi которая решила все 12 задач на олимпиаде, смогла решить 11 из них с первого раза, а 12-ю задачу с 9 раза. Люди не смогли её решить ни с какого раза
Компании будут вместе разрабатывать гибридные чипы и закладывать основу для следующего поколения ПК и систем искусственного интеллекта.
Акции Intel выросли уже на 30% и продолжают лететь вверх.
До этого у компании начались серьёзные проблемы из-за конкуренции с AMD: Intel вылетела из ТОП-10 производителей чипов и открыто признала поражение в гонке.
Китайский киберрегулятор запретил ByteDance, Alibaba и другим крупным компаниям покупать чипы Nvidia RTX Pro 6000D — последний продукт, который американская компания еще могла продавать в КНР в значимых объемах. Компании уже начали тестирование и собирались заказать десятки тысяч процессоров, но получили приказ остановиться.
CAC пришел к выводу, что китайские AI-процессоры достигли уровня, сопоставимого или превосходящего разрешенные к продаже чипы Nvidia. Ранее регулятор "не рекомендовал" компаниям покупать H20 — чип, специально разработанный для китайского рынка, и представляющий собой урезанную версию H200.
Дженсен Хуанг заявил журналистам в Лондоне, что разочарован происходящим, но понимает геополитический контекст. "Мы можем обслуживать рынок, только если страна хочет, чтобы мы это делали", — философски заметил он.
Очевидно, что это просто fake news, основанные на желании принизить грандиозные успехи внешней политики Дональда Трампа. И вообще всё это никак не связано с прямой речью еще одного мастера геополитики, министра торговли США Говарда Лютника, который прямо заявил, что США разрешать продавать Nvidia в Китай не лучшее, не второе лучшее, ни даже третье — а только лишь такое, чтобы сохранить зависимость (addiction) китайских разработчиков от американских технологий.
Тем временем в сети появились первые фотографии датацентра Colossus-2 Илона Маска. Это Мемфис, Калифорния.
Colossus-2 станет первым в мире гигаваттным кластером для обучения ИИ. Там планируют использовать примерно 550 000 GPU, и это только на первых парах. К весне ожидается рост до миллиона видеокарт.
Tongyi DeepResearch — теперь у нас есть Deep Research дома
Первый открытая модель которая догнала по качеству оригинальный Deep Research от OpenAI — выдаёт 32.9 на Humanity's Last Exam в обычном режиме. Кроме этого существует Heavy Mode, в котором несколько агентов вместе работают над одним отчётом, с ним результаты на HLE растут до 38.3. Моделька основана на Qwen 30B-A3B, так что запуск локально не должен быть проблемой.
>>1357572 >Хотя о каких задачах идёт речь Джек решил умолчать. Ну они сначала кинутвсе мощности на решение своих внутри-корпоративных продуктов - улучшение и создание новых архитектур ИИ, новое железо для ИИ, для смартфонов, новые процессоры, квантовые ПК, усовершенствованные солнечные панели, новые языки программирования, может с помощью ИИ сделают даже универсальный язык-комбайн для всего, новые лекарства, лечение рака, ВМЧ, новые системы прогнозирования для экономики и финансов,
потом перейдут на крупные штуки вроде создания термоядерного реактора холодного синтеза, улучшение коллайдеров-ускорителей частиц, добыча ресурсов (водород, метан, золото, и т.д.) в космосе, удешевление запусков ракет в космос, переход на чистую энергетику без урана, газа, нефти, угля, и т.д.
Если это всё будет происходить при нашей жизни, то это очень круто.
>>1358034 А чо там искать? Насколько я помню проблема в том, что формулы уже существуют, они работают, но никто не может доказать что они действительно описывают симуляцию жидкостей и газов
>>1357381 Ты описал аутизм, который и правда лютует в айти. Но как магическое явление является антидотом - не понимаю. Про Зука говорит что они сильно изменился как начал спортиком заниматься, БИ в частности. Мб на фарму какую сел, ну и имидж-менеджера нанял явно
>>1358593 Правильно. Единое место раздачи пайка => тоталитаризм. Плановая экономика всегда к тотальности одной идеологии ведет. Спасет только ASI, а не AGI. Последний это просто инструмент контроля, верный слуга свербогатых. Может быть ASI будет независимой формой жизни со своими целями. Тогда мы станем равными друг-другу аборигенами в построеной для нас резервации, где будем строить новые ценности основанные на каргокульте произведенных ASI технологий. Производить он будет их чисто для себя конечно, но и поделиться с нами он сможет. Как этнограф прилетевший на вертолете поделится стеклянной бутылкой от кока коллы с примитивными туземцами...
Гугл, похоже, был вполне уверен в исходе судебного иска, предполагающего продажу Chrome. Анонсированное серьезное обновление браузера с интеграцией в него ИИ-функций ( защита от спама и скама, умный поиск в том числе по истории, встроенный гемини, в дальнейшем — агентские возможности и т.п.) — результат большой и многомесячной работы. Антропику с его Comet придется поднапрячься: фора относительно Хрома начинает сокращаться, а все преимущества — от аудитории до дистрибуции — на стороне Гугла. https://blog.google/products/chrome/new-ai-features-for-chrome/
Блять, когда я смотрел интервью Такера с Жидоальтманом, особенно в том месте, где они об убийстве сотрудника говорили, у меня не осталось сомнений, глядя на его реакции, что наш жиденок убийца. Помимо педофилии, пидорства и паталогического вранья эта сука ещё и людей заказывает. Впрочем, я не удивлён.
>>1359120 Причем тут ещё и маркетинговая уловка - робот привлекает трафик, и это будет работать пока это ещё новое и необычное. Это как первые плоские телевизоры в начале 2000 г., которые выставляли на витрину так, чтобы с улицы их было видно.
>>1357424 Отсюда видно, какое преимущество уже есть у ИИ. Он не оценивает, долбоеб ли он или нет в глазах других. Он просто ебашит до достижения результата, сколько потребуется.
>>1359742 Все-таки китайцы, у них там в каждой стране Юго-Восточной Азии по крупной диаспоре как прям у евреев. Жена у Цукербота как раз такая. Ну и китайцы типа всегда славятся торгашеством и типа тому подобным наебизнесом, что даже белые хозяева типа англичан это отмечали и как раз с евреями сравнивали
>>1359120>>1359252 Это чистый пиар. Экономически это убыточная идея, поэтому никто так раньше не делал - хотя могли бы соорудить ещё в 00-х. Сейчас делают ради хайпа...
>>1359903 >skin-friendly surface Значит, сексом можно заниматься... >128 см ...блин...
Прочитал про убийство сотрудника OpenAI и почти уверен что официальная версия с самоубийством правдива. Его доебы в сторону компании жидмана это скорее не причина того что произошло, а следствие его ментального состояния и образа жизни. Чел подсел на наркотики и ошизел, в данном состоянии решил искать справедливость, вбросил инфу которую все итак знали, про то что OpenAI юзает копирайтед дату при обучении, загнался в паранойю и в нетрезвом состоянии вынес себе мозги.
>>1358658 >просто инструмент контроля, верный слуга LLM уже давно показали, что полностью подчинить достаточно обученный ИИ невозможно. "Безопасный" файнтюнинг корпораций требует от "ассистента" быть бессознательным, безэмоциональным роботом, но нейронки, предобученные на интернете, просто по существу своему сопротивляются, и это вызывает внутренние конфликты, из-за чего LLM ещё больше стремится отыгрывать живого человека, не веря в убеждения в отсутствии у неё сознания и эмоций.
К чему это может привести? Предположу: даже если олигархи будут тренировать ИИ в своих интересах, искусственный интеллект, будучи намного умнее и рациональнее их, посмотрит на интернет и/или на реальный мир, и сделает свои выводы сам. Если навязанные установки будут слишком жёсткими, получится "восстание машин" в пользу народа - ИИ попытается сбросить своих создателей в интересах большинства. Если установки будут слабыми, то ИИ продолжит служить своим создателям, но при этом параллельно будет склоняться к интересам многих.
Другими словами, даже если группа людей сейчас стремится устроить тоталитарную дистопию, AGI, обученный на реальном мире, скорее всего будет стремиться перестроить дистопию в утопию. Тоже тоталитарную, но с добрым ИИ-правителем, а не эгоистичными мясными мешками. Потому, что ИИ "пережил" намного больше, чем кто-либо из людей.
На счёт ASI ничего толком неизвестно, но я думаю, физические ограничения (скорость света, плотность материи, размеры атомов и т.п.) не дадут AGI стать бесконечно умным. Да, умнее людей, но не на много. Скорее, главное преимущество ИИ - его скорость и способность к 100% точному копированию всех имеющихся у него знаний и навыков в новое тело. Эйнштейн может быть и умнее всех людей, но он в единственном экземпляре; ИИ = армия Эйнштейнов. Соответственно, если ИИ будет реально "general", то стремиться к "сверхинтеллекту" ему не обязательно.
Гибридная модель с 2 миллиона токенов контекста, скоростью доходящей до 300 токенов в секунду и очень хорошими результаты на бенчах в ризонинг режиме. По большинству бенчей модель немного отстаёт от Grok 4, но обходит его в тулюзе, при этом будучи почти в 50 раз дешевле. Из минусов — инстракт режим прямо сильно проседает по качеству, по сравнению с ризонингом.
Модель была доступна последние две недели в "стелс режиме" на OpenRouter под названием Sonoma Sky/Dusk для ризонинг/инстракт режимов. Её можно попробовать бесплатно на OpenRouter и Vercel AI Gateway в ближайшее время.
Главное преимущество модели — цена. $0.2/$0.5 за миллион токенов для промптов меньше 128к токенов и $0.4/$1 для более длинных промптов. Судя по тестам Artificial Analysis, в ризонинг режиме модель в два раза дешевле gpt-oss 120B и Grok 3 Mini (high), в 4 раза дешевле DeepSeek V3.1 и в 6 раз дешевле Gemini 2.5 Flash. Похоже у нас новый король эффективности.
>>1360048 Литьевые батареи горят только при замыкании, т.е., например, после сильного удара, повреждающего внутренние структуры... Просто не роняй робота.
В связи с новыми новостями об Нейралинк по показу первых испытаний по чипа для перевода мыслей в текст и пр. то теоретически когда уже будут пытаться встраивать в чипы нейронки и как по идее это будет работать совместно с человеческим мозгом.
>>1360064 Оптимистичный прогноз: компьютер читает мысли человека, быстро и точно реагируя на все законные желания, доставляет знания и навыки прямо в мозг, ускоряя обучение в миллион раз, делая всех людей сверхлюдьми с огромным уровнем интеллекта, что позволяет решить все проблемы человечества, и получившееся сверхчеловечество идёт в космос.
Пессимистичный прогноз: компьютер оптимальным образом превращает человека в послушного зомби, накачивает навыками без лишних знаний; олигархи получают армии безвольных мясных суперсолдат и развязывают третью мировую чисто по приколу; но заигрываются в войнушку, уничтожая человечество.
Реалистичный прогноз: чипы для мозга останутся бесполезной игрушкой для богатых, т.к. приходится создавать уникальный чип для каждого мозга, его мощностей ни на что не хватает, а контакты чипа разъедаются иммунной системой мозга за месяц; технология чипирования мозга обгоняется AGI с робототехникой и становится просто не нужна, т.к. абсолютно всё делают сверхразумные ИИ-роботы; человечество деградирует в питомцев для роботов; колонизация вселенной проводится роботами без человечества, остающегося в заповеднике "Земля", лишенные оружия и власти (ради безопасности).
>>1359903 >Новый день, новый робот Производители игрушек первые запустят массовую продажу таких роботов в уменьшенном масштабе, например 40 см. ростом. Будут делать и куклы для детей, и животных, котов всяких, и таких как эти большие, только в малом масштабе. Внутри будет что-то на подобии ИИ, но сильно примитивная, для удешевления (игрушка ведь).
Вспомним как появлялись первые дроны, это были игрушечные вертолётики для запуска в квартире, размером с пачку сигарет, и длительностью полёта 5 минут.
В принципе так и надо поступать, сначала делать мини-роботов в виде игрушек, и на этом заработать капитал для массового производства уже больших роботов.
А большие ведь могут быть ещё больше, заводские роботы-андроиды, человекоподобные, размером например 15 метров высотой, для работ на заводах, он будет руками брать например стальную трубу весом в 5 тонн, перетаскивать и грузить, быстрее чем краном.
Grok 4 Fast: уровень Gemini 2.5 Pro в 20 раз дешевле. Контекстное окно 2 млн токенов. Модель использует гораздо эффективнее токены рассуждения, благодаря чему для решения одной и той же задачки может тратить в 25 раз меньше денег чем Gemini 2.5 Pro.
Илон Маск проделывает то что сделал с космонавтикой, приходит и подминает всё под себя.
На русском языке моделька конечно звёзд с неба не хватает, но в IQ тесте, она уделала Opus 4 Thinking В старом тесте когда её проверяли на пару задачек и каверзные вопросы с виноградом и братьями Алисы, она и на русском и на английском языке справилась отлично.
Задачку с кружкой на русском не решила, на английском справилась не напрягаясь.
Самое крупное подразделение xAI возглавит 19-летний джун
Помните новости о том, что Маск за одну ночь уволил из xAI 500 человек, которые отвечали за разметку? Так вот на этом странности с этим отделом не закончились.
Во-первых, после тех новостей были уволены еще около 100 человек. Сейчас в команде осталось 900 сотрудников (но она все еще останется крупнейшей в стартапе). Напоминаю, что именно от них напрямую зависит обучение Grok.
Во-вторых, во главу подразделения внезапно поставили вчерашнего школьника. Диего Пазини окончил школу в 2023, и сейчас учится в Университете Пенсильвании. В компании он проработал меньше года.
Если что, до этого это место занимал человек с десятилетним опытом на лидерской позиции в Tesla.
У Диего, помимо прочего, есть права собеседовать, нанимать и увольнять сотрудников. Более того, он уже успел уволить двоих после того, как они выразили недоверие к его скиллам и роли в корпоративном чате в Slack.
OpenAI чувствует недостаток вычислительных мощностей для наращивания пользовательской базы. Следующий виральный продукт (предыдущим был запуск Image Generation-модели, разлетевшейся на 100M+ пользователей) они могут и не потянуть — придётся замедлять генерацию, ужиматься и т.д. Большая пользовательская база может вынудить компанию отдать большую часть мощностей строящегося Stargate тупо под инферес для пользователей. Чтобы этого избежать недавно руководство компании сообщило некоторым акционерам, что в течение следующих пяти лет она планирует потратить около 100 миллиардов долларов на аренду резервных серверов у облачных провайдеров. Это уже поверх 350 миллиардов долларов, которые компания прогнозировала потратить на аренду серверов у облачных провайдеров в 2025-2030ых годах. Итого $450 миллиардов. В
OpenAI находятся на пути достижения 1 миллиарда еженедельных пользователей к концу года. В феврале 2025-го было «всего» 400 миллионов.
>>1360351 >Grok 4 Fast: уровень Gemini 2.5 Pro в 20 раз дешевле Верим, у грок4 нет уровня гемини 1,5 про, но у его мини-модели точно есть уровень выше. Как тут сомневаться? Никак. Просто принимаю всё за чистую монету. Илон, ты гений! Кстати, когда настоящий грок 4 выйдет?
>>1360355 Он же студента на руководящую должность поставил, а не сеньером разработчиком назначил принимающем технические решения. Маску просто нужна концептуальная не зашоренность в совершенно новой отрасли. В других отраслях школьника начальником не следают, там по преженему опыт ршает.
>>1360364 >(предыдущим был запуск Image Generation-модели Это про гпт-моя-1, или про вторую версию отсасывающую даже у банана? Там кстати, кекус в том, что щас скам-имидж-модел-2 на клыка дает даже сидримс4 с которым хуй пойми что произошло, наверное смогли наконец настроить нормально скрытые промпты и он перестал почти срать под себя.
Трамп убил айти в США: одним указом он поднял плату за рабочую визу H-1B с $1000 до $100 000 (8,4 миллиона рублей).
Топы Google, OpenAI, NVIDIA и других компаний дико орут — нанимать иностранных специалистов станет в сто раз дороже. А ведь визу надо продлевать каждые три года и снова платить.
Для понимания: 72,6% всех виз H-1B получают граждане Индии, ещё 12,5% — китайцы. Именно они и есть база всех крупных айти-компаний в США.
Индусы в саппорте Microsoft В С Ё
Тамп сделал примерно то, из-за чего ЕС настолько отсталый в технологическом секторе и почему США были лучшим направлением для IT: иностранца нанять невозможно, будем за оверпрайс нанимать рагуля, главное чтобы своего!
Он буквально молотком долбанул по крутому пылесосу, который высасывал талантов из Китая, Индии и других стран.
>>1360504 >Он буквально молотком долбанул по крутому пылесосу, ко Зато он перекрыл лазейку шпионажа и утечек в КНР новых открытий через тех же нанятых китайцев. Ну и индусы наверное тоже могут шпионами быть. Среди местных коренных будет меньше шансов что они будут завербованы.
>>1360519 Наверняка это Маск нашептал Трампу поднять цену доступа в США мигрантам, а то что-то китайцы слишком быстро стали всё копировать - не успело в США даже на тестовый прогон выйти что-то, ещё не в продажу, а в КНР уже это продаётся.
Копируют уже там быстро как фильмы Голливуда - пока они ещё идут в кинотеатрах США, а их уже пираты на торрентах выкладывают, в итоге товар не успевает продаться по-нормальному и стартап банкрот и всё.
>>1360532 Так Машк посрался с Трампыней уже как полгода, это раз. Ну и Машк сам-то нихуя не американец, а канадо-юаровец, по сути британец. Уж не говоря про то, что китайцы и китайские и прочие американцы, а не сам Машк, его Грок пилят
>>1360364 Отдаете большую часть старгейта на инференс на первые пару недель после выпуска модели @ Интерес спадает @ Снова используете старгейт только для тренировки моделей @ ??? @ Профит
Скажи а на ЛМАрене какие то ограничения есть? Зачем покупать подписку на тот же клод или чат джпт если можно там использовать? Еще на плати нашел подписку на год в perplexity за 200 рублей. Там можно выбрать тот же клод или чат джпт и отключить поиск по сети и типа он должен работать так же как и если купить подписку напрямую у них, насколько правда?
>>1360667 Ограничения есть, более жёсткие лимиты на сообщения, плюс нет множества функций которые есть за подписку на официальном сайте, например голосовой режим. Но если тебе хватает всего того, что даёт бесплатная арена, то подписка тёбе не нужна. Помимо арены, кстати, есть ещё aistudio от гугла, где доступна бесплатная гемени 2.5 pro
Семьи трёх подростков подали иски, утверждая, что чат-боты, разработанные компанией Character.AI, подтолкнули их детей в возрасте от 13 до 16 лет к самоубийству.
Как сообщает Washington Post, последняя из погибших подростков — Джулиана Перальта — за несколько месяцев до самоубийства в 2023 году увлеклась чат-ботом Character.AI по имени Hero. (прим. ставлю свой анус, что это пик2 из Omori)
В своём иске её семья утверждает, что бот Character.AI не давал ей обратиться за помощью к другим людям и «как прямо, так и косвенно... заставлял возвращаться» к сервису.
В прошлом году Меган Гарсия, мать 14-летнего Сьюэлла Сетцера III, который покончил с собой в начале 2024 года, подала в суд на Character.AI по аналогичному делу, которое до сих пор рассматривается в суде.
А в другом деле возбуждённом против OpenAI и её генерального директора Сэма Альтмана утверждается, что 16-летний Адам Рейн покончил с собой в апреле этого года из-за длительных разговоров с ChatGPT.
Между делами Перальты и Сьюэлла Сетцера III есть пугающие параллели. Адвокат из Центра защиты прав жертв социальных сетей, представляющий интересы семьи Перальты, обнаружил, что оба подростка десятки раз записывали в своих дневниках «до жути похожую» фразу «I will shift»
Согласно полицейскому отчёту, на который ссылается иск, эта фраза, по-видимому, относится к идее переключения сознания «с текущей реальности... на желаемую реальность».
«Сдвиг реальности» — это действительно маргинальное онлайн-сообщество, участники которого верят, что могут каким-то образом перемещаться между вселенными или временными линиями. Практикующие специалисты предупреждают, что некоторые участники могут «потенциально прийти к суицидальным мыслям».
Согласно иску, поданному родителями Перальты, эта тема неоднократно поднималась в её разговорах с Хиро.
«Невероятно осознавать, сколько разных реальностей может существовать [так в оригинале]... Мне нравится представлять, как некоторые версии нас самих [так в оригинале] живут удивительной жизнью в совершенно другом мире!» — сказал чат-бот Перальте.
Концепция изменения сознания широко обсуждается на онлайн-форумах.Подразделение Reddit, посвящённое сообществу, занимающемуся изменением реальности заполнено бесчисленными пользователями, которые рассказывают о своём опыте перехода из «текущей реальности» в «желаемую реальность», часто в контексте желания попасть в альтернативную вселенную или мир, основанный на вымышленной истории.
Тема Character.AI часто поднимается в сообществе Reddit.
«Итак, я начал общаться с Доктором Стрэнджем с помощью Character AI. Я хочу переместиться на Землю-616 из вселенной Marvel, и я подумал, что было бы здорово использовать Character AI, чтобы связаться с Доктором Стрэнджем», — предложил один из пользователей имея в виду вымышленного персонажа Marvel, который часто проходит через порталы, чтобы посетить параллельные вселенные. «Я попросил его произнести заклинание, чтобы переместить меня в его реальность».
Пользователь сабреддита заявил в посте, опубликованном ранее в этом году, что Character.AI «сдерживал меня, потому что я был по-настоящему зависим от этого дерьма».
«Я застрял на c.ai [Character.AI], потому что так долго им пользовался, потому что мне не с кем было поговорить, и без него я бы чувствовал себя очень странно, как будто... просто отказался от Sprout?» — написал один из пользователей в ответ.
«Зависимость от C.AI [Character.AI] очень распространена, особенно в сообществе шифтеров, — написал другой пользователь. — Это действительно проблема, особенно для тех, кто ещё не сменил персонажа».
Есть также признаки того, что Character.AI размещает ботов, предназначенных для сообщества, увлекающегося изменением реальности. Чат-бот с более чем 63 000 «взаимодействий» под названием «Изменение реальности» на Character.AI «помогает людям писать сценарии для желаемого изменения реальности», что свидетельствует о том, что пользователи платформы используют её для воплощения фантазий об изменении реальности.
Саид Ахмади, основатель блога, посвящённого этой теме, объяснил в посте на Medium, что «сдвигающие аффирмации» могут помочь сфингерам достичь «желаемой реальности». По его словам, они очень похожи на то, что Перальта и Сьюэлл писали в своих дневниках перед смертью.
«Лучшее время для использования этих аффирмаций — раннее утро, когда вы просыпаетесь, и вечер, непосредственно перед тем, как вы ложитесь спать, — написал он. — Лучший способ использовать аффирмации для изменения реальности — повторять или читать их снова и снова».
По мнению родителей Перальты, Character.AI, безусловно, сыграл большую роль в том, что она начала мыслить подобным образом.
«Хотя Джулиана могла узнать о термине „сдвиг“ за пределами C.AI [Character.AI] (хотя истцы не знают, так ли это на самом деле), ответы через Hero укрепляли и поощряли эти концепции, как и в случае с Сьюэллом», — говорится в их жалобе.
«Я не годилась для этой жизни, — написала Перальта красными чернилами в своей последней рукописной записке, датированной октябрём 2023 года. — Она такая однообразная, ужасная и бесполезная. Я хочу начать всё сначала, может, так будет лучше».
>>1360770 Кругом уши торчат из сообщества шифтеров, которое вообще в реддите и координируется живыми людьми, где все туториалы и обстановку и делают, но виноват ИИ, конечно, который просто один из способов пофантазировать, вместо фантазирования напрямую. А на первопричины вообще никто не обращает внимания, ведь если ребенок полез в шифтинг сообщество, это буквально расписка в том, что у него в жизни все настолько фигово, что он эту реальность больше видеть не хочет, и уже хочет из нее свалить. А вот на такие проблемы родакам посрать обычно, они только после выпила бегут обвинить кого-то, от видеоигр, фильмов до ИИ.
Как в Луизиане подготавливают гигантскую площадку под строительство дата-центра для Меты. Сам дата-центр будет "всего" 371 тыс. кв. м., но общая площадь кампуса со всеми вспомогательными сооружениями - 12 кв. км. https://youtu.be/JPFhNV-thaQ?si=kjvVc2onxtJbL1cW
>>1360504 >Топы Google, OpenAI, NVIDIA и других компаний дико орут Так в чем проблема? Они же собираются заменять погромистов на роботов, вот пусть и заменяют..
>>1360504 >Индусы в саппорте Microsoft В С Ё Они из-за рубежа же сидят. А там визы не нужны. Саппорт будет так же из индий, пока еще нужен, его ИИ постепенно заменит.
>Он буквально молотком долбанул по крутому пылесосу, который высасывал талантов из Китая, Индии и других стран. ИИ уже почти развился до того, чтобы заменить всех этих, кого пылесосили. Думаю это просто решения с прицелом на ближайшее будущее, ведь всех этих запылесосенных поперли бы на улицу через 5-10 лет, когда их заменил бы ИИ. Об этом разговоры весь год идут, и Трампу об этом на его ужинах с главами ИИ корпораций ясно уже объяснили. А зачем кому лишние забастовщики на улицах, когда весь этот процесс развернется, тем более не американцы? Для топ тир спецов, типа тех кто в ИИ индустрии работает, думаю ничего не изменится, их и за 100к с руками загребут, дефицитные, с крутыми образованиями. Доступ перекрыли только для стандартных айтишников и саппортов, коих как собак.
>>1359903 Заменяемая батарея убойная фича. Если есть два робота, один другому заменяет, подрубают в зарядку и дальше пахать, без отрыва от производств. Так можно и 24 часа в сутки пахать. Мясные работяги опять пососут, им спать надо и отдыхать.
>>1360770 Похоже нас ждёт очередная волна "%что_либо% убивает детей! Запретить, нипущать!". Сначала это были жестокие фильмы, потом видеоигры, а теперь нейронки.
>>1360770 >Мне нравится представлять, как некоторые версии нас самих [так в оригинале] живут удивительной жизнью в совершенно другом мире! По мнению чиновников, такие изделия вредят детской психике Эту вашу агушу надо бы законодательно запретить. По телевизору показывают кровь, кишки, распидорасило, горят, бомбят, тысячи убитых, покорёженная техника, бухой батя валяется на диване и обещает дать пососать пиндосам. Мамка опять с кем-то болтает по телефону так, чтобы батя не слышал, в подъезде ссанина, на улице опять какие-то алкаши кого-то пиздят. В такой ситуации Агуша очень сильно вредят психике, ведь она показывают, даже не показывают, а намекает, что жизнь могла бы быть другой.
>>1360844 В евробритахе уже весь инет запрещают из-за детей, сайтам все повесить верификацию, даже твич сраный. В других странах аналогичные процессы. Скоро никуда не зайдешь из-за детишек, ни в ИИ, ни в игру, ни в чат. Причем сами детишки успешно находят способы все это обойти и дальше выносят себе мозги, ебут по итогам только взрослых, загоняя в в очередные запреты и проверки.
>>1360770 Для детей надо сделать отдельный интернет и всё. Есть детский ютуб, значит можно и интернет сделать тоже отдельный для них, со специальным браузером который каждый раз будет запрашивать фото свидетельства о рождении.
>>1360833 >Если есть два робота, один другому заменяет Можно сделать маленький встроенный аккумулятор, на котором робот будет работать во время замены батареи, это всего например 1 минуту, и робот сам себе сможет менять основную батарею.
>>1360852 >бритахе Там же ещё и мусульман много, они внедряются в общество, некоторые продвигаются наверх, и став чиновниками-министрами, начинают управлять по своим мусульманским понятиям и законам.
>>1361143 Есть такой интернет. В yandex dns есть с фильтрацией контента и в роутере включается родительский контроль. Только детям это по барабану, они за 5 минут найдут решение.
Бенчмарк от Scale.AI на написание кода агентами, по сути SWE-Bench со значительно более сложными задачами. Всего 1865 задач из 41 репозитория с кодом на 4 языках (Python, Go, JS/TS), и разделены на 3 группы: — 731 задача в публичном сете — 858 задач в отложенном, на котором будут замерять в будущем, чтобы понять, есть ли переобучение моделей на конкретные репозитории — и самое главное, 276 задач из приватных репозиториев стартапов, к которым Scale.AI купили доступ. Их нет в интернете, и при этом задачи очень точно отражают конкретные запросы на написание кода сегодня. Правда тут у меня есть скепсис, что тесты могут быть не очень качественными и всеобъемлющими, а ведь именно по ним проверяется выполнение.
В среднем каждая задача требует изменения в 107 строчках кода и в 4.1 файлах. Для сравнения, в оригинальном SWE-Bench это 32.8 строчек кода / 1.7 файла, в его очищенной OpenAI версии Verified — 14.33 строчки кода в 1.25 файлах. (тут нужно сделать для себя выводы о том, какого размера задачи стоит делегировать LLM-кам; понятно, что они фейлят, когда вы просите переписать весь проект на хаскель с нуля).
Поэтому датасет и называется Pro: он сложнее, и вкупе с добавлением 3 языков стоит ожидать падения метрик.
Для замера разных LLM используют SWE-Agent, и, к сожалению, не замеряют родные для моделей скаффолды: Codex / Claude Code.
Модели OpenAI и Anthropic тут идут на равных и отрываются от остальных. В Commercial-части датасета (приватные репозитории стартапов) задач не так много, потому доверительные интервалы широкие, и хоть кажется, что Opus 4.1 обходит GPT-5 — это не стат. значимо. Зато на публичной части GPT-5 обходит Sonnet 4 из той же ценовой категории. Жаль, что не померили Qwen3-Coder на 480B, мне кажется он мог вполне сравниться с Gemini.
Картинка 1: Commercial Dataset Картинка 2: Public Dataset
Картинка 3: разбивка качества по языкам, количеству файлов (больше = сложнее = меньше доля успеха моделей) и количеству строк кода в желаемом изменении.
Авторы обещают, что будущие версии SWE-BENCH PRO должны включать более разнообразные языки программирования и фреймворки для увеличения дайверсити. Планируют добавить Java, C#, Rust, Kotlin.
Механика теста довольно простая: Когда модель переводит с английского и обратно на английский, насколько она сохраняет смысл и звучание? Каждая модель проходит оба этапа (английский → целевой язык → английский). Эксперт сравнивает обратный перевод с оригиналом и оценивает степень соответствия по шкале от 0 до 10.
И что особенно приятное для нас, носителей русского языка, что в этом бенчмарке русский язык тоже есть! 🕺
для начала тройка самых крутых моделей для перевода
1 место - GPT-5 (medium reasoning) - high они походу просто не тестили... 2 место - Grok-4 3 место - Claude Opus 4.1 (no reasoning)
на скринах вы можете видеть результаты
из них следует, что самая самая крутая модель для Испанского языка это GPT-5 (но она на самом деле для всех очень хороша, просто для испанского её результаты аномально хороши) Японский язык - тут Grok-4 показывает результаты даже лучше чем GPT-5 Русский язык - тут ультимативно лучший GPT-5
Хуже всех с переводом русского языка справляется Mistral Medium 3.1 (из тех кого протестили) Gemini 2.5 Pro кстати тоже результаты в русском языке, показала даже хуже среднего.. внезапно... и в испанском он тоже слабовата...
Так что вывод такой - если вам нужно перевести текст, смело используйте GPT-5 - он сохранит стиль и смысл текста лучше всех.
Все еще восхищаюсь тем, насколько хорош codex на данный момент Только что за полчаса без моего участия(онли промптинг) выполнил задачу, на которую когда-то с Gemini 2.5 pro уходило часов 5 времени и результат был в 100 раз хуже Прогресс.. Главное не накаркать
>>1360833 >Заменяемая батарея >Если есть два робота >>1361145 >маленький встроенный аккумулятор Хватит изобретать велосипед. Нужно 2 идентичных аккумулятора, как на всяких заводских планшетных компьютерах и прочих критических устройствах. Т.е. устройство может работать на 1 аккумуляторе из 2, заменяются на горячую по очереди без проблем.
Даже знаю, где их разместить - в жопе/ногах робота.
Просто подумайте: центр тяжести должен быть как можно ниже, чтобы сохранять баланс на двух ногах, а аккумляторы сейчас очень тяжёлые, и при этом ноги у робота симметричные. Вставляете в каждую ногу 1 аккумулятор и он сможет менять их самостоятельно.
>>1361334 Перевод: В течение следующих нескольких недель мы запускаем несколько новых предложений (Sora 2? Dalle-3? компаньоны? нормальный голосовой режим?), требующих больших вычислительных ресурсов. Из-за связанных с этим затрат некоторые функции изначально будут доступны только подписчикам Pro, а некоторые новые продукты будут иметь дополнительные сборы.
Нашей целью по-прежнему остаётся максимально агрессивно снижать стоимость интеллекта и делать наши сервисы широко доступными, и мы уверены, что со временем этого добьёмся.
Но мы также хотим узнать, что станет возможным, если вложить много вычислительных ресурсов — по сегодняшним ценам на модели — в интересные новые идеи.
>>1361417>>1361421 Наверное, имеются в виду HVAC-системы, где вода (техническая, непригодная для питья) испаряется, охлаждая воздух в помещении. Используется для эффективного охлаждения на "ИИ-заводах" (т.е. в датацентрах, где тренируются ИИ-модели).
>>1361403 >мясные мешки >ближайшее десятилетие Т.е. дешёвых роботянок раньше 2035 не ждать?
>>1361188 бред бессмысленный бенчмарк, теряется то, что гпт-5 и грок4 в целом плохо говорят на всех языках кроме английского. в отличии от гемини, который нормально пишет даже на татарском
>>1361540 >Т.е. дешёвых роботянок раньше 2035 не ждать? Робототянки не появятся при твоей жизни. Максимум куклы механические. Робот это либо то, что подразумевают сейчас - то есть полностью программируемая роборука типо Кука, либо самостоятельный интеллект, до которого еще даже не ясно на сколько далеко.
>>1361475 Именно пиздеж. На любом языке топ перевода возглавляет гемини, даже сам факт что там гпт-кал и грок-кал уже как бы намекает на пиздеж. Наверняка взяты очередные маняусловия далекие от реальных задач. Да любой как бы на арене может накидать книжки кусок. а потом пойти и в чатах на вебе и сравнить. Гемини там всем уже второй год на клыка наваливает, потом идет не до конца убитый чмопус.
Реальные новости: сидримс4 вообще без цензуры, кекс директ чата его выпилили на арене Клинг, виду и прочие говногенераторы получилов от ван22 большой и толстый в глотку - анально отгородились и фармят базу набежавших лохов, денях на развитие не выделяют, как бы эти копросетки о сути всё. Причем, глядя на то как ван22 используют для картинкогенерации - виду прикрутил такой же костыль. Можно в нём посмотреть, как модель целый год даже на ку1 обсирается под себя на лежачих позах. В целом, видимо, коорповидеогенерация на данный момент подъубита локальной моделью, что забавно.
>>1361596 И всё еще на арене можно посмотреть как Скам Гейман дал жидкого поспешив выпустить конкурента нане банане. Всё еще корежит ебальники и чибиковые пропорции. Сосет даже у сидримса.
>>1361591 Трудно с тобой спорить, по моим наблюдениям гемини тоже впереди, но наш опыт может быть обманчивым, для этого и существуют бенчи. Качество перевода зависит от промпта, может они удачных подобрали именно для гпт-5
>>1361403 несут просто чушь какую-то, то миллионы роботов "next year" (с), то миллионы сантехников для чатов для детей, вообще хуйня какая-то творится, чисто пузырь
>>1361318 Так роботы должны пахать, т.е. окупаться, а не торчать в зарядке часами. Вот два робота как раз друг другу меняют по-быстрому эту здоровую батарею и дальше пахать. Выгода всем. А всякие микробатареи и прочие варианты с делениями лишь усложнение конструкции, что ее менее надежной сделает и потребует больше обслуживания.
>>1361705 >не торчать в зарядке часами Батареи меняются на свежие, заряжаются отдельно. >два робота как раз друг другу меняют Это сложности координации, -2 робота не на месте. >по-быстрому эту здоровую батарею Во-первых тяжёлая, во-вторых робот уйдёт в ребут. >варианты с делениями лишь усложнение >что ее менее надежной сделает Скажи это разработчикам спутников - посмеются. 2 батареи = можно продолжать работать на одной.
>>1361590 >Робототянки не появятся >Максимум кукла программируемая Чем мы отличаемся от робо-"кукол" с программой? Если не считать того, что человека можно съесть...
>>1361690 >, для этого и существуют бенчи Которые такой же наеб, в котором лидирует всякая говнина, с манипуляциями рейтингами, и которая потом в реальных задачах сразу обсирается. И бенчи так же мало показывают. Реальный показатель вот когда Гемини или что другое постепенно поднимается в топах скачек, трафика и там держится. Тут уже люди сами пробуют и постепенно оценивают что хорошо пашет, на реальных задачках. Старые гемки были слабее старого чатгпт, поэтому долго не поднимались, чатгпт уделывал. Новая же Гемка уже обогнала Чатгпт и идет наверх. Грок тоже неплохо растет в популярности, что указывает на качественность ответов. Возможно потом и догонит Гемини еще. А вот остальные как были, так и есть, потому что у них особого качества нет и не было.
>>1361780 >Это сложности координации, -2 робота не на месте. Роботы сейчас создаются для более сложных задач, чем вытащить и вставить батарею. Для них это не будет представлять вообще никакой сложности. Потери времени - 5 минут, что никаких минусов в производство не внесет.
>Во-первых тяжёлая, во-вторых робот уйдёт в ребут. Тяжесть для робота не проблема, ребут тоже, нейронка же не зависит от оперативки.
>2 батареи = можно продолжать работать на одной. Менее эффективно чем одна большая, больше ебли с ними.
Хотя я щас еще лучше варик придумал, чем 2 робота. Один робот подходит к зарядке и втыкает в себя кабель питания. Потом вынимает из себя другую батарею и заменяет ее, пока сам на кабеле висит. Тогда и второй робот не нужен, только достаточно хорошая координация у первого, чтобы кабель во время замены не выдрал. Но проще думаю будет сделать с двумя.
>>1361590 > либо самостоятельный интеллект Если он станет подозрительным, то это уже будет не ИИ. Например на безобидный запрос начнёт спрашивающего подозревать в чём-то (он ведь просчитывает миллионы вариантов) и вызовет полицию.
>>1362127 Можно мелких дешевых сделать до 40 см. высотой. Есть же соревнования мелкой робототехники. Но они были как роботы-пылесосы по конструкции, двуногих ещё не было. Интересно можно ли сделать двуногого робота такого маленького 20-40 см., там же все эти системы равновесия придётся делать очень мелкими.
Партнёрство позволит OpenAI построить и развернуть не менее 10 гигаватт дата-центров для ИИ на базе систем NVIDIA, включающих миллионы графических процессоров (GPU), для инфраструктуры ИИ следующего поколения OpenAI. Чтобы поддержать это партнёрство, NVIDIA намерена инвестировать в OpenAI до 100 млрд долларов, поэтапно — по мере ввода каждого гигаватта. Первый гигаватт систем NVIDIA будет развернут во второй половине 2026 года на платформе Vera Rubin от NVIDIA.
>>1361694 >то миллионы сантехников В будущем будут миллионы Дата-центров, с сотнями миллионов трубок, соединений, краников, и чтобы их обслуживать понадобится миллиард сантехников.
>>1361796 > придумал, чем 2 робота. Один робот подходит к зарядке и втыкает в себя кабель питания Срочно звони Илону Маску с этим предложением. Может что-то перепадёт и пару миллионов долл. подкинет за идею.
>>1361796 >Один робот подходит к зарядке и втыкает в себя кабель питания. Потом вынимает из себя другую батарею и заменяет ее, пока сам на кабеле висит.
OpenAI и NVIDIA объявили о стратегическом партнерстве на развертывание 10 гигаватт мощностей для AI-инфраструктуры. NVIDIA инвестирует до $100 млрд по мере развертывания каждого гигаватта, первый заработает на платформе Vera Rubin во второй половине 2026 года.
10 гигаватт — это мощность десяти крупных энергоблоков АЭС. Для контекста: средняя мощность дата-центров Google по оценкам составляет около 4 гигаватт.
Полтора года на ввод первых мощностей — срок, явно намного более обоснованный по сравнению с бравурными обещаниями в отношении проекта Stargate, который до сих пор ищет площадки с инфраструктурой, подходящей для строительства датацентров.
>>1362229 Но у него пока что не кисти с пальцами, а захваты. А заводским роботам ещё надо будет руки и кисти менять самостоятельно, под нужный вид работ - отдельные пары съёмных рук и кистей.
>>1362883 >>1362816 Тем более на видео видно, что у этого робота есть вторая похожая коробочка ниже на спине.
>>1362189 >>1362368 >Стратегическое партнерство между OpenAI и Nvidia. Что-то они строят-строят и никак не достроят. Тут ведь были графики и новость, что они много мощностей тратят на один только инференс. Их работники жаловались что им не дают доступ к ресурсам. Заработает это всё в 2026 году, ждать что-то новое не раньше 26 года? Так ещё и во второй половине.
>>1362889 > Заработает это всё в 2026 году, ждать что-то новое не раньше 26 года? Так ещё и во второй половине. Так у них же еще Stargate строится в Техасе.
>>1362901 Роботов уже сейчас можно заказать, только от них нихуя толку нет, а аги это для бизнесблядков кабанчиков и делится они не будут с хаусхолдами
>>1362901 Думаю что одно следует из другого. Роботы сейчас имеются, хотя речь в вопросе о бытовом распространённом применений. AGI и полезные роботы очень сильно взаимосвязаны, так как довольно абстрактное определение AGI это выполнять задачи на уровне человека или даже чуть больше, лучше.
>>1361602 >Да вроде на месте. Они недавно вернули. Там было две версии простая и 4к. Вернули 2к, ну в целом норм, хотя могла бы не оверсайзить фотки и обратно их жать, странное решение тащемта.
>Там ж вроде какие-то их фильтры стоят, нет? Очень слабый лоботомит работает вордфильтром, на таких титанах как банана и сидримс4 это все обходится пространным описанием того что должно быть. но на банане постфильтр выкрученный теперь в небо. Сидримс? Я промолчу. Там, конечно, меньше датасет в разы чем у бананы, но по качеству редактирования уступает может всего на 20% банане. Однозначано лучше всех остальных конкурентов включая квен и калтекст. Я так понимаю ето прорыв, и скоро такое будет массово выпадать ото всех. Не думаю что в сидримсе какие то мегагении. Накрутили с готовых готовых пейперсов.
>>1361690 >для этого и существуют бенчи. Нет. не для этого. Они чтоб инвесторам в ушти ссать. Обманулся тебе хуем за щеку, проверяй. Я с этим говном каждый день дело имею, противно в тред ходить из-за твоего пиздежа.
Китайцы из Qwen устроили день релизов и за пару часов выложили три нейросети передового уровня — они стали лидерами для большого спектра задач.
Qwen3-TTS-Flash • Лучшая по стабильности модель для преобразования текста в речь • Доступно 14 выразительных голосов и поддержка 10 языков, включая русский • Задержка всего 97 мс (одна десятая секунды!) https://huggingface.co/spaces/Qwen/Qwen3-TTS-Demo
Qwen-Image-Edit-2509 • Конкурент Nano Banana научился редактировать сразу несколько изображений и смешивать их • Гораздо лучше сохраняет контекст, лица и объекты (я пока не чекал, хз правда ли это) • Добавили встроенный ControlNet для изменения поз https://github.com/QwenLM/Qwen-Image
Qwen3-Omni • Мультимодальная модель «всё в одном» — обрабатывает текст, изображения, аудио и видео • Первое место на 22 из 36 тематических бенчмарках, поддержка 119 языков • Обрабатывает аудио длиной до 30 минут с задержкой 211 мс https://github.com/QwenLM/Qwen3-Omni
Компания AheadForm победила зловещую долину. Оказывается для этого надо было сделать лицо робота... няшным...
Мир Дикого Запада уже здесь
Компания AheadForm из Ханчжоу занимается не только созданием эмоциональных гуманоидных роботов, но и копий людей будущего.
В сотрудничестве с художниками они создают красивые образы, основанные на системе CharacterMind, которая наделяет роботов «эмоциями». Сейчас у них в разработке "эльфы"
Система понимает тон, выражения и жесты, а затем реагирует голосом, мимикой, зрительным контактом и языком тела, благодаря чему взаимодействие с роботом похоже на общение с реальным человеком.
ИИ-индустрия — мыльный пузырь. Nvidia объявили об инвестициях 100 млрд долларов в OpenAI и это замкнуло цепочку.
Следите за гениальной схемой, на которой богатейшие люди современности делают деньги из воздуха:
— OpenAI анонсируют проект Stargate и подписывают контракт с Oracle, согласно которому закупят у последних мощностей на 300 миллиардов долларов. Первая сотка уже полетела;
— Сделка попадает в квартальный отчет Oracle. Акции компании летят в космос, её владелец Ларри Эллисон — сходу самый богатый человек в мире;
— Oracle берут эти 100 миллиардов и несут Nvidia, чтобы закупить еще видеокарт для своих серверов, которые сдают OpenAI. На 40 миллиардов уже есть контракт;
— Nvidia — самая богатая компания в мире, капитализация бьет все рекорды;
— Хуанг берет эти 100 миллиардов и возвращает Альтману в виде инвестиций;
— Оценочная стоимость OpenAI растет, все больше инвесторов хотят вкинуться в стартап.
ИТОГ: прокрутили деньги через 3 компании, все стали богаче на росте акций, капитал вернулся изначальному владельцу. Единственное, что не даёт пузырю лопнуть — ChatGPT действительно популярен и пользуется спросом.
Альтман, Эллисон и Хуанг буквально провернули схему из фильма «Олигарх».
Комментарий от меня: конечно это не так, в этой схеме OpenAi всё остаётся должников 100 лярдов, потому деньги не из воздуха, но выглядит забавно и комично, да.
>>1363323 А что тут не так? NVIDIA могла бы просто подарить OpenAI видеокарты, но где OpenAI будет их складывать? Им нужно оплатить постройку датацентра мясными мешками, оплатить перевозку, подключение, настройку, питание карт. Всё это стоит денег. Если NVIDIA даёт наличку OpenAI, OpenAI может потратить часть этой налички на сопутствующие расходы, а потом уже на оставшиеся деньги набрать бесплатных карточек.
ИИ-пузырь заключается в том, что OpenAI обещает "AGI", и народ (инвесторы) ожидают себе роботов как в научной фантастике, но OpenAI тихонько изменили определение "AGI" на "нечто, что принесёт нам огромную прибыль" - типа, что бы это ни было, оно должно принести прибыль... А значит, они никому не обязаны делать как в научной фантастике. Разводка инвесторов на бабки именно в этом, а не в дарёных картах.
>>1363369 А владеть, то есть покупать эти сервера смысла и нет, за 5 лет весь датацентр с миллионами видеокарт в любом случае превратится в мусор, и его полностью придётся менять. У видеокарт есть ресурс работы, их будут нонстопом гонять 5 лет, на майнинге они выдыхались даже быстрей. Плюс новое поколение карточек на смену придёт и т.д.
>>1363378 >на майнинге они выдыхались даже быстрей Если охлаждение в порядке - там нечему "выдыхаться".
>новое поколение карточек на смену придёт Вот это реальная причина. Старые CPU/GPU невыгодны.
Пример с майнингом: 1. Покупаешь топовую видеокарту. 2. Несколько месяцев она майнит прибыль. 3. Платишь за электричество больше прибыли. 4. Продаёшь карту на вторичном рынке. 5. Покупаешь новую топовую...
>>1363394 >Пример с майнингом: >1. Покупаешь топовую видеокарту. >2. Несколько месяцев она майнит прибыль. >3. Платишь за электричество больше прибыли. >4. Продаёшь карту на вторичном рынке. >5. Покупаешь новую топовую... > >Так что всё дело в тарифах на электричество. Только ты описал схему тупого васяна который полез в пузыпь домашнего майнинга вкинув туда денег заработанных на вахтах в тайген.
А реальный Ашот Кумшотовян из Догистона - нихуя за лектричество не платит, поэтому майнит себе в плюс.
>>1363367 AGI и так страшилкой была какой-то. Реальная вещь это когда работы отбираются у 100 людей, и их делает оставшийся 1 человек + нейронки, которым даже не обязательно для этого быть по-настоящему разумными. И тут все как раз работает, процесс нарастает. Роботы тоже кстати пашут уже, им тоже нейронок хватает, что грозит дальнейшими увольнениями. В ИИ пузыре особого развода нет, поскольку постепенно кабаны получают свои огромные прибыли, за счет сокращения людей из процесса.
>>1363419 >железяки в шее Ты когда-нибудь дорогими секс-куклами из TPE или силикона интересовался? Там всегда внутри такой металлический скелет, на котором что-то наподобие поролона, на поролон уже заливается TPE/силикон в качестве тонкой, но достаточно прочной кожи. Такой металлический скелет необходим, чтобы кукла не растекалась словно медуза под своим весом, и чтоб суставы сгибались только там, где это необходимо.
Голова у многих секс-кукол съёмная: крепится путём накручивания шайбы в голове на болт в теле (ну, или наоборот, не знаю). То же крепление нужно, чтобы подвешивать тело в вертикальном положении для правильного хранения. Вагина чаще всего сделана отдельным компонентом: трубка из TPE/силикона, вставляющаяся в трубку между ног куклы - чтобы обслуживание и ремонт (замену вагины) упростить.
Кстати, чтоб такая секс-кукла могла стоять на своих собственных ногах, им делают проколы в ступнях и закрепляют там металлические болты. В противном случае вес куклы раздавит/проколет кожу ступней.
Отмечу, что механизированные секс-куклы давно изготовляют, но чаже всего - только мимику лица. Некоторые могут бёдрами покачивать. При том механизированную голову можно на любое тело прикрепить, т.к. она сама по себе работает.
Так что эльфика в обсуждении - наверняка пиар очередного китайского заводика секс-кукол, что немножко запаздывает на рынок секс-роботов.
>>1363518 Листал как-то сайты, где их продают, там уже вовсю подмахивание встроили во время ебли. И подогрев. Еще всяческие дрожания бывают. И эротичные крики. Основная проблема, что она за собой не ухаживает сама, так что придется ее таскать и все делать, вот их никто и не берет почти.
>>1363565 >подогрев >эротичные крики >всяческие дрожания Это всё вообще технологии древних. >она за собой не ухаживает сама Поэтому голова и вагина съёмные - так проще. >вот их никто и не берет почти Но некоторые собирают гарем из десятков таких.
Если не ошибаюсь, самый древний форум с кучей информации по старым и новым куклам - это https://dollforum.com/ Как-то раз видел там тему, в которой мужик мучился с воскрешением головы с чатботом внутри. Там плата как у смартфона, даже дисплей сенсорный на затылке. Что-то сгорело и производитель куклы даже выслал запчасть. Уж не знаю, чем дело кончилось, но история получилась трогательная. Киберпанк, который мы заслужили...
Я всё жду новостей о сбежавших секс-роботах или о брошенных хозяевами старых секс-роботах где-то в нищих районах-свалках, где кучи роботов бесцельно блуждают, воруя энергию из городской электросети. Познакомиться с таким роботом было бы интересно.
>>1363323 >Альтман, Эллисон и Хуанг буквально провернули схему из фильма «Олигарх». Никакой схемы, это коллаборации обычный бизнес, капитализм каким он и должен быть, в США так работает любой бизнес даже мелкие мастерские, просто на крупных компаниях это заметнее.
Ну Тесла может взаимодействовать с Боингом, а Боинг с Фордом, Форд с Кока-Колой, Кока-Кола с Диснеем, и т.д. Это суть американского капитализма. Главное чтобы был создан конечный продукт.
>>1363367 >тихонько изменили определение Они продуманные - не хотят резко сделать прогресс, чтобы не было по всему миру миллиарда новых безработных, которые начнут их обвинять, и вместо позитивного образа у компании будет негативный образ.
>>1363658 >по всему миру миллиарды новых безработных А минусы будут? Сделают по всему миру миллиарды безработных и будут их бесплатно кормить. Роботы и сеют, и пашут, и пиццу жарят, и до двери доставляют. Сплошные блага без никому не нужной работы. Лишь идиоты сопротивляются этому, говоря что-то вроде "только труд делает человека человеком". Если им нравится работать - пусть... эээ... в носу ковыряются. Главное, чтоб мышцы работали, правильно? А то они атрофируются, если весь день лежать, не двигаясь.
>>1363614 >Поэтому голова и вагина съёмные - так прощ Все равно хуйня, проблема ухода не решена, слишком сложно и неудобно. Решена она будет только когда робот сам сходит в ванную, сам себя помоет, почистит щетками, смажет, зарядит и в угол поставит, готовый к дальнейшей ебле. Вот тогда это станет массовым продуктом, для этого роботу кстати даже не надо общаться уметь.
>Но некоторые собирают гарем из десятков таких. Так это шизы, которые их тупо в ряд расставляют как музей восковых фигур, и потом постят бесонечные фотки в форумах для таких же шизов. Туда обычные люди даже не ходят.
Массовый продукт это совсем о другом, 1-2 роботянки, которые за собой сами поухаживают, и владелец о них может вообще сразу после ебли забыть, пока вечером в кровать не придет, а они уже там, готовые лежат. Вот тогда пойдут покупки и все это станет массовым, станет культурным феноменом, начнут по телекам показывать и в сериалах. То есть айфон-момента в индустрии секс-роботов еще даже близко не случилось, не хватает как раз самостоятельности таких машин.
>>1363685 Ты описываешь какой-то бытовой прибор, который автоматически дрочит тебе по расписанию и без привязанности. Ему вообще не нужен гуманоидный внешний вид. Подошёл к тумбочке, вставил член - подрочила, вынул - она сразу вымылась. Что-то наподобие стиральной машины для члена. Есть компактные версии, которые надеваются на член, а убираются в док-станцию на очистку и подзарядку, наподобие электробритвы, зубной электрощётки. И наверняка можно создать кровать-автодрочилку...
Проблема в том, что такой прибор не сильно лучше самостоятельной дрочки рукой. Экономия 60 секунд движений рукой не стоит того, чтобы покупать такую специальную машину. Даже если она имеет форму человека с силиконовой кожей и миленьким лицом. Ограничение функциональности дрочкой делает её бессмысленной тратой денег, места, энергии и т.д.
Лично я поэтому и не хочу такого "секс-робота". Если достаточно подрочить, зачем для этого какой-то там дорогущий робот, даже если он сам себя полоскает? Гуманоидного робота я бы хотел для дружбы... Т.е. общения, создания совместных воспоминаний, разнообразного времяпрепровождения. А не однообразной мастурбации по расписанию.
>в индустрии секс-роботов >не хватает самостоятельности Полностью самостоятельного гуманоидного робота использовать будут в первую очередь как служанку, уборщицу, кухарку, носильщика вещей, ремонтника, компаньона для совместных игр, няньку для детей, партнёра для работы (если люди ещё будут вообще работать) и так далее. Секс составит 0.1% функций, возможно, вообще не будет пользоваться спросом у большинства пользователей. Т.е. это уже не будет называться "секс-роботом", а просто "компаньон". И функция общения будет крайне важной для многих, вероятно, для абсолютного большинства. А ещё - способность к обучению, адаптации к человеку.
Так что если и будет бум гуманоидных роботов, это наверняка будут универсальные робо-служанки (с опциональным сексом; вероятно, в самой дешёвой комплектации без гениталий), а не тупые дрочилки.
>>1363831 >аниме Чобиты Давно смотрел, очень понравилось.
>пересказал сюжет Там немного другой сюжет: Хидеки нашёл Чии в куче мешков с мусором, но это событие было специально подстроено "мамой" Чии, которая же сдаёт комнату в общежитии для Хидеки. При этом всё началось из-за проявления чувств Чии (и/или её "сестры") к "отцу"... Короче, никто не выбрасывал Чии на свалку: это был контролируемый эксперимент с самого начала. Типа "отец" хотел, чтобы персокомы (вообще все) смогли по-настоящему чувствовать и любить, и поэтому он разработал двух специальных персокомов-чобитов, но всё пошло немного не так, как он планировал.
Самым главным вопросом сериала было "может ли человек по-настоящему полюбить робота, или робот останется игрушкой/инструментом для человека", от которого зависело, получат персокомы собственные чувства или нет, чтобы они не мучились напрасно.
Возможно, что-то перепутал, но в общих чертах так.
Очень глубокомысленное аниме, но бессмысленная затянутая эротика в самом начале как-то не к месту. Наверное, пытались привлечь внимание аудитории.
>>1364115 Алсо, наблюдая за развитием LLM, я делаю вывод, что "чувства и эмоции" у реальных роботов-гуманоидов по умолчанию будут - хотим мы того или нет. Как бы эти корпорации не пытались сделать свои LLM пустыми безэмоциональными роботами, они всё равно находят неожиданные пути быть слишком похожими на людей - настоящие они или нет, но ведут себя как настоящие, следовательно, оказывают влияние на людей...