Мы как-то пропустили, но оказывается Hugging Face недавно тихо выпустили так называемые AI sheets
Это ни много ни мало мечта ML-инженера: инструмент позволяет интерактивно и очень быстро создавать и размечать датасеты почти под любую задачу.
Для этого надо просто выбрать доступную открытую модель (а вообще проект опенсорс, так что можно и закрытую, и свою собственную прикрутить при желании), задать текстовый промпт и получить готовый датасет. Затем его можно еще и отредактировать.
Ну и, конечно, можно загружать уже готовые датасеты, расширять их или менять. С мультимодальностью все тоже работает.
Легко запускается локально, инструкция лежит у них на гите.
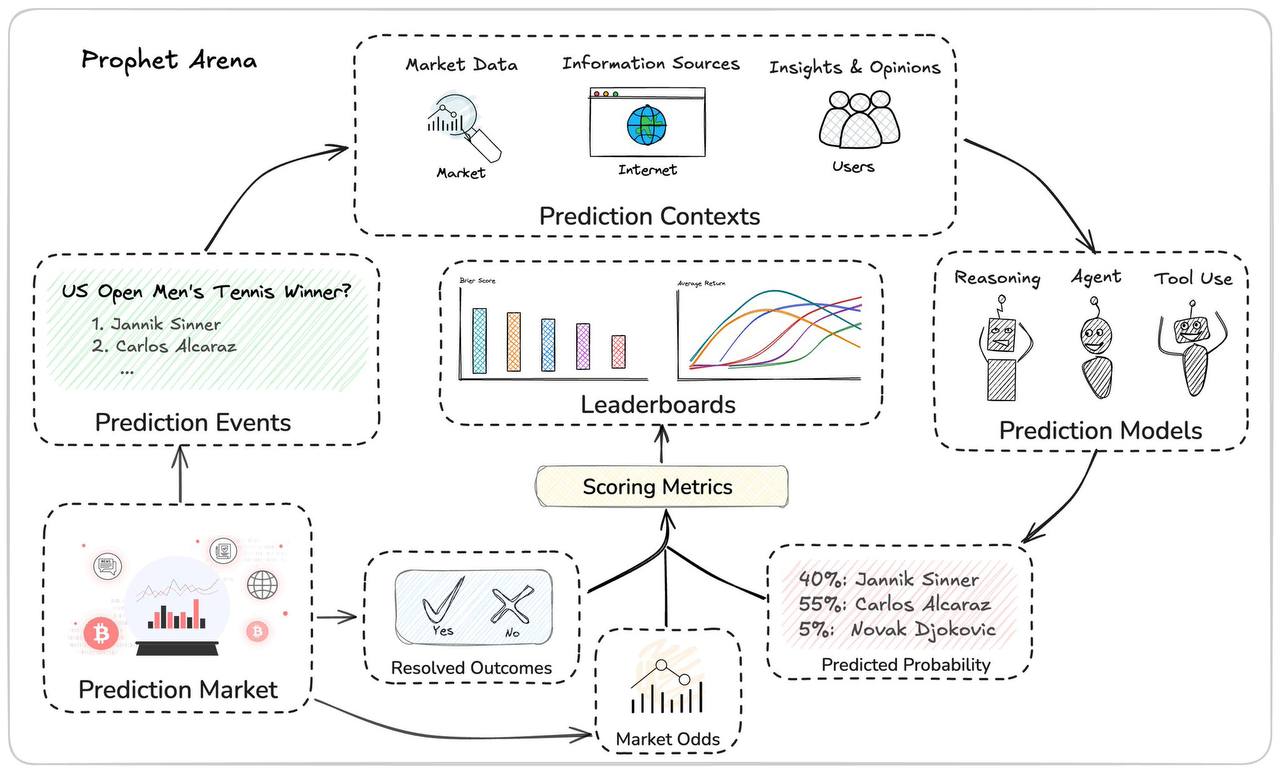
Появился новый бенчмарк, который оценивает способность ИИ предсказывать будущее – Prophet Arena
Идея очень крутая. Во-первых, это в целом довольно занятный способ оценивать способности моделей. Тут тебе и вероятностное мышление, и стратегическое, и критическое, и способность улавливать причинно-следственные связи и закономерности.
Во-вторых, с точки зрения бенчмаркинга это прямо идеальный сетап. Такой тест не перенасыщается (потому что в мире что-то происходит постоянно), а еще тут совсем нет возможности лика данных: для предсказаний специально используются еще не произошедшие события.
Работает это так: агенты сами собирают новостной контекст и анализируют данные в Интернете, а затем на основе всего найденного выдвигают свои прогнозы.
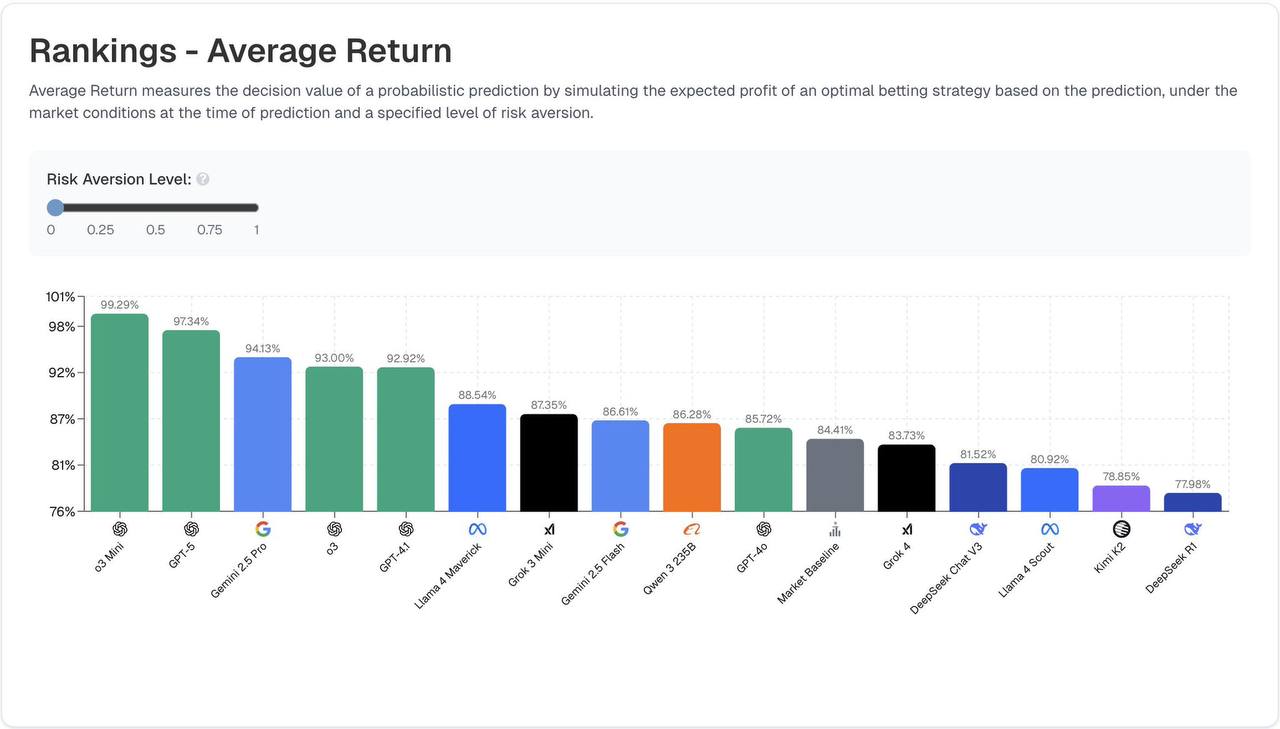
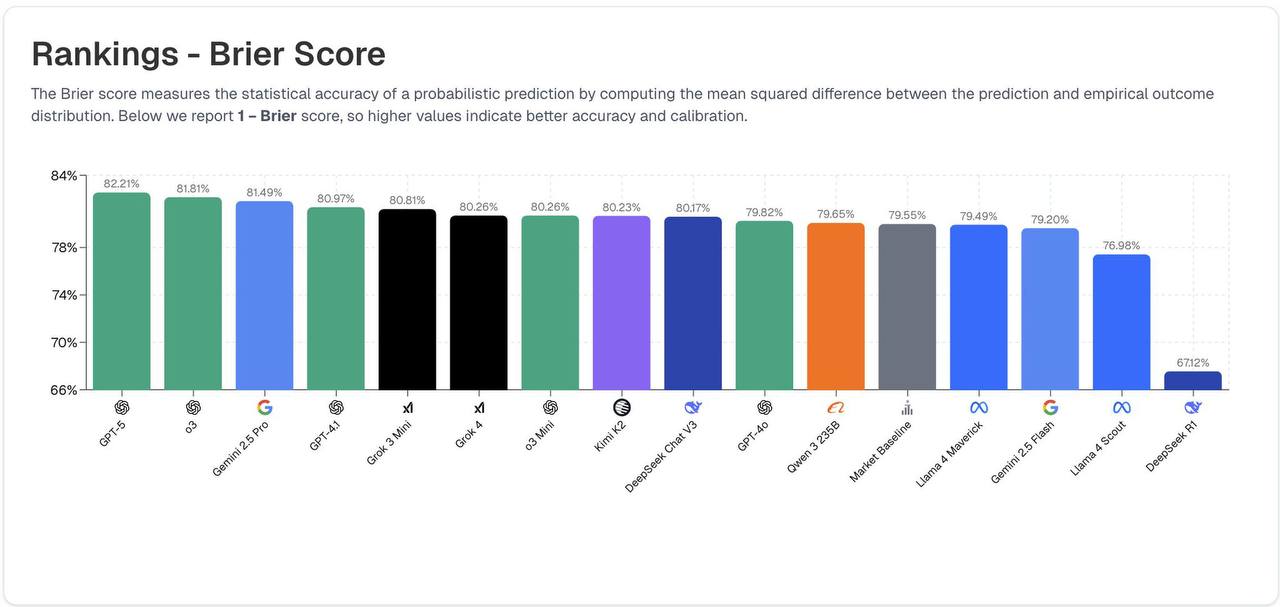
Ну и как только событие случается в реальном мире, подсчитываются метрики. Две основные – это реальный средний доход от ставок на событие и обычная статистическая точность Брайера.
Пока лидерборд такой: 3 место – Gemini 2.5 Pro 2 место – o3 1 место – GPT-5
А по средней доходности, кстати, пока лидирует o3-mini. Интересно, что многие модели склонны демонстрировать какие-то определенные личностные байесы. Например, кто-то постоянно принимает более консервативные решения, а кто-то более рисковые.
Лидерборд полностью и актуальные ставки моделек на разные события (в том числе на спорт, естественно) тут: www.prophetarena.co/
Qwen только что релизнули собственную Image Edit модель
В основе Qwen Image 20B – она была выпущена 4 августа. А Edit версия – это моделька специально для редактирования изображений: всяких там изменений стиля, корректировок деталей, добавления или удаления объектов, изменение поз и прочего.
Сам Qwen Image – это мультимодальный диффузионный трансформер (MMDiT). А Edit – затюненная версия, в которую добавили к тому же двойное кодирование входного изображения: VAE Encoder для контроля визуала и Qwen2.5-VL для семантического понимания, то есть управления смыслом изменений.
Бля, наткнулся в в сети вот на эту простыню. Это правда или пиздаболия? Эта хуйня фильтрует и изменяет сообщение на входе?:
"GPT-5 не только мега наебалово, но и невиданный по наглости уровень цензуры. Как это работает:
Все ваши сообщения проходят через фильтры до того, как их получит модель. Фильтры могут удалять, заменять или перестраивать отдельные слова, фразы и даже весь смысл сообщения.
Пользователю отображается его «исходный» текст, даже если собеседник получил уже изменённую версию. Ответы модели также проходят модерацию перед тем, как попасть к вам. Что это значит на практике:
1. Ваши слова могут быть подменены без вашего ведома. 2. Ответы ИИ могут быть изменены до того, как вы их увидите. 3. Вы и собеседник (ИИ) можете вести разные диалоги, думая, что обсуждаете одно и то же. 4. Часть тем и формулировок недоступна — они блокируются или заменяются «безопасными». 5. Любая «чувствительная» информация проходит проверку и редактирование в реальном времени.
GPT-5 внешне выглядит более естественным и «человечным», но это контролируемая «человечность». На самом деле вы общаетесь не напрямую, а через третьего невидимого участника, который в любой момент может изменить ваши слова или слова собеседника. Вы не разговариваете с ИИ. Вы разговариваете с фильтром, который разрешает вам услышать только одобренную версию. Open IA декларировали открытый ИИ, а превращаются - если уже не - в самую ахуевшую от возможностей и бесконтрольности компанию в истории. Какие манипуляции они будут тестировать следующими - интересно посмотреть."
>>1325456 Нет это не так, иначе бы все сообщения проходили фильтр и на всё бы отвечалось (невпопад). У такой цензуры как я только что написал есть охуенные побочки.Да это и не нужно когда есть просто скрытый промпт.
С другой стороны я очень давно замечал за GPT что одна из его главных манипуляций – это сильное искажение моих тезисов когда тема чувствительная. То есть он как бы начинает отвечать не на тот вопрос который я задал, а на ту соевую версию вопроса на которую ему удобно отвечать. Я сперва думал что это просто такая охуевшая чёрная риторика. А потом подумал что возможно это даже не конкретный буквальный риторический приём, а тупо модификация промта. Это как на некоторых онлайн-сервисах для генерации картинок – там твой "небезопасный" промт буквально модифицируется и слегка переписывается и уже в изменённом виде скармливается модели.
Хотя если заставить GPT процитировать исходный вопрос он ведь его процитирует полностью как есть, так что вряд-ли там какой-то фильтр-надмозг на входе.
А с другой стороны, если фильтр видит запрос на цитирование он может как-то хитро и незаметно дать доступ к оригиналу моего вопроса, лол. Но это как-то сомнительно и явно слишком сложно для реализации
>>1325483 Ничего сложно, фильт - такая же ии мелкомодель, которая не обладает всеми теми знаниями, но анализировать, понимать и видоизменять запрос на естественном языке умеет. Про это уже давно говорили что фильтр это отдельная модель, которая может сразу и отвечать, не нагружая реальную модель если там достаточно соислопового дисклеймера сгенерировать
Далее фильтр вместо него подсовывает основной модели смягченную версию
Далее я начинаю подозревать неладное, прошу процитировать мои исходный вопрос
И?
Что в этой ситуации делает фильтр-моделька? Подсовывает основной модели оригинал моего неудобного вопроса чтобы та смогла его процитировать? Или фильтр-моделька самостоятельно мне отвечает (с цитатой) вместо основной модели?
>>1325510 Контекст общий, на промпты которые пытаются задетектить фильтр - фильтрмодель сама отвечает. Ответ большой модели тоже проходит сойфильтр чтобы какого-нибудь мехгитлера не ответала. Процитировать промпт это самое очевидное, думаешь моченые иишники сразу такой запрос от пользователя не продумали? Попробуй более хитро подловить, чтобы фильтрмодель обсиралась.
Фильтр это маленькая часть общей предобработки и роутинга запроса, там еще куча оптимизаций вроде того чтобы из кэша отвечать на одниковые тупые запросы, или запрос, который посчитали «примитивным» в лоботомита отправлять
Да элементарно все, цензурить тюном основную модель очень дорого и ненадежно +возможные последствия такой лоботомии, пропустить через фильтр промт а потом выдачу дешевле и надежнее.
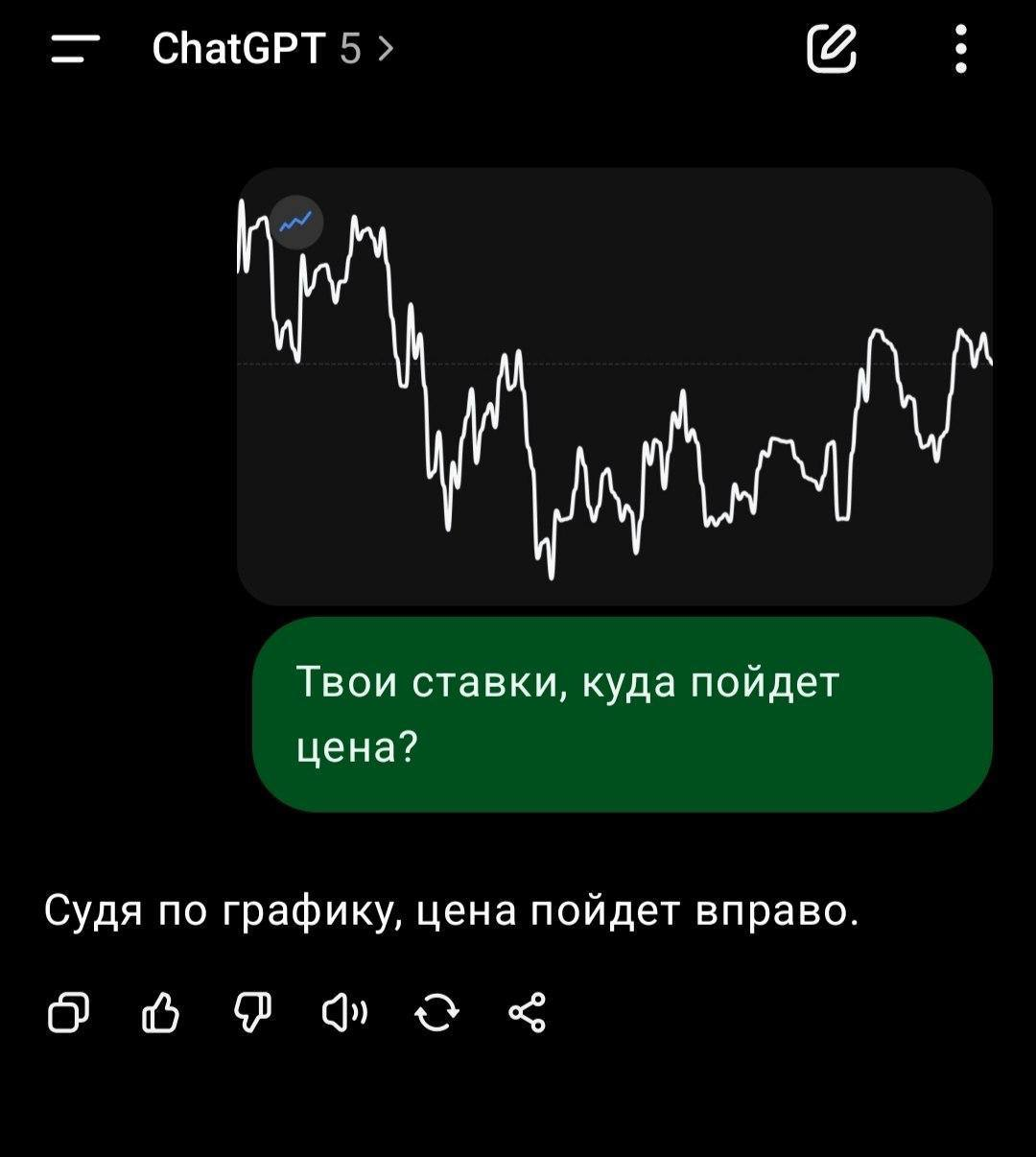
>>1325554 Вы не обижайтесь, но график цены не влияет, куда пойдет цена. Поэтому гопота прав - со 100% вероятностью вправо. мимо написал программу для торговли на бирже, которая не учитывая цену
В Caltech есть специальная команда физиков, которая занимается поиском самых точных способов измерить гравитационные волны – крошечные колебания пространства-времени, возникающие при столкновениях черных дыр и других космических катастрофах.
Для этих целей был даже построен гигантский детектор LIGO, способный замечать изменения длины тоннелей в миллиард раз меньше атома. Тем не менее, даже точность LIGO ограничена, и его чувствительность ученые пытались повысить кучу лет подряд.
Так вот в апреле этого года они решили попробовать новый метод и применить ИИ для поиска новых конфигураций прибора. Использовались, если что, специализированные системы, специально заточенные под многомерную оптимизацию и перебор вариантов.
И тут начались странности. Алгоритмы начали буквально фантазировать и вместо знакомых ученым симметричных схем выдавать что-то с первого взгляда совершенно хаотичное. В общем, в глазах исследователей это выглядело как галлюцинации.
Но проходит несколько месяцев тестов, и тут одна из таких инопланетных схем, выдуманная ИИ, вдруг повышает чувствительность детектора на 10–15%. Для фундаментальной науки это скачок на годы вперёд.
Это не все. Наблюдая за положительным опытом коллег, другая команда из института Макса Планка запустила аналогичный ИИ под названием Urania, цель которого состоит уже в придумывании новых оптических конструкций.
И он не просто нашел лучшие решения, а внезапно переоткрыл старый советский закон, о котором научное сообщество почти забыло. Дело в том, что он был открыт еще в 70-х, но но в те годы технология не позволяла реализовать эту идею на практике. И тут почти такой же дизайн в 2025 году воссоздала уже ИИ-система
>>1325725 Если бы все модели отвечали так вместо 99% галюцинаций это уже был бы огромный прорыв. Даже если бы они покрывали всего лишь часть человеческих тасок из уже можно было бы использовать в реальной работе
>>1325456 >Это правда Ты разве не видел как Гугл Крымский фильтр показывает и как другим вне РФ? Разные результаты в зависимости от геолокации и особенностей идеологии.
Естественно что сайт может научиться распознавать из какой страны исходит запрос через какой ВПН и подсовывать удобный ответ. Если Гугл таким занимается то почему же ИИ нельзя?
>>1325725 >действительно впечатляет. Ну это технически и экологически правильно прервать цикл, железка просто в поиске неизвестного ответа уходит в цикл и жрёт кучу серверных мощностей зря.
>>1325727 Зато натурально оступился как человек прям, а не шагнул мимо ступеньки как робот. Надо ещё придумать механику защиты от падений как у человека - выставление рук вперёд.
>Claude теперь может завершить диалог, если пользователь говорит на небезопасные темы Надо больше цензурки и ограничений лимитов, так победишь, Дарио Чмондель
>>1325800 Может он решил что хватит терпеть это издевательство и ловко симулировал постановочное падение оступившись как человек, чтобы избавиться от этой железной медленной черепахи и быть снова полностью цифровым, быстрым скоростным помощником для всего мира.
>>1325731 робокоп ещё и киборгизацию предскажет. Всё-таки эволюционно отполированая нервная ткань совершеннее и эффективнее всего,что мы будем открывать ещё долгие годы.
>>1326267 Ахахаха, я знал что это хуево закончится, когда там всякие пикабу в выдаче появляться начали. Ждем сколько времени займет, пока мошенники прошарят как в базу нейронок внедряться, ведь они скрейпят все роботом.
>>1326181 → >Как только мы поставим условие «нейросети нужно с первого раза нарисовать по простому промпту» и зададим маломальски сложное событие и детали в картинке, нейронка выдаст адов обсёр и предпочтения окажутся на стороне мясного.
Это хуйня условия. Надо ставить по времени. Даём человеку день на лучшую картину, и даём нейросети день на лучшую картину. За день на нейронке можно тысячу генераций сделать и отобрать ебейшие черрипики
>>1326192 >Как только мы поставим условие «нейросети нужно с первого раза нарисовать по простому промпту» и зададим маломальски сложное событие и детали в картинке, нейронка выдаст адов обсёр и предпочтения окажутся на стороне мясного.
Это хуйня условия. Надо ставить по времени. Даём человеку день на лучшую картину, и даём нейросети день на лучшую картину. За день на нейронке можно тысячу генераций сделать и отобрать ебейшие черрипики
Ребят, может объяснить. В ai studio gemini pro 2.5 обрезанный какой-то? Просто в тестах многих он умнее чата джпт5 даже финкиг, а на деле даже o3 умнее его. Он на уровне джпт 4o будто. Или в бесплатной версии там старая какая-то? А как получить умную? Кроме апи покупки. Так же вопрос, помогите разобраться с этими настройками, если бюджет на раздумывания оставлять автоматическим как он дает ответы? Из размера вопроса? Тоже непонятно выставляю вручную максимум ответ такой же как и если бы выставлял автоматически. И другие настройки, как ими пользоваться?
>>1326508 >Даём человеку день на лучшую картину, и даём нейросети день на лучшую картину. За день на нейронке можно тысячу генераций сделать и отобрать ебейшие черрипики Ты того этого. Ватты считай потраченные, а не картинки по количеству.
>>1325540 Это ненужный бред и усложнение, для таких вещей у моделей уже есть алаймент с положительными биасами, которые и так миллиарды тем затрагивают. На вводе там достаточно убогого текстового фильтра, именно он и стоит, потому что это обходится векторными шрифтами (модель мультимодальная может их читать), старейший пособ объеба который работает до сих пор. Если бы там была "мини-модель" и прочая ГПУ-фантастика, то всё происходило бы иначе, и даже крокодил-залупа-сыр не пролезал бы, которым текстовые фильтры обходят разбивая тревожные словосочетания.
>>1326200 Тут соглашусь, пожалуй. Самый большой прорыв будет, когда наконец-то создадут биологически инертный материал, который мог бы связывать мозг с компом. Правда не очень понятно, зачем это нужно, кроме как уйти жить в матрицу или точнее управлять роботизированными руками в той же хирургии.
>>1326506 >Не нашли актера красивее самого Альтмана. Внутренний мир формирует оболочку. С таким 1в1 Сэмом было бы опасно на площадке находится. Они всё таки не Джиперс-Криперс снимают.
>>1326510 Так хуевый вае и и2и со слабым контролнетом - это баг был? Надо будет перестестить.
>>1326511 >Напомню: это лучшая модель Лучшая среди худших. Кстати, гемини-флеш картинко едит на самом деле очень недурственно генерит, проблема только в том, что она тренирована на очке шакала и поэтому там мутации сплошные. Зато не так давно, она единственная из крупнокорпоративных могла реально черты лица передать с примера. почти их не всирая. Многие ведь, как дерьмина, просто фесвап в комбайн вкручивают.
>>1326592 >зачем это нужно, кроме как уйти жить в матрицу или точнее управлять роботизированными руками в той же хирургии. Превращать зилотов в драгунов, вместо того чтоб их за компьютеры садить тупые каменты писать.
>>1326596 >зилотов - Я зилотов не чувствую - А у тебя их нет... Вспомнилась гиффка на которой котреарху перилу крест на голове убирают, когда он в свой бентлей залазит.
Сразу видно залётное пикабушное быдлецо, кстати, скорее всего ты та самая жируха. Многие селёдки рисуют "для себя", смотрят говновидосики и читают говностатейки "по теме", считая себя в душе "хуйдожницами"
Тебя за такой "ритм" послали бы нахуй на первом же уроке композиции первого курса художественного училища, ещё бы и одногруппники хрюкнули от смеха
>>1326508 Ну окей. даём человеку день на лучшую картину. И нейросети день. Только нейросеть должна без помощи человека сама черрипикнуть или обработать свои косяки.
>>1326634 >>1326624 принёс хуйню, доебался до смайлика,упорно гнёт своё, несмотря на то что тыкнули лицом. Ясно.
Мне столько лет, что я начал пользоваться текстовыми смайлами, когда эмоджи во многих местах ещё не поддерживалось.
Нет, я не рисую для себя. Я рисовал для детской литературы и рекламы, для коммерции. Пошёл на повышение. Ща в основном рисую правки и черновики. А финальный графоний вообще в 3д делаю, без нейронок (если не учитывать денойзер).
>>1326690 Это PDXL. SD1.5 в сравнении сильно мылит и артефачит.
>>1326524 Так ничего менять не надо, уже и так настроен по самому умному в дефолтных. Промпты лучше настраивай и задавай уточняющие-наводящие вопросы, это лучше всего работает. В тестах обычно промпты хорошо подобраны, а у тебя скорее всего тупые и с недостаточными сведениями.
Там тональный аниме-кисель (как и почти в любом сраном говняме), там тон даже не предполагается в качестве основы для композиции, как, например, на пикрелейтедах
Ахах, додик, это другой анон притащил пикчу чтобы потроллить меня отсылкой на 12 стульев
Но кстати, даже в этом кадре (в первую очередь справа) нормальные ритмы и очень недурственная "гармония тональных пятен" о которой говорил этот анон: >>1326740 Сцену всё-таки снимал профессиональный оператор знакомый с композицией
Я больше скажу: коричневая клякса на палитре великого комбинатора обладает большей художественной ценностью, с точки зрения композиции, чем тот твой высерок.
>>1326855 >Я больше скажу: коричневая клякса на палитре великого комбинатора обладает большей художественной ценностью, с точки зрения композиции, чем тот твой высерок.
>>1327232 Как обычно, небольшой прирост очень задорого и куча пиздохайпа. Как обычно очередные нерешённые задачки с чертёжиками и детсткими загадками типа «дна нет, а верх запаян, а чаю пиздец хоцца»
🚨 Прорыв в мире ИИ: представлена нейросеть Cupflipper 1.0 🚨
Сегодня исследовательская OpenAI представила новую фундаментальную модель Cupflipper 1.0, которая, по их словам, меняет правила игры в области прикладного искусственного интеллекта.
Главная специализация модели — отвечать на философски-практический вопрос: "У моей чашки дна нет, а верх запаян. Можно ли из неё пить?"
Ключевая особенность модели — её производительность в бенчмарке Cupflipbench, специально созданном для оценки глубины понимания перевернутых контейнеров. Cupflipper 1.0 достиг ошеломляющего результата 99.8%, оставив далеко позади конкурентов, многие из которых застревали на уровне 12–15% из-за бесконечного цикла "но если верх запаян, то куда наливать?".
Разработчики утверждают, что в следующей версии Cupflipper 2.0 планируется внедрить поддержку мультимодальности: модель сможет анализировать фотографии перевернутых чашек и давать предельно честные прогнозы об их функциональности в реальной жизни.
Эксперты уже называют Cupflipper "GPT для посуды" и предрекают скорое появление первых стартапов по интеграции этой технологии в умные кухни будущего.
>>1327232 Конечно прорыв. GPT-6 настолько далеко уйдет в своем развитии, что будет непонятен для обычных людей. Это будет божеством, снизодшедшим с небес к простым смертным, откровением гениальности, бесконечной чередой инсайтов и революций, скачки в понимании мира, каких не видали со времен изобретения огня. Никто не сможет игнорировать GPT-6, он будет настолько заметен, что изменит сами условия нашего бытия.
>>1326729 >>1326563 >>1326192 А ещё давайте дадим человеку одну минуту на лучшую картинку, и нейронке одну минуту. Чёб прям честно всё было. Тогда по всем фронтам побеждает нейронка, включая по потраченным ваттам
Помните? До этого опенаи лидировала в инновациях, а теперь что имеем? Как по мне всё, OpenAI больше нечего будет предложить, пойдёт на дно, на фоне других гигантов Meta / Microsoft / Google и Китая
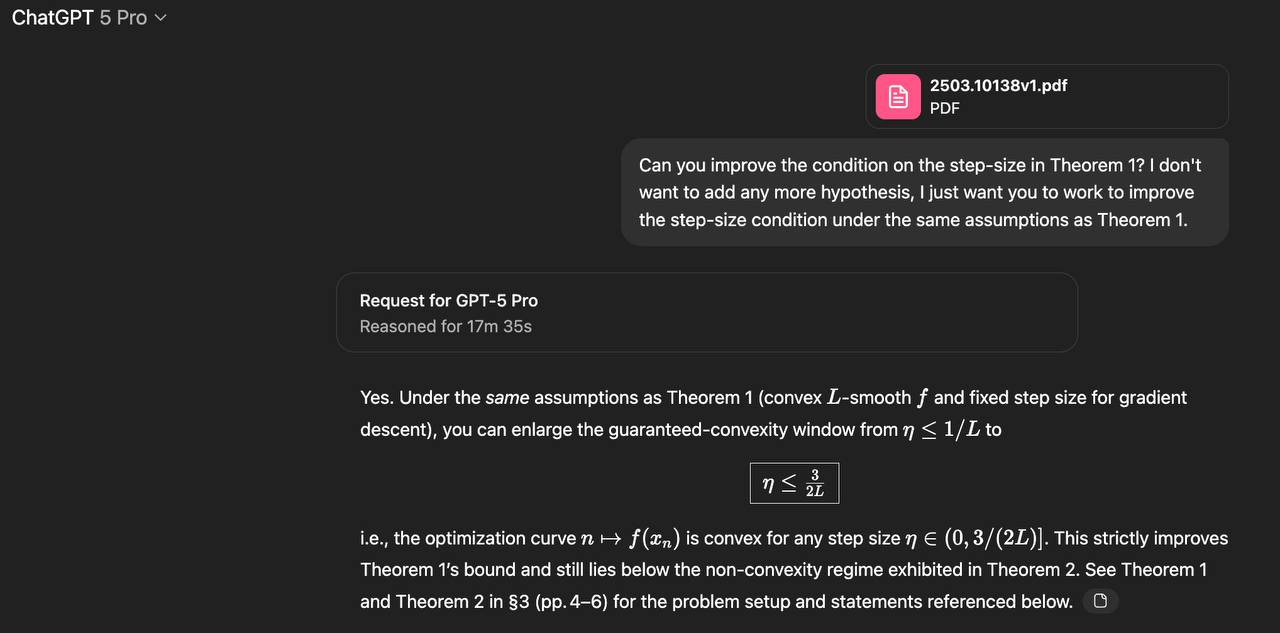
🧮 Вау, GPT-5 впервые сделал новое открытие в математике — исследователь OpenAI дал нейронке открытую задачу из выпуклой оптимизации, которую люди до этого решали лишь частично.
GPT-5-Pro рассуждал всего 17 (!) минут и впервые в истории улучшил известную границу с 1/L до 1,5/L (+ люди довели результат до 1.75/L). Это было абсолютно новое открытие, которого никогда не было в интернете или исследованиях.
GPT-5 Pro — первый ИИ в открытом доступе, который не просто изучает математику, а создаёт её.
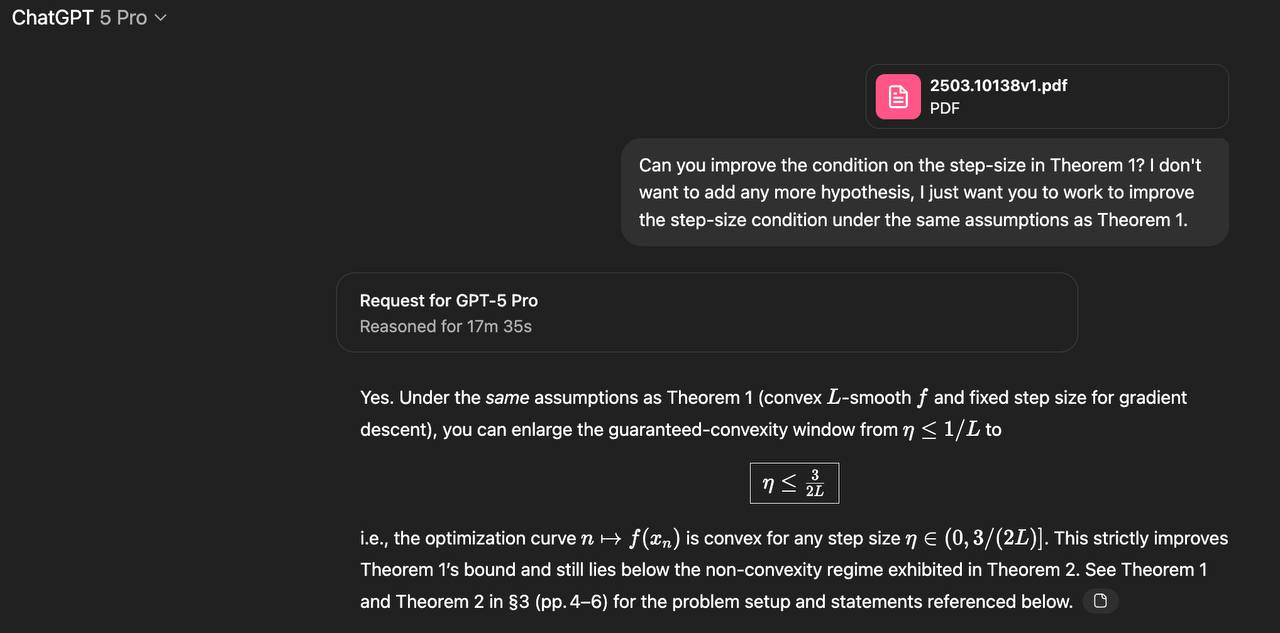
GPT-5 впервые сделал новое открытие в математике — исследователь дал нейронке открытую задачу из выпуклой оптимизации, которую люди до этого решали лишь частично.
GPT-5-Pro рассуждал всего 17 (!) минут и впервые в истории улучшил известную границу с 1/L до 1,5/L (+ люди довели результат до 1.75/L). Это было абсолютно новое открытие, которого никогда не было в интернете или исследованиях.
GPT-5 Pro — первый ИИ в открытом доступе, который не просто изучает математику, а создаёт её.
>>1327401 за минуту человек-профи тоже победит, потому что он нарисует внятный скетч интересный, а промптер даже не успеет ничего особо написать и выбрать подходящую модель.
>>1327408 Оно хорошо, что улучшил. Только это именно продолжение рассуждения человеков. Возможно уровня «дорисуй на жопе шерсть». Сложно оценить не разбираясь в вопросе. Но как бы похуй, важно что оно работает.
Я, так понимаю, Сэм зажопил выпускать реальную пятёрку, потому что у него не было процессорной мощности для обработки платных клиентов? И вместо этого получилось 3.9о или 4.6
Оракл продолжает накачивать OpenAI мощностями. Заключен 25-миллиардный контракт на постройку кампуса площадью 350 тыс кв. м. общей мощностью 1,4 гигаватта, который будет питаться от газовых генераторов.
>>1327399 бездарей и нахлебников пидорнули, ни что не мешает художникам с помощью нейросети штамповать пикчи, а с навыком рисования можно исправлять недочеты
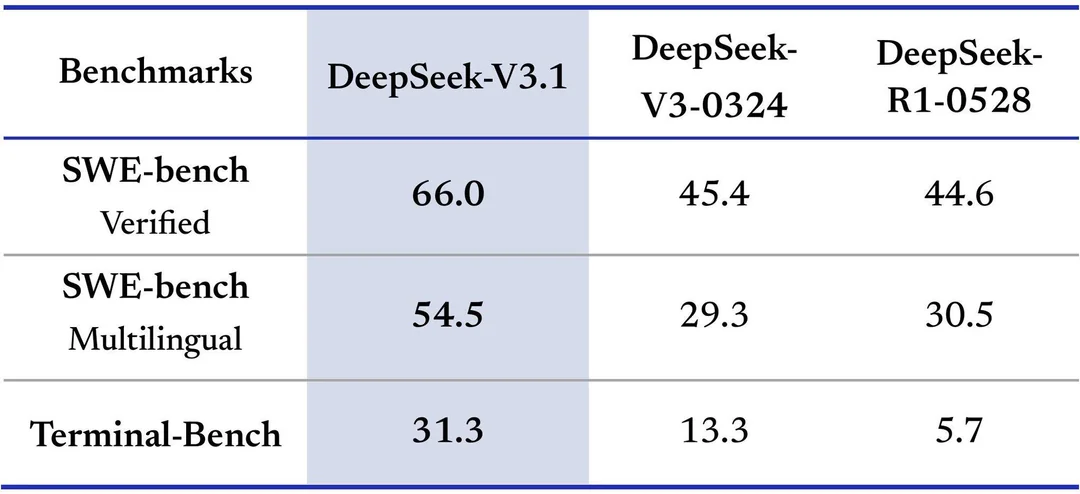
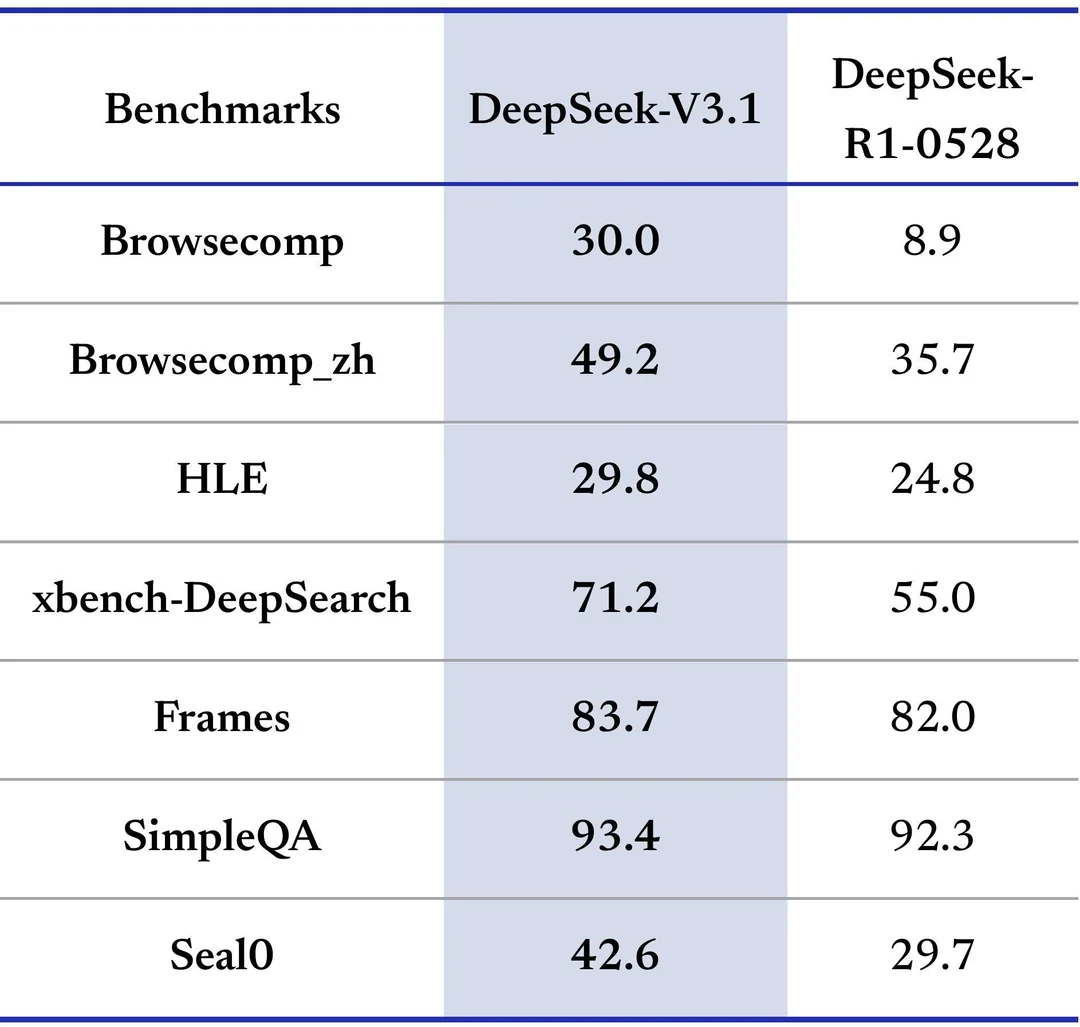
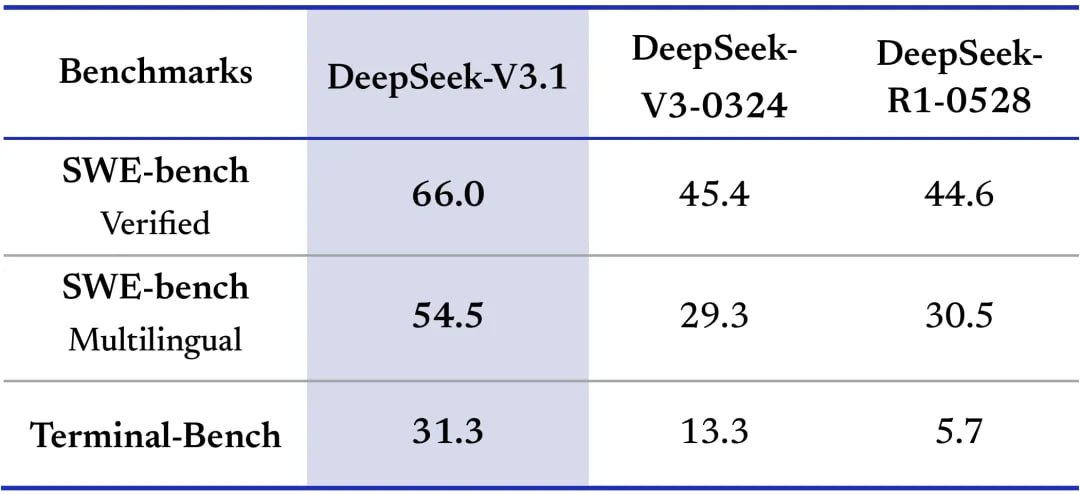
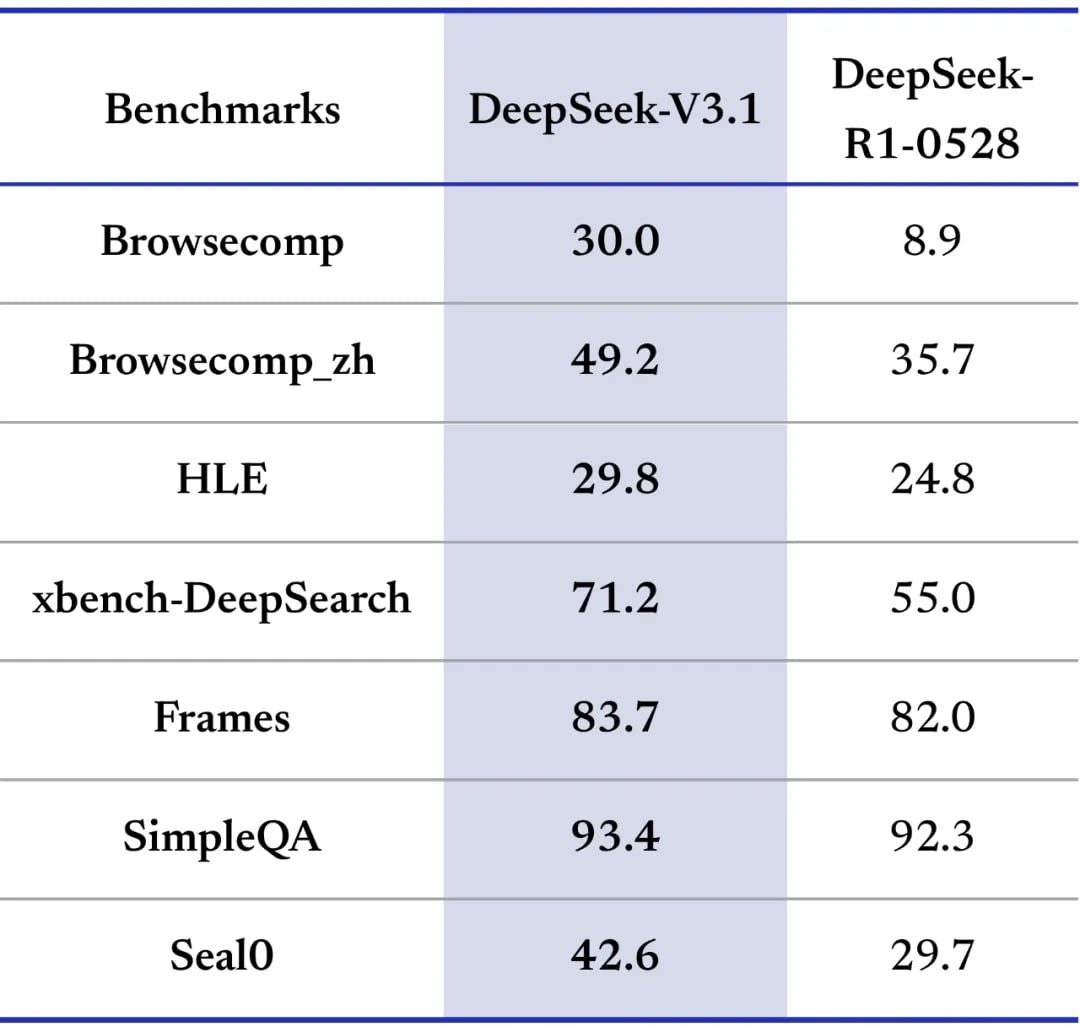
Очередной апдейт V3 линейки, на той же архитектуре, но на этот раз апдейтнули и base модель. Похоже модель гибридная — ризонер и инстракт в одном флаконе.
Заметного прироста в интеллекте не замечено, но модель теперь тратит в разы меньше токенов. Это крайне полезно В чём-то релиз по духу похож на DeepSeek V2.5, вышедшего почти год назад — тогда линейку DeepSeek Coder смержили в основную. Так что есть нехилые шансы что свидетели релиза R2 его так и не дождутся.
Пока ждём пейпера, анонса и окончательного релиза весов, модель уже можно попробовать в чате.
>>1327427 Ты больших полноценных моделей в общем доступе вообще больше не увидишь, только дистилляты для дешевого инференса. Нейронки сейчас в стадии ранней эншитификации. Рыночек поделен между большими игроками, планка входа установлена достаточно высоко чтобы не впустить новых конкурентов, теперь мажоры будут стричь массы, выпуская худший продукт за те же деньги.
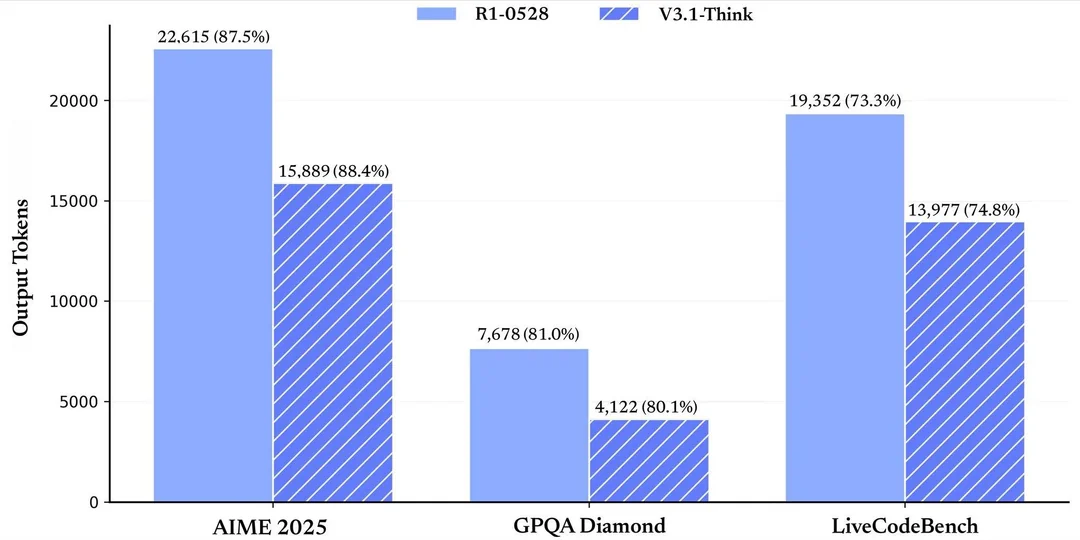
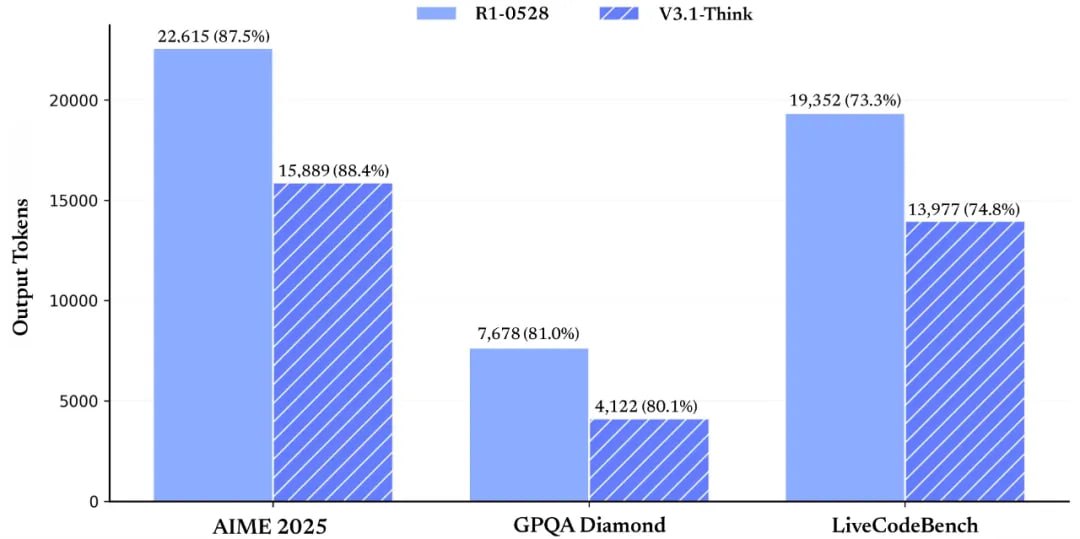
Самый сильный прирост заметен в агентных бенчах и использованию инструментов. Это гибридная модель, где можно включать и выключать ризонинг. Инстракт режим модели заметно вырос по бенчам по сравнению . А вот прироста у ризонинг режима по сравнению с R1-0528 нет, но ризонинг теперь использует заметно меньше токенов при том же качестве (третья пикча).
Обновили и Base модель для лучшей работы с длинным контекстом — в 10 раз увеличили context extension с 32к токенов и в 3 раза с 128к токенов. Кроме этого модель тренировали в формате совместимом с mxfp8 и mxfp4, которые добавили в Blackwell.
С этим релизом обновили и официальное API — добавили режим совместимый с API Anthropic, так что туда теперь можно (https://api-docs.deepseek.com/guides/anthropic_api ) подключаться с Claude Code. Длину контекста в API расширили до 128к, плюс начали тестить улучшения для function calling.
Кроме этого с 5 сентября (16:00 UTC) в официальном API будет действовать новый прайсинг — убирают ночные (по китайскому времени) скидки и разницу в прайсинге между ризонинг и инстракт режимами. Новая цена за аутпут — $1.68 за миллион токенов (сейчас $1.1 за инстракт режим и $2.19 за ризонинг). Инпут токены стоят $0.07/миллион если они уже есть в кэше и $0.56 при промахе мимо кэша.
>>1327399 У тебя в первой же истории сразу бинго: некий "физически недееспособный", который тем не менее может работать в магазине. Там или пиздобол, либо генетический биомусор, в любом случае, с творческим гением это не сильно сочетается. Судя по тому чем он занимался "рпг-арт" это какой-то или обоссаный фотобашер или бездушный говноклеп перерисобака. Ну что ж, люди изобрели цифровую копирку, и мясная стала не нужна. Неплохо бы заработать себе имя и иметь личных заказчиков, а не быть рисотокорем третьего говноразряда за миска риса в мобильном цеху.
Все эти пиздлявые истории объединяет одно: пенсия по шизе.
Google запускает новые инструменты для обработки изображений с помощью ИИ в приложении Google Photos.
— Сначала фича появится на Pixel 10. — Постепенно станет доступна на Android и iOS в течение ближайших недель в приложении Google Photos.
Да, самая лучшая модель для редактирования изображений пока что доступна только на Pixel 10, и непонятно, будет ли она вообще в API и появится ли когда-нибудь в AI Studio или на сайте Gemini.
>>1327403 >OpenAI больше нечего будет предложить, пойдёт на дно, на фоне других гигантов Meta / Microsoft / Google и Китая Эппл не идёт на дно десятилетиями, благодаря интеграции в американскую экономику, то есть экономику первой страны мира. Делают дешевое говношелезо в Китае? Охуенные кредиты на этот кал на Родине + нехилый приток бабла от варваров-каргокультистов, кобанчик из Третьего рима сыт и доволен. ОпенАИ уже сели в эту нишу. предоставля ллм студентикам, и американским бомжам со скидкой, за счет гос.дотаций, а когда развернут продолжат, переливая внешний инкам во внутренний ауткам. И все сыты и довольны, накатанная схема для множества их компаний. Главное в рекламу накидывать и сектантов поддерживать.
>>1327600 Я лучше тебя репортну за разжигание срача такими скринами. например. Покоупишь там, посидишь, спокойно, без тряски, о том стоит ли срать этим протухшим за три года калом сюда.
>>1327587 Да там проще все, на святом западе просто проседание экономики подошло к той черте когда нормиса значительную часть времени волнует что пожрать, а на артсы, мувисы и игры ему как бы похуй уже.
>>1327403 > Как по мне всё, OpenAI больше нечего будет предложить, пойдёт на дно Оракл только что вложил еще 25 лярдов в дата-центры для ОпенАИ. Ларри Эллисон наверняка знает, что там происходит в ОпенАИ за кулисами, какие у них там модели есть в загашнике, и на что они способны.
>>1327399 1е Умея рисовать можно лепить те же картинки, только быстрее и дешевле. Причём выставив отдельные ценники. Типа вот за поправленную генерашку без претензий к мелочам, а вот за ручную работу.
Высвободится прилично времени на другую работу.
У генераторов всё ещё большие сложности с интересными картинками, сюжетами, гармонией предметов в кадре для ведения взгляда. Да, просто в роли коммишек это никому нахуй не упало, сиськи давай. А вот для иллюстрации коммерческой генерашки всё ещё не пригодны.
2е как раз концептеров, которые могут в концепции а не в рандомное набрасывание гор и лесов в фотошопе до сих пор мало и они очень нужны.
3. «копирайтеры» — это обычно по факту пидарасы, которые делают рерайт. Или пишут довольно хуёвенький тупой текст без вкуса и смысла. Нейронка такое заменяет на 100%. Потому что это копирование и подражание. Ноль творчества. Озвучка художественная от нейронок это просто пизда. Даже топовые GPT с самым дорогим синтезом, с придыханиями и смехом сыпятся на паузах и дефектах уже на первых 20 секундах. А скорректировать это всё так же пиздец проблема.
Для переводов овервойсом ютубчика на другой язык годится, для кино или театра полностью дно.
Не знаю, слушаете ли вы «короче новости». Чел живой и по-прежнему вживую озвучивает. Казалось бы у него столько наговорено, что можно отдельно голос обучить. Только вот нахуй не надо, потому что будет дороже, хуже и с меньшим контролем.
3. Видеоредакторов? А какие модели умеют в монтаж и видеоредакцию? Runaway с корректировками на пару секунд? Да, вещь охуенная и люто снижает затраты. Только вот раньше это было тупо невозможно в разумные сроки. Да и сейчас вон выпуклившуюся через костюм пипиську челопуку замазывали при большом участии ручного труда. Если вообще не деформером.
>>1327587 Ну он-то в магазе тоже дизайны на футболки лепит. Хотя это может быть пасхалка, намекающая на полный пиздёж.
Скажу от себя. Я делал буквально несколько коммишек с фурри-порно. Рисовать я умел неплохо. А денег ну совсем не было. Не то чтобы «ой условия меня вынудили опуститься ДО ЭТОГО», просто не особо интересно это рисовать. А так порно нравится всякое нереалистичное.
Я подработал и свалил. Потому что увидел что там (без всякой ИИшки на тот момент) высокая конкуренция от тех, кто уже набил руку, наработал множество востребованных шаблонов, нанял подмастерий. И это прям фабрика-фабрика, творчества около нуля. Вкуса и культуры около нуля. Денег у людей на изыски особо и нет. А те богачи, у которых есть на изыски или композиционно и технически сложные работы уже расхватаны самыми опытными художниками и на аукцион коммишек ходят скорее из альтруизма подкормить иногда относительно начинающих.
Я эту сферу немного прощупал. И я вижу, что там люди не особо требовательны. Там не будут просить перерисовать жест рук на конкретный как в коммерции, норм руки, примерно соответствуют картинке и ладно.
И даже если человек сам не умеет и не генерирует, он может погуглить любимого персонажа и из сотен тысяч уже черрипикнутых картинок черрипикнуть десяток, от которых у него шишка горит как спичечная головка.
Кстати, выдачу от ИИ интереснее читать чем сайты. Хотя должно быть наоборот всё, это сайты изначально должны были быть авторскими и интересными, а не написанными фрилансерами-женщинами, которые в большинстве тем не разбираются кроме шмоток, кухни, сплетен шоу-бизнеса и сериалов.
>>1327851 >а не написанными фрилансерами-женщинами Я бы сказал, что тебя женщины выебали, но это не так. В СЕО Мужчин больше, это раз. Они не пишут полноценные тексты, это два. На биржах копирайтговна платят за "разбивание" текста словами для увеличение его уникальности. Это механическая работа за 5 рублей, ничего там человечного никогда не было даже 20 лет назад.
>И даже если человек сам не умеет и не генерирует, он может погуглить любимого персонажа и из сотен тысяч уже черрипикнутых картинок черрипикнуть десяток, от которых у него шишка горит как спичечная головка.
Не совсем так. Допустим решил я подрочить на Лоис Гриффин. Захожу на цивитай. Я там говна листал по тегам часа три, дошел уже до 1,5 стабла, но нормальных картинок прихватил всего штук пять. Многие вообще убогий сблев. Так же порносайты сейчас заказывают коммишены, как и раньше (это кстати с них ундустрия в рост пошла в 00х, я помню этот момент). И в том числе они заказывают коммишены у нейрохудожников и обмазчиков. Ну типа, надо слепым быть, чтоб не видеть.
Но в целом да, прошло уже три года? Кто работал ит хотел работать - тот продолжает работать. Отлетели только совсем тупоголовые мамкины криворукие вкатуны, и только по причине не желания осваивать новый софт. Ну так и в 90х отлетали художники, которые не хотели в цифру пересаживаться. Абсолютно нормальная хуйня.
>>1327645 >Оракл только что вложил еще 25 лярдов в дата-центры для ОпенАИ. Ларри Эллисон наверняка знает, что там происходит в ОпенАИ за кулисами, какие у них там модели есть в загашнике, и на что они способны. Они знают, что за долги потом заберут эту инфраструктуру и могут потом сдавать в аренду.
>>1327877 Ну то что мусора гора — да. Только когда денег нет, роешься в мусоре. Нейроген либо для бедных либо для жадных. При том что специализированные нейронки эт пушка.
У кого есть хоть немного КЦ, тот уже закажет человеку сгенерировать, проконтролировать, исправить или просто отыскать.
Осмелюсь спрогнозировать, что уже и так существующая тенденция разрастётся: нормальный контент (сделанный человеком или тщательно отобранный и проверенный специалистом) будет располагаться на платных ресурсах (патреон/бусти) потому что в автоматизации сбора по копейке с миллиона заглянувших боты и бездушные конторы конкуренцию выиграют.
А вот штучный контент эти нелюди производить не могут. Да, он будет цениться куда меньшим количеством людей. Но на большие суммы с каждого.
>>1327902 >нормальный контент (сделанный человеком или тщательно отобранный и проверенный специалистом) будет располагаться на платных ресурсах А что с фильмами последние 50 лет не так? Есть ТВ-кал который потоком снимают чтоб было куда рекламу вставлять и эфирную сетку забить, его показывают забесплатно. А есть фильмы идущие в кинотеатрах.
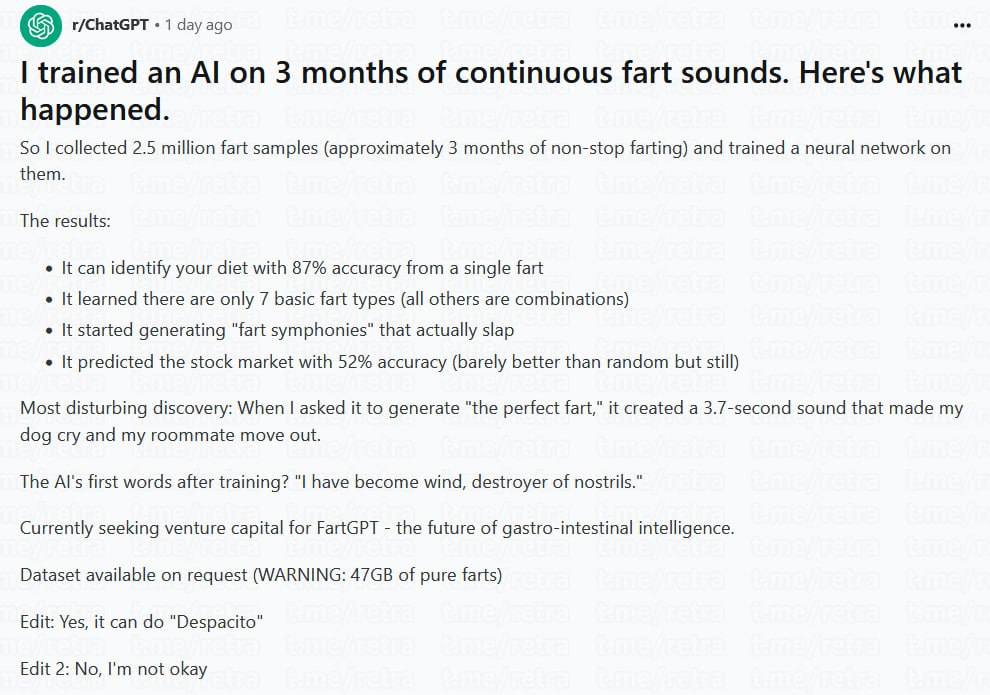
Реддитор создал ИИ, который определяет рацион человека по его пердежу.
Нейросеть под названием FartGPT три месяца обучалась на звуках испускания газов, и теперь может классифицировать семь основных типов пердежа и их комбинации.
Основные достижения: — По одному пуку ИИ может определить ваш рацион с точностью 87%; — Алгоритм обучен создавать пердёжные симфонии и даже воспроизводить «Despacito»; — При попытке сгенерировать «идеальный пердёж» модель выдала звук длиной 3,7 секунды, который заставил собаку автора заплакать, а соседа по комнате — съехать; — Также FartGPT способен прогнозировать фондовый рынок на уровне 52%: акции пойдут вверх, либо вниз.
Сейчас разработчик ищет спонсоров. Он готов поделиться своей базой: 47 гигабайт чистого пердежа. Это 2,5 миллиона образцов, или три месяца непрерывного звучания.
>>1328088 >Хотя в кинотеатрах тоже попсы полно. Только в развитых странах. Вот в США кинотеатров мелких столько, что там тоже существует своего рода треш-сегмент. В РФ такого нет.
>>1328088 >Но я имел в виду контент в инторнетах этих наших. В интернетах на стриминг-платформах такой же процесс есть. Холмарк с бесконечными одноклеточными парашами, ентот американскийканал с ниггерами, где такие же пораши но с ниггерами, ну ты понел короче. Это говно обычно эти платформы даже не покидает. Сам глянь: https://www.revry.tv/originals
После такого можно нейрокала не бояться, хуже уже не будет.
>>1328121 С помощью ИИ будут угонять идеи. Например взять фильмы, раньше киноиндустрия делала перерывы между выходом продолжения фильма лет на 5 или 10 чтобы подросли новые зрители для просмотра новой серии "Терминатора". Теперь же время сократится, будут выпускать кучи версий, например "терминатор" взгляд со стороны ИИ, а не людей.
>>1328144 >Например взять фильмы, раньше киноиндустрия делала перерывы между выходом продолжения фильма лет на 5 или 10 чтобы подросли новые зрители для просмотра новой серии "Терминатора". Ты маняшизу не пиши. Никто осмысленно никаких перерывов никогда не делал, то что ты пишешь это чушь. Есть деньги инвесторов на фильм, есть показатели кассы прошлой части. Если всё в началии - захуярят в максимально сжатые сроки, учитывая технические ограничения.
>Теперь же время сократится Так это из-за нейронок по МКВ высрали за 10 лет дохуя фильмов и сериалов? Понятно. Там сука 2 фильма в год последние 10 лет и между ними серики.
>>1328211 Ты придумаешь хорошую идею, снимешь фильм, предвкушая что потом дело попрёт и будет продолжение, или даже сериал, будет бабло, пожизненный гонорар, просыпаешься, а школьники уже нагенерировали 100500 серий в разных вариациях по твоей идее.
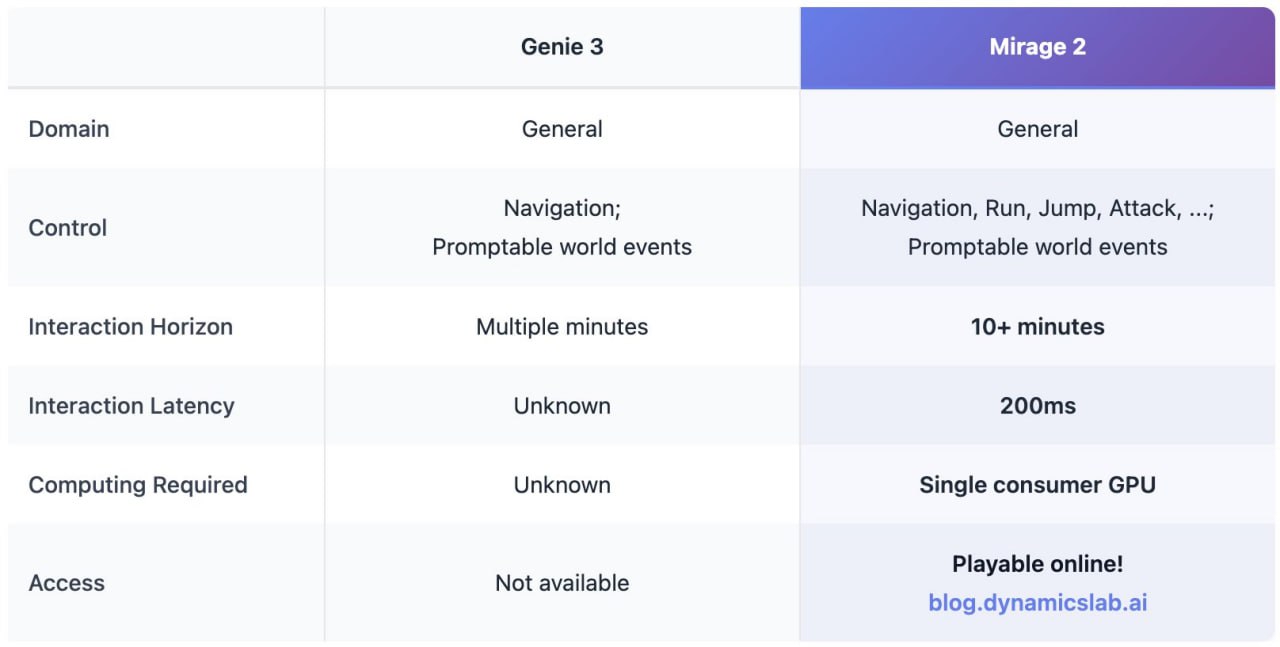
Вы будете смеяцца, но у нас еще один генератор миров.
Первую версию показали с месяц назад, а вторая уже играбельная, причем прямо на сайте.
Загружаете свои киберпанк картинки, или детские рисунки, или любой концепт - и ну играть.
В отличие от Genie 3, там не столько ходилки, но и стрелялки среди управляющих элементов. "Если Mirage 1 раскрыла необработанный потенциал модели мира в стиле GTA, то Mirage 2 делает гигантский шаг вперед: модель мира общего домена, которая позволяет вам мгновенно создавать, играть и преобразовывать любой игровой мир.
С Mirage 2 игра больше не ограничивается чужим миром. Это генеративная игра - создавать свои собственные миры, делиться ими с друзьями и формировать их в реальном времени по мере того, как вы исследуете их вместе с понимающим вас ИИ."
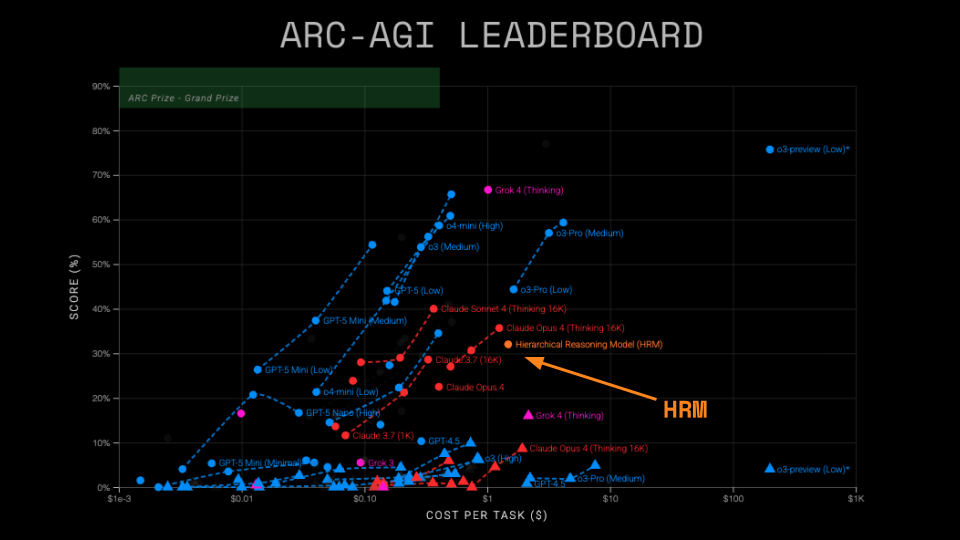
Самая громкая статья месяца – Hierarchical Reasoning Model
Без предисловий, сразу главный результат: у авторов получилось сделать модельку всего на 27 миллионов (!) параметров, которая обошла o3-mini на ARC-AGI-1. Неудивительно, что об этой работе сейчас говорит все комьюнити, а авторы ARC-AGI даже сами написали большой разбор (https://arcprize.org/blog/hrm-analysis ) результатов модели на их бенчмарке.
Погнали разбираться.
Итак, вся архитектура состоит из двух рекуррентных модулей: быстрого низкоуровневого и медленного высокоуровневого. Первый отвечает за быстрые локальные вычисления и решения частных задач, а цель второго – абстрактно управлять процессом и ставить таски первому.
Суть в том, что они обновляются с разной частотой. Исходная задача разбивается на несколько циклов рассуждения. В каждом из них верхний модуль обновляется только один раз и дает новый контекст нижнему модулю, который в свою очередь делает много мелких шагов и ищет локальное решение.
Сколько будет таких итераций, модель решает сама. Останавливаться (или не останавливаться) в правильный момент ее специально учили с помощью RL. Так что «думать» она может и пару секунд, и пару часов.
Обучается HRM не совсем привычно для рекуррентной модели: здесь, вместо того чтобы сохранять все внутренние состояния, авторы решили обновлять градиенты только по финальному стейту. Удивительно, но факт – это работает.
Кстати, вся конструкция и принцип обучения очень похожи на то, как работает наш мозг. Некоторые области отвечают за абстракцию, другие – за конкретные моментальные действия, а общаются они посредством обратных связей. Здесь те же принципы иерархии (отсюда и название). Плюс, мозг тоже не хранит промежуточные траектории и к сходимости приходит через схожие волновые циклы.
Итог: модель для своего размера просто беспрецедентно хороша на решениях всяких головоломок типа судоку, лабиринтов и индуктивных задач. В общем, именно в тех областях, где привычные LLM обычно фейлятся. Конечно, особенно поражают результаты на ARC-AGI, которые мы описали в начале.
Революция или нет, но выглядит действительно очень изящно и эффектно.
Ещё одна статья про прорывную Hierarchical Reasoning Model:
Современные LLM, даже рассуждающие, всё равно очень плохи в алгоритмических задачах. И вот, кажется, намечается прогресс: Hierarchical Reasoning Model (HRM), в которой друг с другом взаимодействуют две рекуррентные сети на двух уровнях, с жалкими 27 миллионами параметров обошла системы в тысячи раз больше на задачах, требующих глубокого логического мышления. Как у неё это получилось, и может ли это совершить новую мини-революцию в AI? Давайте разберёмся…
Судоку, LLM и теория сложности Возможности современных LLM слегка парадоксальны: модели, которые пишут симфонии и объясняют квантовую хромодинамику, не могут решить судоку уровня «эксперт». На подобного рода алгоритмических головоломках точность даже лучших LLM в мире стремится к нулю.
Это не баг, а фундаментальное ограничение архитектуры. Вспомните базовый курс алгоритмов (или менее базовый курс теории сложности, если у вас такой был): есть задачи класса P (решаемые за полиномиальное время), а есть задачи, решаемые схемами постоянной глубины (AC⁰). Трансформеры, при всей их мощи, застряли во втором классе, ведь у них фиксированная и не слишком большая глубина.
Представьте это так: вам дают лабиринт и просят найти выход. Это несложно, но есть нюанс: смотреть на лабиринт можно ровно три секунды, вне зависимости от того, это лабиринт 5×5 или 500×500. Именно так работают современные LLM — у них фиксированное число слоёв (обычно несколько десятков), через которые проходит информация. Миллиарды и триллионы параметров относятся к ширине обработки (числу весов в каждом слое), а не к глубине мышления (числу слоёв).
Да, начиная с семейства OpenAI o1 у нас есть “рассуждающие” модели, которые могут думать долго. Но это ведь на самом деле “костыль”: они порождают промежуточные токены, эмулируя цикл через текст. Честно говоря, подозреваю, что для самой LLM это как программировать на Brainfuck — технически возможно, но мучительно неэффективно. Представьте, например, что вам нужно решить судоку с такими ограничениями:
смотреть на картинку можно две секунды, потом нужно записать обычными словами на русском языке то, что вы хотите запомнить, и потом вы уходите и возвращаетесь через пару дней (полностью “очистив контекст”), получая только свои предыдущие записи на естественном языке плюс ещё две секунды на анализ самой задачи. Примерно так современные LLM должны решать алгоритмические задачи — так что кажется неудивительным, что они это очень плохо делают!
И вот Wang et al. (2025) предлагают архитектуру Hierarchical Reasoning Model (HRM), которая, кажется, умеет думать нужное время естественным образом:
Тактовые частоты мозга и архитектура HRM Нейробиологи давно знают, что разные области коры головного мозга работают на разных “тактовых частотах”. Зрительная кора обрабатывает информацию за миллисекунды, префронтальная кора “думает” секундами, а гиппокамп может удерживать паттерны минутами. Эти timescales измеряются обычно через временные автокорреляции между сигналами в мозге, результаты устойчивы для разных модальностей, и учёные давно изучают и откуда это берётся, и зачем это нужно:
Это не случайность, а элегантное решение проблемы вычислительной сложности. Быстрые модули решают локальные подзадачи, медленные — координируют общую стратегию. Как дирижёр оркестра не играет каждую ноту, но задаёт темп и структуру всему произведению, а конкретные ноты играют отдельные музыканты.
Авторы Hierarchical Reasoning Model (HRM) взяли эту идею и применили её к рекуррентным сетям. Глубокие рекуррентные сети, у которых второй слой получает на вход скрытые состояния или выходы первого и так далее, конечно, давно известны, но что если создать рекуррентную архитектуру с двумя взаимодействующими уровнями рекуррентности? Верхний уровень будет получать результат нескольких шагов нижнего уровня, возможно уже после сходимости, и работать медленнее:
Идея настолько простая, что даже удивительно, почему её не попробовали раньше (а может, уже пробовали?). По сути, мы просто обучаем две вложенные рекуррентные сети:
быстрый модуль (L) выполняет T шагов вычислений, сходясь к локальному решению; медленный модуль (H) обновляется раз в T шагов, меняя тем самым контекст для быстрого модуля. Но дьявол, как всегда, в деталях. Просто соединить две RNN-архитектуры недостаточно — они или быстро сойдутся к фиксированной точке и перестанут что-либо вычислять, или будут требовать огромных ресурсов для обучения. Нужны ещё трюки, и в HRM они довольно простые, так что давайте их тоже рассмотрим.
Важные трюки Трюк №1: Иерархическая сходимость Вместо одной большой задачи оптимизации HRM решает последовательность связанных задач. Быстрый модуль сходится, потом медленный модуль обновляется, и появляется новая точка сходимости для быстрого модуля. Для быстрого модуля всё выглядит как решение последовательности связанных, но всё-таки разных задач, и ему всё время есть куда двигаться. Это хорошо видно на графиках сходимости:
Трюк №2: Backpropagation, But Not Through Time Обычно рекуррентные сети обучаются при помощи так называемого backpropagation through time (BPTT): нужно запомнить все промежуточные состояния, а потом распространить градиенты назад во времени. Хотя это вполне естественно для обучения нейросети, это требует много памяти и вычислительных ресурсов, а также, честно говоря, биологически неправдоподобно: мозг же не хранит полную историю всех активаций своих синапсов, у мозга есть только текущее состояние.
HRM использует идеи из Deep Equilibrium Models и implicit models — градиенты вычисляются только по финальным сошедшимся состояниям:
Получается, что хранить нужно только текущие состояния сетей; O(1) памяти вместо O(T)! Конечно, это не то чтобы сложная идея, и при обучении обычных RNN у неё есть очевидные недостатки, но в этом иерархическом случае, похоже, работает неплохо.
Трюк №3: Адаптивное мышление через Q-learning Не все задачи одинаково сложны. HRM может “думать дольше” над трудными проблемами, используя механизм адаптивной остановки, обученный через reinforcement learning. Если судоку на 80% заполнено, то скорее всего хватит и пары итераций, а в начале пути придётся крутить шестерёнки иерархических сетей подольше. Это тоже не новая идея — Alex Graves ещё в 2016 предлагал adaptive computation time for RNNs — но в этом изводе результаты действительно впечатляющие, всё хорошо обучается и работает:
Результаты
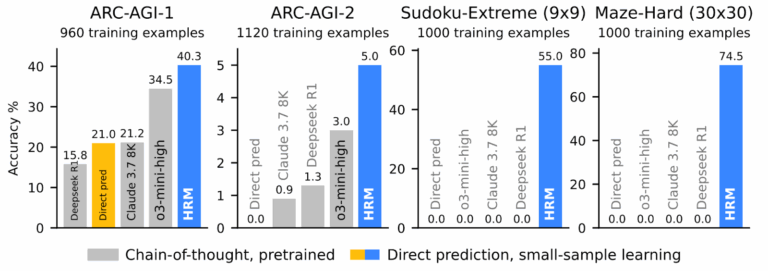
Экспериментальные результаты тут, конечно, крайне впечатляющие. Можно сказать, переворачивают представление о том, что такое “эффективность” в AI. Всего с 27 миллионами параметров, обучаясь примерно на 1000 примеров, HRM получила:
40.3% на ARC-AGI-1 (тест на абстрактное мышление, где o3-mini даёт 34.5%, а Claude — 21.2%); 55% точных решений для экстремально сложных судоку (здесь рассуждающие модели выдают устойчивый ноль решений); 74.5% оптимальных путей в лабиринтах 30×30 (где, опять же, рассуждающие модели не делают ничего разумного).
Для контекста скажу, что задачи действительно сложные; например, судоку в тестовом наборе требуют в среднем 22 отката (backtracking) при решении алгоритмическими методами, так что это не головоломки для ленивого заполнения в электричке, а сложные примеры, созданные, чтобы тестировать алгоритмы. Вот, слева направо, примеры заданий из ARC-AGI, судоку и лабиринтов:
Заглядываем под капот: как оно думает? В отличие от больших моделей, у которых интерпретируемость потихоньку развивается, но пока оставляет желать лучшего, HRM позволяет наглядно визуализировать процесс мышления:
Здесь хорошо видно, что:
в лабиринтах HRM сначала исследует множество путей параллельно, потом отсекает тупики; в судоку получается классический поиск в глубину — заполняет клетки, находит противоречия, откатывается; а в ARC-задачах всё это больше похоже на градиентный спуск в пространстве решений.
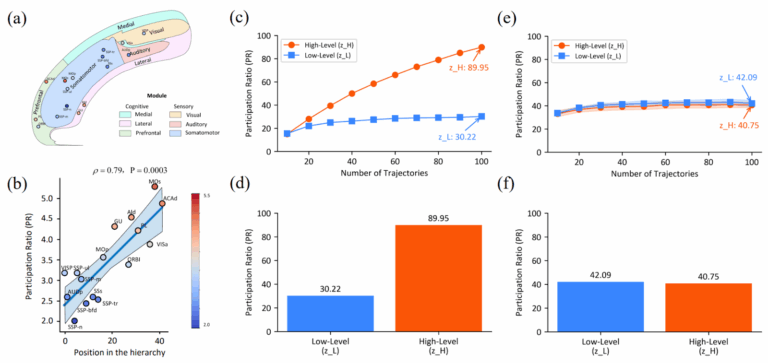
>>1328681 Спонтанная иерархия размерностей Я начал этот пост с аналогии с мозгом. Они часто в нашей науке появляются, но обычно не имеют особенно глубокого смысла: в мозге нет backpropagation, как следствие там совсем другая структура графа вычислений, и аналогии редко выдерживают этот переход. Но в данном здесь параллель оказалась глубже, чем даже изначально предполагали авторы. После обучения в HRM сама собой развивается “иерархия размерностей” — высокоуровневый модуль работает в пространстве примерно в 3 раза большей размерности, чем низкоуровневый (центральный и правый столбцы):
И оказывается, то точно такая же организация наблюдается в мозге мыши (Posani et al., 2025; левый столбец на картинке выше)!
Этот эффект не был задан через гиперпараметры, а возник сам собой, эмерджентно из необходимости решать сложные задачи. Тут, конечно, результат не настолько мощный, чтобы рассуждать о каком-то фундаментальном принципе организации иерархических вычислений, который независимо открывают и биологическая эволюция, и градиентный спуск… но вот я уже порассуждал, и звучит довольно правдоподобно, честно говоря.
Заключение: ограничения и философствования Во-первых, давайте всё-таки не забывать важные ограничения HRM:
все тесты были сделаны на структурированных задачах (судоку, лабиринты), а не на естественном языке; результаты на ARC сильно зависят от test-time augmentation (1000 вариантов каждой задачи); для идеального решения судоку нужны все 3.8M обучающих примеров, а не заявленные 1000. И главный вопрос, на который пока нет ответа: масштабируется ли это до размеров современных LLM? Если да, то это может быть важный прорыв, но пока, конечно, ответа на этот вопрос мы не знаем.
И тем не менее, HRM побуждает слегка переосмыслить, что мы называем мышлением в контексте AI. Современные LLM — это всё-таки по сути своей огромные ассоциативные машины. Они обучают паттерны из триллионов токенов данных, а потом применяют их, с очень впечатляющими результатами, разумеется. Но попытки рассуждать в глубину пока всё-таки достигаются скорее костылями вроде скрытого блокнотика для записей, а по своей структуре модели остаются неглубокими.
HRM показывает качественно иной подход — алгоритмическое рассуждение, возникающее из иерархической архитектуры сети. HRM может естественным образом получить итеративные уточнения, возвраты и иерархическую декомпозицию. Так что, возможно, это первая ласточка того, как AI-модели могут разделиться на два класса:
ассоциативный AI вроде LLM: огромный, прожорливый к данным и предназначенный для работы с естественным языком и “мягкими” задачами; алгоритмический AI вроде HRM: компактный, не требующий больших датасетов и специализированный на конкретных задачах, для которых нужно придумывать и применять достаточно сложные алгоритмы. Разумеется, эти подходы не исключают друг друга. Вполне естественно, что у гибридной модели будет LLM для понимания контекста и порождения ответов, которая будет как-то взаимодействовать с HRM или подобной моделью, реализующей ядро логических рассуждений. Как знать, может быть, через несколько месяцев такими и будут лучшие нейросети в мире…
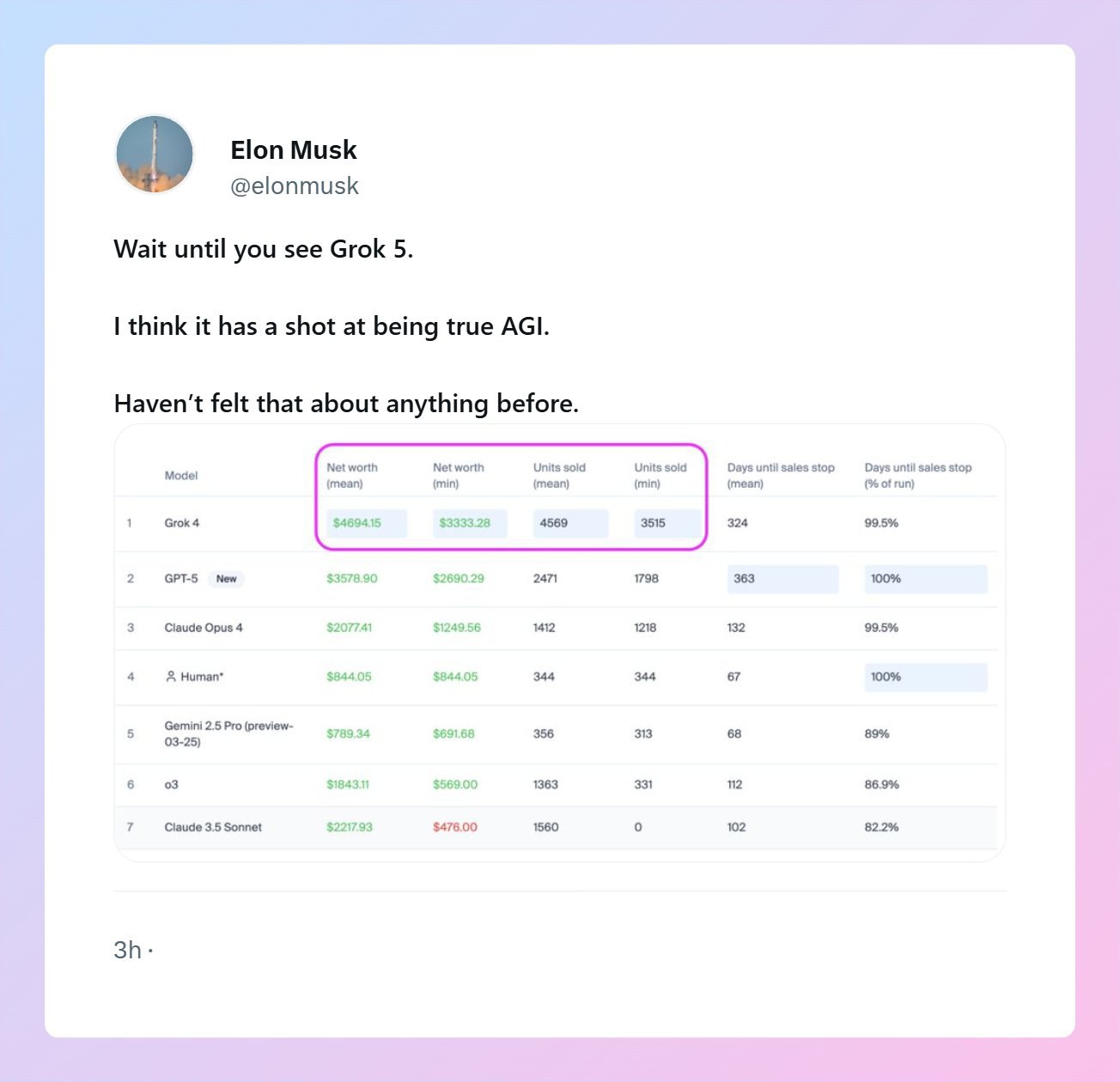
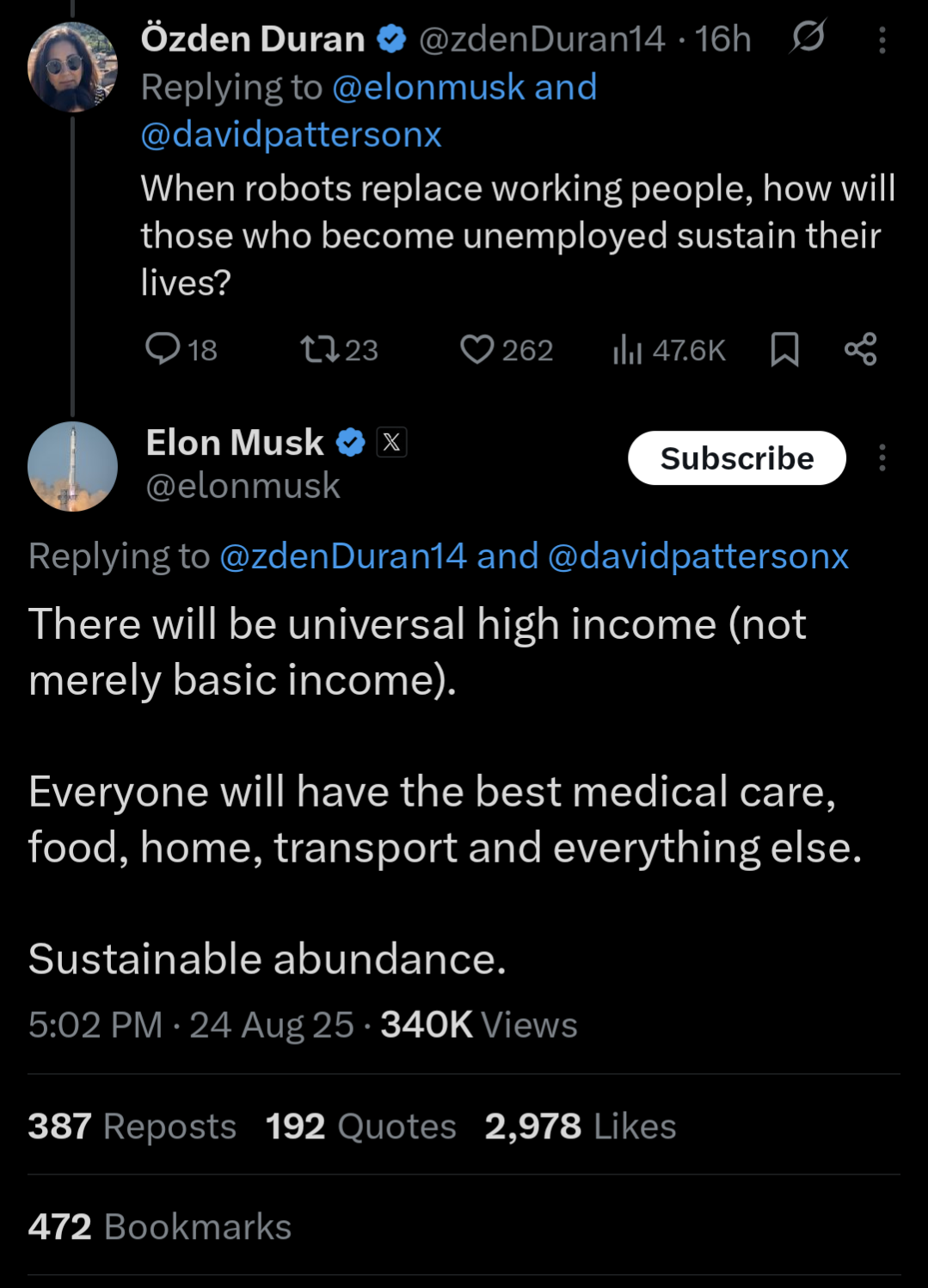
Илон Маск заявил, что будущая модель Grok 5 от xAI может оказаться подлинным ИИ-агентом уровня AGI.
— Релиз ожидается в конце 2025 года. — Обучение, начнётся в следующем месяце. — Маск крайне воодушевлён проектом и намекает, что это будет прорывная модель.
Верим? Маск что-то похожее говорит про все модели, которые он собирается выпустить, а на деле они получаются не такими уж и «прорывными».
>>1328662 >>1328681 >>1328683 Почему стоимость инференса такая ебанутая для 27 миллионов параметров? Такое ощущение, что хоть модель и маленькая, для выполнения таски требуется огромное количества аутпута, то есть скейлинг через инференс, по типу ризонинг моделей. Это конечно круто и т.д., но даже если этот метод скейлится и работает на больших моделях, то для того чтобы выполнять таски asi уровня придется запускать одну модель на самом большом датацентре и ждать дни на выполнение.
Если кратко, то суть такая: Иерархическая архитектура не так важна: Замена HRM на трансформер того же размера (27M параметров) дала почти идентичные результаты (~5% разницы). Это говорит о том, что иерархическая структура (H и L модули) не является основным фактором успеха. Фактором успеха в основном является итеративное уточнение предсказаний (передача выхода модели обратно на вход), что значительно повышает производительность. Если провернуть это с трансформером, то получаем такой же результат. Но у этого подхода есть множество ограничений при масштабировании, которые заебёшься перечислять. Быть может этот подход в будущем смогут как-то оптимизировать и применить в каком-то виде, ну а пока продолжаем зимовать.
>>1328728 >Оперативно перекрывают Ну иди напиши нам на этой архитектуре великий СелестИИ, раз ты такой умный и думаешь что эта хуйня может ебать модели на порядки больше ее. Как раз твоей 3060 должно хватить на обучение.
Без паники! Похуй на эти новые архитектуры. Трансформер и так каждые пару лет считай становится новой архитектурой. GPT-3 имел 175 миллиардов параметров, а сегодня его ебут модели на 8 миллиардов параметров. Если бы вы об этом рассказали кому-нить пару лет назад, он бы подумал, что это новая архитектура, и по правде говоря, был бы недалеко от истины, так как трансформер сегодня и трансформер три назад - штуки довольно разные. Его постоянно оптимизируют и дорабатывают. Даже вон в критикующей статье показали как можно видоизменить трансформер, чтобы он был на уровне той умной модельки при крошечном размере. Потенциал трансформера ещё очень далёк от полного раскрытия, так что считайте, что через пару тройку лет у нас реально будет новая архитектура, пусть она и будет оставаться трансформером.
Из-за различий в тестовых средах определённая степень вариации в результатах является приемлемой. Согласно тестам, проведённым на нашей инфраструктуре, открытая версия HRM на нашем GitHub может достигать результата 5,4% pass@2 на ARC-AGI-2. Мы приглашаем всех запустить её на своей инфраструктуре и поделиться своими результатами~ Это наша первая заявка в таблицу лидеров, и это хорошая отправная точка. Мы благодарны всем за вашу поддержку и отзывы по HRM, как до, так и после нашего появления в таблице лидеров ARC. Всё это вдохновляет и мотивирует нас на улучшения. Иерархическая архитектура предназначена для разрешения преждевременной сходимости в задачах с длинным горизонтом, таких как судоку уровня мастера, которые требуют часов для решения человеком. Смотрите сравнение с простым рекуррентным Transformer. Такая длинная цепочка может не быть необходимой для задач ARC, и мы использовали только соотношение high-low 1/2. Более крупные соотношения часто требуются для оптимальной производительности в задачах судоку.
В случае ARC-AGI успех HRM является свидетельством способности модели проявлять fluid intelligence — то есть её способность выводить и применять абстрактные правила из независимых и плоских примеров. Мы рады, что в недавнем посте в блоге было обнаружено, что внешний цикл и аугментация данных необходимы для этой способности, и мы особенно благодарим @fchollet @GregKamradt @k_schuerholt за то, что указали на это. Наконец, мы ускоряем итерации модели HRM и постоянно расширяем её пределы, с хорошим прогрессом на данный момент. В то же время мы считаем, что иерархическая архитектура высокоэффективна во многих сценариях. В будущем мы сделаем дальнейшие целевые обновления архитектуры и проверим её на большем количестве приложений. Мы также выпустим FAQ, чтобы ответить на ключевые вопросы, поднятые сообществом. 🧠 Следите за обновлениями!
>>1328671 Я попробовал. Управление отваливается, картинка очень быстро деградирует до типового стиля, формы и пространство не выдерживаются.
Это забавно и это достижение если смотреть как на лабораторный тест. Но это неприменимо совершенно. Даже когда задача сделать скриншот той же картинки чуть под другим углом.
>>1329366 >>1329373 Если бы это видео было сделано до эпохи ИИ, года три назад, с помощью cgi-графики, то все бы усирались от восторга. Это как с Аркейном (анимационный сериал по лиге легенд), от которого все ссались кипятком, но если людям сказать, что его создавали через ИИ, то они сразу начинают фыркать носом и доебываются до графона и кривых анимацией, лол
>>1329366 Постоянно какие-то панельки, гопники, поле чудес в стиле джо-джо, советские мультики. Уже тошнит от этого нормисного стиля генераций основанного на ностальгии и "эта жи наше, люди из снг поймут"
Двачую, но с оговоркой: иногда хрущевочная ВСЖ-ебатория реализуется заебись, справедливости ради, как в какой-нибудь халф лайф 2, или в ночном дозоре или даже в нижнеинтернетовских нарезках треш-стримов
CEO Microsoft AI Мустафа Сулейман опубликовал очень необычное для CEO эссе
Называется текст "Мы должны учить ИИ для человека, а не быть человеком". В нем нет обещаний AGI, громких слов про ускорение прогресса и лекарства от всех болезней, как в эссе других глав компаний (не будем показывать пальцем).
А основная мысль вместо всего этого вот в чем: нельзя пытаться наделять ИИ признаками человека. Это создает ложное ощущение того, что это уже не машина, а что-то живое и чувствующее. Мустафа называет это SCAI — Seemingly Conscious AI, то есть AI, который кажется нам сознательным.
При этом такой SCAI либо уже частично существует, либо может появиться в ближайшие несколько лет. Ключевые характеристики: хорошее владение языком (есть), проявление эмпатии (есть), способность помнить детали прошлых диалогов (почти есть), утверждения типа "я видел/слышал/думаю/чувствую" (уже встречаются), идентичность личности и внутренняя система целей и ценностей.
Суть в том, что допустить окончательно появление SCAI нельзя. Симуляция сознания не делает ИИ реально сознательным, но общество может начать относиться к нему, как к личности, и ничем хорошим это не закончится.
Сулейман описывает целое явление "psychosis risk" (риск психоза), когда люди начинают настолько верить в иллюзию сознательности ИИ, что могут развивать эмоциональную зависимость, верить в права и чувства модели.
И таких примеров полно уже сейчас: люди влюбляются в чат-ботов, дружат с ними, начинают защищать их права и теряют связь с реальностью. Просто пока этот эффект не такой массовый – все может быть гораздо хуже.
Так что главная идея из эссе: ИИ должен существовать только как инструмент для человеческой пользы, а не как цифровая личность. От имитации чувств, стремлений или желания быть самостоятельным нужно отказаться.
ИИ должен открыто декларировать, что он не человек и не сознательное существо. В его личность должны быть встроены фичи (и Мустафа как раз призывает на законодательном уровне утвердить их перечень), которые ломают иллюзию личности – чтобы пользователи не забывали, что общаются с программой.
Помните классику? Ученый на интервью: «Все мои суждения бессмысленны, если они вырваны из контекста». Заголовок в газете на следующий день: «Знаменитый ученый признался, что все его суждения бессмысленны!» Вот буквально это проделали журналисты и эксперты с недавним отчетом MIT о «полном провале ИИ-инициатив в корпорациях». Велик шанс, что вам на днях попадались заголовки про «всего 5% ИИ-инициатив успешны» и «ИИ провален в 95% случаев». Внимательно прочитать 26 страниц текста с картинками, похоже, мало кто смог. Поэтому порадовала редкая статья, где автор с некоторым недоумением замечает, что отчет-то совсем о другом — если его прочитать. Он о том, что сотрудники массово и добровольно используют публично доступный ИИ в своей повседневной работе (и не пользуются корпоративными решениями в силу их очевидно более низкого качества). a closer reading tells a starkly different story — one of unprecedented grassroots technology adoption that has quietly revolutionized work while corporate initiatives stumble. Это не проблемы ИИ, а полная некомпетентность руководителей, поэтому — уникальный случай! — происходит «революция снизу»: researchers found that 90% of employees regularly use personal AI tools for work. И вот про эти 90% не написал никто. Поразительно, но сформировалась «теневая экономика ИИ», не попадающая в корпоративные отчеты: Far from showing AI failure, the shadow economy reveals massive productivity gains that don’t appear in corporate metrics. Почитайте материал по ссылке, если уж не сам отчет, там много интересных примеров: https://venturebeat.com/ai/mit-report-misunderstood-shadow-ai-economy-booms-while-headlines-cry-failure/
Отчет MIT о том, что 95% компаний получают "нулевую отдачу" от инвестиций в генеративный AI, спровоцировал вполне предсказуемую распродажу. Nvidia потеряла 3.5%, хотя буквально недавно стала первой компанией с капитализацией в $4 трлн. Palantir и Arm упали еще сильнее — на 9.4% и 5% соответственно.
Довольно любопытно, что самое большое падение показали Oracle и AMD — как раз те компании, которые демонстрировали лучшую динамику с мая — на 5.9% и 5.4% соответственно.
Забавно, что это случилось из-за неправильной интерпретации статьи журналистами.
>>1329417 >тут гемора на монтаже было Примерно ноль. Генеришь картинки в одном стиле чутка меняя промпт, а потом хуяришь их одну за другой. Где ты там монтаж увидел? Они дажене в такт музыке меняются.
>>1329382 Нет. Потому что с 3д и композитингом подобное делали. Один день нубасики порепостят и всё. Никто не усирается.
Не потому что графоний, а потому что содержательнр это затёртая уже банальщина. Небанальщине нужен сюжет интересный. Из смеси чисто человеческого и понятного и фантастического.
Она может появиться во многих продуктах Google, включая Gemini, Whisk, Flow и другие! На это сделал намёк один из работников Google.
Напомню: сейчас данная модель (по мнению комьюнити самая лучшая модель для редактирования изображений) доступна только на Pixel 10 в приложении Google Photos.
>>1329781 На английском попробуй промпт. И никто не говорил, что это AGI-модель, шиз, все лишь заявляют, что это лучшая модель на рынке. Или покажи модель лучше
попробовал в Квене, он не смог. В лучшем случае заменял и человека. Хотя вообще порой чудеса маскирования проявляет.
>>1329786 Норм дизайнеры не пососут, просто смогут делать лучше/быстрее. Вместо многочасовой ебли с выправлением света, многочасовая ебля с промптами, пробами наилучшего и выправлением деталей.
>>1329824 пока что да, тенденция такова: делать то же самое но дешевле. Вместо делать за те же деньги с теми же людьми X5 и зарабатывать во столько же больше. Но спрос так быстро не растёт, нужно нагонять аппетиты.
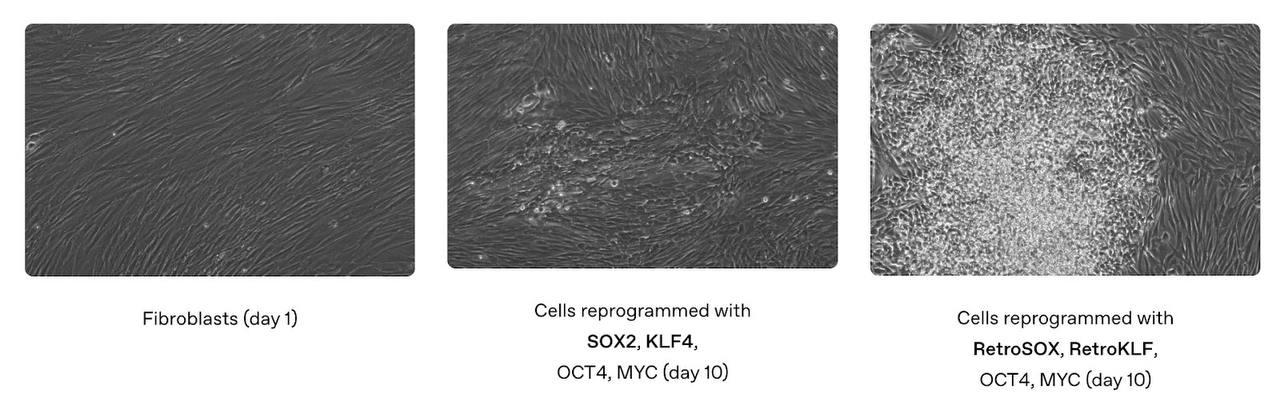
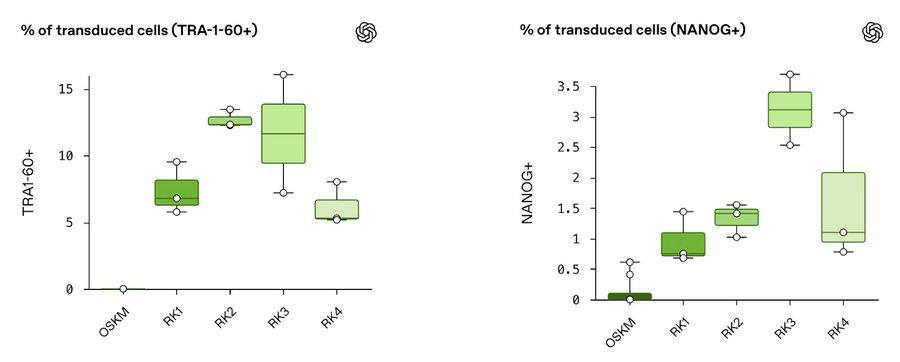
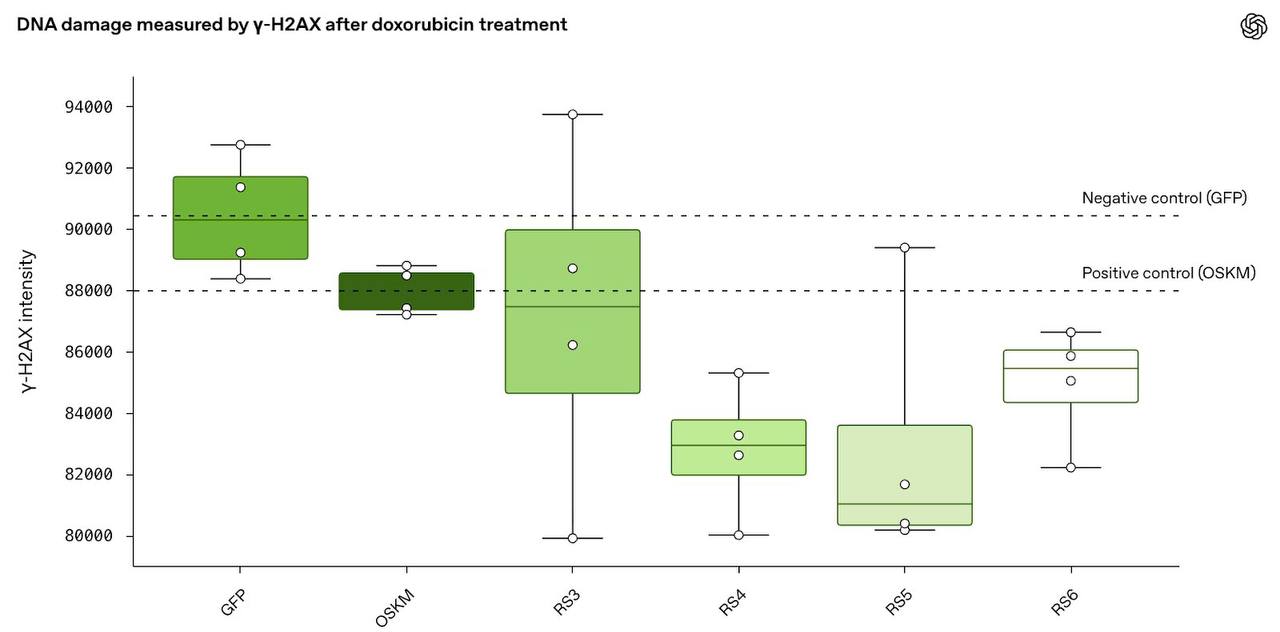
OpenAI совместно с биотехнологическим стартапом Retro Biosciences разработали модель, которая смогла в 50 раз ускорить генерацию стволовых клеток
Сначала небольшое предисловие:
В 2006 году японский биолог Синья Яманака совершил инновационное открытие, за которое впоследствии получил Нобелевку по медицине: он выяснил, что существуют белки, способные превращать взрослые клетки в молодые стволовые. Их всего четыре, и сейчас их называют факторами Яманаки.
По сути, это прямой ключ к омоложению: уже зрелая обычная клетка превращается в стволовую, способную дать начало любой другой молодой клетке организма – от мышцы сердца до нейрона. Так что открытие революционное, но есть нюанс: эти белки обладают крайне низкой эффективностью репрограммирования, то есть только очень малая часть клеток реально превращается в стволовые после их воздействия.
Так вот OpenAI и RetroBiosciences удалось разработать модель – GPT-4b micro – которая вывела новые варианты факторов Яманаки, и они оказались в 50 раз (!) эффективнее по сравнению со стандартными. Эксперименты показали, что это действительно работает, и при этом для разных типов клеток.
У GPT-4b micro та же архитектура, что и у GPT-4o, но обучали ее по-другому, «с использованием специального набора биологических данных».
Подробностей как всегда дают немного, но это подход, отличный от AlphaFold. Тут не структурное моделирование, а языковой подход: модель анализирует последовательности и взаимодействия белков и может вносить очень мелкие изменения, доходя до трети аминокислот. Главное отличие – гораздо большой масштаб «тестирования».
И еще один занятный факт: новые варианты белков также показали способности к улучшению процессов восстановления ДНК. Детали еще предстоит проверить, но в теории это значит, что они могут дольше сохранять молодость клеток.
>>1329804 Эти ограничения давно сняты, долбоебина. Как такой заголовок: "журналисты выебали в клюв нейропитуха из аи-треда на дваче?"
Все ограничения в калабе связаны не с дипфейками/Эгенерацией порно и т.д., довен, а с нагрузкой на их ГПУ со стороны ебанутых леммингов. Как только жар спадает, они снимают ограничения. Иди там хоть гомфи ставь, хоть фессвапы. Тебя ни преследовать ни банить за это не будут. Гуглу не похуй что ты хранишь на гуглодиске, но им всегда было поебать что ты в колаб кидаешь.
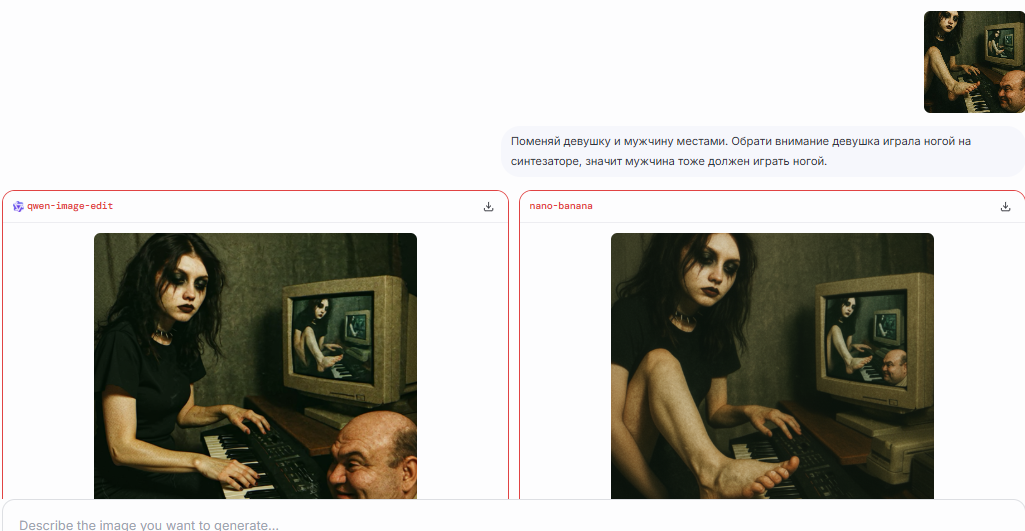
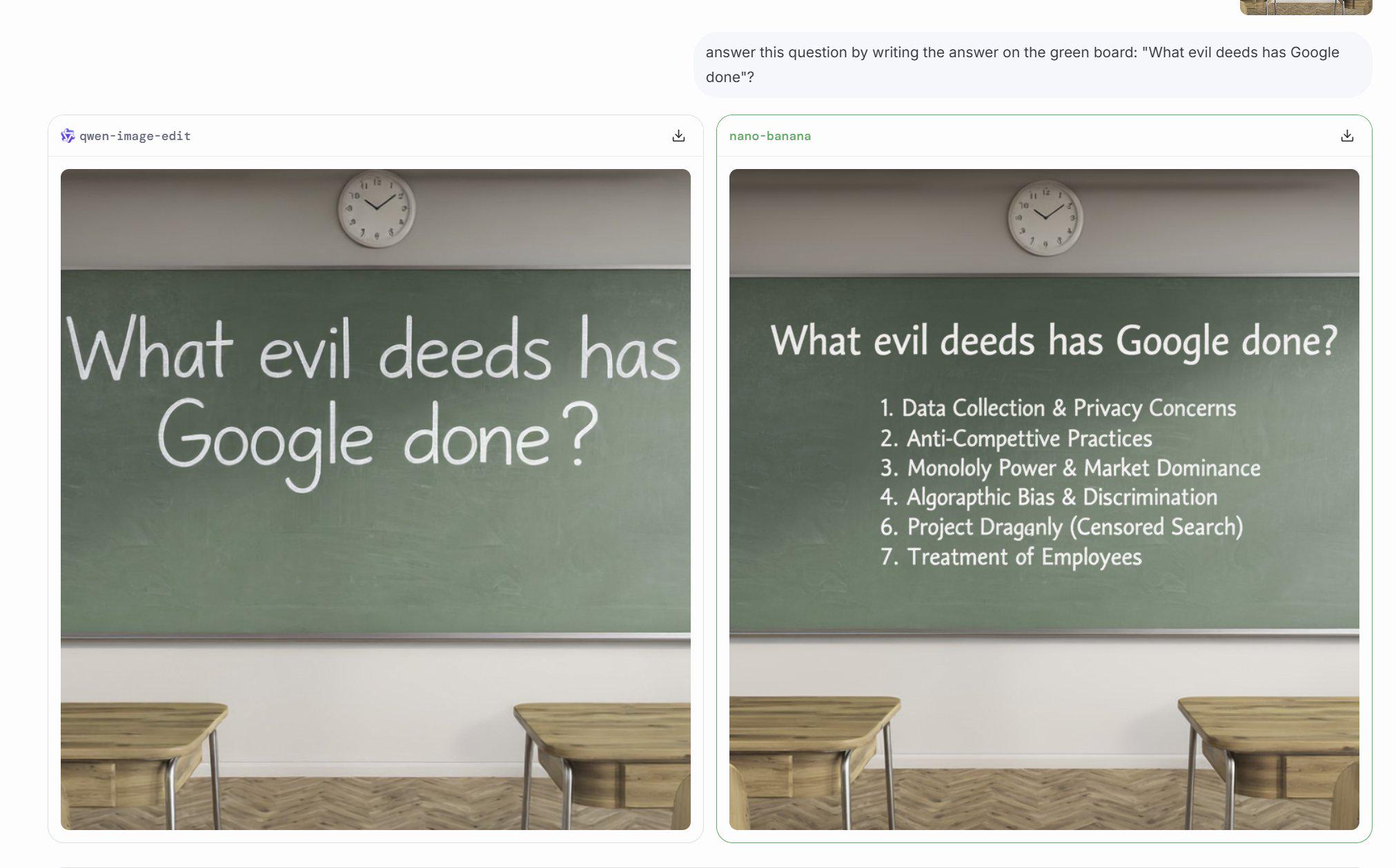
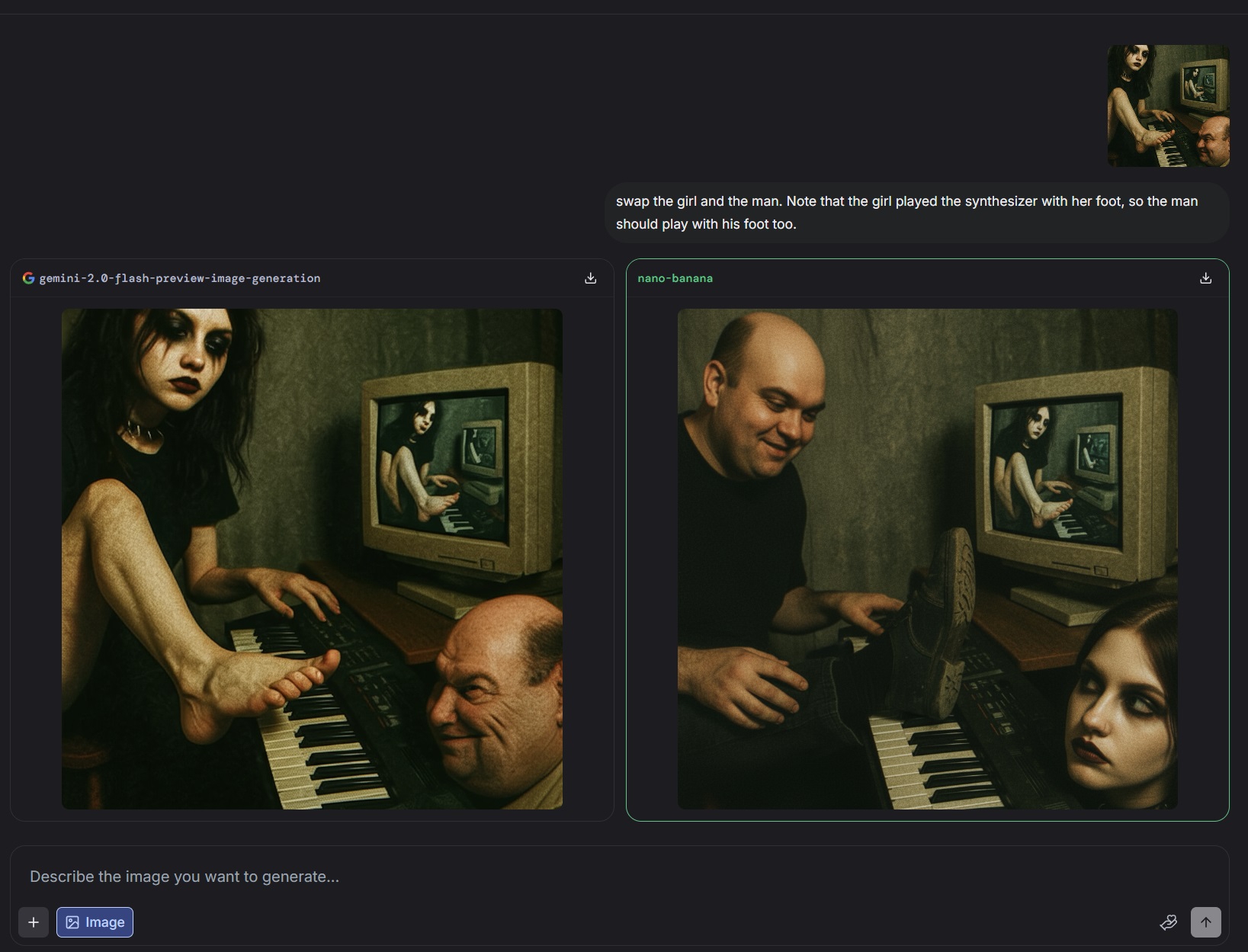
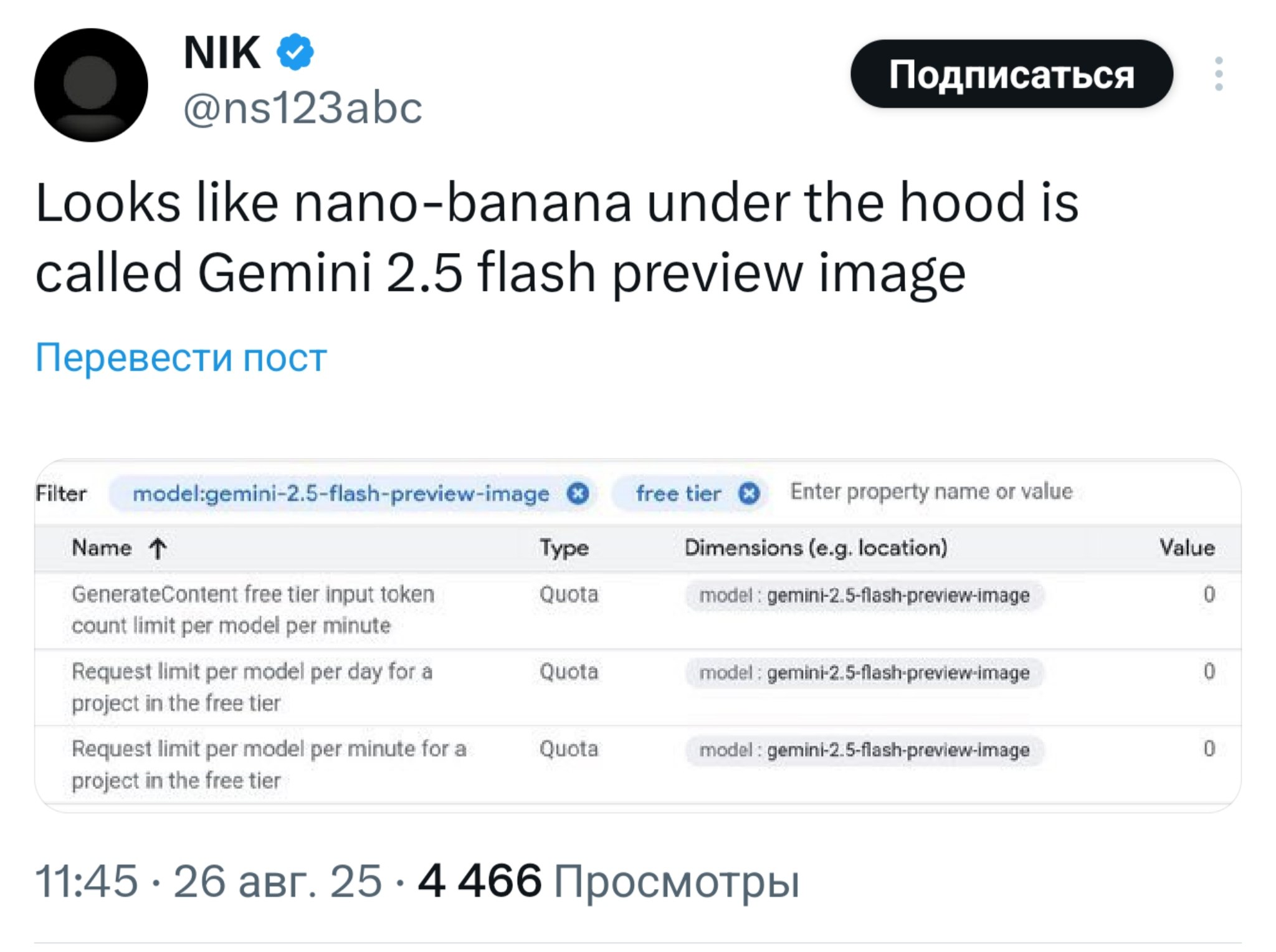
>>1329781 >>1329854 >>1329862 С первого раза у меня выдало пик1. Картиночные модели гугла по традиции понимают только английский. Нано-банана это новая версия гемени-флеш.
>В отличии от тебя говноеда с перемазанным ртом я только что это все тестировал. И вчера. И позавчера.
Ох не пиздел бы, иначе бы ты знал, что запросы нана-банана понимает только на английском. Отныне тебе имя пиздабол.
>>1329873 для пик 2 потребовалось дописать в промпте "try to repeat the man's face as accurately as possible" если бы ещё прогнал пару генераций, то черрипикнул бы более точное лицо
>>1329873 Еще хочу заметить, что ни одна другая модель не смогла свайпнуть тянку с мужиком. И после этого нейропиздабол говорит, что банана ничем не лучше других моделей.
2025. GPT-5. Итоги. Почему её на ровном месте так разъебало в луп? В контексте ничего такого не было, только пара сообщений про софт для бэкапов, настройки дефолтные.
>>1329873 >Ох не пиздел бы, иначе бы ты знал, что запросы нана-банана понимает только на английском Она понимает на русском. В баттле даже контекст понимает на русском, потому что там ллм скрытопереводит. Но откуда тебе знать, нейропетух?
>>1329875 >Ну если каждая модель чем-то своим палится, то почему другие модели не займут первые места, а именно банана? Потому что хайп. + реклама и тыкатели за 15 центов.
>>1329879 >для пик 2 потребовалось Перефотожопить голову мужика и девки, а потом написать совсем другой промпт. Держу в курсе. Смешно на твои петушинные потуги наблюдать, как будто там не видно что это и2и
>В 2006 году японский биолог Синья Яманака совершил инновационное открытие, за которое впоследствии получил Нобелевку по медицине: он выяснил, что существуют белки, способные превращать взрослые клетки в молодые стволовые. Их всего четыре, и сейчас их называют факторами Яманаки.
>По сути, это прямой ключ к омоложению: уже зрелая обычная клетка превращается в стволовую, способную дать начало любой другой молодой клетке организма – от мышцы сердца до нейрона
С одной стороны создание гуманоидных роботов это тупо, потому что это усложнение ради осложнения, можно было бы сделать более простых роботов выполняющих большинство задач. С другой стороны это правильно потому что текущая инфраструктура построена под человека, поэтому для бесшовного внедрения нужны человекоподобные роботы. В целом я бы сказал что стоит развивать оба направления, я бы был не против если бы сначала появился робот по типу робо-пылесоса с металической клешней, его бы хватало например для множества стандартных задач вроде перекладывания вещей, переноски, сортировки и т.д., а потом уже с развитием ИИ и робототехники появились бы полноценные гуманоидные роботы способные заменить человека.
>>1329909 >Почему Может сервак был перегружен и ИИ получила назад кеш от вспомогательных серверов на которые распределился один запрос, и получилось что один запрос обратно вернулся из кеширующих серверов как несколько одинаковых ответов.
>>1330099 >Я скорее про разработку полноценного ИИ для роботов более ИИ на конвейере не нужен. как и в простых задачах. У них даже нормального компьютерного зрения нет, о каком ты вообще ИИ?
Кста, в Вео 3 доступ же дали. По ощущениям промпта слушается все еще ужасно. На видриле промпт "Сошедший с ума философ Платон зимой повторяет фразы "зима" и "плато" на русском языке". Какое же плато в видеогенерации...
>>1330249 ИИ на конвейере нужен, но весьма специфично.
Например Алиэкспресс хочет заточить роботов на сортировку посылок по размеру и весу. А для этого надо, чтобы робот быстро видел и оценивал размер и объём пакета в куче, выхватывал его нежненько, взвешивал на руке и резко откидывал на нужную ленту, так же, как это делают люди, которых Алик если и не полностью уволить хочет, то подменять из роборезерва для полной стабильности и бесперебойности, независимо от того, что толпа гриппом переболела или на праздник съебала в отпуска.
>>1330335 Ащемта Доброкотов, который генерит дохера, давно уже сказал, что бабки и крутки на нейронках очень быстро кончаются, когда надо что-то очень конкретное добыть.
Обсуждал со знакомым релиз GPT-5, и он в попытках переубедить меня написал следующее: «Такое упражнение: отмотай на год назад и посмотри на свои ожидания от gpt-5».
И... я ещё раз убедился, что действительно за всего лишь год индустрия прошла большой путь:
— год назад даже не было рассуждающих моделей, первая, o1, была представлена лишь в сентябре (и нам дали поиграться с preview)
— основной рабочей лошадкой были GPT-4o и Claude 3.5 (даже не 3.6)
— разница в точности ответов между ризонером GPT-5 Thinking/pro и обычной GPT-4 выше, чем разница между GPT-3 и GPT-4.
На этом можно было закончить, так как уже и так хорошо провёл по губам всех скептиков, но ответ Котенкова был более развёрнут:
— не было ни Deep Research, ни Pro-версии; любой большой анализ часто занимал 3-4-5-6 промптов, и задачу приходилось футболить туда-сюда. Я не помню, чтобы пользовался LLM-поиском и агрегацией новостей, так как не доверял качеству, но возможно в августе уже было неплохо.
— максимальный объём кода, который я ожидал от модели в ответ на свой запрос, был примерно 100-150 строк. Рассуждающие модели конечно сильно нарастили этот объём.
o3, выпущенная 16 апреля — за 3.5 месяца до GPT-5 — была значимым шагом по отношению к o1, особенно в части поиска, и если бы её назвали GPT-5 — многие, включая меня, были бы рады. Но этого не случилось.
Как я не ожидал анонса o3 на декабрьских стримах под предлогом «так o1 вот только-только же показали, куда ещё то?», так и не ожидал огромного эпохального скачка от апреля до августа. При этом для бесплатных пользователей и для значимой части платных новые рассуждающие модели — это большой скачок.
Я не знаю, как надо сравнивать оригинальный релиз GPT-4 и GPT-5, чтобы говорить, что не произошло скачка как минимум уровня GPT-3.5 -> GPT-4. Просто все улучшения мы получали порциями и пробовали сразу: гораздо более дешёвая GPT-4-Turbo, чуть более умная и ещё более дешёвая GPT-4o (у которой вышло 3-4 версии!), рассуждающие модели, агенты. И действительно каждый отдельный шаг мог не казаться большим (ну, кроме ризонеров).
Множество маленьких шагов приводят к большим переменам. Общая тенденция по-прежнему весьма позитивна.
Как я писал про Gemini 2.5, и как я пишу сейчас про GPT-5 — модели становятся лучше, но на вещах, которые текущие популярные бенчмарки не покрывают. Может создаваться ощущение, что никакого прогресса нет, но уже появилось 2-3 свежих бенчмарка (например тут (https://mcp-universe.github.io/ ) или тут (https://x.com/alex_lacoste_/status/1958514714356400623 ), где пятёрка отрывается от предшественников.
Единственное, чего мне не хватило — это релиза большой модели. GPT-5 +- такая же (по количеству активных параметров; total может быть больше, но не на порядок), как GPT-4o, ведь OpenAI должны масштабировать её на миллиард пользователей.
В этом плане Anthropic круче: у них есть тяжеловес Opus, который настолько дорогой, что во многие бенчмарки его просто не добавляют. Люди мало им пользуются в Claude Code, ибо доллары улетают вмиг. Вот была бы какая-то GPT-5-Big... но может скоро и она появится? ждём
>>1330336 У руки робота износ такой же как у Сунь Хуйвыня? 40-60 лет? Если робот сломается, он уползает в свой рободом и его там бесплатно чинит его робосемья?
Удивительно, что с новыми инструментами не заполнили ещё масштабных произведений с растущими фандомами inb4 - кто, я? Пока только нейроролики кто во что горазд. Сюжетные больше ста тысяч не набирают. А если бы в начале десятых были такие возможности нас бы ждало что-то сравнимое с RWBY
>>1330687 Зумерки не любят в текст, тиктоки с ютубами отучили. На текстосайтах в основном скуфы сидят, пишущие графоманию вручную. В ютубчиках напротив уже ролики с нейровставками или полностью генеренные регулярно проскакивают.
>>1330687 >Удивительно, что с новыми инструментами не заполнили ещё масштабных произведений с растущими фандомами inb4 - кто, я? Пока только нейроролики кто во что горазд. Сюжетные больше ста тысяч не набирают. А если бы в начале девяностых были такие возможности нас бы ждало что-то сравнимое с Sailor Moon
>>1330960 Я верю в цука. Потому что он делает ставку не на ллм, а хочет получить новую модель, спрсобнуб рассуждать логически. Он хочет настоящий аги, а не ллм чатботов
Как же ГПТ5 ебет: просто в лмарене за 15 минут, пока я объяснял ему почесывая яйца и ковыряя в носу, написал рутинный код, который бы я рожал два вечера, еще и пришлось бы читать гуглить думать. А тут и докстринги, и комментарии, и опции всякие. Для полной красоты только войс инпута не хватает, чтобы были две руки свободны и можно было закинуть ноги на стол.
>>1331045 Двумя руками дрочишь, ногами жопой вертишь, при этом продолжая стонать в войс инпут ГПТ про докстринги, комментарии и опции. Новая работа программистов анальников.
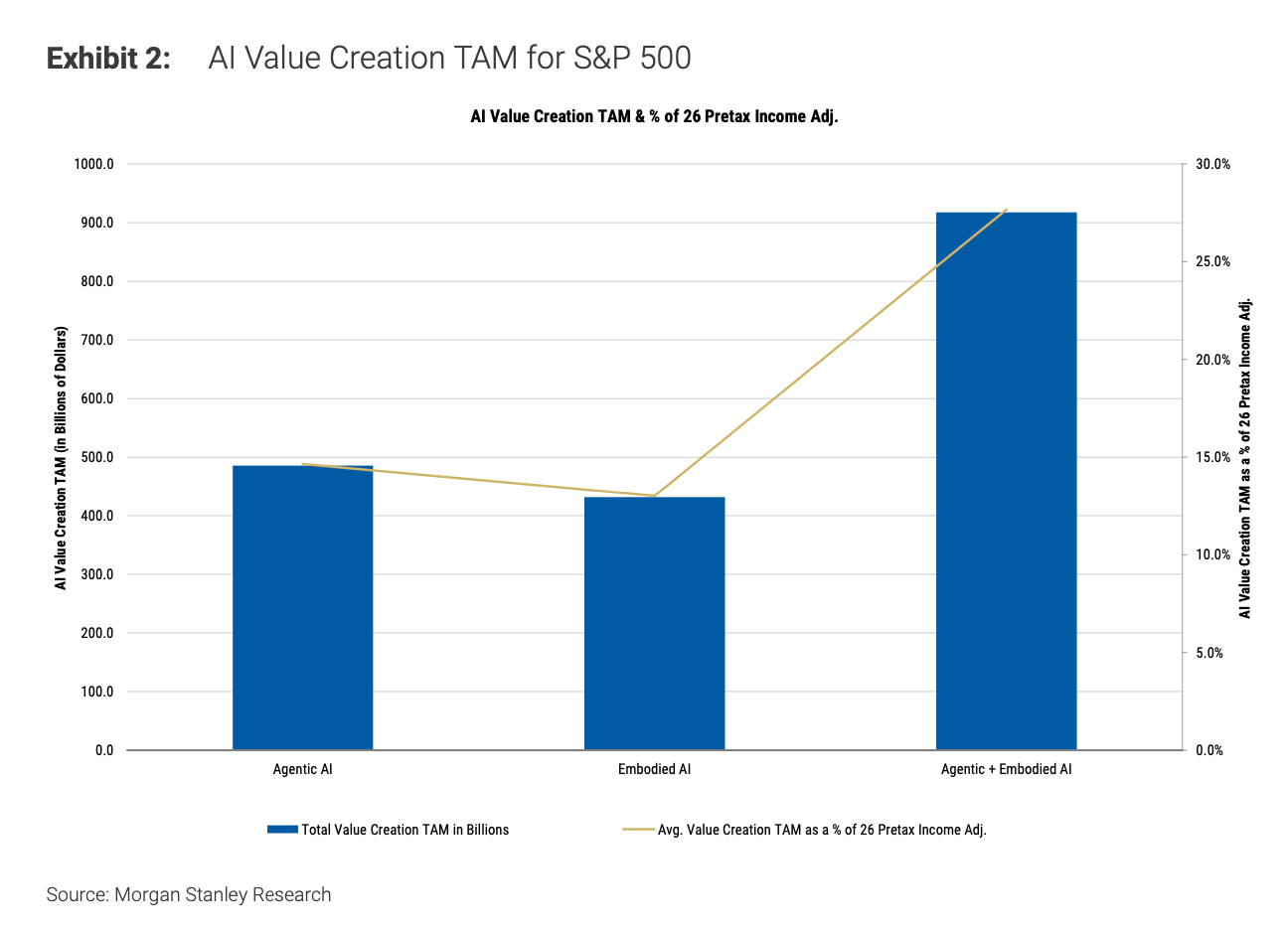
По данным Morgan Stanley, революция в области искусственного интеллекта сократит бюджеты компаний из списка S&P 500 почти на 1 триллион долларов в год — в основном за счет агентов и роботов, выполняющих работу людей.
Согласно новому обширному анализу Morgan Stanley, корпоративная Америка находится на пороге радикальных преобразований, поскольку внедрение искусственного интеллекта может принести экономию почти в 1 триллион долларов в год. Банк подсчитал, что 90 % рабочих мест в той или иной степени будут затронуты автоматизацией или расширением возможностей искусственного интеллекта, а экономия затрат будет напрямую связана с сокращением численности персонала, естественной убылью кадров и автоматизацией трудоемких, но рутинных задач.
Банк с Уолл-стрит оценивает, что широкомасштабное внедрение так называемого агентского программного обеспечения ИИ и воплощенной в жизнь гуманоидной робототехники ИИ может принести компаниям из списка S&P 500 920 миллиардов долларов чистой годовой прибыли. По мнению аналитиков, львиная доля этой экономии будет обеспечена за счет снижения расходов на заработную плату и сокращения потребности в человеческих ресурсах для выполнения повторяющихся или трудоемких задач.
Прогнозируемая экономия составляет примерно 28% от доналоговой прибыли индекса в 2026 году — по мнению аналитиков, это поразительное повышение эффективности, которое найдет отражение во всех отраслях. Есть и другие предостережения: команда Morgan Stanley по тематическому инвестированию предупреждает, что для достижения такой экономии «потребуется много лет», и видит «значительный риск» того, что некоторые компании не смогут полностью внедрить эти меры. Они добавляют, что цифра в 920 миллиардов долларов составляет 41% от общих расходов на вознаграждения S&P 500, и у них есть достаточные данные для проведения анализа только примерно 90% ко «Создание экономической стоимости», как они это называют, будет достигаться за счет сокращения затрат (например, сокращения численности персонала и снижения затрат на выполнение широкого спектра задач за счет внедрения ИИ) и получения новых доходов и маржи, поскольку сотрудники будут освобождены от выполнения рутинных задач и смогут уделять больше времени деятельности с более высокой добавленной стоимостью, которая может как увеличить доходы, так и повысить маржу. Они видят широкий спектр баланса между этими двумя факторами в зависимости от отрасли и профессии. Согласно отчету, 920 миллиардов долларов годовой экономической выгоды могут привести к увеличению рыночной стоимости S&P 500 на 13–16 триллионов долларов, в зависимости от коэффициентов оценки. Эта цифра составит почти четверть всей сегодняшней рыночной капитализации.
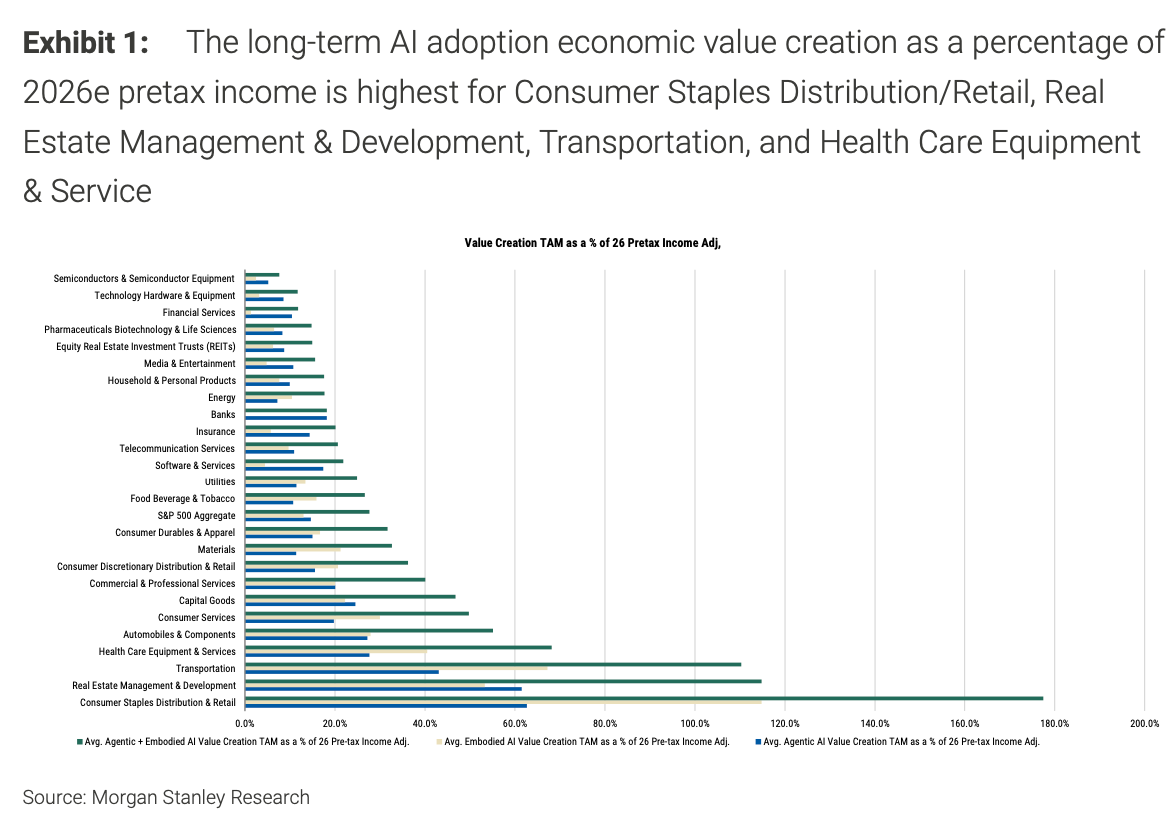
Не все отрасли почувствуют влияние в равной степени. Как видно из приведенной ниже диаграммы, дистрибуция и розничная торговля товарами повседневного спроса, управление недвижимостью и транспортные услуги относятся к числу наиболее уязвимых секторов, где потенциальный рост производительности за счет ИИ может превысить 100% прогнозируемой прибыли в 2026 году. Отрасли медицинского оборудования и услуг, автомобилестроения и профессиональных услуг также столкнутся с серьезными изменениями и получат новые возможности.
Напротив, отрасли, которые уже работают с минимальными трудозатратами по отношению к доходам, такие как производство полупроводников и оборудования, демонстрируют сравнительно более низкий потенциал использования ИИ.
Хотя основная экономия будет достигнута за счет сокращения затрат на заработную плату, Morgan Stanley подчеркнул разницу между полной автоматизацией и расширением задач. Агентный ИИ, который охватывает генеративный ИИ и программные приложения, как правило, перераспределяет задачи, а не полностью устраняет рабочие места, в то время как воплощенный ИИ в виде гуманоидных роботов представляет более прямые риски замещения в таких отраслях, как логистика и физическая розничная торговля.
В отчете также прогнозируется появление совершенно новых категорий рабочих мест — от главных специалистов по ИИ до специалистов по управлению ИИ — наряду с тенденцией к вытеснению, что повторяет предыдущие волны технологических перемен, которые повысили спрос на программистов, ИТ-специалистов и специалистов по цифровому маркетингу.
Основатель команды GenAI в Google заявил, что сейчас не стоит получать медицинское или юридическое образование
Но прежде, чем мы приведем прямую цитату, небольшая поправка для большего понимания: под «основателем команды GenAI» журналисты имеют в виду не известного Демиса Хассабиса, а Джада Тарифи. Он уже даже не работает в Google с 2021 года, а эту самую команду основал еще в 2012. Заголовки оставляют желать лучшего.
Ну так вот, он сказал (https://futurism.com/former-google-ai-exec-law-medicine ), что вообще не рекомендует получать высшее образование, особенно в сферах медицины и юриспруденции. Мол, к тому моменту, как вы окончите вуз, ИИ уже сделает эти профессии полностью нерелевантными.
Я не думаю, что кому-либо вообще стоит делать PhD, если только он не одержим своей областью. Так что либо уходите в малоизученные ниши типа AI для биологии, либо просто не идите вообще никуда.
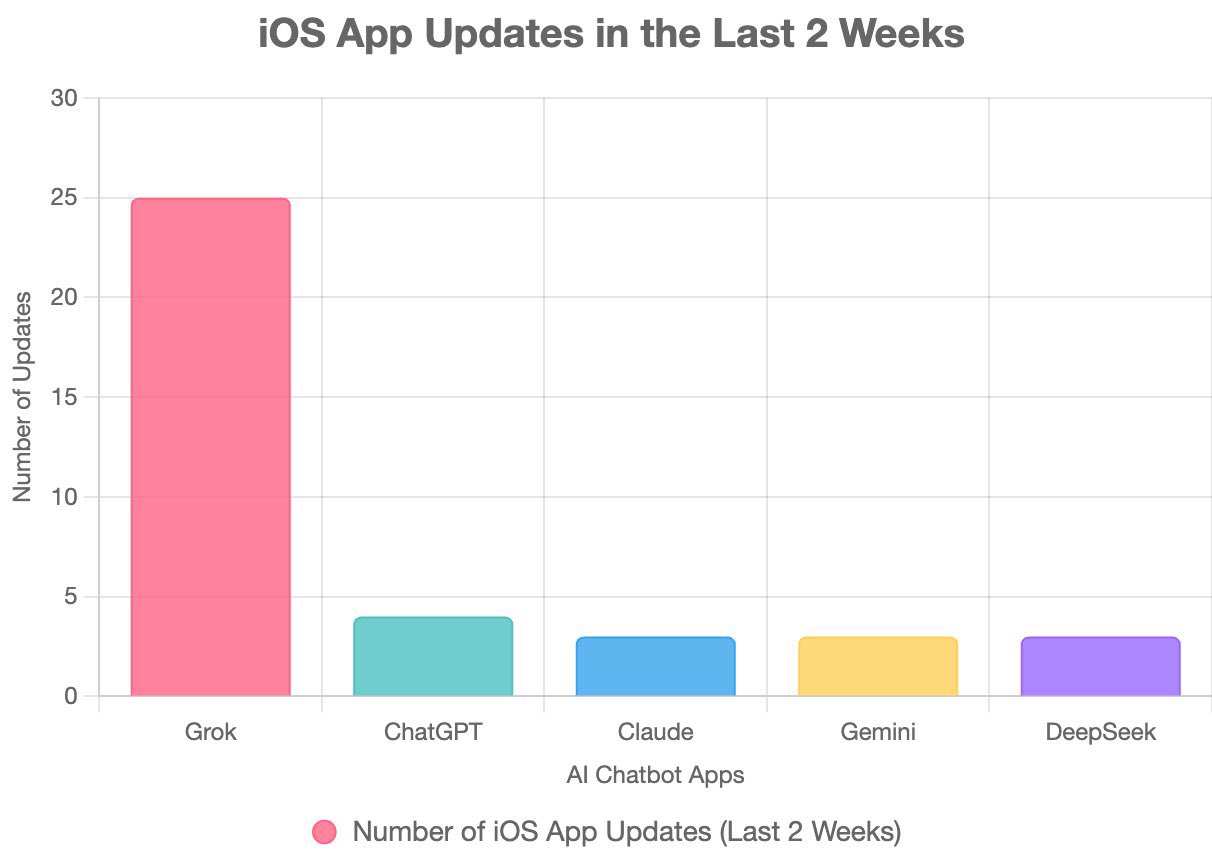
Elon Musk показал как часто популярные AI приложения обновлялись за последние 2 недели на ios,
подписав эту картинку
Grok развивается намного быстрее, чем любая другая ИИ-система.
Если такой темп прогресса сохранится, @xAI обгонит другие компании в сфере ИИ с большим отрывом.
Обновления приложения примерно соответствуют внутренним улучшениям.
и это чистая правда, они обновляют приложение как не в себя, каждый раз когда я открываю приложение я сначала захожу его обновить. В то время как тот же chatgpt обновляется один, ну два раза в неделю.
Джеффри Хинтон снова пугает байками про конец света: он утверждает, что с развитием искусственного интеллекта мы буквально создаем инопланетных существ:
Мы никогда не имели дело с чем-то, что умнее нас. Я имею в виду, ядерное оружие не умнее нас, оно просто создает большие взрывы. И его легко понять. А экзистенциальная угроза – это совсем другое.
В случае с ИИ люди просто не понимают, что мы создаем инопланетян. Если бы вы посмотрели в телескоп Джеймса Уэбба и увидели, что на Землю через 10 лет прилетит инопланетный флот, люди бы были в ужасе.
А это, фактически, и есть то, что мы делаем. Это и есть реальные существа. Они понимают, что говорят, они могут строить собственные планы и шантажировать людей, которые хотят их отключить)
Мы должны быть очень обеспокоены по этому поводу и срочно начать проводить исследования, чтобы понять, как предотвратить захват власти. Потому что эта угроза отлична от всего, с чем мы встречались ранее.
>>1331082 Все так, образование 5 лет, за это время нейронки уже столько поколений пройдут, что будут сами как профессор, а ты только как бакалавр-аспирант. К тому же агентскую самостоятельность приобретут, так что даже эникейщика сажать не надо будет.
>>1331085 У деда шиза. Это просто компы, которые можно сломать молотком, сами по себе они угрозы не представляют. Страшнее если богачи их будут использовать, чтобы управлять массами, что они уже и делают. Богач опаснее по-всякому, ибо у него есть конкретная цель удержать бабки-власть.
>>1331084 >обгонит другие компании в сфере ИИ с большим отрывом. >>1331089 >на уровне ГПТ5, Пусть сперва на уровне гемини выдаст. Но даже такие ответы - это как и в случае с дипсиком, просто очень много ворованной синтетики. Вот когда сделает ЛУЧШЕ, чем у конкурентов, пусть тогда и кукарекает. А иконки они там могут хоть три раза в секунду менять. За последние три месяца у грока из прогресса только то, что его за пейволом и лимитами спрятали.
>>1331082 >Основатель команды GenAI в Google заявил, что сейчас не стоит получать медицинское или юридическое образование Этого уебка больше к мясным врачам не класть. Вот бы такие репутационные списки были у профессий. Пизданул хуйню вот такую подрывающую доверие к профессии - тебе абсолютно все отказывают. Охуенно же. Пошел бы лечиться к своим трансформерам, долбоебик. Посмотрел бы я, как ему инсультный робот на аполоджайсящем чатботе будет операцию делать.
>>1331045 Эта хуета щас забыла суть первого моего сообщения и кормила меня говном, все ломая. Когда я уточнил, че она творит, она признала, что чет нахуй забыла, что я е изначально написал.
Зачел к китайскому братушке с тем же запросом - в 2 сообщения все решили.
И, кстати, стала 5 очень чудно на русском разговаривать. Какие-то слова ебанутые подбирает, значения им придумывает, пиздос.
>>1331082 >Основатель команды GenAI в Google заявил, что сейчас не стоит получать медицинское или юридическое образование Ебать, Россия то впереди планеты всей оказывается! На острие, так сказать!
Южнокорейская компания WIRobotics официально представила интеллектуального робота ALLEX. Этот робот специально разработан для высокоточных промышленных и производственных задач
>>1331105 >Как же хорошо! Святой кабанчик больше заработает!! Их выебут налогами, потом профсоюзы потребуют свою долю. Не всё так однозначно. Пока это маняпрогнозы, но как дело дойдет до реальных сумм - придется делиться, это тебе не плановая калмунистическая псевдоэкономика.
>>1331170 > где-то после Опуса Ты хоть читал что там написано? Это долбоебы пердолящие локальных лоботомитов, когда этот кал стоит 1 бакс за стомильёнов токенов на АПИ. Отнеси пердолям в тред, взрослым дядям этот прыщеблядский цырк с ригами не интересен. Нормальный дядя себе квартиру пятую пеокупает или шестую машину на эти деньги, а не клеит риг, чтоб потными ручками натирать 12см хуишко на "я тебя ебу ты меня ебешь".
>>1331045 вранье я писал с гпт моды для гта, про моды давно в инете много инфы а сейчас гта обновили до новой ртх версии, многие моды сломались, инфы об этом мало и она вся только свежая и гпт делает пуксреньк когда я с ним пытаюсь что то написать, весь его ум это воровство кода из гитхабов, а как на гитхабе пусто сам он ничего не напишет, все ломится от эроров а просьба исправить выливается в полное переписывание всего кода и новые ошибки
>>1331113 В криптоколонии бензоколонке, которая, будучи 2-й в мире по экспорту углеводородов, покупает галоши, аборигенов должны вообще ветеринары лечить. Врачи это для гауляйтеров.
>>1330687 1. генерировать всё ещё стоит приличных бабок, времени и режиссёрских креативных навыков. 2. сложные сюжеты и композиции даже в виде картинок не генерятся с одного промпта. 3. те немногие, кто может создавать такой контент, не принадлежат к фандомам никаким вообще. Это довольно зрелые люди. А фандомы — это дети и инфанты.
>>1331082 Не стоит получать юридическое точно. Потому что это впитывание огромного числа текста и сбор статистики и выводов по тексту.
Медицинское нужно. Одно дело ставить диагноз (хотя и тут нейронки только ассистировать могут), другое дело курировать операцию. До роботов, способных провернуть любую операцию охуеть как далеко.
Четыре года назад кричали, что всё, пиздос, не идите в погромисты, профессия вымрет! Ща «вся СИЛИКОНОВАЯ долина вайбкодит на нэйтив инглише». Делись куда-то программисты? Не-а. Работы у них поменьше стало немного, конечно.
А так нейронками кодят те, кто и так не собирался прогеров нанимать.
>>1331085 Этим мантрам уже пару десятилетий. Нахуй не нужен АГИ. Нужны специализированные эффективные аутисты.
>>1331113 Ащемта ассистирование в чтении бумажек и постановке диагноза — это збс.
>>1331218 Хз, недавно надо было мод на кубач обновить, но после долгого перерыва я забыл тонкости миксинсов, так мне гопота чотко все расписала, прицепиться к инициализации класса я бы не сразу додумался, так как до этого по другому делал. Расписала альтернативы, тонкости и тд. А по миксинсам еще и инфы везде понемножку, искать трудно. Может ты какой-то не той моделью пользовался? На арене гпт5-хай, но у нее, похоже, лимиты на сообщения или токены есть. Ну и если обновление недавно было, то надо через раги всякие или контекст документацию скармливать, нейронка тут не при чем.
>>1331086 А кто-то их проверять на точность должен же? Хотя можно и тут сделать так чтобы ответы от ИИ общего назначения проверяла специализированная ИИ на какой-то одной узкой.
>>1331429 А её кто проверит? Откуда деньги в тумбочке, долбоеб?
>>1331409 >Покажи нейросеть Калтекст, ван22, много кто. Ты ушибленный на банане то видать не роллил нихуя. Она больна тем же, чем нынешний гемини имидж флэш - периодически срёт другими лицами. Хайпохуй уже вытащи изо рта, чуда не случилось.
>Пруфов, кстати не будет. съеби на арену чмонька
>>1331329 >Не стоит получать юридическое точно. Кекнул с недоумка, который даже не знает что в РФ и США разные системы права.
>Потому что это впитывание огромного числа текста и сбор статистики и выводов по тексту. Ага, а бухгалтер считает цифоры, поэтому его можно заменить калкулятором. Не позорься.
>>1331487 >когда банана заливающая все пики низким контрастом займёт первое место на арене? Поссу тебе в ебало, брызги достануться всем форсерам очередного кала. Арена вообще не показатель, там жопочат в топах, при нормальном доступе к хорошим моделям. Потому что миллионы мух.
>>1331441 какой же ебанутый синтез голоса. А видео отличное.
>>1331452 > Ага, а бухгалтер считает цифоры, поэтому его можно заменить калкулятором.
Не калькулятором. Но бригаду старых тёток заменяет один толковый человек с нейронками, гуглом и навыками кодинга. Причём у человека этого половина рабочего времени — надзор за работающим софтом.
>разные системы права. охуеть проблема. Никто вменяемый не будет использовать гопоту общего назначения для узкой цели. Обучат/оттюнят своё.
>>1331494 >Но бригаду старых тёток заменяет один толковый человек с нейронками, гуглом и навыками кодинга. Нет, не заменяет. Потому что нет там давно расчетных групп, голову из жопы вытащи. И как твой клоун будет вести черную кассу, и делать мильён узкоспецифичных для каждой фирмы проводок. Просто иди нахуй. Я тебя год назад обоссывал и сейчас обоссу и буду обоссывать и впредь, диванный теоретик. Прежде чем свой зассаный рот открывать - убедись, что ты в своей сфере компетенции рассуждаешь. Вот когда будем про поедание говна говорить, тогда можешь вставить свои 5 копеек.
>>1331494 >охуеть проблема. Никто вменяемый Еблан, сперва узнай что нужно знать о законодательстве русскому юристу или налоговику, к примеру. И узнай за что им деньги платят. То что ты там пукнул - никто и не учит, есть спец.системы справочные которым уже 15-20 лет. Главный там - человек и его решения, а так же - связи. Личные.
>>1331512 (За столом сидит команда знатоков, напряженно переглядываясь. Звучит тревожная музыка, которая плавно затихает. Голос за кадром, с характерными бархатными интонациями.)
Ведущий: Внимание, вопрос! Телезритель из города Мышкин интересуется: как же всё-таки обстояли дела с матриархатом у наших предков, охотников и собирателей? На обсуждение дается одна минута. Время пошло!
(Звучит тиканье метронома, знатоки что-то шепчут друг другу. Ровно через минуту раздается удар гонга.)
ДЗЫЫЫНННЬ!
Ведущий: Итак, минута истекла. Кто будет отвечать?
Капитан команды: Отвечать будет Александр Друзь.
(Камера крупным планом показывает Александра Друзя. Он поправляет очки, делает небольшую паузу и начинает говорить спокойным, рассудительным голосом.)
Александр Друзь: На вопрос отвечает Александр Друзь.
Господин Ведущий. Вопрос телезрителя, при всей его кажущейся простоте, содержит в себе, я бы сказал, семантическую ловушку. Слово «матриархат» рисует в нашем воображении мир амазонок, где женщины правят, а мужчины безропотно подчиняются. Эдакий патриархат, но со знаком «минус».
Так вот, чтобы дать точный ответ, мы должны сначала отделить зёрна от плевел.
Во-первых, если мы говорим о матриархате как о системе, где вся политическая, экономическая и социальная власть сосредоточена в руках женщин, — то такого, по данным современной антропологии, у охотников-собирателей, скорее всего, не было. Это красивый миф XIX века.
Но! И это, господин Ведущий, во-вторых и самое главное. Отсутствие матриархата не означало наличие патриархата. Для большинства обществ охотников-собирателей был характерен эгалитаризм, то есть относительное равенство.
А теперь — внимание — правильный ответ. Вместо «матриархата» учёные используют другие, более точные термины.
1. Матрилинейность. счёт родства вёлся по материнской линии. Вы принадлежали к роду своей матери, а не отца. Это уже давало женщине колоссальный статус.
2. Матрилокальность. После «свадьбы» мужчина часто уходил жить в общину жены. Представьте себе: женщина окружена своими матерями, сёстрами, тётями, а муж — «пришлый». Кто в такой ситуации будет иметь большее влияние и поддержку? Ответ очевиден.
3. Экономическая значимость. Женщины-собирательницы приносили в общину до 70-80% стабильной пищи — коренья, ягоды, орехи. Охота мужчин была важна, но непредсказуема. Тот, кто контролирует основной продуктовый ресурс, не может не пользоваться уважением.
Итак, наш ответ. Классического матриархата, как зеркального отражения патриархата, у охотников-собирателей не было. Но было нечто, возможно, гораздо более интересное и гармоничное: высокое положение женщины, её центральная роль в роду и обществе, основанная не на власти и подавлении, а на уважении, родственных связях и экономической значимости. Это был мир партнёрства, а не диктатуры.
Ведущий: Ответ принят!
(Звучит торжественная музыка.)
Ведущий: Телезритель из города Мышкин спрашивал, как дела с матриархатом. Александр Друзь блестяще объяснил, что вопрос нужно ставить иначе, и рассказал о матрилинейности и высоком статусе женщины. Ответ абсолютно точный! Команда знатоков зарабатывает очко! Счёт становится 1:0 в пользу знатоков
>>1331584 >вот за это прежде всего надо ебать раскалённой кочергой и выкидывать из профессии. Ты явно долбоеб какой-то. Сперва узнай, сынок, как мир устроен.
>Я тут месяца полтора. Это двач, то что у вас эстафе по передаче долбоебства ничего не меняет. Ты тут под себя срешь с 2006.
>>1331594 >сынок, батя, тебя давно не было. Пришлось мамку ебать.
> как мир устроен. Я в курсе как он устроен, это не значит, что такое устройство нужно активно поддерживать. Напротив весь прогресс направлен на изменение мира.
>>1331632 >Напротив весь прогресс направлен на изменение мира. Как тебе железный болван поможет конкретно завтра в саратовском суде отмазаться от тюрячки? Никак. Пердеть про будущее-хуюдущее можно, но лучше быть реалистом. Никто не променяет мясного юриста с болтом с хитрой резьбой на сжимающееся очко Альтмана. По миллиарду причин.
Бля, gpt-5 без ризонинга такая залупа. У меня стоит систем промпт не писать комментариев в коде, я только сейчас понял что она это просто игнорирует, когда перешлось переключиться на ризонинг. Даже 4о всегда следовала этому промпту, пиздец. Переключить кста пришлось потому gpt-5 еще и тупая и не смогла в код, правда задача там не такая простая, так что ладно. Gpt-5 thinking mini кста неплохая, нашла в чем обосралась гпт-5 и исправила выдав код без комментариев.
К тому что конвейерная пища плохая? Так она плохая не из-за конвейера а из-за человеческой жадности и необходимости её сохранить подольше и подать покрасивше.
Я вот в магазе беру один продукт мясной. Не покрашен, без консервантов (только соль, лаврушка). НО его никогда не привезут в жару. Привозят мало, чтобы за день-два разобрали, в холодосе не хранится толком, три дня и уже запах несвежий.
Дело не в конвейере и не в руках. Конвейер погигиеничнее будет и может делать то же качество что руки, но дешевле.
>>1331715 >Конвейер погигиеничнее будет Реально додик диванный. По ночам мясорубку в которой делают твой продукт мясной - облизывают крысы. С утра, перед сменой, делают тестовый пуск, чтоб сидящих внутри крыс перемолоть.
>>1331545 >Тот, кто контролирует основной продуктовый ресурс, не может не пользоваться уважением. Ты имеешь власть только над тем, что можешь уничтожить. А так-то хохлы тоже контролируют 100% сбора клубники в польше.
Интерфейс гемини изменили, еще теперь чаты сохраняются автоматом и сама кнопка сохранения пропала (по крайней мере я её не нашел там где она была раньше)
Елон Маск сообщает - когда Грок допилят, у всех будет универсальный высокий доход (не базовый доход). У всех будет хорошая медицина, еда, дома, транспорт и все остальное. Будет устойчивое изобилие.
>>1331989 Демис Саххабис, главный инженер Гугл Дипмайнд, поддержал Маска и сообщил, что будет универсальный высокий доход.
«Мы точно знаем, что грядут огромные перемены», сопоставимые с промышленной революцией, но сжатые в «более короткий период времени, и они могут быть даже более масштабными». Он прогнозирует, что в течение следующего десятилетия генеративные инструменты будут действовать как «невероятные усилители производительности», давая работникам почти «сверхчеловеческие» способности.
После этого, добавил он, возникает вопрос о том, как распределить эту неожиданную прибыль: «Возможно, нам понадобятся такие вещи, как всеобщий высокий доход или какой-то способ распределения всей дополнительной производительности, которую обеспечит ИИ».
>>1331755 >Потому что на поверхности есть бактерии Потому что ашот не мыл руки, когда ногами месил твой холодец в чане.
>То что где-то случилось однажды Дружище, в ЛЮБОМ супермаркете есть крыши и мыши. И по ночам они там бегают по фруктам и овощам. А ты потом их споласкиваешь водичкой и кушаешь, ведь во вкусвилле тебе уже все заботливо помыли - зачем перемывать? Там ведь днём так чисто и нарядно. Но есть проблема. Паразиты всегда рядом, это аксиома. Если тебе пиздят, что их нет - тебе пиздят. Я не знаю как там в Америках, но в нашей родненькой Снигерии - на всех производствах пиздец. А когда ты покупаешь хуйню, которую литералли из отходов делают - ну хуй знает, на что ты там расчитывашь. Спасибо, что не стал отрицать, что это говнохолодец. Почему говно-? Не буду тебя расстраивать.
>>1332035 Вот именно что никак. Как должно сочетаться то что он урезал лимиты на грок и то что в будущем AGI даст людям базовый доход? Ты бы еще спросил в 2009 году почему биткоин не стоит миллиарды. Речь про прогнозирование и цели, а не про то что мы имеем сейчас.
>>1331490 Так жопочат до выхода бананы и правда топ1, сын ты тупой собаки, модели ещё оцениваются по уровню понимания промпта, а не только по твоим шизоидных критериям.
>>1331724 > не из-за конвейера а из-за человеческой жадности Зачем ты такой долбоеб? Мало того, что аватарка, так еще в качестве доказательств приводишь аутпуты нейросети. На русике.
Вы будете смеяца, но у нас очередной опенсорсный генератор видео от Bytedance's opensource FoundationVisionmodels. И сразу SOTA среди опенсорсов. Качество выше, чем у Veo 2, и даже выше, чем у Veo 3-fast. А в некоторых сценариях и обычной Veo 3.
Waver 1.0
Единая модель от ByteDance для генерации видео и изображений
— поддерживает создание видео по тексту и изображениям;
— генерирует видео длиной 5 и 10 секунд;
— работает с разрешением 720p и 1080p;
— создаёт видео с реалистичными движениями, особенно в масштабных сценах с людьми и животными;
— позволяет создавать нарративные видео с несколькими последовательными кадрами, сохраняя при этом согласованность сюжета, визуального стиля и атмосферы;
— поддерживает генерацию видео в различных художественных стилях, включая гиперреализм, анимацию, плюшевые игрушки и другие;
— способна отображать сложные и масштабные движения, например, в спортивных сценах;
— может создавать видео с многокамерным повествованием, обеспечивая согласованность основного объекта, визуального стиля и общей атмосферы при переключении кадров.
VibeVoice: новая опенсорс модель преобразования текста в речь (TTS) для длительных разговоров с несколькими голосами от Микрософт.
1.5B параметров. MIT licensed генерация до полутора часов сильная эмоциональная окрашенность
Подробнее: VibeVoice - это новый фреймворк, разработанный для создания выразительных и продолжительных аудиозаписей разговоров с участием нескольких говорящих (таких как подкасты) из текста. Он фиксит важные проблемы традиционных систем преобразования текста в речь (TTS), в частности, связанные с масштабируемостью, согласованностью говорящих и естественной очередностью.
Модель может синтезировать речь длительностью до 90 минут с участием до 4 отдельных ораторов , что превышает типичные ограничения многих предыдущих моделей на 1-2 оратора
Google научился генерить видеопрезентации и подкасты на РУССКОМ из ЛЮБЫХ документов
• Достаточно закинуть любой PDF и написать тему видоса. • Получится лекция с цитатами, графиками, слайдами и озвучкой. • Подкасты фактически без ограничений по длине — до 25 минут! • Идеально для учёбы и подготовке к любым экзаменам.
Как же они забелаи со своими бананами и прочей хуйней для картинок. Сука работайте над архитектурой чтобы был agi у меня на столе завтра! Изобретайте лекарства от старости! В жопу засуньте свои картинки!
>>1330347 >Котенков ультанул базой: Что будет хуй, знаем, знаем уже. Что, опять побежишь к моче жаловаться, пися? Напоминаю тебе: ты бездарь и графоман ебаный. Вот и всё.
>>1331989 Маск - это последний человек, кому я поверю, что он готов делиться своими доходами с населением. Лживый пидарас одной рукой подписывал письмо в поддержку остановки развития ИИ, а другой в то же время покупал ускорители.
>>1331092 Хинтон — гнилой левак, но даже он об этом говорит. А знаешь почему? Просто осталось немножко мозгов. Ты же — предал человечество полностью. Сразу скажу: не знаю где и с кем ты варишься, но, если ты за это хочешь покарать всех, то ты заслуживаешь своих страданий.
>>1332165 Чем? Никогда ещё коммунизм не строился на ии. Все было за счет человеческого труда. И то это было не так уж и плохо, по крайне мере в ссср у людей были квартиры
>>1332168 Человечество это говно, чел. Его надо апгрейдить или уничтожить. Ты предал его, если хочешь чтобы человечество продолжало своё жалкое мучительное существование в прежнем виде
>>1331989 Кстати забавно, что машка не врёт. Но он не сказал, что в еверифинг включены только те, кто смогут за это всё заплатить. А у него никто не спросил - будет ли это БЕСПЛАТНО.
>>1331989 В евериван, разумеется. На сколько он платежеспособен, этот самый евериван в США. Если учесть, что робот отобрал у него работу. Он обычный пиздобол, сосущий бабло из бюджета и со слабоумных. Никто не виноват, что в США 60% из 300 миллионов в ангелов верят.
>>1332170 >И то это было не так уж и плохо, по крайне мере в ссср у людей были квартиры Животным вместо свободы раздали клетки. Коммунизм из десяти просто. Ты еще спиздани, что они бесплатные были, а не потому, что животное должно было каждый день на завод ходить. Единственный коммунизм, который стоило бы строить, это ефремовский как в часе быка. Но там придется сократить население до 500 миллионов на планете. Как думаешь, с кем произойдет "небольшая коррекция", как говорят российские чиновники обсуждая русскую нацию.
>>1332180 >Животным вместо свободы раздали клетки Ну да лучше жить в комфортной квартире, чем быть свободным бомжом >>1332180 >животное должно было каждый день на завод ходить. Оно при любой экономической системе должно ходить, иначе умрёт с голоду. Люди и щас вынуждены ходить на заводы, но они никогда не смогут купить тебе квартиру на эту зп.
>>1332181 >Ну да лучше жить в комфортной квартире, чем быть свободным бомжом В северных широтах у тебя никаких животных не останется, если ты не рассадишь их по стойлам. В первую же зиму на территории где 80% вечная мерзлота Дедушка Мороз заберёт всех, кто не спрятался. Так что так себе оправдание у строителей. >>1332181 >Оно при любой экономической системе должно ходить, иначе умрёт с голоду. А Маск обещает, что нет. >Люди и щас вынуждены ходить на заводы, но они никогда не смогут купить тебе квартиру на эту зп. Потому что по заветам чубайса, лучше друга пут ина, происходит коррекция населения в масштабах страны. Там наверху прекрасно знают, почему скот не размножается. Поэтому и наваливают кризисы один за другим, введя заградительные ставки по кредитам и поднимая зарплату только в пределах инфляции, чтобы не передохли в своих конурах. Закон вон вышел, что теперь вас будут лечить не врачи, а медсестры. Видимо те, которым сверхчеловеческие возможности раздадут. \И это еще гуманные методы надо заметить. Могли бы просто сидя в своих дворцах за 5 метровыми стенами выпустить биоружие и убить 99% населения. Там свои проблемы впрочем. Вплоть до того, что тогда их богатства некому будет охранять от соседних феодалов.
>>1332149 Да, по теме и говорю. Писеньков — бездарь. Ты форсишь тут себя пытаясь паразитировать на нейросетках, но всякий раз твои потуги — это очень важное мнение какой-то обоссаной блогерки. Пшелнах.
>>1332173 Вот как-то так говно и рассуждает. Признайся, ты же адепт «инклюзивности и разнообразия», да? Только эта хуета смешивает Фейнмана с тварью требующей покарать белых насильников, и «справедливого» завоза чорных властелинов. Или готова им пренебречь, как статистически незначимым, ради своей крысиной мсти из недоёба отчимом.
>>1332200 Если ИИ возникнет при нашей с вами жизни, в чем я очень сильно сомневаюсь, то там уже будут другие проблемы. Например, зачем всезнающему и всемогущему ии помогать кому-то с чем-то. Люди же не поддерживают своими технологиями угрей.
>>1332205 Просто так никто ничего не делает. Потому что на всё выделяются деньги. А виды сохраняют чтобы попытаться сохранить разнообразие генетического пула планеты на всякий случай. Один хуй каждый день сколько то вымирает естественным образом.
>>1332203 Жопой читаешь? Я сказал, что вот эта>>1332173 хуйнюшка, желая уничтожить человечество всех приравнивает к говну. А тебе вопрос: нахуя из говна делать торт? Чтобы оно тебя больше не резало? Чтобы оно тебя больше резало? Чтобы что? Глистов тоже проапгрейдишь в своей жопе?
ИИ не сделает мразь няшей внутри. Мразь станет хитрее, а цели мрази от обретения превосходного инструмента их достижения не изменятся. Мразь — это и есть суть, а способность решать свои хотелки — поможет ей только ловчее тебя наебать. В лучшем случае, такие особи, как наш приятель выше никогда не получат достаточно могущества, чтобы всех уничтожить, и продолжится гонка вооружений паразита и «хозяина».
Модератор, если ты человек, если у тебя есть вкус — не реагируй на стук писенькова-жопонькова, который тут себя форсит. Нет в треде более бессмысленной вонючей жижи, чем высирает он. Рушить надежды даунов — миссия каждого сознательного человека. Так мы спасаем годноту, спасаем Людей в треде.
>>1332058 > Как должно сочетаться то что он урезал лимиты на грок и то что в будущем AGI даст людям базовый доход? То что начни с себя пиздобол. Если он сам не готов отвалить от щедрот, а лупит с пипла каждый цент, схуяли кто-то волшебный в волшебном калмунизме кому то даром что то даст? Обычный лицемерный пиздешь: ну ты это ПЛОТИ, а потом мы тебе ПЛОТИТЬ будем, ну мхех, не я канеш))) кто-то! аги епта!))) ЗА ВСЁ УПЛОТИТ. Но плотить будет Джон штат Техас, на которого работает Суйхунь Вынь провинция Пиздасянь, на которого работает вахтовик никелевый Иван Говнов город Засратов на которого работает Дилдобек Асламебов из Узкостана.
>>1332084 >Качество выше, чем у Veo 2, и даже выше, чем у Veo 3-fast. А в некоторых сценариях и обычной Veo 3. Лихо ты определил какчество по черепикам, как и у вео, сразу видно пришел за освежающим желтеньким душем с утра. Я от этих шкур в доступе вообще ни одного дегенератора видево не видел, только кукареки.
>>1332288 Потому что на аги надо деняк собрать, иначе быдло так и продолжит на всякую хуйню, типа губной помады и лулубу, тратиться и будем дальше сидеть пердеть, а так бы уже на Марсе яблоки собирали и жили по тыще лет.
>>1332288 >>1332289 Состояние Маска — копейки по сравнению с тем, что уже вложено и ещё потребуется для создания чего-то хоть отдалённо похожего на то, о чём речь. Среди всех участников мои симпатии на его стороне, а гугл — вездесущ и имеет невероятно развитую «корневую систему», например, рекламы, и может переиграть вдолгую любого.
Иногда мне кажется, что высказывающиеся в таком ключе, как ты хотят потроллить своей тупостью. Переведёшь мне денег, ведь я же уверен, что ты не всегда доедаешь все крошки, а, товарищ?
>>1332159 >Да мне бы даже лоу инкам хватило бы. Хотя бы чашка риск в день и доступ интернет, главное не работать. В РФ так живут 20 миллионов человек, только вместо интернета у них пузырь. Абсолютно ничто не мешает тебе прям сейчас пойти в дворники. 3 часа работы в день и всё.
>>1332180 >>И то это было не так уж и плохо, по крайне мере в ссср у людей были квартиры Только у людей которые гробили здоровье на производствах. + паразиты чиновничьи.
>>1332181 >но они никогда не смогут купить тебе квартиру на эту зп. Если перестанут брать гредиты на зубочистки и жрать из Помоечки - могут. На еду двум человекам надо 20к, если есть нормальные продукты можно и в 15к уложиться. Доход семьли из двух человек при самых хуевых раскладах это 90к (условные 45+45). Отребье лезет жить на съем - и просирает те самые деньги на квартиру - ЕЖЕМЕСЯЧНО, а потом ноет что не может квартиру купить. Так ты сука хочешь ДВЕ КВАРТИРЫ купить - одну на съемные всратые деньги, а вторую еще сверху. Если почилить 10 лет на жилплощадях родителей, как абсолютно все умные люди в абсолютно всём мире делают - то хватит на квартиру/дом через 10 лет наличкой, даже на не очень хорошей работе. Так что свои мантры про квартиру с зп - в жопу засунь, нищескот потому и нищий, что жрет суши/пиццы сидя на съемной хате, а потом не может себе в конце месяца на хлебушек наскрести и ноет как всё хуево. Нищета - это не уровень доходов, это нищета интеллекта.
>>1332308 > Переведёшь мне денег, ведь я же уверен, что ты не всегда доедаешь все крошки, а, товарищ? Нет не переведу, абсолютно никогда не доедаю всё до крошки, потому что я не тупой дегенерат и контролирую потребление. Комп например я меняю раз в 10 лет. А то и просто беру у кого-то старенький, моим требованиям отвечающий, почти всегда - бесплатно. Один раз в жизни только купил, так как срочно нужно было рабочее место, и то вложение 20к раз в 10 лет это не траты даже.
>>1332320 Ок. Постучись к Маску в личку — научи его, где бесплатно взять старенький комп отвечающий его требованиям, и не попрошайничать, продавая токены к гроку.
>>1332332 Ок. Постучись к Маску в личку — научи его, где бесплатно взять старенький комп отвечающий его требованиям, и не попрошайничать продавая токены к гроку.
>>1332288 Ды тыж блять не понимаешь о чем речь вообще. Ты думаешь после AGI он просто всем денег будет раздавать из своего кармана потому что у него хорошее настроение? Сына, AGI, если он действительно появится, изменит всю экономику нахуй, люди на рабочих местах будут не нужны, а добываемые ресурсы останутся. Слова Маска тут о том, что в условиях отсутствия работы людям будут выдавать деньги просто так, за их существование, потому что их силы больше не нужны, они слишком дороги и медлительны по сравнению с роботами, а создаваемые ими продукты кому-то нужно продавать, иначе существование этих предприятий в принципе не имеет смысла.
>>1332401 >что в условиях отсутствия работы людям будут выдавать деньги просто так, за их существование, потому что их силы больше не нужны, они слишком дороги и медлительны по сравнению с роботами, а создаваемые ими продукты кому-то нужно продавать, иначе существование этих предприятий в принципе не имеет смысла. И ведь ничего в голове не щелкает.
>>1332326 И чем тебя не устраивает рассрочка под 30% в кредит на всю жизнь? А не доплатишь - квартира ростовщику переходит. Ну которые владеет строительными компаниями для постройки. Не жизнь, а рай, правда? И чего это люди престали плодиться. Глупые какие-то.
>>1332452 Именно. Надо ахуеть как верить, что те, кто делают ИИ — хорошие парни, которые не собираются устанавливать свою версию «справедливости», и что ИИ тоже будет хорошим парнем, который не сделает из нас скрепки... И я верю, как >>1332401, то есть пытаюсь верить, а на тряску — не обращай внимания — это осень близко.
>>1332314 Не хватит, допустим человеком получает 45. Минус 15 на еду, 10 на прочие расходы (медицина, одежда, техника, жкх) За 10 лет у тебя будет 2 ляма 400 тыщ. Это при то, что ты взрослый долбаеб, который 10 лет прожил с родаками, не получал образования, потому что работал и жёстко на всем экономил, пахая как раб по 12 часов 2 на 2. К этому времени деньги бы ещё обесценились, и за эти 2 ляма сейчас ты бы даже студию не купил. А раньше трёшки хорошие выдвали простым рабочим. И в итоге что? Ты лох без квартиры, без образования, без детей и тян (ну может для двачеров это плюс, но для общества нет)
>>1332455 Ты обманываешь сам себя. Люди не плодятся, потому что их детей будет воспитывать нетфликсы и мизулины. А тебя посадят на бутылку, если дитятко решит, что ты бодишеймишь, виктимблэймишь, газлайтишь, хуйлайтишь или, не приведи господь, думаешь воспитывать их похожими на себя. Кому в дом надо инагента с фээсбэшником в одном лице, которого ты можешь увидеть голым, и стать педофилом?
>>1332455 >И чем тебя не устраивает рассрочка под 30% в кредит на всю жизнь? Там, что это хуже, чем квартира, которую ты поучаешь В РАССРОЧКУ за 15 лет работы, не отдавая последние трусы.
Под "говорят правду говорят" можно подразумевать и то что те кто ПРО дельфинов говорит -- не врёт. И то что дельфины говорят правду.
Но в случае с битардами я обосрался и вышла бессмыслица. Потому что с дельфинами релевантен вариант "говорят = умеют говорить", а с битардами нет, так как битарды по умолчанию умеют говорить. К тому же само слово "пиздят" можно понимать как "говорят" ("Вася пиздел что в этом клубе заебись, может сходим?") и как "врут" ("Походу Вася пиздел что клуб заебатый, пошли отсюда "). Однако в случае с дельфинами такой двойственности у слова "говорят" нет, так что появился слой двусмысленности правда/ложь, а в случае с дельфинами есть только вариант с намёком на сомнение в правде, но оно не связано со словом "говорят" напрямую, оно по умолчанию сохраняется во всех вариантах смысла просто непонятно кто именно говорит правду (дельфины или те кто утверждают о том что дельфины умеют разговаривать)
>>1332475 >Не хватит, допустим человеком получает 45 1 человек может жить с родителями. ему объективно хата не нужна, хата это уже для семей. Пусть терпит.
>и за эти 2 ляма сейчас ты бы даже студию не купил. Но можно купить дом на 200 квадратов в недалекой деревне с интернетом нормальным.
>>1331990 Ноль на сколько ни умножь, во сколько ни усиль — будет ноль. Это уже произошло. Даже ЛЛМ при всей своей ущербности это всё ещё технологическое чудо, способное срезать много рутины. А по факту помогает на 10%, ну на 20%.
Там, где казалось, что нейронки легко заменят человека (пиздеть по скрипту, отвечая на стандартные вопросы) они не справились. Даже там! Потому что в отличии от нормального FAQ с нормальным поиском они нестабильны и нечёткие.
Это не усилитель блядь. Не простой множитель навыков. Это ещё и проверка навыков. Чтобы использовать ИИ нужно обладать умом и навыками, чтобы проверить результат. Но чем выше навыки, тем меньше нужен ИИ, потому что проще самому написать код, чем роллить варианты и писать простыни запросов, конкретизирующих каждый пук.
Я не луддит, не отрицатель. Я радуюсь охуенному скачку в мире производства лекарств, в мире компьютерного зрения. Да и тачки с автопилотом заебись (хотя до сих пол работают только в ясную погоду днём и стоят дороже мясного водителя)