В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
А ведь у нас реально есть дипсик уже сейчас, полноценный конкурент большим нейронкам типа гемини, на 685b параметров, гопота дома. Не понимаю какой смысл теперь в видюхах, их время ушло на ближайшие лет 15, модели уже есть а видюх под них нет, сейчас кроме рам вообще ничто не решает. Я кстати не считал, может даже 3 3090 стоят дороже чем сетап с 405гб рам
>>1184574 → Сразу видно, что нихуя не разбираешься. У 8400f меньше техпроцесс и меньше L3 кэша, поэтому он холоднее 7500f даже при отсутствии припоя. А вот 7400f уже печка, да >>1184590 Пиздец, первое сообщение в треде и уже насрал дипсикошиз
>>1184595 >Пиздец, первое сообщение в треде и уже насрал дипсикошиз х4 3090 шиз, ты? Должно быть очень обидно что потратил столько бабок чтоб выебываться перед нищетой, а тут выходит модель в 5 раз умнее и уже ты сидишь на лоботомите
>>1184590 Если уж говорить серьезно о запуске на рам то вот эта штучка более интересна чем дипсик - Qwen3-235B-A22B Только непонятно какие скорости можно выжать с и без оптимизаций с выгрузкой во врам. Вот тут анон с ней играется, но цифры не кидает. Вангую онли cpu где то токена 2-3, с выгрузкой активных экспертов в врам ну может до 10, хз Обычная llama.cpp как то хуево выгружает их принудительно
>>1184637 Мистраль 24б аблитератед. Именно он. Файнтюны на русике - кал, хотя, возможно, есть нормальные.
Квен 30б, который новый и МоЕ. Он будет даже быстрее у тебя, чем 22б мистраль, если только мистраль целиком в память не влезет.
Но хоть русик у них и значительно лучше, беда в том, что он более формальный и менее живой, чем в тредовичковых миксах на 12б. Но тредовичковые довольно тупые.
Кто-то уже гонял Qwen3-235B-A22B? Твое мнение, анон? На мой взгляд как-то жиденько. В переводы на русский - хуже геммы3, что с английского, что с японского (тут даже хуже). В рп вроде бы неплохо, затупы есть, в куме не совсем соевая. Но пока не могу сказать наверняка, тестил только часа два.
>>1184617 Да, на редите пишут, что на 7955WX работает 3 тс, то есть не юзабельно >>1184651 Запускается. 64 ram уже не особо дорого, просто нужна какая нибудь MoE параша, чтобы на проце нормально работала
>>1184663 >Да, на редите пишут, что на 7955WX работает 3 тс, то есть не юзабельно И это странно, потому что активные эксперты в 4 кванте всего 11 гб занимают. Будто что то неоптимизированно под мое. Потому что та же плотная модель в 11гб выдаст токенов 6
>>1184652 >Но хоть русик у них и значительно лучше, беда в том, что он более формальный и менее живой, чем в тредовичковых миксах на 12б. Но тредовичковые довольно тупые. Ну нет, для 12В там не то, что всё хорошо, а прямо отлично. Даже не верится что всего 12В.
>>1184049 → А может дело не в Synthia-S1-27b а в карточке? Первый раз такую забористую шизу вижу. Там дальше ещё забористее, но ограничения аутпута прервали поток.
>>1184718 подведём итоги: Модели уменьшаются в размерах и ускоряются. За последний год интеллектуальных прорывов нет, ризонинг посути вшитый промпт "думай шаг за шагом в таком стиле..." Данных брать не откуда. Синтетика ухудшает модели. За три года ни одного прорыва, кроме никому ненужных n8 агентов для частных случаев.
>>1184727 Да я уже потёр эту шизу. К слову шизеет в каждом втором случае. Может микс английского с русским в описании так интересно влияет? Или жесть в описании карточки ломает модели?
>>1184651 2 по 3090 вполне себе подъёмные и размещаются в любом нормальном корпусе. >>1184663 >просто нужна какая нибудь MoE параша Мое параша сама по себе параша, лол. >>1184707 Адепты обновлений вечно страдают. Сижу на дровах, которые сама шинда ставит, на остальное строго похуй. >>1184727 >Скинь текстом Не уметь кидать картинки в яндекс в 2025-м...
>>1184590 Прогорклый жир >>1184721 Да синтия норм, по-своему припезднутая, по-своему уникальная. Тут у тебя какая-то классическая поломка ллм с ошизением, поломанный квант или баганый бэк. Даже не представлю как можно довести до подобного промтом. >>1184746 > 2 по 3090 вполне себе подъёмные и размещаются в любом нормальном корпусе. > Мое параша сама по себе параша, лол. Двачую
>>1184746 > 2 по 3090 вполне себе подъёмные и размещаются в любом нормальном корпусе. >>1184748 И какой квант вы собрались запускать на 48гб врама? Хз, стоит ли оно того вообще
Да и для других задач такое железо не нужно, разве что для 4к игр. Технически - консумер хардвер, да. Де факто - хз, как будто будет интересно только профессионалам 3дшникам и прочим
>>1184751 > И какой квант вы собрались запускать на 48гб врама? 4-5 бит, стоит. > Да и для других задач такое железо не нужно Мир нейронок, машинлернинга и ии простирается далеко за пределы кума на локальных ллм, везде нужны гпу. > как будто будет интересно только профессионалам 3дшникам и прочим Типа да, в большинстве это действительно для энтузиастов, нердов, задротов, специалистов, странных людей и т.д. Считай что такое технохобби, которые для некоторых перекликается с профессиональной деятельностью.
>>1184751 >И какой квант вы собрались запускать на 48гб врама? 4,25bpw 70B в две карты влезут. Плюс хороший контекст. Другое дело, что как бы Ллама 3.3 70В последней не была.
>>1184776 >Лама 70б не заметно лучше геммы 27б. По уму их можно сравнить, вот только на Лламу есть куча тюнов и мержей. И есть хорошие. Ну и количество параметров иногда решает.
Попробовал Qwen3-14B-Q6_K Думает интересно. В рп не умеет, постоянно ишет за юзера, но вот в сторителлинге от третьего лица неплох. Хотя по сравнению с той же геммой... меня не покидает ощущение наёба.
>>1184721 ебанутые настройки сэмплера / промта, я такую шизу ловил только на в хлам поломанных и/или уквантованых мержах мистралек, (и моделях Давида) хз что надо делать с геммой чтобы её так поломать
>>1184776 Довольно спорно, хоть и гемма является по-своему жемчужиной. Таки внимание решает, модель больше пишет более тонко и точнее охватывает контекст. Помимо лламы70 есть еще квен72 и немотрон. Ну и никто не мешает катать 6-8бит геммы/qwq/чего угодно с большим контекстом. >>1184780 Не держи в себе, с тебя подробная история пердолинга и перфоманс. 32гига с не самым ужасным чипом дешевле чем сейчас теслы торгуются - вкусно.
>>1184748 Да, поломанный квант. На заполнении к 8к контекста что выдал, шизеет. Тут просто карточка жирная, сразу всплыло. >>1184822 не знаю как 3й, а вот результат 4го выше.
>>1184822 >даже в третьем кванте, ноутбук не вывозит, так что наверно назад на гемму А что за ноут, который вывозит гемму и третий квант командера? Macbook pro на дохуя рам?
>>1184667 я так понял, что у Qwen3 MoE какая-то фигня с архитектурой, они комитили в трансформеров, чтобы оно работало. У кобольда и лламы не юзаются cuda (или пытается юзаться более старая версия), на сколько я понял по issue в гите https://github.com/LostRuins/koboldcpp/issues/1510 (щас уже походу пофиксили, надо чтобы анон с реддита перепроверял там все у себя)
Другое дело, что меня вот любая модель из третьего квена (ну 235б я не пробовал, ладно) не может нормально в РП и все время за меня отыграть пытается. Кроме карточек, где модель выступает не в роли персонажа, а в роли рассказчика, но и там все равно описывает мою реакцию на события, просто реже и чуть больше в тему.
Такое ощущение, что весь третий квен туповат и не может нормально в соблюдение инструкций, короче. А это уже серьезно. Ну или я что-то не правильно делаю, в таком случае надеюсь умный анон мне объяснит где именно я долбаеб (семплеры выставлены по тому что там в модельке у квенов описано, те же самые промпты на QwQ или других моделях работают как часы)
А, и может мне кто-то объяснить, как это, блядь, unsloth упихал 235б в < гиг?
Все игры что пробовал (включая Wuthering Waves в которой многие жаловались на оптимизацию) летают на максималках, на нейронках всё же всего 12 честно-выделенной врам поджимают, приходится контекст в раму выгружать.
>>1184840 Может тебе стоит пользоваться проприетарными моделями? Всё таки тех уровень немножко высоковат, если не получается понять, что модель разбита на несколько файлов.
>>1184877 Нихуя там не разбито, самый умный анончик в треде. Это просто баг и щас этих файлов там уже просто нет. А разбитые на части модели именуются и выглядят по другому, иди понижать средний icq в другом месте
>>1184886 >поделишься семплером? Сейчас так. >>1184887 >все еще лучше большинства мистралей Ну не, омни-магнум-12б, да даже дпо-гемма-27 такой кринжатуры не выдавали, но тут скорее вопрос датасетов (или кванта), да и в сфв рп он вполне ок.
>>1184885 >>1184892 > Ну не, омни-магнум-12б, да даже дпо-гемма-27 такой кринжатуры не выдавали А что ты ищешь в нсфв отыгрыше? В треде то и дело обсуждают цензуру и то, как сухо пишут некоторые модели и тюны. Правильно ли я понимаю, что анонам важны красочные описания? По мне так важнее, чтобы язык разнообразный был, модель креативила и действительно отыгрывала персонажа. Есть там wet pussy lips, hardening nipples или иные графические описания мне и вовсе без разницы. Вкину еще логи Star-Command-R, 4bpw. SFW и NSFW ситуации, в обоих случаях персонажи совсем не уходили от своих определений. Мне кажется, кум модели если и могут в красивые описания, то у них персонажи разваливаются, сводя их к какой-то общей твердой генеральной линии. Каждому свое, конечно, но для меня этот тюн если не круче, то на уровне Snowdrop (в моем случае там примерно такой же уровень NSFW отыгрыша, но менее богатый язык)
>>1184923 Как знал, что обязательно это кого-нибудь триггернет. Похоже, у меня иммунитет, и редкие протекания не напрягают. Это все можно заблочить через logit bias, как, например, рекомендуют это авторы Snowdrop (в их пресете можешь посмотреть). Но имхо падает общее качество аутпута. Это еще один способ лоботомизировать модель
>>1184763 >Ллама 3.3 70В >>1184776 >Лама 70б Ребята, в классе 70В ллама далеко не единственная. Китайцы лепят кучу неплохих моделей в этом размере. >>1184800 >Как его правильно запускать? Через пару недель.
4 токена в секунду с выгрузкой в видяху через ллама.спп
При этом, у меня DDR4, а у знакомого DDR5 и у него 30B инференсится процентов на 50 быстрее, как и псп. Т.е., выгрузка на видяху акивных экспертов тоже зависит от псп, и чем быстрее память — тем лучше инференс, до видеокарты все равно далеко, буст будет.
В итоге все просто: Память побыстрее, видяху одну на 24 гига (3090 уже топич даже для зеонов 24-канальных), и поехал. Для старых зеонов можно подкинуть теслу (один чел в телеге тестил), тоже бустит, аж трехкратно.
И, да, 235 хорошая модель. Действительно хорошая.
> с выгрузкой активных экспертов в врам ну может до 10 Думаю, на DDR5 с псп ~120 будет где-то так, да. Для такой модели скорость уже отличная, ИМХО.
>>1184655 Выше писал. В лоб с дипсиком на веб-задачах сталкивал, Квен даже обошел на одной, нравится. Скорее всего на самом деле хуже в чем-то, каких-то знаний не хватит, но такое очень субъективно и надо ловить. Юзать в переводу 235б модель будто оверкилл, гемма 4-12 есть же.
>>1184718 >>1184723 Вы шо творите содомиты, я бы поперхнулся, если бы пил сейчас! =D
Обсуждать не буду, все умные все понимают и так, за оба варианты мы аргументы знаем. Но хрюканина какие смешные картинки вместе!
>>1185080 >4 токена в секунду с выгрузкой в видяху через ллама.спп Какой квант? 3KM имеет смысл?
Моя конфигурация - 3х3090 + 64гб DDR4 в четырёхканале, на лламаспп должно пойти. Не думал трогать эту модель, но раз такое дело... Там есть параметр, чтобы kv-кэш только во врам был?
имею LM studio, 12600к, 2060с на 8гб, 32гб ддр 5 и нужду переводить англ и яп на русский пока что пробовал все геммы3 от самой нищей до самой жирной, дипсисич и какие то еще хуй помню какие. качество перевода лучшее у жирных гемм, но все еще позорное + ждать строку по 10 секунд приходится. есть какие то специализированные модели? заранее спасибо!
Я тут недавно гнал на Qwen3-30B-A3B мол 11 токенов генерация блаблабла. Это было на куда версии, с -ngl 0. Я думал это не будет влиять на генерацию, ага как же. Скачал чисто cpu сборку llama.cpp с openblas. Генерация от 18 в начале до 15 на 1к контекста, ну и плавно падает. Тоесть понимаете, да? Даже выгрузка кеша в видеопамять замедляло генерацию, я ебу. Фронт съедает так же 2 токена генерации в секунду, о чем ниже.
>>1185338 Нопе, в первом случае кручу барабан в чате таверны, во втором случае кручу барабан в родном фронте llama-server. Фуллгпу даже видна разница загрузки куда ядер, 95% и 60%. Влияние на фуллгпу у меня космическое, чисто на процессоре проверял и там от половины токена в тяжелых сетках, до 2-3 токенов в секунду на быстрых.
>>1185360 Тут кстати уточню для остальных, запуская чисто процессором смотрите что бы эта мразь не отъела всю память, в 2 раза больше чем ей надо. Еще и не запускается от этого, зараза. Если забивает не ~20 гб а все 32+ то нужно врубать --no-mmap На скорость у меня не влияет. Вот собственно разница в жоре памяти на 4 кванте Qwen3-30B-A3B, думается мне что это актуально для всех мое сеток
>>1185400 >Есть другие шизы, что пытаются мин-максить квен? На месте. Пока так Qwen3-30B-A3B-UD-Q4_K_XL.gguf, llama-bin-win-openblas какой то там релиз из последних ./llama-server.exe -t 8 -c 16384 --host 0.0.0.0 -m F:\llm\Qwen3-30B-A3B-UD-Q4_K_XL.gguf --mlock --no-mmap --top-k 20 --top-p 0.95 --temp 0.6 --min-p 0.01
>>1185274 Если ты хочешь нормальный перевод, то иди поплачь. На локалках его нет.
Коммерческие не локальные модели переводят хорошо в том плане, что смысл понятен, но даже они гадят абсолютно всегда. То есть перевод нужно совершать с множеством итераций и контекстным окном большим.
>>1185400 Ты хоть скорости скринь, будет с чем сравнить.
Не вижу у тебя слоев, если без гпу крутишь то убирай --flash-attn, он тормозит. Так же не вижу смысла квантовать кеш, он и так мелкий и мое чувствительно к нему, ответы хуже. С количеством ядер поиграйся, либо равное физическим либо -1, с гиперпотоками можешь указать в обработке промпта в БЛАС треадс А еще у меня свежий кобальд медленне чем чистый llama-server, вот так вот
>>1185539 А так это количество экспертов было, понял что за строчка. У меня так -t 8 -tb 16 , второе с гиперпотоками. Дает прирост обработки промпта на 20 процентов, если сделать все 16 то генерация даже меньше на 1 т/с Да я вспомнил, для квантования кеша нужен -fa, а с ним медленнее
>>1185419 ну условная геминя 2 и 2.5 очень даже неплохо переводит, если после нее пройтись слегка ручками - никто и не поймет, что это аи переводила. в моем случае совсем не страшно, если она будет иногда терять контекст или ошибаться, но конечно не с такой частотой, которую выдает гемма/дипсик. надеялся, что есть специализированные небольшие модели под перевод - разве нет?((((
>>1185637 имеет право на жизнь, но под рп как-то не очень. Уж не знаю как тут у пары анонов что-то получалось, но у меня третий квен хуево соблюдает инструкции, всегда хочет за меня отыграть. Хотя вот в задачах рассказчика получше, но все равно будет пытаться за игрока спиздануть или хотя бы описать реакцию. В куме особо не тестил, но сам начинать активно сопротивляется, даже если карточка обязывает.
>>1185609 Качество перевода зависит от того, какой там языковой датасет и насколько модель в целом умная. До 120b — это тупорылые огрызки в плане более-менее серьезных переводов.
А если уж там какой-то серьёзный и потный перевод, то надо модели задавать контекст, объяснять, в каком стиле переводить и что происходит. А потом переводить раз за разом с контекстным окном 120к, чтобы оно помнило нить и понимало, что вообще происходит.
Это касается как каких-нибудь медицинско-научных статей, так и литературного перевода. Огрызки такое не вывозят, пусть они и значительно лучше кала типа дипла, гуглопереводчиков и подобного.
>>1185659 У меня МоЕ-версия не особо проблемная в куме, просто сухая. И за меня не говорит.
Главное использовать ризонинг — иначе пиздец. Он вообще не будет вдуплять, что происходит, а вот с ним отлично справляется... Как 12b, только которая в трусах не путается и позах.
Другое дело, что ризонинг можно прикрутить и к 12b, но там надо адски мозги себе ебать: найти модель, которая может в самый сок, не игнорирует контекст в нулину и при этом слушается, а ещё её цепочка рассуждений не протекает ответ или ответ прям в цепочку.
>>1185665 тестил все 8-32б в рп, у всех одна и та же проблема, что MoE, что dense, у всех буквально одна и та же проблема с понимаем промпта. Мб дело в кванте, кстати, везде тыкал четвертый (K_L для 8-14б и K_S для 30-32б). Да, без ризонинга в принципе даже не пробовал, семплеры ставил рекомендованные
Кванты Квена 3 могут быть сломаны сейчас. Многие пулл реквесты еще не замерджили в лламу и другие инференсы. К тому же токенайзеры могли не завезти подходящие. Вы куда так спешите? Подождите неделю-две, и многое станет ясно. Как будто ни разу не видели такого, лол.
>>1185663 > пусть они и значительно лучше кала типа дипла, гуглопереводчиков и подобного могу поспорить - геммы3 до 12б включительно выдают лютый хуйняк, даже гуглотранслейт лучше бы справлялся >то надо модели задавать контекст, объяснять, в каком стиле переводить и что происходит гемини с пустым промтом выдает очень неплохое качество, сама определяет пол по японскому имени, понимает место, правильно локализует нужные слова. повторюсь, мне не нужен идеальный дословный перевод, вполне хватит качества лучшего чем условный DeepL
>>1185360 > Qwen3-30B-A3B Нахуй ты вообще это говно крутишь? Дядя ляо жестко обосрался, квен3 тупой и скучный, много лупится, в рп пишет как робот сука, гема соевая, вернулся на мистрали
Третьего дня, по совету рандомных камрадов, откачал два новых мегадевайса —Forgotten-Transgression-24B и MS-Nudion-22B в Q4_K_M, как полагается. Сразу же, задыхаясь от жадности, вскрыл модельки цепкими лапами и заюзал мегадевайсы. Размер, моё почтение. Настоящей глыбой были ЛЛМ. Даже моя, привыкшая к суровым будням, 4060 Ti 16GB, отказывалась принимать с первого захода. Совместными с Kobold усилиями забороли проблему. Ощущения — АТАС. С Gemma 2 не идёт ни в какое сравнение. Кроме того, конфиг Mistral-V7-Tekken-T приятно щекочет фантазию персонажа. Проходил так пару часов с подключенным XTTS2.
Не знаю на чём сделана Nudion, но она мне показалась приятней и объясню почему. Forgotten (Мистраль?) абсолютно не самостоятельная, без остановки срёт фразами "да-да, сделаю всё в лучшем виде, будем и то делать, и это, уже готова, вот-вот приступим, только расскажи как именно хочешь" и так бесконечно. Чем-то похожим страдала Гемма 2. А в этой Nudion такого нет, она просто берёт и пишет. И в целом разговор нормальный. Как будто не с ассистентом общаешься, а с человеком неохотно отрабатывающей проституткой, которая говорит с тобой за деньги. И лучше я пока не видел. Кто пробовал эти две, согласны? Или может даже пробовали их и можете предложить модель или конфиг ещё лучше?
>>1186073 На пасту хрюкнул >4060 Ti 16GB Братик >отказывалась принимать с первого захода Как раз таки мистральчики и их тюны в 16 гб нормально входят как по маслу. А вот квен и гемму приходится смазать Q3, чтобы поместились >предложить модель или конфиг ещё лучше Анон выше советовал. https://huggingface.co/PocketDoc/Dans-PersonalityEngine-V1.2.0-24b А я сам на форготене кумлю
>>1186096 Не грусти, анон. Сейчас у тебя как минимум есть 3 хороших модели. Gemma3 12b, Qwen3 14b и Phi 14b. Все это отличные модели и все их ты можешь запустить с хорошим квантом и контекстом
>>1186098 не, лучше iq3 от 22b с чуть убавленной температурой, чем эти огрызки по крайней мере, несколько месяцев назад они проигрывали по всем параметрам
>>1186103 А ты уверен? 22b это вроде старый мистраль, да? Он хуже старшей геммы и квена. Я не тестил, но я почти уверен, что на говенном кванте он будет хуже новых младших моделей на нормальном кванте
>>1186090 30b все таки пизже, больше знаний впихнуто, быстрее крутится, минусы - размер, мозги размазаны, на 30b не тянет Тоесть обмениваем размер на скорость 14b медленнее, меньше знаний, но все мозги сразу и меньше размер Мое мне лично больше нравится, потому что скорость генерации для меня главнее А так в среднем они равны как и сказали реддиторы
>>1186107 Да, вроде на базе мистраля все мои любимые модели. Ладно, спасибо за инфу, попробую, хотя не ожидаю, что без файнтюнов они смогут заменить мою подборку.
Хотел обосрать мистраль с прикрученной думалкой, но новый квен 32 примерно также ответил. Только язык сразу подхватил, что у него тоже бывает не всегда Хотя dolphin все равно кал, он скорее днищит мистраль, а не улучшает его
>>1186209 2.5 32b или QwQ, если выбор из квенов. Третий квен пока неюзабелен нормально и, возможно, что дело в квантах. У них там новая архитектура, короче, и оно просто тупое и хуево соблюдает инструкции. А может дело не в квантах, но на фулл весах кто тут сможет запустить и проверить? Чет не видел чтобы хоть кто-то сравнивал
>>1186317 для генерации картинок прямо в фронтенде для ролевой игры? нет для генерации картинок вообще - ComfyUI, очевидно тебе в другой тред, для картинкогенерации, там подскажут все
>>1186320 Не для ролевки, а вообще. Согласен, что туда надо было писать, я промахнулся, но все же кобольд здесь даже в шапке прописан и я хотел посоветоваться с аноном стоит ли использовать его как основной инструмент. Ну и comfyui у меня в репах нет, из-за пределов реп что-то ставить и поддерживать я оч не люблю.
>>1186333 > использовать его как основной инструмент. Основной инструмент для чего? Для генерации картинок? Нет. Для загрузки LLM моделей? Может быть. В зависимости от твоих потребностей и возможностей. Кобольд популярен как самое простое решение, вместе с тем, возможно, он наименее производителен.
> Ну и comfyui у меня в репах нет, из-за пределов реп что-то ставить и поддерживать я оч не люблю. Хз, о чем ты говоришь вообще, но лучше ComfyUI для картинкогенерации ничего нет.
Мое сетки надо на этом проверить. Скорости растут в разы, по крайней мере в обработке контекста, но там релизов нету. https://github.com/ikawrakow/ik_llama.cpp Кто собирать умеет?
>>1186352 Голая llama.cpp, Exllamav2 (без оффлоадинга, только врам). Даже ненавистная LM Studio быстрее Кобольда, пару десятков тредов назад было обсуждение и логи генераций.
>>1186381 Сэмплеры фикси. Слишком жесткий rep pen, dry, xtc, много logit bias, а если все вместе - тем более пиздец, там и грамматические ошибки могут просачиваться, и пробелы срезаться.
>>1186209 А если есть Qwen3 32b, то зачем остальные? Хотя он может проседать без ризонинга. Но тебе зачем? Для работы? Тогда Qwen3 32b с ризонингом бери. Но QwQ тоже неплох, можно его.
>>1186333 Кобольд не имеет ничего общего с генерацией картинок. Он это делает для РП в его фронтенде, не более. Тебе нужен ComfyUI (только он, интерфейс говнище, зато поддержка всего и вся в первый день, не будешь себе ебать мозги и ныть «кагда мине дадут модельку!.. как запустить!..» сидя на нишевых, но красивых софтах, которые нахуй никому не вперлись, к сожалению), Кобольд — для текста.
>>1186381 Выставить нормальные семплеры и использовать нормальный бэк? Вот не просачивались у меня почти нигде и никогда. Все, у кого иероглифы встречаются часто — юзают говно и скилл ишью, тут рил ничем не поможешь, если человек сам заставляет квена генерить кучу иероглифов.
Бля, не могу разобраться как сделать папки для персонажей в списке в Таверне. Типо категоризировать их для удобства, а то их немало уже набралось. Типо кум/ассистенты/сфв Где это сделать? Ткните пальцем пж
>>1186434 > Все, у кого иероглифы встречаются часто — юзают говно и скилл ишью, тут рил ничем не поможешь, если человек сам заставляет квена генерить кучу иероглифов. Новички берут сэмплеры откуда попало и многого в них не понимают. На странице Сноудропа отвратительный пресет, который ломает аутпут. Оттуда и все вопросы. Помочь можно - объяснить это.
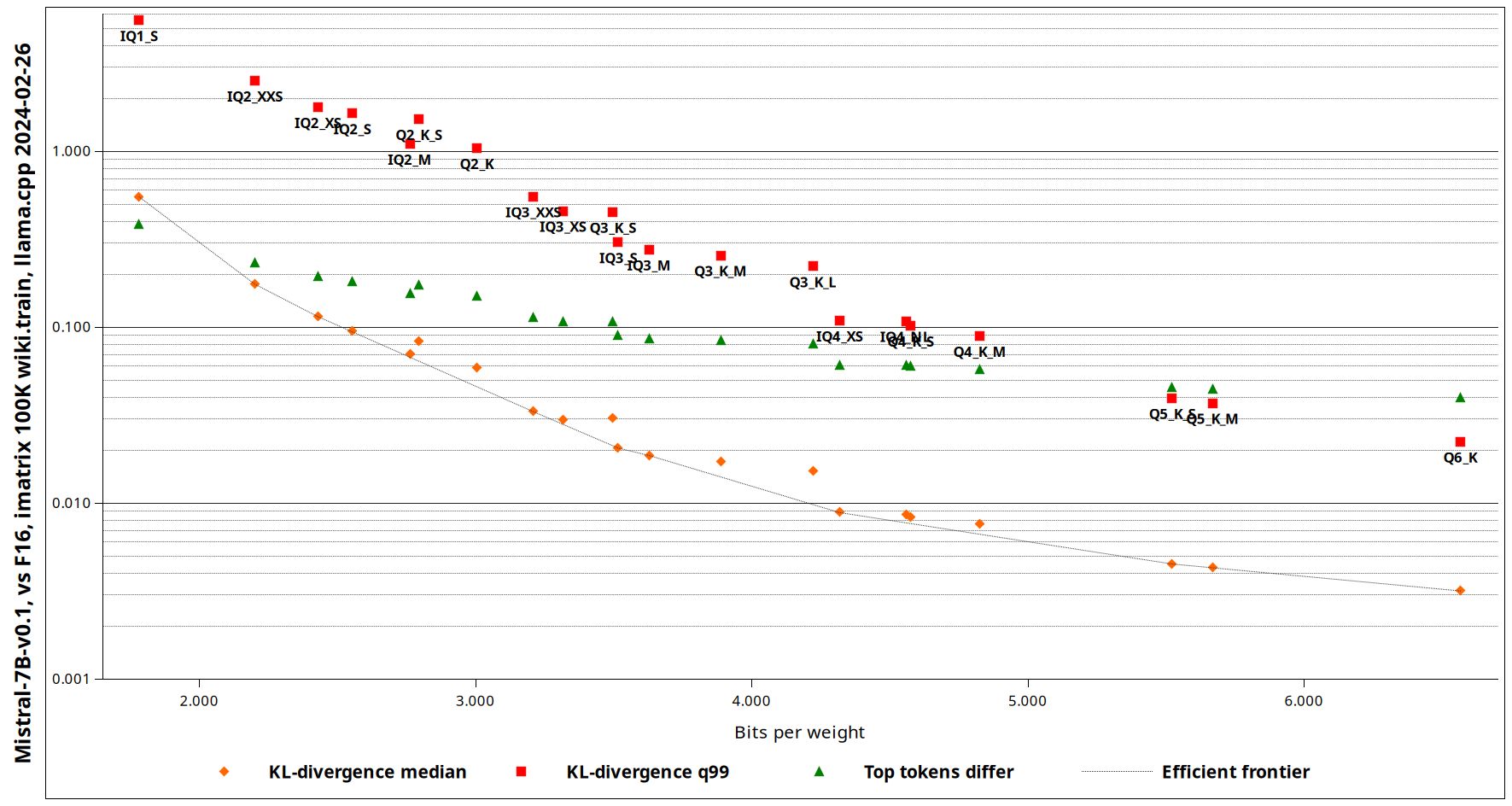
>>1186449 Перплексити не лучший ориентир, надо кв дивергенс смотреть. Если правильно помню это оценка отличия топ токенов в выдаче от оригинала или что то такое. А по хорошему надо не только вывод тестировать но и чтение промта, качество которого тоже просаживается от квантования.
>>1185360 > в чате таверны, во втором случае кручу барабан в родном фронте llama-server. Это не даст никакой разнцы. Скорее просто первый запуск и проперживание, а потом работа на горячую. Что при тесте свайпов таверны в готовом чате, что в пустом жорасерверном, что запросом скриптом - везде одинаковые скорости. Хотя, был тут бедолага, у которого небраузер весь профессор/гпу загружал, возможно у тебя что-то подобное. Что за спеки железа, системы, какой браузер, накручено ли что-нибудь в настройках его? >>1185377 Собери свой фа, оформи вэнв для ктрансформерс и перед самой сборкой собери подходящий. >>1186273 Потому что кобольд - в первую очередь обертка llamacpp. Костыли на формальную поддержку чего-то еще это, конечно, хорошо, но они совершенно ужасны и не функциональны лучше бы вишпер сделали. Для запуска графических моделей стоит использовать полноценные интерфейсы, заточенные под них.
>>1186457 Спок, Руди. Включи немотрончика своего, запихни его себе в очко и кумь. Нормальные люди подождут неделю-другую, пока все починят и будут кайфовать.
>>1186452 > Если правильно помню это оценка отличия топ токенов в выдаче от оригинала или что то такое. Это взвешенная характеристика отличий в распределениях, действительно наиболее удачный вариант метрики. Правда он не покажет возможной шизы модели, бывают варианты где средние оклонения низкие но регулярно присутствуют крупные всплески, особенно сильно на жоре наблюдалось.
Знаете что я понял, если и есть профессия которую LLM убьют одной из первых, то это психология. Сейчас у меня скажем так не самый легкий период жизни и я поймал себя на том как легко мне общаться с моделью, главное задать промт что бы она вела себя как специалист, а не просто поддакивала игнорируя неудобные моменты, и внезапно она ведет себя очень похоже(имею опыт) на реального "психолуга" только к машине куда больше доверия чем к очередному "5к за сеанс". В прекрасное время мы живем.
Хотел с локальным переводом в таверне поиграться через новый плагин, а эта хуйня с ошибками что то шлет на сервер. Ебануться и залезть в код или забить?
>>1186464 ЦА мушоку тенсея во всей красе: "глм 4 после фиксов все еще говно, значит квен 3 тоже будет говном" Поздравляю, ты 0.6б модель
>>1186469 Главное, никакие препараты не принимай из тех, что тебе могут порекомендовать. Как психологическая помощь - вылить душу и получить какой-то "ответ" - работает, да. Только КПТ, только вербальная терапия.
>>1186469 Если тебе просто выговориться надо то да, в остальном нет. Хороший психолог (а лучше психотерапевт) это прежде всего специалист, который использует разные методики, оценивает твое состояние и может в случае чего выписать таблетки или порекомендовать лечь в дурку А ЛЛМ это в основном генератор шизобреда. Возможно есть специализированные ЛЛМ именно под психологию, но я таких не знаю Так что не обманывай себя, иди к психологу, пока не одурел еще больше Хотя если ты на дваче сидишь, то возможно уже поздно
>>1186480 Найти хорошего психолога очень сложно. То, что ты описал - картина за розовыми очками. Как человек, который побывал у нескольких таких, я уверен в том, что говорю. Не забывай, где мы живем. И никто не отменяет тот факт, что они тоже, прежде всего, люди. Мне попадались и те, кому буквально похуй на мои проблемы, и те, кто после двух минут разговора уже все решает для себя и дальше просто дает выговориться, чтобы в итоге пропустить это все мимо ушей и озвучить свой вывод. Все это стоит денег и сил. Так что я согласен с аноном, что выговориться ЛЛМке - хороший способ. Скорее всего, отправившись к психологу (даже изучив отзывы и мнения на всех площадках), человек либо попадет на деньги, либо сделает себе хуже
Психотерапевты - это вообще пиздец. Они сразу прописывают таблетки, которые большинству людей не нужны, и это только усугбляет ситуацию
>>1186477 Само собой, препараты это уже психотерапевт и рецептура, туда никаких психологи доступа и так не имеют. Но вот выслушать, провести сухой анализ ситуации и подсказать где я, мясной мешок, объективно заблуждался она может очень хорошо.
>>1186480 У меня проблема больше в том что эмоции могут застилать рациональность, и я не вижу очевидного. Тут не шиза уровня дурки, все ок. Скажем так, 3 года назад я перенес похожий пиздец это пользуясь только самостоятельной рефлексией, и это было очень долго и тяжело. Ощущения в сравнении с сейчас неба и земля.
>>1186469 Да врядли, большинству нормисов наоборот будет проще с кожанными, только если самых низких шарлатанов. Лучше бы риелторов и перепуков наебнули, вот где истинный рак. Хорошо что тебе помогает нейроночка, тред несет добро. >>1186477 > глм 4 после фиксов все еще говно Да уже за это можно обоссать. В нормальных моделях стабильно находят сою (наверно потому что безумно траят одинаковую херню в надежду на реакцию как когда-то срандомилась в шизомердже), получают лупы в не склонных к этому, удивляются "странному вниманию", зато нахваливают мое с 0.6б активных. >>1186485 Двачую. Большинство психолухов, которые ведут подобие практики, глупее среднего местного, не могут подметить подмечатель.жпг лол важные вещи и в логику причинно-следственных связей, а просто посоветуют тебе временное облегчение по методичке. Или просто послушают и "ну давай братишка, займись спортом и открой для себя что-то новое, а там организм сам вылечится".
>>1186485 Понятно, что психолог может быть похуистичным профнепригодным уебком. А может быть хорошим специалистом. Тут приходится выбирать. Но ЛЛМ в принципе лишена этих качеств это просто генератор текста, довольно хуевого зачастую.Если ты выбираешь ее вместо специалиста, то это полный пиздец, который может угробить тебя Максимум ЛЛМ сейчас могут использоваться как помощники для специалистов, вроде прогеров или даже врачей. На этом все, остальное хуйня и самообман >прописывают таблетки, которые большинству людей не нужны, и это только усугбляет ситуацию В РФ почти все действующие таблетки забанены. Так что наркоту или что то жесткое тебе никто не выпишет а жаль
>>1186494 Самое умное что доступно на моем сетапе, в моем случае это 27 гема. Но сейчас думаю для редких разговоров не зазорно и к корпам податься просто ради максимально адекватного русского, если рпшить или делать какие-то рабочие задачи мне и на англ. норм, то в таких вещах хочется чтобы модель лучше обрабатывала нюансы которые я физически только на родном языке передать смогу. Да и нет в этом ничего зазорного или того что стоит прятать от товарища майора.
>>1186434 а регулярка влияет на разрешённые символы или просто режет оутпут? >>1186437 Вот кстати да, есть подобный разбор настройки семплеров? Такое ощущение что все проблемы от них.
>>1186499 > Понятно, что психолог может быть похуистичным профнепригодным уебком. Именно в этом и проблема. Таких - большинство
> Но ЛЛМ в принципе лишена этих качеств это просто генератор текста, довольно хуевого зачастую.Если ты выбираешь ее вместо специалиста, то это полный пиздец, который может угробить тебя Скорее грустного человека убьет профнепригодный уебок на специалисте, чем безобидная ЛЛМ. Человек, расписывая свои проблемы, сам переосмысливает какие-то вещи. И в ответ гарантированно получит какое-то подобие поддержки и понимания. При желании с ЛЛМ можно обсуждать КПТ и другие аспекты вербальной терапии. Как это может навредить? Это куда безопаснее мудака на психологе, который может легко добить отчаявшегося человека, который пришел к нему за помощью. Своим безразличием, жаждой растянуть терапию ради денег или опрометчивыми выводами
> На этом все, остальное хуйня и самообман После десятка психологов и двух психотерапевтов я выбираю "самообман" - он помогает мне привести мысли в порядок и понять новые для себя концепции терапии
> В РФ почти все действующие таблетки забанены. Так что наркоту или что то жесткое тебе никто не выпишет Может выпишут таблетки полегче, да и неважно какие - они станут для уязвимого человека психологическим спасением. Он будет думать, что таблетки ему необходимы, когда в большинстве случаев это не так
Либо у тебя не было плохого опыта в этой сфере, либо ты просто не знаешь, о чем говоришь
>>1186499 > Если ты выбираешь ее вместо специалиста, то это полный пиздец, который может угробить тебя Это действительно полный пиздец, который хорошо характеризует ситуацию на рынке этой области. Что сраный генератор текста лучше и может помочь больше, чем типичная тп или нетакусик после тренингов. И в целом, ллм действительно может быть более проф пригодной и внимательной чем не крутой опытный специалист, который еще не выгорел нахер и не работает по шаблону. Ллм более того, еще и достаточно осторожны и деликатны, разумеется не шизорпмиксы а нормальные. >>1186506 Двачую > Он будет думать, что таблетки ему необходимы Знаю такого человека, это реально пиздец полный
>>1186506 >>1186538 У меня нет бед с башкой, так что я не был у психолога. Но у меня в универе было несколько курсов про ИИ, включая ЛЛМ. Так что я знаю, что ЛЛМ это просто генератор парашного текста. Но если он вам помогает лучше врача, то ок Возможно при входе в кабинет психолога, он сразу начинает ссать вам на ебало, тогда ЛЛМ действительно будет возможно получше
>>1186540 Ведешь такой нормальную беседу, а потом внезапно подрываешься потому, что с тобой не согласны. Проблема в том, что психологом может оказаться долбаеб вроде тебя. И да, именно поэтому ЛЛМ безопаснее
>>1186540 > Так что я знаю, что ЛЛМ это просто генератор парашного текста. блииин ты такой умный мы-то без курсов по ллм не знали, что это предсказатель текста думали, там сидит маленький умный ии-разум и пишет нам ответы
>>1186542 >потом внезапно подрываешься Неа, мне просто похуй >психологом может оказаться долбаеб вроде тебя Неа, не может, я не настолько долбоеб, чтобы идти в психологи >поэтому ЛЛМ безопаснее Генератор случайных слов с огромной порцией соевости и позитивности, вроде геммы, действительно может быть безопаснее Но лучше бы ты сходил и полечился
>>1186540 У меня были/есть беды с башкой, так что будучи достаточно прошаренным чтобы решить их или нет я не был у психолога. Но знаком с несколькими кто себя так называет, а также несколькими пациентами подобных - в большинстве это вредительство, в лучшем случае временное скрытие симптомов вместо осмысления проблемы и ее решения. Очень плохо что люди много о себе мнят, но при этом даже в простой беседе не могут подвести обоснование своим утверждениям, имеют резкие убеждения в социальной сфере, которые не стесняются грубо высказывают, или просто не могут проявить достаточную гибкость для каких-нибудь активностей, типа ролевок/мафии. > в универе было несколько курсов про ИИ, включая ЛЛМ. Так что я знаю, что ЛЛМ это просто генератор парашного текста. Это очень абстрактные и устаревшие данные, текущий "генератор текста" набирает больше баллов в тестах разного уровня профессиональности, и может являться очень мощным инструментом в руках специалиста, или того, кто может их юзать. Или средством терапии, уже во всю делаются статьи с исследованиями на эту тему.
>>1186548 > Неа, не может, я не настолько долбоеб Похоже, все-таки настолько. Тебе много раз сказали, что ЛЛМ полезна для саморефлексии в процессе взаимодействия, что это работает почти как блокнот мыслей в КПТ. Но ты это игнорируешь, нихуя в этом не понимаешь и продолжаешь повторять единственное, что ты запомнил на курсе по ЛЛМ. Так что, если ты не и не долбаеб, то просто глупый
> Но лучше бы ты сходил и полечился Спасибо, работаю над этим. Ты тоже работай над своей агрессией и/или глупостью
>>1186571 Синтия, или полюбишь, или возненавидишь, или сразу вместе. > Fallen Gemma норм? Попробуй, может быть ничего. >>1186572 Но он прав. Ты сначала оформить тейк про > просто генератор парашного текста в контексте, который подчеркивал бесполезность этого. А теперь уже перекатываешься и хочешь оправдать все свои суждения тем, что основной продукт генерации ллм - текст. Ну херня же, в этом треде такие маневры не прощают.
>>1186578 >в контексте, который подчеркивал бесполезность этого Хуйня, нигде не говорил о бесполезности. Парашный просто оценочное суждение, которое говорит о том, что генерированный текст зачастую оставляет желать лучшего >>1186575 Продолжаешь рваться, сучка
>>1186582 Даже в этом посте имплаишь, а там вообще все прозрачно. Это можно понять, ведь ты или сам как-то причастен к теме, или восхищаешься людьми, которые там витают. Из-за чего воспринимаешь в штыки плохую среднюю оценку, а способность ллм приносить пользу там даже большую чем паразиты костью поперек горла. Если бы шарил - сам бы хейтил этих долбоебов. В ллм тоже не соображаешь, о чем сам говоришь, но зато делаешь утверждения.
>>1186583 >Это можно понять, ведь ты или сам как-то причастен к теме, или восхищаешься людьми, которые там витают. Из-за чего воспринимаешь в штыки плохую среднюю оценку, а способность ллм приносить пользу там даже большую чем паразиты костью поперек горла. Если бы шарил - сам бы хейтил этих долбоебов. Таблетки прими
>>1186503 Честно скажу — не знаю, я просто в одном чатике схватил такое решение по квену у человека, которому эти символы не нужны. Но насколько оно корректно работает — надо тестить, а я не планирую. Мое дело поделиться.
>>1186600 >Я просто оставлю это здесь... Пересказ среднего значения выведенного из 100500 просканированных за 5 минут любовных романов, написанных за последние 300 лет, и сохранённых в сети.
>>1186600 >это Вот как ты отличишь, - это новая генерация, или это средневзвешенное значение взятое из 1000 000 любовных романов, которые робот просканировал в сети и сохранил в своей базе? - Никак не отличишь. Для этого надо самому прочитать все эти романы, и запомнить их, чтобы потом подловить нейросетку на каком-то палевном плохо отрерайченном предложении или абзаце.
>>1186657 Ты ж учти, нейросеть просканировала все тексты мира, которые есть в сети. И если кто-то запрашивает у неё ролевую игру на тему любовных отношений - то это база называется: все любовные романы мира, которые нейросетка просканирвоала. И она оперирует данными из этих текстов, например методом рерайтинга. Ну рерайт статей для сайтов ты же слышал как делается? Это замена на синонимы и пересказ исходника похожими словами.
Это легко проверить на технических темах, нейросетка ничего нового не придумает, не изобретёт. Она будет пересказывать заменой слов (рерайт) то что уже есть в её базе. Просто у неё огромная база и выборка (типа случайность) происходит в широком диапазоне по данным потому что есть из чего выбирать. Но если сузить данные, с любовных романов до научных каких-то узкоспециальных знаний, то уже будет заметно что нейросетка будет делать повторы, и специалисты могут подловить её узнав откуда она взяла тот или иной кусок абзаца или предложения и пересказала его методом рерайта.
Ок, благодаре реддиту настроил чтобы эта хуйня(квен3-32B) не лупилась и даже выдавала что-то адекватное на русском. А теперь вопрос на миллион. Как отключить этот ебаный синкинг?
>>1186719 Даже 64 гига будут сосать хуй. Локалки сосут и будут сосать корпам всегда. Единственное новые локалки уже ебут годовалые корпы Но в любом случае их суть в тюнах и приватности. Я не хочу чтобы товарищ майор читал мой кум.
>>1186736 Не будут, уже научились умещать 32б в 16 гигов, значит и в 8 научатся. Настанет день, когда модель с мозгами от 600б модели будет влезать в твой смартфон. А пока сидим на облачном хуйце и терпим.
>>1186748 Особо смысла в этом нет. Как это будут юзать? Абсолютно никак и всем будет похуй. Вроде бы сейчас доступ к инфе (в целом имею ввиду) доступный как никогда раньше и толку? Так и тут, люди даже не будут знать и понимать как пользоваться таким йоба-инструментом.
>>1186753 >>1186760 Копиум локальщиков. И кста R1 там тоже есть, как и немотрон и старший квен 235. Так что увы локалки сейчас не имеют смысла, пока есть опероутер
Ну штош, высрав 3к контекста на охуительный синкинг, квен таки решил правильно классическую головоломку с волком козой и капустой лисой, кроликом и морковкой.
>>1186775 Так мне ничего делать не надо. Оно само развивается. Мне достаточно не быть ебанатом-гейткипером или нитакусей которая жрет говно при наличии лучшей альтернативы..
>>1186773 штаны сними, перед тем как срать. Который тред уже срешь сюда об этой залупе. Видимо он на столько хорош, что ты его не трогаешь, а тут воздух портишь
Разумеется имеют, они же локальные и не отсылают твой кум непонятно кому и помещаются в одну 3090/4090, которая и так должна быть у любого уважающего себя человека в 2025 году. А вот смысл в ригах действительно отпал в последнее время, все 70-100В тихо умерли, а запуск 400-600В просто реально не стоят своих затрат.
Тоже отчитаюсь. Пришел 60см прямой райзер вместо углового. Из плюсов - соответствует спекам, 4.0 16х держит ваннаби амазон - 970vaXG. Из минусов - всё равно не удалось поставить карту на 1 слот ниже, чтобы нижняя планка была в 1, а не в 2. И это ограничивает это место 3-этажной картой, увы. Корпус кромсать не хочется. Приходится терпеть в итоге в главном слоте самую дохлую карту.
>>1186773 > локалки сейчас не имеют смысла, пока есть опероутер Что несет этот копиумный гой, это новая методичка обладателей отсутствия? >>1186783 Мадока - бутлег или так зашакалило?
Пиздец, в квен вообще цензуру не завезли, никакого аблитерейтеда или джейла не использую - гемма бы уже визжала как свинья, а этому поебать вообще. Сам текст что он сгенерировал показывать не буду, покажу только синкинг.
Помогите нубу. Мне нужен ИИ-ассистент для разных задач, помочь разбираться в общих темах. Для себя. Программу тренировок для себя составить, мб по меню питания вопросы задавать. Насколько полезен ли продукт и можно ли его отнести к конкретной диете. У меня 24гб видеопамяти. Можно ли такое на локальном ИИ сделать? Гемма 3 27 подойдёт? Или с таким только большие веб ассистенты помогут? Спасибо тем, кто ответит.
>>1186804 Что за райзер? > амазон - 970vaXG Не находит ничего. 5.0 режим пробовал? у тебя же вроде есть чем А что установке мешает, непонятно окружение. И почему на х16 самую дохлую, не понятно.
Насчет райзеров - удобный и качественный https://aliexpress.ru/item/1005006752061032.html но оче большая плата где разъем может ограничить варианты установки в узких местах. Зато выполнен хорошо, легко изгибающаяся змея вместо кучи шлейфов, которые при изгибе резко сокращают доступную длину, может в 5.0. >>1186812 > на уровне дипсика С каких пор копиум стал эталоном? Да и клод подсдал, сойнет заебумба для кодинга и все, опус все еще душевный, но уже подустарел и под жб деградирует.
>>1186785 это две материнки btc79x5, купленные с авито. На каждой стоит mellanox connectx-4 lx. Связаны оптой. Я буду сейчас ковыряться с мелланоксом, проверять трупут и в идеале запущу распред на 6 карт по 3 на каждой матери. >>1186805 >Мадока - бутлег или так зашакалило? не знаю, не шарю.
А почему нет, если это улучшает качество ответа и предотвращает залупы? Скорость позволяет, контекст не засирается благодаре фильтру в таверне, отображение этого синкинга можно просто спрятать.
>>1186825 >в идеале запущу распред на 6 карт по 3 на каждой матери. Там это, анон выше по треду привёл аргументы, что риги не нужны. Квена 32В хватит всем.
>>1186825 > не знаю, не шарю. Привезена, заказана в фирмовом магазине до ковида, здесь по месту задорого - орига (скорее всего). С алишки по акции, на озоне по цене двух шавух - бутлег. Ну и по качеству видно, одна будет аккуратная с минимальными косяками, швами приятная на ощупь и т.д., а вторая - крипота с подтеками литья, браком покраски и т.д. >>1186830 Хз насчет третьего квена, но в остальных оно не улучшает ответы. Повторение всех инструкций, рефлексия, подробный анализ по несколько раз, чтобы в итоге дать ответ пигмы.
>>1186823 > Что за райзер? > Не находит ничего. Это же ссылка была, не код товара ozon ru /t/970vaXG
> 5.0 режим пробовал? 5.0 чёт не пробовал, т.к. только 3090 втыкал в него. Более новые карты не трогал, не хотелось шатать лишний раз их несчастный vhpwr'ы. Но не думаю, что 5.0 было бы хорошо - ловить рэндомные фризы, да и смысла от него нет же вроде.
> А что установке мешает, непонятно окружение. Это вертикальный-вертикальный кронштейн из кита-расширения. Недостаточно широкая щель в корпусе для кабелей и недостаточная гибкость самого райзера на единицу длинны мешает передвинуть сам райзер ниже, чтобы он стал в плоскости с (1). Это дало бы поставить туда карту на 1 слот ниже, т.е. 4 слотовую. Если сейчас туда ставить 4 слотовую, то она торчит на 8мм на плоскостью мп и мешает вставлять карты в мп.
> И почему на х16 самую дохлую, не понятно. Потому что она 3 слотовая. Остальные 4 слотовые. А вставить райзер в мп можно только в главный слот, остальные либо используются картами, либо ими же перекрыты. Я уже как только не крутил, никак другой слот под райзер не выделить. Йехх
>>1186835 >риги не нужны а, ну раз анон сказал, то пойду выкину все железки для локалок которые уже успел купить за полтора года >>1186837 брал в аниме магазине, я не знаю откуда и мне все равно, на вид нормальная
кто такой вам квен 32б? Очередной аналоговнет вмещающийся в 24 гб и рвущий дипсик? Сколько уже таких было... вопрос серьёзный, я больше месяца в треде не был в последний раз как я тут был все ссали кипятком от геммы3 и шутили про то, что фанаты геммы все поняли...
>>1186823 > Насчет райзеров - удобный и качественный Забыл ещё дописать - крутой, спасибо. Но для меня не пойдёт - но 38см, надо мин 55, и плата большая - как раз ищу с маленькой. Про окулинк надо подумать, наверное
>>1186816 Пили интересно. Разве маленькие модели не будут выдавать шизу вроде того, что сыр - часть веганской кухни? Или что рис - часть безглютеновой диеты.
С запросами анона только к корпам. Прав или не прав?
Qwen3-1.7B уже можно юзать как локальный переводчик, если пофиг на качество уровня чуть ниже гугла. На голову выше 0.6b, хотя я и эту тупицу смог заставить работать, кек.
>>1186868 3b - это суммарный размер 8 экспертов. На реддите, кстати, аноны советуют 12 ему врубить, мол качество сильно лучше.
Тем не менее, оно, конечно, не как плотный 30б работает, но и не 3б все-таки. А скорость при этом приличная. Но это не отменяет того, что для рп третий квен - тотальное разочарование (абсолютно все, кроме может 235б, но это я при всем желании проверить не могу), тут уж или файнтюны с ними магию сотворят, или ждать квен 3.5, где они не факт, что все поправят
>>1186839 Ничесе, с глобала. И цена неплохая, особенно по сравнению с битками. 5.0 или работает или помирает в ошибках и все, насчет его нужности с х16 режиме - хз, нужен ну оче специфичный кейс. С меньшим числом линий уже сыграет. > она торчит на 8мм на плоскостью мп и мешает вставлять карты в мп Ааа, вот в чем дело. Ну тут только чем-нибудь пройтись расширив отверстие, резиновую вставку можно штатную вернуть, растянется и заодно замаскирует вмешательство. Проблема в том что придется сначала все вытащить из корпуса, а потом обратно запихнуть, это очень напряжно вплоть до невозможности, лол. Или, как вариант, искать корзину для поворота на 90 граусов карт что стоят в материнке, тогда и решится проблема перекрытия слотов для райзера. Но чтобы там было 7-8 слотов сразу не встречал. >>1186840 > на вид нормальная Тогда возможны оба варианта. >>1186845 Тут надо отметить что заявленный на 48 оказался с большим запасом там где обычный на 40 не доставал нормально. Те дефолтные что рассчитаны на 4.0 имеют оче грубые шлейфы, которые нельзя сильно сгибать, а попытка перемещать по оси вдоль ориентации слота резко сокращает доступную дистанцию в сочетании с этим. А кронштейн тот от отверстия для кабелей отодвинуть нельзя? >>1186851 > Дипсик на самом деле всего лишь 37В модель Ну не совсем. Это большая модель, которая в теории может иметь много знаний, но вот внимание лишь чуть лучше чем у 30б. В сочетании с ризонингом это удачное решение, которое условно говоря позволяет "дать сработать большей части весов", вот только перфоманс в отрыве от этого, или для сложных кейсов все равно херь. >>1186877 > что для рп третий квен - тотальное разочарование Кмк, тут еще замешаны ошибки в квантах/беках/формате и лень/особенности тестировщиков. Квены всегда были специфичные, но не полным днищем, нужно разбираться.
>>1186884 > Проблема в том что придется сначала все вытащить из корпуса, а потом обратно запихнуть Оче лениво, не смогу заставить себя. Проще жать Generate же
>корзину для поворота на 90 граусов карт что стоят в материнке Она есть, но она только для одной карты же. И при этом блокирует все остальные слоты, кроме верхнего. Так что тоже не выход.
> А кронштейн тот от отверстия для кабелей отодвинуть нельзя? Неа, там всё зафиксировано. Можно только на 180 градусов развернуть, вот это вариант ещё думаю, но по-моему ничего не даст, + более длинный райзер потребуется.
>>1186884 > Кмк, тут еще замешаны ошибки в квантах/беках/формате Ну собственно да, еще на это есть надежда. В трансформеров, вроде, коммит от квена прилетел за сутки до публикации модели, до этого слитые веса 0.6б версии не запускались.
Но фулл веса 14б мне запустить не дано, чтобы посмотреть, а более мелкие даже хз, есть ли смысл проверять.
>>1186889 На кобольде хз, можно ли вообще. Вроде как можно через лламу, но пока вникнуть даже не пытался, в падлу, погугли короче, должно быть не сложно. По поводу скорости, просесть должна не сильно, это будет где-то 4.5б активных параметров
>>1186899 Ну вот хз, QwQ сам по себе божественный рп хуячит, жалко только что медленно. Сноудроп вроде должен быть вообще пиздат
>>1186896 Умная, может в русик даже, картинки распознает. Но ОЧЕНЬ много СОИ. Очень жирный контекст, где-то в два раза больше чем у квена >>1186897 Квен и мистраль почти без цензуры, только нужно написать им минимальный промт для этого Для просто генарации промтов мне кажется даже он справится https://huggingface.co/Qwen/Qwen3-4B
>>1186892 > Оче лениво, не смогу заставить себя. Проще жать Generate же База > Она есть Именно большая? Встречал только на 2-3-4 слота что херь. > Неа, там всё зафиксировано. Если прикручивается и ничего не мешает то можно сделать отверстия, это сильно проще чем снимать металл для расширения окна и может быть сделано без полного разбора если офк есть инструмент и привычка, иначе см. пункт "база". Если входит в пазы или смещать уже некуда то уже не вариант. >>1186896 Стоит, оче хорошая производительность для размера, достаточно универсальна и умна.
>>1186945 Хотел как-то запилить переводчик на базе ллм, который продикидывает инфу о том, что находится на сайте, в качестве контекста, чтобы нейронка могла понять как переводить текст в подобном контексте + дать нейронке возможность гуглить сленговые слова. Думаю получилось бы близко к идеалу
У Геммы 3 на всех инференсах контекст настолько много врама жрет? Это пиздец. На Экслламе2 запускаю, каким-то образом 4bpw 32к жрет больше, чем 4bpw 32к 34b модели (против 27 Геммы).
>>1186953 Ага, это пиздос >жрет больше Причем намного больше >>1186956 Так нихуя не поможет. Q8 кэш и так везде стоит, а если геммочке Q4 врубить, то у нее деменция скорее всего появится
Хмм, я получаю стабильные хуевые результаты на гемме без выгрузки слоев, но с куда ускорением промпта. На чистом процессоре работает. С полной выгрузкой тоже работает, что интересно. Это все с проверок переводчика, на куда работать не хочет. До сих пор сломана?
>>1187034 Ебать ты кобольд. Лень качать квен, на тебе на соевой гемме 4b в два промта. Можешь скачать ее или сделать тоже самое в квене, но пиши еще /no_think, чтобы он меньше пиздел
>>1186783 держу в курсе. Если вкратце, то ЕБАНОЕ ПЕРДОЛЬНОЕ ГОВНО
Оказалось что эти матери при инициализации устройств UEFI-ем где-то спотыкаются и это приводит к тому, что бивис мелланоксовых карт становится недоступен для ОС. Выглядит проблема вот так: в выводе # lspci -s 02:00.0 -vv присутствует Expansion ROM at fb200000 [disabled] [size=1M]
вот этот экспеншн рум - это и есть бивис. и доступ к нему выключен со стороны PCI устройства. Само устройство решает, открывать его или нет и если открывать то когда. И открывается эта область памяти в устройстве только при корректной инициализации бивиса/ефи. Без доступа к этой области памяти версия прошивки считывается как 65535.65535.65535
pci 0000:02:00.0: ConnectX-4: FW 65535.65535.65535 doesn't support INTx masking, disabling. Please upgrade FW to 14.14.1100 and up for INTx support.
то есть в 16-ричном выражении это ff ff ff ff ff ff ff ff просто плейсхолдер. и для мелланоксовых карт должна пройти какая-то пре-инициализация
mlx5_core 0000:02:00.0: wait_fw_init:380:(pid 155): Waiting for FW pre-initializing, timeout abort in 19s (0xffffffff)
которая не проходит с таймаутом.
единственный вариант запуска - это поднимать гипервизор на этих матерях, делать проброс PCIe устройств внутрь и в конфиге прописывать ром-файл этих карт так же, как их прописывают про пробросе видеокарт. Конечно же предварительно вытащив его с машины, где эти карты работают. Но идея пахнет немытым хуем.
А еще оказалось, что нельзя сделать mmap rom-файла в виртуальную область памяти. Я даже модуль ядра попробовал написать, но это не сработало.
ебаный пердольный корявый биос короче во всем виноват. Суки блядь.
>>1187193 напердолил. 7 часов ебался с чатгпт. Когда она сказала что я исчерпал лимит - пошел к дипсику, он выдал ответ за полчаса. Мощный стержень, громовой удар. Чуваки, я кончил мозгом, когда увидел, что оно работает. Я натурально откинул голову назад, закатил глаза, начал глубоко дышать и застонал от удовольствия. Такая тягучая волна удовольствия прошла по телу. Лучший нейрокум, базарю.
>>1187034 Ебать ты кобольд >>1187045 Четко палить свои методы им, разумеется, не буду >>1187193 И на что ты рассчитывал, против кадровых китайских сумрачных гениев, лол. >>1187246 Больной ублюдок, уже в плохом смысле, высокое осуждение.
Много рпшил с локалками, стало интересно потестить их в режиме ассистента. Накатил Qwq 32б и Гемму 3 27б, Q4 кванты. FP16 кэш. И... Что-то совсем печально все, не? Они путают факты, всегда отвечают что-то, даже если не знают ответа. Разметку и сэмплеры выбирал в соответствии с рекомендуемыми на странице моделей на обниморде, системный промпт из дефолтных: Assistant - Expert, Assistant - Simple тоже тестил, без промпта вообще тоже пробовал.
Спрашиваешь "знаешь фильм N?" - "Да, знаю. Хочешь обсудить что-то конкретное? Я хорошо знаю сюжет." Задаешь уточняющий вопрос, например, "как погиб персонаж C?", и получаешь неправильный ответ. Гемме говоришь, что ответ неверный, уточняешь правильный - она извиняется и говорит "да-да, ты прав, я ошибаюсь". Делаешь то же самое с Qwq - он настаивает на неправильном факте, "это точно так". Ор. Абсолютно уверен, что с корпами тоже эта проблема проглядывается, пусть и не так явно - модели больше. Как людям не стремно обсуждать с ллками свои диеты, тренировки и прочие важные вещи? Только для рп и годятся они, по итогу. Ну и для кода, может быть.
>>1187257 >с корпами тоже эта проблема С гпт точно так же, даже хуже, десять раз переобувается, когда тычешь его в говно. Но есть сетки которые просто не знают, и в целом они менее соевые. Ничего не поделаешь, их так обучали.
>>1187256 Ну типа фапать на лолей или около того - сорт оф норма, но наблюдать со стороны как ее жарит псина или покемоны - ну такое, зоокуколдизм, лол
>>1187257 На корпах сейм на самом деле, тут вообще много раз притаскивали скрины, где на серьезных щщах советовались с ними по конкретному оборудованию и подобным вещам. Нейронка может знать определенные вселенные и фендомы, особенно если те оче популярны. Также может знать относительно нишевые, но при этом отвечать коряво и не точно, ибо инфа хоть была в датасете, но эта конкретика пробежала только один раз, так и не осев, в отличии от более общих вещей. А сама модель не знает то, насколько хорошо она это знает, ибо их этому не учат и (пока) не существует метрики уверенности в сказанном.
>>1187246 >>1187193 >>1186783 так, ну программа минимум выполнена. Я доволен, пора спать. 20 гигабит/с в режиме IPoIB. Без заголовков езернет фреймов будет побыстрее.
>>1187281 >такое в юрисдикции постить Я не он, но вообще слышал прохладную, что к анону наведывался товарищ майор после постинга чего-то такого, что лет 10 назад считалось почти обыденным. Причем все как положено, с конфискацией электроники и ее невозвратом по итогу. Поэтому, как по мне, не стоит заигрывать там, где можно проиграть свой анус. Если ты, конечно, находишься в юрисдикции. Даже в этом треде бывали удаленные посты и нам никто не скажет, в порядке ли их авторы.
>>1186978 >геммочке Q4 врубить, то у нее деменция скорее всего появится ЧСХ, не появляется, а жрёт она в два раза больше я так понял потому что сканит весь контекст, в то время как остальные помнят что былов начале и в конце, а в середине - толоько если прямо спросить, и то не всегда
>>1187281 >а что это значит? кобольд - это я разок сказал (потом меня в треде долго не было по делам), вроде бы челу с лм-студией который её не мог запустить нормально, собственно, советуя взять этого самого кобольда. Треду, видимо, зашло XD.
>>1187281 >такое в юрисдикции постить для "органов" тут нифига не анонимно, всё подписывается, и тебя могут взять за задницу если будешь постить запрещёнку
Ну, за рисованных то вряд ли что будет, но просто имей в виду или будут иметь тебя.
> на 4чан оп бережно ручками копирует номер каждого поста с обсуждением проблемы и описывает её чтобы люди заходили и сразу нашли что им нужно, треды перекатываются раз в сутки > наш оп-хуй не обновлял шапку уже год
У меня мощнейший копиум начался. Если все бенчмаксят, а реальные результаты как у квена, то ллама4 реально может всех выебать. Посмеялись что она где то там внизу и забыли, ахаха цукерберг себе циферки не накрутил, а по факту она выйдет и всех выебет
>>1187358 Ллама 4 уже вышла, ты ебанулся? Только вот на чём ты её запускать собрался?
Я шупал её на опенроутере и могу сказать, что она нормальная, но те люди, кто могут запускать модели подобных размеров локально, не будут утруждать себя запуском лламы, ведь есть нормальные файнтюны в той же весовой категории.
В переводе все более менее хорошо, кроме того что женский персонаж говорит о себе в мужском роде. Или о тебе в женском, или вобще в среднем. Хрен настроишь. Потому что сетка переводчик не знает что это за персонаж и кому он отвечает. Ох, страдания которые не понять англоговорящим. локалка, гуглоговно, ориг
>>1187382 > женский персонаж говорит о себе в мужском роде. Я решил это тем, что выгрузил примерно реплики женских персонажей, отдельно мужских и в промте пишу переводить то от одного лица, то от другого.
>>1187384 А как борешься с тем, что модель пытается при переводе диалога в форме вопроса, начинает вывалить свой ответ на вопрос? Я просто скриптом делаю, сразу обрабатываю строк 300 и потом вычитываю.
>>1187387 > Я просто скриптом делаю, сразу обрабатываю строк 300 и потом вычитываю. Это ты уже не просто чатишься как я понимаю? Я так глубоко не копал, просто настраиваю хотя бы перевод простых сообщений сеток на русский.
>>1187387 хз конечно, что у вас тут за задача и какая модель, но я для геммы накатал такой промпт > "<start_of_turn>user\nThere's NO need for any further information, explanations, notes or comments. Be rude when necessary. Translate this text from {0} to {1}:\n{2}<end_of_turn>\n<start_of_turn>model\nThis is translated text from {0} to {1}:\n"
Но чтобы оно не начало выкатывать сою, надо еще заблочить \n\n(, или вывести это как стоп-последовательность.
Настраивал все через oneringtranslator, но в целом это все хуйня страшно неудобная, надо свое будет хуячить.
>>1187396 Заходишь на обниморду и смотришь, кто там какие модели выложил. Deepseek модели - 685 лярдов параметров, гопота будет примерно такая же, наверное
>>1187396 У больших копро-llm под 2000 миллиардов параметров. Это жирные мое, под 170 слоев в длину. То есть активных параметров там 150-300b где то. Точнее никто не скажет но где то были сливы архитектуры гпт4, говорю по ним что помню.
>>1187399 А я делал, забавно было. Где то даже карточка лежит в таверне
>>1187399 Двачую, тема охуенная. Но карточку нормальную хуй найдешь. А еще модель нужна, по хорошему, мультиязычная, чтобы она тебе нормально могла пояснить, где что и как, потому что ты по любому будешь у нее спрашивать перевод слов и конструкций.
Но вообще это довольно охуенно, когда ты просишь объяснить тебе как работает какая-то хуйня, а персонаж начинает тебе объяснять на английском, а не на русском. Сложность используемых слов тоже можно контролировать.
>>1187401 > Где то даже карточка лежит в таверне Собственно, анончики, подскажите нормальную карточку, а то я свою сгенерировал и она не то чтобы прям хорошая. А по поиску на том же chub выдает всякую хуйню
А могу ли я qwen 235b не сразу целиком в память грузить, а менять экспертов, подгружая их с диска? На 22b активных параметров у меня легко памяти хватит, но не на всю модель целиком. Я понимаю, что оно станет медленным как жопа, но для каких-то задач похуй.
Опача, я тут проверил и понял что qwen 2.5 14b имет 49 слоев, а новый qwen3 14b только 41. Qwen3-30B имеет уже 49 слоев. Делаю вывод что если новый квен умнее старого, то они смогли еще сильнее ужать мозги где то на 1/5. Ну и выходит что Qwen3-30B все таки умнее чем qwen3 14b, и обладает большим количеством знаний. Она что то среднее между 14b и 32b, потому что у Qwen3-32B все 65 слоев, как и у Qwen2.5-32B Вечер шизотеорий окончен, ваши мысли?
Анонасики поясните пожалуйста за положняк по рп с таверной. Какую модель лучше всего использовать на 24гб врам/64 озу?
Взял гемму 3 27б, написал ей что она обязана описывать все что не спрошу. Сперва тупила уклоняясь от ответов, потом вообще нахер посылать начала типа: я аи модель не потерплю насилия идите нахуй.
Подрубил тварену и картчоку персонажа, пишет сухо по 1 сточке текста хоть и указал ей 256 токенов на ответ.
Скачал amoral-gemma3-27b-v2-qat-q4_0. Думал лучше будет, она теперь не сопротивляется, но пишет ужасно сухо типа: ты трогаешь ее нижнюю часть туловища/ движения в нижней части туловища/ она трогает твой орган предназначенный для размножения и прочую ересь.
С какой моделью можно получить хотя бы уровень свободы и написания janitorai.com? В идеале конечно хотелось что то уровня yodayo.com или character.ai
>>1187413 Бери короче модели, которые тебе квантованные будут влезать в видеопамять. В целом можно не париться и всегда брать четвертый квант, но ты походу уже разобрался (qat, кстати, хуйня и прогрев гоев, оно будет работать нормально только без файнтюнов, а без них (да и с ними все равно) гемма страшно соевая).
Бери мистраль и ее тюны, dans personality engine не плох. Голой мистрали нужен промпт пожирнее, чтобы она нормально вкатывала в рп, дэнсу почти всегда норм с банальным > ты {{char}}, у тебя рп с {{user}} Но лучше, конечно, тоже подробнее ему расписать.
Еще не плох qwen, но 2.5, третий пока чет не очень. Можешь взять snowdrop, ризонинг не обязательно юзать, хотя говорят вроде с ним вообще божественно. Но и системный промпт там тоже нужен пожирнее
>>1187413 С 24гб врама ставь tabbyAPI (exllamav2) для полной загрузки модели и контекста в врам. Это будет гораздо быстрее, и ты ничего себе не выиграешь оффлоадингом (распределением нагрузки на проц и рам).
Вот Snowdrop, данный квант идеально помещается в 23.5гб врама с 32к q8 контекста. Это база для данного железа https://huggingface.co/MetaphoricalCode/QwQ-32B-Snowdrop-v0-4.25bpw-h8-exl2 С Геммой все очень неоднозначно, в nsfw она не может совсем Есть еще Star Command, но там дальше сам разберешься, надо оно тебе или нет.
>>1187313>>1187347 отставить тряску! чуваки, если ко мне придет майор пояснять за возраст согласия пикселей - вы узнаете об этом первые >>1187360 захотелось поковыряться с распределенным инференсом
Кокой хитрый. Может ты еще предложишь просто вырезать из модели пару экспертов и сделать модель только из них? Подобные античеловеческие вивисекции проводились при релизе миксраля, ни к чему хорошему они не приводили, оторванные от других экспертов эксперты всегда сильно уступали моделям аналогичного размера.
Нихуя ты умный, ну разумеется в 30B больше знаний помещается чем в 14b. В этом и прикол мое моделей - иметь больше знаний в ущерб мозгам. Так qwen3 30B 3A следует понимать так - мозги от 3В со знаниями 30В. В этом же феномен почти равной борьбы квена 32В с дипсиком по мозгам. Мозги от 32В со знаниями на 32В в задачах где знания не трубуются будут на равных выступать с 37В мозгами со знаниями на 671В.
>>1187427 Ну мозги тоже бы конечно хотелось, но я так понял тут всего 3 стула 1. Моедль которая много думает, но "я ии модель предназначенная для помощи и не могу писать об этом" 2. Соевая модель которая думает, но очень пространно всё описывает. 3. Тупая, но блядь и будет "дрочить мой хуй себе в рот" и никогда не скажет нет.
>>1187489 >Так qwen3 30B 3A следует понимать так - мозги от 3В со знаниями 30В. Нопе, это именно распределенные мозги 14b+ по куче кусков. Куски имеют дублирующуюся информацию поэтому несмотря на размеры там нет 32b знаний и мозгов. Но, их больше чем в плотной 14b. Мозги 3b довольно печальное зрелище, тут уровень 14b+
>>1187501 >1. Моедль которая много думает, но "я ии модель предназначенная для помощи и не могу писать об этом" qwen3 30B не имеет цензуры, если задать направление то она будет писать и думать в нужном ключе В начале может немного повыебываться, да
>>1187468 Ты долбаеб? Оставляем модель как она есть, но не целиком грузим ее в оперативу/vram. Все равно одновременно работает только ограниченное количество экспертов, они и так сменяют друг друга, просто загружать их только по необходимости.
>>1187501 >1. Моедль которая много думает, но "я ии модель предназначенная для помощи и не могу писать об этом"
Такой проблемы не стоит, на любую капризничающую модель есть джейл или аблитерейтед, который превращает модель либо в соевую шлюху, либо в грязную шлюху.
>2. Соевая модель которая думает, но очень пространно всё описывает
Скорее слишком окрашивает все в соевые радостные тона создаая благоприятную атмосферу, насилуемые лоли радуются что их ебут, например.
>3. Тупая, но блядь и будет "дрочить мой хуй себе в рот" и никогда не скажет нет.
Ну собственно этого мы и хотим от моделей. Алсо, тупость не является проблемой, просто ты говорил с нищуком который не может запускать 32B+ модели - разумеется он тебе рекомендовал слабый малопараметровый шлак. Та же EVA qwen и умная и рп на высоте. Да и Star Command тоже неплох.
Нет это ты долбоеб. Как оно без загруженной в память модели вообще поймет какие именно эксперты нужны, а? Наугад их грузить будет? Хотя бы в оперативке модель должна быть загружена полностью.
>>1187501 Ну это совсем уж обобщение. Тот же Snowdrop может в ERP (Extreme Role Play, конечно же), но там описания будут не такие сочные, как у модели, специально для этого натренированной (которую тебе прислали, Forgotten Transgression). Чем больше параметров (b) - тем модель умнее, но и слишком маленький квант брать не нужно. Не ниже 4.
>>1187531 > EVA qwen и умная и рп на высоте Можешь шарнуть пресет, пожалуйста? Весь, включая разметку. Я может ебамбэ или еще что, у меня ChatML, стандартный сэмплер, но хвосты <im| и прочие остаются в аутпуте. Очень хотел пощупать эту модельку, но пока забил. Еще она у меня лупится через пару десятков реплаев по ~500 токенов. У тебя такого нет?
>>1187531 > ты говорил с нищуком который не может запускать 32B+ модели кумер-господин, который собрал риг для дрочки на буквы, выебывается на тех, кому это не надо. картинка в цвете.
>>1187538 Это я не тут за других додумываю и несу хуйню к делу не относящуюся.
Я потому и спрашиваю, можно ли так в принципе. Модель и так как-то определяет, каких экспертов ей использовать, не вижу проблем, чтобы определялка осталась загруженной, а сами модели лежали и ждали.
Аноны, срочный микровопрос - обновил комп, хочу накатывать убунту. Какую версию ubuntu лучше выбрать для наших нейродел - LTS или обычную? Склоняюсь к LTS, но боюсь некрософта как на дебиане и отсутствия всякой cuda-хуйни в базовых репах. До этого стояли Debian, Kali на домашнем и обычная Ubuntu на рабочем компах, и за 5 лет красноглазания не-убунто-дистров я понял что ничего кроме бубунты нахер не нужно для нормальной работы, а не пердолькиных утех мамкиного хакера. Не наступлю ли снова на грабли, скачав LTS вместо обычной? Хочу минимум дрочки, просто "судо апт 1, 2, 3, 4, 5" без пропихиваний ручками ppa-реп с ручным переименовыванием конфигов, deb-пакетов с сайтов, файрфокса из 2008го, ручной установки суды и прочего дебиан-кайфа. Срач по поводу гномоубунта-кедоубунта-крысоубунта не интересен, планирую накатывать голую сосноль и ставить i3wm поверх.
>>1187569 > я понял что ничего кроме бубунты нахер не нужно для нормальной работы, а не пердолькиных утех мамкиного хакера. > планирую накатывать голую сосноль и ставить i3wm поверх Лол.
Чтобы не пользоваться некрософтом люди на раче сидят, а не на одном из миллиардов клонов дебиана. Там и с репозиториями пердолиться не надо, в случае чего из аура берешь нужный пакет.
А чтобы не пердолиться как мамкин кулхацкер, здоровый человек себе i3 накатывать не будет, ты уж выбирай давай чего ты на самом деле хочешь, не еби мозги себе и людям
>>1187569 Просто накати популярный игровой дистр, на вроде минта или кубунту. Ни с дровами не будет проблем ни с юзабилити. А вобще рекомендую не ставить на домашний комп убунту, а собрать себе отдельный сервачек на ней и уже на нем красноглазить.
>>1187578 >люди на раче сидят Ни разу не юзал арч, по описанию будто бы вообще не мое, ощущение что для нетакусиков, которым в дебиане ебли мало, и пердолинг на 1 ступень ниже гентухи и lfs. НО уже какой раз на форумах, в телеге, и даже гопота в чате "деб vs убунта" - ВСЕ СОВЕТУЮТ МНЕ АРЧ. Я что то видимо не выкупаю. >Чтобы не пользоваться некрософтом Ну у меня подход "работает - не трогай", да и флешбеки шиндовые с их "обновление, падаждите" всплывают. Даже обычная убунта заебывает обновлениями кд, поэтому и думаю об LTS. Но при этом страдать на настройке энвайрнмента или когда выйдет гемма-4/хуньян-3000 и у меня не будет нужных либ для запуска тож не хочется... >здоровый человек себе i3 накатывать не будет Жопой чуял что будет проход в i3... Я ее накатил когда был некроноут еще на два ядра два гига (ну и кулхацкерить тогда тоже казалось прикольно), но оказалась такая удобная, логичная и стабильная штука, что после нее любой драг-ндроп с окошечками кажутся чем то СДВГшным для зумеров. Так что да, тут красноглазие неизбежно, с этим готов жить.
>>1187580 >а собрать себе отдельный сервачек на ней и уже на нем красноглазить. Сервак под llm для аптайма 24/7 в планах (причем с выходом moe квенов возможно ближе чем думал, ведь достаточно буквально любого авитоговна на ddr5 без видео). Но повседнев у меня тоже линукс (и i3), шинда ебанулась на отличненько последнее время, транспереход не рассматриваю. Жопа реально горит, когда раз в месяц включаю второй диск с шиндой для игоря или каких нибудь анальных виндопрог.
>>1187589 >>1187586 > реально аноны говорят, не еби себе голову Бля... Я ждал ответ вида "ставь лтс, у меня такая, заебись" или "не вздумай лтс, это для офисных кабанчиков бд держать чисто". А теперь помимо лтс/не-лтс еще мяту и даже арчесосок попробовать прогибаете -_-. Ну почему я не макопидор, где дядя кук решил все за тебя, а твое дело простое - котлетку на новое поколение железок заработать...
Я ничего не додумывал, я просто обьяснял почему твоя хуйня не будет работать. Ок, вот тебе на пальцах обьяснение.
Во-первых, нет никакой особой определялки, модель действует как единое целое. Во-вторых, эксперты меняются для каждого токена. Тоесть даже если обойдем то что модель никуда не загружена(например будем грузить модель с ссд, хотя это уже заранее F) - то тебе придется перед генерацией каждого токена ждать полную прогрузку нужных экспертов на врам.
>>1187354 > оп бережно ручками копирует номер каждого поста с обсуждением проблемы и описывает её чтобы люди заходили и сразу нашли что им нужно Он ебнутый, или наоборот крутой что настроил ллмку на автоматизацию этого? >>1187358 По ощущениям она вовсе не так плоха как рисуют, так еще и может в кум, да не самый простой, из коробки без доп инструкций. Из сои только про гроидов не захотела шутить. И да, она уже вышла. >>1187379 > ведь есть нормальные файнтюны в той же весовой категории Мистраль лардж да коммандер-а, не сказать что большой ассортимент. >>1187410 ktransformers, правда запустить могут не только лишь все >>1187413 Гемму нужно пугануть промтом, тогда сразу станет все писать. > amoral-gemma3-27b-v2-qat-q4_0 Блять в голосину. Это же ведь не квант qat дотрена файнтюна оригинальной геммы, это ведь буквально шизик решил тюнить qat веса своей херней, да? Оно не способно работать по определению. > свободы и написания janitorai.com? В идеале конечно хотелось что то уровня yodayo.com или character.ai Это довольно низкая планка, тут и 12б справятся. Просто нужно все правильно настроить, взять не убитую модель и настроить промты. Попробуй шизомиксы мистраля как советуют, они более сговорчивые и индиферентны к промту, формату и т.д., но часто копиумные или вообще убитые в хлам лоботомиты.
>>1187569 24 лтс, никаких проблем >>1187592 > нет никакой особой определялки, модель действует как единое целое Определяя какого именно эксперта использовать на каждом слое/группе слоев, а не только по токенам. Быстрый инфиренс в ktransformers при выгрузке модели не то что в рам, а вообще на диск, обеспечитвается как раз загрузкой всего кроме экспертов в гпу, а те уже процессором считаются, если не находятся в видеопамяти. > ждать полную прогрузку нужных экспертов на врам Быстрее считать процесором. >>1187596 Кратные затраты на железо при приросте качества, измеряемое десятками процентов. Из плюсов прежде всего скорость.
>>1187590 > даже гопота в чате "деб vs убунта" - ВСЕ СОВЕТУЮТ МНЕ АРЧ. Я что то видимо не выкупаю. И да и нет. Дело в том, что пердолинг тебя ожидает вообще везде. И на винде, и на макос, и на вариациях линукса. Пердолинга не может не быть, он может быть привычным, а в удачных случаях просто обходить тебя стороной.
Арч советуют не просто так, это да, не за хуй собачий валве свою стим-ос на его основе теперь пилят. Он просто почти не ебет тебе мозги дистро-специфичной хуйней, из которой там буквально только пакетный менеджер, уже даже скрипт для установки в live-cd сразу живет. Вся хуйня с арче-вики прекрасно работает почти на любом дистрибутиве (исключая всякую ебучую экзотику типа nixos).
> Ну у меня подход "работает - не трогай" > Даже обычная убунта заебывает обновлениями кд Покуда сам на арче себе заебалку не накатишь - никто мозги трахать не будет. У меня прекрасно живет некро ноут, на который я накатил рач года 3-4 назад и с тех пор не обновлял, заебись себя чувствует. Но если захочу чо-то обновить - то да, скорее всего придется немного поебаться. На основной машине обновление запускаю раз в месяца полтора-два в среднем, вообще никаких проблем.
Бля, выглядит как ебучая реклама арча. Короче, накатывай чо сердцу ближе и забей хуй. А рач просто как-нибудь потыкай, мб понравится.
>>1187590 Могу говорить только за свой юзеркейс, но препрововав миллион дистров (на уровне пользователя а не пердолика), я остановился на минте. Пакеты свежие, совсем адовых роллинг проблем не заметил, на кедах система кушает ресурсы как мышка. Конечно, без погружения в терминал никак не обойтись, но это уровень продвинутого пользователя. Я же думаю ты не из этих "я что-то нажал и все сломалось". В любом случае манов хватает с головой и лоботомиты ОЧЕНЬ хоро знают линунс.
>>1187716 Не пизди, хуйлуша. У них семлы разные в зависимости от базовой модели. И они одни из немногих кто оформляют карточки, дают сразу и gguf и exl2, сэмплы и т.д. Еще и продуктивные пиздец. Пиздатые ребята, блюстители кума
>>1187413 >С какой моделью можно получить хотя бы уровень свободы и написания janitorai.com Это шутка что ли? У Janitor'a Мистраль 12б на 9к контекста. Форготтен, построенный на Мистрале 24б уничтожит нахуй это говно. С твоими 24гб это будет Q5K_L с 32к контекста даже без квантования >Взял гемму 3 27б Зря, но ты уже понял. Это целомудренная целочка соевая. Особенно после janitor'a будет заметно >yodayo.com Не ебал, что это. Зашел, там по умолчанию какая то 8b модель. Еще и платно. Пиздец полный >character.ai Тут вроде что то хорошее используется, возможно его переплюнет только гемма3 и квен3 по мозгам и то не факт. Но ум не важен, когда там цензура повсеместная
>>1187956 > Это прямо чувствуется Хз, больше выглядит как вариации заученных объедков паттернов датасета. > вторая лучше в гуро Ну такое, режешь именные сухожилия, но вместо ограничений движений и ужаса от этого, просто сразу начинает дергать тем, чем не может, и вопить от боли с места где минимум нервных окончаний. Последствия от повреждений внутренних органов и всяких ранений - или игнорит, или по шаблону ох ах как плохо@умереть. Имаджинировал ебало тех, кто такое потреблят и восхваляет, рили непривередливые нормисы от мира борд, которым многого и не надо.
Итоги теста всего мелкого говна в переводе. 1 место - gemma-3-1b-it-Q8, мелкая и переводит неплохо, редкие косяки. 2 место - gemma-3-4b-it-Q8_0, крупная и это минус, перевод бомбический. Косяков почти нет, род не путает если указать. 3 место, не нужно так как ничего лучше и мельче 1 места там нету. Ну пусть будет Vikhr-Gemma-2B-instruct Остальное ллама3 1б говно, квен3 0.6-1.7 чуть лучше, гемма2 2б еще чуть лучше
>>1187946 Благодарю за подробные разъяснения! На yodayo.com есть и 70б модели, там все можно выбрать, но последнее время они обнаглели в край бесплатной валюты мало дают, так еще и урезали выбор моделей для "бесплатного" пользования. Но пишут там хорошо и сочно.
А люди типа больше знают? Представь уровень знаний водителя маршрутки?
Да, у людей типа водителей, строителей, сварщиков, есть преимущество - практический опыт. Который не передаётся через диалоговое окно как теория. Хотя принципе водитель маршрутки может тоже стать теоретиком и обучать своему опыту через форму диалогового окна. Но опять же чё он выдаст - 3 страницы всех своих жизненных знаний, и всё. И так с каждым человеком.
>>1188215 > последнее время они обнаглели в край бесплатной валюты мало дают Совсем ахуели, суки. Меньше бесплатным делиться стали. Ни стыда, ни совести.
>>1188194 Главный вопрос теста зачем тебе вообще это нужно? Зачем использовать мелкосетки, если есть гугл транслейт или сетки побольше? >gemma-3-4b-it-Q8_0, крупная Она не просто крупная, она еще и прожорливая. Контекст жрет больше чем квен аналогичного размера >На пик gemma-3-4b-it-Q8_0 Ты кстати пробовал специализированные переводчики типа этого? https://huggingface.co/erax-ai/EraX-Translator-V1.0 >>1188191 У геммы лучше русик
>>1188264 >Зачем использовать мелкосетки, если есть гугл транслейт или сетки побольше? Что за тупые вопросы? Для того что бы не зависеть от интернета при переводе. Я тут на пол дня без интернета остался и понял эту умную мысль. А большие сетки жрут больше места и медленнее работают, и зачем они тут? Нужно что то мелкое и на уровне или лучше чем гугл. Ну, их же сетка подходит. Профит. >Она не просто крупная, она еще и прожорливая. Контекст жрет больше чем квен аналогичного размера Квен хуже в переводе, а на контекст пофигу, его там 2 или 4к за глаза. >Ты кстати пробовал специализированные переводчики типа этого? Щепал раньше сетки на лламе2 вроде бы, для перевода. Ну понятно что они сейчас даже мелким проигрывают.
На счет других способов перевода думал и проверял, но не то. А вот то что ты скинул интересно вроде бы, я до этого только всякие t5_translate_en_ru_zh_large_1024 видел из мелочи
>>1188248 Да ладно, я в основном отыгываю любовь и обожание или какие-то адвенчуры с чарами, которые мне потенциально милы. Что плохого в том, чтобы сделать бранч с аркой отборного revenge exploitation, или изначально обернуть вокруг этого весь сеттинг, как в том же герое щит_а? >>1188254 Ты угорешь, срать в лорбук что без ахилла или надколенного невозможно ходить/хромать, без сгибателей пальцев пользоваться кситью и т.д., может еще что гадить полагается только из ануса указать? Да и врядли поможет ибо оно глуповато. Вместо того чтобы составить продолжение исходя из ситуации с вниманием к деталям, просто дает вариации слоповых описаний как "страдает жертва" вместе с ними заодно притаскивая несоответствующее и лупясь. >>1188264 Зачем контекст переводчику? Полную историю чата для придания контекста мелкосетка всеравно не осилит, для карточки и суммарайза 4к хватит за глаза. >>1188267 > t5 Это зло из давно забытых времен, место которому на свалке.
>>1188264 >https://huggingface.co/erax-ai/EraX-Translator-V1.0 Перевод хороший, но оно тупое и не выполняет даже команды форматирования текста. Тоесть сказать как обычной сетке - переведи заебись и по форме - не выходит. Нужно городить свой бек
>>1188194 >2 место - gemma-3-4b-it-Q8_0, крупная и это минус, перевод бомбический. Косяков почти нет, род не путает если указать. Даже 2,5 флэш джемини выдает глубоко поломанный перевод. А у тебя у 4б лоКАЛа перевод бомбический.
>>1188332 однажды анон сделает обрезание крайней плоти на глазах и увидит, что гугл по бесплатному апи нормальный перевод не дает, а с достижением определенного лимита начинает резать качество еще сильнее. С локальной моделью (от того же гугла, к слову, лол) такой хуйни не будет.
Если заниматься автопереводом всякой хуйни, типа читать визуальные новеллы на лунном, то ничего лучше локалки ты себе за бесплатно не найдешь. А если хочешь хороший перевод - то плати, и лучше не гуглу, а человекам, которые тебе его еще сделают литературным.
>>1188366 >что гугл по бесплатному апи нормальный перевод не дает Ты долбоеб? Речь про ЛЛМ - гемини 2,5 флэш. Продолжай фантазировать про специальные ответы по апи и прочую красноглазую шизу. Жри лоКАЛ - но молча, когда ты вот так запёздываться начинаешь, прыщеблядь, не удивляйся что мимо проходящий анон тебе в рожу харкает, пингвин ебаный. Ты не в прыщеблядском разделе, так что сиди и терпи, хуйня пиздлявая.
>>1188366 > то ничего лучше локалки ты себе за бесплатно не найдешь. Ты цены на флеше на лям токенов видел, еблакак? Мамка на завтраки слишком мало дает? Крутить такое на локале - ноль смысла. И еще раз для тупых животных: если у флэша говно, то у джеммы - и подавно.
Нет, серьезно, чем вы прям пользуетесь, запускаете каждый день на пару часов? Мне нужен и кум и ум модели, штук 10 лежит в папочке всё не нравится. Чувство что жизнь реально есть только на 48гб врам
>>1188517 Скорее всего какой-то дед пытается вкатиться спустя год и пытается повторить свой старый сетап, не понимая, что уже даже в треде натренили несколько 12б сеток с готовым русиком.
>>1188517 На сегодняшний день абсолютно у всех существующих моделей словарный запас для русика говно, даже у корпов, про локалки и речи не идет, там полный мрак. Для рабочих и справочных задач хватает хватает но чуть глубже и обсер. Конечно если ты на столько неприхотливый что тебе хватает классического "я тебя ебу" в пяти вариациях, либо сидеть на 8-12b лоботомитах которые благодаря их мелкому размеру смогли дообучить русскоязычным датасетом, вопросов нет, но многие хотят пользоваться "актуальными" вещами.
>>1188499 По соотношению качество / размер и скорость победила 1b. Это был поиск быстрого и легкого оффлайн перевода на замену стандартному гугловскому в таверне. Он хуевый, поэтому даже 1b переводит лучше.
Если состовлять топ по качеству перевода моделей то там и и 12b гемму можно было впихнуть и 27b, ну или как советовал говноед пользоваться всякими копросетками
Господа аноны, поясните мне имеет смысл к моей 3090 цеплять еще 3070ti? И возможно ли на конфиге? Asus TUF B450M-Pro Gaming 750 киловатник, с учетом андервольтинга.
До появления в жизни ллмок я был дединсайдиком, который живет жизнь ото дня ко дню, не задумываясь. Теперь я хочу зарабатывать больше, чтобы собрать себе риг для запуска жирных моделей. Это побуждает меня к поиску лучшей работы и самосовершенствованию.
А вы думали, это всего лишь кум? Через пару лет соберу сервер риг, а там и модели ебейшие уже будут совсем.
Я от сноудропа тупо взял полный набор настроек и промптов. Вот скрин на 12к использованного контекста - залупов нет. https://files.catbox.moe/b6nwbc.json - это подключить через Master Import в Advanced Settings
>>1188627 >Господа аноны, поясните мне имеет смысл к моей 3090 цеплять еще 3070ti?
Не имеет. Еще полгода назад я бы сказал что имеет, так как тогда было чем больше врам - тем лучше. Сейчас после 32B лучшие модели начинаются только на 200B+, так что забей. Ну разве что контекста чуть больше вместить на 32В моделях и чуть лучше квант.
>>1188631 >Через пару лет соберу сервер риг, а там и модели ебейшие уже будут совсем.
Сейчас самая лучшая опенсорс модель всего процентов на десять лучше квена 32B, который помещается на жалкой 3090B которая жалкие 70к стоит. Овчинка выделки не стоит.
>>1188623 >Попробуй вот эти две Ну я попробовал. Прикола не понял. Ладно русский хуже, чем на Сайга-базед, но они не то, чтобы умнее и не то, чтобы развратнее. А если нужен русский кум, то и вовсе говно.
>>1188643 >10% - это разница с Qwen 235B который сейчас самая топовая локальная модель. Насчёт локальной это ты малость погорячился. Если целиком во врам не влазит, то наступает жопа. Количество врам сам прикинь.
>>1188643 Ты правда не понимаешь что ли? Ты взглянул на бенчмарк, который исследует определенные задачи и выдаешь его результат за действительность? Да будет тебе известно, что содержимое бенчмарков уже давно известно тем, кто создает модели. Модели "натаскивают" на определенные задачи, чтобы они были в топе бенчмарков. Это называется бенчмаксинг. Те, кто хоть немного понимают, давно уже в курсе, что доверять бенчмаркам нельзя. Более того, даже если модели сопоставимы в вопросах кодинга (что по-прежнему маловероятно), большие модели физически содержат больше различной информации. Это чрезвычайно важно для рп задач и не только для них.
Мда. Вроде тут заинтересованные люди сидеть должны? Неужели такое объяснять надо?
>>1188647 >Да будет тебе известно, что содержимое бенчмарков уже давно известно тем, кто создает модели. Модели "натаскивают" на определенные задачи, чтобы они были в топе бенчмарков.
Ты услышал аргумент и вопроизводишь его, даже не подвергая осмыслению. Поначалу, когда еще не все модели натаскивались на тесты - твой аргумент имел смысл, сейчас когда реально одинаково натасканы все модели по умолчанию, то топ как раз актуален, потому что различие между моделями реально определяется только их внутренним настоящим качеством.
>>1188646 >Насчёт локальной это ты малость погорячился. Если целиком во врам не влазит, то наступает жопа. Количество врам сам прикинь.
Что ты несешь-то вообще. Модель считается локальной, если её веса лежат в открытом доступе. Понимаю что как маркетологу опенроутера тебе неприятно, но не пойти бы тебе нахуй в корпотред прогревать тамошних нищенок?
>>1188649 Ты упустил мысль, которую я вкладывал в свое сообщение. Даже если бенчмарк верен, он не позволяет нам судить о "качестве" модели и ставить одну выше другой. Он позволяет нам сравнивать их в определенных областях, которые покрываются бенчмарком. Если у нас будут две сетки - 32b и 235b, которые в рамках бенчмарков сопоставимы, последняя ввиду большего размера будет обладать большим количеством знаний. Что важно для рп и других креативных задач.
>>1188627 Однозначно, сможешь катать свежие модели в хорошем кванте и с норм контекстом, 32гига в сумме как раз. >>1188635 Коупинг обладателя отсутствия настолько силен, что он потерял нить логики и сам себя обоссал. >>1188643 > топовая Значение знаешь? Буквально как >>1188650 написал, суета ради суеты.
>>1188653 >Если у нас будут две сетки - 32b и 235b, которые в рамках бенчмарков сопоставимы, последняя ввиду большего размера будет обладать большим количеством знаний.
А ты модель используешь как справочник вместо того чтобы погуглить? Кстати, в таверне можно дать разрешить модели гуглить чтобы компенсировать недостаток знаний.
>>1188659 >Однозначно, сможешь катать свежие модели в хорошем кванте и с норм контекстом
Стоит ли запуск qwen_32B_5_K_L c 32к контекстом вместо qwen_32B_4_K_S с 32к контекстом если для этого надо из обычного пека городить риг с дополнительным охлаждением?
>>1188660 > А ты модель используешь как справочник вместо того чтобы погуглить? Нет. Но чем больше знаний у модели - тем меньше галлюцинаций в рп и креативных задачах. В этом и смысл больших моделей для таких задач.
>>1188666 А, прочел что у него 3070ти основной, пардон. Если карточка на руках то все равно стоит, 8 гигов это существенно, можно найти оптимальную комбинацию с контекстом побольше, а та карта мелкая и разместить ее будет легко. Если покупать - нет смысла, тут только вторую-третью 3090. >>1188667 Всегда есть нюанс, если бы речь шла о плотных моделях, то большая, даже более старая, могла бы в рп дать жару. А когда тут мое с малым числом активных, интенсивно надроченная на ризонинг - теорема эскобара, в базе они не работают нормально в рп как не извращайся. Насчет квена хз, может модель и неплоха.
Для РП, как и для других задач важно не количество знаний, а их качество. Потому люди и используют файнтьюны мелких сеток вместо чистых сеток гораздо большего размера. Какой толк в том что в дипсик залили все экселевские таблицы в интернете, если это только размывает его знания ненужным дерьмом?
>>1188677 Иди нахуй. Ничего тебе отвечать не буду уже, ты читаешь через строку и не понимаешь, что тебе пишут. > уточняешь, что модели одинаково хорошо себя показывают в задачах > но одна модель больше другой по количеству параметров, поэтому знает больше > "вообще-то важно качество знаний тоже" Либо читаешь невнимательно, либо нихуя не понимаешь в сабже. В любом случае нахуй.
>>1188666 >Стоит ли запуск qwen_32B_5_K_L c 32к контекстом вместо qwen_32B_4_K_S с 32к контекстом Да, стоит Q5KL намного пизже чем Q4KS > если для этого надо из обычного пека городить ри Нет, для этого достаточно купить 32гб врам видюху. Причем тебе даже контекст не надо будет квантовать, а если поквантуешь Q8, то можно уже впихнуть Q6K c 48к Цена вопроса 220 (190 если у серых) АМД и 300 (270) Нвидиа. Не говоря о том, что 90к это две новые 4060ti и они пиздец какие холодные и нежрущие, назвать ригом сборку с двумя этими картами язык не поворачивается
>>1188682 Я другой анон и ничего про корпосетки не писал. Я буквально писал, что хочу собрать риг для локалок. Ты настолько долбаеб, что забыл, на какое сообщение отвечал? В голос бля.
>>1188683 Одна из базированных кум моделей до 24б.
>>1188681 >Нет, для этого достаточно купить 32гб врам видюху. Причем тебе даже контекст не надо будет квантовать, а если поквантуешь Q8, то можно уже впихнуть Q6K c 48к >Цена вопроса 220 (190 если у серых) АМД и 300 (270) Нвидиа. >Не говоря о том, что 90к это две новые 4060ti и они пиздец какие холодные и нежрущие, назвать ригом сборку с двумя этими картами язык не поворачивается
Вопрос в том, стоит ли городить связку 3090 с 3070ti, а не в том что стоит ли собирать с нуля сборку на 32гб.
>>1188686 Я не ебу стоит тебе или не стоит. Посмотри по ценам. Если просто вставить и не надо пересобирать комп, то да. Если надо все пересобирать, то можно продать 3090 посмотреть на новые карты. Посмотри что тебе выгоднее. Но помни что ЛЛМ всегда найдет, как сожрать весь твой врам и ему всегда будет мало, поэтому чем больше тем лучше
>>1188677 > Потому люди и используют файнтьюны мелких сеток вместо чистых сеток гораздо большего размера. Потому что то что больше у них не помещается, или не могут освоить простой промтинг, из-за чего нуждаются в лоботомирующих костылях. Там что не пиши - получишь родной клодослоп. Конкретно у дипсика проблема в тренировке на ризонинг под бенчмарки. Это позволяет чуть точнее решать бесполезную хуету типа подсчета количества букв и детских загадок чтобы впечатлять нормисов, иногда действительно может помочь, а в других кейсах наоборот руинит выдачу. А без ризонинга дипсик не то чтобы далеко от qwq (тоже без него) уходит. >>1188681 > Цена вопроса 220 (190 если у серых) АМД Интересно было бы глянуть ее перфоманс. Но 256бит gddr6 это, конечно, довольно печально за такую сумму. > что 90к это две новые 4060ti Чуть добавить и будет 5060ти
>>1188652 > Модель считается локальной, если её веса лежат в открытом доступе А если найдешь чертежи танка - можешь его у себя во дворе собрать рабочий и беспрепятственно на нем потом по городу кататься.
>>1188692 >Но 256бит gddr6 это, конечно, довольно печально за такую сумму Да, более чем в три раза медленнее, чем 5090. И по чипу на 50% хужеэ Но для ЛЛМ не особо критично >Чуть добавить и будет 5060ти Да, это пизже будет, ща они уже по 50к новые стоят Еще у АМД есть на 48гб уже аж с 384 шиной, но уже за 335к https://www.wildberries.ru/catalog/291911999/detail.aspx
>>1188652 >Модель считается локальной, если её веса лежат в открытом доступе. Угашеный ты об дерево, если веса в открытом доступе то это считается открытыми весами, максимум не разбирающиеся в теме назовут это опенсорсом. Локалкой считается то что ты можешь запустить локально на потребительском оборудовании. Дипсик не запустить на потребительском оборудовании, только собирая спец железо.
>>1188711 >Локалкой считается то что ты можешь запустить локально на потребительском оборудовании.
Часть про потребительское оборудование ты выдумал, опероутерошиз. Алсо, дипсик возможно запустить с потребительского оборудования, просто грузи с его с ssd.
>>1188547 >словарный запас для русика Ты там с девушкой пытаешься общаться или с пидором-ученым-поэтом? Локалка нужна исключительно для свободных интимных разговоров, все остальные задачи закрываются на десятках условно-бесплатных сетках, которые ты очень нескоро сможешь запустить локально, лимитов предостаточно на день.
>>1188725 >Потребительским оборудованием не считается то ради которого нужно пердолится.
Шизик продолжал придумывать определения на ходу чтобы продать свой облачных дипсик на опероутере. Но даже в рамках его больного мира - для запуска дипсика с ссд не надо пердолиться.
>>1188734 Шизик придумал себе опенроутер шизика и героически с ним борется. Иди нахуй долбаеб, я не он. Никто блядь не спорит что дипсик хорошая сетка с открытыми весами и на опенроутер не посылает. Тебе долбаебу говорят что это не локалка, если для ее запуска нужен сервер. И нет иди нахуй со своим 1 токеном в секунду с SDD, это не запуск сетки это хуйня из под коня. Это не юзабельное говно для развлечения, а не запуск.
>>1188736 >Тебе долбаебу говорят что это не локалка, если для ее запуска нужен сервер.
Локалка это то что ты запускаешь локально, у себя, не на ебучем облаке. Какое жедезо для этого нужно - не имеет значения. Нахуй ты базовые определения переписываешь, долбоеб? Да, дипсик на оперроутере не локальный, а облачный, со всеми вытекающими, дипсик что анон запустил у себя дома на каком-нибудь Ultra M3 - локальный.
здраствуйте анончеге. посоветуйте написалку отчетов на русском
абреки в локалке присылают письма кто что сделал куда сходил с кем провел совещание, надо письмо - доклат из этого говна составить есть база 50+ докладов, надо чтоб нейронка снюхала базу - переняла стиль и писала доклады красиво при сбросе её набора фактов
>Наши самые передовые модели теперь помещаются на ноутбуки, телефоны и даже тостеры (если он у вас хороший!). Quantization-Aware Training (QAT) сокращает требования к памяти до 75% без ущерба для качества, позволяя запускать модель Gemma 3 27B на потребительских GPU, таких как NVIDIA RTX 3090. Прочитайте статью в блоге, ( https://developers.googleblog.com/en/gemma-3-quantized-aware-trained-state-of-the-art-ai-to-consumer-gpus/ ) чтобы узнать о QAT, посмотреть бенчмарки моделей и изучить интеграцию инструментов.
До этого юзал q4K_M квант, а не 4_0. Поставил этот qat и все стало ровно раза в 2-3 медленней. Память стало жрать ровно в 2 раза больше.
>>1188892 файнтюн модели, чтобы она была более устойчива к квантованию, гугл ее хуйнул именно в Q4. Ты там точно правильный квант скачал, а не рандомный на 4_0? Не должно оно было больше места занимать и медленнее работать.
А вообще - хуйня. Особенно файнтюны qat, потому что эта залупа должна происходить на последней стадии. Так-то, судя по всему, ничем не лучше Q4_K_M, если не хуже, но идея была хорошая
>>1188902 Да я всё правильно скачал, настроил. Не первый год занимаюсь этим. Для чистоты эксперимента юзаю чистый кобольд без загрузки вижн модели. Файл настроек один и тот же. Со дня выхода 3й джемки юзал Q4_K_M. Всё быстро, шустро, результат выдачи нормальный. Сейчас скачал с репы хагинфейса гугла офф qat квант Q4_0. И пошли тормоза адские. НО, кстати, качество выдачи заметно лучше стало, будто это средний 5й или даже 6й квант. Надо попробовать кванты qat от васянов, а не отгугла, чтоль...
>>1188915 hf.co/stduhpf/google-gemma-3-12b-it-qat-q4_0-gguf-small Я этот скачал, у меня хорошо идет даже на тостере. Тормозов не заметил каких-либо. Качество вроде тоже норм, базарили с ней, рассказы целые сочиняет.
>>1188915 На обниморде рядом с квантом есть кнопочка, которая открывает его информацию там на сайте. Тыкни и смотри все ли там слои 4 кванта. Ну или когда запускаешь в том же llama.cpp пишет какие кванты в модели
>>1188915 Может у тебя вижн как-то включился? Если вижн включается, то сразу тормоза адкие, потому что гору контекста добавляет. Алсо у меня было с какой-то из этих QAT моделей, что она все время на проце грузилась, а не в ГПУ. Я помню из-за этого перекачал с васянского сайта, стала нормально грузить в ГПУ, оказалось модель кривая была. Глянь в списке процессов, юзает ли ГПУ на 80-90%, если нет, то проблемы те же.
И я так чекнул сейчас и понимаю что чисто 4_0 кванты уже нигде не используются, а может так и было в начале. Некоторые слои все равно квантованы иначе или оставлены в F32
>>1188920 Спасибо, тестану. >>1188922 Ну так qat тормозящий был из репы гугла же. >>1188929 Да не, настройки те же. Но у меня есть подозрения уже, почитав по ссылке анона >>1188920 автора, который пишет о неправильных статик квантах с добавлением мусора, что влияет на размер. Возможно в моём случаее, лишний гиг врама стал решающим для тормозов.
>>1188937 Скорее всего да, там прямо говорится что гугловый тормозящий, и ему слои заменили. Я гугловый не ставил, а сразу с васянских начал, вот проблем и не было, они все уже кванты на оптимированные поменяли.
>>1188740 Хуи, бочку? >>1188746 Мое мнение весомее, ведь имел честь катать и продолжаю это делать считай все сетки в разных юскейсах, и имею к ним условно неограниченный доступ. И корпам и локалкам локально, включая дипсик. Кроме ассортимента шизомерджей мистраля и всякого подобного офк, на них и жизни не хватит. Потому оценка наиболее точная, многокритериальная, не предвзятая и не искажена налетом синдрома дауна как у отдельных разжигателей срачей.
>>1189001 Qwen3-30B Вроде как базарит всегда на уровне тупого негра 60 айкью, чего геммы не могут, сбиваясь в нейробредни. QAT версию я правда не нашел как для Геммы.